Abstract
A method is proposed for forecasting traffic intensity at the border of an agglomeration’s core, using demographic data such as amount (number) and structure of population and housing in the surrounding (suburban) area. Relationships between groups of variables are analyzed by calibrating traffic and demographic models for a selected agglomeration in Poland. The choice of Poland is justified by an intensive suburbanization process that took place during the transition from a centrally controlled market to a free market economy after 1989, such research being quite novel and original for this country. Three assumptions concerning this research methodology (concerning how to specify the research area and parameters characterizing traffic and population) were formulated and tested. Models (dependencies) acquired this way were tested in another Polish agglomeration of similar size, yielding similar results. Very high correlations between characteristic groups of variables were indicated. The best correlation occurred between an intensity of cars leaving the center of an agglomeration in the afternoon rush hour (as a traffic group variable), with the total population, the number of economically active people, and the number of dwellings in the surrounding areas (being population group variables). A novel way of specifying the range of the surrounding areas influencing the main city traffic was proposed. The results obtained and the models constructed should be applicable for other agglomerations, since the universality of the observed phenomena and their relationships are expected.
1. Introduction
Groups of communes investigated in this paper as an “agglomeration” will be analyzed as an interacting pair of a core (main city) and its surroundings (villages and cities neighboring the core). The term “suburbanization” is understood, in general, as a development of the surroundings while the core is dwindling or stable.
The diverse processes of suburbanization (social, economic, morphologic, etc.) in the world has been ongoing since the 1960s, and in Central and Eastern Europe they developed with greater intensity after 1989 [1], when this region was freed from the strict zone of control of the Soviet Union and the communist system fell. The choice of Poland is therefore important because of an intensive suburbanization process that took place during the transition from a centrally controlled to a free market economy after 1989. Such studies are unprecedented for Poland, in part because of limited availability of data, which is discussed below. The economic transition caused land use, and specifically land rent, in spatial development and urban planning to become an important factor in these countries [2,3]. The transition also triggered a rise of wealth within the society, an increase in mobility and motorization, and finally a change in social attitudes related to a perception of quality of life as an important criterion for living [4,5,6]. They were the same factors that caused urbanization of the core cities’ surroundings in Western European and North American countries [7,8]. As in these countries, suburbanization primarily took place in the richest centers, which were successfully—in economic terms—undergoing transformation [9].
The issues of suburbanization are a subject of numerous studies, conducted from the position and with the use of social (human geography, sociology, economics), natural (ecology, biogeography), and technical (transport engineering, urban planning) methods. In this paper the main focus is given to spatial (geographical) and transport issues. For this purpose, the most general definition of suburbanization was adopted, defining it as a process in which the population is shifted from the core (central urban) areas to their respective surrounding areas (suburbs), resulting in the formation of an urban sprawl. As a consequence of these migratory movements of households and business entities away from the core, the surrounding urban areas grew [10].
Suburbanization has its specific demographic, morphological, social, economic, and technical dimensions [11]. There is no singular commonly accepted model of suburbanization. In the context of the phenomena discussed in this paper, the phase model [12], in which suburbanization is a next step of a wider, more general process of urbanization, deserves attention. Attempts to model the spatial structure of settlement location in the surroundings are also noteworthy, in which such forms and processes, known as “frog leap,” “concentric,” “ribbon development,” “one-off housing,” etc., are distinguished [13,14]. The surroundings themselves are also not unambiguous, with terms such as “suburban area,” “peri-urban area,” and “rural-urban fringe” being used. The essence of distinguishing these areas is the transient nature of their use and function, associated with a permeation of areas with urban and rural characteristics [15].
The specificity of suburbanization in European countries that before 1989 were in the Soviet Union’s sphere of control, including Poland, is that it generally occurs in a spontaneous, poorly organized, and uncontrolled manner. In this regard, the urban sprawl process (which rarely takes the form of random or accidental distribution of settlements in Western countries) in countries such as Poland [16,17], Romania [18], Bulgaria [19], or the former Yugoslavia [20] has grown to sizes unprecedented in other countries. Analyses of this process are not sufficiently sensitive to the needs of the common good [16], which is caused by an ambiguity of administrative regulations dealing with construction investments, especially in the first period of transformation [21], as well as the strong commercial nature of land use.
On the other hand, with the emergence of so-called delayed urbanization [22], or under-urbanization [23], in the new market conditions, inhabitants moving to agglomerations from rural areas chose suburban locations (in contrast to urban locations) because of lower real estate prices and their reluctance to give up the existing “rural” lifestyle [14]. A process was observed in which land, well connected to public roads and the public transport network, was bought much more slowly than land in areas with inferior transportation. This resulted in a large supply of building plots in the suburban areas [24,25], which, with the deficiency of urbanization control, led to an increased scattering of buildings [26,27]. This process is also noticeable in the suburban areas of smaller cities and towns [28,29], as well as in countries where the suburbanization processes seem to be less advanced, such as Ukraine [30].
The dispersion of the built-up areas into the suburban areas (suburbs) moves inhabitants into areas of poor public transport services [31]. The service is poor (sometimes negligible) because operational costs on an excessively fragmented network of lines and stops are too high to maintain an economically feasible public transport system. [10,32]. This results in an increase (hypertrophy) of individual motorization, which in turn degrades the environment, increases traffic congestion, increases travel time with negative consequences for social and family interactions and for people commuting to work, decreases traffic safety (causes additional road accidents), and has other negative effects. This generates huge external costs, estimated for Poland at tens of billions of euros per year [33], which are becoming an increasingly serious development barrier for public finances [34,35].
Due to such negative effects, the problem of the population growth’s impact on transport needs is the subject of numerous studies, both in countries with a stable population [36,37] as well as in countries with rapid urbanization such as China [38]. Research shows strong links between population growth and mobility, although these links are considered non-linear and complicated [39,40]. A question arises whether such dependencies are universal or country-specific, e.g., only for countries with strongly vibrant and spontaneous urban sprawl processes. In this setting, as mentioned, Poland and other countries of Central and Eastern Europe can be characterized by particularly chaotic suburbanization processes and a strong growth in motorization, without effective local rail transport services for most agglomerations [41].
For these reasons, the need to study the relationship between urbanization processes and the traffic (transport) structure and volume is currently extremely relevant. More or less advanced analyses of traffic modelling, carried out so far in different regions of Central and Eastern Europe [42], are, however, too general, and are missing detailed research. They therefore fail to precisely explain the main reason for the increase in local traffic volumes, and how this not-specified reason influences this increase, especially in chaotically developed surroundings.
Taking into account the aforementioned formulation of the problem, the main goal of this paper is to find a relationship between population growth and traffic volume in the area of residential suburbanization, under conditions of uncontrolled (chaotic, scattered, ineffective) urbanization. The goal is not only cognitive and methodical, but also has practical significance. The latter is connected with a possibility to use the research results in a policy for sustainable development of the surroundings.
An influence of the type of buildings and development on the volume (share) of car traffic during times of commuting (access to the core of the agglomeration) has been studied many times [43,44,45,46,47]. Other factors influencing car use, such as the quality of the public transport system, of the cycling infrastructure, or both [48,49,50,51,52], or of the availability of parking lots for cars [53,54], have also been identified.
A comprehensive analysis and comparison of transport indicators was carried out in [55], showing an attempt to define the most important transport and socio-economic indicators from 151 agglomerations and 51 countries and obtaining correlations between infrastructure availability (including accessibility), socio-economic indicators, and congestion levels. The relationship between the development of transport infrastructure and population growth, spatial expansion, and changes of land use was highlighted in many works [56,57,58]. The close link between transport and urban development was also acknowledged in earlier studies [59,60,61]. An imbalance between travel demand and the supply of a transport infrastructure has been identified as a cause of increased congestion [56].
