Soil Mapping Based on the Integration of the Similarity-Based Approach and Random Forests


Abstract
1. Introduction
2. Study Area and Materials
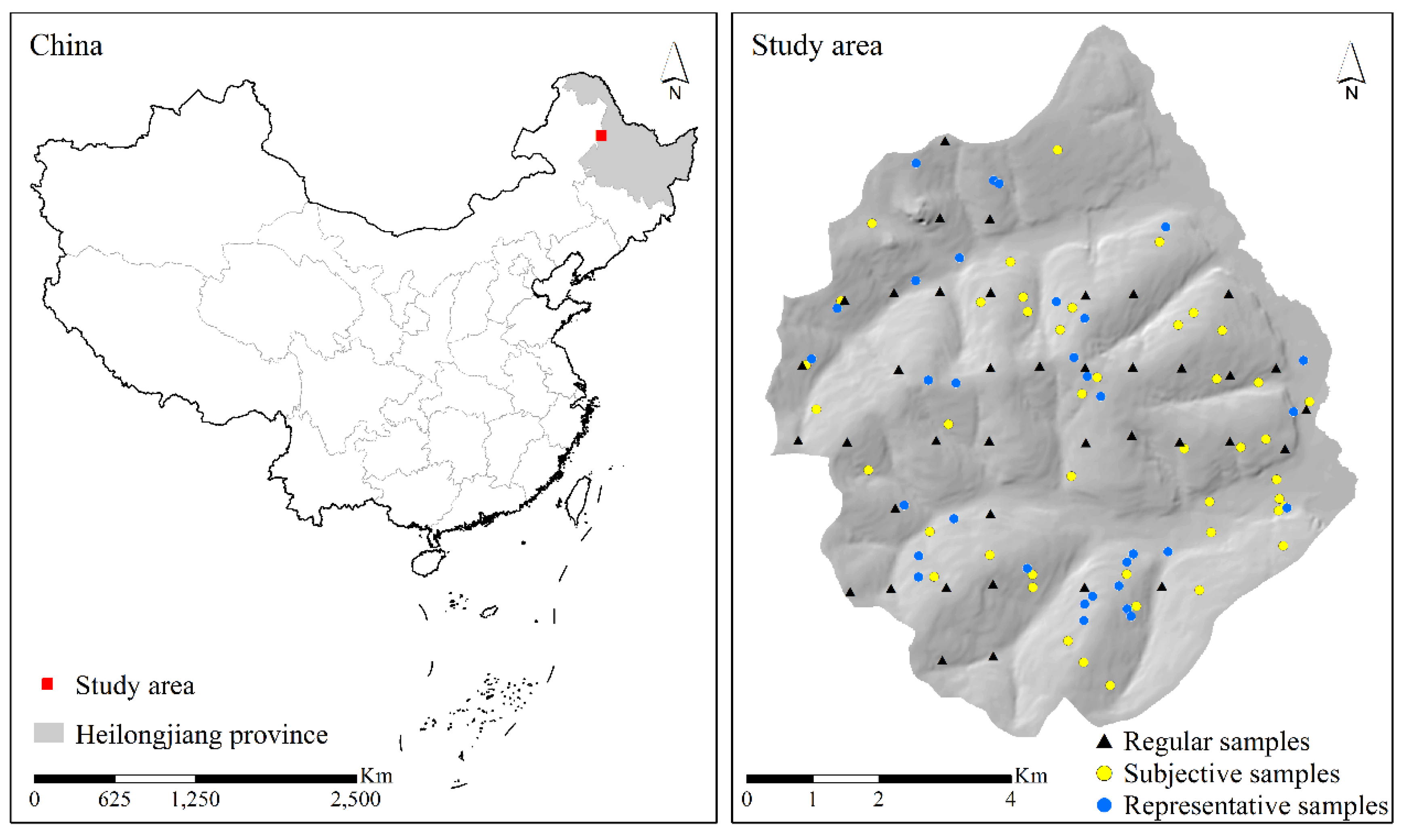
2.1. Study Area
2.2. Environmental Data
2.3. Soil Samples
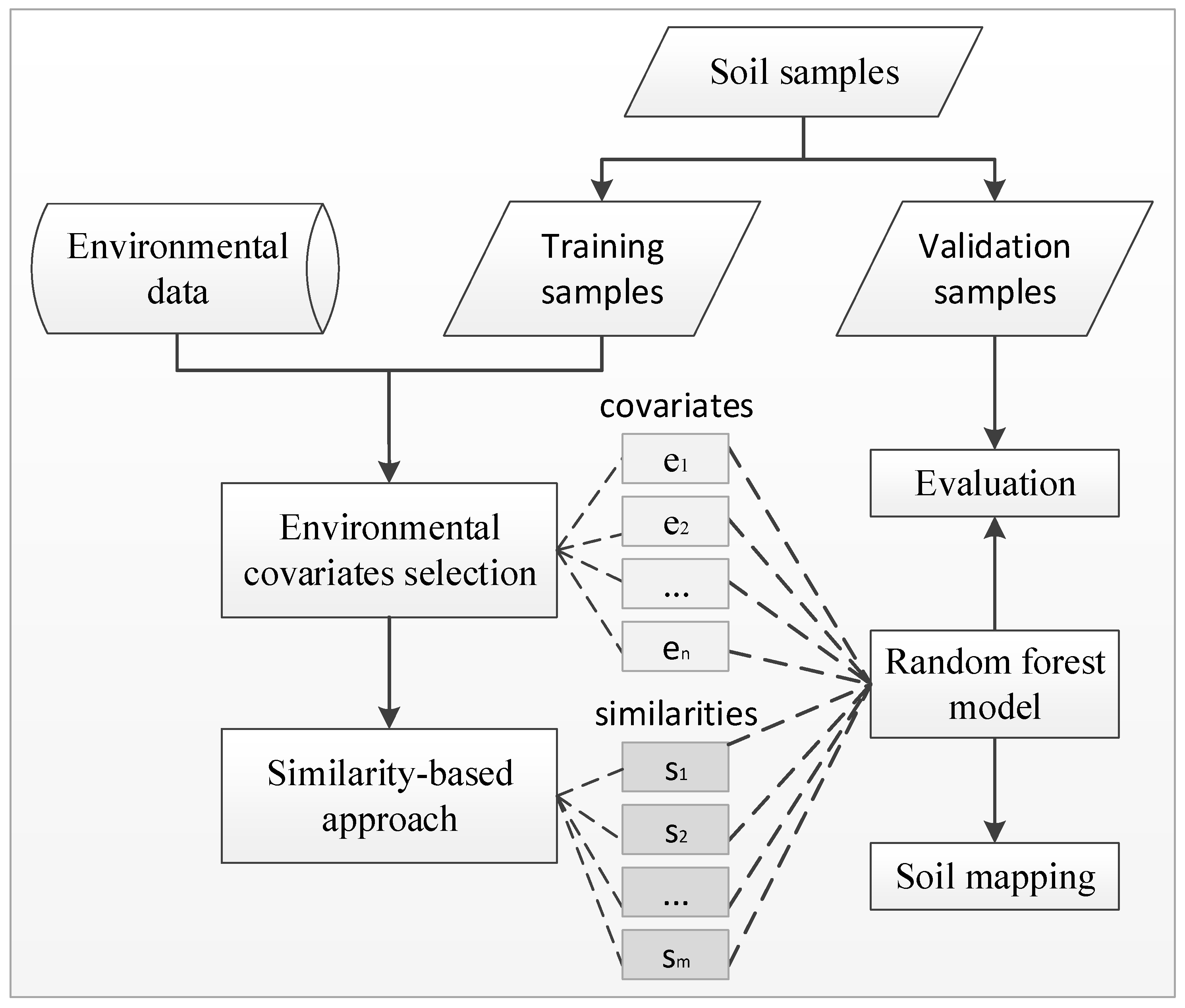
3. Methods
3.1. Environmental Covariates Selection
- (1)
- Calculate the Gini index of node m in a tree:
- (2)
- Calculate the change in the Gini index after node m is divided into m1 and m2:
- (3)
- The importance of covariate in node m is:
- (4)
- For M, a nodes set of covariate in a tree, the importance of covariate in the ith tree is:
- (5)
- The importance of covariate in the random forests composed of n trees is:
- (6)
- Normalize the importance scores of all covariates and rank the covariates according to the normalized results.
3.2. Similarity-Based Approach
3.3. Random Forests
3.4. Integration of Similarity-Based Approach with Random Forests
3.5. Experiment Design and Evaluation
3.5.1. Experiment Design
3.5.2. Evaluation
4. Results and Discussion
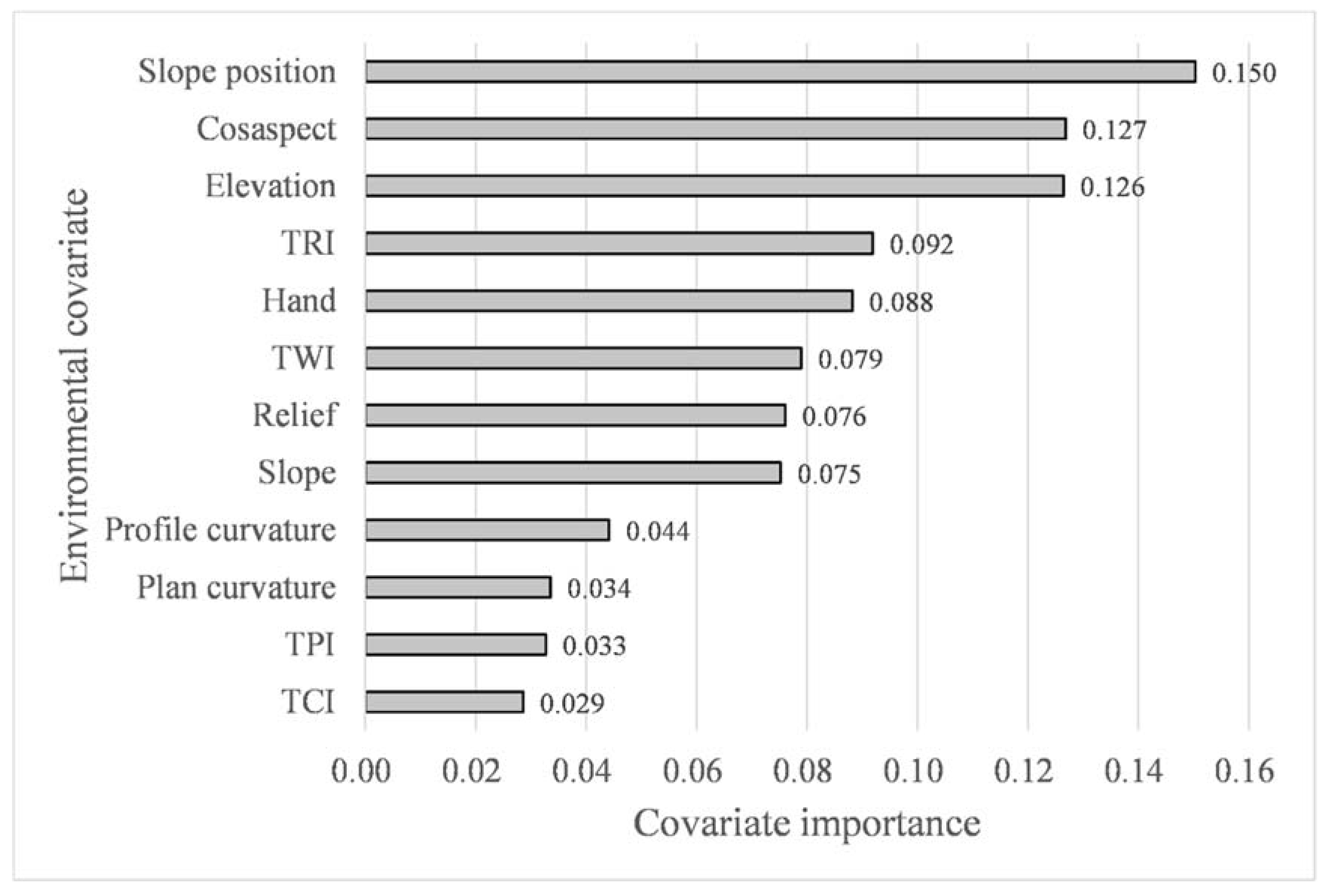
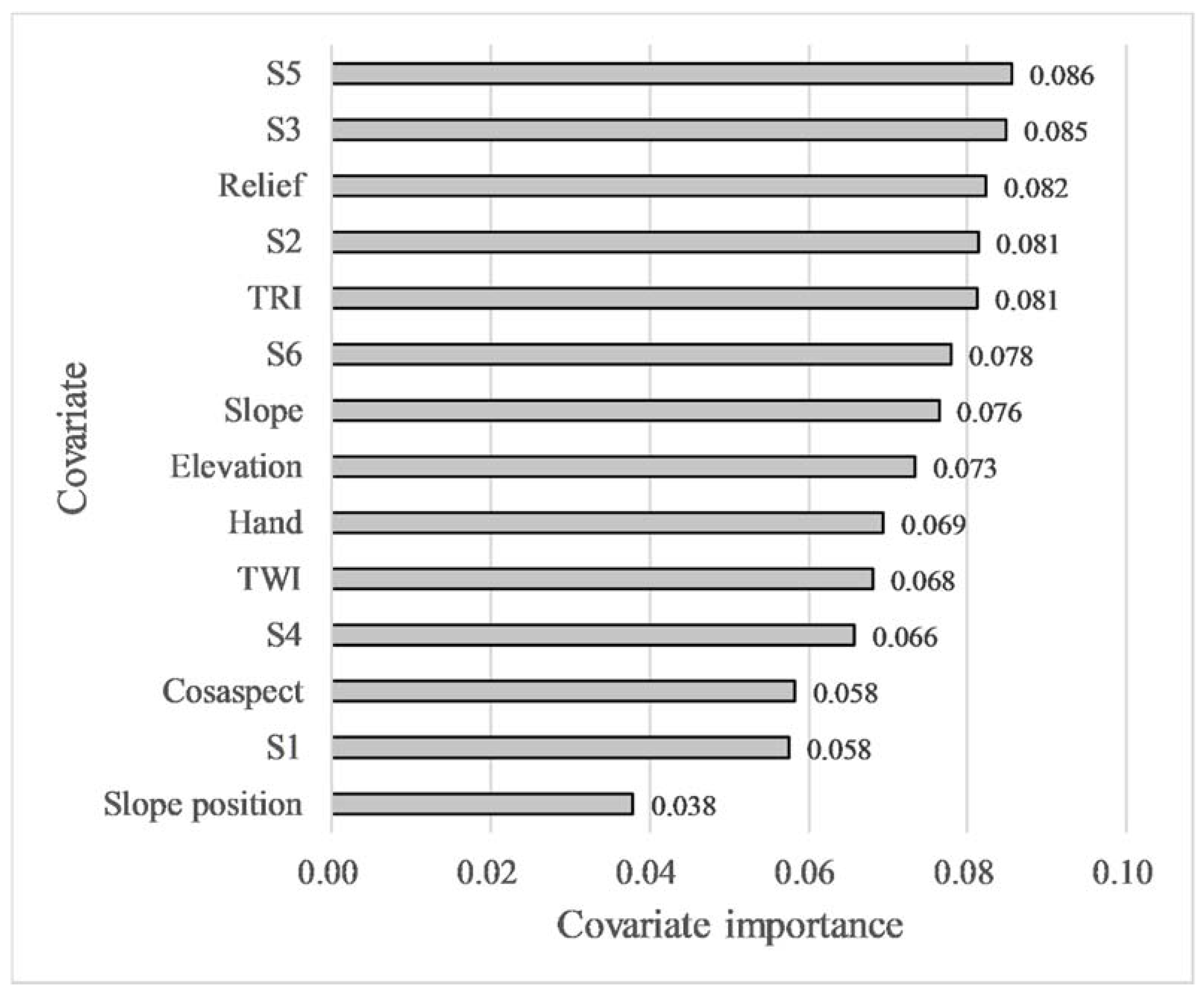
4.1. Results of Environmental Covariates Selection
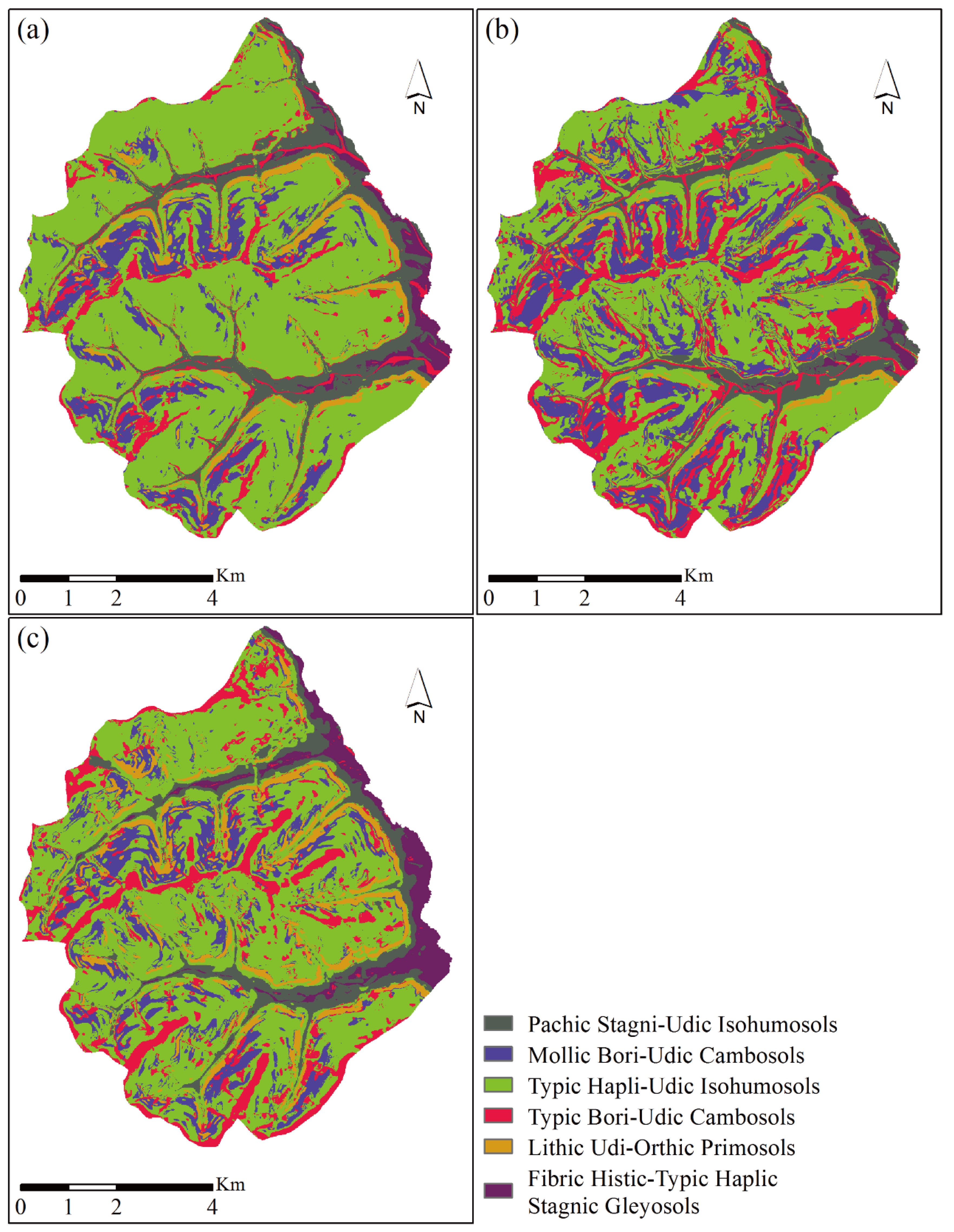
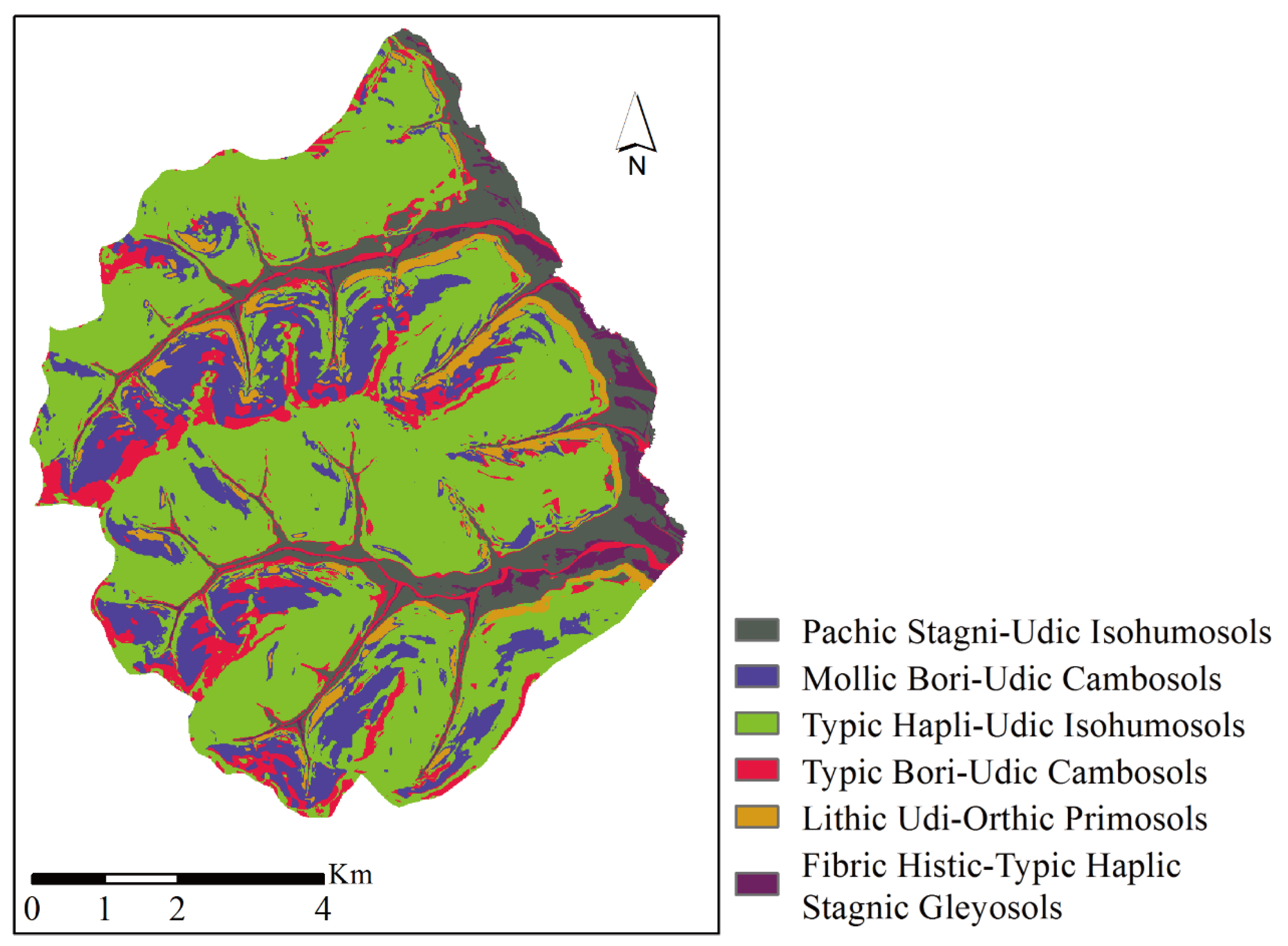
4.2. Soil Mapping Results
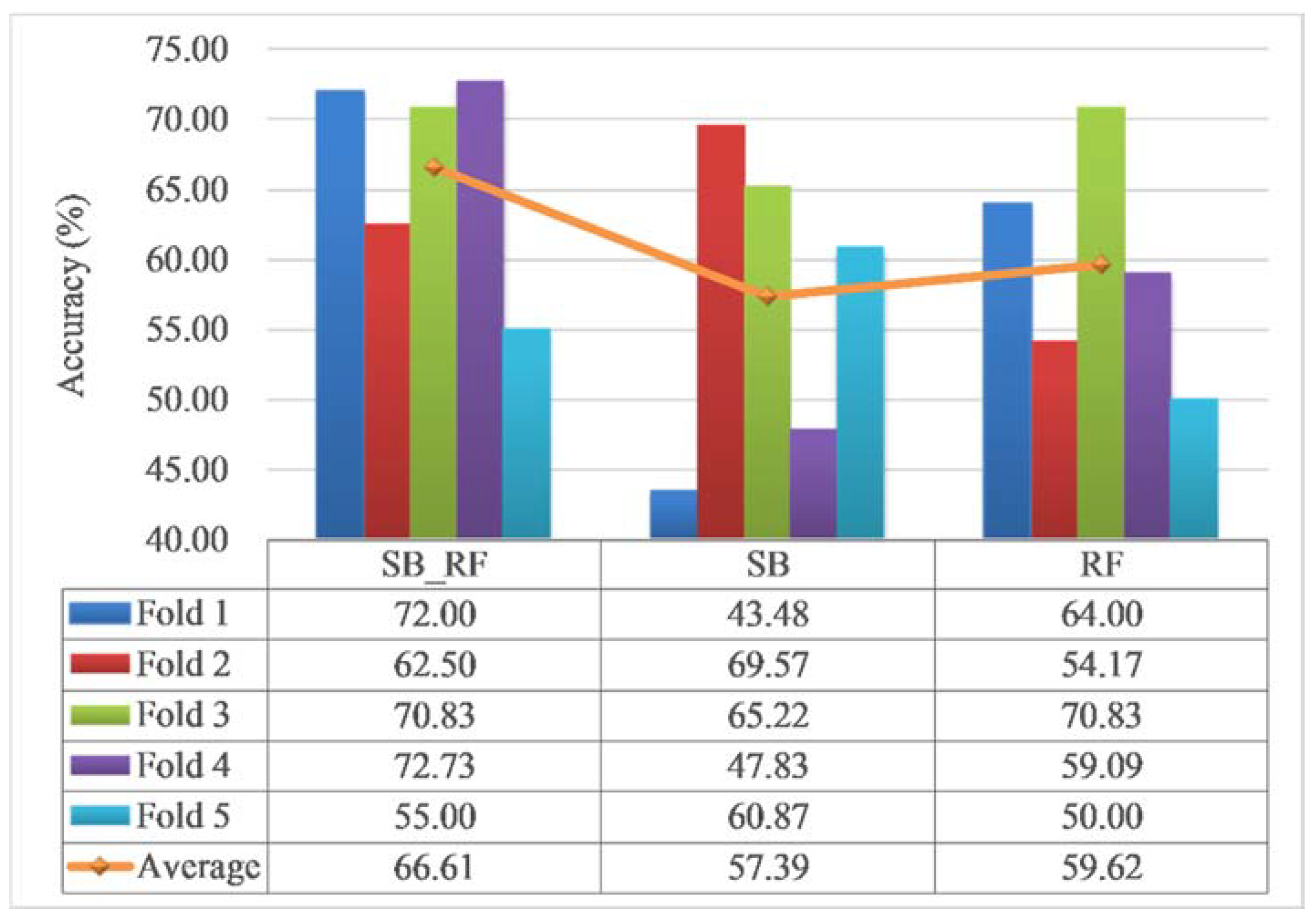
4.3. Model Validation and Comparison
4.4. Effectiveness of the Similarity Covariates
4.5. Impact of the Sampling Strategy and the Quality of Soil Samples
4.6. Applicability and Limitations of the Integrated Approach
