1. Introduction
Snow cover monitoring with fine spatial–temporal resolution has important guiding significance for watershed-scale snow water resource management and sustainable utilization, natural disaster assessment, and early warning in pastoral areas. Spaceborne optical and microwave sensors are important platforms for snow monitoring. However, an optical remote sensing image is sensitive to cloud cover, and it is not possible to obtain information of snow cover under clouds. Exploring the cloud removal algorithm has great significance for restoring the snow condition under the cloud [
1].
A large number of studies have shown that snow cover monitoring using optical remote sensing performs with high accuracy. The principle is that snow shows high reflectivity in visible and infrared bands but low reflectivity in the shortwave infrared (SWIR), which is different from other land covers [
2]. The normalized difference snow index (NDSI) distinguishes snow pixels by measuring the relative magnitude of the reflectance difference between the visible band (GREEN) and SWIR. The moderate resolution imaging spectroradiometer (MODIS) mounted on Terra and Aqua satellites has provided worldwide stable daily snow cover data for nearly 20 years with its excellent spatial–temporal resolution and good stability [
3,
4]. However, the similar spectral reflection characteristics of snow and cloud in the visible and near-infrared bands, especially the similar spectral response of cirrus cloud and snow in the whole infrared spectrum, results in the misjudgment of snow and cloud [
5]. In addition, there are still a large number of cloud pixels in the daily snow cover data of MODIS, which affects the spatial scope of snow monitoring, the accuracy of snow cover mapping, and the temporal resolution of snow, and limits the further application of optical remote sensing snowpack products. Therefore, many scholars have carried out a lot of research on cloud removal of snow remote sensing to improve the temporal resolution of snow cover [
6]. At present, four major methods of cloud removal from snow cover using satellite remote sensing are summarized, the first is temporal filtering-based cloud removal, the second is spatial filtering-based cloud removal, the third is the cloud removal algorithm based on multi-sensor fusion, and the fourth is the cloud removal using snowline elevation.
Gafuov and Bárdossy proposed a cloud removal algorithm from MODIS snow cover products based on temporal filtering [
7], which assumes that the snow will not melt quickly in a short time, but the clouds will move quickly. By synthesizing the snow products from Terra and Aqua, the moving clouds are filtered to maximize the snow cover extent. Cloud removal based on temporal filtering can be deduced and calculated without other satellite or ground auxiliary data. For areas lacking multi-source satellite data or relevant geographical parameters, the real snow cover extent can also be calculated.
The aforementioned studies have proved that selecting the appropriate time window and synthetic days to conduct temporal filtering cloud removal can obtain snow cover recognition results with high accuracy, but the step of “Filtering cloud removal during snow accumulation and melting” will cause many false or missed judgments of snow pixels that are fragmented in time series, thus reducing the accuracy of snow cover recognition. Furthermore, the appropriate time window and synthetic days are uncertain and different for different regions and periods. Therefore, large errors will occur when this method is applied to regions with a wide spatial range, strong snow heterogeneity, and long-time series snow data sets. There will be large errors, and the applicability of the algorithm will be greatly reduced. The core of the spatial filtering cloud removal method is to select cloud-free pixels in the spatial neighborhood to estimate the ground coverage under the cloud. In the spatial filtering cloud removal strategy proposed by Gafurov and Bárdossy, there are the “Near four-pixel method”, “Near eight-pixel method”, and other methods. The cloud removal algorithm based on spatial filtering can be deduced and calculated without other satellite data. Simultaneously, in practical application, although the amount of cloud removal of this algorithm is less, it also maintains the lowest error.
The cloud removal method based on temporal filtering and spatial filtering mainly uses the temporal and spatial variation of snow cover of the same optical remote sensor to extract the ground information under the cloud. In contrast, another cloud removal method based on multi-source data fusion uses complementary information between different data sources, such as optical remote sensing observation, microwave remote sensing observation, and station observation [
8,
9,
10]. But the distribution and number of meteorological stations limit the prediction ability of this method for snow reconstruction. However, the above research can only qualitatively infer the distribution of snow cover under clouds, lacking quantitative characterization of snow cover parameters under clouds.
In recent years, researchers have been striving to use spatiotemporal information for one-step cloud removal algorithm research. Xia et al. [
11] introduced variational interpolation to construct a three-dimensional implicit function containing five consecutive day data, which can easily obtain the shape of the snow cover boundary. The cloud removal method proposed by Poggio and Gimona [
12] is a combination of a generalized additive model (GAM) and a geostatistical spatiotemporal model. The multidimensional spatiotemporal GAM models binary variables, and geostatistical kriging methods are used to explain spatial details. This method utilizes auxiliary data such as surface temperature, land cover, and soil type to effectively simulate the spatiotemporal correlation of snow cover and can achieve satisfactory reconstruction accuracy even under high cloud cover. The adaptive spatiotemporal weighting method [
13] estimates the snow cover of cloud pixels by combining adaptive weights based on the probability of snow cover in space and time, which can completely remove the cloud layer. Huang et al. [
14] established a hidden Markov random field framework to remove cloud pixels from MODIS binary snow cover data. This method effectively utilizes spatiotemporal information and achieves an overall accuracy of 88.0% for the restored snow cover range under the cloud. Additionally, the conditional probability interpolation method [
8] can effectively calculate the conditional probability of snow pixels being covered by clouds and meteorological data to remove clouds, but this method has limited capacity for removing clouds in areas with few in situ observations. Furthermore, Chen [
15] proposes a conditional probability interpolation method based on a space–time cube (STCPI), which takes the conditional probability as the weight of the space–time neighborhood pixels to calculate the snow probability of the cloud pixels, and then the snow condition of the cloud pixels can be recovered by the snow probability. However, existing one-step cloud removal algorithms that utilize spatiotemporal information have significant time computational costs and require multiple auxiliary data, which to some extent limits the application of the algorithm. In addition, the progress of machine learning and deep learning technology has also led to new developments in remote sensing snow cover mapping. Luan et al. proposed an m-day dynamic training strategy, which divides a long-term snow cover mapping task into multiple short-term tasks with consecutive m days and reduces the problems caused by changes in snow cover over time. This strategy is applied to random forest models for binary snow cover (BSC) mapping and fractional snow cover (FSC) mapping, achieving higher accuracy than other training strategies [
16]. A new algorithm based on a machine learning method was designed to improve FSC retrieval from brightness temperature, considering other auxiliary information, including soil property, land cover, geography information, and the overall accuracy of the above method reached 0.88 [
17]. Guo [
18] trained the DeepLap v3+ model using a transfer learning strategy to overcome the computational time and resource consumption of deep learning models. The feasibility and effectiveness of automatically extracting snow cover were demonstrated on high-resolution remote sensing images. Hu trained random forest models using combinations of multispectral bands and normalized difference indices and generated sub-meter and meter-level snow maps based on very-high-resolution images [
19]. Liu introduced a highly accurate snow map acquired by unmanned aerial vehicles as a reference to machine learning models, which significantly improved the MODIS fractional snow cover mapping accuracy [
20]. Yang et al. are committed to designing a cloud snow recognition model based on a lightweight feature map attention network (Lw-fmaNet) to ensure the performance and accuracy of the cloud snow recognition model [
21].
