
A Heuristic Dynamically Dimensioned Search with Sensitivity Information (HDDS-S) and Application to River Basin Management

Abstract
:1. Introduction
2. Methods
2.1. Benchmark Optimization Algorithm
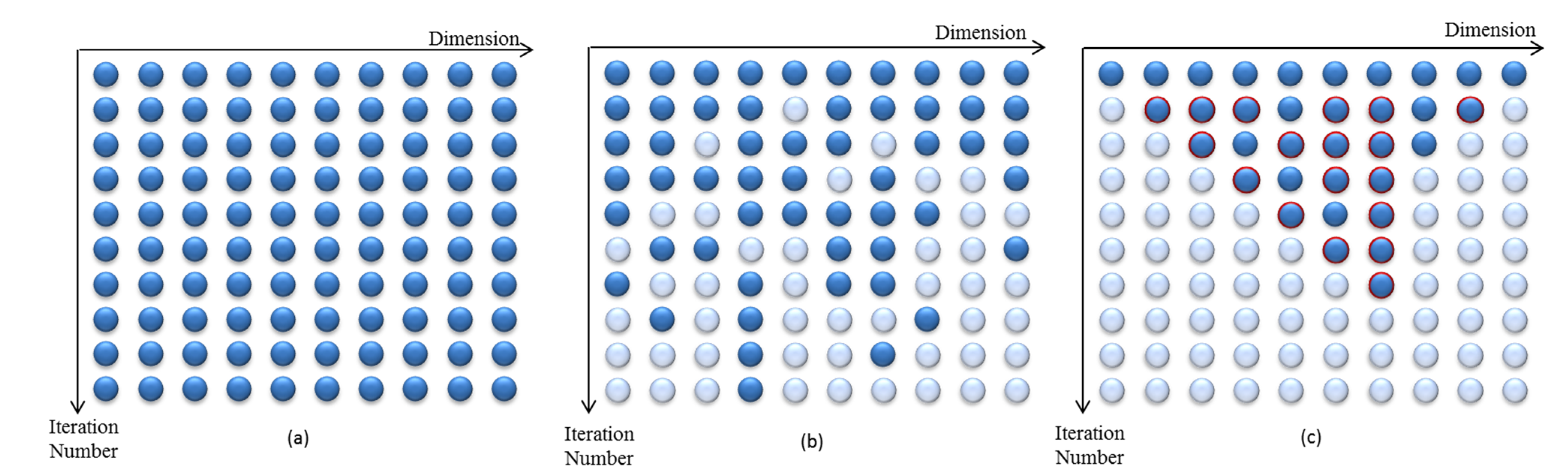
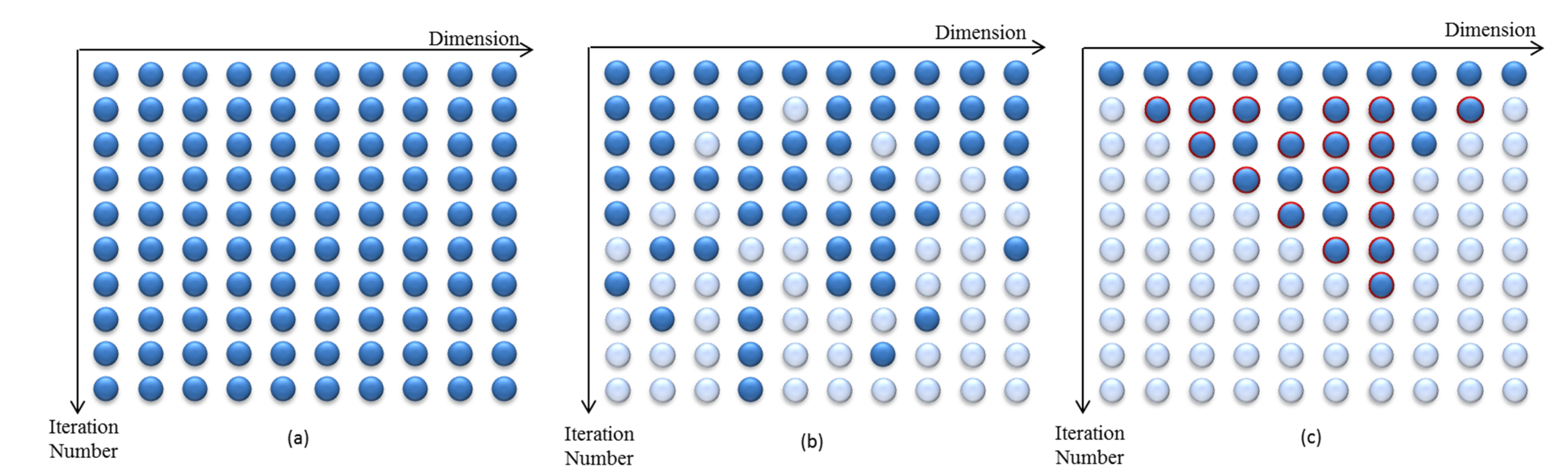
2.2. Heuristic Dynamically Dimensioned Search with Sensitivity Information
3. Model Description and Study Area
3.1. Model Description
3.1.1. River Basin Model
Overview of the SWAT Model

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| No. | Name | Brief Description (units) | Minimum | Maximum |
|---|---|---|---|---|
| 1 | SFTMP | snow fall temperature (°C) | −5 | 5 |
