
Ontology-Based Probabilistic Estimation for Assessing Semantic Similarity of Land Use/Land Cover Classification Systems



Abstract
:1. Introduction
2. Related Works
2.1. Edge-Based Similarity Measuring
2.2. Information Content (IC)-Based Similarity Measuring
2.3. Feature-Based Similarity Measuring
3. Methodology
3.1. Formal Representation of LULC
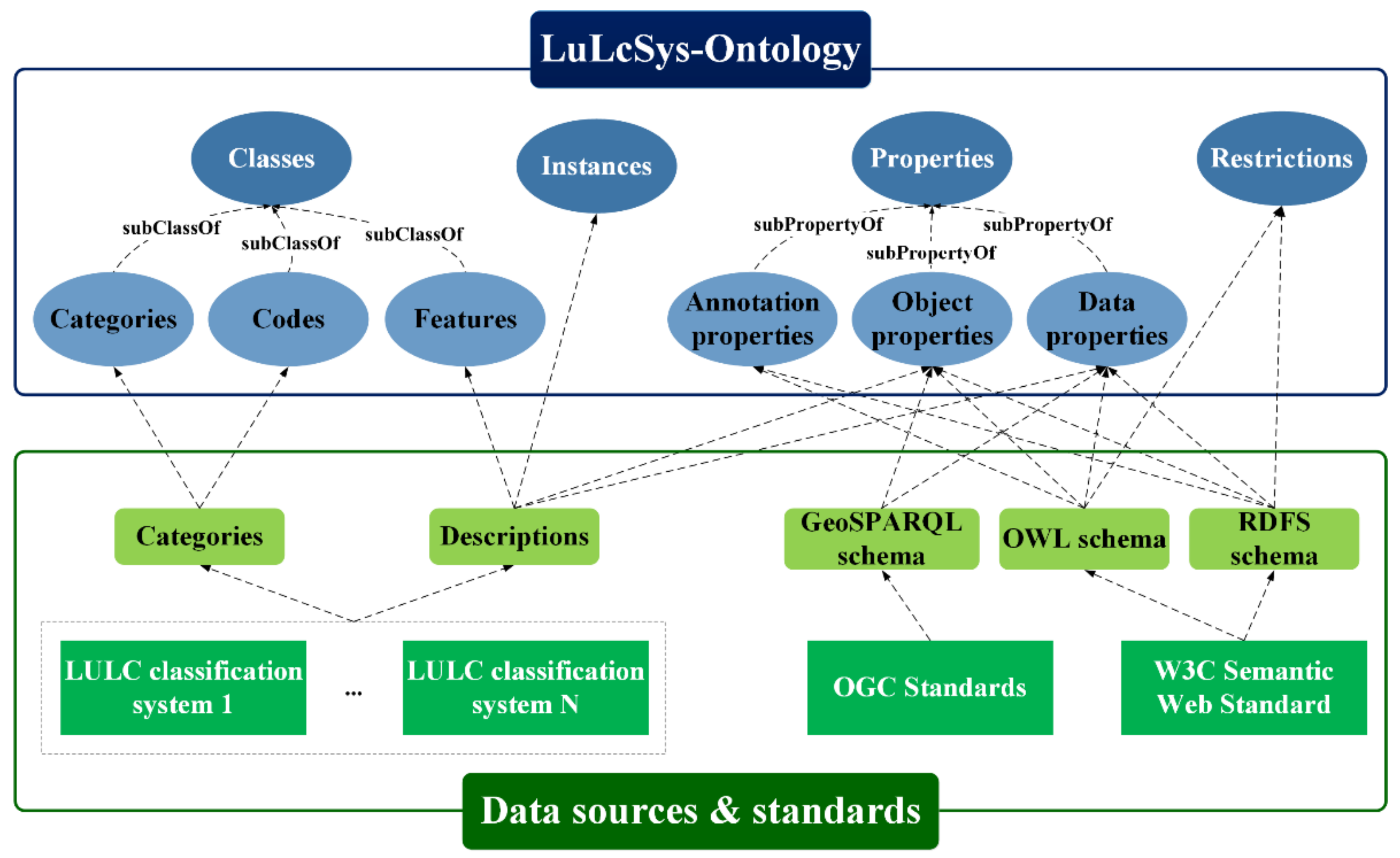
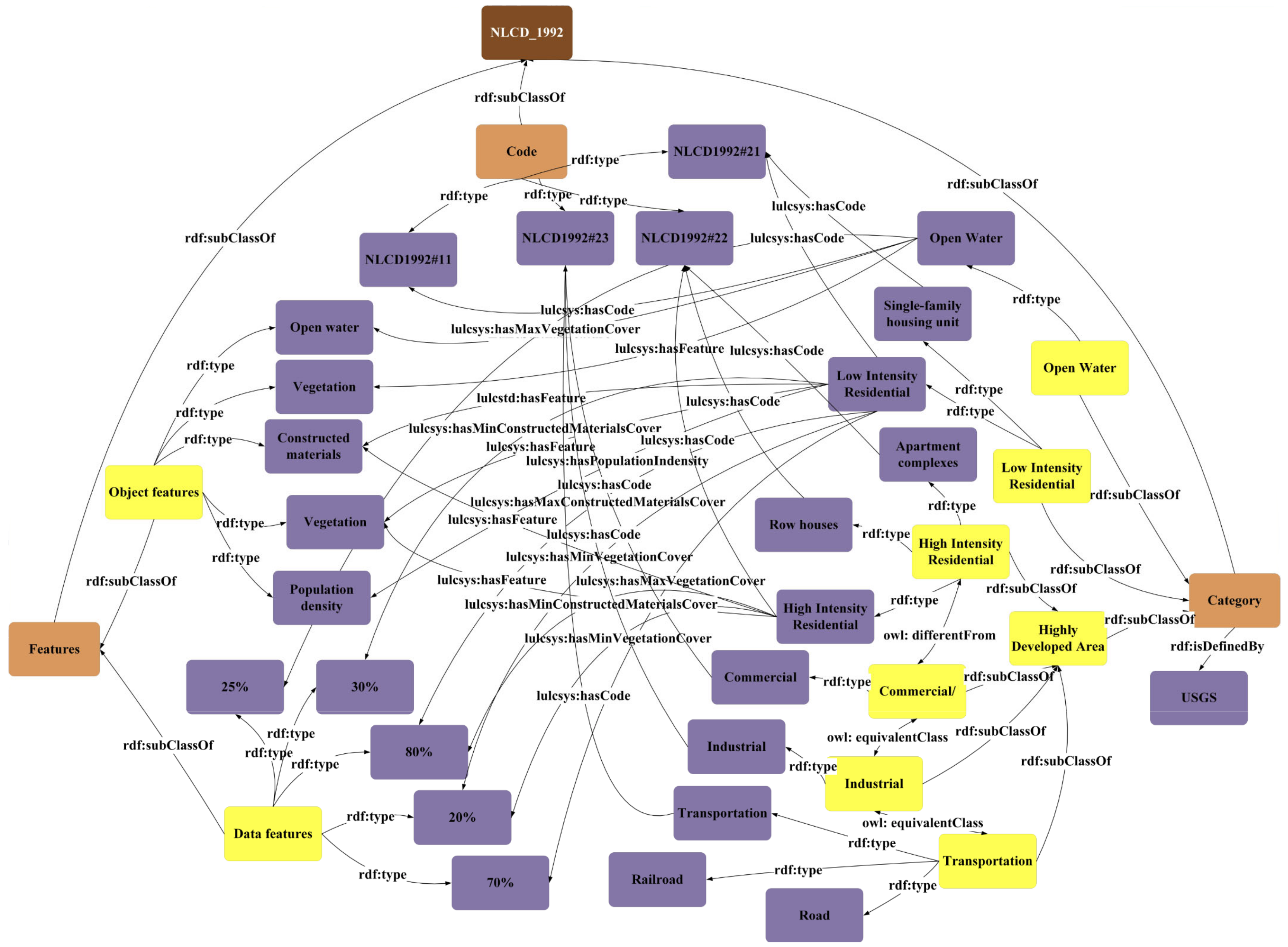
