
Drought Forecasting Using Integrated Variational Mode Decomposition and Extreme Gradient Boosting


Abstract
:1. Introduction
- The present study, rather than focalizing on the PDSI, is intended to forecast the time series of sc-PDSI as it provides more consistent and justifiable results with respect to any climate and location.
- Despite some studies that incorporated some of the signal-processing techniques, no single research examining the integration of the VMD technique to the ML algorithms exists in the drought forecasting literature.
- The past attempts accounted for a limited application of tree-based ensemble algorithms in PDSI/sc-PDSI time series modeling, whereas this research encapsulated the utilization of the XGBoost algorithm in forecasting various lead times, i.e., short-, mid-, and long-term horizons.
- The constructed VMD-XGBoost hybrid framework was benchmarked with not only the standalone XGBoost technique but also the DWT-XGBoost algorithm to accentuate its robustness.
- All the attained results were evaluated based on both divergent performance indicators and statistical significance tests (i.e., Kolmogorov–Smirnov, Shapiro–Wilk, and Mann–Whitney U tests). Such a transparent assessment has not been acknowledged in the drought forecasting literature.
2. Research Design and Model Development
3. Materials
3.1. Study Area
3.2. Self-Calibrated Palmer Drought Severity Index (sc-PDSI)
4. Methods
4.1. Signal-Processing Algorithms
4.1.1. Discrete Wavelet Transform
4.1.2. Variational Mode Decomposition
4.2. Machine Learning Algorithm
4.3. Performance Evaluation Indicators
5. Results
6. Discussion
6.1. Investigating the Statistical Significance of the Obtained Results
6.2. Evaluating the Proposed Framework Compared to the Existing Literature

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| I | II | III | IV | V | VI | VII | VIII | IX | X |
|---|---|---|---|---|---|---|---|---|---|
| Diodato et al. [41] | PDSI | 1801–2014 | PDO, ENSO | PDSI | N/A | N/A | ES | N/A | ES |
| Tufaner and Özbeyaz [42] | PDSI | 1980–2011 | Hydro-meteorological variables * | PDSI | N/A | N/A | LR, ANN, SVM, and DT | N/A | ANN |
| Özger et al. [2] | sc-PDSI | 1901–2016 | sc-PDSI (t − 2, t − 1, t) | sc-PDSI (t + 1, t + 3, t + 6) | EMD and CWT | N/A | ANFIS, SVM, M5 | Kolmogorov–Smirnov | WD-ANFIS |
| Aghelpour et al. [22] | PDSI | 1960–2018 | Temperature, precipitation | PDSI | N/A | DA | ARMA, RBFNN, SVM | N/A | SVM-DA |
| Başakın et al. [86] | sc-PDSI | 1901–2016 | sc-PDSI (t − 1, t) | sc-PDSI (t + 1, t + 3, t + 6) | EMD | N/A | ANFIS | Kolmogorov–Smirnov | EMD-ANFIS |
| This study | sc-PDSI | 1921–2020 | sc-PDSI (t − 2, t − 1) | sc-PDSI (t + 1, t + 3, t + 6, t + 12) | DWT & VMD | N/A | XGBoost | Mann–Whitney U | VMD-XGBoost |
6.3. Practical Implications of the Drought Forecasting for Denizli
7. Conclusions
Funding
Data Availability Statement
Conflicts of Interest
References
- Browder, G.; Sanchez, A.N.; Jongman, B.; Engle, N. An EPIC Response: Innovative Governance for Flood and Drought Risk Management. Rep. Exec. Summ. 2021, 23. [Google Scholar]
- Özger, M.; Başakın, E.E.; Ekmekcioğlu, Ö.; Hacısüleyman, V. Comparison of Wavelet and Empirical Mode Decomposition Hybrid Models in Drought Prediction. Comput. Electron. Agric. 2020, 179, 105851. [Google Scholar] [CrossRef]
- Harou, J.J.; Medellín-Azuara, J.; Zhu, T.; Tanaka, S.K.; Lund, J.R.; Stine, S.; Olivares, M.A.; Jenkins, M.W. Economic Consequences of Optimized Water Management for a Prolonged, Severe Drought in California. Water Resour. Res. 2010, 46, W05522. [Google Scholar] [CrossRef]
- Vicente-Serrano, S.M.; Quiring, S.M.; Peña-Gallardo, M.; Yuan, S.; Domínguez-Castro, F. A Review of Environmental Droughts: Increased Risk under Global Warming? Earth-Sci. Rev. 2020, 201, 102953. [Google Scholar] [CrossRef]
