
MMS-EF: A Multi-Scale Modular Extraction Framework for Enhancing Deep Learning Models in Remote Sensing


Abstract
1. Introduction
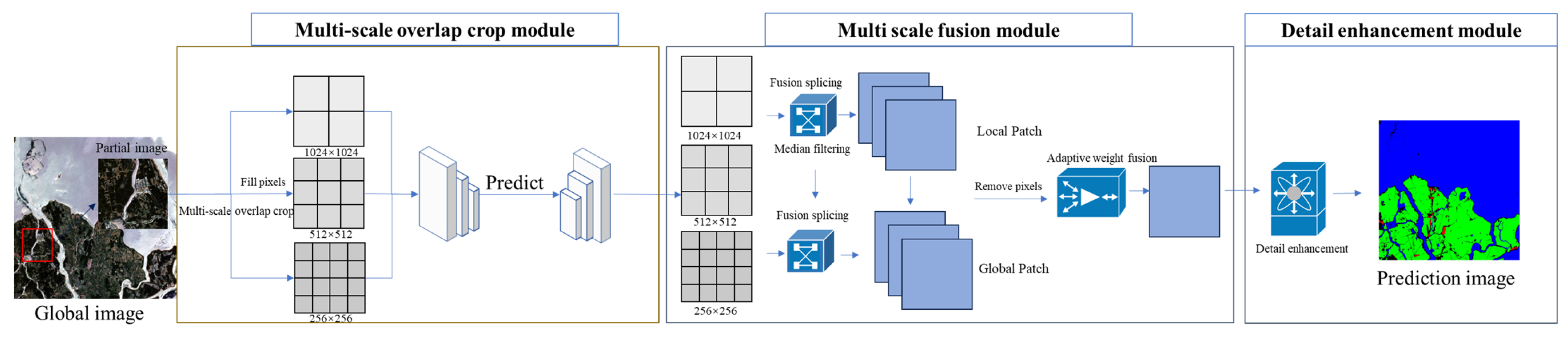
- The proposed multi-scale geographical feature extraction methodology enables the processing of remote sensing imagery across multiple scales and branches, integrating multi-scale feature fusion and detail enhancement techniques to facilitate the multi-scale extraction, fusion, representation, and augmentation of remote sensing imagery.
- The designed fusion function diminishes image boundary distortion, conserves geographical feature information, and facilitates smooth image stitching, thus reducing the incidence of stitching errors. The adaptive fusion function dynamically modulates the weighting of multi-scale information within the fusion, enriching the feature portrayal and enhancing the overall quality of the fusion.
- The multi-scale image perception module developed herein manifests substantial adaptability and generalizability across diverse network models and data sources.
2. Datasets and Deep Learning Models
2.1. Dataset Composition
2.2. Experimental Models
- U-Net: U-Net adopts an encoder–decoder structure, rendering the entire network an end-to-end fully convolutional system. Its architecture and skip connection mechanism play a pivotal role in preserving extensive spatial information from remote sensing imagery, making it particularly adept at handling remote sensing imagery extraction tasks of varying sizes and types, especially formidable in processing small sample sizes [27].
- PSPNet: PSPNet leverages a pyramid pooling module to effectively capture multi-scale information in remote sensing classification tasks. By dividing the acquired feature layers into different-sized grids, each undergoing separate average pooling, it aggregates contextual information from various regions, thereby enhancing the model’s perceptual capacity across the entirety of remote sensing imagery [28].
- DeeplabV3+: DeeplabV3+ employs an atrous spatial pyramid pooling (ASPP) module for the integration of multi-scale information within remote sensing imagery, thereby augmenting the understanding of both global and local information. The application of atrous convolution and depth-wise separable convolution techniques significantly reduces computational complexity and the number of parameters, enhancing the model’s efficiency. The feature fusion module merges high-level semantic information with comprehensive low-level details, improving the accuracy and robustness of remote sensing imagery extraction results [29].
- HRNet: HRNet maintains high-resolution representations through parallel connections of high- and low-resolution convolutions, further executing multi-resolution fusion across parallels to enhance high-resolution expressions. It preserves the detail information of high-resolution remote sensing images and enhances model performance through the integration of multi-scale features [30].
- SegFormer: As an efficient image segmentation encoder–decoder architecture, SegFormer utilizes multi-layer Transformer encoders to capture multi-scale features. Coupled with lightweight Multilayer Perceptrons (MLPs) for semantic information aggregation across different layers, its parallel processing capabilities afford it higher efficiency and speed in handling remote sensing imagery. Furthermore, its scalability and adaptability make it suitable for remote sensing imagery extraction tasks of various sizes and complexities [31].