The development of a road network generally leads to a lower population density in the cores [10,62]. Empirical estimates [63] indicate, moreover, that every expansion of a motorway into a core of an American agglomeration results in an average 18% decrease in the number of inhabitants in the core. An analysis in Wisconsin revealed that the expansion of motorways caused population growth in the surroundings and increased urban sprawl [64]. The expansion of the road network tends to reduce the urban density and efficiency of road-based public transport, creating conditions for growth in car ownership. The consequence of these effects is a further increase in the demand for private car use, often referred to as “induced demand” [65].
An inhabitant’s lifecycle proved to be an important factor in the transport mode choice of travel from the surroundings to the core. Experiences from an earlier place of residence [66,67], as well as changes in life situation [68], such as taking up employment after graduation [69], starting a family, or children becoming independent, influences the commuter’s decisions.
2. Research Methods and Source Data
Studies of traffic dependence on population face a number of obstacles, such as obtaining reliable data, comparing study periods and locations, or selecting appropriate variables (parameters). The basic dilemmas can be listed here: where and when to measure traffic, which groups (categories) of vehicles should be taken into account, how to separate transit traffic data, which area of the surroundings should be taken into account, and how to supplement traffic measurements with other surveys (e.g., questionnaires).
In light of additional obstacles in obtaining a complete set of up-to-date and reliable data, presented further on, we looked for a correspondence of parameters not widely used at present, such as the number of personal vehicles in the three rush hours versus the number of the working-age population or the quantity of houses. Our intention was to propose a very simple (but effective) method based on a modest (but obtainable) set of data. As is shown further on (this is shown by a correlation of results for two agglomerations), this method is authoritative for cities in Poland. It is however expected that this method is applicable in other countries, creating a valuable contribution to the research methodology.
For the purpose of this research, the following assumptions were formulated:
A1—While it is important to initially include in a study all inlets to the core (on the border cordon), some of them may be omitted in the study’s subsequent stages.
A2—For correlation analyses specific traffic characteristics can be selected, such as private vehicle peak period intensity, distinguishing a source–destination relationship.
A3—For correlation analyses, specific population characteristics should be taken into account, with a focus on specific groups in the population and with data on housing, as well as with a specification of the surrounding area.
These assumptions allowed us to propose a very simple but effective method for calculating and forecasting traffic intensity at the border of an agglomeration’s core by using a relatively easy obtainable set of data. The adopted method starts with a delimitation of the surroundings (in other papers also referred to as “source area,” “catchment area,” and “suburban area”) based on commuter traffic and the location of services, acquiring demographic and spatial data for this area, followed by a comparison of changes in the intensity of commuter traffic. Thus, the relationship between the traffic volumes recorded at the border of the agglomeration’s core and the data on the population in the surroundings is analyzed. The exact delimitation of the border between the core and the surroundings depends on the location of the traffic measurement points (inlets).
Traffic volume data is represented by 6 variables (VTi): the total number of vehicles per day (VT1), the number of private vehicles per day (VT2), the number of private vehicles during the morning rush-hour period from 06:00 to 9:00 (VT3), the number of private vehicles during the morning rush-hour period from 6:00 to 9:00 only towards the core (VT4), the number of private vehicles during the evening rush-hour period from 15:00 to 18:00 (VT5), and the number of private vehicles during the evening rush-hour period from 15:00 to 18:00 only from the core (VT6).
The traffic data was acquired from official measurements done for the Comprehensive Traffic Analysis (CTA) in the studied areas [70,71,72]. The CTA included traffic measurements on the circumference of specified areas—for this paper data gathered at the circumference of the core was used. In the CTA the intensity of the incoming and the exiting traffic was measured and investigated, differentiating vehicle types and allocating the measured data to every hour or quarter of an hour. Measurements at all locations were done by analysts standing by a roadside or by video filming during 24 h of one spring workday, assisted by measurements on the following days (including weekend days) at chosen locations. The results were confronted with data from other periods and in rare cases, where the difference between measured and anticipated volumes was too big, repeated in the following days. The date of the measurements was arranged with local road authorities to minimize road work in the week the measurement were taken, ensuring undistorted traffic distribution. CTA measurements from earlier years were done at a greater number of locations, covering practically all paved inlets to the core. Measurements done in later years skipped some locations that were considered to have no visible impact on city traffic—this assumption could be verified by automated measurements installed at certain locations, but also acquired from responsive traffic light controllers, for which traffic measurement is an important element. The data from the CTA was used primarily to create a traffic model, but was ready to be used for other purposes, such as the research presented in this paper.
The demographic data used in this paper came from publicly available statistical studies: the number and structure of the population in the years 2010 and 2018, as well as the number of existing and completed houses within the 2010–2018 period, noted for each commune (with a separation of cities and rural areas in urban–rural communes) and registered by the Central Statistical Office in Poland (www.stat.gov.pl). This data was compiled in the form of 5 variables (VPj): total population (VP1), population aged 5–17 (VP2), working age population (VP3), population of post-working age (VP4), and number of houses (VP5).
The data on the population came from the “population balance,” i.e., the current registration, carried out by the relevant municipal offices. This registration consisted of an administrative statement that a certain person was registered. It should be noted here that in Poland the approval of the data (not only population data) quality, timeliness, and relevance is limited. The data quality of population registration (and thus migration) [73], location of buildings and address points [74], and car registration [75], affects various indicators, especially mobility and motorization. Thus, it was not possible to analyze in detail issues such as the impact of household characteristics, professional status, etc., on traffic.
Unfortunately, in Poland, other potentially useful data including the structure of households in communes and smaller units (e.g., statistical regions), are not available (despite censuses). This, however, cannot reduce the importance of research needed for Poland, being the largest country in Central-Eastern Europe, and therefore providing a sufficient data pool for research on such important issues as the cause-and-effect relationships between transport, mobility, and demographic development. These are the key issues in understanding the mechanisms of urbanization in the countries undergoing transformation. Finding regularities and correlations can make a significant contribution to the theory and methodology of developing complex settlement systems such as urban agglomerations, which are the subject of this paper.
3. Characteristics of the Research Area
For the analyses, Wrocław and Poznań agglomerations were selected. The core cities of these agglomerations seem to be quite representative in terms of the suburbanization process in Poland: They are quite large cities (530,000–640,000 inhabitants), constituting the nucleus (“kernel”) of the so-called polycentric settlement system of Poland [3]. In both centers, the surroundings developed quite intensively but unevenly along their perimeter [9,17]. The demographic and economic growth of the surroundings was caused in part by an inflow of foreign investments, which created jobs [76,77]. In both agglomerations the process of “urban sprawl” [78,79], characteristic for the whole of Poland, is common.
For creation of the model, the Wrocław agglomeration was selected, being conditioned by several factors. Firstly, there are comparable traffic measurements for 2010 and 2018 for this area [70,71]. Secondly, the surroundings of Wrocław are characterized by an extremely large intensity of demographic urbanization processes [17], which are related to, among others, numerous investments creating several thousand jobs [76,80]. Thirdly, the agglomeration is well recognized in terms of traffic conditions, development of transport networks, sustainable development, and the phenomenon of urban sprawl [81,82,83,84]. Wrocław is the fourth largest city in Poland with more than 600,000 inhabitants in the core and with the residents of the surroundings approximately doubling this number (creating the “MAX” area).
