1. Introduction
Extracting and detecting natural resources such as water bodies and forests from satellite imagery had a huge significance in the recent past. Exploitation of these water bodies is a huge complication. Water bodies need to be monitored periodically for their sustainable development.
Monitoring these water bodies has a large range of applications such as detecting drought and flood conditions and disaster management.
Satellite images have become a major source for detecting traffic, vegetation, buildings, water bodies and ships. This study mainly concentrates on detecting the water bodies from huge dataset of satellite images which were sourced from Kaggle. A deep learning approach of fully convolution network of UNet for semantic segmentation is used. There were many existing neural networks which tried to act as an image segmentation tool, but UNet does its best among all other existing approaches with lowest information loss [
1].
This work proposes an implementation of U-Net with the help of tensor flow from scratch. Pooling is specifically embedded to minimize the number of arguments. The use of Nadam optimizer made the model run fast and increase the performance significantly in Training Phase. Nadam is an improved version of this Adam Optimization Technique [
2].
The proposed model also ensures integrity by applying ECDSA (Elliptic Curve Digital Signature Algorithm) to the prediction mask of Water Bodies. ECDSA is used in many secure applications and is treated as the crucial factor for maintaining Bitcoin Security [
3]. The feature that makes ECDSA more popular among its peers is that it uses short key lengths, which were derived from ECC and provides high security. This model can also be applied to detect the AquaTrash from WaterBodies by slightly changing the parameters for object detection. Thus, the model has huge range of applications in maintaining sustainable environment.
The rest of the paper is coordinated as follows:
Section 2 illustrates the literature survey,
Section 3 outlines the proposed methodology continued by result and analysis, and the concludes with the conclusion in
Section 5.
Figure 1 represents the architecture diagram of U-Net where in grey boxes represents the multi channel feature map and total number of channels are shown on the upper top of the rectangular box and unfilled boxes show the copied phenomena of feature maps.
2. Literature Survey
Teng Fei et al. [
4] build up a model to detect small water bodies and quality analysis in Wuhan. The model is based on image classification and band analysis. A semi-empherical deep learning method is used for quality analysis. Accuracy assessment is done at regular stages which are then concluded by the inversion of water quality as it is completely based on inversion model. The pitfalls in this analysis are that detection of water bodies is difficult in the case of mixed images.
Jorge Lira et al. [
5] propose a mechanism for a large number of issues in the field of remote sensing. This model uses mechanisms such as segmentation and optical reflectance’s. A special model named PCA is used to segment the water bodies from satellite images. Clustering process is used to divide the remote sensing satellite image into two based on pixels. The first segment is the water body and the next segment is rest of the satellite image. The flaws in the above mechanism is that False Overlay is observed at some parts of detection.
Fengyu Yang et al. [
6] recommends a mechanism for segmentation of water bodies from remote sensing images using mask R-CNN. The proposed system overcomes the difficulties of having low resolution and pixel clarity in remote sensing images. The model was developed based on the imagery obtained from Google Earth. Fine-tuning of the dataset is obtained by Data Augmentation. The model was trained by using both ResNet-50 and Resnet-101 mechanisms. The supremacy of the work is (i) The accuracy of prediction is virtuous and (ii) the model is highly feasible and flexible.
Debashish Chakraborty et al. [
7] put forward an approach that uses Holder exponents and variance for segmentation of remote sensing imagery. The main debate is that neither pixel-based nor texture-based segmentation techniques can perform well in yielding satisfactory result. Segmented image mask is used to derive textured and non-textured regions of an image. Later, ISODATA classification algorithm is applied to sourced data. The outputs of both classified and non-classified pixels are merged in the end to obtain a final output image. The method has its advantages by (i) classifying images with both textured and non-textured background and (ii) effectively classifying panchromatic spatial resolution images. The pitfall is that mutli-scale classification of textured background is not performed.
Gordana Kaplan et al. [
8] presents a mechanism that combines the use of pixel-based index and object-based method on a multispectral image containing 13 bands. The model uses Sentinel-2 images, each having 10m to 60m resolution. The model considers an urban and mountainous range for better understanding the performance. The indexes are obtained using NWDI. Additional methods are added using a simple pixel-based method, which results in having low albedo. The added advantages of the model are (i) water monitoring in case of adverse climatic conditions and varied regions is accurate and (ii) water extraction was improved by the combined usage of pixel- and object-based classification. The model has its disadvantage is that it uses only two bands out of the available 13 bands.
R. Lalchhanhima et al. [
9] proposed a method that uses SAR images which are not available in abundance and consists of speckle noise image segmentation is done using hybrid CNN considering U-Net and Inception. The result of the model in different variations is mainly dependent upon training time, size of dataset and accuracy, among others. Higher kernels increase training time. The output image is given to Otsu’s threshold method to obtain 128X128 size binary image. The model shows dominance by (i) providing superior performance to other CNN methods and (ii) requires less training data and less training time to provide high performance.
Zhili Zhang et al. [
10] put forward the challenges faced in accurately identifying the boundaries of water bodies due ariety of criteria. To overcome these challenges, a novel combination and multi-feature extraction are presented. Three feature extraction sub modules are used for varying spaces and relationships to gain rich feature representation. Concurrently, multi scale prediction fusion module is used for detecting contours. Additionally, encoding–decoding semantic feature fusion module is also used. The advantages are it (i) gains cutting-edge segmentation performance and (ii) the model is robust.
Xiao Yang et al. [
11] introduced a mechanism, namely verifiable ECDSA. The main motto is that it can encrypt the produced digital signature using a public key which is provided by the trusted service. This work adds more features to the existing VES scheme. It can cover a huge number of signatures with almost same structures or similar ones under different variants. It was later applied to many crypto currencies. The only limitation of this proposed work is that it needs to store a 270 MB size look-up table for evaluation.
Yuanbo Shnag et al. [
12] introduced an improvement for the existing ECDSA and their applications. This work improves the effectiveness and the security of the ECDSA. The work selects the ECDSA algorithm as is has shorter key length and more pros when compared to the RSA. It analyzes different attacks such as a side-channel attack and thereby improves the efficiency. This work has its own advantages by improving the efficiency and also protecting it from various attcks.
Lin et al. [
13] proposed a protocol for IOV with a fault-tolerant ECDSA signature. The internet of vehicles is a growing domain these days. At the same time, it is also open to many attacks. Vehicles can communicate with each other, pedestrians. During this transmission there is a possibility where an unauthorized person can look into this personal information. To protect from the following attacks a fast fault tolerant ECDSA protocol is proposed.
Fang Chen et al. [
14] proposed a method to detect the buildings using a U-Net. This model helps to detect the buildings from remote sensing images. This is formed by replacing n channel feature maps with a series of smaller networks. Furthermore, to improve the detection performance a boundary loss function is introduced. The main advantages of the model are (i) it can detect the buildings from a granular level, it (ii) reaches state-level accuracies and (iii) it is highly robust.
Serban et al. [
15] implemented a model to detect the change in surface water. This case study is taken from a lake named Nuntasi-Tuzla from Romania. The main cause to propose this model is, in the year 2000, the surface water of the lake decreased gradually. The approach is based on water indices, Normalized Difference Vegetation Index (NDVI). At the end of the research, the detected causes for the problem were found. Drought and human intervention were the major causes for the drastic decrease in surface water.
Gadekallu et al. [
16] proposed an approach to detect the ships from remote sensing satellite imagery. This is based on a deep learning approach, namely You only look once version 3 (YOLOV3). Several layers were trained to identify the region of detection. Later, SHA-256 is embedded to the region of detection as well as count of ships. This improves the integrity of the developed model. The main perks of the model are (i) it can effectively detect the ships in land-sea interface region and (ii) it works better for all sort of images such as blurred, reversed and small satellite images.
Jatin Sharma et al. [
17] identified a case study for photovoltaic power forecasting using LSTM with Nadam Optimizer. The LSTM provides better results for time series data. The work compares the LSTM with two time series and eight different neural network models and optimizers. The accuracy is calculated for each optimizer and compared accordingly. In the end, Nadam with LSTM shows the better accuracy.
Kousalya et al. [
18] predicted the best suitable optimizer for CNN models. The work is based on the deep learning models with a huge input data in a nonlinear fashion. The study is based on CNN models, which involves complex tasks such as recognition if speech, classification of pictures and many more. For training, the research uses the input as human emotions. The comparison study is performed for different optimizers, namely Adam, gradient descent and Nadam, of which Nadam provides the best results.
Rupa et al. [
19] developed a model to identify the bounding box region from satellite images. It further produces the count of number of ships present in the given satellite image. The detection is made using 106 (53 + 53) layers of YOLOV3 stack. The images are detected from three predictions. The layers are partitioned for detecting smaller, middle shaped and large ships. Utmost care is given to the data preprocessing section to remove duplicate and false images. The limitations of this work is that it is not suitable for video input.
Erfani et al. [
20] introduced a study of semantic segmentation for water bodies. This work is based on the ATLANTIS dataset. This can prevent emergencies during floods. The dataset contains several classes on several groups. For detecting under aquatic and non-aquatic regions, a model said to be AQUANET is developed. The best feature of the work its dataset which can cover wide range of classes with different classes of dataset.
Rajyalakshmi et al. [
21] presented an approach to detect water bodies from high resolution satellite images. This work uses thresholding techniques. The dataset consists of images with wide range of spectral and temporal characteristics. The unique approach said to be single-band threshold using bilateral filtering is used in this work. The limitation of the work is that the work is limited to only high-resolution satellite images.
Carles et al. [
22] introduced a prototype to secure the COVID-19 patient information using ECDSA in the blockchain. Patient data is very crucial for the treatment and diagnosis. There were cases where unauthorized person can intervene to the network and change this crucial data, which may result in the death of the person. Hence, the work proposed an approach to carefully transmit the data through block chain using ECDSA. The advantages observed is that the patient data becomes immutable once the model is applied.
Wang et al. [
23] developed a framework for scientific computing of fluid flows using tensorflow. The work uses a graph based tensorflow module. The performance and accuracies are calculated further which exhibited strong scaling upto TPU v3 pod. The model is developed with the TPU platform.
Ikram et al. [
24] presented a framework on the top of UNet. Semantic segementation is handled using the VGG16 encoder. Transfer learning is used to make an effective UNet architecture. The tuned network architecture is used to predict the breast cancer in earlier stages. The developed Unet architecture produces an accuracy of over 80%. The limitation of the model is that the architecture can be further optimized to improve the accuracy.
Jing et al. [
25] developed a model based on Mobile-UNet. It is a CNN approach for fabric detection. It can effectively detect end to end fabric defect segmentation. Simple imbalance is reduced via loss function of median frequency. The encoder part is built under MobileNetv2 and five layers of decoders are introduced. To detect segmentation mask softmax layer is used. The main advantages of the model is that it attains state of the art accuracy.
Table 1 specifies the analysis and summary of the literature survey. Several approaches are compared to the proposed method and analysis on different parameters is done.
