


Research on Prediction Method of Ferrous Oxide Content in Sinter Based on Optimized Neural Network


Abstract
1. Introduction
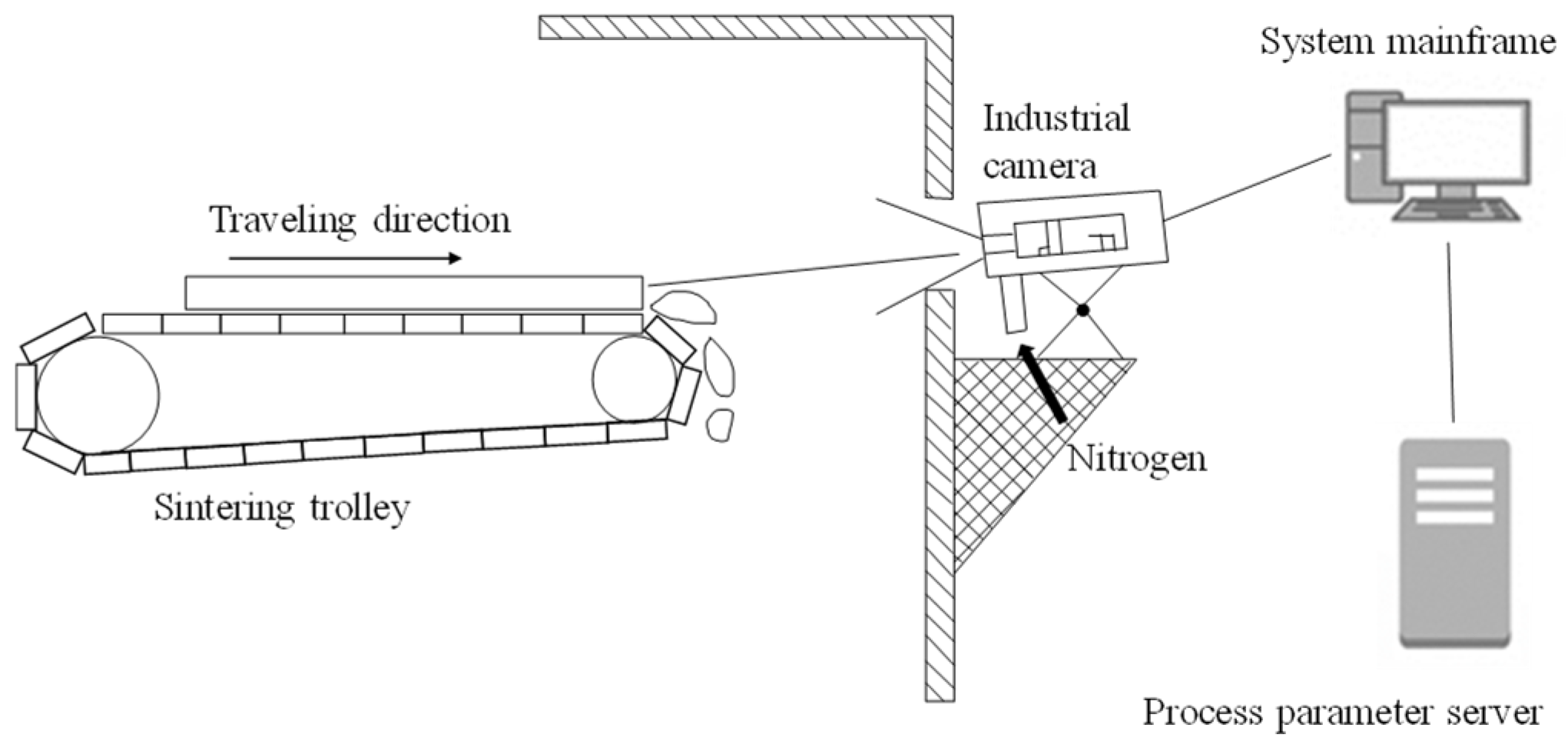
2. Measuring Principle
3. Prediction Method of Ferrous Oxide Content
3.1. Optimal Cross-Section Image Selection Method Based on Brightness Difference
3.1.1. Image Region of Interest Extraction
3.1.2. Method of Selecting the Best Cross-Section Image
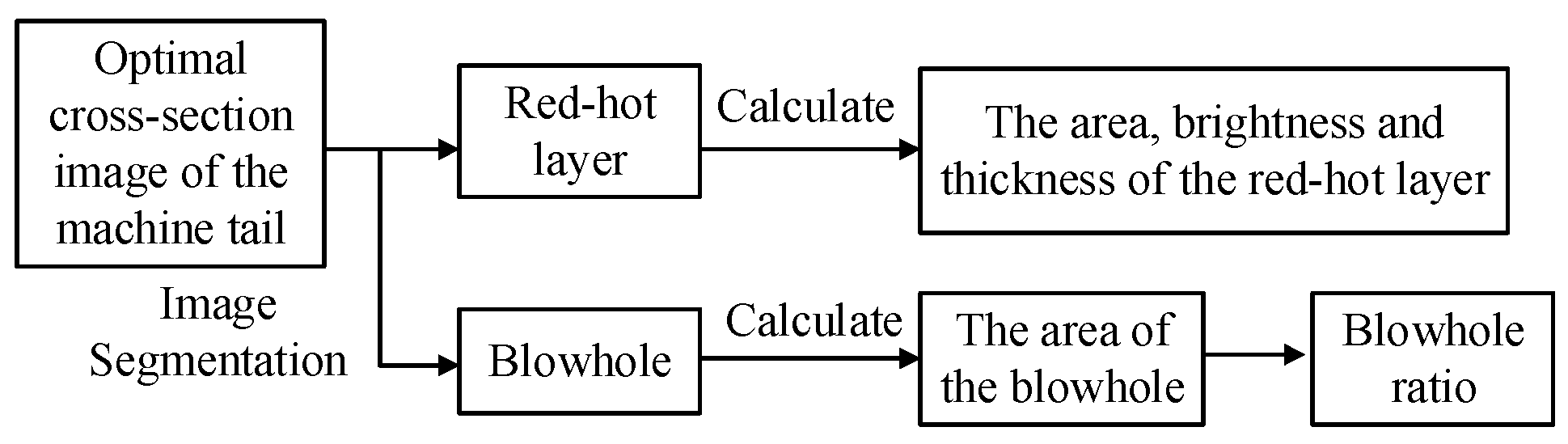
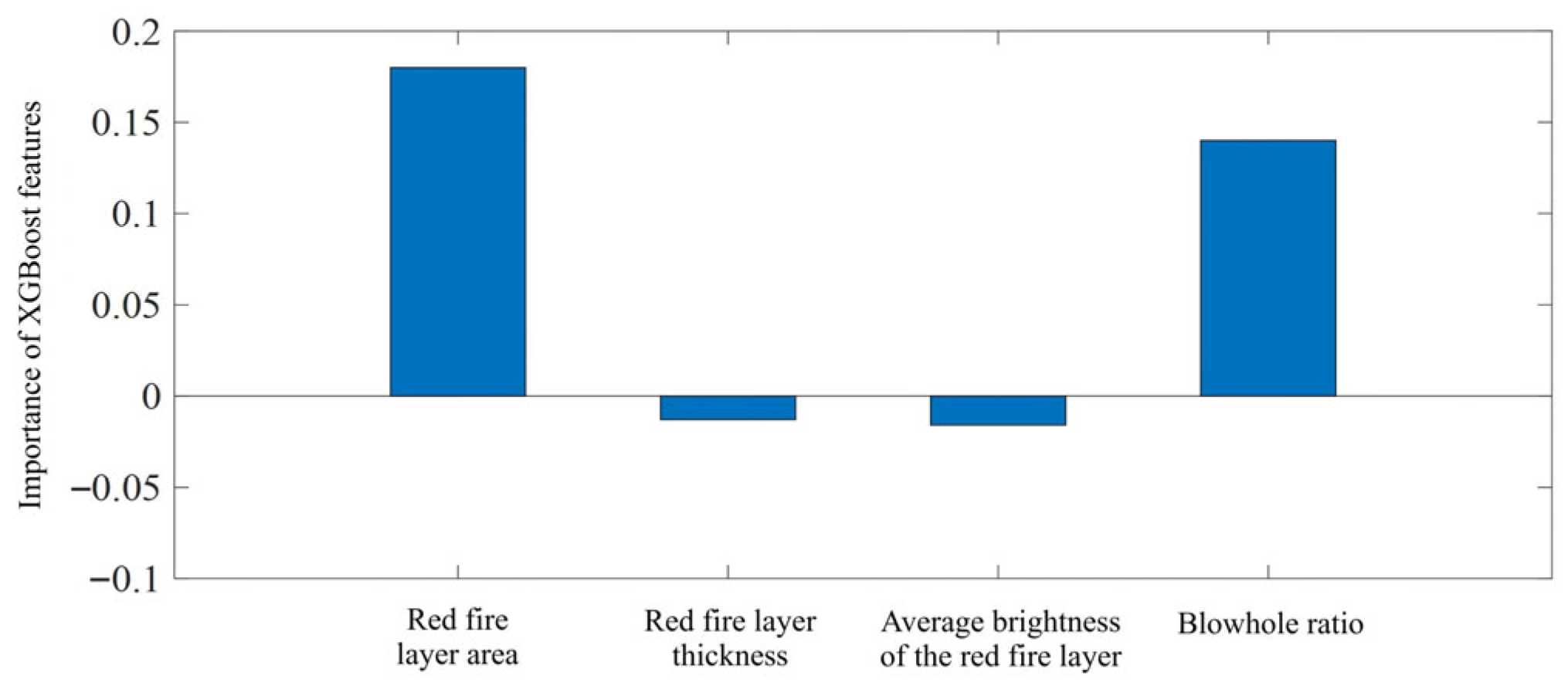
3.2. Feature Parameter Extraction and Processing
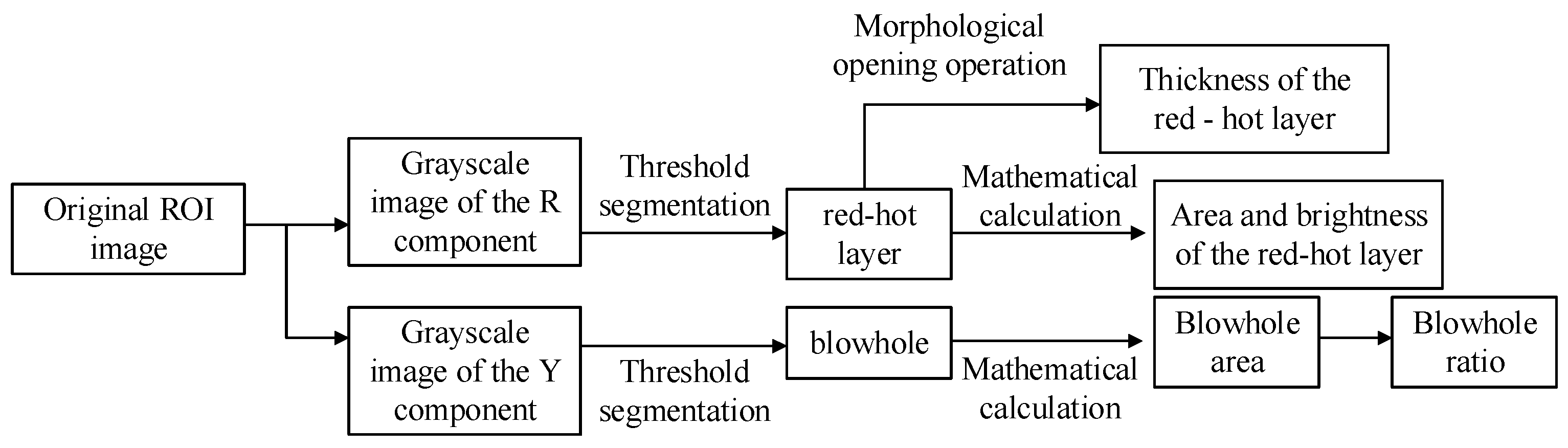
3.2.1. Image Parameter Extraction
- (1)
- Area of red fire layer:
- (2)
- Thickness of red fire layer:
- (3)
- Average brightness of red fire layer:
- (4)
- Blowhole ratio:
3.2.2. Process Parameter Extraction
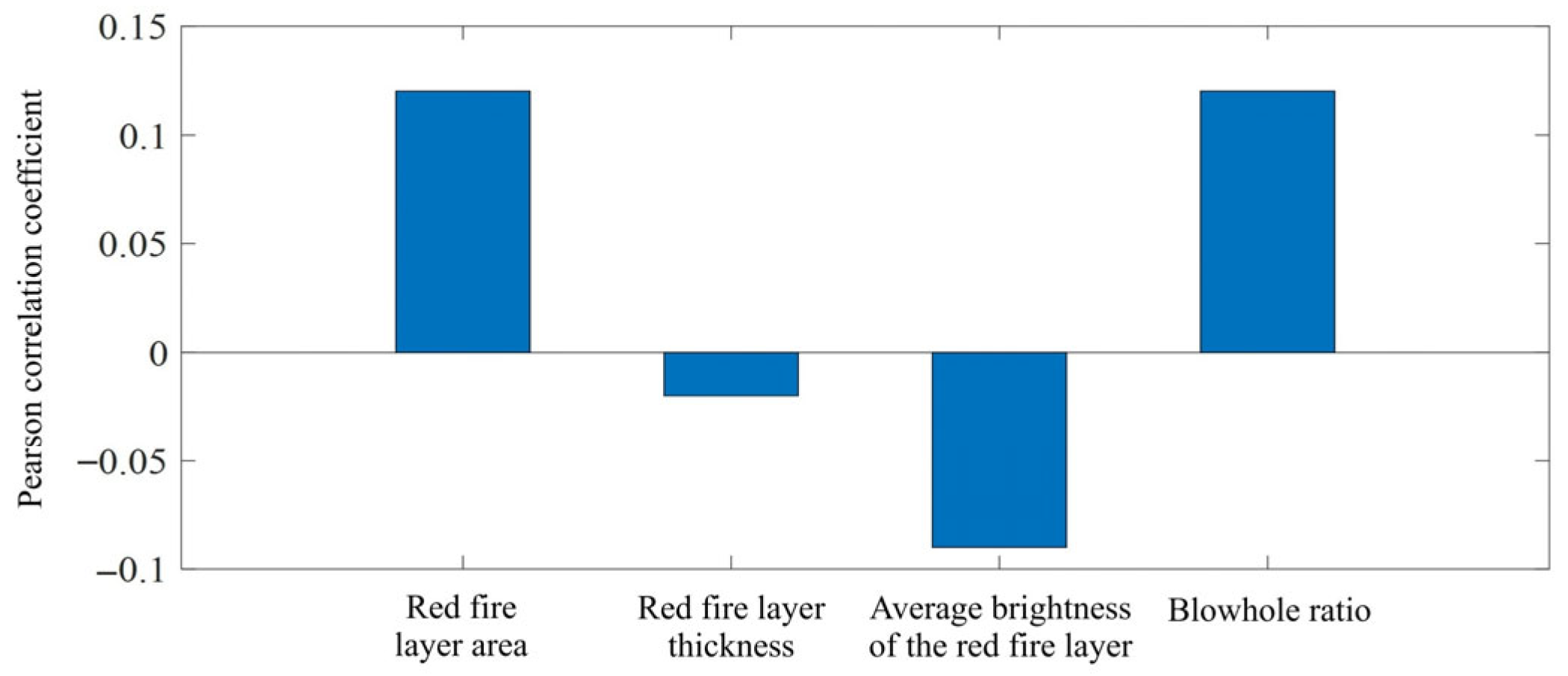
3.2.3. Processing of Characteristic Parameters
3.3. Realization and Optimization of BP Neural Network
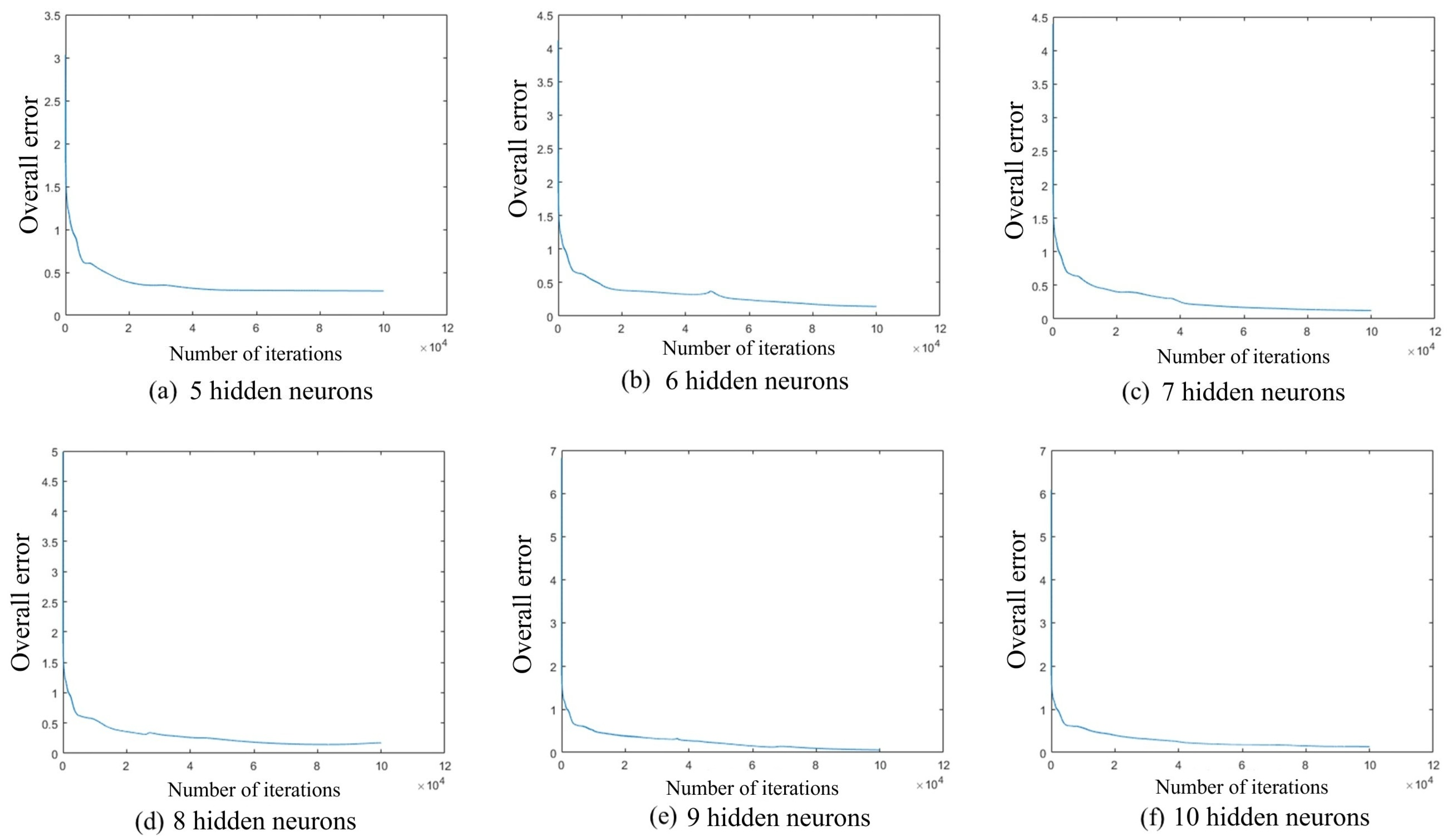
3.3.1. Design of BP Neural Network Structure
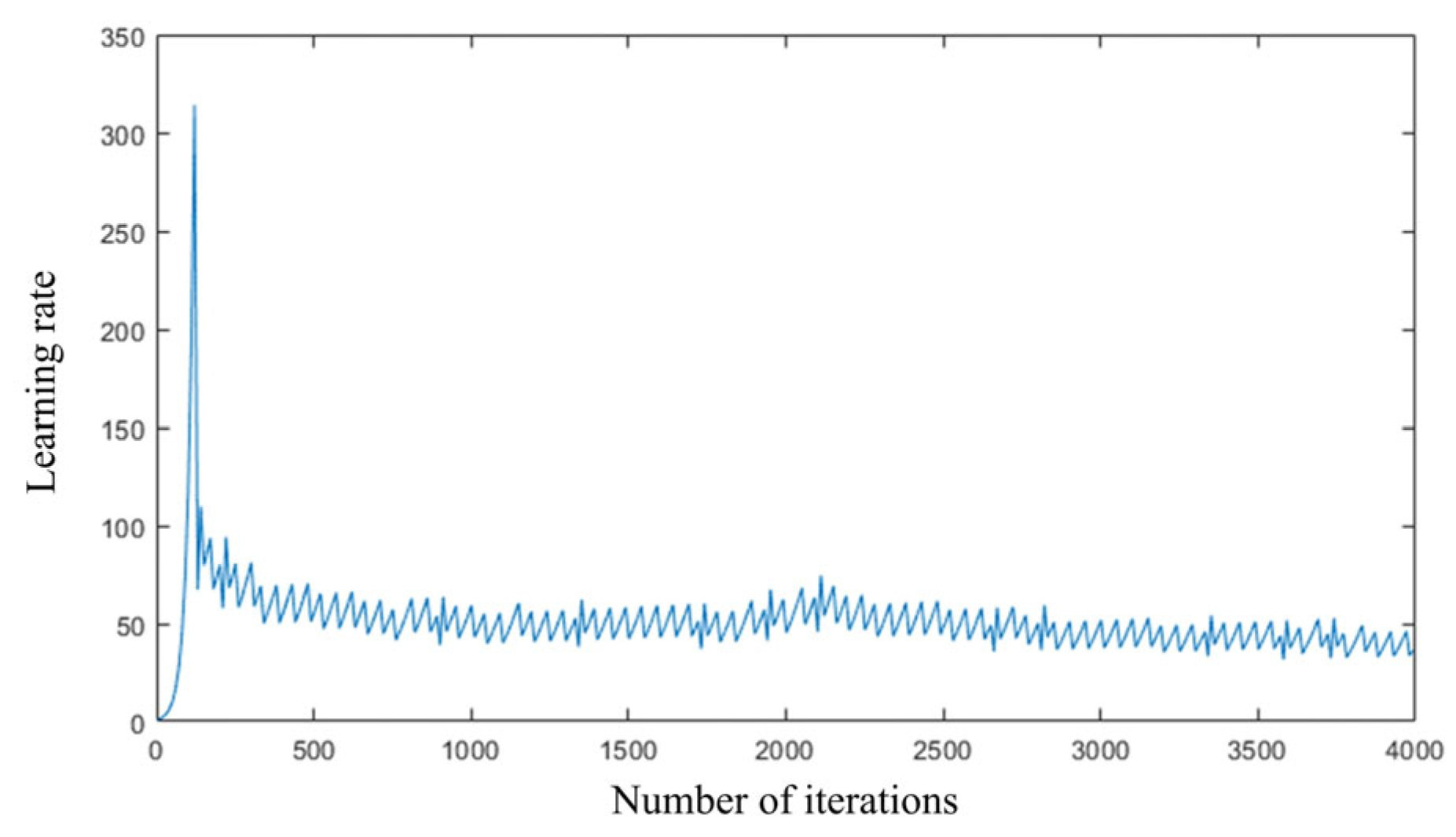
