
A Spatiotemporal Deep Learning Approach for Urban Pluvial Flood Forecasting with Multi-Source Data
 , ,
, , 
Abstract
1. Introduction
- High temporal and spatial resolution of flood forecasts;
- Sufficient lead time between prediction and event occurrence.
- Development of a prediction model for pluvial flooding based on deep learning that can predict the spatial and temporal evolution of the flooding situation. In contrast to other studies investigating the use of deep learning to predict pluvial flooding [31,33,34,35], the model output is a flooding sequence for the upcoming time steps instead of the maximum water levels. The chosen model design also allows predictions to be generated at any point in an event and is not limited to specific durations of an event. The accuracy of the results is expected to be as close as possible to that of physically based models, with drastically reduced computation times at the same time.
- Compared to existing studies on predicting pluvial flash floods using deep learning approaches [31,33,34,35], the sewer network is considered as an extra retention volume here. To achieve this, an event-specific overflow forecast is taken as an additional input variable informing whether the sewer network is overloaded or not. In subsequent operational use, this input can be provided either by hydrodynamic sewer network models or data-driven models.
- Different model setups are evaluated. This refers, on the one hand, to the considered model inputs and in the case of overflow prediction, to the data format and the model architecture depending on it. Furthermore, different modern deep learning architectures such as encoder-decoder networks, graph neural networks, or generative adversarial networks are combined and compared with each other in the investigations.
2. Methodology
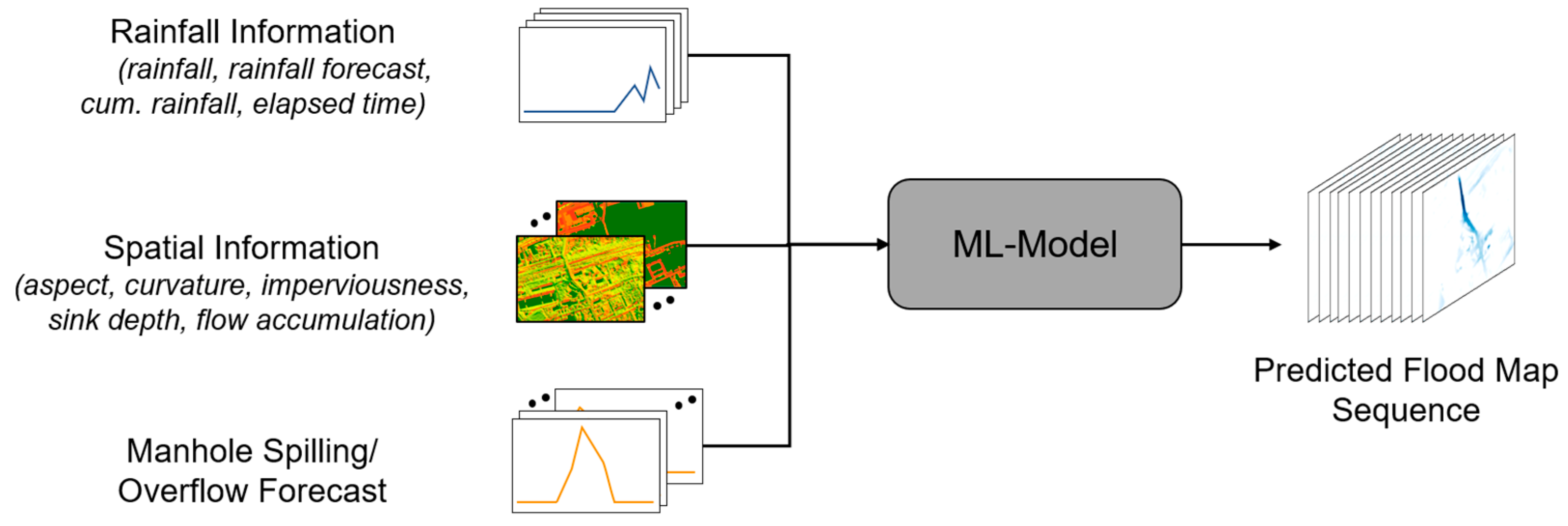
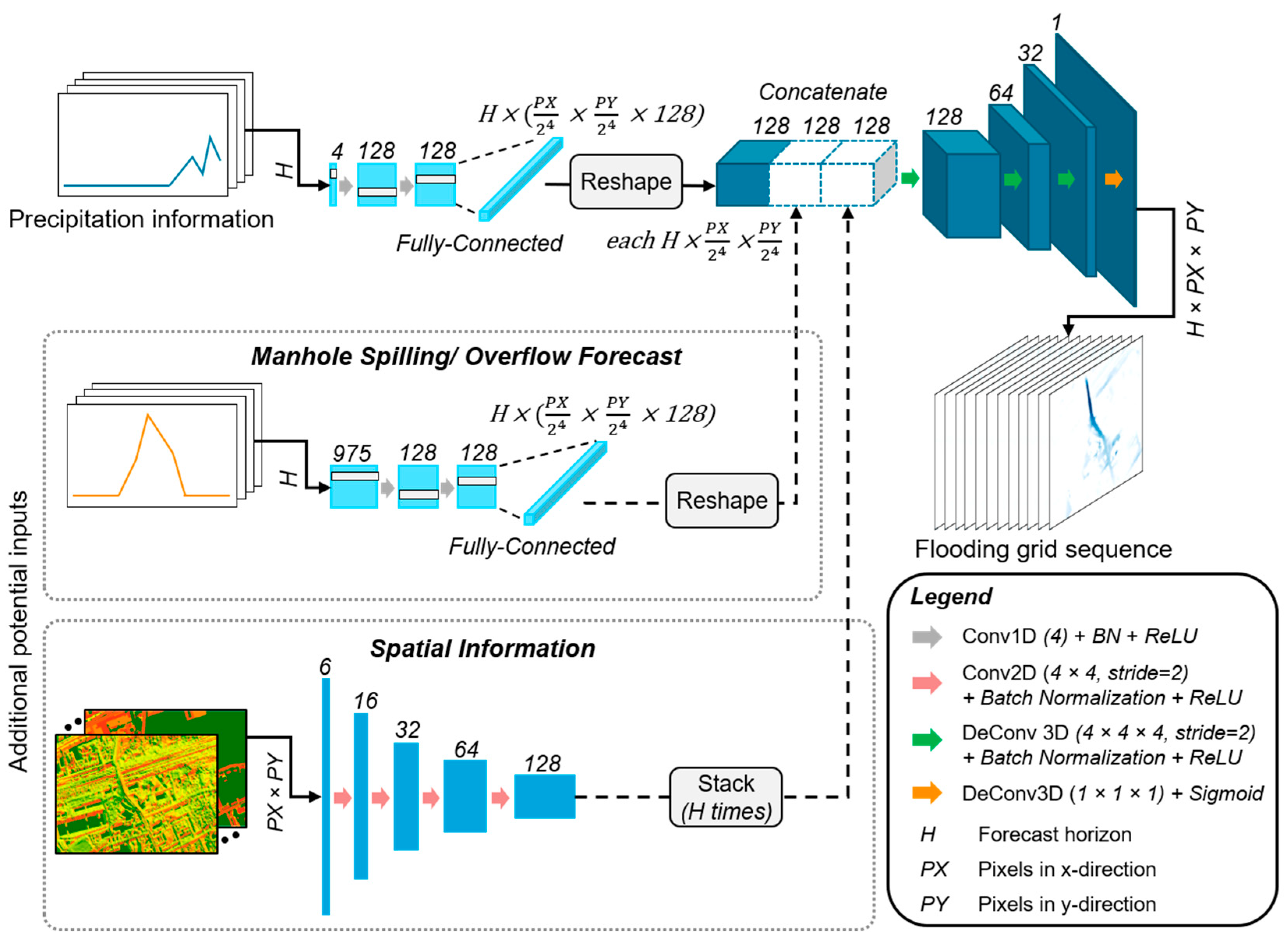
2.1. Modeling Concept
- 1D time series (precipitation information and overflow forecast): These are time series whose values vary along the temporal axis but are assumed to be constant over the spatial extent of the study area (precipitation) or correspond only to a single spatial unit in the study area (overflow).
- 2D raster (spatial information): These are raster data sets whose values vary across the spatial extent of the study area but are assumed to be constant over time.