3. Proposed Methodology
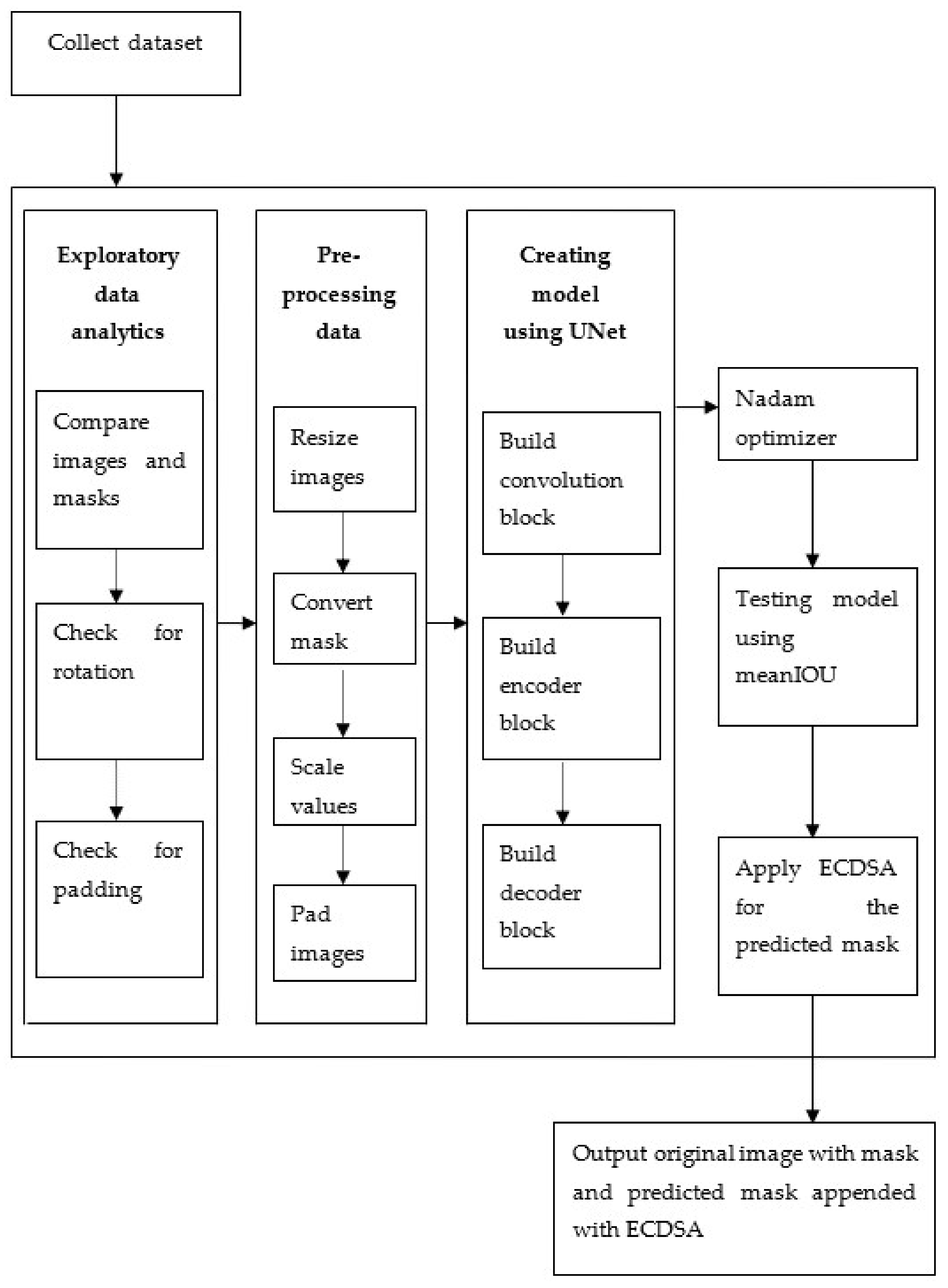
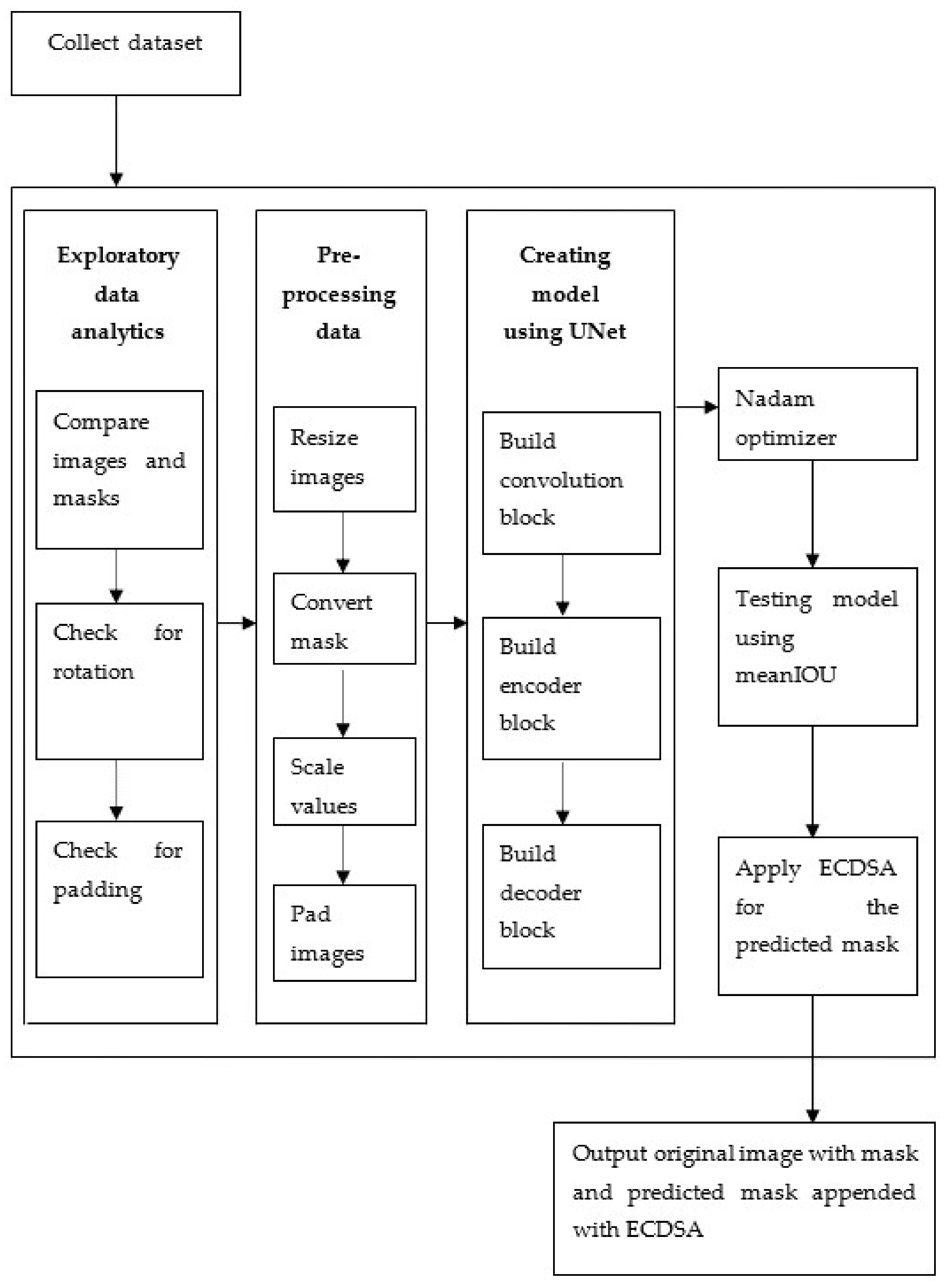
The proposed model derives data from the Water Bodies dataset sourced from kaggle. The dataset consists of original images added up with masks for the corresponding original images. The dataset constitutes of only the images and no other parameters. The model is developed in a step-wise fashion following agile software methodology to facilitate the inclusion of any future advancement along with convenience for maintenance. Seven crucial steps on a high level are deployed for constructing the model.
Initially, the dataset is fed to the model. This dataset acts as fuel for the exploratory data analytics step. Exploratory data analytics means sourcing statistics of the data and is used for censuring any irregularities or commotion, which can result in dropping the performance of the model. This is a precautionary step, done at the beginning to ensure smooth performance of the model. As a part of exploratory data analytics, first, the original images and masks are comparatively visualized. A significant difference is observed in some images. Ground truths seem to be contradicted. Therefore, the images are verified for any rotation or padding. The images are transformed in the data pre-processing step. Several transformation functions are applied on the images. The prior transformation to be done is resizing. Some images having larger dimensions are complex to fit in memory and have enormous difference to other images. Therefore, a threshold of 1500 is applied to both height and width and all those images having dimensions greater than the threshold are rescaled.
The next transformation function applied to the data is mask conversion. When a histogram is plotted for the original images, most of the values are concentrated towards zero. This may be a result of rotation. For those values at the center, the contrast has to be improved. To do this, histogram equalization is used. On the other hand, masks are stored in jpeg format and they have to be separated using a threshold into two discrete values. For this purpose, mask conversion is used. The third transformation function required is scale values. The primary intention is to make the model converge faster. To do this, the original image is divided into the range [0, 1]. The masks are not considered for the range division.
The final transformation function to be applied on the data is padding images. The model accepts arbitrary-sized images, therefore predetermined padding values must not be considered. Depending on the strides, downsamplings must be able to divide the image size. Additional connections between non-consecutive layers and the same size of input and output images are present due to the specificity of the neural net used. Therefore, padding must be applied.
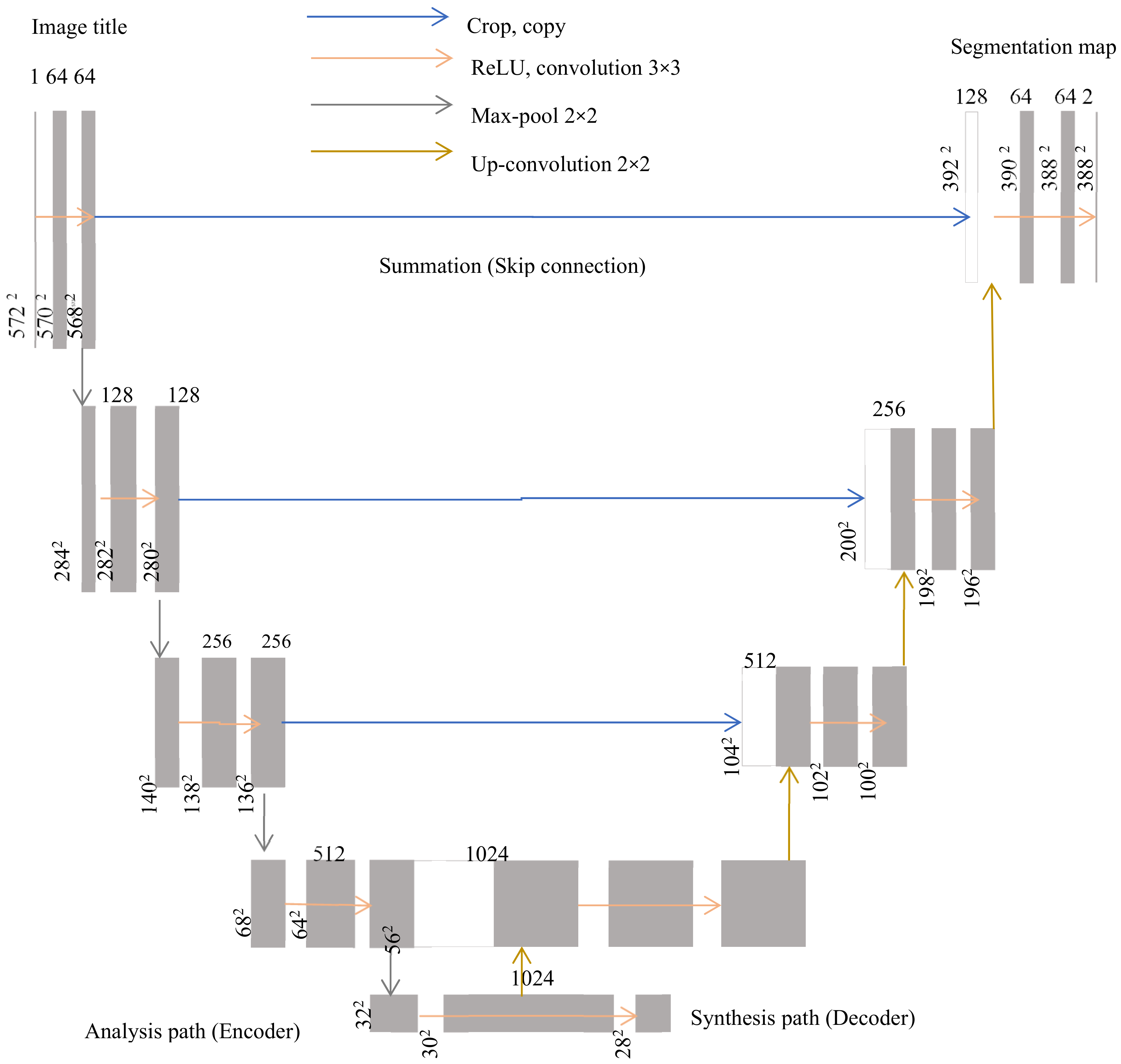
The fourth significant step is training the model using UNet. Compared to other approaches, UNet has higher performance in the segmentation task [
26]. UNet is initialized using he_normal in addition to relu hidden activation and sigmoid output activation. Creating model using UNet involves building convolution, encoder and decoder blocks. For the construction of the convolution block, two important factors are considered. First, the input for the convolution layer and the other one is the filter count, which is by default 64. In the proposed model, partial convolution is used. Construction of encoder and decoder is simple. Encoder consumes consecutive inputs from top to bottom. It consists of two convolution layers along with ReLU and their corresponding batch normalization layers. Decoder requires inputs, skip connection and filter count in each block. The given input is up-sampled and the previous input is also concatenated to obtain final skip connection value.
