1. Introduction
Reference Evapotranspiration hereinafter referred to as evaporation plays a critical role in the hydrological cycle, where water transforms from liquid to vapor through heat energy input. Managing limited water resources sustainably, especially amidst rapid population growth, is increasingly crucial for agricultural production [
1]. Evaporation uses up a large amount of the water supplies accessible in hot regions by contributing considerably to water loss from rivers, canals, and open-water bodies. Even in humid areas, evaporation is still important, albeit accumulating precipitation, especially during rainy seasons, may dominate it. Additionally, the rate of evaporation plays a crucial role in understanding climate change and global warming, as it accounts for a significant portion of global precipitation loss [
2].
Understanding the magnitude and variability of evaporation losses is essential for designing and managing water resources effectively [
3]. Reliable models are necessary to quantify these losses accurately, especially as water resources become scarcer. Water resource development projects and irrigation systems rely heavily on long-term average values of evaporation for their design and operation [
4]. As a result, an accurate evaporation calculation is essential to guaranteeing the sustainable and effective management of water resources. In addition to machine learning-based models, another widely used approach for measuring evaporation is the Penman evaporation equation, which combines energy balance and aerodynamic principles to estimate evaporation from a surface. This method accounts for factors such as the temperature, solar radiation, wind speed, and humidity. A recent study by [
5] applied the Penman equation in the context of rainwater harvesting systems for ablution purposes, highlighting its feasibility and accuracy in predicting evaporation rates.
Evaporation rates are affected by various meteorological factors, such as maximum and minimum temperatures, sunshine duration or solar radiation, wind speed, relative humidity, rainfall, and vapor pressure, which are specific to each location [
6]. However, continuously and accurately measuring pan evaporation is difficult. In these cases, stochastic or neural network models are vital for estimating pan evaporation from available climatic data, often producing more reliable results than direct measurements [
7]. Since a direct evaporation measurement using evaporation pans is costly and inconvenient due to the experimental setup and logistical issues, evaporation is typically estimated through regression-based methods or other parametric models like Empirical Evaporation Equations, as well as the Water-Budget and Energy-Budget methods [
8].
Researchers have developed various models for predicting evaporation pan evaporation across different locations in this globe. Numerous evaporation forecasting techniques currently in use are based on empirical correlations derived from climatological parameters or deterministic principles, such as the integrated energy balance-vapor transfer approach. These approaches often require rigorous local calibration, which limits their applicability on a global scale [
9]. To recognize these limitations, there is a growing need to enhance conventional modeling techniques to achieve a better performance by adopting new and advanced methods.
Evaporation is a complex process characterized by non-linear behavior, making it suitable for modeling using Artificial Neural Networks (ANNs). To anticipate evaporation data, artificial intelligence (AI) methods like support vector machines (SVM) and artificial neural networks (ANN) have been widely and successfully applied. A major benefit of these AI methods is their nonparametric nature, meaning they do not require prior knowledge of the relationships between input variables and output data. ANNs are capable of capturing complex patterns and relationships in data, which traditional methods may find difficult to handle [
10]. By leveraging ANNs, researchers aim to improve the accuracy and robustness of evaporation predictions across diverse geographical and climatic conditions. In summary, the evolution towards advanced modeling techniques like ANNs is driven by the desire to overcome the limitations of existing models, enhance the predictive accuracy, and enable the more effective management of water resources impacted by evaporation [
11].
Numerous researchers have developed various models using Artificial Neural Networks to predict pan evaporation in different regions around the world. For instance, Al-Sudan and Saleem [
7] demonstrated in their study the evaporation prediction by using machine learning techniques in Diyala in Iraq by using different models with five input variables; the results showed a prediction enhancement in terms of MAE and RMSE by 7.17% and 21.01%, 16.51% and 15.74%, and 23.14% and 26.64%, respectively. While Gohrbani et al. [
12] utilized a hybrid model of an artificial neural network to predict pan evaporation in northern Iran as a semi-arid region, the results show that an optimal MLP-FFA model outperforms the MLP and SVM model for both tested stations. For Talesh, a value of WI = 0.926, NS = 0.791, and RMSE = 1.007 mm day
−1 is obtained using the MLP-FFA model, compared with 0.912, 0.713, and 1.181 mm day
−1 (MLP) and 0.916, 0.726, and 1.153 mm day
−1 (SVM), whereas for Manjil, a value of WI = 0.976, NS = 0.922, and 1.406 mm day
−1 is attained that contrasts 0.972, 0.901, and 1.583 mm day
−1 (MLP) and 0.971, 0.893, and 1.646 mm day
−1 (SVM). Hamza [
13] used an artificial neural network to predict evaporation in the southern region of Iraq in Basrah as a semi-arid region and he used four input variables (temperature, rainfall, sunshine hours, and wind speed).
Konapala et al. [
1] examined seasonal hydro-climate regimes using a non-parametric analysis methodology. They assessed changes in the water availability brought on by simultaneous changes in the mean and seasonal precipitation and evaporation using precipitation and evaporation. Rai et al. [
14] used support vector machines, random forest approaches, multiple linear regression, multivariate adaptive regression splines, and weekly pan evaporation modeling. Statistical metrics including the coefficient of determination (R
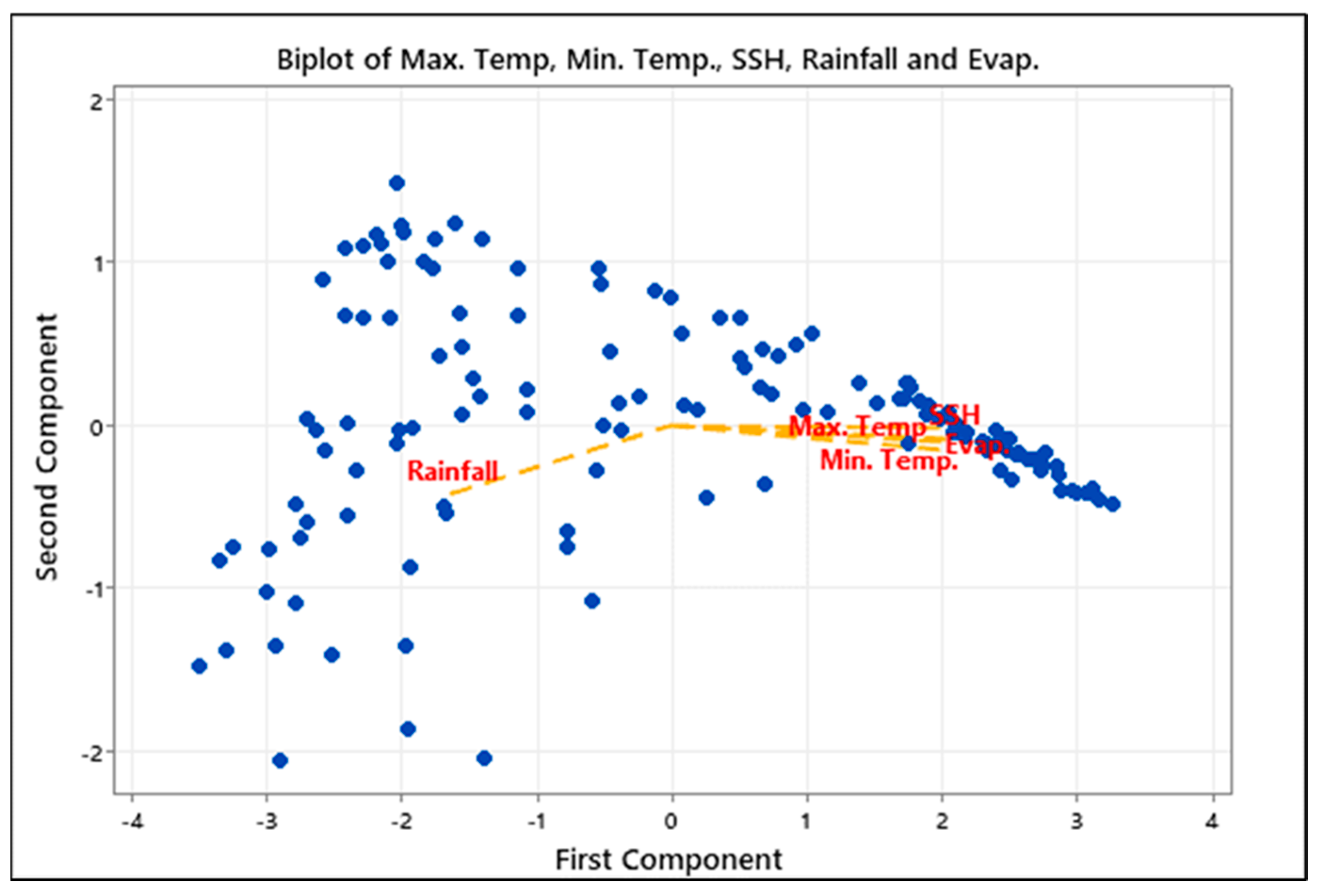
2), the Nash–Sutcliffe coefficient of efficiency (NSE), and root mean square error (RMSE) were used to assess the efficacy of weekly pan-evaporation-estimating models for the Ranichauri station, which is situated in Uttarakhand, India’s Mid-Himalayan area. Both under- and over-predicted outcomes can be seen in the weekly pan evaporation values. However, all these researchers utilized the pan evaporation prediction in different locations, but none of these studies utilized the evaporation prediction under the impact of climate change and a future projection. This study presents an original approach by employing and comparing three advanced machine learning models—a Multi-Layer Perceptron (MLP), Support Vector Machine (SVM), and Gaussian Process Regression (GPR)—which are integrated with climate projections and climatic scenarios. A unique aspect of this research is the incorporation of Principal Component Analysis (PCA) for dimensionality reduction, enhancing the accuracy and performance of the models. Principal Component Analysis (PCA) and Linear Discriminant Analysis (LDA) are both widely used dimensionality reduction techniques, but they differ significantly in their approach and objectives. PCA is an unsupervised technique, meaning it does not take into account any class labels when reducing dimensions. It aims to maximize the variance in the data by identifying principal components in orthogonal directions in which the data vary the most. PCA is particularly useful when the goal is to capture as much information (variance) as possible from the original dataset, irrespective of any classification or group membership. This study leverages five global climate models under two significant climate scenarios: Shared Socioeconomic Pathways (SSP2-4.5 and SSP5-8.5), providing a robust analysis of the potential impacts of climate change. The research focuses on the semi-arid region of Kirkuk, in northern Iraq, to predict evaporation rates under changing climate conditions, which has critical implications for water resource management in such vulnerable environments.