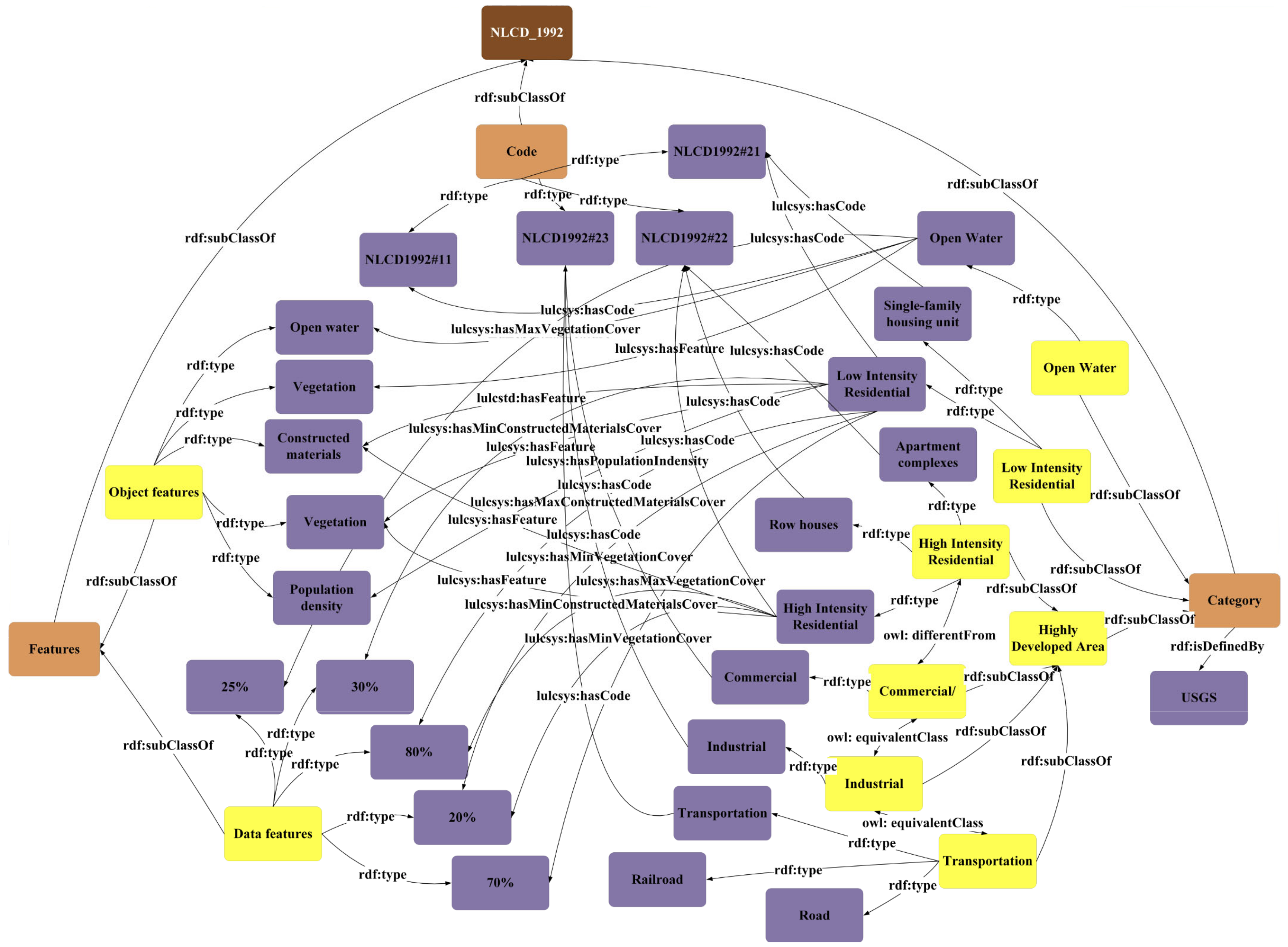
3.1.1. LuLcSys-Ontology
- Category and Code are two subclasses of Classes: the instances in these two subclasses are from the names and legends of LULC categories;
- Features is the third subclasses of Classes: the instances in Features are from the descriptions of each LULC category;
- Annotation properties, Data properties, and Object properties are three subclasses of Properties. Annotation