1. Introduction
In groundwater modeling, great attention is paid to the calibration and the predictive accuracy of models in relation to their complexity, especially to the distribution of hydraulic conductivity K. There are three key parameters of the K-field calibration: the shape and distribution of K zones, thickness of the aquifer within a particular zone, and optimized K values in each zone. The most important issue is the determination of spatial K distribution since the lithological data are generally insufficient due to their point character. Typically, we sample less than one millionth of the material we are characterizing [
1]. The K values are also affected by the thickness of an aquifer generally interpolated from only limited point data. The attempt of K-field calibration with artificial zonation based on residuals of water level distribution has only limited validity, but may result in a better approximation of a real system in terms of calibration and predictions.
When simulating most natural systems, commonly there are alternative plausible models. For example, alternative models of a groundwater system may be developed due to uncertainty associated with the following: (1) The structure and character of boundary conditions. (2) Relevant processes. (3) The spatial and temporal distribution of system characteristics such as hydraulic conductivity, recharge, reaction coefficients, and so on, including alternatives based on different ideas about the deposition and deformation of geologic materials. (4) The inclusion or exclusion of transients associated with, for example, pumping rates, source concentrations, recharge, and so on [
2]. A framework for dealing with uncertainty due to model structure error was introduced, e.g., by [
3].
To determine the most probable modeling scenarios, selected descriptive statistics and the Akaike information criterion (AIC) [
4], Bayesian information criterion (BIC) [
5], and corrected Akaike information criterion (AICc) [
6] can be used in the post-calibration stage. Those and other criteria based on information theory have been widely implemented in the groundwater modeling field. An example can be cited in [
7,
8,
9,
10,
11,
12,
13,
14,
15], beside many others. However, despite their broad use in modeling, the foundations of the AIC, AICc, and BIC, which penalize the likelihoods in order to select the simplest model, are, in general, according to [
