

Risk Identification of Mountain Torrent Hazard Using Machine Learning and Bayesian Model Averaging Techniques

Abstract
1. Introduction
2. Materials and Methods
2.1. Study Area
2.2. Data
2.3. Applied Machine Learning Method
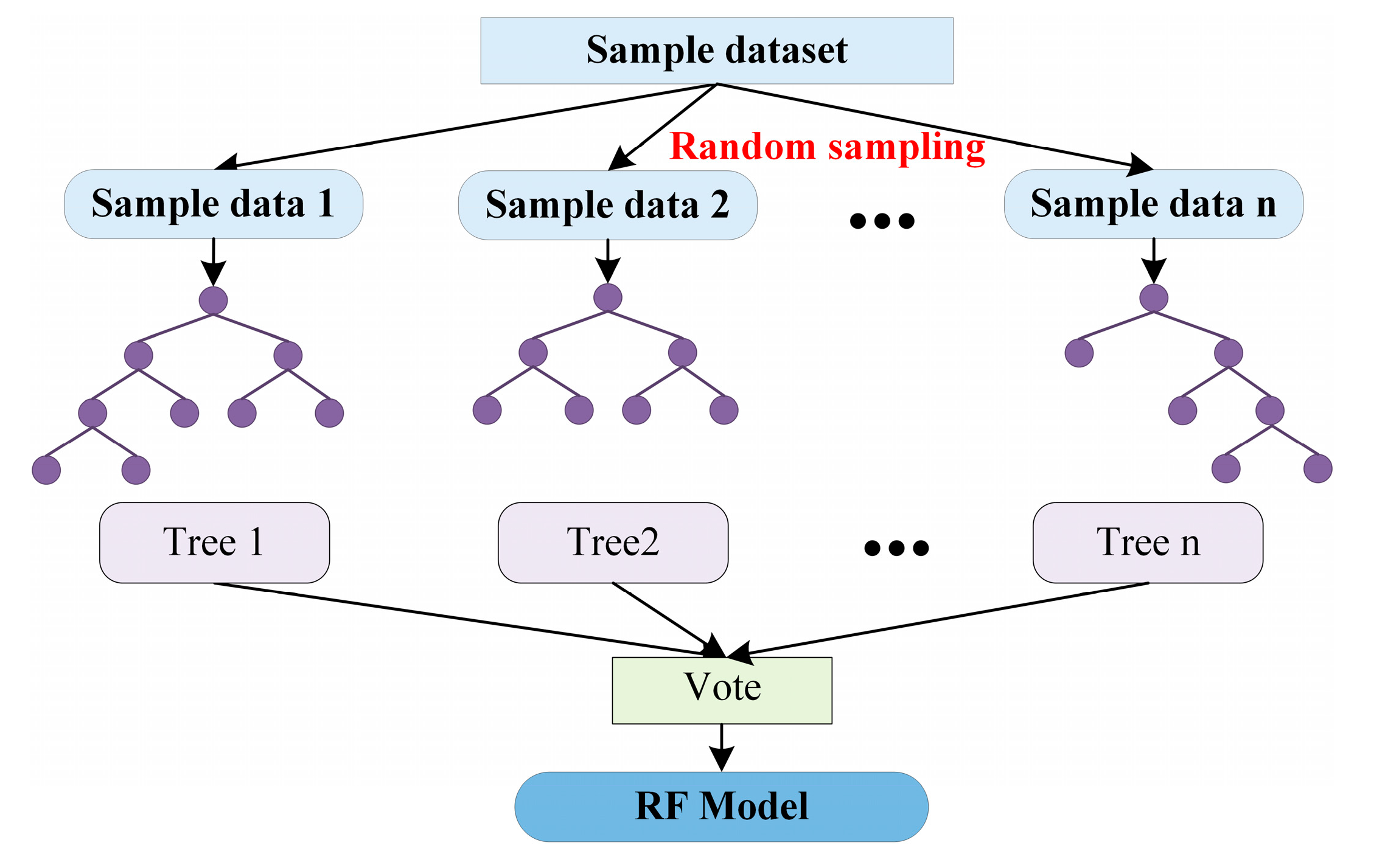
2.3.1. Machine Learning Models
2.3.2. Model Training and Parameter Optimization
2.4. Construction of the BMA Model
2.5. Model Performance Evaluation
3. Results and Discussion
3.1. Model Performance of Single Models
3.2. Performance of BMA Model
3.3. Feature Importance Analysis
3.4. Risk Assessment of Mountain Torrent Based on BMA
4. Conclusions
- (1)
- The proposed BMA model consistently has the highest testing accuracy under the three different test samples; the F1-score of the BMA model was 3.31–24.61% higher than that of the three single models under the three different test samples. These results demonstrate that the BMA model that integrated multiple machine learning methods significantly improved the accuracy and stability of mountain torrent hazard prediction. This can provide a reference for improving the performance of mountain torrent hazard prediction based on machine learning methods.