Figure 2 depicts the methodology structure for the model detection of water bodies through UNet and tensor flow using ECDSA. It collects the dataset and follows several steps in the mid way and finally outputs the original image with the predicted mask and with ECDSA Digital Signature.
3.1. Module Wise Approach
3.1.1. Input: Dataset Collection
The input given to the model is the water bodies dataset. The dataset is sourced from the Kaggle with the name Satellite Images of WaterBodies. These images are obtained and captured by sentinel-2 Satellite. The dataset contains two directories. The first one is Images and the other one is Masks. Masks are in black–white where white shows the presence of water and black shows something other than water. These masks are obtained by Normalized Water Difference Index (NWDI).
where
B3 = Band3 (Sentinental-2 Green Channel)
B8 = Band8 (Sentinental-2 Infrared Channel)
Figure 3 indicates the regions on the sentinel-2 images corresponding to their derived NWDI values.
3.1.2. Approach
Module 1: Exploratory Data Analytics
Data preprocessing is the next step after feeding the input to the model. There are numerous ways to preprocess the image data.
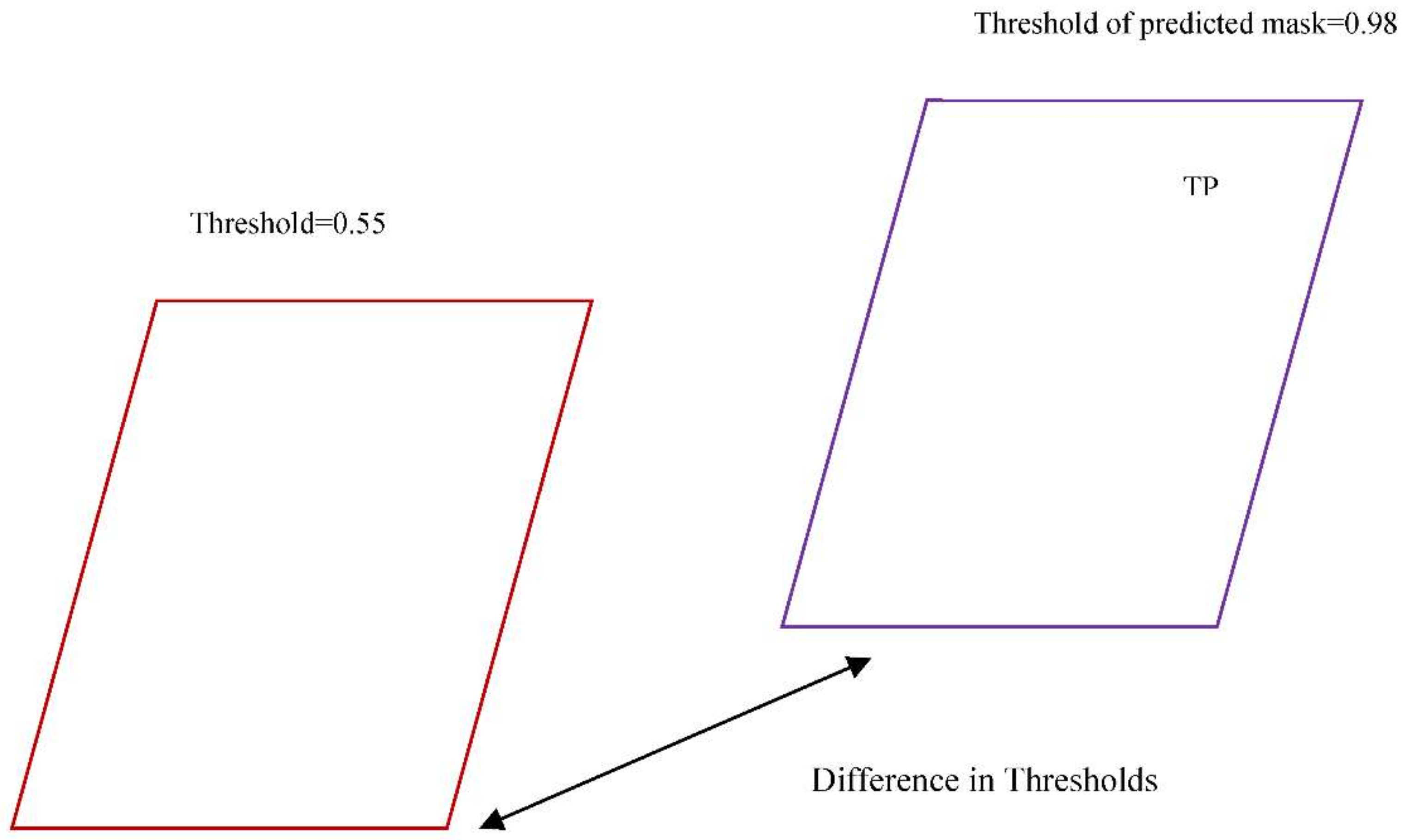
Each image is compared with subsequent mask and if there are any duplicates they are removed. They are identified using difference in thresholds.
Some of the input images are rotated these becomes hectic during training and testing phases. These can be modified using Histogram Equalization. Mathematically, to rotate with an angle θ the coordinates (x, y) are given by,
The co-ordinates (x2, y2) are to be rotated to a specified angle θ from (x1, y1) becomes (X, Y).
All the images should be of same size while passing to the network and these sizes and the count of downsamplings should be divisible. Hence, the images are divided by their size and masks are separated based on the threshold. Furthermore, target width and height are achieved after processing. For generating an image size of (
m ×
m),
where,
pl = Number of padding layers added or subtracted to make everything into same Size and
fl = Image filter.
Module 2: Data Preprocessing
Data preprocessing is the first step before training any model. Only once the data is preprocessed can it pass as an input through the model. This step removes the noise, unwanted and unused data. It helps in maintaining consistency with the dataset.
All images of dataset are resized to same value. Small-size images take less time compared to the larger ones. Hence, the images are resized using resize function from cv2 module.
Every image is passed to mask_split_threshold function and scales the value between [0, 1].
Unnecessary padding bits are removed. During training and testing phases every image must be identical in size to produce better results. Hence, removal of these bits is necessary.
Module 3: Creating model using UNet
UNet model performs well for the image segmentation task. It also works best for binary classification. Multi-channel feature maps are used in the implementation. A series of operations are further applied.
Firstly, the kernel gets initialized, later on activation function for output layer is applied. Sigmoid is considered as the output activation. All the parameters such as hidden activation, initialization, output activation need to be defined with appropriate values. Convolution block performs basic operations. There were 64 filters in the convolution layer and the padding remains same.
The architecture of encoder takes sequence of input starting from topmost layer to the bottom. It utilizes convolution blocks which is then added to the batch normalization layers. Once input is passed to these layers downsampling and maxpooling are done. The subsequent outputs are passed after these functions gets applied.
where
MPO represents max-pooling spatial output,
I represents the input shape,
W represents pooling window length and
ST represents the stride value.
Construction of decoder block is simple it takes the input from upper layers and the filters count in a particular cycle. Upsampling is done on the input and filters count. The output is used to execute the convolution block function and the obtained output value is returned.
Module 4: Nadam Optimizer
Once after building the model, Optimizer is invoked. Nadam is sourced from the keras module. Nadam is the best optimization technique, which is an improved version of Adam. Gradient descent is the basic optimization technique further versions like Adam, Nadam were introduced to remove flaws in the Gradient Descent [
15]. NAG momentum is used in the Nadam optimizer.
where
represents learning rate,
nh represents second moment decay factor,
mh represents first moment decay factor.
Module 5: Testing using MeanIOU
The model is now tested with mean intersection over union metric. This is sourced from keras module. It contains three parameters number of classes, name and type. The model shows a value of 0.89 when tested with this metric.
tp represents true positives, fp represents false positives and fn represents false negatives.
The cumulative pixel accuracy for the model is 94.1%. The precision obtained for the proposed model is 0.94. The recall is derived to be 0.939. The detailed derivation of these performance metric values is described under
Section 5 Performance analysis.