7], poorly understood. There have also been various averaging schemes developed to deal with multiple models (variants) in order to generate the most probable scenario [
2,
8,
9]. Weighting of models within such schemes can be based on mentioned information criteria. After the probability of models is set, the real prediction accuracy can be evaluated for chosen scenarios in the form of a post-audit [
16,
17], in accordance with the statement of [
18], i.e., that in any event, the accuracy of the prediction cannot be assessed until the predicted period of time has passed.
Ref. [
4] saw that the difficulty of constructing an adequate model based on the information provided by a finite number of observations was not fully recognized (by professionals). Therefore, he introduced the AIC, which provides a mathematical formulation of the principle of parsimony in the field of model construction [
4]. Ref. [
5] introduced the BIC, which qualitatively, like the AIC, gives a mathematical formulation of the principle of parsimony in model building. Quantitatively, the BIC procedure leans more towards lower-dimensional models. For a large number of observations, the procedures differ markedly from each other [
5]. AICc, which is another information criterion that was introduced by [
6], is a bias-corrected version of AIC for nonlinear regression and autoregressive time series models. In view of the theoretical and simulation results, the AICc should be used routinely instead of the AIC for regression and autoregressive model selection [
6].
Since the end of the last century, one can find the prevailing opinion for inverse modeling methodology, in which it was emphasized, e.g., by [
19,
20], to begin calibration estimation with very few parameters that together represent most of the features of interest, and to increase the complexity of the parameterization slowly. The importance of keeping a model simple, the principle of parsimony [
2,
8,
9,
10,
11,
19,
20], is demonstrated by noting that more complex models generally fit the observations more closely, yet they can have greater prediction error compared to simpler models [
20] and others.
It is not easy to decide whether to use a more complex model or simple calculations combined with expert judgement. Ref. [
21] introduced several examples of opinions regarding model simplicity vs. complexity from experts in the field. Some authors advocate complexity, e.g., [
22], while others are not convinced about its definite benefits, e.g., [
20,
23,
24]. Ref. [
