
Contextual Representation in NLP to Improve Success in Accident Classification of Mine Safety Narratives


Abstract
1. Introduction
2. Research Methodology
2.1. Data Collection: MSHA Accident Database
Selection of Accident Categories for the Study
2.2. Data Preparation for Training and Test Sets
2.3. Performance Metrics
2.4. Previous Research: Random Forest Classifier
2.5. Previous Research: Similarity Score (SS), ASECV, and “Stacked” Approaches
2.6. Current Research: Bidirectional Encoder Representations from Transformers (BERT) Approach
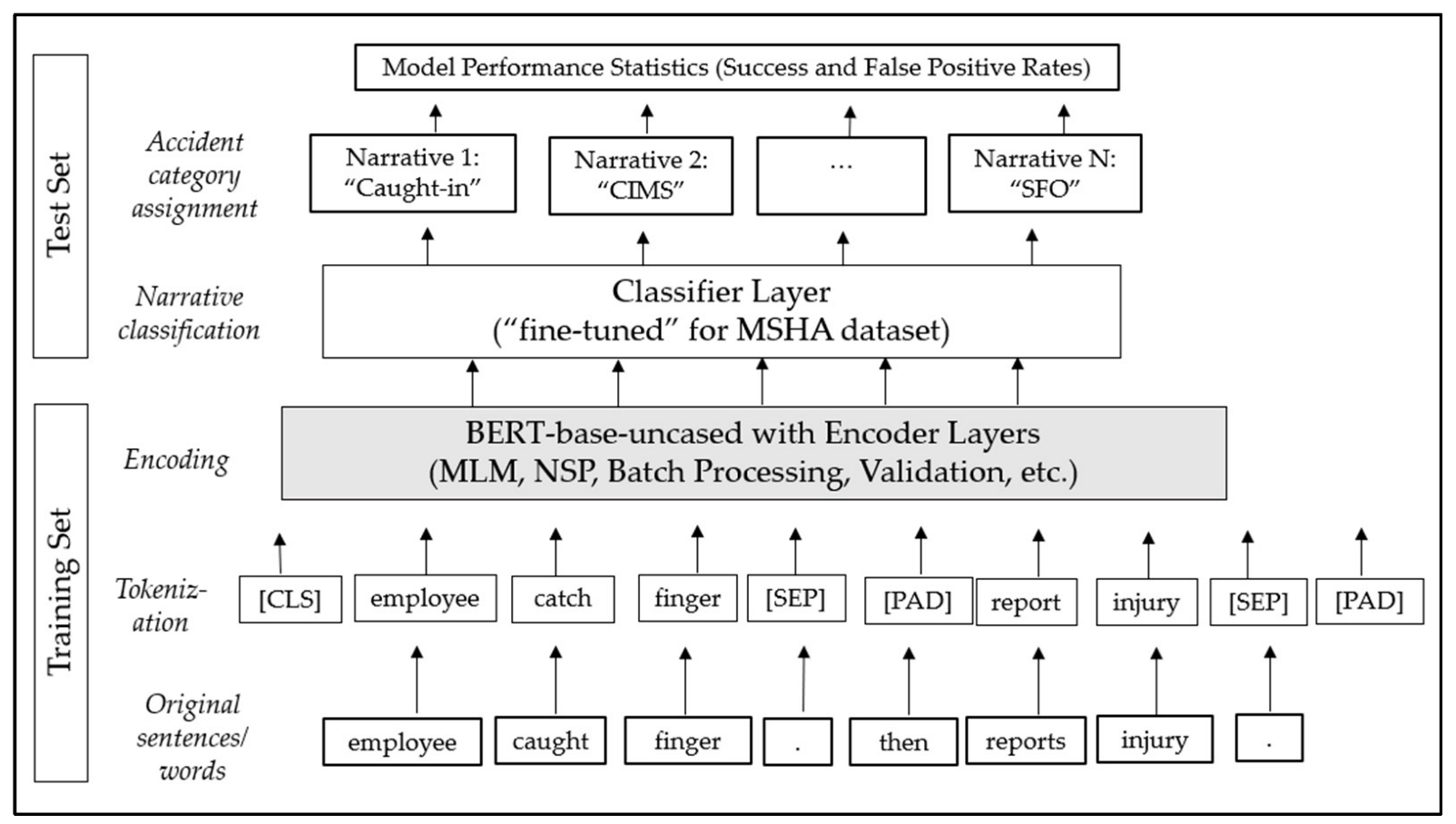
Development of MineBERT for MSHA Dataset
- To allow comparison with past research, the MSHA accident narratives are divided into 50:50 training to testing subsets. In case of MineBERT, however, the training set is randomly split into two, a sub_training set and a validation subset. The training occurs on the sub_training set, while the validation subset is used to ensure the generalization of the training. Overall, the split between sub_training, validation, and test set is a 40:10:50. This split does not affect comparison with the other methods as it is simply an internal procedure of MineBERT training.