The research area initially covered 51 units (communes and towns) around Wrocław (“MAX” area), but stage A of the analysis reduced this number to 24 (including Wrocław). Communes distant from the core were rejected due to the lower intensity of mutual relations expressed by lower dependence values. For further analysis, such reduced catchment areas, called the “Inner Area,” turned out to be significant—this area covered the communes surveyed in the Comprehensive Traffic Analysis (“KBR” area, year 2018), but accompanied two other communes. The towns in seven urban–rural communes that are not separate communes were analyzed both as parts of communes and as independent units. The topography of the “Inner Area” is shown in Figure 1. The following units were considered:
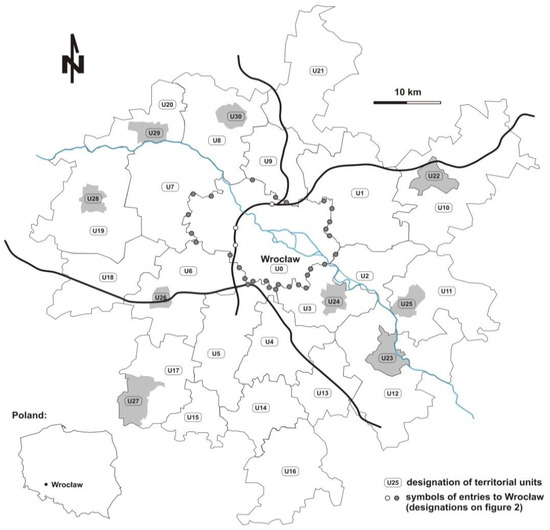
Figure 1.
The study area: the Wrocław agglomeration (source: own research).
- U0—the core of the agglomeration—Wrocław;
- U1–U21—rural or urban–rural communes surrounding the core (including two communes not covered in the Comprehensive Traffic Analysis (2018): U15—Jordanów Śl. and U17—Sobótka);
- U22 and U23—two urban communes; and
- U24–U30—seven towns that are parts of urban–rural communes.
Basic data for the aforementioned units are given in Table 1. In Figure 1 black lines mark “limited access roads” (motorways and expressways). Urban communes or towns that are parts of urban–rural communes are distinguished in grey. The Odra River is also marked, because outside Wrocław there are only three bridges on the Odra in the analyzed area, so the river is a barrier to traffic. The boundaries of the communes are shown with black lines.

Table 1.
Basic data on the examined administrative units.
A total of 32 inlets (entries) to the core were identified (Figure 2, Table 2 and Table 3). The numbering refers to the one used in the Comprehensive Traffic Analysis [70], hence numbers 19 and 33 are missing. Inlet Nos. 1, 25, and 32 were exits from the AOW (Motorway Bypass of Wrocław). Other inlets were located where roads crossed the core border (or nearby). The classification of these roads (function, agglomeration affiliation, technical class) varied, but they all served agglomeration traffic to a greater or lesser extent. Some of them also served long-distance traffic (“long-distance” meaning the traffic was traveling outside the agglomeration). Table 2 summarizes the basic characteristics of inlets in 2018. Some inlets, on roads of higher categories—national and regional (voivoideship)—for which the share of traffic not related to the core (long distance) was significant, were marked. Some of the regional roads were marked “formally regional road,” because they were formally assigned to be regional, but did not carry supra-local traffic. In addition to the average daily traffic intensity (ADT), the following parameters characterizing the traffic are given:
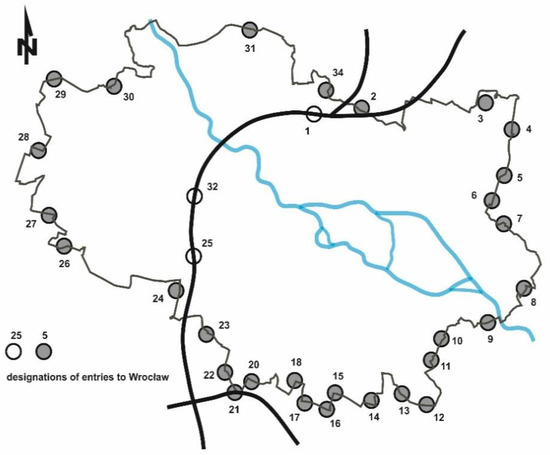
Figure 2.
Location and numbering of inlets. Source: own research
Table 2.
Characteristics of inlets to the core (Wrocław) from a survey in the year 2018.
Table 3.
Characteristics of inlets from surveys in the year 2010.
r1—share (ratio) of private vehicles relative to the total traffic [%];
r2—share (ratio) of the direction to the core relative to both directions in the morning rush-hour period (06:00–09:00) in the private vehicles group [%]; and
r3—traffic share in the morning rush-hour period (06:00–09:00) relative to the daily traffic in the private vehicles group [%].
The current traffic survey (CTA) was made in 2018 for the city (“core”) and for 21 neighboring communities making up the “surroundings.” The surroundings were inhabited by about 364,000 people, including about 336,000 people over six years of age. Data was collected from various sources: surveys taken from households; an online survey; surveys taken from public transport passengers; complementary surveys taken at bus stations, railway stations, shopping centers, municipal entities, universities, and companies; surveys taken from people in public transport vehicles; and car, bike, and pedestrian traffic. A complete description of the survey and access to the database of results are available on the Internet [70], with an English summary. The traffic volume on the core cordon was measured continuously for 24 and 16 h, using conventional measurements and image recording devices (video recorders), allowing the measurements to be archived.
The inlet characteristics for the year 2010 are given in Table 3 in the same way as for the year 2018. The numbering of these inlets was used according to CTA (2018), hence some of them are missing as they did not exist in 2010.
4. Calculations and Analyses
Following an analysis of the traffic surveys [70,71] for all inlets on the border of the core (Wrocław), a preliminary aggregation procedure was done considering the parameters characterizing the traffic described in chapter 2. The results of the aggregation allowed us to identify several groups with characteristic features. It has to be noted that between the years 2010 and 2018 the road network was expanded, significantly increasing capacity and traffic quality of some inlets—changes in traffic distribution caused by this expansion require additional research exceeding this paper’s scope. However, a fourth assumption was made, stating that specific inlets could be aggregated or eliminated to acquire groups “accused” of having specific dependencies from variables describing demographic and spatial characteristics. A total of 12 groups of aggregating inlets were assembled and shown in Table 4 (T1–T12). For demographic data, 17 groups aggregating administrative units were assembled and shown in Table 5 (P1–P17). Differences between the groups’ content validated assumptions A1–A3 stated in chapter 1 (selection of inlets, traffic parameters, and demographic data).
Table 4.
Groups aggregating traffic parameters for the Wrocław agglomeration.
Table 5.
Groups aggregating demographic parameters within administrative units.
The results of an analysis of dependencies (here as a simple correspondence between two variables) between changes in traffic and population changes between the years 2018 and 2010, done for pairs of traffic and demographic data groups, are given in Table 6. For the first approach, 34 pairs were taken for comparison. Values close to 1 represent a high correspondence value between traffic and population changes. Average correspondence values for all pairs showing specified variables are given in Table 7.
Table 6.
Pairs of groups used in the first approach of the analysis.
Table 7.
Average values of correspondence between VTi and VPj in the first approach of the analysis.
In the second approach, the analyses excluded groups that had the four inlets with the biggest traffic intensity (1, 4, 20, and 25), reducing the number of group pairs to 17. The results of the second approach are given in Table 8, showing that the obtained correspondence values were closer to 1 (the average correspondence value in Table 8 is 1.106, whereas in Table 7 it is 1.169). In the third approach the reduction of the group pairs was continued, eliminating outer administrative units and cities (according to assumption A3). This left only six pairs, but resulted in an even better correspondence value, presented in Table 9 (the average correspondence value is 1.101). These sets of six pairs of groups were identified as reliable for further analysis and used for correlation investigation in further stages of this work.
Table 8.
Average values of correspondence between VTi and VPj in the second approach of the analysis.
Table 9.
Average values of correspondence between VTi and VPj in the third approach of the analysis.
The presented analysis confirmed that there existed a dependence between traffic and demographic parameters, proving at this stage assumptions A1–A3. Elimination of specific inlets (with big traffic intensity and large long-distance traffic) and cities (corresponding with Friedman and Gordon’s research showing different travel characteristics between new and traditional neighborhoods [85]), and concentrating on rush hours of traffic limited to private cars, led to more strict correlations between the variable pair groups. The choice of the specific (best) pairs of variables (a pair of traffic and demographic variables) could be done according to a correlation analysis.