3. Multi-Scale Modular Extraction Framework
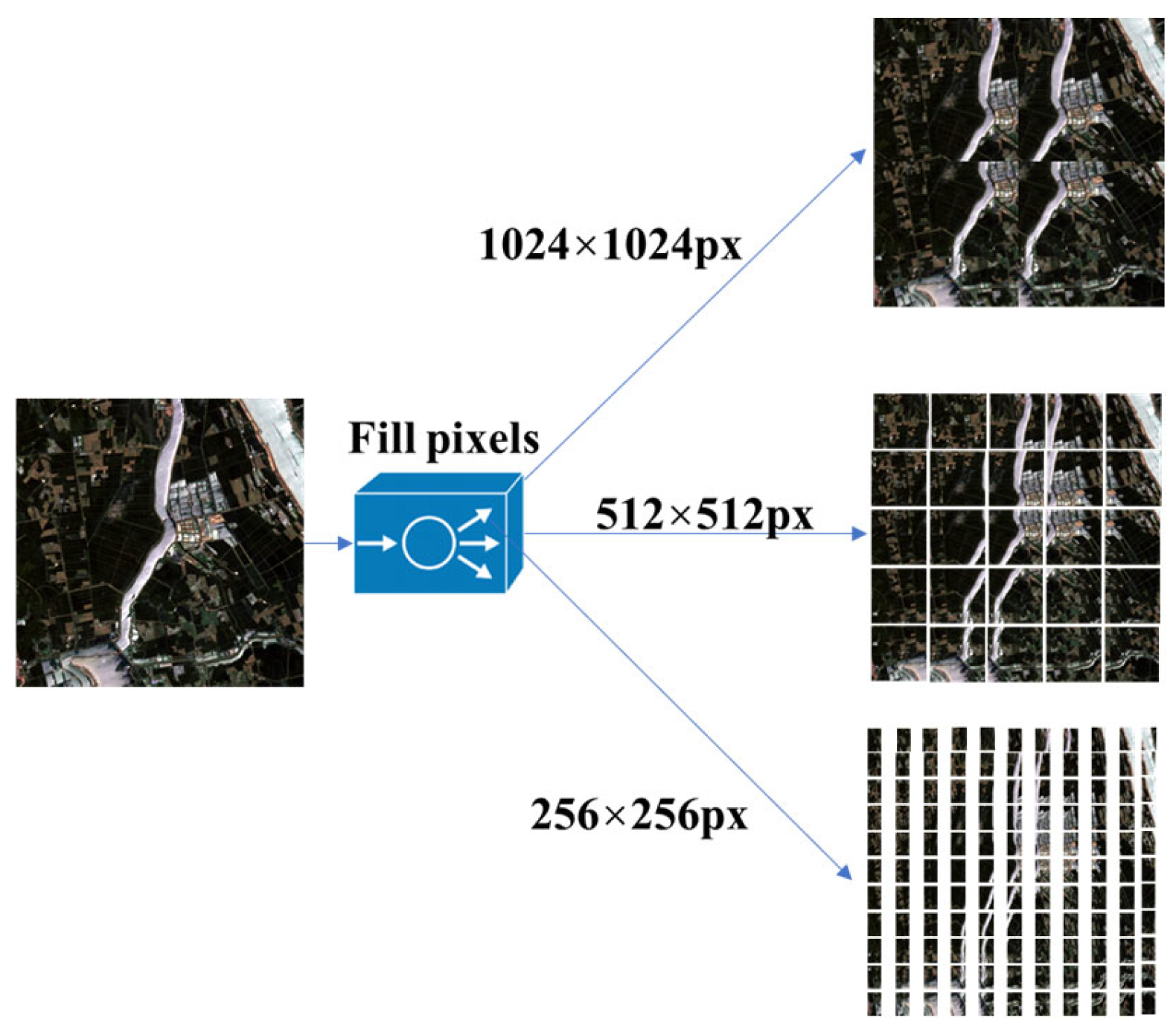
3.1. Multi-Scale Overlapping Tile Segmentation Module
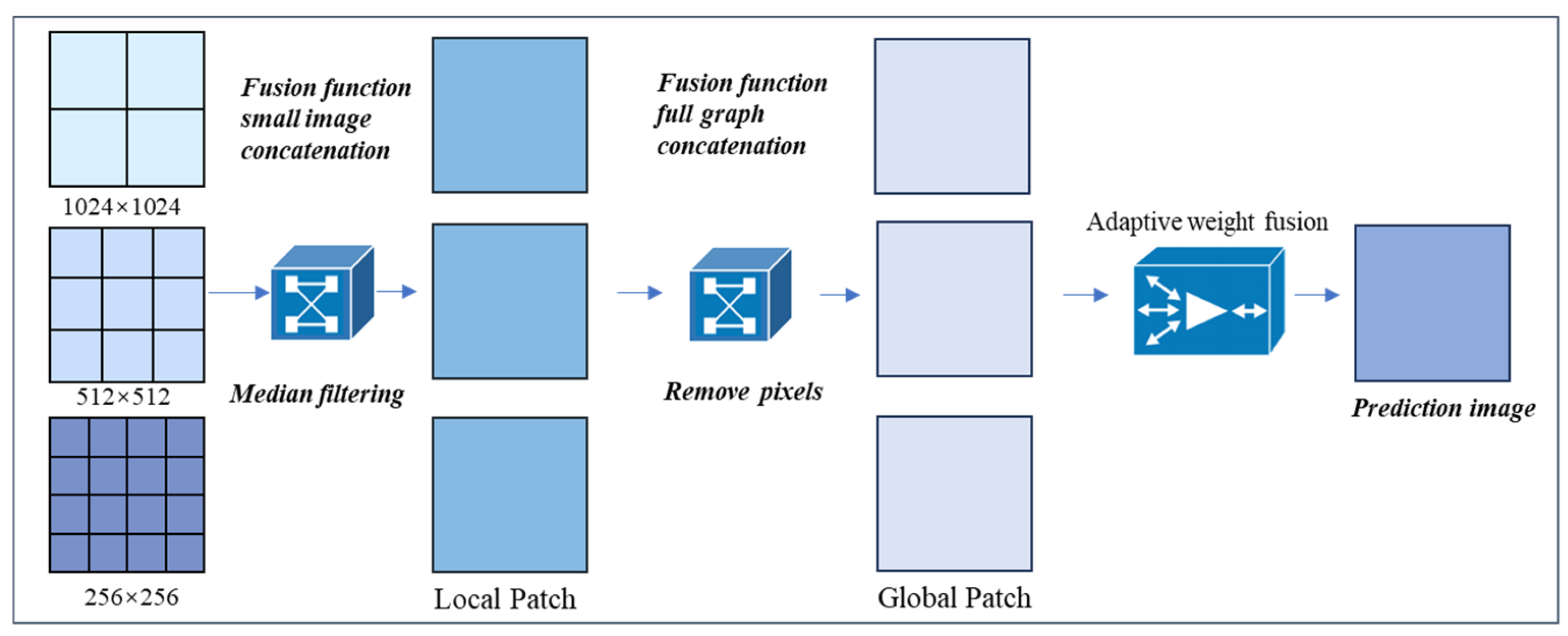
3.2. Multi-Scale Fusion Module
3.3. Detail Enhancement Module
4. Experiments
4.1. Model Training
4.2. Accuracy Evaluation
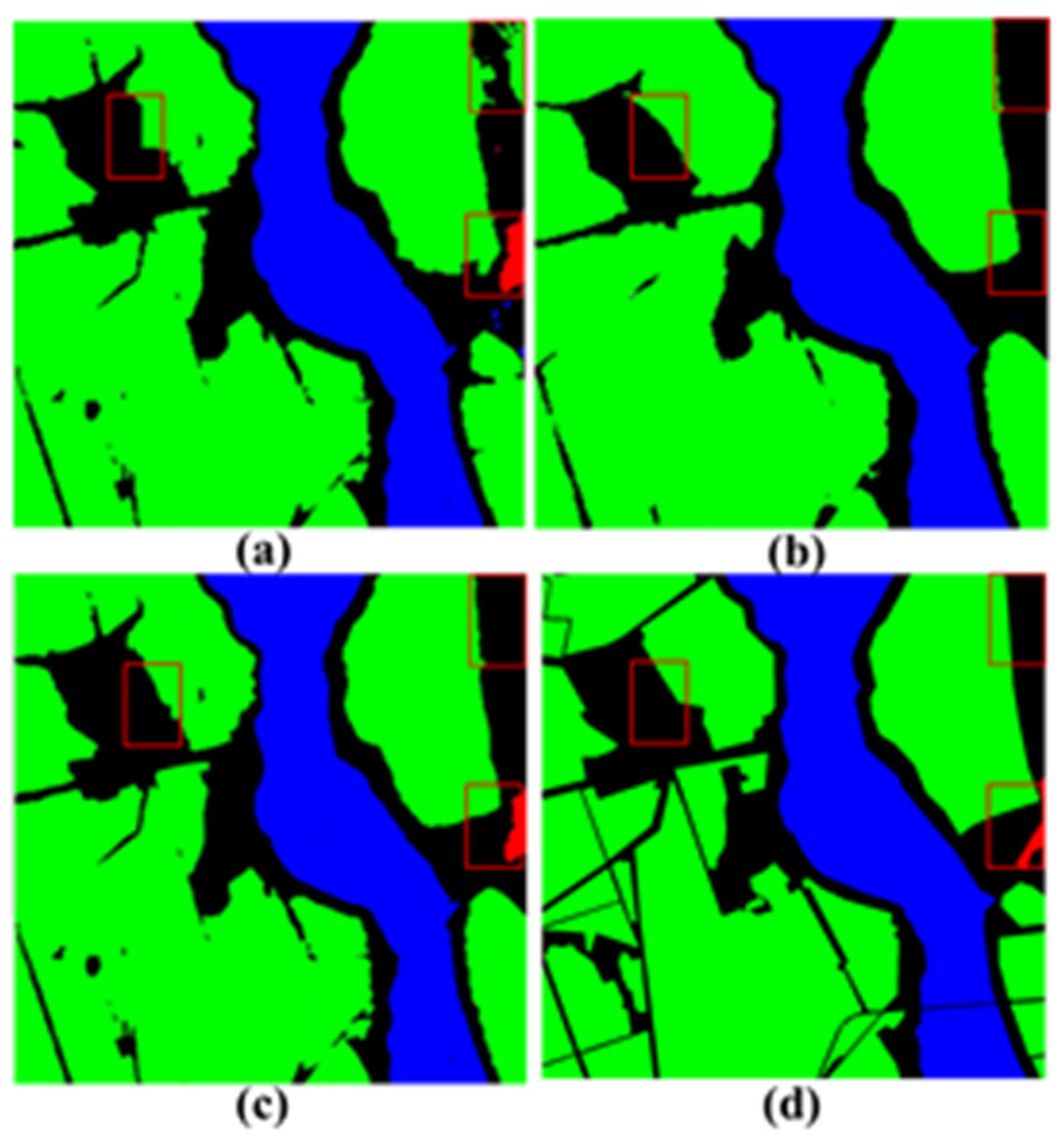
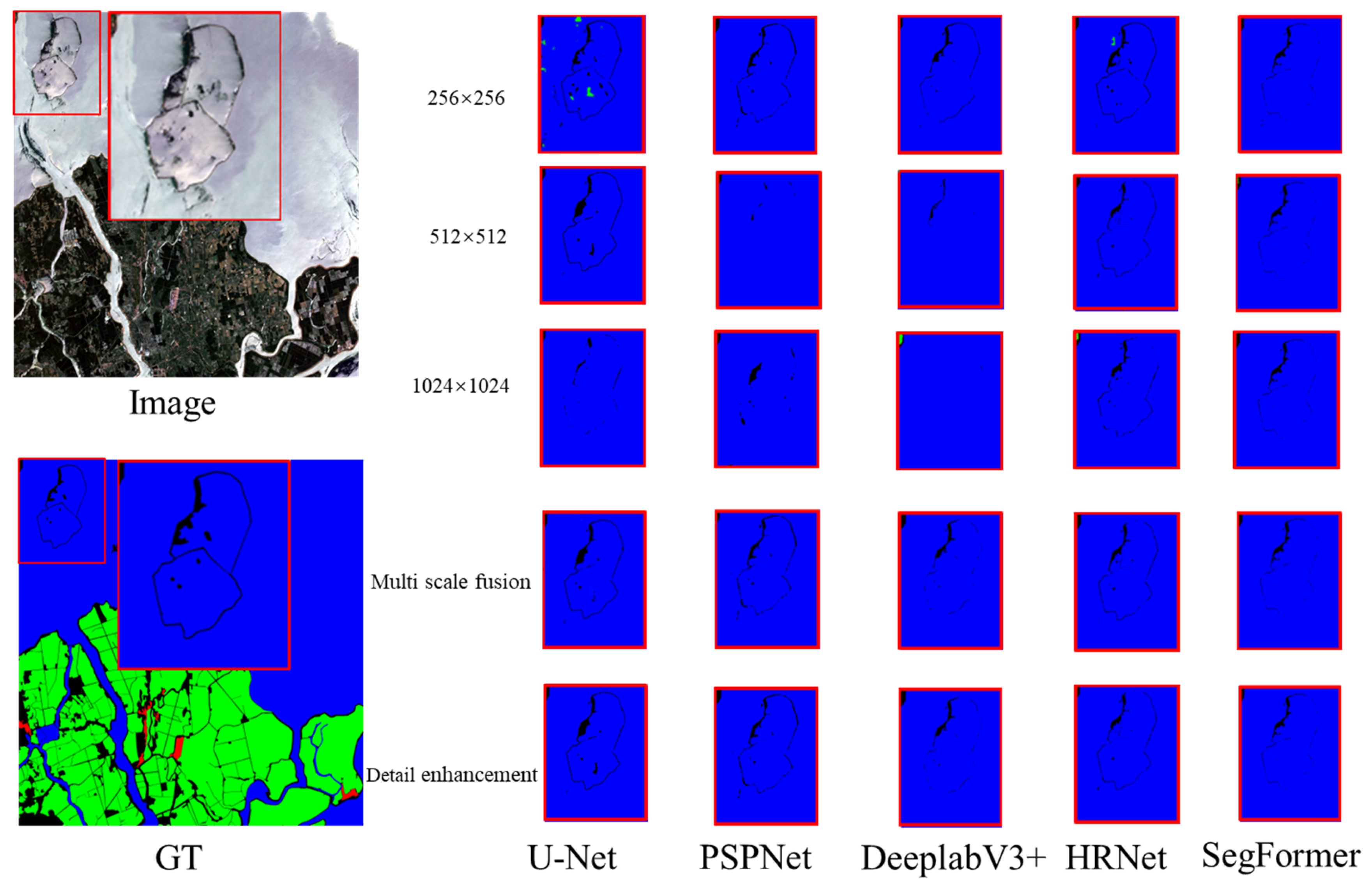
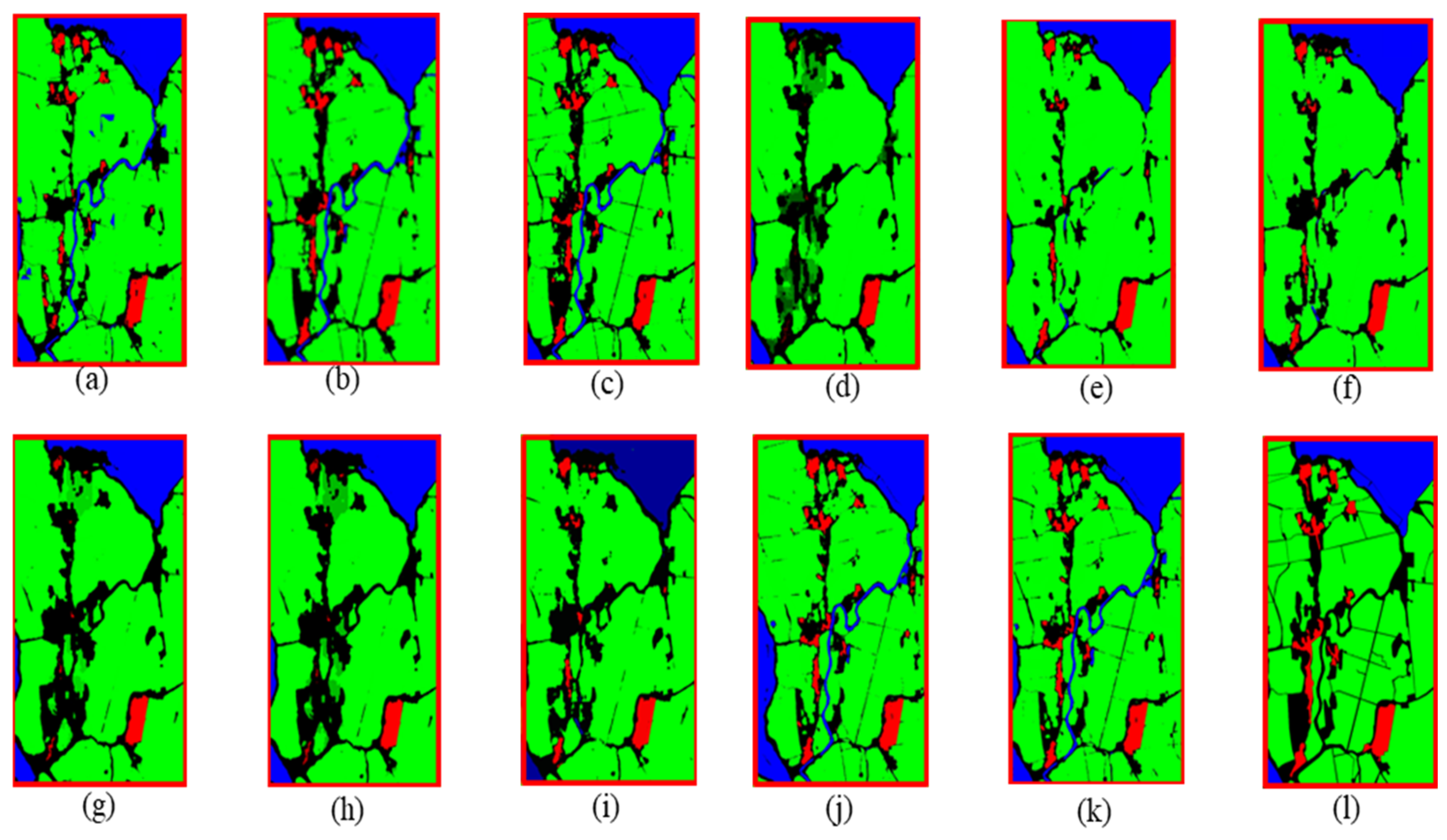
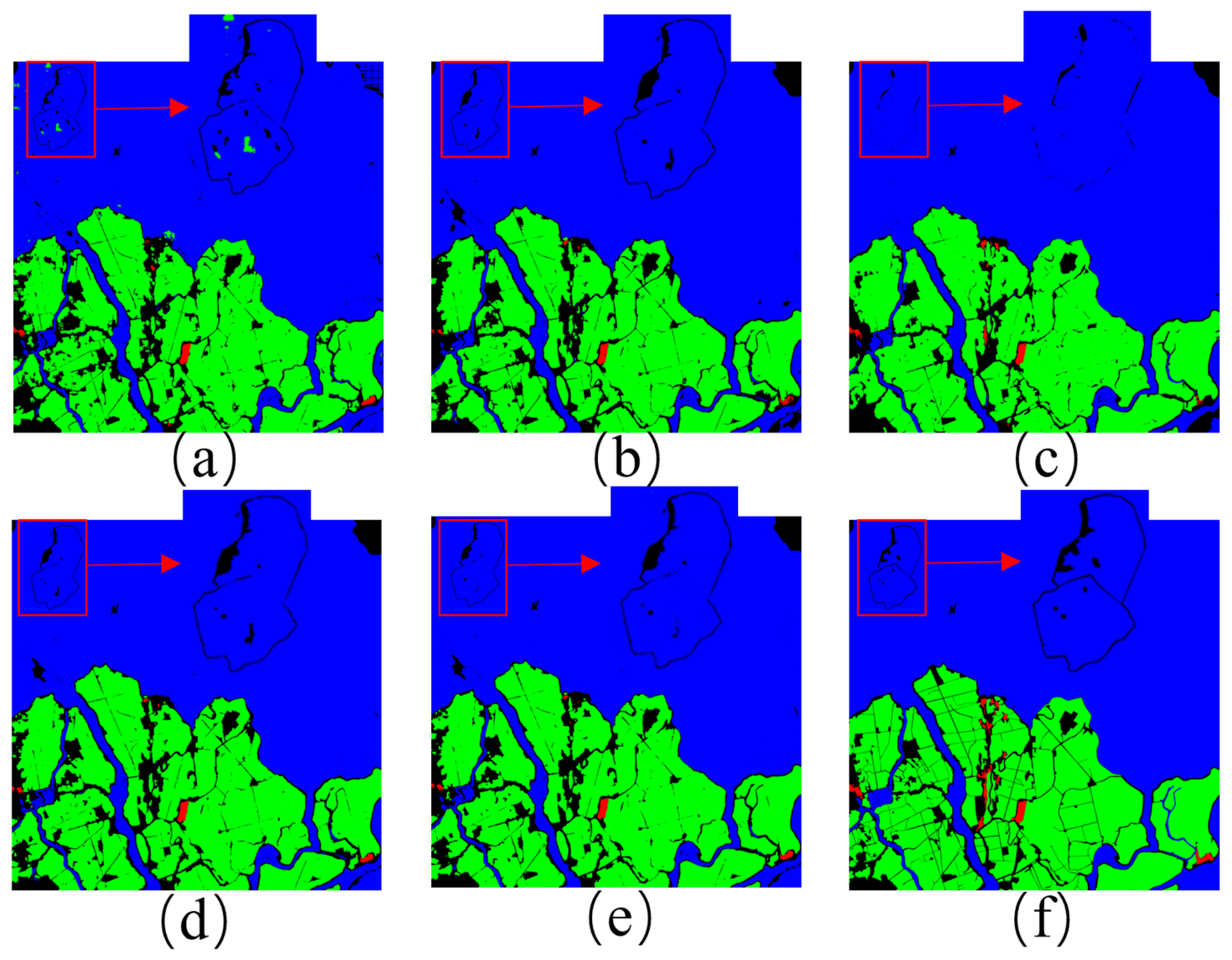
4.3. Experimental Results
4.4. Ablation Study
5. Discussion
5.1. Geographic Feature Segmentation
5.2. Image Stitching
5.3. Data Applicability
5.4. Limitations and Future Research
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Aghdami-Nia, M.; Shah-Hosseini, R.; Rostami, A.; Homayouni, S. Automatic coastline extraction through enhanced sea-land segmentation by modifying Standard U-Net. Int. J. Appl. Earth Obs. Geoinformatio 2022, 109, 102785. [Google Scholar] [CrossRef]
- Khoshboresh-Masouleh, M.; Alidoost, F.; Arefi, H. Multiscale building segmentation based on deep learning for remote sensing RGB images from different sensors. J. Appl. Remote Sens. 2020, 14, 034503. [Google Scholar] [CrossRef]
- Rostami, A.; Shah-Hosseini, R.; Asgari, S.; Zarei, A.; Aghdami-Nia, M.; Homayouni, S. Active fire detection from landsat-8 imagery using deep multiple kernel learning. Remote Sens. 2022, 14, 992. [Google Scholar] [CrossRef]
- Yang, B.; Qin, L.; Liu, J.; Liu, X. UTRNet: An unsupervised time-distance-guided convolutional recurrent network for change detection in irregularly collected images. IEEE Trans. Geosci. Remote Sens. 2022, 60, 1–16. [Google Scholar] [CrossRef]
- Ji, S.; Wei, S.; Lu, M. Fully convolutional networks for multisource building extraction from an open aerial and satellite imagery data set. IEEE Trans. Geosci. Remote Sens. 2018, 57, 574–586. [Google Scholar] [CrossRef]
