
River Stage Modeling with a Deep Neural Network Using Long-Term Rainfall Time Series as Input Data: Application to the Shimanto-River Watershed


Abstract
1. Introduction
2. Study Watershed and Dataset
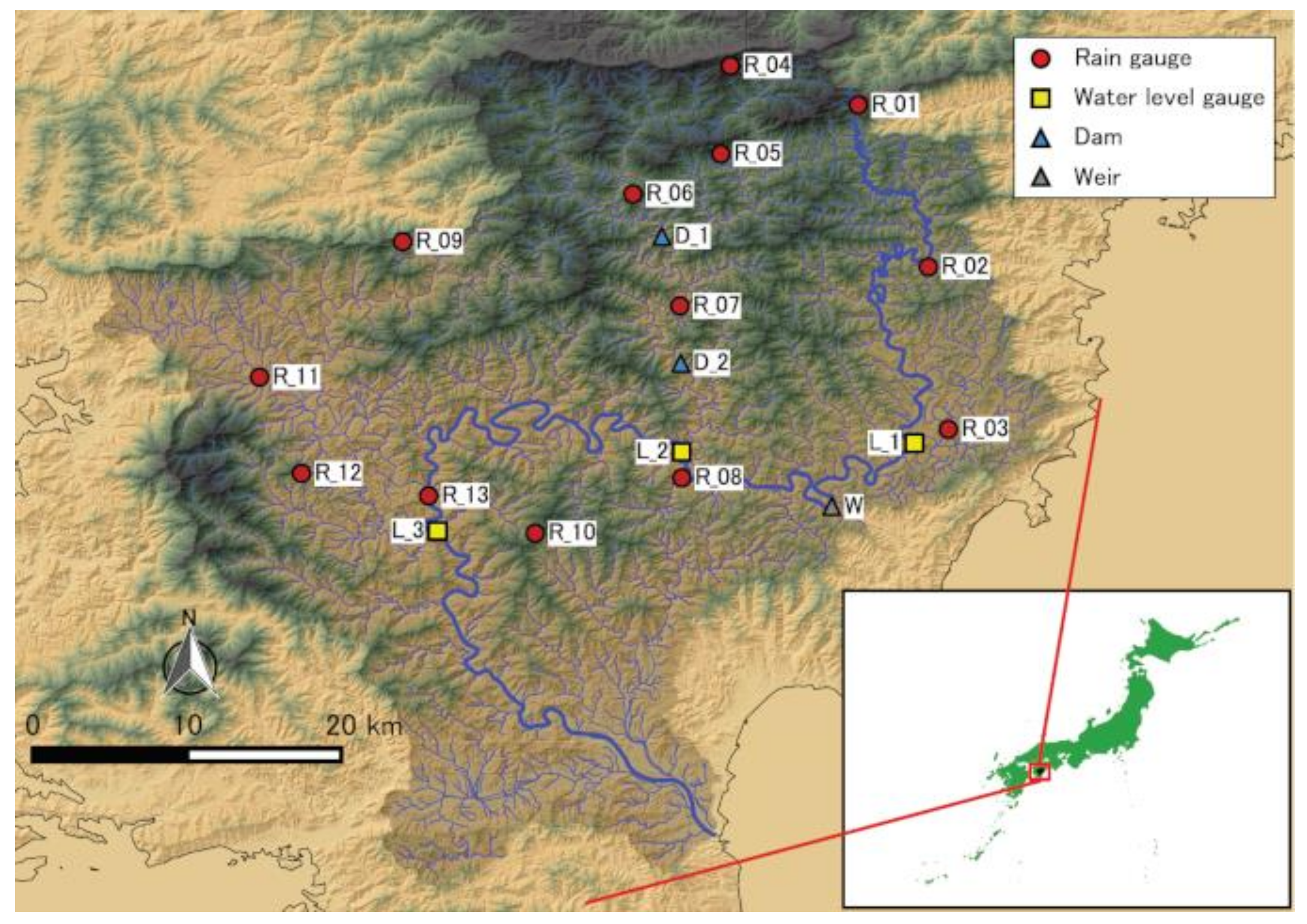
