
Enhanced Landslide Risk Evaluation in Hydroelectric Reservoir Zones Utilizing an Improved Random Forest Approach

Abstract
1. Introduction
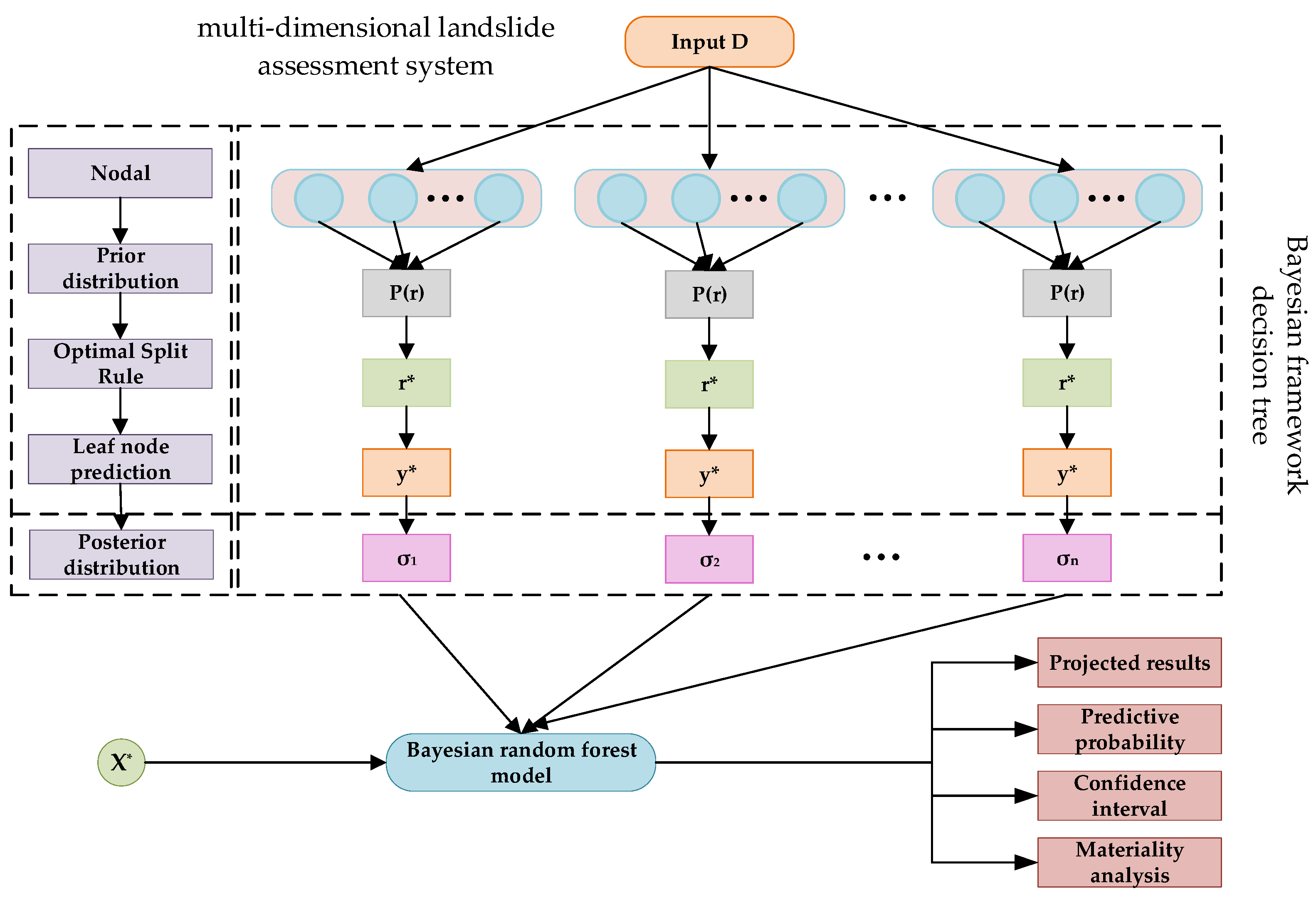
2. Modeling of Multidimensional Landslide Assessment System
2.1. Modeling Process
