
Water Quality Prediction of the Yamuna River in India Using Hybrid Neuro-Fuzzy Models

 ,
,  , ,
, ,  and
and
Abstract
:1. Introduction
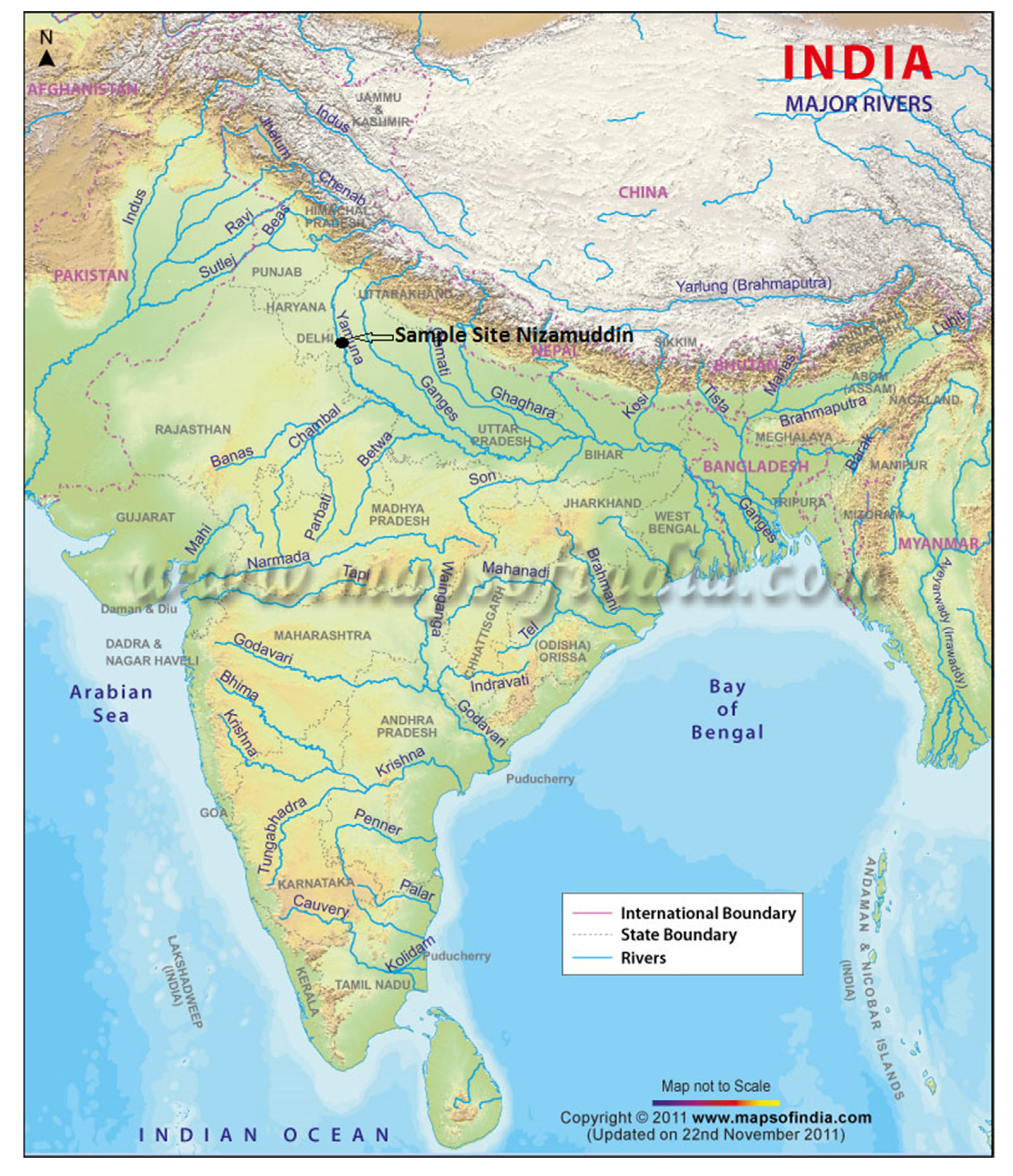
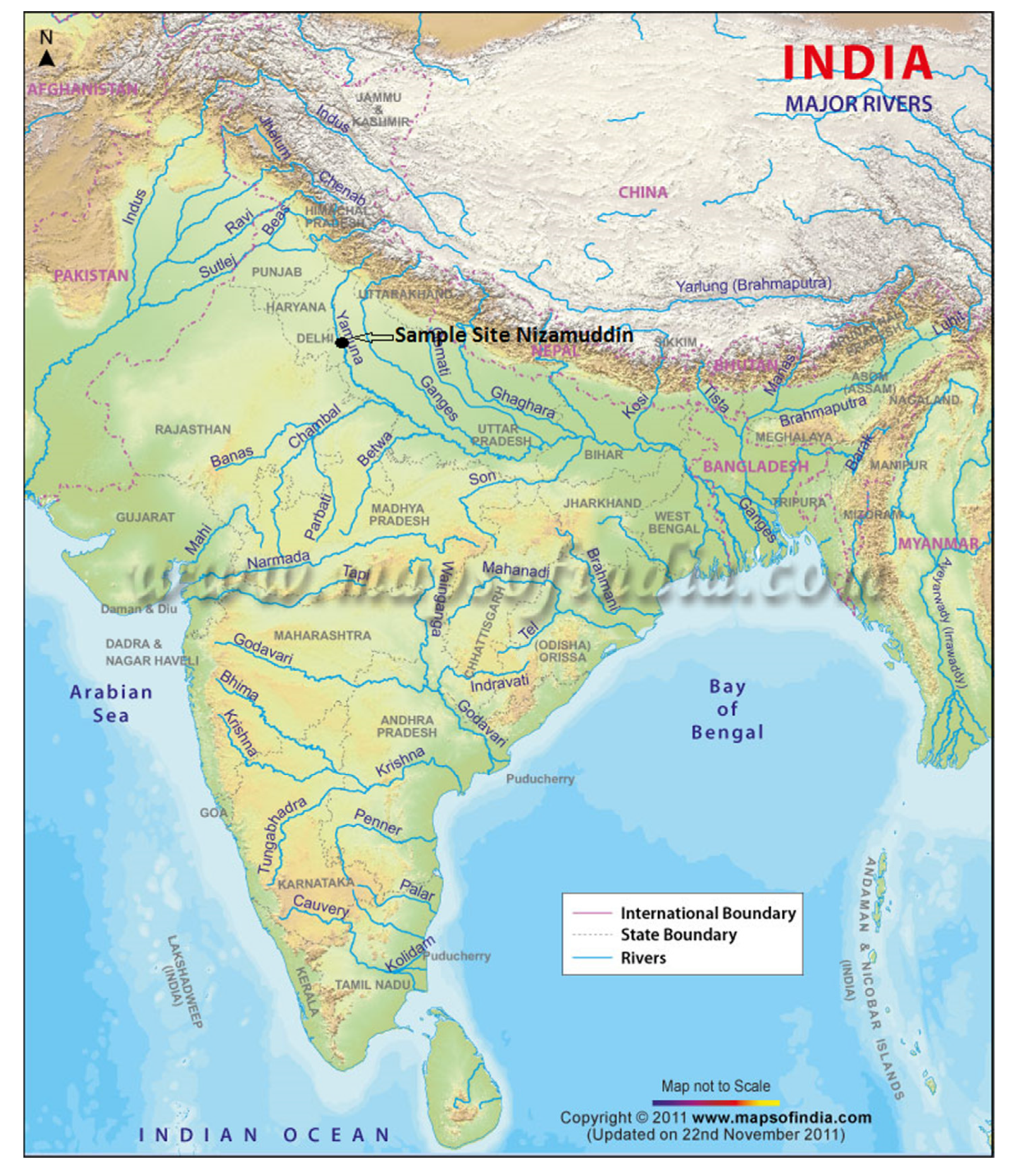
2. Case Study
3. Methods
3.1. Least Square Support Vector Machine
3.2. Adaptive Neuro-Fuzzy Inference System
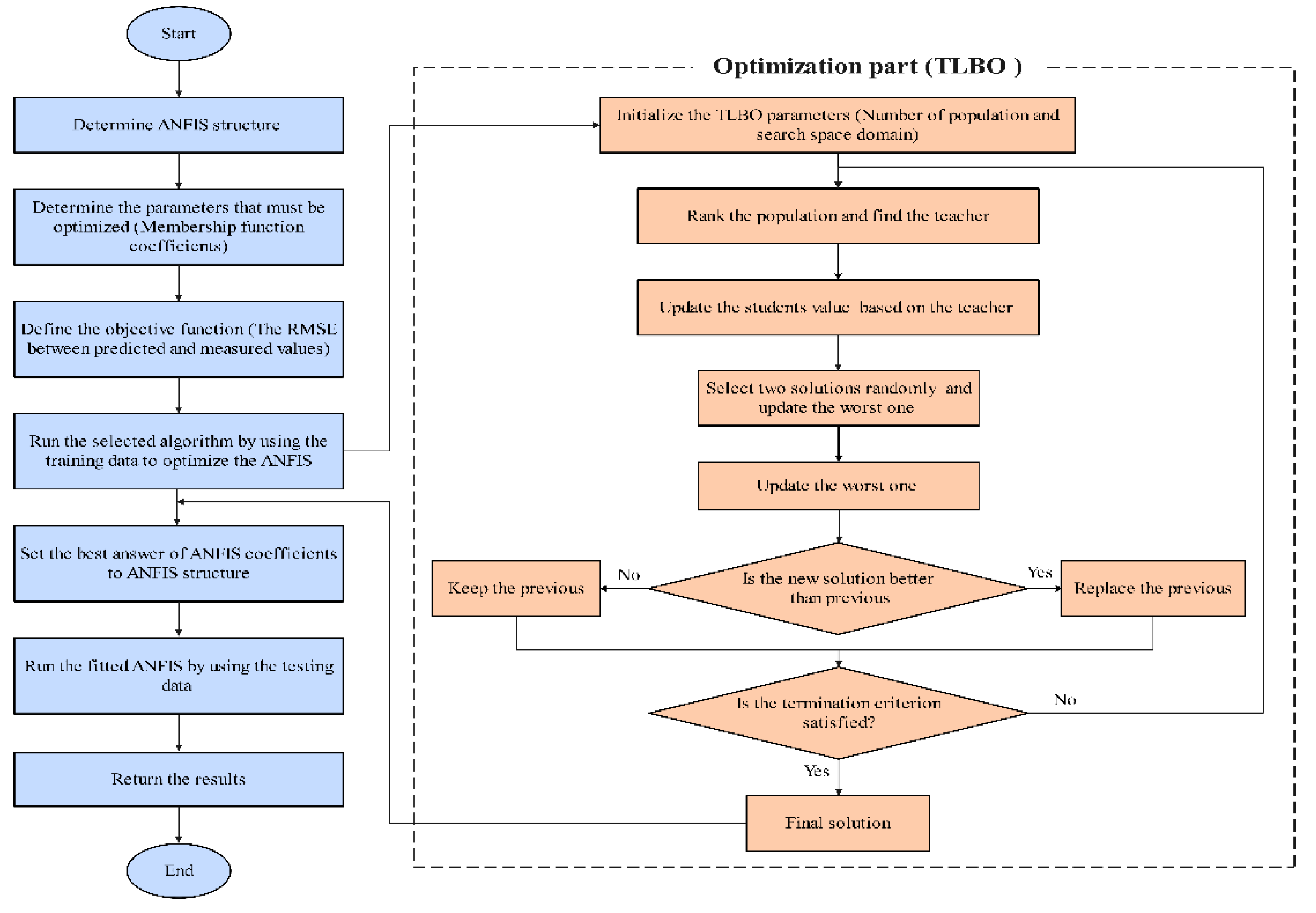
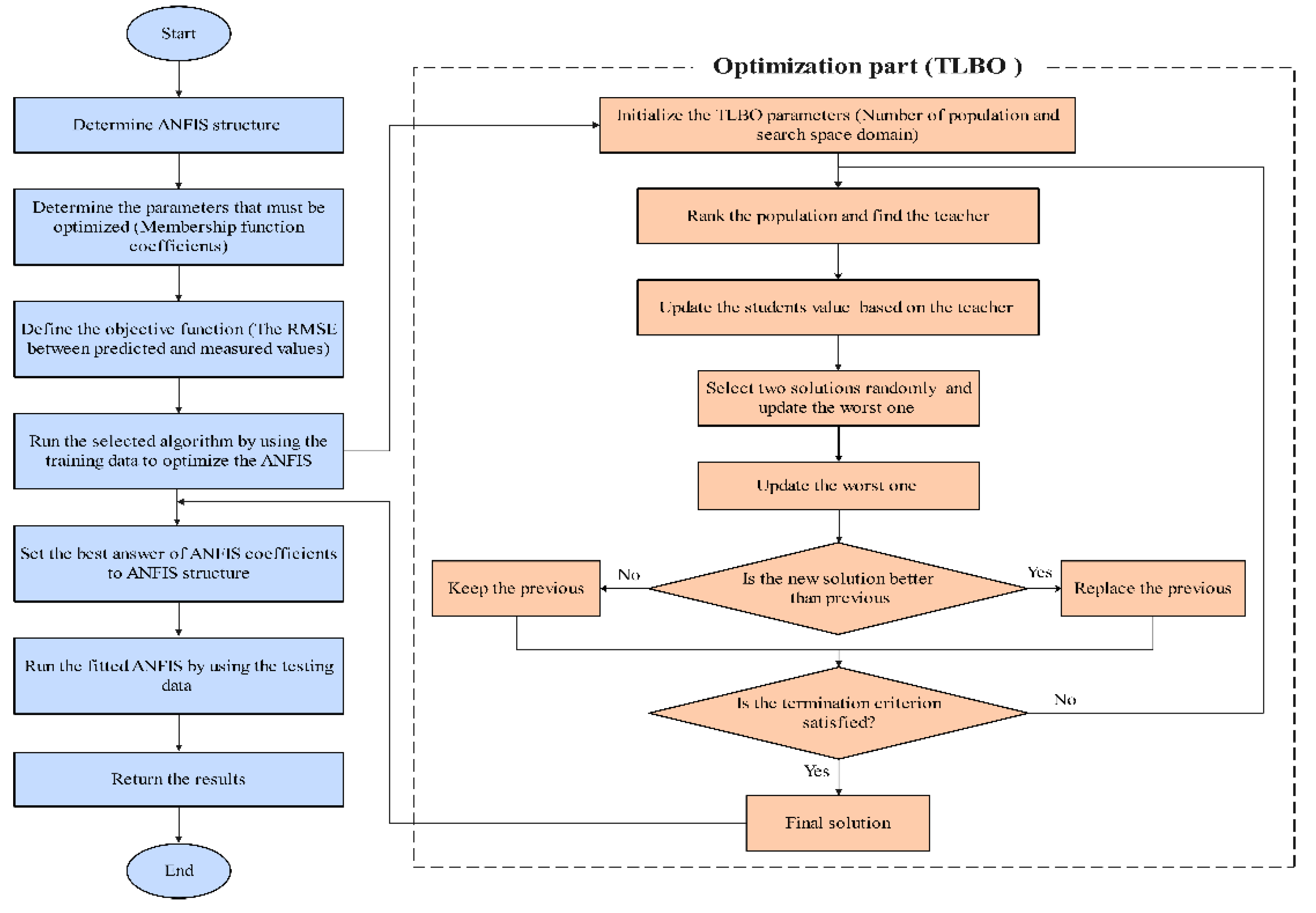
3.3. The Hybrid Procedure of ANFIS and Meta-Heuristic Algorithms
3.3.1. Particle Swarm Optimization
3.3.2. Genetic Algorithm
3.3.3. Harmony Search
3.3.4. Teaching–Learning-Based Optimization Algorithm
4. Application of the Methods
- AMM, TKN, and WT;
- AMM, TKN, WT, and TC;
- AMM, TKN, WT, TC, and FC;
- AMM, TKN, WT, TC, FC, and PH.
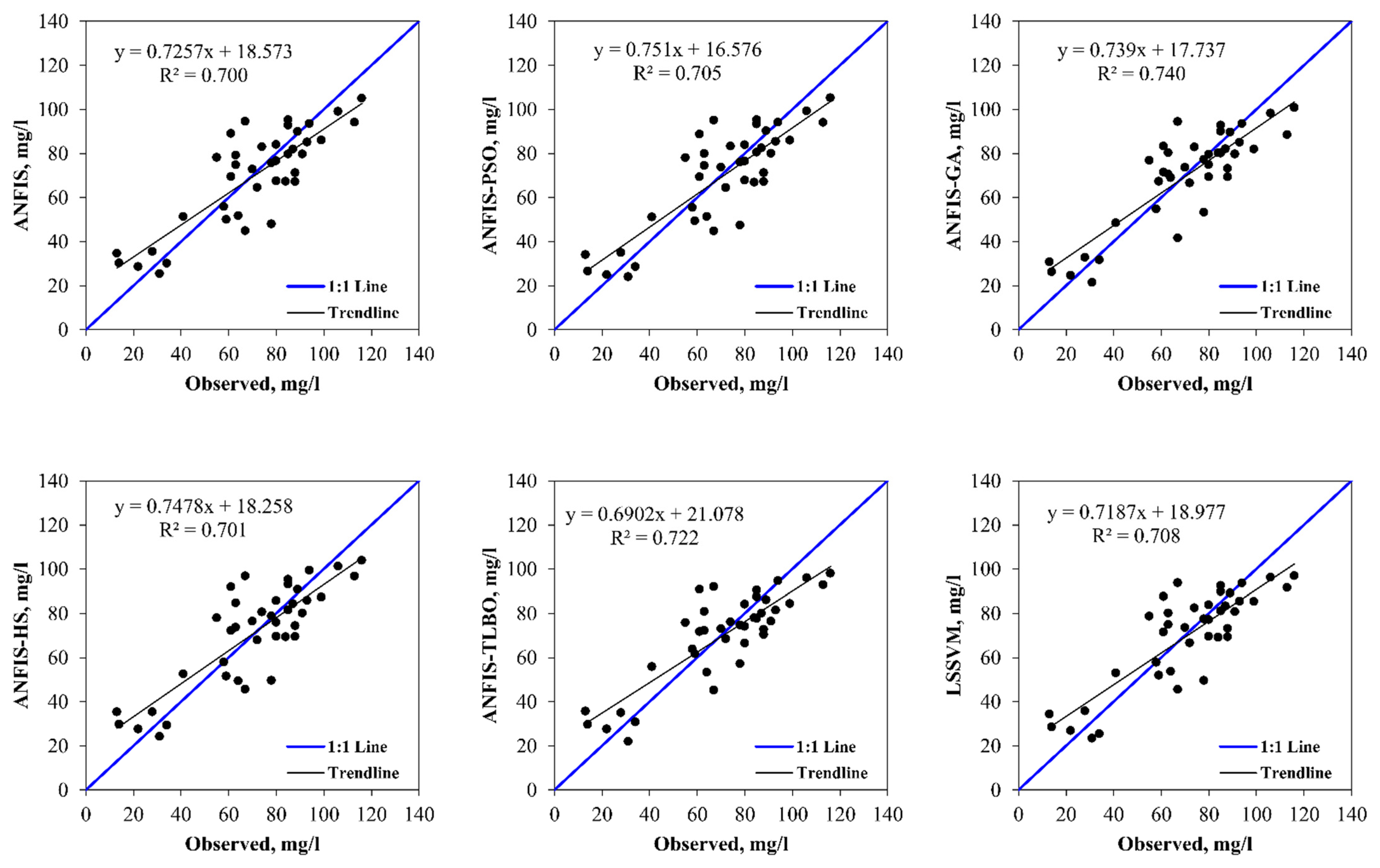
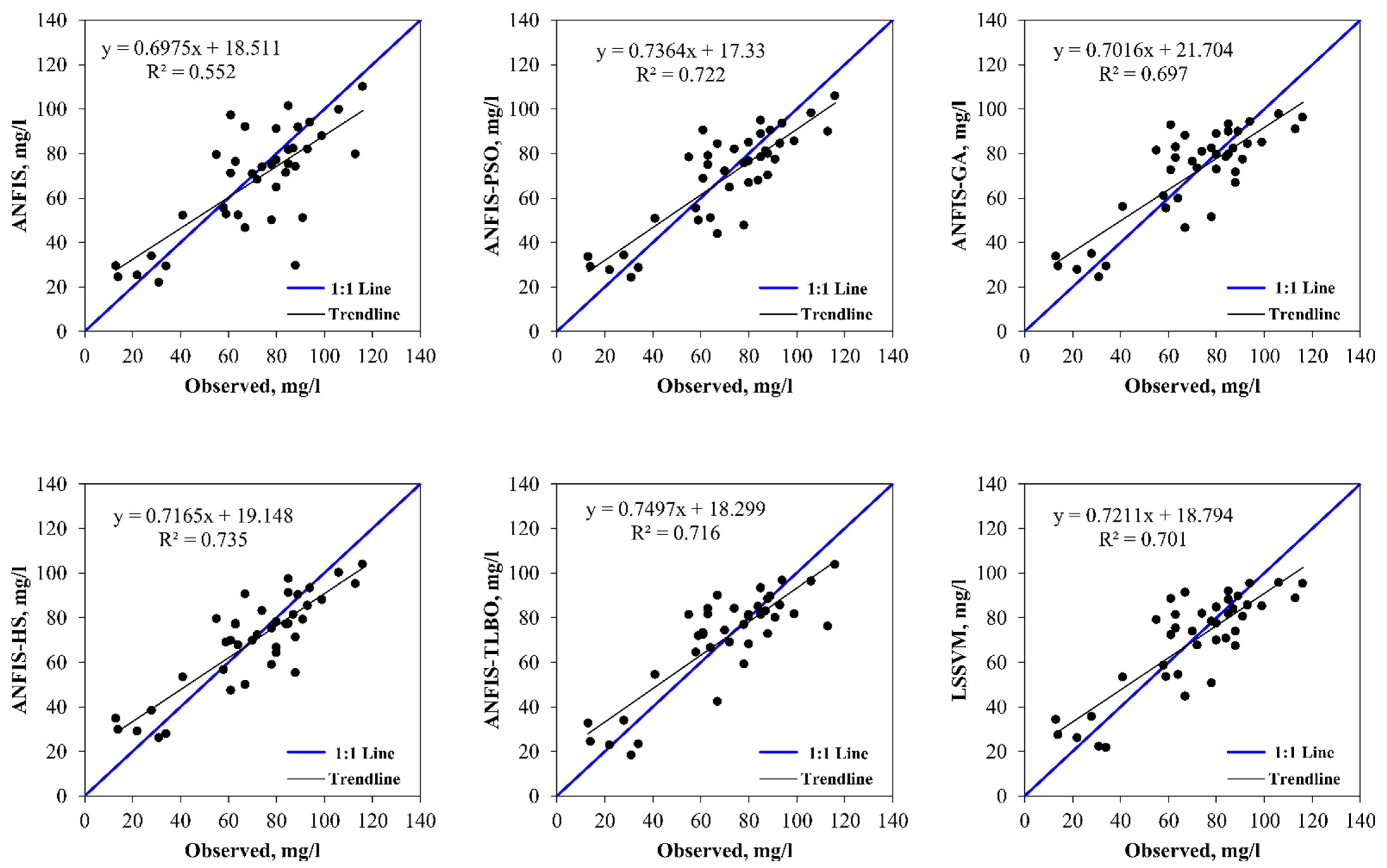
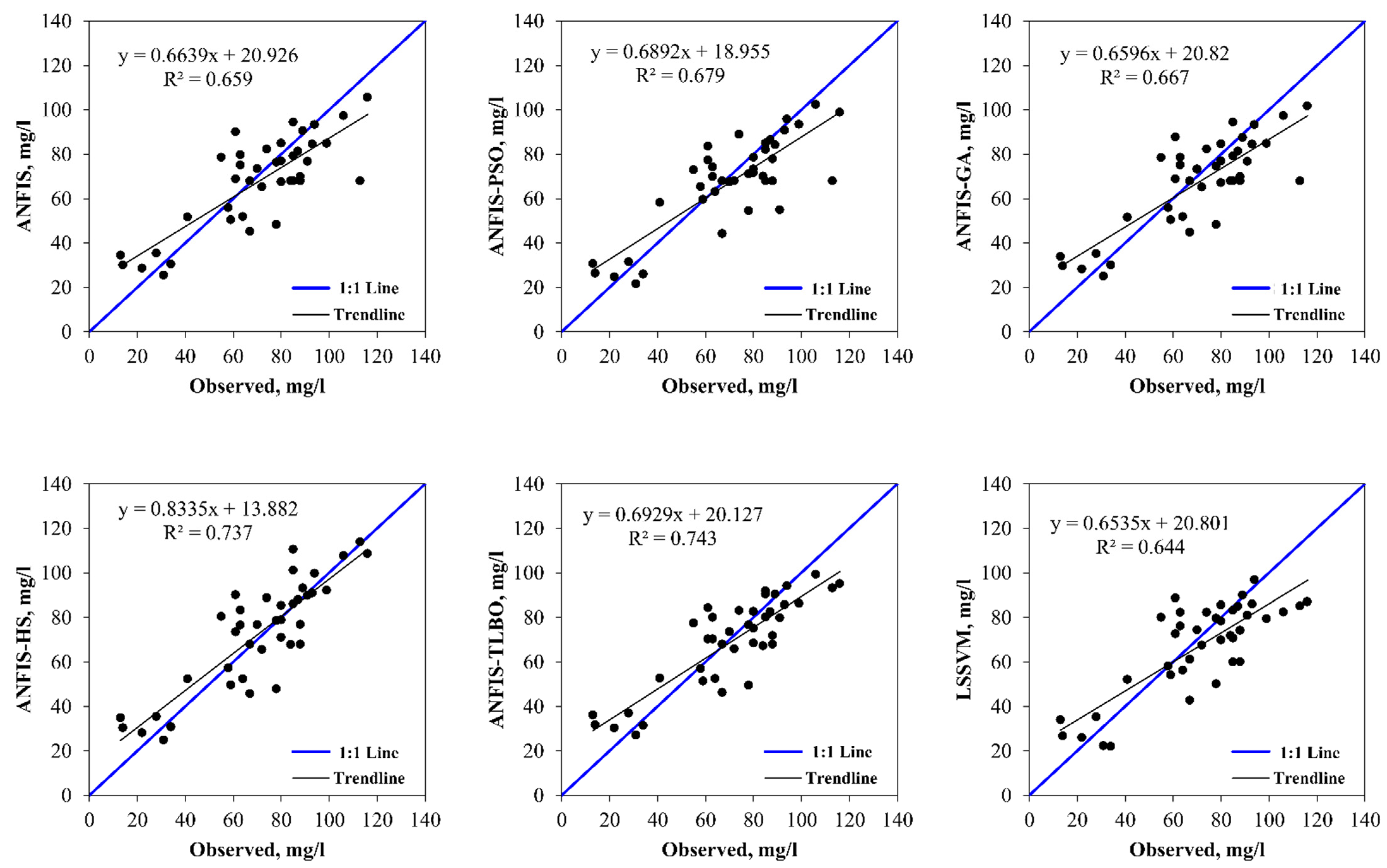
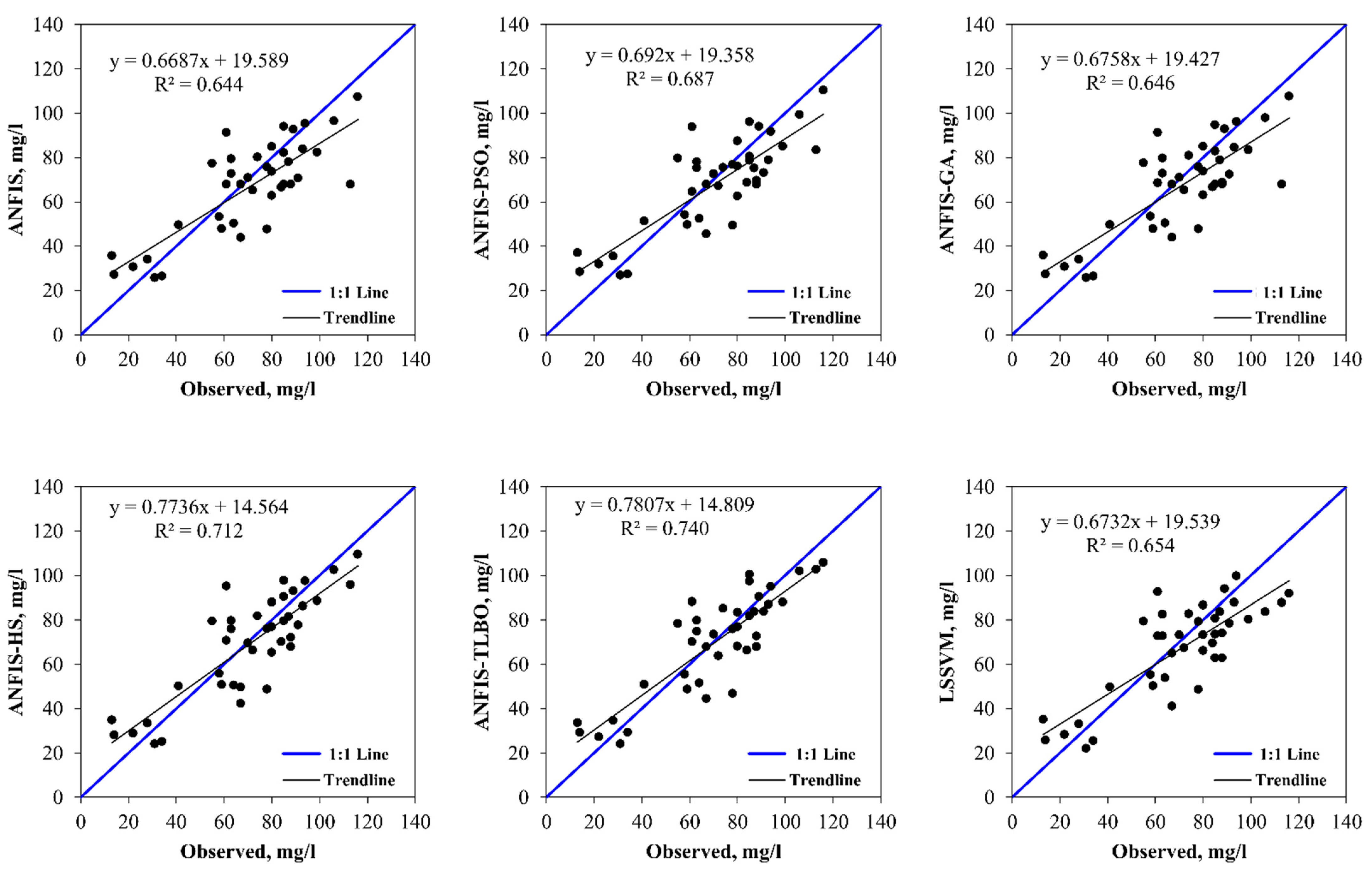
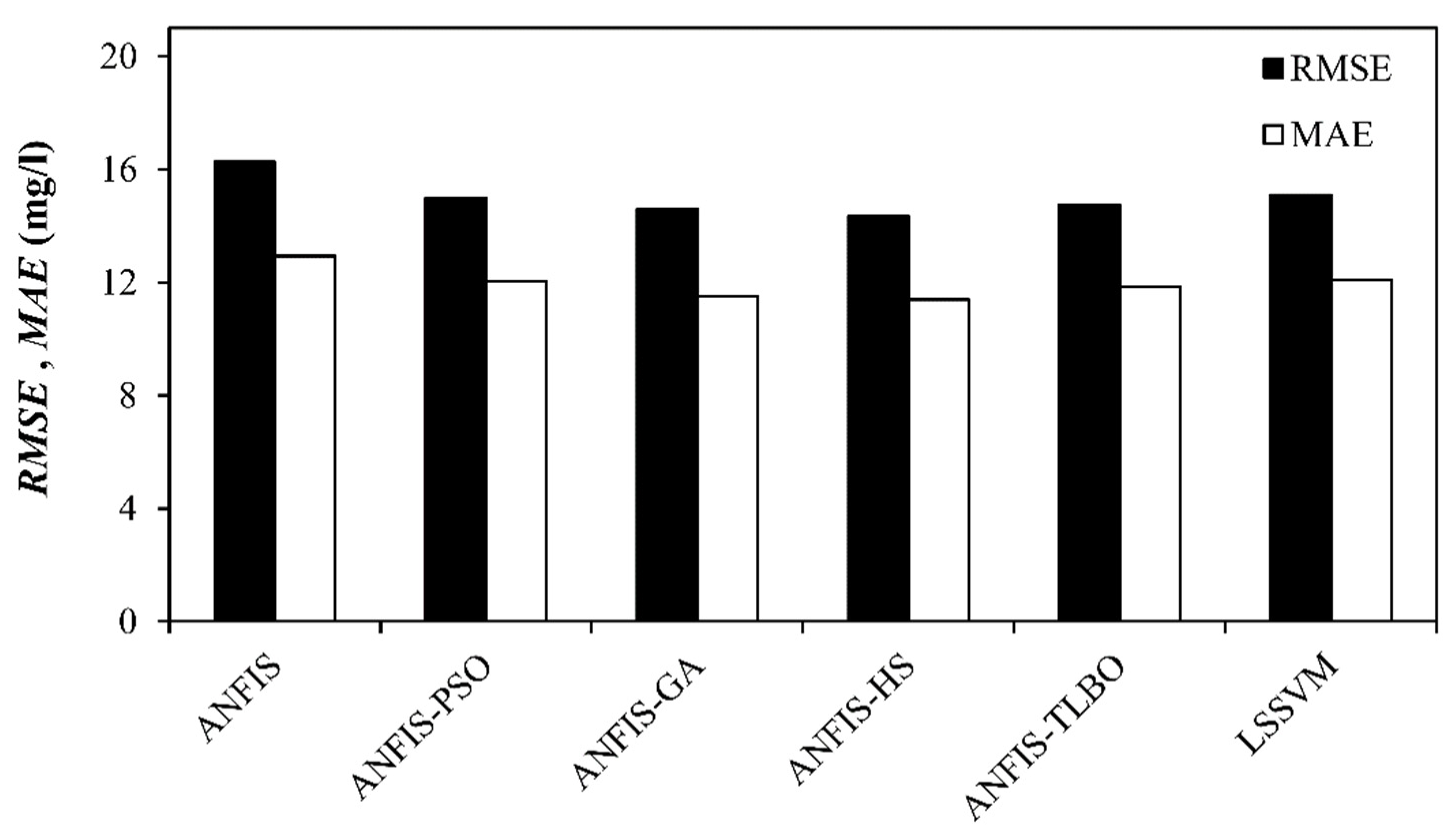
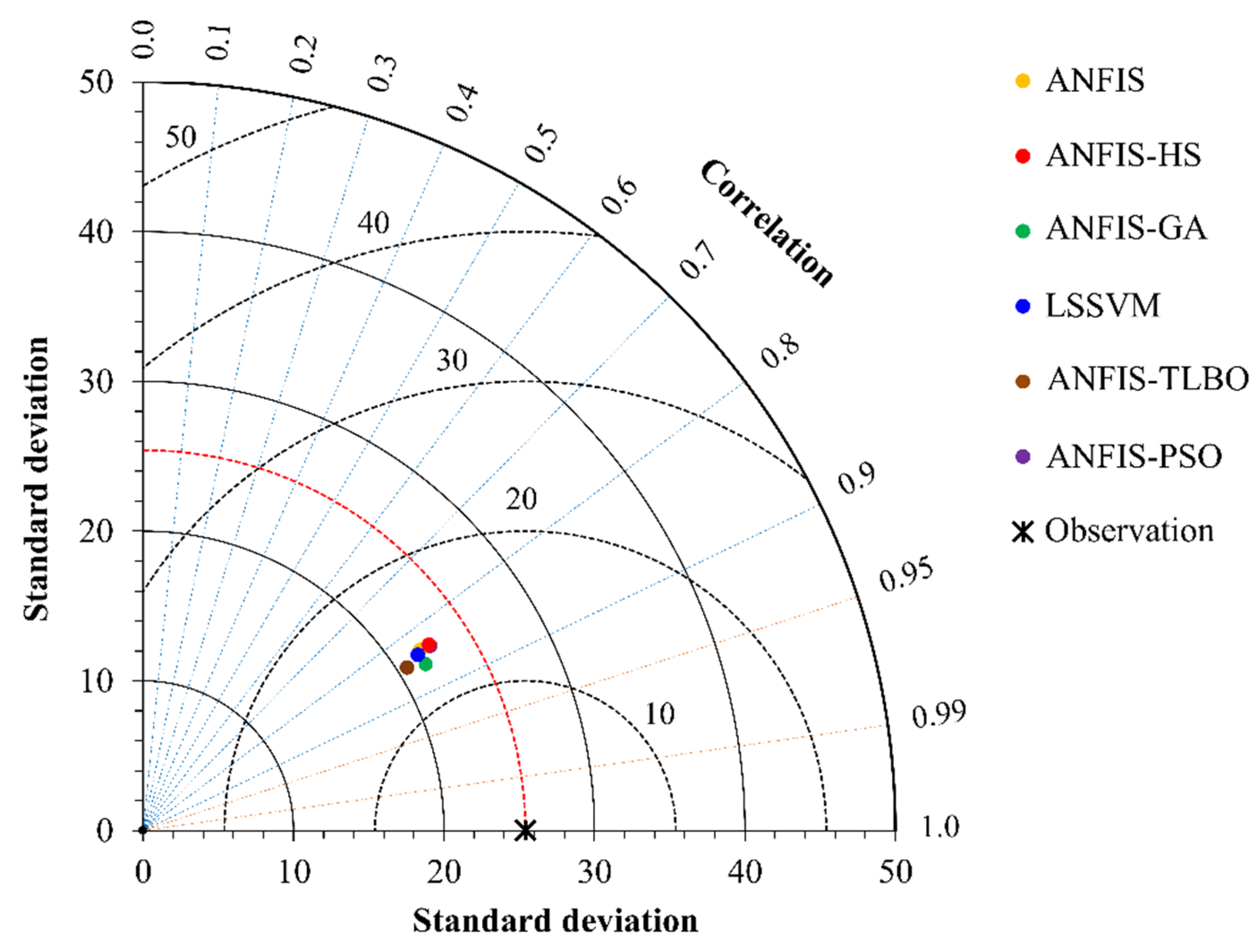
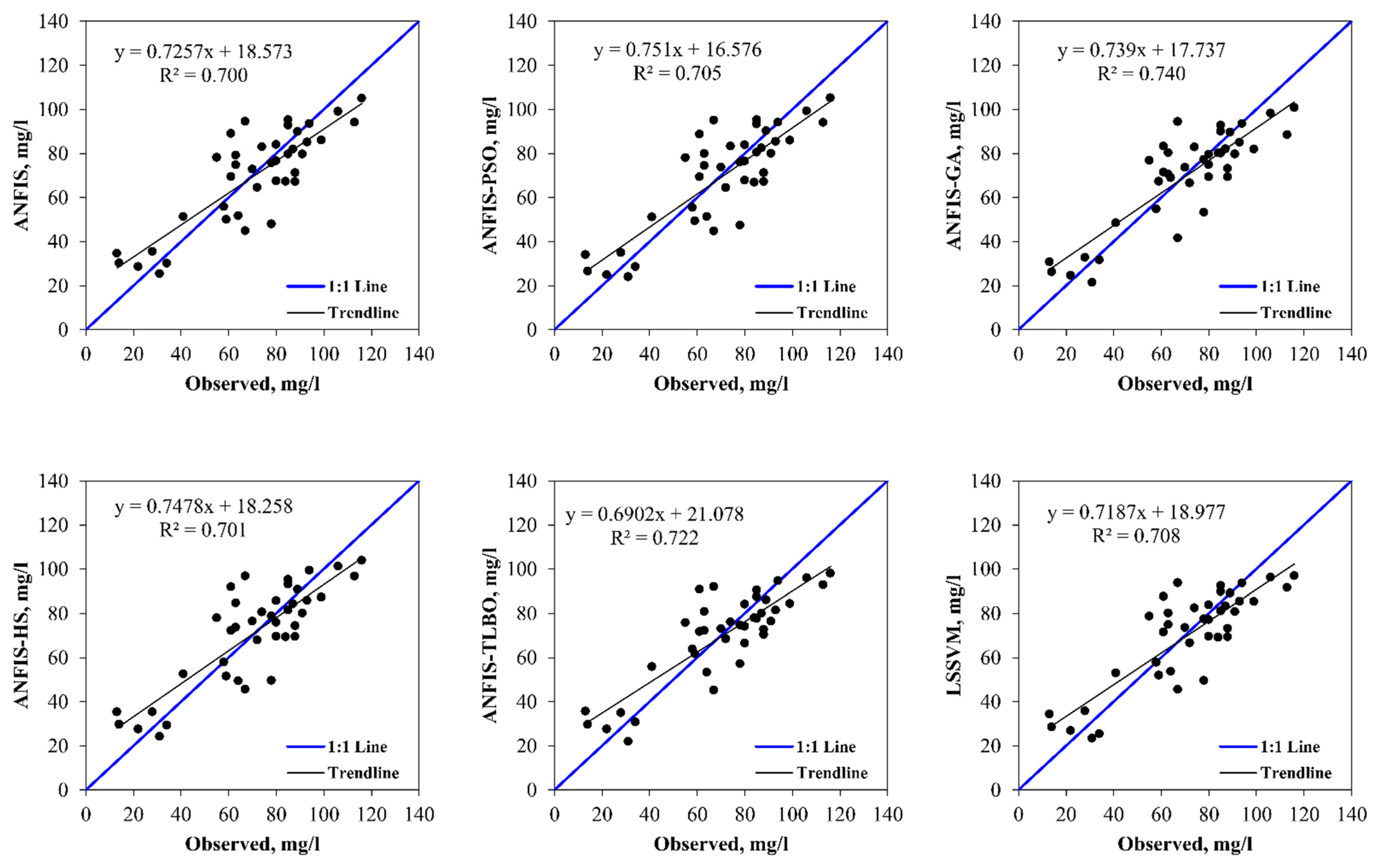
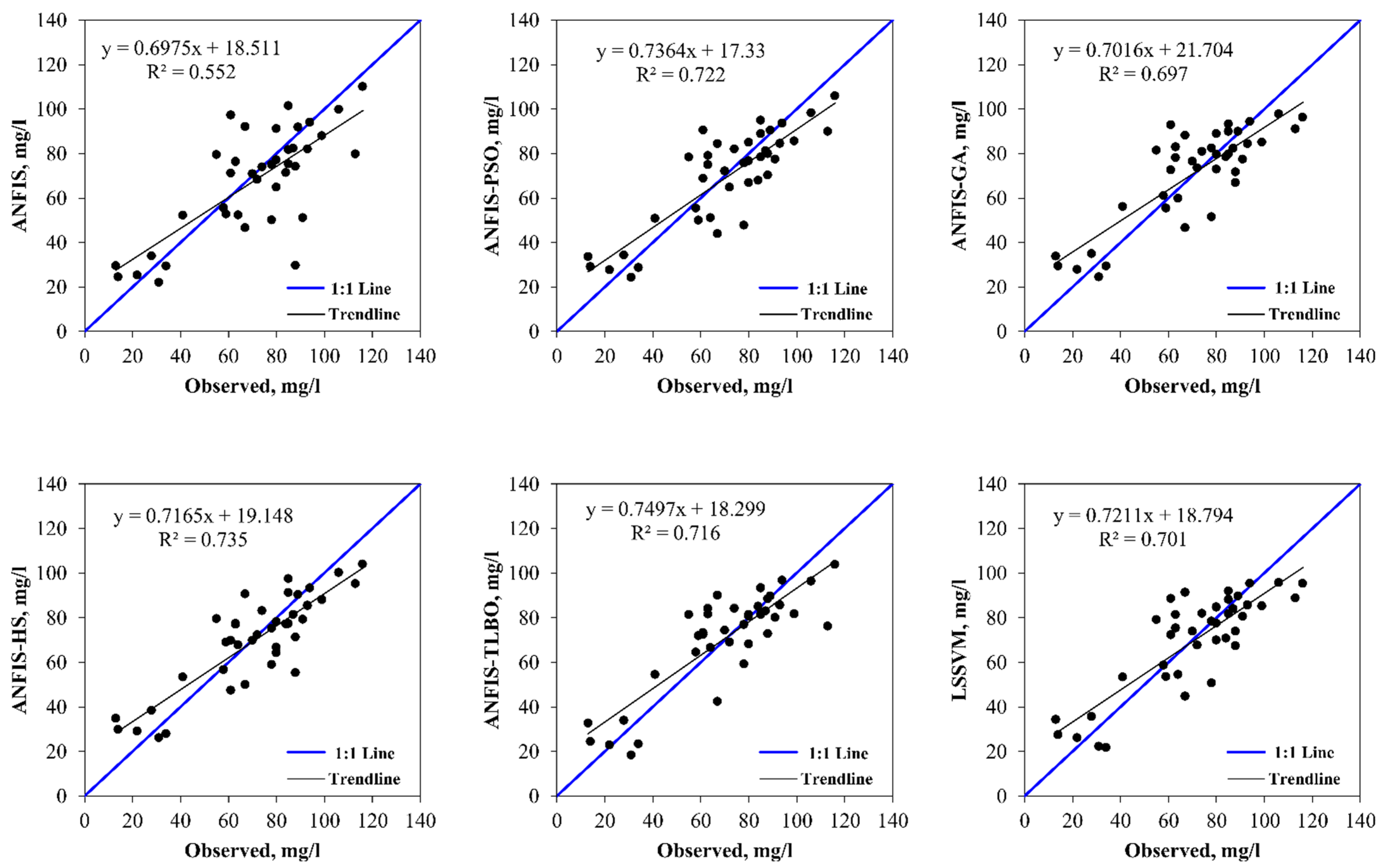
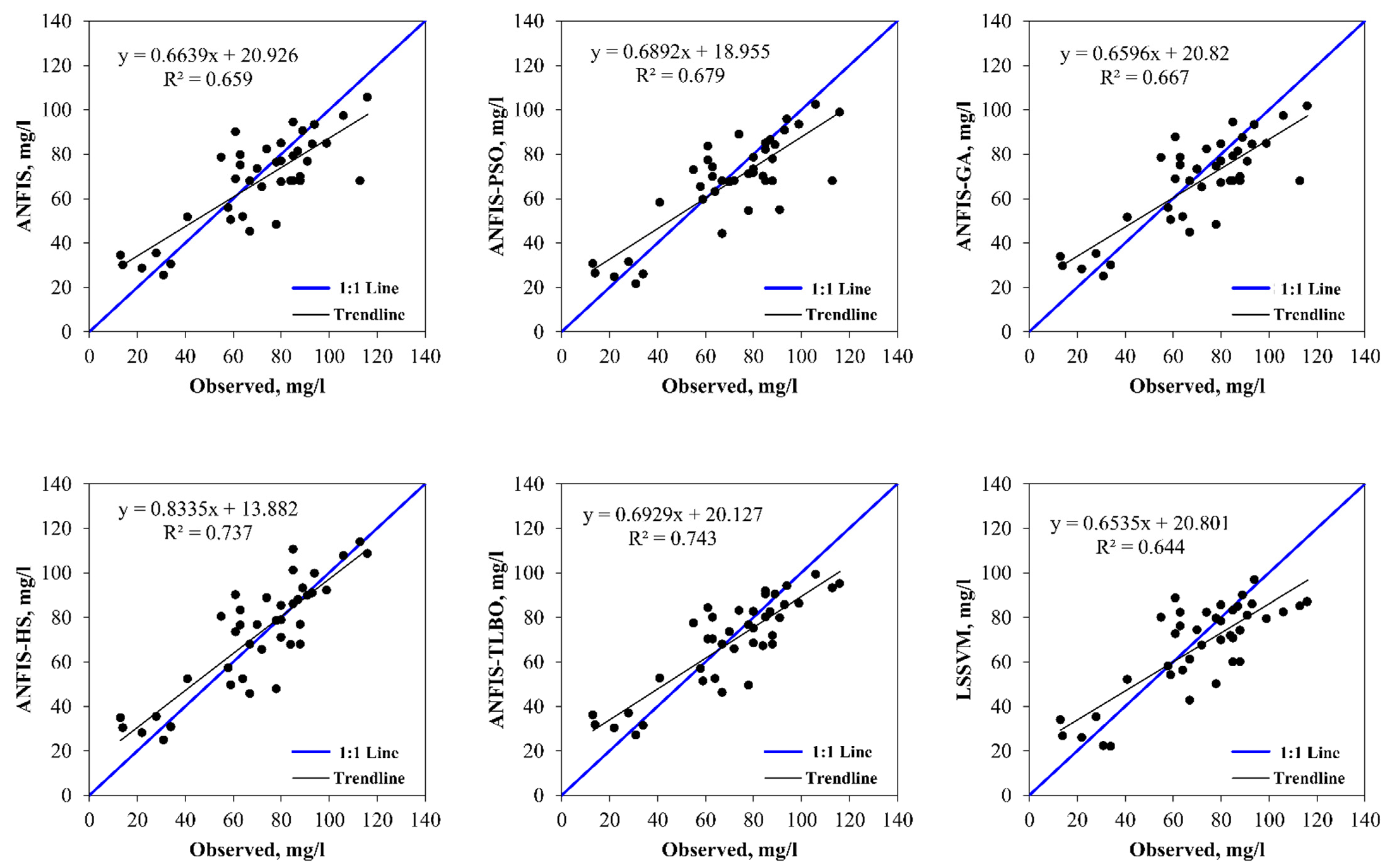
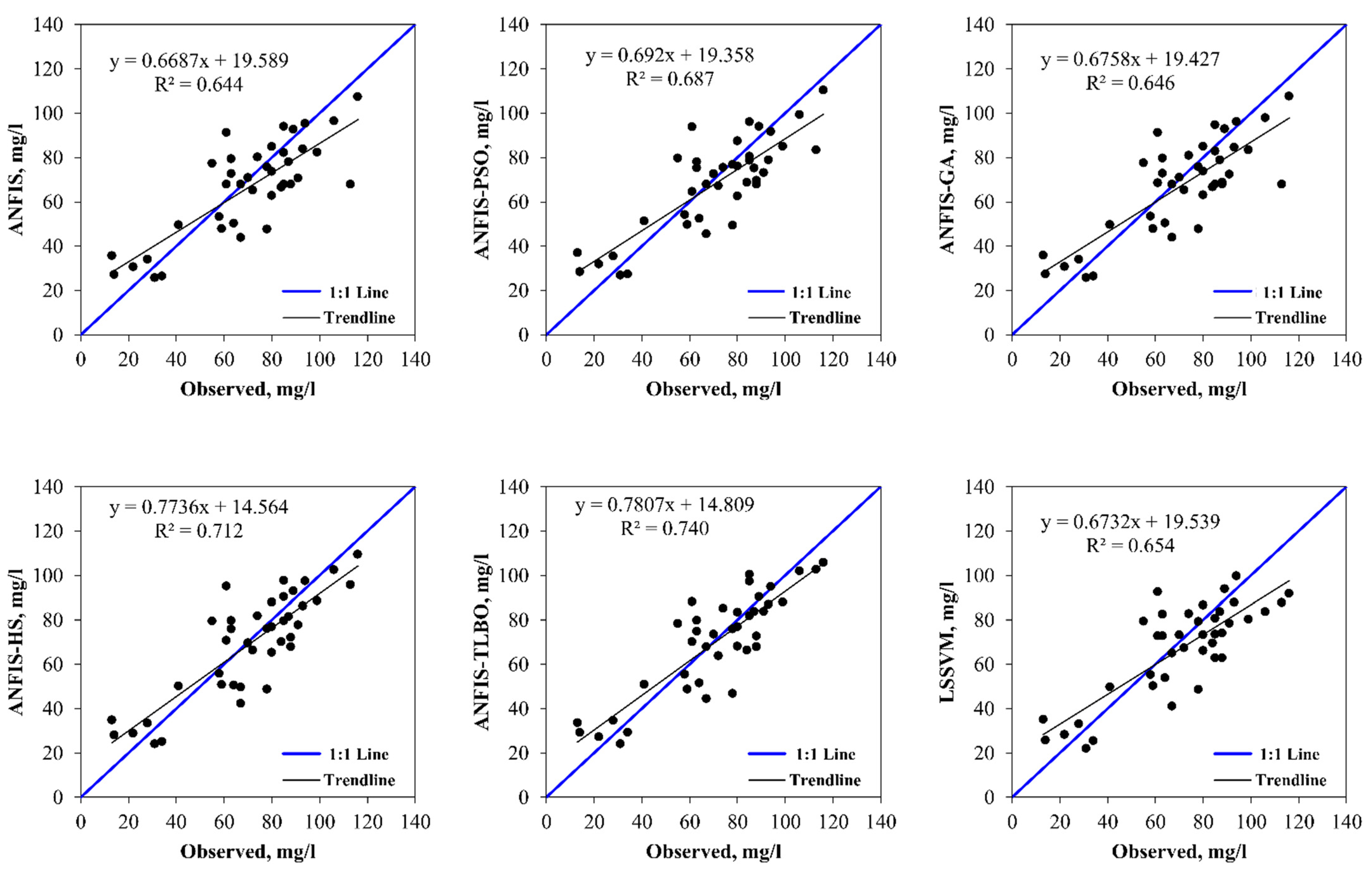
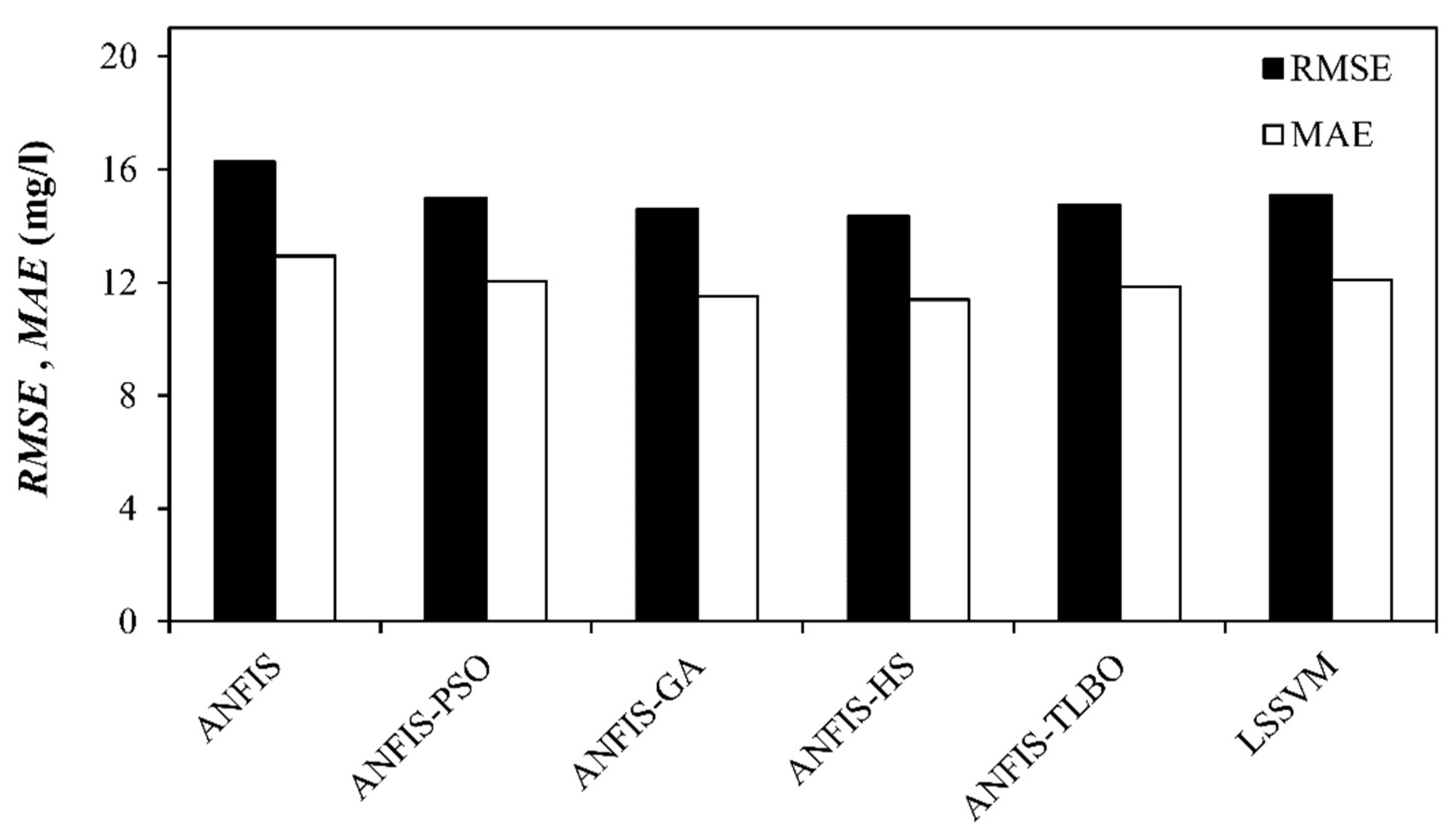
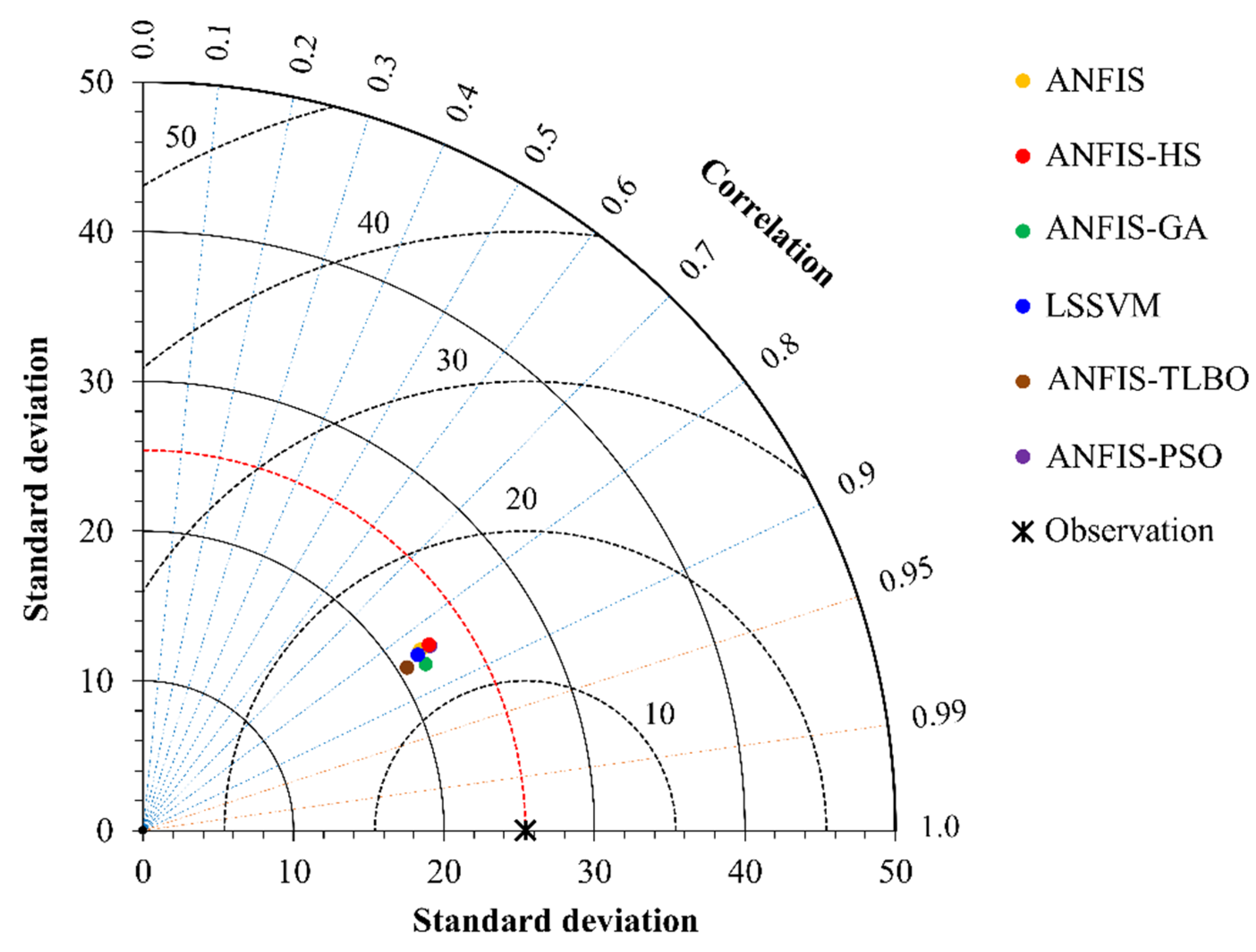
5. Results and Discussion
6. Discussion
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- A/RES/70/1; United Nations General Assembly. United Nations: New York, NY, USA, 2015. Available online: https://www.un.org/en/development/desa/population/migration/generalassembly/docs/globalcopact/A_RES_70_1_E.pdf (accessed on 2 June 2020).
- Shah, M.I.; Alaloul, W.S.; Alqahtani, A.; Aldrees, A.; Musarat, M.A.; Javed, M.F. Predictive Modeling Approach for Surface Water Quality: Development and Comparison of Machine Learning Models. Sustainability 2021, 13, 7515. [Google Scholar] [CrossRef]
- Soni, K.; Parmar, K.S.; Agarwal, S. Modeling of Air Pollution in Residential and Industrial Sites by Integrating Statistical and Daubechies Wavelet (Level 5) Analysis. Model. Earth Syst. Environ. 2017, 3, 1187–1198. [Google Scholar] [CrossRef]
- Akoto, O.; Adiyiah, J. Chemical analysis of drinking water from some communities in the Brong A hafo region. Int. J. Environ. Sci. Technol. 2007, 4, 211–214. [Google Scholar] [CrossRef] [Green Version]
- Alam, M.J.B.; Muyen, Z.; Islam, M.R.; Islam, S.; Mamun, M. Water quality parameters along rivers. Int. J. Environ. Sci. Technol. 2007, 4, 159–167. [Google Scholar] [CrossRef] [Green Version]
- APHA. Standard Methods for Examination of Water and Waste Water; American Public Health Association: Washington, DC, USA, 1995. [Google Scholar]
- WHO. International Standards for Drinking Water; World Health Organization: Geneva, Switzerland, 1971. [Google Scholar]
- Rodríguez, R.; Pastorini, M.; Etcheverry, L.; Chreties, C.; Fossati, M.; Castro, A.; Gorgoglione, A. Water-Quality Data Imputation with a High Percentage of Missing Values: A Machine Learning Approach. Sustainability 2021, 13, 6318. [Google Scholar] [CrossRef]
