Towards a Reproducible LULC Hierarchical Class Legend for Use in the Southwest of Pará State, Brazil: A Comparison with Remote Sensing Data-Driven Hierarchies

 ,
,
Abstract
1. Introduction
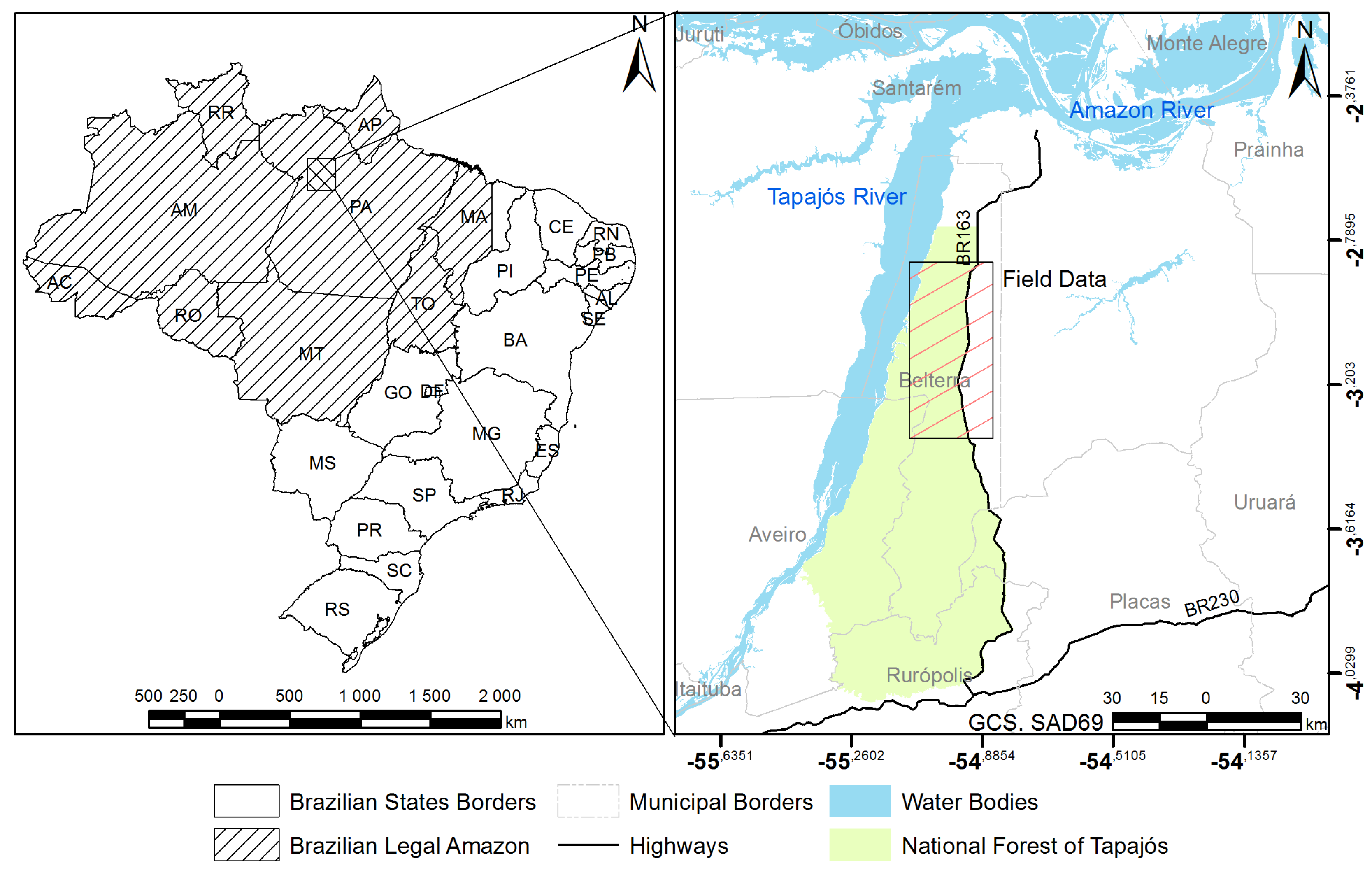
2. Study Area
3. Materials
3.1. Field Data
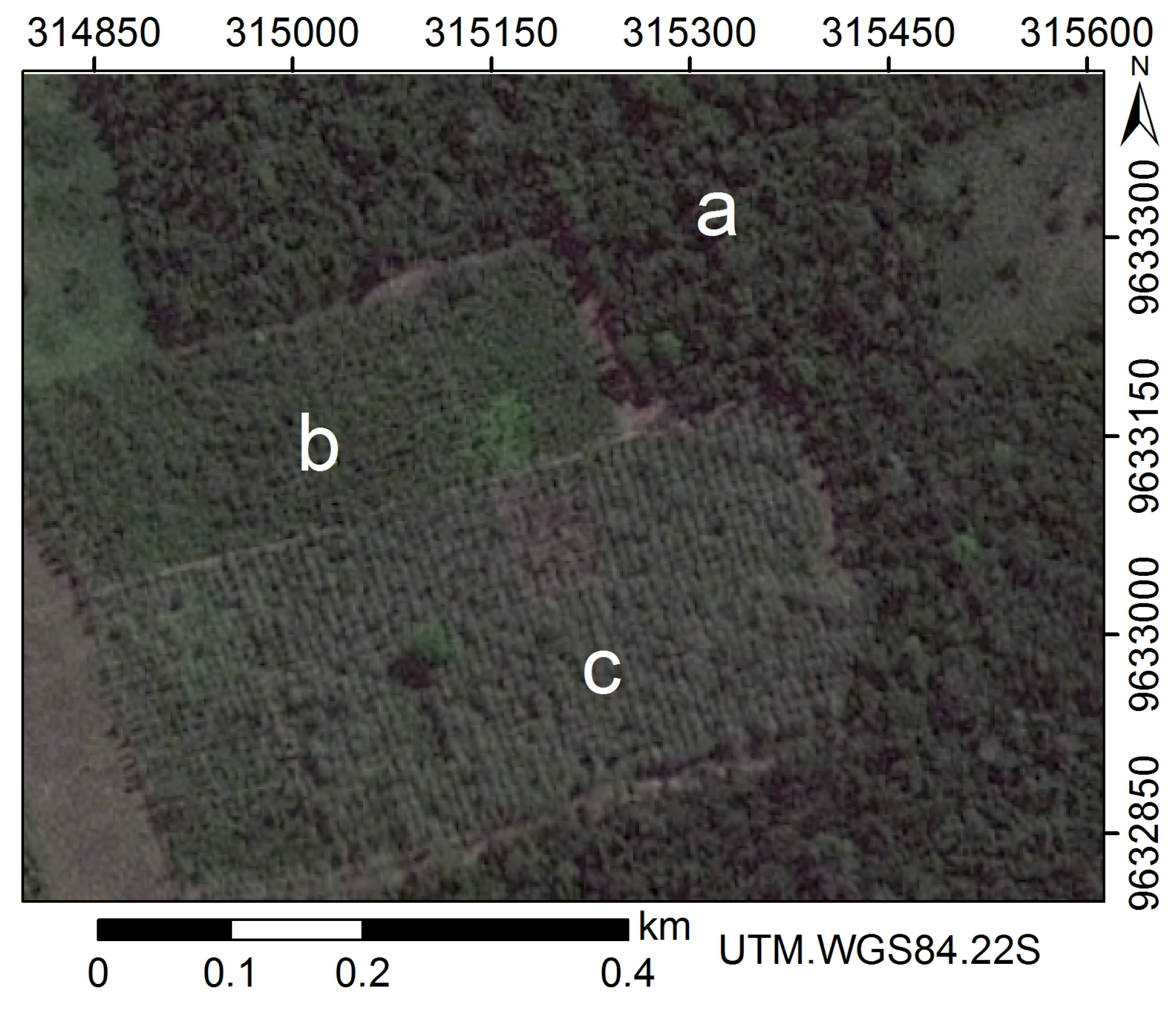
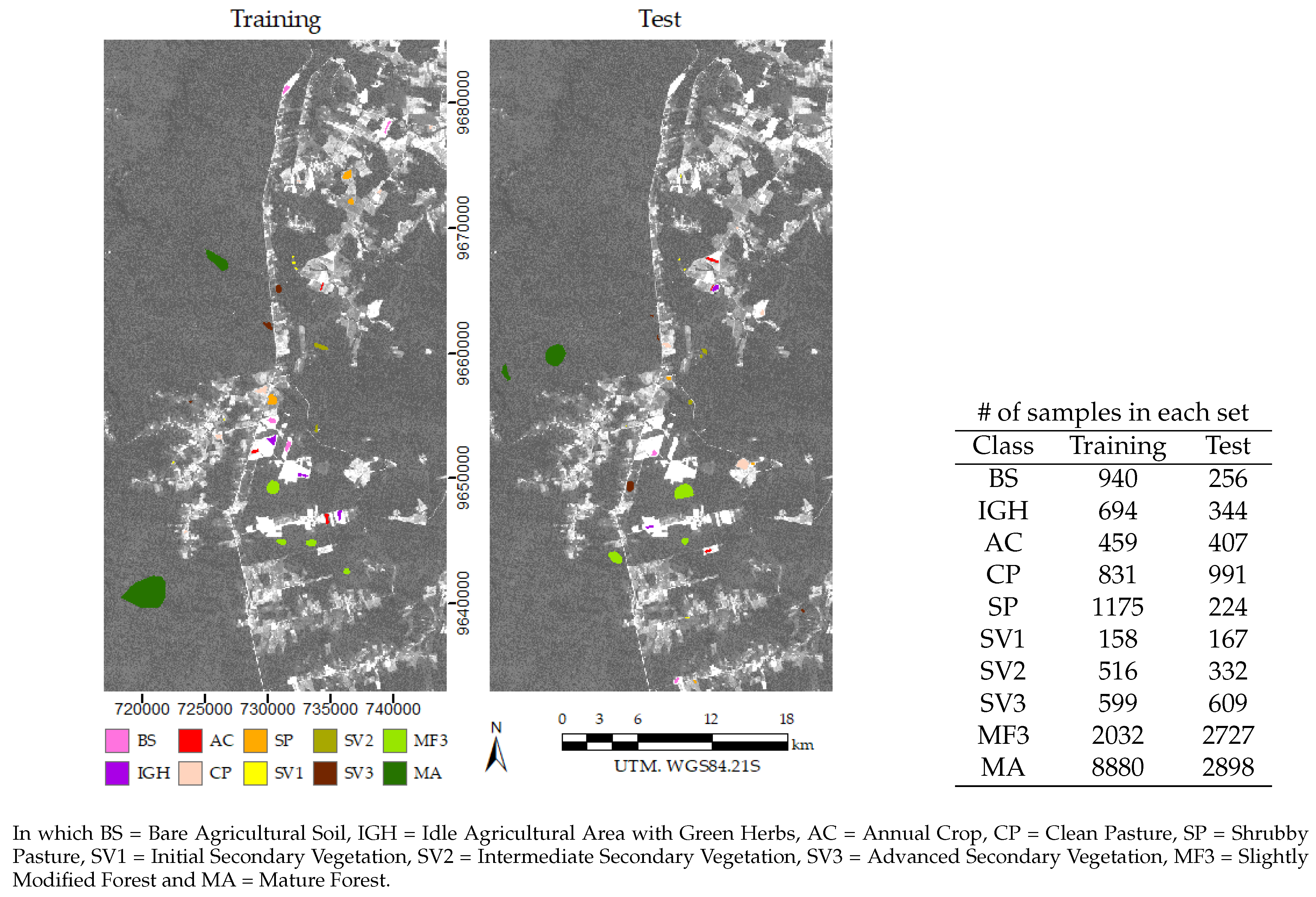
3.2. Remote Sensing Image and Class Samples
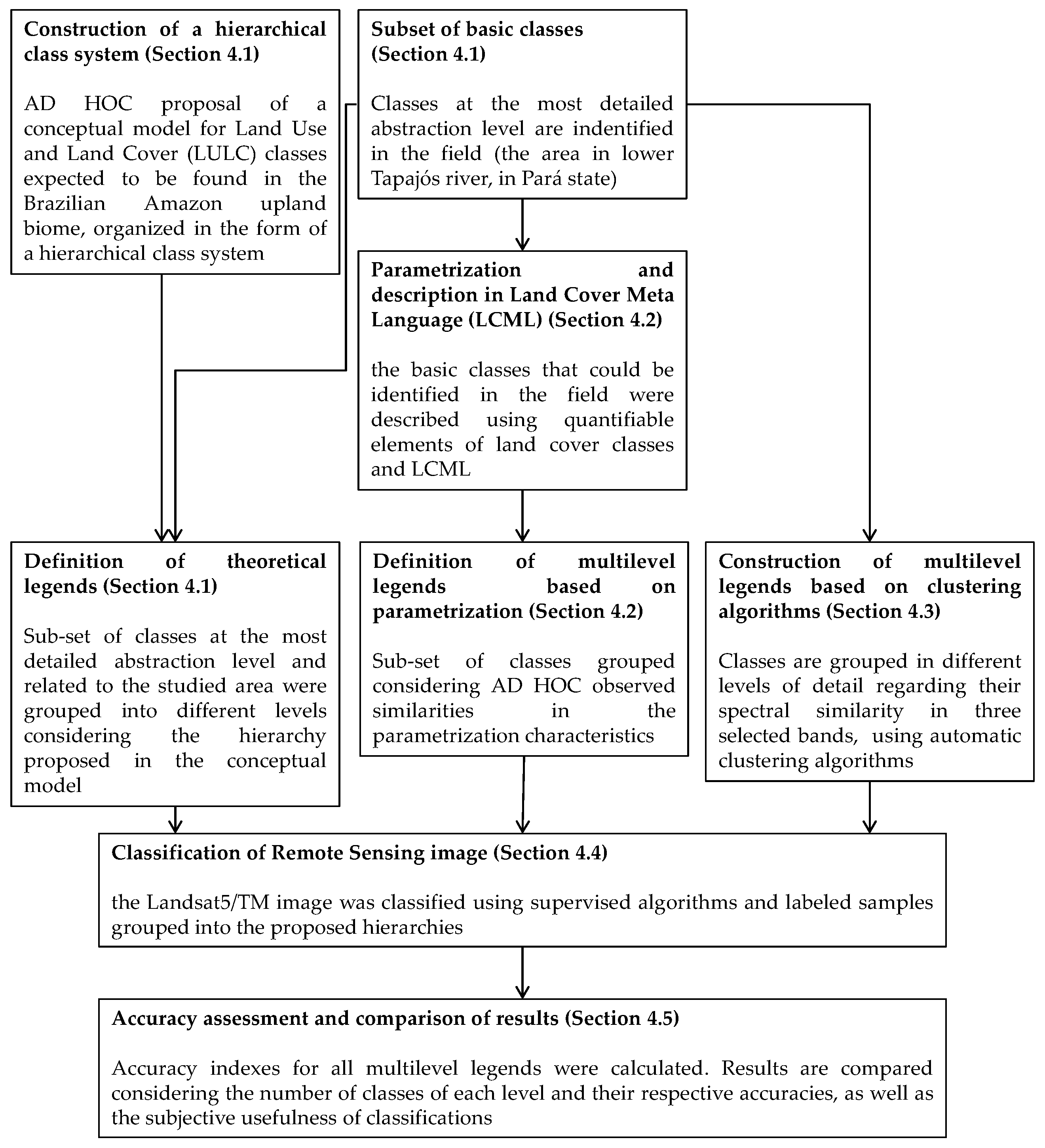
4. Methods
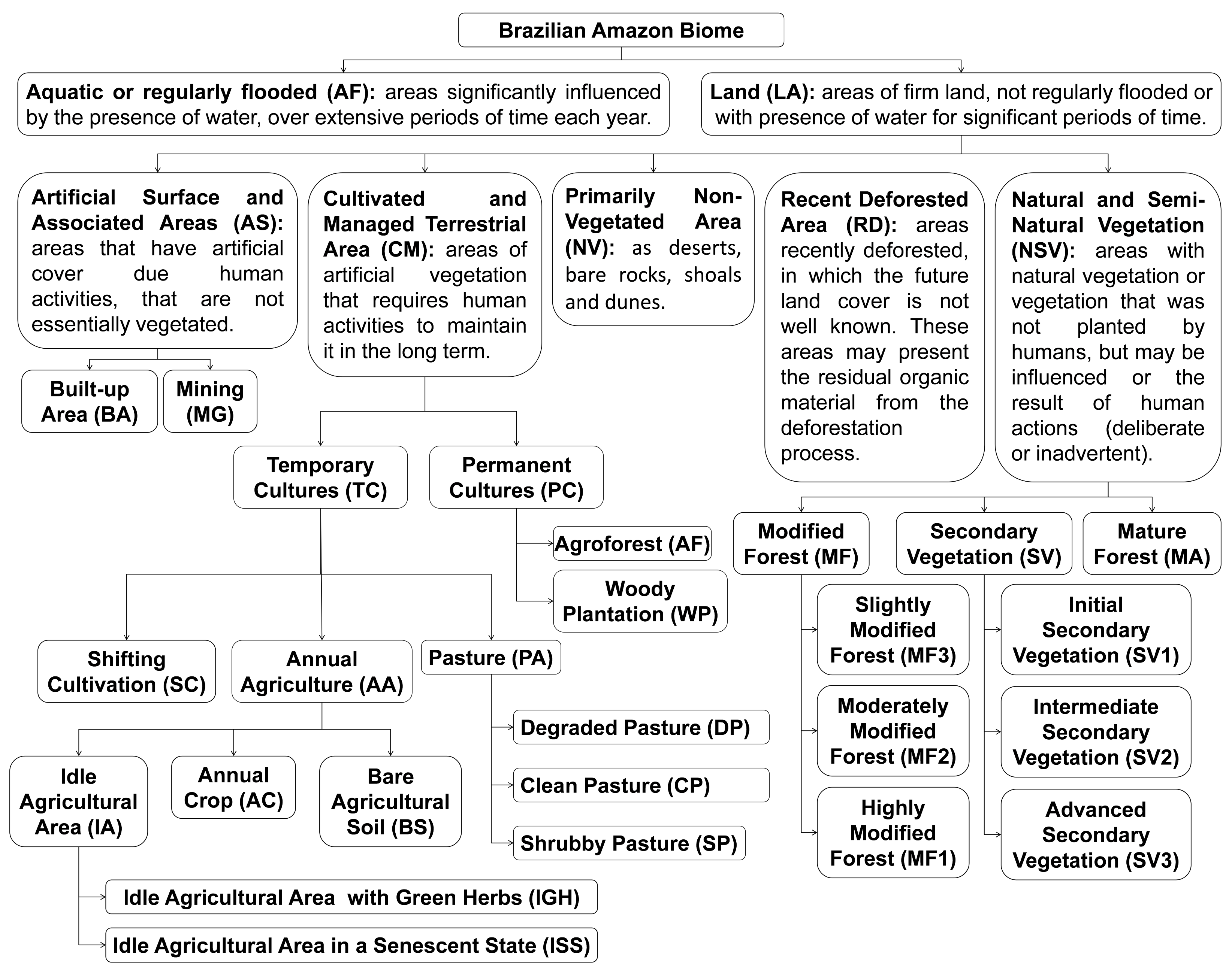
4.1. Construction of a Hierarchical Class System for the Brazilian Amazon Upland Biome
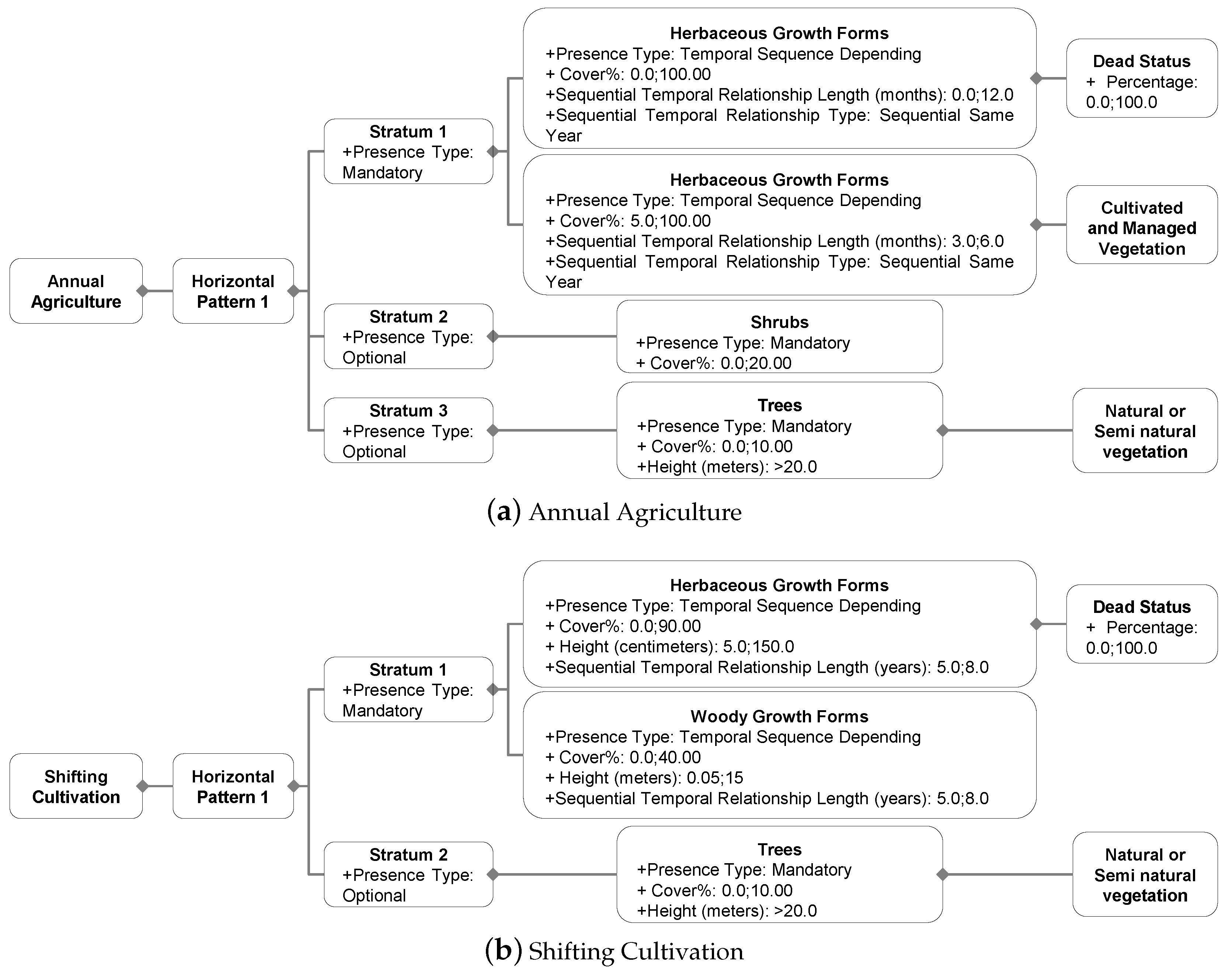
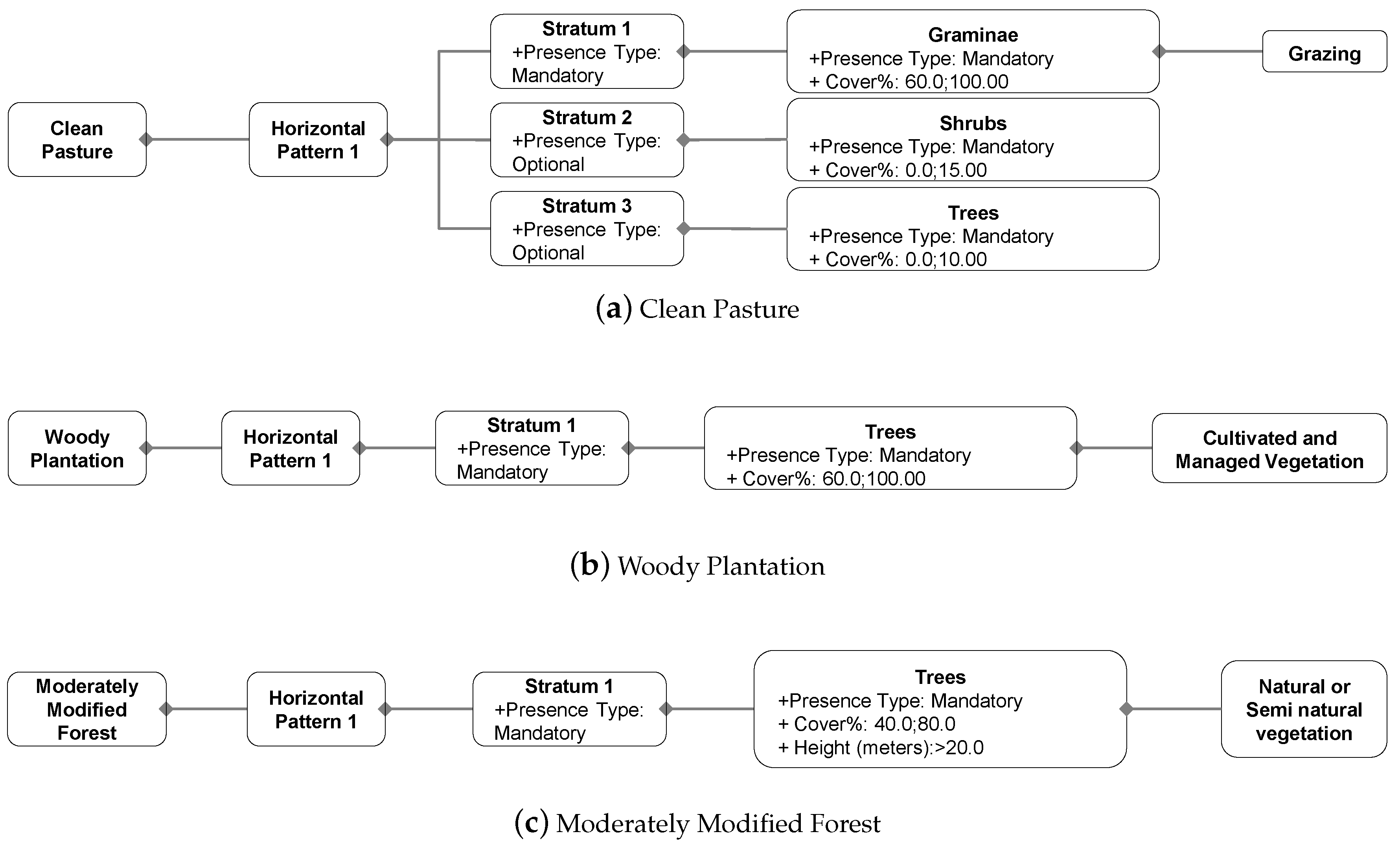
4.2. Parametrization of LULC Classes and Translation to LCML
- Soil: exposed soil. This feature height equals to zero. Therefore, only the proportion in relation to other features in the same stratum is considered;
- Litter: organic debris. It occurs in the same stratum as ‘Soil’ and a height equal to zero was considered;
- Herbaceous vegetation: plants that have no persistent woody stem above ground. Height may vary and it can be in the same stratum than ‘Soil’ and ‘Litter’ or not, depending on height and structure. The height usually varies up to 2 m;
- Shrubs: plants that have persistent woody stem above ground and height smaller than 5 m;
- Trees: plants with elongated woody stem and higher than 5 m. In the presence of emergent trees, two strata may be composed of trees.
4.3. Construction of Multilevel Legends Based on Automatic Clustering Algorithms
4.4. Classification of Remote Sensing Image
4.5. Accuracy Assessment and Comparison of Results
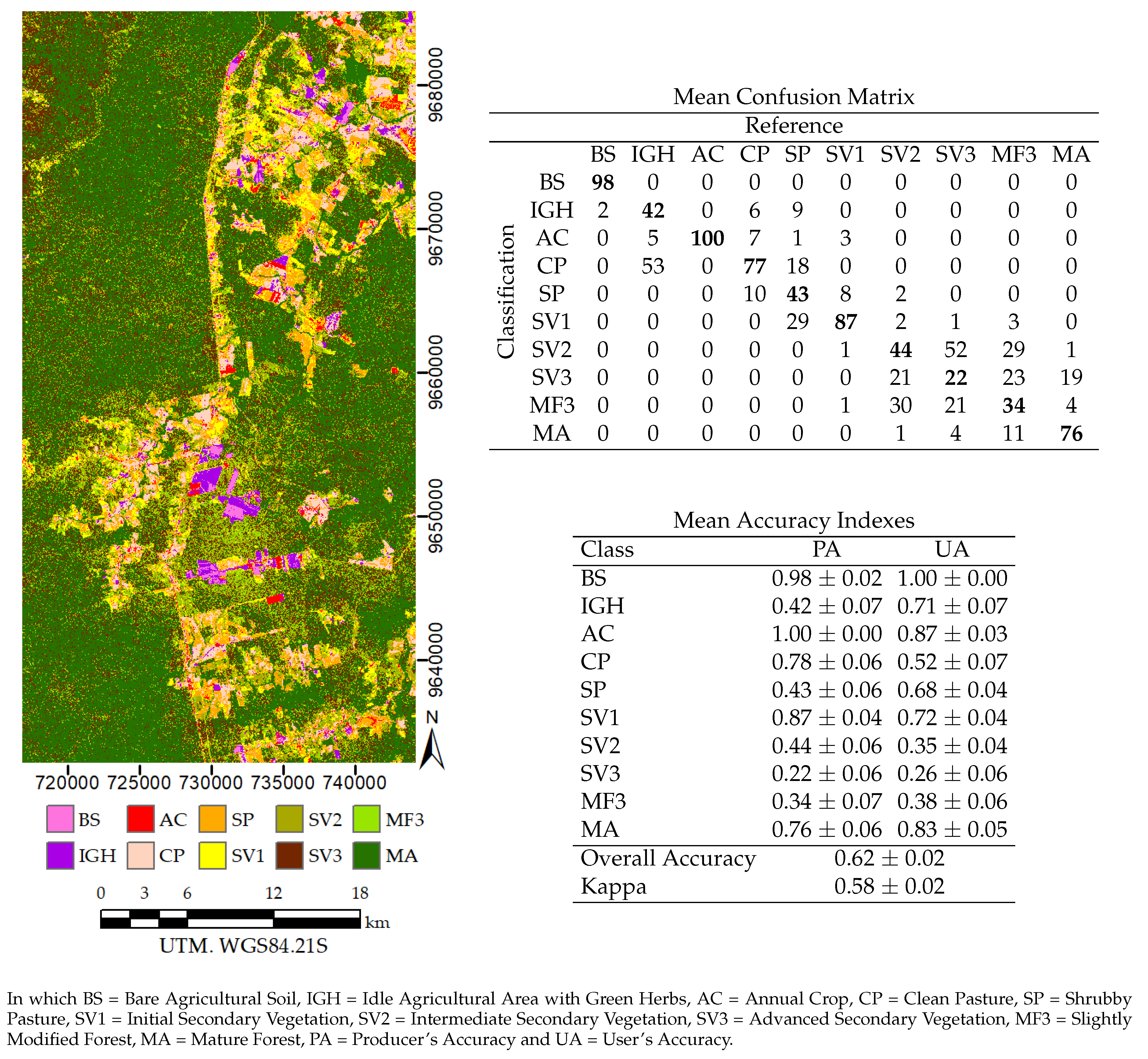
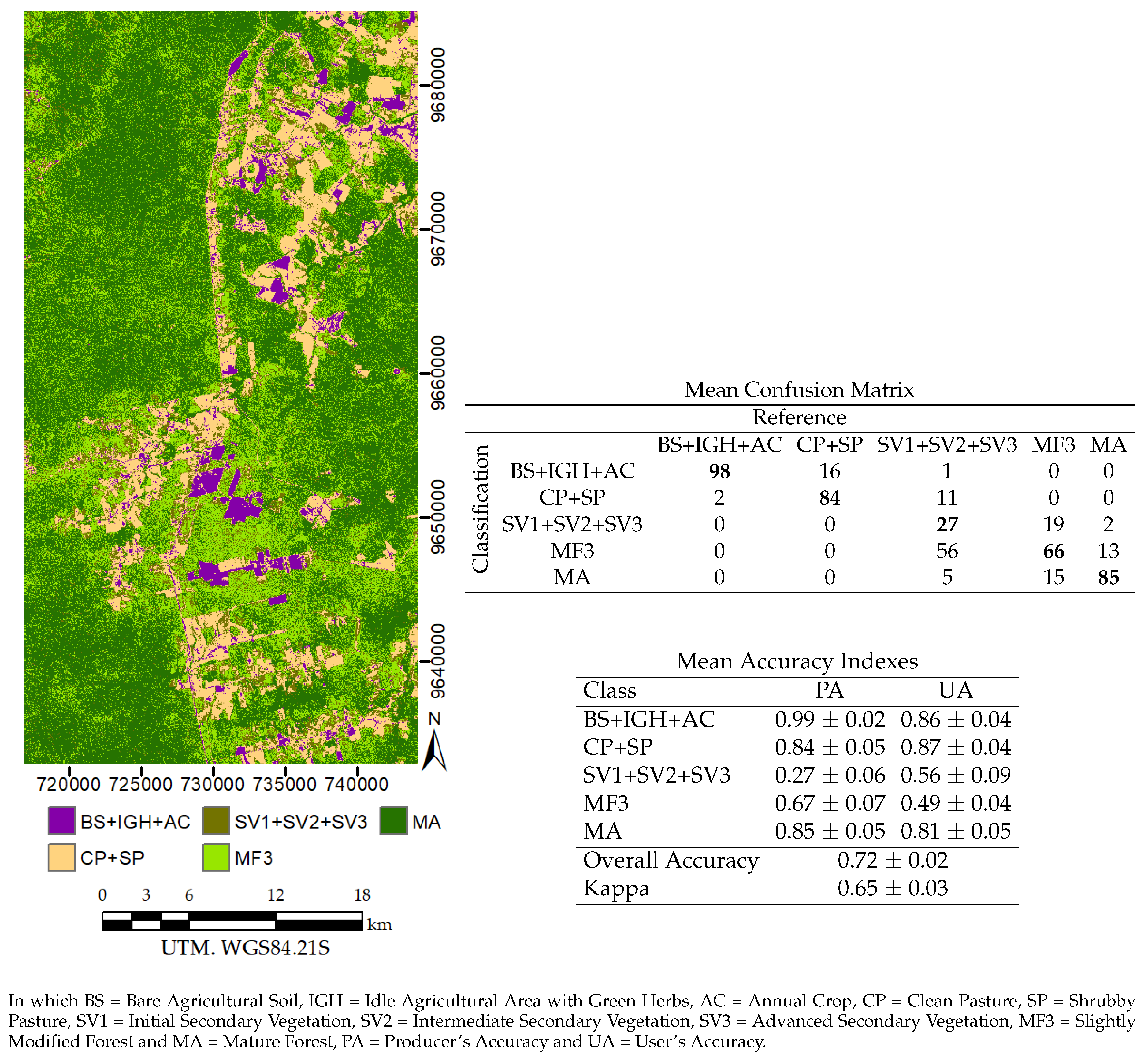
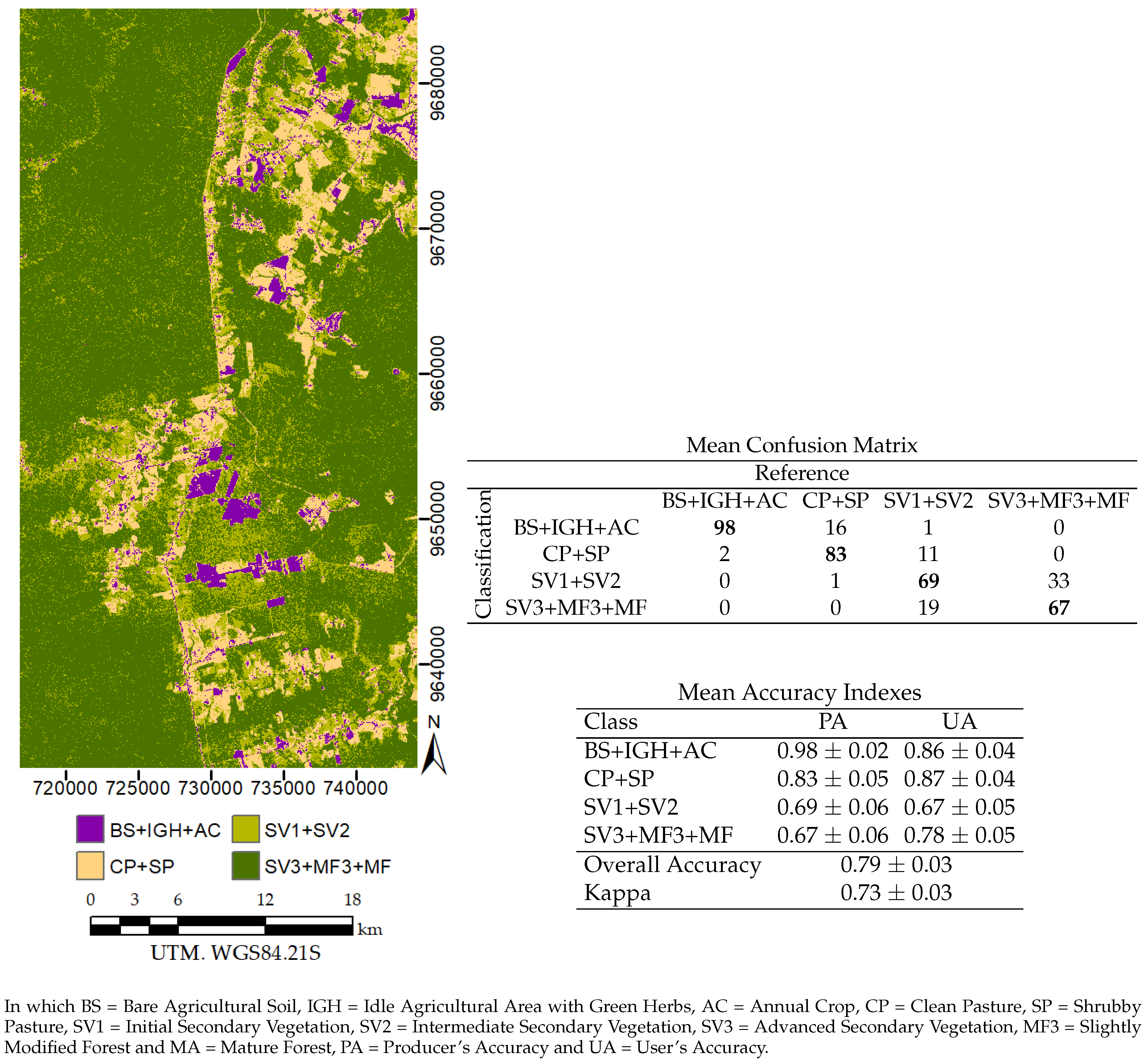
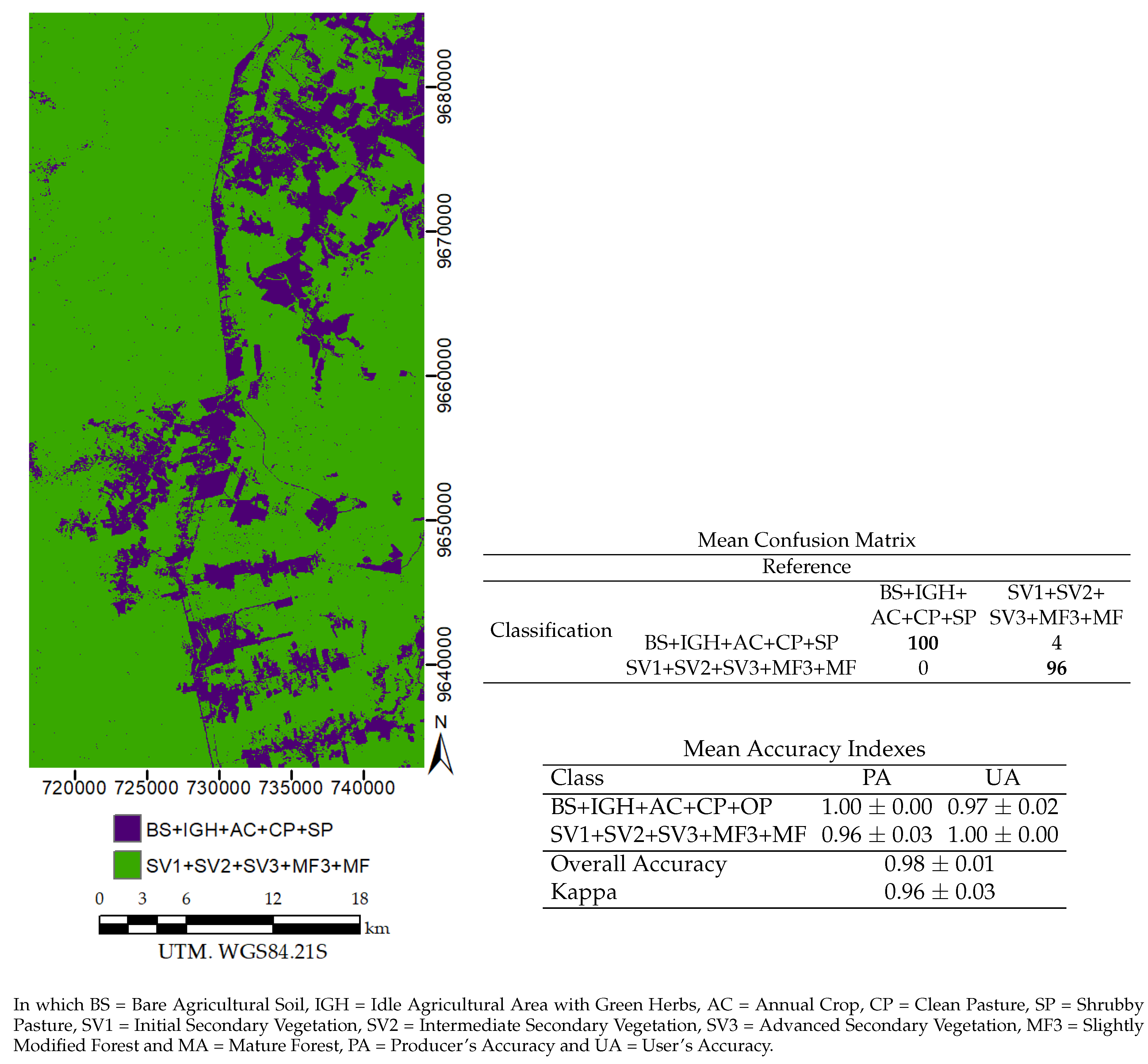
5. Results
5.1. Proposed Hierarchical Class System for the Brazilian Amazon Biome
5.2. Parametrization of LULC Classes and LCML Translation
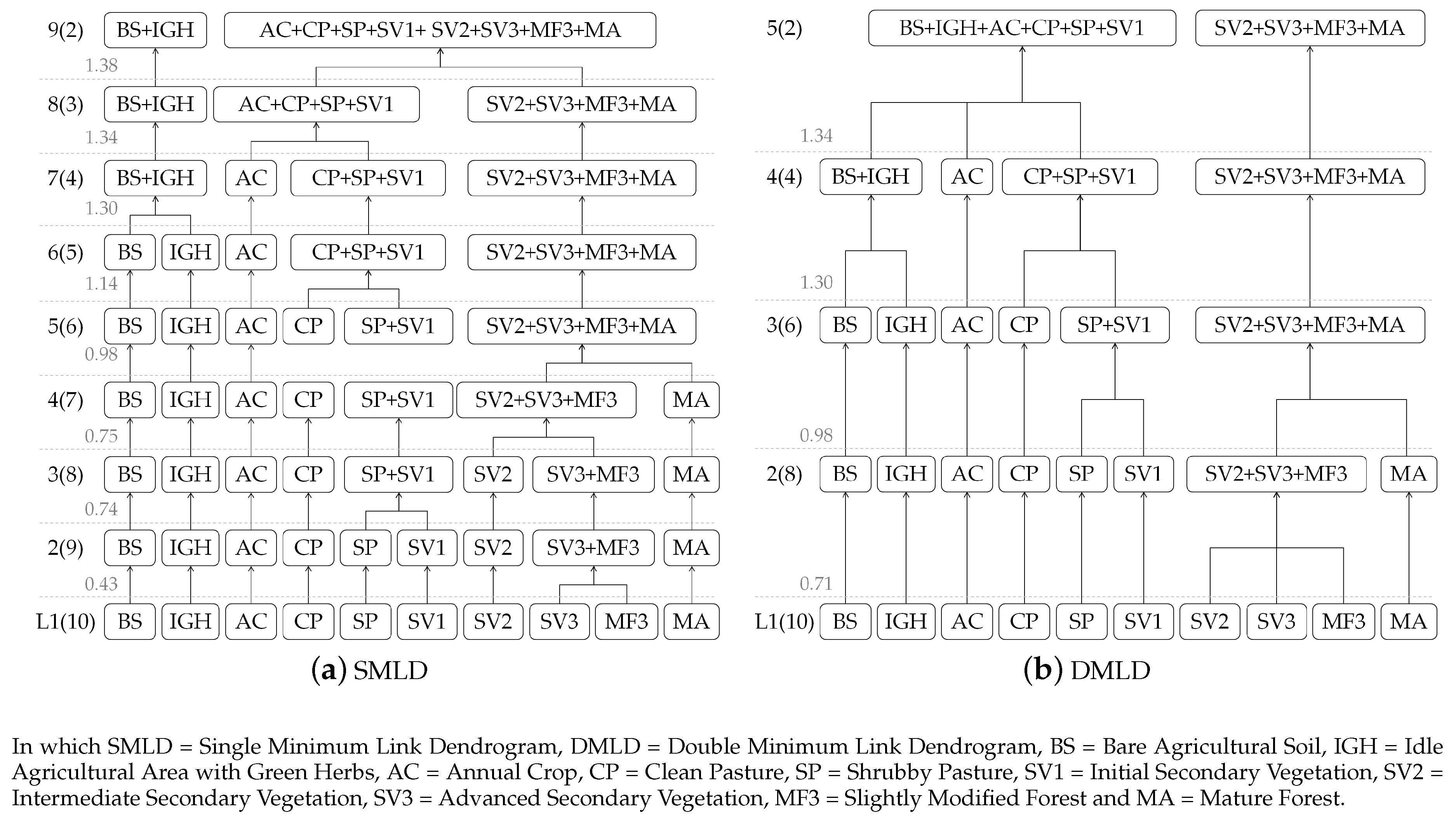
5.3. Defined Legends
- L1(10): the ten identified LULC classes. This is the most detailed legend and may be useful for data field collection and mappings with diverse objectives;
- L2.1(5): first grouping of the ten LULC classes, following the relationships established by the hierarchical class system. This legend has the potential to yield better classification results than L1(10) while maintaining significant classes for decision-makers;