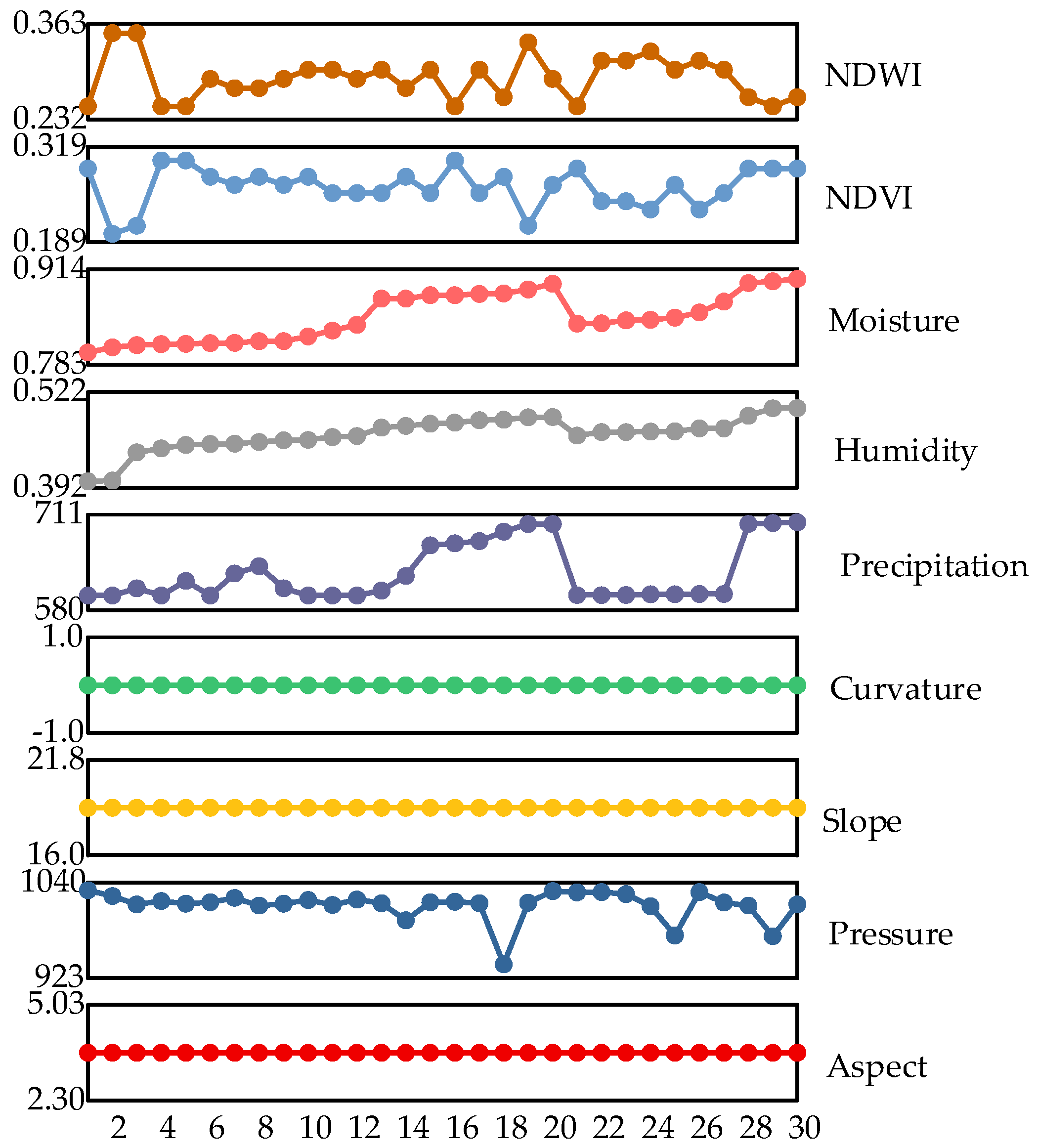
2.2. Selection of Assessment Indicators
2.3. Correlation Analysis
2.4. Sample Dataset Preprocessing
2.4.1. Outlier Detection
2.4.2. Data Sample Balance
3. Bayesian Random Forest for Slope Risk Assessment
