Figure 1.
Examples of sampling conducted in different environments. (a) Daytime, (b) night, (c) rain, (d) fog, (e) sheltered, (f) wavy, (g) drift, (h) ice-covered, (i) Tyndall effect, and (j) shadow.
Figure 1.
Examples of sampling conducted in different environments. (a) Daytime, (b) night, (c) rain, (d) fog, (e) sheltered, (f) wavy, (g) drift, (h) ice-covered, (i) Tyndall effect, and (j) shadow.
Figure 2.
Flow chart of water level detection scheme without water gauge.
Figure 2.
Flow chart of water level detection scheme without water gauge.
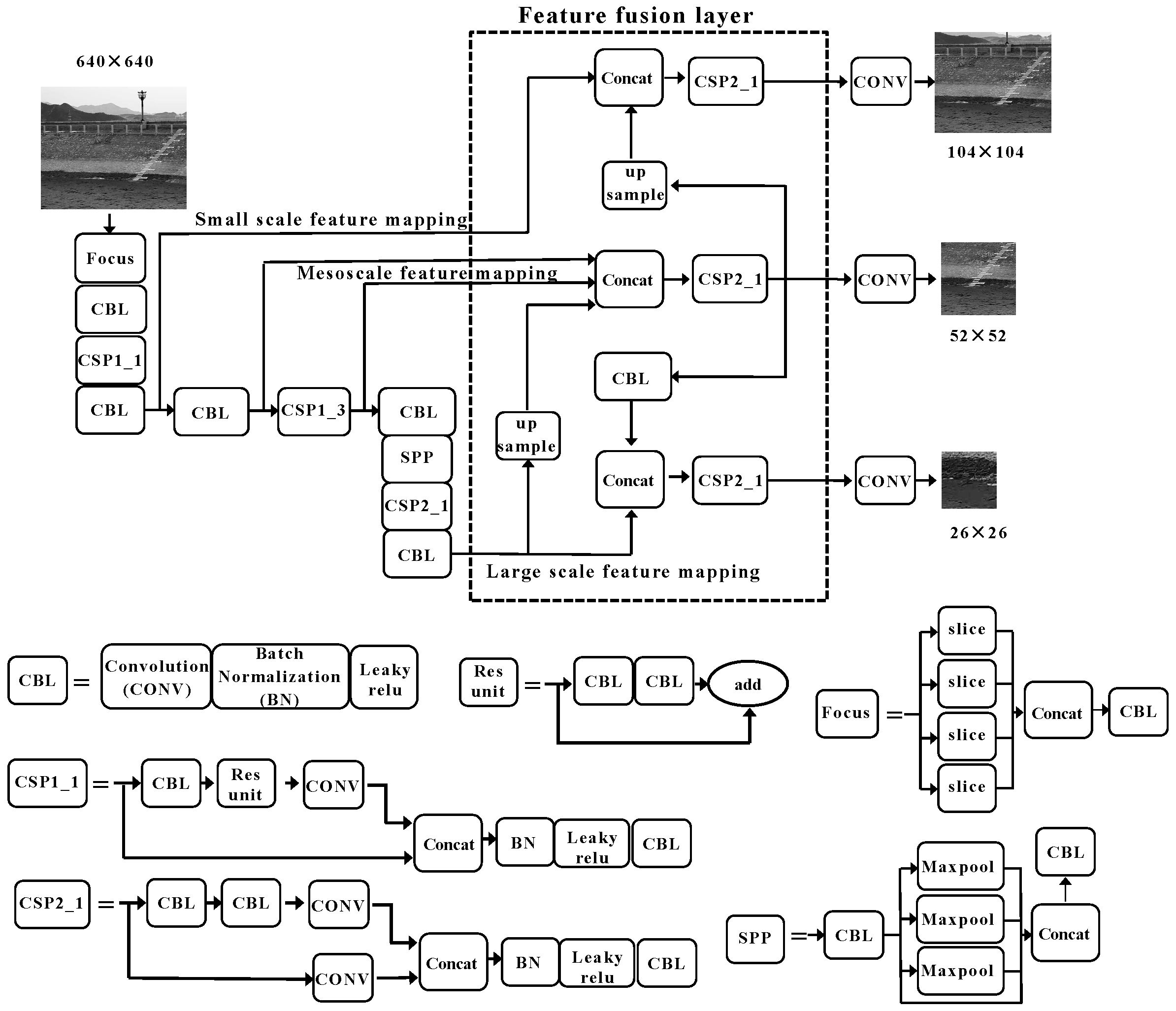
Figure 3.
Improved YOLOv5 network structure.
Figure 3.
Improved YOLOv5 network structure.
Figure 4.
A flow chart of the intelligent detection method of water level in this study.
Figure 4.
A flow chart of the intelligent detection method of water level in this study.
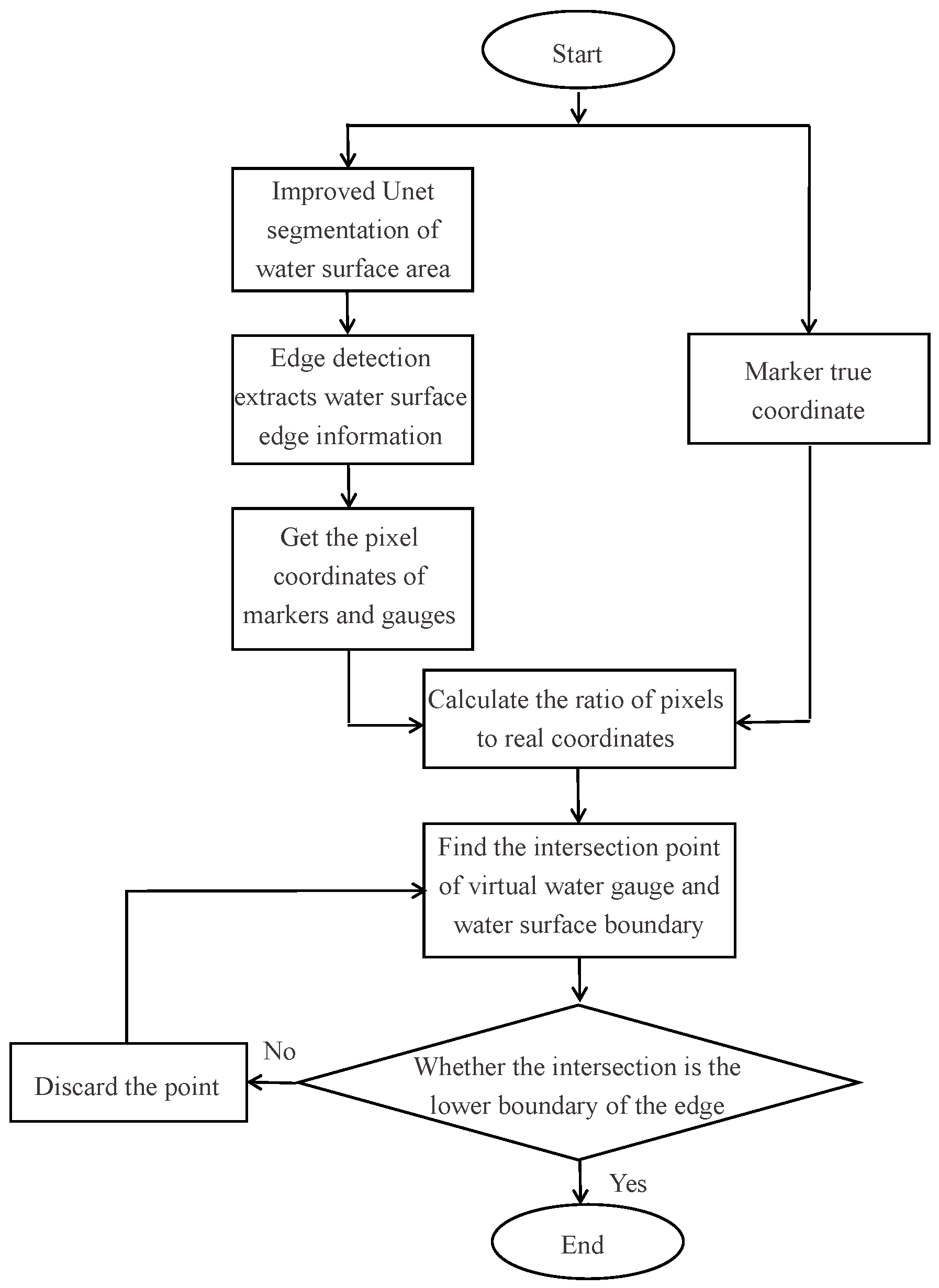
Figure 5.
