1. Introduction
As a case of precision agriculture, golf courses can be considered; this is called precision turfgrass in the literature [
1]. The huge dimensions of maintained turfgrass can be highlighted by the fact that it is estimated to cover 20 million ha in the USA [
2]. Spatio-temporal variation of soil, climate, plants and irrigation requirements are new challenges for precision agriculture and, above all, complex turfgrass sites [
3]. The irrigation of golf courses is a major concern in this crop maintenance, especially in a Mediterranean climate, both in the USA and in Europe [
4]. Golf courses in the southwestern United States are rapidly transitioning to reuse water (treated sewage effluent), as municipalities provide price incentives or mandate the use of reuse water for irrigation purposes [
5]. So, when reuse water of poor quality is used, as on golf courses in the arid southwestern United States, proper irrigation management is critical [
6], so greenkeepers should pay attention to irrigation strategies employed on reuse water irrigated golf courses to properly manage for higher nitrogen and salt loads. In Spain, it is estimated that water consumption for a golf course is 6.727 m
3/ha per year (this is due to the use of poor water, 2.5 dS/m) [
7].
Recently, unmanned aerial vehicles (UAVs) have provided a technological breakthrough with potential application in PA [
8,
9]. UAVs enable the quick production of cartographic material because they rely on different technologies, including cameras, video and GPS (Global Positioning System) [
10]. Even though an UAV has very restricted, heavy limitations, the minimization of the sensors during the last year is allowing the use of lighter vehicles, or the use of more features and sensors to a given platform [
11]. The opportunity offered by UAVs to observe the world from the sky provides the opportunity to study crops or turfgrass from an unusual viewpoint, allowing the visualization of details that cannot be easily seen from the ground [
12,
13].
Regarding agricultural purposes, aerial photography and colour video from UAVs presents an alternative to imagery from satellite and aerial platforms [
14], which are often difficult to obtain or expensive [
15]. Hassan et al. [
15] highlight the problem of conventional methods in the classification process, using high resolution images to overcome or minimize the difficulty in classification of the mixed pixel areas. A huge number of applications are achieved using UAVs to monitoring the health of crops through spectral information, e.g., stressed or damaged crops change their internal leaf structure which could be rapidly detected by a thermal infrared sensor [
16], therefore, this information is very important to detect stress such as water and nutrient deficiency in growing crops [
17].
On the other hand, texture measurements from images obtained by UAVs have been integrated in object-oriented classification, specifically in the classification and management of agricultural land cover [
18]. Likewise, there are studies that demonstrate the feasibility of using UAVs with thermal multispectral cameras for estimating crop water requirements, determining the ideal time for watering and saving water consumption without affecting productivity [
19,
20,
21]. Therefore, the technology is versatile and capable of producing very useful cartographic material for working with PA; the technique also facilitates working with aerial photography in addition to LIDAR (Laser Imaging Detection and Ranging) or video cameras [
22,
23]. UAVs on golf courses have been used for some time to monitor certain agronomic variables, such as nitrogen [
24], and should be considered as a valuable tool to monitor plant nutrition. In this case study, a rapid classification of turfgrass, among others, can play an important role to determine the water requirements of the different areas in order to plan water use.
For this purpose, information of important use can be analyzed and extracted from the images through the employment of powerful and automatic software. The object-based image classification techniques are applied not only for a high level of adaptability but automation as well. These techniques overcome some limitations of pixel-based classification by creating objects on the image through segmentation, using adjacent pixels with a spectral similarity [
25]. Subsequently, object-based classification combines spectral contextual information for these objects to perform more complex classifications. These techniques have been successfully applied to images obtained by UAVs in agricultural [
26,
27], aquatic ecosystems [
28] and urban [
29] areas.
Therefore, for golf courses, irrigation need planning, especially if it is employed in large areas, and has to be monitored more frequently than other crops. UAVs, due to low cost and fast response time, are the technology that allows this monitoring. A monitoring system based on the video image analysis and classification, will allow a real-time control of crops. Thus, this research is the first step to show the technical viability of real-time control of crops.
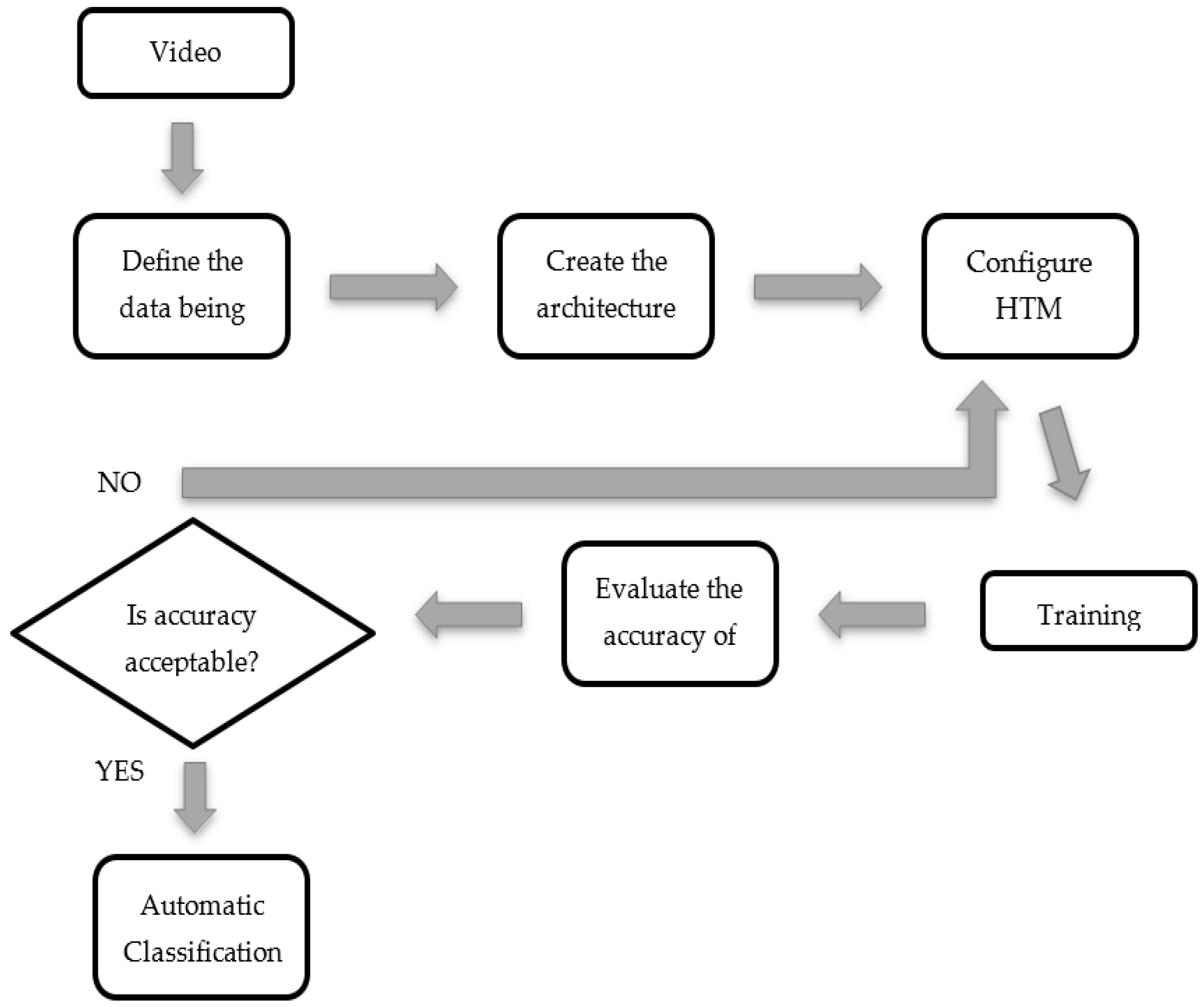
Thus, given the positive results previously obtained in the classification of images and given that the applications developed using the HTM algorithm are capable of analyzing video images, the objective of the current study is to develop a recognition methodology for golf courses in real-time using video images taken by an UAV based in a HTM for possible application in planning irrigation needs in order to maximize the water use efficiency and help to plan water requirements of reuse water.
