1. Introduction
Since observed rainfall records tend to be more accurately and completely observed at daily or longer intervals than at sub-daily intervals, temporal disaggregation models are commonly used for the synthesis of sub-daily rainfall as part of flood estimation. Multiplicative discrete random cascades (MDRCs) [
1,
2,
3] make up one class of disaggregation model. Using a MDRC model, the rainfall falling in any interval (say, one day) is divided into two or more sub-intervals (say, two intervals each of 12 h) using a set of weights,
W. This is repeated over a number of disaggregation levels until the required time interval (say, one hour) is reached. This requires the probability distribution functions (PDFs) of
W to be estimated from rainfall observations. Using the ‘microcanonical’ type of MDRC model, the PDF parameters are estimated for each disaggregation level independently, although empirically derived scaling relationships may be used to generalise between levels.
Much of the work on microcanonical MDRCs has pointed out the strong volume-dependence of the PDF parameters [
4,
5,
6]. This is intuitive; the more rainfall falling in an interval, the more likely the rainfall will be distributed evenly between its sub-intervals, so that the PDF of
W is expected to have lower variance around the value
W = 0.5. This volume dependence may be included in the model by making the PDF parameters a function of volume [
4]; however, due to the low number of observations covering the extreme high rainfall volumes, the PDFs that are most important for flood estimation applications will have high uncertainty. Conversely, obtaining a sufficient number of samples will require a large range of volumes to be used; hence the parameter estimates may not be sufficiently applicable to the relevant extremes. Furthermore, the applicability of the parameter estimates to volumes beyond the observed range yet within the range to be simulated will be unknown. This may contribute to the over-estimation of high rainfall volumes seen in some previous applications of microcanonical MDRC models [
5,
6,
7]. The problem of reducing uncertainty in the parameters of rainfall disaggregation models applicable to high extreme rainfall volumes is the subject of this paper.