- 3D raster sequence (predicted inundation areas): These are grid sequences with the same format as video sequences. The values vary both spatially and temporally.
2.2. Considered Layers and Network Architectures
2.2.1. Fully Connected Layers
2.2.2. Convolutional Layer
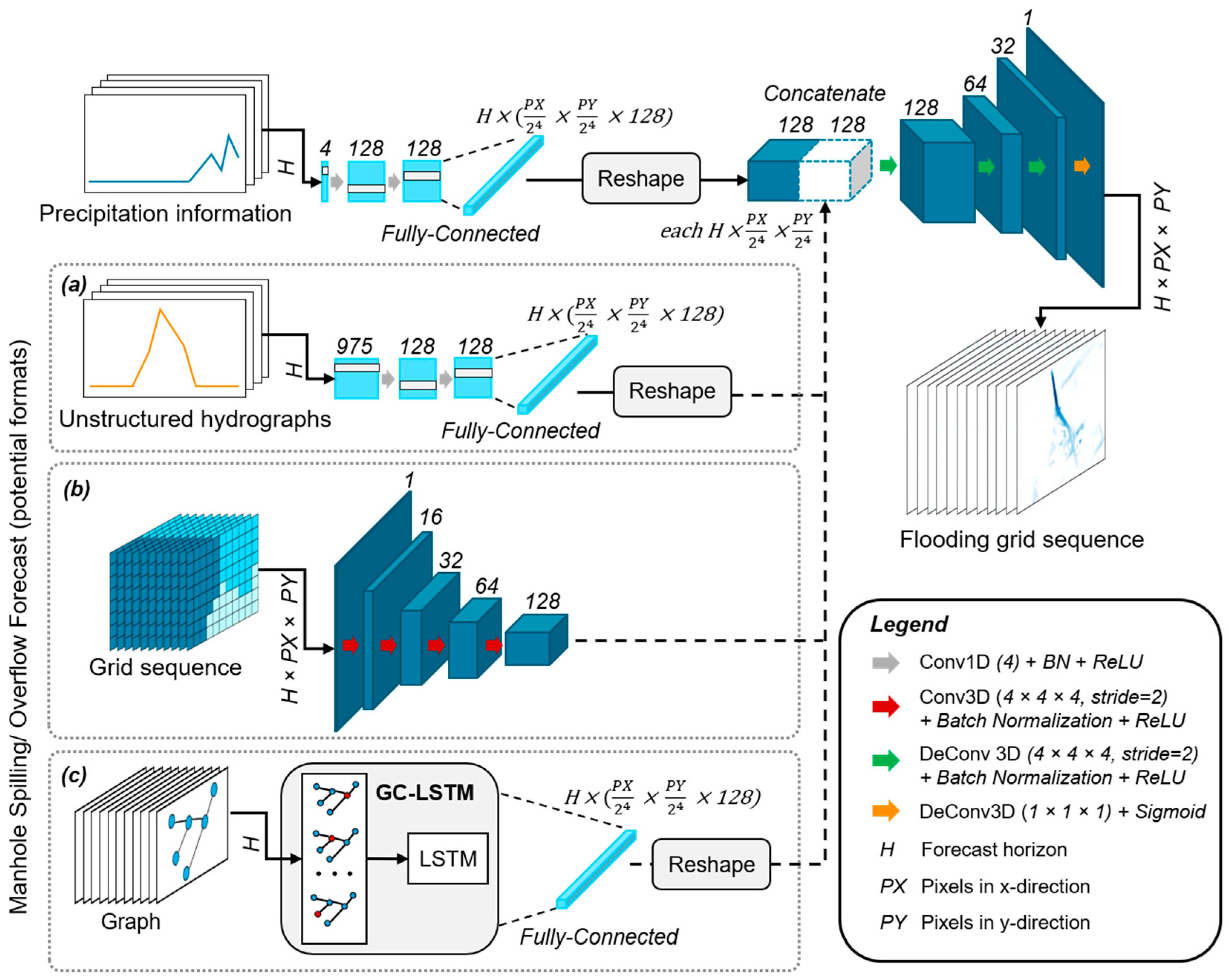
2.2.3. Recurrent Layer
2.2.4. Graph Neural Networks (GNNs)
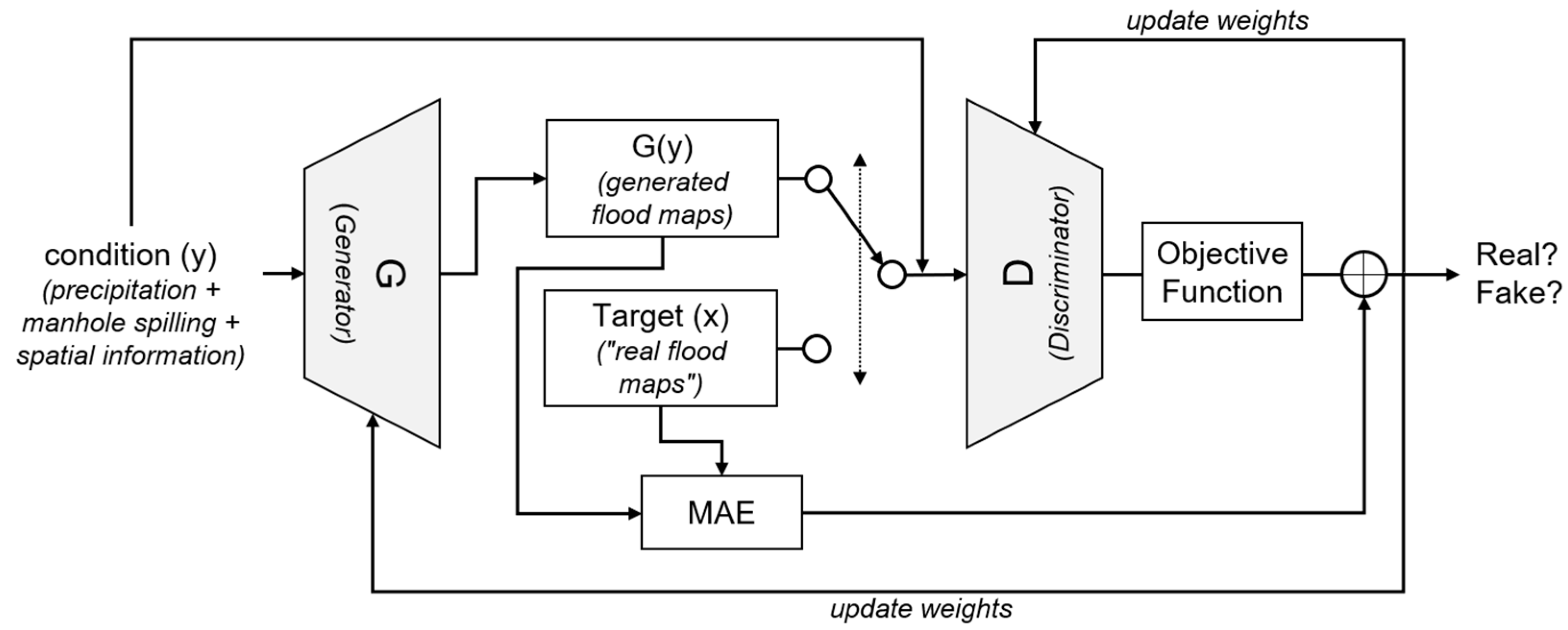
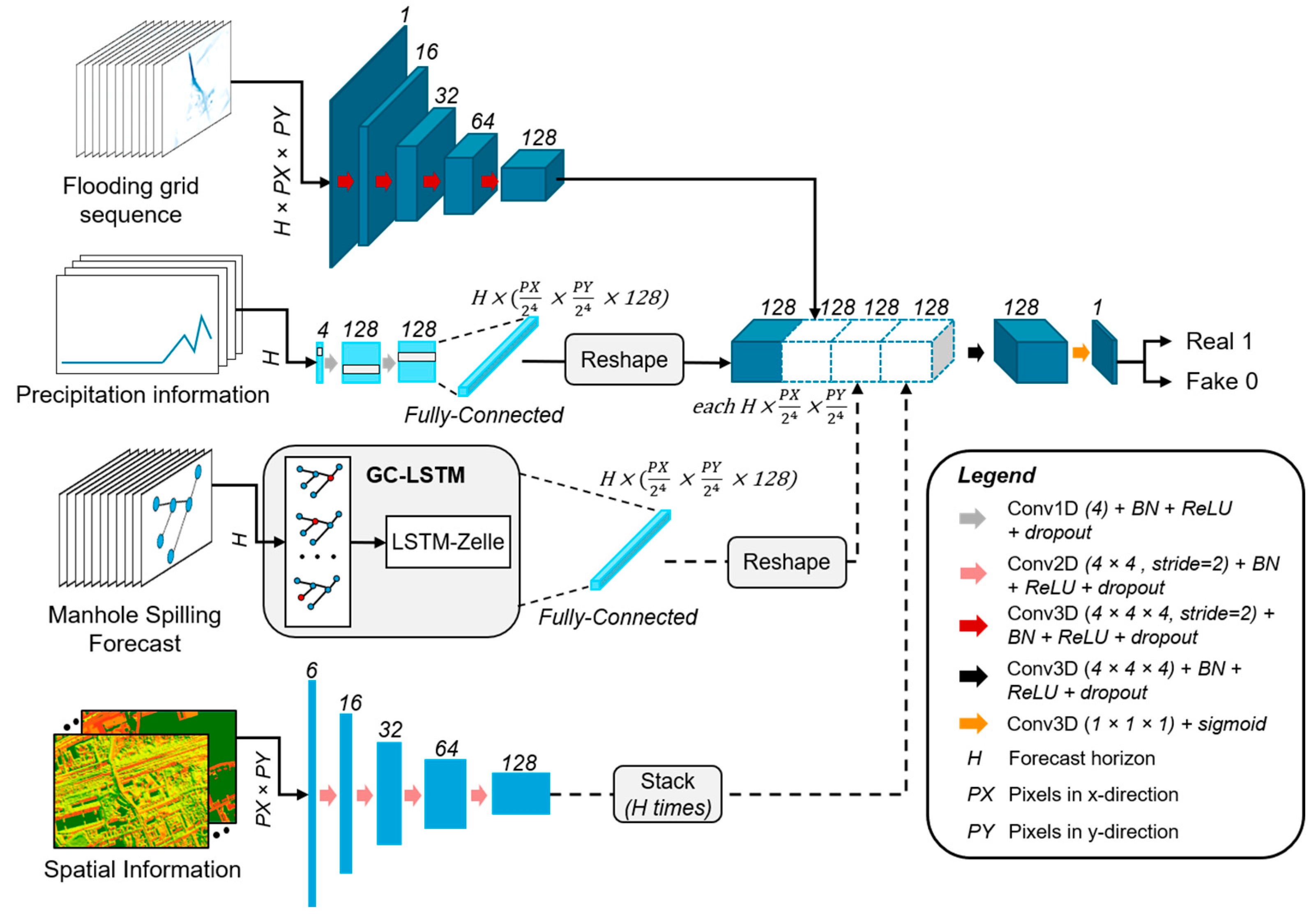
2.2.5. Generative Adversarial Networks
3. Case Study