3.1. Bayesian Random Forest Risk Assessment Model Structure
3.2. Characteristic Importance Analysis Methods
3.3. Risk Assessment Model Training
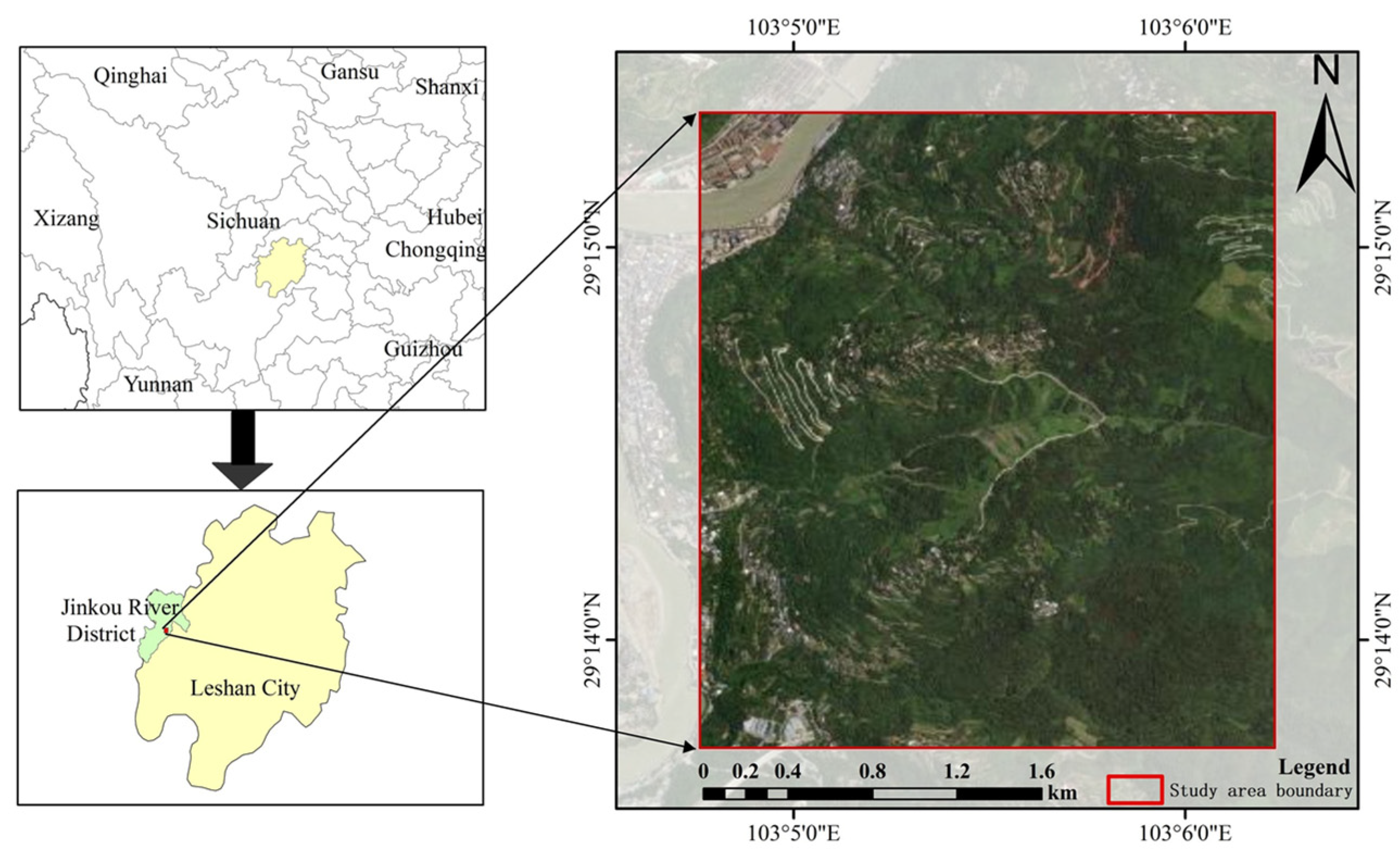
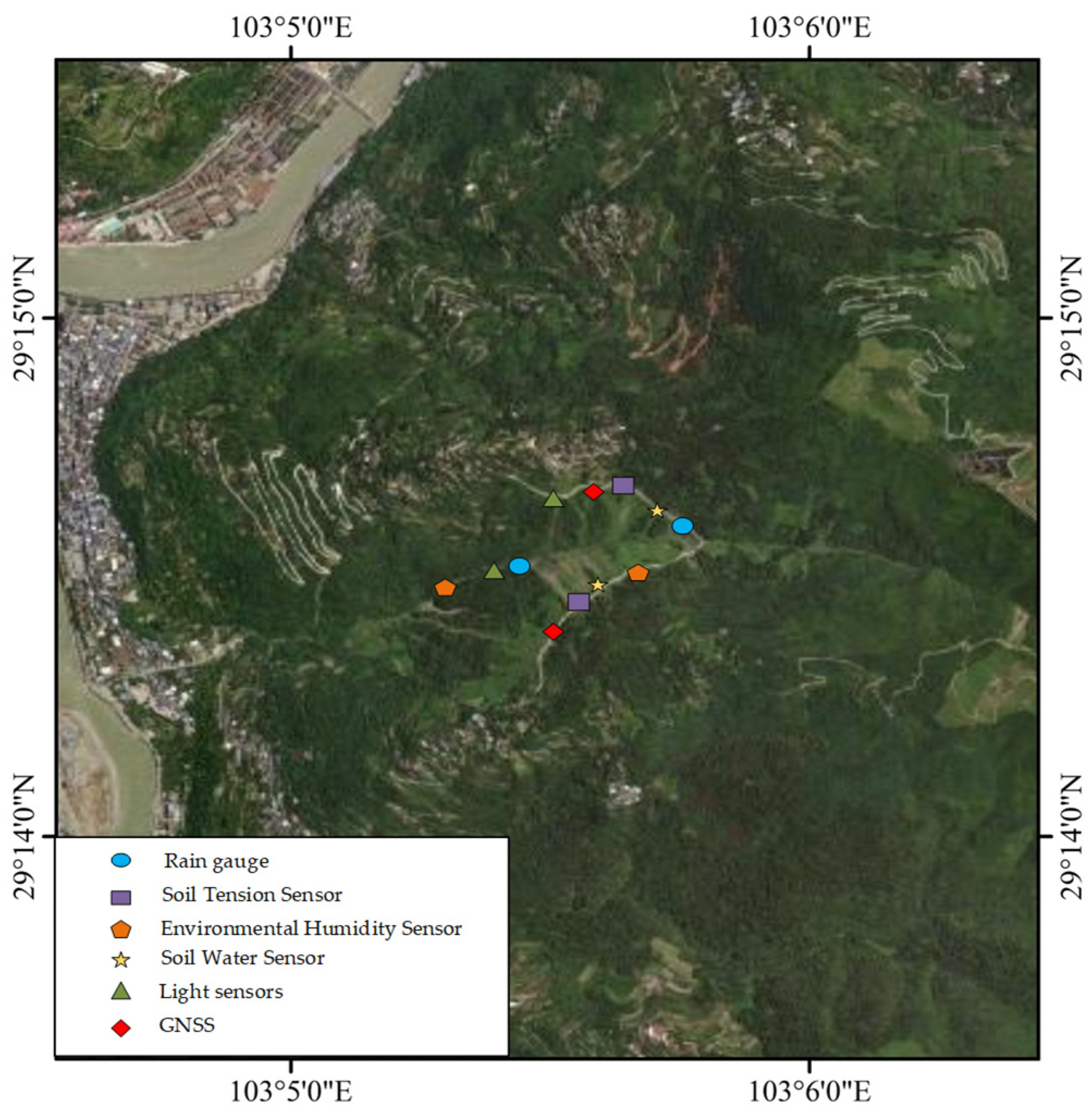
4. Application Testing and Analysis