properties defines the meta-information of ontologies. Data properties defines the relationship between two objects. Data properties defines the relationship between an object and the range or value of its feature. All properties are predefined by OGW standards and W3C Semantic Web Standard;
- The items in Restriction are predefined by OGW standards and W3C Semantic Web Standard.
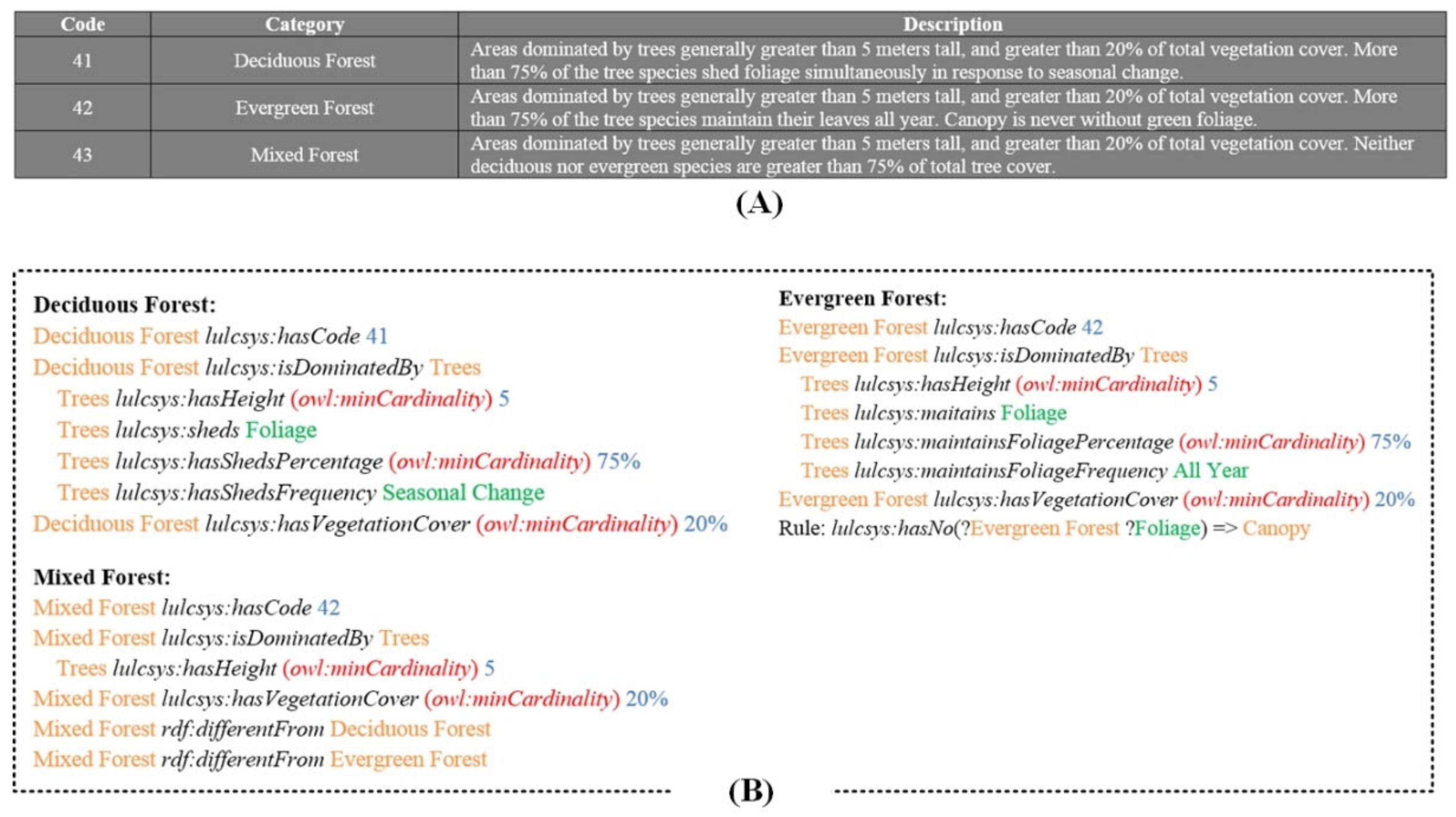
