1. Introduction
As turbulent water flows into the flow channel of a pumping station, the unit and the concrete house will generate long-term continuous vibrations. These vibrations may cause severe damage to the unit instruments and pump house structure, as well as adversely affecting the health of the staff. Moreover, the relatively strong vibrations can pose a threat to the overall safety and functionality of the pumping station project. Therefore, research on the evaluation and prediction of these vibrations is crucial in aiding managers’ decision-making process, minimizing potential damage and ensuring the safe operation of the pumping station. For this purpose, it is vital to select suitable methods for establishing a vibration prediction model and a safety early warning model for the pumping station.
There are numerous models available for predicting structural vibrations. Forsat [
1] proposed a higher-order shear deformation beam theory to predict the vibrations of hyper-elastic beams. Mirjavadi [
2] employed the Timoshenko beam theory to predict the thermal vibrational behavior of 2D functionally graded porous microbeams. Due to their complex construction, pumping stations may not be suitable for the application of the mathematical model. Methods based on an artificial neural network (ANN) and its intelligent optimization are in full swing in predicting the structural behavior of pumping houses and hydropower houses. In 2007, Lian et al. [
3] utilized the back-propagation (BP) neural network method to predict the vibration displacement amplitude of the Three Gorges Hydropower Station, and the predictions were compared with the measured data. Miao et al. [
4] used a radial basis function (RBF) neural network to predict the vibration acceleration amplitude of a pier. Since 2014, scholars have conducted a series of studies on predicting the vibration responses of powerhouses. Xu et al. [
5] combined the generalized regression neural network (GRNN) and the fruit fly optimization algorithm (FOA) to predict the radial displacement amplitude of the flood discharge surface hole cover plate under various working conditions. The results confirmed the superior prediction ability and learning speed of the FOA–GRNN method compared to BP and ELMAN neural networks. Xu et al. [
6] used the survival-of-the-fittest and step-by-step selection particle swarm optimization algorithm (SSPSO) to optimize the smoothing parameter
P of GRNN, and they carried out prediction research on vibration problems of hydropower stations under various load conditions. Their results demonstrate that SSPSO-GRNN outperforms PSO–GRNN, self-competitive PSO–GRNN and GA–PSO–GRNN in terms of prediction accuracy, convergence performance and generalization ability. Wang et al. [
7] established a model based on relevant vector machine (RVM) regression to predict the vertical displacement standard deviation of a large underground hydropower station under different loads. The results indicate that the RVM model has higher prediction accuracy than the support vector machine (SVM) model. Based on the vibration response data of the same powerhouse, Liu and Du [
8] confirmed that the vibration prediction model based on an RBF neural network and improved bat algorithm (IBA) is superior to the RVM model in terms of prediction accuracy and generalization ability. Song et al. [
9] utilized the improved firefly algorithm (IFA) and BP neural network to predict the amplitude of hydropower house vibrations. The results demonstrate that the prediction accuracy and convergence speed of the IFA–BP model are significantly improved compared to the BP and FA–BP models. All of the proposed prediction methods and results are highly significant for the advancement of vibration research in pumping station engineering. However, current research on predicting vibrations in pumping houses and hydropower houses mainly focuses on the vibration amplitude under specific working conditions, with fewer studies addressing the prediction of time trend responses of structural vibrations.
Vibration trend prediction can accurately depict the operational behavior of a unit through a time series of vibration responses, surpassing the limited scope of vibration amplitude analysis for specific working conditions. In the field of vibration trend prediction research, the autoregressive integrated moving average (ARIMA) has gained widespread adoption as a statistical method for accurate time-series prediction. ARIMA effectively handles non-stationary time series by employing lag value regression of the dependent variable and the present value of the random error term, thereby harnessing trend characteristics, dynamic information and series persistence to forecast future trends [
10,
11]. The adaptive network-based fuzzy inference system (ANFIS) represents an intelligent prediction model that combines the principles of fuzzy inference and artificial neural networks (ANNs). ANFIS incorporates fuzzy rules into its inference system to handle uncertainty related to influencing factors and utilizes ANN for simulation and prediction tasks. Compared with the single prediction model, ANFIS offers distinct advantages, such as simplicity in expressing fuzzy logic and the capability for self-learning in a neural network. These merits have contributed to the successful utilization of ANFIS across various domains. Milan et al. [
12] employed ANFIS and optimized ANFIS methods to predict the optimal exploitation of groundwater resources. Tran et al. [
13] developed an ANFIS-based prediction model for assessing the processing performance of the thrust and surface roughness in biological composites. Sharifi et al. [
14] used the ANFIS method to evaluate the intelligent performance of the agricultural surface water distribution system, yielding superior prediction results when compared to ANN and FIS methods.