- Dong, Q.; Wang, Y.; Li, P. Ultifractal behavior of an air pollutant time series and the relevance to the predictability. Environ. Pollut. 2017, 222, 444–457. [Google Scholar] [CrossRef]
- Bhardwaj, R.; Parmar, K.S. Water quality index and fractal dimension analysis of water Parameters. Int. J. Environ. Sci. Technol. 2013, 10, 151–164. [Google Scholar]
- Wong, Y.J.; Shimizu, Y.; He, K.; Nik Sulaiman, N.M. Comparison among different ASEAN water quality indices for the assessment of the spatial variation of surface water quality in the Selangor river basin, Malaysia. Environ. Monit. Assess. 2020, 192, 644. [Google Scholar] [CrossRef]
- Singh, S.; Parmar, K.S.; Kumar, J. Soft computing model coupled with statistical models to estimate future of stock market. Neural Comput. Appl. 2021, 33, 7629–7647. [Google Scholar] [CrossRef]
- Li, X.; Peng, L.; Yao, X.; Cui, S.; Hu, Y.; You, C.; Chi, T. Long short-term memory neural network for air pollutant concentration predictions: Method development and evaluation. Environ. Pollut. 2017, 231, 997–1004. [Google Scholar] [CrossRef]
- Li, Y.; Jiang, P.; She, Q.; Lin, G. Research on air pollutant concentration prediction method based on self-adaptive neuro-fuzzy weighted extreme learning machine. Environ. Pollut. 2018, 241, 1115–1127. [Google Scholar] [CrossRef] [PubMed]
- Sharma, P.; Said, Z.; Kumar, A.; Nižetić, S.; Pandey, A.; Hoang, A.T.; Huang, Z.; Afzal, A.; Li, C.; Le, A.T.; et al. Recent Advances in Machine Learning Research for Nanofluid-Based Heat Transfer in Renewable Energy System. Energy Fuels 2022, 36, 6626–6658. [Google Scholar] [CrossRef]
- Yilma, M.; Kiflie, Z.; Windsperger, A.; Gessese, N. Application of artificial neural network in water quality index prediction: A case study in Little Akaki River, Addis Ababa, Ethiopia. Model. Earth Syst. Environ. 2018, 4, 175–187. [Google Scholar] [CrossRef]
- Ahmed, A.N.; Othman, F.B.; Afan, H.A.; Ibrahim, R.K.; Fai, C.M.; Hossain, M.S.; Ehteram, M.; Elshafie, A. Machine learning methods for better water quality prediction. J. Hydrol. 2019, 578, 124084. [Google Scholar] [CrossRef]
- Abba, S.I.; Pham, Q.B.; Saini, G.; Linh, N.T.T.; Ahmed, A.N.; Mohajane, M.; Khaledian, M.; Abdulkadir, R.A.; Bach, Q.V. Implementation of data intelligence models coupled with ensemble machine learning for prediction of water quality index. Environ. Sci. Pollut. Res. 2020, 27, 41524–41539. [Google Scholar] [CrossRef]
- Lee, E.; Kim, T. Predicting BOD under Various Hydrological Conditions in the Dongjin River Basin Using Physics-Based and Data-Driven Models. Water 2021, 13, 1383. [Google Scholar] [CrossRef]
- Wong, Y.J.; Shimizu, Y.; Kamiya, A.; Maneechot, L.; Bharambe, K.P.; Fong, C.S.; Sulaiman, N.M.N. Application of artificial intelligence methods for monsoonal river classification in Selangor river basin, Malaysia. Environ. Monit. Assess. 2021, 193, 438. [Google Scholar] [CrossRef]