We propose a new strategy for reconstructing snow cover under clouds to achieve the following objectives: (a) exploring the correlation between snow particle size and geographic and meteorological information at the watershed scale, and (b) improving the temporal resolution of snow cover at the watershed scale by filling gaps in SGS and achieving snow mapping for the entire watershed. The organization of the entire article is as follows. After introducing the study area and data preprocessing in
Section 2, the methodology for cloud removal and snow cover reconstruction is expounded in
Section 3. The results of accuracy verification and mapping will be presented in
Section 4. Ultimately, a summary of the research will be described in
Section 5.
3. Methodology
3.1. Construction of Space–Time Extra Trees Model
Among the current mainstream machine learning algorithms, the random forest (RF) has outstanding performance in both regression and classification. A RF can effectively handle thousands of input samples with high-dimensional features without dimensionality reduction. It is also able to evaluate the importance of each input feature on the objective function. In the algorithm execution, an unbiased estimate of the internally generated error is obtained and a high tolerance for certain missing data is obtained. However, extra trees (ETs) make full use of all samples compared to the Bagging strategy applied with the RF, only the features are randomly selected due to the random splitting, leading to a better regression result than the RF [
36]. Also, a RF is used to get the best splitting attributes within a random subset, but ET is used to get the splitting values completely randomly in the global data.
An ET is an integrated machine-learning method developed from an RF [
37]. The algorithm is denoted by
, where
is the final classifier model,
is the sample set, and
is the number of base classifiers. Each classifier produces a prediction based on the input samples. The execution steps of the ET are shown below [
38]:
Step 1: Sample selection: Given the original data sample set , the number of samples , and the number of features . In the ET classification model, each base classifier is trained using the full set of samples.
Step 2: Feature selection: The Base classifier is generated from the Classification and Regression Tree (CART) decision tree. At each node splitting, m features are randomly selected from W features, the optimal attribute is selected for each node for node splitting, and the splitting process is not pruned. Step 2 is performed iteratively on the subset of data generated by splitting until a decision tree is generated.
Step 3: Construction of additional trees: Create additional trees and repeat Steps 1 and 2 for V times to generate V decision trees and ET.
Step 4: Regression of result: Test results are generated from test samples based on designed ET, and the prediction results of all basic classifiers are counted. The final result is determined according to the average value of all decision tree outputs.
ET is the random bifurcation of rows and columns of data, which will lead to the generalization ability of ET being stronger than that of RF. At the same time, each regression tree in the ET makes full use of all the training samples and randomly selects the bifurcation attributes on the node bifurcation, which enhances the randomness of the node splitting of the base classifier.
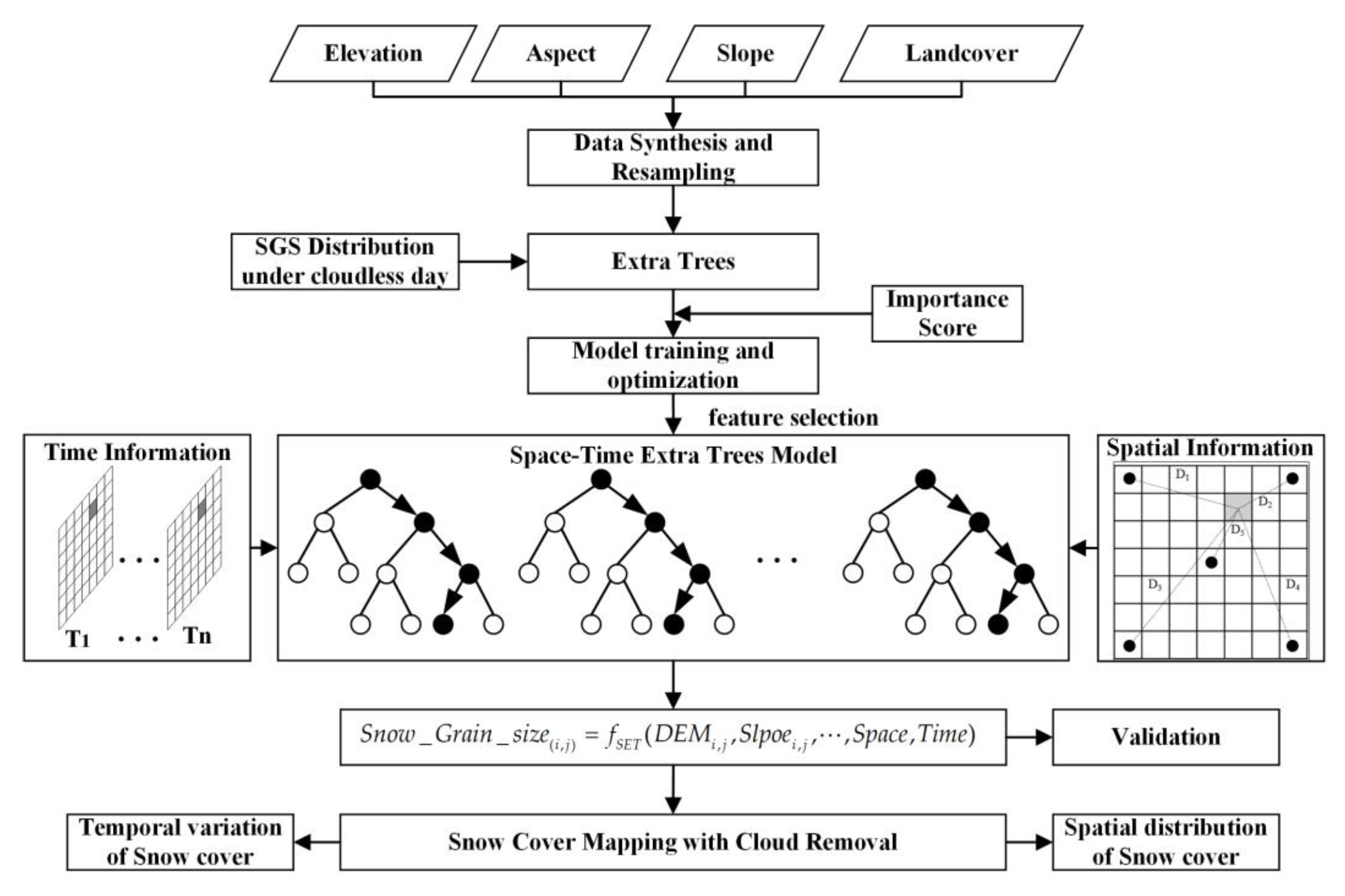
In this study, an SGS filling model based on ET is constructed to implement the reconstruction of snow cover under clouds at the watershed scale, as shown in
Figure 3. Geographic elements such as altitude, slope, aspect, and land cover are resampled to 500 m resolution using nearest-neighbor sampling technology as input, and the SGS under a clear sky is used as a sample label. The nonlinear mapping relationship between multi-source data is constructed based on ET.