Single prediction algorithms are usually simple in principle and easy to implement, and they can provide the time-varying characteristics of the prediction object from different angles, but they have limitations, such as incomplete information reflection and limited scope of application. To overcome these limitations, hybrid models combine the strengths of multiple models to compensate for the shortcomings of a single model. The research of Armstrong [
15] confirmed that the hybrid prediction model presents greater advantages in solving short-term prediction problems. In the specific context of dam monitoring [
16,
17,
18], hydrological forecasting [
19,
20,
21,
22] and other hydraulic engineering fields, several hybrid prediction models have been proposed and have achieved higher precision results. For example, in a study by Luo et al. [
23], a constrained PSO-SVR model was developed for centrifugal pumps. The research results demonstrated well-predicted performance under multiple operating conditions, compared to experimental results. Similarly, Huang et al. [
24] proposed a hybrid neural network model that incorporates multiple geometrical parameters and operation conditions to predict the energy performance of centrifugal pumps. These hybrid prediction models show promising results in the field of pump energy performance prediction and can contribute to better decision making and optimization for pump operations in various industries and applications.
The pumping station is a complex system with different types of components and sources of vibration. Therefore, it is essential to assess the safety level using predicted vibration data. Safety early warning is a comprehensive research subject that involves multiple projects and levels and provides a higher level of safety prediction.
Compared with other engineering production fields, research on safety early warning in the field of hydraulic engineering had a later start. This delay can be attributed to the challenges in using analytical relations or mathematical models to describe the strong nonlinearity, fuzziness and complexity of the hydraulic system. In the early 1980s, the United States made a preliminary attempt to introduce risk analysis technology into the safe operation and maintenance of dams, which was achieved through the introduction of risk early warning theory. In 1984, the international dam conference further promoted the application of risk theory in dam management. Concurrently, the United States and Western Europe, together with other countries, improved the risk early warning technology and developed diverse safety early warning theories [
25]. The research on safety early warning of hydraulic projects has been conducted using the risk early warning theory. Sang et al. [
26] proposed an extended cloud model (ECM) combined with the extended analytic hierarchy process (EAHP) to assess the overall safety trend of dams and select a safety trend warning indicator. He et al. [
27] proposed an integrated variable fuzzy evaluation model to evaluate the social and environmental impact of dam breaks. Yang et al. [
28] presented a systematic approach for analyzing the law and early warning of vertical displacements in sluice clusters located in coastal soft soil.
Intelligent safety management technology is increasingly being applied to practical projects, and the concept of risk early warning has gained widespread recognition and attention. Previous safety early warning studies focused on reservoirs, dams and sluices in hydraulic projects, primarily from a risk analysis perspective, and they yielded favorable outcomes. Unfortunately, there has been a lack of attention paid to safety early warning systems for pumping stations and hydropower houses, resulting in a dearth of research in this area. Therefore, addressing these gaps in research is essential to guarantee the safe operation and improve the productivity of pumping stations and hydropower houses. The D-S evidence theory is a commonly used information fusion technology. D-S evidence theory introduces the probability distribution function, confidence function and likelihood function, lessening the reliance on traditional probability theory’s prerequisites of prior probabilities, conditional probability and unified identification framework. The D-S evidence theory has wide application in fault detection [
29] as well as in safety evaluation for the ocean environment [
30] and the cloud platform [
31]. In the field of hydraulic engineering, Chen et al. [
32] enhanced the evidence distance measure method in D-S evidence theory by utilizing the belief Wasserstein-1 distance (BWD) and applied it to dam health diagnosis. Their findings indicate that the proposed method achieves significantly higher accuracy when compared to existing approaches. Xu et al. [
33] proposed a D-S evidence theory based on neural networks for turbine fault diagnosis. They utilized the BP and RBF networks to form the initial diagnosis layer and observed that the proposed method yields superior diagnostic results compared to single diagnosis methods. Recently, the D-S evidence method has been sparsely employed in the field of pumping stations.
In light of the demand for real-time data processing and analysis in the management system of pumping stations, this study aims to evaluate the level of vibration in the pumping station by developing a system for predicting vibrations and providing early warnings for safety purposes. To achieve this goal, a hybrid model is proposed, which combines the ARIMA single model, the ANFIS model and the whale optimization algorithm (WOA) to predict vibration responses. Furthermore, the D-S evidence theory is used to conduct safety early warning research. The prediction of the vibration trend of the effective stress on the blades is compared with that of a single prediction model and other models that employ different optimization algorithms. The vibration data collected will also serve as a source of data for the safety early warning system. In the early warning model, the fusion indicators for analyzing the vibration data are chosen to be the displacement, velocity, acceleration and stress of the vibration. The probability of each safety level is then quantitatively calculated and evaluated. This research could provide guidance for vibration control and attention of the pumping station project.