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- McBratney, A.; Field, D.J.; Koch, A. The dimensions of soil security. Geoderma 2014, 213, 203–213. [Google Scholar] [CrossRef]
- Nauman, T.W.; Thompson, J.A.; Rasmussen, C. Semi-Automated Disaggregation of a Conventional Soil Map Using Knowledge Driven Data Mining and Random Forests in the Sonoran Desert, USA. Photogramm. Eng. Remote Sens. 2014, 80, 353–366. [Google Scholar] [CrossRef]
- Keesstra, S.D.; Bouma, J.; Wallinga, J.; Tittonell, P.; Smith, P.; Cerda, A.; Montanarella, L.; Quinton, J.N.; Pachepsky, Y.; van der Putten, W.H.; et al. The significance of soils and soil science towards realization of the United Nations Sustainable Development Goals. Soil 2016, 2, 111–128. [Google Scholar] [CrossRef]
- Bouma, J. Reaching out from the soil-box in pursuit of soil security. Soil Sci. Plant Nutr. 2015, 61, 556–565. [Google Scholar] [CrossRef]
- Minasny, B.; McBratney, A.B. Digital soil mapping: A brief history and some lessons. Geoderma 2016, 264, 301–311. [Google Scholar] [CrossRef]
- Petersen, C. Precision gps navigation for improving agricultural productivity. GPS World 1991, 2, 38–44. [Google Scholar]
- MacMillan, R.A.; Moon, D.E.; Coupe, R.A. Automated predictive ecological mapping in a forest region of BC, Canada, 2001–2005. Geoderma 2007, 140, 353–373. [Google Scholar] [CrossRef]
- Zhang, G.-L.; Liu, F.; Song, X.-D. Recent progress and future prospect of digital soil mapping: A review. J. Integr. Agric. 2017, 16, 2871–2885. [Google Scholar] [CrossRef]
- Bouma, J.; Broll, G.; Crane, T.A.; Dewitte, O.; Gardi, C.; Schulte, R.P.O.; Towers, W. Soil information in support of policy making and awareness raising. Curr. Opin. Environ. Sustain. 2012, 4, 552–558. [Google Scholar] [CrossRef]