- Kisi, O.; Parmar, K.S. Application of least square support vector machine and multivariate adaptive regression spline models in long term prediction of river water pollution. J. Hydrol. 2016, 534, 104–112. [Google Scholar] [CrossRef]
- Adnan, R.M.; Liang, Z.; Trajkovic, S.; Zounemat-Kermani, M.; Li, B.; Kisi, O. Daily streamflow prediction using optimally pruned extreme learning machine. J. Hydrol. 2019, 577, 123981. [Google Scholar] [CrossRef]
- Cheng, M.Y.; Cao, M.T. Evolutionary multivariate adaptive regression splines for estimating shear strength in reinforced-concrete deep beams. Eng. Appl. Artif. Intell. 2014, 28, 86–96. [Google Scholar] [CrossRef]
- Alizamir, M.; Kisi, O.; Adnan, R.M.; Kuriqi, A. Modelling reference evapotranspiration by combining neuro-fuzzy and evolutionary strategies. Acta Geophys. 2020, 68, 1113–1126. [Google Scholar] [CrossRef]
- Fadaee, M.; Amin Mahdavi-Meymand, A.; Zounemat-Kermani, M. Seasonal Short-Term Prediction of Dissolved Oxygen in Rivers via Nature-Inspired Algorithms. CLEAN—Soil Air Water 2020, 48, 1900300. [Google Scholar] [CrossRef]
- Song, C.; Yao, L.; Hua, C.; Ni, Q. A water quality prediction model based on variational mode decomposition and the least squares support vector machine optimized by the sparrow search algorithm (VMD-SSA-LSSVM) of the Yangtze River, China. Environ. Monit. Assess. 2021, 193, 363. [Google Scholar] [CrossRef]
- Arya Azar, N.; Milan, S.G.; Kayhomayoon, Z. The prediction of longitudinal dispersion coefficient in natural streams using LS-SVM and ANFIS optimized by Harris hawk optimization algorithm. J. Contam. Hydrol. 2021, 240, 103781. [Google Scholar] [CrossRef]
- Maheshwaran, R.; Khosa, R. Long term forecasting of groundwater levels with evidence of non-stationary and nonlinear characteristics. Comput. Geosci. 2013, 52, 422–436. [Google Scholar] [CrossRef]
- Emadi, A.; Zamanzad-Ghavidel, S.; Fazeli, S.; Zarei, S.; Rashid-Niaghi, A. Multivariate modeling of pan evaporation in monthly temporal resolution using a hybrid evolutionary data-driven method (case study: Urmia Lake and Gavkhouni basins). Environ. Monit. Assess. 2021, 193, 355. [Google Scholar] [CrossRef]
- Ikram, R.M.A.; Dai, H.L.; Ewees, A.A.; Shiri, J.; Kisi, O.; Zounemat-Kermani, M. Application of improved version of multi verse optimizer algorithm for modeling solar radiation. Energy Rep. 2022, 8, 12063–12080. [Google Scholar]
- Adnan, R.M.; Mostafa, R.R.; Islam, A.R.M.T.; Gorgij, A.D.; Kuriqi, A.; Kisi, O. Improving Drought Modeling Using HybridRandom Vector Functional Link Methods. Water 2021, 13, 3379. [Google Scholar] [CrossRef]
- Sapankevych, N.I.; Sankar, R. Time series prediction using support vector machines: A survey. Comput. Intell. Mag. IEEE 2009, 4, 24–38. [Google Scholar] [CrossRef]
- Shamir, E.; Megdal, S.B.; Carrillo, C.; Castro, C.L.; Chang, H.; Chief, K.; Corkhill, F.E.; Georgakakos, S.E.K.P.; Nelson, K.M.; Prietto, J. Climate change and water resources management in the Upper Santa Cruz River, Arizona. J. Hydrol. 2015, 521, 18–33. [Google Scholar] [CrossRef] [Green Version]