- L2.2(4): grouping of the ten LULC classes based on similarity in the parametrization. Good classification results Remote Sensing data classification are expected with this legend [62];
- L3(2): this legend possesses only two classes, which can be achieved either by following the hierarchical class system or the classifiers in LCML and for which the most accurate classification results are expected. This legend may be particularly interesting for deforestation related studies.
5.4. Image Classification
6. Discussion
7. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Pielke, R.A.; Pitman, A.; Niyogi, D.; Mahmood, R.; McAlpine, C.; Hossain, F.; Goldewijk, K.K.; Nair, U.; Betts, R.; Fall, S.; et al. Land use/land cover changes and climate: modeling analysis and observational evidence. Wiley Interdiscip. Rev. Clim. Change 2011, 2, 828–850. [Google Scholar] [CrossRef]
- Verburg, P.H.; Erb, K.H.; Mertz, O.; Espíndola, G. Land System Science: between global challenges and local realities. Curr. Opin. Environ. Sustain. 2013, 5, 433–437. [Google Scholar] [CrossRef] [PubMed]
- Lu, D.; Mausel, P.; Brondízio, E.; Moran, E. Classification of successional forest stages in the Brazilian Amazon basin. For. Ecol. Manag. 2003, 181, 301–312. [Google Scholar] [CrossRef]
- Fujiki, S.; Aoyagi, R.; Tanaka, A.; Imai, N.; Kusma, A.D.; Kurniawan, Y.; Lee, Y.F.; Sugau, J.B.; Pereira, J.T.; Samejima, H.; et al. Large-Scale Mapping of Tree-Community Composition as a Surrogate of Forest Degradation in Bornean Tropical Rain Forests. Land 2016, 5, 45. [Google Scholar] [CrossRef]
- Deus, D. Integration of ALOS PALSAR and Landsat Data for Land Cover and Forest Mapping in Northern Tanzania. Land 2016, 5, 43. [Google Scholar] [CrossRef]
- Angelis, C.F.; Freitas, C.C.; Valeriano, D.M.; Dutra, L.V. Multitemporal analysis of land use/land cover JERS-1 backscatter in the Brazilian tropical rainforest. Int. J. Remote Sens. 2002, 23, 1231–1240. [Google Scholar] [CrossRef]
- Viet Nguyen, L.; Tateishi, R.; Kondoh, A.; Sharma, R.C.; Thanh Nguyen, H.; Trong To, T.; Ho Tong Minh, D. Mapping Tropical Forest Biomass by Combining ALOS-2, Landsat 8, and Field Plots Data. Land 2016, 5, 31. [Google Scholar] [CrossRef]
- Negri, R.G. Avaliação de Dados Polarimétricos Do Sensor ALOS PALSAR Para Classificação da Cobertura da Terra da Amazônia. Master’s Thesis, Brazilian National Institute for Space Research, São José dos Campos, Brazil, 2009. [Google Scholar]
