

Improved Convolutional Neural Network with Attention Mechanisms for River Extraction

Abstract
1. Introduction
2. Overview of the Study Area
3. Materials and Methods
3.1. Data
3.2. Methods
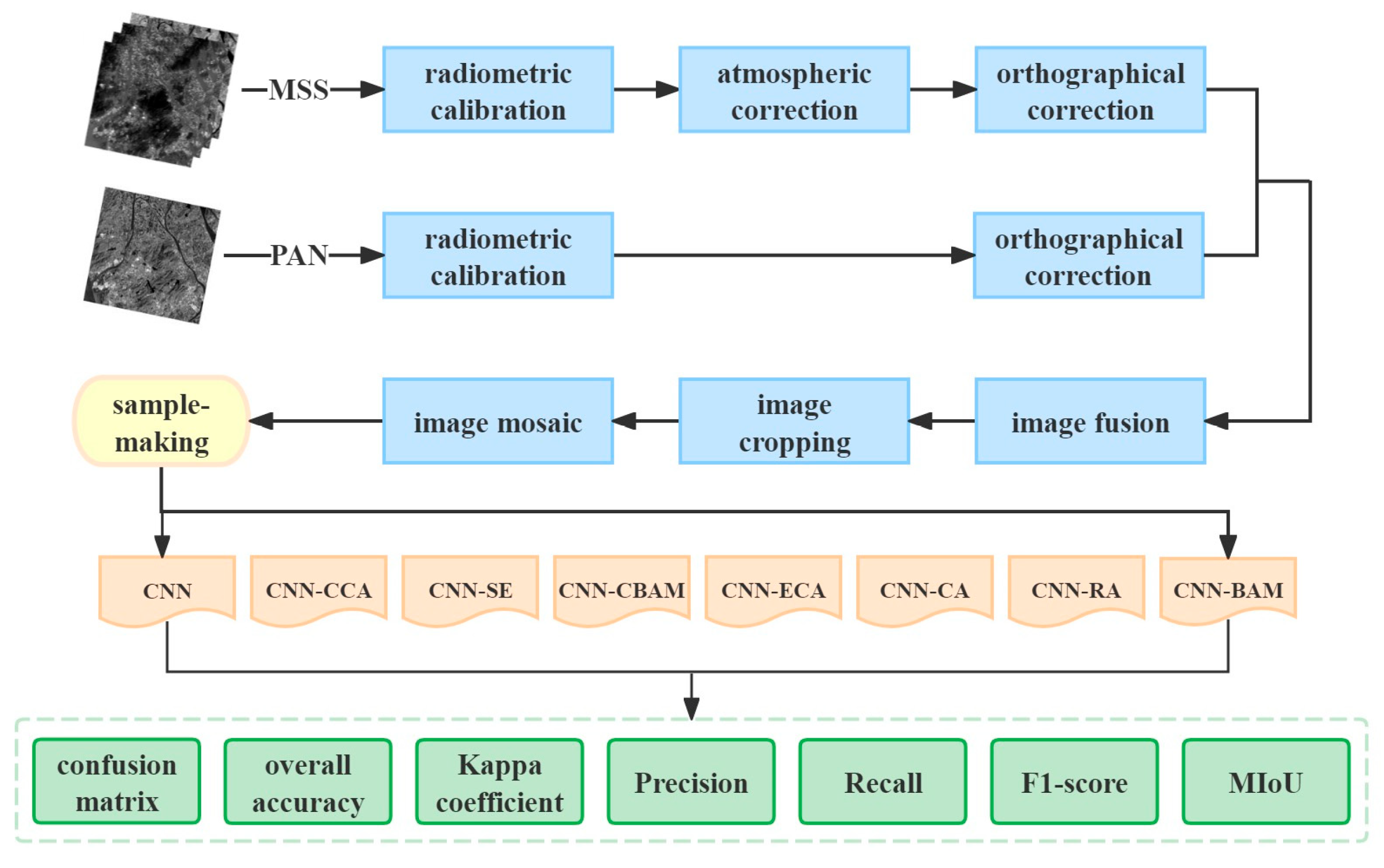
3.2.1. Data Processing
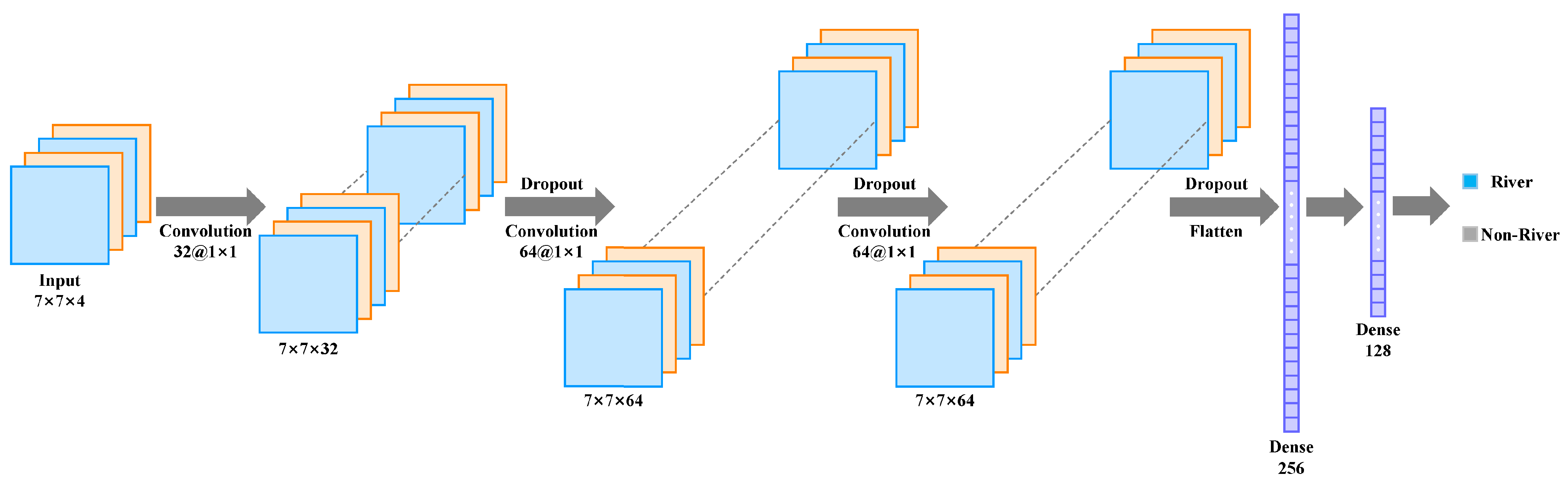
3.2.2. CNN
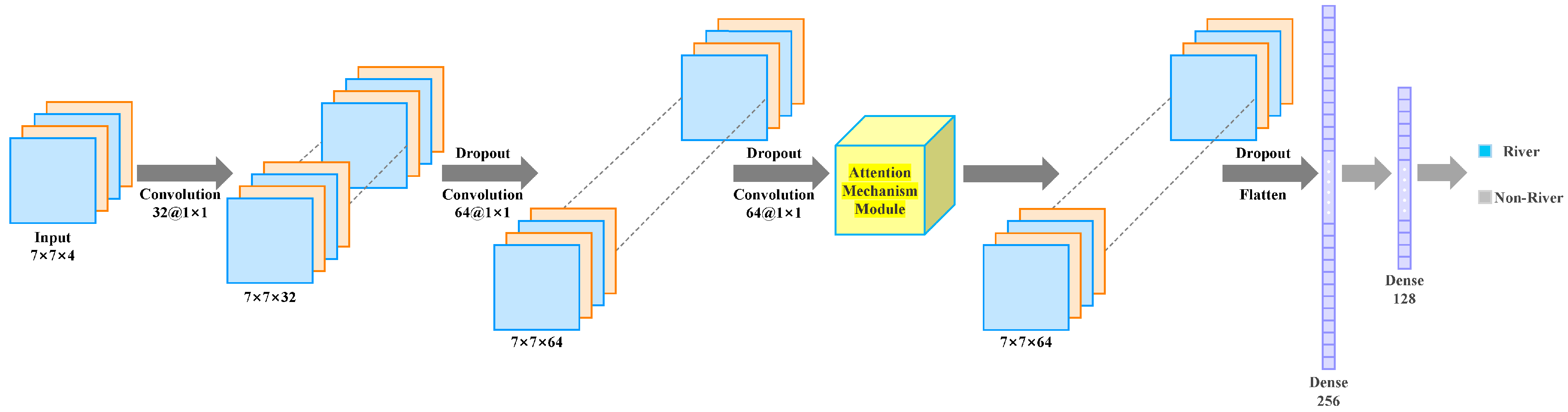
3.2.3. Attention Mechanism Module
- 1.