The probable maximum precipitation (PMP) is often considered to be an estimate of the theoretical maximum rainfall volume at a given location, time, and space scale. This paper proposes that the PMP can be used to define a theoretical bound on the parameters of the PDFs used for MDRC models. The paper aims to develop this concept into a modelling procedure, test its performance on a case study, and discuss the potential for improvement. While the concept of bounded disaggregation to describe the time scale dependence of parameters, i.e., that the variance of the PDF tends to zero as the time interval becomes shorter, is established [
8], the concept of bounding the disaggregation using theoretical volume constraints is new.
2. Theory
The theory presented here is restricted to microcanonical MDRC models in which each interval is divided into two sub-intervals and the disaggregation is symmetrical so that a given volume of rainfall is equally likely to fall in the first sub-interval as in the second. Deeper insight into the theory and application of MDRC models can be found in [
7] and the papers cited therein.
The ratio of rainfall volume
R (mm) in the time interval
t to
t + ∆
t/2 to rainfall volume in the interval
t to
t + ∆
t is:
which we write as
where
L is the disaggregation level and
N is the total number of levels. For example,
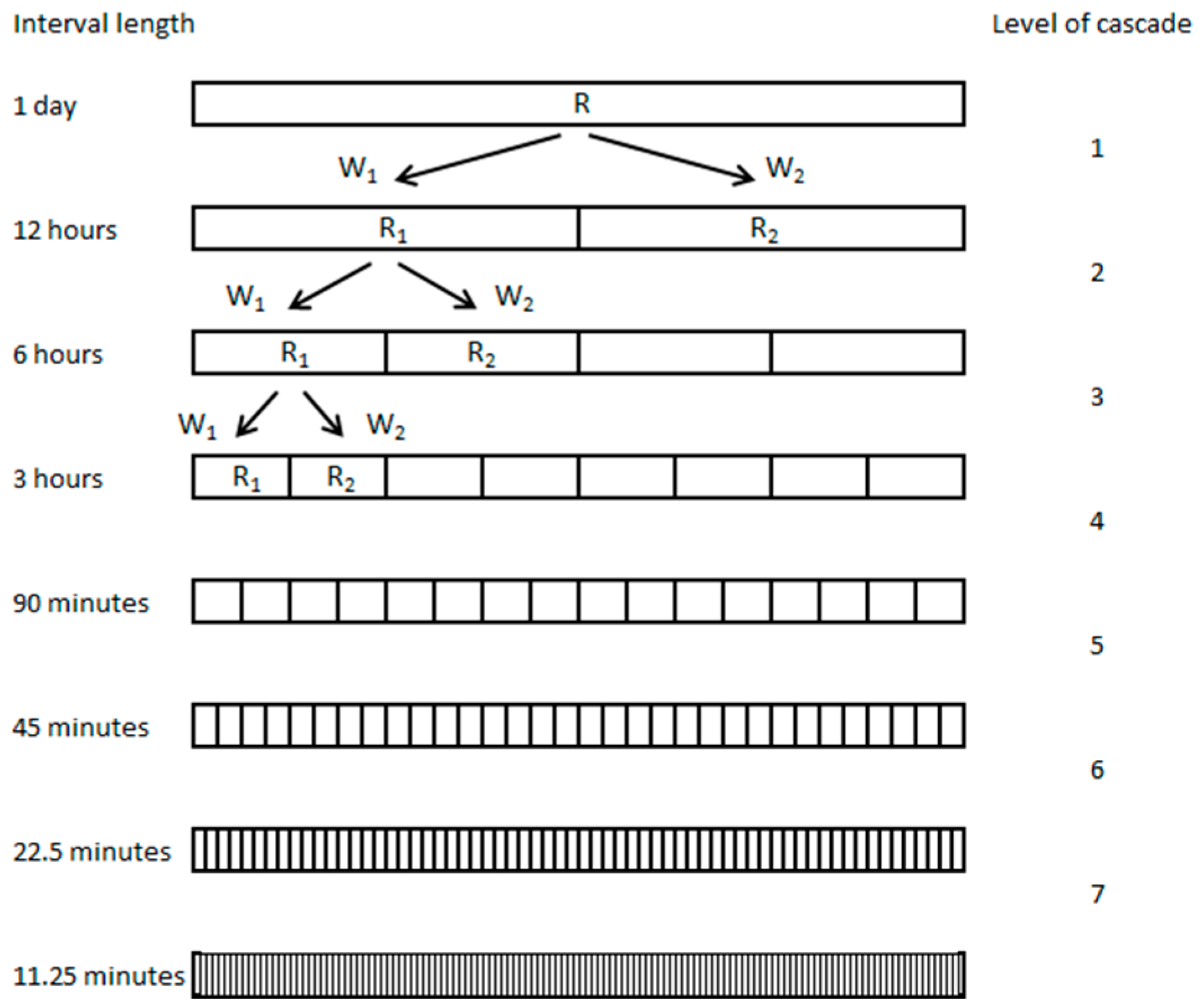
Figure 1 shows a cascade with
N = 7, where
R1 has a time-step of one day and
R8 has a time-step of 11.25 min. Assuming that volumes are preserved from intervals to sub-intervals, 0 ≤
WL ≤ 1 and the proportion of the interval’s rainfall falling in the second sub-interval equals 1 −
WL.A sample of W over each disaggregation level may be obtained from the observed rainfall. The MDRC model may then be estimated by fitting probability distribution functions to the available sample of W. Typically the model has two parts. First, from the probability that W is equal to zero or equal to one, P01, is estimated. Then 1 − P01 is the probability that 0 < W < 1, and, in this range, W is modelled using a probability distribution function, Px.
The PMP estimate at each level is termed
PMPL. If an available estimate of PMP is taken to be the maximum possible rainfall, then, if the rainfall volume
RL is greater than
PMPL+1, it is impossible for it all to fall within only one of the two sub-intervals, so
P01 = 0. More generally, it is impossible for
W to be large or small enough for