- Elz, I.; Tansey, K.; Page, S.E.; Trivedi, M. Modelling Deforestation and Land Cover Transitions of Tropical Peatlands in Sumatra, Indonesia Using Remote Sensed Land Cover Data Sets. Land 2015, 4, 670–687. [Google Scholar] [CrossRef]
- Newby, J.; Cramb, R.; Sakanphet, S. Forest Transitions and Rural Livelihoods: Multiple Pathways of Smallholder Teak Expansion in Northern Laos. Land 2014, 3, 482–503. [Google Scholar] [CrossRef]
- Pereira, L.O.; Freitas, C.C.; Sant’Anna, S.J.S.; Lu, D.; Moran, E.F. Optical and radar data integration for land use and land cover mapping in the Brazilian Amazon. Gisci. Remote Sens. 2013, 50, 301–321. [Google Scholar]
- Silva, W.B.; Pereira, L.O.; Sant’Anna, S.J.S.; Freitas, C.C.; Guimarães, R.J.P.S.; Frery, A.C. Land cover discrimination at Brazilian Amazon using region based classifier and stochastic distance. In Proceedings of the 2011 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Vancouver, BC, Canada, 24–29 July 2011; pp. 2900–2903. [Google Scholar]
- Almeida, C.A.D.; Coutinho, A.C.; Esquerdo, J.C.D.M.; Adami, M.; Venturieri, A.; Diniz, C.G.; Dessay, N.; Durieux, L.; Gomes, A.R. High spatial resolution land use and land cover mapping of the Brazilian Legal Amazon in 2008 using Landsat-5/TM and MODIS data. Acta Amazon. 2016, 46, 291–302. [Google Scholar] [CrossRef]
- Arino, O.; Gross, D.; Ranera, F.; Leroy, M.; Bicheron, P.; Brockman, C.; Defourny, P.; Vancutsem, C.; Achard, F.; Durieux, L.; et al. GlobCover: ESA service for global land cover from MERIS. In Proceedings of the 2007 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Barcelona, Spain, 23–28 July 2007; pp. 2412–2415. [Google Scholar]
- Diniz, C.G.; Souza, A.A.A.; Santos, D.C.; Dias, M.C.; Luz, N.C.; Moraes, D.R.V.; Maia, J.S.; Gomes, A.R.; Narvaes, I.S.; Valeriano, D.M.; et al. DETER-B: the new Amazon near real-time deforestation detection system. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2015, 8, 3619–3628. [Google Scholar] [CrossRef]
- Matthews, E. Global vegetation and land-use: New-high resolution data bases for climate studies. J. Clim. Appl. Meteorol. 1983, 22, 474–487. [Google Scholar] [CrossRef]
- Loveland, T.; Belward, A. The International Geosphere Biosphere Programme Data and Information System global land cover data set (DISCover). Acta Astronaut. 1997, 41, 681–689. [Google Scholar] [CrossRef]
- Loveland, T.R.; Reed, B.C.; Brown, J.F.; Ohlen, D.O.; Zhu, Z.; Yang, L.; Merchant, J.W. Development of a global land cover characteristics database and IGBP DISCover from 1 km AVHRR data. Int. J. Remote Sens. 2000, 21, 1303–1330. [Google Scholar] [CrossRef]