2. Calculation Method and Procedure
2.1. Autoregressive Integrated Moving Average Algorithm
The ARIMA model, proposed by Box and Jenkins [
34], is a time-series analysis method commonly known as the Box–Jenkins model. The ARIMA model utilizes the historical information of a time series and employs a linear combination of predictions from multiple white noise processes. It can be applied to both stationary and non-stationary time series after differencing to achieve stability. The mathematical expression of the ARIMA model is as follows.
where
µ is a constant,
εt is the white noise sequence,
θi is the moving average coefficient,
p is the order of autoregression and
q is the order of moving average.
The ARIMA model is established for predicting the vibration response of pumping stations. The procedure is performed as follows.
- (1)
The time-series data of vibration response are obtained and preprocessed. This may involve removing any outliers or missing data points, as well as normalizing the data.
- (2)
The stationarity test is conducted after the data preprocessing step. If the test fails, differential processing shall be carried out until it passes the stationarity test.
The ADF-KPSS joint test is a statistical test commonly used to assess both stationarity and long memory in a time series. The ADF test controls for high-order sequence correlation by including lagged difference terms of the dependent variable in the regression equation. This test is used to determine if the time-series data exhibit a unit root, which implies non-stationarity. Assuming that the vibration response
yt follows an AR(
p) process, the model used for the unit root test can be represented by Equations (2)–(4).
where
μ is the drift term and
t is the time trend term. In the testing process, the test model is selected based on the characteristics of the sequence. If
ρ = 0 in Equations (2)–(4), then the null hypothesis of a unit root exists; if
ρ is significantly less than 0, the null hypothesis of a unit root in the test sequence is rejected.
The KPSS test, on the other hand, examines whether the data have a trend or exhibit long memory behavior. The null hypothesis of the KPSS test is that the sequence {
yt} is stationary, and the alternative hypothesis is that the sequence {
yt} is non-stationary. The principle is to remove the intercept term and trend term from the residual estimate sequence {
} and construct the
LM statistic. The basis for the existence of a unit root in the original sequence is whether there is a unit root in the test {
}.
The construction of the KPSS statistic
LM is as follows:
where
f0 is the residual spectral density when
f = 0, and
S(
t)
2 is a consistent estimate of the residual variance. The stationarity of the sequence can be determined by comparing with the critical value.
If the sequence rejects the ADF test but accepts the KPSS null hypothesis, the sequence is stationary. If the sequence simultaneously rejects the ADF and KPSS null hypotheses, the sequence may exhibit long memory and further testing is required.
- (3)
The autocorrelation and partial correlation coefficients of the series are calculated to determine the order of the ARIMA model. Information criteria, including Akaike’s Information Criterion (
AIC) and Bayesian Information Criterion (
BIC), are adopted to select the optimal ARIMA model.
where
L is the likelihood of time series,
K is the number of estimated parameters and
T is the size of the time series. The model with the least
AIC is the best model.
BIC criterion penalizes the number of parameters more than
AIC. The best model is selected similar to the
AIC criterion by choosing the model with the lowest
BIC value.
- (4)
A residual sequence independence test is conducted. The Durin–Watson test, also known as DW test, is used to test for first-order autocorrelation of residuals in regression analysis, especially in the case of time series. Assuming the residual is
e, the equation for the autocorrelation of each residual is
et =
ρet−1 +
Vt. The null hypothesis for the test is
ρ = 0, and the alternative hypothesis is
ρ ≠ 0. The test statistic
d is shown in Equation (9).
Since d is approximately equal to 2(1 − p), the closer the value of this statistic is to 2, the better. If it is less than 1, it indicates the presence of autocorrelation in the residuals.
2.2. Adaptive Network-Based Fuzzy Inference System
ANFIS is a combined prediction model, which was proposed by Jang [
35]. Combining fuzzy logic and the neural network organically, ANFIS has the decision-making judgment ability of a fuzzy system and the self-learning ability of a neural network. It automatically generates if–then rules, learns from sample data and adapts the parameters of the neural network model. The front parameters are adjusted using the BP algorithm in the reverse transmission of ANFIS. The rear parameters are adjusted using the Least Square Method (LSM) in the forward transmission. The combined algorithm based on the BP algorithm and LSM improves the calculation efficiency and prediction accuracy of the ANFIS model.
Based on the Takagi–Sugeno model [
36], the structure of two input–single output ANFIS is shown in
Figure 1. Corresponding if–then rules are expressed as follows.
- (1)
If x1 is A1 and x2 is B1, then y = p1x1 + q1x2 + r1;
- (2)
If x1 is A2 and x2 is B2, then y = p2x1 + q2x2 + r2.