25] preferred constructing models that were a compromise between the effort of the professional’s perfection expressed in very complex models and oversimplified models which strive for speed and efficiency. He also saw the real role of models in extracting the maximum amount of information from the data and minimizing the uncertainty, both via history matching approaches. Ref. [
26] provided a theoretical analysis of the model simplification process, yielding insights into the costs of model simplification, as well as into how some of these costs may be reduced. They claim that modern environmental management and decision making is based on the use of increasingly complex numerical models. They see the advantage of complex models in the possibility of the expert knowledge application within them. The disadvantage of such models lies in the problematic calibration and analysis of their prediction uncertainty. On the other hand, many system and process details on which uncertainty may depend are, by design, omitted from simple models. According to the authors, this can lead to underestimation of the uncertainty associated with many predictions of management interest.
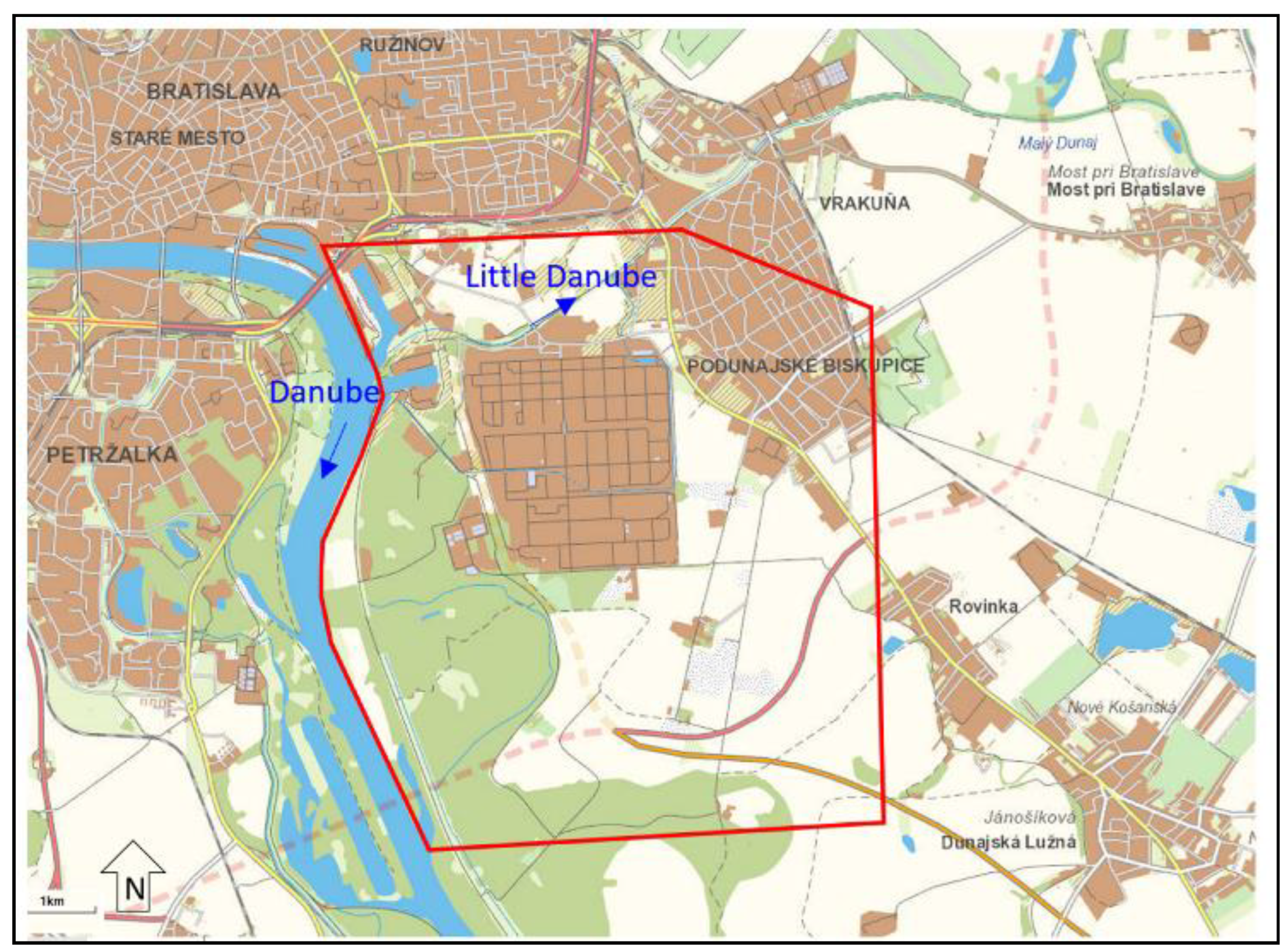
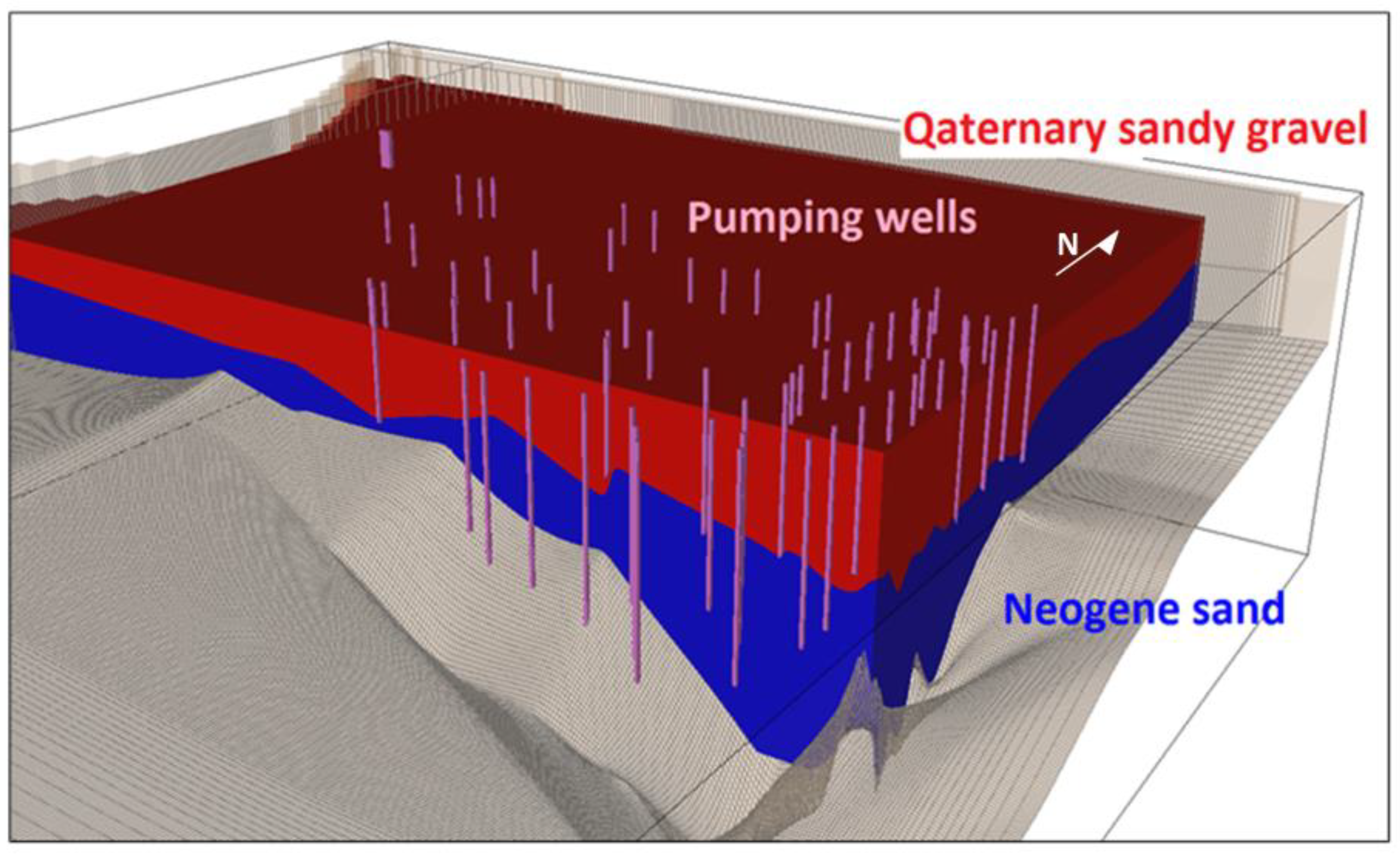
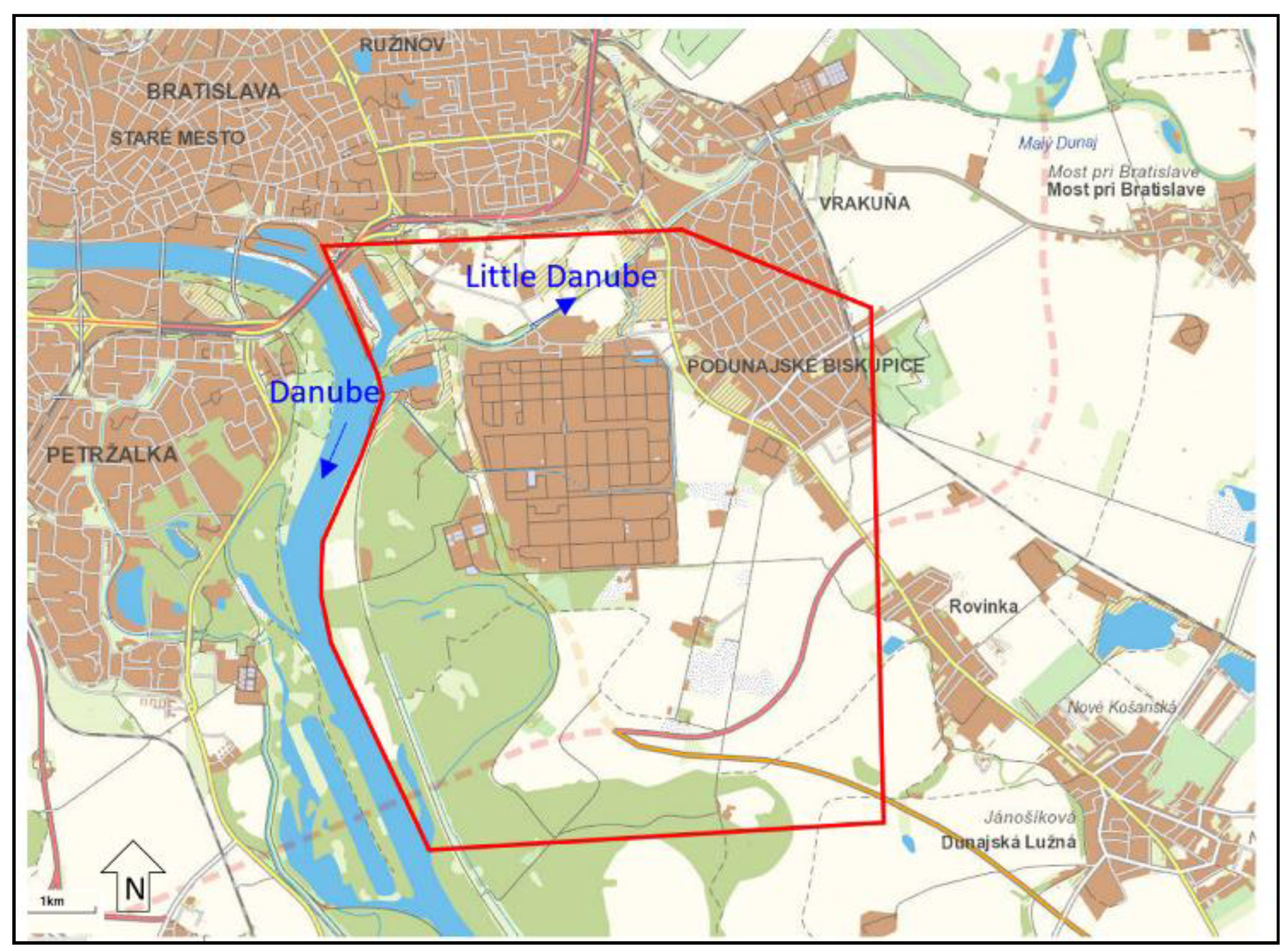
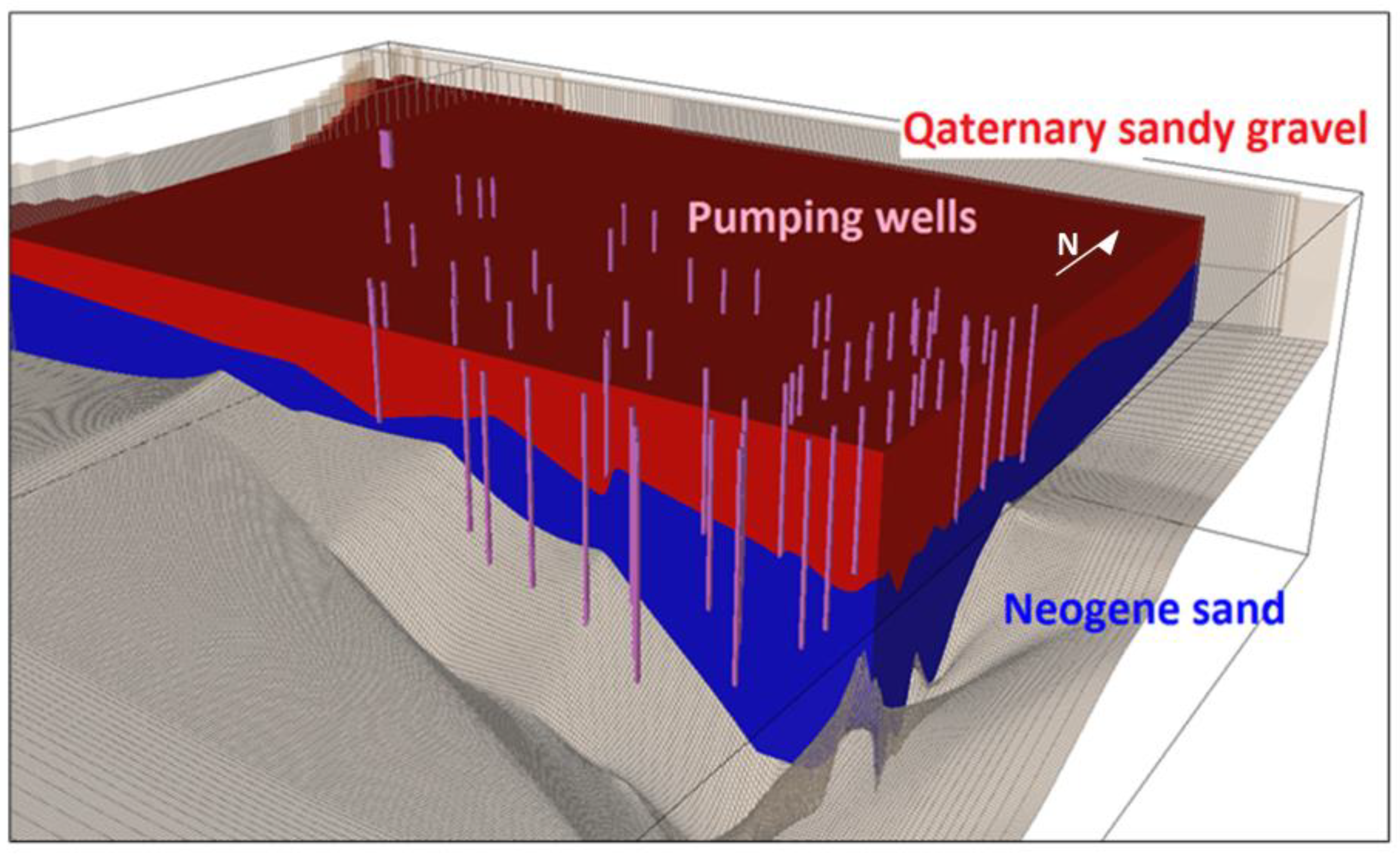
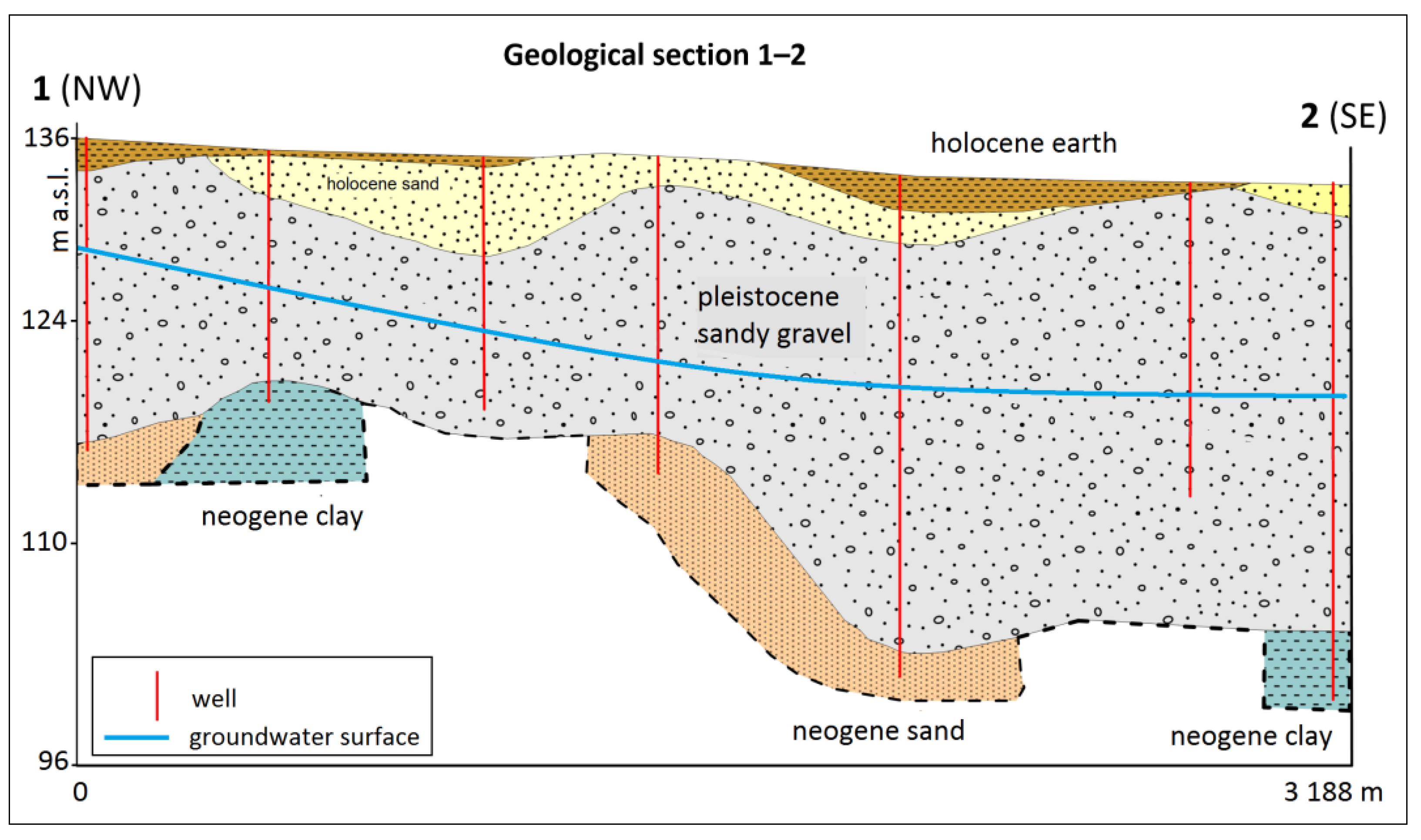
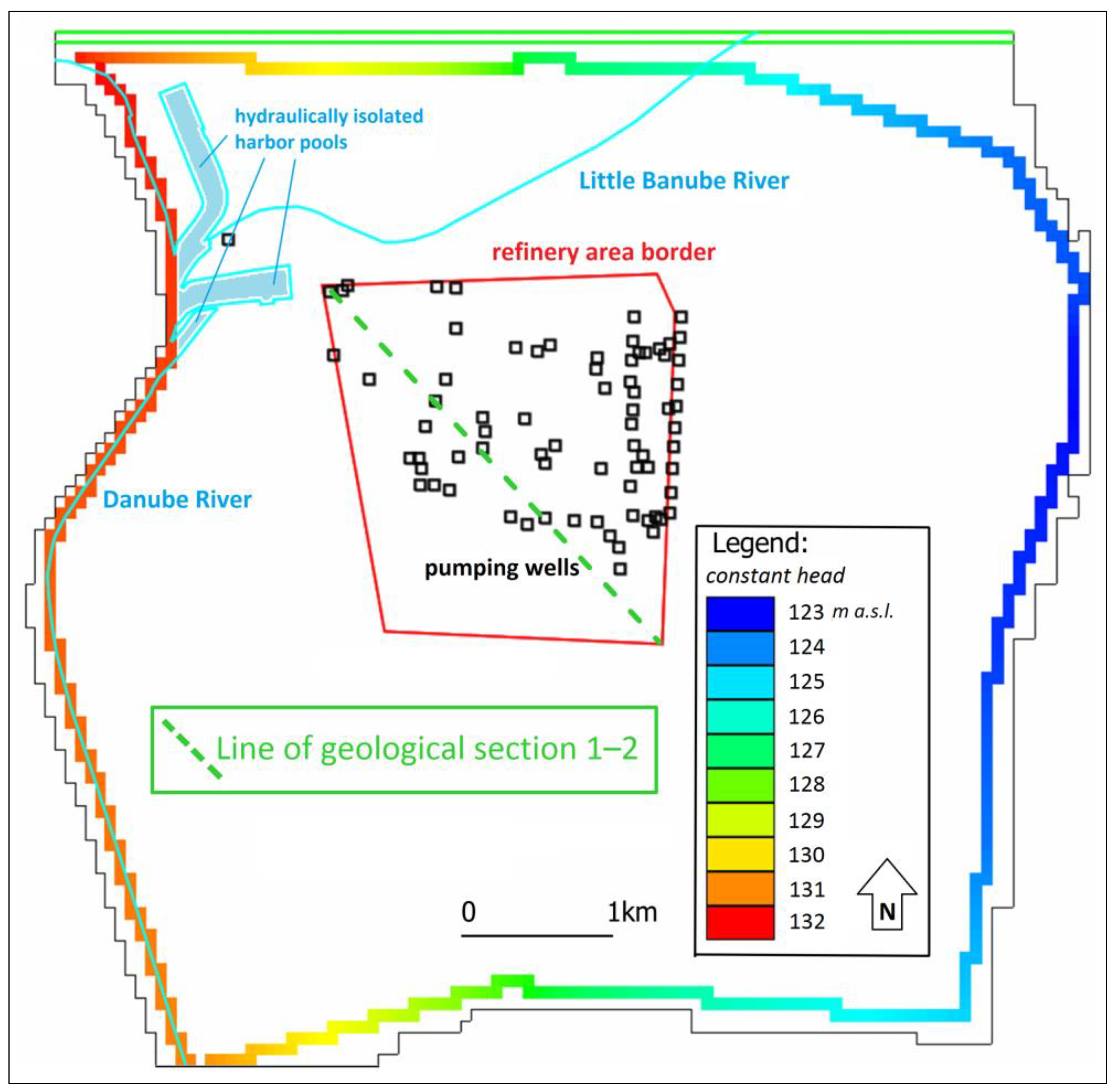
Our study site is located in southwest Slovakia close to Bratislava (
Figure 1), in the proximity of the Danube River. In the past, the site was strongly affected by contamination from petroleum products from the Slovnaft refinery and the hydraulic protection system connected to the monitoring system has been operating there for several decades. This means that long-term monitoring data are available for groundwater modeling.
The main objective of this work is to illustrate the impact of simple to medium model complexity (parametrization) on the simulated groundwater head agreement with field observations within calibration and prediction processes. Additionally, this objective also includes its impact on calculated groundwater pathlines at the study site.
3. Results
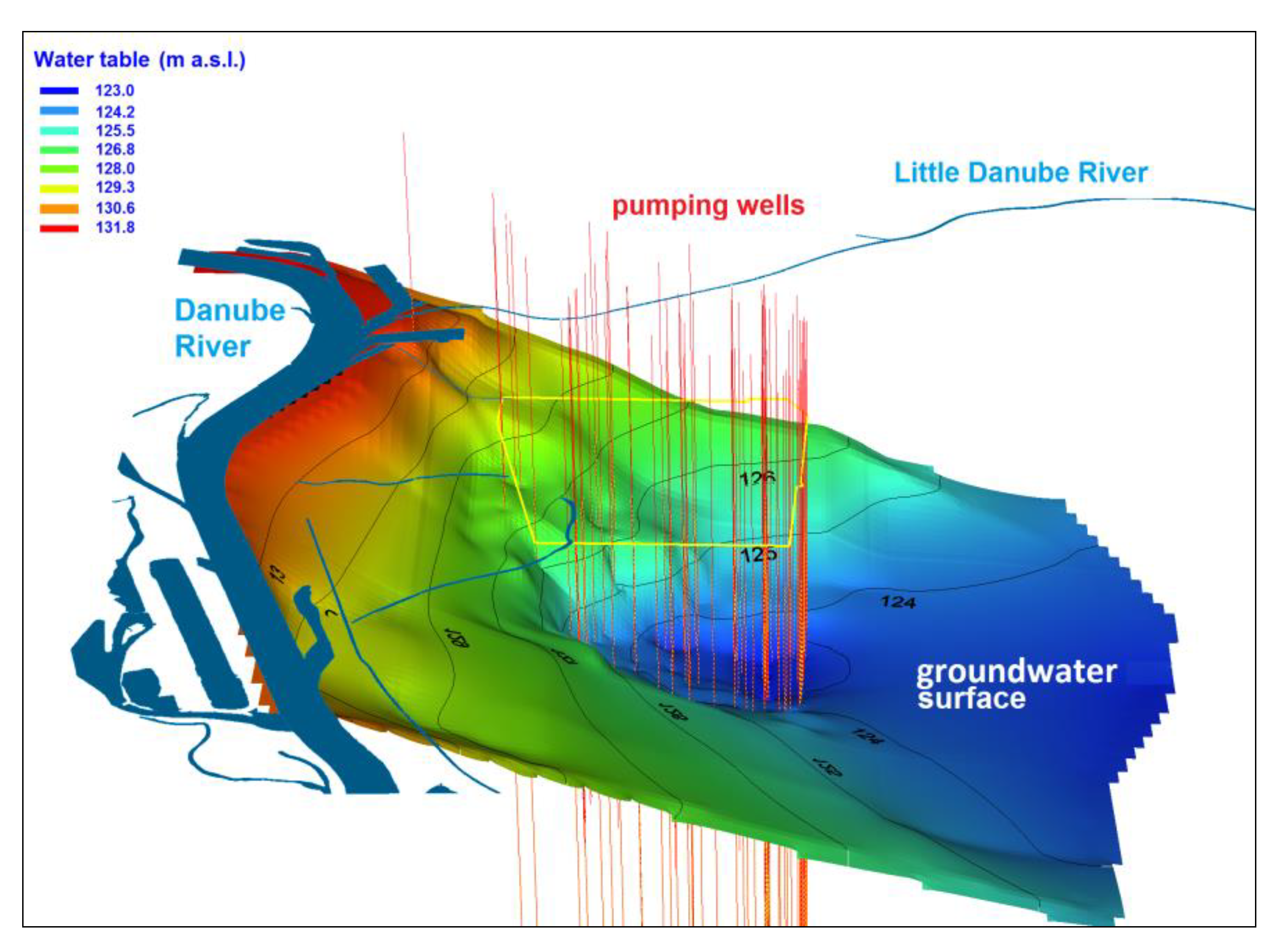
The resulting groundwater table for the V4 variant is depicted in
Figure 9. The groundwater table within all model variants is approximately the same in the main characteristics (GW gradients and flow directions). Differences, however, are in the accurateness of the simulated groundwater level compared to observations at a relatively small scale.