- McBratney, A.B.; Santos, M.M.; Minasny, B. On digital soil mapping. Geoderma 2003, 117, 3–52. [Google Scholar] [CrossRef]
- Jenny, H. Factors of Soil Formation: A System of Quantitative Pedology; Dover Publications: New York, NY, USA, 1941. [Google Scholar]
- Henderson, B.L.; Bui, E.N.; Moran, C.J.; Simon, D. Australia-wide predictions of soil properties using decision trees. Geoderma 2005, 124, 383–398. [Google Scholar] [CrossRef]
- Kovačević, M.; Bajat, B.; Gajić, B. Soil type classification and estimation of soil properties using support vector machines. Geoderma 2010, 154, 340–347. [Google Scholar] [CrossRef]
- Heung, B.; Bulmer, C.E.; Schmidt, M.G. Predictive soil parent material mapping at a regional-scale: A Random Forest approach. Geoderma 2014, 214, 141–154. [Google Scholar] [CrossRef]
- Zhu, A.-X.; Liu, J.; Du, F.; Zhang, S.j.; Qin, C.Z.; Burt, J.; Behrens, T.; Scholten, T. Predictive soil mapping with limited sample data. Eur. J. Soil Sci. 2015, 66, 535–547. [Google Scholar] [CrossRef]
- Li, J.; Heap, A.D. A review of comparative studies of spatial interpolation methods in environmental sciences: Performance and impact factors. Ecol. Inform. 2011, 6, 228–241. [Google Scholar] [CrossRef]
- Li, J.; Heap, A.D. Spatial interpolation methods applied in the environmental sciences: A review. Environ. Model. Softw. 2014, 53, 173–189. [Google Scholar] [CrossRef]
- Odeh, I.O.A.; McBratney, A.B.; Chittleborough, D.J. Further results on prediction of soil properties from terrain attributes: Heterotopic cokriging and regression-kriging. Geoderma 1995, 67, 215–226. [Google Scholar] [CrossRef]