In the process of model training, importance scores given by the ET can help select the input factors with high importance, optimize the feature selection process of the model, reduce the amount of parameter calculation, and overcome the overfitting caused by parameter redundancy. Simultaneously, considering the spatial distribution information characterizing the SGS and the variation with time, the input data of two-dimensional characterized temporal information and two-dimensional characterized spatial information are designed when training the ET model, and the data about the spatial and temporal information are elaborated as shown in
Section 3.2.
3.2. Design of Temporal and Spatial Dimensional Information
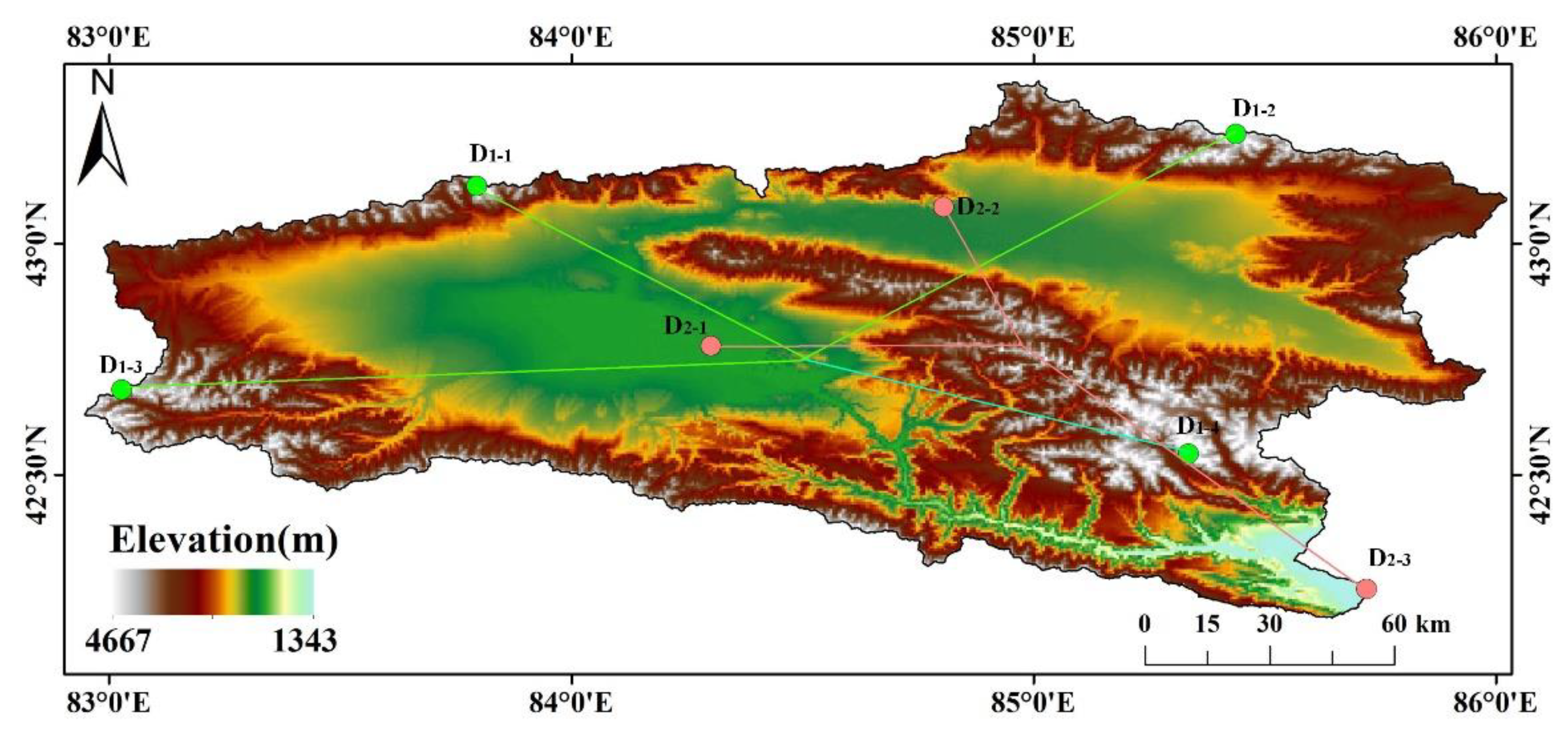
In many previous studies, especially for parameter retrieval at large spatial scales, latitude and longitude were introduced into the model as spatial information parameters to characterize the position of a grid in the whole region. However, it is difficult to accurately quantify the spatial information using latitude and longitude because of the proximity and fine resolution of the grids in the watershed-scale parameter retrieval. In this study, the KRB features a topographic landscape with mountains surrounding the basin, and the Elpin Mountains divide the basin into the Big Urdus Basin and Small Urdus Basins on the east and west sides, forming a typical geomorphic feature of mountains surrounding and blocking the basin. Wei et al. calculated the Haversine distance from each rater point to the upper left corner of the rectangular study area as
, and analogously, the distance to the upper right corner as
, the distance to the lower left corner as
, the distance to the lower right corner as
, and the distance to the center of the matrix noted as
, to improve the representation of the model for spatial information [
39]. However, the Haversine distance is more suitable for the expression of large-scale spatial information. The study area of the KRB is characterized by high elevation around and low elevation in the middle. We divided the KRB into four quadrants and selected the highest elevation positions of the mountains in four directions in the basin, which are located at (83.7943° E, 43.12466° N), (85.43821° E, 43.23695° N), (83.02624° E, 42.68449° N), and (85.33491° E, 42.54525° N). The Euclidean distance from each grid to the four highest elevation positions was calculated and denoted as
,
,
, and
, respectively.
characterizes the weighted sum of each grid to the highest elevation position in the watershed, as shown by the green line in
Figure 4.
Following a similar idea, the lowest elevation positions in Big Urdus Basin, Small Urdus Basin, and Yanqi Basin, located at (84.30185° E, 42.77881° N), (84.80490° E, 43.07975° N), and (85.72118° E, 42.2533° N), respectively, were selected, and the Euclidean distances from each grid to the lowest positions were calculated and denoted as
,
, and
.
characterizes the weighted sum of each grid to the lowest elevation position in the watershed, as shown by the pink line in
Figure 4. The aforementioned two data
and
are constructed to improve the model’s representation of spatial information.