RL+1 to exceed
PMPL+1. If
RL >
PMPL+1, then:
If
Px is assumed to be a uniform distribution, for example [
1], for which the only parameters are the upper and lower bounds, deriving
Px from (3) is straightforward. However, in general, alternative distributions are preferable for
Px, in which case the parameters cannot be directly derived from (3).
In the hypothetical case that
RL = 2 ×
PMPL+1 because
RL+1 cannot exceed
PMPL+1:
where
δx0 is the Dirac delta. Although hypothetical, (4) provides an asymptote that may be useful for the extrapolation of the observed volume dependency, as illustrated by the case study results.
Henceforth, the subscript L is dropped for convenience of presentation, except where it is necessary to use it because an equation includes variables from two different levels. It should be kept in mind that all model inputs, outputs, and parameters are specific for each level of disaggregation.
4. Results
For each of the seven disaggregation levels,
Table 3 shows the model parameter estimates as well as the PMP values and other relevant properties of the data. Two values are given for
M; the value for the entire record and the value for the fitting period (in parenthesis). Comparing these two values (and also the
R99 values, which are derived from the entire record) indicates the high degree of extrapolation required of the model in its evaluation.
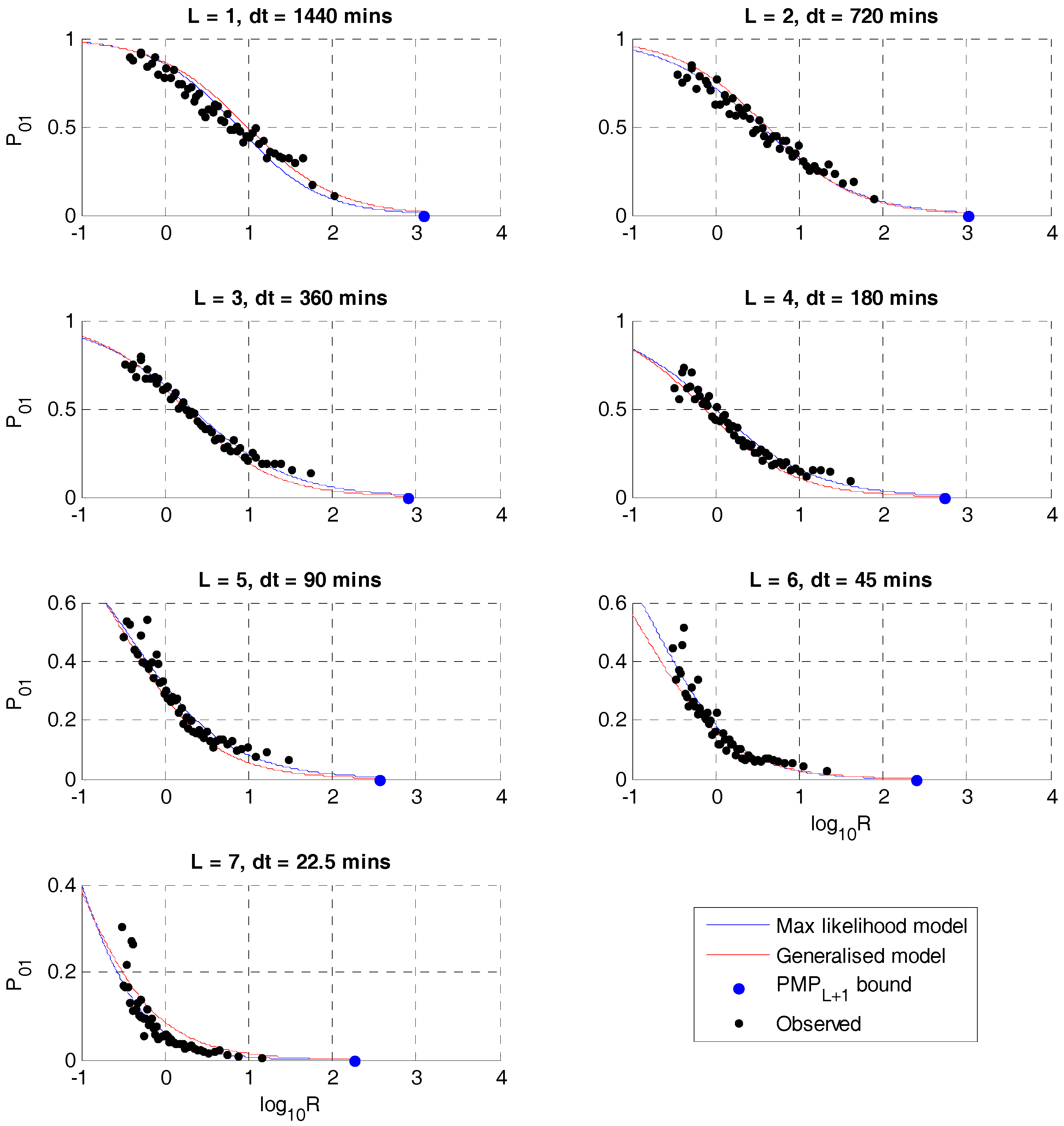
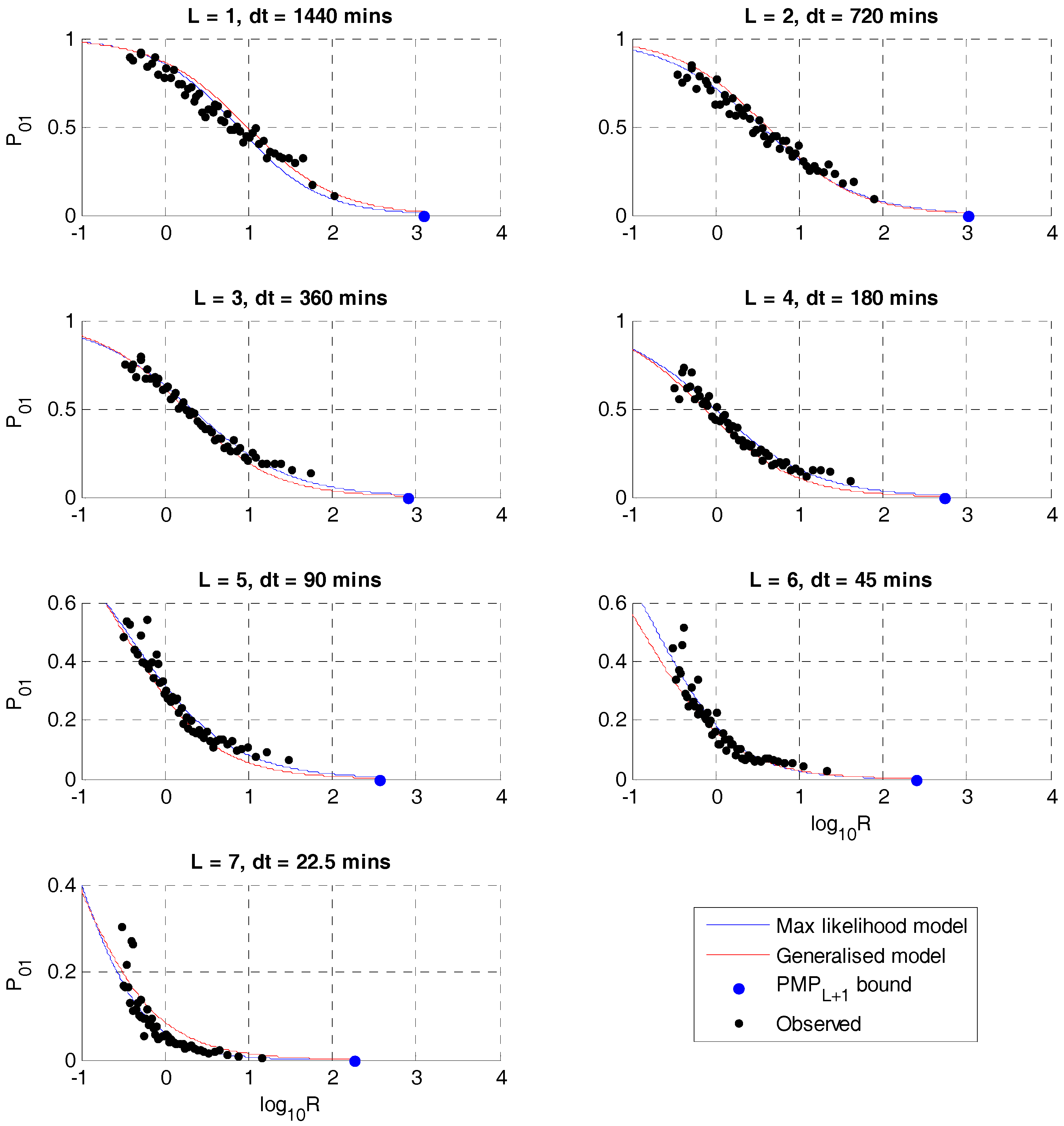
Figure 2 shows the maximum likelihood result for the unbounded logistic regression, (5). Superimposed on this are the ‘observed’ values of
P01 estimated by fitting to the observed values of
W within each second percentile range of
R, plotted against the mean values of
R in these ranges, using data from the entire historical record. Although there is considerable noise in these estimates, they show that the logistic regression models are reasonably consistent with the observed volume dependency and that the model identified using only the fitting period translates reasonably to the entire historical record. Also included in
Figure 2 are the theoretical point,
RL =
PMPL+1, at and above which
P01 = 0 in the bounded model and the results of a generalised model (see Discussion). The results for the bounded model are barely distinguishable from those of the unbounded model so are not included in
Figure 2.