Water level detection program without water gauge.
Figure 5.
Water level detection program without water gauge.
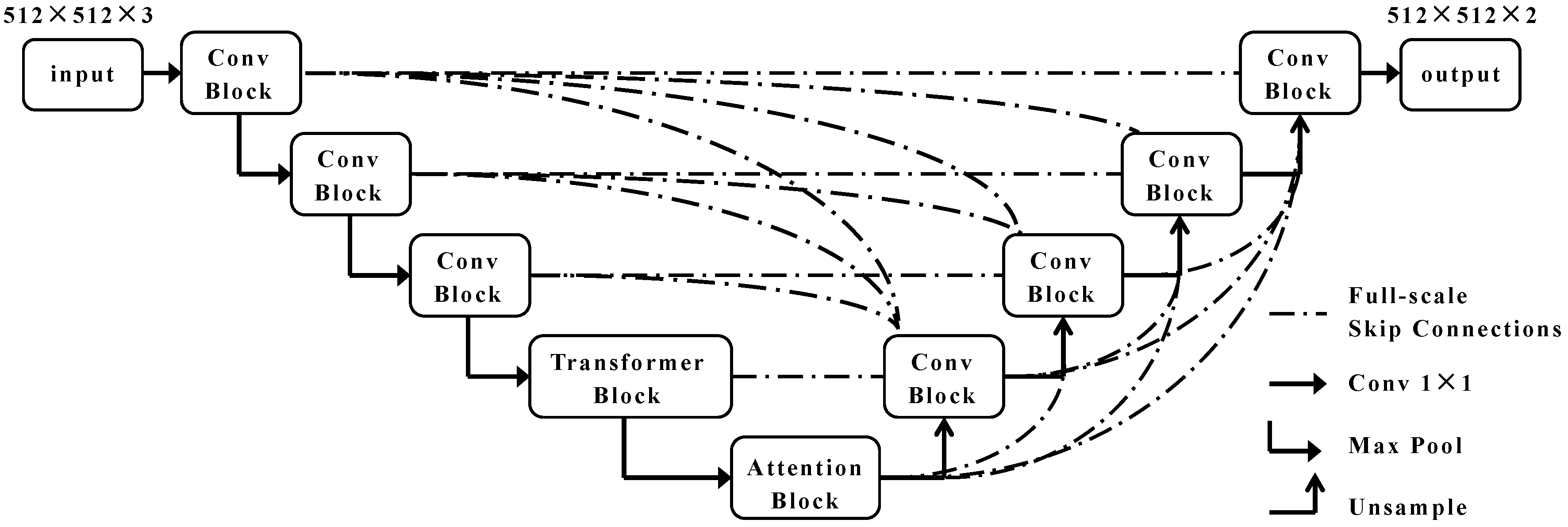
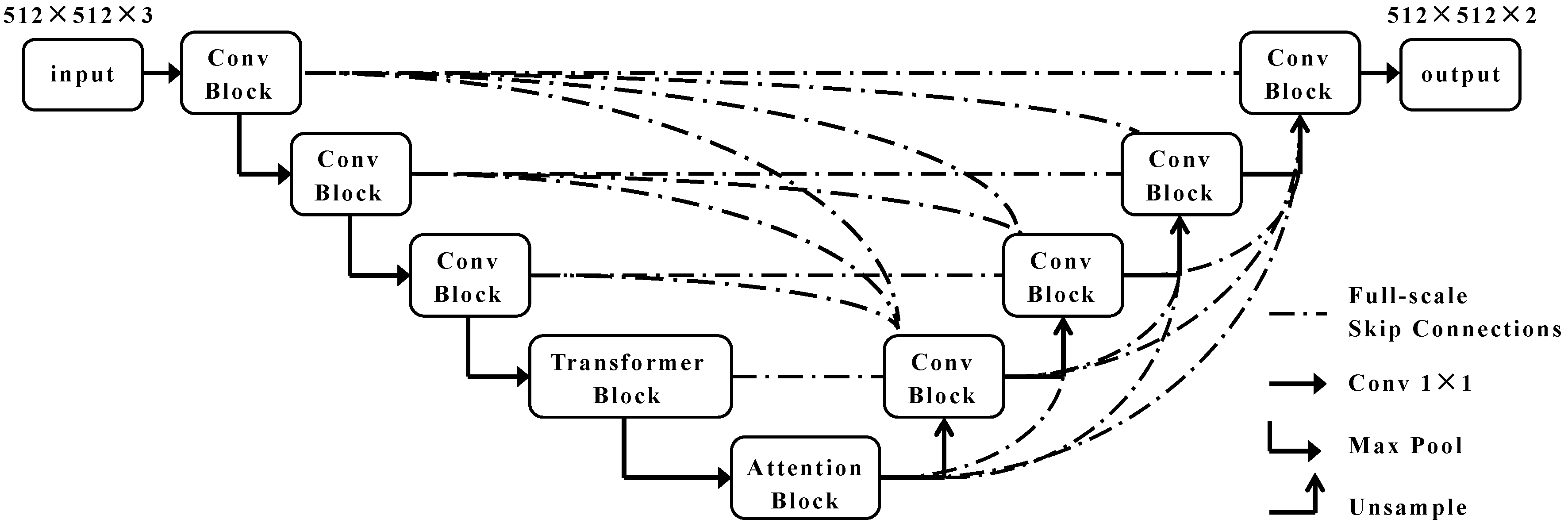
Figure 6.