- Li, J.; Yang, B.; Bai, L.; Dou, H.; Li, C.; Ma, L. TFIV: Multi-grained Token Fusion for Infrared and Visible Image via Transformer. IEEE Trans. Instrum. Meas. 2023, 72, 1–14. [Google Scholar]
- Luo, L.; Li, P.; Yan, X. Deep learning-based building extraction from remote sensing images: A comprehensive review. Energies 2021, 14, 7982. [Google Scholar] [CrossRef]
- Mei, J.; Li, R.-J.; Gao, W.; Cheng, M.-M. CoANet: Connectivity attention network for road extraction from satellite imagery. IEEE Trans. Image Process. 2021, 30, 8540–8552. [Google Scholar] [CrossRef]
- Zhang, R.; Newsam, S.; Shao, Z.; Huang, X.; Wang, J.; Li, D. Multi-scale adversarial network for vehicle detection in UAV imagery. ISPRS J. Photogramm. Remote Sens. 2021, 180, 283–295. [Google Scholar] [CrossRef]
- Chen, W.; Jiang, Z.; Wang, Z.; Cui, K.; Qian, X. Collaborative Global-Local Networks for Memory-EFFICIENT segmentation of Ultra-High Resolution Images. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 8924–8933. [Google Scholar]
- Zhang, Z.; Lu, M.; Ji, S.; Yu, H.; Nie, C. Rich CNN features for water-body segmentation from very high resolution aerial and satellite imagery. Remote Sens. 2021, 13, 1912. [Google Scholar] [CrossRef]
- Xia, G.-S.; Hu, J.; Hu, F.; Shi, B.; Bai, X.; Zhong, Y.; Zhang, L.; Lu, X. AID: A benchmark data set for performance evaluation of aerial scene classification. IEEE Trans. Geosci. Remote Sens. 2017, 55, 3965–3981. [Google Scholar] [CrossRef]
- Liu, Y.; Zhong, Y.; Shi, S.; Zhang, L. Scale-aware deep reinforcement learning for high resolution remote sensing imagery classification. ISPRS J. Photogramm. Remote Sens. 2024, 209, 296–311. [Google Scholar] [CrossRef]
- Zhao, X.; Zhang, J.; Tian, J.; Zhuo, L.; Zhang, J. Residual dense network based on channel-spatial attention for the scene classification of a high-resolution remote sensing image. Remote Sens. 2020, 12, 1887. [Google Scholar] [CrossRef]