3.1. Study Area and Hydrodynamic Model
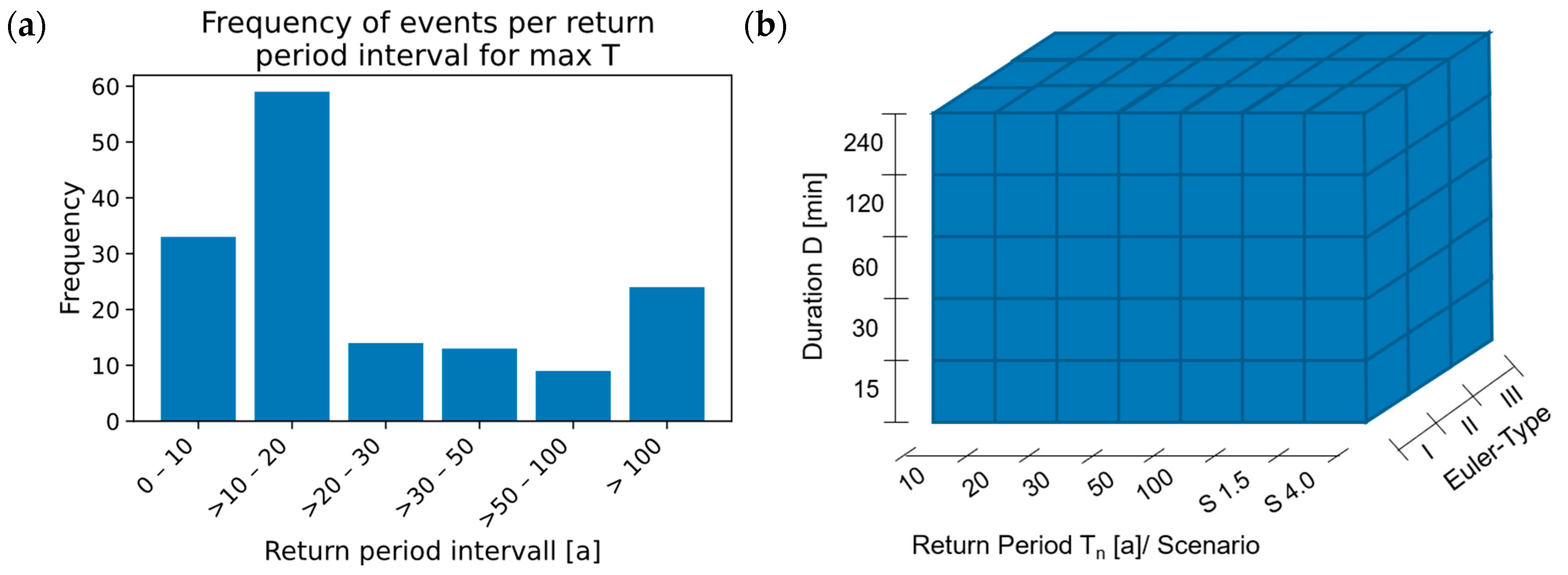
3.2. Pluvial Flood Event Data Sets
3.3. Data Generation and Preprocessing
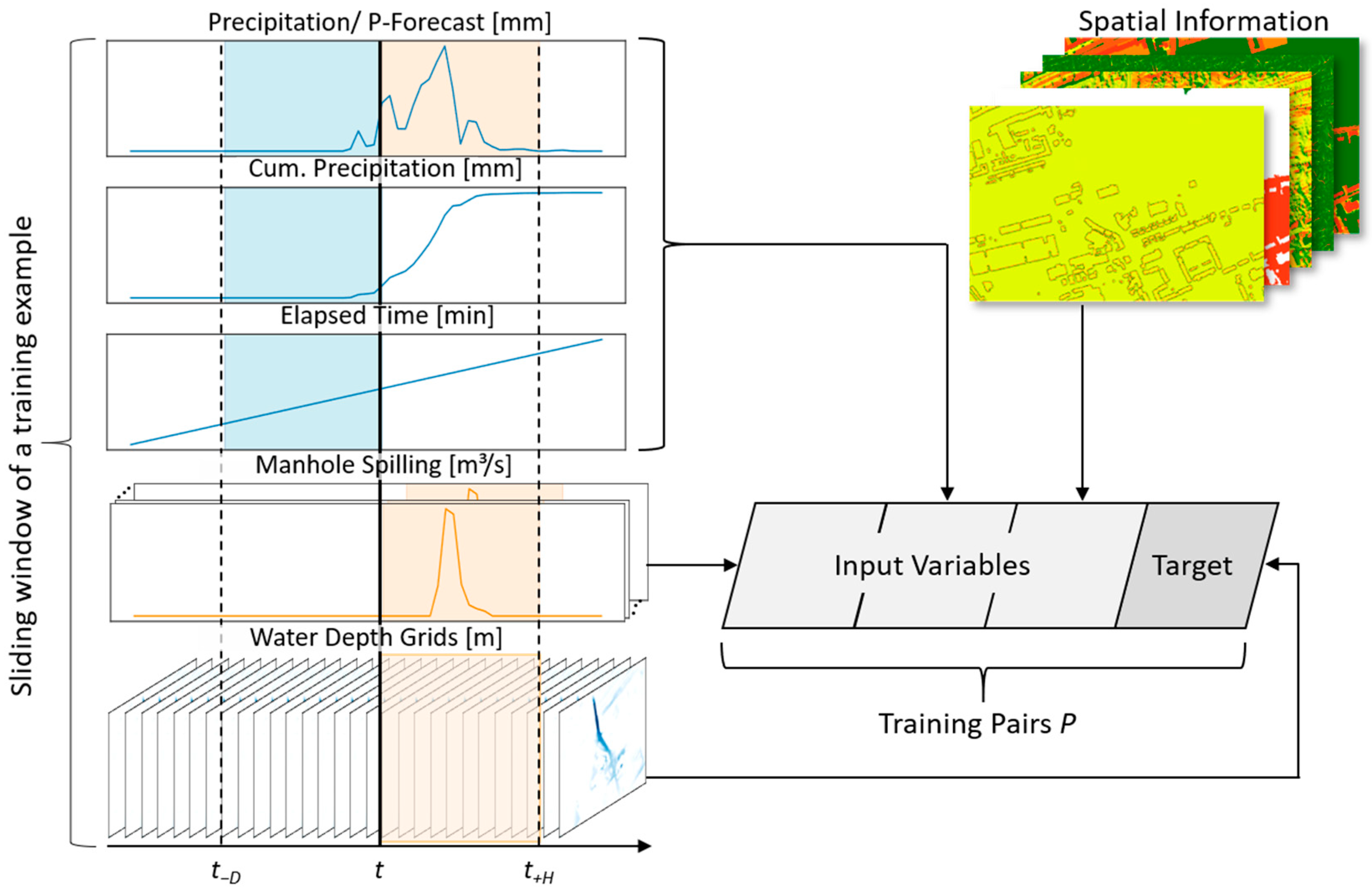
3.3.1. Data Generation Process
3.3.2. Data Preprocessing
3.4. Investigated Model Setups
3.4.1. Experiment 1: Comparison of Different Input Variables
- Model 1: Precipitation;
- Model 2: Precipitation + Overflow forecast;
- Model 3: Precipitation + Spatial information;
- Model 4: Precipitation + Overflow forecast + Spatial information.