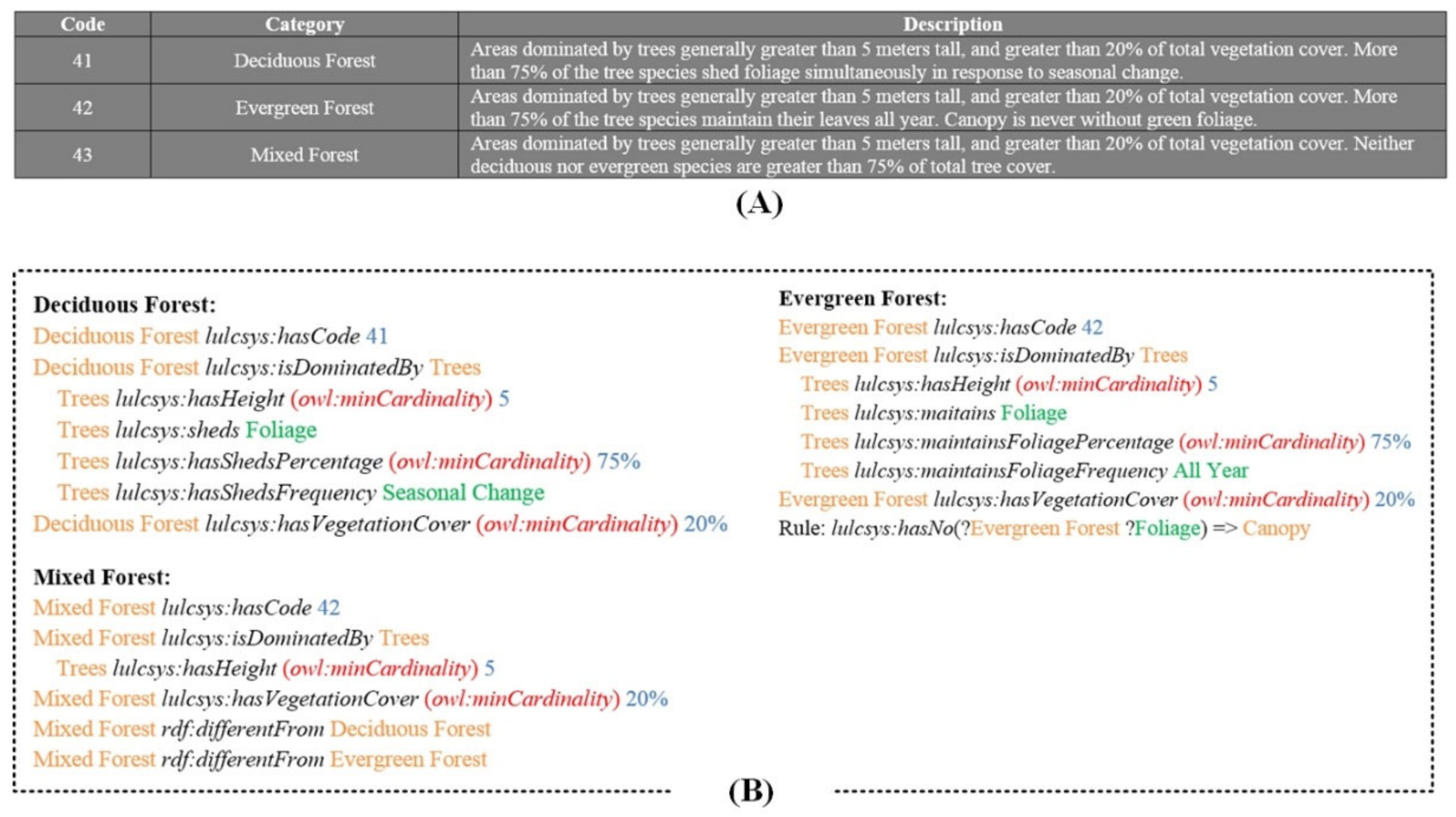
3.1.2. Rules Building
- Data property-based triple 1: Trees lulcsys:hasHeight (owl:minCardinality) 5.
- Data property-based triple 2: Trees lulcsys:hasShedsPercentage (owl:minCardinality) 75%.
- Object property-based triple 1: Deciduous Forest lulcsys:isDominatedBy Trees.
- Object property-based triple 1:target_tree rdf:isInstancceOf Trees.
- target_tree rdf:isInstancceOf Deciduous Forest.
