

Meanders on the Move: Can AI-Based Solutions Predict Where They Will Be Located?


Abstract
1. Introduction
2. Material and Methods
2.1. Planform Evolution Processing
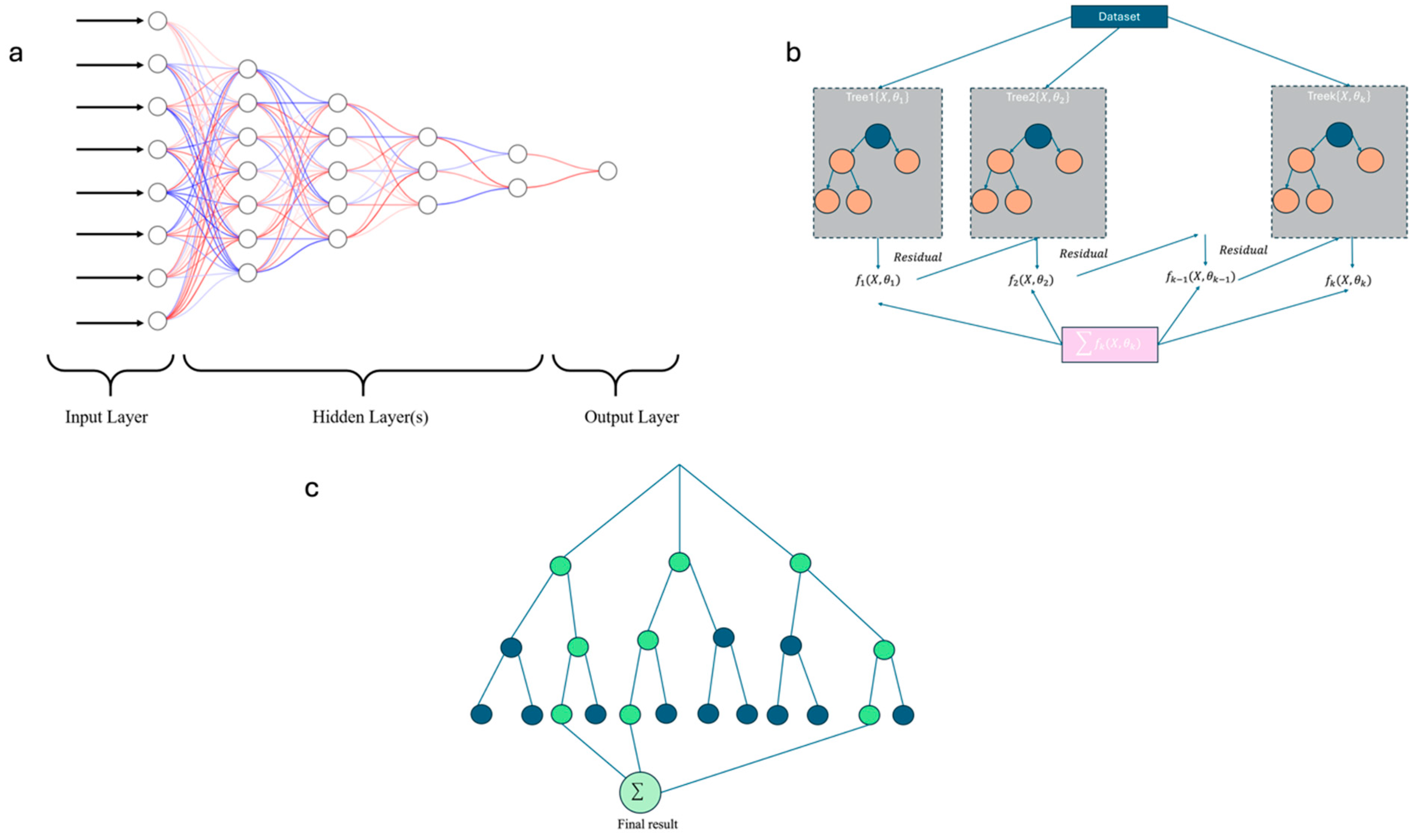
2.2. Artificial Intelligence (AI)
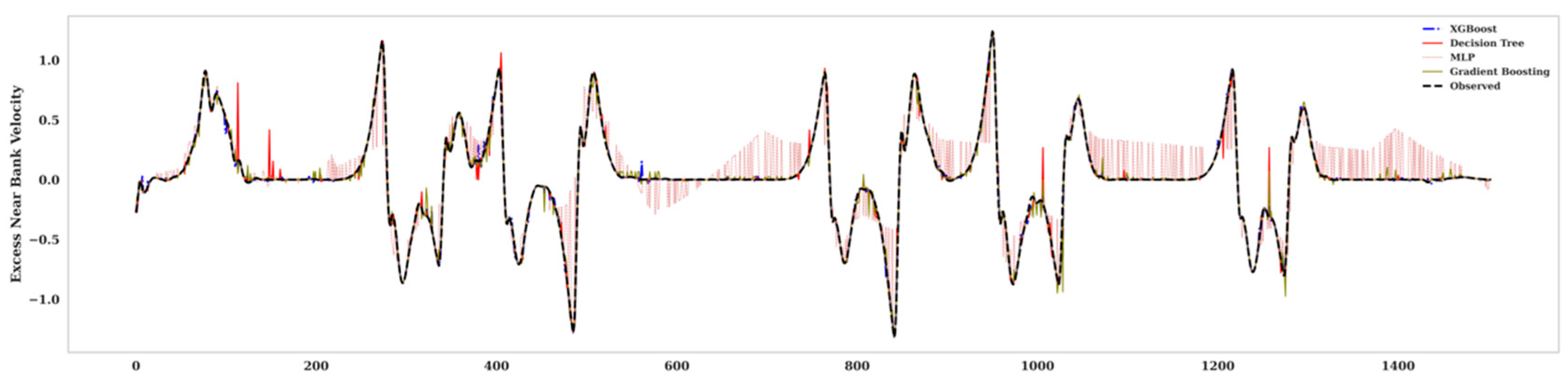
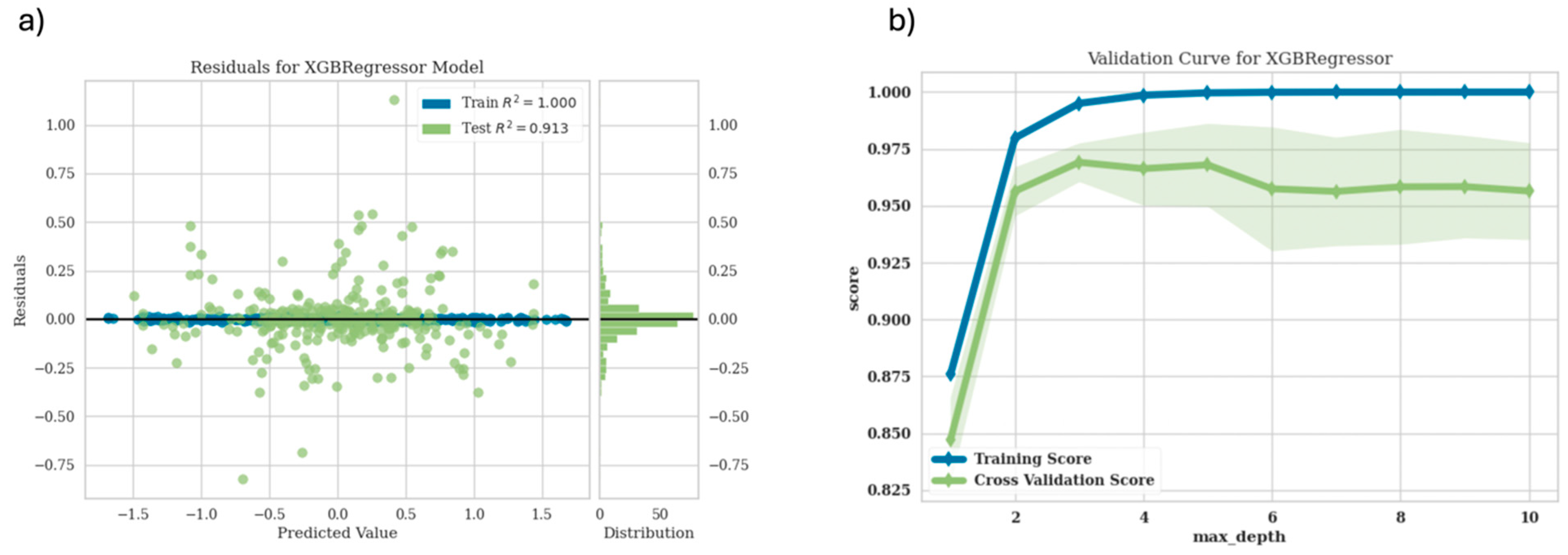
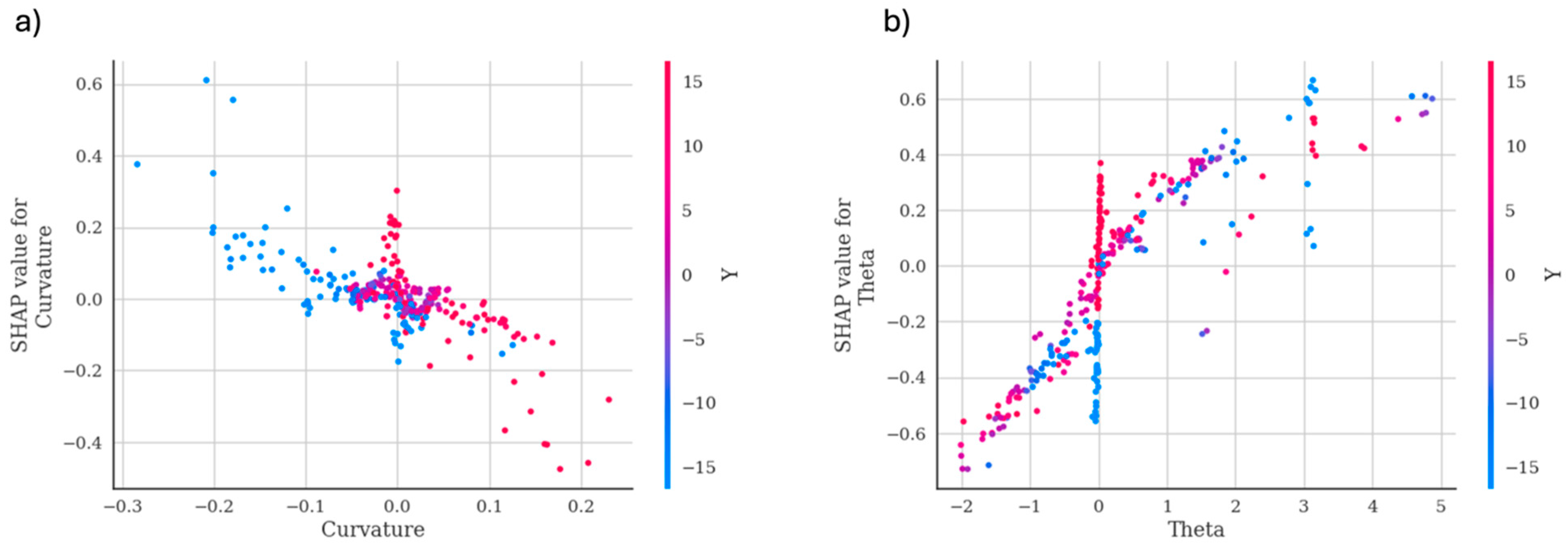
3. Results and Discussion
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Leopold, L.B.; Langbein, W.B. River Meanders. Sci. Am. 1966, 214, 60–70. [Google Scholar] [CrossRef]
- Seminara, G. Meanders. J. Fluid Mech. 2006, 554, 271–297. [Google Scholar] [CrossRef]
- Zolezzi, G.; Seminara, G. Downstream and upstream influence in river meandering. Part 1. General theory and application to overdeepening. J. Fluid Mech. 2001, 438, 183–211. [Google Scholar] [CrossRef]