- Zhang, Y.; Mei, X.; Ma, Y.; Jiang, X.; Peng, Z.; Huang, J. Hyperspectral panoramic image stitching using robust matching and adaptive bundle adjustment. Remote Sens. 2022, 14, 4038. [Google Scholar] [CrossRef]
- Cheng, H.K.; Chung, J.; Tai, Y.-W.; Tang, C.-K. Cascadepsp: Toward Class-Agnostic and Very High-Resolution Segmentation via Global and Local Refinement. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 8890–8899. [Google Scholar]
- Ding, Y.; Wu, M.; Xu, Y.; Duan, S. P-linknet: Linknet with spatial pyramid pooling for high-resolution satellite imagery. ISPRS-Int. Arch. Photogramm. Remote. Sens. Spat. Inf. Sci. 2020, 43, 35–40. [Google Scholar] [CrossRef]
- Wei, S.; Ji, S.; Lu, M. Toward automatic building footprint delineation from aerial images using CNN and regularization. IEEE Trans. Geosci. Remote Sens. 2019, 58, 2178–2189. [Google Scholar] [CrossRef]
- Xu, Q.; Chen, J.; Luo, L.; Gong, W.; Wang, Y. UAV image stitching based on mesh-guided deformation and ground constraint. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 4465–4475. [Google Scholar] [CrossRef]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S. An image is worth 16×16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Bay, H.; Tuytelaars, T.; Van Gool, L. Surf: Speeded Up Robust Features. In Proceedings of the Computer Vision–ECCV 2006: 9th European Conference on Computer Vision, Graz, Austria, 7–13 May 2006; Proceedings, Part I 9. pp. 404–417. [Google Scholar]
- Ashish, V. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30, 1. [Google Scholar]
- Abuhasel, K. Geographical Information System Based Spatial and Statistical Analysis of the Green Areas in the Cities of Abha and Bisha for Environmental Sustainability. ISPRS Int. J. Geo-Inf. 2023, 12, 333. [Google Scholar] [CrossRef]
