
Permutation Groups Generated by γ-Cycles

Abstract
:1. Introduction
For any integers such that
distinct -cycles and generate when is even and otherwise.
- We provide a brief presentation of our method for computational experiments with permutations. Maude can be understood mathematically through a few elementary forms of model theory, which we present briefly.
- We develop a general formula for factoring any -cycle as a product of other -cycles of arbitrary fixed length. A corollary of this is a general result of the generating power of -cycles of fixed length. Although this can be derived from P.4 of [6], our formulas provide a very different proof route to this consequence.
- We establish the exact generating properties of the three exceptions from P.4 of Piccard’s article [6].
2. Preordered Algebra and Its Computational Side
2.1. Preordered Algebra
- Signatures, which are language symbols that are structured in a certain way and that vary across logical theories;
- Sentences, which are logical formulas built with the symbols provided by the respective signatures;
- Models, which are interpretations of the signatures in set theory and provide meaning to logical theories;
- A satisfaction relation between models (M) and sentences (), which denotes which axioms hold in which models.
- an S-indexed set A (the set is called the carrier of A of sort s), and
- a function for each .
- if for equations,
- if for rules,
- if and , and similarly for ⇒, and
- for each -sentence , if for each expansion of M with interpretations of the variables of X as elements of M.
2.2. Term Rewriting in Maude
- In order to compute equalities between elements of models using equations, terms are reduced to normal forms; for this, it is important that the set of equations enjoy the properties known as confluence and termination. The former means that when several equations can be used in rewriting, the choice does not matter. The latter means that the rewriting of any terms eventually comes to an end, and does not run indefinitely.
- In order to compute elements along preorder relations in models. In a more computing science-oriented terminology, elements of the models are states and the preorder relations are transitions. This approach concerns which statesare reached from which other states, and uses rules rather than equations. Here, neither the confluence nor the termination property is required. Lack of confluence means an open door to non-deterministic programming, a crucial distinctive computational paradigm that we use in the present project.
2.3. Implications
“such a combination is just a mathematical proof consisting of more informal parts (i.e., the mathematical arguments in a conventional style) and of purely formal parts, and nothing else.”
3. -Cycles Generated by -Cycles of Fixed Length
3.1. Computational Experiments with Fixed Length -Cycles
What is the subgroup of generated by all m--cycles?
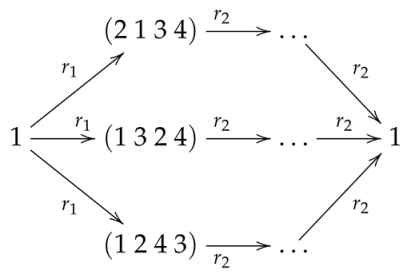
- We represented permutations as lists of numbers in the obvious way. For example, the list represents the permutation . This choice of representation is motivated by the fact that Maude provides unparalleled computational support for lists through rewriting modulo associativity.
- One rule (denoted ) generates non-deterministically the inverses of all k--cycles. Its corresponding logical formula iswhere are variables ranging over lists of naturals, b is a variable ranging over the naturals, and is the length of .
- The other rule (denoted ) applies m--cycles non-deterministically, its corresponding logical formula being
 |
3.2. The Mathematical Results
- (i)
- If m is even, then
- (ii)
- If m is odd, then
- when ℓ is even, then either both i and are even or else both and are even, and
- when ℓ is odd, then m is even, which implies that either both i and are even or else both and are even; in this case, in order to invoke the results of Proposition 2, we use .
4. The Three Exceptions
- We computed the orders of all elements of G as follows. The program that computes the subgroup of generated by and implements the logical formulasandwhere range over naturals and over lists of naturals. Of course, the parts of the POA models considered refer only to the case in which the terms of the equations are permutations in . To these, we added another sentence used for specifying powers of permutations:where P and L are lists of naturals (which are used only as permutations) and is their composition as permutations. We implemented these three POA sentences as a Maude program, which is explained in detail in Appendix B. By running it for and , we obtained the list of all elements of G together with their respective orders.
- We noticed that the set of the orders of the elements of G is . We ran the program again in order to partition G into six order classes (the order class of , denoted , consists of all elements of G of the same order with ).