- (2)
- The analysis of feature importance showed that the distance to the river and elevation were the main factors affecting mountain torrent hazards in Yuanyang County. Therefore, the residents in low-lying areas near the river should relocate to safe areas as far away as possible from the river, and the construction of new projects should also avoid low-lying river valleys as much as possible.
- (3)
- The results of the mountain torrent risk assessment based on the BMA model indicate that very high-risk areas are mainly concentrated near the northern boundary and southern valleys of Yuanyang County. The area of very high-risk areas in Nansha Town is the greatest, accounting for 25.65% of the total area of very high-risk areas in the county. Therefore, the relevant management personnel of Yuanyang County should pay more attention to the prevention and monitoring of mountain torrent hazards in Nansha Town during the flood season.
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Liu, Z.; Yang, Z.; Chen, M.; Xu, H.; Yang, Y.; Zhang, J.; Wu, Q.; Wang, M.; Song, Z.; Ding, F. Research Hotspots and Frontiers of Mountain Flood Disaster: Bibliometric and Visual Analysis. Water 2023, 15, 673. [Google Scholar] [CrossRef]
- Tien Bui, D.; Hoang, N.-D.; Martínez-Álvarez, F.; Ngo, P.-T.T.; Hoa, P.V.; Pham, T.D.; Samui, P.; Costache, R. A novel deep learning neural network approach for predicting flash flood susceptibility: A case study at a high frequency tropical storm area. Sci. Total Environ. 2020, 701, 134413. [Google Scholar] [CrossRef] [PubMed]
- Kundzewicz, Z.W.; Stoffel, M.; Wyzga, B.; Ruiz-Villanueva, V.; Niedzwiedz, T.; Kaczka, R.; Ballesteros-Cánovas, J.A.; Pinskwar, I.; Lupikasza, E.; Zawiejska, J.; et al. Changes of flood risk on the northern foothills of the Tatra Mountains. Acta Geophys. 2017, 65, 799–807. [Google Scholar] [CrossRef]
- Wang, Z.; Lai, C.; Chen, X.; Yang, B.; Zhao, S.; Bai, X. Flood hazard risk assessment model based on random forest. J. Hydrol. 2015, 527, 1130–1141. [Google Scholar] [CrossRef]
- Palutikof, J.P.; Boulter, S.L.; Field, C.B.; Mach, K.J.; Manning, M.R.; Mastrandrea, M.D.; Meyer, L.; Minx, J.C.; Pereira, J.J.; Plattner, G.-K.; et al. Enhancing the review process in global environmental assessments: The case of the IPCC. Environ. Sci. Policy 2023, 139, 118–129. [Google Scholar] [CrossRef]
- Liu, J.; Feng, S.; Gu, X.; Zhang, Y.; Beck, H.E.; Zhang, J.; Yan, S. Global changes in floods and their drivers. J. Hydrol. 2022, 614, 128553. [Google Scholar] [CrossRef]
- Mohanty, M.P.; Mudgil, S.; Karmakar, S. Flood management in India: A focussed review on the current status and future challenges. Int. J. Disaster Risk Reduct. 2020, 49, 101660. [Google Scholar] [CrossRef]
- Terzi, S.; Torresan, S.; Schneiderbauer, S.; Critto, A.; Zebisch, M.; Marcomini, A. Multi-risk assessment in mountain regions: A review of modelling approaches for climate change adaptation. J. Environ. Manag. 2019, 232, 759–771. [Google Scholar] [CrossRef] [PubMed]