- Shoorehdeli, M.A.; Teshnehlab, M.; Sedigh, A.K.; Khanesar, M.A. Identification using ANFIS with intelligent hybrid stable learning algorithm approaches and stability analysis of training methods. Appl. Soft Comput. 2009, 9, 833–850. [Google Scholar] [CrossRef]
- Suykens, J.A.; De Brabanter, J.; Lukas, L.; Vandewalle, J. Weighted least squares support vector machines: Robustness and sparse approximation. Neurocomputing 2002, 48, 85–105. [Google Scholar] [CrossRef]
- Jang, J.S. ANFIS: Adaptive-network-based fuzzy inference system. IEEE Trans. Syst. Man Cybern. 1993, 23, 665–685. [Google Scholar] [CrossRef]
- Kisi, O.; Shiri, J.; Karimi, S.; Adnan, R.M. Three different adaptive neuro fuzzy computing techniques for forecasting long-period daily streamflows. In Big Data in Engineering Applications; Springer: Singapore, 2018; pp. 303–321. [Google Scholar]
- Kumar, V.; Yadav, S.M. Optimization of Reservoir Operation with a New Approach in Evolutionary Computation Using TLBO Algorithm and Jaya Algorithm. Water Resour. Manag. 2018, 32, 4375–4391. [Google Scholar] [CrossRef]
- Ikram, R.M.A.; Mostafa, R.R.; Chen, Z.; Islam, A.R.M.T.; Kisi, O.; Kuriqi, A.; Zounemat-Kermani, M. Advanced Hybrid Metaheuristic Machine Learning Models Application for Reference Crop Evapotranspiration Prediction. Agronomy 2023, 13, 98. [Google Scholar] [CrossRef]
- Adnan, R.M.; Mostafa, R.R.; Elbeltagi, A.; Yaseen, Z.M.; Shahid, S.; Kisi, O. Development of new machine learning model for streamflow prediction: Case studies in Pakistan. Stoch. Environ. Res. Risk Assess. 2022, 36, 999–1033. [Google Scholar] [CrossRef]
- Poli, R. Analysis of the publications on the applications of particle swarm optimization. J. Artif. Evol. Appl. 2008, 2008, 685175. [Google Scholar]
- Chaganti, R.; Mourade, A.; Ravi, V.; Vemprala, N.; Dua, A.; Bhushan, B. A Particle Swarm Optimization and Deep Learning Approach for Intrusion Detection System in Internet of Medical Things. Sustainability 2022, 14, 12828. [Google Scholar] [CrossRef]
- Dai, L.; Lu, H.; Hua, D.; Liu, X.; Chen, H.; Glowacz, A.; Królczyk, G.; Li, Z. A Novel Production Scheduling Approach Based on Improved Hybrid Genetic Algorithm. Sustainability 2022, 14, 11747. [Google Scholar] [CrossRef]
- Mirjalili, S. Genetic algorithm. In Evolutionary Algorithms and Neural Networks; Springer: Berlin/Heidelberg, Germany, 2019; pp. 43–55. [Google Scholar]
- Katoch, S.; Chauhan, S.S.; Kumar, V. A review on genetic algorithm: Past, present, and future. Multimed. Tools Appl. 2021, 80, 8091–8126. [Google Scholar] [CrossRef]
- Manjarres, D.; Landa-Torres, I.; Gil-Lopez, S.; Del Ser, J.; Bilbao, M.N.; Salcedo-Sanz, S.; Geem, Z.W. A survey on applications of the harmony search algorithm. Eng. Appl. Artif. Intell. 2013, 26, 1818–1831. [Google Scholar] [CrossRef]
- Ocak, A.; Nigdeli, S.M.; Bekdaş, G.; Kim, S.; Geem, Z.W. Optimization of Seismic Base Isolation System Using Adaptive Harmony Search Algorithm. Sustainability 2022, 14, 7456. [Google Scholar] [CrossRef]