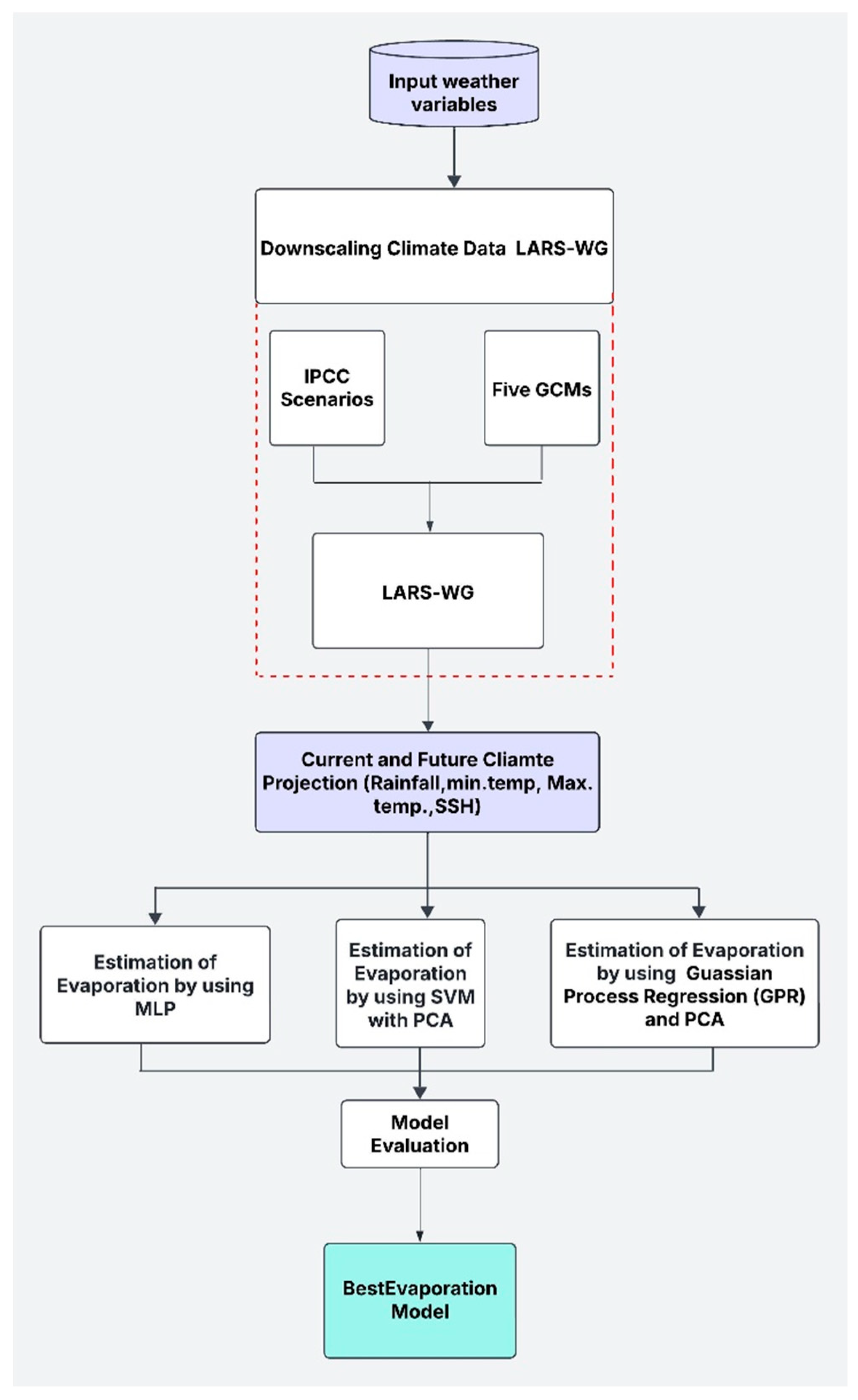
The comparative analysis of three sophisticated models (MLP, SVM, and GPR), in combination for this application with the integration of PCA with these models, improves the model efficiency and highlights the most important features influencing evaporation. The application of this advanced methodology integrated under two climate scenarios (SSP2-4.5 and SSP5-8.5) is specific to a semi-arid, climate-sensitive region (Kirkuk), offering valuable insights into climate change impacts on evaporation in arid environments. The main aim of this study is to predict evaporation under the impact of climate change by developing multiple models including MLP, SVM with PCA, and GPR with PCA under the impact of climate change and GCMs, and comparing these models and choosing the best model for the evaporation prediction. This paper is organized as follows:
Section 2 includes the climatic data and study region, then
Section 3 illustrates the methodology,
Section 4 the results and discussion, and finally,
Section 5 includes the conclusion.
3. Methodology
3.1. Input Data and Calibration
The study’s method for statistically downscaling future climate variables follows the approach outlined by [
16]. The downscaling employs statistical relationships between large-scale GCM outputs and local climate variables to produce high-resolution projections. This method assumes that historical climate data and large-scale atmospheric patterns (from GCMs) can be used to predict local future climate conditions based on the projected changes. Several statistical downscaling models, such as Nonhomogeneous Hidden Markov Models (NHMM), MarkSim GCM, and the Long Ashton Research Station Weather Generator (LARS-WG), have been identified [
17]. The sixth Assessment Report of the Intergovernmental Panel on Climate Change (IPCC AR6) uses data from the Coupled Model Intercomparison Project Phase 6 (CMIP6) (IPCC, 2023), which is incorporated into LARS-WG 8.0 [
18,
19]. Numerous tests have demonstrated that this model is successful in reproducing past climatic conditions in a variety of locations [
20].
Based on baseline parameters obtained from recorded weather data for the Kirkuk Governorate from 1980 to 2010, climate forecasts for future periods were generated [
21]. These projections were created using CMIP6 data from the LARS-WG version 8.0 weather generator. The five global climate models (GCMs), CSIRO-Mk3.6.0, HadGEM2-ES, CanESM2, MIROC5, and NorESM1-M, were chosen for the downscaling of future precipitation projections. These GCMs simulate how the Earth’s climate system will respond to increasing greenhouse gas concentrations, providing important insights into future climate changes. CSIRO-Mk3.6.0: developed by the Commonwealth Scientific and Industrial Research Organization (CSIRO), this model focuses on understanding the interaction between the atmosphere, oceans, and land, with a specific emphasis on Australian and regional climate impacts. HadGEM2-ES: Created by the UK Met Office, this model includes a fully coupled Earth system approach, simulating physical, chemical, and biological processes. It is particularly used for climate change projections across the globe.
CanESM2: developed by the Canadian Center for Climate Modeling and Analysis, CanESM2 is an Earth system model that integrates atmospheric, oceanic, and biogeochemical processes, providing climate projections for various regions, including Canada and beyond. MIROC5: The Model for Interdisciplinary Research on Climate (MIROC) is developed by Japan. MIROC5 focuses on the interaction between atmosphere, oceans, and sea ice and provides projections related to regional and global climate impacts. NorESM1-M: the Norwegian Earth System Model (NorESM1-M) is developed to understand climate change from both a regional and global perspective, particularly focusing on high-latitude regions like the Arctic. These GCMs were selected for downscaling future precipitation under two climate scenarios: SSP2-4.5 and SSP5-8.5, which are part of the Shared Socioeconomic Pathways (SSPs) framework.
The SSP framework represents different pathways of socioeconomic development, combined with varying levels of greenhouse gas (GHG) emissions, to project possible future climate conditions. This approach allows for the evaluation of the impacts of both moderate (SSP2-4.5) and more extreme (SSP5-8.5) warming scenarios on regional precipitation patterns.
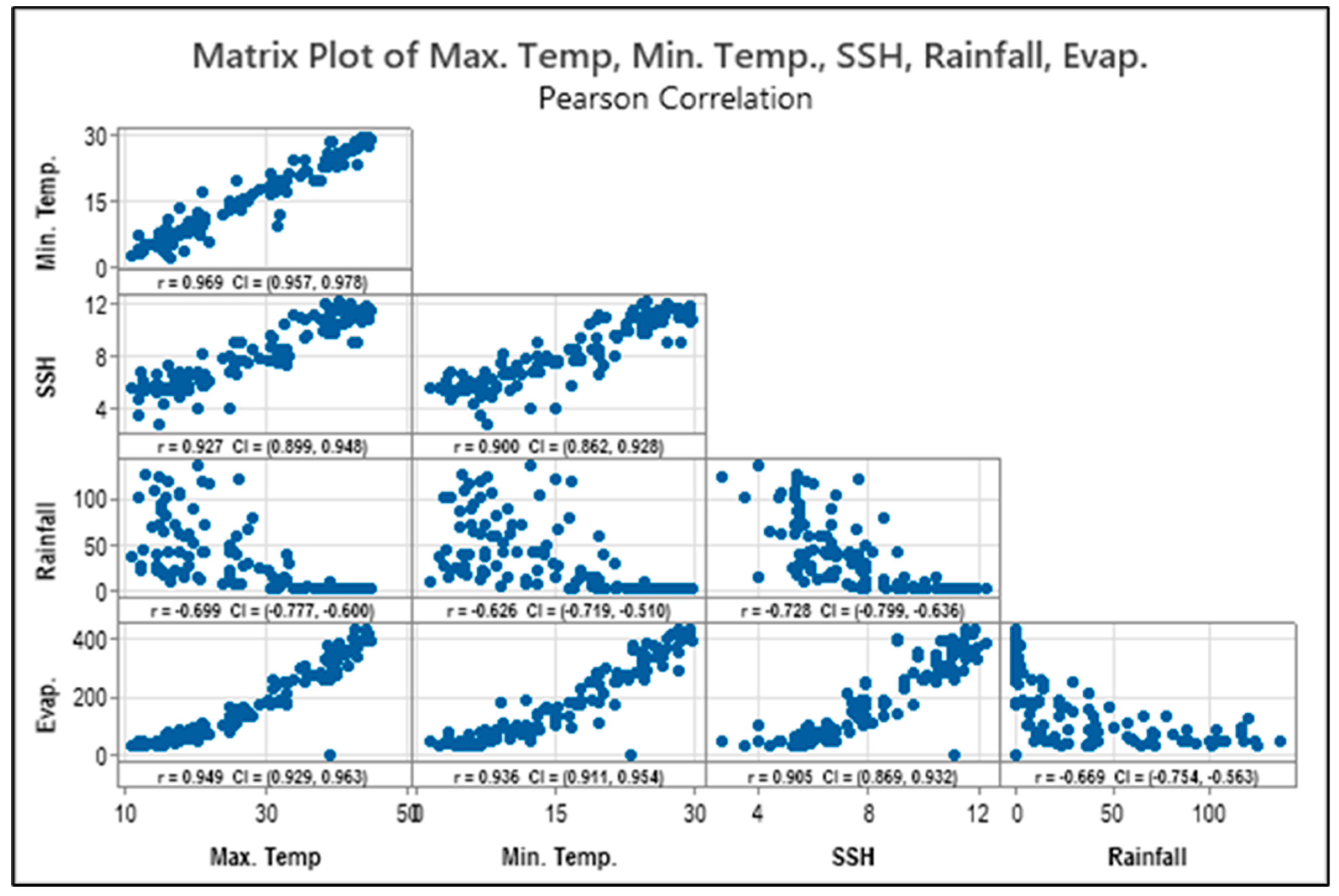
The input parameters used in this study are rainfall, minimum and maximum temperatures, and solar radiation (sunshine hours), which are utilized to predict evaporation for the same period. However, future predictions beyond 2022 and extending to 2100 are not solely based on historical data from 1980–2022. Instead, they are derived from climate projections using global and regional climate models (GCMs/RCMs) under different emission scenarios. Specifically, future climate data are generated based on Shared Socioeconomic Pathways (SSPs), including SSP2-4.5 and SSP5-8.5, which simulate future climate conditions under varying greenhouse gas emission levels.