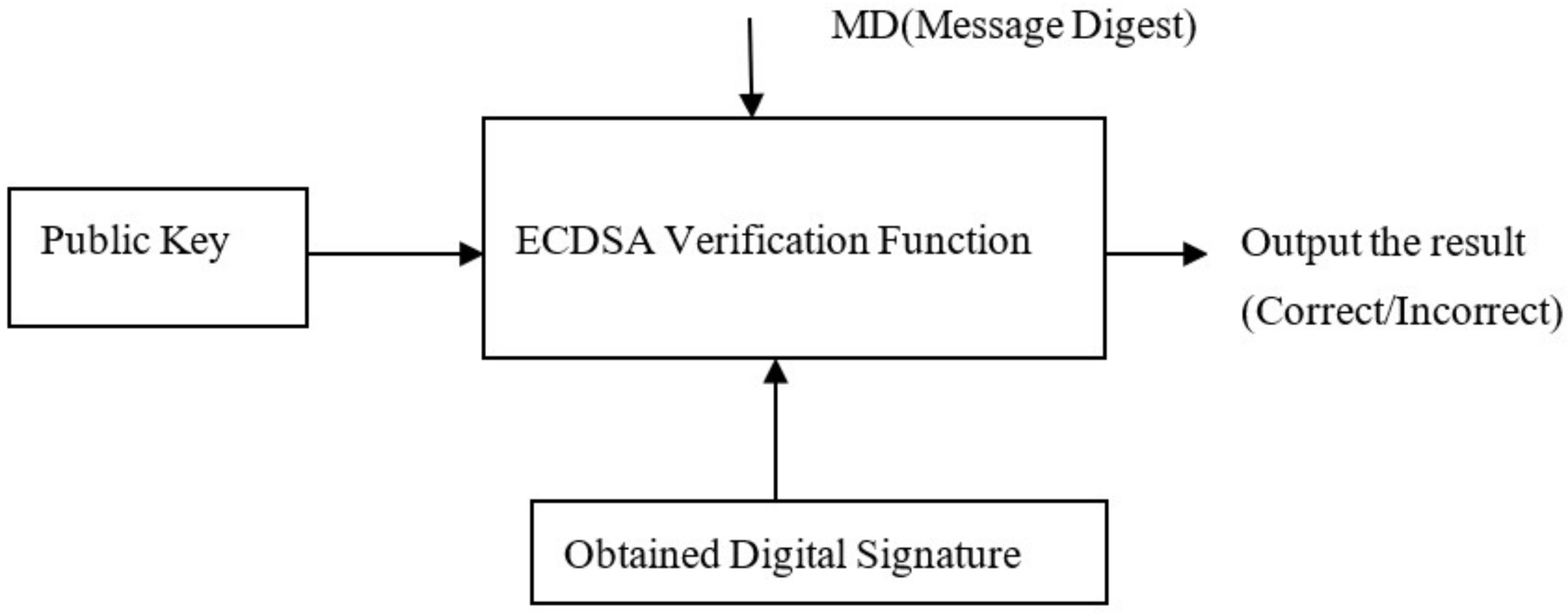
Module 6: Applying ECDSA
To add integrity to the designed deep learning model Elliptic curve digital signature (ECDSA) is added to the predicted mask. ECDSA shows better performance and highly scalable than other algorithms such as Rivest, Shamir, Adleman (RSA) [
27]. It uses keys obtained from elliptic curve cryptography. It does the same work as other digital signature algorithms with shorter key lengths. The output digital signature is obtained by converting signing key to bytes. The signing key is obtained by NIST192p, which is of the length of 24 bytes. Similarly, the verifying key can be obtained from this signing key to verify the digital signature at other end.
Figure 4 shows ECDSA verification steps. The obtained digital signature together with a public key is passed to the verification function and checks for the corresponding results.
3.1.3. Output
The original image with the mask and predicted mask appended with ECDSA digital signature is observed as the output. Algorithm 1 explains the total process of detection of water bodies. The algorithm takes the input dataset and produces the predicted mask for the given input. It follows several steps such as data preprocessing, building model, apply optimizer, compiling the model and finally, displaying the output.
| Algorithm 1: Water Bodies Detection |
| Input: Dataset with Water body images and their respective masks |
| Output: Detects the predicted mask of water body from sentinel-2 satellite image |
| Process |
| Step 1: Collects the DataSet |
| ClassA = WaterBodies images |
| ClassB = WaterBodies Masks |
| Step 2: Apply data preprocessing |
| Step 2a: Resize images |
| Resizes all the images to same width and using cv2.resize() method |
| Step 2b: convert the mask |
| Step 2c: scale the values |
| Scales the masks using split_threshold from [0, 1] |
| Step 2d: check for padding |
| Predetermined padded values are removed |
|
| Step 3: Building model with UNet and Tensorflow |
| Step 3a: Build Convolution Block |
| Step 3b: Build Encoder Block |
| Step 3c: Build Decoder Block |
| Step 4: Apply Nadam Optimizer |
|
| Step 5: Compile the model |
| Loss = binary cross_entropy |
| optimizer = Op |
| Step 6: Check for summary of model |
| Step 7: Outputs the orginal image, mask and predicted mask |
Algorithm 2 shows the procedure of appending an ECDSA module to the deep learning model. It involves the generation of the signing key, verifying the key and producing a signature using this signing key. The signing key uses default elliptic curve (ECC) known to be NIST192p [
28].
| Algorithm 2: Appending ECDSA to the predicted Mask |
| Input: Orginal image, mask and predicted mask |
| Output: Detects the predicted mask with ECDSA digital signature |
| Process |
| Step 1: Generation of Signing Key from NIST192p default curve
|
| Step 2: Obtain verifying key from the signing key
|
| Step 3: Obtain the Signature by signing the co-ordinates of masked region with |
|
| Step 4: Verify the signature using
upon |
| Step 5: Append the signature to predicted mask |
| Step 6: Outputs the original image, mask and predicted mask with ECDSA digital signature |
4. Results
The proposed model is used for the segmentation of water bodies from satellite images and then the detected region is secured using elliptic curve digital signature.
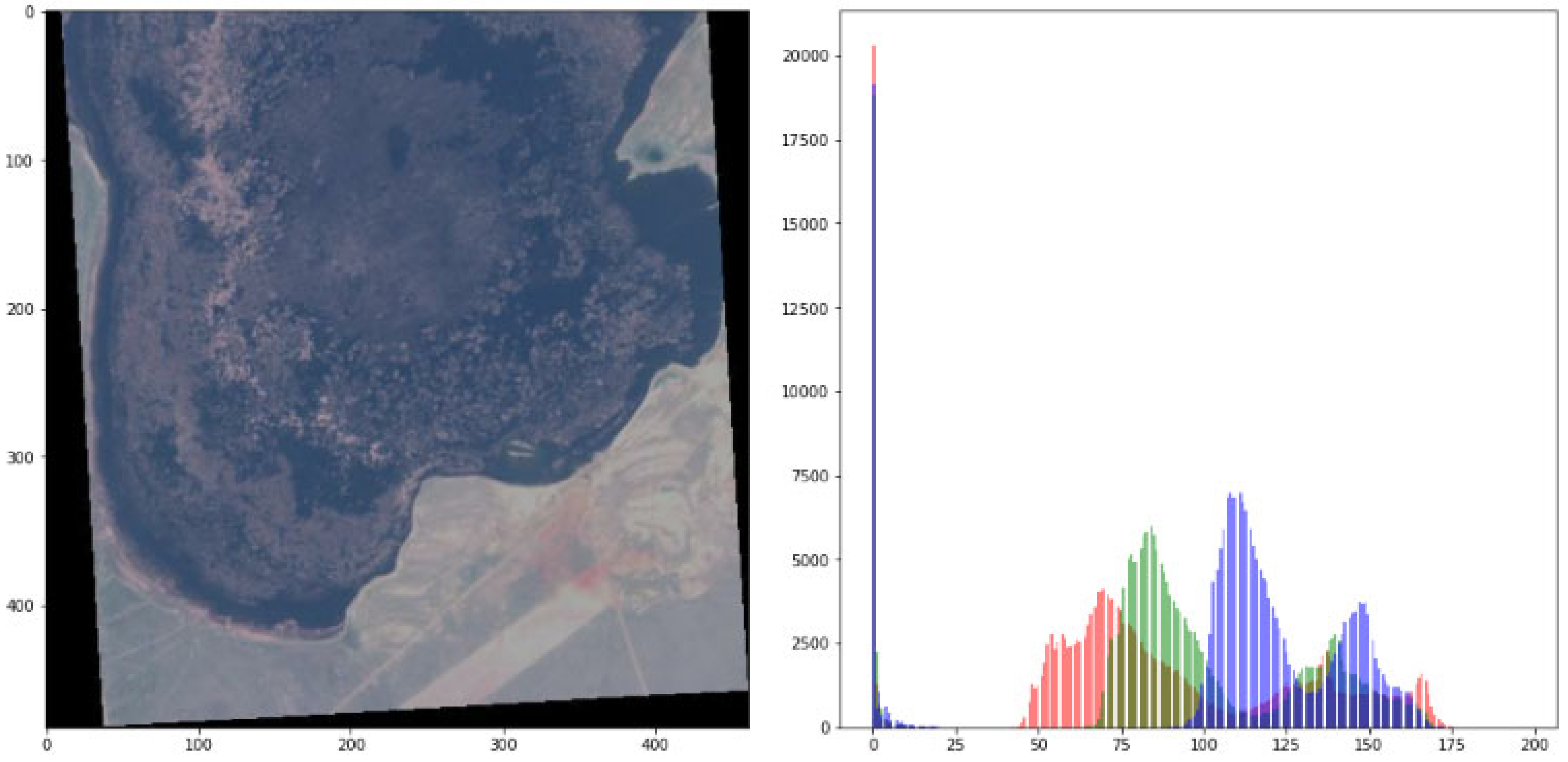
Figure 5 represents the sample image displayed along with its corresponding original mask.
Figure 6 represents the statistics drawn out of the exploratory data analysis. For the original image, ravel function is applied to transform the data in jpg format to flat list and then histogram is drawn to observe the behavior of the data. It is observed that most of the data is concentrated around zero which can be a result of rotation. For the values concentrated around the center, histogram equalization can be applied to improve the contrast.
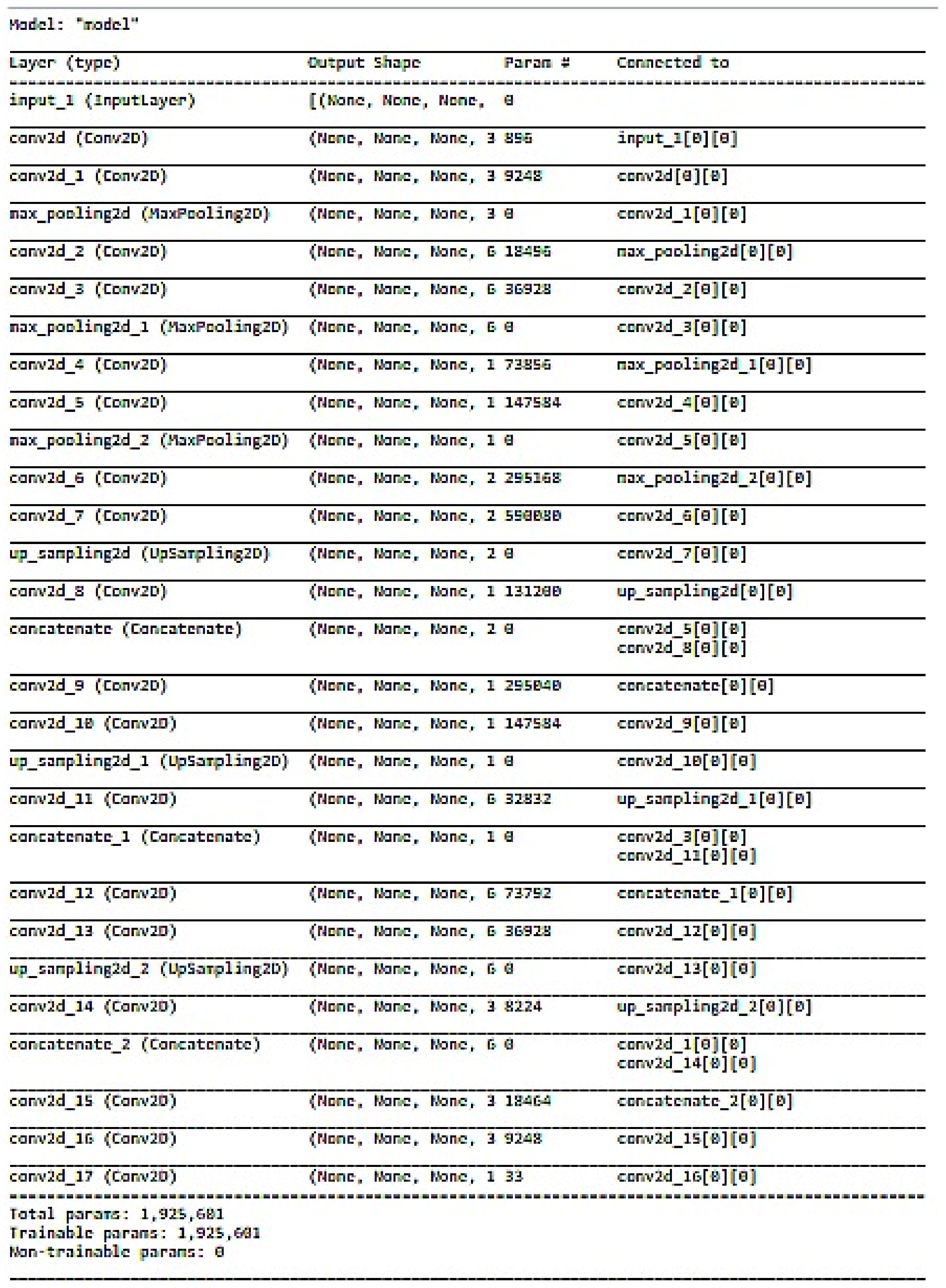
Figure 7 represents the summary of the model after training with UNet. The total parameters are 1,925,001, of which all parameters are used for training. The figure clearly depicts the working of the UNet model for current data. The input to each layer, operation and the output are shown.