- Schneiderbauer, S.; Fontanella Pisa, P.; Delves, J.L.; Pedoth, L.; Rufat, S.; Erschbamer, M.; Thaler, T.; Carnelli, F.; Granados-Chahin, S. Risk perception of climate change and natural hazards in global mountain regions: A critical review. Sci. Total Environ. 2021, 784, 146957. [Google Scholar] [CrossRef]
- Namgyal, T.; Thakur, D.A.; Rishi, D.S.; Mohanty, M.P. Are open-source hydrodynamic models efficient in quantifying flood risks over mountainous terrains? An exhaustive analysis over the Hindu-Kush-Himalayan region. Sci. Total Environ. 2023, 897, 165357. [Google Scholar] [CrossRef]
- Mignot, E.; Li, X.; Dewals, B. Experimental modelling of urban flooding: A review. J. Hydrol. 2019, 568, 334–342. [Google Scholar] [CrossRef]
- Lee, B.-J.; Kim, S. Gridded Flash Flood Risk Index Coupling Statistical Approaches and TOPLATS Land Surface Model for Mountainous Areas. Water 2019, 11, 504. [Google Scholar] [CrossRef]
- Wang, W.-j.; Kim, D.; Han, H.; Tak Kim, K.; Kim, S.; Soo Kim, H. Flood risk assessment using an indicator based approach combined with flood risk maps and grid data. J. Hydrol. 2023, 627, 130396. [Google Scholar] [CrossRef]
- Lyu, H.-M.; Zhou, W.-H.; Shen, S.-L.; Zhou, A.-N. Inundation risk assessment of metro system using AHP and TFN-AHP in Shenzhen. Sust. Cities Soc. 2020, 56, 102103. [Google Scholar] [CrossRef]
- Wang, W.-j.; Kim, D.; Kim, G.; Kim, K.T.; Kim, S.; Kim, H.S. Flood risk assessment of the naeseongcheon stream basin, Korea using the grid-based flood risk index. J. Hydrol.-Reg. Stud. 2024, 51, 101619. [Google Scholar] [CrossRef]
- Peng, J.; Zhang, J. Urban flooding risk assessment based on GIS- game theory combination weight: A case study of Zhengzhou City. Int. J. Disaster Risk Reduct. 2022, 77, 103080. [Google Scholar] [CrossRef]
- Lv, H.; Wu, Z.; Meng, Y.; Guan, X.; Wang, H.; Zhang, X.; Ma, B. Optimal Domain Scale for Stochastic Urban Flood Damage Assessment Considering Triple Spatial Uncertainties. Water Resour. Res. 2022, 58, e2021WR031552. [Google Scholar] [CrossRef]
- Li, J.; Zhang, H.; Zhao, J.; Guo, X.; Rihan, W.; Deng, G. Embedded Feature Selection and Machine Learning Methods for Flash Flood Susceptibility-Mapping in the Mainstream Songhua River Basin, China. Remote Sens. 2022, 14, 5523. [Google Scholar] [CrossRef]
- Costache, R.; Hong, H.; Pham, Q.B. Comparative assessment of the flash-flood potential within small mountain catchments using bivariate statistics and their novel hybrid integration with machine learning models. Sci. Total Environ. 2020, 711, 134514. [Google Scholar] [CrossRef]
- Rahman, M.; Chen, N.; Elbeltagi, A.; Islam, M.M.; Alam, M.; Pourghasemi, H.R.; Tao, W.; Zhang, J.; Shufeng, T.; Faiz, H.; et al. Application of stacking hybrid machine learning algorithms in delineating multi-type flooding in Bangladesh. J. Environ. Manag. 2021, 295, 113086. [Google Scholar] [CrossRef]
- Xu, K.; Han, Z.; Xu, H.; Bin, L. Rapid Prediction Model for Urban Floods Based on a Light Gradient Boosting Machine Approach and Hydrological–Hydraulic Model. Int. J. Disaster Risk Sci. 2023, 14, 79–97. [Google Scholar] [CrossRef]