- Gao, W.; Chen, N.; Chen, J.; Gao, B.; Xu, Y.; Weng, X.; Jiang, X. A Novel and Extensible Remote Sensing Collaboration Platform: Architecture Design and Prototype Implementation. ISPRS Int. J. Geo-Inf. 2024, 13, 83. [Google Scholar] [CrossRef]
- Tong, X.-Y.; Xia, G.-S.; Lu, Q.; Shen, H.; Li, S.; You, S.; Zhang, L. Land-cover classification with high-resolution remote sensing images using transferable deep models. Remote Sens. Environ. 2020, 237, 111322. [Google Scholar] [CrossRef]
- Song, W.; Zhang, Z.; Zhang, B.; Jia, G.; Zhu, H.; Zhang, J. ISTD-PDS7: A Benchmark Dataset for Multi-Type Pavement Distress Segmentation from CCD Images in Complex Scenarios. Remote Sens. 2023, 15, 1750. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional Networks for Biomedical Image Segmentation. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention–MICCAI 2015: 18th International Conference, Munich, Germany, 5–9 October 2015; proceedings, part III 18. pp. 234–241. [Google Scholar]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid Scene Parsing Network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2881–2890. [Google Scholar]
- Chen, L.-C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 834–848. [Google Scholar] [CrossRef]
- Wang, J.; Sun, K.; Cheng, T.; Jiang, B.; Deng, C.; Zhao, Y.; Liu, D.; Mu, Y.; Tan, M.; Wang, X.; et al. Deep high-resolution representation learning for visual recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 43, 3349–3364. [Google Scholar] [CrossRef]
- Xie, E.; Wang, W.; Yu, Z.; Anandkumar, A.; Alvarez, J.M.; Luo, P. SegFormer: Simple and efficient design for semantic segmentation with transformers. Neural Inf. Process. Syst. 2021, 34, 12077–12090. [Google Scholar]
- Cao, N.; Liu, Y. High-Noise Grayscale Image Denoising Using an Improved Median Filter for the Adaptive Selection of a Threshold. Appl. Sci. 2024, 14, 635. [Google Scholar] [CrossRef]