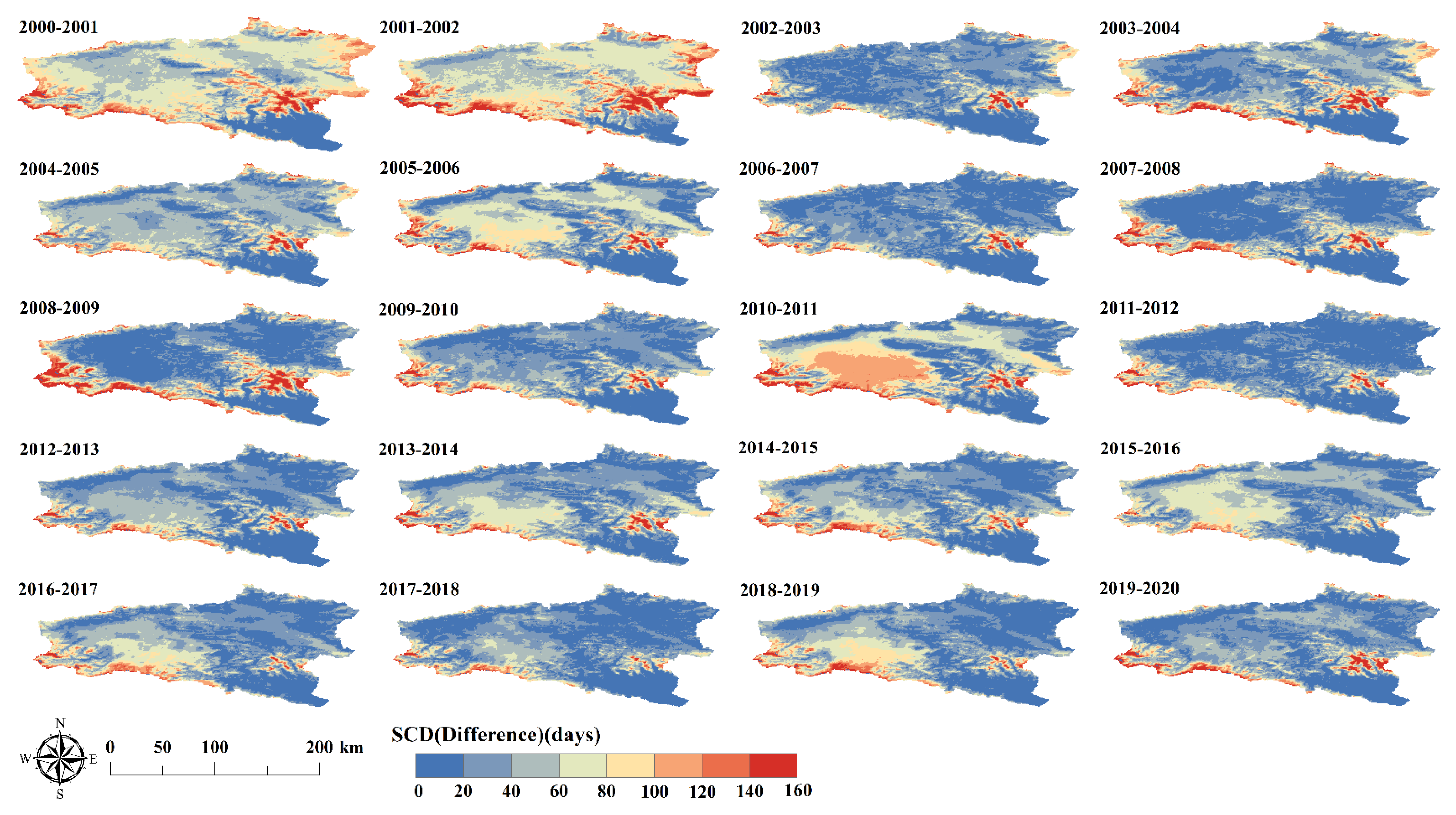
Theoretically, the hydrological year is based on the Earth’s hydrological cycle, which begins at the point of return of runoff, which is usually the beginning of the flood season and the end of the dry season. There is some variability in the start and end times in different regions and between years. In the research of snowpack phenology, the hydrological year can also be defined by using the day of onset of snowpack accumulation and the day of final melt as a boundary [
40]. In this study, a hydrological year from 1 Sept to 31 Aug of the following year was delineated, taking into account the snowpack characteristics and the characteristics of the study area. The hydrological year is divided into four seasons: spring (March to May), summer (June to August), autumn (September to November), and winter (December to February). The snow cover days (SCDs) of the hydrological year in which the single-view data are located are used as one-dimensional, temporal information, and the SCDs characterize the number of days a grid is covered by snow in a hydrological year. Areas with high SCDs generally have lower temperatures, more snowfall, and more abrupt variability in SGS.
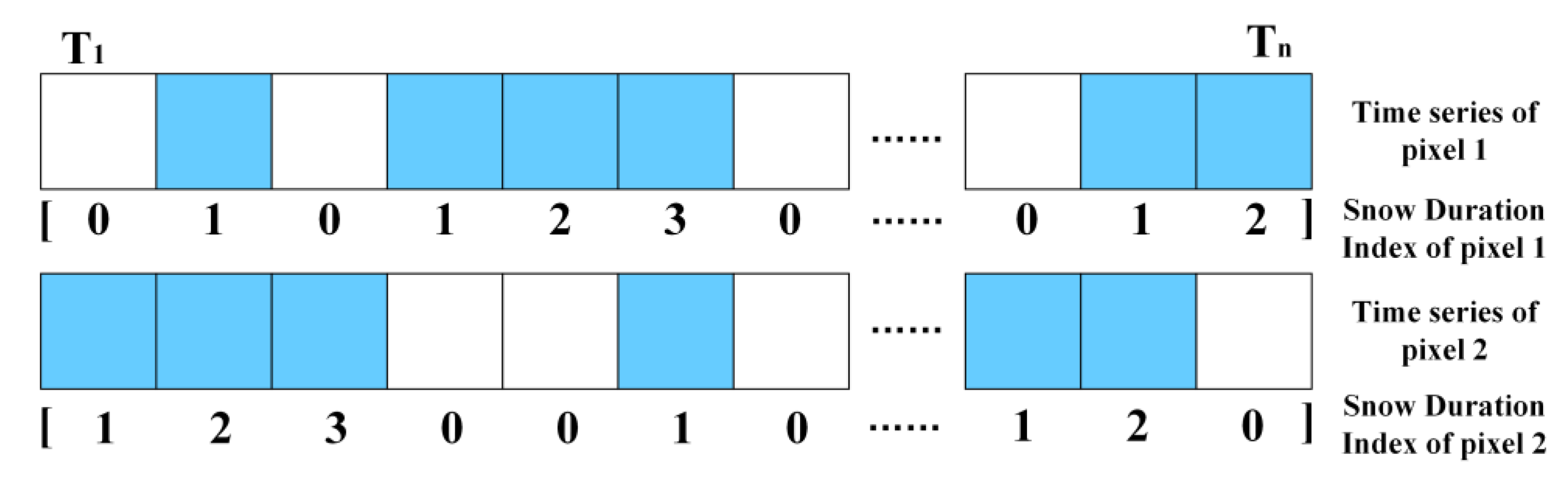
The principle of the second-dimensional temporal information construction is as follows: the grain size of new snow is tiny when in contact with the ground, and the distribution of its grain size shows obvious distribution characteristics that change with altitude and slope. Therefore, the second-dimensional data characterizes the number of consecutive days with snow cover (Snow Duration Index, SDI) at the current moment of a grid, with daily resolution. Compared with the SCDs, the SDI can better reflect the snow status at the current moment. As shown in
Figure 5, it represents the state presented by a grid on the time series, where white indicates a snow-free grid and blue indicates a snow grid. Based on the duration of the presence of snow on the time series, the SDI constructed from the 1st grid is
, the SDI constructed from the 2nd grid is
, the 1, 2, 3, and 4 in arrays indicate that the snow has existed for 1, 2, 3, and 4 days, respectively, at the current moment.