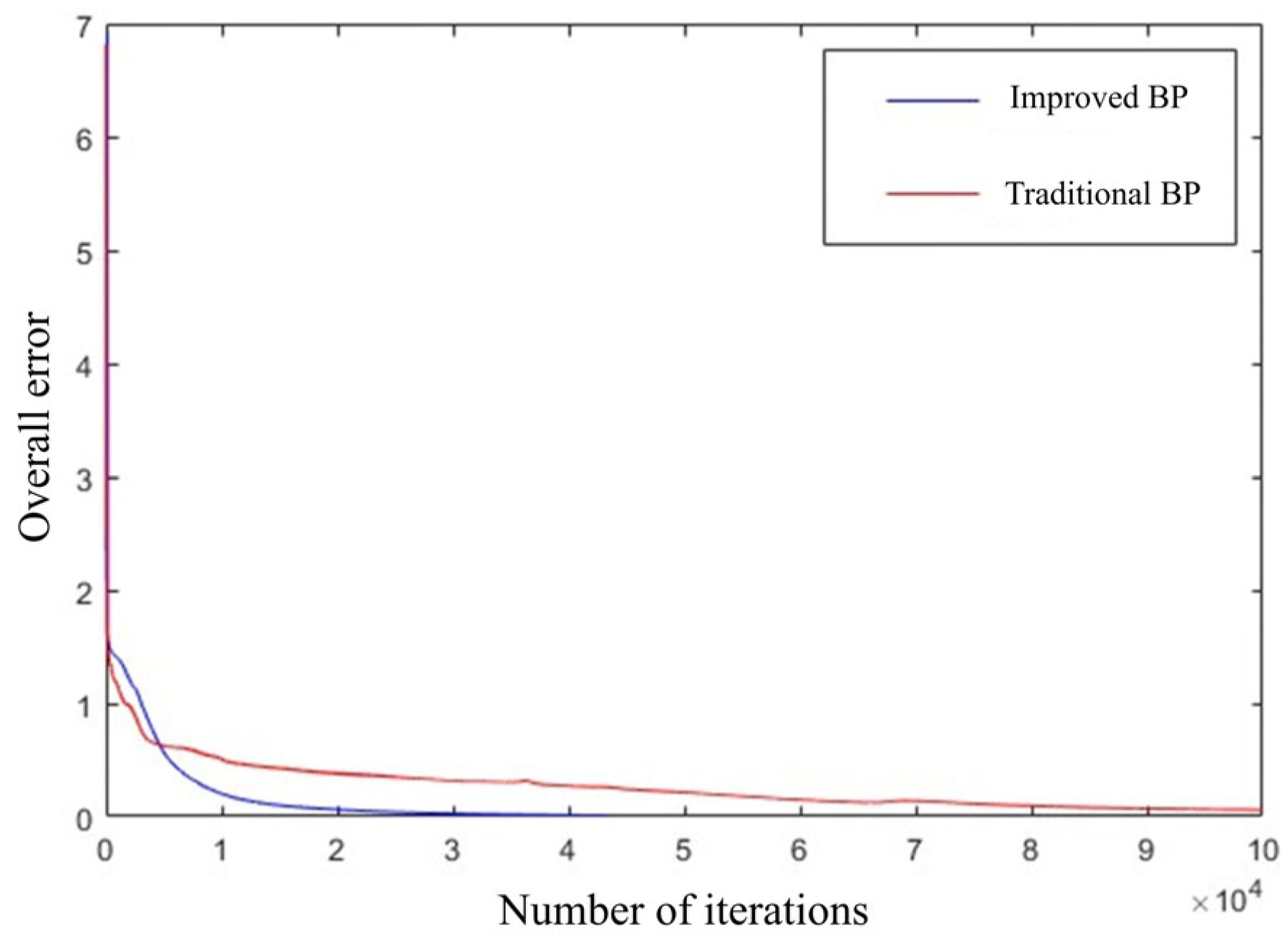
3.3.2. Improvement and Optimization of BP Neural Network
- (1)
- Adaptive learning rate
- (2)
- Additional momentum term
- (1)
- Mean absolute error
- (2)
- Mean relative error
- (3)
- Root Mean Square Error
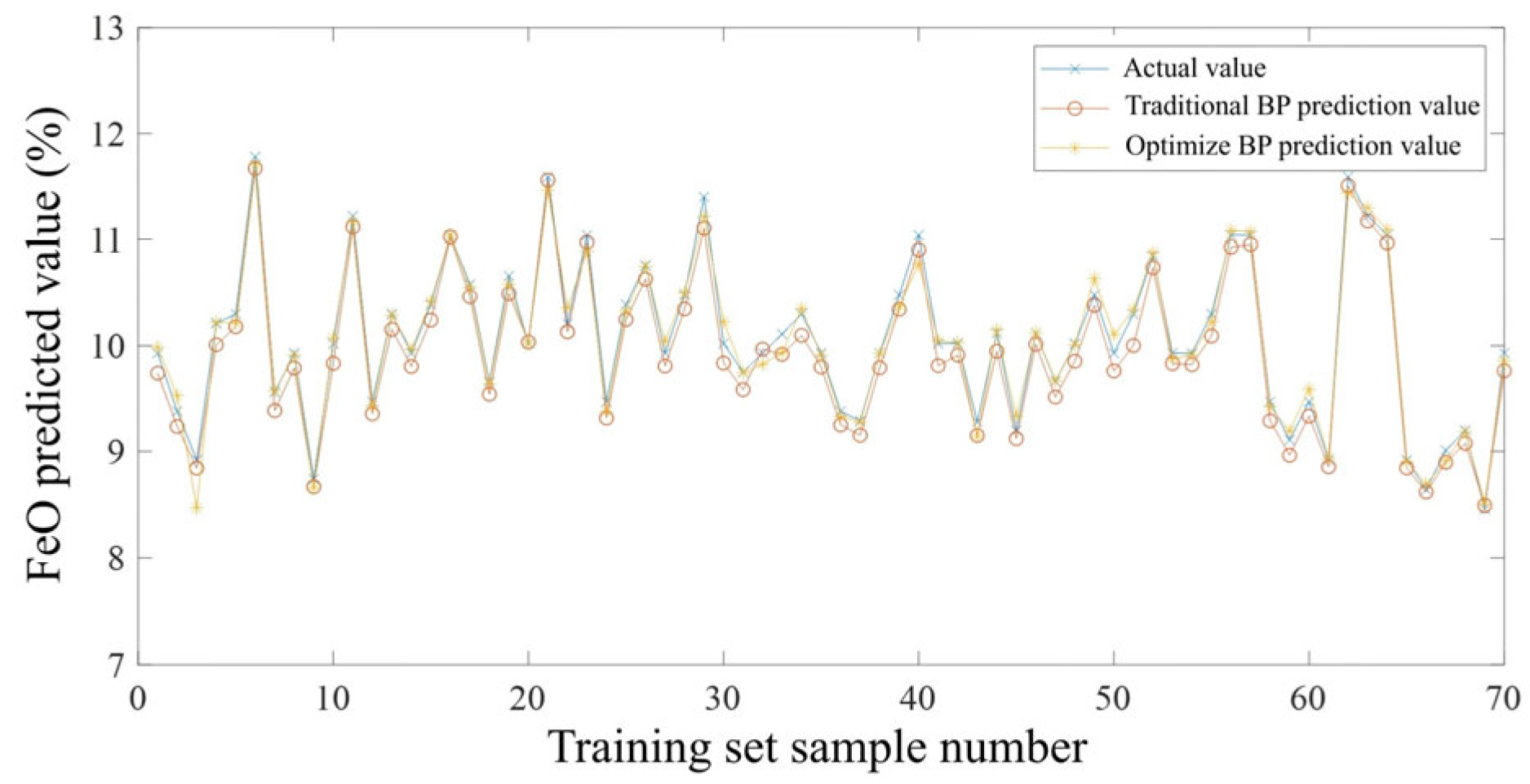
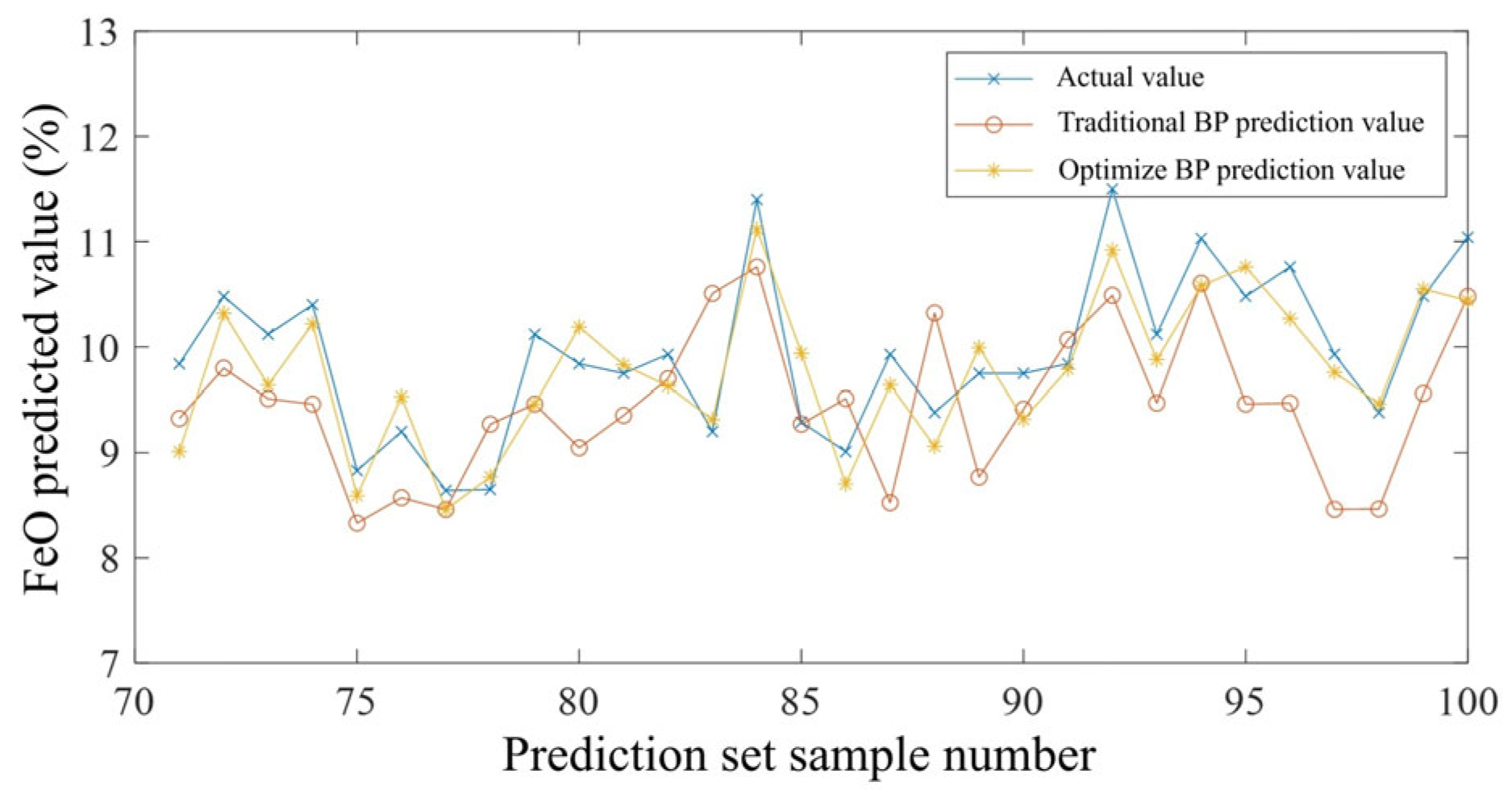
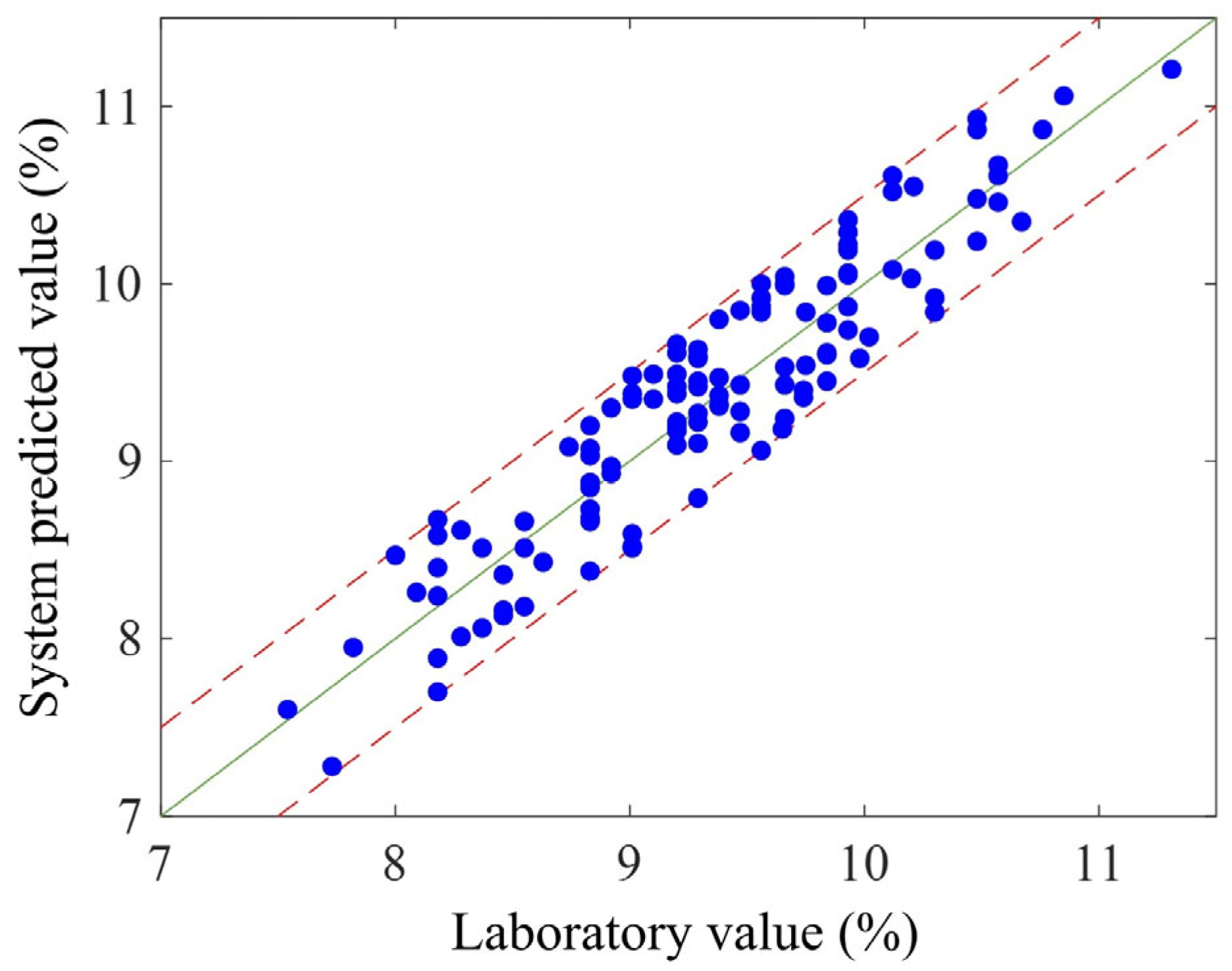
4. Experimental Analysis
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Liu, Y.Q.; Pan, D.; Jiang, Z.H.; Yu, H.Y.; Gui, W.H.; Yang, C.J. A review of detection methods of key parameters in sintering process of iron and steel manufacturing. Sinter. Pelletizing 2023, 48, 10–21. [Google Scholar]
- Wang, Y. Research on Key Technologies of Real Time Prediction System of Sinter FeO Content. Master’s Thesis, Chongqing University, Chongqing, China, 2007. [Google Scholar]
- Ji, X.S.; Jing, T.T.; Xiong, N.Y. Study on FeO content of sinter prediction. Comput. Simul. 2015, 32, 318–322. [Google Scholar]
- Fang, Y.J.; Jiang, Z.H.; Huang, L.; Gui, W.H.; Pan, D. FeO content prediction in sintering process based on fusion of data-knowledge and AW-ESN. Acta Autom. Sin. 2024, 50, 282–294. [Google Scholar]