- Oboué, Y.A.S.I.; Chen, Y.; Fomel, S.; Zhong, W.; Chen, Y. An advanced median filter for improving the signal-to-noise ratio of seismological datasets. Comput. Geosci. 2024, 182, 105464. [Google Scholar] [CrossRef]
- Filintas, A.; Gougoulias, N.; Kourgialas, N.; Hatzichristou, E. Management Soil Zones, Irrigation, and Fertigation Effects on Yield and Oil Content of Coriandrum sativum L. Using Precision Agriculture with Fuzzy k-Means Clustering. Sustainability 2023, 15, 13524. [Google Scholar] [CrossRef]
- Han, S.; Lee, J. Parallelized Inter-Image k-Means Clustering Algorithm for Unsupervised Classification of Series of Satellite Images. Remote. Sens. 2023, 16, 102. [Google Scholar] [CrossRef]
- Kanwal, M.; Riaz, M.M.; Ali, S.S.; Ghafoor, A. Fusing color, depth and histogram maps for saliency detection. Multimed. Tools Appl. 2022, 81, 16243–16253. [Google Scholar] [CrossRef]
- Li, S.; Zou, Y.; Wang, G.; Lin, C. Infrared and visible image fusion method based on principal component analysis network and multi-scale morphological gradient. Infrared Phys. Technol. 2023, 133, 104810. [Google Scholar] [CrossRef]
- Wang, J.; Xi, X.; Li, D.; Li, F.; Zhang, G. A gradient residual and pyramid attention-based multiscale network for multimodal image fusion. Entropy 2023, 25, 169. [Google Scholar] [CrossRef] [PubMed]
- Zhou, J.; Zhang, D.; Zhang, W. Adaptive histogram fusion-based colour restoration and enhancement for underwater images. Int. J. Secur. Netw. 2021, 16, 49–59. [Google Scholar] [CrossRef]
- Chen, L.; Rao, P.; Chen, X. Infrared dim target detection method based on local feature contrast and energy concentration degree. Optik 2021, 248, 167651. [Google Scholar] [CrossRef]
- Liu, X.; Qiao, S.; Zhang, T.; Zhao, C.; Yao, X. Single-image super-resolution based on an improved asymmetric Laplacian pyramid structure. Digit. Signal Process. 2024, 145, 104321. [Google Scholar] [CrossRef]
