
Disaggregation of the Copernicus Land Use/Land Cover (LULC) and Population Density Data to Fit Mesoscale Flood Risk Assessment Requirements in Partially Urbanized Catchments in Croatia



Abstract
:1. Introduction
2. Materials and Methods
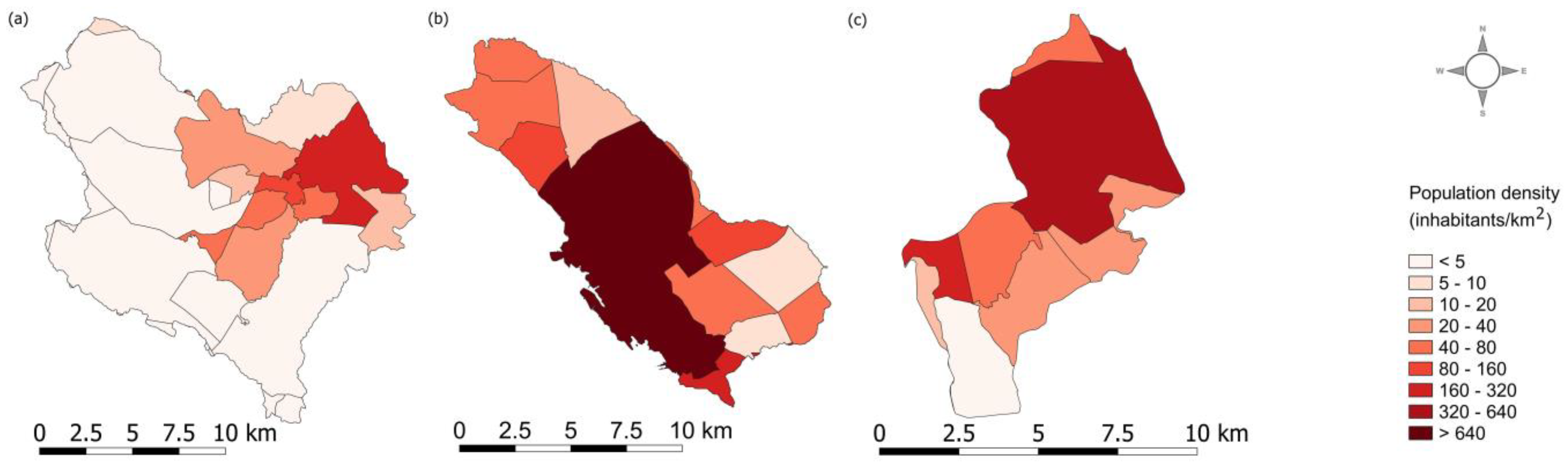
2.1. Study Areas
2.2. Copernicus LULC Data
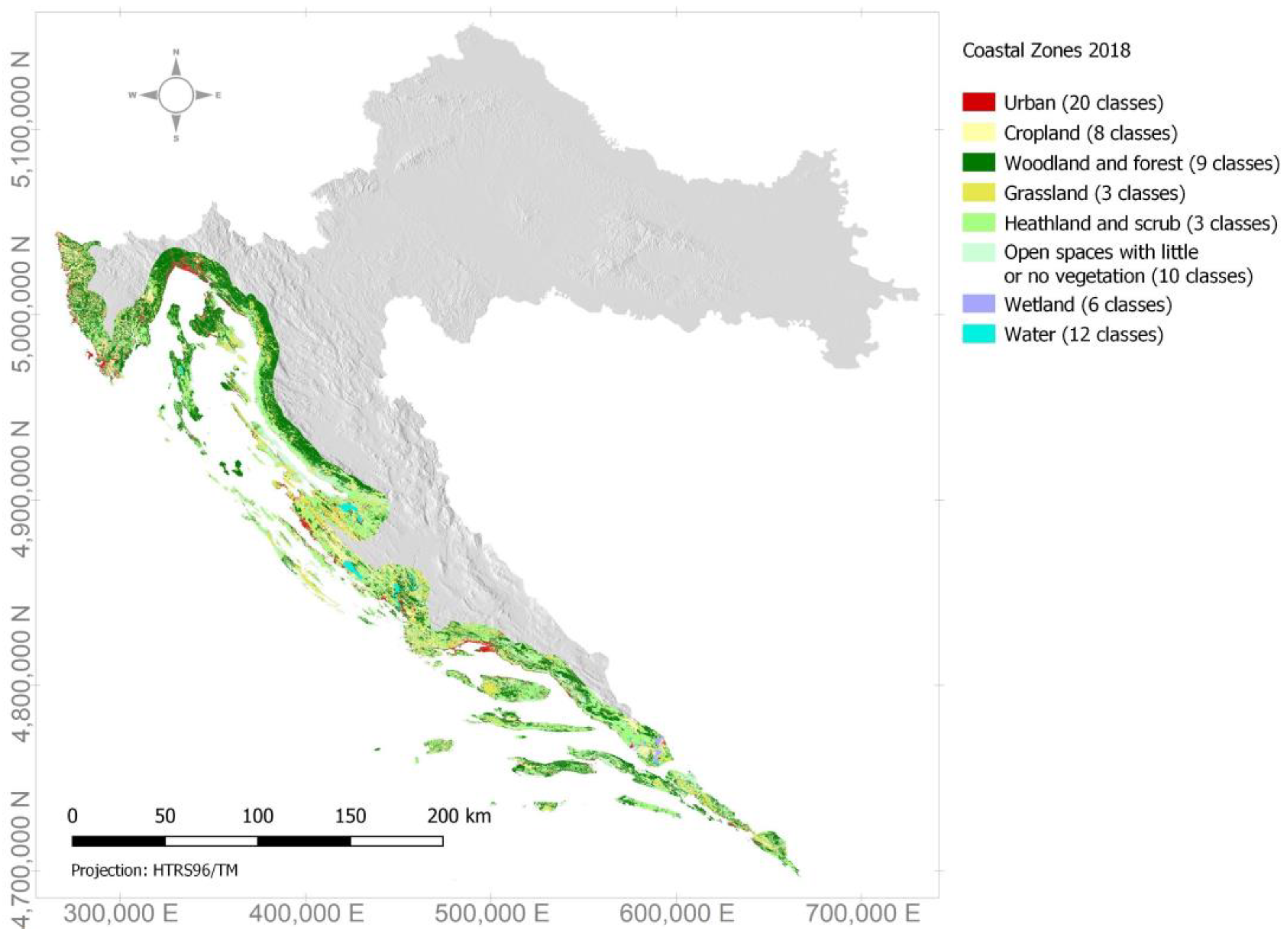
2.2.1. Coastal Zones (CZ 2018)
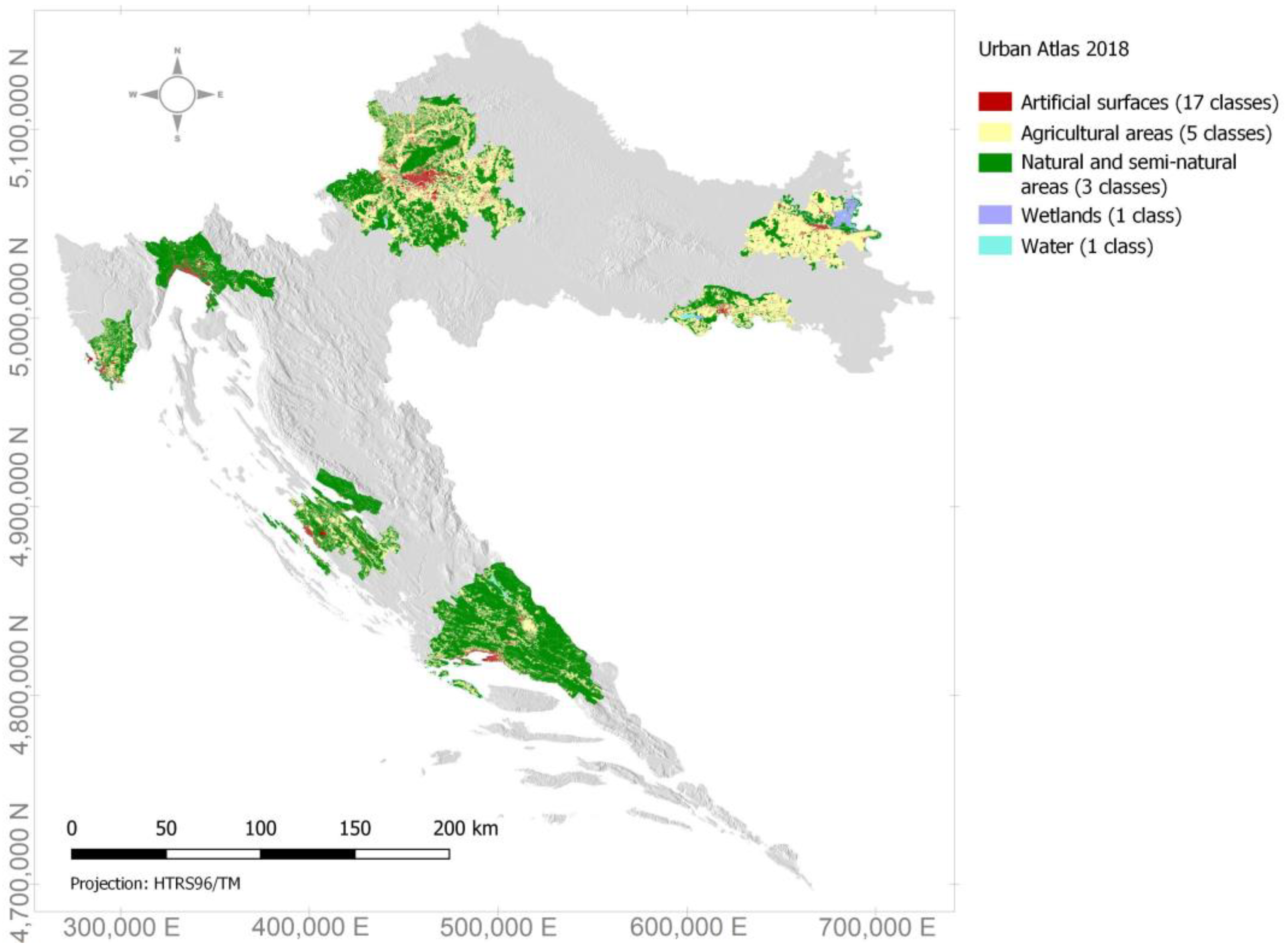
2.2.2. Urban Atlas (UA 2018)
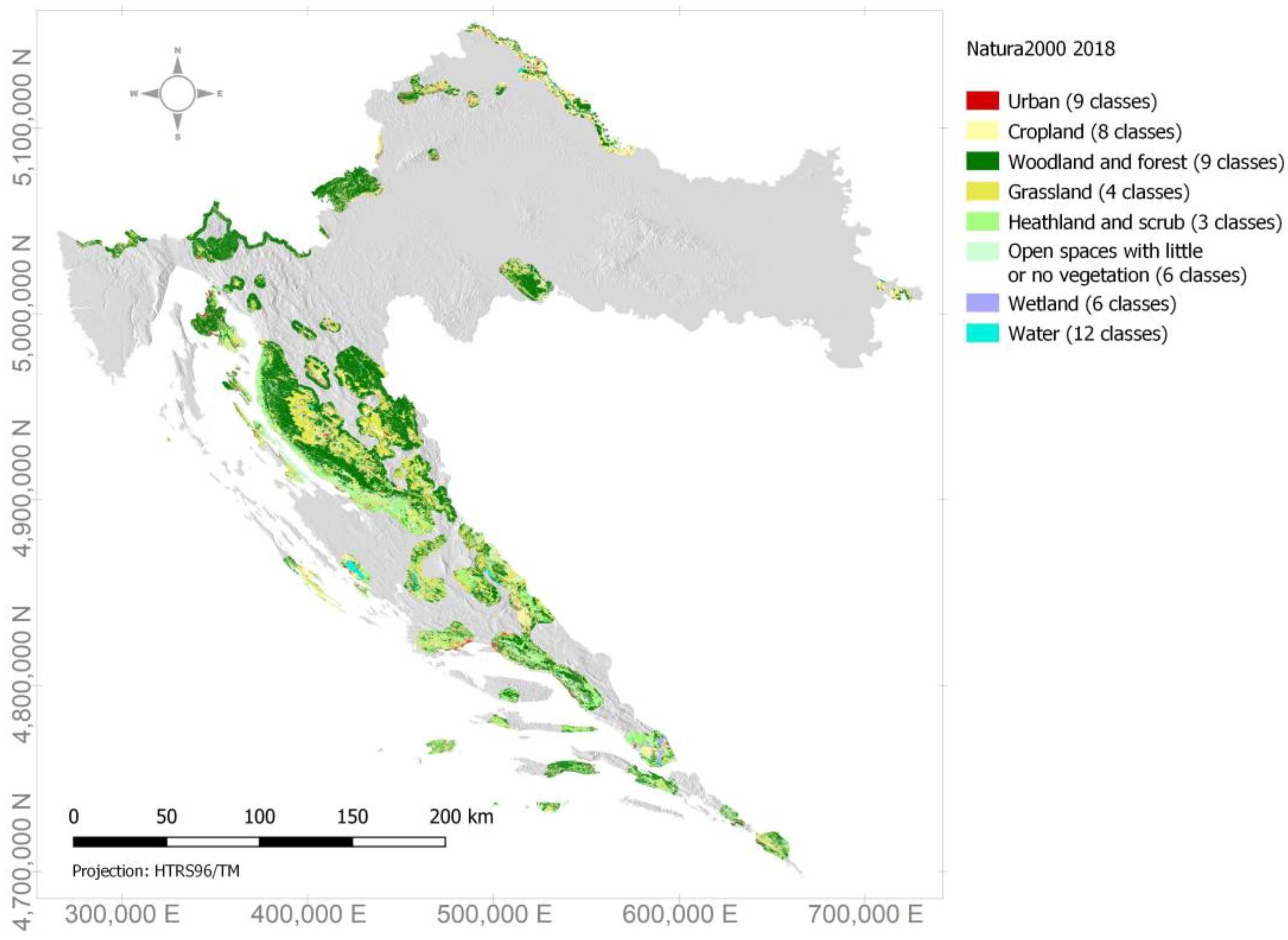
2.2.3. Natura 2000 (N2K 2018)
2.3. Imperviousness Density (IMD 2018) and Imperviousness Built-Up (IBU 2018) Data
2.4. Census Data
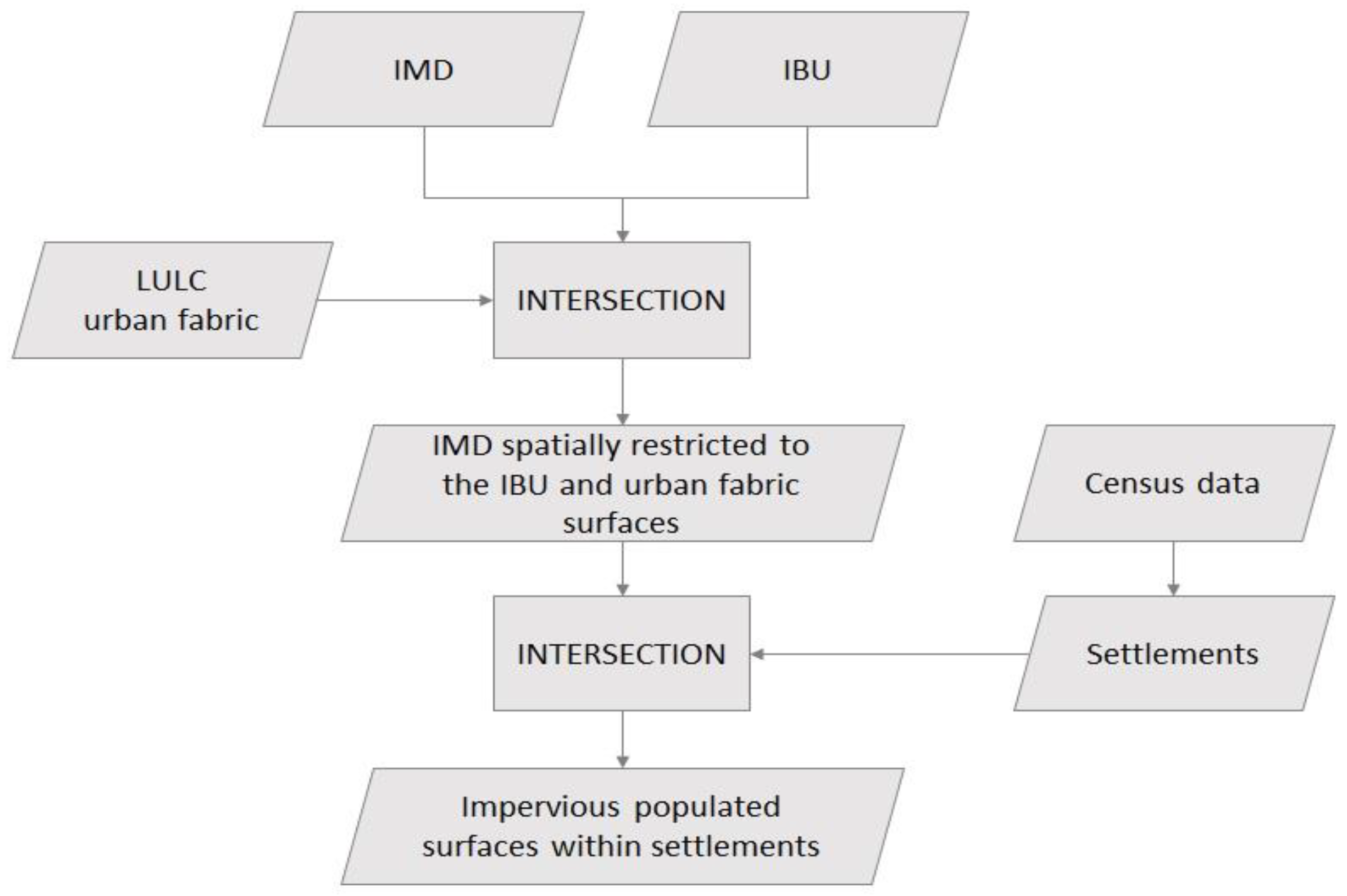
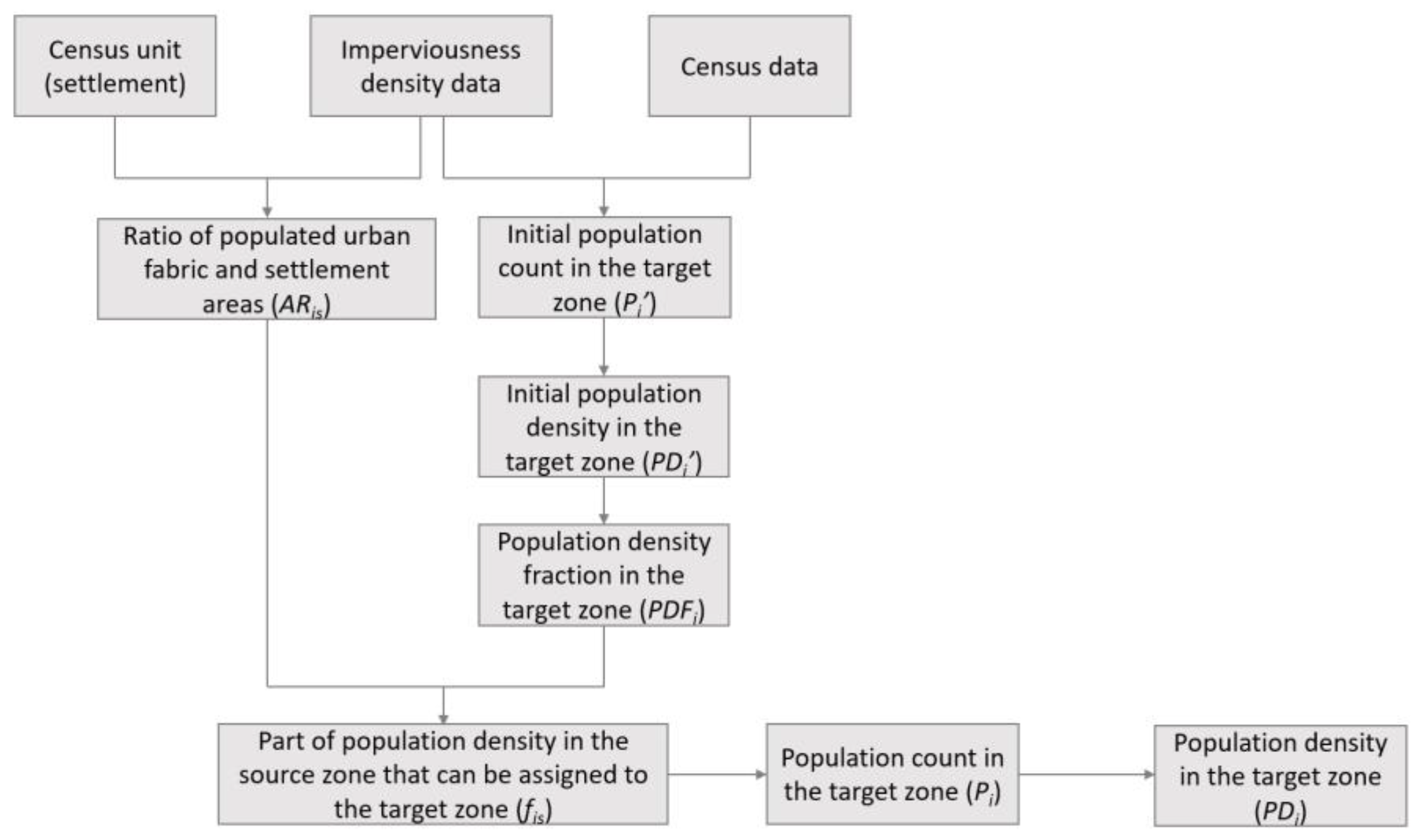
2.5. Methodological Framework
- Phase 1: Data selection and preparation
- Phase 2: Data disaggregation
- Population density is related to the imperviousness density: IMD values are used as auxiliary data in estimating populations exposed to flooding;
- The population resides only in built-up areas [37]: to avoid the dissemination of the census data to areas occupied by non-residential buildings, built-up areas are removed from the IBU layer and used to spatially constrain the IMD distribution;
- The IMD values indicate the density of built-up areas: they consider the variability of built-up density and, consequently, the variability of a population.
- Phase 3: Evaluation
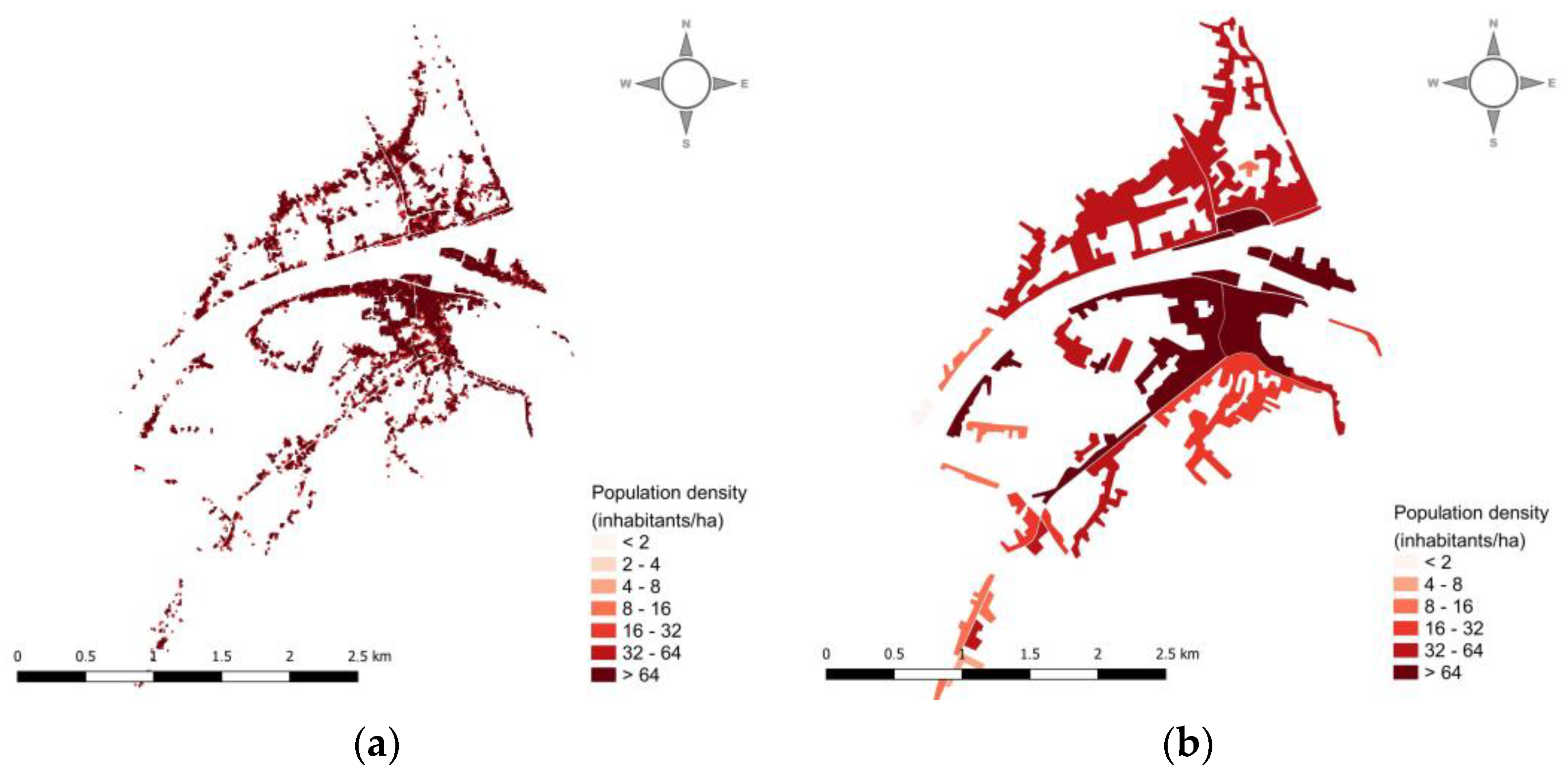
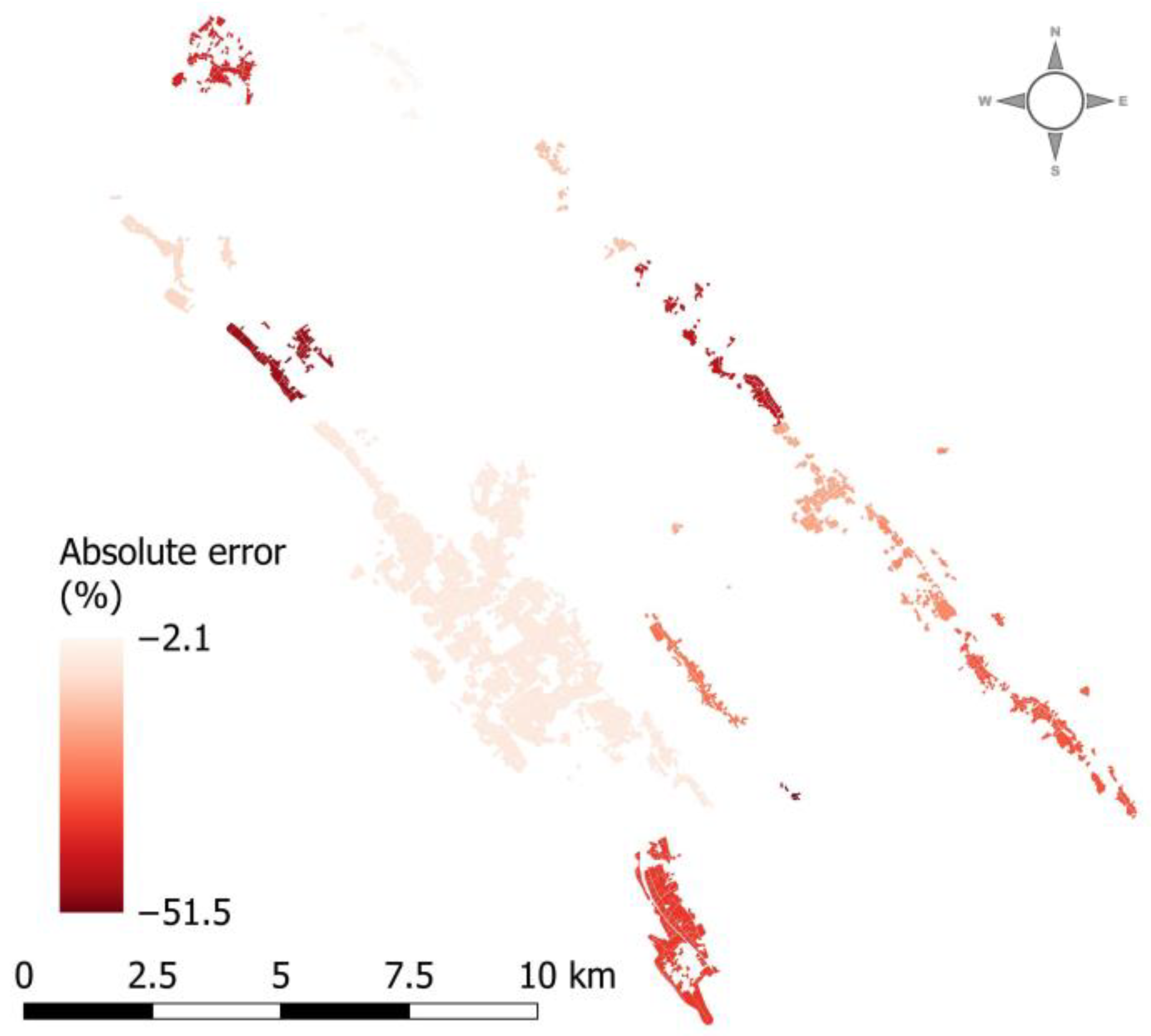
3. Results
4. Discussion
5. Conclusions