3. Results and Discussion
During the experiments, internal network parameters that affect the learning process were modified, with the main goal of obtaining an optimal methodology for the recognition of video image patterns.
As mentioned above, the maxDist parameter defined the Euclidean distance between a known pattern and a new one, which is critical in the recognition and classification of patterns. An optimal value is essential for the successful creation of temporal groups during the training phase. A high value of the maxDist parameter contributes to the formation of fewer temporal groups, which could seriously impact the total recognition accuracy. On the other hand, a low value of the maxDist parameter generates a high number of temporal groups, which on top of the large memory demand, also results in poor recognition performance. To avoid these undesirable effects, it is very important to evaluate the optimal value for maxDist to achieve the best accuracy in the classifications.
In the original configuration, the
maxDist parameter has a starting value of 1, and the influence of this parameter on the overall accuracy values in the different classifications was studied. The
maxDist values (
Table 2) used in this experiment were defined based on the results of the initial studies performed [
41,
42,
45].
Table 2 presents the
maxDist parameter values with respect to the overall accuracy obtained for each of the test classifications. The maximum accuracy value was 96% and was obtained at an intermediate value for a
maxDist of 3. After this value, there is nearly a linear drop in the overall accuracy of the classifications. This drop is due to the number of coincidences detected during the training phase and the temporal groups formed.
For the previously mentioned optimal value of
maxDist, the Urban class was the class that obtained the largest number of misclassified frames, as seen in
Table 3, whereas the Grape class reached the highest accuracy of all the classes during classification.
Looking at the second and third columns of
Table 2, a large number of matches was not related to a greater overall accuracy of classification, as the number of matches in input patterns might be unrealistic, classifying new similar patterns in different categories. For example, if we set a low value for the parameter
maxDist, it is forcing the creation of many different, but similar, groups. So, several categories may correspond to the same pattern.
For the case with
maxDist of 3, which can be considered optimal, the number of matches obtained was 44.79. On the other hand, the effect of the value of the
maxDist parameter on the creation of temporal groups during the training phase of the network can be seen in
Table 2; the smaller the
maxDist parameter, the greater the number of temporal groups was obtained, leading similar patterns to be classified in different classes. Conversely, increasing the value of the
maxDist parameter reduces the formation of temporal groups, an effect that is not conducive in any way to obtaining an optimal accuracy in the classification, as the images of wineries and images of forest areas are classified in the same category (
Table 4). For the case with the optimal
maxDist value of 3, the number of temporal groups obtained was 20.
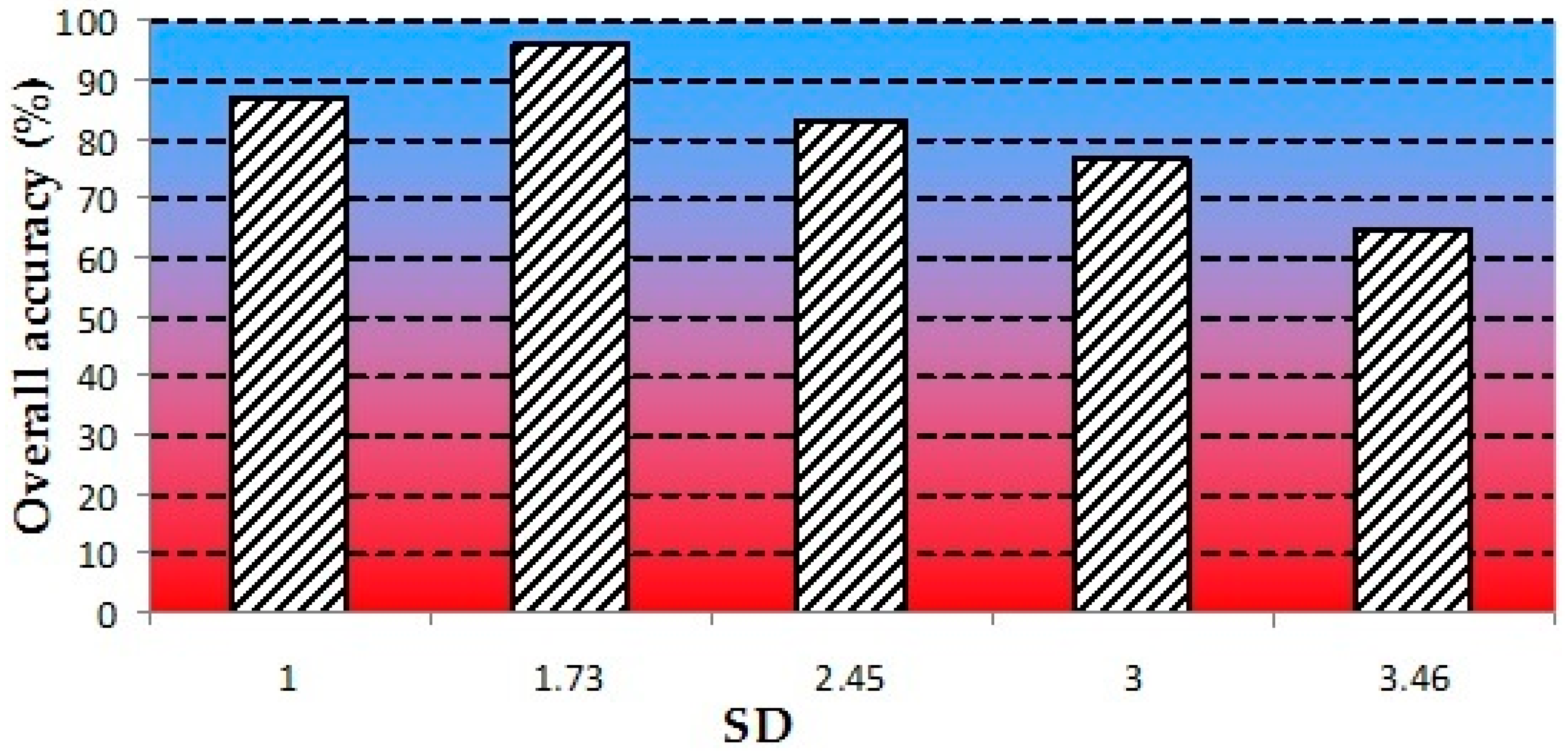
The effect of the SD parameter on the accuracy of the classification was verified. This parameter is calculated as the square root of the maxDist. This value is a reasonable starting value for SD because the distances between the matches are calculated as the square of the Euclidean distance instead of the normalized Euclidean distance.