| 2 | SMTMP | snowmelt temperature threshold (°C) | −5 | 5 |
| 3 | SMFMX | melt factor for snow on June 21 (mm/°C) | 1.5 | 8 |
| 4 | TIMP | snowpack temperature lag factor | 0.01 | 1 |
| 5 | ESCO | soil evaporation compensation factor | 0.001 | 1 |
| 6 | SURLAG | surface runoff lag coefficient | 1 | 24 |
| 7 | GW_DELAY | groundwater delay time (days) | 0.001 | 500 |
| 8 | ALPHA_BF | base flow alpha factor | 0.001 | 1 |
| 9 | GWQMN | threshold groundwater depth for return flow (mm) | 0.001 | 500 |
| 10 | LAT_TTIME | lateral flow traveltime (days) | 0.001 | 180 |
| 11 | CN2 a | SCS runoff curve number multiplicative factor for moisture condition II | 0.75 | 1.25 |
Evaluation Criterion and Objective Function
3.1.2. Multi-Reservoir Optimal Operation Model
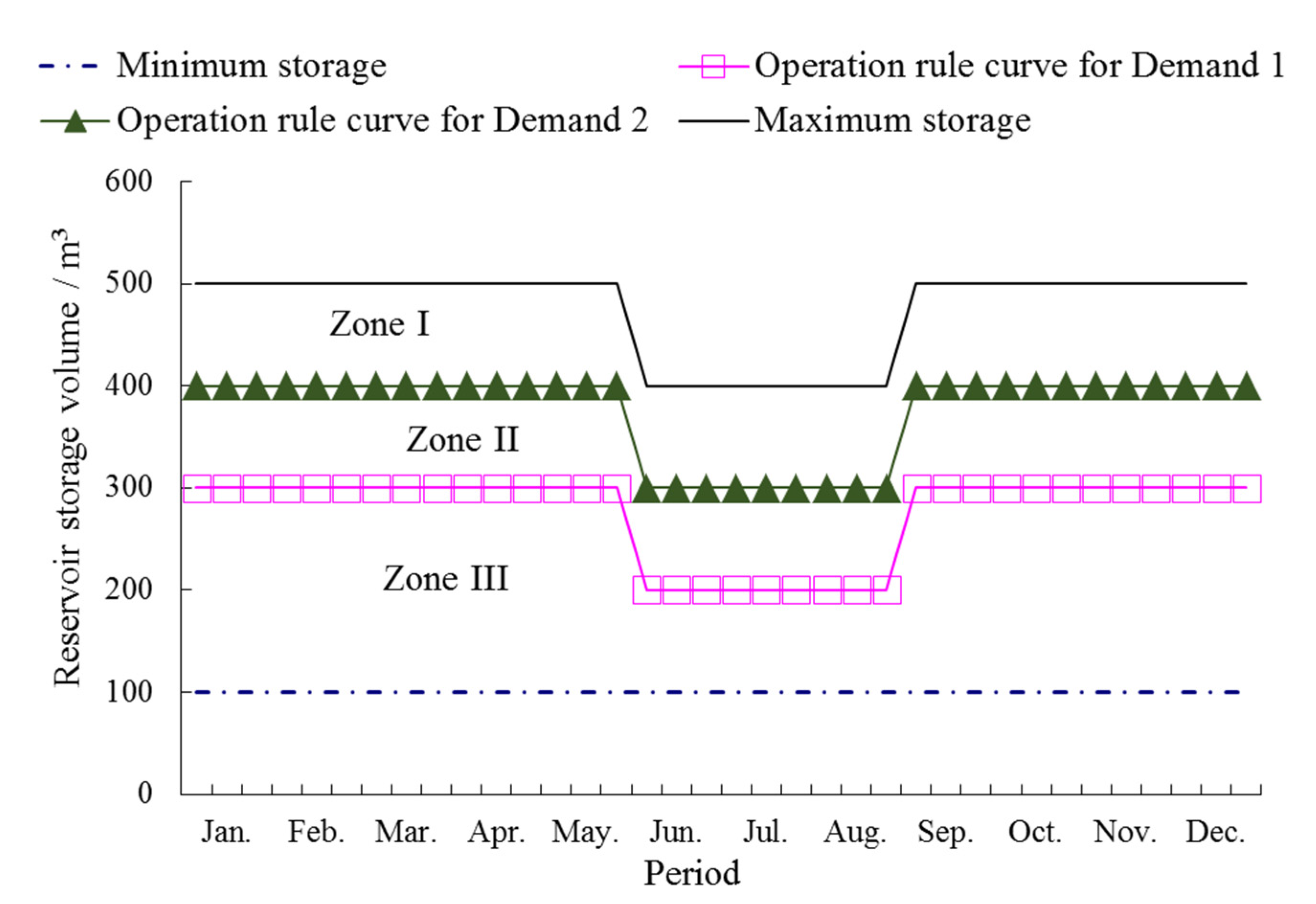
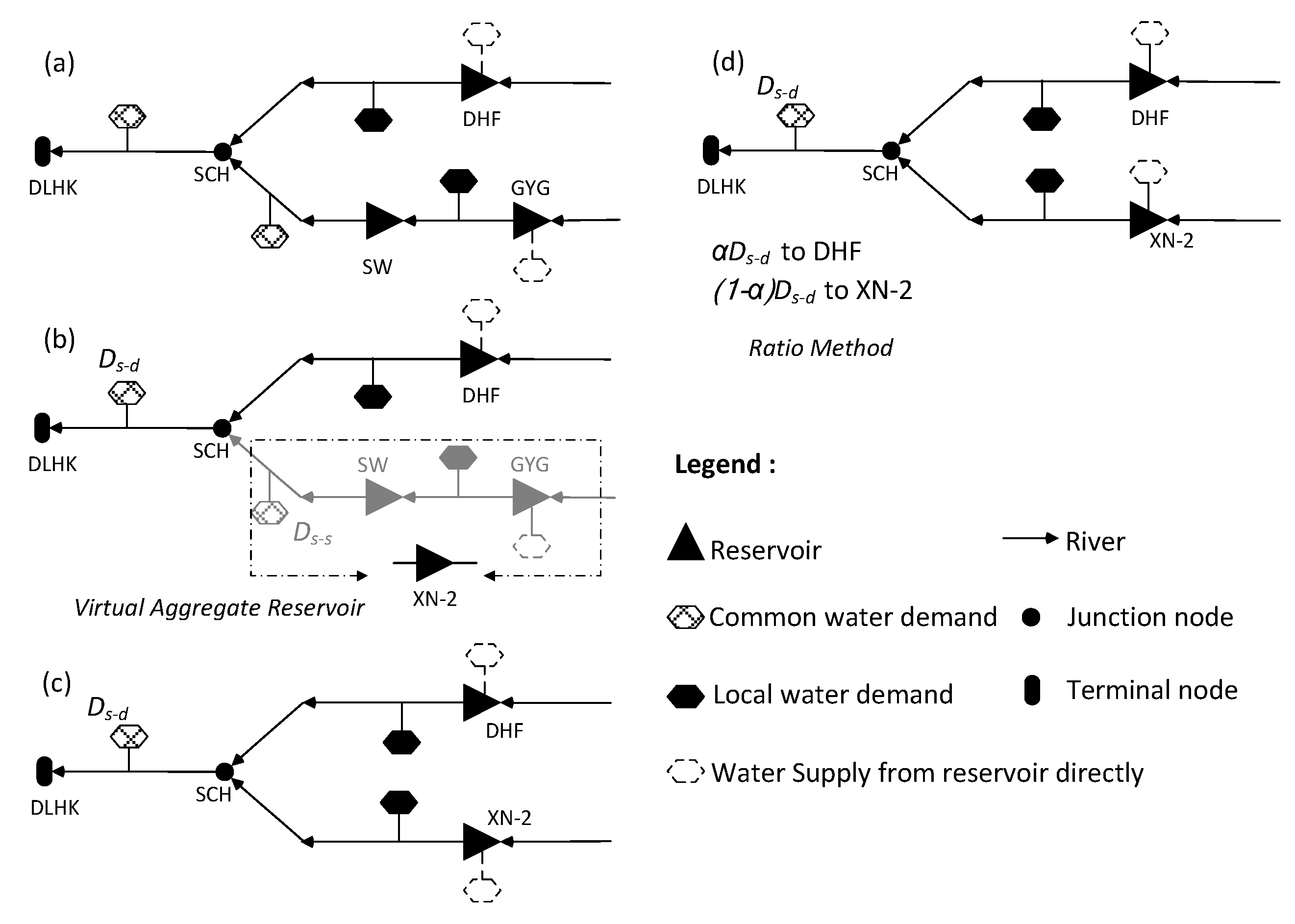
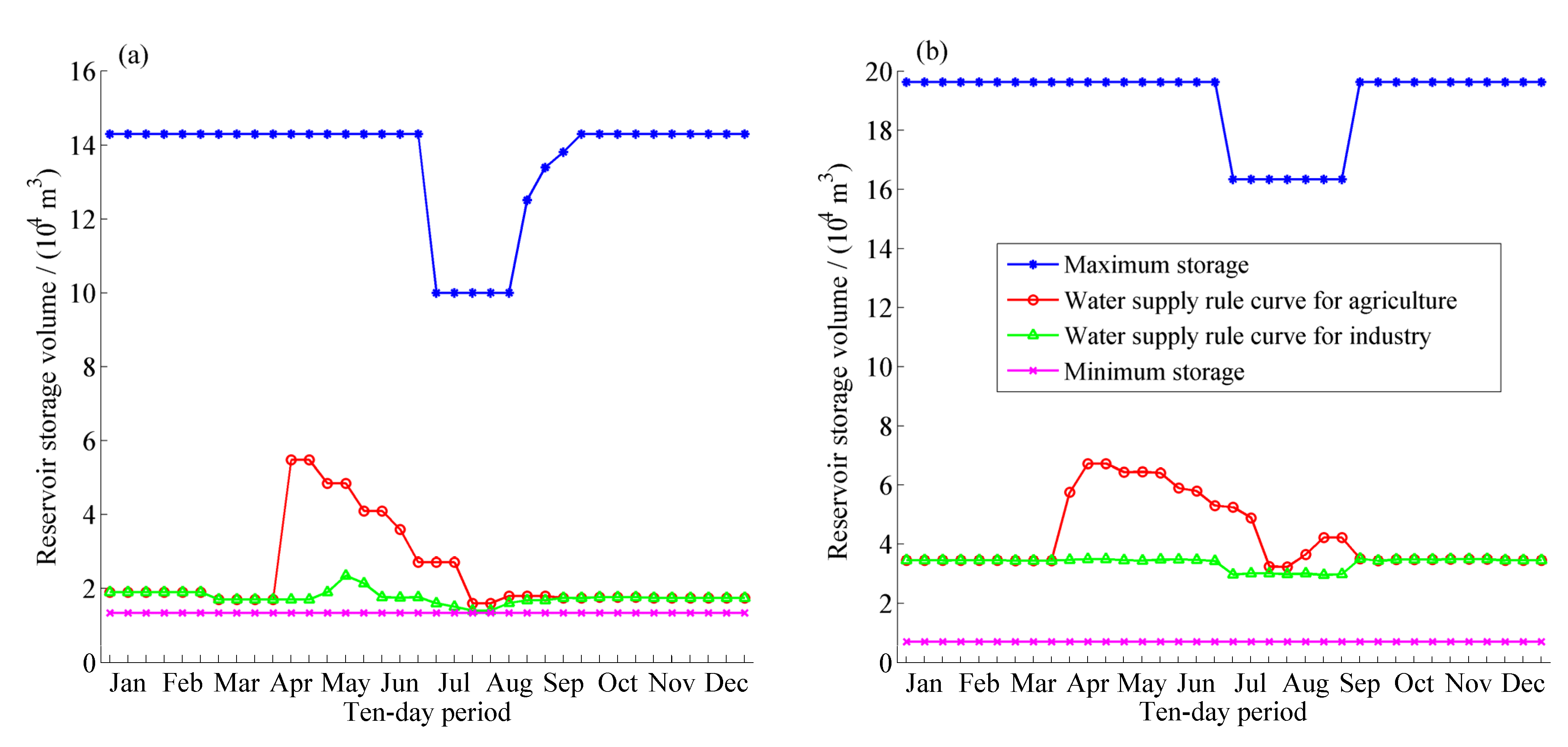
Multi-Reservoir Operation Rule
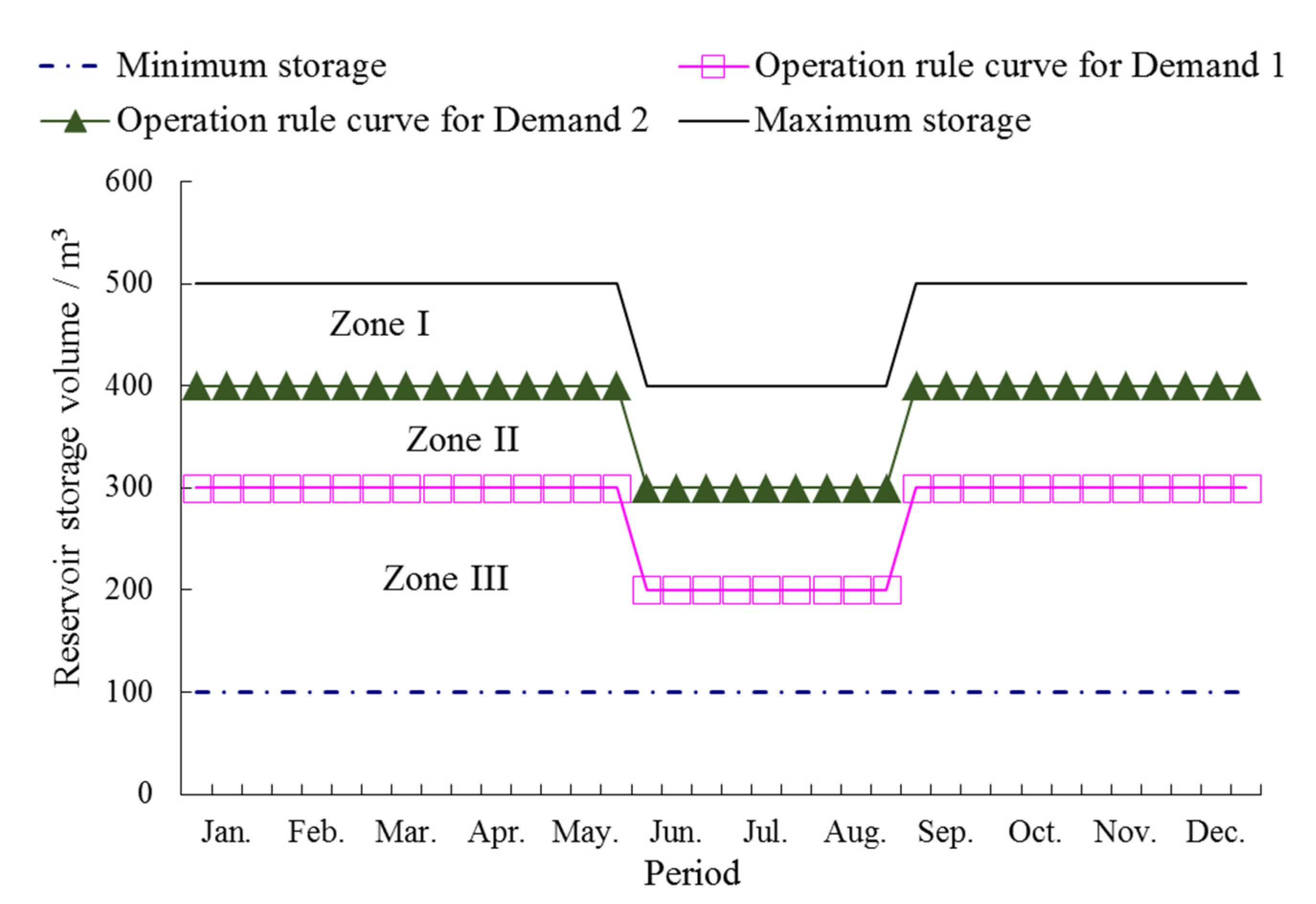
| Reservoir Storage | Water Supply for Each Demand | |
|---|---|---|
| Demand 1 (D1) | Demand 2 (D2) | |
| Zone I | D1 | D2 |
| Zone II | D1 | α2× D2 |
| Zone III | α1× D1 | α2× D2 |
| Rationing factor | α1 | α2 |
Multi-Reservoir Operation Model
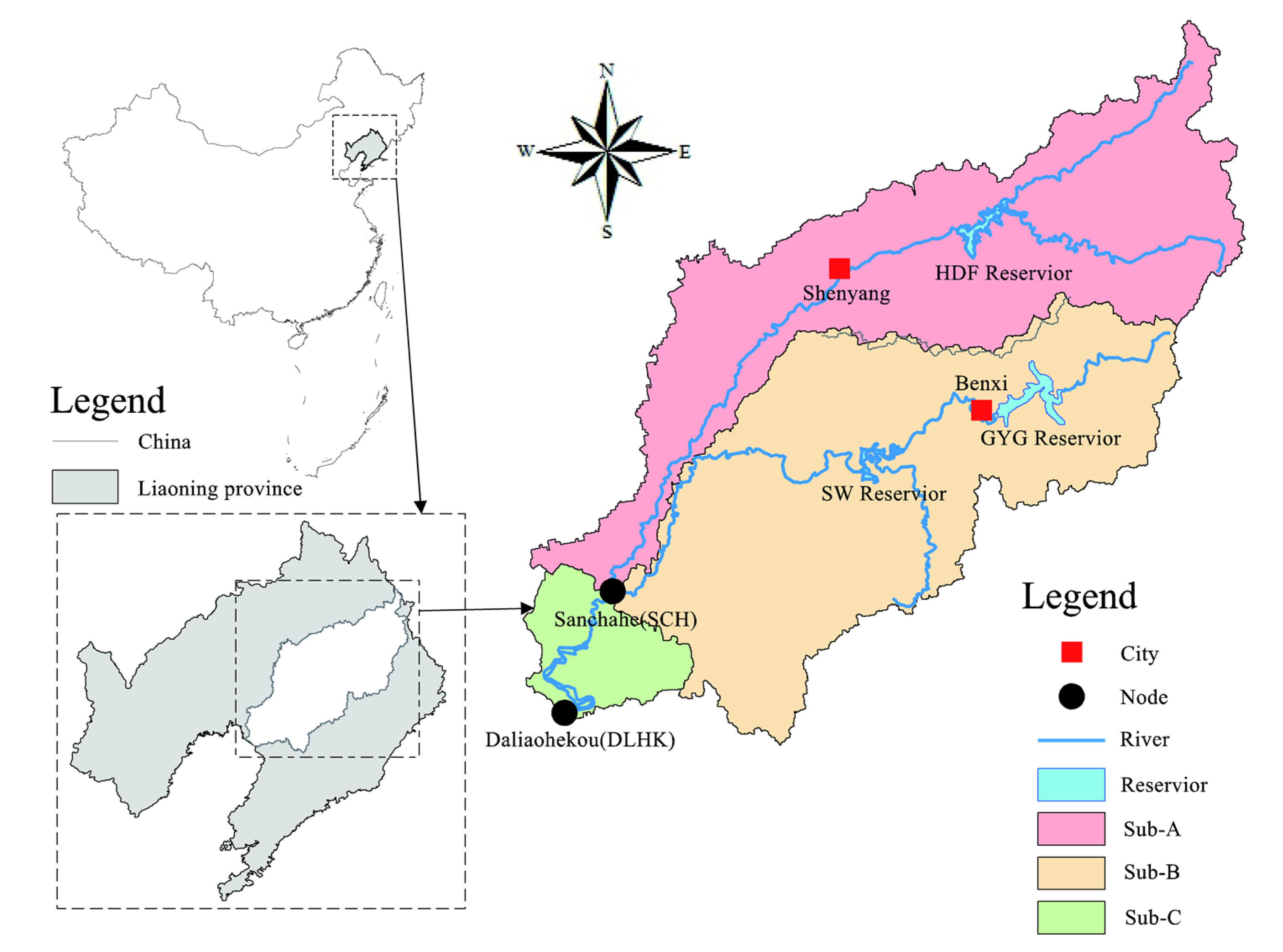
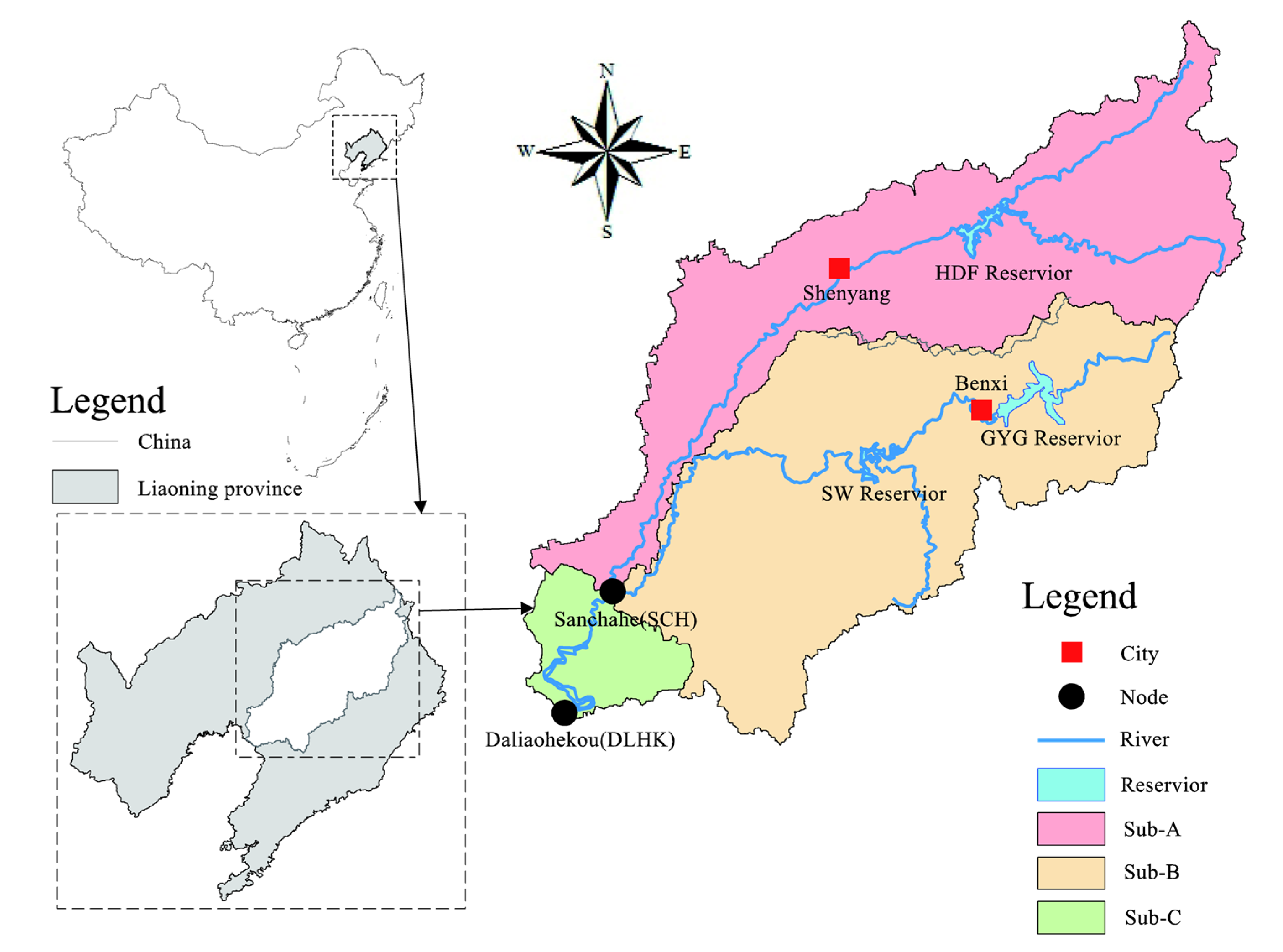
3.2. Study Area
3.2.1. Tang-Wang River Basin