- Jiang, Z.H.; Guo, Y.H.; Pan, D.; Gui, W.H.; Maldague, X. Polymorphic measurement method of FeO content of sinter based on heterogeneous features of infrared thermal images. IEEE Sens. J. 2021, 21, 12036–12047. [Google Scholar] [CrossRef]
- Li, T.; Zhang, Z.; Chen, H. Predicting the combustion state of rotary kilns using a convolutional recurrent neural network. J. Process Control 2019, 84, 207–214. [Google Scholar] [CrossRef]
- Wu, J. Research on Artificial Intelligence Method of Sintering Quality Based on Sectional Image of Sintering Machine Discharge End. Master’s Thesis, Northeastern University, Shenyang, China, 2013. [Google Scholar]
- Liang, X.M.; Jin, A.M.; Cao, X.H.; Zeng, K.; Wang, F.B. Flame image recognition of sintering section based on improved MobileNetV3. Electron. Meas. Technol. 2023, 46, 182–187. [Google Scholar]
- Zhang, F.; Wei, G.; Pang, W.; Gao, Q.J.; Chen, W.L.; Wen, Q.L.; Du, G. A study on mathematical model of prediction of FeO content in the sintering ore. J. Mater. Metall. 2013, 12, 159–162+168. [Google Scholar]