Figure 8 presents the overall accuracy values obtained for different
SD values. Similar to the
maxDist parameter, there is growth in the overall accuracy value until it reaches a maximum of 96% for an
SD value of 1.73. Smaller
SD parameter values cause high beliefs to be assigned only to matches that are very close to the inferred pattern. Conversely, when using lower
SD values, between 1 and 1.73, all of the matches receive high belief values independent of their distance to the inferred pattern.
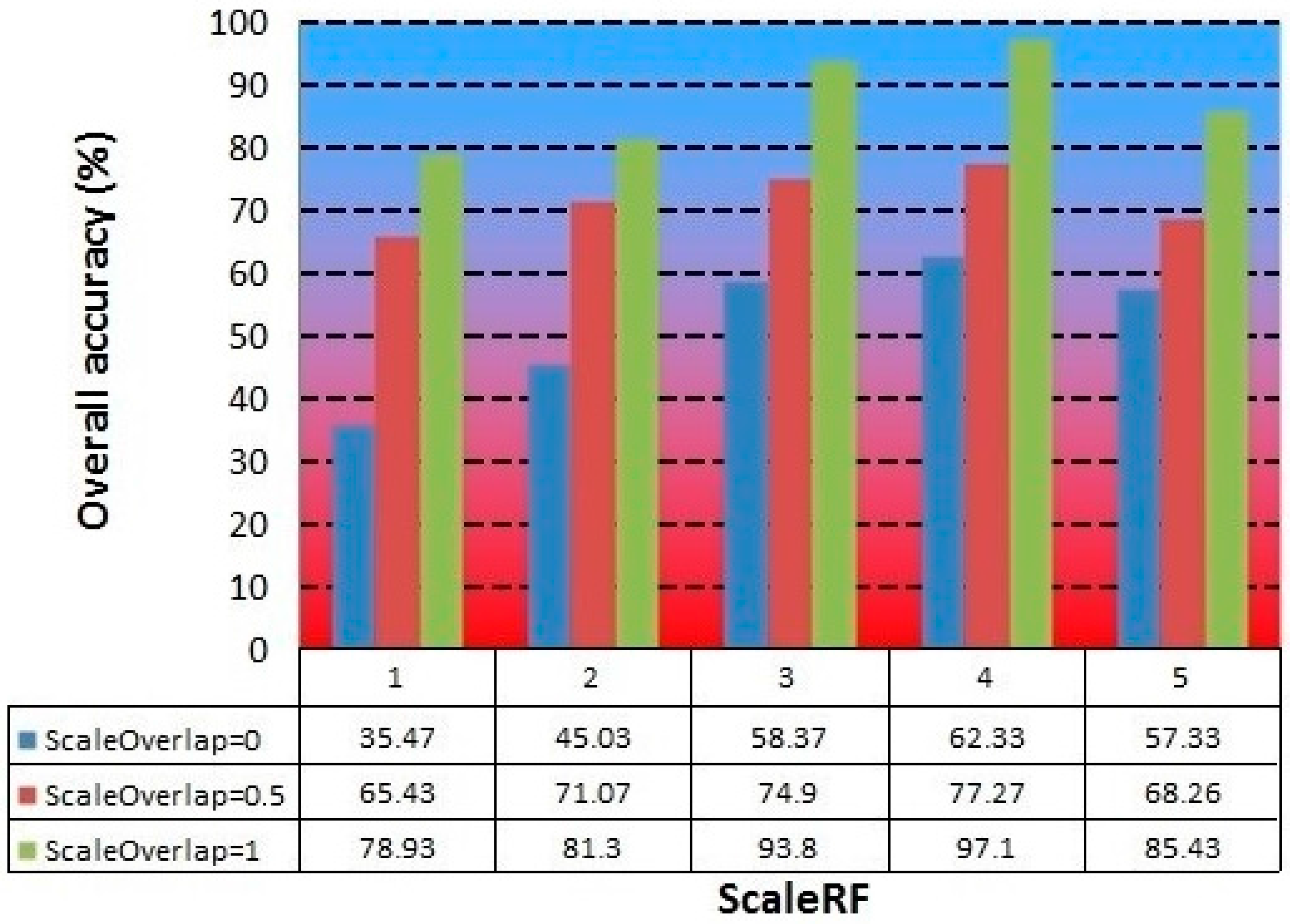
Based on the optimal maxDist and SD values previously discussed, we studied the effect of the ScaleRF and ScaleOverlap parameters on the network training and overall accuracy obtained in the classification of the images.