The ANFIS network consists of the following layers: fuzzification layer, rule inference layer, normalization layer, defuzzification layer and output layer. The fuzzification layer transforms each precise input into several fuzzy subsets, each represented by a membership function indicating the degree of belonging. The nodes in the fuzzification layer are adaptive nodes, and their calculation formula is described in Equation (10).
where
is the node output of the first fuzzification layer.
xi (
i = 1, 2) is the precise input of node
i.
Ai (or
Bi) is the fuzzy subset corresponding to
xi.
µAi and
µBi are the membership functions of
Ai and
Bi, respectively. {
δi,
bi,
ci} are antecedent parameters, whose values are related to the shape of the membership function.
The rule inference layer multiplies the output of the membership function signals by the fuzzification layer to obtain the excitation intensity value of the if–then fuzzy rules. The node output
is expressed in Equation (11).
The normalization layer is responsible for normalizing the excitation intensity value output by the rule-reasoning layer. Specifically, the percentage of the excitation intensity of the corresponding node is calculated, as well as the sum of all the excitation intensities. The output
of the third normalization layer is described in Equation (12).
The nodes of the defuzzification layer and the fuzzification layer are adaptive nodes. The role of the defuzzification layer is to convert fuzzy variables into precise variables. Based on if–then fuzzy rules, the normalized parameters are weighted and summed to obtain accurate output
.
where {
pi,
qi,
ri} are the subsequent parameters, which will be constantly adjusted during the training process.
The output layer is used to sum all input signals, represented by fixed nodes marked with ‘Σ’. The output
is shown in Equation (14).
In ANFIS, the generation of fuzzy variables usually adopts the unsupervised learning clustering analysis method. The samples are divided into different types of subspaces according to the similarity. There are generally three methods of generating fuzzy variables in ANFIS, namely, grid partition (GP), subtractive clustering (SC) and fuzzy C-means clustering (FCM).
- (1)
Grid partition algorithm
The GP algorithm is a clustering method that transforms data samples into grid cells. The data sample is divided into grid cells using parallel lines along the membership function axis. The correlation of each grid cell is then calculated and compared to the threshold of the data cluster to determine whether to merge it with the surrounding grid and form a data cluster, thus achieving the purpose of classification.
The GP clustering algorithm overcomes the limitations of other clustering algorithms that are sensitive to the shape and size of the cluster. It reduces model training time by connecting the subspaces divided based on the data dimension in a grid-based manner. However, GP clustering has poor scalability, and the accuracy of the GP algorithm is easily influenced by noisy sample data, resulting in relatively rough results.
- (2)
Subtractive clustering algorithm
The SC algorithm is a density-based clustering algorithm that was proposed by S. Chiu [
37] in 1994. The SC algorithm assumes that any data point may be the cluster center. The probability of the data point as the cluster center is evaluated based on the data point density near each point. The data point with the highest density is selected as the cluster center, while data points with lower density are excluded. After the first cluster center is selected, the next cluster center is selected from the remaining data points using the same method. This process continues until the density near the data points is lower than the defined threshold.
Generally, it is assumed that all data points are located in a hypercube with a unit of 1, meaning that each one-dimensional coordinate of the data point is between 0 and 1. The density
Di of the data point
xi is defined as [
38]:
where
ra represents the influence radius of the data point density range. Obviously, the more data points within the influence radius, the greater the density
Di, and the greater the probability that the data point will become the cluster center.
After calculating and comparing the density of all data points, the highest density of data points is selected as the first cluster center
Xi, and its density is defined as
DXi. The density of the remaining data points is then adjusted based on
DXi as follows.
where
is constant, which is defined as
. The inhibition factor
η should be greater than 1 to prevent the distance between different cluster centers from being too close.
It is more suitable to use the SC algorithm to divide the input space when the number of input variables is greater than three. This approach results in fewer fuzzy rules compared to the adaptive grid method. It also provides a more reasonable division of the input space with reduced training time. Moreover, the fuzzy rules could be increased one by one, which prevents gaining over-fitting results, improves the generalization and accuracy ability of the model.
- (3)
Fuzzy C-means algorithm
The FCM clustering algorithm, originally proposed by J. C. Dunn [
39] in 1974 and improved by J. Bezdek [
40] in 1981, has established itself as a highly accurate and widely applicable method in many clustering algorithms [
41,
42]. The core of the FCM algorithm is to perform iterative calculations and update the cluster center point based on the minimum cost function.
FCM decomposes the sample data {
x1,
x2, …,
xn} into
k fuzzy groups and determines the cluster center {
c1,
c2, …,
ck} for each fuzzy group based on the minimum cost function. The membership value of the
jth data point
xj to the
ith cluster center
ci is denoted as
uij, and it ranges from 0 to 1. The sum of the entire membership matrix is 1 after data normalization, namely:
The cost function of FCM is typically represented by Equation (18).
where
U is the membership matrix,
ci is the
ith cluster center point,
dij is the Euclidean distance from the
jth data point
xj to the
ith cluster center
ci and
m is the weighted index and ranges in [1, +∞).