- Zhang, X.F.; Wen, Y.X.; Xiong, D.L.; Long, H.M. Prediction of FeO content in sinter based on BiLSTM model. Metall. Ind. Autom. 2023, 47, 85–92. [Google Scholar]
- Chen, X.X.; Lan, T.; Shi, X.H.; Tong, C.D. A semi-supervised linear–nonlinear least-square learning network for prediction of carbon efficiency in iron ore sintering process. Control Eng. Pract. 2020, 100, 104454. [Google Scholar] [CrossRef]
- Du, S.; Ma, X.; Li, X.; Cao, W.H.; Wu, M. Perception of working condition of sintering process based on information granulation and fuzzy rules. Sinter. Pelletizing 2023, 48, 124–131. [Google Scholar]
- Khagi, B.; Lee, K.H.; Choi, K.Y.; Lee, J.J.; Kwon, G.R.; Yang, H.D. VBM-based alzheimer’s disease detection from the region of interest of T1 MRI with supportive Gaussian smoothing and a bayesian regularized neural network. Appl. Sci. 2021, 11, 6175. [Google Scholar] [CrossRef]
- Wang, X.F.; Sun, X.D.; Sun, Q.K.; Zhang, J.L.; Liu, Z.J.; Wang, Y.Z. Prediction of compressive strength of pellet ore based on feature selection and PSO XGBoost. Shanxi Metall. 2024, 47, 110–113. [Google Scholar]