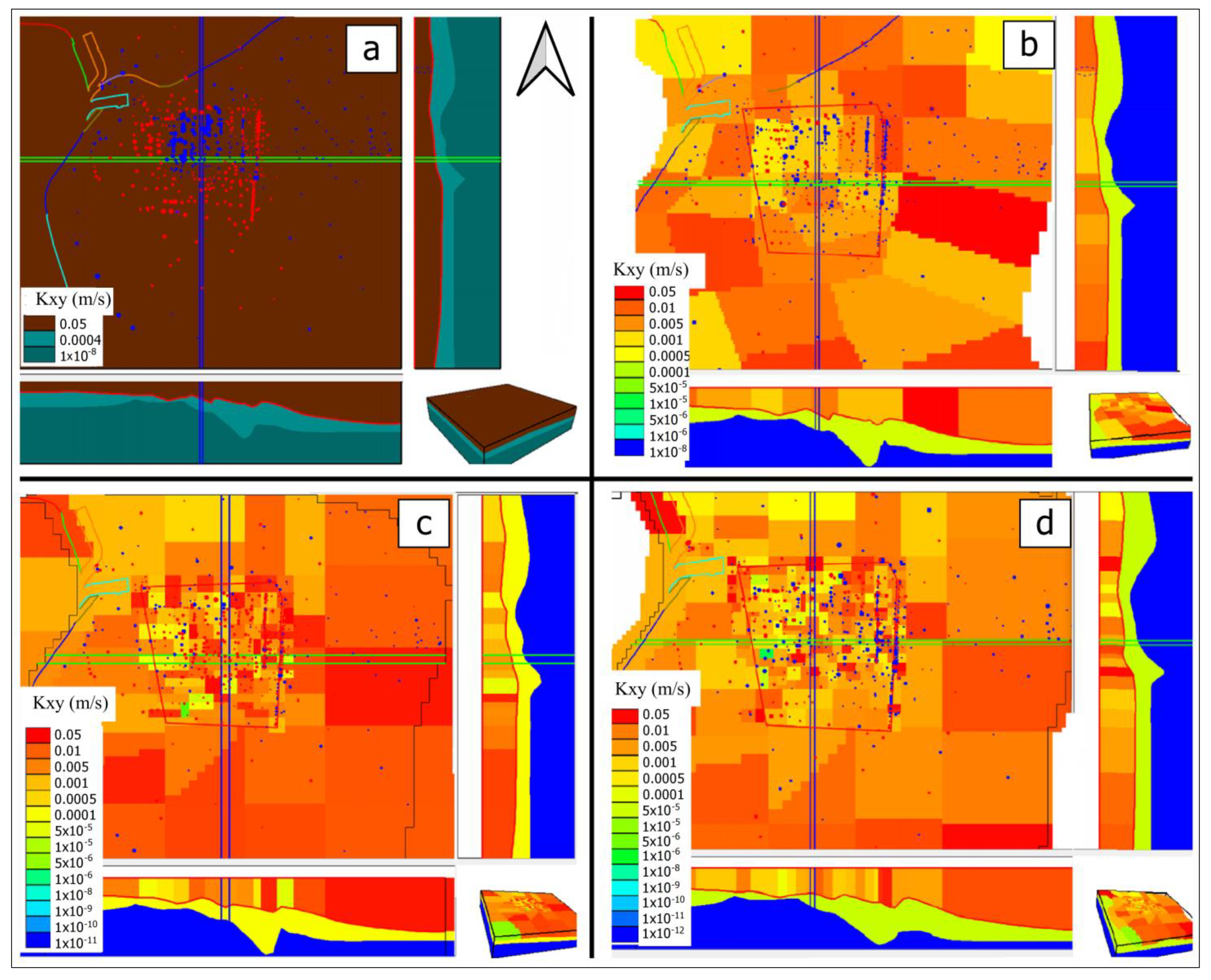
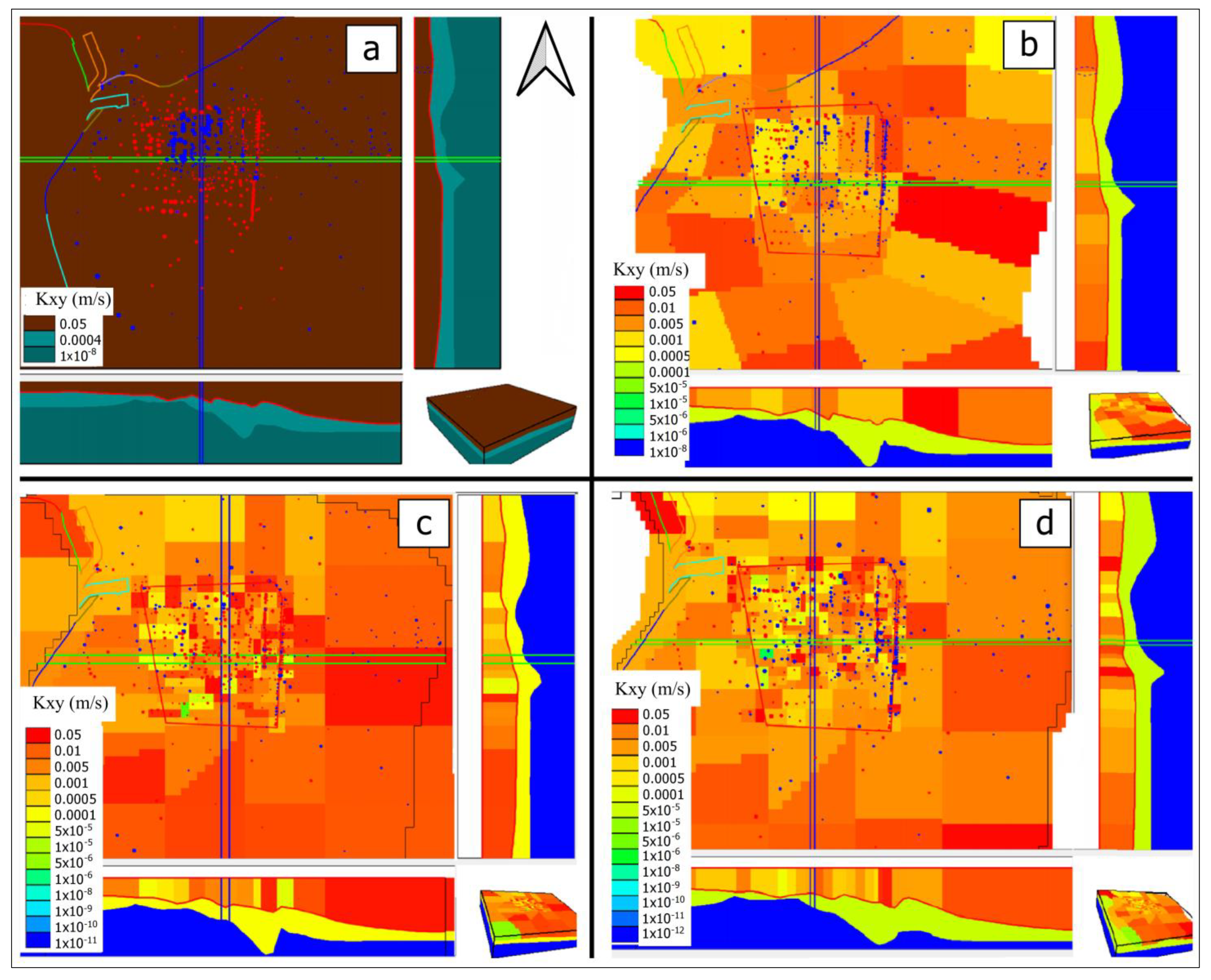
For
V1 calibration, the resulting K values are shown in
Figure 6a. They range from 0.005 m·s
−1 to 1 × 10
−8 m·s
−1. The variant V1 can be characterized as the worst one among all variants in each of the evaluated criteria listed in
Table 2. In the scatter plot of OBS vs. SIM (
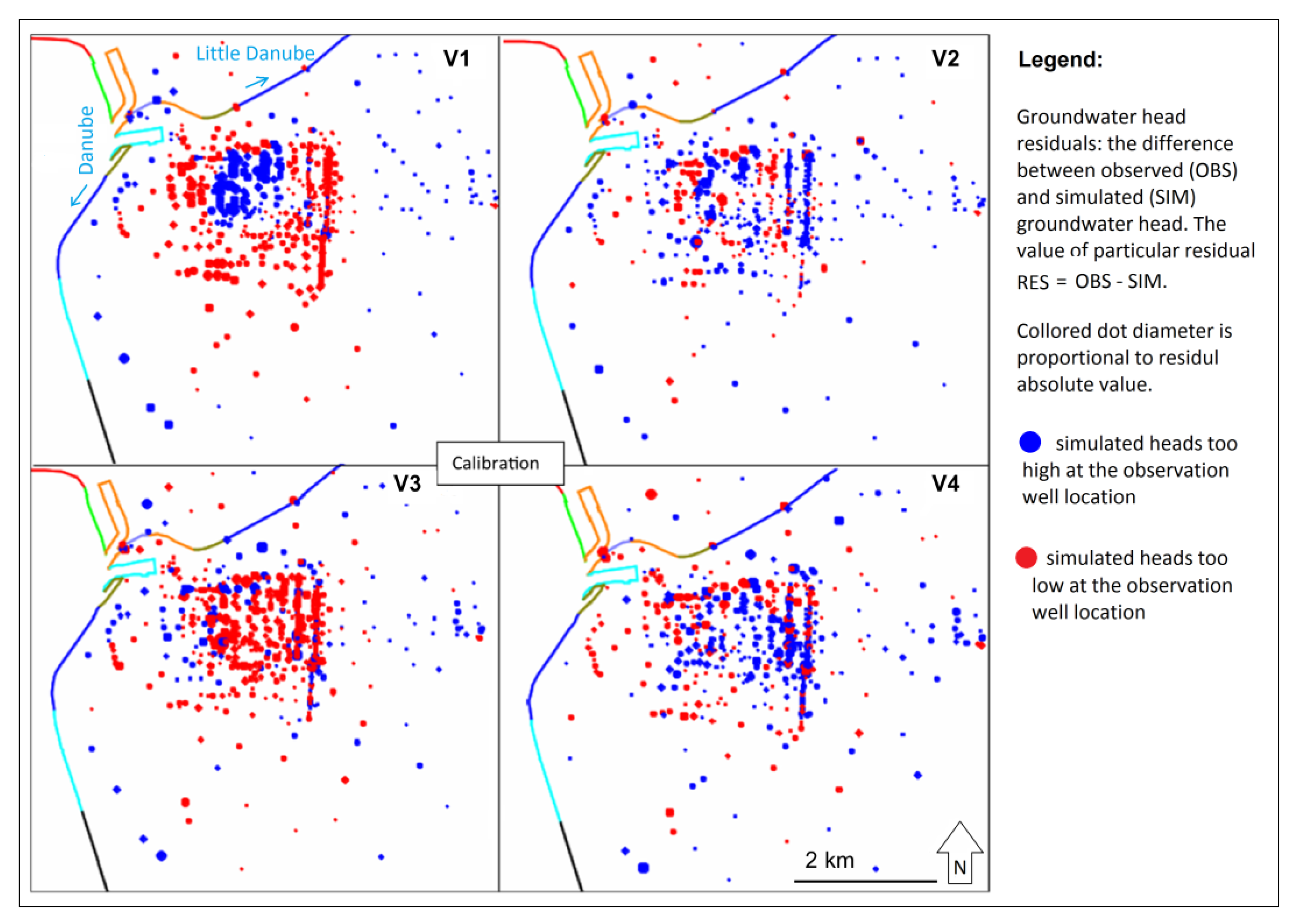
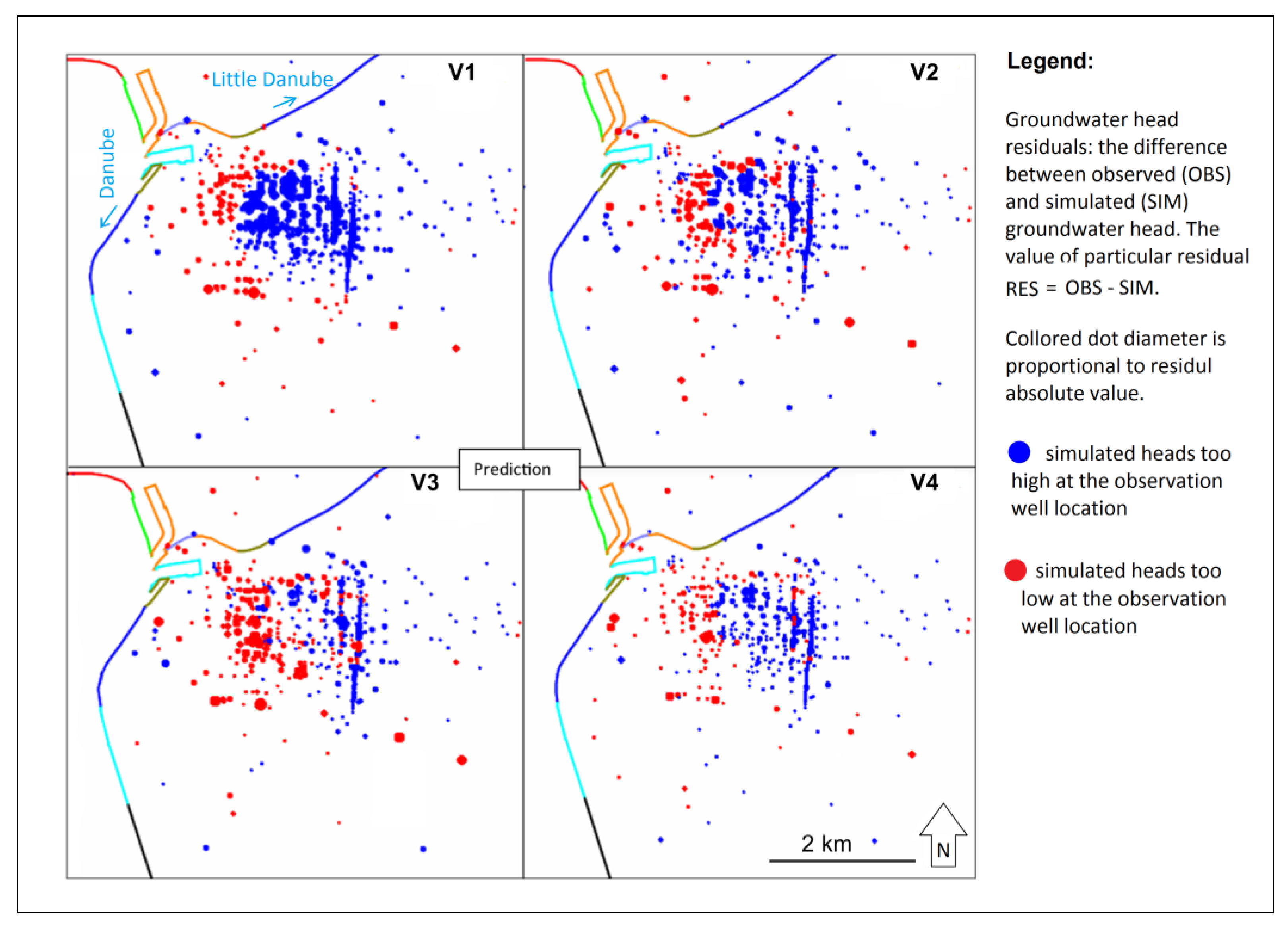