3.2. Probabilistic Reasoning Embedded Ontology-Based Semantic Similarity Measuring
4. Experiments
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Rounsevell, M.D.A.; Arneth, A.; Alexander, P.; Brown, D.G.; Ellis, E.; Finnigan, G.; Galvin, K.; Grigg, N. Towards decision-based global land use models for improved understanding of the Earth system. Earth Syst. Dynam. 2014, 5, 117–137. [Google Scholar] [CrossRef] [Green Version]
- Perez-Hoyos, A.; García-Haro, F.J.; Valcárcel, N. Incorporating Sub-Dominant Classes in the Accuracy Assessment of Large-Area Land Cover Products: Application to GlobCover, MODISLC, GLC2000 and CORINE in Spain. IEEE J.-STARS 2014, 7, 187–205. [Google Scholar] [CrossRef]
- Jepsen, M.R.; Levin, G. Semantically based reclassification of Danish land-use and land-cover information. Int. J. Geogr. Inf. Sci. 2013, 27, 2375–2390. [Google Scholar] [CrossRef]
- Netzel, P.; Stepinski, T.F. Pattern-Based Assessment of Land Cover Change on Continental Scale with Application to NLCD 2001–2006. IEEE Trans. Geosci. Remote 2015, 53, 1773–1781. [Google Scholar] [CrossRef]
- Novack, T.; Kux, H.J.H. Urban land cover and land use classification of an informal settlement area using the open-source knowledge-based system InterIMAGE. Health Risk Soc. 2010, 55, 23–41. [Google Scholar]
- Tomaselli, V.; Dimopoulos, P.; Marangi, C.; Kallimanis, A.S.; Adamo, M.; Tarantino, C.; Panitsa, M.; Terzi, M.; Veronico, G.; Lovergine, F.; et al. Translating land cover classifications to habitat taxonomies for landscape monitoring: A Mediterranean assessment. Landsc. Ecol. 2013, 28, 905–930. [Google Scholar] [CrossRef] [Green Version]
- Aydinoglu, A.C.; Yomralioglu, T.; Inan, H.I.; Sesli, F.A. Managing land use/cover data harmonized to support land administration and environmental applications in turkey. Sci. Res. Essays 2010, 5, 275–284. [Google Scholar]
- Li, C.; Ling, T.W. OWL-Based Semantic Conflicts Detection and Resolution for Data Interoperability. Conceptual Modeling for Advanced Application Domains. In Proceedings of the ER 2004 Workshops CoMoGIS, COMWIM, ECDM, CoMoA, DGOV, and ECOMO, Shanghai, China, 8–12 November 2004. [Google Scholar]
- Cave, K.R. The Feature Gate model of visual selection. Psychol. Res. 1999, 62, 182–194. [Google Scholar] [CrossRef]
- Comber, A.; Fisher, P.; Wadsworth, R. You know what land cover is but does anyone else? An investigation into semantic and ontological confusion. Int. J. Remote Sens. 2005, 26, 223–228. [Google Scholar] [CrossRef] [Green Version]
- Ahlqvist, O. Using uncertain conceptual spaces to translate between land cover categories. Int. J. Geogr. Inf. Sci. 2005, 19, 831–857. [Google Scholar] [CrossRef]
- Ahlqvist, O. Using semantic similarity metrics to uncover category and land cover change. In GeoSpatial Semantics; Springer: Berlin, Germany, 2005; pp. 107–119. [Google Scholar]
- Ahlqvist, O. Extending post-classification change detection using semantic similarity metrics to overcome class heterogeneity: A study of 1992 and 2001 US National Land Cover Database changes. Remote Sens. Environ. 2008, 112, 1226–1241. [Google Scholar] [CrossRef]
- Pazúr, R.; OŤaheľ, J.; Maretta, M. The distribution of selected CORINE land cover classes in different natural landscapes in Slovakia: Methodological framework and applications. Morav. Geogr. Rep. 2015, 23, 45–56. [Google Scholar] [CrossRef] [Green Version]
- Stepinski, T.F.; Cohen, J.P. Comparing semantically-blind and semantically-aware landscape similarity measures with application to query-by-content and regionalization. Ecol. Inform. 2014, 24, 69–77. [Google Scholar] [CrossRef]
- Feranec, J.; Solin, L.; Kopecka, M.; Otahel, J.; Kupkova, L.; Stych, P.; Bicik, I.; Kolar, J.; Cerba, O.; Soukup, T.; et al. Analysis and expert assessment of the semantic similarity between land cover classes. Prog. Phys. Geog. 2014, 38, 301–327. [Google Scholar] [CrossRef]
- Gan, M.; Dou, X.; Jiang, R. From ontology to semantic similarity: Calculation of ontology-based semantic similarity. Sci. World J. 2013, 2013, 793091. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Batet, M.; Sánchez, D.; Valls, A.; Gibert, K. Semantic similarity estimation from multiple ontologies. Appl. Intell. 2013, 38, 29–44. [Google Scholar] [CrossRef]
- Taieb, M.A.H.; Aouicha, M.B.; Hamadou, A.B. Ontology-based approach for measuring semantic similarity. Eng. Appl. Artif. Intell. 2014, 36, 238–261. [Google Scholar] [CrossRef]
- Rodriguez, M.A.; Egenhofer, M.J. Comparing geospatial entity classes: An asymmetric and context-dependent similarity measure. Int. J. Geogr. Inf. Sci. 2004, 18, 229–256. [Google Scholar] [CrossRef]