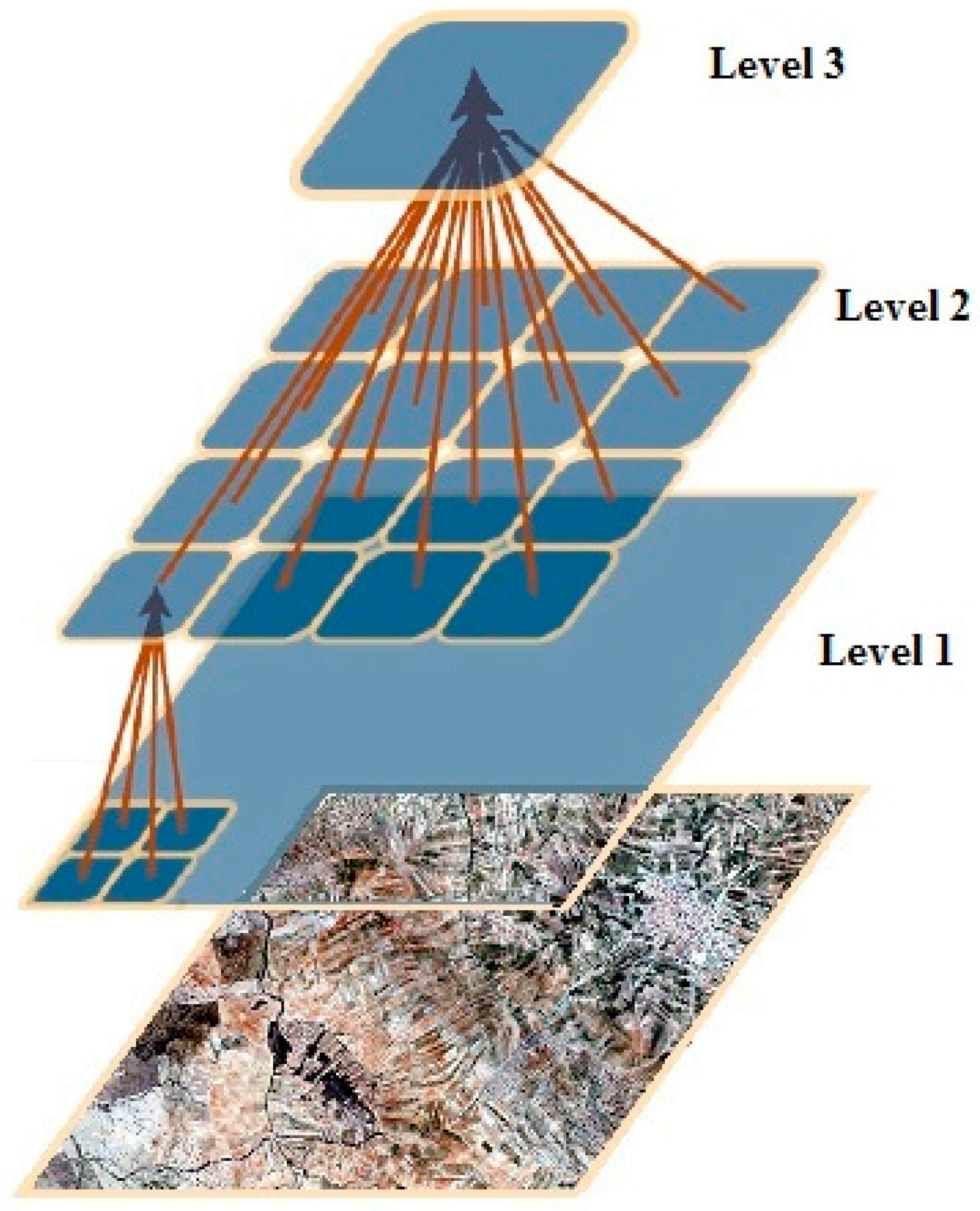
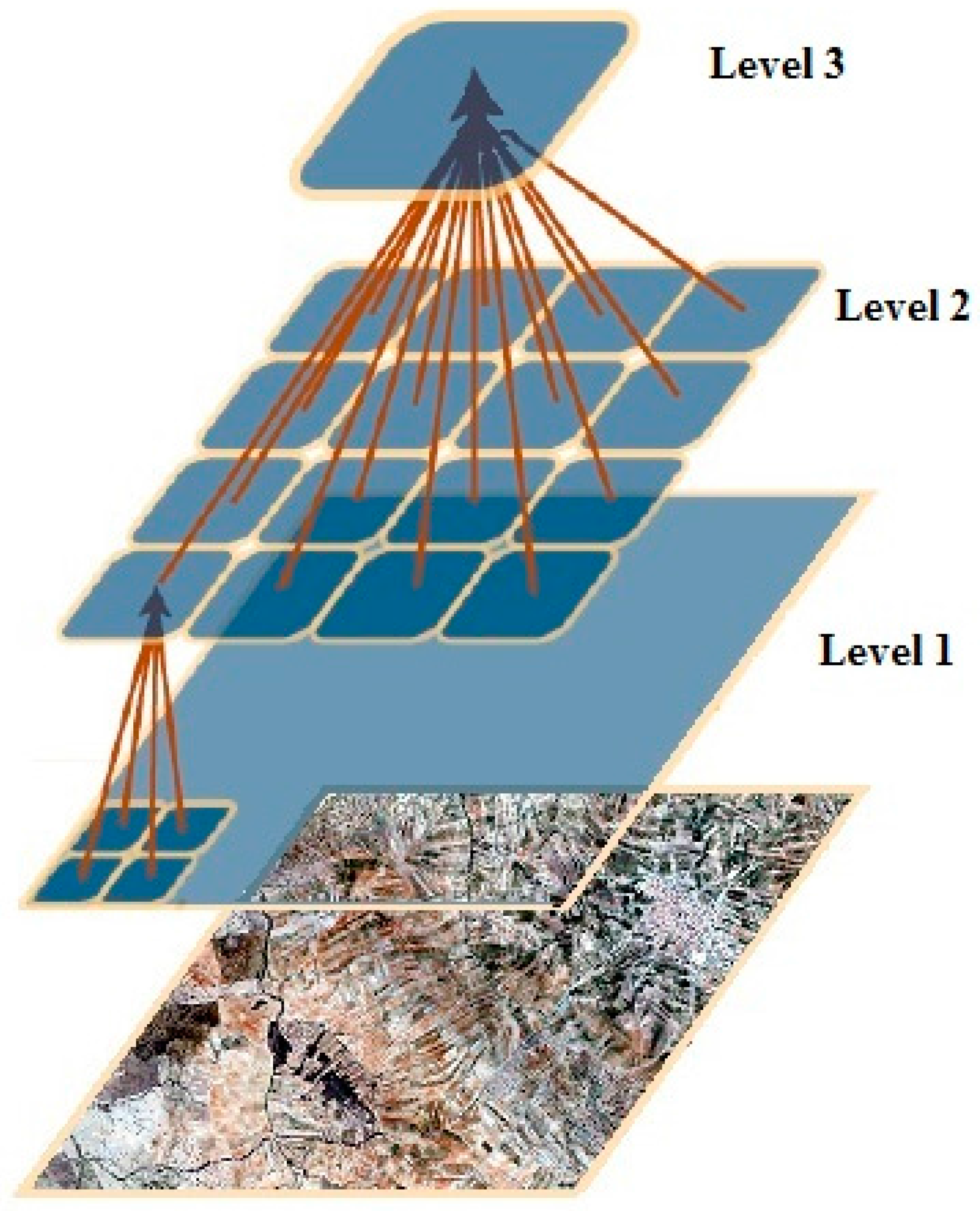
As mentioned above, the ScaleRF and ScaleOverlap parameters are related to the scale or the resolution of the images that are presented to the network; thus, by changing these parameters, we can vary the number of different scales of the image that are presented to the nodes and the overlap among them. This change is critical because changes in the image resolutions allow the network to extract patterns of the same image in different levels to create invariant representations (or models of stored patterns) used to classify new images.
The basic network starts from intermediate values of
ScaleOverlap and
ScaleRF (1 and 1, respectively).