- Narratives from the training set are tokenized, and the length of the longest sentence (“maximum length”) in terms of the number of words will be captured. Then, a vector of maximum length is created for the “word embedding” of each sentence.
- Sentence embedding: In the maximum length vector or tensor space, each sentence is identified starting with the code or notation [CLS], and sentences are separated with [SEP] to recognize individual sentences. Empty spaces in the maximum length vector are padded with [PAD] notation.
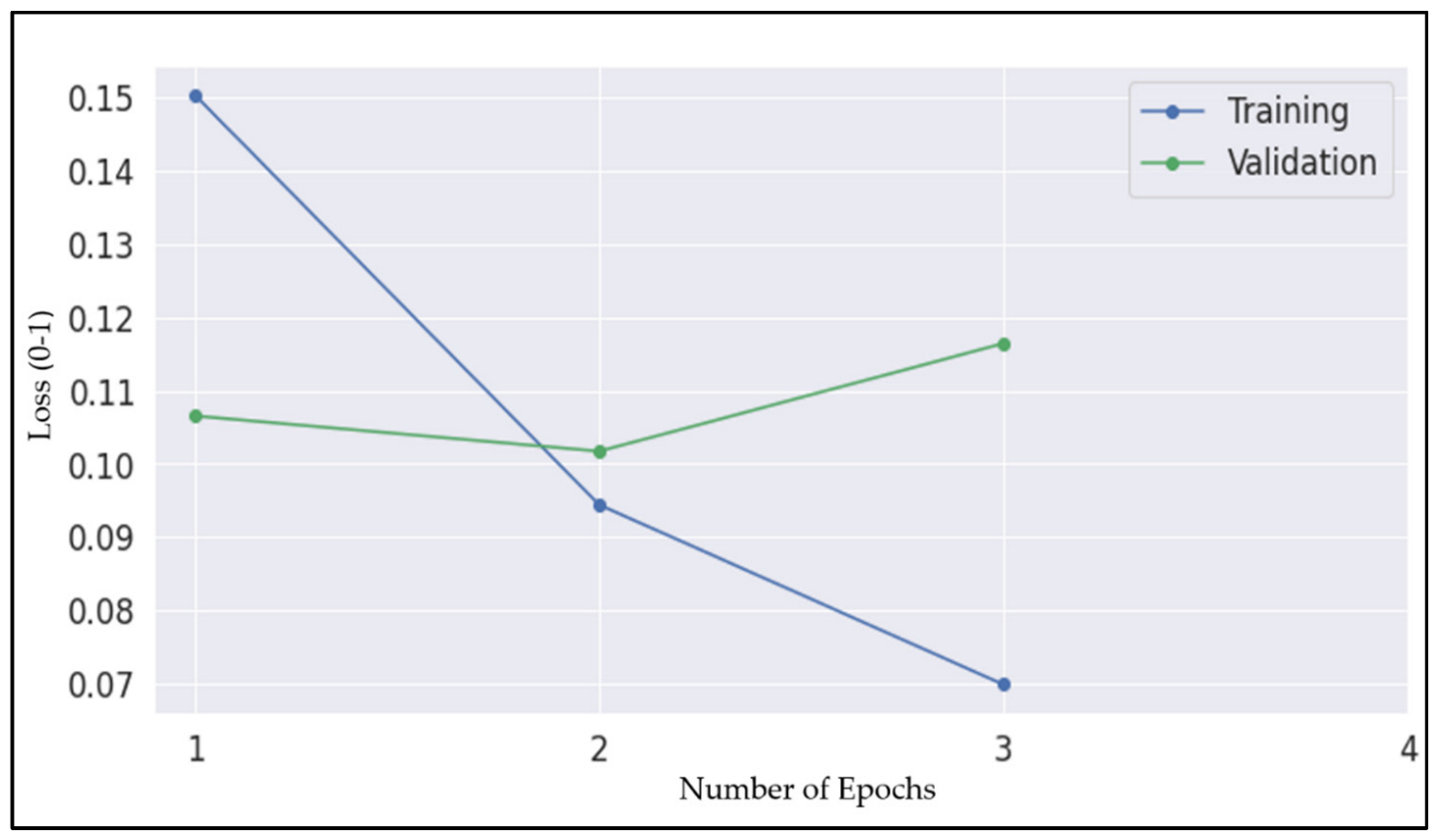
- In the training process, 15% of the tokens from sentence embedding (sub_training set) are masked with a notation [MASK] and predicted during the encoding process. The Transformer based encoders in BERT-base perform training and validation processes at the given (optimum) batch and epoch sizes.