- Janowicz, K.; Kessler, C. The role of ontology in improving gazetteer interaction. Int. J. Geogr. Inf. Sci. 2008, 22, 1129–1157. [Google Scholar] [CrossRef]
- Li, Y.; Bandar, Z.A.; McLean, D. An approach for measuring semantic similarity between words using multiple information sources. IEEE Trans. Knowl. Data Eng. 2003, 15, 871–882. [Google Scholar]
- Al-Mubaid, H.; Nguyen, H.A. A cluster-based approach for semantic similarity in the biomedical domain. In Proceedings of the 28th Annual International Conference of the IEEE Engineering in Medicine and Biology Society, New York, NY, USA, 31 August–3 September 2006. [Google Scholar]
- Resnik, P. Semantic similarity in a taxonomy: An information-based measure and its application to problems of ambiguity in natural language. J. Artif. Intell. Res. 1999, 11, 95–130. [Google Scholar] [CrossRef]
- Sebti, A.; Barfroush, A.A. A new word sense similarity measure in WordNet. In Proceedings of the International Multiconference on Computer Science and Information Technology, Wisła, Poland, 18–20 October 2008; pp. 369–373. [Google Scholar]
- Sánchez, D.; Batet, M. Semantic similarity estimation in the biomedical domain: An ontology-based information-theoretic perspective. J. Biomed. Inform. 2011, 44, 749–759. [Google Scholar] [CrossRef] [Green Version]
- Taieb, M.A.H.; Aouicha, M.B.; Hamadou, A.B. Computing semantic relatedness using Wikipedia features. Know.-Based Syst. 2013, 50, 260–278. [Google Scholar] [CrossRef]
- Taieb, M.A.H.; Aouicha, M.B.; Hamadou, A.B. A new semantic relatedness measurement using WordNet features. Knowl. Inform. Syst. 2014, 41, 467–497. [Google Scholar]
- Tversky, A. Features of similarity. Psychol. Rev. 1997, 84, 327–352. [Google Scholar] [CrossRef]
- Cross, V.; Silwal, P.; Xi, C. Experiments Varying Semantic Similarity Measures and Reference Ontologies for Ontology Alignment. In Proceedings of the Extended Semantic Web Conference, Montpellier, France, 26–30 May 2013; Springer: Berlin/Heidelberg, Germany, 2013. [Google Scholar]
- Rodríguez, M.A.; Egenhofer, M.J. Determining semantic similarity among entity classes from different ontologies. IEEE Trans. Knowl. Data Eng. 2003, 15, 442–456. [Google Scholar] [CrossRef] [Green Version]
- Petrakis, E.G.M.; Varelas, G.; Hliaoutakis, A.; Raftopoulou, P. X-Similarity: Computing semantic similarity between concepts from different ontologies. J. Digit. Inform. Manag. 2006, 4, 233–237. [Google Scholar]
- Pirró, G. A semantic similarity metric combining features and intrinsic information content. Data Knowl. Eng. 2009, 68, 1289–1308. [Google Scholar] [CrossRef]
- Sánchez, D.; Batet, M.; Isern, D.; Valls, A. Ontology-based semantic similarity: A new feature-based approach. Expert Syst. Appl. 2012, 39, 7718–7728. [Google Scholar] [CrossRef]
- Jiang, Y.; Zhang, X.; Tang, Y.; Nie, R. Feature-based approaches to semantic similarity assessment of concepts using Wikipedia. Inform. Process. Manag. 2015, 51, 215–234. [Google Scholar] [CrossRef]
- Solé-Ribalta, A.; Sánchez, D.; Batet, M.; Serratosa, F. Towards the estimation of feature-based semantic similarity using multiple ontologies. Know. -Based Syst. 2014, 55, 101–113. [Google Scholar] [CrossRef]
- Gennari, J.H.; Musen, M.A.; Fergerson, R.W.; Grosso, W.E.; Crubézy, M.; Eriksson, H.; Noy NFTu, S.W. The evolution of Protégé: An environment for knowledge-based systems development. Int. J. Hum. -Comput. Stud. 2003, 58, 89–123. [Google Scholar] [CrossRef]
- Hendler, J.; Lassila, O.; Berners-Lee, T. The semantic web. Sci. Am. 2001, 284, 34–43. [Google Scholar]
- Horrocks, I.; Patel-Schneider, P.F.; Boley, H.; Tabet, S.; Grosof, B.; Dean, M. SWRL: A semantic web rule language combining OWL and RuleML. W3C Memb. Submiss. 2004, 21, 79. [Google Scholar]

{kind=link}
{kind=link}
{kind=link}
| Component | Triple Relationship | Content |
|---|---|---|
| Classes | “subject” or “object” in the triple | Three subclasses: Categories: the categories or classes of LULC classification systems and standards. Codes: the codes corresponding to categories or classes. Features: the characteristics of each category or class. |
| Instances | “subject” or “object” in the triple | The terms or notations derived from the textural descriptions of LULC classification systems and standards. |
| Properties | “predicate” in the triple | Three types of properties: the details are shown in Table 2. |
| Restrictions | “predicate” in the triple | Restrictions define the validity of a property under specific conditions. |