4.1. Access to Evaluation Indicators
4.2. Example Assessment Results
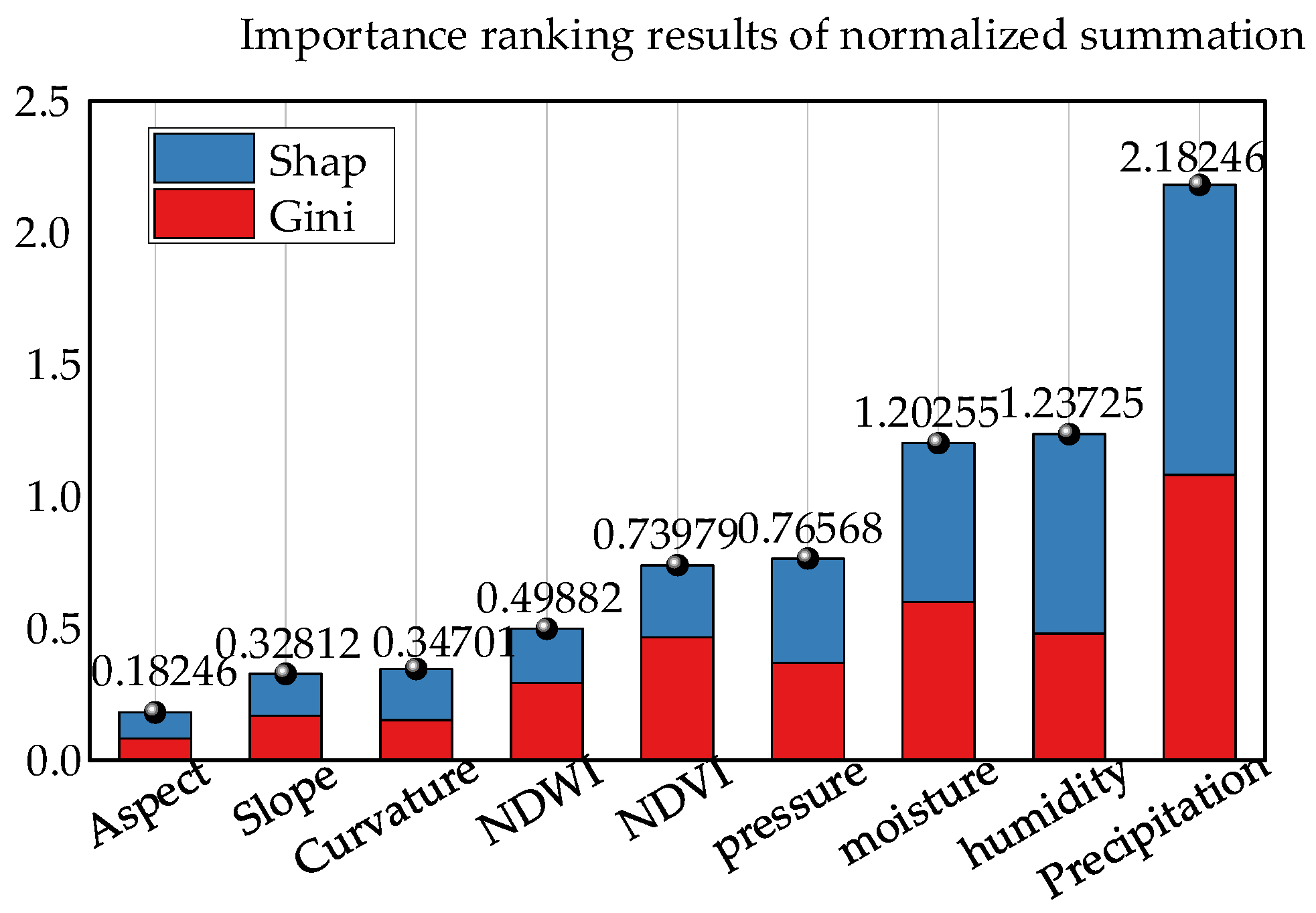
4.3. Characteristic Importance Analysis
5. Conclusions
- This study carried out a landslide risk assessment of hydropower station slopes, integrating meteorological and ecological data, and thoroughly investigated the multifaceted factors affecting slope stability. A multidimensional landslide risk assessment system covering geological conditions, meteorological conditions, and the ecological environment was established.