2.1. The Shimanto Watershed
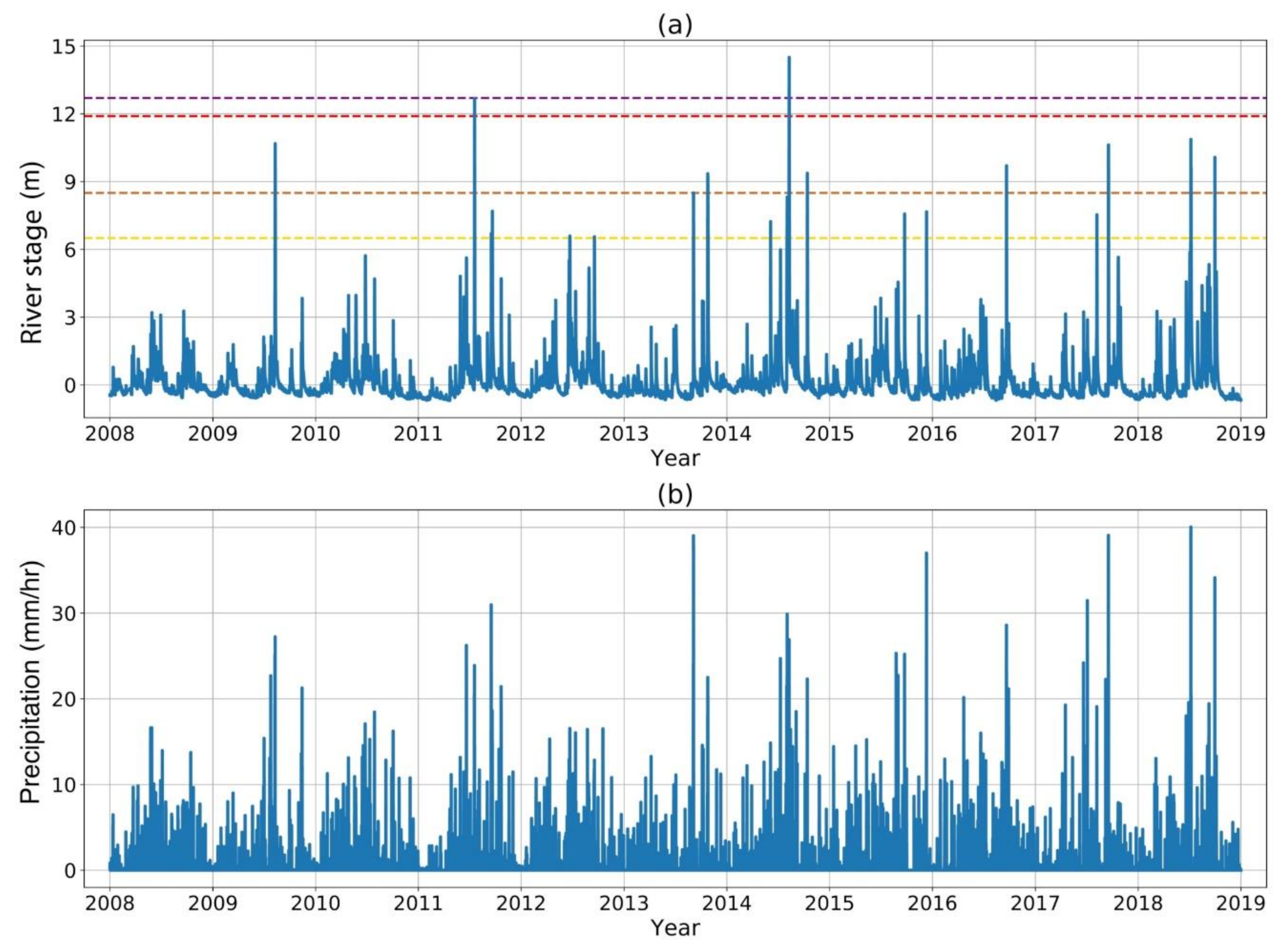
2.2. Dataset
3. Method
3.1. Modeling Concept
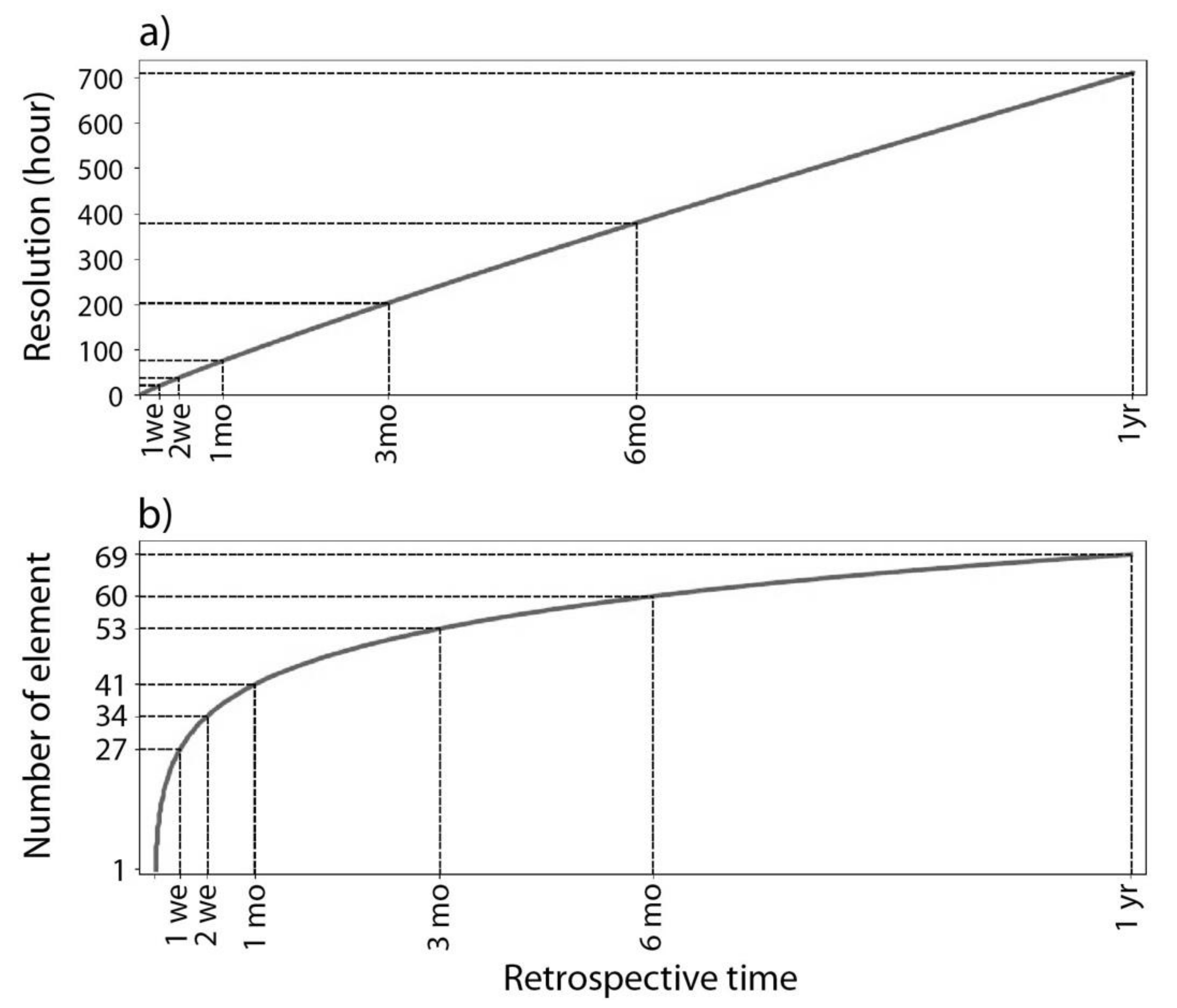
3.2. Precipitation Time Series Data as Input Data
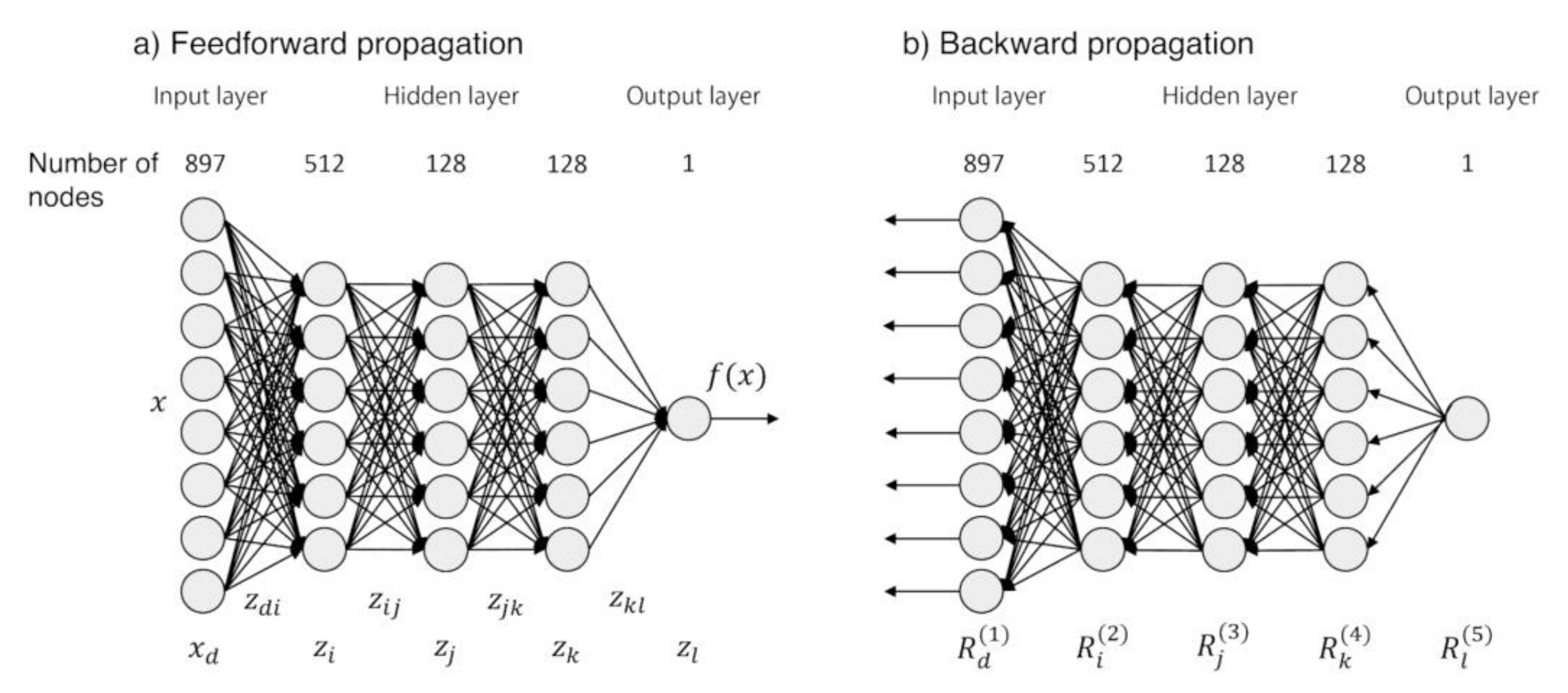
3.3. MLP Model