- Youssef, A.M.; Mahdi, A.M.; Pourghasemi, H.R. Landslides and flood multi-hazard assessment using machine learning techniques. Bull. Eng. Geol. Environ. 2022, 81, 370. [Google Scholar] [CrossRef]
- Fang, L.; Huang, J.; Cai, J.; Nitivattananon, V. Hybrid approach for flood susceptibility assessment in a flood-prone mountainous catchment in China. J. Hydrol. 2022, 612, 128091. [Google Scholar] [CrossRef]
- Salvati, A.; Nia, A.M.; Salajegheh, A.; Ghaderi, K.; Asl, D.T.; Al-Ansari, N.; Solaimani, F.; Clague, J.J. Flood susceptibility mapping using support vector regression and hyper-parameter optimization. J. Flood Risk Manag. 2023, 16, e12920. [Google Scholar] [CrossRef]
- Zhou, M.; Lu, W.; Ma, Q.; Wang, H.; He, B.; Liang, D.; Dong, R. Study on the Snowmelt Flood Model by Machine Learning Method in Xinjiang. Water 2023, 15, 3620. [Google Scholar] [CrossRef]
- Yan, H.; Moradkhani, H. Toward more robust extreme flood prediction by Bayesian hierarchical and multimodeling. Nat. Hazards 2016, 81, 203–225. [Google Scholar] [CrossRef]
- Guan, X.; Xia, C.; Xu, H.; Liang, Q.; Ma, C.; Xu, S. Flood risk analysis integrating of Bayesian-based time-varying model and expected annual damage considering non-stationarity and uncertainty in the coastal city. J. Hydrol. 2023, 617, 129038. [Google Scholar] [CrossRef]
- Liu, Z.; Merwade, V. Accounting for model structure, parameter and input forcing uncertainty in flood inundation modeling using Bayesian model averaging. J. Hydrol. 2018, 565, 138–149. [Google Scholar] [CrossRef]
- Zhou, Y.; Wu, Z.; Xu, H.; Wang, H.; Ma, B.; Lv, H. Integrated dynamic framework for predicting urban flooding and providing early warning. J. Hydrol. 2023, 618, 129205. [Google Scholar] [CrossRef]
- Moknatian, M.; Mukundan, R. Uncertainty analysis of streamflow simulations using multiple objective functions and Bayesian Model Averaging. J. Hydrol. 2023, 617, 128961. [Google Scholar] [CrossRef]
- Rings, J.; Vrugt, J.A.; Schoups, G.; Huisman, J.A.; Vereecken, H. Bayesian model averaging using particle filtering and Gaussian mixture modeling: Theory, concepts, and simulation experiments. Water Resour. Res. 2012, 48, W05520. [Google Scholar] [CrossRef]
- Notaro, V.; Liuzzo, L.; Freni, G. A BMA Analysis to Assess the Urbanization and Climate Change Impact on Urban Watershed Runoff. Procedia Eng. 2016, 154, 868–876. [Google Scholar] [CrossRef]
- Darbandsari, P.; Coulibaly, P. Inter-Comparison of Different Bayesian Model Averaging Modifications in Streamflow Simulation. Water 2019, 11, 1707. [Google Scholar] [CrossRef]
- Asfaw, W.; Rientjes, T.; Haile, A.T. Blending high-resolution satellite rainfall estimates over urban catchment using Bayesian Model Averaging approach. J. Hydrol.-Reg. Stud. 2023, 45, 101287. [Google Scholar] [CrossRef]
- Jianjin, W.; Shi, P.; Jiang, P.; Hu, J.; Qu, S.; Chen, X.; Chen, Y.; Dai, Y.; Xiao, Z. Application of BP Neural Network Algorithm in Traditional Hydrological Model for Flood Forecasting. Water 2017, 9, 48. [Google Scholar] [CrossRef]