| Function terms | “predicate” in the triple | The characteristics of properties. |
| Property Types | Properties |
|---|---|
| Annotation properties | rdfs: seeAlso, rdfsLisdefinedBy, owl:priorVersion, owl:versionInfo, owl:deprecatedclass, owl:deprecatedproperty |
| Data properties | owl:hasvalue, lulcsys:hasMaxValue, lulcsys:hasMinValue, lulcsys:hasCode, lulcsys:hasMaxCover, lulcsys:hasMinCover, lulcsys:hasArea, lulcsys:hasPerimeter, lulcsys:hasTall\Height |
| Object properties | lulcsys:hasFeatures, lulcsys:isDominatedBy, lulcsys:isUsedFor, lulcsys:isUsedBy, lulcsys:isPlantedFor, lulcsys:isPlantedBy, lulcsys:isSaturated/CoveredBy, lulcsys:isOnlyIn, lulcsys:isRemoved/ModifiedBy, lulcsys:isReplacedBy, lulcsys:isInfluncedBy, lulcsys:isResultFrom, LuLcSys:hasDuration, rdf:type, rdfs:subclassof, rdfs:subpropertyof, rdf:member, owl:equivalentClass, owl:equivalentProperty, owl:sameAs, owl:differentFrom, owl:AllDifferent, owl:distinctMembers |
| Restriction types | Restrictions |
| Data/Object restrictions | Some (existential), Only (universal), Min (min cardinality), Max (max cardinality), Exactly (exact cardinality) |
| allValueFrom, someValueFrom | |
| Property restrictions | inverseOf, TransitiveProperty, SymmetricProperty, FunctionalProperty, InverseFunctionalProperty |
| Function terms | |
| Functional, Inverse functional, Transitive, Symmetric, Asymmetric, Reflexive, Irreflexive | |
| High-Intensity Residential Class in NLCD 1992 | Developed High-Intensity Class in NLCD 2011/2006/2011 | ||
|---|---|---|---|
| Constructed materials account for 80 to100 percent of the cover. | Impervious surfaces account for 80% to 100% of the total cover. | ||
| Parameters | Meaning | Parameters | Meaning |
| Object () | Constructed materials | Object () | Impervious surfaces |
| Object property () | hasCover | Object property () | hasCover |
| Data () | 80%–100% | Data () | 80%–100% |
| Data property () | noLessThan | Data property () | noLessThan |
| The probability of observing the coverage of constructed materials. | The probability of observing the coverage of impervious surfaces. | ||
| The probability that the coverage is no less than 80%, when the coverage of constructed materials is observed. | The probability that the coverage is no less than 80%, when the coverage of impervious surfaces is observed. | ||
| Common object features and data features of these two classes | |||
| NLCD 1992 | NLCD 2001/2006/2011 | NOAA Regional Land Cover Classification Scheme |
|---|---|---|
| Open Water | Open Water | Developed, High Intensity |
| Perennial Ice/Snow | Perennial Ice/Snow | Developed, Medium Intensity |
| Low Intensity Residential | Developed, Open Space | Developed, Low Intensity |
| High Intensity Residential | Developed, Low Intensity | Developed, Open Space |
| Commercial/Industrial/Transportation | Developed, Medium Intensity | Cultivated Crops |
| Bare Rock/Sand/Clay | Developed High Intensity | Pasture/Hay |
| Quarries/Strip Mines/Gravel Pits | Barren Land (Rock/Sand/Clay) | Grassland/Herbaceous |
| Transitional | Deciduous Forest | Deciduous Forest |
| Deciduous Forest | Evergreen Forest | Evergreen Forest |
| Evergreen Forest | Mixed Forest | Mixed Forest |
| Mixed Forest | Dwarf Scrub | Scrub/Shrub |
| Shrubland | Shrub/Scrub | Barren Land |
| Orchards/Vineyards/Other | Grassland/Herbaceous | Tundra |
| Grasslands/Herbaceous | Sedge/Herbaceous | Perennial Ice/Snow |
| Pasture/Hay | Lichens | Palustrine Forested Wetland |
| Row Crops | Moss | Palustrine Scrub/Shrub Wetland |
| Small Grains | Pasture/Hay | Palustrine Emergent Wetland (Persistent) |
| Shrubland | Shrub/Scrub | Barren Land |
| Orchards/Vineyards/Other | Grassland/Herbaceous | Tundra |
| Grasslands/Herbaceous | Sedge/Herbaceous | Perennial Ice/Snow |
| Pasture/Hay | Lichens | Palustrine Forested Wetland |
| Row Crops | Moss | Palustrine Scrub/Shrub Wetland |
| Small Grains | Pasture/Hay | Palustrine Emergent Wetland (Persistent) |
| NLCD 1992 Class | NLCD 2011/2006/2011 Class | PDBM * | FBM ** | ICBM *** | Our **** |
|---|---|---|---|---|---|
| Open Water | Open water | 1 | 0.67 | 0.29 | 0.75 |
| Perennial Ice/Snow | Perennial Ice/Snow | 1 | 0.5 | 0.69 | 0.75 |
| Low-Intensity Residential | Developed, Low Intensity | 1 | 0.48 | 0.59 | 0.68 |
| Low-Intensity Residential | Developed, Medium Intensity | 1 | 0.52 | 0.59 | 0.70 |
| High-Intensity Residential | Developed High Intensity | 1 | 0.75 | 0.81 | 0.82 |