- The last layers of MineBERT are used for fine-tuning the whole model to the MSHA dataset from the knowledge gained from the training process.
- The trained model is then applied to test set narratives to get the accident category assignment. A “classifier layer” is used to assign accident categories to the narratives while in the testing stage.
- Performance metrics such as success (“% from category accurately predicted”) and failure (false positive) rates for the test set are then calculated.
3. Results
4. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Sebastiani, F. Machine learning in automated text categorization. ACM Comput. Surv. 2002, 34, 1–47. [Google Scholar] [CrossRef]
- Joachims, T. Text categorization with support vector machines: Learning with many relevant features. In Proceedings of the 10th European Conference on Machine Learning (ECML ‘98), Chemnitz, Germany, 21–23 April 1998. [Google Scholar]
- Dumais, S.T.; Platt, J.; Heckerman, D.; Sahami, M. Inductive learning algorithms and representations for text categorization. In Proceedings of the Seventh International Conference on Information and Knowledge Managemen (CIKM ‘98), Bethesda, MD, USA, 2–7 November 1998. [Google Scholar]
- Ganguli, R.; Miller, P.; Pothina, R. Effectiveness of natural language processing based machine learning in analyzing incident narratives at a mine. Minerals 2021, 11, 776. [Google Scholar] [CrossRef]
- Pothina, R.; Ganguli, R. The importance of specific phrases in automatically classifying mine accident narratives using natural language processing. Knowledge 2022, 2, 365–387. [Google Scholar] [CrossRef]
- Rogers, A.; Kovaleva, O.; Rumshisky, A. A Primer in BERTology: What We Know about How BERT Works. Trans. Assoc. Comput. Linguist. 2020, 8, 842–866. [Google Scholar] [CrossRef]
- Almeida, F.; Xexeo, G. Word Embeddings: A Survey. Available online: https://arxiv.org/pdf/1901.09069.pdf (accessed on 21 May 2023).
- Jurafsky, D.; Martin, D.J. Speech and Language Processing. Available online: https://web.stanford.edu/jurafsky/slp3/6.pdf (accessed on 21 May 2023).
- ELMo. Available online: https://allenai.org/allennlp/software/elmo (accessed on 20 May 2023).
- Devlin, J.; Ming-Wei, C.; Kenton, L.; Toutanova, K. BERT: Pre-training of deep bidirectional transformers for language understanding. arXiv 2022, arXiv:1810.04805. [Google Scholar]
- Brown, T.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.D.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A.; et al. Language models are few-shot learners. In Proceedings of the Advances in Neural Information Processing Systems 33: Annual Conference on Neural Information Processing Systems (NeurIPS 2020), Virtual, 6–12 December 2020. [Google Scholar]
- Mnasri, M. Recent advances in conversational NLP: Towards the standardization of Chatbot building. arXiv 2022, arXiv:1903.09025. [Google Scholar]
- ChatGPT. Available online: https://openai.com/blog/chatgpt/ (accessed on 2 January 2023).