- Chen, J.; Huang, G.; Chen, W. Towards better flood risk management: Assessing flood risk and investigating the potential mechanism based on machine learning models. J. Environ. Manag. 2021, 293, 112810. [Google Scholar] [CrossRef] [PubMed]
- Gharekhani, M.; Nadiri, A.A.; Khatibi, R.; Sadeghfam, S.; Asghari Moghaddam, A. A study of uncertainties in groundwater vulnerability modelling using Bayesian model averaging (BMA). J. Environ. Manag. 2022, 303, 114168. [Google Scholar] [CrossRef]
- Zhou, Y.; Wu, Z.; Xu, H.; Yan, D.; Jiang, M.; Zhang, X.; Wang, H. Adaptive selection and optimal combination scheme of candidate models for real-time integrated prediction of urban flood. J. Hydrol. 2023, 626, 130152. [Google Scholar] [CrossRef]
- Friedman, J.H. Greedy function approximation: A gradient boosting machine. Ann. Stat. 2001, 29, 1189–1232. [Google Scholar] [CrossRef]
- Ding, C.; Cao, X.; Næss, P. Applying gradient boosting decision trees to examine non-linear effects of the built environment on driving distance in Oslo. Transp. Res. Part A-Policy Pract. 2018, 110, 107–117. [Google Scholar] [CrossRef]
- Wu, Z.; Zhou, Y.; Wang, H.; Jiang, Z. Depth prediction of urban flood under different rainfall return periods based on deep learning and data warehouse. Sci. Total Environ. 2020, 716, 137077. [Google Scholar] [CrossRef] [PubMed]
- Wang, D.; Luo, H.; Grunder, O.; Lin, Y.; Guo, H. Multi-step ahead electricity price forecasting using a hybrid model based on two-layer decomposition technique and BP neural network optimized by firefly algorithm. Appl. Energy 2017, 190, 390–407. [Google Scholar] [CrossRef]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Abu-Salih, B.; Wongthongtham, P.; Coutinho, K.; Qaddoura, R.; Alshaweesh, O.; Wedyan, M. The development of a road network flood risk detection model using optimised ensemble learning. Eng. Appl. Artif. Intell. 2023, 122, 106081. [Google Scholar] [CrossRef]
- Min, J.H.; Lee, Y.-C. Bankruptcy prediction using support vector machine with optimal choice of kernel function parameters. Expert Syst. Appl. 2005, 28, 603–614. [Google Scholar] [CrossRef]
- Basher, A.; Islam, A.K.M.S.; Stiller-Reeve, M.A.; Chu, P.-S. Changes in future rainfall extremes over Northeast Bangladesh: A Bayesian model averaging approach. Int. J. Climatol. 2020, 40, 3232–3249. [Google Scholar] [CrossRef]
- Najafi, M.R.; Moradkhani, H. Ensemble Combination of Seasonal Streamflow Forecasts. J. Hydrol. Eng. 2016, 21, 04015043. [Google Scholar] [CrossRef]
- Ajami, N.K.; Duan, Q.; Gao, X.; Sorooshian, S. Multimodel Combination Techniques for Analysis of Hydrological Simulations: Application to Distributed Model Intercomparison Project Results. J. Hydrometeorol. 2006, 7, 755–768. [Google Scholar] [CrossRef]
- Chen, W.; Li, Y.; Xue, W.; Shahabi, H.; Li, S.; Hong, H.; Wang, X.; Bian, H.; Zhang, S.; Pradhan, B.; et al. Modeling flood susceptibility using data-driven approaches of naïve Bayes tree, alternating decision tree, and random forest methods. Sci. Total Environ. 2020, 701, 134979. [Google Scholar] [CrossRef]