- Wilhite, D.A.; Svoboda, M.D.; Hayes, M.J. Understanding the Complex Impacts of Drought: A Key to Enhancing Drought Mitigation and Preparedness. Water Resour. Manag. 2007, 21, 763–774. [Google Scholar] [CrossRef]
- Mapedza, E.; McLeman, R. Drought Risks in Developing Regions: Challenges and Opportunities. In Current Directions in Water Scarcity Research; Elsevier: Amsterdam, The Netherlands, 2019; pp. 1–14. [Google Scholar]
- Zhang, X.; Chen, N.; Sheng, H.; Ip, C.; Yang, L.; Chen, Y.; Sang, Z.; Tadesse, T.; Lim, T.P.Y.; Rajabifard, A.; et al. Urban Drought Challenge to 2030 Sustainable Development Goals. Sci. Total Environ. 2019, 693, 133536. [Google Scholar] [CrossRef] [PubMed]
- Nilsson, M.; Griggs, D.; Visbeck, M. Policy: Map the Interactions between Sustainable Development Goals. Nature 2016, 534, 320–322. [Google Scholar] [CrossRef]
- Belete, Y.; Shimelis, H.; Laing, M. Wheat Production in Drought-Prone Agro-Ecologies in Ethiopia: Diagnostic Assessment of Farmers’ Practices and Sustainable Coping Mechanisms and the Role of Improved Cultivars. Sustainability 2022, 14, 7579. [Google Scholar] [CrossRef]
- Bahrami, N.; Reza Nikoo, M.; Al-Rawas, G.; Al-Wardy, M.; Gandomi, A.H. Reservoir Optimal Operation with an Integrated Approach for Managing Floods and Droughts Using NSGA-III and Prospect Behavioral Theory. J. Hydrol. 2022, 610, 127961. [Google Scholar] [CrossRef]
- Kumar, P.; Debele, S.E.; Sahani, J.; Rawat, N.; Marti-Cardona, B.; Alfieri, S.M.; Basu, B.; Basu, A.S.; Bowyer, P.; Charizopoulos, N.; et al. Nature-Based Solutions Efficiency Evaluation against Natural Hazards: Modelling Methods, Advantages and Limitations. Sci. Total Environ. 2021, 784, 147058. [Google Scholar] [CrossRef] [PubMed]
- Svoboda, M.; Fuchs, B. Handbook of Drought Indicators and Indices; Springer: Berlin/Heidelberg, Germany, 2017. [Google Scholar]
- Wang, C.-N.; Yang, F.-C.; Nguyen, V.T.T.; Vo, N.T.M. CFD Analysis and Optimum Design for a Centrifugal Pump Using an Effectively Artificial Intelligent Algorithm. Micromachines 2022, 13, 1208. [Google Scholar] [CrossRef]
- Başakın, E.E.; Ekmekcioğlu, Ö.; Stoy, P.C.; Özger, M. Estimation of Daily Reference Evapotranspiration by Hybrid Singular Spectrum Analysis-Based Stochastic Gradient Boosting. MethodsX 2023, 10, 102163. [Google Scholar] [CrossRef]
- Peng, F.; Wang, Y.; Xuan, H.; Nguyen, T.V.T. Efficient Road Traffic Anti-Collision Warning System Based on Fuzzy Nonlinear Programming. Int. J. Syst. Assur. Eng. Manag. 2022, 13, 456–461. [Google Scholar] [CrossRef]
- Koc, K. Role of National Conditions in Occupational Fatal Accidents in the Construction Industry Using Interpretable Machine Learning Approach. J. Manag. Eng. 2023, 39, 04023037. [Google Scholar] [CrossRef]
- Başakın, E.E.; Ekmekcioğlu, Ö.; Mohammadi, B. Letter to the Editor “Comparing Artificial Intelligence Techniques for Chlorophyll-a Prediction in US Lakes”. Environ. Sci. Pollut. Res. 2020, 27, 22131–22134. [Google Scholar] [CrossRef]
- Shahdad, M.; Saber, B. Drought Forecasting Using New Advanced Ensemble-Based Models of Reduced Error Pruning Tree. Acta Geophys. 2022, 70, 697–712. [Google Scholar] [CrossRef]
- Dikshit, A.; Pradhan, B. Interpretable and Explainable AI (XAI) Model for Spatial Drought Prediction. Sci. Total Environ. 2021, 801, 149797. [Google Scholar] [CrossRef]
- Elbeltagi, A.; Althobiani, F.; Kamruzzaman, M.; Shaid, S.; Roy, D.K.; Deb, L.; Islam, M.M.; Kundu, P.K.; Rahman, M.M. Estimating the Standardized Precipitation Evapotranspiration Index Using Data-Driven Techniques: A Regional Study of Bangladesh. Water 2022, 14, 1764. [Google Scholar] [CrossRef]