- Then, with a simple Maude program implementing the logical formulaswe pick one element from each of the six order classes and compute its conjugacy class. For the orders 1, 3, 4, 5, 6, we have , which implies , because it is always the case that . This consumed five short computations. For the second order, we used a random permutation from the respective order class and obtained . Then, we tried randomly with another permutation, , and obtained . It follows that the set of the permutations in G of the second order is partitioned into two conjugacy classes. To summarise, with seven short computations we were able to establish that G has seven conjugacy classes of sizes 1(1), 10(2), 15(2), 20(3), 30(4), 24(5), and 20(6), where means that the conjugacy class has size a and elements of order b.
- Finally, we relied on established knowledge about groups of order 120 as follows. According to the database [11], is the only group with order 120 and seven conjugacy classes, which means that G is isomorphic to .
4.1. Grasping Concrete Isomorphisms
5. Conclusions
Funding
Acknowledgments
Conflicts of Interest
Appendix A. Programs for Proposition 2 and Theorem 1
- The current value of the permutation that suffers the computation process. When this becomes the identity permutation, the computation process stops
- The value of m
- The value of k
- The value of the flag that ensures that the k- cycles are first generated in parallel, then starts the non-deterministic sorting process that applies successive m- cycles
- The inverse of the k- cycle that is currently sorted.
Appendix B. Programs for Proposition 3
Appendix C. Programs for Section 4.1
- Generate all permutations P of non-deterministically.
- For each , we inductively generate the pairs of elements , , such that . This is achieved non-deterministically by two rules, one for each of the two generators (on the one hand P and , on the other hand and ), and by relying on the basic fact that the generated group is just the generated monoid. Moreover, during the generation process we keep trace of the current corresponding element in the free monoid (with two generators, 1 for P and and 2 for and ).
- For each pair , by one rule we establish whether they have the same order by successively computing their powers and . If they have different orders, then the whole computation branch for P halts; otherwise, we continue by going back to stage 2 and generating a new pair .
References
- Cameron, P. Permutation Groups; LMS Student Textbook; Cambridge University Press: Cambridge, UK, 1999; Volume 45. [Google Scholar]
- Hall, M. The Theory of Groups; Macmillan: New York, NY, USA, 1959. [Google Scholar]
- Isaacs, I.M. Finite Group Theory; American Mathematical Society: Providence, RI, USA, 2008. [Google Scholar]
- Passman, D.S. Permutation Groups; Benjamin: New York, NY, USA, 1968. [Google Scholar]
- Wielandt, H. Finite Permutation Groups; Academic Press: New York, NY, USA, 1964. [Google Scholar]
- Piccard, S. Sur les bases du groupe symétrique et du groupe alternant. Math. Ann. 1939, 116, 752–767. [Google Scholar] [CrossRef]
- Clavel, M.; Durán, F.; Eker, S.; Lincoln, P.; Martí-Oliet, N.; Meseguer, J.; Talcott, C. All about Maude—A High-Performance Logical Framework, Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2007; Volume 4350. [Google Scholar]
- Diaconescu, R. Institution-Independent Model Theory; Birkhäuser: Basel, Switzerland, 2008. [Google Scholar]
- Birkhoff, G. On the Structure of Abstract Algebras. Proc. Camb. Philos. Soc. 1935, 31, 433–454. [Google Scholar] [CrossRef]
- Conrad, K. Generating Sets. Available online: http://kconrad.math.uconn.edu/blurbs/grouptheory/genset.pdf (accessed on 1 July 2021).
- Naik, V. The Group Properties Wiki. Available online: http://groupprops.subwiki.org (accessed on 1 July 2021).
- GAP. Groups, Algorithms, Programming—A System for Computational Discrete Algebra. Available online: https://www.gap-system.org (accessed on 1 July 2021).
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Diaconescu, R. Permutation Groups Generated by γ-Cycles. Axioms 2022, 11, 528. https://doi.org/10.3390/axioms11100528
Diaconescu R. Permutation Groups Generated by γ-Cycles. Axioms. 2022; 11(10):528. https://doi.org/10.3390/axioms11100528
Chicago/Turabian StyleDiaconescu, Răzvan. 2022. "Permutation Groups Generated by γ-Cycles" Axioms 11, no. 10: 528. https://doi.org/10.3390/axioms11100528
APA StyleDiaconescu, R. (2022). Permutation Groups Generated by γ-Cycles. Axioms, 11(10), 528. https://doi.org/10.3390/axioms11100528