- Squeeze-and-Excitation Networks
- (1)
- Squeeze: the features of each channel are compressed by global average pooling, which compresses the spatial information of each channel into a global descriptor.
- (2)
- Excitation: The model uses a small, fully connected network to learn the excitation of the channels, and then a sigmoid activation function is used to obtain a weight value between 0 and 1, which indicates the importance of each channel.
- (3)
- The adjusted channel weights are applied to the original feature map, thus reinforcing the important channels and suppressing irrelevant channels.
- 2.
- Efficient Channel Attention
- (1)
- Perform global average pooling for each channel of the input feature map to generate a global description of each channel.
- (2)
- Compute the channel weights through a one-dimensional convolutional layer and learn the local interaction information between channels without relying on the complex fully connected layer, resulting in a more lightweight model structure. However, it maintains a strong feature modeling capability, reduces the number of parameters and computational complexity, and achieves high efficiency.
- (3)
- The weight values are normalized by a sigmoid function to obtain the weights of each channel. Finally, these weights are applied to the input feature map to complete the recalibration of channel features.
- 3.
- Convolutional Block Attention Module
- (1)
- Channel attention: global information about the channel is obtained by compressing each channel through global average pooling and global maximum pooling. Then, this information is used to generate the attention weights of each channel through a shared MLP (multilayer perceptron) network, and finally, the weights obtained by the sigmoid activation function are weighted channel-by-channel with the original feature map.
- (2)
- Spatial attention: on the channel-weighted feature maps, CBAM generates a spatial attention map using convolutional operations to further emphasize important regions in the image. The module fuses the information using maximum pooling and average pooling and generates spatial attention weights through a convolutional layer.
- 4.
- Coordinate Attention
- (1)
- By generating coordinate information (e.g., coordinates relative to the image center) for each pixel location, this information is passed to the attention module. This coordinate information helps the network to capture the relationship between different locations in space.
- (2)
- Assign weights to horizontal and vertical coordinates in space by introducing 1D convolution operations along the direction of the coordinate axes (X and Y axes), respectively. This approach explicitly captures the spatial relationships in different directions.
- (3)
- With the learned coordinate weights, they are applied to the input feature map to enhance the feature response of important regions while suppressing irrelevant regions.
- 5.
- Criss-Cross Attention
- (1)
- It is a cross-over convolutional structure that extracts features along the horizontal and vertical directions of the image, respectively. This approach allows the model to capture a wider range of spatial information.
- (2)
- Features are propagated in the row and column directions of the image by incrementally augmenting the contextual information between pixels to form long-range dependencies both horizontally and vertically. This avoids the computationally intensive global attention mechanism.
- (3)
- Fusion of features in different directions to enhance important information and suppress irrelevant background by weighting.
- 6.
- Residual Attention Network
- (1)
- Extract the feature map of the input image by convolutional layer;
- (2)
- Generate spatial attention weights using the attention module to weight the feature maps and highlight important regions;
- (3)
- Sum the weighted feature maps with the original feature maps through residual linking to retain the original information while enhancing the key features. This design avoids information loss while improving the model’s ability to model multi-target scenes.
- 7.
- Bottleneck Attention Module
- (1)
- Input features are processed through a ‘bottleneck layer’ to reduce the feature dimension (i.e., the number of channels);
- (2)
- The channel attention branch generates channel weights through global average pooling and multilayer perceptron (MLP) to emphasize the important feature channels, and the spatial attention branch generates spatial weights through convolutional layers to highlight the key regions in the feature map;
- (3)
- Combine the outputs of the two branches to generate attention weights and multiply them with the original feature map to enhance feature representation.