- Friedl, M.; McIver, D.; Hodges, J.; Zhang, X.; Muchoney, D.; Strahler, A.; Woodcock, C.; Gopal, S.; Schneider, A.; Cooper, A.; et al. Global land cover mapping from MODIS: Algorithms and early results. Remote Sens. Environ. 2002, 83, 287–302. [Google Scholar] [CrossRef]
- Friedl, M.A.; Sulla-Menashe, D.; Tan, B.; Schneider, A.; Ramankutty, N.; Sibley, A.; Huang, X. MODIS Collection 5 global land cover: Algorithm refinements and characterization of new datasets. Remote Sens. Environ. 2010, 114, 168–182. [Google Scholar] [CrossRef]
- Townshend, J.R.; Masek, J.G.; Huang, C.; Vermote, E.F.; Gao, F.; Channan, S.; Sexton, J.O.; Feng, M.; Narasimhan, R.; Kim, D.; et al. Global characterization and monitoring of forest cover using Landsat data: Opportunities and challenges. Int. J. Digit. Earth 2012, 5, 373–397. [Google Scholar] [CrossRef]
- Hansen, M.C.; Potapov, P.V.; Moore, R.; Hancher, M.; Turubanova, S.A.; Tyukavina, A.; Thau, D.; Stehman, S.V.; Goetz, S.J.; Loveland, T.R.; et al. High-Resolution Global Maps of 21st-Century Forest Cover Change. Science 2013, 342, 850–853. [Google Scholar] [CrossRef] [PubMed]
- Herold, M.; Latham, J.S.; Gregorio, A.D.; Schmullius, C.C. Evolving standards in land cover characterization. J. Land Use Sci. 2006, 1, 157–168. [Google Scholar] [CrossRef]
- Herold, M.; Hubald, R.; Gregorio, A.D. Translating and Evaluating Land Cover Legends Using the UN Land Cover Classfication System (LCCS); GOFC-GOLD Report No. 43. Technical Report 189p; Global Observation of Forest and Land Cover Dynamics (GOFC-GOLD): Jena, Germany, 2009. [Google Scholar]
- Jansen, L.J.; Groom, G.; Carrai, G. Land-cover harmonisation and semantic similarity: some methodological issues. J. Land Use Sci. 2008, 3, 131–160. [Google Scholar] [CrossRef]
- McConnell, W.; Moran, E. Meeting in the Middle: The Challenge of Meso-Level Integration; LUCC Report Series No. 5. Technical Report 62p; Land Utilization Coordinating Council: Rome, Italy, 2001. [Google Scholar]
- Herold, M.; Woodcock, C.; di Gregorio, A.; Mayaux, P.; Belward, A.; Latham, J.; Schmullius, C. A joint initiative for harmonization and validation of land cover datasets. IEEE Trans. Geosci. Remote Sensi. 2006, 44, 1719–1727. [Google Scholar] [CrossRef]
- Ahlqvist, O. Extending post-classification change detection using semantic similarity metrics to overcome class heterogeneity: A study of 1992 and 2001 U.S. National Land Cover Database changes. Remote Sens. Environ. 2008, 112, 1226–1241. [Google Scholar] [CrossRef]