- Faceli, K.; Lorena, A.C.; Gama, J.; Carvalho, A. Inteligência Artificial: Uma Abordagem de Aprendizado de Máquina; LTC: Rio de Janeiro, Brazil, 2011. [Google Scholar]
- Zhou, Y.; Wu, Z.; Xu, H.; Wang, H. Prediction and early warning method of inundation process at waterlogging points based on Bayesian model average and data-driven. J. Hydrol.-Reg. Stud. 2022, 44, 101248. [Google Scholar] [CrossRef]
- Yin, J.; Medellín-Azuara, J.; Escriva-Bou, A.; Liu, Z. Bayesian machine learning ensemble approach to quantify model uncertainty in predicting groundwater storage change. Sci. Total Environ. 2021, 769, 144715. [Google Scholar] [CrossRef] [PubMed]
- Samadi, S.; Pourreza-Bilondi, M.; Wilson, C.A.M.E.; Hitchcock, D.B. Bayesian Model Averaging With Fixed and Flexible Priors: Theory, Concepts, and Calibration Experiments for Rainfall-Runoff Modeling. J. Adv. Model. Earth Syst. 2020, 12, e2019MS001924. [Google Scholar] [CrossRef]
- Liu, J.; Shao, W.; Xiang, C.; Mei, C.; Li, Z. Uncertainties of urban flood modeling: Influence of parameters for different underlying surfaces. Environ. Res. 2020, 182, 108929. [Google Scholar] [CrossRef] [PubMed]
- Berkhahn, S.; Fuchs, L.; Neuweiler, I. An ensemble neural network model for real-time prediction of urban floods. J. Hydrol. 2019, 575, 743–754. [Google Scholar] [CrossRef]
- Li, Y.; Hong, H. Modelling flood susceptibility based on deep learning coupling with ensemble learning models. J. Environ. Manag. 2023, 325, 116450. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Statistical Indicator | Elevation (m) | Slope | Population | Rainfall (mm) | Distance to River (m) |
|---|---|---|---|---|---|
| Max | 2518 | 0.60 | 4952 | 105.5 | 10,824 |
| Min | 164 | 0.02 | 0 | 80 | 0 |
| Average | 1124.62 | 0.22 | 386 | 93.11 | 2534.02 |
| Data | Statistical Indicator | Elevation (m) | Slope | Population | Rainfall (mm) | Distance to River (m) |
|---|---|---|---|---|---|---|
| Training | Max | 2518 | 0.60 | 4952 | 105.5 | 10,824 |
| Min | 164 | 0.02 | 0 | 80 | 0 | |
| Average | 1124.62 | 0.22 | 386 | 93.11 | 2534.02 | |
| Testing | Max | 2277 | 0.43 | 2043 | 103 | 8343 |
| Min | 174 | 0.02 | 0 | 80 | 0 | |
| Average | 1321 | 0.24 | 255 | 92 | 3111 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chu, Y.; Song, W.; Chen, D. Risk Identification of Mountain Torrent Hazard Using Machine Learning and Bayesian Model Averaging Techniques. Water 2024, 16, 1556. https://doi.org/10.3390/w16111556
Chu Y, Song W, Chen D. Risk Identification of Mountain Torrent Hazard Using Machine Learning and Bayesian Model Averaging Techniques. Water. 2024; 16(11):1556. https://doi.org/10.3390/w16111556
Chicago/Turabian StyleChu, Ya, Weifeng Song, and Dongbin Chen. 2024. "Risk Identification of Mountain Torrent Hazard Using Machine Learning and Bayesian Model Averaging Techniques" Water 16, no. 11: 1556. https://doi.org/10.3390/w16111556
APA StyleChu, Y., Song, W., & Chen, D. (2024). Risk Identification of Mountain Torrent Hazard Using Machine Learning and Bayesian Model Averaging Techniques. Water, 16(11), 1556. https://doi.org/10.3390/w16111556