- Mokhtar, A.; Jalali, M.; He, H.; Al-Ansari, N.; Elbeltagi, A.; Alsafadi, K.; Abdo, H.G.; Sammen, S.S.; Gyasi-Agyei, Y.; Rodrigo-Comino, J. Estimation of SPEI Meteorological Drought Using Machine Learning Algorithms. IEEE Access 2021, 9, 65503–65523. [Google Scholar] [CrossRef]
- Aghelpour, P.; Mohammadi, B.; Mehdizadeh, S.; Bahrami-Pichaghchi, H.; Duan, Z. A Novel Hybrid Dragonfly Optimization Algorithm for Agricultural Drought Prediction. Stoch. Environ. Res. Risk Assess. 2021, 35, 2459–2477. [Google Scholar] [CrossRef]
- Anshuka, A.; Chandra, R.; Buzacott, A.J.V.; Sanderson, D.; van Ogtrop, F.F. Spatio Temporal Hydrological Extreme Forecasting Framework Using LSTM Deep Learning Model. Stoch. Environ. Res. Risk Assess. 2022, 36, 3467–3485. [Google Scholar] [CrossRef]
- Belayneh, A.; Adamowski, J.; Khalil, B. Short-Term SPI Drought Forecasting in the Awash River Basin in Ethiopia Using Wavelet Transforms and Machine Learning Methods. Sustain. Water Resour. Manag. 2016, 2, 87–101. [Google Scholar] [CrossRef]
- Ali, M.; Deo, R.C.; Downs, N.J.; Maraseni, T. Multi-Stage Committee Based Extreme Learning Machine Model Incorporating the Influence of Climate Parameters and Seasonality on Drought Forecasting. Comput. Electron. Agric. 2018, 152, 149–165. [Google Scholar] [CrossRef]
- Malik, A.; Kumar, A.; Salih, S.Q.; Kim, S.; Kim, N.W.; Yaseen, Z.M.; Singh, V.P. Drought Index Prediction Using Advanced Fuzzy Logic Model: Regional Case Study over Kumaon in India. PLoS ONE 2020, 15, e0233280. [Google Scholar] [CrossRef] [PubMed]
- Li, Z.; Zhang, Z.; Zhang, L. Improving Regional Wheat Drought Risk Assessment for Insurance Application by Integrating Scenario-Driven Crop Model, Machine Learning, and Satellite Data. Agric. Syst. 2021, 191, 103141. [Google Scholar] [CrossRef]
- Lotfirad, M.; Esmaeili-Gisavandani, H.; Adib, A. Drought Monitoring and Prediction Using SPI, SPEI, and Random Forest Model in Various Climates of Iran. J. Water Clim. Chang. 2022, 13, 383–406. [Google Scholar] [CrossRef]
- Danandeh Mehr, A. Drought Classification Using Gradient Boosting Decision Tree. Acta Geophys. 2021, 69, 909–918. [Google Scholar] [CrossRef]
- Yaseen, Z.M.; Ali, M.; Sharafati, A.; Al-Ansari, N.; Shahid, S. Forecasting Standardized Precipitation Index Using Data Intelligence Models: Regional Investigation of Bangladesh. Sci. Rep. 2021, 11, 3435. [Google Scholar] [CrossRef]
- Rose, M.A.J.; Chithra, N.R. Tree-Based Ensemble Model Prediction for Hydrological Drought in a Tropical River Basin of India. Int. J. Environ. Sci. Technol. 2022, 20, 4973–4990. [Google Scholar] [CrossRef]
- Citakoglu, H.; Coşkun, Ö. Comparison of Hybrid Machine Learning Methods for the Prediction of Short-Term Meteorological Droughts of Sakarya Meteorological Station in Turkey. Environ. Sci. Pollut. Res. 2022, 29, 75487–75511. [Google Scholar] [CrossRef]
- Gholizadeh, R.; Yılmaz, H.; Danandeh Mehr, A. Multitemporal Meteorological Drought Forecasting Using Bat-ELM. Acta Geophys. 2022, 70, 917–927. [Google Scholar] [CrossRef]
- Jamei, M.; Ahmadianfar, I.; Karbasi, M.; Malik, A.; Kisi, O.; Yaseen, Z.M. Development of Wavelet-Based Kalman Online Sequential Extreme Learning Machine Optimized with Boruta-Random Forest for Drought Index Forecasting. Eng. Appl. Artif. Intell. 2023, 117, 105545. [Google Scholar] [CrossRef]
- Raja, A.; Gopikrishnan, T. Drought Prediction and Validation for Desert Region Using Machine Learning Methods. Int. J. Adv. Comput. Sci. Appl. 2022, 13, 47–53. [Google Scholar] [CrossRef]
- Vicente-Serrano, S.M.; Beguería, S.; López-Moreno, J.I. A Multiscalar Drought Index Sensitive to Global Warming: The Standardized Precipitation Evapotranspiration Index. J. Clim. 2010, 23, 1696–1718. [Google Scholar] [CrossRef]