- Duan, X.Y. Research on Feature Selection to Improve the Accuracy of LIBS Steel Classification. Master’s Thesis, Changchun University of Technology, Changchun, China, 2024. [Google Scholar]
- Liu, Y.P.; Liu, Y.J.; Lv, F.C.; Xie, Q.; Gao, S.G.; Gao, F. Application prospect and key technology of digital twin in power transmission and transformation equipment. High Volt. Eng. 2022, 48, 1621–1633. [Google Scholar]
- Chen, Z.Y.; Liu, J.B.; Li, C.; Ji, X.H.; Li, D.P.; Huang, Y.H.; Di, F.C.; Gao, X.Y.; Xu, L.Z. Ultra Short-term Power Load Forecasting Based on Combined LSTM-XGBoost Model. Power Syst. Technol. 2020, 44, 614–620. [Google Scholar]
- Kang, J.; Mi, X.X.; Wang, H.L.; Wu, L.; Sun, K.; Tang, A.T. Research progress of artificial neural networks in material science. Mater. Rep. 2020, 34, 21172–21179. [Google Scholar]
- Zhang, D.; Chen, L. A BP neural network-assisted smart decision method for education quality. IEEE Access 2023, 11, 74569–74578. [Google Scholar] [CrossRef]
- Xia, J.M.; Ding, C.J.; Tan, L. Deep belief network intrusion detection method based on grey wolf algorithm. Comput. Eng. Des. 2020, 41, 1534–1539. [Google Scholar]
- Yan, X.D.; Xu, Y.; Xing, X.F.; Cui, B.J.; Guo, Z.H.; Guo, T.B. Trustworthy network anomaly detection based on an adaptive learning rate and momentum in IIoT. IEEE Trans. Ind. Inform. 2020, 16, 6182–6192. [Google Scholar] [CrossRef]
- Deng, Q.; Gao, J.J.; Ge, D.D.; He, S.M.; Jiang, B.; Li, X.C.; Wang, Z.Z.; Yang, C.L.; Ye, Y.Y. Modern optimization theory and applications. Sci. Sin. Math. 2020, 50, 899–968. [Google Scholar]
- Deng, L.K.; Lv, D.P. PID parameter tuning of remotely operated vehicle control attitude based on genetic algorithm. Manuf. Autom. 2023, 45, 177–179+206. [Google Scholar]
- Lin, Y.; Zhao, H.; Ding, H. Solution of inverse kinematics for general robot manipulators based on multiple population genetic algorithm. J. Mech. Eng. 2017, 53, 1–8. [Google Scholar] [CrossRef]