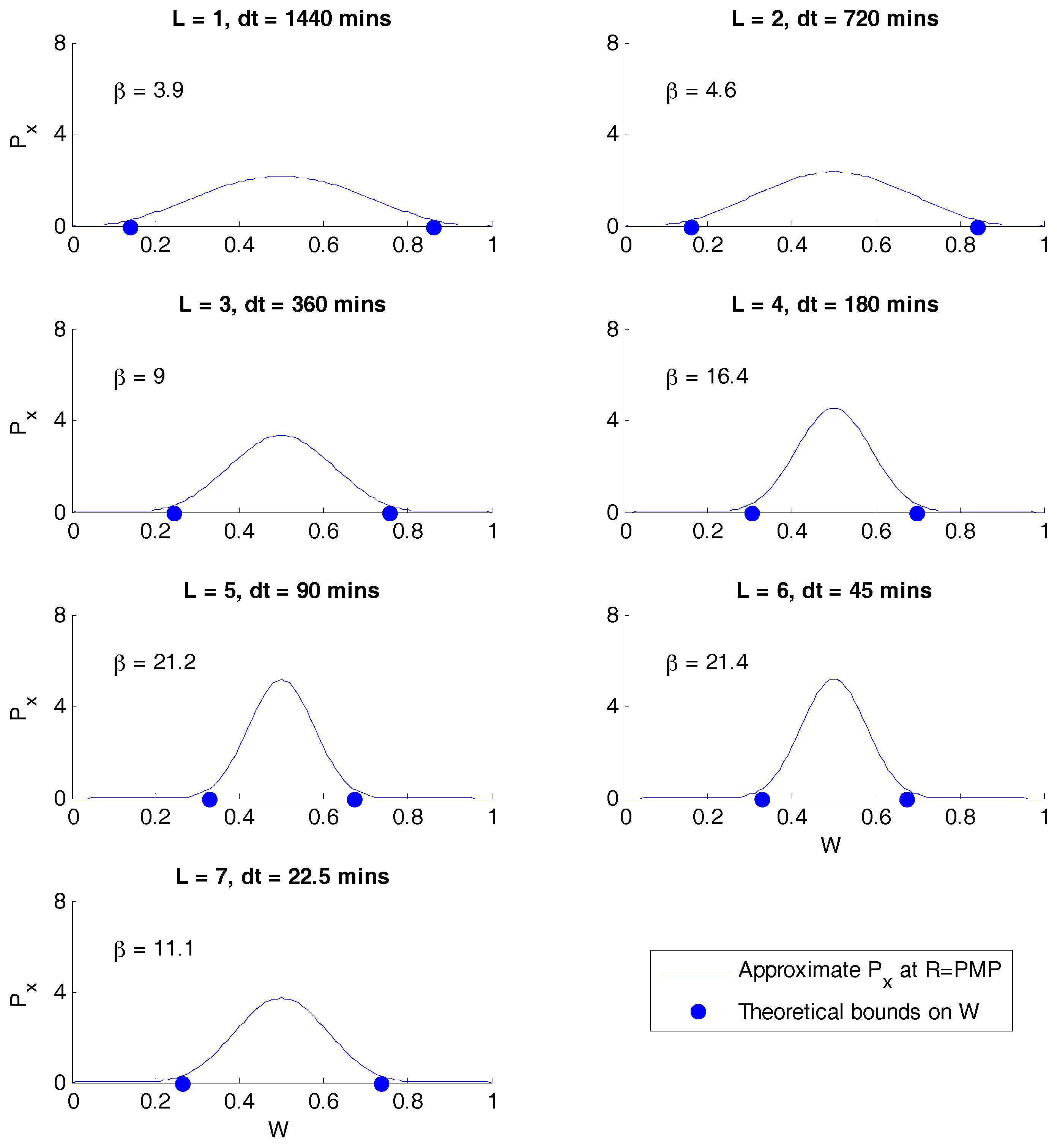
Figure 3 shows the Beta distributions corresponding to the estimate of
βPMP, illustrating the degree to which the theoretical bounds on
W are compromised.
Figure 4 shows the baseline model estimate of
β that is used in all three versions of the model and also the volume dependency of
β obtained from (10). Superimposed on these curves are the ‘observed’ values of
β estimated using the entire historical record, as previously explained for
P01. These ‘observed’ values indicate the errors that arise from using only the fitting period for estimation, most notably at
L = 1.