Figure 10), the V1 variant performed relatively poorly within the calibration. The spatial distribution of residuals is not random (
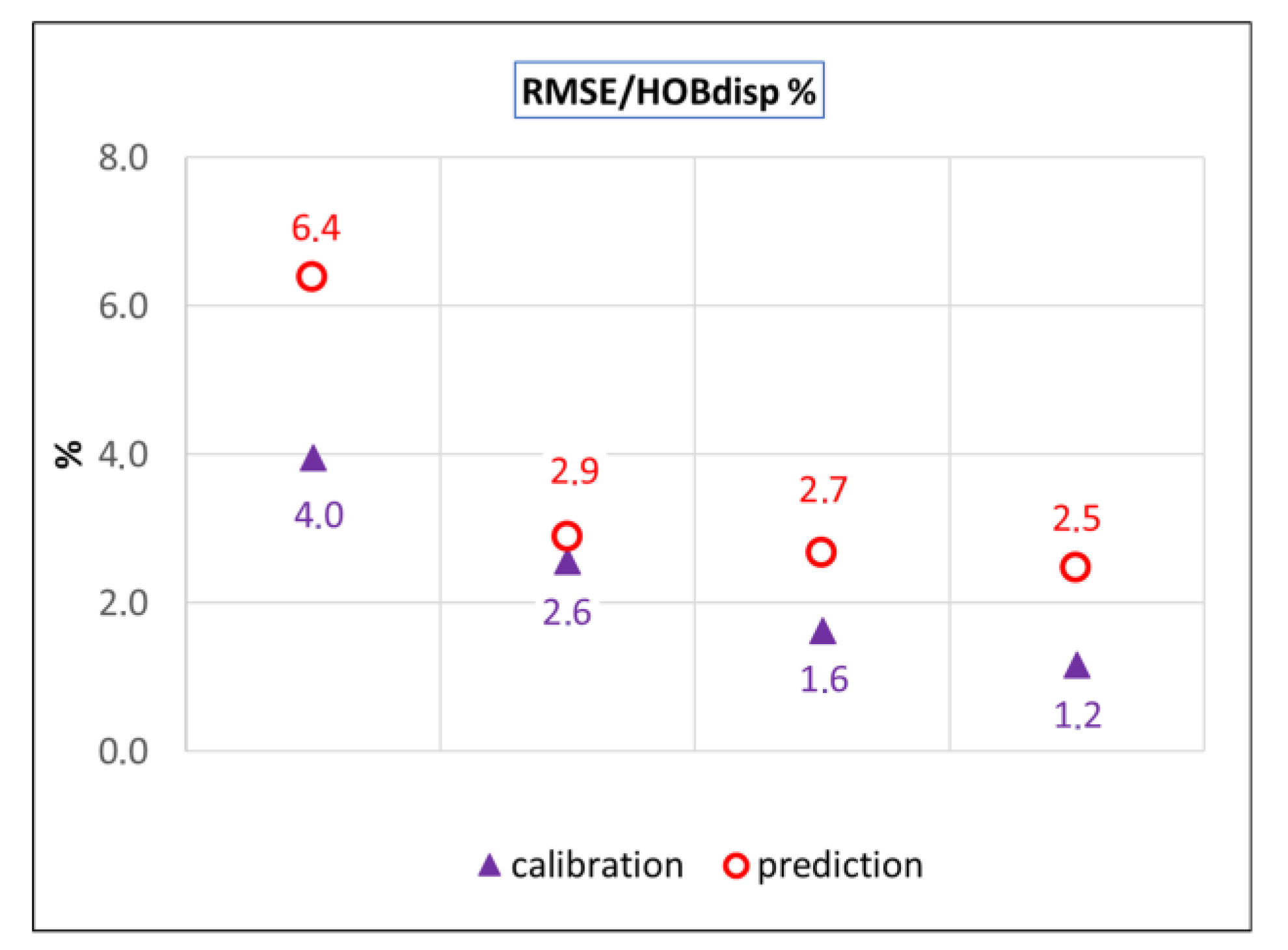
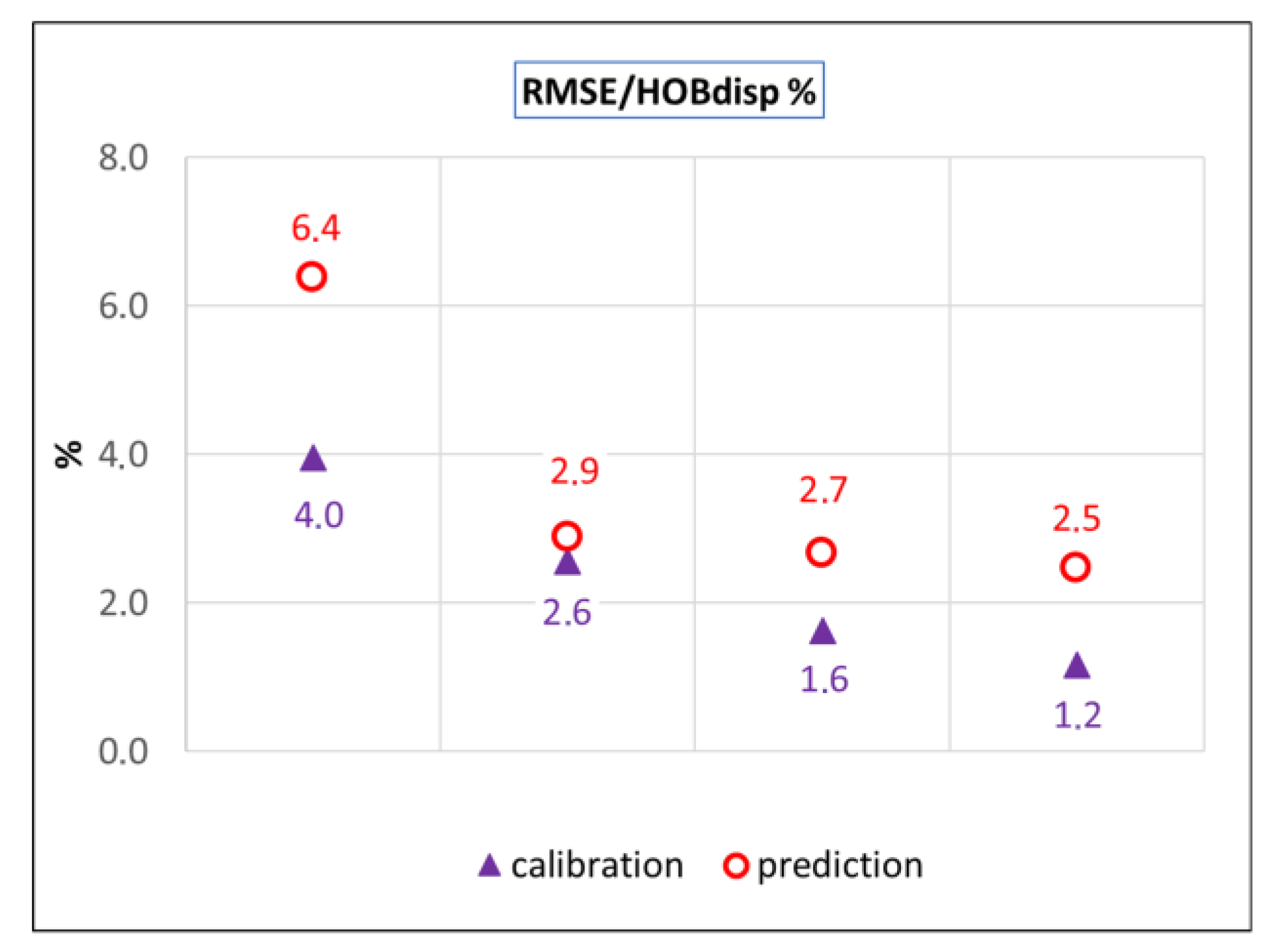
Figure 11) and the ratio of RMSE and OBS dispersion is 4.0% (
Figure 12). The lowest value of AIC, AICc, and BIC criteria (
Table 2) is achieved due to the extremely low number of calibrated parameters. Regarding the mentioned information criteria, the V1 scenario is assumed to provide the best prediction accuracy.