TRCAM-Unet module.
Figure 6.
TRCAM-Unet module.
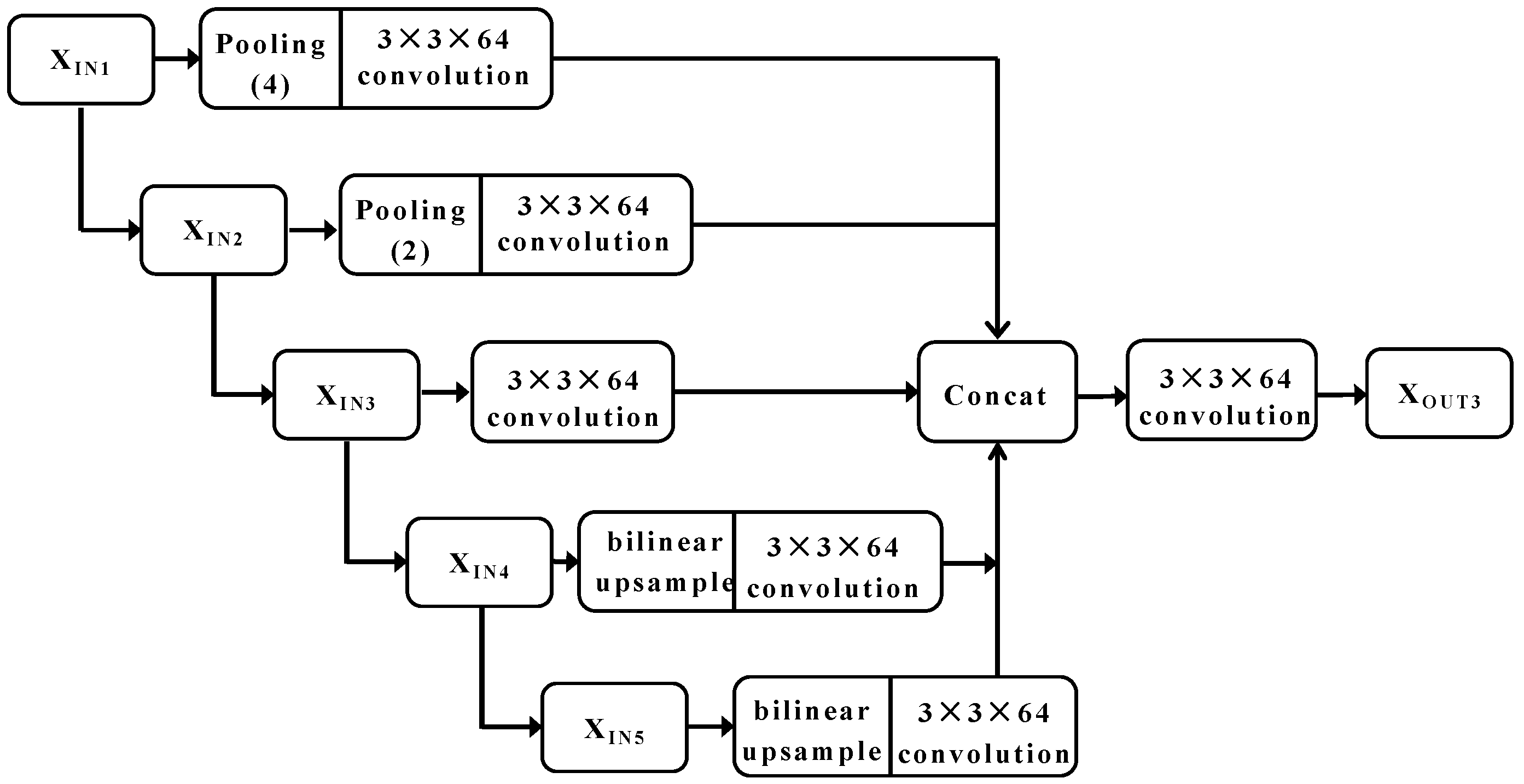
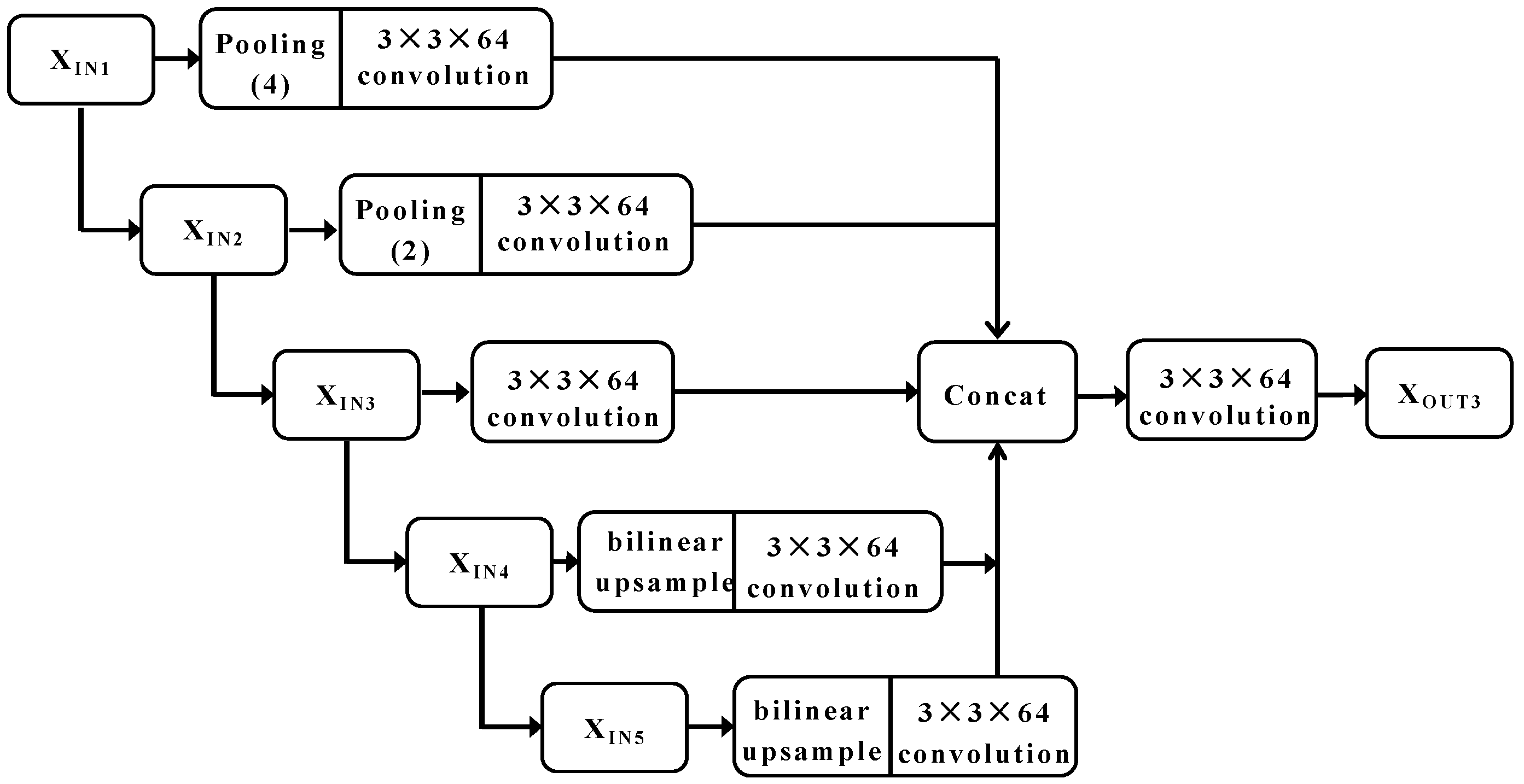
Figure 7.