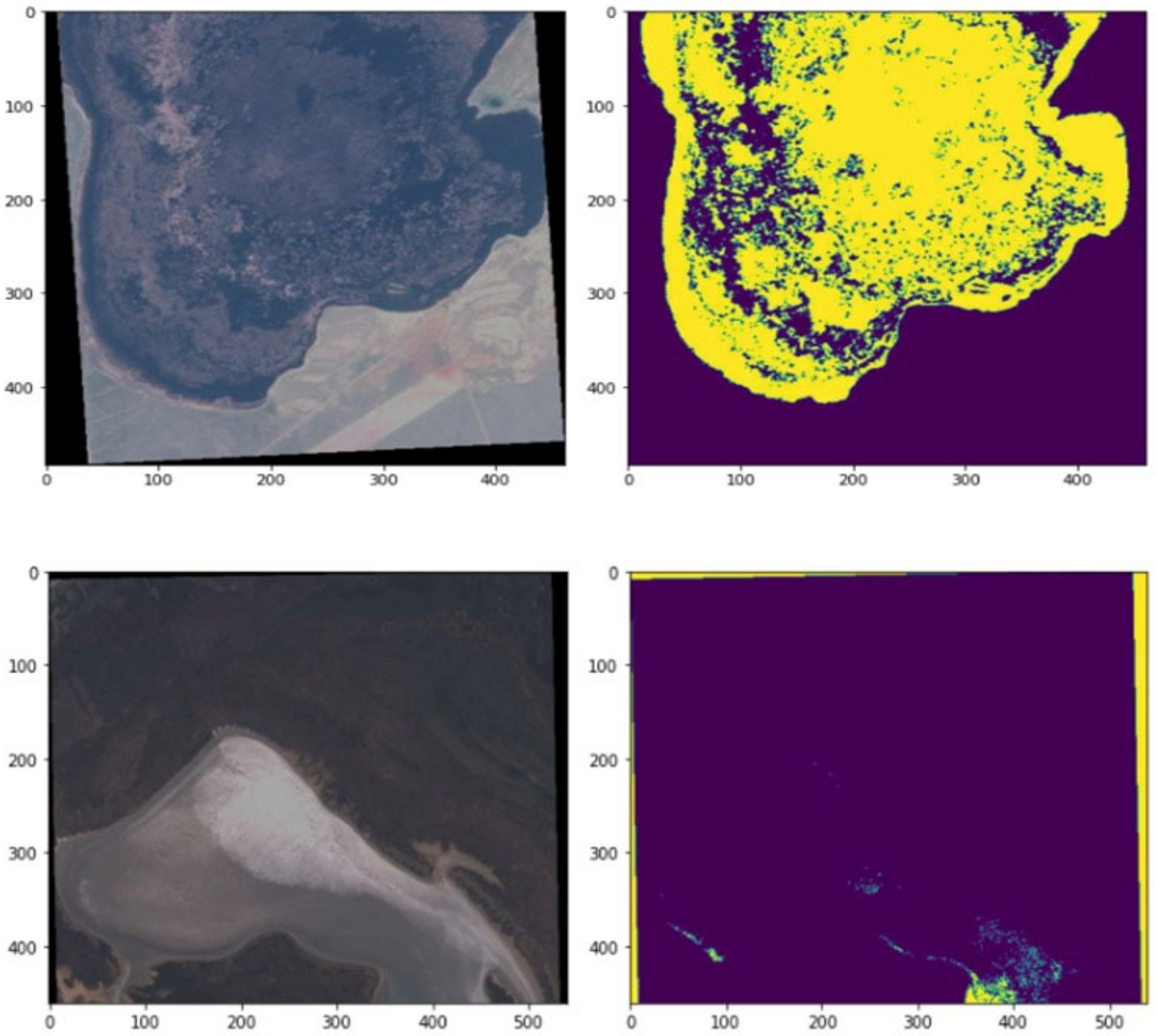
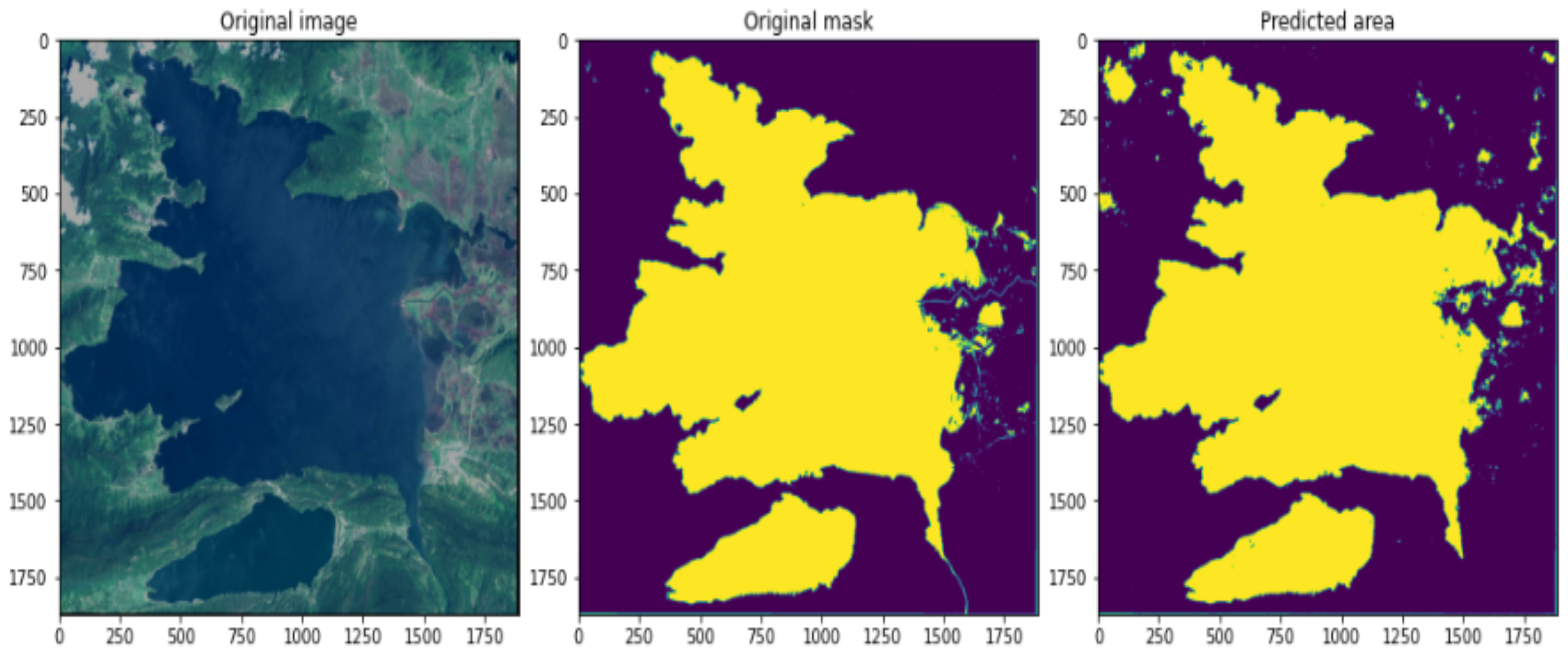
Figure 8 shows the original image along with its mask and corresponding mask detected by the proposed model. To get most out of visualization, the images are displayed along with scale for precise understanding.
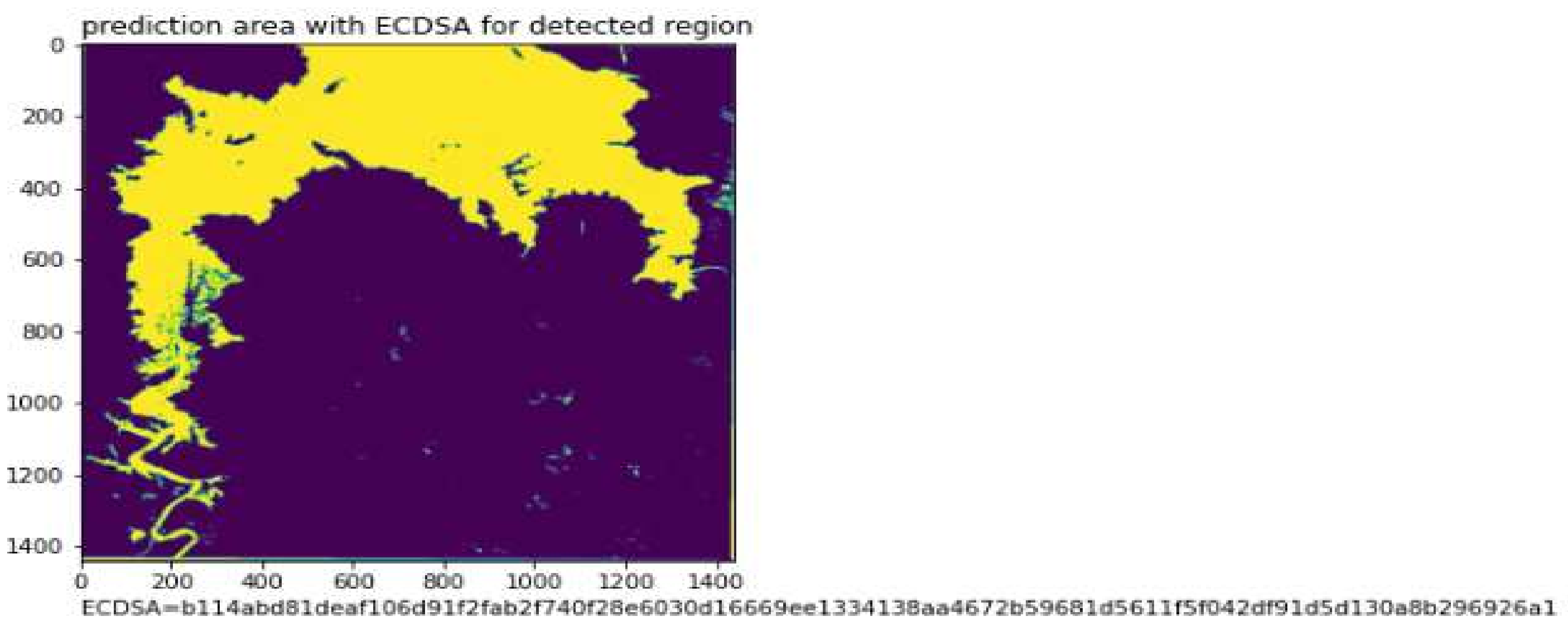
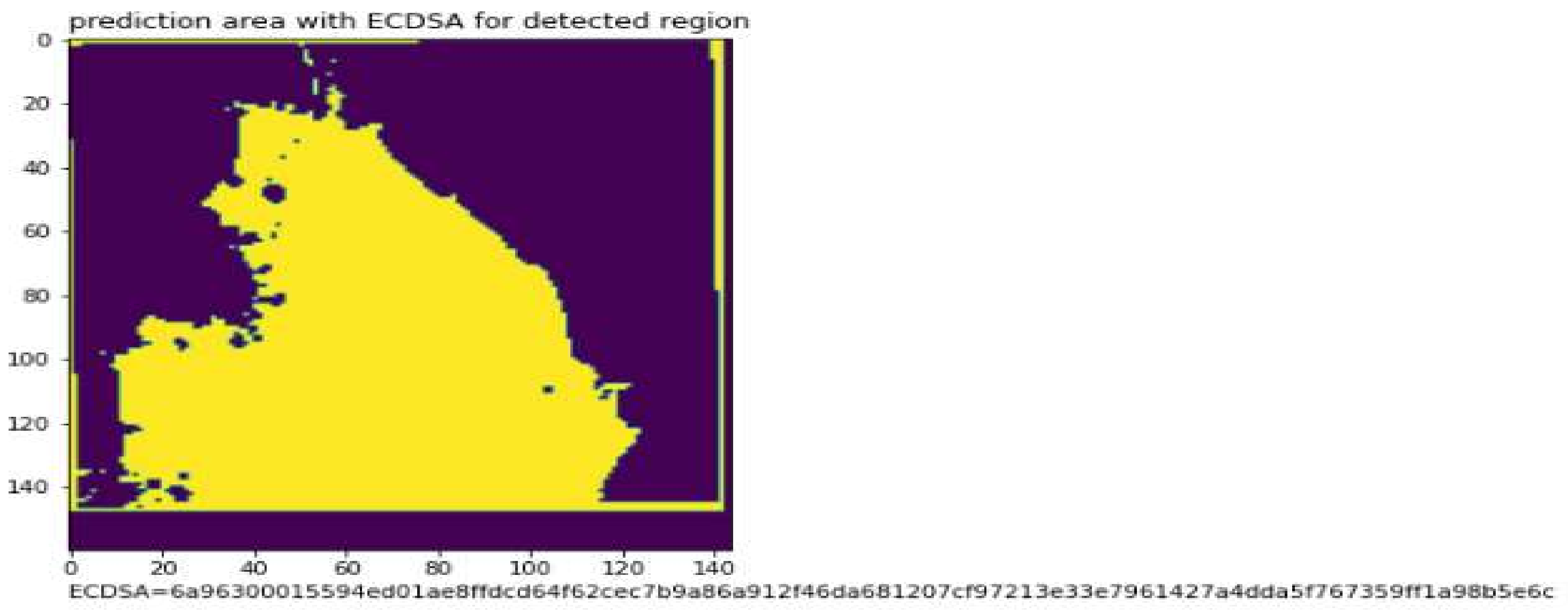
Figure 9 shows the added advantage of the proposed model achieved by the inclusion of Elliptic curve digital signature. Detection of any tampering along the way of transmission can be done with ease.