- Abualigah, L.; Diabat, A.; Geem, Z.W. A comprehensive survey of the harmony search algorithm in clustering applications. Appl. Sci. 2020, 10, 3827. [Google Scholar] [CrossRef]
- Rao, R.V.; Savsani, V.J.; Vakharia, D.P. Teaching–learning-based optimization: A novel method for constrained mechanical design optimization problems. Comput.-Aided Des. 2011, 43, 303–315. [Google Scholar] [CrossRef]
- Sahu, R.K.; Shaw, B.; Nayak, J.R. Short/medium term solar power forecasting of Chhattisgarh state of India using modified TLBO optimized ELM. Eng. Sci. Technol. Int. J. 2021, 24, 1180–1200. [Google Scholar] [CrossRef]
- Almutairi, K.; Algarni, S.; Alqahtani, T.; Moayedi, H.; Mosavi, A. A TLBO-Tuned Neural Processor for Predicting Heating Load in Residential Buildings. Sustainability 2022, 14, 5924. [Google Scholar] [CrossRef]
- Gao, N.; Zhang, Z.; Tang, L.; Hou, H.; Chen, K. Optimal design of broadband quasi-perfect sound absorption of composite hybrid porous metamaterial using TLBO algorithm. Appl. Acoust. 2021, 183, 108296. [Google Scholar] [CrossRef]
- Adnan, R.M.; Yuan, X.; Kisi, O.; Adnan, M.; Mehmood, A. Stream Flow Forecasting of Poorly Gauged MountainousWatershed by Least Square Support Vector Machine, Fuzzy Genetic Algorithm and M5 Model Tree Using Climatic Data from Nearby Station. Water Resour. Manag. 2018, 32, 4469–4486. [Google Scholar] [CrossRef]
- Ikram, R.M.A.; Hazarika, B.B.; Gupta, D.; Heddam, S.; Kisi, O. Streamflow prediction in mountainous region using new machine learning and data preprocessing methods: A case study. Neural Comput. Appl. 2022, 1–18. [Google Scholar] [CrossRef]
- Bhardwaj, R.; Parmar, K.S. Wavelet and statistical analysis of river water quality parameters. Appl. Math. Comput. 2013, 219, 10172–10182. [Google Scholar]
- Kora, A.J.; Rastogi, L.; Kumar, S.J.; Jagatap, B.N. Physico-chemical and bacteriological screening of Hussain Sagar lake: An urban wetland. Water Sci. 2017, 31, 24–33. [Google Scholar] [CrossRef] [Green Version]
- Kagalou, I.; Tsimarakis, G.; Bezirtzoglou, E. Inter-relationships between bacteriological and chemical variations in Lake Pamvotis-Greece. Microb. Ecol. Health Dis. 2002, 14, 37–41. [Google Scholar]
- Sharafati, A.; Asadollah, S.B.H.S.; Hosseinzadeh, M. The potential of new ensemble machine learning models for effluent quality parameters prediction and related uncertainty. Process Saf. Environ. Prot. 2020, 140, 68–78. [Google Scholar] [CrossRef]
- Liu, H.; Zhang, Y.; Zhang, H. Prediction of effluent quality in papermaking wastewater treatment processes using dynamic kernel-based extreme learning machine. Process Biochem. 2020, 97, 72–79. [Google Scholar] [CrossRef]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Data Set | xmean | Sx | Csx | xmin | xmax |
|---|---|---|---|---|---|
| January 1999 to April 2002 | 56.8 | 22.6 | −0.08 | 18 | 104 |
| April 2002 to September 2005 | 70.4 | 25.4 | −0.64 | 13 | 116 |
| September 2005 to December 2009 | 68.0 | 31.9 | −0.24 | 9 | 127 |