Full-scale connected framework.
Figure 7.
Full-scale connected framework.
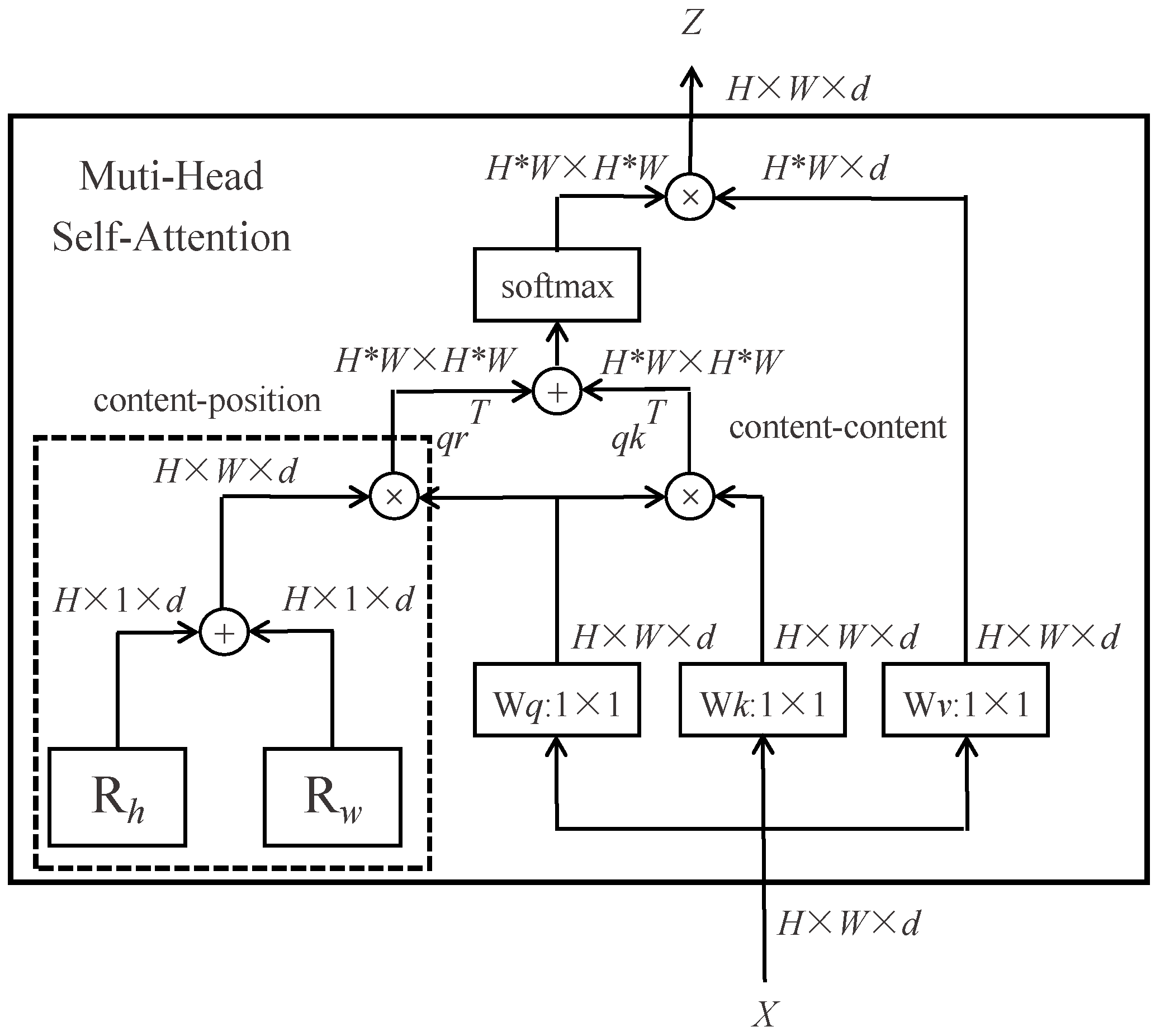
Figure 8.
Feature extraction mechanism for single attention head.
Figure 8.
Feature extraction mechanism for single attention head.
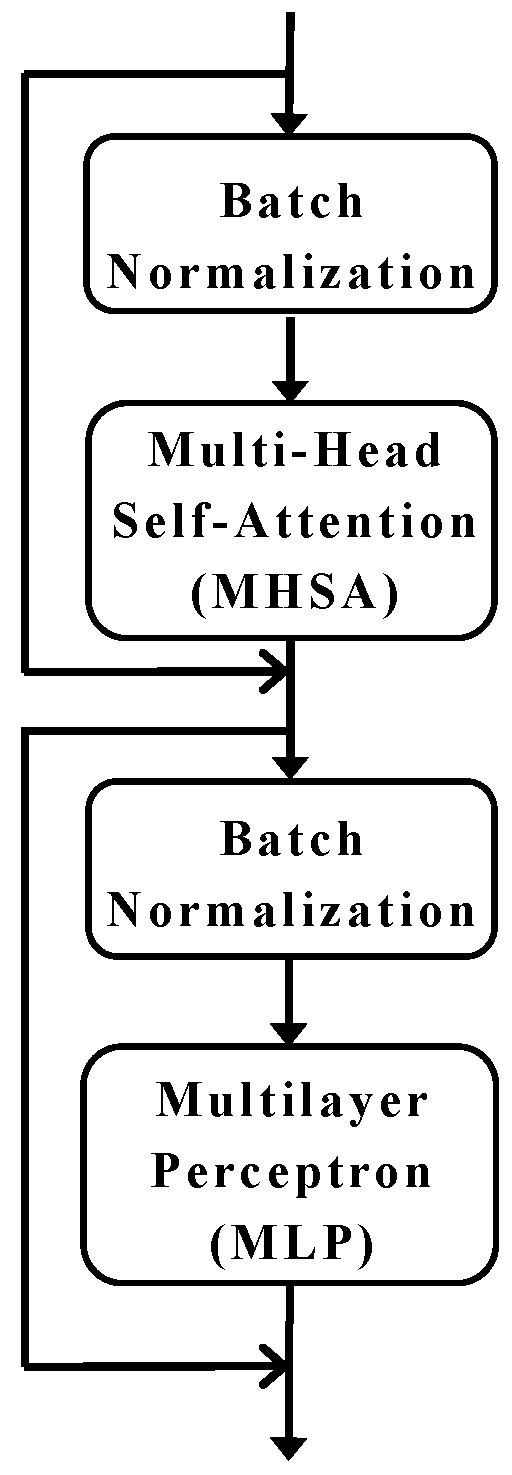
Figure 9.