Limitations of the Proposed Method and Further Improvement
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| CORINE Based Level 1 | MAES Based Level 1 | CLC | UA | CZ | N2K |
|---|---|---|---|---|---|
| Artificial surfaces | Urban | Continuous urban fabric | Continuous urban fabric (SL > 80%) | Continuous urban fabric (IMD > 80%) | Urban fabric (predominantly public and private units) |
| Discontinuous urban fabric | Discontinuous dense urban fabric (SL 50–80%) | Dense urban fabric (IMD 30–80%) | |||
| Discontinuous medium-density urban fabric (SL 30–50%) | |||||
| Discontinuous low-density urban fabric (SL 10–30%) | Low-density fabric (IMD < 30%) | ||||
| Discontinuous very-low-density urban fabric (SL < 10%) | |||||
| Industrial or commercial units | Industrial, commercial, public, military and private units | Industrial, commercial, public and military units (other) | Industrial, commercial and military units | ||
| Nuclear energy plants and associated land | |||||
| Road and rail networks and associated land | Fast transit roads and associated land | Road networks and associated land | Road networks and associated land | ||
| Other roads and associated land | |||||
| Railways and associated land | Railways and associated land | Railways and associated land | |||
| Port areas | Port areas | Cargo ports | Port areas | ||
| Passenger ports | |||||
| Fishing ports | |||||
| Naval ports | |||||
| Marinas | |||||
| Local multi-functional harbours | |||||
| Shipyards | |||||