- Ghasemi, P.; Karbasi, M.; Zamani Nouri, A.; Sarai Tabrizi, M.; Azamathulla, H.M. Application of Gaussian Process Regression to Forecast Multi-Step Ahead SPEI Drought Index. Alex. Eng. J. 2021, 60, 5375–5392. [Google Scholar] [CrossRef]
- Fung, K.F.; Huang, Y.F.; Koo, C.H.; Mirzaei, M. Improved Svr Machine Learning Models for Agricultural Drought Prediction at Downstream of Langat River Basin, Malaysia. J. Water Clim. Chang. 2020, 11, 1383–1398. [Google Scholar] [CrossRef]
- Li, J.; Wang, Z.; Wu, X.; Xu, C.Y.; Guo, S.; Chen, X.; Zhang, Z. Robust Meteorological Drought Prediction Using Antecedent SST Fluctuations and Machine Learning. Water Resour. Res. 2021, 57, e2020WR029413. [Google Scholar] [CrossRef]
- Szép, I.J.; Mika, J.; Dunkel, Z. Palmer Drought Severity Index as Soil Moisture Indicator: Physical Interpretation, Statistical Behaviour and Relation to Global Climate. Phys. Chem. Earth Parts A/B/C 2005, 30, 231–243. [Google Scholar] [CrossRef]
- Diodato, N.; de Guenni, L.B.; Garcia, M.; Bellocchi, G. Decadal Oscillation in the Predictability of Palmer Drought Severity Index in California. Climate 2019, 7, 6. [Google Scholar] [CrossRef]
- Tufaner, F.; Özbeyaz, A. Estimation and Easy Calculation of the Palmer Drought Severity Index from the Meteorological Data by Using the Advanced Machine Learning Algorithms. Environ. Monit. Assess. 2020, 192, 576. [Google Scholar] [CrossRef]
- Self-Calibrating Palmer Drought Severity Index (ScPDSI). Available online: https://crudata.uea.ac.uk/cru/data/drought/ (accessed on 4 April 2023).
- Alsharif, M.; Younes, M.; Kim, J. Time Series ARIMA Model for Prediction of Daily and Monthly Average Global Solar Radiation: The Case Study of Seoul, South Korea. Symmetry 2019, 11, 240. [Google Scholar] [CrossRef]
- Khan, F.M.; Gupta, R. ARIMA and NAR Based Prediction Model for Time Series Analysis of COVID-19 Cases in India. J. Saf. Sci. Resil. 2020, 1, 12–18. [Google Scholar] [CrossRef]
- TUIK Geographic Statistics Portal. Available online: https://cip.tuik.gov.tr/# (accessed on 18 September 2021).
- MGM State Meteorological Service Statistics. Available online: https://www.mgm.gov.tr/eng/about.aspx (accessed on 18 September 2021).
- Palmer, W.C. Meteorological Drought; Research Paper No. 45; US Department of Commerce, Weather Bureau: Washington, DC, USA, 1965.
- Maule, C.F.; Thejll, P.; Christensen, J.H.; Svendsen, S.H.; Hannaford, J. Improved Confidence in Regional Climate Model Simulations of Precipitation Evaluated Using Drought Statistics from the ENSEMBLES Models. Clim. Dyn. 2013, 40, 155–173. [Google Scholar] [CrossRef]
- Wells, N.; Goddard, S.; Hayes, M.J. A Self-Calibrating Palmer Drought Severity Index. J. Clim. 2004, 17, 2335–2351. [Google Scholar] [CrossRef]
- Grossmann, A.; Morlet, J. Decomposition of Hardy Functions into Square Integrable Wavelets of Constant Shape. SIAM J. Math. Anal. 1984, 15, 723–736. [Google Scholar] [CrossRef]
- Estévez, J.; Bellido-Jiménez, J.A.; Liu, X.; García-Marín, A.P. Monthly Precipitation Forecasts Using Wavelet Neural Networks Models in a Semiarid Environment. Water 2020, 12, 1909. [Google Scholar] [CrossRef]
- Wei, M.; You, X. yi Monthly Rainfall Forecasting by a Hybrid Neural Network of Discrete Wavelet Transformation and Deep Learning. Water Resour. Manag. 2022, 36, 4003–4018. [Google Scholar] [CrossRef]
- Saraiva, S.V.; de Carvalho, F.O.; Santos, C.A.G.; Barreto, L.C.; Freire, P.K. de M.M. Daily Streamflow Forecasting in Sobradinho Reservoir Using Machine Learning Models Coupled with Wavelet Transform and Bootstrapping. Appl. Soft Comput. 2021, 102, 107081. [Google Scholar] [CrossRef]
- Al-Qazzaz, N.K.; Mohd Ali, S.H.; Bin; Ahmad, S.A.; Islam, M.S.; Escudero, J. Selection of Mother Wavelet Functions for Multi-Channel EEG Signal Analysis during a Working Memory Task. Sensors 2015, 15, 29015–29035. [Google Scholar] [CrossRef]