- Wang, Y.; Sohn, S.; Liu, S.; Shen, F.; Wang, L.; Atkinson, E.J.; Amin, S.; Liu, H. A clinical text classification paradigm using weak supervision and deep representation. BMC Med. Inform. Decis. Mak. 2019, 19, 1. [Google Scholar] [CrossRef] [PubMed]
- Radford, A.; Narasimhan, K.; Salimans, T.; Sutskever, I. Improving language understanding with unsupervised learning. Available online: https://cdn.openai.com/research-covers/language-unsupervised/language_understanding_paper.pdf (accessed on 10 January 2023).
- Zhen, H.; Xu, S.; Hu, M.; Wang, X.; Qiu, J.; Fu, Y.; Zhao, Y.; Peng, Y.; Wang, C. Recent trends in deep learning based open-domain textual question answering systems. IEEE Access 2020, 8, 94341–94356. [Google Scholar]
- Howard, J.; Ruder, S. Universal Language Model Fine-tuning for Text Classification. Available online: https://arxiv.org/pdf/1801.06146.pdf (accessed on 21 May 2023).
- Zhu, Y.; Kiros, R.; Zemel, R.; Salakhutdinov, R.; Urtasun, R.; Torralba, A.; Fidler, S. Aligning books and movies: Towards story-like visual explanations by watching movies and reading books. arXiv 2023, arXiv:1506.06724. [Google Scholar]
- Hegazi, Y.S. Resilience adaptation approach for reducing the negative impact of climate change on coastal heritage sites through machine learning. Appl. Sci. 2022, 12, 10916. [Google Scholar] [CrossRef]
- Wettig, A.; Gao, T.; Zhong, Z.; Chen, D. Should You Mask 15% in Masked Language Modeling? arXiv 2022, arXiv:2202.08005. [Google Scholar]
- Liu, Y.; Ott, M.; Goyal, N.; Du, J.; Joshi, M.; Chen, D.; Levy, O.; Lewis, M.; Zettlemoyer, L.; Stoyanov, V. RoBERTa: A Robustly Optimized BERT Pretraining Approach. Available online: https://arxiv.org/abs/1907.11692 (accessed on 22 May 2023).
- Beltagy, I.; Kyle, L.; Cohan, A. SciBERT: A pretrained language model for scientific text. arXiv 2022, arXiv:1903.10676. [Google Scholar]
- Dogu, T.A. Finbert: Financial sentiment analysis with pre-trained language models. arXiv 2022, arXiv:1908.10063. [Google Scholar]
- Jinhyuk, L.; Wonjin, Y.; Sungdong, K.; Donghyeon, K.; Sunkyu, K.; Chan, H.S.; Jaewoo, K. BioBERT: A pre-trained biomedical language representation model for biomedical text mining. Bioinformatics 2020, 36, 1234–1240. [Google Scholar]
- Duan, J.; Hui, Z.; Qian, Z.; Meikang, Q.; Meiqin, L. A study of pre-trained language models in natural language processing. In Proceedings of the 2020 IEEE International Conference on Smart Cloud (SmartCloud), Washington, DC, USA, 6–8 November 2020. [Google Scholar]
- Hu, Y.; Ding, J.; Dou, Z.; Chang, H. Short-Text Classification Detector: A Bert-Based Mental Approach. Comput. Intell. Neurosci. 2022, 2022, 8660828. [Google Scholar] [CrossRef] [PubMed]
- Weili, F.; Hanbin, L.; Shuangjie, X.; Peter, E.D.L.; Zhenchuan, L.; Cheng, Y. Automated text classification of near-misses from safety reports: An improved deep learning approach. Adv. Eng. Inform. 2020, 44, 101060. [Google Scholar]
- IBM: What is Random Forest? Available online: https://www.ibm.com/cloud/learn/random-forest#:~:text=Providesflexibility%3A (accessed on 15 April 2022).