3.4. Model Evaluation Criteria
4. Results and Discussion
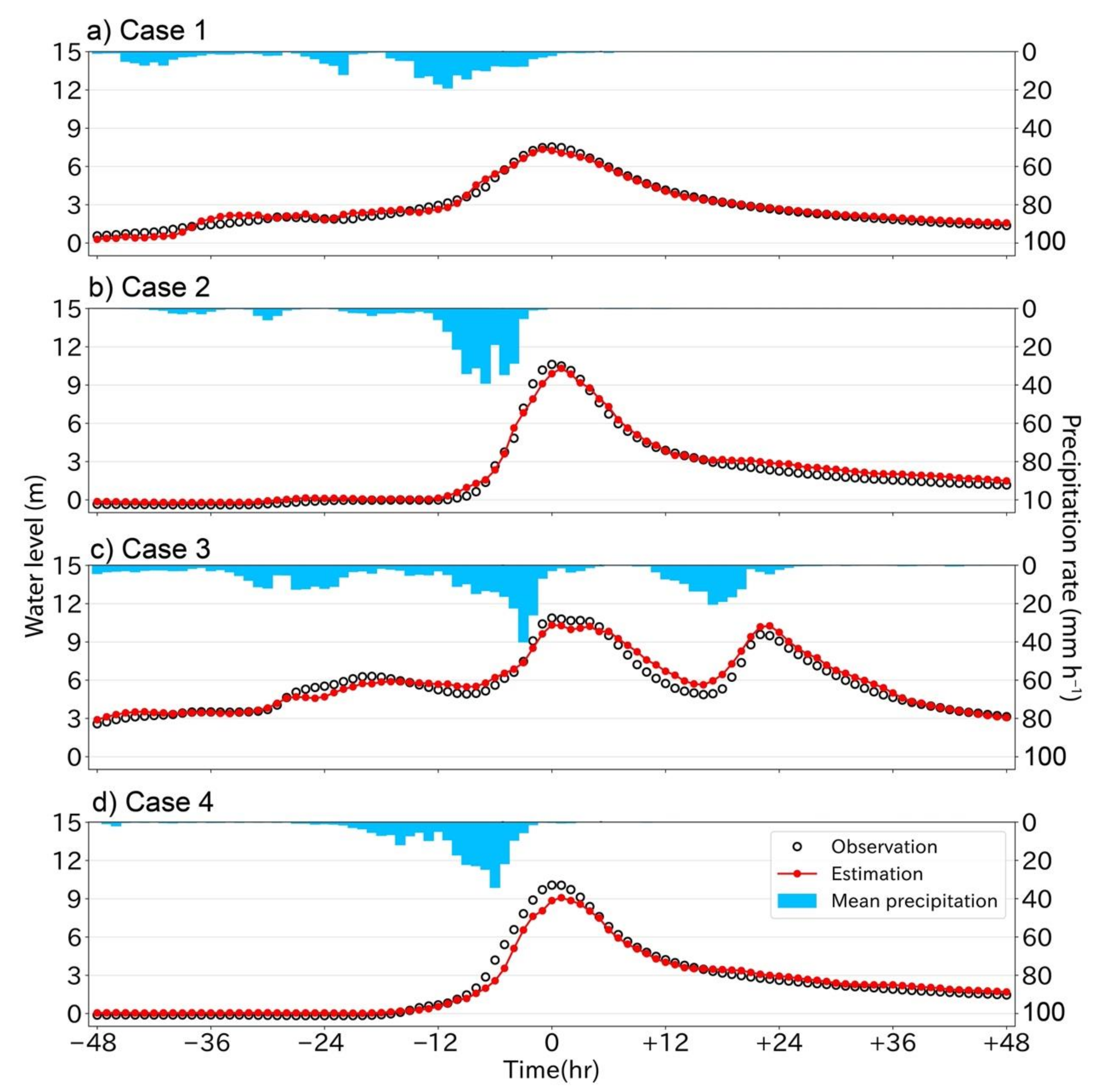
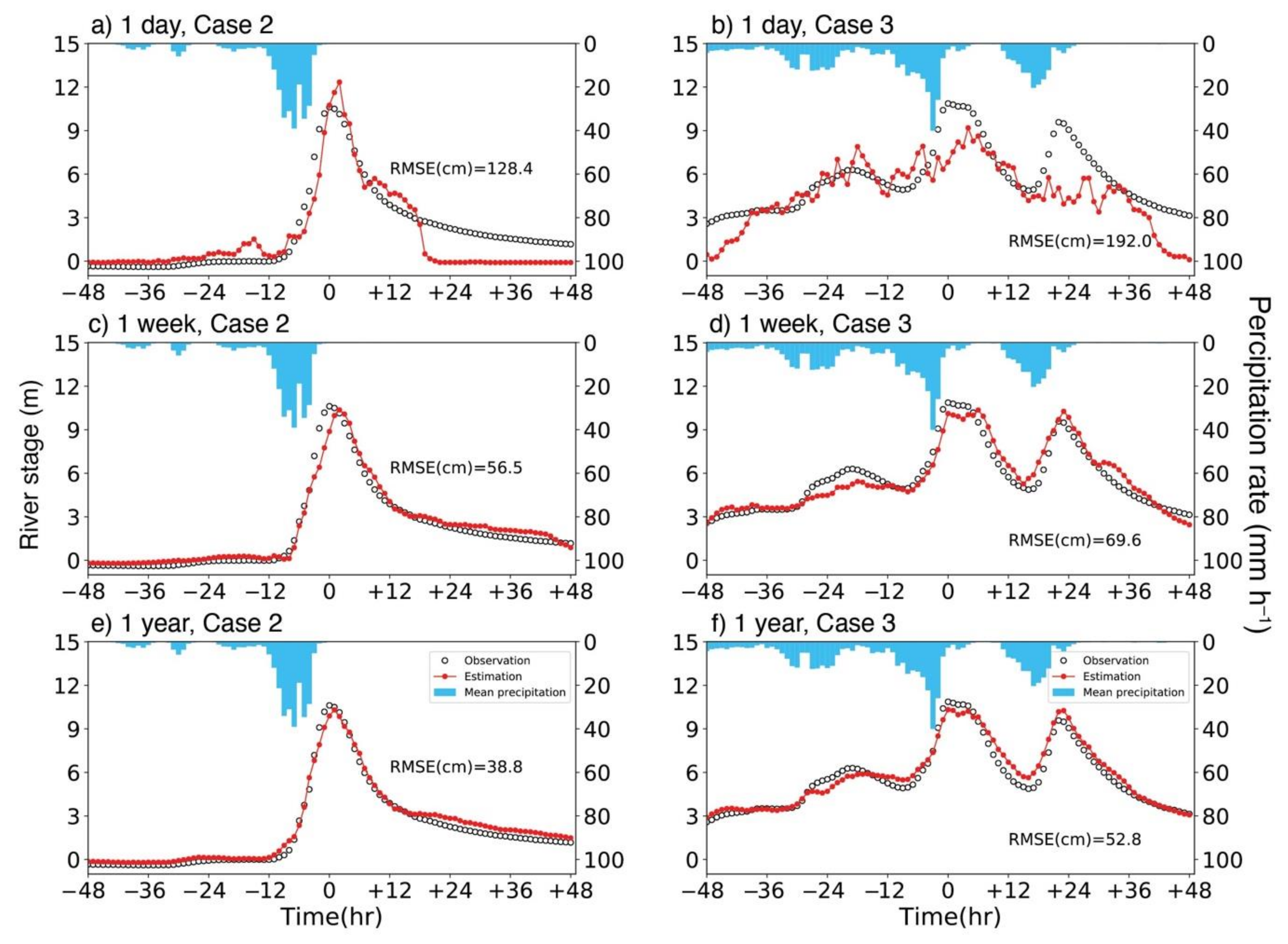
4.1. Stage Estimation
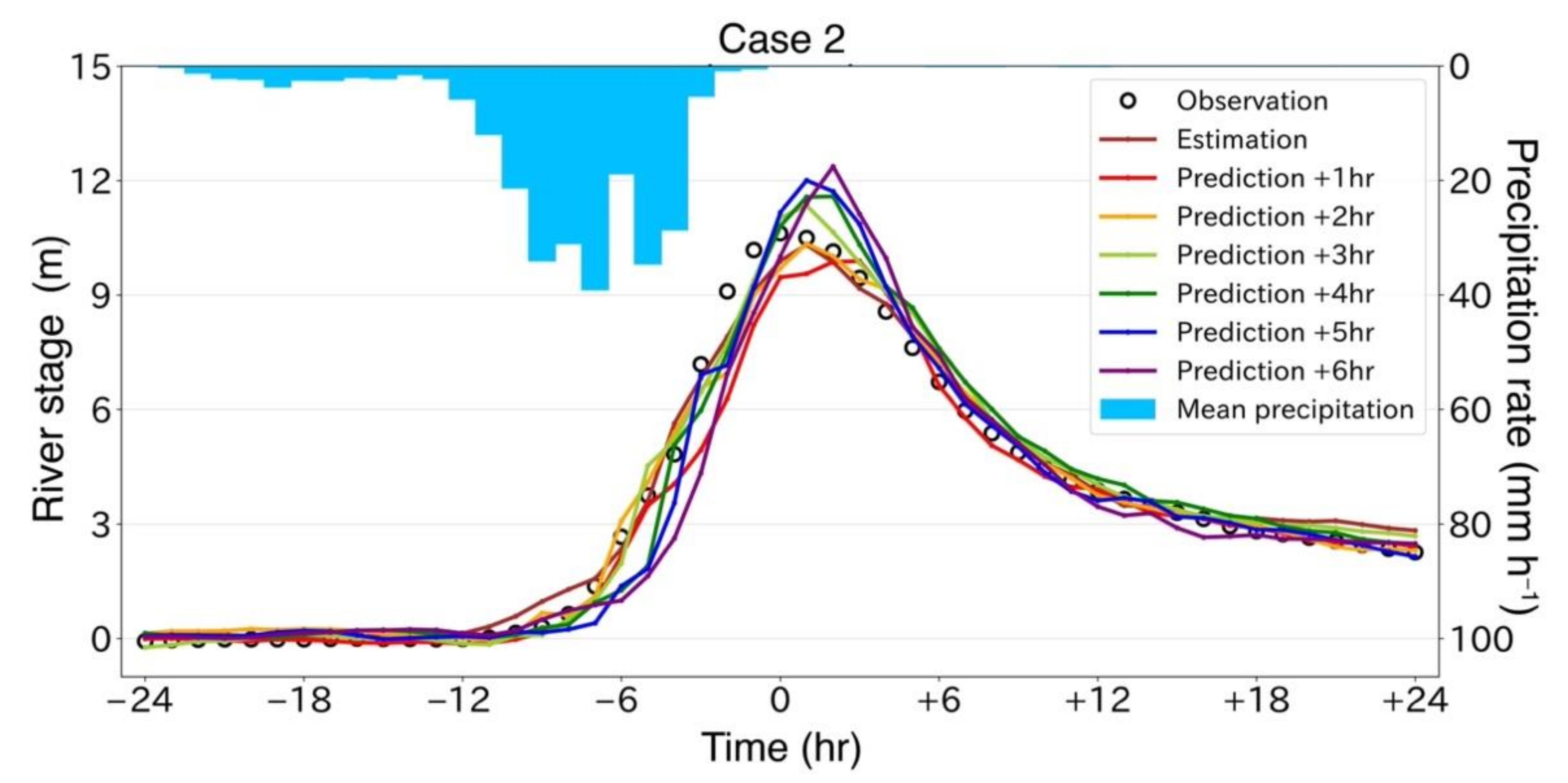
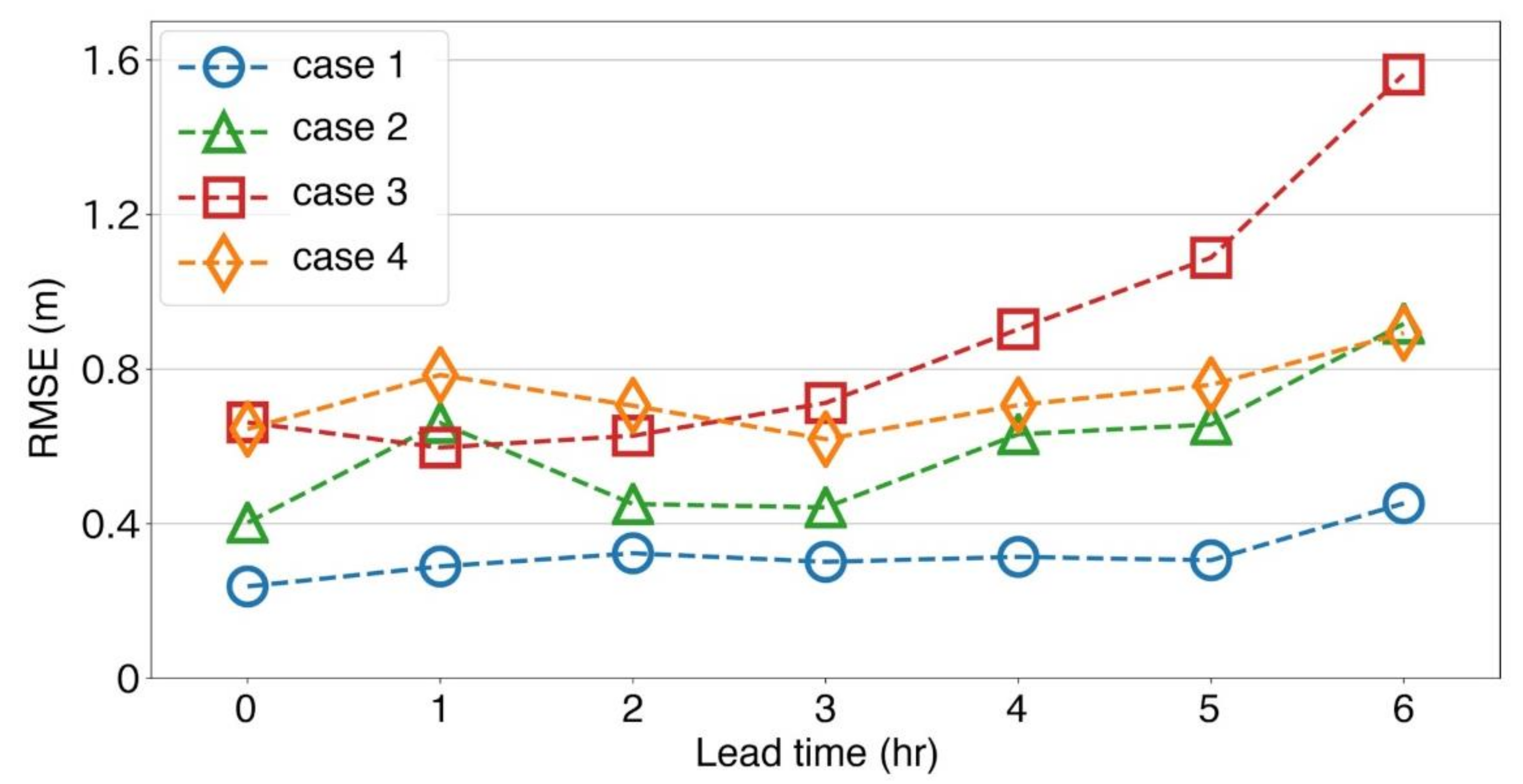
4.2. Stage Forecast