3.3. Applicability Evaluation and Factor Optimization of the Model
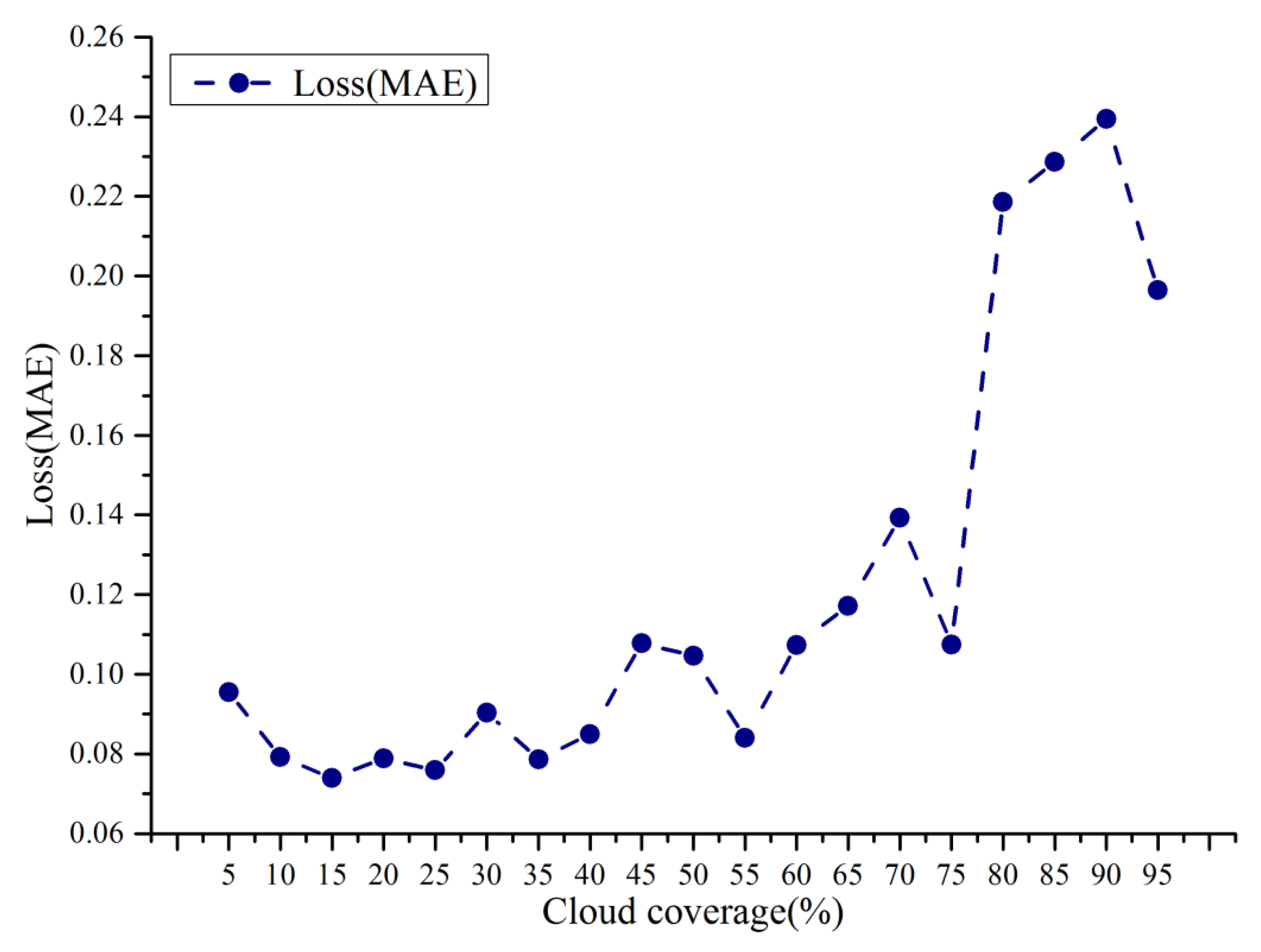
Daily SGS data of the KRB were generated in batches based on the asymptotic radiative transfer model in the GEE for a long series. However, for the SGS data with too much cloud, the mapping relationship between geographic, spatial–temporal information, and SGS cannot be fitted better due to the limited effective training data. Therefore, the training set and test set are divided according to the ratio of 8:2, and the experiments are conducted with different data missing rates (i.e., cloud percentage in the watershed). It can be seen that in
Figure 6 the test error increases abruptly when the cloud percentage is greater than 75%. The data missing rate increases to a certain threshold, resulting in too few effective training samples and causing underfitting in model training. Thus, SGS data with cloud coverage below 70% are selected for snow reconstruction in this study.
Under the premise of determining the missing data rate applied to the model, the corresponding altitude, slope, aspect, land cover, spatial dimension data and , and temporal dimension data of SCDs and SDI are extracted according to the latitude and longitude, and are used to construct an SGS filling model. The points with an SGS of zero, (i.e., no snow) are also added to balance the snow cover and snow-free surfaces in the model.
In the model training phase, the importance scores are used to evaluate the contributions of the input factors to the results and to optimize the input factors. Since the model is trained for daily images and fills in the missing SGS information to achieve snow reconstruction, the difference in snow status and cloud percentage due to the environmental changes will make the importance scores of input factors ranked differently on each day. In this study, the ranking of the mean importance scores obtained from model training for consecutive years was calculated, as shown in
Figure 7. It can be seen that altitude, as the most significant topographic element, is the most important factor influencing the retrieval results, with a score of 0.192. The importance scores of the SDI and SCDs are 0.14126 and 0.13605, respectively, indicating that the present time of the grid at the current moment and the distribution of snow accumulation throughout the hydrological year show a great role in the filling of SGS. While the importance scores of aspects,
and land cover were all closer. The lowest importance score is the slope, which is only 0.077, one order of magnitude behind other input factors. Therefore, the importance scores of the hydrological year scale are combined, and altitude, SDI, SCD,
, aspect,
, and land cover are finally selected as the inputs of the model for retrieval of SGS under the cloud layer, to realize snow reconstruction. Altitude, aspect, and land cover are geographic information inputs that come into direct contact with snow cover, thereby affecting the SGS through surface temperature conduction, gravity accumulation caused by terrain, and the amount of solar radiation received from different aspects.
and
further characterize the spatiotemporal properties of snow particles within the watershed, which helps to improve the accuracy of SGS estimation at the watershed scale. SDI and SCD characterize the phenology of snow cover on short and annual time scales, respectively, especially SDI, which is closely related to the evolution and size of the snow grain.