- Hansen, M.C.; Loveland, T.R. A review of large area monitoring of land cover change using Landsat data. Remote Sens. Environ. 2012, 122, 66–74. [Google Scholar] [CrossRef]
- Putz, F.E.; Redford, K.H. The Importance of Defining ‘Forest’: Tropical Forest Degradation, Deforestation, Long-term Phase Shifts, and Further Transitions. Biotropica 2010, 42, 10–20. [Google Scholar] [CrossRef]
- Morales-Barquero, L.; Skutsch, M.; Jardel-Peláez, E.J.; Ghilardi, A.; Kleinn, C.; Healey, J.R. Operationalizing the Definition of Forest Degradation for REDD+, with Application to Mexico. Forests 2014, 5, 1653–1681. [Google Scholar] [CrossRef]
- Chazdon, R.L.; Brancalion, P.H.S.; Laestadius, L.; Bennett-Curry, A.; Buckingham, K.; Kumar, C.; Moll-Rocek, J.; Vieira, I.C.G.; Wilson, S.J. When is a forest a forest? Forest concepts and definitions in the era of forest and landscape restoration. Ambio 2016, 456, 1–13. [Google Scholar] [CrossRef] [PubMed]
- Freitas, C.C.; Soler, L.S.; Sant’Anna, S.J.S.; Dutra, L.V.; Santos, J.R.; Mura, J.C.; Correia, A.H. Land use and land cover mapping in Brazilian Amazon using polarimetric airborne P-band SAR data. IEEE Trans. Geosci. Remote Sens. 2008, 46, 2956–2970. [Google Scholar] [CrossRef]
- Dutra, L.V.; Scofield, G.B.; Aboud Neta, S.R.; Negri, R.G.; Freitas, C.C.; Andrade, D. Land Cover Classification in Amazon Using Alos Palsar Full Polarimetric Data; Simpósio Brasileiro de Sensoriamento Remoto, 14. (SBSR); Instituto Nacional de Pesquisas Espaciais (INPE): São José dos Campos, Brazil, 2009; pp. 7259–7264. [Google Scholar]
- Pantaleão, E.; Dutra, L.V.; Sandri, S.A. Scenario analysis for image classification using multi-objective optimization. InfoComp 2012, 11, 15–22. [Google Scholar]
- Negri, R.G.; Sant’Anna, S.J.S.; Dutra, L.V. A new contextual version of Support Vector Machine based on hyperplane translation. In Proceedings of the 2013 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Melbourne, VIC, Australia, 21–26 July 2013; pp. 3116–3119. [Google Scholar]
- Reis, M.S.; Torres, L.; Sant’Anna, S.J.S.; Freitas, C.C.; Dutra, L.V. Evaluation of SAR-SDNLM filter for change detection classification. In Proceedings of the 2014 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Quebec City, QC, Canada, 13–18 July 2014; pp. 2042–2045. [Google Scholar]