3.4.2. Experiment 2: Comparison of Different Preprocessing of the Overflow Data
3.4.3. Experiment 3: Comparison of Different Model Setups
3.5. Performance Evaluation
4. Results
4.1. Comparison of the Investigated Model Setups
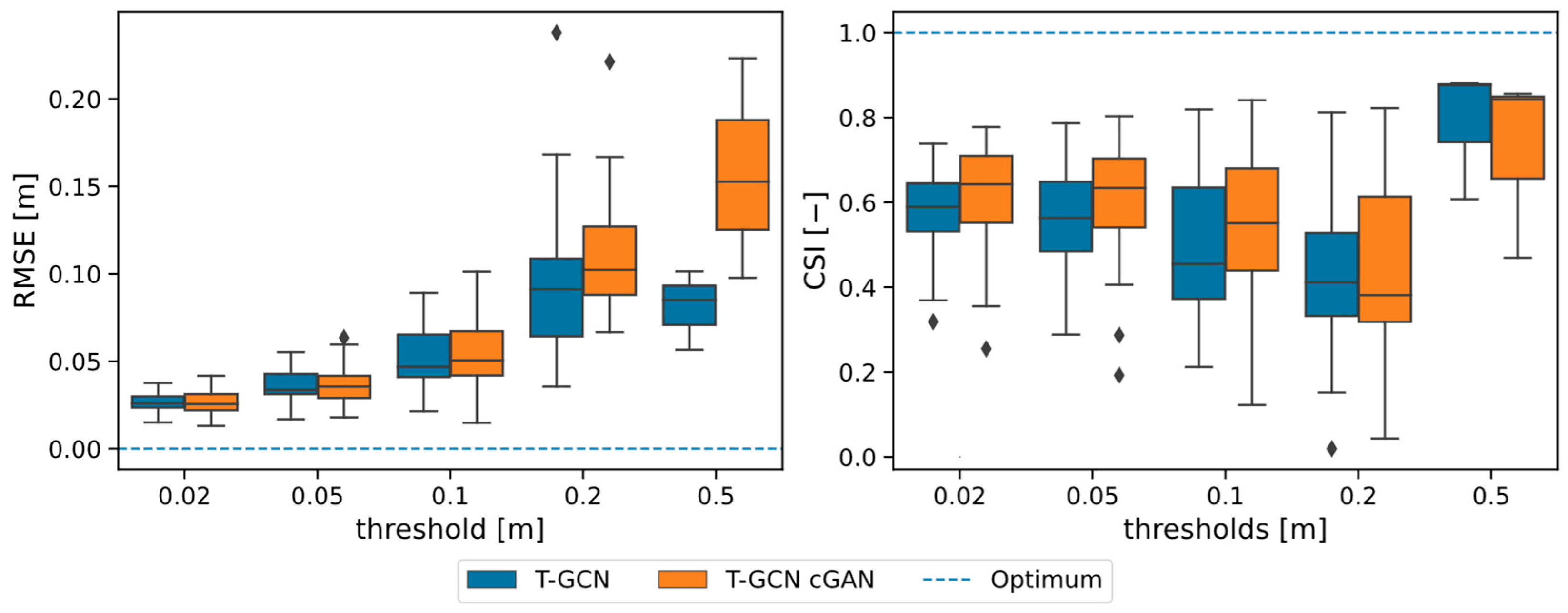
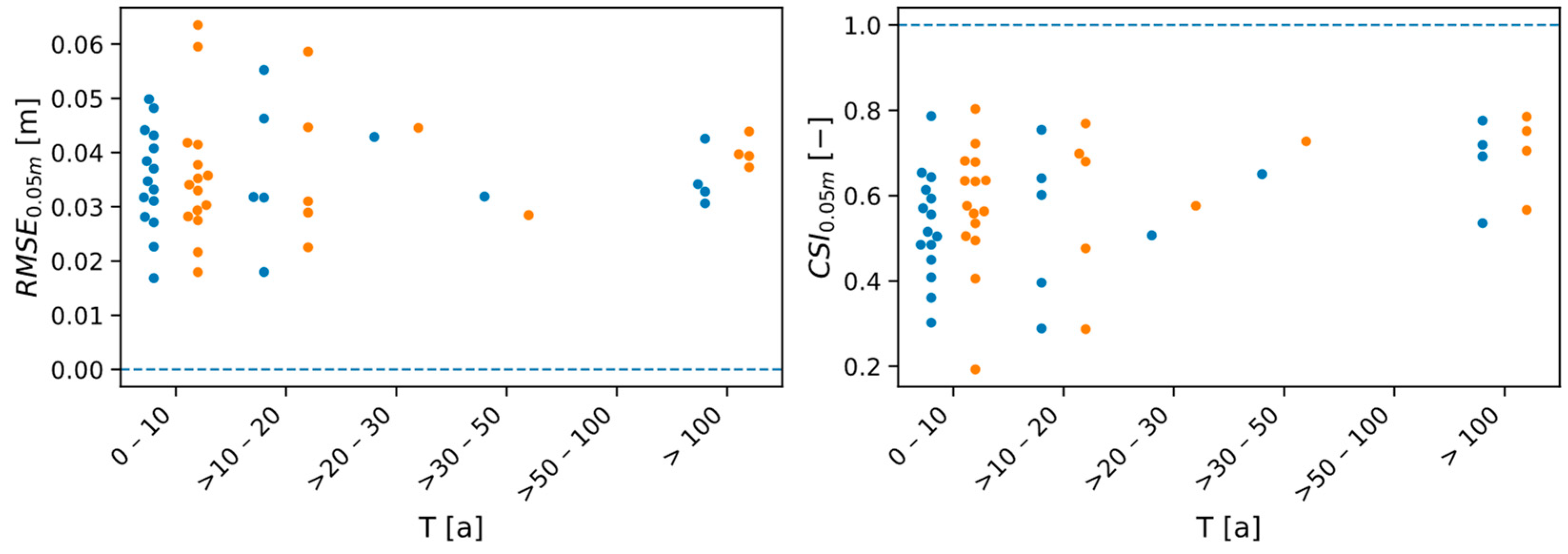
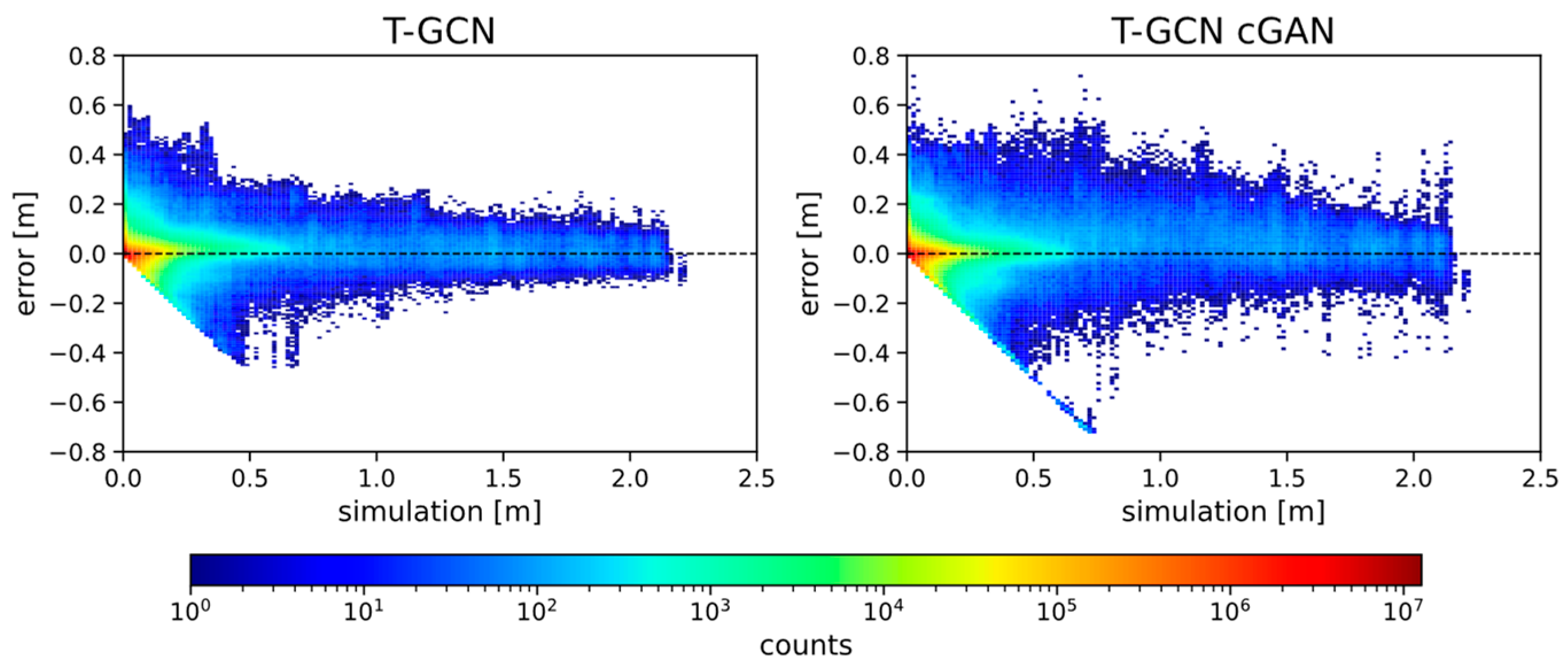
4.2. Assessment of the Prediction Accuracy
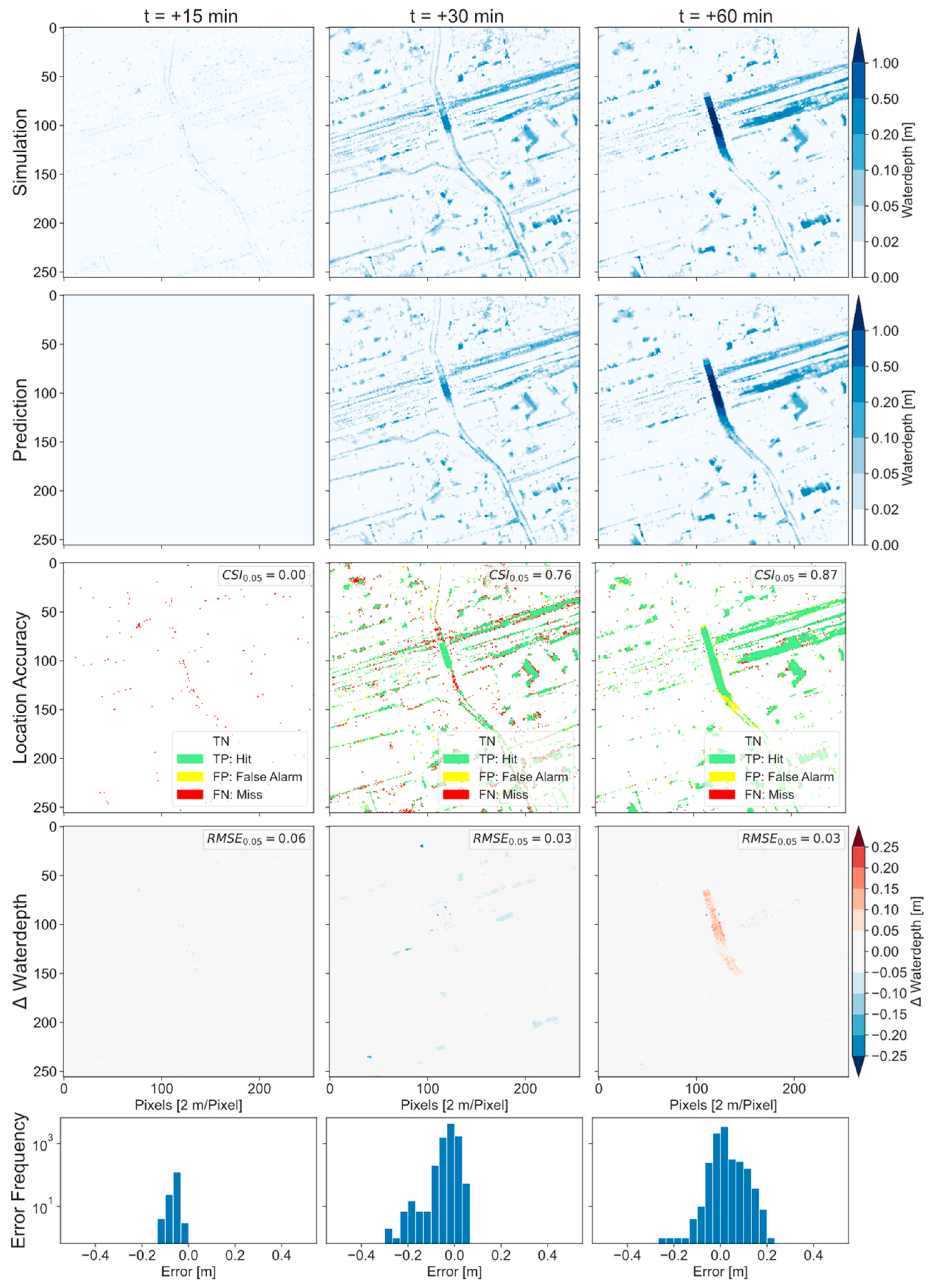
4.3. Forecast for a Historical Heavy Rainfall Event
- Predictions with shallow water depths and only a few flooded pixels often lead to large errors. This problem is particularly evident at step t = +15 min with a CSI of 0, the worst possible result. The RMSE also shows the worst value compared to the other time steps. The same problem was also found by Löwe et al. [35]. On the other hand, predicted flood maps with many flooded pixels usually show a high accuracy, as is the case for time steps t = +30 min and + 60 min. Accordingly, the flooding patterns particularly relevant for crisis management are predicted with high accuracy.
- The model reacts with a slight delay to the precipitation load. While increasing flood areas before the peak are underestimated, the extent of areas after the peak is slightly overestimated. This behavior is illustrated by the histogram with the error frequencies, and it is also displayed in other events.
- In the center of the depicted section, there is an underpass where the most considerable differences of up to 25 cm occur. However, it should be noted that the water levels there are sometimes more than two meters high. In this case, the relative error would be in the range of about 10–15% and thus within an acceptable range.