- Koc, K.; Ekmekcioğlu, Ö.; Gurgun, A.P. Accident Prediction in Construction Using Hybrid Wavelet-Machine Learning. Autom. Constr. 2022, 133, 103987. [Google Scholar] [CrossRef]
- Merchant, F.A.; Castleman, K.R. Computer-Assisted Microscopy. In The Essential Guide to Image Processing; Elsevier: Amsterdam, The Netherlands, 2009; pp. 777–831. ISBN 9780123744579. [Google Scholar]
- Kambalimath, S.S.; Deka, P.C. Performance Enhancement of SVM Model Using Discrete Wavelet Transform for Daily Streamflow Forecasting. Environ. Earth Sci. 2021, 80, 101. [Google Scholar] [CrossRef]
- Kadkhodazadeh, M.; Farzin, S. A Novel Hybrid Framework Based on the ANFIS, Discrete Wavelet Transform, and Optimization Algorithm for the Estimation of Water Quality Parameters. J. Water Clim. Chang. 2022, 13, 2940–2961. [Google Scholar] [CrossRef]
- Shoaib, M.; Shamseldin, A.Y.; Melville, B.W. Comparative Study of Different Wavelet Based Neural Network Models for Rainfall-Runoff Modeling. J. Hydrol. 2014, 515, 47–58. [Google Scholar] [CrossRef]
- Dragomiretskiy, K.; Zosso, D. Variational Mode Decomposition. IEEE Trans. Signal Process. 2014, 62, 531–544. [Google Scholar] [CrossRef]
- Liu, Y.; Wang, L.H.; Yang, L.B.; Liu, X.M. Drought Prediction Based on an Improved VMD-OS-QR-ELM Model. PLoS ONE 2022, 17, e0262329. [Google Scholar] [CrossRef]
- Ribeiro, M.H.D.M.; da Silva, R.G.; Ribeiro, G.T.; Mariani, V.C.; dos Coelho, L.S. Cooperative Ensemble Learning Model Improves Electric Short-Term Load Forecasting. Chaos Solitons Fractals 2023, 166, 112982. [Google Scholar] [CrossRef]
- Chen, T.; Guestrin, C. XGBoost. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13 August 2016; ACM: New York, NY, USA, 2016; pp. 785–794. [Google Scholar]
- Ma, M.; Zhao, G.; He, B.; Li, Q.; Dong, H.; Wang, S.; Wang, Z. XGBoost-Based Method for Flash Flood Risk Assessment. J. Hydrol. 2021, 598, 126382. [Google Scholar] [CrossRef]
- Ekmekcioğlu, Ö.; Koc, K.; Özger, M.; Işık, Z. Exploring the Additional Value of Class Imbalance Distributions on Interpretable Flash Flood Susceptibility Prediction in the Black Warrior River Basin, Alabama, United States. J. Hydrol. 2022, 610, 127877. [Google Scholar] [CrossRef]
- Özger, M.; Serencam, U.; Ekmekcioğlu, Ö.; Başakın, E.E. Determining the Water Level Fluctuations of Lake Van through the Integrated Machine Learning Methods. Int. J. Glob. Warm. 2022, 27, 123. [Google Scholar] [CrossRef]
- Koc, K.; Ekmekcioğlu, Ö.; Gurgun, A.P. Integrating Feature Engineering, Genetic Algorithm and Tree-Based Machine Learning Methods to Predict the Post-Accident Disability Status of Construction Workers. Autom. Constr. 2021, 131, 103896. [Google Scholar] [CrossRef]
- Humbird, K.D.; Peterson, J.L.; Mcclarren, R.G. Deep Neural Network Initialization With Decision Trees. IEEE Trans. Neural Networks Learn. Syst. 2019, 30, 1286–1295. [Google Scholar] [CrossRef] [PubMed]
- Probst, P.; Wright, M.N.; Boulesteix, A. Hyperparameters and Tuning Strategies for Random Forest. Wiley Interdiscip. Rev. Data Min. Knowl. Discov. 2019, 9, e1301. [Google Scholar] [CrossRef]
- Lv, F.; Wang, J.; Cui, B.; Yu, J.; Sun, J.; Zhang, J. An Improved Extreme Gradient Boosting Approach to Vehicle Speed Prediction for Construction Simulation of Earthwork. Autom. Constr. 2020, 119, 103351. [Google Scholar] [CrossRef]
- Dong, W.; Huang, Y.; Lehane, B.; Ma, G. XGBoost Algorithm-Based Prediction of Concrete Electrical Resistivity for Structural Health Monitoring. Autom. Constr. 2020, 114, 103155. [Google Scholar] [CrossRef]
- XGBoost Parameters. Available online: https://xgboost.readthedocs.io/en/stable/parameter.html (accessed on 28 August 2023).