- Motta, D.; Abad, J.D.; Langendoen, E.J.; García, M.H. The effects of floodplain soil heterogeneity on meander planform shape. Water Resour. Res. 2012, 48, 1–17. [Google Scholar] [CrossRef]
- Lanzoni, S.; Seminara, G. On the nature of meander instability. J. Geophys. Res. 2006, 111, F04006. [Google Scholar] [CrossRef]
- Schwendel, A.C.; Nicholas, A.P.; Aalto, R.E.; Sambrook Smith, G.H.; Buckley, S. Interaction between meander dynamics and floodplain heterogeneity in a large tropical sand-bed river: The Rio Beni, Bolivian Amazon. Earth Surf. Process. Landf. 2015, 40, 2026–2040. [Google Scholar] [CrossRef]
- Rozowski, I.L. Flow of Water in Bends of Open Channels; Academy of Sciences of the Ukrainian SSR: Kyiv, Ukraine, 1957. [Google Scholar]
- Thorne, C.R.; Hey, R.D. Direct measurements of secondary currents at a river inflexion point. Nature 1979, 280, 226–228. [Google Scholar] [CrossRef]
- Bolla Pittaluga, M.; Nobile, G.; Seminara, G. A nonlinear model for river meandering. Water Resour. Res. 2009, 45. [Google Scholar] [CrossRef]
- Duan, J.G.; Julien, P.Y. Numerical simulation of the inception of channel meandering. Earth Surf. Process. Landf. 2005, 30, 1093–1110. [Google Scholar] [CrossRef]
- Leopold, L.B.; Wolman, M.G. River Channel Patterns, Braided, Meandering and Straight; Schumm, S.A., Ed.; US Geological Survey: Reston, VA, USA, 1957; Volume 282-B.