| pH | AMM | TKN | WT | TC | FC | ||
|---|---|---|---|---|---|---|---|
| COD | Pearson Correlation | −0.048 | 0.823 ** | 0.741 ** | −0.273 ** | 0.211 * | 0.164 |
| Sig. (2-tailed) | 0.603 | 0.000 | 0.000 | 0.003 | 0.021 | 0.074 | |
| N | 120 | 120 | 120 | 120 | 120 | 120 | |
| Cross-Validation | Training | Testing |
|---|---|---|
| M1 | Jan1999 to August 2005 | September 2005 to December 2009 |
| M2 | January 1999 to April 2002 & September 2005 to December 2009 | May 2002 to August 2005 |
| M3 | May 2002 to December 2009 | January 1999 to August 2002 |
| Optimization Method | Parameters |
|---|---|
| PSO | Population Size = 500 Maximum Iteration = 2000 Iteration Weight = 1 Inertia Weight Damping Ratio = 0.95 Personal Learning Coefficient = 1 Global Learning Coefficient = 2 |
| GA | Population Size = 500 Maximum Iteration = 2000 Crossover Percentage = 0.7 Mutation Rate = 0.01 |
| HS | Harmony Memory Size = 500 Maximum Iteration = 2000 Pitch Adjustment Rate = 0.1 Harmony Memory Consideration Rate = 0.9 |
| TLBO | Population Size = 500 Maximum Iteration = 2000 |
| Method | Cross-Validation | Statistics | |||||
|---|---|---|---|---|---|---|---|
| RMSE | R | MAE | PPTS 5% | PPTS 10% | PPTS 20% | ||
| ANFIS | M1 | 17.874 | 0.824 | 13.845 | 29.360 | 30.872 | 34.236 |
| M2 | 13.770 | 0.837 | 11.411 | 23.314 | 24.465 | 26.914 | |
| M3 | 17.139 | 0.743 | 13.552 | 30.714 | 32.284 | 35.637 | |
| Mean | 16.261 | 0.801 | 12.936 | 27.796 | 29.207 | 32.262 | |
| ANFIS–PSO | M1 | 15.872 | 0.864 | 12.333 | 26.291 | 27.624 | 30.582 |
| M2 | 13.723 | 0.840 | 11.327 | 22.364 | 23.469 | 25.750 | |
| M3 | 15.396 | 0.759 | 12.399 | 27.155 | 28.470 | 31.163 | |
| Mean | 14.997 | 0.821 | 12.020 | 25.270 | 26.521 | 29.165 | |
| ANFIS–GA | M1 | 15.646 | 0.870 | 11.970 | 24.669 | 25.931 | 28.535 |
| M2 | 13.802 | 0.837 | 11.315 | 23.415 | 24.597 | 27.082 | |
| M3 | 15.372 | 0.739 | 12.298 | 28.318 | 29.796 | 32.933 | |
| Mean | 14.940 | 0.815 | 11.861 | 25.467 | 26.775 | 29.517 | |
| ANFIS–HS | M1 | 15.226 | 0.878 | 11.650 | 24.416 | 25.659 | 28.400 |
| M2 | 12.802 | 0.860 | 10.249 | 19.934 | 20.978 | 23.030 | |
| M3 | 14.043 | 0.795 | 11.199 | 25.386 | 26.671 | 29.228 | |
| Mean | 14.024 | 0.844 | 11.033 | 23.245 | 24.436 | 26.886 | |
| ANFIS–TLBO | M1 | 15.470 | 0.874 | 11.946 | 25.600 | 26.902 | 29.749 |
| M2 | 13.280 | 0.850 | 11.051 | 22.889 | 23.966 | 26.371 | |
| M3 | 15.479 | 0.747 | 12.523 | 28.691 | 30.174 | 33.405 | |
| Mean | 14.743 | 0.824 | 11.840 | 25.727 | 27.014 | 29.842 | |
| LSSVM * | M1 | 16.460 | 0.867 | 12.720 | 28.110 | 29.520 | 32.520 |
| M2 | 13.590 | 0.915 | 11.150 | 22.760 | 23.980 | 26.500 | |
| M3 | 15.230 | 0.841 | 12.420 | 28.760 | 30.200 | 33.270 | |
| Mean | 15.093 | 0.874 | 12.097 | 26.543 | 27.900 | 30.763 | |
| Method | Cross-Validation | Statistics | |||||
|---|---|---|---|---|---|---|---|
| RMSE | R | MAE | PPTS 5% | PPTS 10% | PPTS 20% | ||
| ANFIS | M1 | 16.403 | 0.860 | 12.637 | 28.844 | 30.341 | 33.574 |