- Nash, J.E.; Sutcliffe, J.V. River Flow Forecasting through Conceptual Models. Part 1: A Discussion of Principles. J. Hydrol. 1970, 10, 282–290. [Google Scholar] [CrossRef]
- Willmott, C.J.; Robeson, S.M.; Matsuura, K. A Refined Index of Model Performance. Int. J. Climatol. 2012, 32, 2088–2094. [Google Scholar] [CrossRef]
- Gandomi, A.H.; Roke, D.A. Assessment of Artificial Neural Network and Genetic Programming as Predictive Tools. Adv. Eng. Softw. 2015, 88, 63–72. [Google Scholar] [CrossRef]
- Adnan, R.M.; Liang, Z.; Heddam, S.; Zounemat-Kermani, M.; Kisi, O.; Li, B. Least Square Support Vector Machine and Multivariate Adaptive Regression Splines for Streamflow Prediction in Mountainous Basin Using Hydro-Meteorological Data as Inputs. J. Hydrol. 2020, 586, 124371. [Google Scholar] [CrossRef]
- Umar, I.K.; Nourani, V.; Gökçekuş, H. A Novel Multi-Model Data-Driven Ensemble Approach for the Prediction of Particulate Matter Concentration. Environ. Sci. Pollut. Res. 2021, 28, 49663–49677. [Google Scholar] [CrossRef]
- Başakın, E.E.; Ekmekcioğlu, Ö.; Çıtakoğlu, H.; Özger, M. A New Insight to the Wind Speed Forecasting: Robust Multi-Stage Ensemble Soft Computing Approach Based on Pre-Processing Uncertainty Assessment. Neural Comput. Appl. 2022, 34, 783–812. [Google Scholar] [CrossRef]
- Moriasi, D.N.; Arnold, J.G.; Van Liew, M.W.; Bingner, R.L.; Harmel, R.D.; Veith, T.L. Model Evaluation Guidelines for Systematic Quantification of Accuracy in Watershed Simulations. Trans. ASABE 2007, 50, 885–900. [Google Scholar] [CrossRef]
- Bayram, S.; Çıtakoğlu, H. Modeling Monthly Reference Evapotranspiration Process in Turkey: Application of Machine Learning Methods. Environ. Monit. Assess. 2023, 195, 67. [Google Scholar] [CrossRef]
- Özbayrak, A.; Ali, M.K.; Çıtakoğlu, H. Buckling Load Estimation Using Multiple Linear Regression Analysis and Multigene Genetic Programming Method in Cantilever Beams with Transverse Stiffeners. Arab. J. Sci. Eng. 2022, 48, 5347–5370. [Google Scholar] [CrossRef]
- Sullivan, L.M.; D’Agostino, R.B. Robustness of the t Test Applied to Data Distorted from Normality by Floor Effects. J. Dent. Res. 1992, 71, 1938–1943. [Google Scholar] [CrossRef]
- McKnight, P.E.; Najab, J. Mann-Whitney U Test. In The Corsini Encyclopedia of Psychology; Wiley: Hoboken, NY, USA, 2010; pp. 1–10. [Google Scholar]