- Mondal, A.; Khare, D.; Kundu, S.; Mondal, S.; Mukherjee, S.; Mukhopadhyay, A. Spatial soil organic carbon (SOC) prediction by regression kriging using remote sensing data. Egypt. J. Remote Sens. Space Sci. 2017, 20, 61–70. [Google Scholar] [CrossRef]
- Kumar, S.; Lal, R.; Liu, D. A geographically weighted regression kriging approach for mapping soil organic carbon stock. Geoderma 2012, 189–190, 627–634. [Google Scholar] [CrossRef]
- Brus, D.J.; Heuvelink, G.B.M. Optimization of sample patterns for universal kriging of environmental variables. Geoderma 2007, 138, 86–95. [Google Scholar] [CrossRef]
- Zhu, A.X.; Lu, G.; Liu, J.; Qin, C.Z.; Zhou, C. Spatial prediction based on Third Law of Geography. Annals of GIS 2018, 24, 1–16. [Google Scholar] [CrossRef]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Cutler, D.R.; Edwards, T.C., Jr.; Beard, K.H.; Cutler, A.; Hess, K.T.; Gibson, J.; Lawler, J.J. Random forests for classification in ecology. Ecology 2007, 88, 2783–2792. [Google Scholar] [CrossRef] [PubMed]
- Breiman, L. Bagging predictors. Mach. Learn. 1996, 24, 123–140. [Google Scholar] [CrossRef]
- Liaw, A.; Wiener, M. Classification and regression by randomForest. R News 2002, 2, 18–22. [Google Scholar]
- Grunwald, S. Multi-criteria characterization of recent digital soil mapping and modeling approaches. Geoderma 2009, 152, 195–207. [Google Scholar] [CrossRef]
- Hua, J.P.; Xiong, Z.X.; Lowey, J.; Suh, E.; Dougherty, E.R. Optimal number of features as a function of sample size for various classification rules. Bioinformatics 2005, 21, 1509–1515. [Google Scholar] [CrossRef]