In
V1 prediction performance, the value of all evaluated characteristics, which are introduced in
Table 3, are the worst from all evaluated variants. In the scatterplot of OBS vs. SIM (
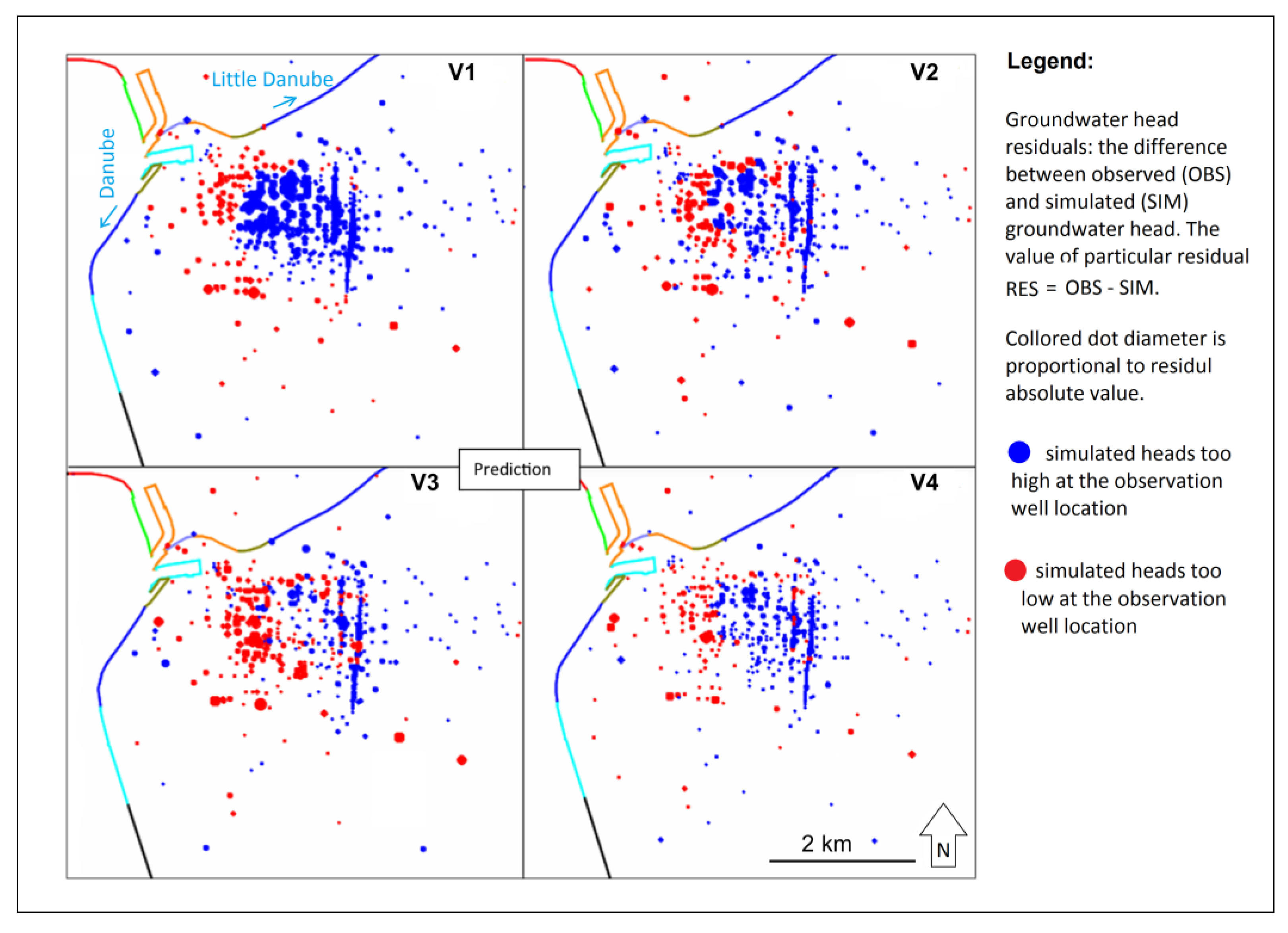
Figure 10), the V1 variant performed relatively poorly within calibration for 2008, and even worse in the prediction for 2019. Residual distribution maps (
Figure 13) show significant grouping of negative and positive residuals. The residual spatial distribution cannot be classified as random. The ratio of RMSE and OBS dispersion is 6.4% (
Table 3,
Figure 12). In all evaluated characteristics, the V1 model performed significantly worse in prediction compared to its calibration fit. Despite the best values of AIC, AICc, and BIC information criteria, the V1 prediction performance is the worst among evaluated scenarios. Considering the results, the V1 variant can be considered an example of conceptual oversimplification.
For
V2 calibration, the resulting distribution of K values is shown in
Figure 6b. They range from 0.05 m·s
−1 to 1 × 10
−8 m·s
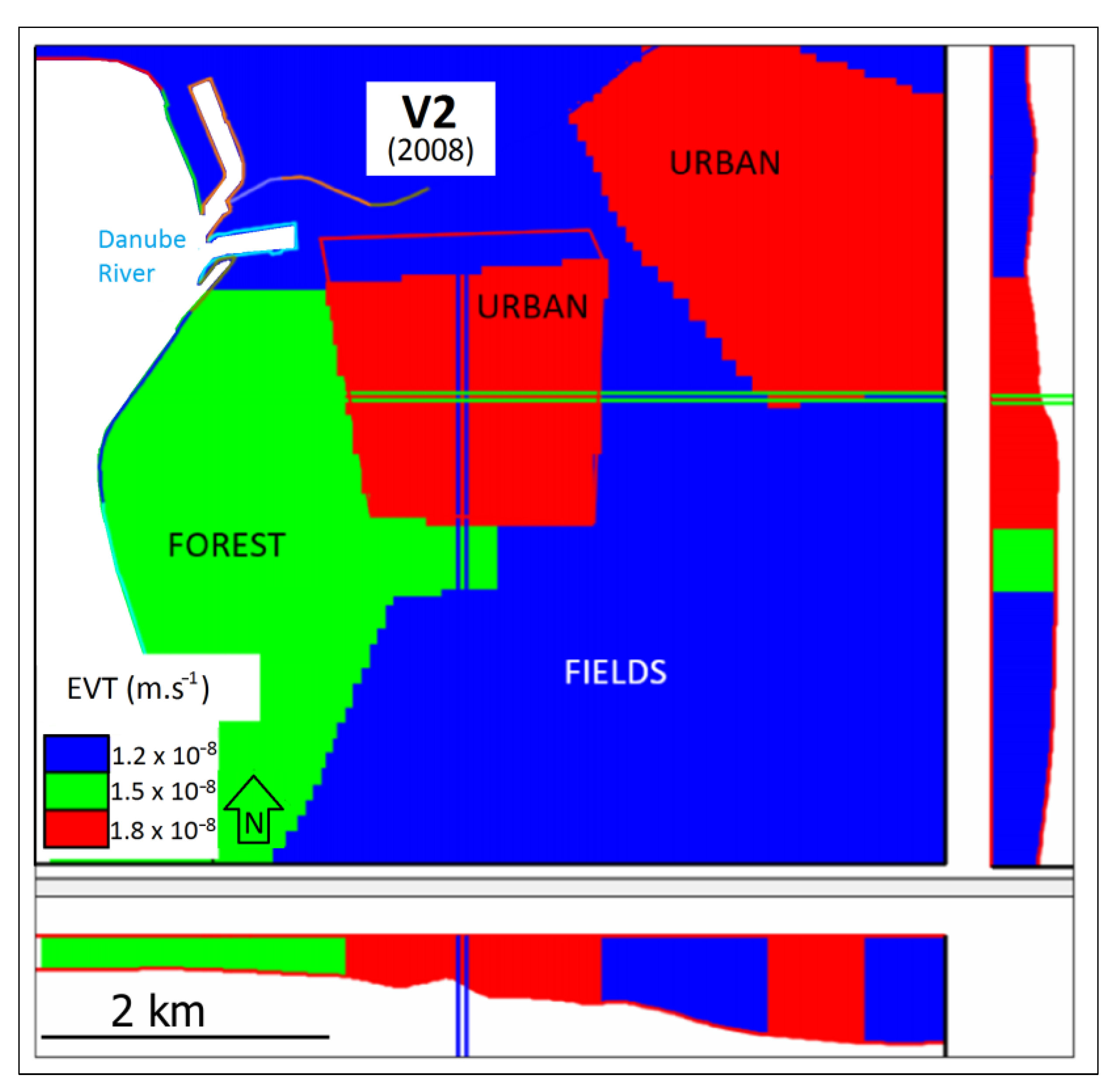
−1. The resulting EVT values are shown in
Figure 7. EVT in urbanized areas reached the highest value of 567 mm·y
−1. Here, it is likely that a significant effect of the interception and drainage of precipitation from the artificial surfaces of the area takes place. In the forests, the EVT reached a calibrated value of 473 mm·y
−1. In agriculture fields, the EVT had the lowest value of 378 mm·y
−1. OF and RMSE values are significantly lower compared to V1 (
Table 2). This result represents a significantly better overall fit of the higher parametrized scenario V2 over V1 within the calibration. In the scatterplot of OBS vs. SIM (
Figure 10), the V2 variant performs significantly better than V1. The spatial distribution of residuals is partly random and partly grouped (
Figure 11). The ratio of RMSE and OBS dispersion is 2.6% (
Figure 12). The relatively favorable values of AIC, AICc, and BIC criteria (
Table 2) are achieved due to the relatively low number of calibrated parameters at a relatively low value of OF. From the V1 and V2 comparison, where the conceptual difference lies in the zonal calibration of the Quaternary aquifer K and zonal calibration of EVT, it can be concluded that the effect of higher parametrization has a significant impact on the overall model fit. Regarding the AIC, AICc, and BIC evaluation results, V2 is the second most successful calibration scenario.
V2 prediction performance is significantly better than the V1 model (
Table 3), but still worse than its calibration fit. This is evident from the scatterplot of OBS vs. SIM (
Figure 10). Residual distribution maps (
Figure 13) show significant grouping of negative and positive residuals. The residual spatial distribution is not random and is worse in the prediction than in the calibration. The ratio of RMSE and OBS dispersion is 2.9%, which is slightly higher than for the calibration (
Figure 12). In all the evaluated characteristics, the V2 model performs worse in prediction compared to its calibration fit.
For
V3 calibration, the resulting distribution of K values is shown in
Figure 6c. They range from 0.05 m·s
−1 to 1 × 10
−11 m·s
−1. The overall improvement in the calibration fit against the V1 and V2 models was indicated by the statistics introduced in
Table 2. In the scatterplot of OBS vs. SIM (
Figure 10), the V3 variant performs slightly better than the V2 variant. The spatial distribution of residuals is still not random (
Figure 11) and is even worse than in the case of the V2 scenario. The V3 solution represents a ratio of RMSE and OBS dispersion of 1.6% (
Table 2,
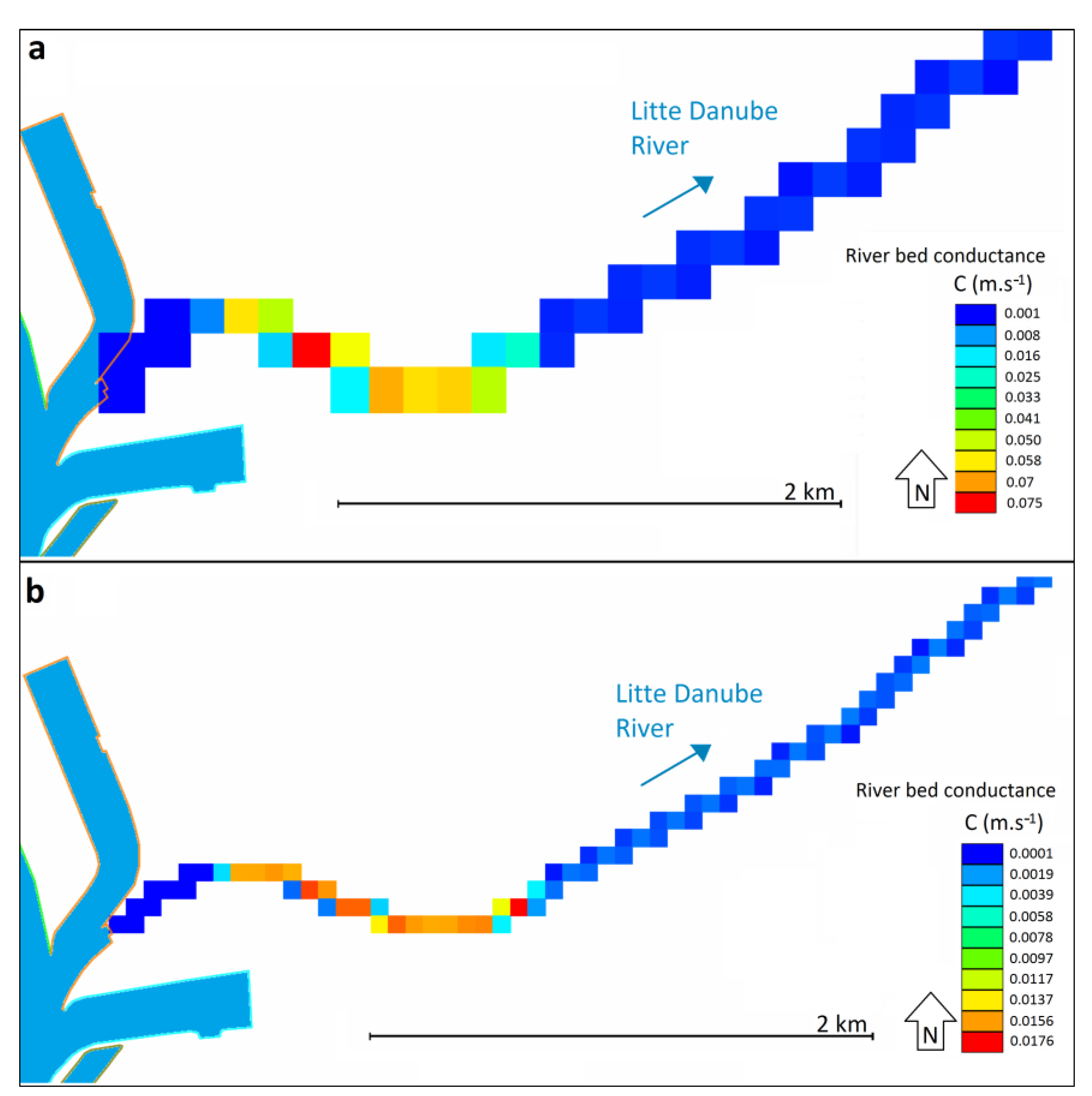
Figure 12). This is the best value among the evaluated variants so far. The calibrated riverbed conductance of the Little Danube River is shown in
Figure 8a. It ranges between the values 0.075 m·s
−1 and 2.12 × 10
−12 m·s
−1. From the AIC, AICc, and BIC evaluation, it follows that the V3 calibration variant is significantly less accurate for prediction than the V2 and V1 scenarios, due to the increased number of parameters and less significant OF value reduction (
Table 2). Despite a reduction in the computation grid density, the value of RMSE, OF, and other related criteria are better than in the previous scenarios. The input precipitation and evapotranspiration difference of 4.76 × 10
−9 m·s
−1 (150 mm·y
−1), which was applied as one parameter for the whole model domain (the initial value is regional, not exact for local areas), has been optimized to 4.6 × 10
−9 m·s
−1 (145 mm·y
−1).