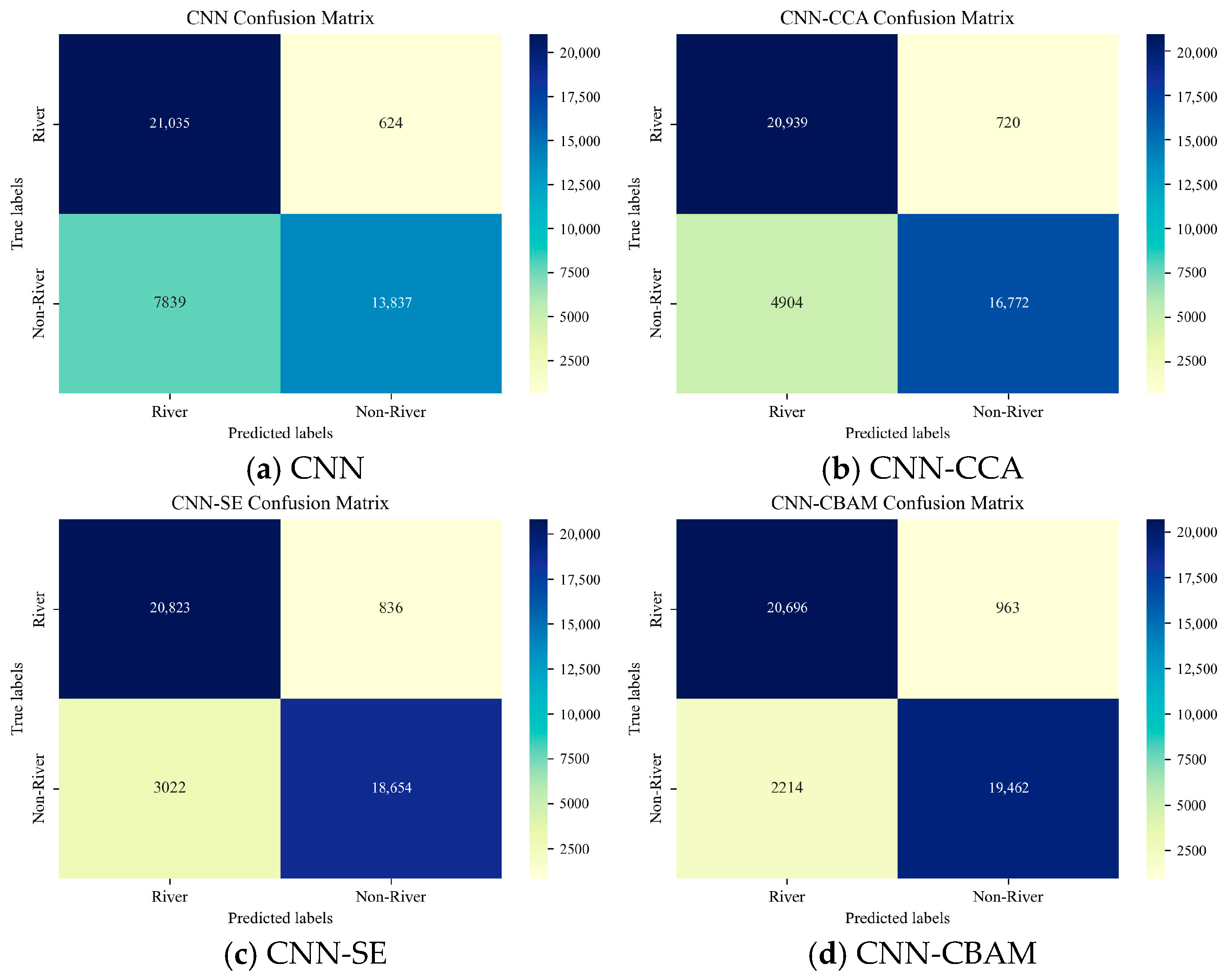
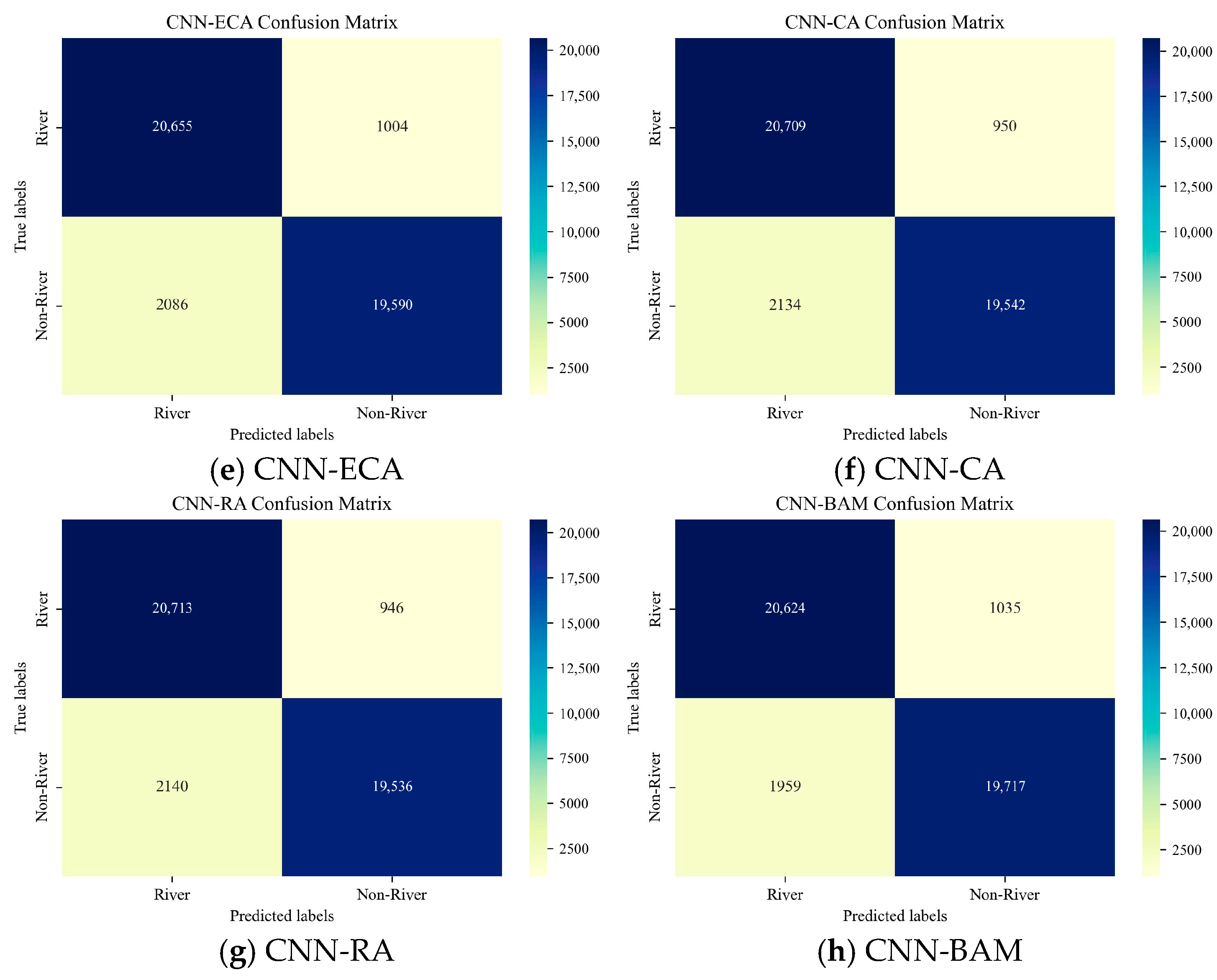
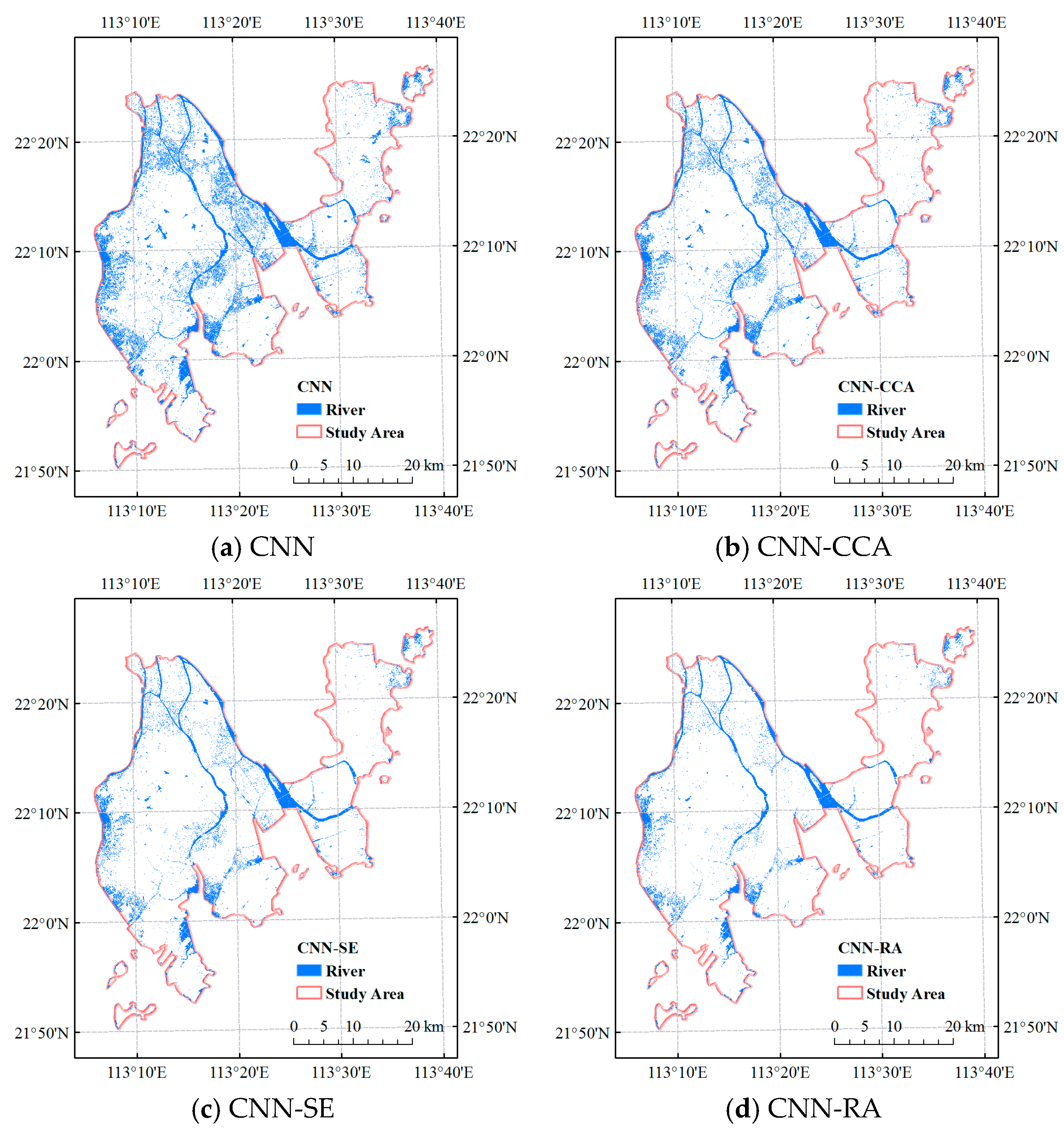
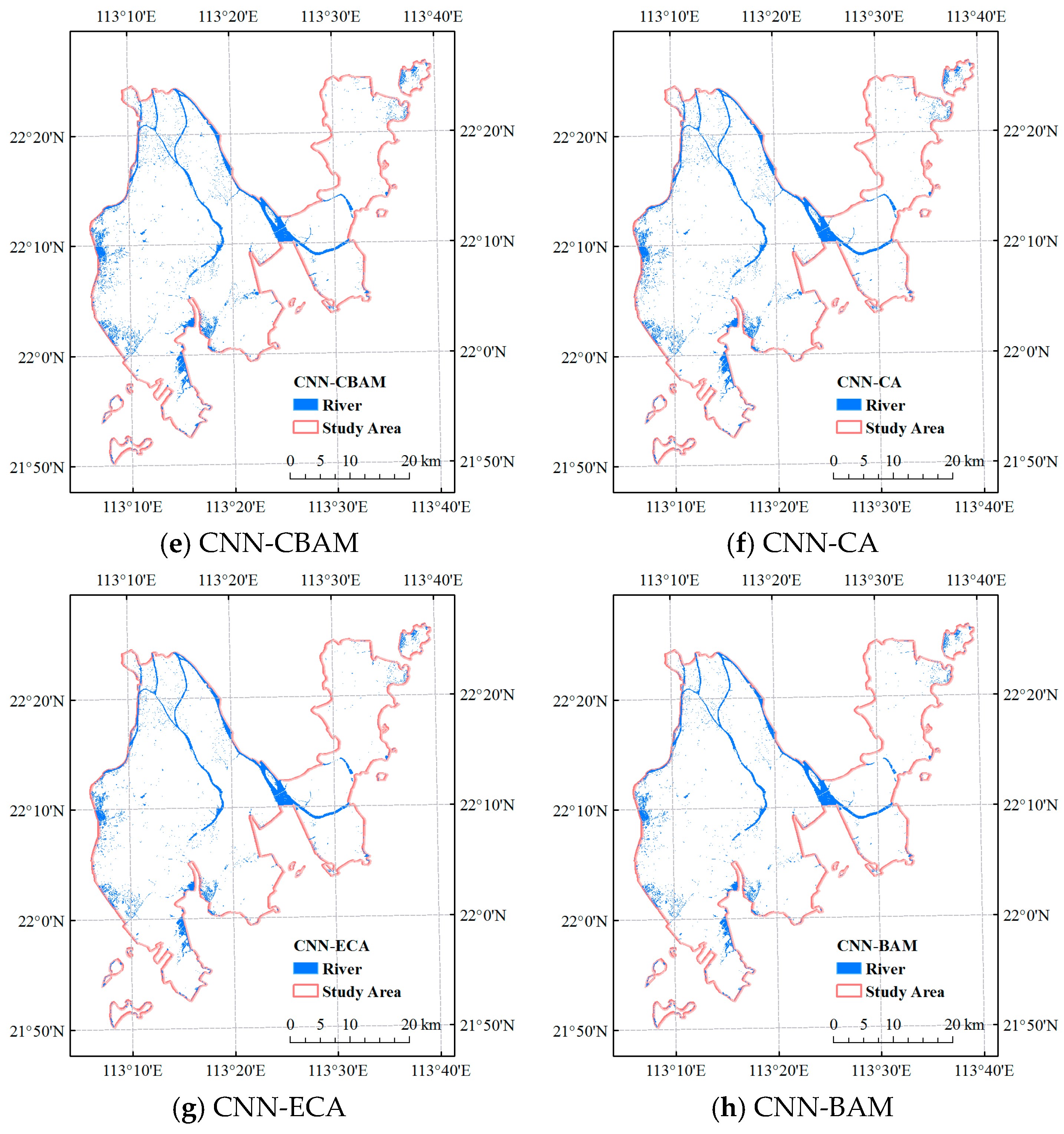
4. Results
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Isikdogan, F.; Bovik, A.C.; Passalacqua, P. Surface Water Mapping by Deep Learning. IEEE J. Sel. Top. Appl. Earth Observ. Remote Sens. 2017, 10, 4909–4918. [Google Scholar] [CrossRef]
- Chen, Y.; Fan, R.S.; Yang, X.C.; Wang, J.X.; Latif, A. Extraction of Urban Water Bodies from High-Resolution Remote-Sensing Imagery Using Deep Learning. Water 2018, 10, 585. [Google Scholar] [CrossRef]
- Bui, X.N.; Nguyen, H.; Tran, Q.H.; Nguyen, D.A.; Bui, H.B. Predicting Ground Vibrations Due to Mine Blasting Using a Novel Artificial Neural Network-Based Cuckoo Search Optimization. Nat. Resour. Res. 2021, 30, 2663–2685. [Google Scholar] [CrossRef]