- Zhu, A.-X. A similarity model for representing soil spatial information. Geoderma 1997, 77, 217–242. [Google Scholar] [CrossRef]
- Yang, L.; Zhu, A.-X.; Qi, F.; Qin, C.-Z.; Li, B.; Pei, T. An integrative hierarchical stepwise sampling strategy for spatial sampling and its application in digital soil mapping. Int. J. Geogr. Inf. Sci. 2013, 27, 1–23. [Google Scholar] [CrossRef]
- Qin, C.Z.; Shi, X.; Li, B.L.; Pei, T.; Zhou, C.H. Quantification of spatial gradation of slope positions. Geomorphology 2009, 110, 152–161. [Google Scholar] [CrossRef]
- Qin, C.-Z.; Pei, T.; Li, B.-L.; Scholten, T.; Behrens, T.; Zhou, C.-H. An approach to computing topographic wetness index based on maximum downslope gradient. Precis. Agric. 2011, 12, 32–43. [Google Scholar] [CrossRef]
- Qin, C.-Z.; Lu, Y.; Bao, L.; Qiu, W.; Cheng, W. Simple Digital Terrain Analysis Software (SimDTA 1.0) and Its Application in Fuzzy Classification of Slope Positions. Geo-inf. Sci. 2009, 11, 737–743. [Google Scholar] [CrossRef]
- Gharari, S.; Hrachowitz, M.; Fenicia, F.; Savenije, H.H.G. Hydrological landscape classification: Investigating the performance of HAND based landscape classifications in a central European meso-scale catchment. Hydrol. Earth Syst. Sci. 2011, 15, 3275–3291. [Google Scholar] [CrossRef]
- Shary, P.A.; Sharaya, L.S.; Mitusov, A.V. Fundamental quantitative methods of land surface analysis. Geoderma 2002, 107, 1–32. [Google Scholar] [CrossRef]
- Skidmore, A.K. Terrain position as mapped from a gridded digital elevation model. Int. J. Geogr. Inf. Syst. 1990, 4, 33–49. [Google Scholar] [CrossRef]