- Sun, T.; Meakin, P.; Jøssang, T.; Schwarz, K. A simulation model for meandering rivers. Water Resour. Res. 1996, 32, 2937–2954. [Google Scholar] [CrossRef]
- Zolezzi, G.; Luchi, R.; Tubino, M. Morphodynamic regime of gravel bed, single-thread meandering rivers. J. Geophys. Res. 2009, 114, 1. [Google Scholar] [CrossRef]
- Johannesson, H.; Parker, G. Theory of River Meanders; University of Minnesota: Minneapolis, MN, USA, 1988; Available online: http://purl.umn.edu/114112 (accessed on 18 July 2024).
- Bogoni, M.; Putti, M.; Lanzoni, S. Modeling meander morphodynamics over self-formed heterogeneous floodplains. Water Resour. Res. 2017, 53, 5137–5157. [Google Scholar] [CrossRef]
- Ikeda, S.; Parker, G.; Sawai, K. Bend theory of river meanders. Part 1. Linear development. J. Fluid Mech. 1981, 112, 363–377. [Google Scholar] [CrossRef]
- Parker, G. On the cause and characteristic scales of meandering and braiding in rivers. J. Fluid Mech. 1976, 76, 457. [Google Scholar] [CrossRef]
- Bouaziz, M.; Medhioub, E.; Csaplovisc, E. A machine learning model for drought tracking and forecasting using remote precipitation data and a standardized precipitation index from arid regions. J. Arid Environ. 2021, 189, 104478. [Google Scholar] [CrossRef]
- Grbčić, L.; Družeta, S.; Mauša, G.; Lipić, T.; Lušić, D.V.; Alvir, M.; Lučin, I.; Sikirica, A.; Davidović, D.; Travaš, V.; et al. Coastal water quality prediction based on machine learning with feature interpretation and spatio-temporal analysis. Environ. Model. Softw. 2022, 155, 105458. [Google Scholar] [CrossRef]
- Tahmasebi, P.; Kamrava, S.; Bai, T.; Sahimi, M. Machine learning in geo- and environmental sciences: From small to large scale. Adv. Water Resour. 2020, 142, 103619. [Google Scholar] [CrossRef]
- Wang, Y.; Chen, J.; Cai, H.; Yu, Q.; Zhou, Z. Predicting water turbidity in a macro-tidal coastal bay using machine learning approaches. Estuar. Coast. Shelf Sci. 2021, 252, 107276. [Google Scholar] [CrossRef]
- Camporeale, C.; Perona, P.; Porporato, A.; Ridolfi, L. Hierarchy of models for meandering rivers and related morphodynamic processes. Rev. Geophys. 2007, 45. [Google Scholar] [CrossRef]
- Frascati, A.; Lanzoni, S. Morphodynamic regime and long-term evolution of meandering rivers. J. Geophys. Res. 2009, 114, 1–9. [Google Scholar] [CrossRef]
- Parsaie, A.; Haghiabi, A.H.; Moradinejad, A. Prediction of Scour Depth below River Pipeline using Support Vector Machine. KSCE J. Civ. Eng. 2019, 23, 2503–2513. [Google Scholar] [CrossRef]
- Seminara, G.; Tubino, M. Free–forced interactions in developing meanders and suppression of free bars. J. Fluid Mech. 1990, 214, 131–159. [Google Scholar]
- Van de Lageweg, W.I.; Van Dijk, W.M.; Hoendervoogt, R.; Kleinhans, M.G. Effects of riparian vegetation on experimental channel dynamics. Riverflow 2010, 2, 1331–1338. [Google Scholar]
- Monegaglia, F.; Zolezzi, G.; Gunerlap, I.; Henshaw, A.J.; Tubino, M. Automated extraction of meandering river morphodynamics from multitemporal remotely sensed data. Environ. Model. Softw. 2018, 105, 171–186. [Google Scholar] [CrossRef]
- Seminara, G.; Zolezzi, G.; Tubino, M.; Zardi, D. Downstream and upstream influence in river meandering. Part 2. Planimetric development. J. Fluid Mech. 2001, 438, 213–230. [Google Scholar] [CrossRef]