Figure 10 represents another case of predicted mask for a water body image. The ECDSA function works by constructing a signing key from NIST192p. This signing key is used to obtain a verifying key. By signing the coordinates of the masked region with the signing key, the ECDSA signature is obtained. Then, the ECDSA signature is verified using verifying key. Finally, the ECDSA signature is applied to the predicted mask.
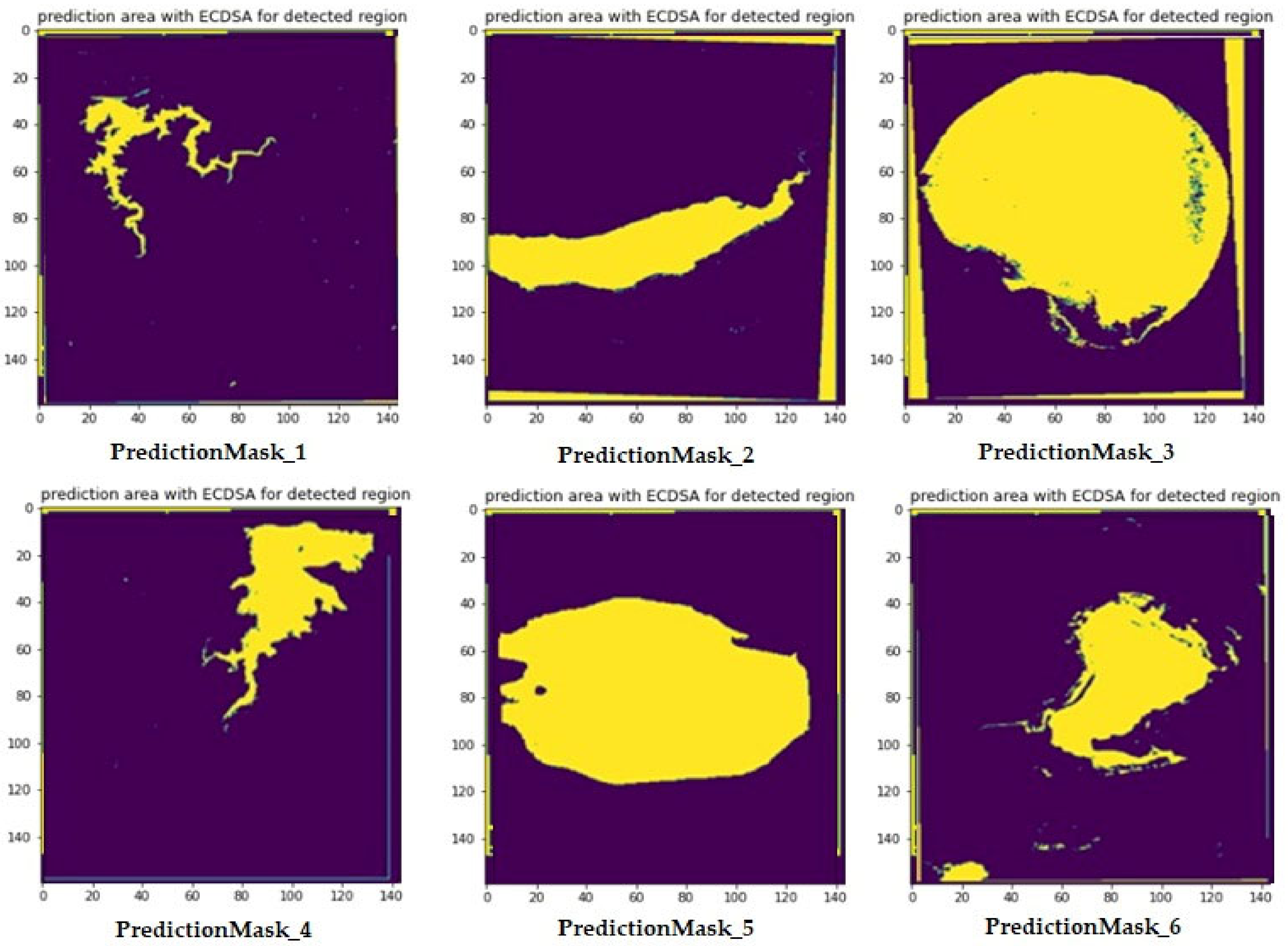
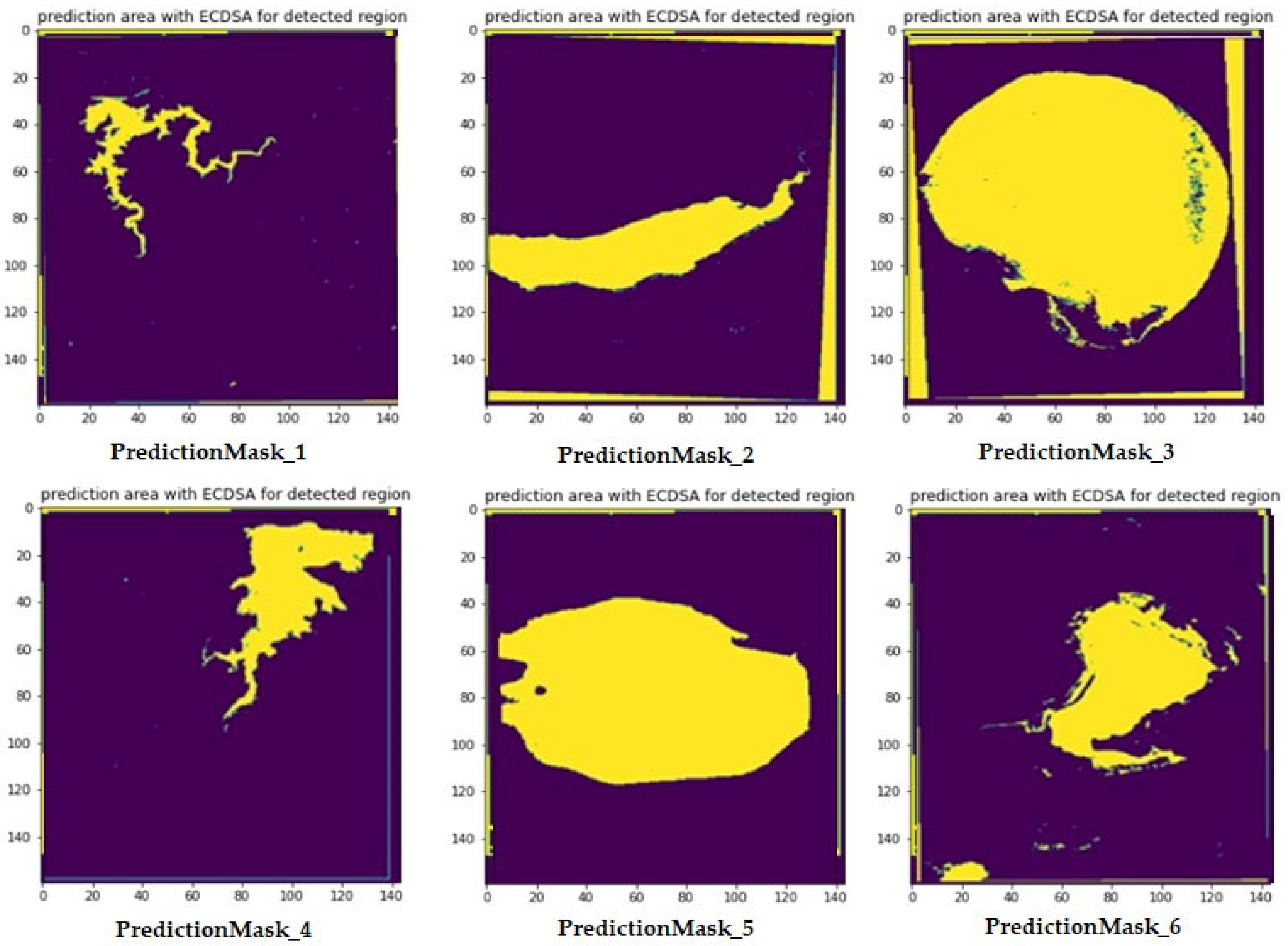
Table 2 represents Elliptic curve digital signature values for corresponding images. The ECDSA function is applied to the detected mask to achieve integrity. The main advantage of such a feature enables detecting any change in the transmitted data. This is because the hash function, which is also termed as message digest, is one way. While transmitting the mask, the message digest is also concatenated and sent to the destination. In case, there is any modification to the data, it can be verified by checking the hash value at the destination.