- In view of the complexity of the slope landslide system and the uncertainty of the prediction results, this study introduced a Bayesian statistical framework into a random forest model and established a Bayesian random forest model for slope landslide risk assessment. This model not only assessed and predicted the slope risk but also quantified the uncertainty of the model prediction results, which is of great significance for the development of risk strategies for hydropower stations.
- This study also analyzed feature importance using the Gini index and SHAP value, identified the key factors affecting the slope landslide risk, and provided a scientific basis and technical support for the safety management of hydropower station reservoir areas. A model was applied to the slopes of the hydropower station reservoir area in the Dadu River Basin, Southwest China, to verify its ability to accurately assess the slope landslide risk, which provides strong support for long-term slope risk management and prevention.
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Solarin, S.A.; Bello, M.O.; Olabisi, O.E. Toward sustainable electricity generation mix: An econometric analysis of the substitutability of nuclear energy and hydropower for fossil fuels in Canada. Int. J. Green Energy 2021, 18, 834–842. [Google Scholar] [CrossRef]
- Chu, S.J.; Dhakal, S.; Ou, C. Greening small hydropower: A brief review. Energy Strategy Rev. 2021, 36, 100676. [Google Scholar] [CrossRef]
- Bessa, R.; Moreira, C.; Silva, B. Role of pump hydro in electric power systems. J. Phys. Conf. Ser. 2017, 813, 012002. [Google Scholar] [CrossRef]
- Padmaja, S.B.; Reddy, G.; Reddy, E.S. Landslide stability analysis using mathematical approach. Mater. Today Proc. 2022, 51, 596–599. [Google Scholar] [CrossRef]
- Cai, F.; Ugai, K. Numerical Analysis of Rainfall Effects on Slope Stability. Int. J. Geomech. 2004, 4, 69–78. [Google Scholar] [CrossRef]
- Machay, F.; El Moussaoui, S.; El Talibi, H. Insights into large landslide mechanisms in tectonically active Agadir, Morocco: The significance of lithological, geomorphological, and soil characteristics. Sci. Afr. 2023, 22, e01901. [Google Scholar] [CrossRef]
- Alemdag, S.; Yalvaç, S.; Oršulić, O.B.; Kara, O.; Zeybek, H.I.; Bostanci, H.T.; Markovinović, D. Monitoring Surface Deformations in a Fossil Landslide Zone and Identifying Potential Failure Mechanisms: A Case Study of Gümüşhane State Hospital. Sensors 2024, 24, 4995. [Google Scholar] [CrossRef]
- Steger, S.; Moreno, M.; Crespi, A.; Gariano, S.L.; Brunetti, M.T.; Melillo, M.; Peruccacci, S.; Marra, F.; de Vugt, L.; Zieher, T.; et al. Adopting the margin of stability for space–time landslide prediction—A data-driven approach for generating spatial dynamic thresholds. Geosci. Front. 2024, 15, 101822. [Google Scholar] [CrossRef]