| Time Scale | Hydrologic/Meteorologic Element | Station | Period |
|---|---|---|---|
| Daily | Precipitation | 16 gauges, such as Dongsheng | 1979–2001 |
| Streamflow | Yixin | 1979–2001 | |
| Temperature, relative humidity, weed speed and solar radiation | Yichun | 1979–2001 |
3.2.2. DHF-GYG-SW Multi-Reservoir
| Reservoir | Minimum Capacity (108 m3) | Active Capacity (108 m3) | Annual Average Inflow (108 m3) | Tasks of Water Supply | |
|---|---|---|---|---|---|
| Drought Season | Flood Season | ||||
| DHF | 1.34 | 14.30 | 10.00 | 15.70 | (2) (5) |
| GYG | 0.35 | 14.20 | 14.20 | 11.10 | (1) (3) (4) (5) |
| SW | 0.35 | 5.43 | 2.14 | 12.80 | (4) (5) |
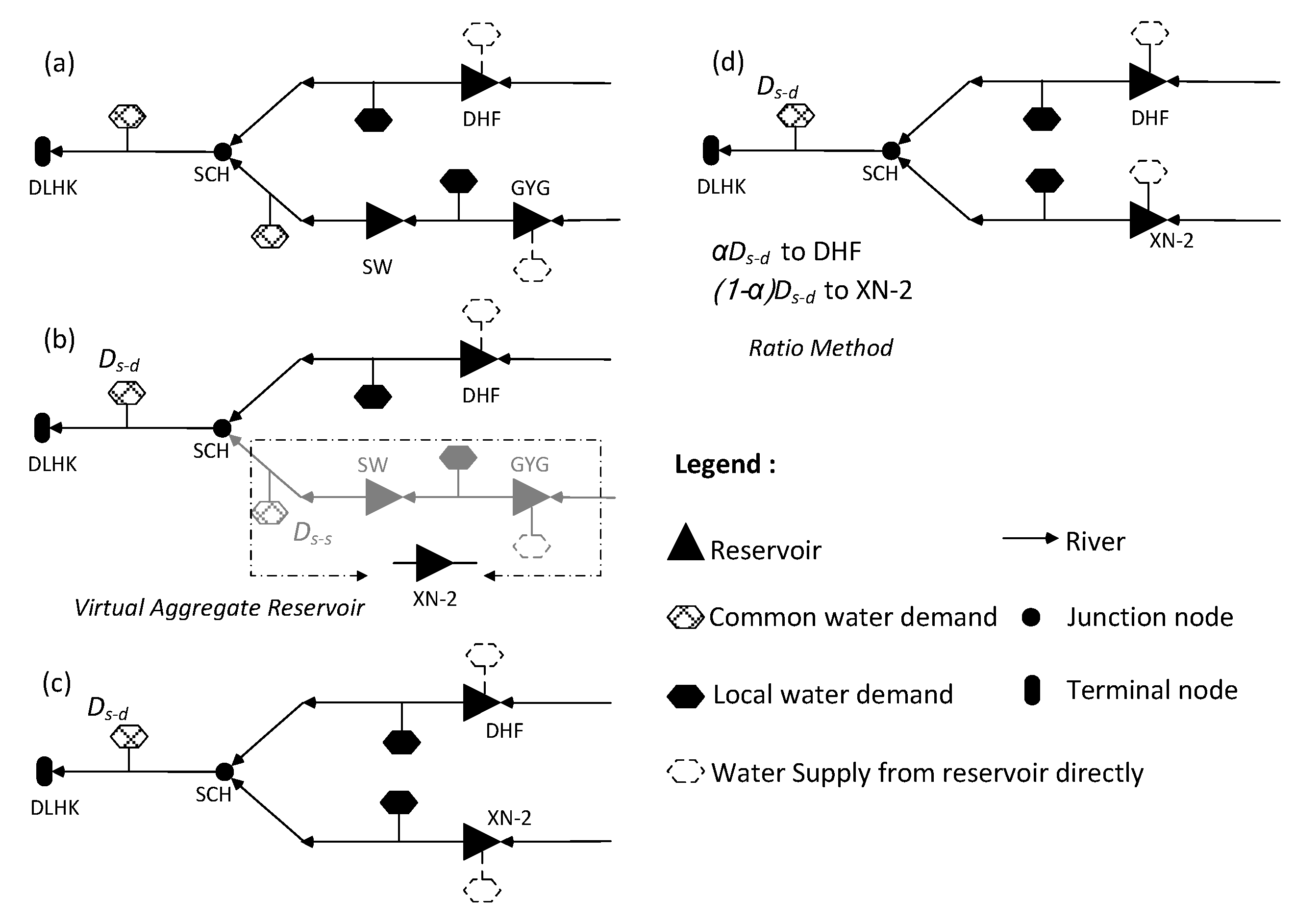
4. Applications of the HDDS-S Algorithm and Results
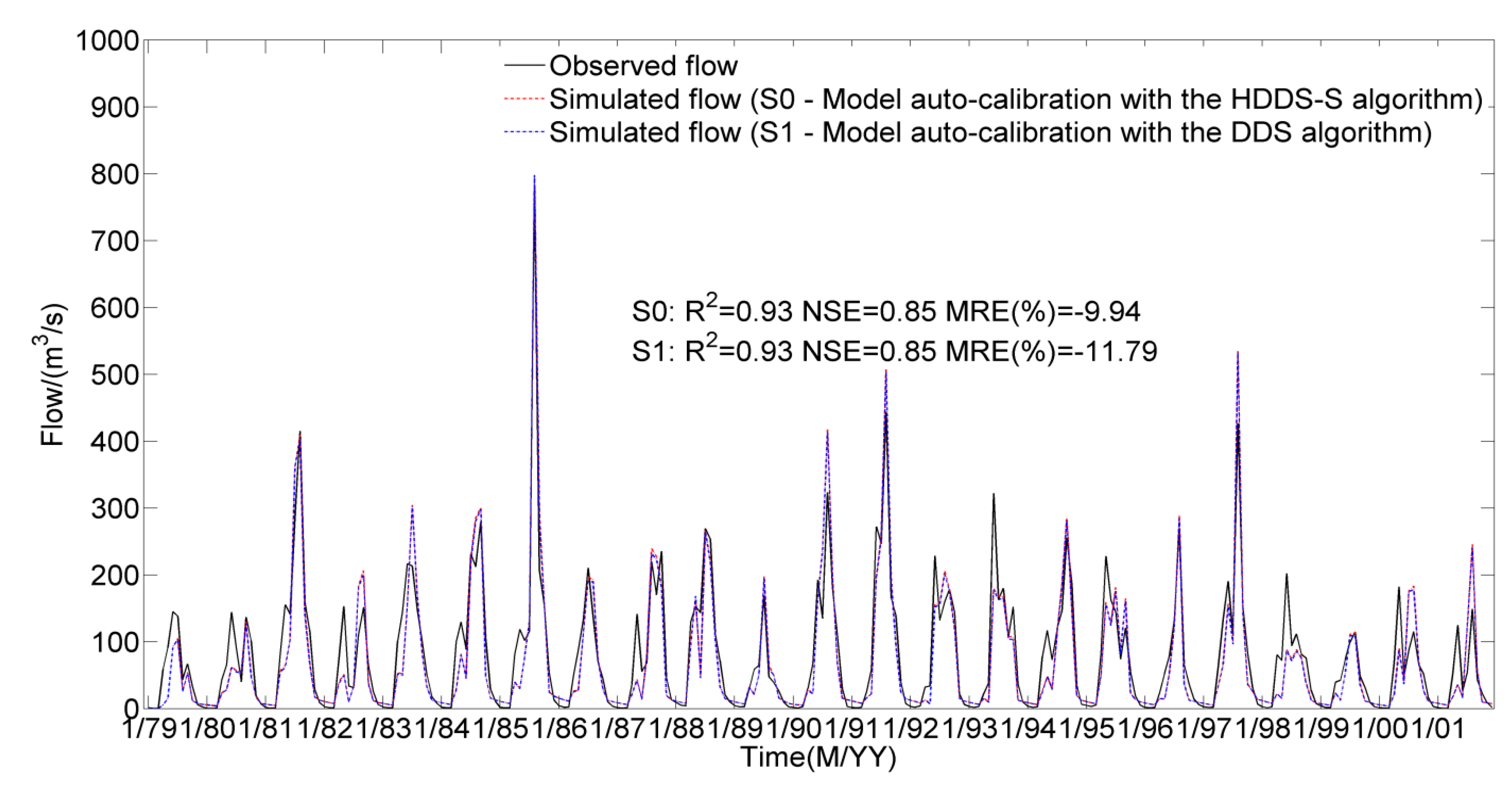
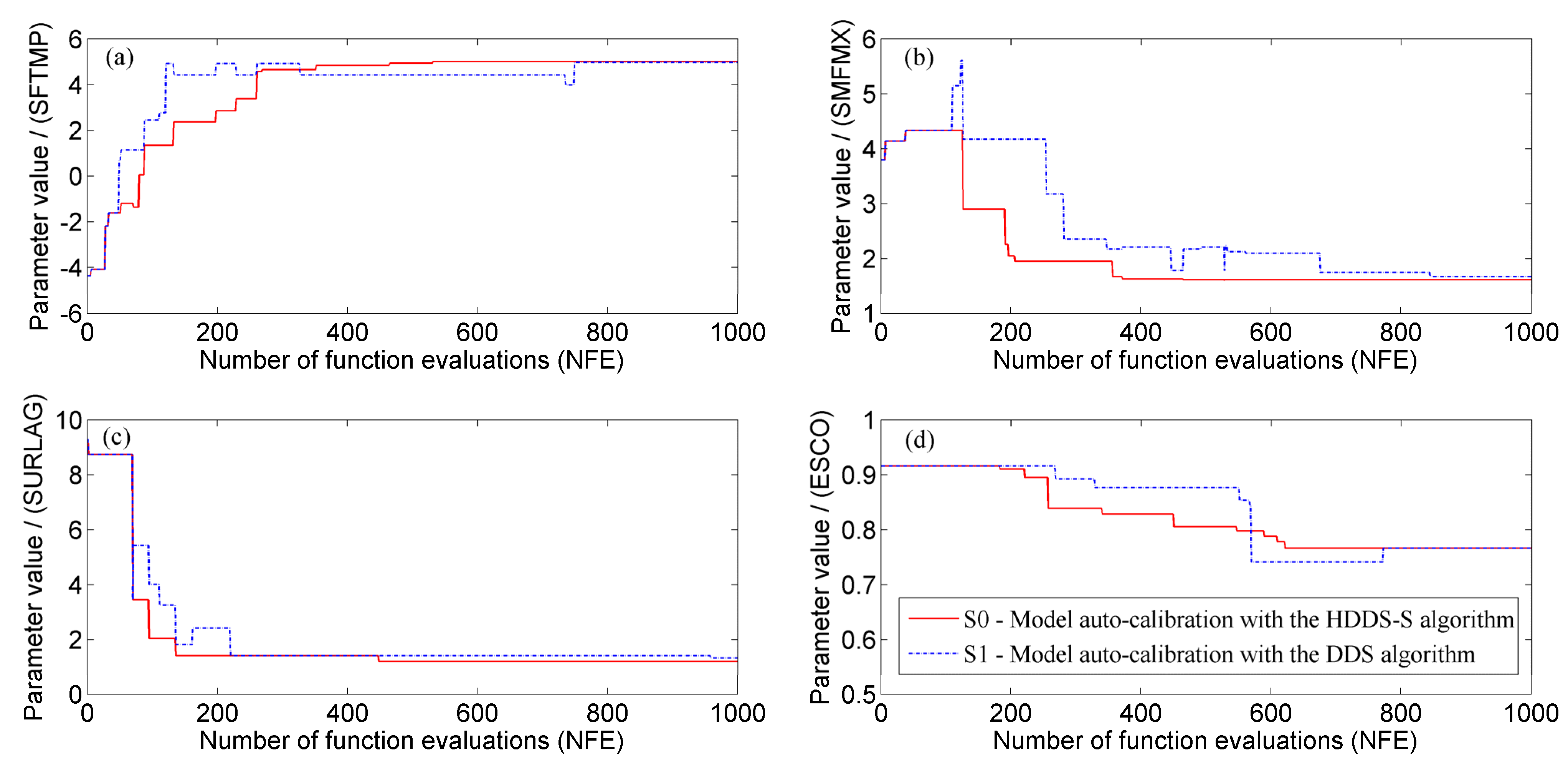
4.1. River Basin Model Calibration
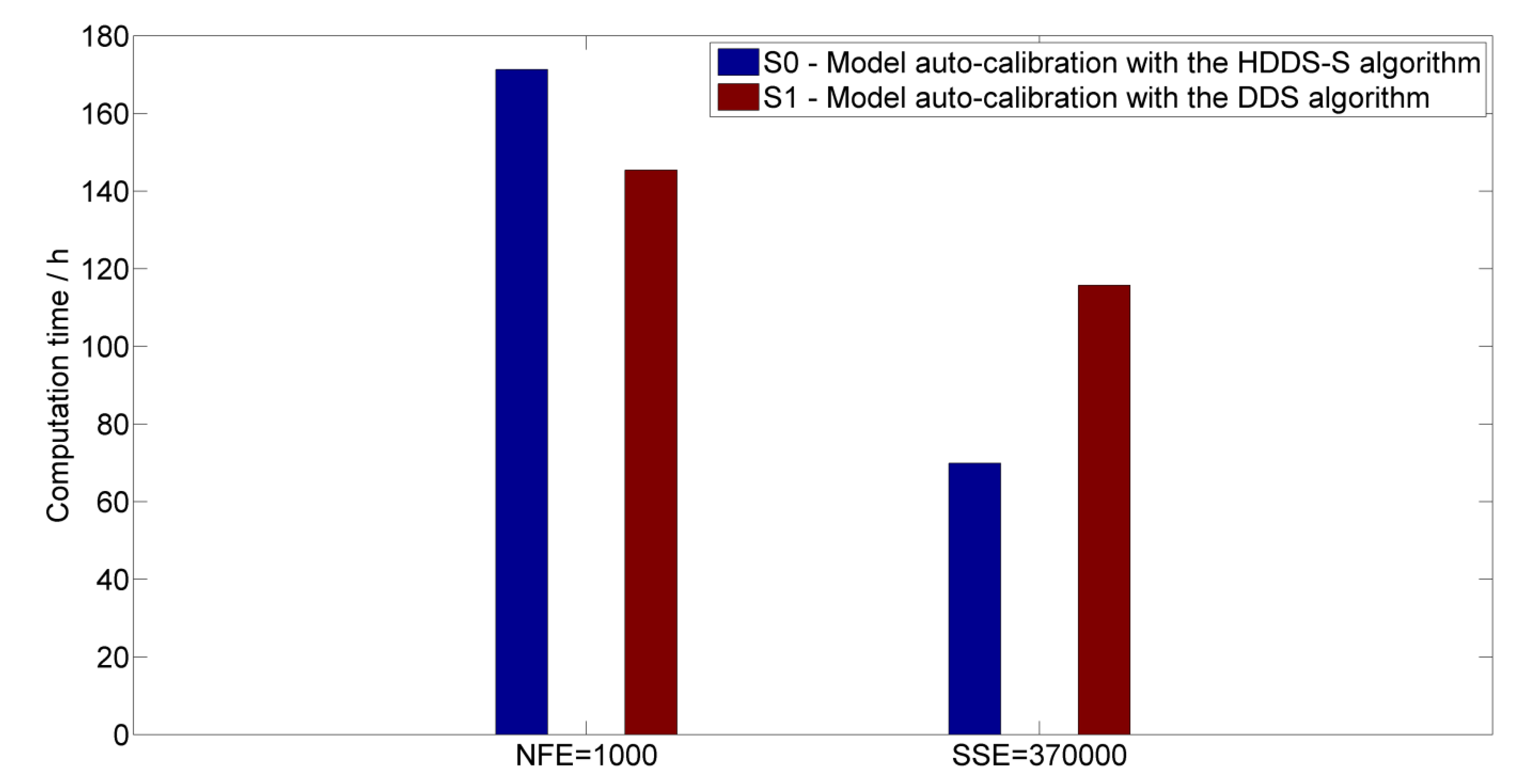
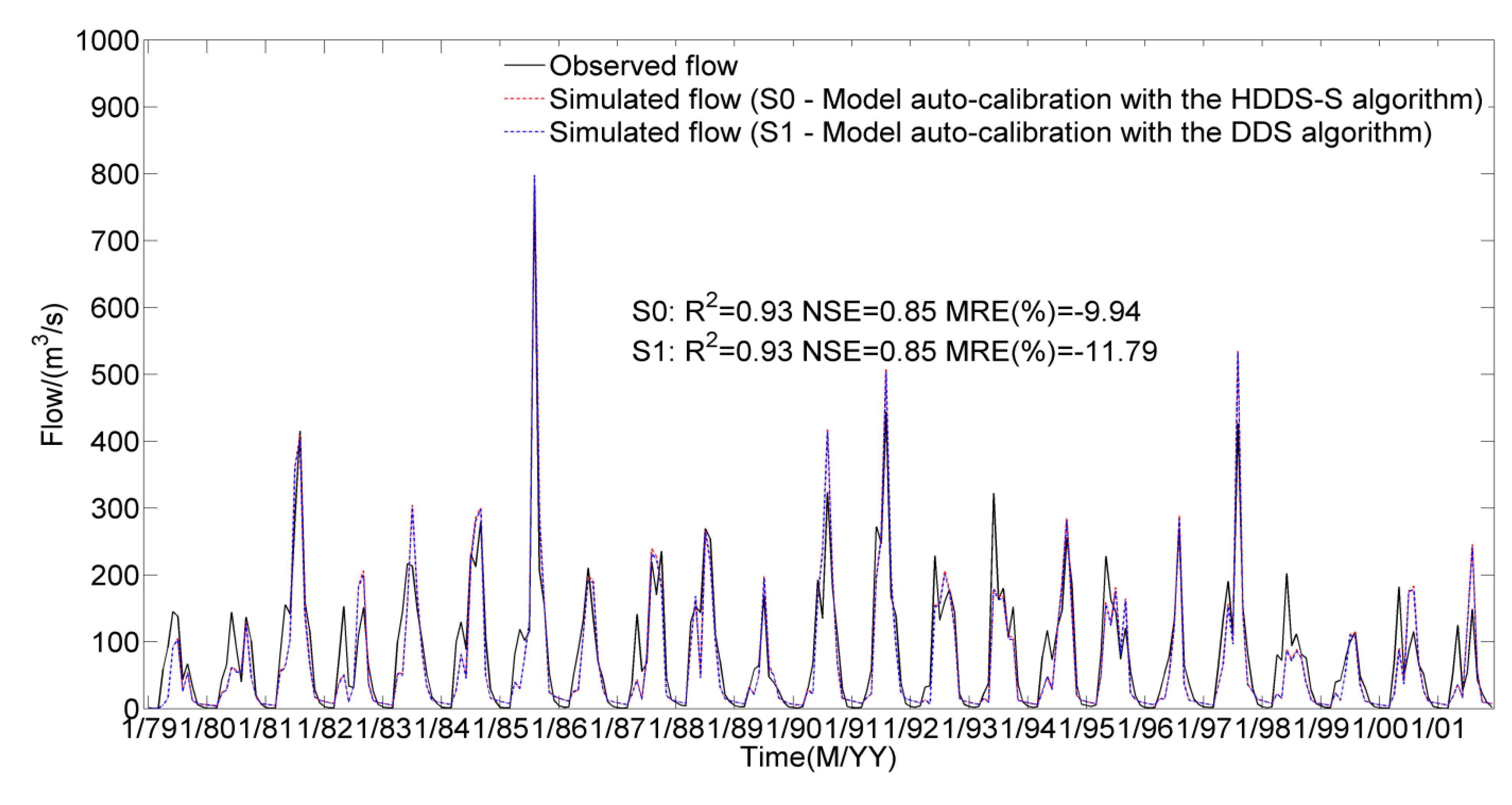
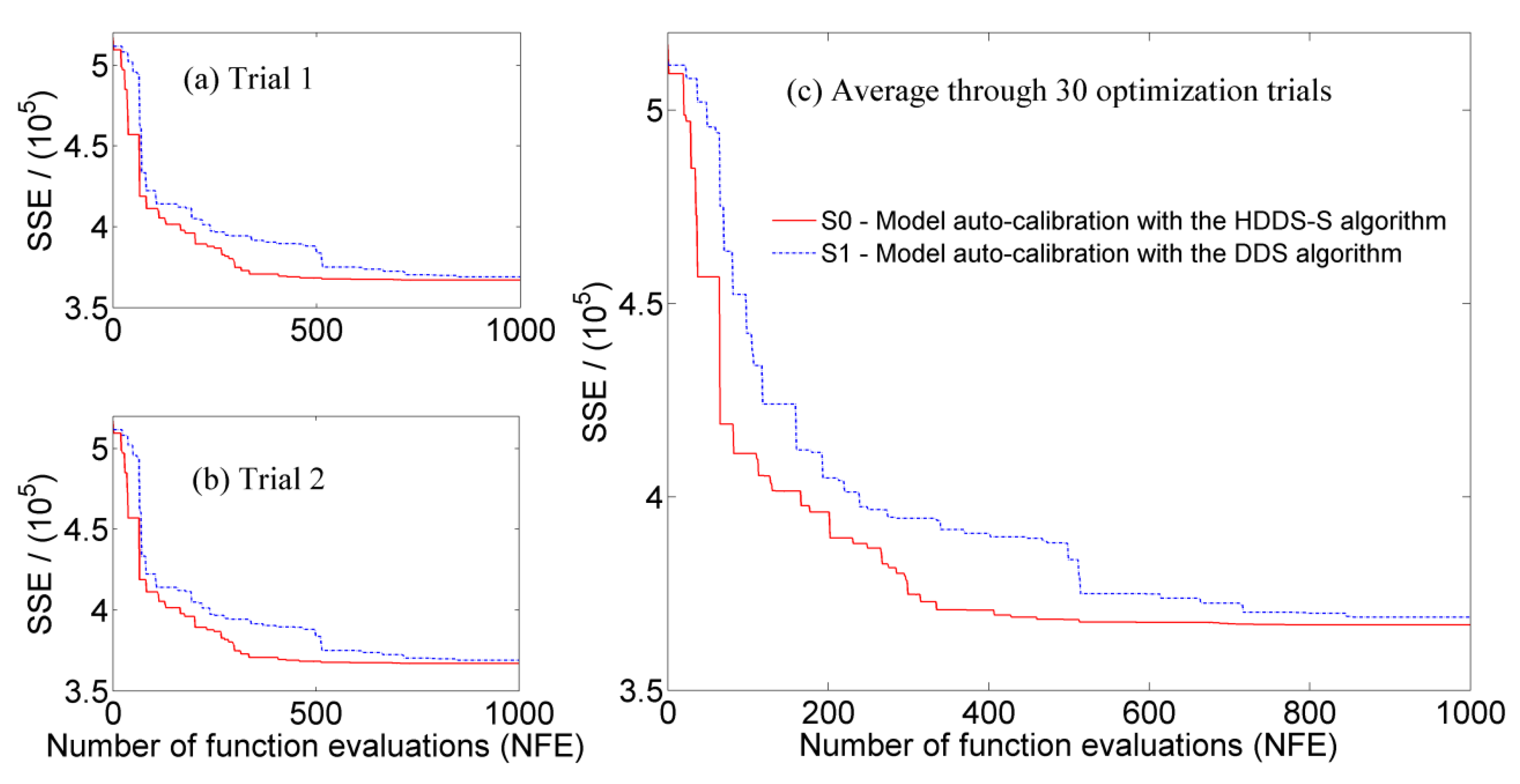
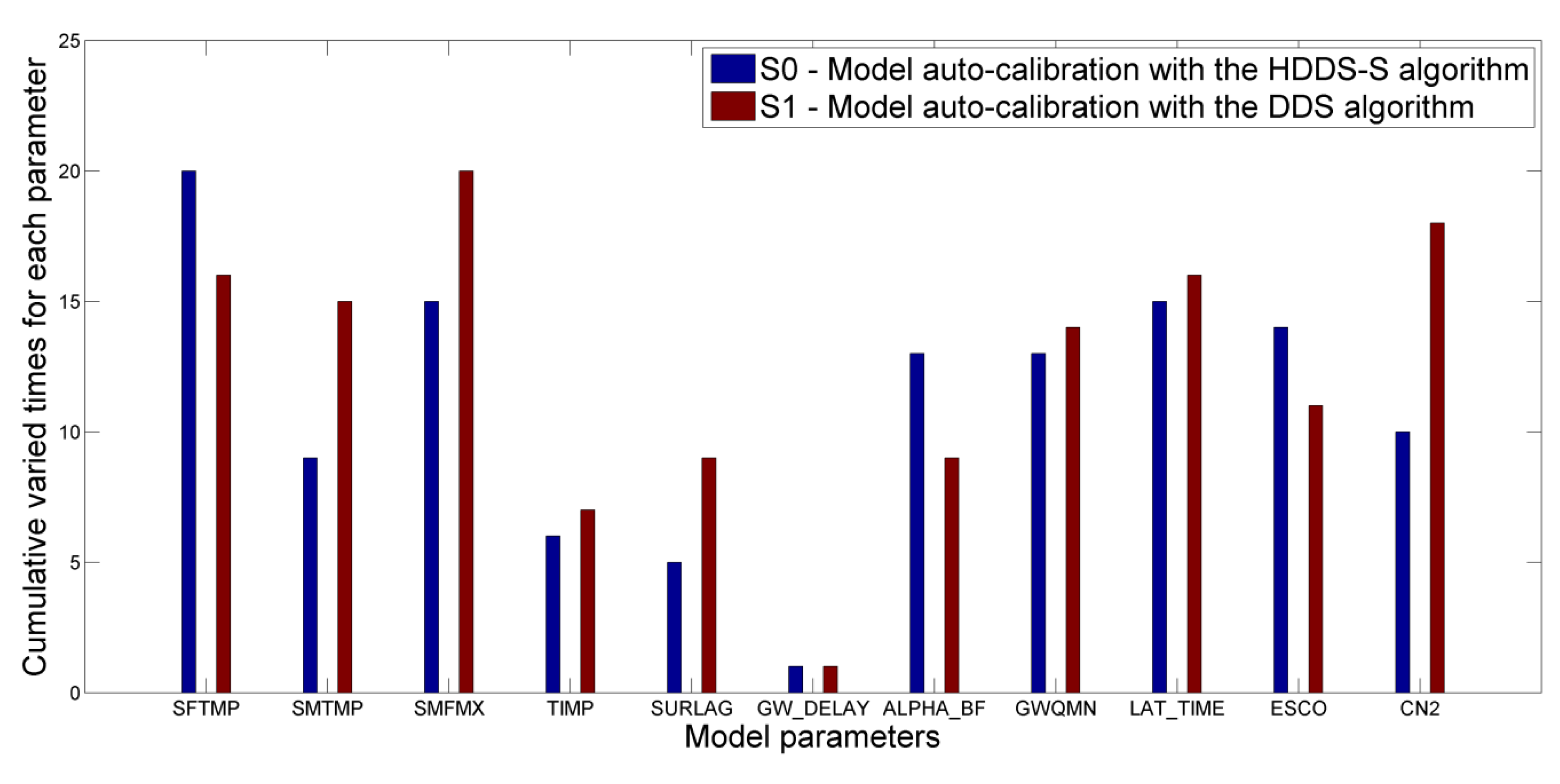
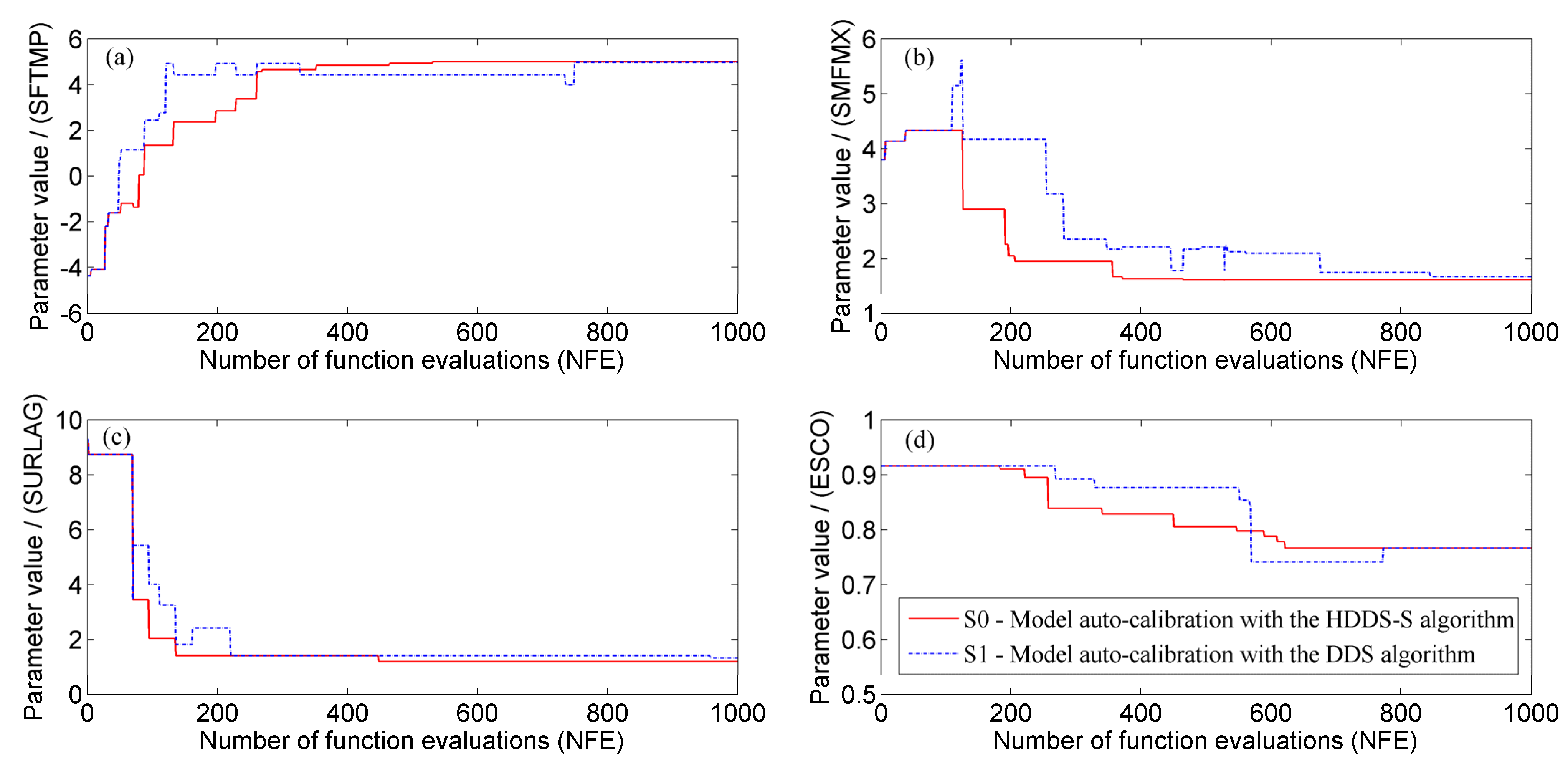
4.2. Multi-Reservoir Optimal Operation
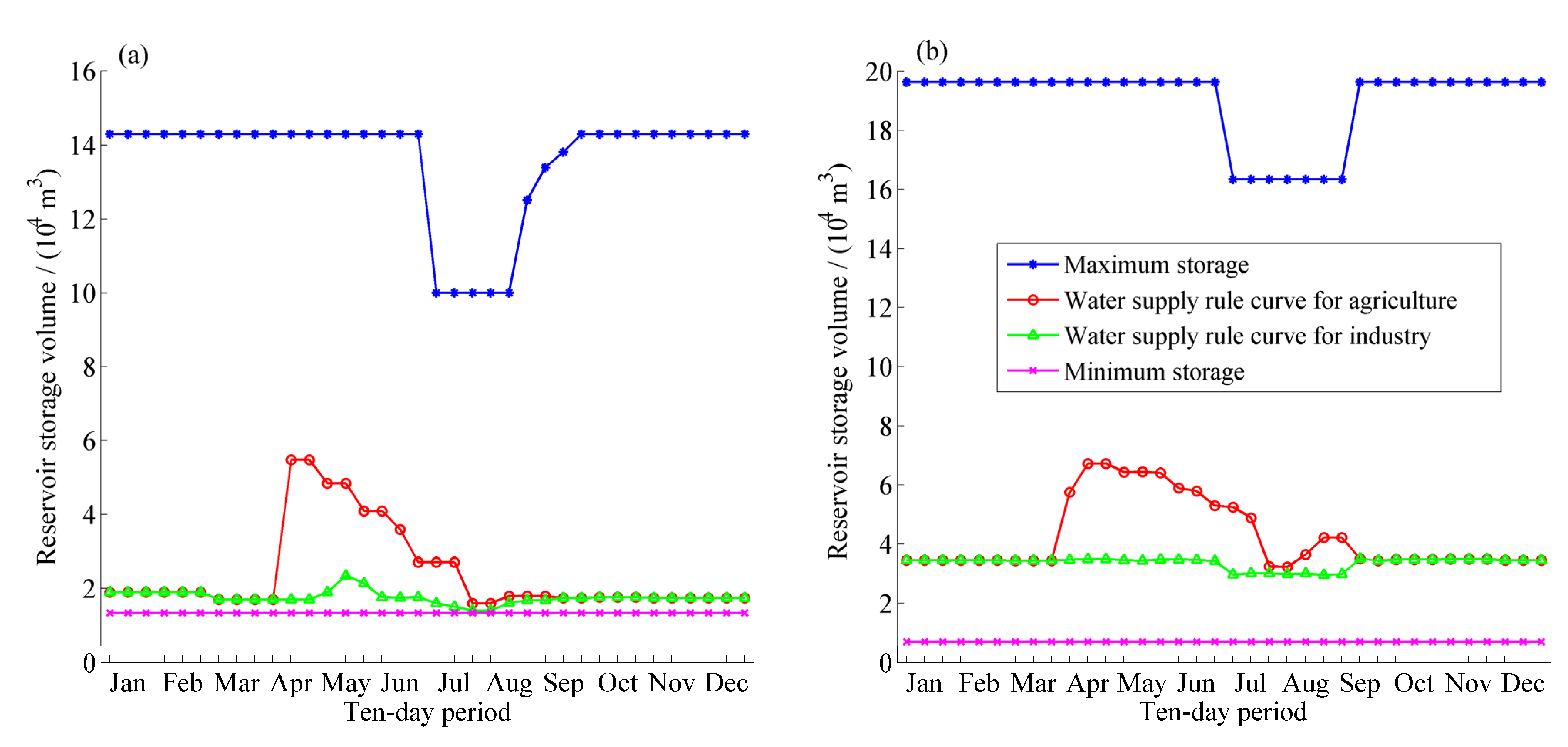
| Scenario | Objective Function Value | Computation Time/Second |
|---|---|---|
| S0 | 9.13 | 723.73 |
| S1 | 25.68 | 294.37.2 |