- Park, S.J.; van de Giesen, N. Soil-landscape delineation to define spatial sampling domains for hillslope hydrology. J. Hydrol. 2004, 295, 28–46. [Google Scholar] [CrossRef]
- Weiss, A. Topographic position and landforms analysis. In Proceedings of the Poster Presentation, ESRI User Conference, San Diego, CA, USA, 9–13 July 2001. [Google Scholar]
- Riley, S.; Degloria, S.; Elliot, S.D. A Terrain Ruggedness Index that Quantifies Topographic Heterogeneity. Int. J. Sci. 1999, 5, 23–27. [Google Scholar]
- Chinese Soil Taxonomy Research Group. Keys to Chinese Soil Taxonomy; University of Science and Technology of China Press: Hefei, China, 2001. [Google Scholar]
- Staff, S.S. Soil Taxonomy; Government Printing Office: Washington, DC, USA, 1999. [Google Scholar]
- Louppe, G. Understanding Random Forests: From Theory to Practice. arXiv 2014, arXiv:1407.7502. [Google Scholar]
- Gini, C.; Pizetti, E.; Salvemini, T. Reprinted in Memorie di Metodologica Statistica; Libreria Eredi Virgilio Veschi: Rome, Italy, 1912; Volume 1. [Google Scholar]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V. Scikit-learn: Machine learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Hudson, B.D. The soil survey as paradigm-based science. Soil Sci. Soc. Am. J. 1992, 56, 836–841. [Google Scholar] [CrossRef]
- Lagacherie, P.; Arrouays, D.; Bourennane, H.; Gomez, C.; Martin, M.; Saby, N.P.A. How far can the uncertainty on a Digital Soil Map be known?: A numerical experiment using pseudo values of clay content obtained from Vis-SWIR hyperspectral imagery. Geoderma 2019, 337, 1320–1328. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Covariate | Description | Processing Tool |