- Li, K.; Wang, J.L.; Yao, J.Y. Effectiveness of Machine Learning Methods for Water Segmentation with Roi as the Label: A Case Study of The Tuul River in Mongolia. Int. J. Appl. Earth Obs. Geoinf. 2021, 103, 102497–102507. [Google Scholar] [CrossRef]
- Hubel, D.H.; Wiesel, T.N. Receptive Fields of Single Neurones in The Cat’s Striate Cortex. J. Physiol. 1959, 148, 574–591. [Google Scholar] [CrossRef] [PubMed]
- Hu, J.; Shen, L.; Albanie, S.; Sun, G.; Wu, E. Squeeze-and-Excitation Networks. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]
- Wang, Q.; Wu, B.; Zhu, P.; Li, P.; Zuo, W.; Hu, Q. ECA-Net: Efficient Channel Attention for Deep Convolutional Neural Networks. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 14–19 June 2020. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.-Y.; Kweon, I.S. CBAM: Convolutional Block Attention Module. In Proceedings of the 2018 European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018. [Google Scholar]
- Hou, Q.B.; Zhou, D.Q.; Feng, J.S. Coordinate Attention for Efficient Mobile Network Design. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Online, 19–25 June 2021. [Google Scholar]
- Huang, Z.; Wang, X.; Wei, Y.; Huang, L.; Shi, H.; Liu, W.; Huang, T.S. CCNet: Criss-Cross Attention for Semantic Segmentation. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019. [Google Scholar]
- Zhu, K.; Wu, J.X. Residual Attention: A Simple but Effective Method for Multi-Label Recognition. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 11–17 October 2021. [Google Scholar]
- Park, J.C.; Woo, S.H.; Lee, J.Y. BAM: Bottleneck Attention Module. In Proceedings of the British Machine Vision Conference (2018), Newcastle, UK, 3–6 September 2018. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Total Params (M) | FLOPs (M) | Training Time (s) |