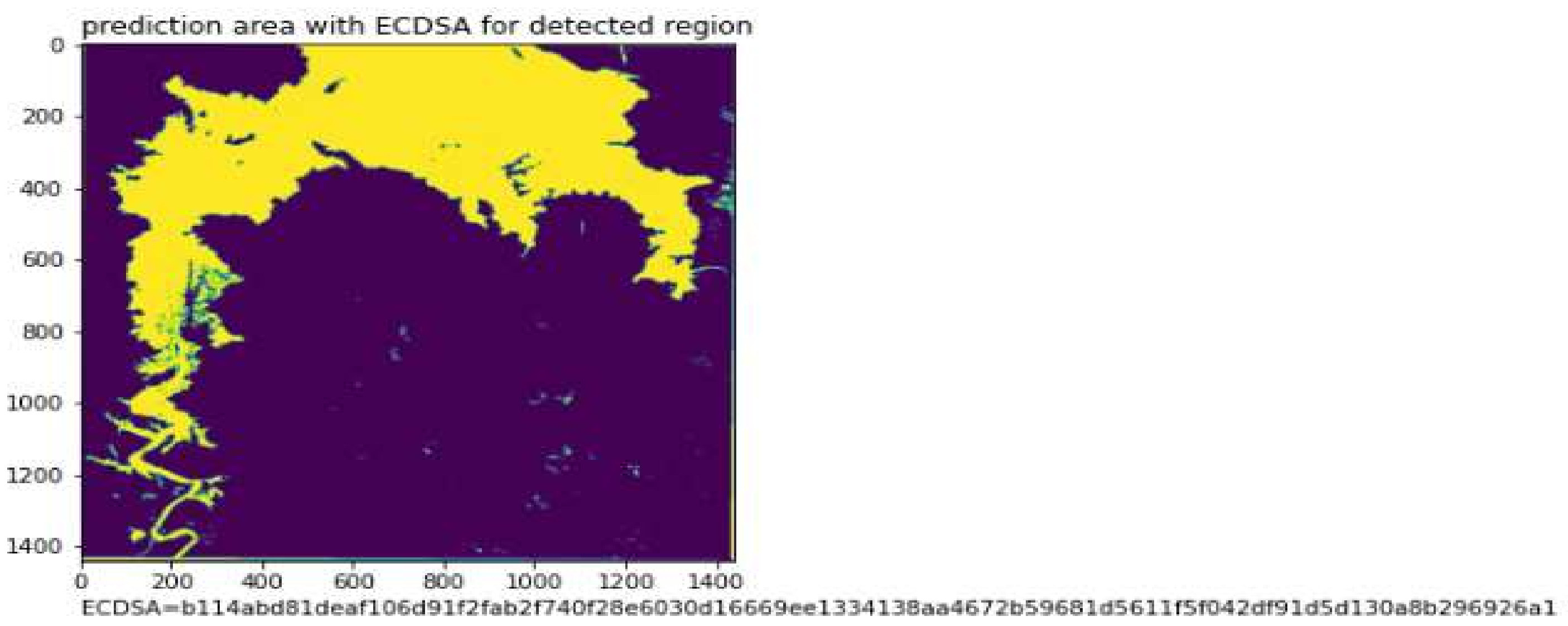
Figure 11 represents Predicted Masks for water bodies sentinel-2 satellite Images. The ECDSA values for these predicted Masks are present in the
Table 2.
5. Performance Analysis
Performance Analysis is the key factor for any model. It helps to check how good the model shows results. It is also used to compare the model with other existing ones. This section shows the analysis of the water bodies detection model with different metrics.
5.1. MeanIOU
It is a popular evaluation metric used to evaluate segmentation models. It is mainly used to identify the overlap percentage between the original output and predicted mask.
The model shows the MeanIOUscore of 0.89.
Table 3 shows the different metric values for the water bodies prediction model. The score > 0.5 is considered to be a good model.
5.2. Pixel Accuracy
The pixel accuracy is another evaluation metric where it checks the percentage of the pixel that is correctly predicted. It compares Ground Truth and Prediction.
represents the prediction is in that certain class and similarly
indicates the pixel doesn’t belong to the wrong class. The cumulative Pixel Accuracy is given by,
The model shows the Cumulative Accuracy of 94.1%.
5.3. Instance Segmentation
Instance segmentation contains a group of local segmentation masks. IOU for each mask is calculated instead of calculating on a single bounding box in Object detection models. To calculate this metric precision values are obtained for each mask.
5.3.1. Precision Calculation
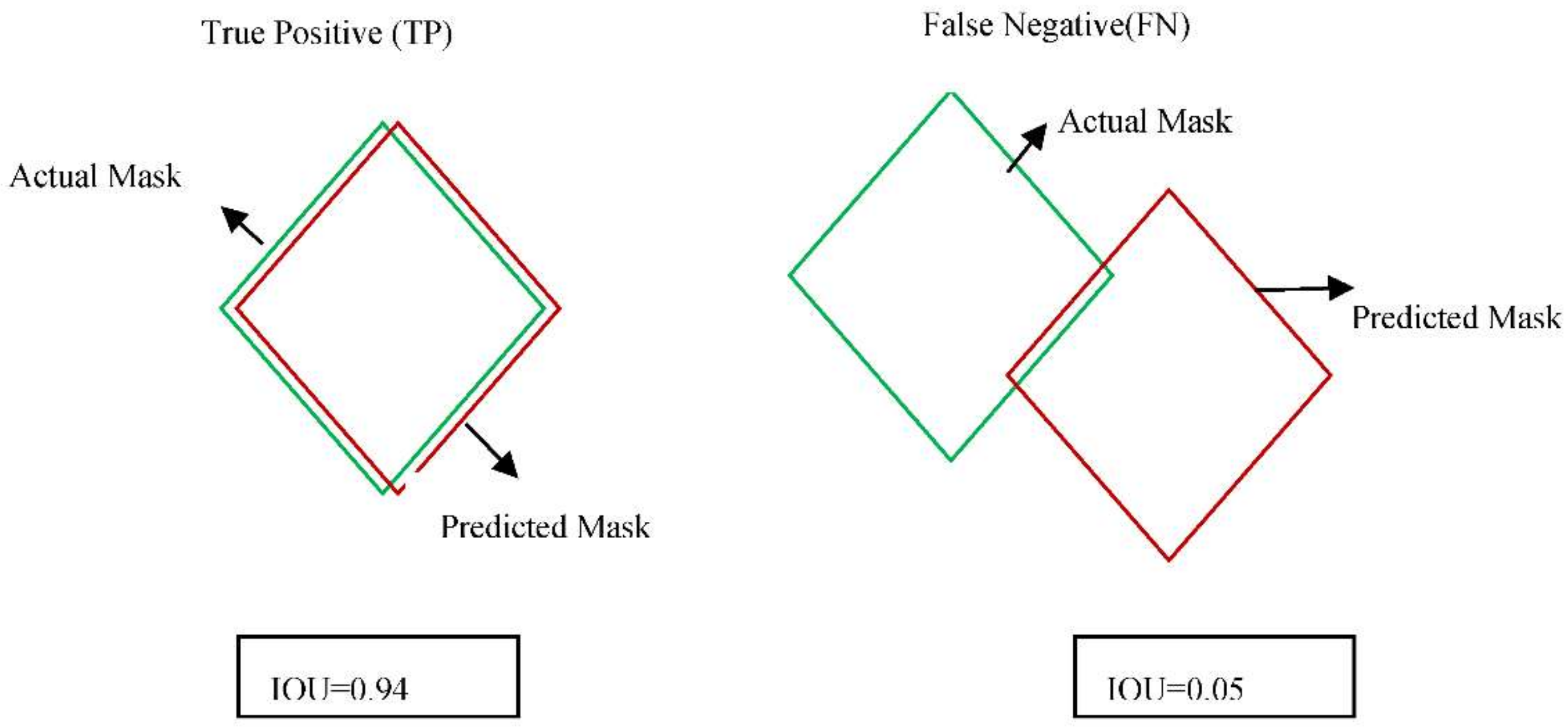
True positive is seen when truth and predicted pair IOU value exceeds certain threshold.
Figure 12 depicts the prediction of TP and FN based on IOU values. Let the IOU threshold be 0.8. TP and FN are observed based on the threshold value.
The precision value for the model is 0.94.
5.3.2. Recall
It determines total positive predictions in compared with ground truth. To determine precision and recall true positive, they need to be done before hand. To calculate
, IOU is processed between target and prediction. The recall value for the model is 0.939.
Figure 13 shows the difference between predicted image threshold to the default threshold.
5.4. Comparison of U-Net with Other Methods
Table 4 shows the comparison of metrics between the existing method and other methods. The proposed UNet model with tensorflow is compared to Region-Based Convolution Network (R-CNN), Conditional Random Field CNN (CRF-CNN), Efficient Neural Network (ENet) and Semantic Segmentation Model (SegNet).
Based on the above represented statistics, it is clear that the proposed model shows a higher degree of total pixel accuracy, recall, precession and also MeanIOU, which is the metric that is used for evaluating segmentation rate of a semantic image. This indicates the better performance of the model on a whole.
Figure 14 shows the comparison of the present method with different existing methods. The metrics used for comparison are Recall, Accuracy, Precision and MeanIOU. The X-Axis represents different methods. Y-Axis represents metric values in percentages.
5.5. Comparison between Sentinel-2 and Landsat 8 OLI Datasets
Table 5 shows the deviation in values obtained for the same metrics MeanIOU, Precision, Recall, Pixel Accuracy for the Sentinel-2 and Landsat 8 OLI Datasets.
5.6. Comparison between Optimizers
Table 6 shows the comparison of different optimizers under different parameters Learning Rate, Test Loss, Test Accuracy and Momentum. The test loss and test accuracy are for the UNet model.
From the above drawn table, it can be observed that Gradient descent optimizer has a decline in the learning rate capability compared to others. While Adam and Nadam optimizers have same same learning rate, there is a less test loss and higher test accuracy in the case of the Nadam optimizer. Therefore, the Nadam optimizer was considered the best to be implemented with the model.