| Airports | Airports | Airports and associated land | Airports and associated land | ||
| Mineral extraction sites | Mineral extraction and dump sites | Mineral extraction sites | Mineral extraction sites, dump and construction sites | ||
| Dump sites | Dump sites | ||||
| Construction sites | Construction sites | Construction sites | |||
| - | Land without current use | Land without current use | Land without current use | ||
| Green urban areas | Green urban areas | Green urban, sports and leisure facilities | Green urban, sports and leisure facilities | ||
| Sport and leisure facilities | Sport and leisure facilities | ||||
| Agricultural areas | Cropland | Non-irrigated arable land | Arable land (crops) | Arable irrigated and non-irrigated land | Arable irrigated and non-irrigated land |
| Permanently irrigated arable land | |||||
| Rice fields | |||||
| - | - | Greenhouses | Greenhouses | ||
| Vineyards | Permanent crops | Vineyards, fruit trees and berry plantations | Vineyards, fruit trees and berry plantations | ||
| Fruit trees and berry plantations | |||||
| Olive groves | Olive groves | Olive groves | |||
| Pasture | Pastures | Annual crops associated with permanent crops | Annual crops associated with permanent crops | ||
| Annual crops associated with permanent crops | - | ||||
| Complex cultivation patterns | Complex and mixed cultivation | Complex cultivation patterns | Complex cultivation patterns | ||