5. Discussion
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Seneviratne, S.I.; Zhang, X.; Adnan, M.; Badi, W.; Dereczynski, C.; Di Luca, A.; Ghosh, S.; Iskandar, I.; Kossin, J.; Lewis, S.; et al. Weather and Climate Extreme Events in a Changing Climate. In Climate Change 2021: The Physical Science Basis. Contribution of Working Group I to the Sixth Assessment Report of the Intergovernmental Panel on Climate Change; Masson-Delmotte, V., Zhai, P., Pirani, A., Connors, S.L., Péan, C., Berger, S., Caud, N., Chen, Y., Goldfarb, L., Gomis, M.I., et al., Eds.; Cambridge University Press: Cambridge, UK; New York, NY, USA, 2021; pp. 1513–1766. [Google Scholar]
- Rosenzweig, B.R.; McPhillips, L.; Chang, H.; Cheng, C.; Welty, C.; Matsler, M.; Iwaniec, D.; Davidson, C.I. Pluvial flood risk and opportunities for resilience. WIREs Water 2018, 5, e1302. [Google Scholar] [CrossRef]
- Zhao, G.; Balstrøm, T.; Mark, O.; Jensen, M.B. Multi-Scale Target-Specified Sub-Model Approach for Fast Large-Scale High-Resolution 2D Urban Flood Modelling. Water 2021, 13, 259. [Google Scholar] [CrossRef]
- Wang, Y.; Chen, A.S.; Fu, G.; Djordjević, S.; Zhang, C.; Savić, D.A. An integrated framework for high-resolution urban flood modelling considering multiple information sources and urban features. Environ. Model. Softw. 2018, 107, 85–95. [Google Scholar] [CrossRef]
- Chaudhary, P.; D’Aronco, S.; Moy de Vitry, M.; Leitão, J.P.; Wegner, J.D. Flood-Water level estimation from social media images. ISPRS Ann. Photogramm. Remote Sens. Spatial Inf. Sci. 2019, IV-2/W5, 5–12. [Google Scholar] [CrossRef]
- Moy de Vitry, M.; Kramer, S.; Wegner, J.D.; Leitão, J.P. Scalable flood level trend monitoring with surveillance cameras using a deep convolutional neural network. Hydrol. Earth Syst. Sci. 2019, 23, 4621–4634. [Google Scholar] [CrossRef]
- Zischg, A.P.; Mosimann, M.; Bernet, D.B.; Röthlisberger, V. Validation of 2D flood models with insurance claims. J. Hydrol. 2018, 557, 350–361. [Google Scholar] [CrossRef]
- Henonin, J.; Russo, B.; Mark, O.; Gourbesville, P. Real-time urban flood forecasting and modelling—A state of the art. J. Hydroinf. 2013, 15, 717–736. [Google Scholar] [CrossRef]
- Giannaros, C.; Dafis, S.; Stefanidis, S.; Giannaros, T.M.; Koletsis, I.; Oikonomou, C. Hydrometeorological analysis of a flash flood event in an ungauged Mediterranean watershed under an operational forecasting and monitoring context. Meteorol. Appl. 2022, 29, e2079. [Google Scholar] [CrossRef]
- Faure, D.; Schmitt, P.; Auchet, P. Limits of radar rainfall forecasting for sewage system management: Results and application in Nancy. In Proceedings of the 8th International Conference on Urban Storm Drainage, Sydney, Australia, 30 August 1999. [Google Scholar]
- Quirmbach, M. Nutzung von Wetterradardaten für Niederschlags- und Abflussvorhersagen in Urbanen Einzugsgebieten. Ph.D. Thesis, Ruhr-Universität Bochum, Bochum, Germany, 2003. [Google Scholar]
- Jasper-Tönnies, A.; Hellmers, S.; Einfalt, T.; Strehz, A.; Fröhle, P. Ensembles of radar nowcasts and COSMO-DE-EPS for urban flood management. Water Sci. Technol. 2017, 2017, 27–35. [Google Scholar] [CrossRef]
- René, J.-R.; Djordjević, S.; Butler, D.; Mark, O.; Henonin, J.; Eisum, N.; Madsen, H. A real-time pluvial flood forecasting system for Castries, St. Lucia. J. Flood Risk Manag. 2015, 11, 269–283. [Google Scholar] [CrossRef]
- Hofmann, J.; Schüttrumpf, H. Risk-Based and Hydrodynamic Pluvial Flood Forecasts in Real Time. Water 2020, 12, 1895. [Google Scholar] [CrossRef]
- Neal, J.C.; Fewtrell, T.J.; Bates, P.D.; Wright, N.G. A comparison of three parallelisation methods for 2D flood inundation models. Environ. Model. Softw. 2010, 25, 398–411. [Google Scholar] [CrossRef]
- Leandro, J.; Chen, A.S.; Schumann, A. A 2D parallel diffusive wave model for floodplain inundation with variable time step (P-DWave). J. Hydrol. 2014, 517, 250–259. [Google Scholar] [CrossRef]
- Bates, P.D.; Horritt, M.S.; Fewtrell, T.J. A simple inertial formulation of the shallow water equations for efficient two-dimensional flood inundation modelling. J. Hydrol. 2010, 387, 33–45. [Google Scholar] [CrossRef]
- Jamali, B.; Löwe, R.; Bach, P.M.; Urich, C.; Arnbjerg-Nielsen, K.; Deletic, A. A rapid urban flood inundation and damage assessment model. J. Hydrol. 2018, 564, 1085–1098. [Google Scholar] [CrossRef]
- Xu, K.; Ba, J.; Kiros, R.; Cho, K.; Courville, A.; Salakhutdinov, R.; Zemel, R.; Bengio, Y. Show, Attend and Tell: Neural Image Caption Generation with Visual Attention. arXiv 2015, arXiv:1502.03044. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. arXiv 2015, arXiv:1505.04597. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778, ISBN 9781467388511. [Google Scholar]
- Isola, P.; Zhu, J.-Y.; Zhou, T.; Efros, A.A. Image-to-Image Translation with Conditional Adversarial Networks. In Proceedings of the 30th IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–27 July 2017. [Google Scholar]
- Reichstein, M.; Camps-Valls, G.; Stevens, B.; Jung, M.; Denzler, J.; Carvalhais, N.; Prabhat. Deep learning and process understanding for data-driven Earth system science. Nature 2019, 566, 195–204. [Google Scholar] [CrossRef]
- Shen, C. A Transdisciplinary Review of Deep Learning Research and Its Relevance for Water Resources Scientists. Water Resour. Res. 2018, 54, 8558–8593. [Google Scholar] [CrossRef]
- Mosavi, A.; Ozturk, P.; Chau, K. Flood Prediction Using Machine Learning Models: Literature Review. Water 2018, 10, 1536. [Google Scholar] [CrossRef]
- Bentivoglio, R.; Isufi, E.; Jonkman, S.N.; Taormina, R. Deep Learning Methods for Flood Mapping: A Review of Existing Applications and Future Research Directions. Hydrol. Earth Syst. Sci. 2022, 26, 4345–4378. [Google Scholar] [CrossRef]
- Bermúdez, M.; Ntegeka, V.; Wolfs, V.; Willems, P. Development and Comparison of Two Fast Surrogate Models for Urban Pluvial Flood Simulations. Water Resour. Manag. 2018, 32, 2801–2815. [Google Scholar] [CrossRef]
- Jhong, B.-C.; Wang, J.-H.; Lin, G.-F. An integrated two-stage support vector machine approach to forecast inundation maps during typhoons. J. Hydrol. 2017, 547, 236–252. [Google Scholar] [CrossRef]
- Lin, G.-F.; Lin, H.-Y.; Chou, Y.-C. Development of a real-time regional-inundation forecasting model for the inundation warning system. J. Hydroinf. 2013, 15, 1391–1407. [Google Scholar] [CrossRef]
- Bermúdez, M.; Cea, L.; Puertas, J. A rapid flood inundation model for hazard mapping based on least squares support vector machine regression. J. Flood Risk Manag. 2019, 12, e12522. [Google Scholar] [CrossRef]