- Achite, M.; Katipoğlu, O.M.; Jehanzaib, M.; Elshaboury, N.; Kartal, V.; Ali, S. Hydrological Drought Prediction Based on Hybrid Extreme Learning Machine: Wadi Mina Basin Case Study, Algeria. Atmosphere 2023, 14, 1447. [Google Scholar] [CrossRef]
- Başakın, E.E.; Ekmekcioğlu, Ö.; Özger, M. Drought Prediction Using Hybrid Soft-Computing Methods for Semi-Arid Region. Model. Earth Syst. Environ. 2021, 7, 2363–2371. [Google Scholar] [CrossRef]
- Yang, L.; Shami, A. On Hyperparameter Optimization of Machine Learning Algorithms: Theory and Practice. Neurocomputing 2020, 415, 295–316. [Google Scholar] [CrossRef]
- Dikshit, A.; Pradhan, B.; Alamri, A.M. Short-Term Spatio-Temporal Drought Forecasting Using Random Forests Model at New South Wales, Australia. Appl. Sci. 2020, 10, 4254. [Google Scholar] [CrossRef]
- Malik, A.; Tikhamarine, Y.; Souag-Gamane, D.; Rai, P.; Sammen, S.S.; Kisi, O. Support Vector Regression Integrated with Novel Meta-Heuristic Algorithms for Meteorological Drought Prediction. Meteorol. Atmos. Phys. 2021, 133, 891–909. [Google Scholar] [CrossRef]
- Kisi, O.; Docheshmeh Gorgij, A.; Zounemat-Kermani, M.; Mahdavi-Meymand, A.; Kim, S. Drought Forecasting Using Novel Heuristic Methods in a Semi-Arid Environment. J. Hydrol. 2019, 578, 124053. [Google Scholar] [CrossRef]







| PDSI/sc-PDSI Values | Class |
|---|---|
| ≥4.00 | Extremely wet |
| 3.00 to 3.99 | Very wet |
| 2.00 to 2.99 | Moderately wet |
| 1.00 to 1.99 | Slightly wet |
| 0.50 to 0.99 | Incipient wet spell |
| −0.49 to 0.49 | Near normal |
| −0.99 to −0.50 | Incipient dry spell |
| −1.99 to −1.00 | Mild drought |
| −2.99 to −2.00 | Moderate drought |
| −3.99 to −3.00 | Severe drought |
| ≤−4.00 | Extreme drought |
| Abbreviation | Corresponding Equation |
|---|---|
| RMSE | |
| PI | |
| NSE | |
| WI | |
| R2 |
| Performance Metrics | |||||||
|---|---|---|---|---|---|---|---|
| Inputs | Output | RMSE | PI | NSE | WI | R2 | |
| Standalone XGBoost | t − 1, t − 2 | t + 1 | 0.7310 | −0.4744 | 0.8688 | 0.8579 | 0.8693 |
| t − 1, t − 2 | t + 3 | 1.2046 | −0.8604 | 0.6394 | 0.7343 | 0.6410 | |
| t − 1, t − 2 | t + 6 | 1.6016 | −1.3218 | 0.3572 | 0.6252 | 0.3692 | |
| t − 1, t − 2 | t + 12 | 2.0210 | −2.2747 | −0.0330 | 0.5008 | 0.0617 | |