- Drakatos, G.; Paradissis, D.; Anastasiou, D.; Elias, P.; Marinou, A.; Chousianitis, K.; Papanikolaou, X.; Zacharis, E.; Argyrakis, P.; Papazissi, K.; et al. Joint approach using satellite techniques for slope instability detection and monitoring. Int. J. Remote Sens. 2013, 34, 1879–1892. [Google Scholar] [CrossRef]
- Leung, M.F.; Santos, J.R.; Haimes, Y.Y. Risk Modeling, Assessment, and Management of Lahar Flow Threat. Risk Anal. 2003, 23, 1323–1335. [Google Scholar] [CrossRef]
- Atkinson, P.; Massari, R. Generalized linear modelling of susceptibility to landsliding in the central Apennines, Italy. Comput. Geosci. 1998, 24, 373–385. [Google Scholar] [CrossRef]
- Chen, Y.; Liu, Y. Research on the Application of Dynamic Process Correlation Based on Radar Data in Mine Slope Sliding Early Warning. Sensors 2024, 24, 4976. [Google Scholar] [CrossRef]
- Oh, H.; Lee, S. Shallow Landslide Susceptibility Modeling Using the Data Mining Models Artificial Neural Network and Boosted Tree. Appl. Sci. 2017, 7, 1000. [Google Scholar] [CrossRef]
- Chih, Y.; Yuan, C. Semantic Segmentation of Satellite Images for Landslide Detection Using Foreground-Aware and Multi-Scale Convolutional Attention Mechanism. Sensors 2024, 24, 6539. [Google Scholar] [CrossRef]
- Xin, B.; Huang, Z. Ensemble Learning Improves the Efficiency of Microseismic Signal Classification in Landslide Seismic Monitoring. Sensors 2024, 24, 4892. [Google Scholar] [CrossRef]
- Bui, D.T.; Tsangaratos, P. Comparing the prediction performance of a Deep Learning Neural Network model with conventional machine learning models in landslide susceptibility assessment. Catena 2020, 188, 104426. [Google Scholar] [CrossRef]
- Ye, K.; Wang, Z. Deformation Monitoring and Analysis of Baige Landslide (China) Based on the Fusion Monitoring of Multi-Orbit Time-Series InSAR Technology. Sensors 2024, 24, 6760. [Google Scholar] [CrossRef]
- Yang, Y.; Zhao, Z. Identification and Analysis of the Geohazards Located in an Alpine Valley Based on Multi-Source Remote Sensing Data. Sensors 2024, 24, 4057. [Google Scholar] [CrossRef]
- Jiang, N.; Li, H.-B.; Li, C.-J.; Xiao, H.-X.; Zhou, J.-W. A fusion method using terrestrial laser scanning and unmanned aerial vehicle photogrammetry for landslide deformation monitoring under complex terrain conditions. IEEE Trans. Geosci. Remote Sens. 2022, 60, 4707214. [Google Scholar] [CrossRef]
- Bao, X.; Jiang, Y.; Zhang, L.; Liu, B.; Chen, L.; Zhang, W.; Xie, L.; Liu, X.; Qu, F.; Wu, R. Accurate Prediction of Dissolved Oxygen in Perch Aquaculture Water by DE-GWO-SVR Hybrid Optimization Model. Appl. Sci. 2024, 14, 856. [Google Scholar] [CrossRef]
- Wu, R.; Qi, J.; Li, W. Landscape genomics analysis provides insights into future climate change-driven risk in rhesus macaque. Sci. Total Environ. 2023, 899, 165746. [Google Scholar] [CrossRef] [PubMed]
- Zou, D.; Xiang, Y.; Zhou, T. Outlier detection and data filling based on KNN and LOF for power transformer operation data classification. Energy Rep. 2023, 9, 698–711. [Google Scholar] [CrossRef]