These projected climate variables (rainfall, temperature, and solar radiation) serve as inputs into our model for estimating future evaporation rates. The model is first trained on historical data (1980–2022) to establish relationships between the input variables and evaporation. Once the model is trained, it uses the projected climate data from the SSP scenarios to predict evaporation rates for the period up to 2100.
For this study, all data were carefully calibrated, validated, and adjusted according to the specific conditions of the Kirkuk study area, following the methodology outlined in the study by [
19]. The validation process involved both graphical tests (based on mean and standard deviation) and statistical tests, including the
p-value and Kolmogorov–Smirnov (K-S) test, to ensure a close similarity between the measured and synthetic climate data.
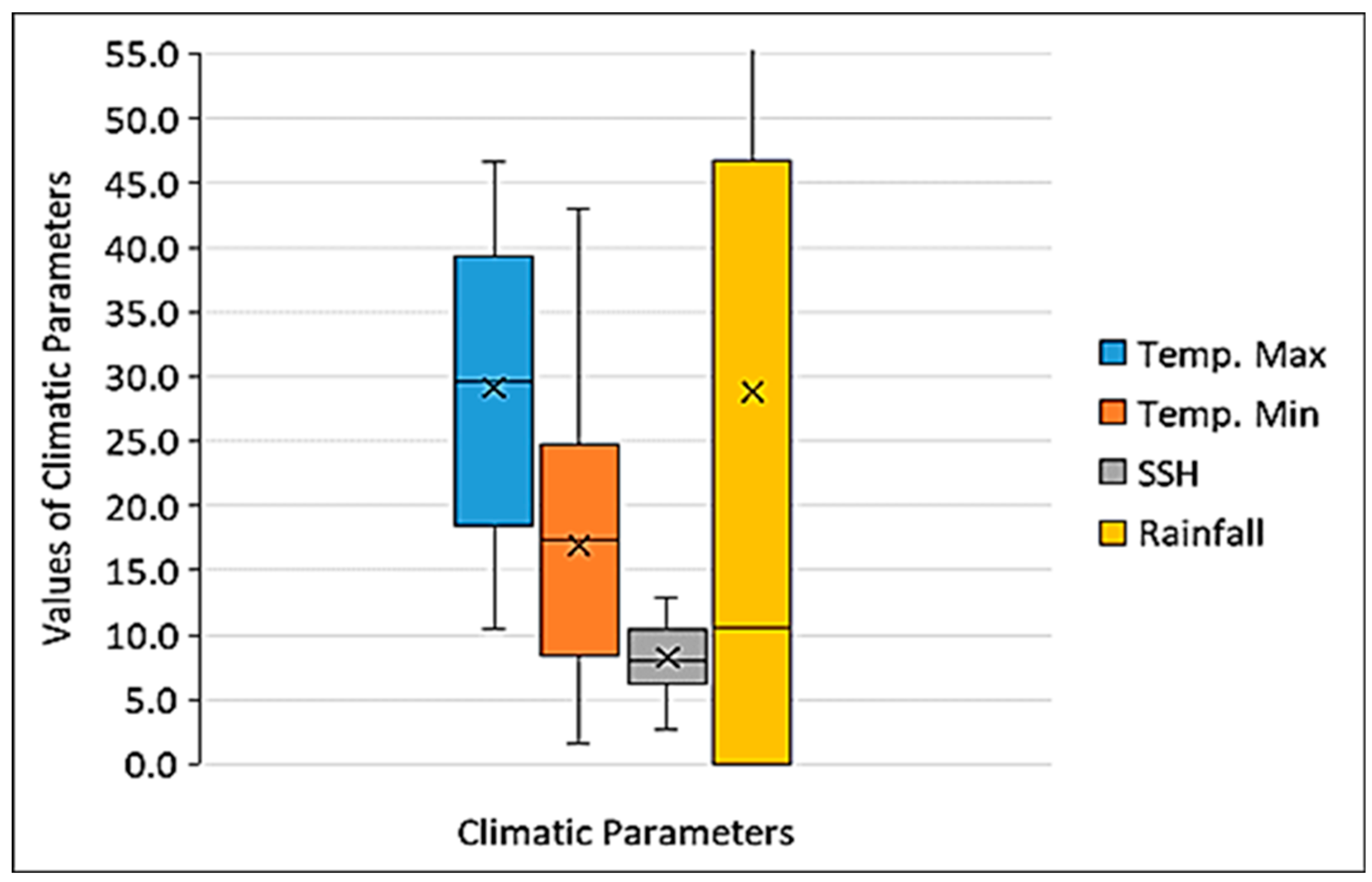
Figure 3 illustrates the study’s methodological framework, providing a comprehensive overview of the steps taken in the analysis. The model uses daily input parameters, including rainfall, minimum temperature (Tmin), maximum temperature (Tmax), and sunshine hours (SSH). These daily inputs are aggregated to produce monthly evaporation estimates, which serve as the output of the model. To account for variations in the number of days per month, the model dynamically adjusts by summing or averaging daily data depending on the context. This ensures that the input dimensions remain consistent and reliable across all months, providing accurate monthly evaporation predictions. The evaporation was calculated by using Penman–Monteith evaporation method for the monthly observed evaporation.
3.2. Multi-Layer Perceptron Neural Network
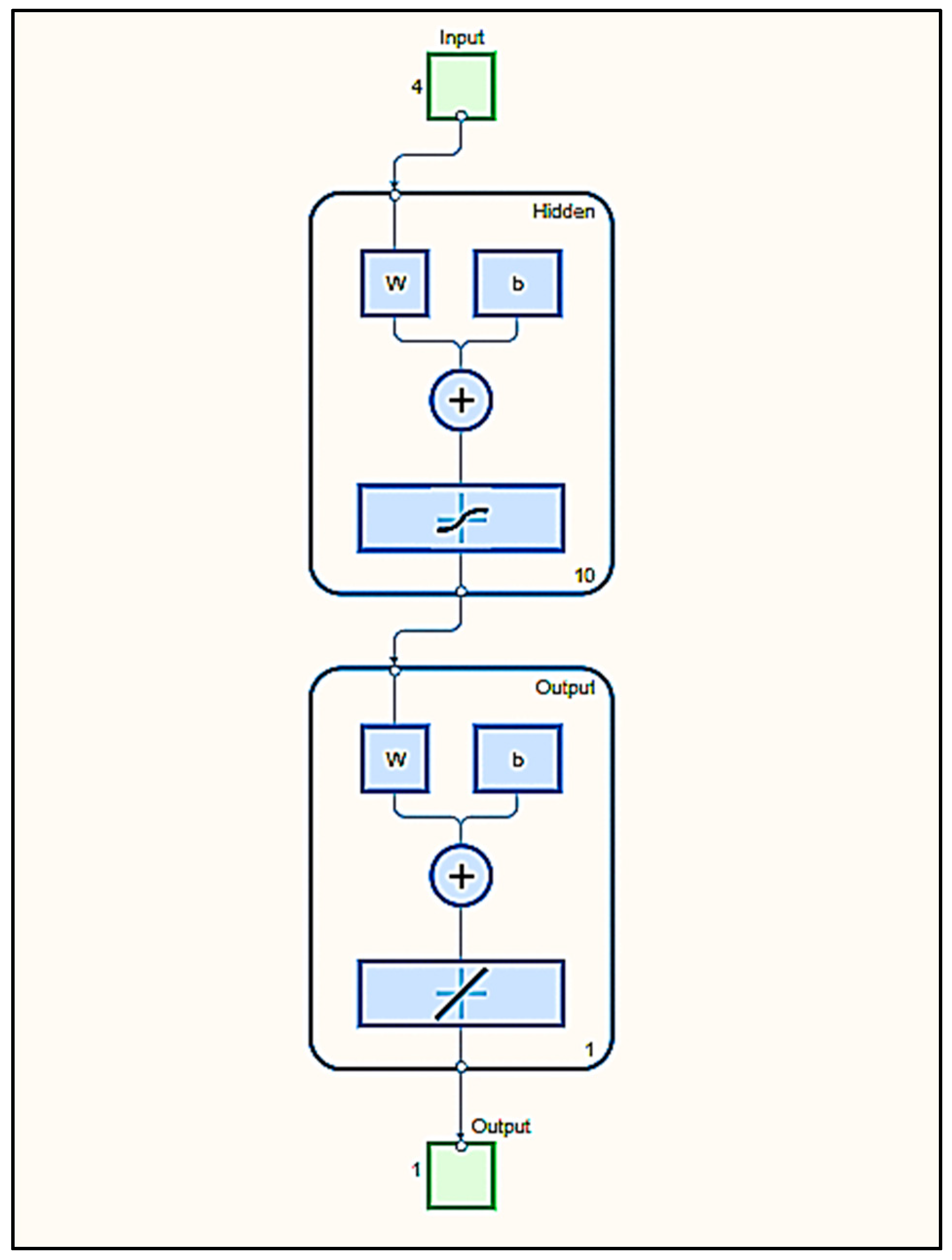
A multi-layer neural network, also known as a multi-layer perceptron (MLP), is an artificial neural network composed of multiple layers of interconnected nodes (neurons). Each node functions as a simple processing unit, and the network is designed to model complex relationships between inputs and outputs [
8]. A multi-layer perception consists of several interconnected layers of nodes (neurons), each acting as a simple processing element. The network’s architecture is defined by the number of layers and nodes per layer [
22]. These hidden layers contain neurons that serve as computational units, often described as the “black box” of the network due to their role in processing and transforming the input data through complex computations.
The architecture of an MLP is characterized by the connections between neurons, which are organized into a network of synaptic weights. Each of these weights signifies the strength of the connection between two neurons. A weight of zero indicates the absence of a connection, effectively isolating the neurons from each other.
Notably, connections between neurons are only formed between different layers; there are no intra-layer connections, meaning neurons within the same layer do not directly interact [
23]. This organized structure enables the network to learn patterns and make predictions based on the input data.