Lagrange multiplier
λj (
j = 1, 2, …,
n) is brought into Equation (18) to solve the necessary conditions for
J to reach the minimum value.
The expression for the cluster center
ci (Equation (20)) and membership degree
uij (Equation (21)) is obtained by taking the derivative of cost function
J with respect to
ci and
uij, respectively. The FCM clustering algorithm iteratively solves the problem. The cost function
J stops when it becomes less than the threshold or reaches the maximum number of iterations, resulting in the determination of the final clustering center
c and membership matrix
U.
2.3. Optimization Algorithms
WOA, proposed by S. Mirjalili and A. Lewis [
43], is a metaheuristic optimization algorithm based on humpback whale hunting behavior. Humpback whales like to prey on fish and shrimps near the water surface in the form of circular contraction and spiral rise, as shown in
Figure 2. In contrast to other traditional single algorithms, WOA offers several advantages, including a simple structure, easy implementation and high convergence accuracy. Despite being a relatively new optimization algorithm introduced in recent years, WOA has been widely applied in fault diagnosis [
44,
45] and other fields, with successful prediction outcomes.
A mathematical model is established to describe the predatory behavior of whales. Assuming that the current optimal candidate solution is target prey, the search agent will update the current position towards the target prey. The whale’s prey encirclement behavior is expressed in Equations (22) and (23).
where
D represents the distance between the search agent and the target prey.
X and
X* are the current position and optimal position vector of the whale, respectively.
t is the number of iterations.
A and
C are vector factors and are expressed as follows.
where
a decreases linearly from 2 to 0 during iteration, and
ra and
rc are random vectors between 0 and 1.
Humpback whales surround their prey along the spiral path and emit bubbles. The whale’s bubble net hunting strategy is shown as follows.
where
is the line length from whale to prey,
b is the shape parameter of the logarithmic spiral and
l is a random number between −1 and 1.
Assuming that the probability of humpback whales using the ring contraction and spiral rise mechanisms to update the position is 50%, respectively, then:
where
p is the random number of selection probability in [0, 1].
Random prey search is required to update the position of the Humpback whales, as shown in Equations (28) and (29).
where
Xrand(
t) is a randomly selected search agent position vector.
Two additional algorithms are adopted to optimize the weight coefficients in the hybrid models, which are Genetic Algorithm (GA) and Particle Swarm Optimization (PSO). GA is an intelligent optimization algorithm proposed based on evolutionary theory and genetic principles. It simulates the principles of survival of the fittest and natural selection by designing a specific population to survive in a particular environment, using three operations, selection, crossover and mutation, to obtain the optimal individual and, ultimately, the optimal solution to a problem. Selection, crossover and mutation are the core operations of genetic algorithms.
The PSO algorithm originated from the study of bird flock predation behavior. It is a global optimization algorithm that utilizes cooperation and information sharing among individuals in a population to find the optimal solution with good global search ability. The updating formulas for the velocity and position of the particles in the population are given by:
where
and
represent the current velocity and position of particle
i,
and
represent the individual best and global best,
and
represent the newly updated velocity and position of the particle,
ω is the inertia weight,
c1 and
c2 are non-negative constant learning factors and
r1 and
r2 are random numbers between 0 and 1.