- Berkhahn, S.; Fuchs, L.; Neuweiler, I. An ensemble neural network model for real-time prediction of urban floods. J. Hydrol. 2019, 575, 743–754. [Google Scholar] [CrossRef]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef]
- Guo, Z.; Leitão, J.P.; Simões, N.E.; Moosavi, V. Data-driven flood emulation: Speeding up urban flood predictions by deep convolutional neural networks. J. Flood Risk Manag. 2020, 14, e12684. [Google Scholar] [CrossRef]
- Hofmann, J.; Schüttrumpf, H. floodGAN: Using Deep Adversarial Learning to Predict Pluvial Flooding in Real Time. Water 2021, 13, 2255. [Google Scholar] [CrossRef]
- Löwe, R.; Böhm, J.; Jensen, D.G.; Leandro, J.; Rasmussen, S.H. U-FLOOD—Topographic deep learning for predicting urban pluvial flood water depth. J. Hydrol. 2021, 603, 126898. [Google Scholar] [CrossRef]
- Seleem, O.; Ayzel, G.; Bronstert, A.; Heistermann, M. Transferability of data-driven models to predict urban pluvial flood water depth in Berlin, Germany. Nat. Hazards Earth Syst. Sci. 2023, 23, 809–822. [Google Scholar] [CrossRef]
- do Lago, C.A.; Giacomoni, M.H.; Bentivoglio, R.; Taormina, R.; Gomes, M.N.; Mendiondo, E.M. Generalizing rapid flood predictions to unseen urban catchments with conditional generative adversarial networks. J. Hydrol. 2023, 618, 129276. [Google Scholar] [CrossRef]
- Zhao, G.; Pang, B.; Xu, Z.; Peng, D.; Zuo, D. Urban flood susceptibility assessment based on convolutional neural networks. J. Hydrol. 2020, 590, 125235. [Google Scholar] [CrossRef]
- Tien Bui, D.; Hoang, N.-D.; Martínez-Álvarez, F.; Ngo, P.-T.T.; Hoa, P.V.; Pham, T.D.; Samui, P.; Costache, R. A novel deep learning neural network approach for predicting flash flood susceptibility: A case study at a high frequency tropical storm area. Sci. Total Environ. 2020, 701, 134413. [Google Scholar] [CrossRef]
- Seleem, O.; Ayzel, G.; de Souza, A.C.T.; Bronstert, A.; Heistermann, M. Towards urban flood susceptibility mapping using data-driven models in Berlin, Germany. Geomat. Nat. Hazards Risk 2022, 13, 1640–1662. [Google Scholar] [CrossRef]
- Kabir, S.; Patidar, S.; Xia, X.; Liang, Q.; Neal, J.; Pender, G. A deep convolutional neural network model for rapid prediction of fluvial flood inundation. J. Hydrol. 2020, 590, 125481. [Google Scholar] [CrossRef]
- Lin, Q.; Leandro, J.; Wu, W.; Bhola, P.; Disse, M. Prediction of Maximum Flood Inundation Extents with Resilient Backpropagation Neural Network: Case Study of Kulmbach. Front. Earth Sci. 2020, 8, 332. [Google Scholar] [CrossRef]
- Shi, X.; Chen, Z.; Wang, H.; Yeung, D.-Y.; Wong, W.; Woo, W. Convolutional LSTM Network: A Machine Learning Approach for Precipitation Nowcasting. arXiv 2015, arXiv:1506.04214. [Google Scholar]
- Ayzel, G.; Heistermann, M.; Sorokin, A.; Nikitin, O.; Lukyanova, O. All convolutional neural networks for radar-based precipitation nowcasting. Procedia Comput. Sci. 2019, 150, 186–192. [Google Scholar] [CrossRef]
- Ravuri, S.; Lenc, K.; Willson, M.; Kangin, D.; Lam, R.; Mirowski, P.; Fitzsimons, M.; Athanassiadou, M.; Kashem, S.; Madge, S.; et al. Skilful precipitation nowcasting using deep generative models of radar. Nature 2021, 597, 672–677. [Google Scholar] [CrossRef]
- Ma, X.; Dai, Z.; He, Z.; Ma, J.; Wang, Y.; Wang, Y. Learning Traffic as Images: A Deep Convolutional Neural Network for Large-Scale Transportation Network Speed Prediction. Sensors 2017, 17, 818. [Google Scholar] [CrossRef] [PubMed]
- Bao, J.; Liu, P.; Ukkusuri, S.V. A spatiotemporal deep learning approach for citywide short-term crash risk prediction with multi-source data. Accid. Anal. Prev. 2019, 122, 239–254. [Google Scholar] [CrossRef] [PubMed]
- Zhang, J.; Zheng, Y.; Sun, J.; Qi, D. Flow Prediction in Spatio-Temporal Networks Based on Multitask Deep Learning. IEEE Trans. Knowl. Data Eng. 2020, 32, 468–478. [Google Scholar] [CrossRef]
- Rosenblatt, F. The perceptron: A probabilistic model for information storage and organization in the brain. Psychol. Rev. 1958, 65, 386–408. [Google Scholar] [CrossRef]
- LeCun, Y.; Boser, B.; Denker, J.S.; Henderson, D.; Howard, R.E.; Hubbard, W.; Jackel, L.D. Backpropagation Applied to Handwritten Zip Code Recognition. Neural Comput. 1989, 1, 541–551. [Google Scholar] [CrossRef]
- LeCun, Y.; Bengio, Y. Convolutional networks for images, speech, and time-series. In The Handbook of Brain Theory and Neural Networks; Arbib, M.A., Ed.; MIT Press: Cambridge, MA, USA, 1995. [Google Scholar]
- Bengio, Y.; Simard, P.; Frasconi, P. Learning long-term dependencies with gradient descent is difficult. IEEE Trans. Neural Netw. 1994, 5, 157–166. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Scarselli, F.; Gori, M.; Tsoi, A.C.; Hagenbuchner, M.; Monfardini, G. The graph neural network model. IEEE Trans. Neural Netw. 2009, 20, 61–80. [Google Scholar] [CrossRef]
- Defferrard, M.; Bresson, X.; Vandergheynst, P. Convolutional Neural Networks on Graphs with Fast Localized Spectral Filtering. Adv. Neural Inf. Process. Syst. 2016, arXiv:1606.09375. [Google Scholar]
- Kipf, T.N.; Welling, M. Semi-Supervised Classification with Graph Convolutional Networks. arXiv 2016, arXiv:1609.02907. [Google Scholar]
- Yu, B.; Yin, H.; Zhu, Z. Spatio-Temporal Graph Convolutional Networks: A Deep Learning Framework for Traffic Forecasting. arXiv 2017, arXiv:1709.04875. [Google Scholar]
- Hajgató, G.; Gyires-Tóth, B.; Paál, G. Reconstructing nodal pressures in water distribution systems with graph neural networks. arXiv 2021, arXiv:2104.13619. [Google Scholar]
- Fritz, C.; Dorigatti, E.; Rügamer, D. Combining graph neural networks and spatio-temporal disease models to improve the prediction of weekly COVID-19 cases in Germany. Sci. Rep. 2022, 12, 3930. [Google Scholar] [CrossRef]
- Goodfellow, I.J.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative Adversarial Networks. arXiv 2014, arXiv:1406.2661. [Google Scholar] [CrossRef]
- Mirza, M.; Osindero, S. Conditional Generative Adversarial Nets. arXiv 2014, arXiv:1411.1784. [Google Scholar]
- Abadi, M.; Agarwal, A.; Barham, P.; Brevdo, E.; Chen, Z.; Citro, C.; Corrado, G.S.; Davis, A.; Dean, J.; Devin, M.; et al. TensorFlow: Large-Scale Machine Learning on Heterogeneous Systems. Available online: https://www.tensorflow.org/ (accessed on 25 January 2022).
- Andersson, H.; Mariegaard, J.; Ridler, M. MIKE IO: Input/Output of MIKE Files in Python. 2022. Available online: https://dhi.github.io/mikeio/ (accessed on 20 January 2023).
- DHI. MIKE+: Release 2021 Update 1; DHI: Hørsholm, Denmark, 2021; Available online: www.mikepoweredbydhi.com (accessed on 18 November 2022).
- Bezirksregierung Köln. 3D-Messdaten. Available online: https://www.bezreg-koeln.nrw.de/brk_internet/geobasis/hoehenmodelle/3d-messdaten/index.html (accessed on 20 July 2021).