Each node (neuron) in the network computes an input (
Ij), which is the weighted sum of the outputs (
Oj) from the nodes in the preceding layer. Mathematically, this can be expressed as:
where
Wij represents the weight connecting node
i in the previous layer to node
j in the current layer.
Oi is the output of node
I in the preceding layer.
Figure 3 illustrates a classic MLP structure, providing a visual representation of this interconnected architecture.
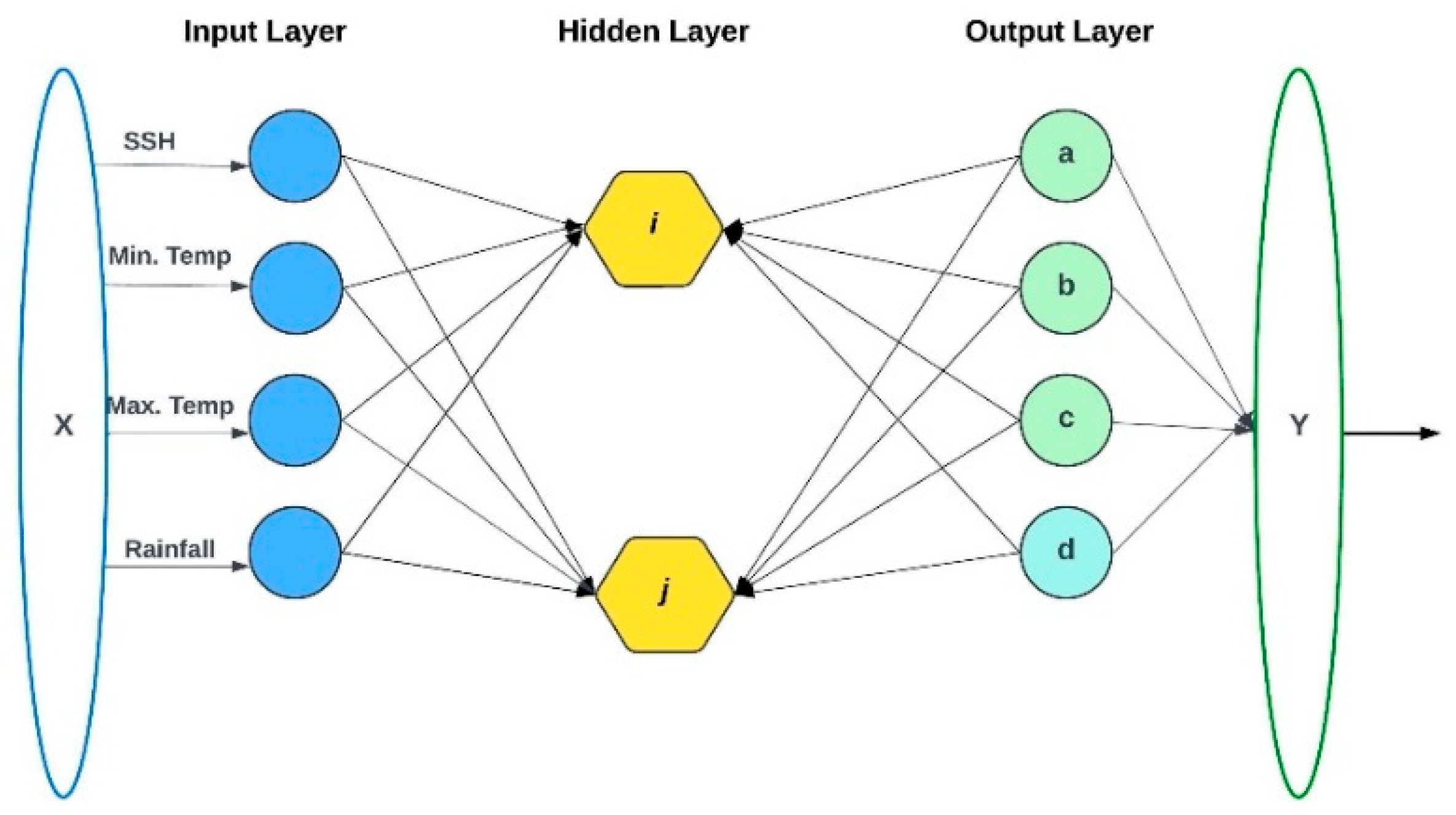
Figure 4 illustrates the input variables with hidden layers and output variables of MLP.
Figure 5 shows the training structure of input layers and a number of variables, the hidden layers, and output layers of the multi-layer perceptron neural network of this research study.
3.3. Support Vector Machine with PCA
SVM is a powerful tool that has been extensively applied to both classification and regression tasks due to its robustness and effectiveness. SVM is not only useful for classification, but also highly effective in regression problems, where it is referred to as Support Vector Regression (SVR). The key idea behind SVM is to find a function that best fits the data while maintaining a balance between model complexity and prediction accuracy. This balance is achieved by minimizing a loss function subject to certain constraints, ensuring that the predictions are as accurate as possible while avoiding overfitting [
24]. The SVM regression function can be expressed as:
where
w is the weight vector that defines the orientation of the hyperplane in the transformed feature space and
ϕ(
x) is a non-linear function that maps the input vector
x into a higher-dimensional space, allowing the model to handle non-linear relationships in the data, while
b is the bias term that adjusts the output to align with the target values. The objective of SVM in regression is to find the optimal weight vector
w and bias
b that minimize the prediction error while satisfying the margin constraints. The model tries to fit the best possible hyperplane (or line, in the case of linear regression) that lies within a predefined margin of tolerance for error. The model was combined with PCA to improve the results and minimize the error. This model was developed by using MATLAB software version 23.
3.4. Guassian Process Regression (GPR) and PCA
Gaussian Process Regression (GPR) is a non-parametric, Bayesian approach to regression that provides a probabilistic framework for modeling and predicting complex, non-linear relationships between input variables and outputs. Unlike traditional regression models, GPR offers flexibility by defining distribution over functions, allowing for the incorporation of prior knowledge and the estimation of uncertainty in predictions. The method relies on a kernel function to measure the similarity between data points, with common choices including the squared exponential and Matérn kernels [
25].
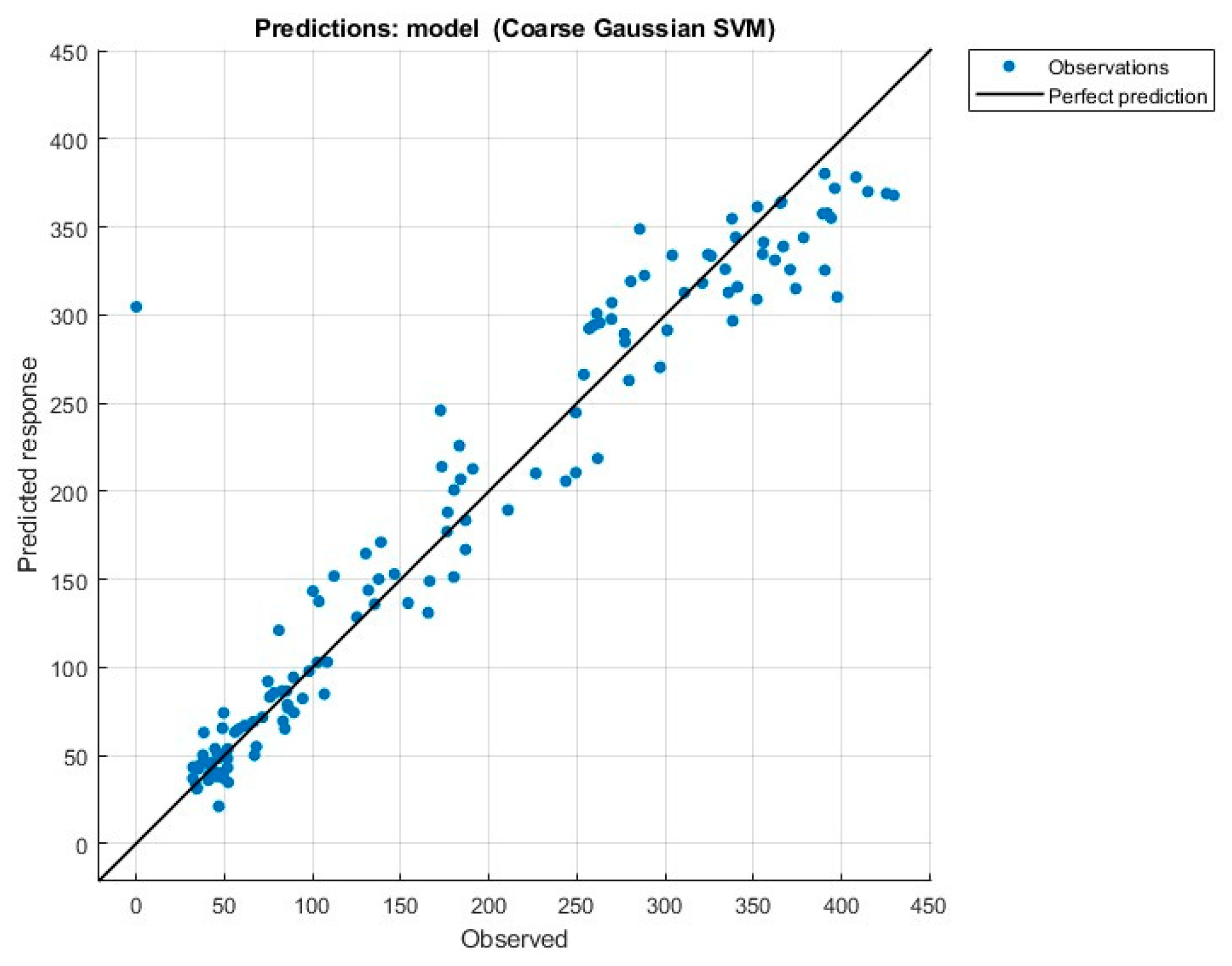
3.5. Model Evaluation and Performance
Several common statistical parameters were used to evaluate the model structures’ performance after they had been calibrated using the training dataset. According to Adamowski [
24], these standards are crucial for measuring model prediction mistakes and giving a precise indication of accuracy in subsequent forecasts [
25]. Several different statistical measurements, including the coefficient of correlation (
R), mean absolute error (
MAE), mean squared error (
MSE), and root mean squared error (
RMSE), will be used in the model calibration. Equations (3)–(6) provide a summary of these indications.
where
N is the sample size,
xo stands for observed water consumption,
xp for expected water demand,
for the mean of predicted demand, and
for the mean of observed consumption.
To estimate future evaporation, the projected climate data from the downscaled model are applied to an MLP. It is assumed that the model parameters, such as weights and the number of MLP neurons, remain constant in the future.
