Factor Analysis and Estimation Model of Water Consumption of Government Institutions in Taiwan




Abstract
:1. Introduction
2. Materials and Methods
2.1. Water Consumption Impact Factors
2.2. Regression Model
2.3. Artificial Neural Networks (ANNs)
2.4. Model of the Current Study
2.5. Model Efficiency Indexes
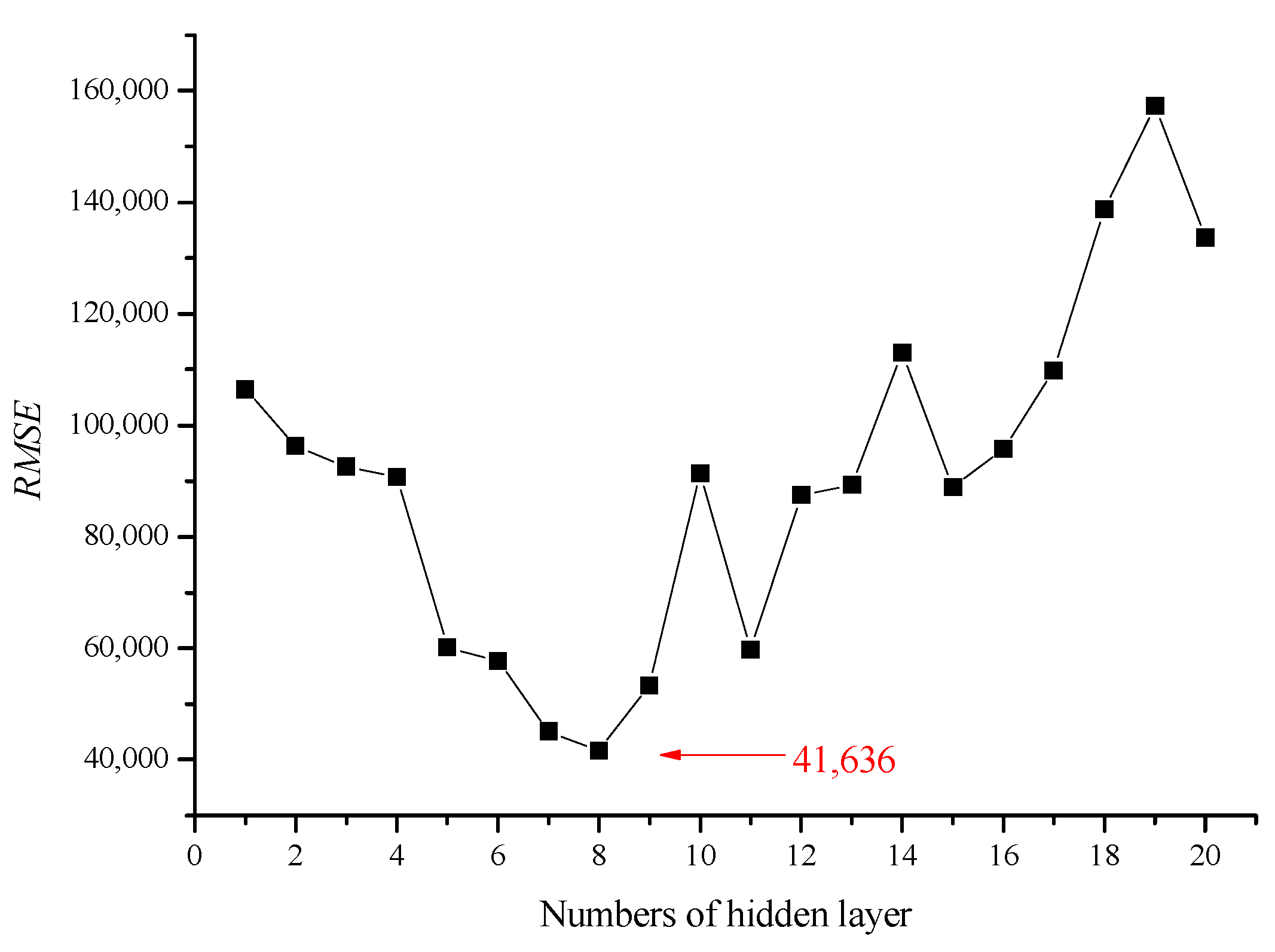
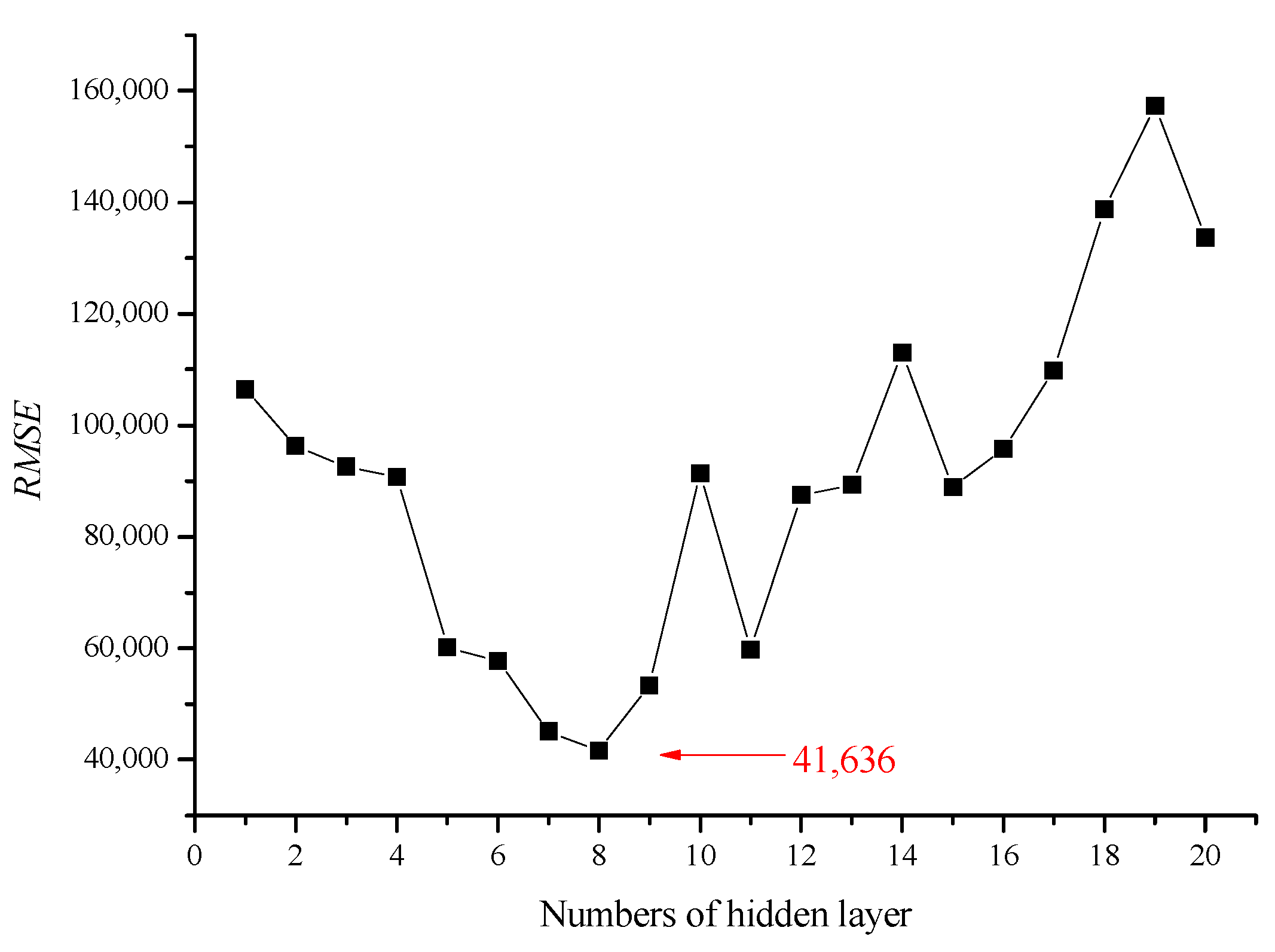
3. Results
4. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Peng, T.R.; Lu, W.C.; Chen, K.Y.; Zhan, W.J.; Liu, T.K. Groundwater-recharge connectivity between a hills-and-plains’ area of western Taiwan using water isotopes and electrical conductivity. J. Hydrol. 2014, 517, 226–235. [Google Scholar] [CrossRef]
- Chen, Y.C.; Chang, K.T.; Lee, H.Y.; Chiang, S.H. Average landslide erosion rate at the watershed scale in southern Taiwan estimated from magnitude and frequency of rainfall. Geomorphology 2015, 228, 756–764. [Google Scholar] [CrossRef]
- Shiau, J.T.; Huang, W.H. Detecting distributional changes of annual rainfall indices in Taiwan using quantile regression. J. Hydro-Environ. Res. 2014, 9, 1053–1069. [Google Scholar] [CrossRef]
- Cheng, F.Y.; Jian, S.P.; Yang, Z.M.; Yen, M.C.; Tsuang, B.J. Influence of regional climate change on meteorological characteristics and their subsequent effect on ozone dispersion in Taiwan. Atmos. Environ. 2015, 103, 66–81. [Google Scholar] [CrossRef]
- Chou, K.T. The public perception of climate change in Taiwan and its paradigm shift. Energy Policy 2013, 61, 1252–1260. [Google Scholar] [CrossRef]
- Keshavarzi, A.R.; Sharifzadeh, M.; Kamgar Haghighi, A.A.; Amin, S.; Keshtkar, S.; Bamdad, A. Rural domestic water consumption behavior: A case study in Ramjerd area, Fars province, I.R. Iran. Water Res. 2006, 40, 1173–1178. [Google Scholar] [CrossRef] [PubMed]
- Romano, M.; Kapelan, Z. Adaptive water demand forecasting for near real-time management of smart water distribution systems. Environ. Model. Softw. 2014, 60, 265–276. [Google Scholar] [CrossRef]