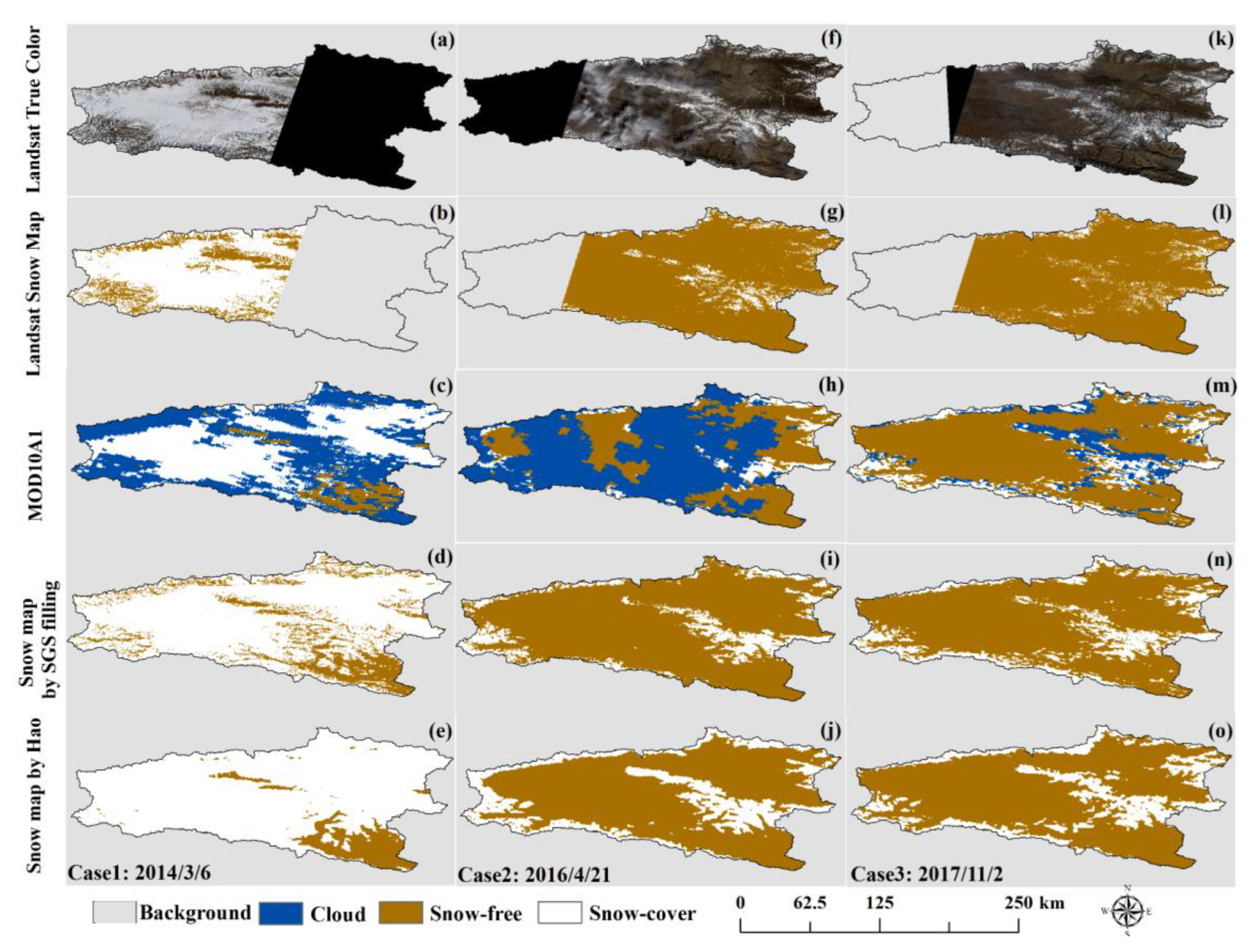
3.4. Snow Recognition of Landsat
Based on the property that both clouds and snow show high reflectance in the visible band, and the difference between the high reflectance of clouds and the high absorption of snow in the short-wave infrared band, the SNOWMAP algorithm [
41] was used to identify the snow cover in the Landsat images. In this study, the Normalized Difference Snow Index (NDSI) is calculated in the GEE platform for the green band (band 3) and the short infrared band (band 6) of Landsat-OLI images that have completed radiometric calibration and atmospheric correction, and the threshold of the NDSI for snow identification is set greater or equal to 0.4. The calculation method of the NDSI is shown in Equation (1):
Given the low reflectance of the water body in both visible and short-wave infrared bands, the threshold of band 5 is set as greater than 0.11 as a way to eliminate the interference of the water body. The combined criterion of and can achieve snow identification at 30 m resolution. In the snow binary map, 1 denotes a snow element and 0 denotes a snow-free element.
3.5. Metrics for Evaluating the Accuracy of Snow after Cloud Removal
The accuracy evaluation of snow reconstruction is divided into two parts. The first is the accuracy evaluation of the SGS estimated based on the machine learning model, and the second is the accuracy evaluation of the snow reconstruction results. The root mean squared error (RMSE) and mean absolute error (MAE) between the predicted SGS and the measured SGS are evaluated employing ten-fold cross-validation, and the above indexes are calculated as shown in Equations (2) and (3):
In the accuracy evaluation system of snow reconstruction, the measured snow depth at the meteorological station is taken as the ground truth, and the ground is judged to be snowy when the snow depth is greater than 1 cm, and vice versa. Based on the aforementioned criteria, the results of snow reconstruction have the following four cases: True Positive (TP), True Negative (TN), False Positive (FP), and False Negative (FN), and the detailed definitions of TP, TN, FP, and FN are described in
Table 3. TP refers to both snow reconstruction data and ground observation being judged as snow, and TN refers to both being snow-free. FP means that the snow reconstruction data shows snow, while ground observation is snow-free, which generally occurs when the reconstruction misidentifies cirrus clouds as snow, and FN means that the ground observation shows snow, while the snow reconstruction is snow-free, which belongs to snow omission.