- Hyndman, R.J.; George, A. Forecasting: Principles and Practice, 3rd ed.; OTexts: Melbourne, Australia, 2019. [Google Scholar]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Brightness Difference Value | >1 × 108 | 7 × 107∼1 × 108 | 5 × 107∼7 × 107 | <5 × 107 |
| Occurrence times | 19 | 63 | 15 | 3 |
| Computation Model | MAE | MRE | RMSE |
|---|---|---|---|
| Traditional BP | 0.127 | 0.013 | 0.139 |
| BP optimized by genetic algorithm | 0.072 | 0.007 | 0.103 |
| Prediction Method | MAE | MRE | RMSE |
|---|---|---|---|
| Traditional BP | 0.713 | 0.071 | 0.800 |
| BP optimized by genetic algorithm | 0.319 | 0.032 | 0.374 |
| Testing Time | Chemical Detection Value (%) | System Prediction Time | Estimate (%) | Absolute Error (%) |
|---|---|---|---|---|
| 2023/12/1 2:55 | 8.92 | 2023/12/1 1:02 | 9.0 | 0.08 |
| 2023/12/1 5:04 | 9.56 | 2023/12/1 3:02 | 9.9 | 0.34 |
| 2023/12/1 6:48 | 9.01 | 2023/12/1 5:02 | 9.4 | 0.39 |
| 2023/12/1 9:16 | 9.66 | 2023/12/1 7:02 | 10.0 | 0.34 |
| …… | …… | …… | …… | …… |
| 2023/12/10 17:00 | 8.55 | 2023/12/10 15:02 | 8.5 | 0.05 |
| 2023/12/10 19:05 | 8.83 | 2023/12/10 17:02 | 8.4 | 0.43 |
| 2023/12/10 20:58 | 8.18 | 2023/12/10 19:02 | 8.4 | 0.22 |