| Land principally occupied by agriculture with significant areas of natural vegetation | - | Land principally occupied by agriculture with significant areas of natural vegetation | Land principally occupied by agriculture with significant areas of natural vegetation | ||
| Agro-forestry areas | - | Agro-forestry areas | Agro-forestry areas |
References
- Rentschler, J.; Salhab, M.; Jafino, B.A. Flood Exposure and Poverty in 188 Countries. Nat. Commun. 2022, 13, 3527. [Google Scholar] [CrossRef] [PubMed]
- Tellman, B.; Sullivan, J.A.; Kuhn, C.; Kettner, A.J.; Doyle, C.S.; Brakenridge, G.R.; Erickson, T.A.; Slayback, D.A. Satellite Imaging Reveals Increased Proportion of Population Exposed to Floods. Nature 2021, 596, 80–86. [Google Scholar] [CrossRef] [PubMed]
- Yang, L.; Smith, J.A.; Wright, D.B.; Baeck, M.L.; Villarini, G.; Tian, F.; Hu, H. Urbanization and Climate Change: An Examination of Nonstationarities in Urban Flooding. J. Hydrometeorol. 2013, 14, 1791–1809. [Google Scholar] [CrossRef]
- Paprotny, D.; Sebastian, A.; Morales-Nápoles, O.; Jonkman, S.N. Trends in Flood Losses in Europe over the Past 150 Years. Nat. Commun. 2018, 9, 1985. [Google Scholar] [CrossRef]
- CRED 2021 Disasters in Numbers. Brussels. 2022. Available online: https://www.un-spider.org/news-and-events/news/cred-publication-2021-disasters-numbers (accessed on 1 March 2023).
- EEA Economic Losses and Fatalities from Weather- and Climate-Related Events in Europe. 2022. Available online: https://www.eea.europa.eu/publications/economic-losses-and-fatalities-from/economic-losses-and-fatalities-from (accessed on 15 March 2023).