- Mohammed, H.; Longva, A.; Seidu, R. Predictive analysis of microbial water quality using machine-learning algorithms. Environ. Res. Eng. Manag. 2018, 74, 7–20. [Google Scholar] [CrossRef]
- Zhong, S.; Zhang, K.; Bagheri, M.; Burken, J.G.; Gu, A.; Li, B.; Ma, X.; Marrone, B.L.; Ren, Z.J.; Schrier, J.; et al. Machine Learning: New Ideas and Tools in Environmental Science and Engineering. Environ. Sci. Technol. 2021, 55, 12741–12754. [Google Scholar] [CrossRef]
- Schmidt, L.; Heße, F.; Attinger, S.; Kumar, R. Challenges in Applying Machine Learning Models for Hydrological Inference: A Case Study for Flooding Events Across Germany. Water Resour. Res. 2020, 56, e2019WR025924. [Google Scholar] [CrossRef]
- Lamba, A.; Cassey, P.; Segaran, R.R.; Koh, P.L. Deep learning for environmental conservation. Curr. Biol. 2019, 29, 977–982. [Google Scholar] [CrossRef]
- Goodwin, M.; Halvorsen, K.T.; Jiao, L.; Knausgård, K.M.; Martin, A.H.; Moyano, M.; Oomen, R.A.; Rasmussen, J.H.; Sørdalen, T.K.; Thorbjørnsen, S.H. Unlocking the potential of deep learning for marine ecology: Overview, applications, and outlook. ICES J. Mar. Sci. 2022, 79, 319–336. [Google Scholar] [CrossRef]
- Mitchell, T.M. Machine Learning and Data Mining. Commun. ACM 1999, 42, 30–36. [Google Scholar] [CrossRef]
- Malde, K.; Handegard, N.O.; Eikvil, L.; Salberg, A.B. Machine intelligence and the data-driven future of marine science. ICES J. Mar. Sci. 2020, 77, 1274–1285. [Google Scholar] [CrossRef]
- Rubbens, P.; Brodie, S.; Cordier, T.; Destro Barcellos, D.; Devos, P.; Fernandes-Salvador, J.A.; Fincham, J.I.; Gomes, A.; Handegard, N.O.; Howell, K.; et al. Machine learning in marine ecology: An overview of techniques and applications. ICES J. Mar. Sci. 2023, 80, 1829–1853. [Google Scholar] [CrossRef]
- Casanovas-Massana, A.; Gómez-Doñate, M.; Sánchez, D.; Belanche-Muñoz, L.A.; Muniesa, M.; Blanch, A.R. Predicting fecal sources in waters with diverse pollution loads using general and molecular host-specific indicators and applying machine learning methods. J. Environ. Manag. 2015, 151, 317–325. [Google Scholar] [CrossRef] [PubMed]
- Chianese, E.; Camastra, F.; Ciaramella, A.; Landi, T.C.; Staiano, A.; Riccio, A. Spatio-temporal learning in predicting ambient particulate matter concentration by multi-layer perceptron. Ecol. Inform. 2019, 49, 54–61. [Google Scholar] [CrossRef]
- Bentéjac, C.; Csörgő, A.; Martínez-Muñoz, G. A comparative analysis of gradient boosting algorithms. Artif. Intell. Rev. 2021, 54, 1937–1967. [Google Scholar] [CrossRef]
- Chen, T.; Guestrin, C. XGBoost: A Scalable Tree Boosting System. In Proceedings of the 22nd ACM Sigkdd International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016. [Google Scholar] [CrossRef]
- Joshi, A.; Pradhan, B.; Chakraborty, S.; Behera, M.D. Winter wheat yield prediction in the conterminous United States using solar-induced chlorophyll fluorescence data and XGBoost and random forest algorithm. Ecol. Inform. 2023, 77, 102194. [Google Scholar] [CrossRef]
- Shakeri, R.; Amini, H.; Fakheri, F.; Ketabchi, H. Assessment of drought conditions and prediction by machine learning algorithms using Standardized Precipitation Index and Standardized Water-Level Index (case study: Yazd province, Iran). Environ. Sci. Pollut. Res. 2023, 30, 101744–101760. [Google Scholar] [CrossRef]