Within the
V3 prediction performance, all evaluated statistics are slightly better than in the case of the V2 scenario; however, from a practical point of view, the prediction accuracies of V2 and V3 are very similar. The prediction performance of V3 is worse than its calibration fit. In the scatter plot of OBS vs. SIM (
Figure 10), V3 performs similar to the V2 variant. Residual distribution maps (
Figure 13) show a significant grouping of negative and positive residuals, as well as in the V2 case. The ratio of RMSE and OBS dispersion is 2.7% (
Figure 12).
For
V4 calibration, the resulting distribution of K values is shown in
Figure 6d. They range from 0.05 m·s
−1 to 1 × 10
−11 m·s
−1. The increased parametrization leads to increased calibration accuracy, which is the best among the evaluated scenarios. The improvement was recorded in all the evaluated characteristics (
Table 2), and the RMSE reaches 0.1 m. In the scatterplot of OBS vs. SIM (
Figure 10), V4 provides the best solution. Spatial distribution of residuals is close to random (
Figure 11). The ratio of RMSE and OBS dispersion is 1.2% (
Table 2,
Figure 12). The resulting riverbed conductance of the Little Danube is shown in
Figure 8b. From the AIC, AICc, and BIC evaluation point of view, the V4 variant is the least probable (
Table 2) due to a significant increase in the number of parameters and a relatively slight decrease in OF and RMSE.
V4 prediction performance is the best, but is similar to V2 and V3 (
Table 3). In the scatterplots of OBS vs. SIM (
Figure 10), the V4 scenario prediction performs the best, as well as in the calibration stage. Residual distribution randomness (
Figure 13) is worse than in V2 and quite similar to V3. The V4 model performs significantly worse in prediction compared to the calibration stage.
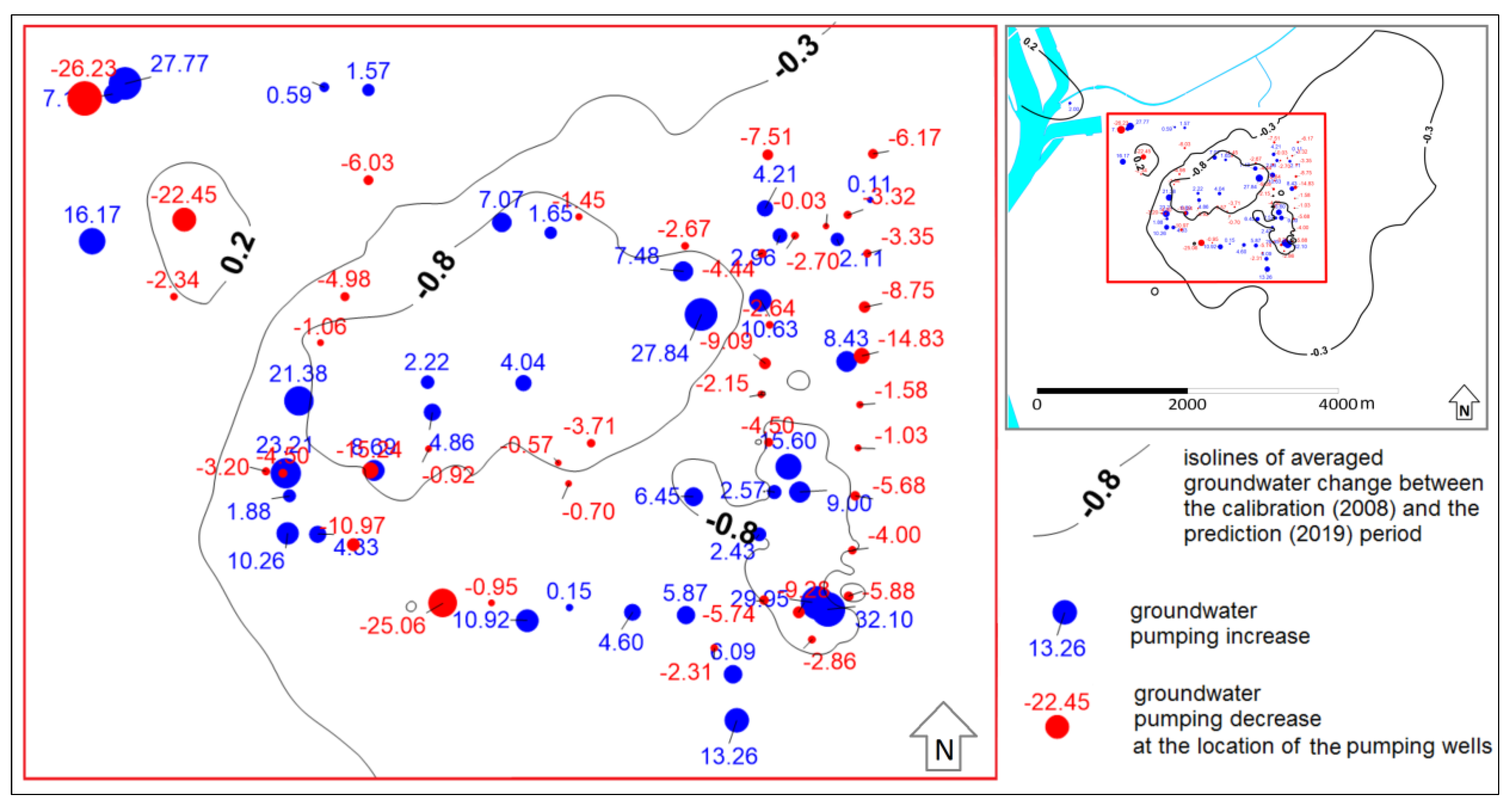
Particularly interesting is the greater improvement of model prediction accuracy between the V1 and V2 models compared to the improvement in model calibration fit between the V1 and V4 models (
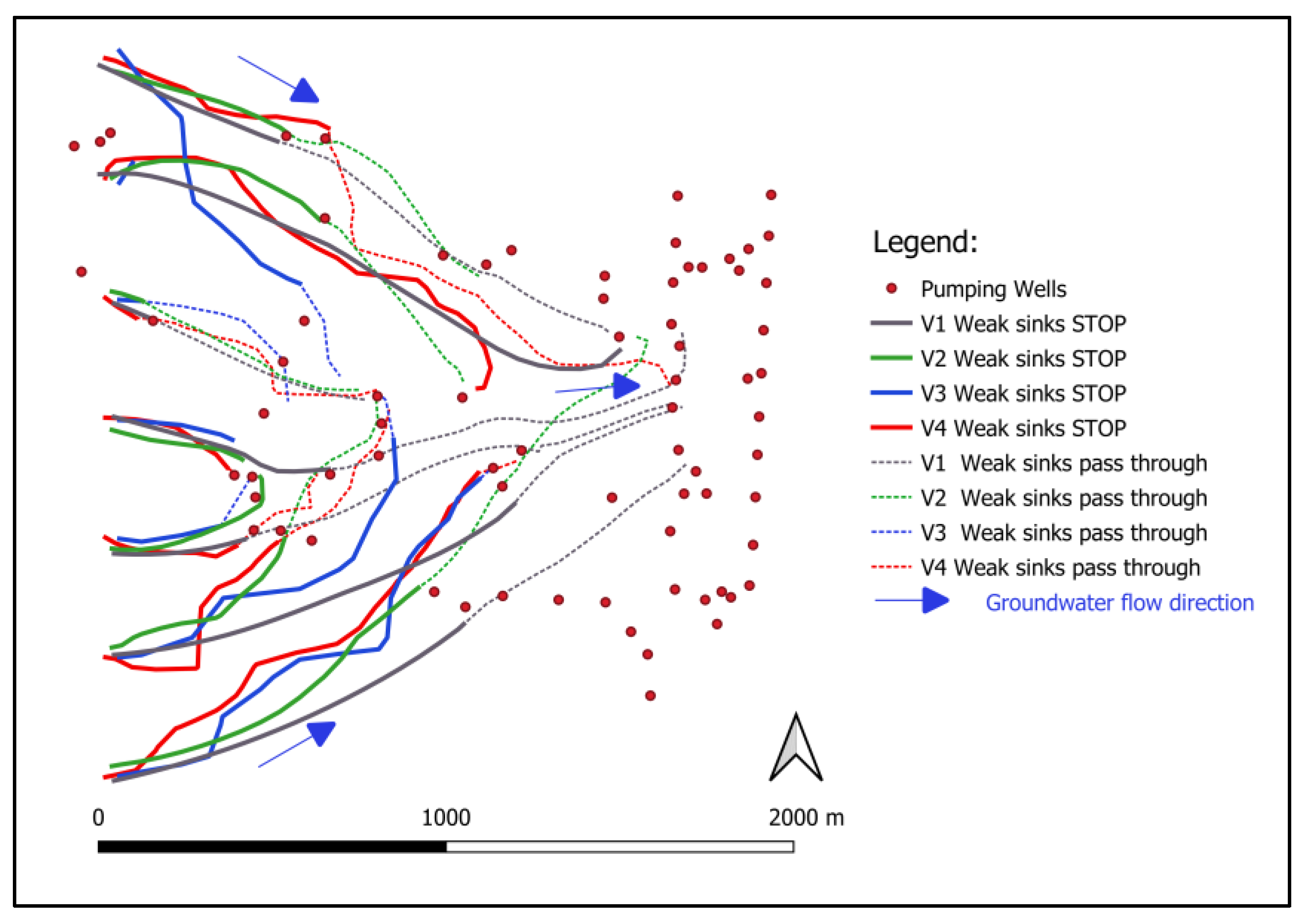
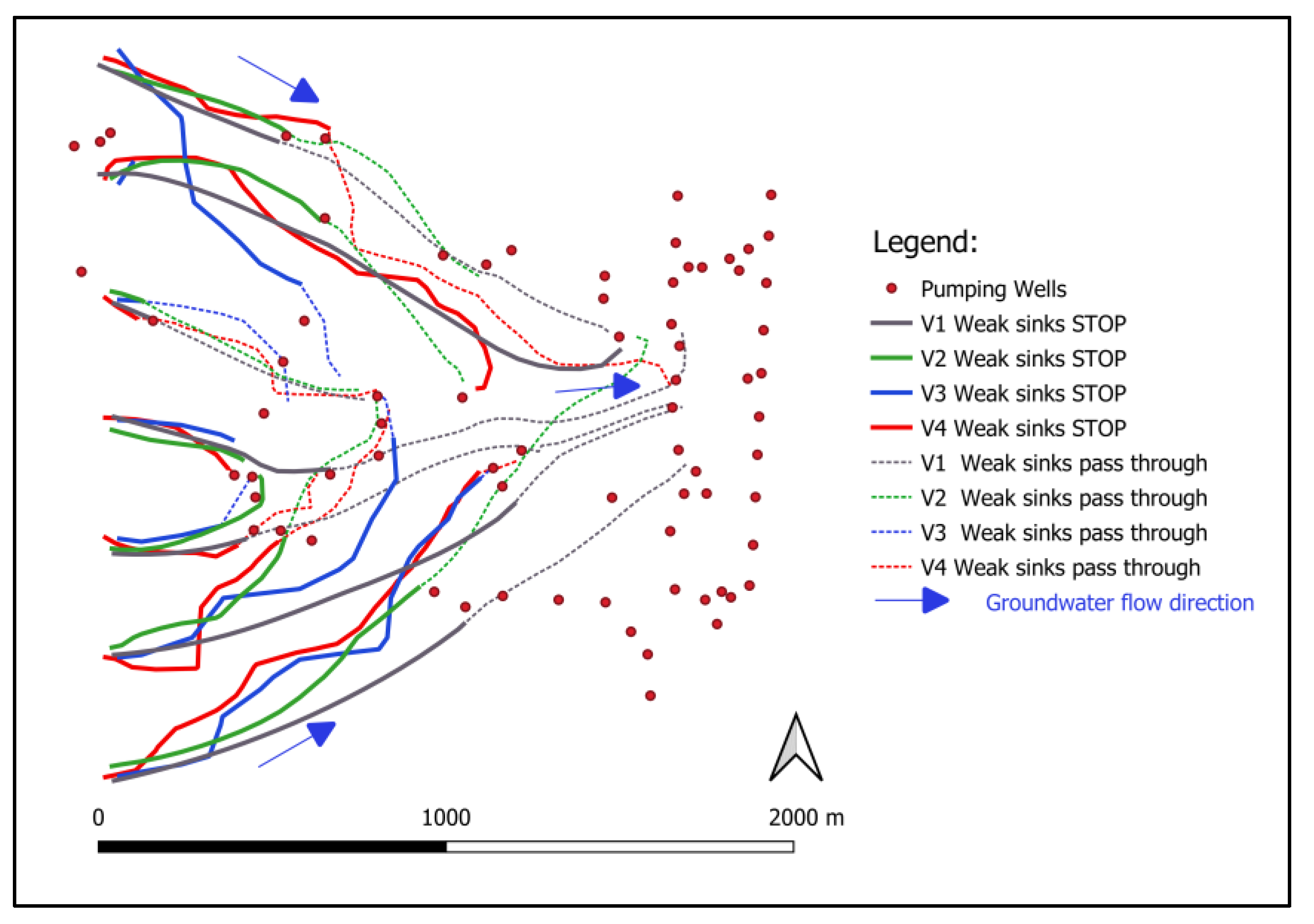
Figure 12). The finer K zonation (V3 and V4 models) overcompensated the absence of EVT zonation (applied only in the V2 model) within the impact on the calibration and prediction accuracy. Flow path analysis (
Figure 14) shows that similarly successful scenarios (by prediction accuracy) can generate different GW pathlines. This is especially the case in the V3 model, in which the relatively low grid density has an impact on the shape of the predicted groundwater pathlines. The V1 model produces the most conservative (if GW is polluted) pathlines, e.g. the virtual particles propagate furthest between the pumping wells in both (stop or pass-through) representations of the “weak sinks” using MODPATH 6 code.
In the calibration process, the difference between particular information criteria values becomes larger with an increasing number of parameters. The most penalizing criterion is the BIC followed by AICc and AIC. At the same time, the overall model fit with observation improves. Within prediction performance, a near constant accuracy of the V2, V3, and V4 models was recorded. This can be an indication of unproper K zonation, which does not represent the real K distribution with a near-constant structural error effect.
4. Discussion
Larger numbers of zones may lead to a better calibration fit with observation, but too many zones may lead to poor parameter estimation [
32]. This also corresponds to the claim of [
33] that no matter which regularization methodology is employed (e.g. zonation), the inevitable consequence of its use is a loss of detail in the calibrated field. This, in turn, can lead to erroneous predictions made by a model that is ‘‘well-calibrated’’. Additionally, the “unknown unknowns” in addition to the “known unknowns” always exist, which deteriorate the prediction accuracy [
34]. Ref. [
35], seeking different model conceptualizations within the Generalized Likelihood Uncertainty Estimation—Bayesian Model Averaging methods (GLUE—MBA), considered any spatial distribution (zonation) of a hydraulic conductivity field obtained through proper calibration as a valid representation of the K field. Since modelers usually know almost nothing about the exact distribution of K, this approach can then be assumed relevant. Ref. [
36] claimed that with the increase in extrapolation, conceptual uncertainty also increases. The author of [
37] in [
38] demonstrated that the values estimated for lumped parameters can only be interpreted as the outcomes of a user-specified averaging process of pertinent system properties. The lumping of parameters (e.g., replacement of a continuous property field by a small number of zones of piecewise properties) introduces a structural error [
38]. From the K-zonation point of view, the more K zones, the closer the resemblance to a continuum and a better calibration and prediction accuracy can be expected. In the current study, the overall calibration fit and real prediction accuracy are consistent with this conclusion.
The imperfection in the presented models may also be due to the temporal structure (measurement frequency) of the observation data and boundary condition data with average values for the calibration period, as well as the various frequencies of GW head measurement for various parts of the model area and lack of detailed information in the RCH and EVT distribution. Moreover, the spatial distribution of head observation points is far from uniform.
In [
13], where the horizontal K was zonally calibrated, the information criterion BIC selected the simplest scenario as the best. This result also corresponds with our results. Ref. [
14] found that the values of the AICc, BIC, and GCV statistics suggest that only the homogeneous model is clearly inferior, revealing that variations in K are important. Ref. [