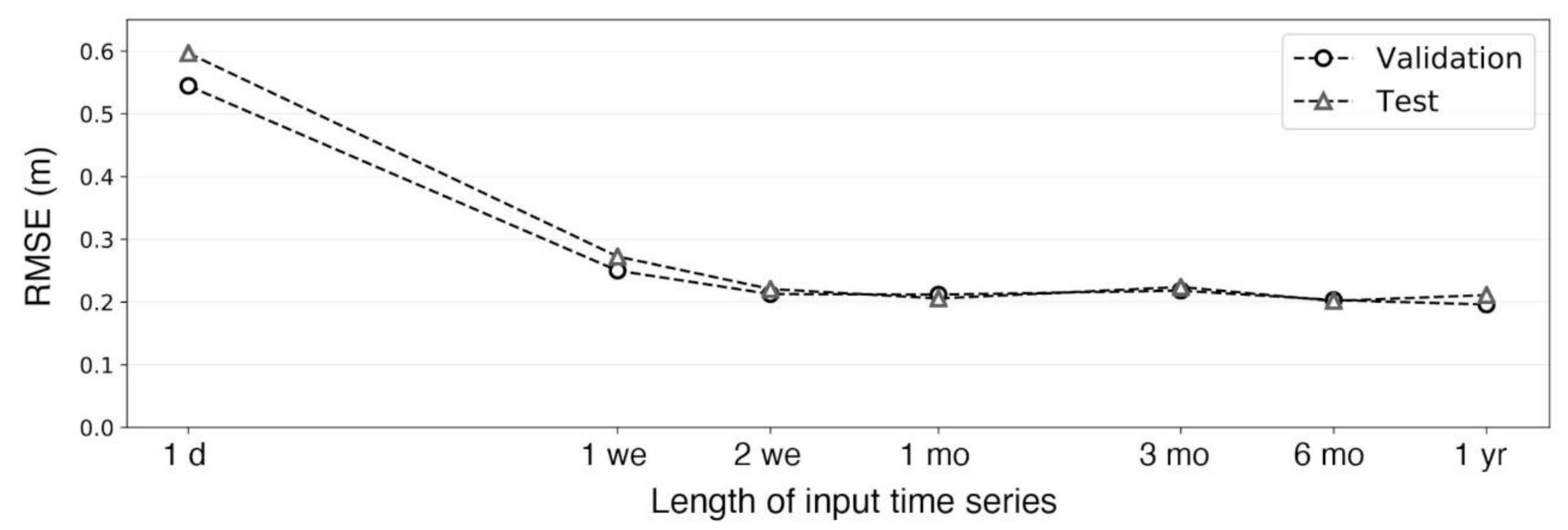
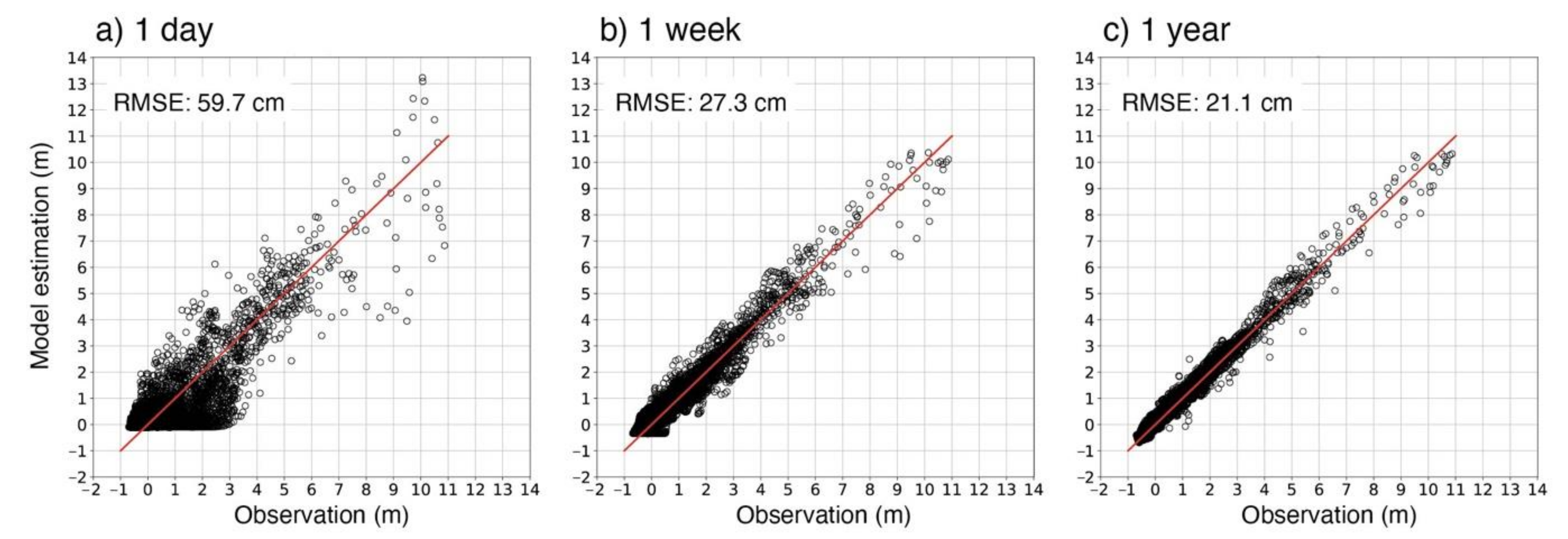
4.3. Effects of Precipitation Time Series Length on Stage Estimation
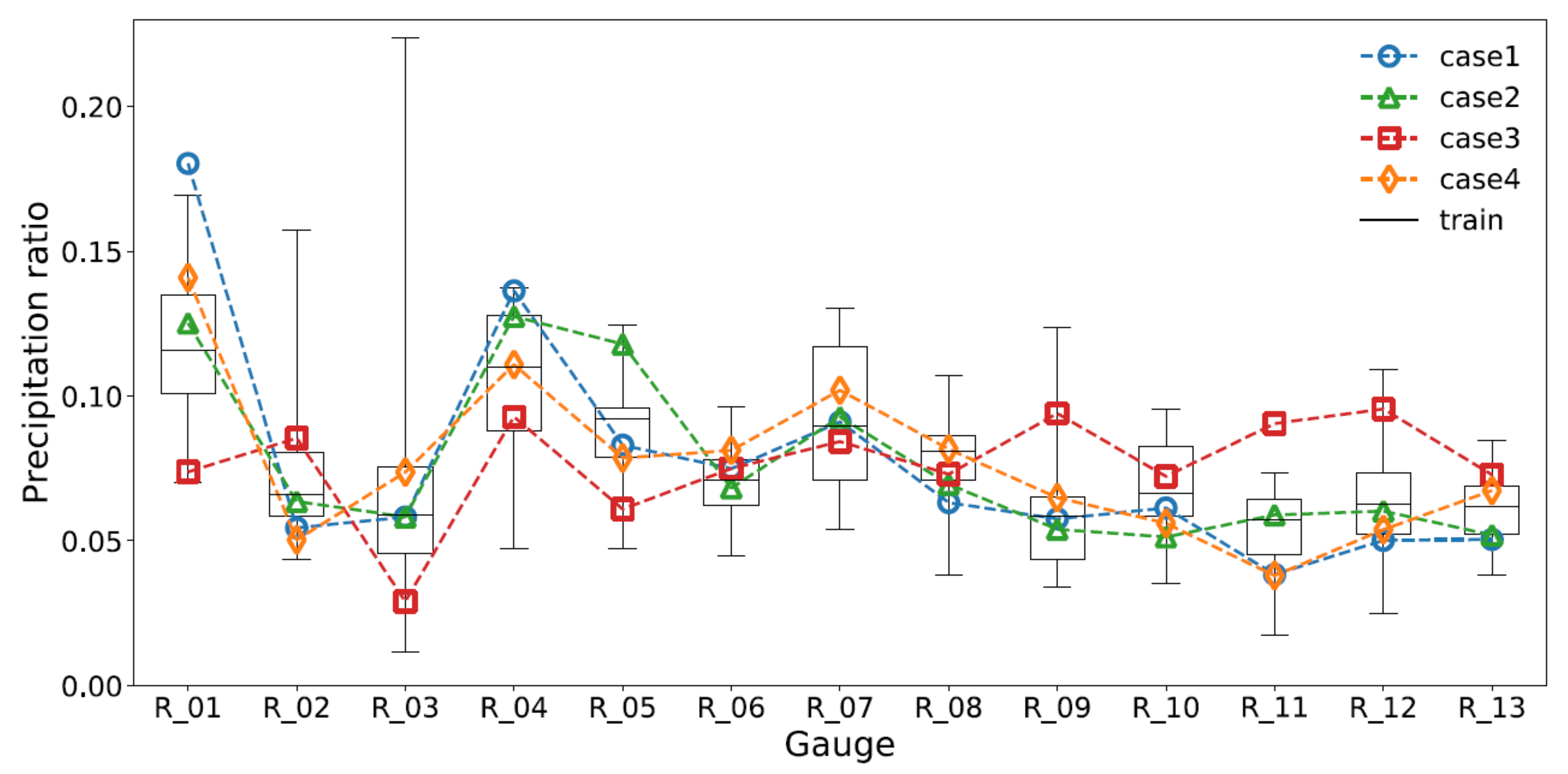
4.4. Stage Estimation Sensitivity to the Rain Gauges

4.5. Comparison with a Previous Research
5. Conclusions
- Models that estimated the stage at the latest time of the input precipitation time series captured the time fluctuation of stages with RMSEs between 30 and 67 cm for flood peaks of about 10 m.