- Lyashevska, O.; Harma, C.; Minto, C.; Clarke, M.; Brophy, D. Long-term trends in herring growth primarily linked to temperature by gradient boosting regression trees. Ecol. Inform. 2020, 60, 101154. [Google Scholar] [CrossRef]
- Persson, C.; Bacher, P.; Shiga, T.; Madsen, H. Multi-site solar power forecasting using gradient boosted regression trees. Sol. Energy 2017, 150, 423–436. [Google Scholar] [CrossRef]
- Otchere, D.A.; Ganat, T.O.A.; Ojero, J.O.; Tackie-Otoo, B.N.; Taki, M.Y. Application of gradient boosting regression model for the evaluation of feature selection techniques in improving reservoir characterisation predictions. J. Pet. Sci. Eng. 2022, 208, 109244. [Google Scholar] [CrossRef]
- Bennett, N.D.; Croke, B.F.W.; Guariso, G.; Guillaume, J.H.A.; Hamilton, S.H.; Jakeman, A.J.; Marsili-Libelli, S.; Newham, L.T.H.; Norton, J.P.; Perrin, C.; et al. Characterising performance of environmental models. Environ. Model. Softw. 2013, 40, 1–20. [Google Scholar] [CrossRef]
- Everaert, G.; Bennetsen, E.; Goethals, P.L.M. An applicability index for reliable and applicable decision trees in water quality modelling. Ecol. Inform. 2016, 32, 1–6. [Google Scholar] [CrossRef]
- Oseibryson, K. Post-pruning in regression tree induction: An integrated approach. Expert Syst. Appl. 2008, 34, 1481–1490. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| MLP | |||||
|---|---|---|---|---|---|
| Activation function | Alpha | Hidden layer size | Solver | ||
| Tanh | 0.0005 | 10 | lbfgs | ||
| XGBoost | |||||
| Learning rate | Max depth | Objective | Sub sample | Col sample | Min child weight |
| 0.2 | Uniform | Auto | 40 | 2 | Minkowsiki |
| Gradient Boosting Regressor (GBR) | |||||
| Min sample split | Min sample leaf | Max variable | Learning rate | Number of estimators | Sub sample |
| 6 | Uniform | Auto | 0.1 | 150 | Minkowski |
| Decision Tree | |||||
| Criterion | Max depth | Splitter | ccp_alpha | ||
| Friedman_mse | 5 | Best | 0.1 | ||
| Metric | eXtreme Gradient Boosting | MLP Regressor | Gradient Boosting Regressor | Decision Tree Regressor |
|---|---|---|---|---|
| MAE | 0.0264 | 0.2042 | 0.0424 | 0.0343 |
| MSE | 0.0023 | 0.0647 | 0.0054 | 0.0064 |
| RMSE | 0.0475 | 0.2545 | 0.0733 | 0.0802 |
| R2 | 0.9197 | 0.4171 | 0.9516 | 0.9021 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Amini, H.; Monegaglia, F.; Shakeri, R.; Tubino, M.; Zolezzi, G. Meanders on the Move: Can AI-Based Solutions Predict Where They Will Be Located? Water 2024, 16, 2460. https://doi.org/10.3390/w16172460
Amini H, Monegaglia F, Shakeri R, Tubino M, Zolezzi G. Meanders on the Move: Can AI-Based Solutions Predict Where They Will Be Located? Water. 2024; 16(17):2460. https://doi.org/10.3390/w16172460
Chicago/Turabian StyleAmini, Hossein, Federico Monegaglia, Reza Shakeri, Marco Tubino, and Guido Zolezzi. 2024. "Meanders on the Move: Can AI-Based Solutions Predict Where They Will Be Located?" Water 16, no. 17: 2460. https://doi.org/10.3390/w16172460
APA StyleAmini, H., Monegaglia, F., Shakeri, R., Tubino, M., & Zolezzi, G. (2024). Meanders on the Move: Can AI-Based Solutions Predict Where They Will Be Located? Water, 16(17), 2460. https://doi.org/10.3390/w16172460