Transformer module.
Figure 9.
Transformer module.
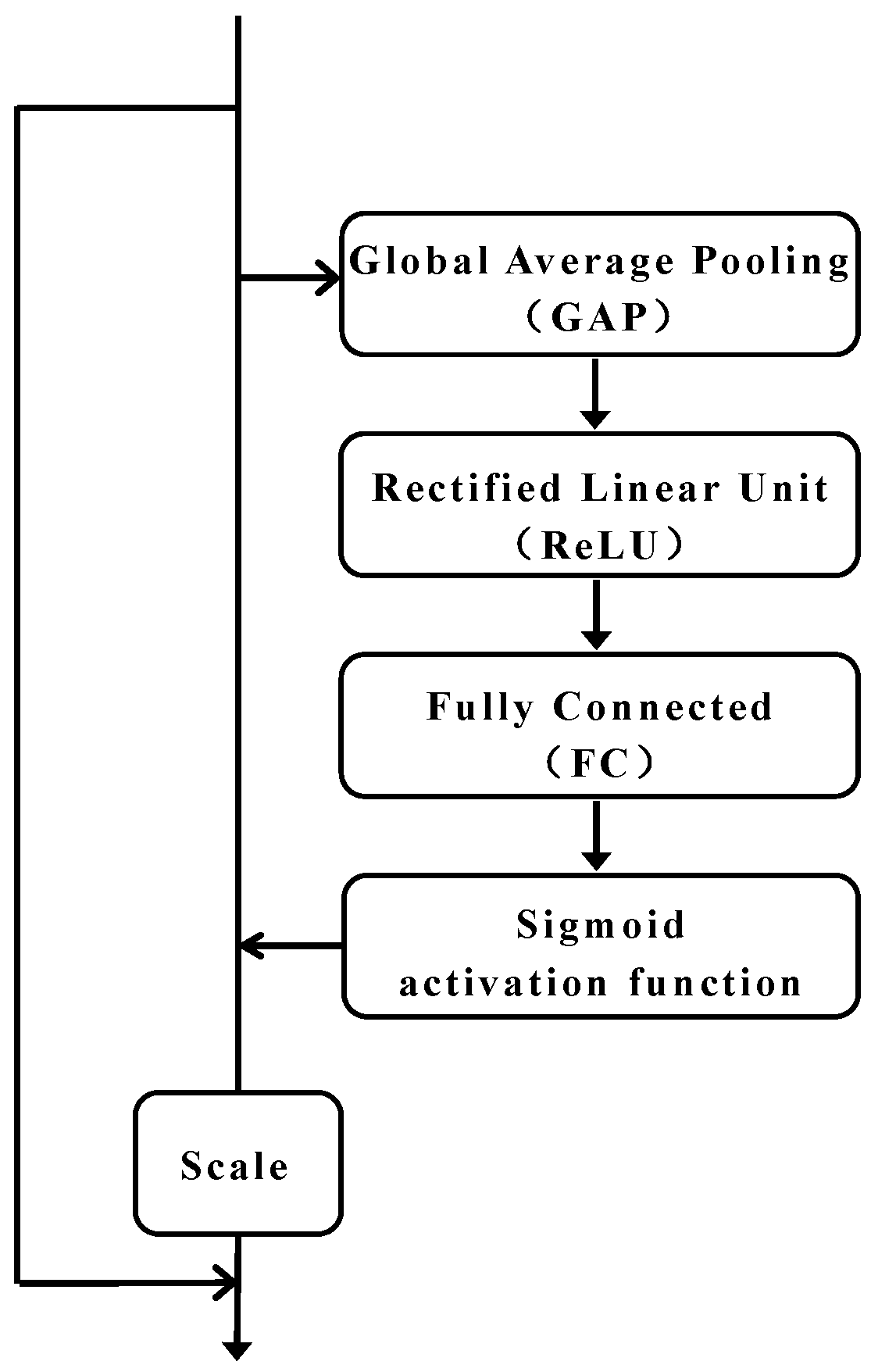
Figure 10.
Residual channel attention module.
Figure 10.
Residual channel attention module.
Figure 11.
Example diagram of water level label (The red boxes are label boxes.).
Figure 11.
Example diagram of water level label (The red boxes are label boxes.).
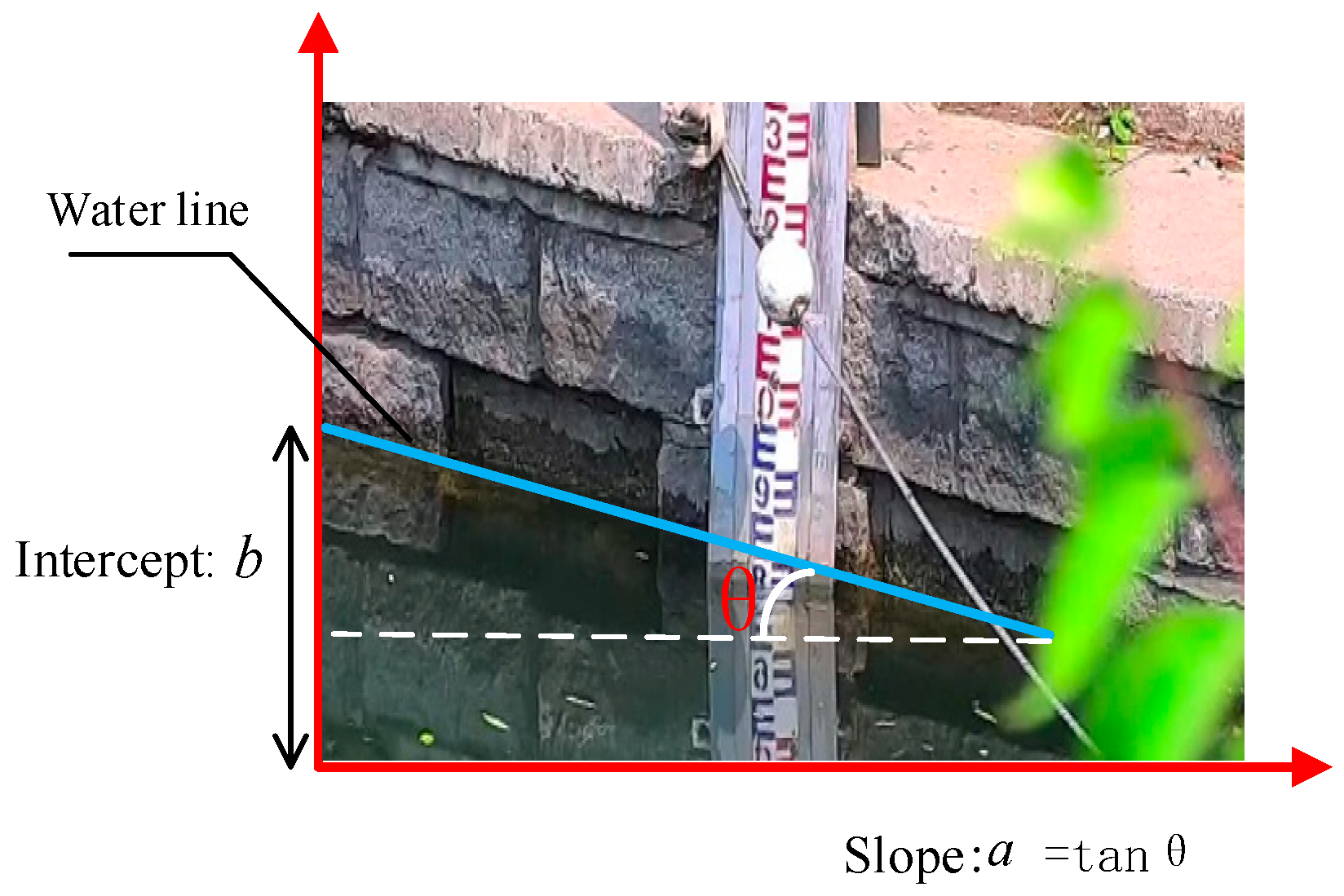
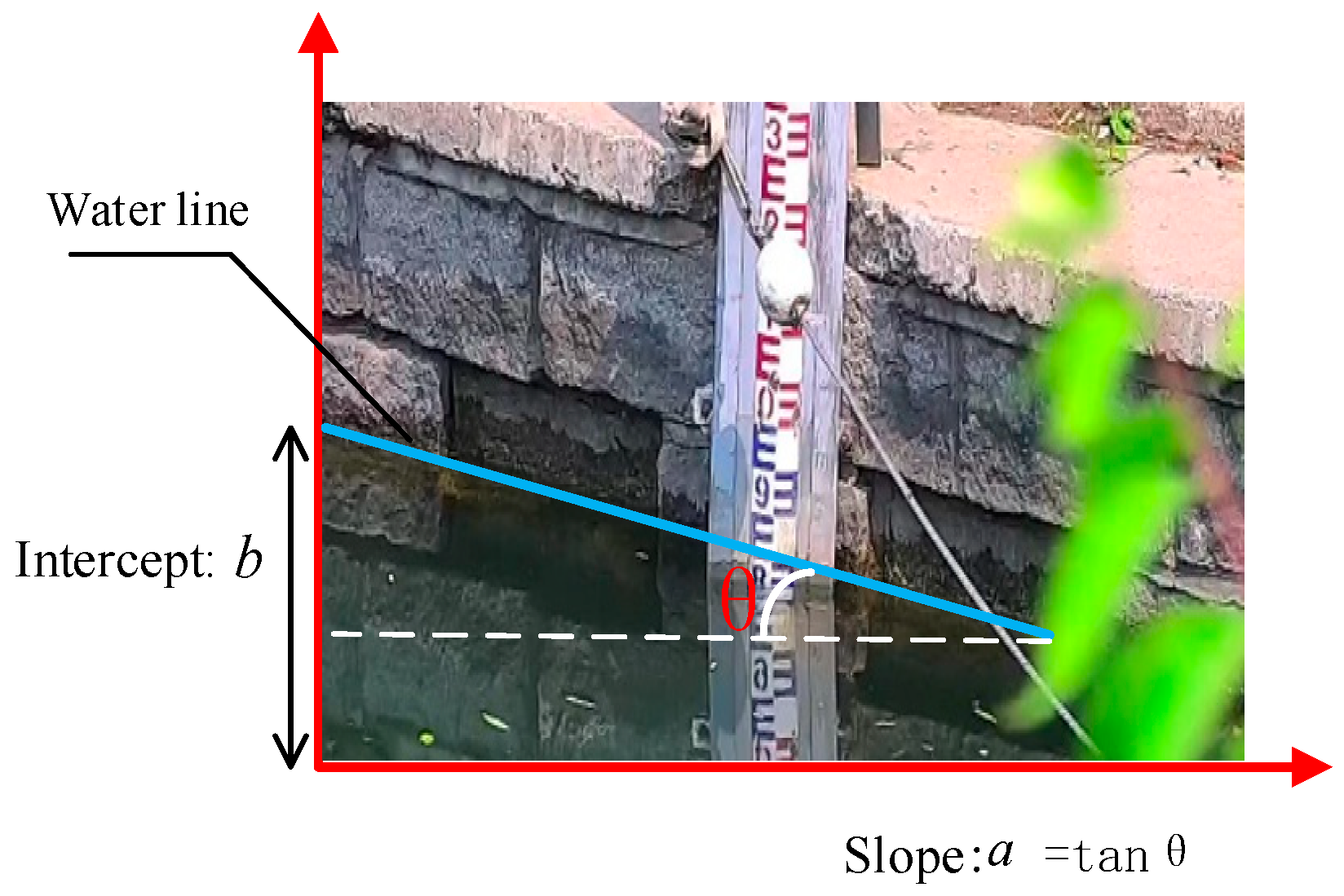
Figure 12.
Schematic diagram of the intercept and slope of the water level line.
Figure 12.
Schematic diagram of the intercept and slope of the water level line.
Figure 13.
Comparison of predictive effectiveness of different network models. (a) daytime, (b) night, (c) rain, (d) fog, (e) sheltered, (f) wavy, (g) flotage, (h) snow, (i) Tyndall effect, and (j) shadow. (The original image, YOLOv3, YOLOv5, and the methods in this study are arranged from left to right, and the red box is the recognition result box).
Figure 13.
Comparison of predictive effectiveness of different network models. (a) daytime, (b) night, (c) rain, (d) fog, (e) sheltered, (f) wavy, (g) flotage, (h) snow, (i) Tyndall effect, and (j) shadow. (The original image, YOLOv3, YOLOv5, and the methods in this study are arranged from left to right, and the red box is the recognition result box).
Figure 14.
Dataset label. (a) Original image. (b) Label image.
Figure 14.
Dataset label. (a) Original image. (b) Label image.