- Sharvani, H.K. Lung Cancer Detection using Local Energy-Based Shape Histogram (LESH) Feature Extraction Using Adaboost Machine Learning Techniques. Int. J. Innov. Technol. Explor. Eng. 2020, 9, 167–171. [Google Scholar] [CrossRef]
- Wang, W.; Wang, G.; Jiang, Y.; Guo, W.; Ren, G.; Wang, J.; Wang, Y. Hyperspectral image classification Based on weakened Laplacian pyramid and guided filtering. Int. J. Remote. Sens. 2023, 44, 5397–5419. [Google Scholar] [CrossRef]
- Garcia-Garcia, A.; Orts-Escolano, S.; Oprea, S.; Villena-Martinez, V.; Garcia-Rodriguez, J. A review on deep learning techniques applied to semantic segmentation. arXiv 2017, arXiv:1704.06857. [Google Scholar]
- Zhang, M.-L.; Zhou, Z.-H.J. A review on multi-label learning algorithms. IEEE Trans. Knowl. Data Eng. 2013, 26, 1819–1837. [Google Scholar] [CrossRef]
- Demir, I.; Koperski, K.; Lindenbaum, D.; Pang, G.; Huang, J.; Basu, S.; Hughes, F.; Tuia, D.; Raskar, R. Deepglobe 2018: A Challenge to Parse the Earth Through Satellite Images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Salt Lake City, UT, USA, 18–22 June 2018; pp. 172–181. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Epoch | Batch Size | Initial Learning Rate | Optimizer |
|---|---|---|---|---|
| Value | 200 | 8 | 5 × 10−4 | Adam |
| Methods | U-Net (%) | PSPNet (%) | DeepLabV3+ (%) | HRNet (%) | SegFormer (%) |
|---|---|---|---|---|---|
| 256 | 75.54 | 71.37 | 76.93 | 76.55 | 78.14 |
| 512 | 75.51 | 70.89 | 74.42 | 76.35 | 75.51 |
| 1024 | 73.40 | 70.84 | 72.39 | 73.91 | 73.55 |
| Multi-scale fusion | 76.01 | 74.32 | 77.25 | 78.01 | 78.97 |
| Detail enhancement | 77.53 | 75.11 | 78.02 | 79.15 | 79.93 |
| Methods | U-Net (%) | PSPNet (%) | DeepLabV3+ (%) | HRNet (%) | SegFormer (%) |
|---|---|---|---|---|---|
| 256 | 84.79 | 82.03 | 86.46 | 85.50 | 87.70 |
| 512 | 84.71 | 81.07 | 84.42 | 85.03 | 84.71 |
| 1024 | 81.79 | 80.39 | 81.32 | 83.33 | 83.95 |