- Mitchell, T.M. Machine Learning. In Machine Learning; McGraw-Hill: New York, NY, USA, 1997; Volume 45. [Google Scholar]
- Morita, K.; Atlam, E.; Fuketra, M.; Tsuda, K.; Oono, M.; Aoe, J. Word classification and hierarchy using co-occurrence word information. Inf. Process. Manag. 2004, 40, 957–972. [Google Scholar] [CrossRef]
- Goot, R.V. We Need to Talk About train-dev-test Splits. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, Online and Punta Cana, Dominican Republic, 7–11 November 2021; pp. 4485–4494. [Google Scholar]



{kind=link}
{kind=link}
| MSHA Narrative | Text |
|---|---|
| Original | “Employee was assisting 3 other miners move Grizzly component in place. While maintaining a vertical position on the component to rehook, the component became unstable and shifted. The employee’s effort to maintain it upright failed and it leaned, pinned his elbow against the rib, bending back and breaking left wrist.” |
| Lemmatized form | assist 3 miner move grizzly component place maintain vertical position component rehook component become unstable shift’s effort maintain upright fail lean pin elbow rib bend back break left wrist |
| Accident type | Caught in, under or between a moving and a stationary object (CIMS) |
| Parameter | Value/Information |
|---|---|
| NLP model adapted | BERT-base-uncased |
| Type of encoder | Bi-directional Transformer |
| Number of encoders | 12 |
| Number of self-attention heads | 12 |
| Total parameters | 110 million |
| % of tokens used in masked LM | 15% |
| Type of text processed | Uncased MSHA accident narratives |
| Major data processing steps | Pre-training followed by fine-tuning |
| % data split | Training set: 50% (training: 40%, validation: 10%) and Test set: 50% |
| Training batch size | 32 |
| Number of epochs used for fine-tuning | 2 |
| Metrics | Type Group: OE | Type Group: Caught in | Type Group: Struck by | Type Group: Fall | OEP | OEL | FWW | CIMS | SFO |
|---|---|---|---|---|---|---|---|---|---|
| Records from Category | 8979 | 4524 | 10,226 | 4926 | 1275 | 2961 | 2130 | 3310 | 1590 |
| Overall Success | 92% | 96% | 90% | 95% | 98% | 96% | 96% | 95% | 97% |
| MineBERT→ | 95% | 97% | 95% | 97% | 98% | 97% | 98% | 96% | 97% |
| % from Category Accurately Predicted | 81% | 71% | 75% | 71% | 37% | 59% | 34% | 55% | 25% |
| MineBERT→ | 90% | 85% | 89% | 87% | 70% | 83% | 73% | 80% | 64% |
| False Positives | 4% | 1% | 5% | 2% | <1% | <1% | <1% | 2% | <1% |
| MineBERT→ | <1% | <1% | <1% | <1% | <1% | <1% | <1% | <1% | <1% |
| Metrics | Major or Type Groups | Narrow Groups | ||
|---|---|---|---|---|
| Average | Range | Average | Range | |
| Overall Success: | ||||
| RF | 93% | (90%–95%) | 96% | (95%–98%) |
| MineBERT | 96% | (95%–97%) | 97% | (96%–98%) |
| % from Category Accurately Predicted: | ||||
| RF | 75% | (71%–81%) | 42% | (25%–59%) |
| MineBERT | 88% | (85%–90%) | 74% | (64%–83%) |
| False Positives: | ||||
| RF | 3% | (1%–5%) | 96% | (1%–2%) |
| MineBERT | 1% | (0%–1%) | 97% | (0%–1%) |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Pothina, R.; Ganguli, R. Contextual Representation in NLP to Improve Success in Accident Classification of Mine Safety Narratives. Minerals 2023, 13, 770. https://doi.org/10.3390/min13060770
Pothina R, Ganguli R. Contextual Representation in NLP to Improve Success in Accident Classification of Mine Safety Narratives. Minerals. 2023; 13(6):770. https://doi.org/10.3390/min13060770
Chicago/Turabian StylePothina, Rambabu, and Rajive Ganguli. 2023. "Contextual Representation in NLP to Improve Success in Accident Classification of Mine Safety Narratives" Minerals 13, no. 6: 770. https://doi.org/10.3390/min13060770
APA StylePothina, R., & Ganguli, R. (2023). Contextual Representation in NLP to Improve Success in Accident Classification of Mine Safety Narratives. Minerals, 13(6), 770. https://doi.org/10.3390/min13060770