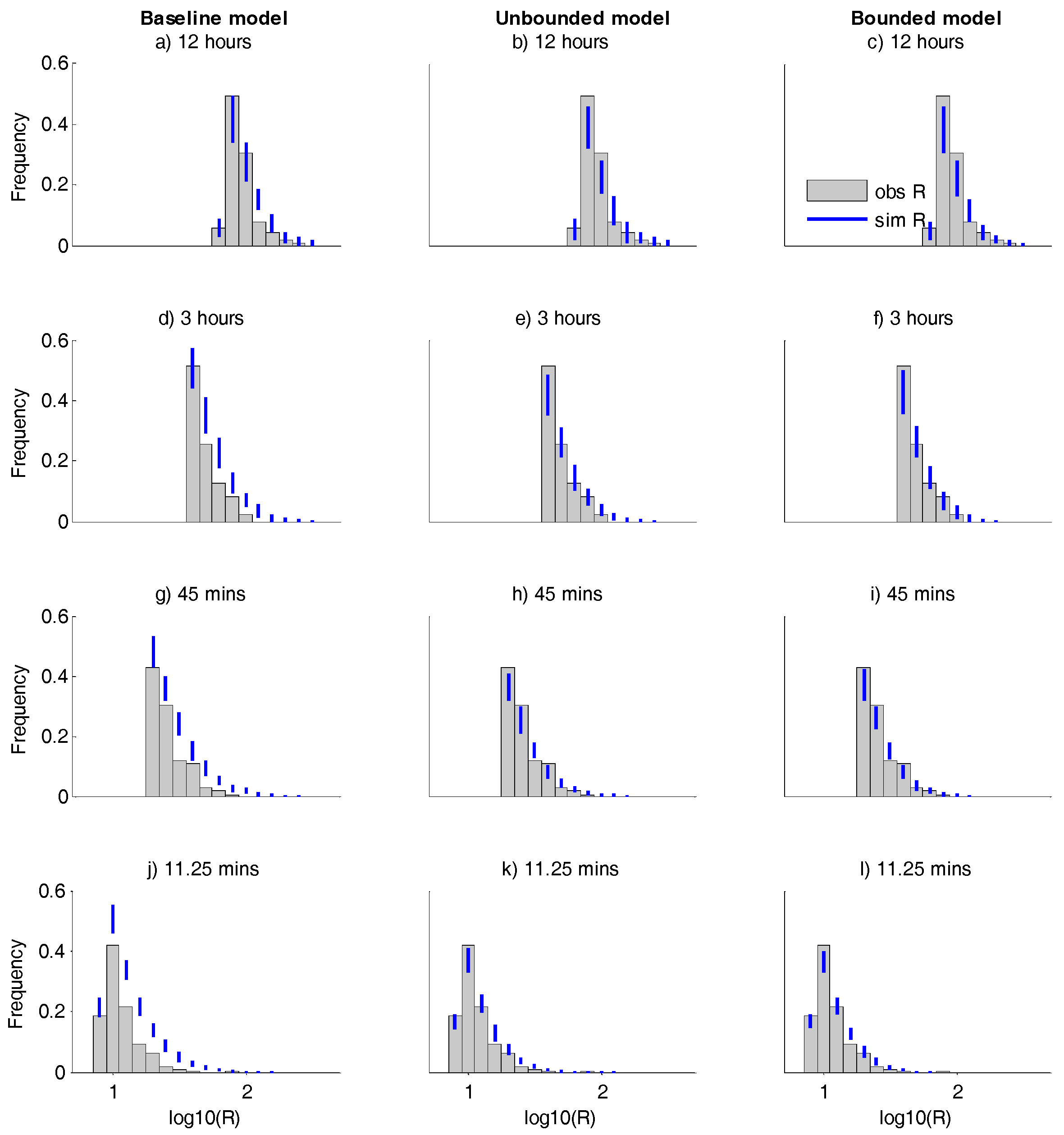
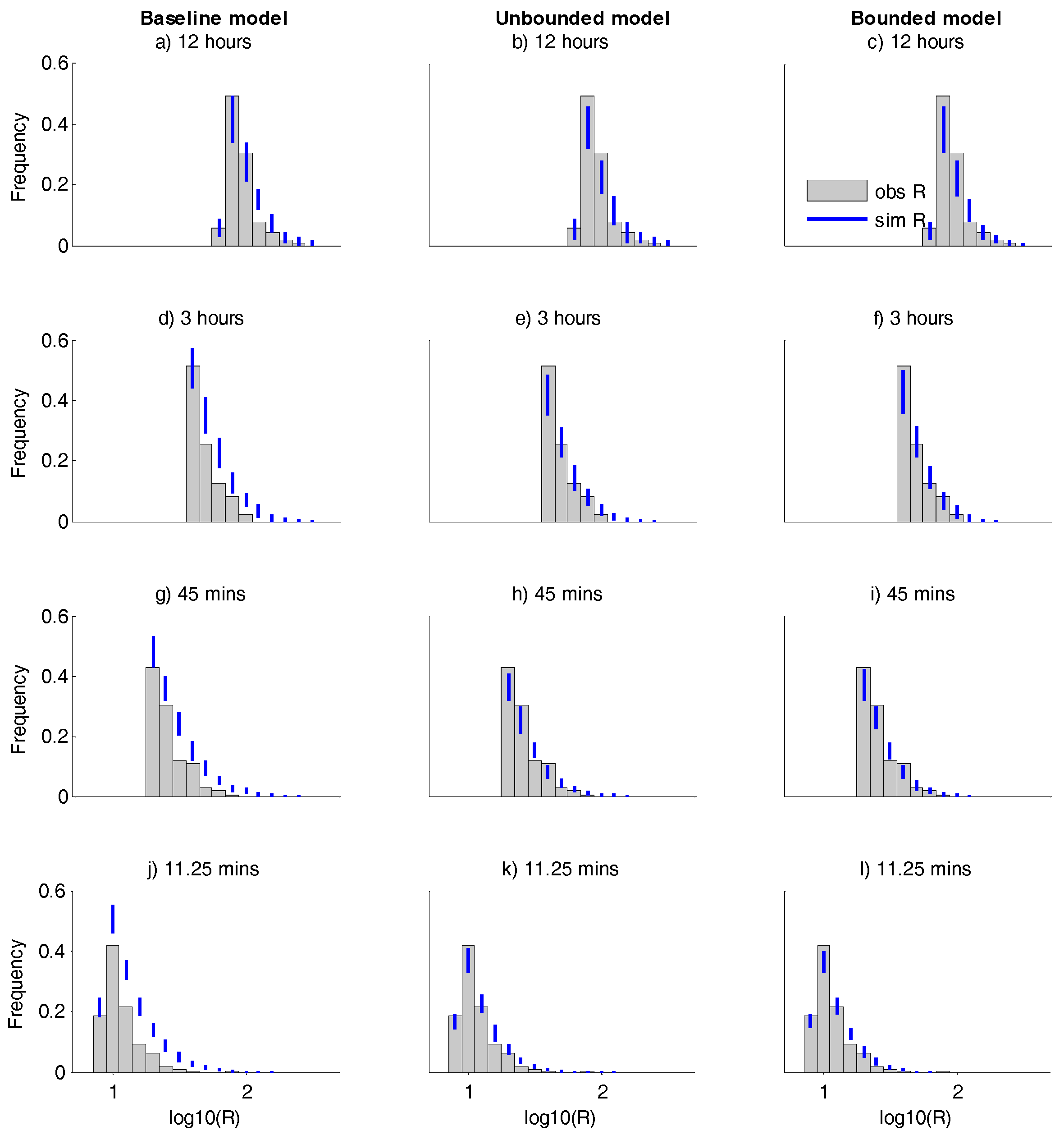
For the same three model baselines, unbounded and bounded,
Figure 5 compares the histograms of the observed and simulated extreme rainfall over the 1908–2015 period. The observed and the simulated results in
Figure 5 include only the
R values that are above
R99, and the frequencies are relative to the total number of included observed values. Therefore the differences in the shape and magnitude of the observed and simulated histograms can be used to visually assess the magnitude and frequency performance of the model. For the same set of observed and simulated extremes,
Table 4 compares the magnitude and frequency metrics.
Table 4 also shows the means and standard deviations of the results over the 100 realisations, which, for practical purposes, were the same between models so are only given once.
5. Discussions
This paper explores the concepts of volume bounded temporal rainfall disaggregation. The case study illustrates that using logistic regression to incorporate volume dependency (the unbounded model) can allow more accurate simulation of high extremes than can be achieved using a baseline model that uses constant parameters (
Figure 5). Although the volume dependent model tends to over-estimate the magnitudes and under-estimate the frequency (
Table 3) of extreme rainfall, this error is small compared to the baseline model error. A further small improvement is obtained by the bounded model, in which the volume dependency is forced to honour theoretically–based bounds derived from PMP estimates.
Although the unbounded and bounded models perform better than the baseline model in general, the results in
Figure 5 and
Table 4 show that the baseline model is better at predicting the frequency of extreme 12 h rainfall. This may be partly explained by
Figure 2, which shows that, at level 1, the logistic regression underestimates the
P01 values at log
10R > ~1.4, resulting in weaker disaggregation than observed. This error persists even if fitting the logistic regression to the entire record. This may be explained by diurnal convective processes that dominate wet season rainfall in Brisbane, whereby extreme values of daily rainfall are often concentrated in the latter half of the day. In other words, while in general higher volumes mean weaker disaggregation, this is not necessarily the case due to strong convective processes that dominate extremes in this case. As the time–interval decreases, this effect seems to become less important.
The errors at level 1 lead to the recognition that the better overall performance of the unbounded and bounded models is because their level 1 errors are less compounded by level 2 to 7 errors; indeed there is some recovery in performance. The ‘recovery’ is not unexpected as the volume dependence included in these models requires that, if rainfall volumes at level L + 1 tend to be underestimated due to a weak disaggregation at level L, a stronger disaggregation will apply at level L + 1. Therefore, to