| Multi-scale fusion | 84.98 | 84.21 | 86.59 | 87.49 | 88.32 |
| Detail enhancement | 86.67 | 84.47 | 87.53 | 88.87 | 89.89 |
| Methods | U-Net (%) | PSPNet (%) | DeepLabV3+ (%) | HRNet (%) | SegFormer (%) |
|---|---|---|---|---|---|
| 256 | 71.49 | 71.35 | 72.31 | 73.55 | 74.14 |
| 512 | 71.01 | 70.13 | 70.39 | 70.24 | 72.21 |
| 1024 | 70.14 | 70.01 | 70.25 | 70.24 | 71.55 |
| Multi-scale fusion | 73.98 | 73.81 | 74.33 | 75.49 | 75.96 |
| Detail enhancement | 74.67 | 74.02 | 74.63 | 76.18 | 76.99 |
| Methods | U-Net (%) | PSPNet (%) | DeepLabV3+ (%) | HRNet (%) | SegFormer (%) |
|---|---|---|---|---|---|
| 256 | 82.36 | 82.15 | 83.54 | 85.32 | 86.17 |
| 512 | 81.66 | 80.40 | 80.77 | 80.37 | 83.39 |
| 1024 | 80.41 | 80.22 | 80.57 | 80.56 | 82.44 |
| Multi-scale fusion | 85.88 | 85.72 | 86.59 | 87.12 | 88.88 |
| Detail enhancement | 86.95 | 86.01 | 86.67 | 89.07 | 89.89 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yu, H.; Song, W.; Zhang, B.; Zhu, H.; Dai, J.; Zhang, J. MMS-EF: A Multi-Scale Modular Extraction Framework for Enhancing Deep Learning Models in Remote Sensing. Land 2024, 13, 1842. https://doi.org/10.3390/land13111842
Yu H, Song W, Zhang B, Zhu H, Dai J, Zhang J. MMS-EF: A Multi-Scale Modular Extraction Framework for Enhancing Deep Learning Models in Remote Sensing. Land. 2024; 13(11):1842. https://doi.org/10.3390/land13111842
Chicago/Turabian StyleYu, Hang, Weidong Song, Bing Zhang, Hongbo Zhu, Jiguang Dai, and Jichao Zhang. 2024. "MMS-EF: A Multi-Scale Modular Extraction Framework for Enhancing Deep Learning Models in Remote Sensing" Land 13, no. 11: 1842. https://doi.org/10.3390/land13111842
APA StyleYu, H., Song, W., Zhang, B., Zhu, H., Dai, J., & Zhang, J. (2024). MMS-EF: A Multi-Scale Modular Extraction Framework for Enhancing Deep Learning Models in Remote Sensing. Land, 13(11), 1842. https://doi.org/10.3390/land13111842