- Thevs, N.; Nurtazin, S.; Beckmann, V.; Salmyrzauli, R.; Khalil, A. Water Consumption of Agriculture and Natural Ecosystems along the Ili River in China and Kazakhstan. Water 2017, 9, 207. [Google Scholar] [CrossRef]
- Angelakis, A. Evolution of rainwater harvesting and use in Crete, Hellas, through the millennia. Water Sci. Technol. 2016, 16, 1624–1638. [Google Scholar] [CrossRef]
- Shrestha, S.; Aihara, Y.; Bhattarai, A.P.; Bista, N.; Rajbhandari, S.; Kondo, N.; Kazama, F.; Nishida, K.; Shindo, J. Dynamics of Domestic Water Consumption in the Urban Area of the Kathmandu Valley: Situation Analysis Pre and Post 2015 Gorkha Earthquake. Water 2017, 9, 222. [Google Scholar] [CrossRef]
- Bakker, M.; van Duist, H.; van Schagen, K.; Vreeburg, J.; Rietveld, L. Improving the performance of water demand forecasting models by using weather input. Procedia Eng. 2014, 70, 93–102. [Google Scholar] [CrossRef]
- Chen, Z.; Ngo, H.H.; Guo, W.; Wang, X.C.; Miechel, C.; Corby, N.; Listowski, A.; O’Halloran, K. Analysis of social attitude to the new end use of recycled water for household laundry in Australia by the regression models. J. Environ. Manag. 2013, 126, 79–84. [Google Scholar] [CrossRef] [PubMed]
- Carvalho, P.; Marques, R.C.; Berg, S. A meta-regression analysis of benchmarking studies on water utilities market structure. Util. Policy 2012, 21, 40–49. [Google Scholar] [CrossRef]
- Candelieri, A. Clustering and Support Vector Regression for Water Demand Forecasting and Anomaly Detection. Water 2017, 9, 224. [Google Scholar] [CrossRef]
- Lin, Y.; Li, Q.; Li, X.; Ji, K.; Zhang, H.; Yu, Y.; Song, Y.; Fu, Y.; Sun, L. Pyrolysates distribution and kinetics of Shenmu long flame coal. Energy Convers. Manag. 2014, 86, 428–434. [Google Scholar] [CrossRef]
- Trichakis, I.C.; Nikolos, I.K.; Karatzas, G. Artificial neural network (ANN) based modeling for karstic groundwater level simulation. Water Resour. Manag. 2011, 25, 1143–1152. [Google Scholar] [CrossRef]