|---|---|---|
| Elevation | Elevation | ArcGIS 10.1 |
| TWI | Topographic wetness index [32] | SimDTA [33] |
| Hand | Height above the nearest drainage [34] | Python |
| Plan curvature | Plan curvature [35] | ArcGIS 10.1 |
| Profile curvature | Profile curvature [35] | ArcGIS 10.1 |
| Relief | Topographic relief [36] | SimDTA |
| Slope | Slope measured in degrees | ArcGIS 10.1 |
| Slope position | Fuzzy slope position [31] | SimDTA |
| TCI | Terrain characterization index [37] | SimDTA |
| TPI | Topographic position index [38] | SimDTA |
| TRI | Terrain ruggedness index [39] | SimDTA |
| Cosaspect | Cosine value of the aspect | ArcGIS 10.1 |
| Model | Parameters |
|---|---|
| SB-RF | n_estimators, 370; max_depth, 12; min_samples_split, 2; min_samples_leaf, 1; max_features, 1; oob_score, True; bootstrap, True; random_state, 10; number of features, 14 |
| RF | n_estimators, 190; max_depth, 8; min_samples_split, 4; min_samples_leaf, 1; max_features, 2; oob_score, True; bootstrap, True; random_state, 10; number of features, 8 |
| Model | Soil Type * | I | II | III | IV | V | VI | UA (%) * |
|---|---|---|---|---|---|---|---|---|
| SB_RF | I | 1 | 0 | 0 | 0 | 0 | 0 | 100 |
| II | 0 | 0 | 2 | 0 | 0 | 0 | 0 | |
| III | 1 | 2 | 21 | 4 | 0 | 0 | 75 | |
| IV | 0 | 0 | 1 | 4 | 0 | 0 | 80 | |
| V | 0 | 0 | 1 | 0 | 1 | 0 | 50 | |
| VI | 0 | 0 | 0 | 0 | 0 | 1 | 100 | |
| PA (%) | 50 | 0 | 84 | 50 | 100 | 100 | OA = 71.79% | |
| SB | I | 1 | 0 | 0 | 0 | 0 | 0 | 100 |