5. Conclusions
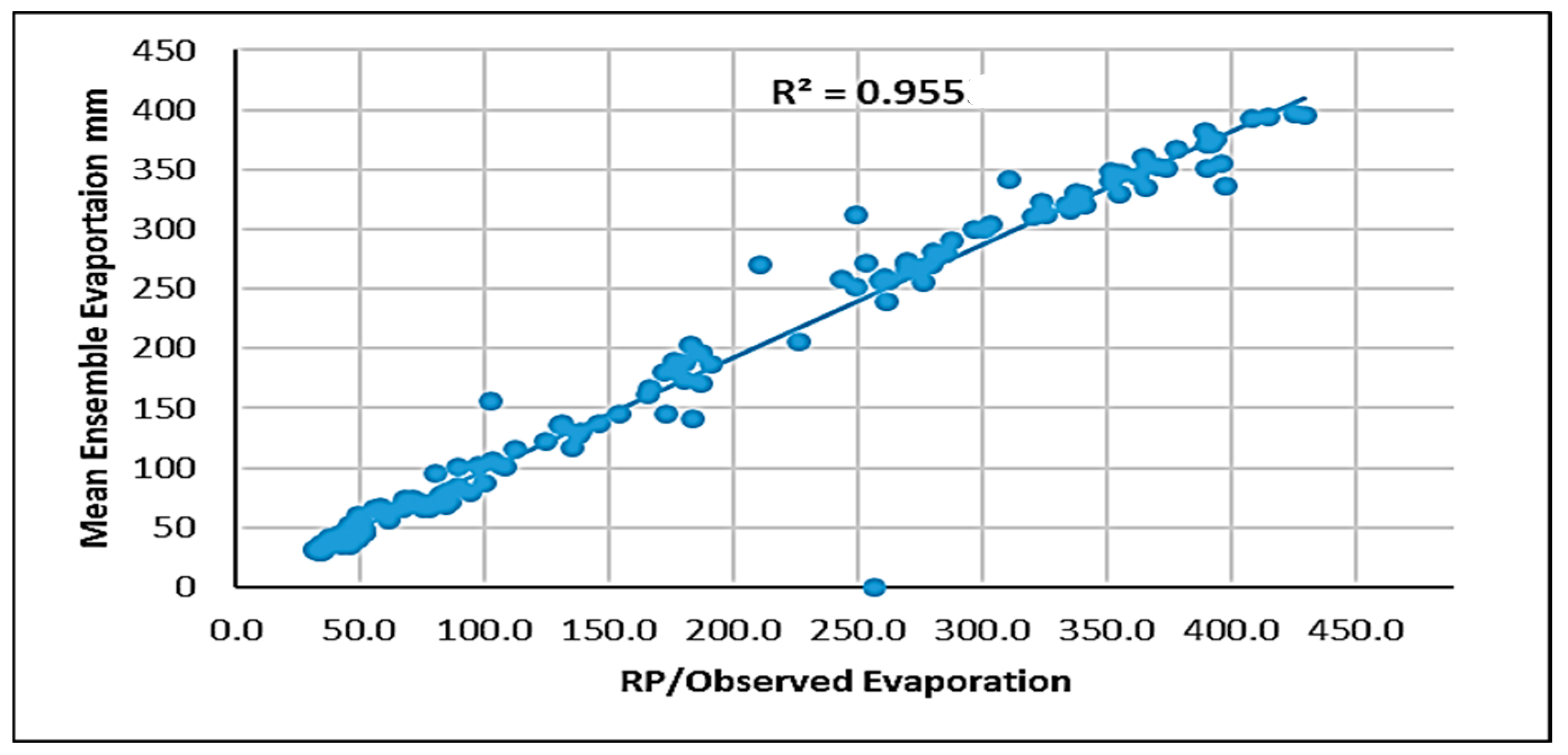
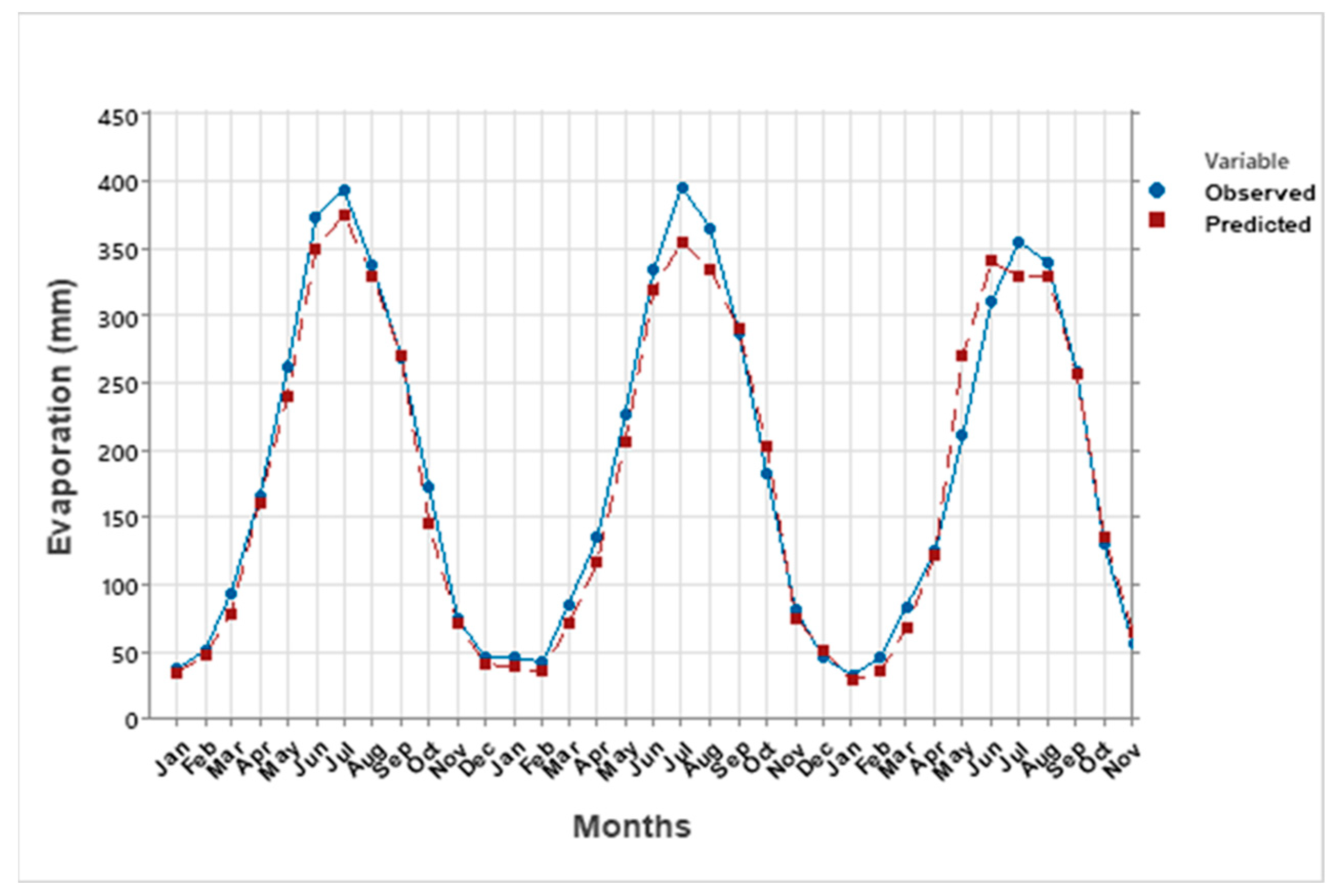
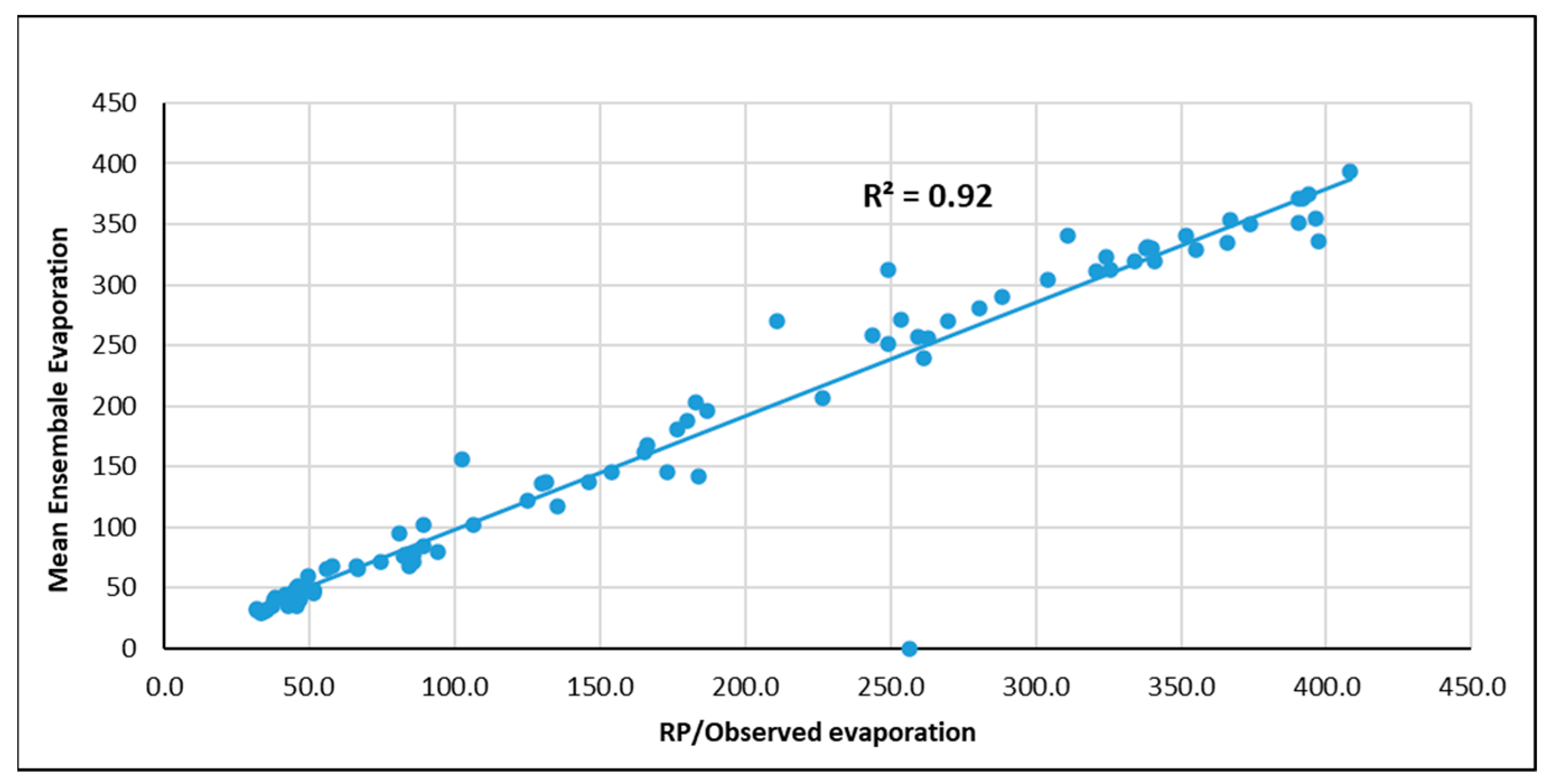
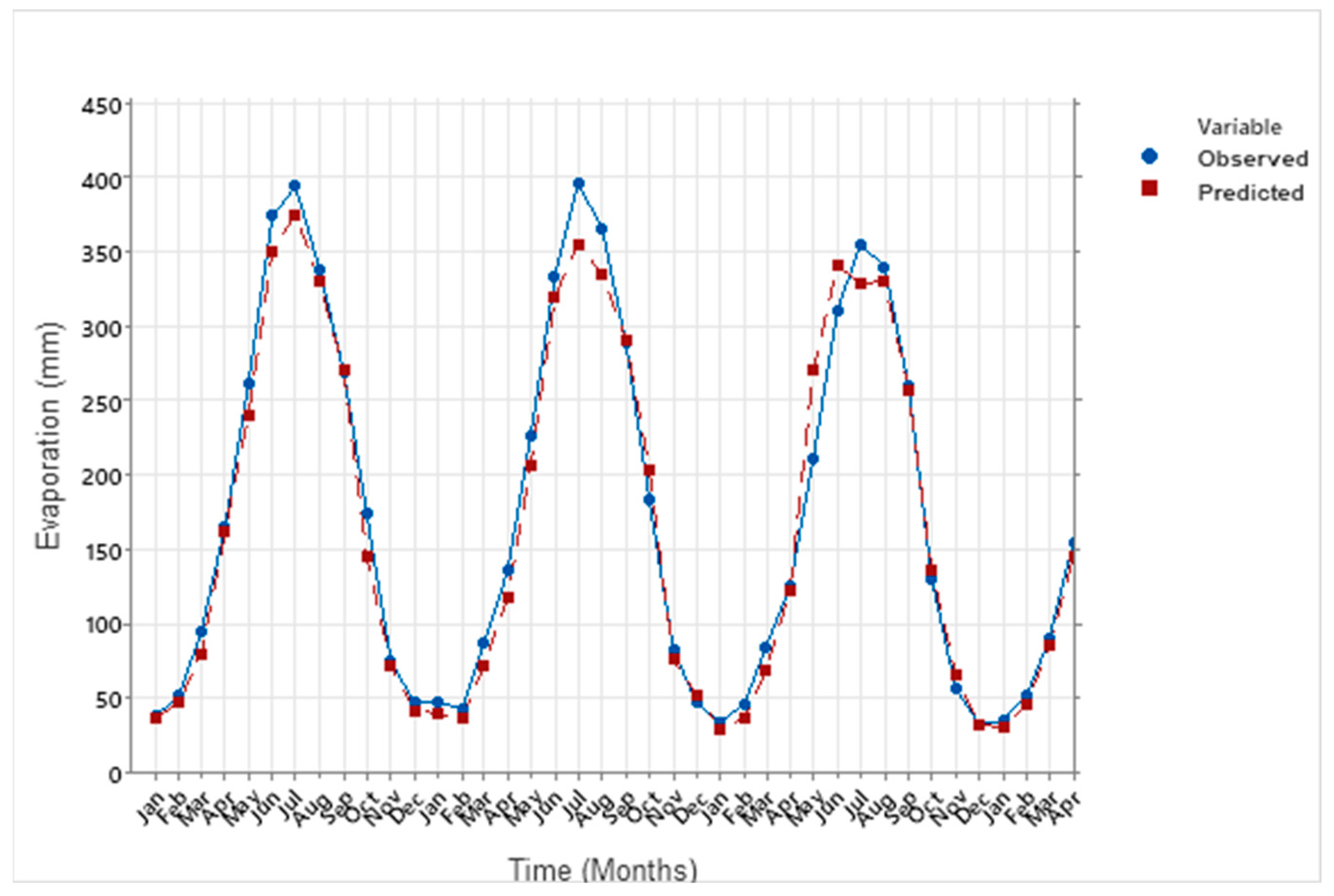
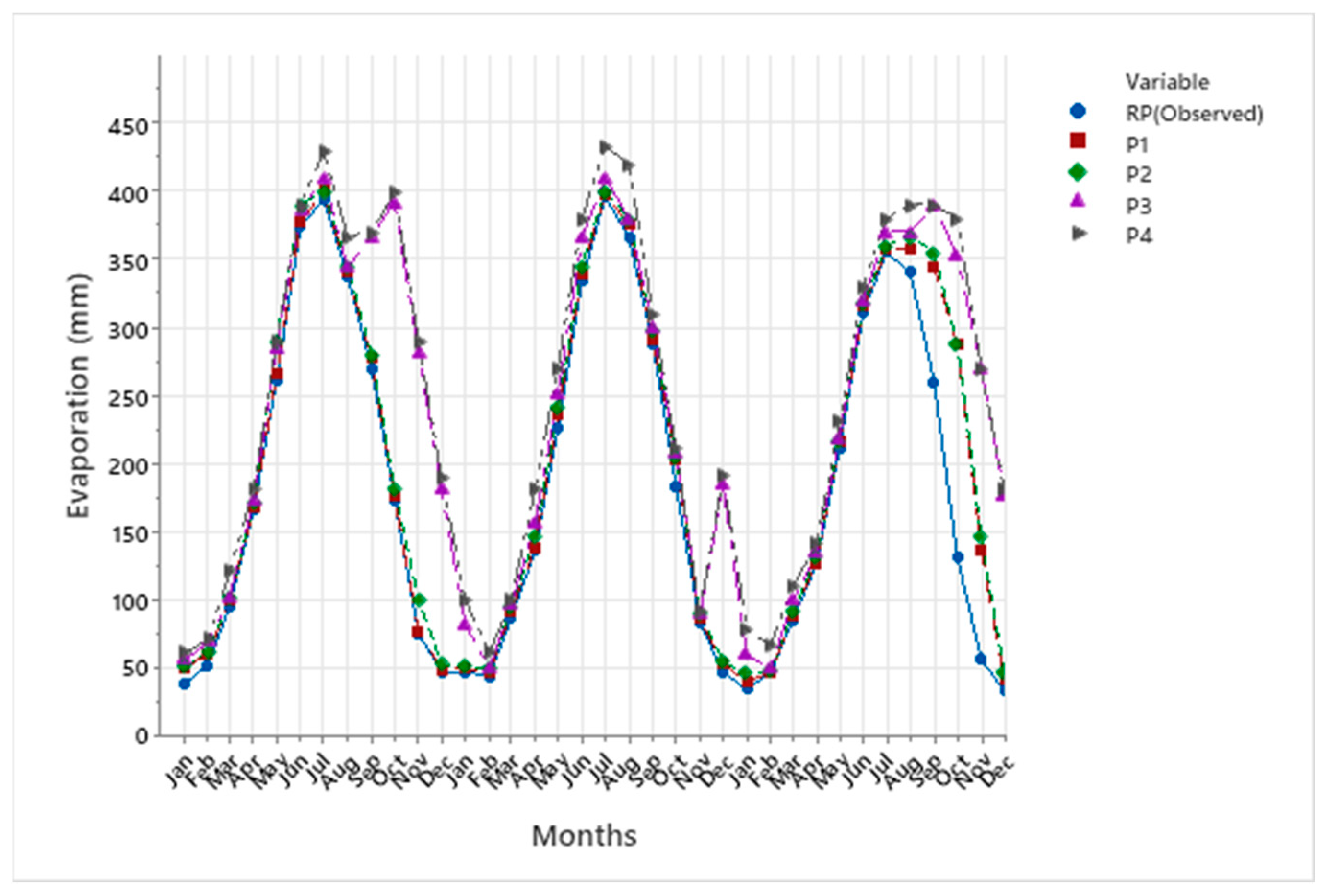
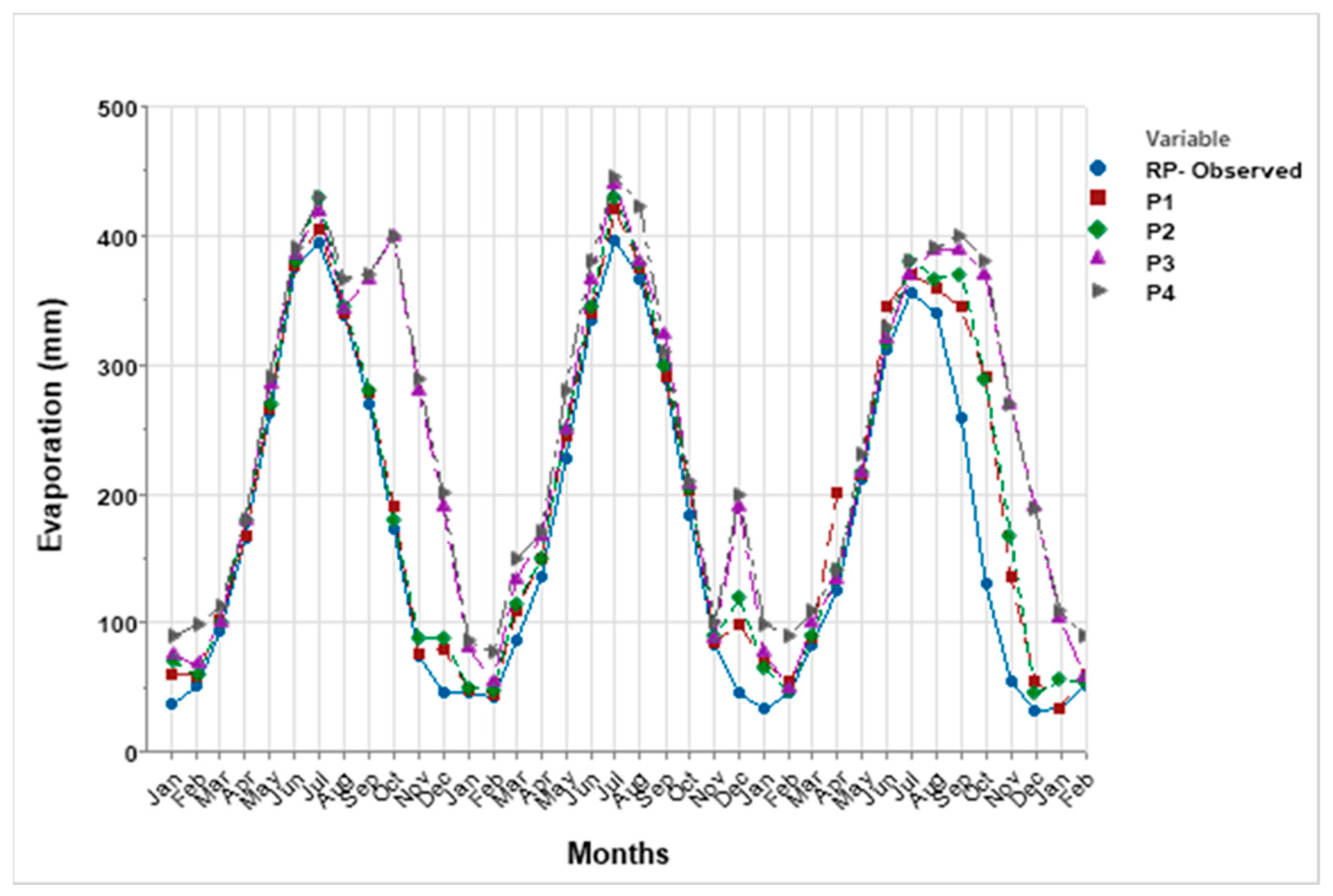
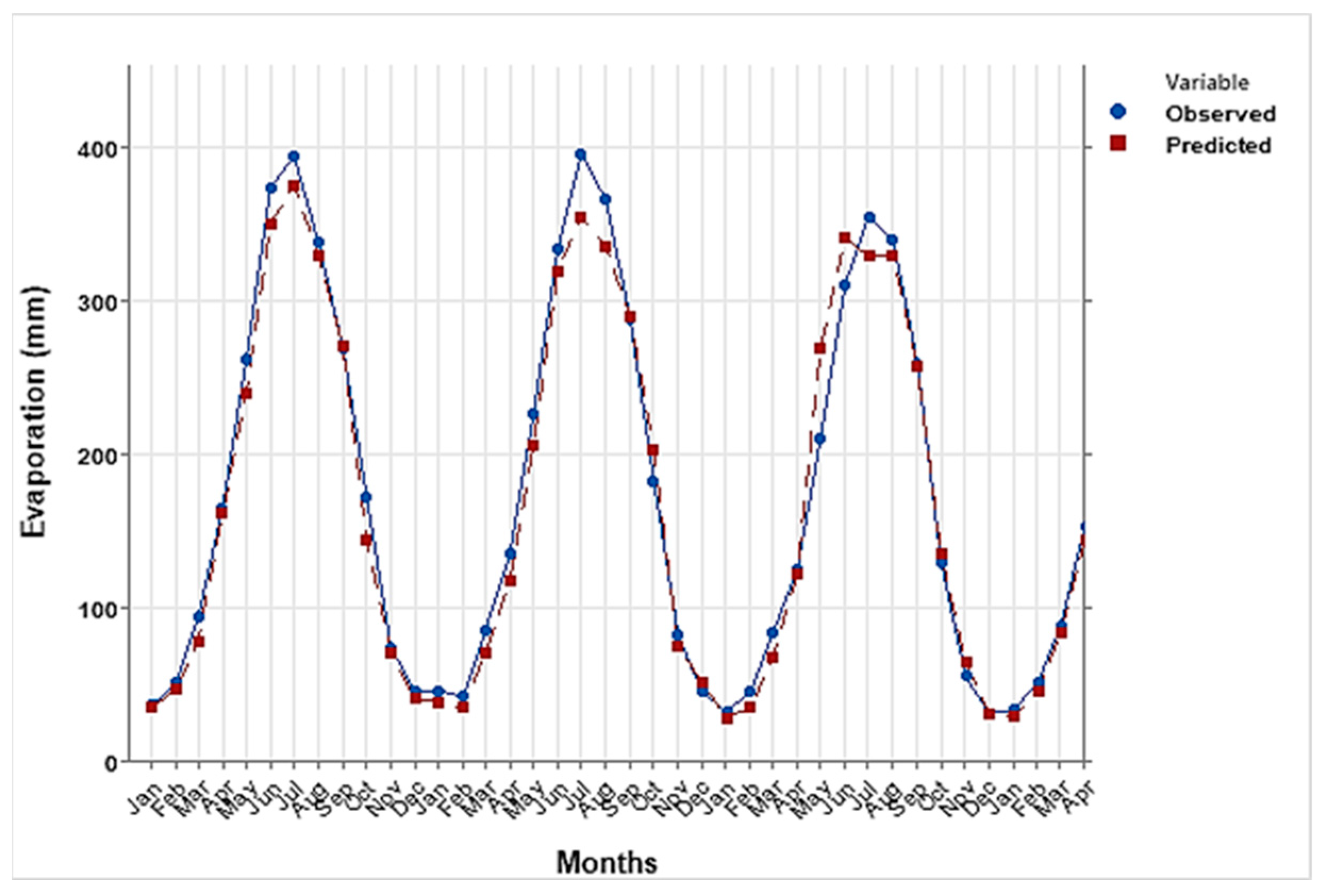
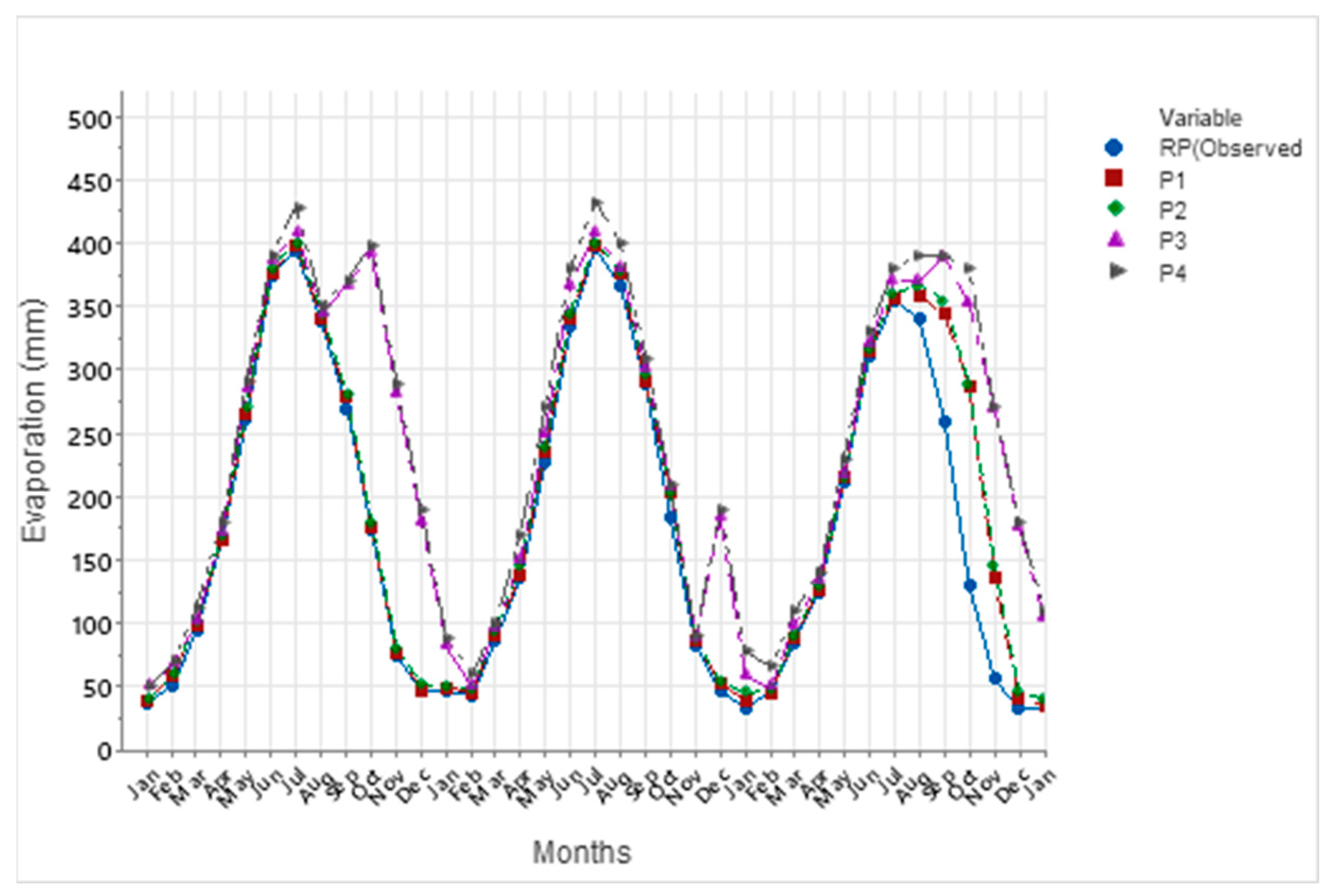