- Afan, H.A.; El-Shafie, A.; Yaseen, Z.M.; Hameed, M.M.; Mohtar, W.H.M.W.; Hussain, A. ANN based sediment prediction model utilizing different input scenarios. Water Resour. Manag. 2015, 29, 1231–1245. [Google Scholar] [CrossRef]
- Zangooei, H.; Delnavaz, M.; Asadollahfardi, G. Prediction of coagulation and flocculation processes using ANN models and fuzzy regression. Water Sci. Technol. 2016, 74, 1296–1311. [Google Scholar] [CrossRef] [PubMed]
- Huang, H.X.; Li, J.C.; Xiao, C.L. A proposed iteration optimization approach integrating backpropagation neural network with genetic algorithm. Expert Syst. Appl. 2015, 42, 146–155. [Google Scholar] [CrossRef]
- Lan, Y.; Soh, Y.C.; Huang, G.B. Constructive hidden nodes selection of extreme learning machine for regression. Neurocomputing 2010, 73, 3191–3199. [Google Scholar] [CrossRef]

{kind=link}
| Year | 2007 | 2008 | 2009 | 2010 | 2011 | 2012 | 2013 | 2014 | 2015 | 2016 | Average in 10 Years |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Per capita domestic water consumption (Liter/day) | 265 | 261 | 258 | 259 | 258 | 257 | 259 | 264 | 263 | 265 | 260 |
| Primary Categories | Minor Categories | Primary Categories | Minor Categories | ||||||
|---|---|---|---|---|---|---|---|---|---|
| No. | Subject | No. | Title | Data Amount | No. | Subject | No. | Title | Data Amount |
| 1 | Perform official institution | 01 | Executive branch | 186 | 3 | Investigate training institution | 01 | Research institution | 4 |
| 02 | Local government | 20 | 02 | Training institution | 2 | ||||
| 03 | Institution belong local government | 114 | 03 | Vocational training center | 7 | ||||
| 2 | Specialized government agencies | 01 | Tax administration institution | 35 | 04 | Other kinds of training center | 4 | ||
| 02 | Engineering department | 13 | 4 | Medical treatment institution | 01 | Medical treatment department | 39 | ||
| 03 | Court | 11 | 02 | Nursing house | 18 | ||||