5. Correlation Analysis (Pearson’s Coefficient) and a Mathematical Description of Dependence of Traffic Volumes on Population
Considering variables VTi and VPi for the chosen six pairs of groups (T2 vs. P1, T4 vs. P4, T5 vs. P8, T7 vs. P12, T9 vs. P15, and T11 vs. P17), Pearson’s correlation coefficients (rVTVP) were calculated separately for the horizons of years 2010 and 2018. The calculations were done using Equation (1), with k showing the quantity of the correlated data (k = 1…6), and assembled in Table 10 and Table 11.
Table 10.
Pearson’s correlation matrix for the year 2010.
Table 11.
Pearson’s correlation matrix for the year 2018.
For given pairs of variables and for the presented time horizons (years) different correlation coefficient values were obtained. Generally, these values were very large (above 0.99) for all investigated pairs, which proved a very strong dependence between parameters describing suburban population and traffic. The next step was a search for mathematical models describing these dependencies, which should enable, or rather predict, changes in traffic, based on population data or housing developments. As the modeled (dependent variable) parameter, the intensity of private vehicles leaving the core in the afternoon rush-hour period (VT6) was chosen. Chosen for independent variables were the working-age population (VP3) and the quantity of houses (VP5).
For the chosen variable pairs VT6 with VP5 and VT6 with VP3, and for the two time horizons (the years 2010 and 2018—taken separately and together), linear dependency was identified, in a form shown in Equation (2). Parameters a and b acquired for this equation are presented in Table 12.
VTi = a + b ∙ VPj
Table 12.
Parameters of the investigated model for the Wrocław agglomeration.
6. Model Verification
The undertaken analyses and their results were verified for another Polish agglomeration, similar to Wrocław. The Poznań agglomeration was chosen, with 530,000 inhabitants living in the core, making the city the fifth largest in Poland, with dynamically developing surroundings. The core is surrounded by a poviat (county; second-level administrative unit) including 17 communes, with a total of 390,000 inhabitants and an expectation for the population to swiftly counterpoise (equalize) the population of the core.
The verification was done for 18 administrative units (the city of Poznań; three other towns—Swarzędz, Luboń, and Puszczykowo; seven urban–rural communes—Buk, Kostrzyn, Kórnik, Mosina, Murowana Goślina, Pobiedziska, and Stęszew; and seven rural communes—Czerwonak, Dopiewo, Kleszczewo, Komorniki, Rokietnica, Suchy Las, and Tarnowo Podgórne) and a road network with inlets into the core shown in Figure 3. The uneven distribution of inlets was caused by local terrain obstacles, such as lakes, the river Warta, big forested areas, and a semicircular railway line around the core—for these reasons inlet 22 was not located on the core’s border. In contrast to Wrocław, all exits from limited access roads were located outside the inlets.
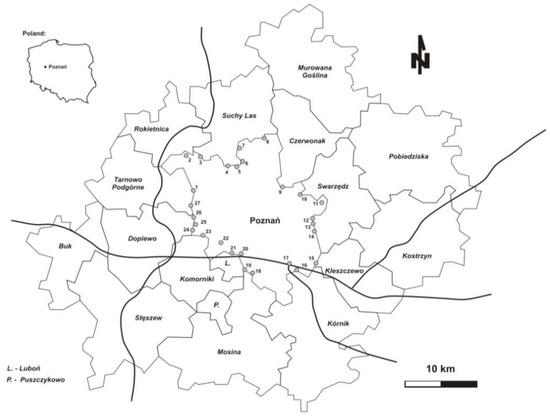
Figure 3.
The verification area: the Poznań agglomeration (Source: own elaboration).
A total of 27 inlets taken for the verification are presented in Table 13. Data from different time horizons (the years 2006, 2011, 2013, and 2015) provided different sets of parameters, so the year 2013 was chosen because it had the widest data scope [70]. Taken for the investigation was data based on the intensity of private vehicles leaving the core (VT6) with the working-age population (VP3) and quantity of houses (VP5) for Poznań’s surroundings. A selection was made of specified sets of traffic data (Table 14) and population (Table 15), in accordance with the method used for Wrocław. Therefore, the specified sets, inlets with the biggest traffic (including long-distance traffic) intensity (”5 max”: 1, 12, 17, 20, and 22), and chosen towns were eliminated.
Table 13.
Characteristics of inlets to the core (Poznań) from the survey in the year 2013.
Table 14.
Groups aggregating traffic parameters for the Poznań agglomeration in the year 2013.
Table 15.
Groups aggregating demographic parameters (VP3, VP5) within administrative units for the Poznań agglomeration in the year 2013.
Using population data for the Poznań agglomeration (from Table 15), the model used (Equation (2)) and parameters identified for the Wrocław agglomeration (Table 12) to calculate hypothetical (model) values of traffic parameters VT6. These values were then compared with real traffic parameters for the Poznań agglomeration (from Table 14). Data for this comparison and the acquired differences (absolute and in percentage) are given in Table 16. For specified pairs of groups referring to the utilization (or not) of each of the assumptions A1–A3, a correspondence of model and real results were acquired. Such correspondence allowed for a final evaluation of the proposed methodology and model, and to direct further research.
Table 16.
Differences between modeled and real traffic values for specified pairs of groups. Bold numbers signify three best pairs of groups providing the best results, the best pair being additionally underlined.
A very high correspondence of the model with the real (measured) values was acquired for the whole catchment area, but excluded towns (P2–P) and selected inlets (T2–P: eliminating five inlets with the biggest traffic intensity). This proved assumptions A1 and A3 (assumption A2 was proved earlier). Unfortunately, for other pairs of groups the correspondence was lower: Only for two other pairs was the difference smaller than 10 percentage points. One of these pairs correlated with a chosen direction (set of communes, including a town) with appropriate inlets (including one with big traffic intensity); the second pair also included a town, but without a big traffic inlet.
Finally, parameters for the model (Equation (2)) were calculated for data from Poznań in the year 2013. Table 17 presents the values of the a and b parameters, shown separately for the three best pairs and for the addition of the following five pairs of compared groups of data. The obtained results and their dispersion caused some uncertainty about the usefulness of the model. For the three best pairs, the results from Poznań were similar to the results from Wrocław, whereas the addition of the following pairs provided separate values. Further research is therefore required, extending the methodology, which currently is sufficient only for analyzing a full perimeter of the agglomeration’s core.
Table 17.
Parameters of the investigated model for the Poznań agglomeration.
7. Discussion
Numerous studies included and investigated dependencies between a built environment and travel (i.e., [86,87,88,89]). Ewing and Cervero [90] found more than 200 such studies. Naess [91] stated that there is a dependence between agglomeration structure and travel behavior in Copenhagen, showing differences between the core and its surroundings, i.e., in population density. As a residential area grows, the distances of travel also grows: A correlation between density and traffic intensity, as shown by the average daily travel factor, was given in [92]. There are selected concrete D-variables (density, diversity, design, destination accessibility, distance to transit) that influence household decisions [93]. A recent study [94] tried to determine which opposing point of view of sprawl and congestion is correct: Their model suggests that an increase in compactness reduces the amount of driving done by inhabitants of such a village, but also concentrates the driving into smaller areas.
Complex models describing the dependency between land use and traffic parameters were developed, as shown above, but all of them need a rich set of concrete and comprehensive data. The major obstacle for such research is to collect sufficient and reliable data sets [86,87,88,89]. A comprehensive analysis requires a selection of the data and a separation of specific groups (variables), e.g., regarding the number of personal vehicles during the rush-hour period (three hours) highlighting their direction (from the core). It is important to include specific inlets (with a recommendation to select and reject phase inlets with maximum traffic at calibration). Collecting population data is a separate problem since statistics are not reliable: A failure to comply with registration obligations (or their absence) results in incorrect population data of a given area—in practice in an underestimation of the number of inhabitants. This problem is especially troublesome in the most residentially attractive agglomerations, in which a strong influx of new residents is observed [25,73] (including Wrocław and Poznań, classified next to Warsaw in the so-called “Big Five” agglomerations of Poland [17,27]). Better results were obtained considering the number of houses, although this may also cause an underestimation (new buildings are often reported to the register after a certain period of delay). In such a situation, the most reliable method is to record houses by field observation [52] and on the basis of unprocessed, “raw,” remote-sensing materials (as the recent research shows, in Poland there is a large share of scattered built-up areas, often single-family houses, and the use of bases such as Corine Land Cover is not appropriate for studying changes in the settlement structure [74]).