| Water Supply Area | Guaranteed Water-Supply Rate (%) | ||||
|---|---|---|---|---|---|
| Industry | Agriculture | ||||
| S0 | S1 | S0 | S1 | ||
| Sub-system | Sub A (DHF subsystem) | 95.10 | 95.06 | 75.35 | 67.52 |
| Sub B (GYG-SW subsystem) | 95.81 | 96.00 | 75.46 | 64.78 | |
| Sub C (SCH-DLHK subsystem) | 96.08 | 96.25 | 62.54 | 50.94 | |
5. Discussions and Conclusions
Acknowledgments
Author Contributions
Appendix
- ●
- maximum number of objective function evaluations, ,
- ●
- neighborhood perturbation size parameter, ( is default),
- ●
- vectors of lower, , and upper, , bounds for all decision variables,
- ●
- Set initial solution within the bond of each decision variable randomly, ,
- ●
- Initial decision variable changing sensitivity matrix, .
- ●
- , and .
- ●
- Calculate the sensitivity on iteration : .
- ●
- Calculate the cumulative sensitivity from beginning to iteration : .
- ●
- Calculate the probability of choosing to search based on its cumulative sensitivity from beginning to iteration : .
- ●
- Add to with probability .
- ●
- If empty, select all decision variables to .
- ●
- , where .
- ●
- If , reflect perturbation:
- ●
- ,
- ●
- If , set .
- ●
- If , reflect perturbation:
- ●
- ,
- ●
- If , set .
- ●
- If , update new best solution:
- ●
- and .
- ●
- If , STOP, save (e.g., ).
- ●
- Else, go to STEP 3.