- Merz, B.; Kreibich, H.; Schwarze, R.; Thieken, A. Review Article “Assessment of Economic Flood Damage”. Nat. Hazards Earth Syst. Sci. 2010, 10, 1697–1724. [Google Scholar] [CrossRef]
- De Moel, H.; Jongman, B.; Kreibich, H.; Merz, B.; Penning-Rowsell, E.; Ward, P.J. Flood Risk Assessments at Different Spatial Scales. Mitig. Adapt. Strateg. Glob. Chang. 2015, 20, 865–890. [Google Scholar] [CrossRef] [PubMed]
- Gabriels, K.; Willems, P.; Van Orshoven, J. A Comparative Flood Damage and Risk Impact Assessment of Land Use Changes. Nat. Hazards Earth Syst. Sci. 2022, 22, 395–410. [Google Scholar] [CrossRef]
- Krvavica, N.; Šiljeg, A.; Horvat, B.; Panđa, L. Pluvial Flash Flood Hazard and Risk Mapping in Croatia: Case Study in the Gospić Catchment. Sustainability 2023, 15, 1197. [Google Scholar] [CrossRef]
- Tsakiris, G. Flood Risk Assessment: Concepts, Modelling, Applications. Nat. Hazards Earth Syst. Sci. 2014, 14, 1361–1369. [Google Scholar] [CrossRef]
- Meyer, V.; Becker, N.; Markantonis, V.; Schwarze, R.; van den Bergh, J.C.J.M.; Bouwer, L.M.; Bubeck, P.; Ciavola, P.; Genovese, E.; Green, C.; et al. Review Article: Assessing the Costs of Natural Hazards—State of the Art and Knowledge Gaps. Nat. Hazards Earth Syst. Sci. 2013, 13, 1351–1373. [Google Scholar] [CrossRef]
- Wagenaar, D.J.; de Bruijn, K.M.; Bouwer, L.M.; de Moel, H. Uncertainty in Flood Damage Estimates and Its Potential Effect on Investment Decisions. Nat. Hazards Earth Syst. Sci. 2016, 16, 1–14. [Google Scholar] [CrossRef]
- Messner, F.; Meyer, V. Flood Damage, Vulnerability and Risk Perception—Challenges for Flood Damage Research. In Flood Risk Management: Hazards, Vulnerability and Mitigation Measures; Schanze, J., Zeman, E., Marsalek, J., Eds.; Springer: Dordrecht, The Netherlands, 2006; pp. 149–167. [Google Scholar]
- Messner, F.; Penning-Rowsell, E.; Green, C.; Meyer, V.; Tunstall, S.; van der Veen, A. Evaluating Flood Damages: Guidance and Recommendations on Principles and Methods, T09-06-01; FLOOD Site Project Report: Wallingford, UK, 2007. [Google Scholar]
- De Moel, H.; Aerts, J.C.J.H. Effect of Uncertainty in Land Use, Damage Models and Inundation Depth on Flood Damage Estimates. Nat. Hazards 2011, 58, 407–425. [Google Scholar] [CrossRef]
- Hall, J.W.; Sayers, P.B.; Dawson, R.J. National-Scale Assessment of Current and Future Flood Risk in England and Wales. Nat. Hazards 2005, 36, 147–164. [Google Scholar] [CrossRef]
- Barredo, J.I.; de Roo, A.; Lavalle, C. Flood Risk Mapping at European Scale. Water Sci. Technol. 2007, 56, 11–17. [Google Scholar] [CrossRef]
- Fleischmann, A.; Paiva, R.; Collischonn, W. Can Regional to Continental River Hydrodynamic Models Be Locally Relevant? A Cross-Scale Comparison. J. Hydrol. X 2019, 3, 100027. [Google Scholar] [CrossRef]
- Kreibich, H.; Seifert, I.; Merz, B.; Thieken, A.H. Development of FLEMOcs—A New Model for the Estimation of Flood Losses in the Commercial Sector. Hydrol. Sci. J. 2010, 55, 1302–1314. [Google Scholar] [CrossRef]
- Krvavica, N.; Horvat, B.; Ružić, I.; Tadić, A.; Roland, V.; Šiljeg, A.; Marić, I.; Šiljeg, S.; Domazetović, F.; Panđa, L.; et al. Experiences with Pluvial Flood Risk Mapping in Croatia at Multiple Spatial Scales. In Proceedings of the 40th IAHR World Congress, Vienna, Austria, 21–25 August 2023; IAHR: Vienna, Austria, 2023. [Google Scholar]
- Lin, J.; Zhang, W.; Wen, Y.; Qiu, S. Evaluating the Association between Morphological Characteristics of Urban Land and Pluvial Floods Using Machine Learning Methods. Sustain. Cities Soc. 2023, 99, 104891. [Google Scholar] [CrossRef]
- McBean, E.; Fortin, M.; Gorrie, J. A Critical Analysis of Residential Flood Damage Estimation Curves. Can. J. Civil. Eng. 1986, 13, 86–94. [Google Scholar] [CrossRef]
- Smith, D.I. Flood Damage Estimation—A Review of Urban Stage-Damage Curves and Loss Functions. Water SA 1994, 20, 231–238. [Google Scholar]
- Jongman, B.; Kreibich, H.; Apel, H.; Barredo, J.I.; Bates, P.D.; Feyen, L.; Gericke, A.; Neal, J.; Aerts, J.C.J.H.; Ward, P.J. Comparative Flood Damage Model Assessment: Towards a European Approach. Nat. Hazards Earth Syst. Sci. 2012, 12, 3733–3752. [Google Scholar] [CrossRef]
- Thieken, A.H.; Müller, M.; Kreibich, H.; Merz, B. Flood Damage and Influencing Factors: New Insights from the August 2002 Flood in Germany. Water Resour. Res. 2005, 41, W12430. [Google Scholar] [CrossRef]
- Pistrika, A.; Tsakiris, G.; Nalbantis, I. Flood Depth-Damage Functions for Built Environment. Environ. Process. 2014, 1, 553–572. [Google Scholar] [CrossRef]
- Shah, M.A.R.; Rahman, A.; Chowdhury, S.H. Challenges for Achieving Sustainable Flood Risk Management. J. Flood Risk Manag. 2018, 11, S352–S358. [Google Scholar] [CrossRef]
- Huizinga, J.; de Moel, H.; Szewczyk, W. Global Flood Depth-Damage Functions: Methodology and the Database with Guidlines; Publications Office of the European Union: Luxembourg, 2017. [Google Scholar]
- Balogun, A.-L.; Mohd Said, S.A.; Sholagberu, A.T.; Aina, Y.A.; Althuwaynee, O.F.; Aydda, A. Assessing the Suitability of GlobeLand30 for Land Cover Mapping and Sustainable Development in Malaysia Using Error Matrix and Unbiased Area Estimation. Geocarto Int. 2022, 37, 1607–1627. [Google Scholar] [CrossRef]
- Chen, J.; Cao, X.; Peng, S.; Ren, H. Analysis and Applications of GlobeLand30: A Review. ISPRS Int. J. Geoinf. 2017, 6, 230. [Google Scholar] [CrossRef]
- Gallego, F.J.; Batista, F.; Rocha, C.; Mubareka, S. Disaggregating Population Density of the European Union with CORINE Land Cover. Int. J. Geogr. Inf. Sci. 2011, 25, 2051–2069. [Google Scholar] [CrossRef]
- Mennis, J.; Hultgren, T. Intelligent Dasymetric Mapping and Its Application to Areal Interpolation. Cartogr. Geogr. Inf. Sci. 2006, 33, 179–194. [Google Scholar] [CrossRef]
- Gallego, F.J. A Population Density Grid of the European Union. Popul. Environ. 2010, 31, 460–473. [Google Scholar] [CrossRef]
- Briggs, D.J.; Gulliver, J.; Fecht, D.; Vienneau, D.M. Dasymetric Modelling of Small-Area Population Distribution Using Land Cover and Light Emissions Data. Remote Sens. Environ. 2007, 108, 451–466. [Google Scholar] [CrossRef]
- Eicher, C.L.; Brewer, C.A. Dasymetric Mapping and Areal Interpolation: Implementation and Evaluation. Cartogr. Geogr. Inf. Sci. 2001, 28, 125–138. [Google Scholar] [CrossRef]
- Starmans, S.M. Spatial Disaggregation of Population Data onto Urban Footprint Data; Leopold-Franzens-Universität Innsbruck: Innsbruck, Austria, 2014. [Google Scholar]
- Wu, C.; Murray, A.T. A Cokriging Method for Estimating Population Density in Urban Areas. Comput. Environ. Urban. Syst. 2005, 29, 558–579. [Google Scholar] [CrossRef]
- Stevens, F.R.; Gaughan, A.E.; Linard, C.; Tatem, A.J. Disaggregating Census Data for Population Mapping Using Random Forests with Remotely-Sensed and Ancillary Data. PLoS ONE 2015, 10, e0107042. [Google Scholar] [CrossRef] [PubMed]
- Tatem, A.J. WorldPop, Open Data for Spatial Demography. Sci. Data 2017, 4, 170004. [Google Scholar] [CrossRef] [PubMed]
- Sherba, J.T.; Sleeter, B.M.; Davis, A.W.; Parker, O. Downscaling Global Land-Use/Land-Cover Projections for Use in Region-Level State-and-Transition Simulation Modeling. AIMS Environ. Sci. 2015, 2, 623–647. [Google Scholar] [CrossRef]
- Le Page, Y.; West, T.O.; Link, R.; Patel, P. Downscaling Land Use and Land Cover from the Global Change Assessment Model for Coupling with Earth System Models. Geosci. Model. Dev. 2016, 9, 3055–3069. [Google Scholar] [CrossRef]
- Hoskins, A.J.; Bush, A.; Gilmore, J.; Harwood, T.; Hudson, L.N.; Ware, C.; Williams, K.J.; Ferrier, S. Downscaling Land-use Data to Provide Global 30″ Estimates of Five Land-use Classes. Ecol. Evol. 2016, 6, 3040–3055. [Google Scholar] [CrossRef]
- Giuliani, G.; Rodila, D.; Külling, N.; Maggini, R.; Lehmann, A. Downscaling Switzerland Land Use/Land Cover Data Using Nearest Neighbors and an Expert System. Land 2022, 11, 615. [Google Scholar] [CrossRef]
- DZS. Census of Population, Households and Dwellings 2021; First Results by Settlements; Statistical Report; Croatian Bureau of Statistics (DZS): Zagreb, Croatia, 2022. [Google Scholar]
- EEA. Coastal Zones Monitoring Nomenclature Guideline; European Union, Copernicus Land Monitoring Service, European Environment Agency (EEA); 2021; Available online: https://land.copernicus.eu/en/technical-library/coastal-zones-nomenclature-and-mapping-guideline/@@download/file (accessed on 13 May 2023).