some extent, the cascade has in–built error correction. Further insight into the role of the level 1 error is gained by removing level 1 and instead making the level 3 to 7 results conditional on the observed 12 h rainfall. This improved performance generally, as it should, except for the number of extremes simulated for the 11.25 min interval, which increased from the original bounded model result of 688 to 733. This further highlights the relevance of how errors compound and cancel over levels, with improved performance at level L not necessarily improving performance at the higher levels. However, when observed R are used as inputs to each disaggregation level, while the performances at levels 2 to 7 were better for all models, the relative performances between models do not change appreciably.
Another point of discussion is whether changes to the baseline model may improve its relative performance. The baseline model is simple, with only two parameters per level, whereas the new unbounded and bounded models both have three parameters estimated from the observations per level. In [
6], a number of alternative MDRC models were tested on the same case study using up to 16 parameters per level without including volume dependency. The improvements in extreme value performance using these models are marginal compared with the improvement using the new models. Nevertheless, there may be alternatives to the Beta distribution that lead to more identifiable volume dependencies and improved extreme value performance. For example, differences between the observed and modelled distributions in
Figure 5b,c may stem partly from the limitations of the standard Beta distribution [
13]. However, using an alternative distribution with more than one parameter would create further challenges for determining the volume dependency.
The results of the sensitivity analysis (
Table 2) show that using a more extreme range of rainfall volumes (upper 2nd percentile instead of the original upper quartile) for the estimation of the baseline values of
P01 and
β deteriorated the performance for all models. This illustrates that restricting the data used for model fitting to a more relevant range of volumes is not useful here due to the lower number of observations and hence higher variance in the baseline estimates of
P01 and
β. Reducing the PMP estimates to the HNPR values caused the bounded model to substantially underestimate the number of extremes above the threshold
R99. This sensitivity confirms that the asymptote defined by (4) is an active constraint and hence that reasonable approximations of PMPs are valuable. Since in practice there is considerable uncertainty in PMP estimates [
9,
11], applications of the bounded approach to the PMP should ideally be described by a probability distribution function; for example, the approach described by [
14] could be adapted. Changing the arbitrary values of
βPMP and
M as described in
Table 2 also affected the simulated magnitudes and frequencies as expected, although to a relatively small extent.