- Dutra, L.V.; Negri, R.G.; Sant’Anna, S.J.S.; Lu, D. Development of Dissimilarity Functions Using Stochastic Distances for Region-Based Land Cover Classification: A Case Study Near Tapajós Flona, Pará State, Brazil; Simpósio Brasileiro de Sensoriamento Remoto, 17. (SBSR); Instituto Nacional de Pesquisas Espaciais (INPE): São José dos Campos, Brazil, 2015; pp. 1655–1662. [Google Scholar]
- Anjos, D.S.; Lu, D.; Dutra, L.V.; Sant’Anna, S. Change Detection Techniques Using Multisensor Data. In Remotely Sensed Data Characterization, Classification, and Accuracies; Crc Press: London, UK, 2015; Volume 1, pp. 375–395. [Google Scholar]
- Pereira, L.O.; Freitas, C.C.; Sant’Anna, S.J.S.; Reis, M.S. ALOS/PALSAR Data Evaluation for Land Use and Land Cover Mapping in the Amazon Region. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2016, 9, 5413–5423. [Google Scholar] [CrossRef]
- Anderson, J.R. A Land Use and Land Cover Classification System for Use with Remote Sensor Data; US Government Printing Office: Washington, DC, USA, 1976; Volume 964.
- Di Gregorio, A.; Jansen, L. Land Cover Classificiation System; Food and Agriculture Organization of the United Nations: Rome, Italy, 2005. [Google Scholar]
- Uddin, K.; Shrestha, H.L.; Murthy, M.; Bajracharya, B.; Shrestha, B.; Gilani, H.; Pradhan, S.; Dangol, B. Development of 2010 national land cover database for the Nepal. J. Environ. Manag. 2015, 148, 82–90. [Google Scholar] [CrossRef] [PubMed]
- Arafat, S.M.; Saleh, N.S.; Aboelghar, M.; Elshrkawy, M. Mapping of North Sinai land cover according to FAO-LCCS. J. Remote Sens. Space Sci. 2014, 17, 29–39. [Google Scholar] [CrossRef]
- Cord, A.; Conrad, C.; Schmidt, M.; Dech, S. Standardized FAO-LCCS land cover mapping in heterogeneous tree savannas of West Africa. J. Arid Environ. 2010, 74, 1083–1091. [Google Scholar] [CrossRef]
- Coutinho, A.; Almeida, C.; Venturieri, A.; Esquerdo, J.; Silva, M. Uso e Cobertura da Terra Nas Áreas Desflorestadas da AMazônia Legal: TerraClass, 2008; Technical Report; Embrapa, INPE: Brasília, Belém, 2013; 116p. [Google Scholar]
- Kosmidou, V.; Petrou, Z.; Bunce, R.G.; Mücher, C.A.; Jongman, R.H.; Bogers, M.M.; Lucas, R.M.; Tomaselli, V.; Blonda, P.; Padoa-Schioppa, E.; et al. Harmonization of the Land Cover Classification System (LCCS) with the General Habitat Categories (GHC) classification system. Ecol. Indic. 2014, 36, 290–300. [Google Scholar] [CrossRef]
- IBGE. Manual Técnico de Uso da Terra—3 Edição; Technical Report; Instituto Brasileiro de Geografia e Estatística (IBGE): Rio de Janeiro, Brazil, 2015; 171p.