Based on the four categories of snow reconstruction data compared with ground observations, a series of performance metrics were introduced to evaluate the accuracy of snow reconstruction by the algorithm in this study and to compare the accuracy with existing snow cover products from MODIS. Based on the ground-based meteorological station observations in the study area, the values of TP, TN, FP, and FN are counted for the period of hydrological years from 2000 to 2020, and the four perspectives of overall accuracy (OA), precision, recall and the combined performance index of F1-score are used to evaluate the performance of snow reconstruction data. The specific formulas for calculating the above four types of indicators are shown in Equations (4)–(7):
Using the measured snow depth from ground-based meteorological stations as the ground truth to assess the effect of snow reconstruction will result in the problem of underrepresentation due to the sparse stations, taking the KRB as an example, with 20,507 km
2, while there is only one meteorological station in the basin, Bayanbulak (51,542), with an elevation of 2458 m. As a result, there is a lack of ground truth to evaluate the effect of snow reconstruction in other areas of the basin, especially in high mountain regions. Therefore, after evaluating the accuracy by ground truth, 30 m resolution snow cover derived from Landsat was also used to assess the 500 m snow reconstruction data. The Kappa coefficient is used to calculate the image agreement between snow cover derived from Landsat and snow reconstruction data derived from MODIS, and the formula is shown in Equations (8)–(10):
where
is the actual consistency rate and
is the theoretical consistency rate. In Equations (8) and (9), the total pixels of the remote sensing image is
, the number of snow pixels in the Landsat image representing the real situation of the ground is
, and the number of snow-free pixels is
. In the corresponding snow reconstruction data, the number of snow pixels is
, and the number of snow-free pixels is
,
represents the same number of the corresponding pixels in the two images.
According to the literature [
42], the Kappa test can be used to represent different levels of consistency using five sets of classifications.
Table 4 illustrates the level of consistency of the two images corresponding to Kappa in different intervals.
5. Discussion
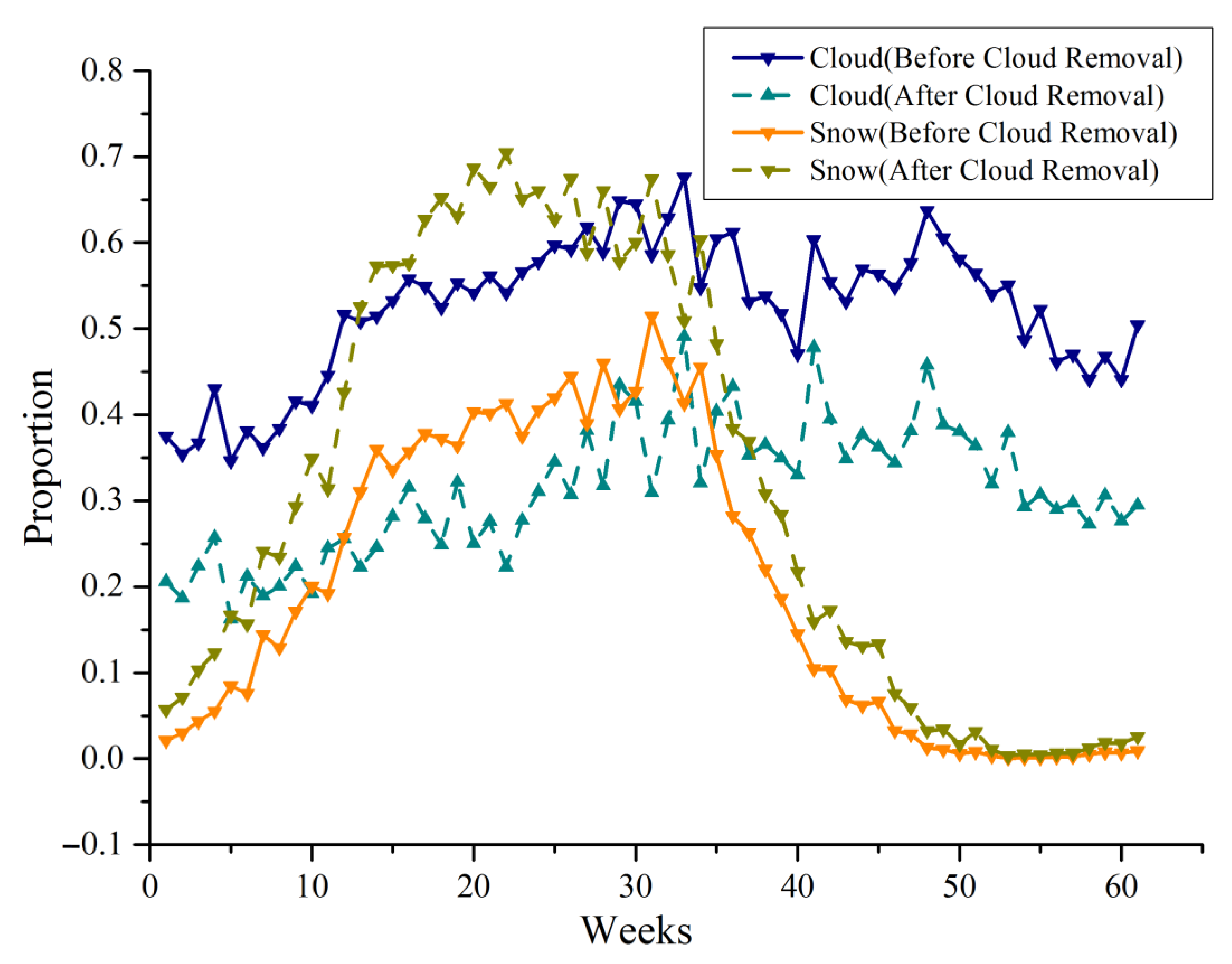
The objective of this study was to remove cloud-covered areas from the original MODIS snow cover products to obtain snow cover information for data-limited regions such as the KRB where no abundant snow cover data is available locally. As stated in
Section 4.2, combining 66.75% reconstructed snow cover data and 33.25% unreconstructed snow cover data, the average annual cloud coverage decreased from 52.46% to 34.41%, while the average annual proportion of snow cover and snow-free surface increased to 33.84% and 31.75%, respectively. As a comparison, the spatiotemporal filtering method in a previous study [
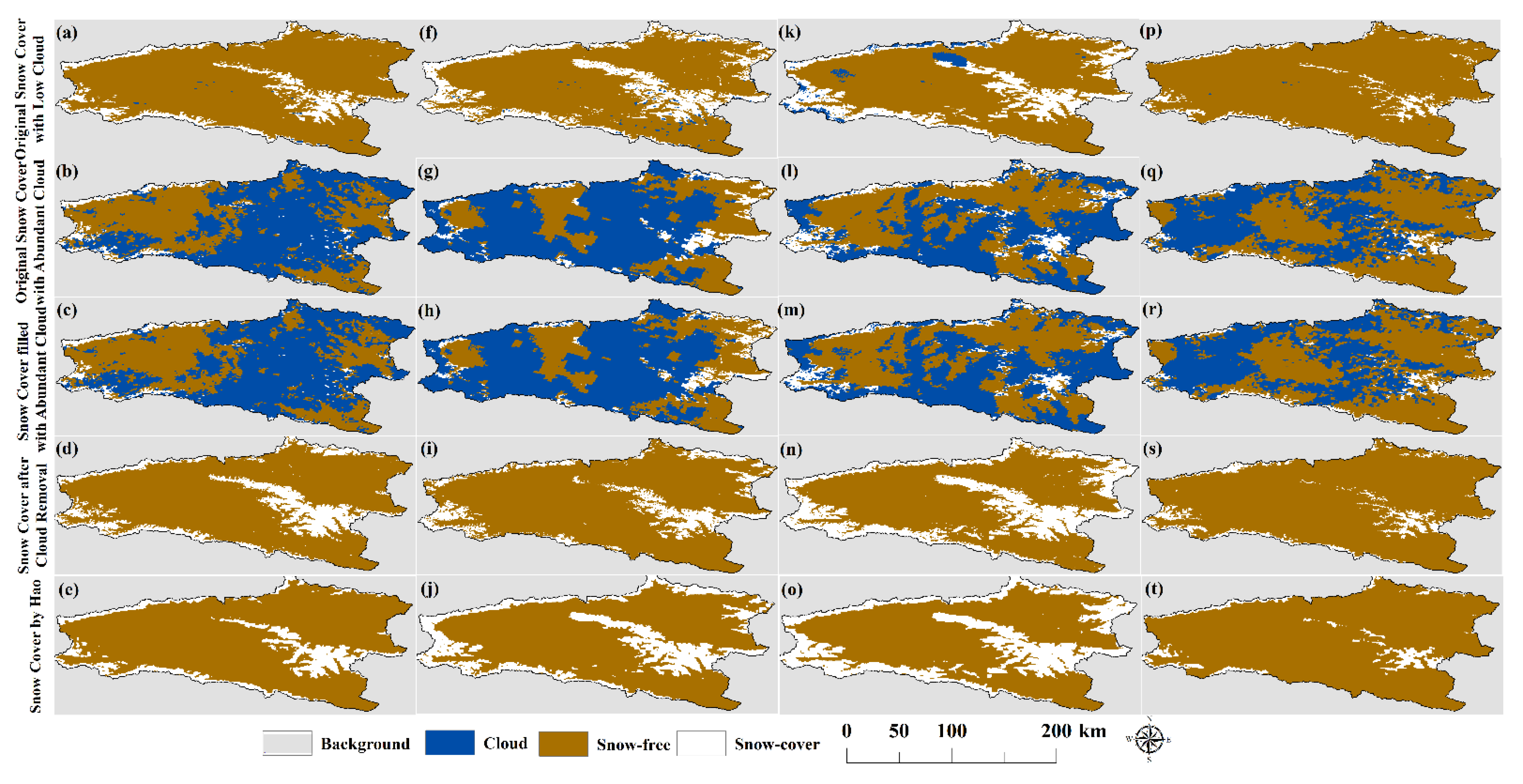
43] can remove 21.47% of cloud coverage from the KRB, increasing the annual snow cover rate from 20.34% to 41.81%. The SCE data, which has undergone spatiotemporal filtering and cloud removal, has an average annual accuracy of approximately 93% based on site validation in the KRB, slightly higher than the 92% OA of the proposed method. Multi-sensor fusion can further remove 2.59% of cloud coverage and achieve cloud-free mapping of the KRB, with an average annual snow cover rate of 44.40%. Under the condition of complete cloud removal, the overall accuracy based on site verification decreased to 89%, indicating that the uncertainty of multi-sensor cloud removal in complex mountain environments is relatively high. From this point of view, the proposed method in this study maintains higher snow recognition accuracy after cloud removal. The limitation of this study is that it cannot achieve cloud removal of all data on an annual scale.
Except for differences in specific accuracy indicators, the proposed method provides more detailed and consistent mountain trends in restoring snow cover under clouds, as shown in the comparison between