- Fang, Z.; Zhang, F. Strip Steel Defect Prediction Based on Improved Immune Particle Swarm Optimisation–Improved Synthetic Minority Oversampling Technique–Stacking. Appl. Sci. 2024, 14, 5849. [Google Scholar] [CrossRef]
- Weidner, L.; Walton, G. Generalized Extraction of Bolts, Mesh, and Rock in Tunnel Point Clouds: A Critical Comparison of Geometric Feature-Based Methods Using Random Forest and Neural Networks. Remote Sens. 2024, 16, 4466. [Google Scholar] [CrossRef]
- Masuda, A.; Matsuodani, T. Knowledge of Time-bin Data Selection using Gini Index based Type Classification in GitHub. Procedia Comput. Sci. 2022, 207, 1783–1791. [Google Scholar] [CrossRef]
- Luo, Z.; Qi, X. Investigation of influential variations among variables in daylighting glare metrics using machine learning and SHAP. Build. Environ. 2024, 254, 111394. [Google Scholar] [CrossRef]
- Zhang, B.; Zhao, P. Acceleration model of online educational games based on improved ensemble ML algorithm. Entertain. Comput. 2024, 50, 100654. [Google Scholar] [CrossRef]
- Li, X.; Zhou, S. CNN-BiGRU sea level height prediction model combined with bayesian optimization algorithm. Ocean Eng. 2024, 315, 119849. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Type of Indicator | Indicator | Mathematical Unit | Empirical Results |
|---|---|---|---|
| Geologic factors | Slope direction | / | 1–8 |
| Pressure | KPa | −50–1200 | |
| Slope gradient | % | 0–1 | |
| Curvature | rad/m | 0–1 | |
| Meteorological factors | Precipitation | mm | 0–1000 |
| Humidity | % | 0–1 | |
| Moisture | % | 0–1 | |
| Ecological factors | NDVI | / | −1–1 |
| NDWI | / | −1–1 |
| Percentage | Accuracy | Train Time/s | Percentage | Accuracy | Train Time/s | Percentage | Accuracy | Train Time/s |
|---|---|---|---|---|---|---|---|---|
| 0.9 | 0.9069 | 12.7639 | 0.6 | 0.8869 | 6.3445 | 0.3 | 0.8472 | 5.4732 |
| 0.8 | 0.9374 | 8.5481 | 0.5 | 0.8691 | 6.1206 | 0.2 | 0.8268 | 5.3219 |
| 0.7 | 0.9227 | 7.1437 | 0.4 | 0.8632 | 5.9572 | 0.1 | 0.7570 | 5.0207 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wei, A.; Ke, H.; He, S.; Jiang, M.; Yao, Z.; Yi, J. Enhanced Landslide Risk Evaluation in Hydroelectric Reservoir Zones Utilizing an Improved Random Forest Approach. Water 2025, 17, 946. https://doi.org/10.3390/w17070946
Wei A, Ke H, He S, Jiang M, Yao Z, Yi J. Enhanced Landslide Risk Evaluation in Hydroelectric Reservoir Zones Utilizing an Improved Random Forest Approach. Water. 2025; 17(7):946. https://doi.org/10.3390/w17070946
Chicago/Turabian StyleWei, Aichen, Hu Ke, Shuni He, Mingcheng Jiang, Zeying Yao, and Jianbo Yi. 2025. "Enhanced Landslide Risk Evaluation in Hydroelectric Reservoir Zones Utilizing an Improved Random Forest Approach" Water 17, no. 7: 946. https://doi.org/10.3390/w17070946
APA StyleWei, A., Ke, H., He, S., Jiang, M., Yao, Z., & Yi, J. (2025). Enhanced Landslide Risk Evaluation in Hydroelectric Reservoir Zones Utilizing an Improved Random Forest Approach. Water, 17(7), 946. https://doi.org/10.3390/w17070946