| 2023/12/10 23:21 | 8.28 | 2023/12/10 21:02 | 8.6 | 0.32 |
| 2023/12/11 1:08 | 8.09 | 2023/12/10 23:02 | 8.3 | 0.21 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, S.; Cao, Y.; Zhou, Z.; Li, X.; Zhu, Y. Research on Prediction Method of Ferrous Oxide Content in Sinter Based on Optimized Neural Network. Minerals 2025, 15, 553. https://doi.org/10.3390/min15060553
Li S, Cao Y, Zhou Z, Li X, Zhu Y. Research on Prediction Method of Ferrous Oxide Content in Sinter Based on Optimized Neural Network. Minerals. 2025; 15(6):553. https://doi.org/10.3390/min15060553
Chicago/Turabian StyleLi, Shaohui, Yuanyuan Cao, Zhenjie Zhou, Xinghua Li, and Yanlong Zhu. 2025. "Research on Prediction Method of Ferrous Oxide Content in Sinter Based on Optimized Neural Network" Minerals 15, no. 6: 553. https://doi.org/10.3390/min15060553
APA StyleLi, S., Cao, Y., Zhou, Z., Li, X., & Zhu, Y. (2025). Research on Prediction Method of Ferrous Oxide Content in Sinter Based on Optimized Neural Network. Minerals, 15(6), 553. https://doi.org/10.3390/min15060553