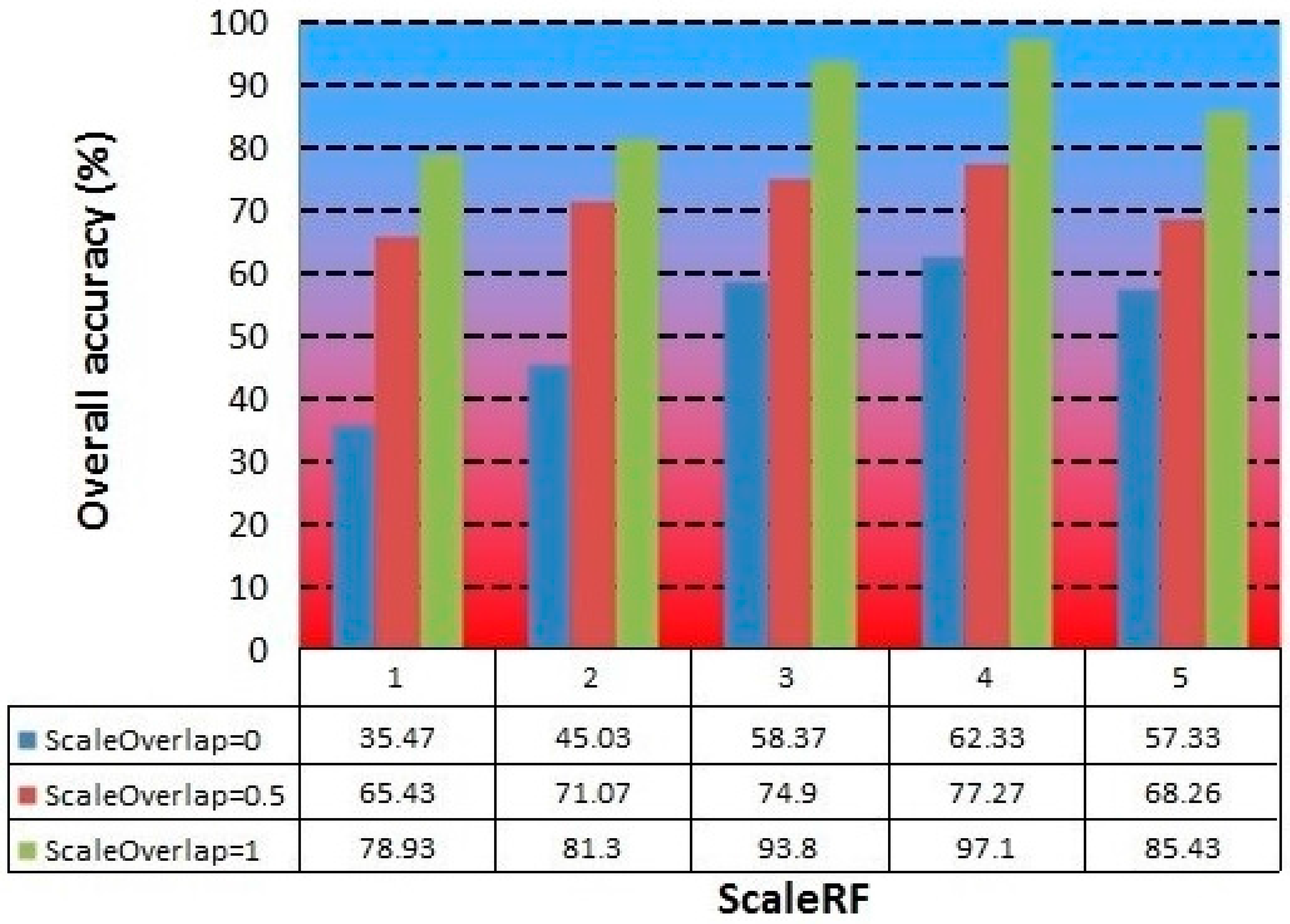
Figure 9 presents a bar chart in which the
ScaleOverlap and the
ScaleRF parameters are related to the overall accuracy for each case. The highest overall accuracy (97.1%) was obtained for a value of 4 for the
ScaleRF parameter and 1 for the
ScaleOverlap. The worst results were obtained for a
ScaleOverlap parameter value of 0; this value creates no spatial overlap among the input patterns, worsening the training stage in the temporal module and thereby reducing the number of temporal groups formed and their time sequence.
In general, it is observed in this study that a value of 4 for the ScaleRF parameter optimizes the capacity of the network to extract patterns from images at different resolutions. From a value of 5, the overall classification accuracy starts to fall again.
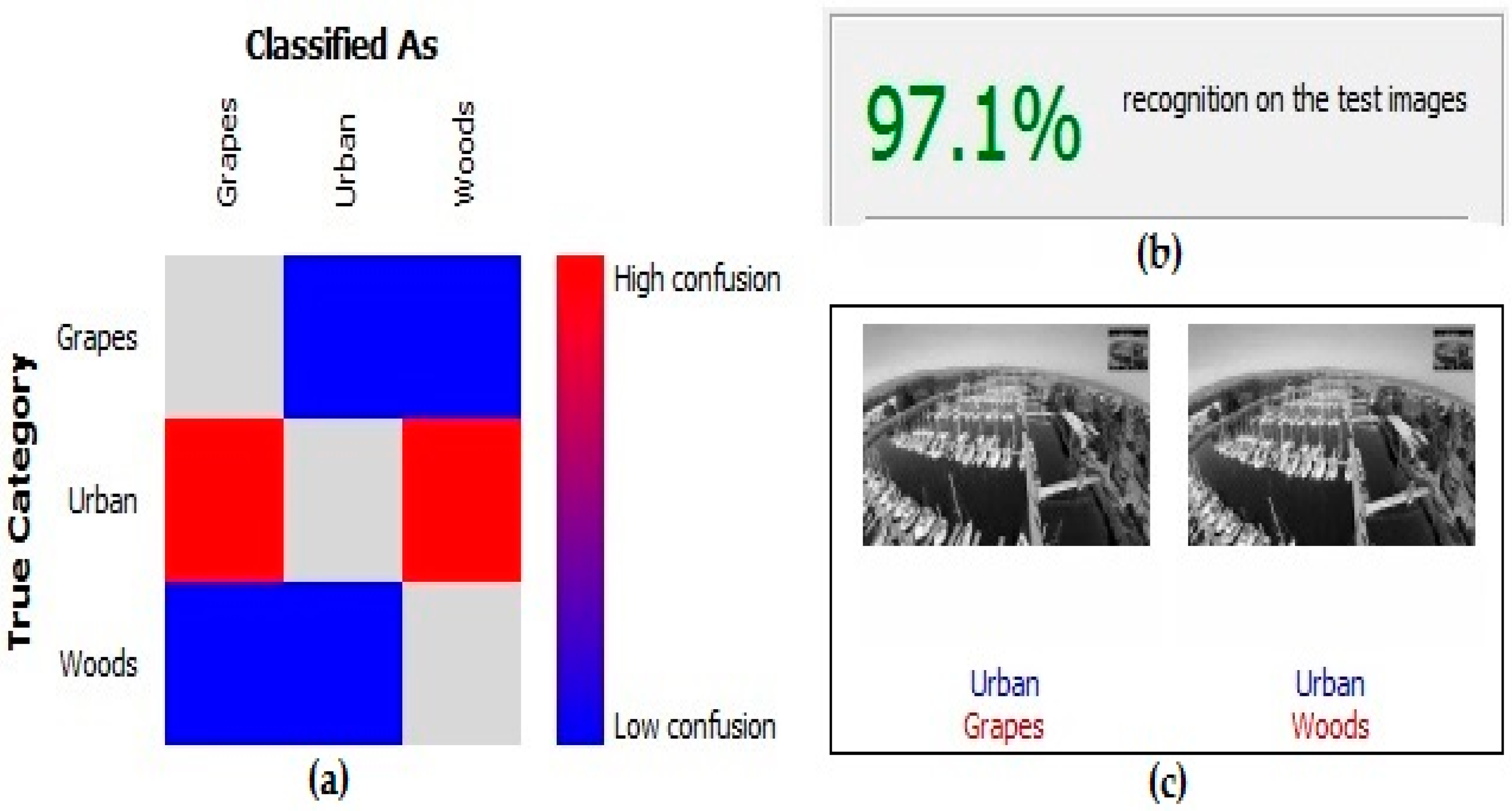
After the analysis of the videos, the abilities of the model to learn the invariant representation of the visual pattern, to store these patterns in the hierarchy and to automatically retrieve them associatively, was verified.