Our research shows that the growth of residential and apartment buildings and of the population living in the surroundings allows us to assume a future increase in traffic between the two main agglomeration units: the core and the surroundings. This is especially true for new developments in “virgin” (greenfield) areas. For towns already existing, the construction of new developments is filling existing gaps, therefore in such locations we suggest a cautious application. Focusing on household development, the proposed method is not able to determine other parameters of the forecasted changes in traffic structure, such as, in particular, travel distance, which was quantified in the Copenhagen studies [91]. All the more, it is not possible to predict the structure of this traffic in terms of household decisions [93].
In view of the presented obstacles, our method provides a possibility to use selected and easy-to-collect data to approximate the correspondence between the number of people and the passenger-car traffic volume in the border of an agglomeration’s core. The importance of this relationship and its quantification is one of the main current issues in transport and settlement research [90]. The model proved to be feasible for all roads, but the elimination of higher-class roads (leaving only local roads) improved correlation, showing that transit traffic plays a significant role. It also gave a hint that a class of a road might have an influence on traffic volumes, proving assumption A1. On the other hand, this result showed a potential to use the model to evaluate the agglomeration component of traffic on transit roads.
Initially, all traffic crossing the core’s border was taken into consideration, but at the first stage of the analysis the results showed better correspondence when only private (passenger) cars were used, proving assumption A2. Therefore, the volume of cargo vehicles was not investigated in the main study (analysis) of this article. The best results were obtained for private vehicles traveling at rush hours, becoming a welcome outcome: It was the rush-hour traffic that generated the most problems in agglomerations. The evaluation of traffic outside peak hours was therefore less reliable, but such traffic was also less problematic.
The A3 assumption was also proven by showing that not all demographic data showed an appropriate correspondence. The best results were obtained for the quantity of houses and working-age population. This confirmed the results of these studies, which were based on the influence of the age of the structure as the main predicator of changes in the structure of the movement [90].
Suburbanization in the analyzed agglomeration was not homogeneous. Many communes based their success on inviting new inhabitants into housing developments, but some, such as Kobierzyce near Wrocław [76,80,81] and Tarnowo Podgórne near Poznań [78,79], created strong industrial areas. Such differences did not change the feasibility of the model, resulting in the conclusion that in agglomerations with a strongly dominant core, the location of shopping or industrial centers has a small influence on general traffic distribution. On the other hand, the elimination of existing cities—towns with developed urban forms [85]—in the conducted analysis improved correlation values, showing that such suburban cities should be modeled differently. It was also expected that the size of the agglomeration would play an important role—in medium-size cities, location of a large industrial plant might be significant.
Data for the two investigated agglomerations were taken from different years, with the first traffic measurement carried out when limited access roads bypassing the core were absent (under construction). The opening of these bypasses in Poznań and Wrocław did not change the correlation values significantly, allowing us to eliminate circumferential roads (roads directly connecting the dwellings of the surroundings) from considering their influence on the proposed model’s results.
The methodology was generally successful for the whole catchment area. However, for specified inlets, or groups of inlets, it could not be clearly verified. Such a defect might have been caused by specific details skipped in the analysis, such as the mixing and interweaving of agglomeration traffic, making it difficult to assign inlets or groups of them to certain communes or groups of them. Better results were obtained when inlets with large traffic intensity were excluded, which gives an indication on the need to explore the influence of a roads’ technical parameters: Since better roads outside the core lead to better roads inside the core, drivers might not choose the shortest, but rather the fastest option. Terrain obstacles may also play a role: A forest divides the Suchy Las commune into two disconnected parts (to travel between those parts a driver has to ride through the core, crossing two inlets). These deficiencies within the model show a need for further research, using larger data sets and different time horizons for other agglomerations. Such research would be justified by the frequency of this phenomenon, signaled in other agglomerations, especially those located in the vicinity of large undeveloped areas, e.g., forests [29]. As the review of the studies [90] indicated, the travel variables are generally inflexible in relation to the increase in population and to the area of residential and apartment buildings, which may result from specific land-use characteristics.
Nevertheless, on the basis of the performed research, intriguing relationships between traffic intensity on the perimeter of the core’s border and data on the surrounding population were discovered. These dependencies were similar for two considered agglomerations, despite the obstacles indicated above and different periods of research. High correlations of specific variable pairs were obtained and model parameters were estimated. Preliminarily and indicatively, it can be assumed that the traffic outgoing from the core in the rush-hour period (the number of private vehicles) is about half the number of houses and about a quarter of the working-age population. This allows us to estimate the amount of traffic in relation to current and future parameters of the surrounding environment using simple, linear relationships. Such evaluation possibilities are important, since dynamic growth population in the surroundings of Polish agglomerations is very distinct; for example, some communes near Wrocław increased their population by 42% over 10 years.
In addition to the listed advantages of the proposed method, its limitations should also be indicated. Above all, it was difficult to carry out a more advanced modeling of the impact of factors on traffic intensity resulting from the socio-occupational structure of the population. Such modeling was conducted in Poland on a much larger scale for the estimation of traffic on major roads [95], where it was shown that over longer distances the position of a locality in the settlement system and the directions of migration (i.e., the origin of the population) are important for traffic intensity. It should also be noted that the developed method is poorly suited for the analysis of very small spatial units (e.g., statistical micro-areas), and the scale of a district or commune (a few dozen or so sq. km) seems optimal. The results of analyses on the basis of the presented method are also sensitive to a large portion of transit traffic, which has repeatedly been a methodological and interpretative problem (so-called travel flexibility) in many other studies [90].
The development of the proposed method is closely related to the initial assumptions. In future, it is worth examining in more detail which entrances to the city (characteristics resulting from, for example, geographical location) influence the higher or lower correlation score (assumption A1). It would also be worthwhile to examine the effect the choice of time intervals has on the accuracy of the results (assumption A2). It would be interesting to have an accurate variate of the biological structure of the population (assumption A3), especially in the situation described at the beginning of the study where there was no detailed data on the structure of households or the work of residents. It also seems that further development of the methodology in relation not only to the number and structure of the population in a given area (commune), but also to the characteristics of its spatial distribution, i.e., patterns of concentration and dispersion of housing development, has a particularly high research potential. This should be important for the study of agglomerations in post-communist countries [2,6,9,19], where the dispersion of built-up areas is larger [4,15] than in Western European and generally in highly developed countries [7,8]. The conducted research also brings important conclusions of the application of nature, related to local development policy. Very similar correlations found between population growth and traffic volume in two large agglomerations in Poland may be helpful for other centers where there are no traffic measurements (especially on cordons). Knowing these correlations and regularities may allow for better planning of transport policy in relation to recorded population changes. Demographic forecasts are of particular importance here: The results of the studies also provide arguments for limiting the pace of development in areas where transport systems are not yet sufficiently developed.
8. Conclusions
Because obtaining reliable data in Poland might be a problem, including data on where people live or to which commune cars should be registered, crippling the quality of motorization factors, it became necessary to develop a method that would eliminate these difficulties. Therefore, an attempt was made to propose a simple but effective method using a modest but adequate and easily available set of data. The correlation analysis for two agglomerations shows that this method is reliable, at least for agglomerations in Poland. It improves research and modeling methodology, but should be verified in other countries.