- Stage forecasts were made 1 to 6 h after the latest precipitation observation with the MLP framework. The performance was highly accurate with up to a 3 h lead time. This suggests that the current precipitation information in the watershed contributes significantly to the stage 3 h later.
- Input of precipitation that occurred one day to one week prior to a flood influences the river stage estimate during flood events, which is likely related to the infiltration to soils and interflow processes. Precipitation further back, up to one year, has non-negligible impacts on the base flow, which implies that the MLP models learned the ground water flow over long timescales.
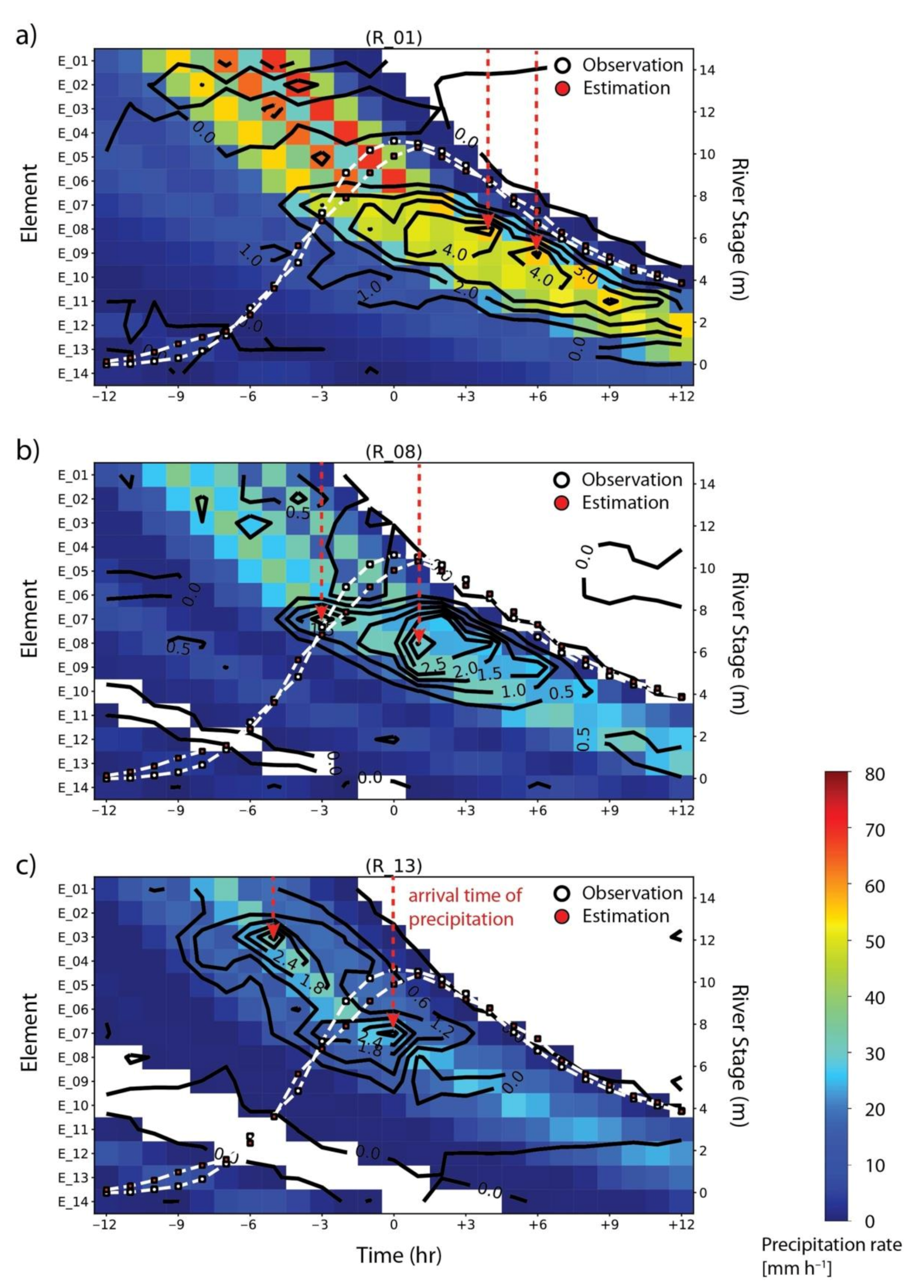
- Use of LRP (layer-wise relevance propagation) enabled us to estimate the arrival time of precipitation based on the increase of the contribution (called relevance). The arrival time correlated to the distance between rain gauge and stage observatory, indicating that the MLP models likely captured the geographical characteristics of the watershed. However, more detailed analysis is required to relate the arrival time to physical parameters such as gradients and vegetation.
- Comparison with a previous MLP modeling and the proposed modeling indicates that use of stage changes as a label gives more accurate prediction for one- to two-hour forecasts than the use of stages themselves, and rainfall time series can substitute the stage changes observed upstream in the input. Furthermore, the proposed models with the lead time of three and five hours performed better than the previous models in some cases.
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Appendix A
Appendix A.1. Development Environment
Appendix A.2. LRP

References
- Intergovernmental Panel on Climate Change (IPCC). Climate Change 2013, The Physical Science Basis. Available online: https://archive.ipcc.ch/report/ar5/wg1/ (accessed on 12 December 2021).
- Japan Meteorological Agency (JMA). Special Feature: To Protect Lives and Livelihoods from the Intensifying Torrential Rain Disaster. Available online: https://www.jma.go.jp/jma/kishou/books/hakusho/2020/index1.html (accessed on 12 December 2021).
- Kawase, H.; Yamaguchi, M.; Imada, Y.; Hayashi, S.; Murata, A.; Nakaegawa, T.; Miyasaka, T.; Takayabu, I. Enhancement of extremely heavy precipitation induced by Typhoon Hagibis (2019) due to historical warming. SOLA 2021, 17, 7–13. [Google Scholar] [CrossRef]
- Kato, R.; Shimose, K.; Shimizu, S. Predictability of precipitation caused by linear precipitation systems during the July 2017 Northern Kyushu heavy rain event using a cloud-resolving numerical weather prediction model. J. Disaster Res. 2018, 13, 846–859. [Google Scholar] [CrossRef]
- Uchida, T.; Akamatsu, Y.; Suzuki, Y.; Moriguchi, S.; Oikawa, Y.; Shirahata, H.; Izumi, N. Special issue on the heavy rain event of July 2018 in western Japan. J. JSCE 2021, 9, 1–7. [Google Scholar] [CrossRef]
- Ministry of the Environment; Government of Japan. Natural Environment of Japan. Available online: https://www.env.go.jp/en/nature/npr/ncj/section1.html (accessed on 12 December 2021).