| 04 | Security department | 25 | 5 | School | 01 | National school of technology | 10 | ||
| 05 | Police office | 52 | 02 | National university | 15 | ||||
| 06 | Library | 40 | 03 | Armed and policed school | 118 | ||||
| 07 | Citizen delegate center | 37 | 04 | National senior high school | 282 | ||||
| 08 | District office | 111 | 05 | Public junior high school | 933 | ||||
| 09 | Household registration office | 120 | 06 | Public elementary school | 5 | ||||
| 10 | Hygiene institution | 124 | 07 | Preschool | 38 | ||||
| 11 | Land administration | 48 | 08 | Special education school | 14 | ||||
| 12 | Election committee | 9 | 6 | Other kinds | 01 | Retail market | 16 | ||
| 13 | Weather bureau | 9 | 02 | Gymnasium | 7 | ||||
| 14 | Accident investigation committee | 2 | 03 | Prison | 30 | ||||
| 15 | Veterans service office | 15 | 04 | Agricultural institution | 9 | ||||
| 16 | Airport | 9 | 05 | Cleaning squad | 20 | ||||
| 17 | Funeral institution | 2 | 06 | Landfill | 1 | ||||
| 18 | Other kinds of specialized institution | 13 | 07 | Radio | 3 | ||||
| 19 | Fire bureau | 11 | 08 | Other kinds of management institution | 10 | ||||
| 20 | Police force | 4 | 09 | Preparatory office | |||||
| 21 | Cultural center | 7 | 0 | ||||||
| 22 | Museum | 9 | |||||||
| Code | Independent Variable | Code | Independent Variable |
|---|---|---|---|
| v1 | Major institution categories | v12 | Usage of simple faucet water |
| v2 | Minor institution categories | v13 | Usage of groundwater |
| v3 | Floor space | v14 | Usage of rainwater |
| v4 | Irrigate area | v15 | Usage of reclaimed water |
| v5 | Number of staff | v16 | Usage of other kinds of water |
| v6 | Number of visitor | v17 | Unit of faucet water demand |
| v7 | Number of accommodation | v18 | Cost of faucet water |
| v8 | With kitchen | v19 | Simple faucet water demand |
| v9 | With swimming pool | v20 | Groundwater demand |
| v10 | Number of water kinds | v21 | Rainwater demand |
| v11 | Usage of faucet water | v22 | Reclaimed water demand |