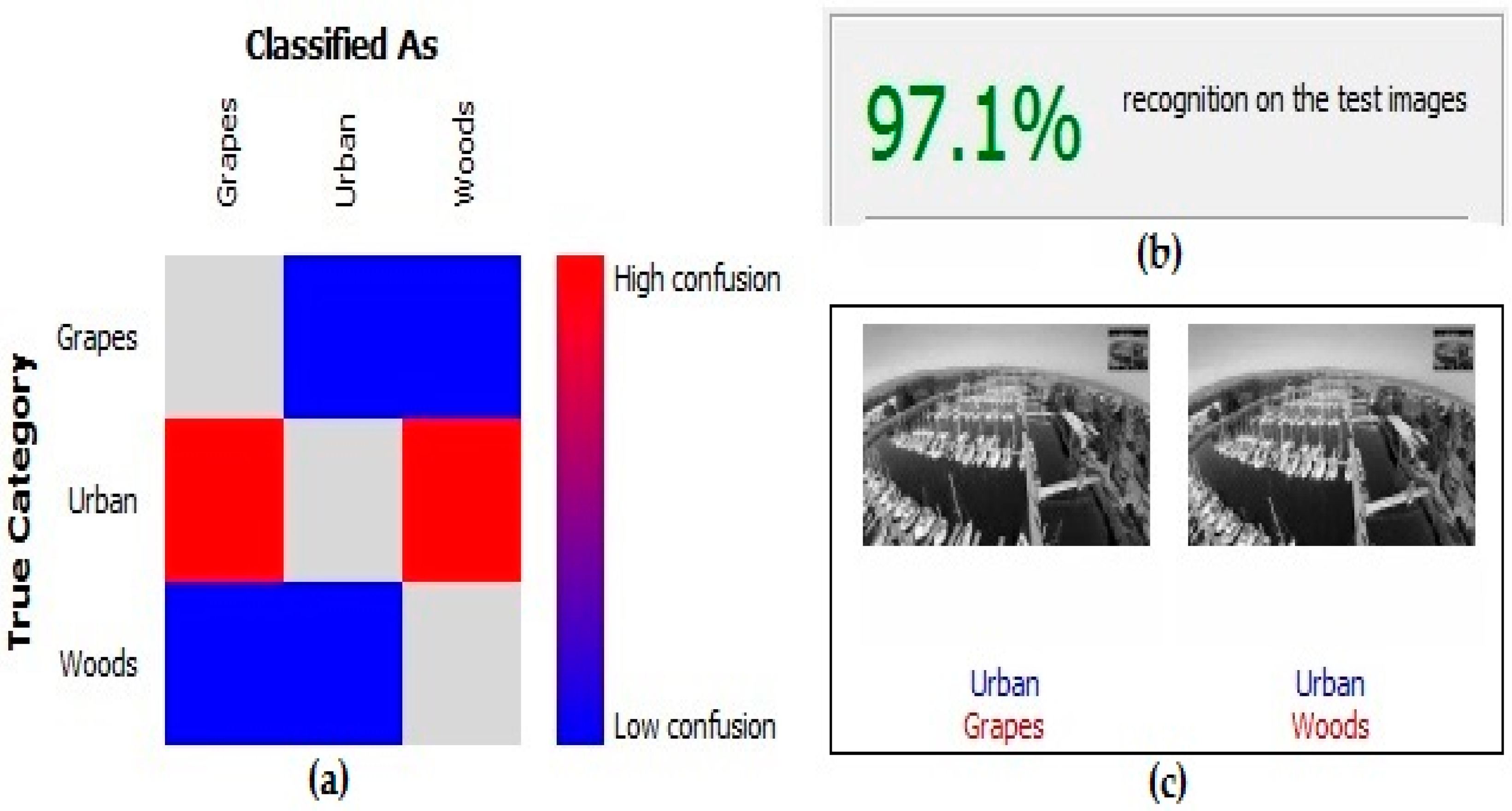
For this experience, the maximum overall accuracy obtained among the different classifications made was 97.1% (
Figure 10), avoiding problems related to the use of images with high spatial resolution, as in the salt-and-pepper noise effect. The salt-and-pepper effect makes it difficult to obtain and cleanly classify images, resulting in different cases for a plot where there should only be a single case.
Comparing the results of the Confusion matrix (
Table 5), lower accuracy in the Urban class is observed; there were a few misclassified frames because in the same image, two different classes could coexist, such as buildings and parks (
Table 5). In 59 frames, the Urban class was classified as the Woods class, and in 11 frames, it was classified as the Grapes class. The higher accuracy obtained was for the Grapes class, where one frame was classified as Urban class and five frames as Woods class.