- IBAMA. Floresta NAcional do TApajós Plano de Manejo: Volume I—Informações Gerais; Technical Report; Instituto Brasileiro do Meio Ambiente e dos Recursos Naturais Renováveis: Federal District, Brazil, 2004; 76p.
- Shimabukuro, Y.; Amaral, S.; Ahern, F.; Pietsch, R. Land Cover Classification from RADARSAT Data of the Tapajós National Forest, Brazil. Can. J. Remote Sens. 1998, 24, 393–401. [Google Scholar] [CrossRef]
- Asner, G.P.; Bustamante, M.M.; Townsend, A.R. Scale dependence of biophysical structure in deforested areas bordering the Tapajós National Forest, Central Amazon. Remote Sens. Environ. 2003, 87, 507–520. [Google Scholar] [CrossRef]
- Keller, M.; Varner, R.; Dias, J.D.; Silva, H.; Crill, P.; de Oliveira, R.C., Jr.; Asner, G.P. Soil–Atmosphere Exchange of Nitrous Oxide, Nitric Oxide, Methane, and Carbon Dioxide in Logged and Undisturbed Forest in the Tapajos National Forest, Brazil. Earth Interact. 2005, 9, 1–28. [Google Scholar] [CrossRef]
- Alves, D.A. Science and technology and sustainable development in Brazilian Amazon. In Stability of Tropical Rainforest Margins; Environmental Science and Engineering; Tscharntke, T., Leuschner, C., Zeller, M., Guhardja, E., Bidin, A., Eds.; Springer: Heidelberg/Berlin, Germany, 2007; pp. 491–510. [Google Scholar]
- Keller, M.; Palace, M.; Hurtt, G. Biomass estimation in the Tapajos National Forest, Brazil: Examination of sampling and allometric uncertainties. For. Ecol. Manag. 2001, 154, 371–382. [Google Scholar] [CrossRef]
- Lei, Y.; Treuhaft, R.; Keller, M.; dos Santos, M.; Gonçalves, F.; Neumann, M. Quantification of selective logging in tropical forest with spaceborne SAR interferometry. Remote Sens. Environ. 2018, 211, 167–183. [Google Scholar] [CrossRef]
- Green, G.; Schweik, C.; Hanson, M. Radiometric Calibration of LANDSAT Multi-Spectral Scanner and Thematic Mapper Images: Guidelines for the Global Change Community; Technical Report; CIPEC Working Paper CWP-02-03; Bloomington Center for the Study of Institutions, Population, and Environmental Change (CIPEC), Indiana University: Bloomington, IN, USA, 2002. [Google Scholar]
- Schowengerdt, R. Remote Sensing, 3rd ed.; Academic Press: Washington, DC, USA, 2006; p. 560. [Google Scholar]
- Moran, E.; Brondízio, E.; Tucker, J.; da Silva-Forsberg, M.; Falesi, I.; McCracken, S. Land-use change after deforestation in Amazônia. In People and Pixels: Linking Remote Sensing and Social Science; Liverman, D., Moran, E., Rindfuss, R., Stern, P., Eds.; National Academy Press: Washington, DC, USA, 1998; pp. 129–149. [Google Scholar]
- Moran, E.; Brondízio, E. Strategies for Amazonian forest restoration: Evidence for afforestation in five regions of the Brazilian Amazon. In Amazônia at the Crossroads: The Challenge of Sustainable Development; Hall, A., Ed.; Institute for Latin American Studies, University of London: London, UK, 2000; pp. 94–120. [Google Scholar]
- Moran, E.F.; Brondizio, E.S.; Tucker, J.M.; da Silva-Forsberg, M.C.; McCracken, S.; Falesi, I. Effects of soil fertility and land-use on forest succession in Amazônia. For. Ecol. Manag. 2000, 139, 93–108. [Google Scholar] [CrossRef]
- Food and Agriculture Organization. FAO Land Cover Classification System 3, (Version 1.8.0); Food and Agriculture Organization: Rome, Italy, 2015. [Google Scholar]
- Reis, M.S.; Dutra, L.V.; Sant’Anna, S.J.S.; Escada, M.I.S. Examining Multi-Legend Change Detection in Amazon with Pixel and Region Based Methods. Remote Sens. 2017, 9, 77. [Google Scholar] [CrossRef]
- Hornik, K.; Buchta, C.; Zeileis, A. Open-Source Machine Learning: R Meets Weka. Comput. Stat. 2009, 24, 225–232. [Google Scholar] [CrossRef]
- Witten, I.H.; Frank, E. Data Mining: Practical Machine Learning Tools and Techniques, 2nd ed.; Morgan Kaufmann: San Francisco, CA, USA, 2005. [Google Scholar]
- Hornik, K.; Buchta, C.; Hothorn, T.; Karatzoglou, A.; Meyer, D.; Zeileis, A. RWeka: R/Weka Interface, Version 3.9.2. 2018. Available online: https://www.google.com.hk/url?sa=t&rct=j&q=&esrc=s&source=web&cd=2&ved=0ahUKEwikt_Krg4fbAhUMkpQKHdgkBQkQFgg0MAE&url=ftp%3A%2F%2Fcran.r-project.org%2Fpub%2FR%2Fweb%2Fpackages%2FRWeka%2FRWeka.pdf&usg=AOvVaw1wK2Z8V4vD-W3PUV4kKRO (accessed on 14 May 2018).
- Wies, D. Rasclass: Supervised Raster Image Classification, Version 0.2.2. 2016. Available online: https://cran.r-project.org/web/packages/rasclass/index.html (accessed on 14 May 2018).
- Congalton, R.G.; Green, K. Assessing the Accuracy of Remotely Sensed Data: Principles and Practices, 2nd ed.; CRC Press: Boca Raton, FL, USA, 2008. [Google Scholar]
- Congalton, R.G. A review of assessing the accuracy of classifications of remotely sensed data. Remote Sens. Environ. 1991, 37, 35–46. [Google Scholar] [CrossRef]
- Vieira, I.C.G.; de Almeida, A.S.; Davidson, E.A.; Stone, T.A.; de Carvalho, C.J.R.; Guerrero, J.B. Classifying successional forests using Landsat spectral properties and ecological characteristics in eastern Amazônia. Remote Sens. Environ. 2003, 87, 470–481. [Google Scholar] [CrossRef]
- Salomão, R.P.; Vieira, I.C.G.; Brienza, S., Jr.; Amaral, D.D.; Santana, A.C. Sistema Capoeira Classe: Uma proposta de sistema de classificação de estágios sucessionais de florestas secundárias para o estado do Pará. Mus. Para. Emilio Goeldi 2012, 7, 297–317. [Google Scholar]
- Asner, G.P.; Keller, M.; Silva, J.N. Spatial and temporal dynamics of forest canopy gaps following selective logging in the eastern Amazon. Glob. Chang. Biol. 2004, 10, 765–783. [Google Scholar] [CrossRef]
- Pinheiro, T.F.; Escada, M.I.S.; Valeriano, D.D.M.; Hostert, P.; Gollnow, F.; Muller, H. Forest degradation associated with logging frontier expansion in the Amazon: the BR-163 region in southwestern Pará, Brazil. Earth Interact. 2016, 20, 17. [Google Scholar] [CrossRef]
- Souza, C., Jr.; Firestone, L.; Silva, L.M.; Roberts, D. Mapping forest degradation in the Eastern Amazon from SPOT 4 through spectral mixture models. Remote Sens. Environ. 2003, 87, 494–506. [Google Scholar] [CrossRef]
- Romero-Sanchez, M.E.; Ponce-Hernandez, R. Assessing and Monitoring Forest Degradation in a Deciduous Tropical Forest in Mexico via Remote Sensing Indicators. Forests 2017, 8, 302. [Google Scholar] [CrossRef]
- Tritsch, I.; Sist, P.; Narvaes, I.S.; Mazzei, L.; Blanc, L.; Bourgoin, C.; Cornu, G.; Gond, V. Multiple Patterns of Forest Disturbance and Logging Shape Forest Landscapes in Paragominas, Brazil. Forests 2016, 7, 315. [Google Scholar] [CrossRef]
- Jarron, L.R.; Hermosilla, T.; Coops, N.C.; Wulder, M.A.; White, J.C.; Hobart, G.W.; Leckie, D.G. Differentiation of Alternate Harvesting Practices Using Annual Time Series of Landsat Data. Forests 2017, 8, 15. [Google Scholar] [CrossRef]