- Deutsches Institut für Normung e. V. Entwässerungssysteme außerhalb von Gebäuden-Kanalmanagement; Beuth Verlag GmbH: Berlin, Germany, 2017. [Google Scholar]
- DWA. Hydraulische Bemessung und Nachweis von Entwässerungssystemen: Arbeitsblatt DWA-A 118; Deutsche Vereinigung für Wasserwirtschaft, Abwasser und Abfall (DWA): Hennef, Germany, 2006; ISBN 9783939057154. [Google Scholar]
- Schmitt, T.G. Ortsbezogene Regenhöhen im Starkregenindexkonzept SRI12 zur Risikokommunikation in der kommunalen Überflutungsvorsorge. KA Korresp. Abwasser Abfall 2017, 64, 294–300. [Google Scholar]
- Meon, G.; Stein, K.; Förster, K.; Riedel, G. Abschlussbericht zum Forschungsprojekt "Untersuchung starkregengefährdeter Gebiete; TU Braunschweig: Braunschweig, Germany, 2009. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift. arXiv 2015, arXiv:1502.03167. [Google Scholar]
- Nair, V.; Hinton, G.E. Rectified Linear Units Improve Restricted Boltzmann Machines. In Proceedings of the 27th International Conference on International Conference on Machine Learning, Haifa, Israel, 21–24 June 2010; Omnipress: Madison, WI, USA, 2010; pp. 807–814, ISBN 9781605589077. [Google Scholar]
- Han, J.; Moraga, C. The influence of the sigmoid function parameters on the speed of backpropagation learning. In From Natural to Artificial Neural Computation; Goos, G., Hartmanis, J., Leeuwen, J., Mira, J., Sandoval, F., Eds.; Springer: Berlin/Heidelberg, Germany, 1995; pp. 195–201. ISBN 9783540594970. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Smith, L.N. Cyclical Learning Rates for Training Neural Networks. arXiv 2015, arXiv:1506.01186. [Google Scholar]
- Zhao, L.; Song, Y.; Zhang, C.; Liu, Y.; Wang, P.; Lin, T.; Deng, M.; Li, H. T-GCN: A Temporal Graph ConvolutionalNetwork for Traffic Prediction. IEEE Trans. Intell. Transport. Syst. 2018, 21, 3848–3858. [Google Scholar] [CrossRef]
- Srivastava, N.; Hinton, G.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Dropout: A Simple Way to Prevent Neural Networks from Overfitting. J. Mach. Learn. Res. 2014, 15, 1929–1958. [Google Scholar]
- Jamali, B.; Bach, P.M.; Cunningham, L.; Deletic, A. A Cellular Automata Fast Flood Evaluation (CA-ffé) Model. Water Resour. Res. 2019, 55, 4936–4953. [Google Scholar] [CrossRef]
- Guo, Z.; Moosavi, V.; Leitão, J.P. Data-driven rapid flood prediction mapping with catchment generalizability. J. Hydrol. 2022, 609, 127726. [Google Scholar] [CrossRef]
- Sun, J.; Xue, M.; Wilson, J.W.; Zawadzki, I.; Ballard, S.P.; Onvlee-Hooimeyer, J.; Joe, P.; Barker, D.M.; Li, P.-W.; Golding, B.; et al. Use of NWP for Nowcasting Convective Precipitation: Recent Progress and Challenges. Bull. Am. Meteorol. Soc. 2014, 95, 409–426. [Google Scholar] [CrossRef]
- Shazeer, N.; Cheng, Y.; Parmar, N.; Tran, D.; Vaswani, A.; Koanantakool, P.; Hawkins, P.; Lee, H.; Hong, M.; Young, C.; et al. Mesh-TensorFlow: Deep Learning for Supercomputers. arXiv 2018, arXiv:1811.02084. [Google Scholar]
- Serpico, S.B.; Dellepiane, S.; Boni, G.; Moser, G.; Angiati, E.; Rudari, R. Information Extraction from Remote Sensing Images for Flood Monitoring and Damage Evaluation. Proc. IEEE 2012, 100, 2946–2970. [Google Scholar] [CrossRef]
- Mateo-Garcia, G.; Veitch-Michaelis, J.; Smith, L.; Oprea, S.V.; Schumann, G.; Gal, Y.; Baydin, A.G.; Backes, D. Towards global flood mapping onboard low cost satellites with machine learning. Sci. Rep. 2021, 11, 7249. [Google Scholar] [CrossRef]
- Nedergaard Pedersen, A.; Wied Pedersen, J.; Vigueras-Rodriguez, A.; Brink-Kjær, A.; Borup, M.; Steen Mikkelsen, P. The Bellinge data set: Open data and models for community-wide urban drainage systems research. Earth Syst. Sci. Data 2021, 13, 4779–4798. [Google Scholar] [CrossRef]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | RMSE ↓ | CSI ↑ | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| d ≥ 0.02 | d ≥ 0.05 | d ≥ 0.1 | d ≥ 0.2 | d ≥ 0.5 | d ≥ 0.02 | d ≥ 0.05 | d ≥ 0.1 | d ≥ 0.2 | d ≥ 0.5 | |
| Experiment 1: Model Inputs | ||||||||||
| Model 1 (Inputs: rain) | 0.039 | 0.052 | 0.074 | 0.140 | 0.553 | 0.504 | 0.488 | 0.399 | 0.299 | 0.122 |
| Model 2 (Inputs: rain, manhole spilling) | 0.028 | 0.037 | 0.052 | 0.096 | 0.096 | 0.538 | 0.543 | 0.495 | 0.414 | 0.768 |
| Model 3 (Inputs: rain, spatial information) | 0.037 | 0.050 | 0.074 | 0.144 | 0.547 | 0.510 | 0.466 | 0.384 | 0.293 | 0.157 |
| Model 4 (Inputs: rain, spatial information, manhole spilling) | 0.026 | 0.035 | 0.051 | 0.092 | 0.118 | 0.595 | 0.574 | 0.511 | 0.421 | 0.746 |
| Experiment 2: Manhole Spilling Forecast Format | ||||||||||
| Model 5 (Unordered) | 0.026 | 0.035 | 0.051 | 0.094 | 0.118 | 0.595 | 0.574 | 0.511 | 0.421 | 0.746 |
| Model 6 (Raster Sequence) | 0.030 | 0.040 | 0.058 | 0.115 | 0.148 | 0.548 | 0.514 | 0.434 | 0.340 | 0.679 |
| Model 7 (Graph) | 0.026 | 0.036 | 0.052 | 0.092 | 0.081 | 0.575 | 0.557 | 0.492 | 0.424 | 0.788 |
| Experiment 3: Model Architecture | ||||||||||
| Model 8 (T-GCN) | 0.026 | 0.036 | 0.052 | 0.092 | 0.081 | 0.575 | 0.557 | 0.492 | 0.424 | 0.788 |
| Model 9 (T-GCN cGAN) | 0.027 | 0.037 | 0.055 | 0.113 | 0.158 | 0.623 | 0.602 | 0.545 | 0.440 | 0.723 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Burrichter, B.; Hofmann, J.; Koltermann da Silva, J.; Niemann, A.; Quirmbach, M. A Spatiotemporal Deep Learning Approach for Urban Pluvial Flood Forecasting with Multi-Source Data. Water 2023, 15, 1760. https://doi.org/10.3390/w15091760
Burrichter B, Hofmann J, Koltermann da Silva J, Niemann A, Quirmbach M. A Spatiotemporal Deep Learning Approach for Urban Pluvial Flood Forecasting with Multi-Source Data. Water. 2023; 15(9):1760. https://doi.org/10.3390/w15091760
Chicago/Turabian StyleBurrichter, Benjamin, Julian Hofmann, Juliana Koltermann da Silva, Andre Niemann, and Markus Quirmbach. 2023. "A Spatiotemporal Deep Learning Approach for Urban Pluvial Flood Forecasting with Multi-Source Data" Water 15, no. 9: 1760. https://doi.org/10.3390/w15091760
APA StyleBurrichter, B., Hofmann, J., Koltermann da Silva, J., Niemann, A., & Quirmbach, M. (2023). A Spatiotemporal Deep Learning Approach for Urban Pluvial Flood Forecasting with Multi-Source Data. Water, 15(9), 1760. https://doi.org/10.3390/w15091760