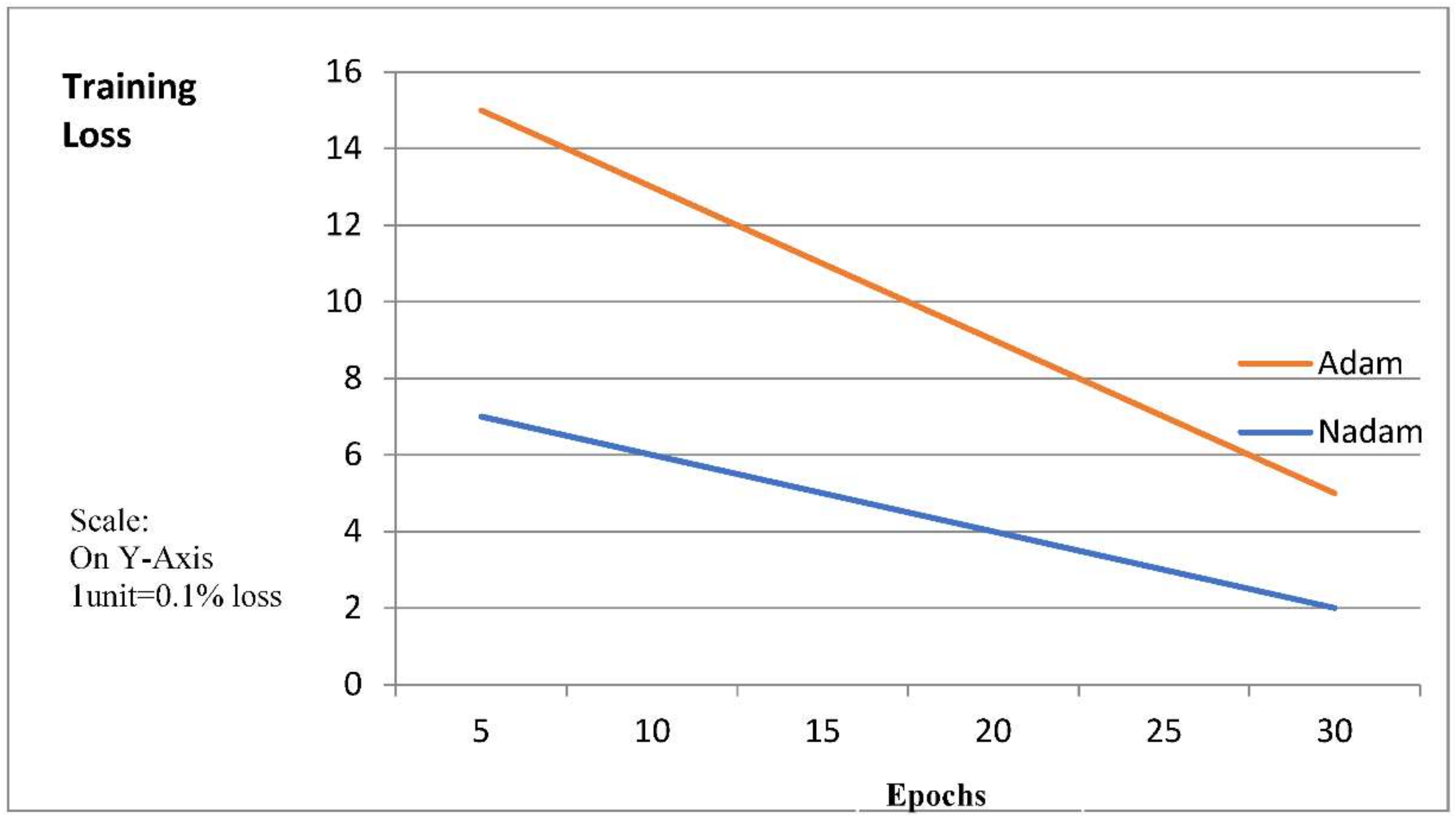
Figure 15 shows the Comparison between Adam and Nadam optimizers. The graph shows the Training Loss of two optimizers when executed under different epochs. The x-axis indicates the Iterations and Y-axis indicates the training loss.
This comparison clearly states that as number of iterations increases the loss is reduced gradually in Nadam as compared to Adam.
5.7. Analysis of Security Algorithms
5.7.1. RSA vs. ECDSA
A major comparison is done between ECDSA and Rivest, Shamir, Adleman (RSA). Although both algorithms use public key cryptography, they are differed by many aspects. RSA has longer keys when compared to ECDSA [
29,
30,
31,
32,
33,
34,
35,
36,
37,
38]. Signing the message undergoes numerous multiplication and division operation in which ECDSA is faster compared to RSA. Shor’s Algorithm is a popular approach to break keys, but is not practically present. RSA is vulnerable to Shor’s algorithm of breaking keys but it is not possible to break the keys using shor’s in ECDSA.
Table 7 shows the comparison of keysizes between RSA algorithm and ECDSA algorithm with different security levels. It is observed that ECDSA has shorter keys compared to RSA.
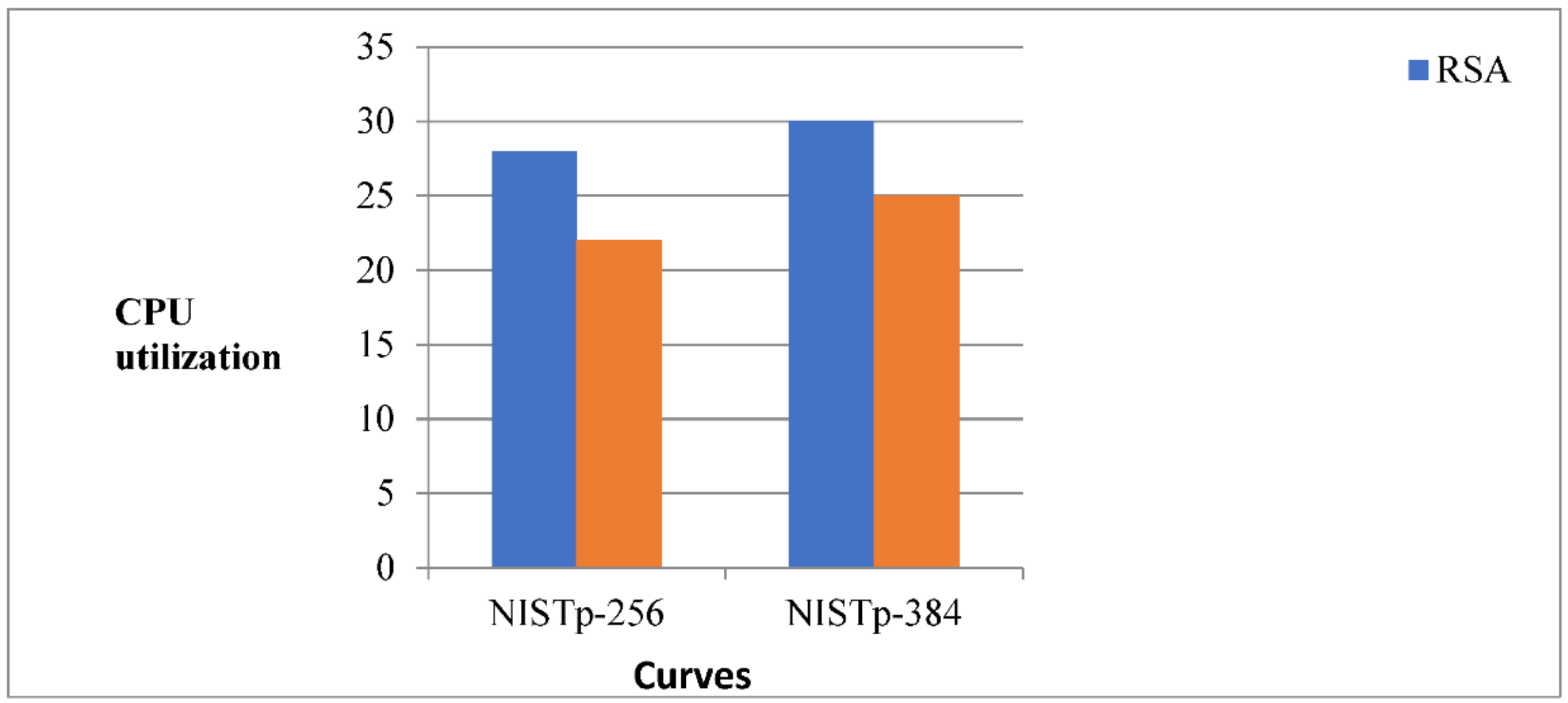
Figure 16 shows the comparison between RSA and ECDSA in terms of CPU Utilization.
5.7.2. RSA vs. DSA vs. ECDSA
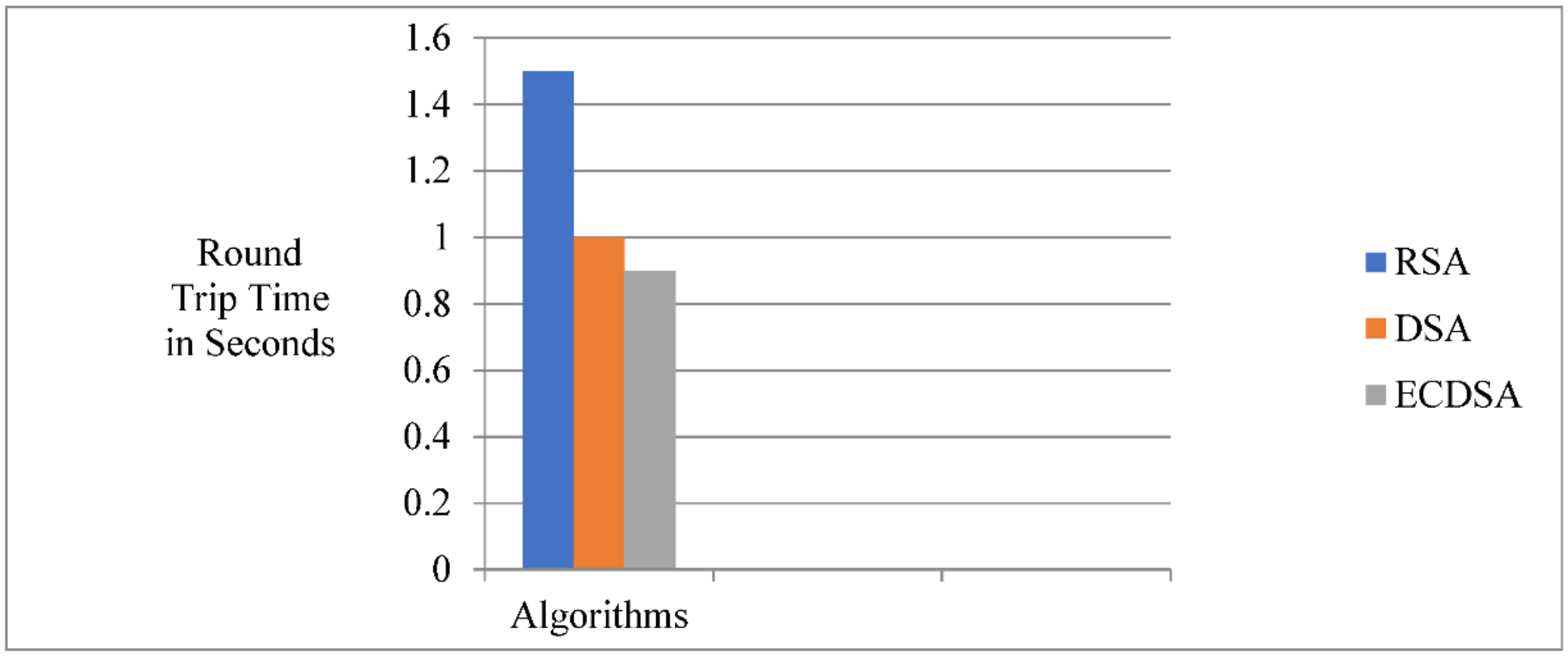
Figure 17 shows the round Trip Time of RSA, Digital Signature Algorithm (DSA), ECDSA. Round Trip Time (RTT) indicates the total time in which the signature is sent through the channel and time taken to receive the acknowledgement. ECDSA takes less RTT compared to other algorithms.
6. Conclusions
In this work, a deep learning model is proposed to detect water bodies from satellite Images using UNet and Tensorflow. This model works best even in the case of small and blurred satellite images. Furthermore, it also gives best results in the case of water bodies present on the land interface because of the architecture of UNet. Additionally, the model also uses a best suitable optimization technique (Nadam Optimizer). The computation time is relatively faster using this Nadam Optimizer. Moreover, data analysis is done with keen interest by following the stages like resizing, converting to masks, padding as it defines the perfection and performance of the model. The proposed UNet architecture uses multiple channels and feature maps. It also initiates hidden activation function, output activation function, kernel Initializers. Max pooling is done in the model to reduce the dimensionality of images which increases the performance. The following model detects the prediction area from the satellite images with a higher accuracy compared to other existing ones. It also works best under images with adverse climatic conditions. The superiority of the model is that it uses ECDSA to secure the detected water region and produces the secured signature, such that this water bodies region can be protected from unauthorized person. In future, this model can be extended to video inputs. The detected regions of water bodies can be stored to the cloud.


 ,
, 

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}