| II | 0 | 0 | 4 | 1 | 0 | 0 | 0 | |
| III | 1 | 2 | 18 | 5 | 0 | 0 | 69.23 | |
| IV | 0 | 0 | 3 | 2 | 0 | 0 | 40 | |
| V | 0 | 0 | 0 | 0 | 1 | 0 | 100 | |
| VI | 0 | 0 | 0 | 0 | 0 | 1 | 100 | |
| PA (%) | 50 | 0 | 72 | 25 | 100 | 100 | OA = 58.97% | |
| RF | I | 1 | 0 | 0 | 0 | 0 | 0 | 100 |
| II | 0 | 1 | 1 | 0 | 0 | 0 | 50 | |
| III | 1 | 1 | 20 | 6 | 0 | 0 | 71.43 | |
| IV | 0 | 0 | 2 | 2 | 0 | 0 | 50 | |
| V | 0 | 0 | 2 | 0 | 1 | 0 | 33.33 | |
| VI | 0 | 0 | 0 | 0 | 0 | 1 | 100 | |
| PA (%) | 50 | 50 | 80 | 25 | 100 | 100 | OA = 66.67% |
| No. | Representative Samples (%) | Regular Samples (%) | Subjective Samples (%) |
|---|---|---|---|
| 1 | 66.27 | 47.37 | 64.79 |
| 2 | 66.27 | 52.63 | 63.38 |
| 3 | 66.27 | 47.37 | 64.79 |
| 4 | 63.86 | 51.32 | 63.38 |
| 5 | 63.86 | 47.37 | 64.79 |
| Average | 65.31 | 49.21 | 64.23 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, D.; Zhu, A.-X. Soil Mapping Based on the Integration of the Similarity-Based Approach and Random Forests. Land 2020, 9, 174. https://doi.org/10.3390/land9060174
Wang D, Zhu A-X. Soil Mapping Based on the Integration of the Similarity-Based Approach and Random Forests. Land. 2020; 9(6):174. https://doi.org/10.3390/land9060174
Chicago/Turabian StyleWang, Desheng, and A-Xing Zhu. 2020. "Soil Mapping Based on the Integration of the Similarity-Based Approach and Random Forests" Land 9, no. 6: 174. https://doi.org/10.3390/land9060174
APA StyleWang, D., & Zhu, A.-X. (2020). Soil Mapping Based on the Integration of the Similarity-Based Approach and Random Forests. Land, 9(6), 174. https://doi.org/10.3390/land9060174