- EC. Mapping Guide v6.3 for European Urban Atlas; European Commission (EC); 2020; Available online: https://land.copernicus.eu/en/technical-library/urban_atlas_2012_2018_mapping_guide/@@download/file (accessed on 13 May 2023).
- EEA. N2K User Manual; European Union, Copernicus Land Monitoring Service, European Environment Agency (EEA); 2021; Available online: https://land.copernicus.eu/en/technical-library/n2k-2006-2012-2018-nomenclature-and-mapping-guidelines/@@download/file (accessed on 13 May 2023).
- GeoVille. Lot1: Imperviousness 2018, Imperviousness Change 2015–2018 and Built-Up 2018, User Manual; European Union, Copernicus Land Monitoring Service, European Environment Agency (EEA); 2018; Available online: https://land.copernicus.eu/en/technical-library/hrl-imperviousness-2018-user-manual/@@download/file (accessed on 13 May 2023).
- Batista e Silva, F.; Gallego, J.; Lavalle, C. A High-Resolution Population Grid Map for Europe. J. Maps 2013, 9, 16–28. [Google Scholar] [CrossRef]
- Batista e Silva, F.; Poelman, H.; Martens, V.; Lavalle, C. Population Estimation for the Urban Atlas Polygons; Publications Office of the European Union: Luxembourg, 2013. [Google Scholar]
- Mennis, J. Generating Surface Models of Population Using Dasymetric Mapping. Prof. Geogr. 2003, 55, 31–42. [Google Scholar] [CrossRef]
- Langford, M.; Unwin, D.J. Generating and Mapping Population Density Surfaces within a Geographical Information System. Cartogr. J. 1994, 31, 21–26. [Google Scholar] [CrossRef]
- Bondarenko, M.; Kerr, D.; Sorichetta, A.; Tatem, A.J. Census/Projection-Disaggregated Gridded Population Datasets for 189 Countries in 2020 Using Built-Settlement Growth Model (BSGM) Outputs. 2020. Available online: https://hub.worldpop.org/doi/10.5258/SOTON/WP00684 (accessed on 24 October 2023).



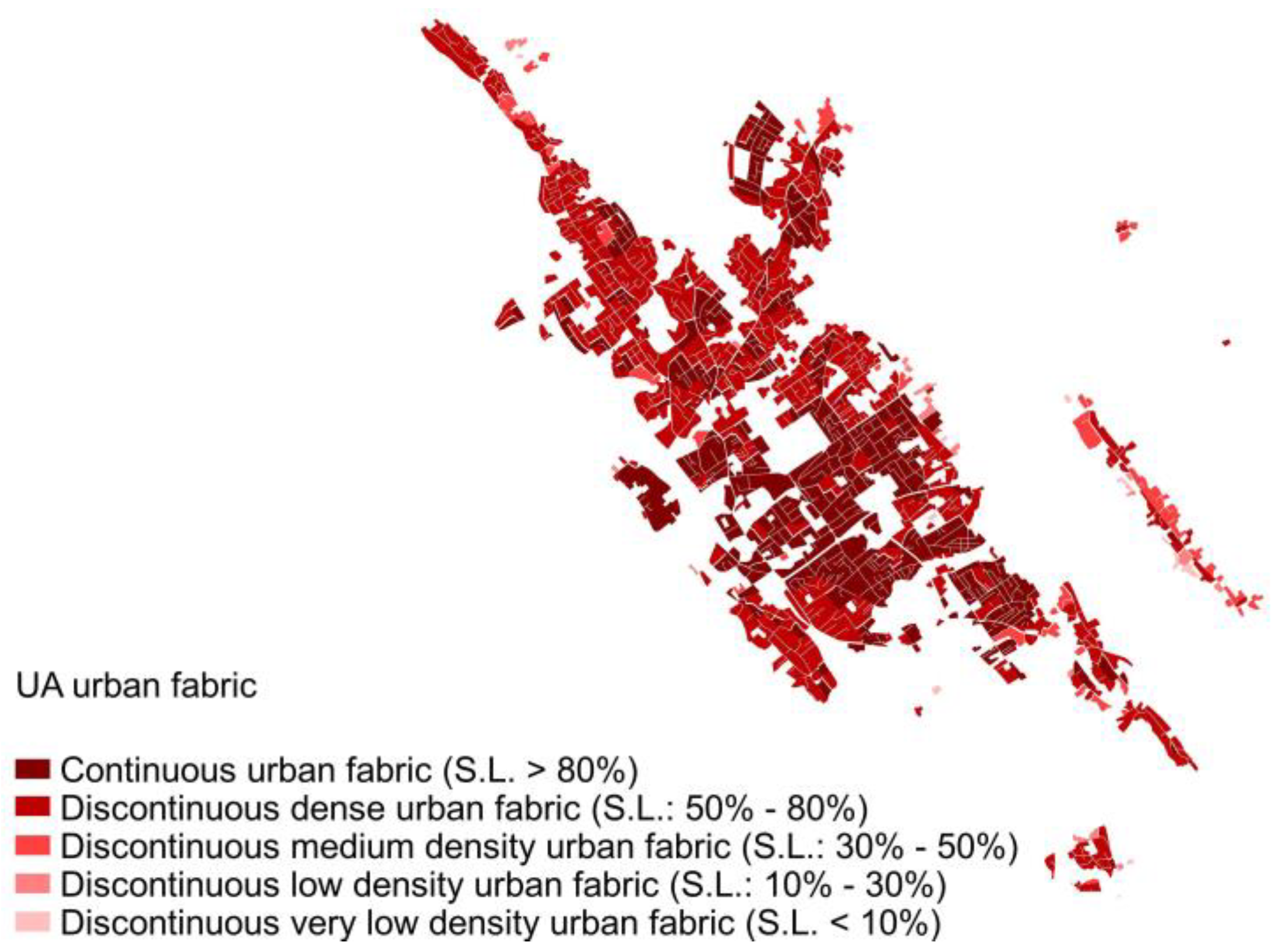