It is also important to indicate the legitimacy of integrating the analyzed inlets to the core. This is a clear contribution to the agglomeration travel modeling and deserves presentation and verification by other researchers at other centers. The use of a more complex statistical apparatus is not necessary in this case.
An analysis of the increase in the number of houses and residents allows forecasting changes in traffic volumes at the perimeter of the core’s border and in its interior. If an average occupancy of a private vehicle is known, the model makes calculations of the number of people traveling by car through the perimeter of the core’s border possible. The above parameters are crucial in the planning of urban mobility, determining investment tasks, and striving to balance transport in agglomerations.
The proposed method was tested for parameters giving the best correlation results. Other parameter sets also provided good (although not as high) correspondence. The method should therefore make it feasible to also evaluate other parameters, such as morning or daily (not only rush-hour) agglomeration traffic.
The model was created and tested at two agglomerations of approximately 1 million inhabitants each, with their cores dominating over surrounding communes. This domination neglects the influence of economic differences between these communes on the traffic model. Such differences might be significant if the core’s influence is comparable to the influence of some surrounding communes.
Author Contributions
Conceptualization, M.K.; methodology, M.K.; software, M.K., J.R. and P.Ś.; validation, M.K., J.R. and P.Ś.; formal analysis, M.K., J.R. and P.Ś.; investigation, M.K., J.R. and P.Ś.; resources, M.K., J.R. and P.Ś.; data curation, M.K., J.R. and P.Ś.; writing—original draft preparation, M.K., J.R. and P.Ś.; writing—review and editing, M.K., J.R. and P.Ś.; visualization, M.K.; supervision, M.K.; project administration, M.K. and P.Ś. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Data Availability Statement
Local Data Bank of Central Statistical Office of Poland: https://bdl.stat.gov.pl/BDL/start.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Stanilov, K.; Sýkora, L. Confronting Suburbanization: Urban Decentralization in Postsocialist Central and Eastern Europe; IJURR Studies in Urban and Social Change Book Series; Wiley-Blackwell: Chichester, UK, 2014. [Google Scholar]
- Tammaru, T.; Leetmaa, K.; Silm, S.; Ahas, R. Temporal and spatial dynamics of the new residential areas around Tallinn. Eur. Plan. Stud. 2009, 17, 423–439. [Google Scholar] [CrossRef]
- Węcławowicz, G. Contemporary Poland: Space and Society; UCL Press: London, UK, 1996. [Google Scholar]
- Halleux, J.M.; Marcinczak, S.; van der Krabben, E. The adaptive efficiency of land use planning measured by the control of urban sprawl. The cases of the Netherlands, Belgium and Poland. Land Use Policy 2012, 29, 887–898. [Google Scholar] [CrossRef]
- Krzysztofik, R.; Kantor-Pietraga, I.; Runge, A.; Spórna, T. Is the suburbanisation stage always important in the transformation of large urban agglomerations? The case of the Katowice conurbation. Geogr. Pol. 2017, 90, 71–85. [Google Scholar] [CrossRef]
- Matlovič, R.; Sedláková, A. The impact of suburbanisation in the hinterland of Prešov (Slovakia). Morav. Geogr. Rep. 2007, 15, 22–31. [Google Scholar]
- Champion, T. Urbanization, suburbanization, counterurbanization and reurbanization. In Handbook of Urban Studies; Paddison, R., Ed.; Sage: London, UK, 2001; pp. 143–161. [Google Scholar]
- Kahn, M.E. The environmental impact of suburbanization. J. Policy Anal. Manag. 2000, 19, 569–586. [Google Scholar] [CrossRef]
- Gałka, J.; Warych-Juras, A. Suburbanization and migration in polish metropolitan areas during political transition. Acta Geogr. Slov. 2018, 58, 63–72. [Google Scholar] [CrossRef]
- Banister, D. (Ed.) Transport and Urban Development; E&FN Spon: London, UK, 1995. [Google Scholar]
- Caves, R.W. Encyclopedia of the City; Routledge: Abingdon, UK, 2004. [Google Scholar]
- van den Berg, L.; Klaassen, L.H.; Drewett, R.; Rossi, A.; Vijverbert, C.H. Urban Europe: A Study of Growth and Decline; Pergamon Press: Oxford, UK, 1982. [Google Scholar]
- Garreau, J. Edge City: Life on the New Frontier New York; Anchor Books: New York, NY, USA, 1992. [Google Scholar]
- Mantey, D.; Sudra, P. Types of suburbs in post-socialist Poland and their potential for creating public spaces. Cities 2019, 88, 209–221. [Google Scholar] [CrossRef]
- Korcelli, P.; Grochowski, M.; Kozubek, E.; Korcelli-Olejniczak, E.; Werner, P. Development of urban-rural regions: From European to local perspective. Monografie 2012, 14, 158. [Google Scholar]
- Kurek, S.; Rachwał, T.; Wójtowicz, M. Industrial and commercial suburbanization in post-socialist city: The Kraków Metropolitan Area (Poland). Ann. Univ. Paedagog. Crac. Studia Geogr. 2014, 5, 55–76. [Google Scholar]
- Śleszyński, P. Suburbanization processes in Poland after 1989. Probl. Geogr. 2006, 1–2, 105–117. [Google Scholar]
- Dumitrache, L.; Zamfir, D.; Nae, M.; Simion, G.; Stoica, I.-V. The urban nexus: Contradictions and dilemmas of (post)communist (sub)urbanization in Romania. Hum. Geogr.-J. Stud. Res. Hum. Geogr. 2016, 10, 39–58. [Google Scholar] [CrossRef]
- Hirt, S. Suburbanizing Sofia: Characteristics of post-socialist peri-urban change. Urban Geogr. 2007, 28, 755–780. [Google Scholar] [CrossRef]
- Slaev, A.D.; Nedović-Budić, Z.; Krunić, N.; Petrić, J.; Daskalova, D. Suburbanization and sprawl in post-socialist Belgrade and Sofia. Eur. Plan. Stud. 2018, 26, 1389–1412. [Google Scholar] [CrossRef]
- Sulukhia, T. Suburbanization in Tbilisi: Global trend in a local context. In City Culture and City Planning in Tbilisi: Where Europe and Asia Meet; Van Assche, K., Salukvadze, J., Shavishvili, N., Eds.; Edwin Mellen Press: New York, NY, USA, 2009; pp. 225–241. [Google Scholar]
- Dziewoński, K. Urbanization in contemporary Poland. Geogr. Pol. 1964, 3, 37–57. [Google Scholar]
- Huang, X. Underurbanization in developed countries. Urban Probl. 1997, 6, 8–9. [Google Scholar]
- Kok, H.; Kovács, Z. The process of suburbanization in the agglomeration of Budapest. Neth. J. Hous. Built Environ. 1999, 14, 119–141. [Google Scholar] [CrossRef]
- Krisjane, Z.; Berzins, M. Post-socialist urban trends: New patterns and motivations for migration in the suburban areas of Riga, Latvia. Urban Stud. 2012, 49, 289–306. [Google Scholar] [CrossRef]
- Gutry-Korycka, M. (Ed.) Urban Sprawl: Warsaw Agglomeration Case Study; Warsaw University Press: Warsaw, Poland, 2005. [Google Scholar]
- Komornicki, T.; Szejgiec-Kolenda, B.; Degórska, B.; Goch, K.; Śleszyński, P.; Bednarek-Szczepańska, M.; Siłka, P. Spatial planning determinants of cohesion policy implementation in Polish regions. Europa XXI 2018, 35, 69–87. [Google Scholar] [CrossRef]
- Bajmócy, P. Suburbanization in Eastern-Hungary. In Regionalism and Integration: Culture, Space and Development; Nicolae, P., Ed.; Brumar, Timişoara-Tubingen-Anger: Tuttlingen, Germany, 2000; pp. 149–153. [Google Scholar]
- Wolny, A.; Źróbek, R. The interdependence between suburban enclaves and the road network in the development process: A case study in Poland. Geogr. Pol. 2017, 90, 41–57. [Google Scholar] [CrossRef]
- Gnatiuk, O. Demographic dimension of suburbanization in Ukraine in the light of urban development theories. AUC Geogr. 2017, 52, 151–163. [Google Scholar] [CrossRef]
- Brueckner, J.K. Transport subsidies, system choice, and urban sprawl. Reg. Sci. Urban Econ. 2005, 35, 715–733. [Google Scholar] [CrossRef]