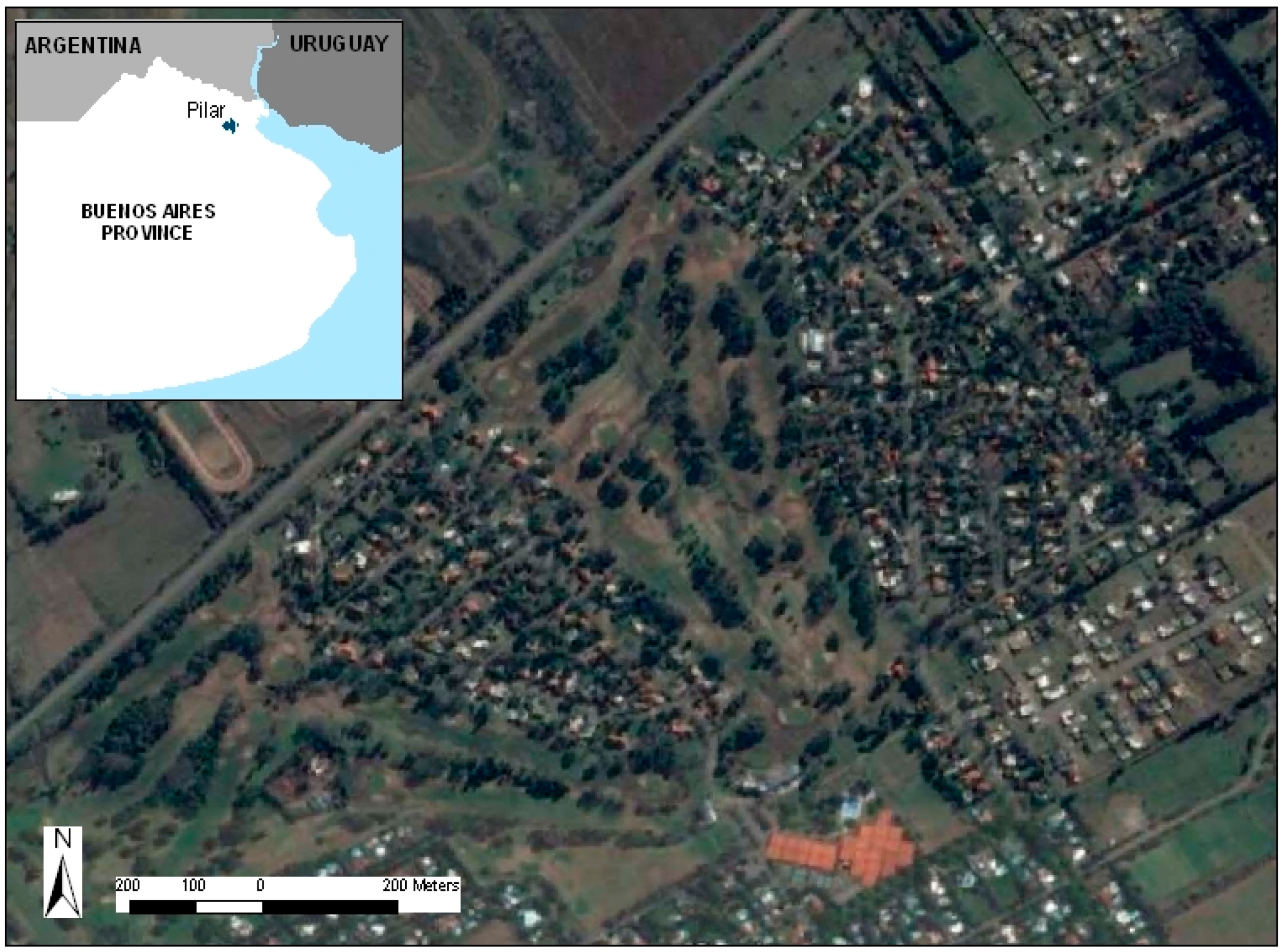
Case Study: Golf Course
The analyzed patterns to check the accuracy of this case study were turfgrass (see
Figure 11) and other uses, namely urban, water, bunker and wood areas.
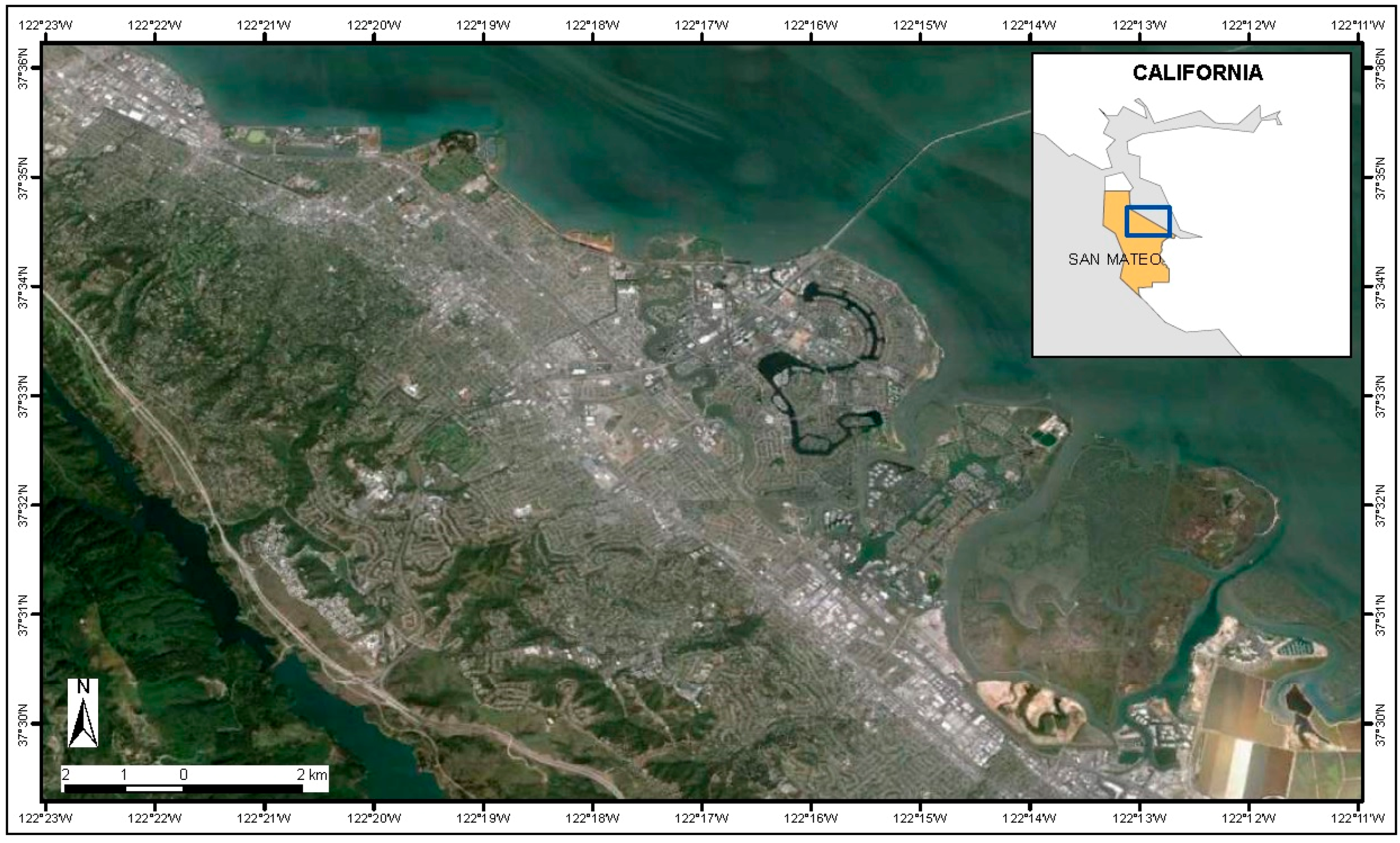
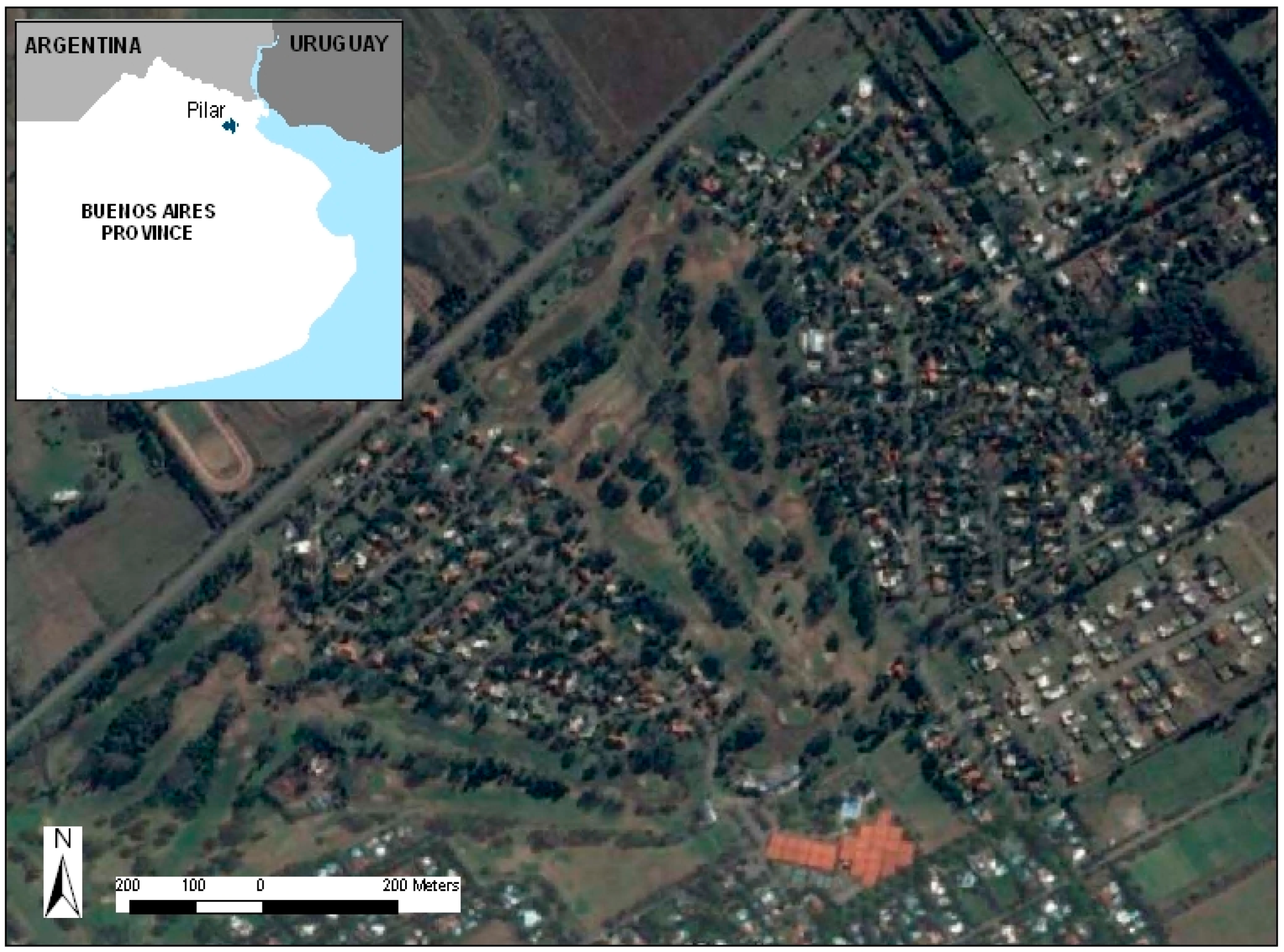
For each of these categories, 300 training videos and 150 testing videos with a total duration of 60 min were used. The videos were obtained in different areas of a golf course in Pilar, Buenos Aires (34°29′52.62′′ S; 58°56′11.68′′ O;
Figure 12).
Based on the optimal parameter values previously discussed, we studied the effect of and the overall accuracy obtained in the classification of the images.
For this case study, the overall accuracy obtained, using the optimal values parameters studied above, was 98.28% (
Table 6).
We compared our results to those of other works. For example, Revollo et al. [
49] develop an autonomous application for geographic feature extraction and recognition in coastal videos and obtained an overall accuracy of 95%; Duro et al. [
50] used object-oriented classification and decision trees in Spot images to identify vegetal coverings and obtained an overall accuracy of 95%; Karakizi et al. [
51] developed and evaluated an object-based classification framework towards the detection of vineyards reaching an overall accuracy rate of 96%.
Therefore, the accuracy value obtained from the classification using the algorithm based on HTM is similar or superior to values obtained by other authors using object-oriented classification and neural networks, which demonstrates that the methodology is appropriate for discriminating agricultural covers in real-time.
Furthermore, as an added benefit, HTM and the methodology developed in this study enable the classification and decision making to be performed in real-time. As we commented before, the operator can control the camera using Wi-Fi. The Wi-Fi computer camera system allows for real-time viewing of everything being seen by the camera, even without taking an image or video. Once the network has been trained and tested, the algorithm classifies the videos, which are received in real-time from the Wi-Fi computer camera system of the DJI Phantom 2 Vision+ (