Several attempts were made to improve upon the bounded model of
β. Although this model was considered reasonable, using the standard Beta distribution over all possible values of
R allowed the theoretical constraint of (3) to be compromised in the range
PMPL+1 < RL < PMPL. An alternative translation of (3), which would avoid this compromise, would be scaling the Beta distribution so that it’s upper and lower bounds are equal to the theoretical bounds calculated from (3). The
β parameter could then, in the absence of a better estimate, be fixed at zero (a uniform distribution) or at the baseline model value. An alternative adjustment would be to maintain the standard Beta distribution but to curtail it so that the probability density of
W is zero outside the theoretical bounds defined by (3). However, forcing the model to honour (3) is not useful for the case study because a very small number of the observed
R are high enough (
RL > PMPL+1) to be directly affected by (3), and for each of these the probability of an unrealistic sample of
W is small. Rather, the value of (3) is supporting the extrapolation of
β in the range
ML < RL < PMPL+1. Another subjectivity in developing the bounded model of
β is the arbitrary value of
M, at which the model transitions from the constant baseline value of
β to volume dependence.
M can be eliminated from the model by applying (10) over the full range of
R, in which case
c can be fitted to the observations using maximum likelihood and
d can be fixed by still requiring (10) to pass through the point [
PMP,
βPMP]. This produces a reasonable volume dependency over the higher ranges of
R, similar to the results in
Figure 4; however it only matches the performance of the original bounded model in the less relevant case that the observed values of
R are used as inputs to every disaggregation level.
From the exploration of alternative bounded models of β, it is concluded that the ‘bounded’ concept raises some theoretical challenges due to the facts that (1) Px must transition, as the PMP value is approached, from a distribution function bounded by the values W = 0 and W = 1 to a distribution function with narrower bounds and (2) sufficient observations of extremes do not exist to examine the transition. Therefore a reasonable judgment of how the theoretical bounds on W should be used to bound Px as R tends to PMP was necessary in the case study and seems likely to be necessary in future applications. It is possible that pooling extremes from a large number of sites, which adhere to the same volume dependency model, will increase the number of extreme value observations and hence permit a reduced level of subjectivity in developing the model.
Previous work on this case study [
6] found that the baseline model parameters
P01 and