- Banister, D. Cities, Urban form and Sprawl: A European Perspective. In Proceedings of the European Conference of Ministers of Transport OECD, Berkeley, CA, USA, 27–28 March 2006; OECD Publishing: Paris, France, 2007; pp. 113–142. [Google Scholar]
- Lityński, P.; Hołuj, A. Urban sprawl costs: The valuation of households’ losses in Poland. J. Settl. Spat. Plan. 2017, 8, 11–35. [Google Scholar] [CrossRef]
- Carruthers, J.I.; Ulfarsson, G.F. Urban sprawl and the cost of public services. Environ. Plan. B Plan. Des. 2003, 30, 503–522. [Google Scholar] [CrossRef]
- Smutek, J. Change of municipal finances due to suburbanization as a development challenge on the example of Poland. Bulletin of Geography. Socio-Econ. Ser. 2017, 37, 139–149. [Google Scholar]
- Chi, G. The Impacts of transport accessibility on population change across rural, suburban and urban areas: A Case study of Wisconsin at sub-county levels. Urban Stud. 2012, 49, 2711–2731. [Google Scholar] [CrossRef]
- Craven, J.; Horan, E.; Goulding, R. Population growth and infrastructure development in Melbourne. WIT Trans. Ecol. Environ. 2014, 191, 509–520. [Google Scholar]
- Wang, L.; Chen, L. The impact of new transportation modes on population distribution in Jing-Jin-Ji region of China. Sci. Data 2018, 5, 170204. [Google Scholar] [CrossRef]
- Duranton, G.; Turner, M.A. Urban growth and transportation. Rev. Econ. Stud. 2012, 79, 1407–1440. [Google Scholar] [CrossRef]
- Pablo-Marti, F.; Sánchez, A. Improving transportation networks: Effects of population structure and decision making policies. Sci. Rep. 2017, 7, 4498. [Google Scholar] [CrossRef]
- Nadin, V.; Fernández Maldonado, A.; Zonneveld, W.; Stead, D.; Dąbrowski, M.; Piskorek, K.; Sarkar, A.; Schmitt, P.; Smas, L.; Cotella, G.; et al. COMPASS—Comparative Analysis of Territorial Governance and Spatial Planning Systems in Europe Applied Research 2016–2018 Final Report; ESPON: Luxembourg, 2018; Available online: https://www.espon.eu/planning-systems (accessed on 22 December 2020).
- Oblak, R.; Kos, S. Modelling of national multimodal transport network in container traffic. In Proceedings of the 14th ICTS Conference, Portoroz, Slovenia, 27 May 2011; p. 12. [Google Scholar]
- Adkins, A.; Makarewicz, C.; Scanze, M.; Ingram, M.; Luhr, G. Contextualizing Walkability: Do Relationships Between Built Environments and Walking Vary by Socioeconomic Context? J. Am. Plan. Assoc. 2017, 83, 296–314. [Google Scholar] [CrossRef]
- Gori, S.; Nigro, M.; Petreli, M. The impact of land use characteristics for sustainable mobility: The case study of Rome. Eur. Transp. Res. Rev. 2012, 4, 153–166. [Google Scholar] [CrossRef]
- Næss, P. Urban form and travel behaviour: Experience from a Nordic context. J. Transp. Land Use 2012, 5, 21–45. [Google Scholar] [CrossRef]
- Tirachini, A.; Hensher, D.A.; Bliemer, M.C.J. Accounting for travel time variability in the optimal pricing of cars and buses. Transportation 2014, 41, 947–971. [Google Scholar] [CrossRef]
- Zhou, J. Sustainable commute in a car-dominant city: Factors affecting alternative mode choices among university students. Transp. Res. Part A 2012, 46, 1013–1029. [Google Scholar] [CrossRef]
- Beirão, G.; Cabral, J. Understanding attitudes towards public transport and private car: A qualitative study. Transp. Policy 2007, 14, 478–489. [Google Scholar] [CrossRef]
- Cass, N.; Faulconbridge, J. Commuting practices: New insights into modal shift from theories of social practice. Transp. Policy 2016, 45, 1–14. [Google Scholar] [CrossRef]
- Cervero, R.; Denman, S.; Jin, Y. Network design, built and natural environments, and bicycle commuting: Evidence from British cities and towns. Transp. Policy 2019, 74, 153–164. [Google Scholar] [CrossRef]
- Kruszyna, M. Towards the Best Public Transport in Suburban Areas on the Example from One Polish Agglomeration. Logist. Transp. 2014, 23, 63–72. [Google Scholar]
- Newman, P.; Kosonen, L.; Kenworthy, J. Theory of urban fabrics: Planning the walking, transit/public transport and automobile/motor car cities for reduced car dependency. Town Plan. Rev. 2016, 87, 429–458. [Google Scholar] [CrossRef]
- Holguı’n-Veras, J.; Yushimito, W.F.; Aros-Vera, F.; Reilly, J. User rationality and optimal park-and-ride location under potential demand maximization. Transp. Res. Part B 2012, 46, 949–970. [Google Scholar] [CrossRef]
- Tyrinopoulos, Y.; Antoniou, C. Factors affecting modal choice in urban mobility. Eur. Transp. Res. Rev. 2013, 5, 27–39. [Google Scholar] [CrossRef]
- Dingil, A.E.; Schweizer, J.; Rupi, F.; Stasiskiene, Z. Transport indicator analysis and comparison of 151 urban areas, based on open source data. Eur. Transp. Res. Rev. 2018, 10, 58. [Google Scholar] [CrossRef]
- Aljoufie, M.; Zuidgeest, M.; Brussel, M.; van Maarseveen, M. Urban growth and transport understanding the spatial temporal relationship. In Urban Transport XVII: Urban Transport and the Environment in the 21st Century; WIT Press: Southampton, UK, 2011; pp. 315–328. [Google Scholar]
- Bertolini, L. Integrating mobility and urban development agendas: A manifesto. disP Plan. Rev. 2012, 48, 16–26. [Google Scholar] [CrossRef]
- Wegener, M.; Fürst, F. Land-Use Transport Interaction: State of the Art; Project TRANSLAND (integration of transport and land use planning); University of Dortmund: Dortmund, Germany, 1999. [Google Scholar]
- Muller, P. Transportation and Urban Form: Stages in the Spatial Evolution of the American Metropolis. In The Geography of Urban Transportation; Guilford Publications: New York, NY, USA, 2004; pp. 59–85. [Google Scholar]
- Newman, P.; Kenworthy, J.R. The land use-transport connection: An overview. Land Use Policy 1996, 13, 1–22. [Google Scholar] [CrossRef]
- Blonk, W.A.G. (Ed.) Transport and Regional Development: An International Handbook; Farnborough: Teakfield, South Africa, 1979. [Google Scholar]
- Baum-Snow, N.; Brandt, L.; Henderson, J.V.; Turner, M.A.; Zhang, Q. Roads, railroads and decentralization of Chinese cities. Rev. Econ. Stat. 2012, 99, 435–448. [Google Scholar] [CrossRef]
- Baum-Snow, N. Did highways cause suburbanization? Q. J. Econ. 2007, 122, 775–805. [Google Scholar] [CrossRef]
- Chi, G. The impacts of highway expansion on population change: An integrated spatial approach. Rural Sociol. 2010, 75, 58–89. [Google Scholar] [CrossRef]
- Litman, T. Generated Traffic: Implications for Transport Planning; Victoria Transport Policy Institute: Victoria, BC, Canada, 2018. [Google Scholar]
- Lin, T.; Wang, D.; Zhou, M. Residential relocation and changes in travel behavior: What is the role of social context change. Transp. Res. Part A 2018, 111, 360–374. [Google Scholar] [CrossRef]
- Muromachi, Y. Experiences of past school travel modes by university students and their intention of future car purchase. Transp. Res. Part A 2017, 104, 209–220. [Google Scholar] [CrossRef]
- Beige, S.; Axhausen, K.W. The dynamics of commuting over the life course: Swiss experiences. Transp. Res. Part A 2017, 104, 179–194. [Google Scholar] [CrossRef]
- Busch-Geertsema, A.; Lanzendorf, M. From university to work life—Jumping behind the wheel? Explaining mode change of students making the transition to professional life. Transp. Res. Part A 2017, 106, 181–196. [Google Scholar] [CrossRef]
- Urząd Miejski Wrocławia. Comprehensive Traffic Analysis in Wrocław and Its Vicinity, 2018; Municipality of Wrocław: Wrocław, Poland, 2018; Available online: http://bip.um.wroc.pl/artykul/565/37499/kompleksowe-badania-ruchu-we-wroclawiu-i-otoczeniu-kbr-2018 (accessed on 21 January 2019).