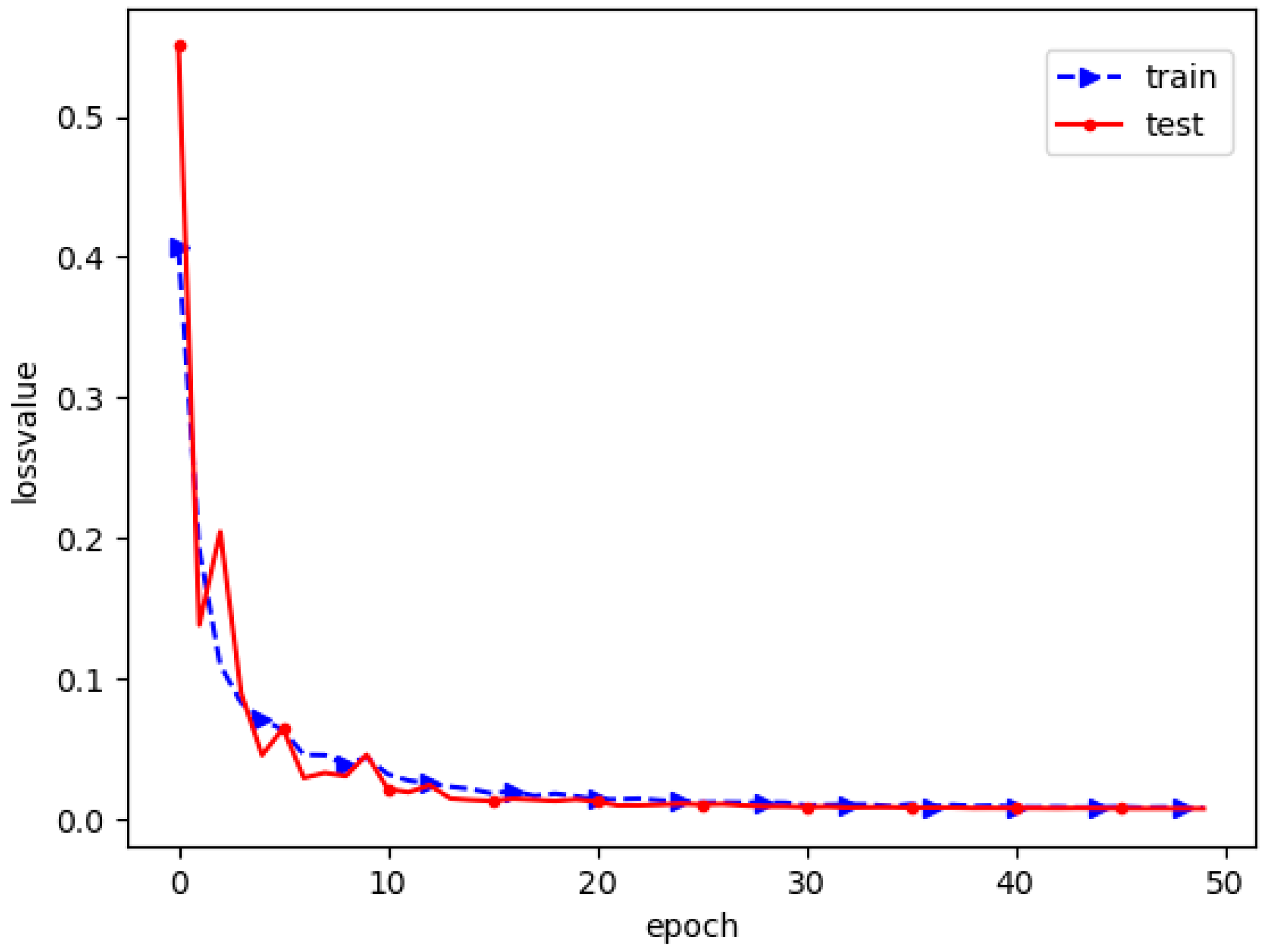
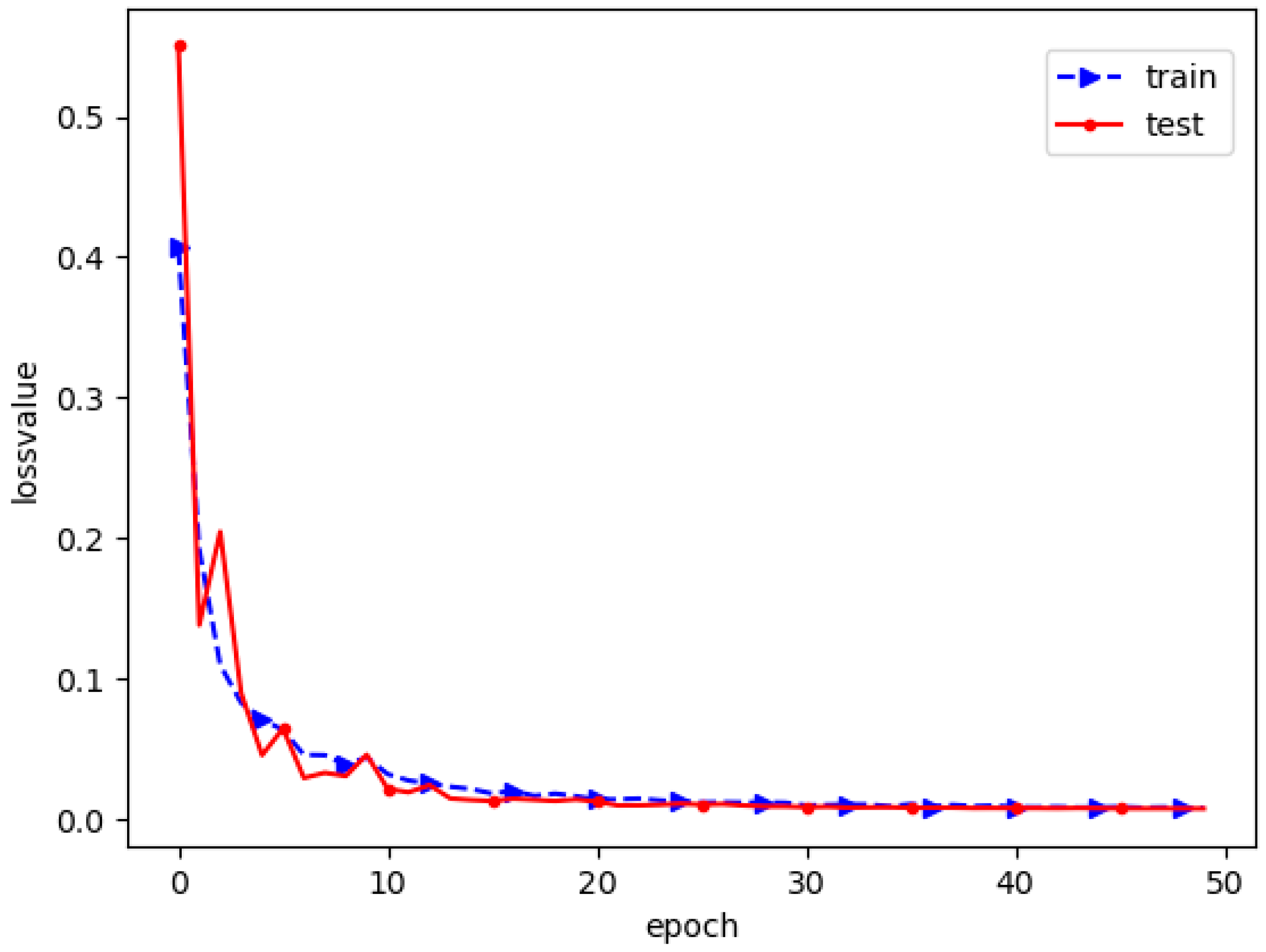
Figure 15.
Training effect of network model loss function.
Figure 15.
Training effect of network model loss function.