| M2 | 17.720 | 0.743 | 12.928 | 23.115 | 24.323 | 26.839 | |
| M3 | 16.042 | 0.710 | 12.944 | 28.882 | 30.297 | 33.398 | |
| Mean | 16.722 | 0.771 | 12.836 | 26.947 | 28.320 | 31.270 | |
| ANFIS–PSO | M1 | 16.588 | 0.856 | 12.786 | 28.556 | 30.046 | 33.303 |
| M2 | 13.290 | 0.850 | 11.006 | 22.369 | 23.454 | 25.810 | |
| M3 | 15.652 | 0.728 | 12.421 | 28.336 | 29.807 | 32.971 | |
| Mean | 15.177 | 0.811 | 12.071 | 26.420 | 27.769 | 30.695 | |
| ANFIS–GA | M1 | 16.827 | 0.850 | 12.990 | 29.630 | 31.141 | 34.486 |
| M2 | 13.830 | 0.835 | 11.213 | 22.845 | 24.036 | 26.378 | |
| M3 | 15.757 | 0.720 | 12.601 | 28.231 | 29.685 | 32.898 | |
| Mean | 15.471 | 0.802 | 12.268 | 26.902 | 28.287 | 31.254 | |
| ANFIS–HS | M1 | 16.184 | 0.859 | 12.482 | 26.589 | 27.955 | 31.013 |
| M2 | 12.940 | 0.858 | 10.683 | 22.403 | 23.580 | 26.161 | |
| M3 | 14.571 | 0.786 | 11.517 | 25.569 | 26.822 | 29.547 | |
| Mean | 14.565 | 0.834 | 11.561 | 24.854 | 26.119 | 28.907 | |
| ANFIS–TLBO | M1 | 15.539 | 0.872 | 11.843 | 24.392 | 25.652 | 28.355 |
| M2 | 13.427 | 0.846 | 10.578 | 21.101 | 22.192 | 24.656 | |
| M3 | 14.729 | 0.770 | 11.906 | 26.633 | 28.049 | 30.984 | |
| Mean | 14.565 | 0.829 | 11.442 | 24.042 | 25.298 | 27.998 | |
| LSSVM * | M1 | 16.540 | 0.865 | 12.830 | 28.130 | 29.520 | 32.490 |
| M2 | 13.760 | 0.837 | 11.250 | 22.840 | 24.020 | 26.580 | |
| M3 | 15.230 | 0.749 | 12.420 | 28.760 | 30.200 | 33.270 | |
| Mean | 15.177 | 0.817 | 12.167 | 26.577 | 27.913 | 30.780 | |
| Method | Cross-Validation | Statistics | |||||
|---|---|---|---|---|---|---|---|
| RMSE | r | MAE | PPTS 5% | PPTS 10% | PPTS 20% | ||
| ANFIS | M1 | 16.766 | 0.851 | 12.959 | 29.562 | 31.069 | 34.420 |
| M2 | 14.895 | 0.812 | 11.793 | 23.277 | 24.444 | 26.965 | |
| M3 | 15.709 | 0.722 | 12.570 | 28.059 | 29.511 | 32.677 | |
| Mean | 15.790 | 0.795 | 12.441 | 26.966 | 28.341 | 31.354 | |
| ANFIS–PSO | M1 | 16.595 | 0.853 | 12.559 | 28.952 | 30.457 | 33.915 |
| M2 | 14.517 | 0.824 | 10.678 | 20.474 | 21.536 | 23.953 | |
| M3 | 15.644 | 0.724 | 12.449 | 28.473 | 29.961 | 33.219 | |
| Mean | 15.585 | 0.800 | 11.895 | 25.966 | 27.318 | 30.362 | |
| ANFIS–GA | M1 | 16.764 | 0.851 | 12.959 | 29.560 | 31.066 | 34.416 |
| M2 | 14.823 | 0.816 | 11.822 | 23.061 | 24.225 | 26.661 | |
| M3 | 14.985 | 0.749 | 12.128 | 27.780 | 29.207 | 32.282 | |
| Mean | 15.524 | 0.805 | 12.303 | 26.800 | 28.166 | 31.120 | |
| ANFIS–HS | M1 | 15.761 | 0.866 | 11.738 | 23.790 | 25.013 | 27.775 |
| M2 | 13.358 | 0.858 | 10.324 | 22.240 | 23.391 | 26.072 | |
| M3 | 15.177 | 0.762 | 11.486 | 23.987 | 25.145 | 27.593 | |
| Mean | 14.765 | 0.829 | 11.183 | 23.339 | 24.516 | 27.147 | |
| ANFIS–TLBO | M1 | 16.243 | 0.858 | 11.936 | 25.587 | 26.867 | 29.685 |
| M2 | 12.889 | 0.862 | 10.489 | 22.358 | 23.483 | 25.978 | |
| M3 | 15.522 | 0.726 | 12.419 | 27.342 | 28.685 | 31.691 | |
| Mean | 14.885 | 0.815 | 11.615 | 25.096 | 26.345 | 29.118 | |
| LSSVM * | M1 | 16.440 | 0.868 | 12.620 | 27.800 | 29.260 | 32.350 |