- Kadoya, M.; Fukushima, A. Concentration time of flood in small or medium river basin. Disaster Prev. Res. Inst. Annu. 1976, 19, 143–152. [Google Scholar]
- Kanda, T.; Kanki, K.; Yoshioka, Y. Estimation of time of concentration for overland flow on a sloping plane. J. JSCE 1990, 417, 53–62. [Google Scholar] [CrossRef][Green Version]
- Kubo, T.; Yamaji, H.; Okabayashi, F.; Shinkawa, K.; Kakehi, Y. Report of the Monobe river flood in July 2018. J. JSCE 2019, 75, 208–213. [Google Scholar] [CrossRef]
- Kikumori, Y.; Ikeuchi, K.; Egashira, S.; Ito, H. Development of flood early warning methodologies using rational formula model in mountainous rivers. J. JSCE 2018, 74, I_1345–I_1350. [Google Scholar] [CrossRef]
- Shen, C. A Transdisciplinary Review of Deep Learning Research and Its Relevance for Water Resources Scientists. Water Resour. Res. 2018, 561, 918–929. [Google Scholar] [CrossRef]
- Gude, V.; Corns, S.; Long, S. Flood prediction and uncertainty estimation using deep learning. Water 2020, 12, 884. [Google Scholar] [CrossRef]
- Rao, G.S.; Giridhar, M.V.S.S. Daily Runoff Forecasting using Artificial Neural Network. Int. J. Sci. Eng. Res. 2016, 7, 478–484. [Google Scholar]
- Chanu, S.N.; Kumar, P. Modelling of Daily Rainfall-Runoff Using Multi-Layer Perceptron Based Artificial Neural Network and Multi-Linear Regression Techniques in A Himalayan Watershed. Indian J. Hill Farming 2018, 31, 166–176. [Google Scholar]
- Oluwatobi, A.; Gbenga, O.; Joy, A.; Oluwole, A. Modeling and simulation of river discharge using artificial neural networks. J. Sci. 2018, 20, 362–370. [Google Scholar] [CrossRef]
- Hitokoto, M.; Sakuraba, M.; Sei, Y. Development of the real-time river stage prediction method using deep learning. J. JSCE 2017, 5, 422–429. [Google Scholar] [CrossRef]
- Nakano, H. Forest Hydrology; Kyoritsu Publisher: Tokyo, Japan, 1976; p. 228. [Google Scholar]
- Hashino, M.; Yao, H.; Yoshida, H. Studies and evaluations on interception processes during rainfall based on a tank model. J. Hydrol. 2002, 255, 1–11. [Google Scholar] [CrossRef]
- Nakane, H.; Wakatsuki, Y. Startup of Deep Learning Application to Environmental Research. Kochi Univ. Technol. Res. Bull. 2018, 15, 111–120. [Google Scholar]
- Nakane, H.; Wakatsuki, Y.; Yamamoto, K.; Takeda, T.; Hashino, T. Application of Deep Learning to River Disaster Prevention and Environmental Conservation—On the Shimanto River and Kagami River Water Levels, and the Ohdo Dam Inflow of the Niyodo River. Kochi Univ. Technol. Res. Bull. 2019, 16, 227–244. [Google Scholar]
- Organization for Promotion of Tourism in SHIKOKU, Shimanto River. Available online: https://shikoku-tourism.com/en/see-and-do/10071 (accessed on 12 December 2021).
- Ministry of Land, Infrastructure, Transport and Tourism (MLIT). River Maintenance Plan, Overview of Watari-Gawa Basin. Available online: http://www.skr.mlit.go.jp/nakamura/seibikeikaku/about/outline.html (accessed on 12 December 2021).
- Ministry of Land, Infrastructure, Transport and Tourism. Water Information System. Available online: http://www1.river.go.jp/ (accessed on 12 December 2021).
- Japan Meteorological Agency. Available online: http://www.jma.go.jp/jma/indexe.html (accessed on 12 December 2021).
- Maidment, D.R. Chapter 9 Flood Runoff. In Handbook of Hydrology; McGaw-Hill: New York, NY, USA, 1992. [Google Scholar]
- Takasao, T. Occurrence area of direct runoff and its variation process. Disaster Prev. Res. Inst. Annu. 1963, 6, 166–180. [Google Scholar]
- Tanaka, T.; Yasuhara, M.; Sakai, H. The Hachioji Experimental Basin Study—Storm Runoff Processes and the Mechanism of its Generation. J. Hydrol. 1988, 102, 139–164. [Google Scholar] [CrossRef]
- Sayama, T.; McDonnell, J.J. A new time-space accounting scheme to predict stream water residence time and hydrograph source components at the watershed scale. Water Resour. Res. 2009, 45, W07401. [Google Scholar] [CrossRef]
- Mejia, A.I.; Moglen, G.E. Spatial distribution of imperviousness and the space-time variability of rainfall, runoff generation, and routing. Water Resour. Res. 2010, 46, W07509. [Google Scholar] [CrossRef]
- Rumelhart, D.E.; Hinton, G.; Williams, R.J. Learning representations by back-propagating errors. Nature 1986, 323, 533–536. [Google Scholar] [CrossRef]
- Maas, A.L.; Hannun, A.Y.; Ng, A.Y. Rectifier Nonlinearities Improve Neural Network Acoustic Models; Stanford University: Stanford, CA, USA, 2013. [Google Scholar]
- Gulli, A.; Pal, S. Regression Network. In Deep Learning with Keras; Packt: Birmingham, UK, 2017; pp. 223–228. [Google Scholar]
- Gorr, W.L.; Nagin, D.; Szczypula, J. Comparative study of artificial neural network and statistical models for predicting student grade point averages. Int. J. Forecast. 1994, 10, 17–34. [Google Scholar] [CrossRef]
- Dozat, T. Incorporating Nesterov Momentum into Adam. In Proceedings of the ICLR 2016 Workshop Paper, San Juan, Puerto Rico, 2–4 May 2016; p. 107. [Google Scholar]
- Moriasi, D.; Arnold, J.G.; Van Liew, M.W.; Bingner, R.L.; Harmel, R.D.; Veith, T.L. Model evaluation guidelines for systematic quantification of accuracy in watershed simulations. Trans. ASABE 2007, 50, 885–900. [Google Scholar] [CrossRef]
- Katz, R.W.; Murphy, A. Economic Value of Weather and Climate Forecasts; Cambridge University Press: Cambridge, UK, 1997. [Google Scholar]
- Nash, J.; Sutcliffe, J.V. River flow forecasting through conceptual models part I—A discussion of principles. J. Hydrol. 1970, 10, 282–290. [Google Scholar] [CrossRef]