Figure 16.
Comparison of prediction effects of different network models. (a) Low light level. (b) Haze. (c) Snow. (d) Tyndall effect. (e) Camera shake. (f) Wavy. (g) Water surface freezing. (h) Rain. (The original image, TRCAM-Unet, Deeplab, PSPNet, and Unet are arranged from left to right).
Figure 16.
Comparison of prediction effects of different network models. (a) Low light level. (b) Haze. (c) Snow. (d) Tyndall effect. (e) Camera shake. (f) Wavy. (g) Water surface freezing. (h) Rain. (The original image, TRCAM-Unet, Deeplab, PSPNet, and Unet are arranged from left to right).
Figure 17.
Semantic segmentation effect details display. (a) Low light detail display. (b) Rain block detail display.
Figure 17.
Semantic segmentation effect details display. (a) Low light detail display. (b) Rain block detail display.
Figure 18.
Schematic diagram of marker selection.
Figure 18.
Schematic diagram of marker selection.
Figure 19.
Detection results of water level without water gauge in complex and harsh environment. (a) Wavy, (b) rain, (c) fog, (d) shadow, and (e) Tyndall effect.
Figure 19.
Detection results of water level without water gauge in complex and harsh environment. (a) Wavy, (b) rain, (c) fog, (d) shadow, and (e) Tyndall effect.
Figure 20.
Overall monitoring results of water level in a reservoir (22 March 2022–8 April 2022).
Figure 20.
Overall monitoring results of water level in a reservoir (22 March 2022–8 April 2022).
Figure 21.
Detection results of water level without water gauge in complex and harsh environment.
Figure 21.
Detection results of water level without water gauge in complex and harsh environment.
Figure 22.
Overall monitoring results of water level in a reservoir. (22 March 2022–8 April 2022).
Figure 22.
Overall monitoring results of water level in a reservoir. (22 March 2022–8 April 2022).
Table 1.
Test results of different target detection algorithms on COCO dataset.
Table 1.
Test results of different target detection algorithms on COCO dataset.
| Evaluation Index | Faster-RCNN | SSD | YOLOv3 | YOLOv4 | YOLOv5 |
|---|
| mAP (%) | 59.1 | 48.5 | 55.3 | 65.7 | 69.6 |
| Frames per second | - | 22 | 35 | 33 | 40 |
Table 2.
Number of model participants.
Table 2.
Number of model participants.
| Algorithm | Layer Number | Parameters | Giga Floating Point Operations per Second |
|---|
| The original YOLOv5 | 283 | 6.74 M | 16.5 |
| Method used in this study | 252 | 6.36 M | 15.4 |
Table 3.
Water level line detection data statistics.
Table 3.
Water level line detection data statistics.
| Environment | Photo Count | YOLOv5 | YOLOv5 | Improved YOLOv5 | Improved YOLOv5
| YOLOv5-K
| YOLOv5-K
| Improved YOLOv5-K
| Improved YOLOv5-K
|
|---|
| daytime | 104 | 95.4% | 99.3% | 97.5% | 99.6% | 95.4% | 99.3% | 97.5% | 99.6% |
| night | 60 | 95.0% | 98.9% | 96.3% | 99.1% | 95.7% | 99.2% | 97.6% | 99.4% |
| rain | 37 | 94.4% | 98.5% | 96.2% | 98.8% | 95.5% | 98.8% | 97.1% | 99.0% |
| fog | 35 | 94.4% | 98.3% | 95.4% | 98.5% | 94.8% | 98.6% | 96.6% | 98.8% |
| sheltered | 50 | 95.0% | 98.9% | 97.4% | 99.4% | 96.0% | 99.0% | 97.4% | 99.4% |
| wavy | 58 | 95.2% | 99.1% | 97.6% | 99.6% | 96.5% | 99.1% | 97.6% | 99.6% |
| flotage | 60 | 94.7% | 98.6% | 97.4% | 99.1% | 96.2% | 98.9% | 97.4% | 99.1% |
| snow | 49 | 94.5% | 98.4% | 95.9% | 98.6% | 94.9% | 98.5% | 96.7% | 98.9% |
| Tyndall | 47 | 94.6% | 98.3% | 95.5% | 98.6% | 95.0% | 98.6% | 96.9% | 99.0% |
| average | | 94.9% | 98.8% | 96.6% | 99.0% | 95.5% | 98.9% | 97.3% | 99.3% |
Table 4.
Hardware and software parameters.
Table 4.
Hardware and software parameters.
| Type | Parameter |
|---|
| CPU | Intel Xeon Gold 5218 R CPU |
| GPU | Nvidia Quadro RTX6000 |
| RAM | 256 GB |
| VRAM | 24 GB |
| Operating system | Windows 10 |
| Cuda | 11.3 |
| Deep learning framework | Pytorch1.7.1 |
| Language | Python 3.8 |
| Other key libraries | Numpy 1.92.2, Pillow 8.2.0 |
Table 5.
Ablation experiments.
Table 5.
Ablation experiments.
| Structure | 1 | 2 | 3 | 4 | 5 |
|---|
| Unet | ◎ | ◎ | ◎ | ◎ | ◎ |
| Full connection | | | | | ◎ |
| Transformer | | ◎ | | ◎ | ◎ |
| Residual attention | | | ◎ | ◎ | ◎ |
| MPA/% | 98.12 | 99.21 | 99.32 | 99.39 | 99.42 |
| MIOU/% | 96.09 | 98.45 | 98.64 | 98.79 | 98.84 |
| Parameters/106 | 23.84 | 19.32 | 23.88 | 19.35 | 16.48 |
Table 6.
Semantic segmentation results of each model with water level monitoring results.
Table 6.
Semantic segmentation results of each model with water level monitoring results.
| | TRCAM-Unet | Deeplabv3 | Unet | Pspnet |
|---|
| MIOU/% | 98.84 | 97.35 | 96.09 | 97.87 |
| MPA/% | 99.42 | 98.67 | 98.12 | 98.96 |
| MLD/m | 9.717 × 10−3 | 4.915 × 10−2 | 4.405 × 10−2 | 4.279 × 10−2 |
| Parameters/×106 | 16.48 | 2.76 | 23.84 | 2.45 |
Table 7.
Real-time processing capabilities of different models.
Table 7.
Real-time processing capabilities of different models.
| Model | Frames per Second (FPS) |
|---|
| Improved YOLOv5 | 48 |
| TRCAM-Unet | 31 |
Table 8.
Comparison of the methods proposed in this study.
Table 8.
Comparison of the methods proposed in this study.
| Methodology | Applicable Scenarios | Advantages | Disadvantages |
|---|
| A method of water level detection without a water stage gage by integrating improved YOLOv5 and Kalman filtering principle | Scenarios of water level detection without a water stage gage with gentle water surface | Small number of model parameters, thus facilitating mobile deployment | Limited suitable scenarios |
| A method for water level detection without a water stage gage based on TRCAM-Unet | All water level detection scenarios without dipstick | Higher compatibility for all scenarios | Higher number of model participants |


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}