| M2 | 15.400 | 0.802 | 12.460 | 23.690 | 24.890 | 27.620 | |
| M3 | 15.250 | 0.748 | 12.450 | 28.640 | 30.070 | 33.130 | |
| Mean | 15.697 | 0.806 | 12.510 | 26.710 | 28.073 | 31.033 | |
| Method | Cross-Validation | Statistics | |||||
|---|---|---|---|---|---|---|---|
| RMSE | r | MAE | PPTS 5% | PPTS 10% | PPTS 20% | ||
| ANFIS | M1 | 16.864 | 0.848 | 13.068 | 29.912 | 31.473 | 34.998 |
| M2 | 15.451 | 0.802 | 12.383 | 23.949 | 25.160 | 27.705 | |
| M3 | 17.038 | 0.707 | 13.315 | 30.207 | 31.728 | 34.754 | |
| Mean | 16.451 | 0.786 | 12.922 | 28.023 | 29.454 | 32.486 | |
| ANFIS–PSO | M1 | 15.534 | 0.873 | 11.782 | 24.583 | 25.842 | 28.630 |
| M2 | 14.224 | 0.829 | 11.550 | 23.603 | 24.783 | 27.307 | |
| M3 | 15.726 | 0.722 | 12.583 | 28.078 | 29.529 | 32.684 | |
| Mean | 15.161 | 0.808 | 11.972 | 25.421 | 26.718 | 29.540 | |
| ANFIS–GA | M1 | 16.634 | 0.860 | 12.679 | 27.777 | 29.227 | 32.420 |
| M2 | 15.335 | 0.804 | 12.276 | 23.917 | 25.103 | 27.664 | |
| M3 | 15.250 | 0.748 | 12.174 | 27.890 | 29.352 | 32.517 | |
| Mean | 15.740 | 0.804 | 12.376 | 26.528 | 27.894 | 30.867 | |
| ANFIS–HS | M1 | 16.498 | 0.857 | 12.703 | 24.229 | 25.408 | 27.878 |
| M2 | 13.659 | 0.844 | 11.272 | 23.102 | 24.198 | 26.654 | |
| M3 | 15.998 | 0.717 | 12.759 | 28.147 | 29.606 | 32.547 | |
| Mean | 15.385 | 0.806 | 12.245 | 25.159 | 26.404 | 29.026 | |
| ANFIS–TLBO | M1 | 16.746 | 0.851 | 12.842 | 28.011 | 29.456 | 32.690 |
| M2 | 12.850 | 0.860 | 10.480 | 21.734 | 22.821 | 25.178 | |
| M3 | 15.878 | 0.725 | 12.663 | 27.699 | 29.131 | 32.144 | |
| Mean | 15.158 | 0.812 | 11.995 | 25.815 | 27.136 | 30.004 | |
| LSSVM * | M1 | 16.590 | 0.861 | 12.720 | 28.400 | 29.870 | 33.170 |
| M2 | 15.180 | 0.809 | 12.630 | 23.970 | 25.080 | 27.530 | |
| M3 | 16.190 | 0.706 | 13.140 | 31.150 | 32.680 | 35.950 | |
| Mean | 15.987 | 0.792 | 12.830 | 27.840 | 29.210 | 32.217 | |
| Optimization Method | Inputs | |||
|---|---|---|---|---|
| AMM, TKN and WT | AMM, TKN, WT and TC | AMM, TKN, WT, TC and FC | Total Average CPU Time (min) | |
| ANFIS–PSO | 20 | 21 | 23 | 21 |
| ANFIS–GA | 104 | 106 | 114 | 108 |
| ANFIS–HS | 12 | 13 | 13 | 13 |
| ANFIS–TLBO | 22 | 24 | 25 | 24 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kisi, O.; Parmar, K.S.; Mahdavi-Meymand, A.; Adnan, R.M.; Shahid, S.; Zounemat-Kermani, M. Water Quality Prediction of the Yamuna River in India Using Hybrid Neuro-Fuzzy Models. Water 2023, 15, 1095. https://doi.org/10.3390/w15061095
Kisi O, Parmar KS, Mahdavi-Meymand A, Adnan RM, Shahid S, Zounemat-Kermani M. Water Quality Prediction of the Yamuna River in India Using Hybrid Neuro-Fuzzy Models. Water. 2023; 15(6):1095. https://doi.org/10.3390/w15061095
Chicago/Turabian StyleKisi, Ozgur, Kulwinder Singh Parmar, Amin Mahdavi-Meymand, Rana Muhammad Adnan, Shamsuddin Shahid, and Mohammad Zounemat-Kermani. 2023. "Water Quality Prediction of the Yamuna River in India Using Hybrid Neuro-Fuzzy Models" Water 15, no. 6: 1095. https://doi.org/10.3390/w15061095