β can be generalised over the seven disaggregation levels using linear regression. This is potentially advantageous for generating rainfall at unobserved time–resolutions; for example, extrapolating the regression would provide eighth and ninth levels of disaggregation to generate rainfall at approximately 5.6 and 2.8-min intervals. Furthermore, reducing the number of parameters by generalising over levels may assist with the regionalisation of the model. To transfer these potential benefits to the improved, volume–dependent models would require the parameters
a and
b to be generalised over levels as well as the baseline value of
β (recalling that parameters
c and
d can then be fixed given
βPMP and
M).
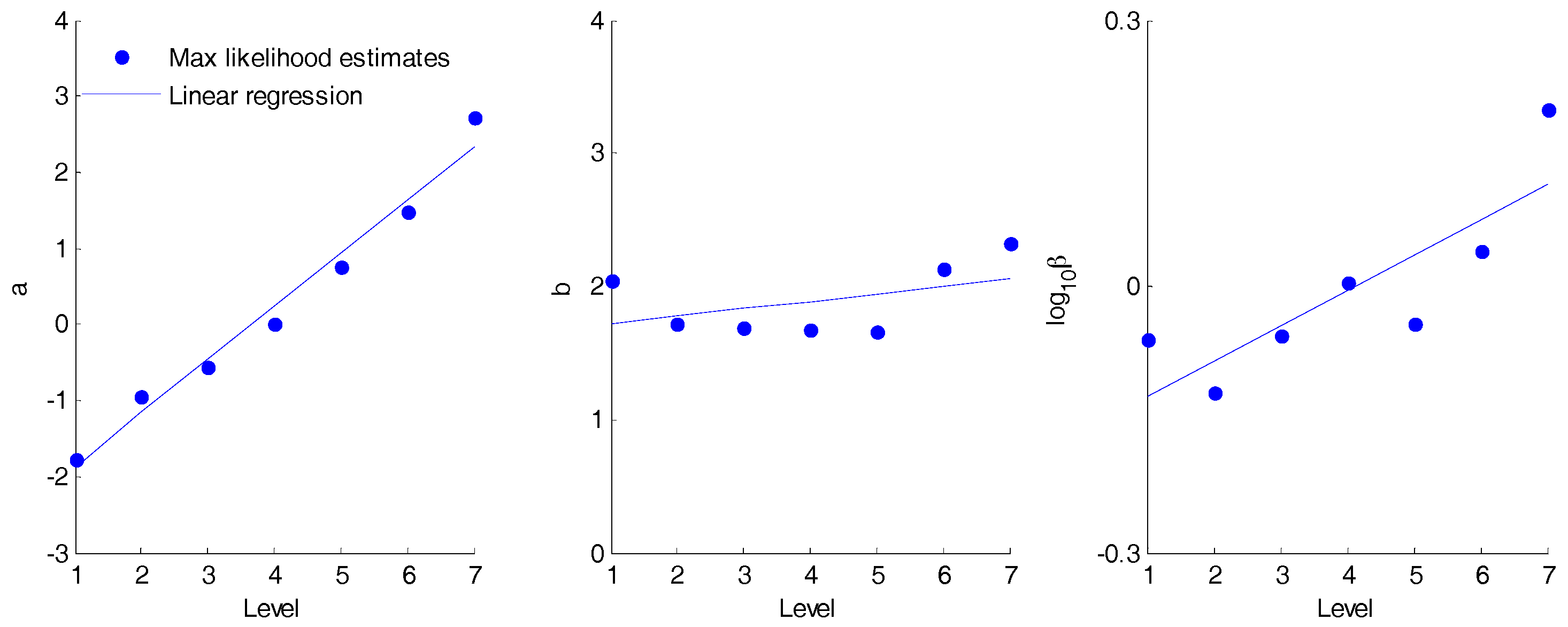
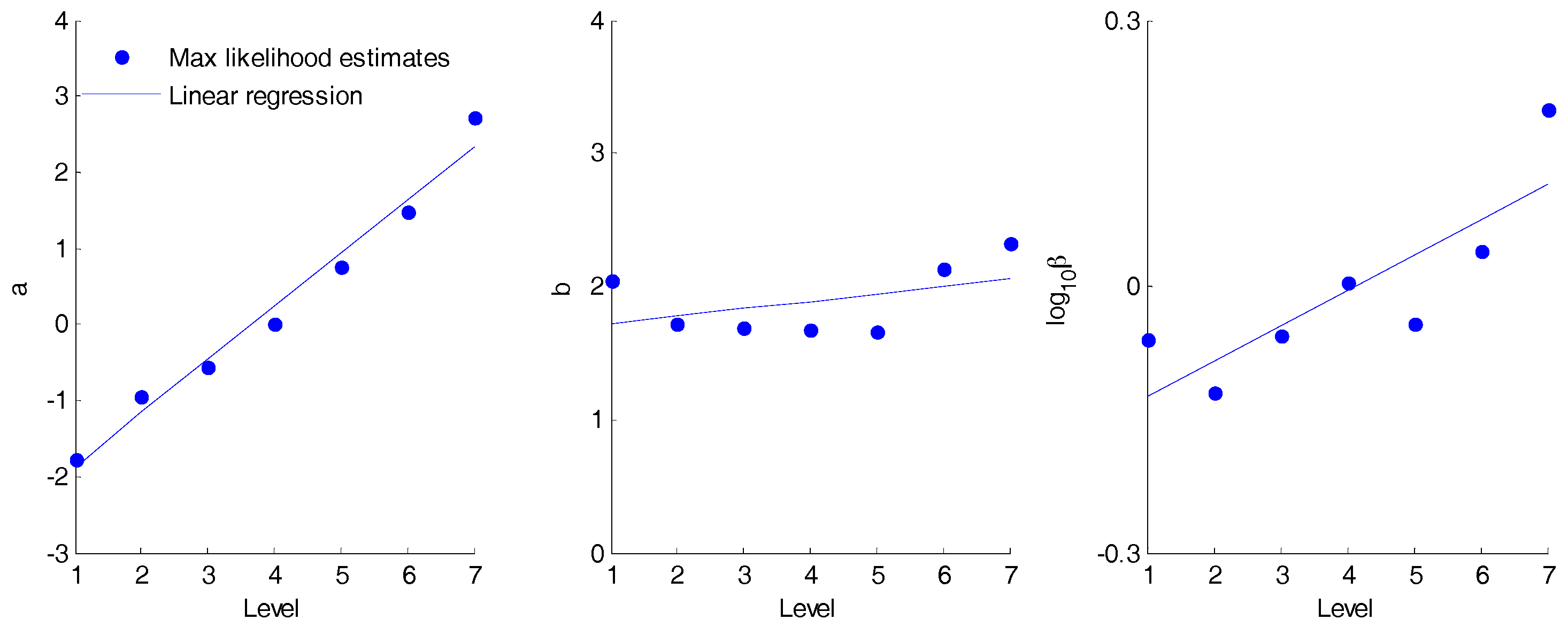
Figure 6 plots the estimates of log
10β for the baseline model against
L and the estimates of
a and
b for the bounded model against
L. More or less the same results for
a and
b are obtained for the unbounded model.
From
Figure 6, parameter
b is taken to be constant and
a is taken to be linearly dependent on
L (
R2 = 0.98). There is much less of a relationship between level and log
10β than previously found by [
6], which must be due to the different fitting periods used (here, the 12 years with fewest extremes; there the 12 available years between 1987 and 2015). It seems that either using a lower range of volumes for fitting the model or relying more on the older pluviograph record rather than more modern tipping bucket data produces less well–behaved
β values. To generalise the volume dependency of
β, a generalised estimate of the point of transition,
M, is also required. For the purpose of illustrating the potential for generalising the model, an arbitrary value,
M =
PMP/10, is adopted. The generalised volume dependencies are included in
Figure 3 and
Figure 5. As should be expected, overall, the generalised models are less consistent with the observations than the originals. However, for some levels, the generalisation is actually better, presumably because in these cases the regression smooths out random errors in the original estimates; for example, errors associated with the relatively short fitting period used. The model output statistics for the generalised bounded models, included in
Table 4, show a slightly reduced performance compared to the original bounded model but still a considerably better performance than the baseline model. In summary, there is evidence that scaling relationships exist in the bounded and unbounded models, and it is speculated that these are useful for extending the application to unobserved time intervals and regionalisation.
As a final point of discussion, although this paper has focused entirely on the MDRC type of model, the principle that rainfall disaggregation can be bounded by the consideration of PMPs could be applied more broadly. This may include, in the context of climate change impacts on rainfall, deriving the volume-dependence of change factors and their PMP-derived bounds in much the same way as
Figure 4 has been constructed, noting that the consideration of climate change may require the PMPs to be treated as non-stationary.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}