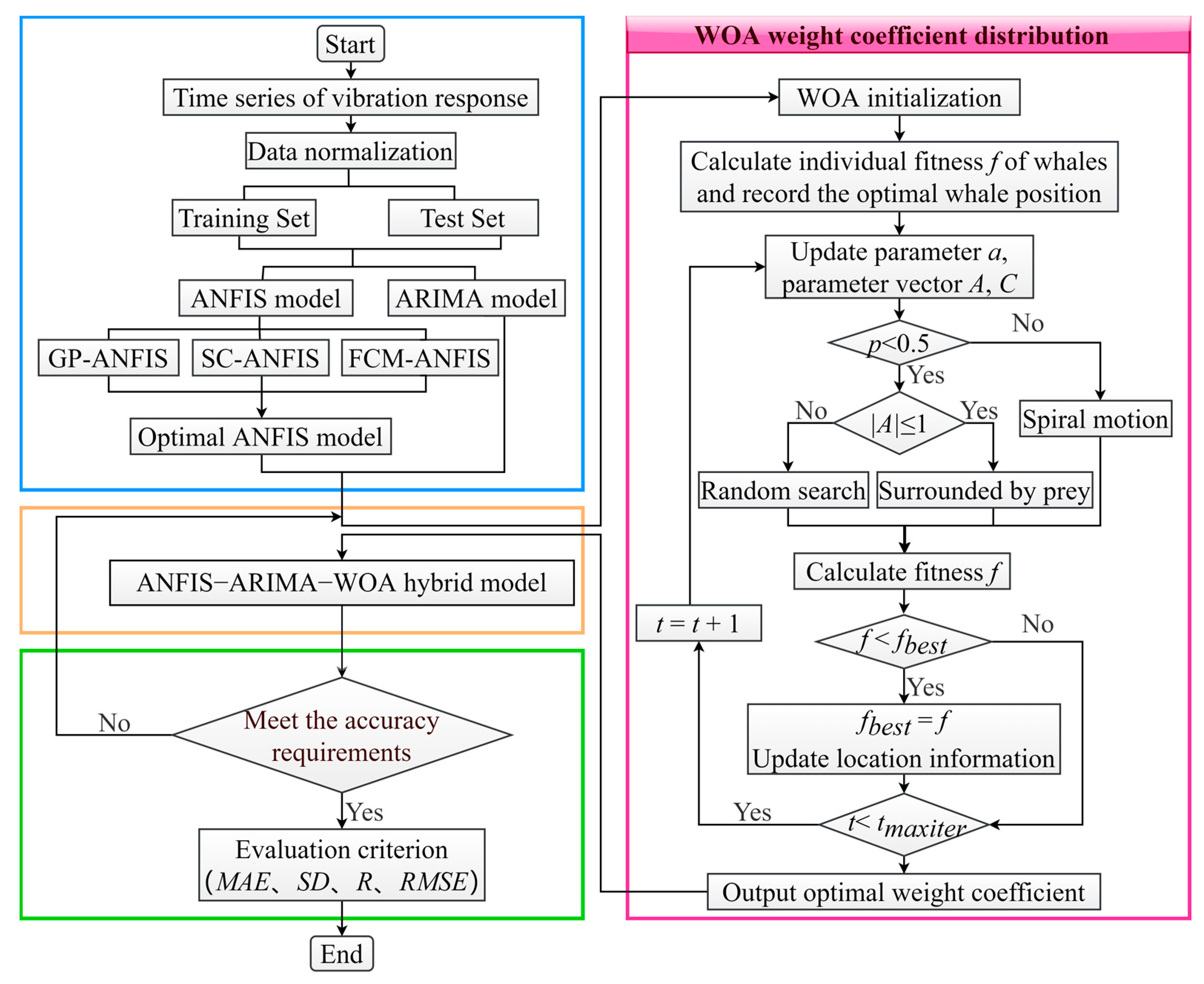
2.4. Calculation Procedure of ARIMA–ANFIS–WOA Hybrid Model and Evaluation Criterion
There are certain limitations in the traditional single-time series prediction model in terms of prediction accuracy. Based on the ARIMA single prediction model, ANFIS combined prediction model and WOA, the ARIMA–ANFIS–WOA hybrid prediction model is proposed and applied to predict the vibration response of the pumping station.
The hybrid prediction theory allocates appropriate weight coefficients to different prediction methods for the same prediction problem. The final prediction results of the hybrid model are achieved by superimposing the results of the single prediction model. For the ARIMA–ANFIS–WOA hybrid prediction model,
Yt = {
yt} is assumed as the actual time-series data.
is the final prediction result of the hybrid prediction model.
is expressed as follows.
where
f1t and
f2t represent the prediction results of the first and second prediction model at time
t, respectively.
m is the maximum prediction time.
w1 and
w2 are the weight coefficients of the first and second prediction results, respectively.
The calculation process of the ARIMA–ANFIS–WOA hybrid prediction model is shown in
Figure 3. The specific implementation steps are described as follows.
Step 1: Select and normalize the time series of the vibration response of the pumping station. Since the time history response of the effective stress of the blades exhibits both linear and nonlinear characteristics, we choose the effective stress curve calculated from numerical simulation for the prediction study. The dataset is divided into training set and test set.
Step 2: Train and predict the time series at each time point using the ANFIS model and the ARIMA model, respectively. The prediction results at this step serve as intermediate results during the prediction process of the hybrid model. In the prediction study based on the ANFIS model, we employ three different algorithms, namely GP, SC and FCM, to generate the fuzzy structure, and we compare the prediction results to determine the optimal ANFIS results.
Step 3: WOA is used to obtain the weight coefficients of intermediate results. Firstly, WOA is initialized to calculate the individual fitness of whales. The optimal position is recorded, and parameters a, A and C are updated. Then, the probability p value discrimination is conducted. If p ≥ 0.5, spiral motion will be performed according to Equation (26). Otherwise, if |A| > 1, random search will be performed according to Equations (28) and (29). If |A| ≤ 1, prey surrounding will be conducted according to Equations (22) and (23). Next, the fitness f is calculated and compared with the optimal fitness fbest. If f < fbest, the position is updated, and the next iteration is proceeded until the optimal solution is achieved. Otherwise, the next iteration proceeds without updating the position.