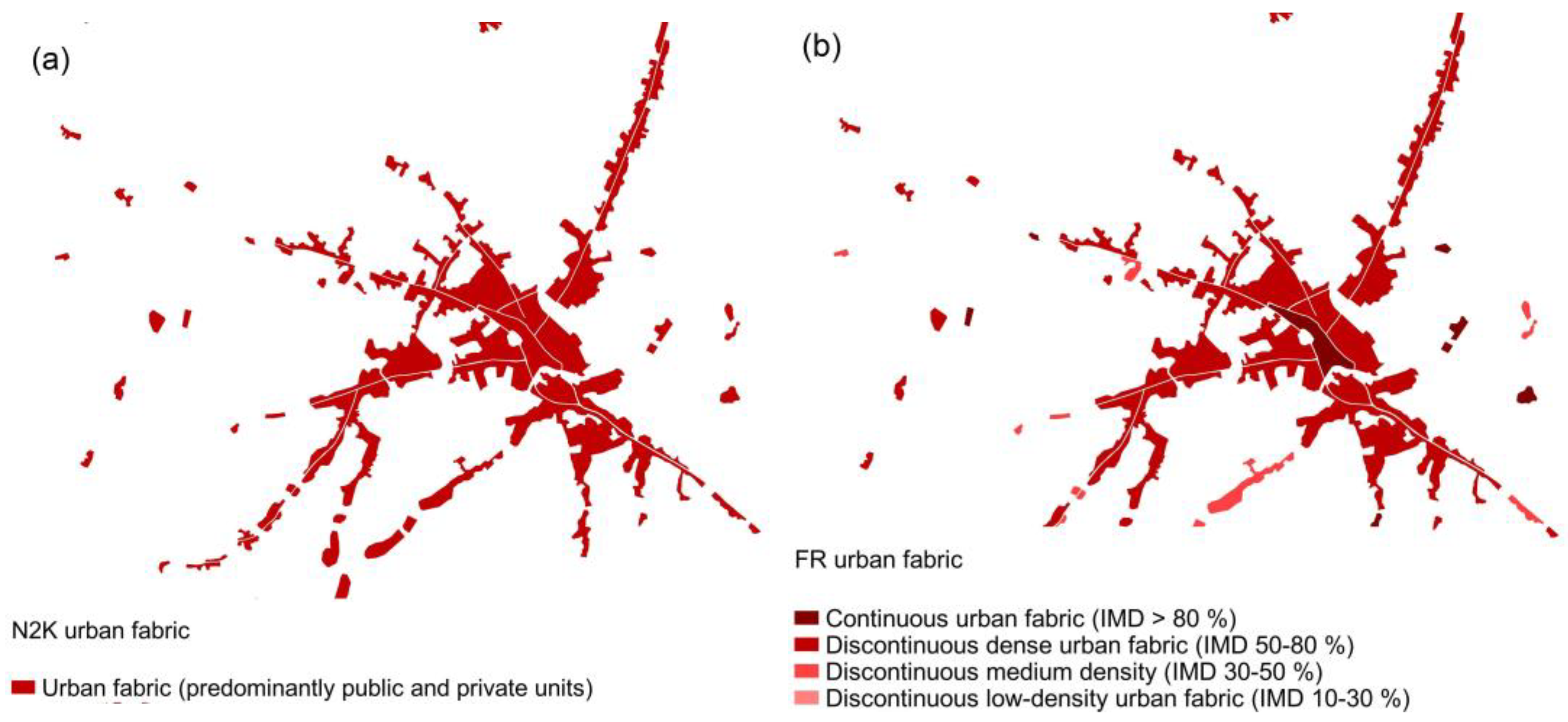
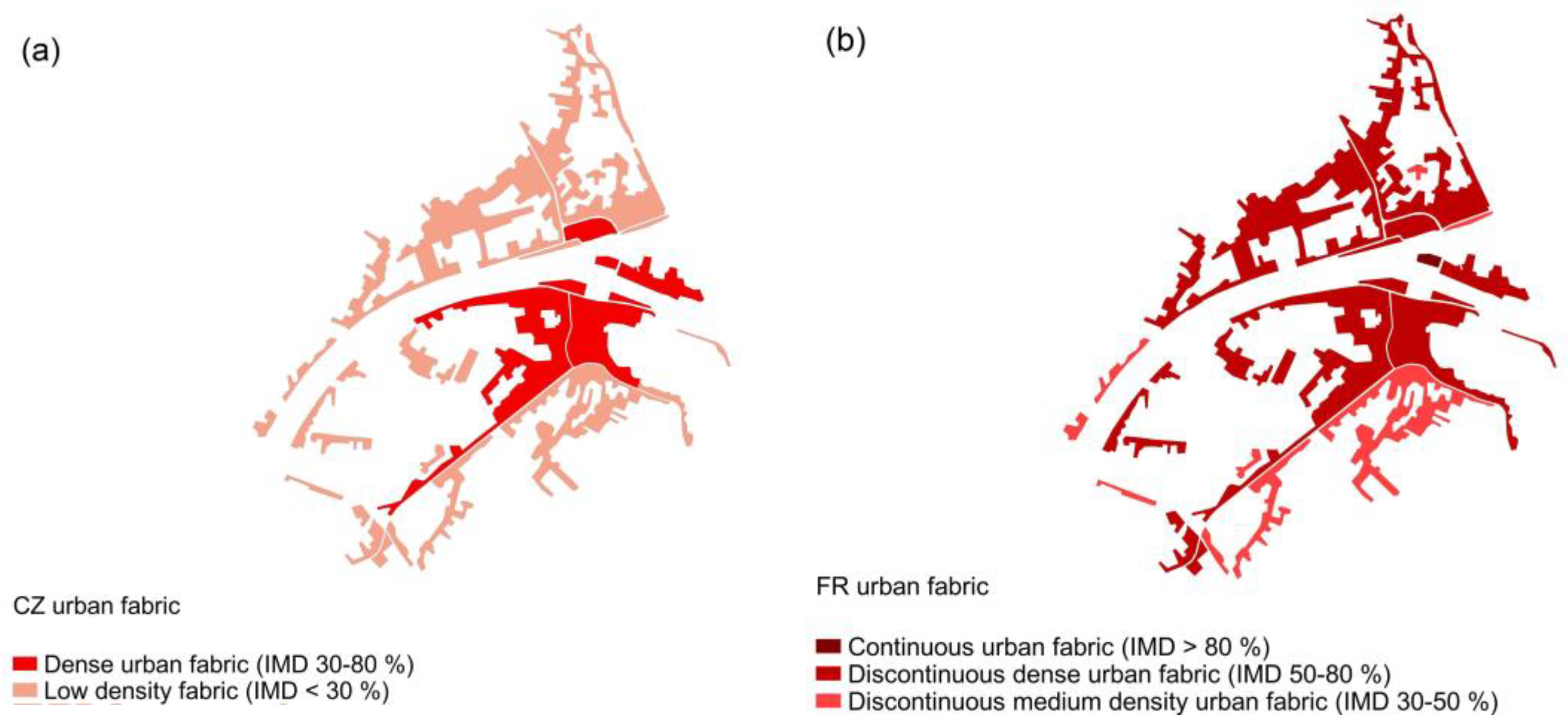

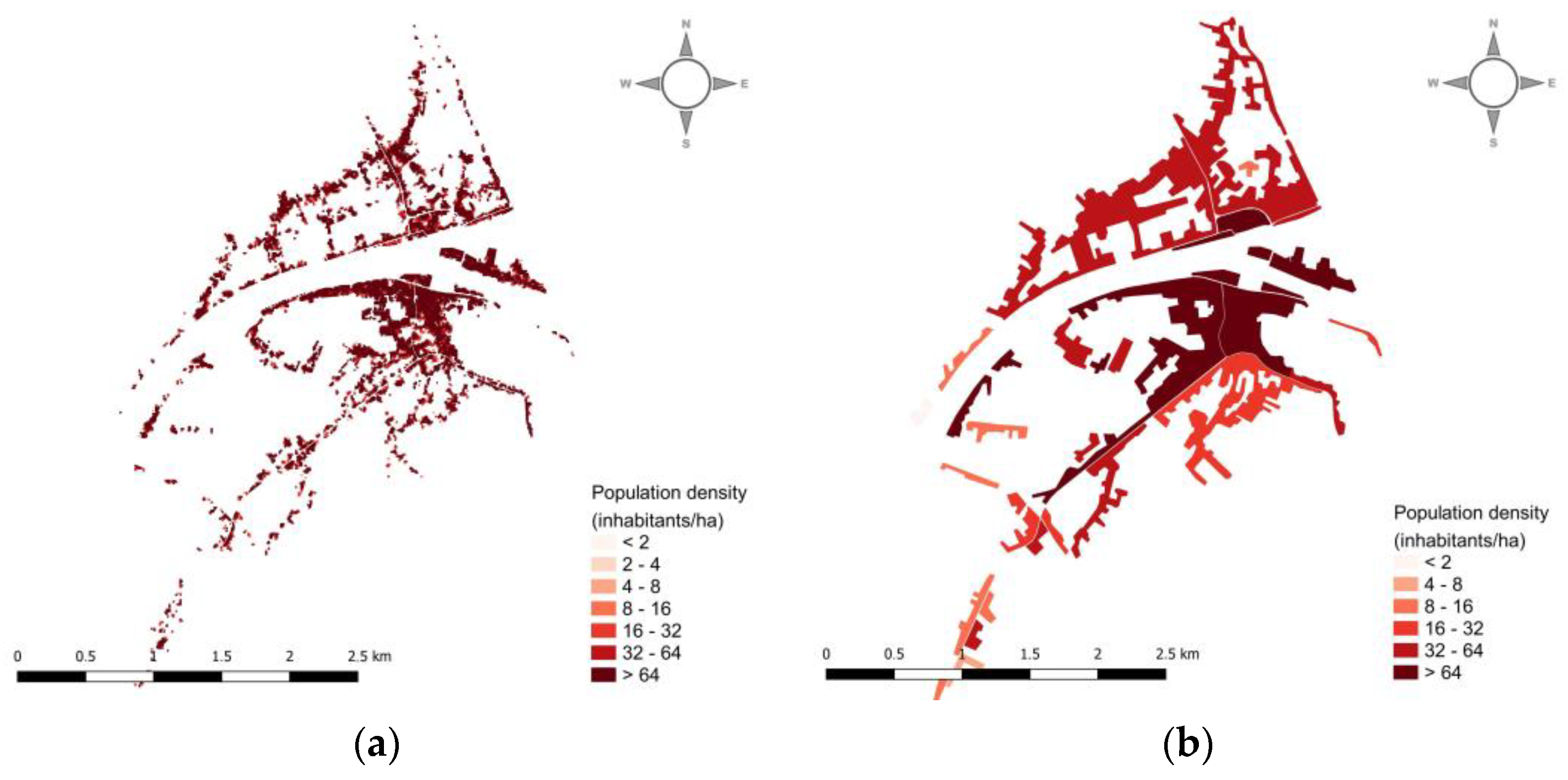
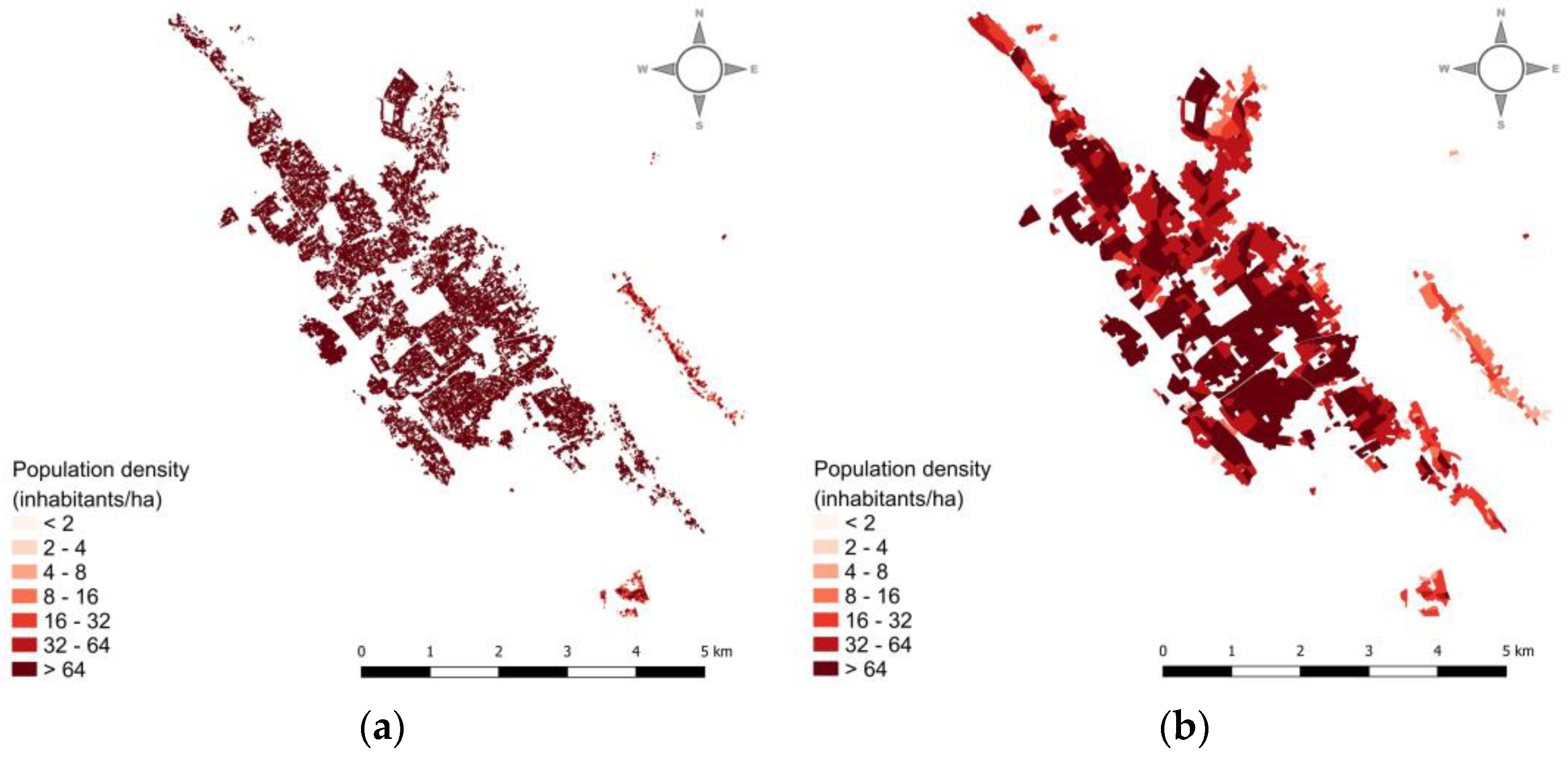
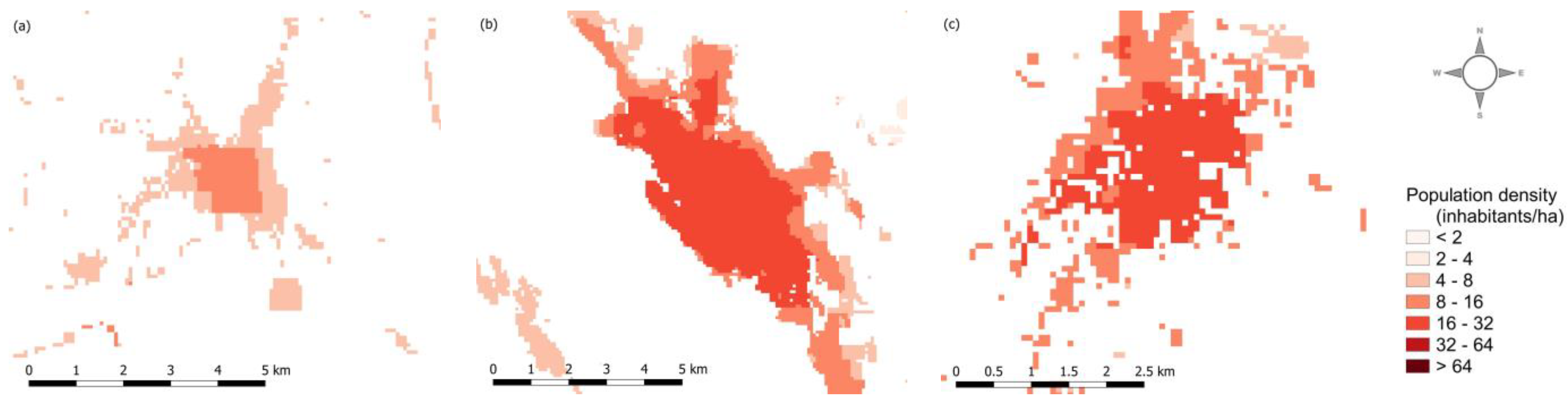
| LULC Dataset | Minimum Mapping Units (MMU) | Scale | |
|---|---|---|---|
| Area (ha) | Width (m) | ||
| UA 2018 | 0.25 (urban) 1 (rural) | 10 | 1:5000 |
| CZ 2018 | 0.5 | 10 | 1:5000–1:10,000 |
| N2K 2018 | 0.5 | 10 | 1:5000–1:10,000 |
| CLC 2018 | 25 | 100 | 1:100,000 |
| LULC Dataset | No. of Classes at the 1st Level | No. of Levels | No. of Classes at the Last Level | ||
|---|---|---|---|---|---|
| Artificial | Natural | Artificial | Natural | ||
| UA 2018 | 5 | 4 | 2 | 16 | 5 |
| CZ 2018 | 8 | 4 | 3 | 20 | 8 |
| N2K 2018 | 8 | 3 | 3 | 9 | 8 |
| CLC 2018 | 5 | 3 | 3 | 11 | 11 |
| LULC Level 1 | UA | CZ | N2K | Proposed FR * |
|---|---|---|---|---|
| Urban fabrics | Continuous urban fabric (S.L. > 80%) | Continuous urban fabric (IMD > 80%) | Urban fabric (predominantly public and private units) | Continuous urban fabric (IMD > 80%) |
| Discontinuous dense urban fabric (S.L. 50–80%) | Dense urban fabric (IMD 30–80%) data | Discontinuous dense urban fabric (IMD 50–80%) | ||
| Discontinuous medium-density (S.L. 30–50%) | Discontinuous medium-density (IMD 30–50%) | |||
| Discontinuous low-density urban fabric (S.L. 10–30%) | Low-density fabric (IMD < 30%) data | Discontinuous low-density urban fabric (IMD 10–30%) | ||
| Discontinuous very-low-density urban fabric (S.L. < 10%) | Discontinuous very-low-density urban fabric (IMD < 10%) |
| Data | N * | Mean | SD ** | SEM *** | t-Test | SED **** |
|---|---|---|---|---|---|---|
| Census 2021 | 13 | 5985.15 | 18,465.22 | 5121.33 | 0.0463 | 7124.594 |
| UA 2018 | 5655.08 | 17,858.15 | 4952.96 |
| Catchment | Available LULC Dataset | Selected LULC Dataset |