15] performed zonal calibration of K in which the most complex scenario had the best fit to observation data in the calibration stage. The AIC, AICc, and BIC criteria selected the simplest model as the most probable. These results also correspond with our findings.
The simplest scenario in the presented work can be considered (based on the post-audit of prediction accuracy results) as the oversimplification example. This statement is similar to the conclusion of [
20] that neither very simple nor very complex models are likely to provide the most accurate predictions. However, no increased level of complexity that leads to worse prediction accuracy was found in the presented work. Starting from the V2 variant stage, the build-up of more complex models (V3, V4) resulted in a better fit in calibration but, at the same time, to almost zero improvement in prediction accuracy; thus, from a practical point of view, it can be seen as a meaningless effort.
The principal contribution of the presented study is the given picture of the parametrization influence on calibration fit and on the real prediction accuracy of the models at the study site. Since the hydrogeological measurements have been continually performed at this site for decades, the presented procedure of model prediction accuracy assessment can be repeated for various calibration and prediction time periods to verify or widen the presented results and to obtain more general views. The broader or more specifically focused investigation findings can lead to savings in parametrization efforts within new models and to better future optimization. Especially interesting would be the comparison of the resulting catchment areas of the pumping wells or the whole GWHP system between individual model scenarios and the field measurements. These analyses are crucial for predicting the impact of possible changes (for example, new pumping wells or different pumping rates at existing wells) in GWHP system operation with the resulting system optimization.
5. Conclusions
In this study performed at the Slovnaft site close to Bratislava in southwestern Slovakia contaminated by petroleum products, the calibration fit and prediction accuracy of four model variants with gradually increasing parametrization from the V1 to V4 models were evaluated in the post-audit procedure. The principal factor considered in parametrization was the complexity of K zonation.
In terms of objective function in the calibration process, the best value of 5.8 was recorded in the most parametrized V4 model scenario. Within prediction, the best objective function was reached in the same scenario with the value of 31.4. The objective function improved with increasing parametrization in calibration as well as in the prediction stage. The same development can be seen in all numerical and graphical evaluations performed.
In contrast, the information criteria AIC, AICc, and BIC increased significantly with model parameterization. The “penalization” for the number of parameters here was much more significant than the improvement of the calibration fit. From the performed study, it follows that the prediction accuracy in terms of the calibration fit should be the highest in the V4 model. In terms of the information criteria, the prediction accuracy should be highest in the case of the simplest V1 scenario. The real prediction accuracy assessment revealed that the information criteria provided an inaccurate evaluation.
The residuals’ RMSE to observed head dispersion ratio within the calibration stage reached 4.0%, 2.6%, 1.6%, and 1.2% in the V1, V2, V3, and V4 models, respectively. The same indicator in the prediction stage reached 2.9%, 2.7%, and 2.5% in the V2, V3, and V4 models, respectively. The simplest V1 scenario with the value of 6.4% was significantly worse. The slight prediction improvement from the V2 to the V4 scenario reveals ineffective parametrization in the V3 and the V4 scenarios from the prediction accuracy perspective.
The procedure of manual refinement of K-field zonation based on the groundwater level residuals’ distribution reveals a high efficiency for obtaining a better fit within the model calibration. However, within prediction performance, this procedure was not effective after an intermediate level of parametrization (V2 scenario). The prediction accuracy remained almost the same in more parametrized scenarios (V3 and V4 models). From the perspective of all related circumstances summarized as calibration effort vs. accuracy of prediction, the V2 scenario with a medium level of parametrization can be considered as the best solution of the study.
Flow path analysis showed that similarly successful scenarios (based on their prediction accuracy) can generate different groundwater pathlines. This is especially so in the case of the V3 model, in which the lower grid density has an impact on the shape of predicted groundwater pathlines. The simplest model scenario produces the most conservative outcome with respect to pathline propagation and possible spreading of groundwater contamination.
Based on the study results, there can be the following recommendations:
- -
the K-field zonation based on groundwater level residuals’ distribution can be valuable in the calibration process if there are only limited K data from the field survey;
- -
higher parametrization does not necessarily lead to a more effective solution regarding prediction accuracy and several variants of a solution with continual post-audit evaluation should be used whenever possible;
- -
different model variants with similar prediction accuracy in terms of groundwater level fit can produce different groundwater pathlines; and, finally,
- -
the information criteria AIC, AICc, and BIC can be inaccurate in the evaluation of model prediction accuracy.

 ,
, 








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}