Figure 13).
In contrast, in the works [
1,
2,
51] of classical classification, post-processing work was required.
4. Conclusions
Pattern recognition is an important step in remote sensing applications for precision agriculture. Unmanned aerial vehicles (UAVs) are currently a valuable source of aerial photographs and video images for inspection, surveillance and mapping in precision agriculture purposes. This is because UAVs can be considered in many applications as a low-cost alternative to classical remote sensing. New applications in the real-time domain are expected. The problem of video image analysis taken from an UAV is approached in this paper. A new recognition methodology based on the Hierarchical Temporal Memory (HTM) algorithm for classifying video imagery was proposed and tested for agricultural areas.
As a case study of precision agriculture, golf courses have been considered, namely precision turfgrass. The analyzed patterns to check the accuracy of this case study were turfgrass (see
Figure 11) and other uses, namely urban, water, bunker and wood areas.
In the classification process, based on the optimal parameter values obtained during the first stage, a maximum overall accuracy of 98.28% was obtained with a minimum number of misclassified frames. In this case study, a rapid classification of turfgrass, among others, can play an important role to determine water requirements of the different areas in order to plan water use.
Additionally, these results provide evidence that the analysis of UAV-based video images through HTM technology represents a first step for video imagery classification. As a final conclusion, the use of HTM has shown that it is possible to perform, in real-time, pattern recognition of video data images taken from an UAV. This opens new perspectives for precision irrigation methods in order to save water, increase yields and improve water, as well as indicating many possible future research topics.


 ,
, 








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}