Step 4: Combine the intermediate prediction results of the ANFIS model and ARIMA model with the optimal weight coefficient obtained from the WOA algorithm to establish the ANFIS-ARIMA-WOA hybrid prediction model for predicting the vibration response of the pumping station.
Step 5: Verify the prediction accuracy of the hybrid model. If the prediction results of the ARIMA-ANFIS-WOA model satisfy the accuracy requirements, the final prediction results are generated, and a corresponding performance evaluation is conducted. Otherwise, return to step 3 to optimize the weight coefficient until the desired prediction accuracy is attained.
The model’s prediction accuracy is evaluated using root mean square error (
RMSE), mean absolute error (
MAE), standard deviation (
SD) and correlation coefficient (
R). The calculation formula is provided in Equations (34)–(37) [
46,
47,
48].
RMSE and
SD assess the accuracy and stability of the model, respectively. Consequently, smaller values of
MAE,
RMSE and
SD indicate better prediction results, while a larger
R value signifies greater predictive ability.
where
N is the number of sample data,
yk is the predicted value of the model,
ŷk is the mean value of the predicted value and
μ is the mean value of the sample data.
2.5. D-S Evidence Theory
The D-S evidence theory, proposed by A.P. Dempster and G. Shafer, is a decision-making method used to address uncertain problems. This theory has found widespread application in various fields, such as data fusion, risk assessment and modern decision making, where a rigorous reasoning process and robust fusion of multiple sources of information are required. In essence, the D-S evidence theory involves establishing an identification framework that represents all possible outcomes of a decision problem. Subsequently, subsets within this framework are evaluated, generating a trust function. The trust function assigns a truth value to propositions recognized by the framework. In cases where multiple subsets exist, the trust functions obtained from each subset can be combined using Dempster’s composition rule, thereby yielding the evidence synthesis result for each subset.
The accuracy of fusion results relies heavily on the basic probability distribution function of the evidence. Since evidence exhibits characteristics of discrete probability distribution, the basic probability value for small probability events is set at 5%. The solution of the basic probability value
mi(
Aj) of the evidence
mi for the proposition
Aj could be referred to Equation (38).
where
xi represents the monitoring value of the evidence
mi.
aij1 and
aij2 denote the lower and upper limits of the range for proposition
Aj, respectively. These limits are determined based on threshold parameter results. The average value of the range of proposition
Aj is represented by
uij, as shown in Equation (39).
Normalization is performed for
mi(
Aj) obtained from Equation (38).
where
z is the number of small probability propositions in the evidence.
mi′(
Aj) is the normalized probability distribution value.
Figure 4 illustrates the safety warning process for the vibration response of the pumping station based on the D-S evidence theory. The process begins by defining evaluation indexes and criteria, establishing an evaluation system for the vibration response of the pumping station. Specifically, displacement, velocity, acceleration and stress are employed as evaluation indexes. Subsequently, a D-S evidence set is constructed using vibration response prediction data for the pumping station. The threshold value for the vibration response is determined based on the vibration control standard of the pumping station. Basic probability distribution is then conducted on the evidence set to create an early safety warning identification framework for vibration. Finally, the identification results of each piece of evidence are integrated and reasoned using the D-S evidence theory. This involves assessing basic probability, trust measure, likelihood measure and other indicators. The evidence fusion results of the operation state of the pumping station units are evaluated.
4. The Safety Early warning Study of the Pumping Station Based on the D-S Evidence Theory
Structural safety prediction is based on the variation pattern of vibration response. It estimates the changing trends of historical monitoring data, providing reasonable references for pumping station vibration response status and future trends to maintenance personnel. However, it usually cannot evaluate the goodness or badness of these variable changes in terms of value significance. On the other hand, warning utilizes useful information from the abundant data in pumping station operation to define safety warning indicators and evaluation criteria. It constructs a safety warning system for the pumping station, evaluates the predictive values from a value perspective and provides an interval for objective safety judgment and decision making by decision makers. Therefore, safety prediction provides a data foundation for safety warning, while safety warning represents a higher-level safety prediction that can support decision making and operations.
Considering the pumping station’s complex structural components, multiple vibration sources and uncertainty of measured data, this study proposes a safety early warning model based on D-S evidence theory for the pumping station. The evidence set is established based on the vibration response prediction results of the pumping station, specifically focusing on the responses of the extreme points. The vibration data are analyzed using the D-S information fusion method, with vibration displacement, velocity, acceleration and stress being chosen as the fusion indicators. The operational status of the pumping station is evaluated, and early warnings are issued accordingly.