- Pratihast, A.K.; DeVries, B.; Avitabile, V.; de Bruin, S.; Kooistra, L.; Tekle, M.; Herold, M. Combining Satellite Data and Community-Based Observations for Forest Monitoring. Forests 2014, 5, 2464–2489. [Google Scholar] [CrossRef]
- Zadeh, L. Fuzzy sets. Inf. Control 1965, 8, 338–353. [Google Scholar] [CrossRef]
- Fisher, P.F. Remote Sensing of land cover classes as type 2 fuzzy sets. Remote Sens. Environ. 2010, 114, 309–321. [Google Scholar] [CrossRef]
- Reis, M.S.; Escada, M.I.S.; Sant’Anna, S.J.S.; Dutra, L.V. Harmonização de Legendas Formalizadas em Land Cover Meta Language-LCML; Gherardi, D.F.M., Aragão, L.E.O.e.C.d., Eds.; Simpósio Brasileiro de Sensoriamento Remoto, 18. (SBSR); Instituto Nacional de Pesquisas Espaciais (INPE): São José dos Campos, Brazil, 2017; pp. 863–870. [Google Scholar]
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Land Cover Class | 2013 Field Data | 2015 Field Data |
|---|---|---|
| Pasture | 114 | 116 |
| Annual Agriculture | 41 | 69 |
| Secondary Vegetation | 30 | 23 |
| Modified Forest | 6 | 4 |
| Mature Forest | 5 | 0 |
| Shifting Cultivation | 3 | 0 |
| Woody Plantation | 1 | 0 |
| Land | Cover Element Proportion | Element Mean Height | |||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Cover | Herbaceous | Shrubs | Trees | Litter | Soil | Shrubs | Trees | ||||||||
| Classes | Min | Max | Min | Max | Min | Max | Min | Max | Min | Max | Min | Max | Min | Max | |
| BS | 0 | 10 | 0 | 5 | 0 | 10 a | 0 | 20 | 80 | 100 | * | * | * | * | |
| ISS | 0 | 10 | 0 | 20 | 0 | 10 a | 20 | 100 | 0 | 80 | * | * | * | * | |
| IGH | 20 | 100 | 0 | 20 | 0 | 10 a | 0 | 20 | 0 | 80 | * | * | * | * | |
| AC | 5 | 100 | 0 | 5 | 0 | 10 a | 0 | 20 | 0 | 95 | * | * | * | * | |
| RD | 0 | 15 | 0 | 15 | 30 a,b | 100 a,b | 0 | 70 | 0 | 70 | * | * | * | * | |
| SC | 30 | 80 | 0 | 40 | 0 | 0 | 0 | 40 | 0 | 40 | * | * | * | * | |
| CP | 60 | 100 | 0 | 15 | 0 | 10 a | * | * | 0 | 40 | * | * | * | * | |
| SP | 20 | 85 | 15 | 40 | 0 | 10 a | * | * | * | * | * | * | * | * | |
| WP | * | * | * | * | 60 | 100 | * | * | * | * | * | * | * | * | |
| SV1 | * | * | 40 | 100 | 0 | 10 a | * | * | 0 | 40 | 0.5 | 5 | * | * a | |
| SV2 | * | * | 0 | 40 | 60 | 100 a | * | * | * | * | 2 | 5 | 5 | 15 a | |
| SV3 | * | * | 0 | 40 | 60 | 100 a | * | * | * | * | 2 | 5 | 15 | 20 a | |
| MF1 | * | * | * | * | 10 | 40 | * | * | * | * | * | * | 20 | ** | |
| MF2 | * | * | * | * | 40 | 80 | * | * | * | * | * | * | 20 | ** | |
| MF3 | * | * | * | * | 80 | 90 | * | * | * | * | * | * | 20 | ** | |
| MA | * | * | * | * | 90 | 100 | * | * | * | * | * | * | 20 | ** | |
| PA | UA | |
|---|---|---|
| SMLD_5(6)/DMLD_3(6) | ||
| BS | 0.98 ± 0.02 | 1.00 ± 0.00 |
| IGH | 0.43 ± 0.06 | 0.76 ± 0.07 |
| AC | 1.00 ± 0.00 | 0.88 ± 0.044 |
| CP | 0.79 ± 0.05 | 0.56 ± 0.03 |
| SP+SV1 | 0.82 ± 0.05 | 0.88 ± 0.04 |
| SV2+SV3+MF3+MA | 0.98 ± 0.02 | 1.00 ± 0.00 |
| Overall Accuracy | 0.83 ± 0.02 | |
| Kappa | 0.80 ± 0.02 | |
| SMLD_6(5) | ||
| BS | 0.98 ± 0.02 | 1.00 ± 0.00 |
| IGH | 0.46 ± 0.07 | 0.87 ± 0.06 |
| AC | 1.00 ± 0.00 | 0.90 ± 0.03 |
| CP+SP+SV1 | 0.89 ± 0.05 | 0.63 ± 0.03 |
| SV2+SV3+MF3+MA | 0.97 ± 0.02 | 1.00 ± 0.00 |
| Overall Accuracy | 0.86 ± 0.02 | |
| Kappa | 0.83 ± 0.02 | |
| SMLD_7(4)/DMLD_4(4) | ||
| BS+IGH | 0.71 ± 0.06 | 0.90 ± 0.04 |
| AC | 1.00 ± 0.00 | 0.93 ± 0.03 |
| CP+SP+SV1 | 0.87 ± 0.05 | 0.75 ± 0.04 |
| SV2+SV3+MF3+MA | 0.97 ± 0.02 | 1.00 ± 0.00 |
| Overall Accuracy | 0.89 ± 0.02 | |
| Kappa | 0.85 ± 0.03 | |
| SMLD_9(2) | ||
| BS+IGH | 0.88 ± 0.04 | 0.96 ± 0.03 |
| AC+CP+SP+SV1+SV2+SV3+MF3+MA | 0.97 ± 0.03 | 0.89 ± 0.03 |
| Overall Accuracy | 0.92 ± 0.03 | |
| Kappa | 0.85 ± 0.05 | |
| DMLD_5 (2) | ||
| BS+IGH+AC+CP+SP+SV1 | 0.99 ± 0.01 | 0.98 ± 0.02 |
| SV2+SV3+MF3+MA | 0.98 ± 0.02 | 0.99 ± 0.01 |
| Overall Accuracy | 0.99 ± 0.01 | |
| Kappa | 0.97 ± 0.02 | |
| SMLD_2(9) | ||
| BS | 0.97 ± 0.02 | 1.00 ± 0.00 |
| IGH | 0.42 ± 0.07 | 0.71 ± 0.07 |
| AC | 1.00 ± 0.00 | 0.86 ± 0.04 |
| CP | 0.78 ± 0.05 | 0.52 ± 0.03 |
| SP | 0.43 ± 0.06 | 0.70 ± 0.07 |
| SV1 | 0.88 ± 0.04 | 0.73 ± 0.04 |
| SV2 | 0.48 ± 0.07 | 0.55 ± 0.06 |
| SV3+MF3 | 0.48 ± 0.07 | 0.43 ± 0.05 |
| MA | 0.84 ± 0.05 | 0.86 ± 0.04 |
| Overall Accuracy | 0.70 ± 0.02 | |
| Kappa | 0.66 ± 0.02 | |
| SMLD_3(8) | ||
| BS | 0.98 ± 0.02 | 1.00 ± 0.00 |
| IGH | 0.43 ± 0.06 | 0.78 ± 0.07 |
| AC | 1.00 ± 0.00 | 0.88 ± 0.04 |
| CP | 0.79 ± 0.06 | 0.56 ± 0.04 |
| SP+SV1 | 0.81 ± 0.06 | 0.87 ± 0.04 |
| SV2 | 0.47 ± 0.06 | 0.56 ± 0.06 |
| SV3+MF3 | 0.51 ± 0.07 | 0.43 ± 0.05 |
| MA | 0.84± 0.05 | 0.86 ± 0.04 |
| Overall Accuracy | 0.73 ± 0.02 | |
| Kappa | 0.69 ± 0.02 | |
| DMLD_2(8) | ||
| BS | 0.98 ± 0.02 | 1.00 ± 0.00 |
| IGH | 0.43 ± 0.06 | 0.71 ± 0.07 |
| AC | 1.00 ± 0.00 | 0.87 ± 0.04 |
| CP | 0.79 ± 0.06 | 0.53 ± 0.04 |
| SP | 0.43 ± 0.06 | 0.70 ± 0.07 |
| SV1 | 0.87 ± 0.04 | 0.73 ± 0.04 |
| SV2+SV3+MF3 | 0.84 ± 0.05 | 0.85 ± 0.04 |
| MA | 0.87 ± 0.05 | 0.88 ± 0.04 |
| Overall Accuracy | 0.77 ± 0.02 | |
| Kappa | 0.74 ± 0.02 | |
| SMLD_4(7) | ||
| BS | 0.98 ± 0.02 | 1.00 ± 0.00 |
| IGH | 0.43 ± 0.06 | 0.74 ± 0.07 |
| AC | 1.00 ± 0.00 | 0.87 ± 0.04 |
| CP | 0.78 ± 0.06 | 0.56 ± 0.04 |
| SP+SV1 | 0.81 ± 0.05 | 0.89 ± 0.04 |
| SV2+SV3+MF3 | 0.86 ± 0.05 | 0.86 ± 0.04 |
| MA | 0.86 ± 0.05 | 0.88 ± 0.04 |
| Overall Accuracy | 0.82 ± 0.02 | |
| Kappa | 0.79 ± 0.02 | |
| SMLD_8(3) | ||
| BS+IGH | 0.68 ± 0.06 | 0.95 ± 0.04 |
| AC+CP+SP+SV1 | 0.95 ± 0.03 | 0.74 ± 0.04 |
| SV2+SV3+MF3+MA | 0.98 ± 0.02 | 0.99 ± 0.01 |
| Overall Accuracy | 0.87 ± 0.02 | |
| Kappa | 0.81 ± 0.04 | |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Reis, M.S.; Escada, M.I.S.; Dutra, L.V.; Sant’Anna, S.J.S.; Vogt, N.D. Towards a Reproducible LULC Hierarchical Class Legend for Use in the Southwest of Pará State, Brazil: A Comparison with Remote Sensing Data-Driven Hierarchies. Land 2018, 7, 65. https://doi.org/10.3390/land7020065
Reis MS, Escada MIS, Dutra LV, Sant’Anna SJS, Vogt ND. Towards a Reproducible LULC Hierarchical Class Legend for Use in the Southwest of Pará State, Brazil: A Comparison with Remote Sensing Data-Driven Hierarchies. Land. 2018; 7(2):65. https://doi.org/10.3390/land7020065
Chicago/Turabian StyleReis, Mariane S., Maria Isabel S. Escada, Luciano V. Dutra, Sidnei J. S. Sant’Anna, and Nathan D. Vogt. 2018. "Towards a Reproducible LULC Hierarchical Class Legend for Use in the Southwest of Pará State, Brazil: A Comparison with Remote Sensing Data-Driven Hierarchies" Land 7, no. 2: 65. https://doi.org/10.3390/land7020065
APA StyleReis, M. S., Escada, M. I. S., Dutra, L. V., Sant’Anna, S. J. S., & Vogt, N. D. (2018). Towards a Reproducible LULC Hierarchical Class Legend for Use in the Southwest of Pará State, Brazil: A Comparison with Remote Sensing Data-Driven Hierarchies. Land, 7(2), 65. https://doi.org/10.3390/land7020065