|---|---|---|
| Gospić | N2K | N2K |
| Zadar | UA, CZ | UA |
| Metković | CZ, N2K | CZ |
| Catchment | Selected LULC | IMD Class | Area (%) | RMSE per Class | RMSE Total |
|---|---|---|---|---|---|
| Zadar | UA | >80% | 34.4 | 0.78 | 0.86 |
| 50–80% | 48.9 | 0.43 | |||
| 30–50% | 11.1 | 0.87 | |||
| 10–30% | 3.2 | 1.61 | |||
| <10% | 2.4 | 2.05 |
| Catchment | P * (Inhabitants) | PD ** (Inhabitants/ha) | RMSE | PE (%) | ||
|---|---|---|---|---|---|---|
| P * | PD ** | P * | PD ** | |||
| Gospić | 8679 | 0.186 | 6.2 | 1.9 | 17.4 | 17.42 |
| Zadar | 77,807 | 4.022 | 5.75 | 0.11 | 0.007 | 0.012 |
| Metković | 18,157 | 1.760 | 25.83 | 9.1 | 22.22 | 22.23 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Horvat, B.; Krvavica, N. Disaggregation of the Copernicus Land Use/Land Cover (LULC) and Population Density Data to Fit Mesoscale Flood Risk Assessment Requirements in Partially Urbanized Catchments in Croatia. Land 2023, 12, 2014. https://doi.org/10.3390/land12112014
Horvat B, Krvavica N. Disaggregation of the Copernicus Land Use/Land Cover (LULC) and Population Density Data to Fit Mesoscale Flood Risk Assessment Requirements in Partially Urbanized Catchments in Croatia. Land. 2023; 12(11):2014. https://doi.org/10.3390/land12112014
Chicago/Turabian StyleHorvat, Bojana, and Nino Krvavica. 2023. "Disaggregation of the Copernicus Land Use/Land Cover (LULC) and Population Density Data to Fit Mesoscale Flood Risk Assessment Requirements in Partially Urbanized Catchments in Croatia" Land 12, no. 11: 2014. https://doi.org/10.3390/land12112014
APA StyleHorvat, B., & Krvavica, N. (2023). Disaggregation of the Copernicus Land Use/Land Cover (LULC) and Population Density Data to Fit Mesoscale Flood Risk Assessment Requirements in Partially Urbanized Catchments in Croatia. Land, 12(11), 2014. https://doi.org/10.3390/land12112014