4.1. Evaluation Criteria for Vibration Response of the Pumping Station
According to the vibration control standard of the pumping station, the maximum permissible vibration displacement for concrete is 0.20 mm, the maximum permissible vibration velocity is 5.0 mm/s and the maximum permissible vibration acceleration is 1.0 m/s
2. The stress control value for the concrete structure is 17.5 MPa, and for the metal structure, it is 175 MPa. Based on relevant literature [
49], the criteria for evaluating the vibration response of pumping stations using D-S evidence theory are defined and presented in
Table 4. The limit values for extremely unsafe level IV, unsafe level III, relatively safe level II and safe level I are 90%, 80~90%, 70~80% and 70% of the allowable value, respectively.
4.2. Identification Framework for Vibration Safety Warning of Pumping Station
The D-S evidence theory combines multiple pieces of evidence to reduce system uncertainty and determines to which subset of Θ an event belongs. Its essence lies in synthesizing the basic probability distribution function for multiple pieces of evidence. In this research, the identification framework for vibration safety includes the subsets
A1,
A2,
A3,
A4,
As and
Au within the set Θ. The evidence set Θ consists of L1, L2, L3, L4 and L5, which correspond to extreme response point data for displacement, velocity, acceleration, first principal stress and effective stress, respectively. The basic probability distribution function,
m1,
m2,
m3,
m4 and
m5, represents the supporting probability set for each level within Θ.
Figure 14 depicts the D-S evidence theory matrix, where each line represents the support probability of the corresponding evidence for different operation levels of the pumping station, with a sum value of 1. Column
j indicates the support probability for a specific level of pumping station operation. A high value indicates a high probability for this level.
As depicted in
Figure 13, the maximum vibration amplitudes of displacement, velocity, acceleration and the first principal stress of the concrete structure in the pumping station are 1.75 µm, 0.04 mm/s, 4.15 mm/s
2 and 0.13 MPa, respectively. The effective stress of the blade is 24.80 MPa. The basic probability distribution value of each piece of evidence is calculated and normalized according to Equations (38) and (40), as shown in
Table 5.
4.3. Multi-Source Information Fusion Results
Information fusion research is conducted to determine the operational status of the pumping station. This process involves two levels of fusion: data-level fusion and decision-level fusion. In data-level fusion, each evaluation index datum represents evidence of the pumping station’s safety. By fusing the evaluation index data of the same type, comprehensive evidence for that type can be obtained. In decision-level fusion, the fusion results from data-level fusion, which are obtained from different types of evaluation indicators, serve as evidence for the overall safety of the pumping station. This evidence is further fused to obtain the final results, which represent the comprehensive evaluation of the pumping station’s safety.
The fused basic probability distribution after the fusion of
m41 and
m42 is
m4{
A1,
A2,
A3,
A4,
As,
Au} = {0.6919, 0.0600, 0.0107, 0.0107, 0.2230, 0.0036}. The vibration data of measurement points L1, L2, and L3, as well as the stress data after the first-level fusion, were then subjected to second-level fusion. The final result of the information fusion is
M{
A1,
A2,
A3,
A4,
As,
Au} = {0.9462, 0.0240, 0.0000, 0.0000, 0.0297, 0.0000}, the belief measure
Bel{
A1,
A2,
A3,
A4,
As,
Au} = {0.9462, 0.0240, 0.0000, 0.0000, 1.0000, 0.0000} and the plausibility measure
Pl{
A1,
A2,
A3,
A4,
As,
Au} = {0.9759, 0.0537, 0.0000, 0.0000, 1.0000, 0.0000}. They are listed in
Table 6 and
Figure 15.
Bel(
A) represents the degree of trust in the proposition
A being true, while
Pl(
A) represents the degree of not opposing the proposition
A.
Table 6 shows that
Bel(
A1) = 0.9462, indicating that the trust interval for the safe operation status of the pumping station is [0.9462, 1.0000]. It demonstrates that the pumping station’s safety status under design operating conditions is very good. Based on the upper and lower limits of the trust interval, the uncertainty interval is only 0.0538, indirectly proving the high reliability of the D-S evidence theory for the evaluation of the pumping station’s safety status.
Bel(
As) =
Pl(
As) = 1, meaning that the supporting evidence interval for the pumping station’s safety warning model reaches 1, indicating that the pumping station’s operating status is safe. Considering the complexity and fuzziness of the safety influencing factors of the pumping station, the D-S evidence method integrates different types of evidence information, including the displacement, velocity, acceleration and stress indicators, of the pumping station’s vibration response. It quantitatively displays the probabilities and degrees of trust of each proposition, providing reliable references for the evaluation and decision making of the pumping station’s operation status.


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}