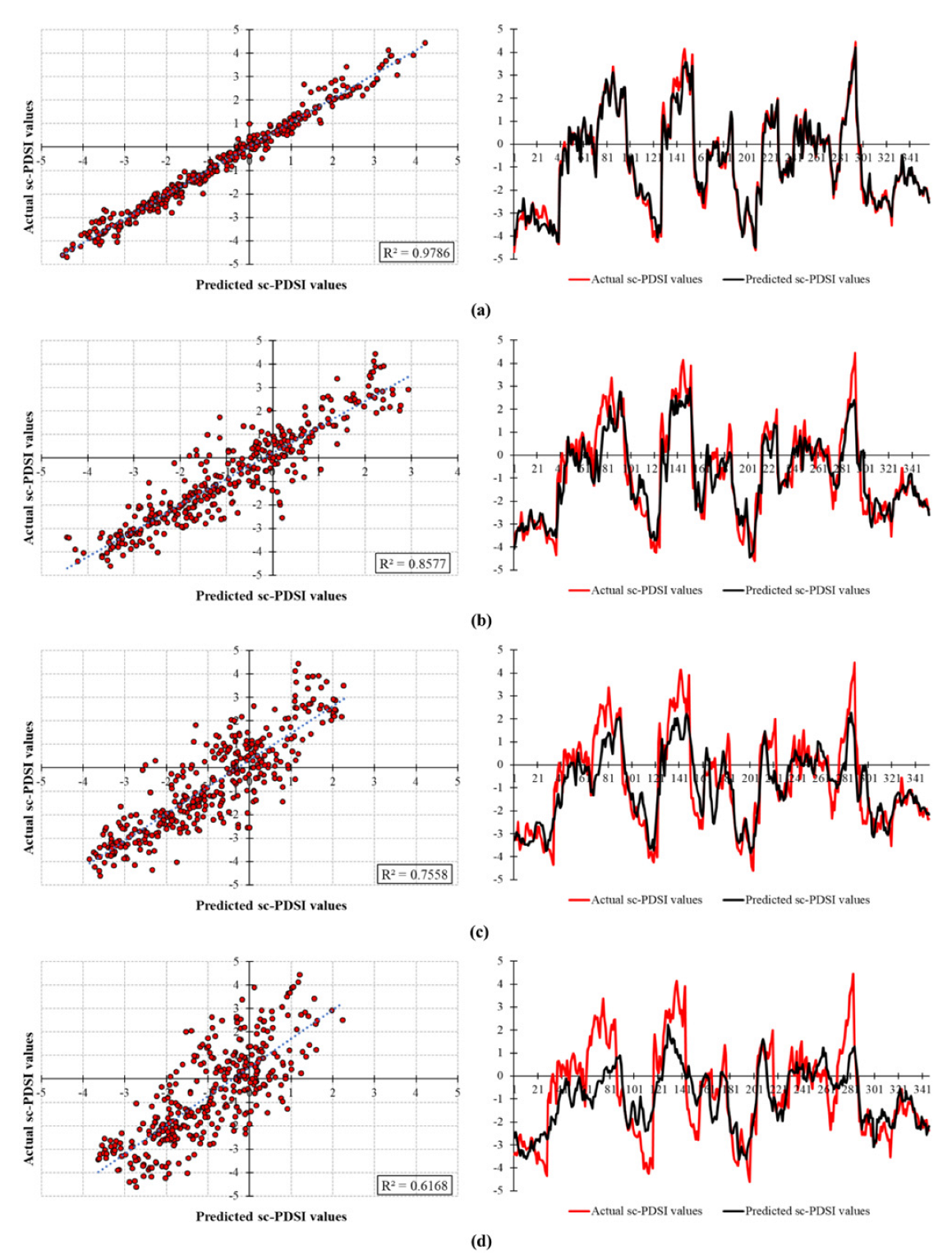
| VMD-XGboost | t − 1, t − 2 | t + 1 | 0.3004 | −0.1894 | 0.9778 | 0.9364 | 0.9786 |
| t − 1, t − 2 | t + 3 | 0.4893 | −0.3194 | 0.9405 | 0.8938 | 0.9421 | |
| t − 1, t − 2 | t + 6 | 0.7798 | −0.5383 | 0.8476 | 0.8284 | 0.8503 | |
| t − 1, t − 2 | t + 12 | 1.1456 | −0.8850 | 0.6681 | 0.7308 | 0.6704 | |
| DWT-XGboost | t − 1, t − 2 | t + 1 | 0.3004 | −0.1894 | 0.9778 | 0.9364 | 0.9786 |
| t − 1, t − 2 | t + 3 | 0.7879 | −0.5261 | 0.8457 | 0.8284 | 0.8577 | |
| t − 1, t − 2 | t + 6 | 1.0294 | −0.7306 | 0.7345 | 0.7704 | 0.7558 | |
| t − 1, t − 2 | t + 12 | 1.2916 | −1.0165 | 0.5781 | 0.7046 | 0.6168 | |
| Kolmogorov–Smirnov | Shapiro–Wilk | |||||
|---|---|---|---|---|---|---|
| Statistic | df | Sig. | Statistic | df | Sig. | |
| Observed test | 0.204 | 357 | 0.000 | 0.905 | 357 | 0.000 |
| Levene’s Statistic | df1 | df2 | df3 |
|---|---|---|---|
| 773.694 | 1 | 712 | 0.000 |
| Lead Time | Model | p Value | |
|---|---|---|---|
| t + 1 | Standalone XGBoost | 0.805 | Accept |
| VMD-XGBoost | 0.910 | Accept | |
| DWT-XGBoost | 0.909 | Accept | |
| t + 3 | Standalone XGBoost | 0.351 | Accept |
| VMD-XGBoost | 0.825 | Accept | |
| DWT-XGBoost | 0.639 | Accept | |
| t + 6 | Standalone XGBoost | 0.278 | Accept |
| VMD-XGBoost | 0.749 | Accept | |
| DWT-XGBoost | 0.437 | Accept | |
| t + 12 | Standalone XGBoost | 0.167 | Accept |
| VMD-XGBoost | 0.874 | Accept | |
| DWT-XGBoost | 0.223 | Accept |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ekmekcioğlu, Ö. Drought Forecasting Using Integrated Variational Mode Decomposition and Extreme Gradient Boosting. Water 2023, 15, 3413. https://doi.org/10.3390/w15193413
Ekmekcioğlu Ö. Drought Forecasting Using Integrated Variational Mode Decomposition and Extreme Gradient Boosting. Water. 2023; 15(19):3413. https://doi.org/10.3390/w15193413
Chicago/Turabian StyleEkmekcioğlu, Ömer. 2023. "Drought Forecasting Using Integrated Variational Mode Decomposition and Extreme Gradient Boosting" Water 15, no. 19: 3413. https://doi.org/10.3390/w15193413
APA StyleEkmekcioğlu, Ö. (2023). Drought Forecasting Using Integrated Variational Mode Decomposition and Extreme Gradient Boosting. Water, 15(19), 3413. https://doi.org/10.3390/w15193413