| Data | Model | MAD | RMSE | RTIC | CC | CE |
|---|---|---|---|---|---|---|
| Full adoption | Linear regression | 9,020.42 | 92,010.83 | 0.7153 | 0.6657 | 0.4431 |
| Non-linear regression | 6,890.49 | 31,581.66 | 0.7058 | 0.6917 | 0.4580 | |
| ANN | 5,591.42 | 15,936.16 | 0.3561 | 0.9285 | 0.8620 | |
| Exclude outlier of qA | Linear regression | 6,547.07 | 22,858.52 | 0.6693 | 0.7098 | 0.5037 |
| Non-linear regression | 5,172.72 | 24,286.02 | 0.7111 | 0.6985 | 0.4398 | |
| ANN | 4,652.40 | 13,857.35 | 0.4057 | 0.9043 | 0.8176 | |
| Exclude outlier of qN | Linear regression | 5,633.69 | 16,870.19 | 0.5967 | 0.7730 | 0.5973 |
| Non-linear regression | 4,453.26 | 18,383.52 | 0.6503 | 0.7375 | 0.5219 | |
| ANN | 3,734.64 | 8,083.06 | 0.2859 | 0.9528 | 0.9076 | |
| Exclude outlier of qAN | Linear regression | 9,033.15 | 31,288.56 | 0.6931 | 0.6879 | 0.4732 |
| Non-linear regression | 7,013.14 | 31,088.85 | 0.6887 | 0.7201 | 0.4799 | |
| ANN | 6,867.00 | 21,605.54 | 0.4786 | 0.8662 | 0.7488 |
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Huang, A.-C.; Lee, T.-Y.; Lin, Y.-C.; Huang, C.-F.; Shu, C.-M. Factor Analysis and Estimation Model of Water Consumption of Government Institutions in Taiwan. Water 2017, 9, 492. https://doi.org/10.3390/w9070492
Huang A-C, Lee T-Y, Lin Y-C, Huang C-F, Shu C-M. Factor Analysis and Estimation Model of Water Consumption of Government Institutions in Taiwan. Water. 2017; 9(7):492. https://doi.org/10.3390/w9070492
Chicago/Turabian StyleHuang, An-Chi, Tzong-Yeang Lee, Yu-Chen Lin, Chung-Fu Huang, and Chi-Min Shu. 2017. "Factor Analysis and Estimation Model of Water Consumption of Government Institutions in Taiwan" Water 9, no. 7: 492. https://doi.org/10.3390/w9070492
APA StyleHuang, A.-C., Lee, T.-Y., Lin, Y.-C., Huang, C.-F., & Shu, C.-M. (2017). Factor Analysis and Estimation Model of Water Consumption of Government Institutions in Taiwan. Water, 9(7), 492. https://doi.org/10.3390/w9070492