- Urząd Miejski Wrocławia. Comprehensive Traffic Analysis in Wrocław, 2010–2011; Municipality of Wrocław: Wrocław, Poland, 2011; Available online: http://bip.um.wroc.pl/artykul/565/19091/kompleksowe-badania-ruchu-wroclaw-2010-2011 (accessed on 21 January 2019).
- Municipality of Poznań, Poland. Comprehensive Traffic Analysis in Poznań and Its Vicinity; KBR 2010 and 2016 with intermediate verifications done in 2013 and 2015; Official documents of the Municipality of Poznań; Municipality of Poznań: Poznań, Poland, 2016.
- Śleszyński, P. Directions of migration registered in the Warsaw Metropolitan Area. In Internal Migrations in Poland, Migration—Ethnicity—Nation: Studies in Culture, Society and Politics; Skoczylas, Ł., Smolarkiewicz, E., Eds.; Peter Lang: Berlin, Germany, 2019; pp. 97–117. [Google Scholar]
- Śleszyński, P.; Gibas, P.; Sudra, P. The problem of mismatch between the CORINE Land Cover data classification and the development of settlement in Poland. Remote Sens. 2020, 12, 2253. [Google Scholar] [CrossRef]
- Komornicki, T. Car ownership level as the indicator of the socio-economic transformations in Poland. Geopolit. Stud. 2004, 23, 520–533. [Google Scholar]
- Namyślak, B. Problems and Chances of Development of Regional Metropolises. The Case of Wrocław. Bull. Geogr. Socio-Econ. Ser. 2006, 6, 107–118. [Google Scholar]
- Domański, B. Industrial Change and Foreign Direct Investment in the Postsocialist Economy: The Case of Poland. Eur. Urban Reg. Stud. 2003, 10, 99–118. [Google Scholar] [CrossRef]
- Kacprzak, E.; Maćkiewicz, B. Farmland Conversion and Changes in the Land Use Pattern in the Poznań Agglomeration over the years 2000–2009. Quaest. Geogr. 2013, 32, 91–102. [Google Scholar] [CrossRef]
- Kaczmarek, T.; Mikuła, Ł. The Housing Market in Poland in the Liberalized Spatial Planning System: The National Context and Metropolitan Dimension of the Poznań Agglomeration. In Housing and Housing Politics in European Metropolises; StadtRegion, J., Wehrhahn, R., Pohlan, J., Hannemann, C., Othengrafen, F., Schmidt-Lauber, B., Eds.; Springer: Wiesbaden, Germany, 2019; pp. 71–92. [Google Scholar] [CrossRef]
- Łoboda, J. Development strategies of towns. The case of Wrocław. In Polish Geography: Problems, Researches, Applications; Chojnicki, Z., Parysek, J.J., Eds.; Bogucki Wyd. Naukowe: Poznań, Poland, 2000; pp. 69–76. [Google Scholar]
- Bednarska-Olejniczak, D.; Olejniczak, J.; Svobodova, L. Towards a smart and sustainable city with the involvement of public participation—The case of Wroclaw. Sustainability 2019, 11, 332. [Google Scholar] [CrossRef]
- Huk, J. Effectiveness of migration, for Wrocław, from 1989 to 2001. Bull. Geogr. Socio-Econ. Ser. 2003, 2, 17–25. [Google Scholar]
- Miszewska, B.; Szmytkie, R. Morphological processes in the spatial structure of the southern district of Wrocław city. Bull. Geogr. Socio-Econ. Ser. 2015, 27, 133–151. [Google Scholar] [CrossRef]
- Solecka, I.; Sylla, M.; Świąder, M. Urban sprawl impact on farmland conversion in suburban area of Wroclaw, Poland. IOP Conf. Ser. Mater. Sci. Eng. 2017, 245, 072002. [Google Scholar] [CrossRef]
- Friedman, B.; Gordon, S.; Peers, J.B. Effect of neotraditional neighbourhood design on travel characteristics. Transp. Res. Rec. 1994, 1466, 63–70. [Google Scholar]
- Brownstone, D. Key Relationships between the Built Environment and VMT; Committee on the Relationships among Development Patterns, Vehicle Miles Traveled, and Energy Consumption Transportation Research Board and the Division on Engineering and Physical Sciences: Washington, DC, USA, 2008. [Google Scholar]
- Cao, X.; Mokhtarian, P.L.; Handy, S.L. Examining the impacts of residential self-selection on travel behavior: A focus on empirical findings. Transp. Rev. 2009, 29, 359–395. [Google Scholar] [CrossRef]
- Pont, K.; Ziviani, J.; Wadley, D.; Bennett, S.; Abbott, R. Environmental correlates of children’s active transportation: A systematic literature review. Health Place 2009, 15, 827–840. [Google Scholar] [CrossRef] [PubMed]
- Salon, D.; Boarnet, M.G.; Handy, S.; Spears, S.; Tal, G. How do local actions affect VMT? A critical review of the empirical evidence. Transp. Res. Part D 2012, 17, 495–508. [Google Scholar] [CrossRef]
- Ewing, R.; Cervero, R. Travel and the built environment: A meta-analysis. J. Am. Plan. Assoc. 2010, 76, 265–294. [Google Scholar] [CrossRef]
- Næss, P. Accessibility, Activity Participation and Location of Activities: Exploring the Links between Residential Location and Travel Behaviour. Urban Stud. 2006, 43, 627–652. [Google Scholar] [CrossRef]
- Sarzynski, A.; Wolman, H.L.; Galster, G.; Hanson, R. Testing the Conventional Wisdom about Land Use and Traffic Congestion: The More We Sprawl, the Less We Move? Urban Stud. 2006, 43, 601–626. [Google Scholar] [CrossRef]
- Ewing, R.; Tian, G.; Goates, J.P.; Zhang, M.; Greenwald, M.J.; Joyce, A.; Kircher, J.; Greene, W. Varying influences of the built environment on household travel in 15 diverse regions of the United States. Urban Stud. 2015, 52, 2330–2348. [Google Scholar] [CrossRef]
- Ewing, R.; Tian, G.; Lyons, T. Does compact development increase or reduce traffic congestion? Cities 2018, 72, 94–101. [Google Scholar] [CrossRef]
- Rosik, P.; Komornicki, T.; Goliszek, S. Traffic modeling in Poland at the municipal level. Multi-purpose model. In Advances in Intelligent Systems and Computing; Sierpiński, G., Ed.; Springer: Cham, Germany, 2018; pp. 129–140. [Google Scholar]



Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).