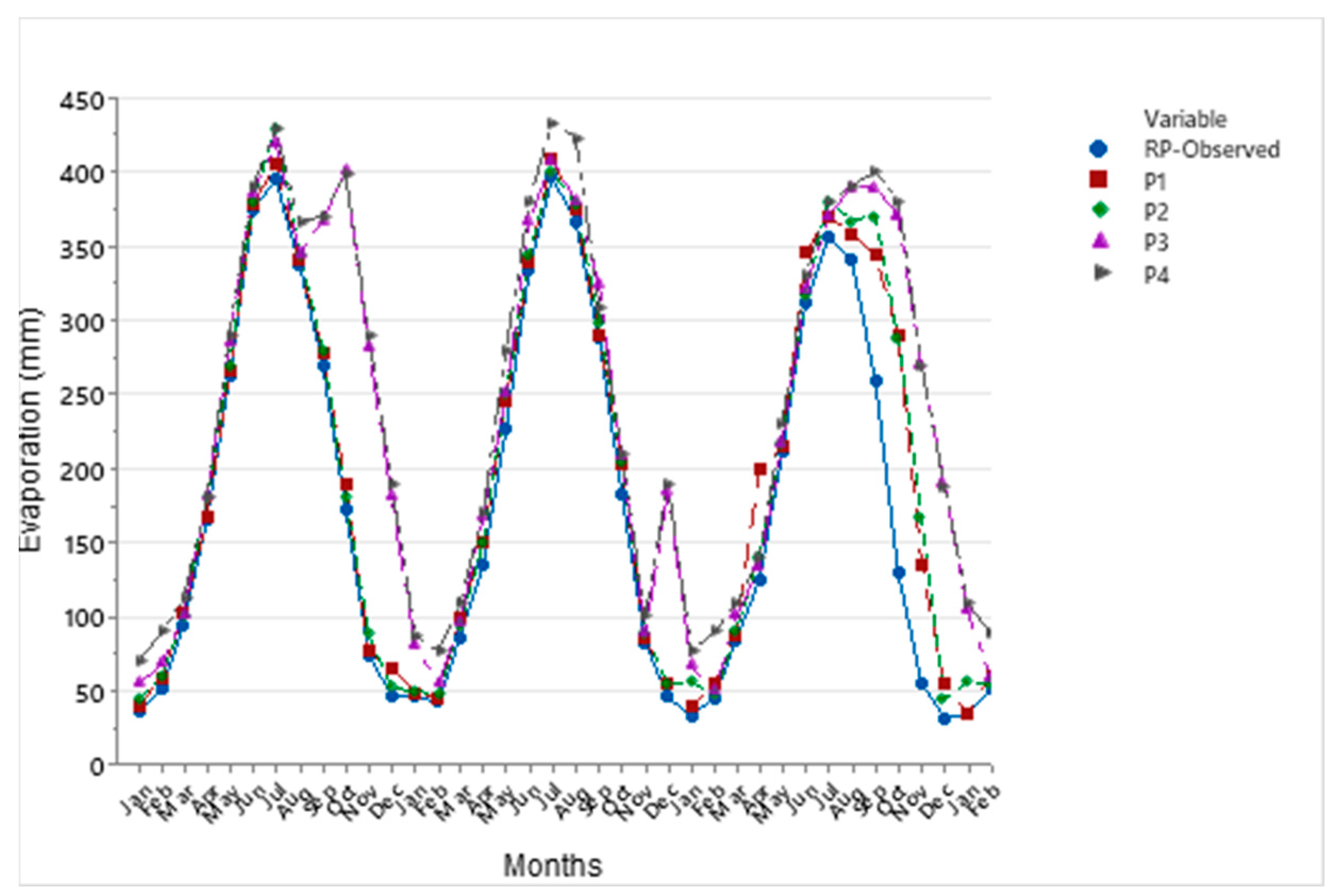
Evaporation plays a critical role in the hydrological cycle, though its natural process is inherently complex and often unpredictable. In this study, we utilized machine learning techniques, namely the Multi-Layer Perceptron (MLP), Support Vector Machine (SVM), and Gaussian Process Regression (GPR) with Principal Component Analysis (PCA), to estimate and predict evaporation rates. These models were based on historical data and future projections under two climate scenarios: SSP2-4.5 and SSP5-8.5. Among these techniques, the MLP model demonstrated a superior performance, providing the most accurate evaporation estimates compared to the SVM and GPR models, though all three were effective.