Conflicts of Interest
References
- Labat, D.; Godderis, Y.; Probst, J.L.; Guyot, J.L. Evidence for global runoff increase related to climate warming. Adv. Water Resour. 2004, 27, 631–642. [Google Scholar] [CrossRef]
- Barnett, T.P.; Pierce, D.W.; Hidalgo, H.G.; Bonfils, C.; Santer, B.D.; Das, T.; Dettinger, M.D. Human-induced changes in the hydrology of the western United States. Science 2008, 319, 1080–1083. [Google Scholar] [CrossRef] [PubMed]
- Zhang, A.; Zhang, C.; Chu, J.; Fu, G. Study on the human-induced runoff change in Northeast China. J. Hydrol. Eng. 2014. [Google Scholar] [CrossRef]
- Zhang, A.; Zhang, C.; Fu, G.; Wang, B.; Bao, Z.; Zheng, H. Assessments of impacts of climate change and human activities on runoff with SWAT for the Huifa River Basin, Northeast China. Water Resour. Manag. 2012, 26, 2199–2217. [Google Scholar] [CrossRef]
- Zhang, C.; Shoemaker, C.A.; Woodbury, J.D.; Cao, M.; Zhu, X. Impact of human activities on stream flow in the Biliu River basin, China. Hydrol. Process. 2013, 27, 2509–2523. [Google Scholar] [CrossRef]
- Zhang, C.; Zhu, X.; Fu, G.; Zhou, H.; Wang, H. The impacts of climate change on water diversion strategies for a water deficit reservoir. J. Hydroinform. 2013. [Google Scholar] [CrossRef]
- Zhang, C.; Wang, D.; Wang, G.; Yang, W.; Liu, X. Regional differences in hydrological response to canopy interception schemes in a land surface model. Hydrol. Process. 2014, 28, 2499–2508. [Google Scholar] [CrossRef]
- Wang, F.; Zhang, C.; Peng, Y.; Zhou, H. Diurnal temperature range variation and its causes in a semiarid region from 1957 to 2006. Int. J. Climatol. 2014, 34, 343–354. [Google Scholar] [CrossRef]
- Labadie, J.W. Optimal operation of multireservoir systems: State-of-the-art review. J. Water Resour. Plan. Manag. 2004, 130, 93–111. [Google Scholar] [CrossRef]
- Draper, A.J.; Lund, J.R. Optimal hedging and carryover storage value. J. Water Resour. Plan. Manag. 2004, 130, 83–87. [Google Scholar] [CrossRef]
- Sadegh, M.; Mahjouri, H.; Kerachian, R. Optimal inter-basin water allocation using crisp and fuzzy Shapley games. Water Resour. Manag. 2010, 24, 2291–2310. [Google Scholar] [CrossRef]
- Zhang, C.; Wang, G.; Peng, Y.; Tang, G.; Liang, G. A negotiation-based multi-objective, multi-party decision-making model for inter-basin water transfer scheme optimization. Water Resour. Manag. 2012, 26, 4029–4038. [Google Scholar] [CrossRef]
- Zhao, T.; Zhao, J.; Yang, D. Improved dynamic programming for hydropower reservoir operation. J. Water Resour. Plan. Manag. 2014, 140, 365–374. [Google Scholar] [CrossRef]
- Xu, W.; Zhang, C.; Peng, Y.; Fu, G.; Zhou, H. A two stage Bayesian stochastic optimization model for cascaded hydropower systems considering varying uncertainty of flow forecasts. Water Resour. Res. 2014, 50. [Google Scholar] [CrossRef]
- Fu, G.; Kapelan, Z.; Reed, P. Reducing the complexity of multi-objective water distribution system optimization through global sensitivity analysis. J. Water Resour. Plan. Manag. 2012, 138, 196–207. [Google Scholar] [CrossRef]
- Fu, G.; Kapelan, Z.; Kasprzyk, J.R.; Reed, P. Optimal design of water distribution systems using many-objective visual analytics. J. Water Resour. Plan. Manag. 2013, 139, 624–633. [Google Scholar] [CrossRef]
- Wang, Q. The genetic algorithm and its application to calibrating rainfall-runoff models. Water Resour. Res. 1991, 27, 2467–2471. [Google Scholar] [CrossRef]
- Simpson, A.R.; Dandy, G.C.; Murphy, L.J. Genetic algorithms compared to other techniques for pipe optimization. J. Water Resour. Plan. Manag. 1994, 120, 423–443. [Google Scholar] [CrossRef]
- Savic, D.A.; Walters, G.A. Genetic algorithms for least-cost design of water distribution networks. J. Water Resour. Plan. Manag. 1997, 123, 67–77. [Google Scholar] [CrossRef]
- Wu, Z.; Boulos, P.F.; Orr, C.H.; Ro, J.J. Using genetic algorithms to rehabilitate distribution systems. Am. Water Works Assoc. J. 2001, 93, 74–85. [Google Scholar]
- Tolson, B.A.; Maier, H.R.; Simpson, A.R.; Lence, B.J. Genetic algorithms for reliability-based optimization of water distribution systems. J. Water Resour. Plan. Manag. 2004, 130, 63–72. [Google Scholar] [CrossRef]
- Fu, G.; Butler, D.; Khu, S.T. Multiple objective optimal control of integrated urban wastewater systems. Environ. Model. Softw. 2008, 23, 225–234. [Google Scholar] [CrossRef]
- Fu, G.; Kapelan, Z. Fuzzy probabilistic design of water distribution networks. Water Resour. Res. 2011, 47. [Google Scholar] [CrossRef]
- Suribabu, C.R.; Neelakantan, T.R. Design of water distribution networks using particle swarm optimization. Urban Water J. 2006, 3, 111–120. [Google Scholar] [CrossRef]
- Montalvo, I.; Izquierdo, J.; Pérez, R.; Iglesias, P.L. A diversity-enriched variant of discrete PSO applied to the design of water distribution networks. Eng. Optim. 2008, 40, 655–668. [Google Scholar] [CrossRef]
- Duan, Q.; Sorooshian, S.; Gupta, V. Effective and efficient global optimization for conceptual rainfall-runoff models. Water Resour. Res. 1992, 28, 1015–1031. [Google Scholar] [CrossRef]
- Duan, Q.; Gupta, V.K.; Sorooshian, S. Shuffled complex evolution approach for effective and efficient global minimization. J. Optim. Theory Appl. 1993, 76, 501–521. [Google Scholar] [CrossRef]
- Maier, H.R.; Simpson, A.R.; Zecchin, A.C.; Foong, W.K.; Phang, K.Y.; Seah, H.Y.; Tan, C.L. Ant colony optimization for design of water distribution systems. J. Water Resour. Plan. Manag. 2003, 129, 200–209. [Google Scholar] [CrossRef]
- Zecchin, A.C.; Simpson, A.R.; Maier, H.R.; Leonard, M.; Roberts, A.J.; Berrisford, M.J. Application of two ant colony optimization algorithms to water distribution system optimization. Math. Comput. Model. 2006, 44, 451–468. [Google Scholar] [CrossRef]
- Zecchin, A.C.; Maier, H.R.; Simpson, A.R.; Leonard, M.; Nixon, J.B. Ant colony optimization applied to water distribution system design: Comparative study of five algorithms. J. Water Resour. Plan. Manag. 2007, 133, 87–92. [Google Scholar] [CrossRef]
- Duan, Q.; Sorooshian, S.; Gupta, V.K. Optimal use of the SCE-UA global optimization method for calibrating watershed models. J. Hydrol. 1994, 158, 265–284. [Google Scholar] [CrossRef]
- Tolson, B.A.; Shoemaker, C.A. Dynamically dimensioned search algorithm for computationally efficient watershed model calibration. Water Resour. Res. 2007, 43. [Google Scholar] [CrossRef]
- Hansen, N.; Ostermeier, A. Completely derandomized self-adaptation in evolution strategies. Evol. Comput. 2001, 9, 159–195. [Google Scholar] [CrossRef] [PubMed]
- Hansen, N.; Müller, S.D.; Koumoutsakos, P. Reducing the time complexity of the derandomized evolution strategy with covariance matrix adaptation (CMA-ES). Evol. Comput. 2003, 11, 1–18. [Google Scholar] [CrossRef] [PubMed]
- Vrugt, J.A.; Robinson, B.A. Improved evolutionary optimization from genetically adaptive multimethod search. Proc. Natl. Acad. Sci. USA 2007, 104, 708–711. [Google Scholar] [CrossRef] [PubMed]
- Zhang, X.; Srinivasan, R.; Van Liew, M. On the use of multi-algorithm, genetically adaptive multi-objective method for multi-site calibration of the SWAT model. Hydrol. Process. 2010, 24, 955–969. [Google Scholar] [CrossRef]
- Liu, P.; Guo, S.; Xu, X.; Chen, J. Derivation of aggregation-based joint operating rule curves for cascade hydropower reservoirs. Water Resour. Manag. 2011, 25, 3177–3200. [Google Scholar] [CrossRef]
- Liu, P.; Cai, X.; Guo, S. Deriving multiple near-optimal solutions to deterministic reservoir operation problems. Water Resour. Res. 2011, 47. [Google Scholar] [CrossRef]
- Zhu, X.; Zhang, C.; Yin, J.; Zhou, H.; Jiang, Y. Optimization of water diversion based on reservoir operating rules—A case study of the Biliu River reservoir, China. J. Hydrol. Eng. 2014, 19, 411–421. [Google Scholar] [CrossRef]
- Arnold, J.G.; Srinivasan, R.; Muttiah, R.S.; Williams, J.R. Large area hydrologic modeling and assessment part I: Model development. J. Am. Water Resour. Assoc. 1998, 34, 73–89. [Google Scholar] [CrossRef]
- Neitsch, S.L.; Arnold, J.G.; Kiniry, J.R.; Williams, J.R. Soil and Water Assessment Tool User’s Manual-Version 2000; Texas Water Resources Institute: College Station, TX, USA, 2002; p. 412. [Google Scholar]
- Hao, F.; Cheng, H.; Yang, S. Non-Point Source Pollution Model; Environmental Science Press: Beijing, China, 2006. [Google Scholar]
- Moriasi, D.N.; Arnold, J.G.; van Liew, M.W.; Bingner, R.L.; Harmel, R.D.; Veith, T.L. Model evaluation guidelines for systematic quantification of accuracy in watershed simulations. Trans. ASABE 2007, 50, 885–900. [Google Scholar] [CrossRef]
- Luo, Y.; He, C.; Sophocleous, M.; Yin, Z.; Hongrui, R.; Ouyang, Z. Assessment of crop growth and soil water modules in SWAT2000 using extensive field experiment data in an irrigation district of the Yellow River Basin. J. Hydrol. 2008, 352, 139–156. [Google Scholar] [CrossRef]
- Behrangi, A.; Khakbaz, B.; Vrugt, J.A.; Duan, Q.; Sorooshian, S. Comment on “Dynamically dimensioned search algorithm for computationally efficient watershed model calibration” by Bryan A. Tolson and Christine A. Shoemaker. Water Resour. Res. 2008, 44. [Google Scholar] [CrossRef]
- Tolson, B.A.; Shoemaker, C.A. Reply to comment on “Dynamically dimensioned search algorithm for computationally efficient watershed model calibration” by Ali Behrangi et al. Water Resour. Res. 2008, 44. [Google Scholar] [CrossRef]
© 2015 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chu, J.; Peng, Y.; Ding, W.; Li, Y. A Heuristic Dynamically Dimensioned Search with Sensitivity Information (HDDS-S) and Application to River Basin Management. Water 2015, 7, 2214-2238. https://doi.org/10.3390/w7052214
Chu J, Peng Y, Ding W, Li Y. A Heuristic Dynamically Dimensioned Search with Sensitivity Information (HDDS-S) and Application to River Basin Management. Water. 2015; 7(5):2214-2238. https://doi.org/10.3390/w7052214
Chicago/Turabian StyleChu, Jinggang, Yong Peng, Wei Ding, and Yu Li. 2015. "A Heuristic Dynamically Dimensioned Search with Sensitivity Information (HDDS-S) and Application to River Basin Management" Water 7, no. 5: 2214-2238. https://doi.org/10.3390/w7052214
APA StyleChu, J., Peng, Y., Ding, W., & Li, Y. (2015). A Heuristic Dynamically Dimensioned Search with Sensitivity Information (HDDS-S) and Application to River Basin Management. Water, 7(5), 2214-2238. https://doi.org/10.3390/w7052214