Figure 12i and
Figure 12j. This may be because this method is based on continuous numerical retrieval, which is then used to obtain the value of SGS and determine the snow cover. Moreover, the method in the article mainly relies on cloud pixels themselves or small-scale neighborhood information, lacking overall feature extraction for watershed scale. Based on the above expression, the snow reconstruction-based method on SGS gap filling can be extended to the reconstruction of other missing data (continuous values), such as the reconstruction of ground temperature under clouds and the filling of soil moisture under clouds. For the reconstruction of snow cover under clouds, the proposed method can also be extended to use parameters such as snow density and snow wetness to reconstruct snow cover under clouds [
12].
6. Conclusions
The “spatiotemporal” dimensional data that can fully characterize the geomorphic characteristics of the KRB and temporal characteristics of snow was designed and constructed as input data. At the same time, based on the physical characteristics of the variation of SGS with altitude, slope, aspect, and land cover in the watershed scale, the daily SGS filling algorithm of the space–time ET model is constructed and trained, so that the snow cover reconstruction under clouds in the KRB is realized. The algorithm applies to the daily data with a missing rate of less than 70% (i.e., the cloud coverage is less than 70%). A total of 66.75% of snow products have realized the snow cover reconstruction under the cloud based on this method from 2000 to 2020. Compared with MOD10A1 snow cover products, the average annual cloud coverage rate decreased from 52.46% to 34.41%, while the snow coverage rate increased from 21.52% to 33.84%. The data source of this study is SGS data derived from MODIS L1B data. The cloud removal algorithm based on SGS gap-filling can be applied to daily data with cloud coverage less than 70% and achieve one-step cloud removal. Daily data with cloud coverage greater than 70% has poor performance when applying this algorithm. Therefore, this part of the data is not within the scope of this study. In summary, on a year-round scale, the cloud removal algorithm reduced the average annual cloud cover rate of the KRB from 52.46% to 34.41%, and 68.25% of the removed cloud pixels were classified as snow cover, while the remaining 31.75% were classified as snow-free surface.
The main contribution of this study is to carry out SGS filling based on the physical characteristics of SGS distribution at the watershed scale for the first time. Different from the traditional spatiotemporal filtering cloud removal algorithm, the proposed method focuses on considering the spatial and temporal distribution characteristics of snow cover across the entire watershed scale and reconstructed snow cover that fits the geographic and meteorological characteristics of the watershed. Therefore, it better realizes the reconstruction of snow information under continuous large-scale clouds, improves the time resolution of snow, and realizes the deep integration of physical mechanisms and machine learning in the field of snow remote sensing. This article is an exploratory study designed and conducted based on the strong correlation between the spatiotemporal distribution of SGS within a small-scale watershed (KRB) and the terrain and meteorological elements of the watershed. On a larger spatiotemporal scale (such as the entire northern Xinjiang), the strong spatiotemporal heterogeneity of snow grain size can lead to the failure of the method in this study. Meanwhile, the algorithm in this study relies on training with a large amount of effective data. When the cloud coverage rate is higher than 70%, the training effect of the model will deteriorate due to the reduction in data volume, which is also a limitation of this study. In the future, we will attempt to conduct relevant research on a broader basin scale and explore the differences in our research methods across different basin scales to obtain more applicable strategies and methods.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}