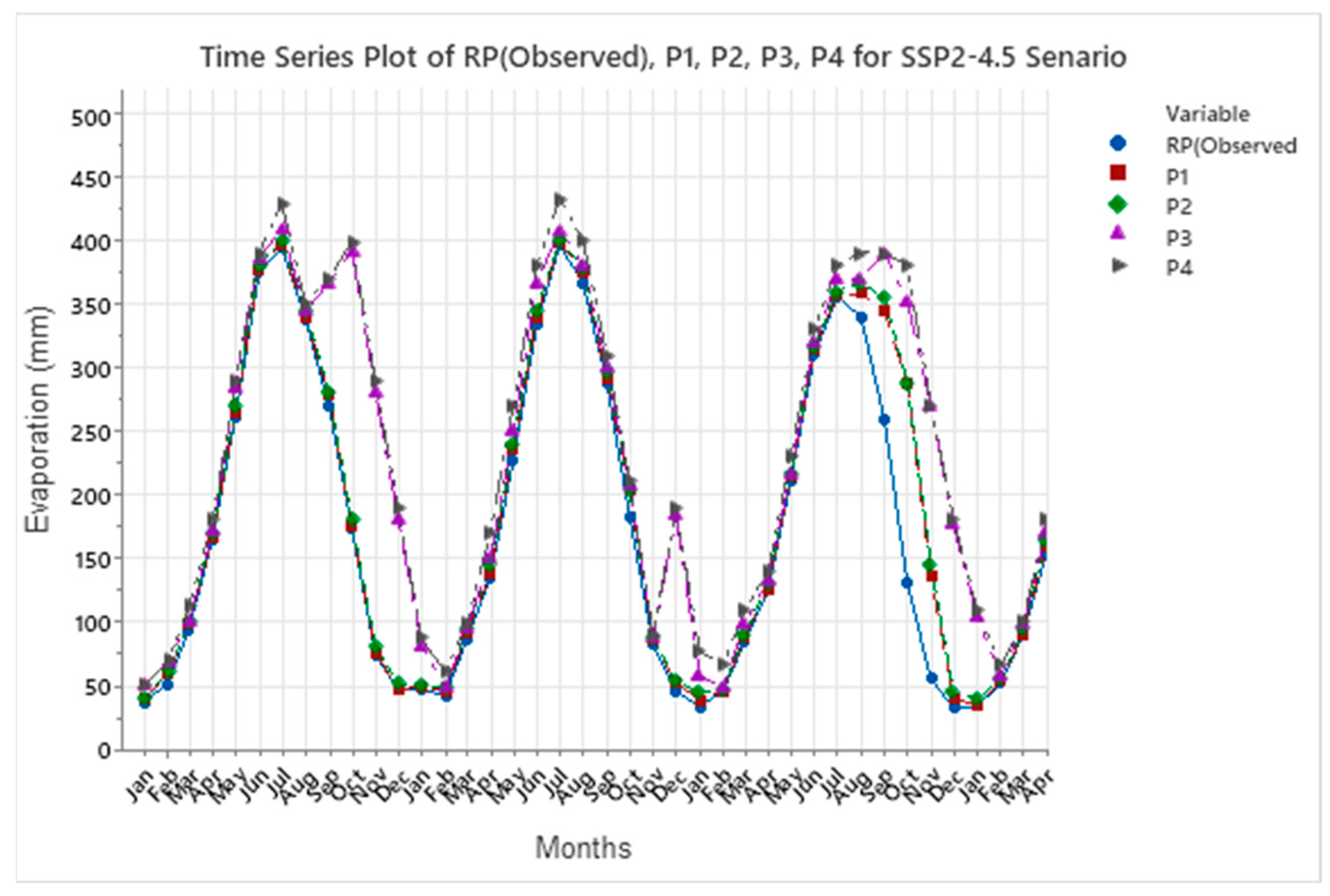
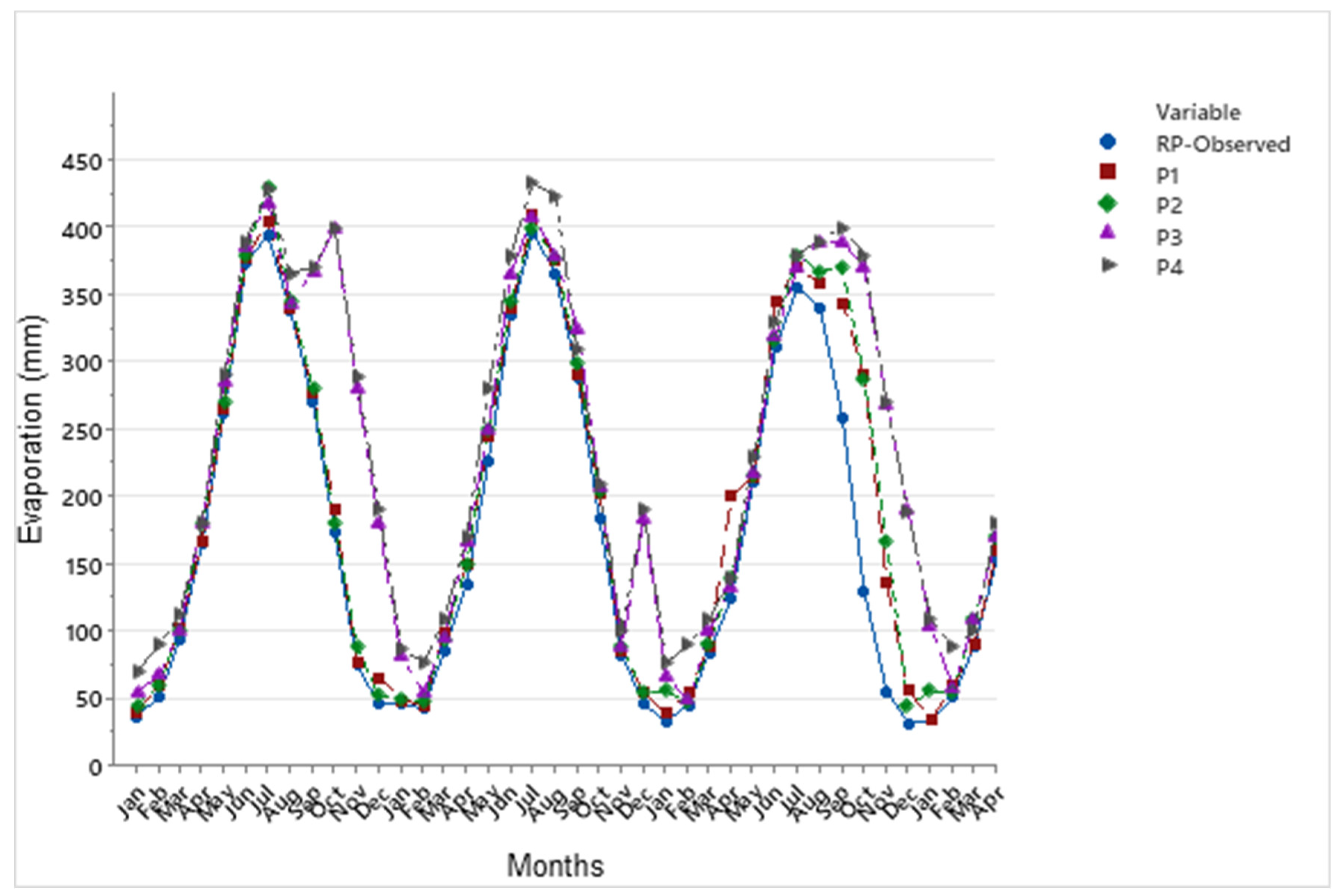
The evaporation model incorporated key input variables such as rainfall, sunshine hours (SSH), and the minimum and maximum temperatures (Tmin and Tmax). Both the SSP2-4.5 and SSP5-8.5 climate scenarios indicated an increase in evaporation rates, with SSP5-8.5 exhibiting a notably larger rise. When compared to historical evaporation rates, the SSP5-8.5 scenario projected a significantly greater increase than SSP2-4.5, highlighting the impact of more extreme climate changes.
The evaluation values for GPR with PCA, MAE and RMSE are equal to 0.22 and 0.37 mm respectively, and higher than SVM with PCA and MLP equal to (0.21, 0.13, 0.02, and 0.10 mm respectively). This study underscores the importance of estimating and forecasting evaporation rates, particularly in the context of changing climates, which is especially relevant for semi-arid regions where the impacts on water resources are more pronounced. The findings emphasize the need for resilient and sustainable water management strategies to ensure future water security in these vulnerable areas.


 ,
, 


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}