- Kastridis, A.; Kirkenidis, C.; Sapountzis, M. An integrated approach of flash flood analysis in ungauged Mediterranean watersheds using post-flood surveys and unmanned aerial vehicles. Hydrol. Process. 2021, 34, 4920–4939. [Google Scholar] [CrossRef]
- Singh, J.; Knapp, H.V.; Arnold, J.G.; Demissie, M. Hydrological modeling of the iroquois river watershed using hspf and swat1. J. Am. Water Resour. Assoc. 2005, 41, 343–360. [Google Scholar] [CrossRef]
- Bach, S.; Binder, A.; Montavon, G.; Klauschen, F.; Müller, K.R.; Samek, W. On Pixel-Wise Explanations for Non-Linear Classifier Decisions by Layer-Wise Relevance Propagation. PLoS ONE 2015, 10, e0130140. [Google Scholar] [CrossRef]
- Hitokoto, M.; Sakuraba, M. Hybrid Deep Neural Network and Distributed Rainfall-Runoff Model for Real-Time River-Stage Prediction. J. JSCE 2020, 8, 46–58. [Google Scholar] [CrossRef]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Hidden Layers | Nodes | L1-Regularization |
|---|---|---|
| 2 | 64 | 0 |
| 3 | 128 | |
| 4 | 256 | |
| 512 | ||
| 1024 |
| Case | SS | Rel | Bias | AE at Peak (cm) | MAE (cm) | RMSE (cm) | |
|---|---|---|---|---|---|---|---|
| Estimation | |||||||
| 1 | 0.972 | 0.978 | 0.002 | 0.004 | 50 | 24 | 30 |
| 2 | 0.988 | 0.990 | 0.000 | 0.001 | 55 | 29 | 37 |
| 3 | 0.889 | 0.892 | 0.003 | 0.001 | 69 | 60 | 67 |
| 4 | 0.968 | 0.981 | 0.006 | 0.008 | 89 | 36 | 57 |
| 1-h lead time prediction | |||||||
| 1 | 0.974 | 0.979 | 0.005 | 0.000 | 32 | 21 | 29 |
| 2 | 0.961 | 0.970 | 0.003 | 0.005 | 115 | 33 | 67 |
| 3 | 0.909 | 0.912 | 0.002 | 0.001 | 114 | 49 | 60 |
| 4 | 0.940 | 0.972 | 0.019 | 0.013 | 140 | 49 | 79 |
| 3-h lead time prediction | |||||||
| 1 | 0.972 | 0.983 | 0.005 | 0.006 | 32 | 24 | 30 |
| 2 | 0.983 | 0.986 | 0.002 | 0.001 | 40 | 33 | 45 |
| 3 | 0.870 | 0.879 | 0.003 | 0.006 | 48 | 57 | 72 |
| 4 | 0.963 | 0.983 | 0.013 | 0.007 | 68 | 42 | 62 |
| 5-h lead time prediction | |||||||
| 1 | 0.971 | 0.982 | 0.000 | 0.010 | 11 | 21 | 31 |
| 2 | 0.962 | 0.966 | 0.005 | 0.000 | 55 | 39 | 66 |
| 3 | 0.697 | 0.714 | 0.003 | 0.014 | 321 | 80 | 110 |
| 4 | 0.944 | 0.967 | 0.009 | 0.014 | 67 | 48 | 77 |
| Element | Time (h) | Resolution (h) |
|---|---|---|
| E_01 | t | 1 |
| E_02 | t − 1 | 1 |
| E_03 | t − 2 | 1 |
| E_04 | t − 3 | 1 |
| E_05 | t − 4 | 1 |
| E_06 | t − 5 | 1 |
| E_07 | t − 6~t − 7 | 2 |
| E_08 | t − 8~t − 9 | 2 |
| E_09 | t − 10~t − 11 | 2 |
| E_10 | t − 12~t − 13 | 2 |
| E_11 | t − 14~t − 16 | 3 |
| E_12 | t − 17~t − 19 | 3 |
| E_13 | t − 20~t − 22 | 3 |
| E_14 | t − 23~t − 26 | 4 |
| Input | Output | |||
|---|---|---|---|---|
| Type | Number of gauges | Time | Change in the river stage measured at the Tsunokawa observatory between 0 and t hour. | |
| River stage | 1 | −1, 0 | ||
| Hourly change in stage | 3 | −2, −1, 0 | ||
| Hourly rainfall | 13 | t − 5 to t − 1 | ||
| Case | SS | Rel | Bias | AE at Peak [cm] | MAE [cm] | RMSE [cm] | |
|---|---|---|---|---|---|---|---|
| H_1 1-h lead time prediction | |||||||
| 1 | 0.999 | 0.999 | 0.000 | 0.000 | 0 | 4 | 7 |
| 2 | 0.991 | 0.992 | 0.000 | 0.001 | 10 | 13 | 33 |
| 3 | 0.982 | 0.983 | 0.000 | 0.001 | 14 | 15 | 26 |
| 4 | 0.998 | 0.998 | 0.000 | 0.000 | 5 | 8 | 16 |
| PCL_1 1-h lead time prediction | |||||||
| 1 | 0.997 | 0.998 | 0.000 | 0.000 | 11 | 6 | 9 |
| 2 | 0.994 | 0.995 | 0.000 | 0.000 | 1 | 12 | 25 |
| 3 | 0.990 | 0.991 | 0.000 | 0.000 | 20 | 15 | 20 |
| 4 | 0.998 | 0.998 | 0.000 | 0.000 | 6 | 8 | 14 |
| H_2 2-h lead time prediction | |||||||
| 1 | 0.996 | 0.997 | 0.001 | 0.000 | 7 | 7 | 11 |
| 2 | 0.970 | 0.974 | 0.001 | 0.003 | 50 | 25 | 59 |
| 3 | 0.929 | 0.932 | 0.000 | 0.003 | 100 | 32 | 53 |
| 4 | 0.991 | 0.992 | 0.001 | 0.001 | 15 | 16 | 31 |
| PCL_2 2-h lead time prediction | |||||||
| 1 | 0.978 | 0.982 | 0.004 | 0.000 | 52 | 20 | 27 |
| 2 | 0.974 | 0.977 | 0.002 | 0.000 | 85 | 25 | 54 |
| 3 | 0.926 | 0.935 | 0.008 | 0.001 | 139 | 36 | 54 |
| 4 | 0.992 | 0.994 | 0.003 | 0.000 | 80 | 19 | 29 |
| H_3 3-h lead time prediction | |||||||
| 1 | 0.992 | 0.994 | 0.001 | 0.000 | 19 | 11 | 16 |
| 2 | 0.945 | 0.953 | 0.003 | 0.005 | 152 | 37 | 80 |
| 3 | 0.862 | 0.870 | 0.001 | 0.007 | 194 | 48 | 74 |
| 4 | 0.982 | 0.985 | 0.002 | 0.001 | 68 | 21 | 44 |
| PCL_3 3-h lead time prediction | |||||||
| 1 | 0.950 | 0.960 | 0.010 | 0.000 | 94 | 30 | 40 |
| 2 | 0.942 | 0.947 | 0.005 | 0.000 | 230 | 41 | 82 |
| 3 | 0.819 | 0.840 | 0.021 | 0.000 | 240 | 60 | 85 |
| 4 | 0.974 | 0.981 | 0.007 | 0.000 | 149 | 33 | 52 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wakatsuki, Y.; Nakane, H.; Hashino, T. River Stage Modeling with a Deep Neural Network Using Long-Term Rainfall Time Series as Input Data: Application to the Shimanto-River Watershed. Water 2022, 14, 452. https://doi.org/10.3390/w14030452
Wakatsuki Y, Nakane H, Hashino T. River Stage Modeling with a Deep Neural Network Using Long-Term Rainfall Time Series as Input Data: Application to the Shimanto-River Watershed. Water. 2022; 14(3):452. https://doi.org/10.3390/w14030452
Chicago/Turabian StyleWakatsuki, Yuki, Hideaki Nakane, and Tempei Hashino. 2022. "River Stage Modeling with a Deep Neural Network Using Long-Term Rainfall Time Series as Input Data: Application to the Shimanto-River Watershed" Water 14, no. 3: 452. https://doi.org/10.3390/w14030452
APA StyleWakatsuki, Y., Nakane, H., & Hashino, T. (2022). River Stage Modeling with a Deep Neural Network Using Long-Term Rainfall Time Series as Input Data: Application to the Shimanto-River Watershed. Water, 14(3), 452. https://doi.org/10.3390/w14030452