|---|---|---|---|
| CNN | 0.8433 | 2.2959 | 125.6719 |
| CNN-CCA | 0.8433 | 2.4653 | 9119.9862 |
| CNN-SE | 0.8454 | 2.3095 | 145.2962 |
| CNN-CBAM | 0.8476 | 2.3264 | 187.7041 |
| CNN-ECA | 0.8433 | 2.3057 | 140.9470 |
| CNN-CA | 0.8450 | 2.6048 | 271.4967 |
| CNN-RA | 0.8474 | 2.7068 | 171.2819 |
| CNN-BAM | 0.8447 | 2.3961 | 277.7017 |
| Model | OA (%) | Kappa Coefficient | Precision (%) | Recall (%) | F1-Score (%) | MioU (%) |
|---|---|---|---|---|---|---|
| CNN | 80.47 | 0.6095 | 72.85 | 97.12 | 83.25 | 71.31 |
| CNN-CCA | 87.02 | 0.7405 | 81.02 | 96.68 | 88.16 | 78.83 |
| CNN-SE | 91.10 | 0.8220 | 87.33 | 96.14 | 91.52 | 84.37 |
| CNN-CBAM | 92.67 | 0.8534 | 90.34 | 95.55 | 92.87 | 86.69 |
| CNN-ECA | 92.87 | 0.8574 | 90.83 | 95.36 | 93.04 | 86.99 |
| CNN-CA | 92.88 | 0.8577 | 90.66 | 95.61 | 93.07 | 87.04 |
| CNN-RA | 92.88 | 0.8576 | 90.64 | 95.63 | 93.07 | 87.03 |
| CNN-BAM | 93.09 | 0.8618 | 91.33 | 95.22 | 93.23 | 87.32 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cui, H.; Liang, J.; Li, C.; Tian, X. Improved Convolutional Neural Network with Attention Mechanisms for River Extraction. Water 2025, 17, 1762. https://doi.org/10.3390/w17121762
Cui H, Liang J, Li C, Tian X. Improved Convolutional Neural Network with Attention Mechanisms for River Extraction. Water. 2025; 17(12):1762. https://doi.org/10.3390/w17121762
Chicago/Turabian StyleCui, Hanwen, Jiarui Liang, Cheng Li, and Xiaolin Tian. 2025. "Improved Convolutional Neural Network with Attention Mechanisms for River Extraction" Water 17, no. 12: 1762. https://doi.org/10.3390/w17121762
APA StyleCui, H., Liang, J., Li, C., & Tian, X. (2025). Improved Convolutional Neural Network with Attention Mechanisms for River Extraction. Water, 17(12), 1762. https://doi.org/10.3390/w17121762