| Commercial/Industrial/Transportation | Developed High Intensity | 1 | 0.4 | 0.52 | 0.67 |
| Bare Rock/Sand/Clay | Barren Land (Rock/Sand/Clay) | 1 | 0.5 | 1 | 0.56 |
| Quarries/Strip Mines/Gravel Pits | Developed, Low Intensity | 0 | 0.25 | 0 | 0.25 |
| Quarries/Strip Mines/Gravel Pits | Developed, Medium Intensity | 0 | 0.25 | 0 | 0.25 |
| Quarries/Strip Mines/Gravel Pits | Developed High Intensity | 0 | 0.25 | 0 | 0.25 |
| Quarries/Strip Mines/Gravel Pits | Developed, Open Space | 0 | 0.25 | 0 | 0.25 |
| Transitional | Developed, Low Intensity | 0 | 0.2 | 0 | 0.2 |
| Transitional | Developed, Medium Intensity | 0 | 0.2 | 0 | 0.2 |
| Transitional | Developed High Intensity | 0 | 0.2 | 0 | 0.33 |
| Transitional | Developed, Open Space | 0 | 0.2 | 0 | 0.33 |
| Deciduous Forest | Deciduous Forest | 1 | 0.67 | 0.29 | 0.94 |
| Evergreen Forest | Evergreen Forest | 1 | 0.75 | 0.81 | 0.95 |
| Mixed Forest | Mixed Forest | 1 | 0.75 | 0.29 | 0.92 |
| Shrubland | Dwarf Scrub | 0.66 | 0.17 | 0.59 | 0.31 |
| Shrubland | Shrub/Scrub | 1 | 0.43 | 0.59 | 0.79 |
| Orchards/Vineyards/Other | Cultivated Crops | 0 | 0.25 | 0.13 | 0.65 |
| Grasslands/Herbaceous | Grassland/Herbaceous | 1 | 0.75 | 0.81 | 0.86 |
| Grasslands/Herbaceous | Sedge/Herbaceous | 0.66 | 0.2 | 0 | 0.61 |
| Grasslands/Herbaceous | Lichens | 0.66 | 0.2 | 0 | 0.25 |
| Grasslands/Herbaceous | Moss | 0.66 | 0.2 | 0 | 0.25 |
| Pasture/Hay | Pasture/Hay | 1 | 0.67 | 0.16 | 0.83 |
| Row Crops | Cultivated Crops | 1 | 0.25 | 0.82 | 0.84 |
| Small Grains | Cultivated Crops | 1 | 0.25 | 0.37 | 0.65 |
| Fallow | Cultivated Crops | 1 | 0.25 | 0 | 0.33 |
| Urban/Recreational Grasses | Developed, Open Space | 1 | 0.75 | 0.81 | 0.95 |
| Woody Wetlands | Woody Wetlands | 1 | 0.75 | 0.69 | 0.97 |
| Emergent Herbaceous Wetlands | Emergent Herbaceous Wetlands | 1 | 0.75 | 0.69 | 0.97 |
| NLCD 2001/2006/2011 Class | NOAA Class | PDBM * | FBM ** | ICBM *** | Our **** |
|---|---|---|---|---|---|
| Open water | Open Water | 1 | 1 | 1 | 1 |
| Perennial Ice/Snow | Perennial Ice/Snow | 1 | 1 | 1 | 1 |
| Developed, Low Intensity | Developed, Low Intensity | 1 | 1 | 1 | 1 |
| Developed, Medium Intensity | Developed, Medium Intensity | 1 | 1 | 1 | 1 |
| Developed High Intensity | Developed, high intensity | 1 | 1 | 1 | 1 |
| Open space | Open Space | 1 | 0.75 | 0.59 | 0.75 |
| Barren Land (Rock/Sand/Clay) | Barren Land | 1 | 0.5 | 0.45 | 0.67 |
| Barren Land (Rock/Sand/Clay) | Tundra | 0.66 | 0.11 | 0 | 0.31 |
| Deciduous Forest | Deciduous Forest | 1 | 1 | 1 | 1 |
| Evergreen Forest | Evergreen Forest | 1 | 1 | 1 | 1 |
| Mixed Forest | Mixed Forest | 1 | 1 | 1 | 1 |
| Dwarf Scrub | Scrub/Shrub | 0.5 | 0.2 | 0.11 | 0.31 |
| Shrub/Scrub | Scrub/Shrub | 0.5 | 1 | 1 | 1 |
| Cultivated Crops | Cultivated Crops | 1 | 1 | 1 | 1 |
| Grassland/Herbaceous | Grassland/Herbaceous | 1 | 1 | 1 | 1 |
| Sedge/Herbaceous | Grassland/Herbaceous | 0.66 | 0.33 | 0 | 0.61 |
| Lichens | Grassland/Herbaceous | 0 | 0.25 | 0 | 0.25 |
| Moss | Grassland/Herbaceous | 0 | 0.25 | 0 | 0.25 |
| Pasture/Hay | Pasture/Hay | 1 | 1 | 1 | 1 |
| Woody Wetlands | Palustrine Forested Wetland | 0.66 | 0.6 | 0.59 | 0.83 |
| Woody Wetlands | Palustrine Scrub/Shrub Wetland | 0.66 | 0.4 | 0.33 | 0.67 |
| Woody Wetlands | Estuarine Forested Wetland | 0.66 | 0.6 | 0.59 | 0.83 |
| Woody Wetlands | Estuarine Scrub/Shrub Wetland | 0.66 | 0.4 | 0.33 | 0.67 |
| Emergent Herbaceous Wetlands | Palustrine Emergent Wetland (Persistent) | 0.66 | 0.33 | 0.11 | 0.83 |
| Emergent Herbaceous Wetlands | Estuarine Emergent Wetland (Persistent) | 0.66 | 0.33 | 0.11 | 0.83 |
| Unconsolidated Shore |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhou, X.; Xie, X.; Xue, Y.; Xue, B. Ontology-Based Probabilistic Estimation for Assessing Semantic Similarity of Land Use/Land Cover Classification Systems. Land 2021, 10, 920. https://doi.org/10.3390/land10090920
Zhou X, Xie X, Xue Y, Xue B. Ontology-Based Probabilistic Estimation for Assessing Semantic Similarity of Land Use/Land Cover Classification Systems. Land. 2021; 10(9):920. https://doi.org/10.3390/land10090920
Chicago/Turabian StyleZhou, Xiran, Xiao Xie, Yong Xue, and Bing Xue. 2021. "Ontology-Based Probabilistic Estimation for Assessing Semantic Similarity of Land Use/Land Cover Classification Systems" Land 10, no. 9: 920. https://doi.org/10.3390/land10090920
APA StyleZhou, X., Xie, X., Xue, Y., & Xue, B. (2021). Ontology-Based Probabilistic Estimation for Assessing Semantic Similarity of Land Use/Land Cover Classification Systems. Land, 10(9), 920. https://doi.org/10.3390/land10090920