
Deep Learning in Water Resources Management: Τhe Case Study of Kastoria Lake in Greece



Abstract
:1. Introduction
2. Materials and Methods
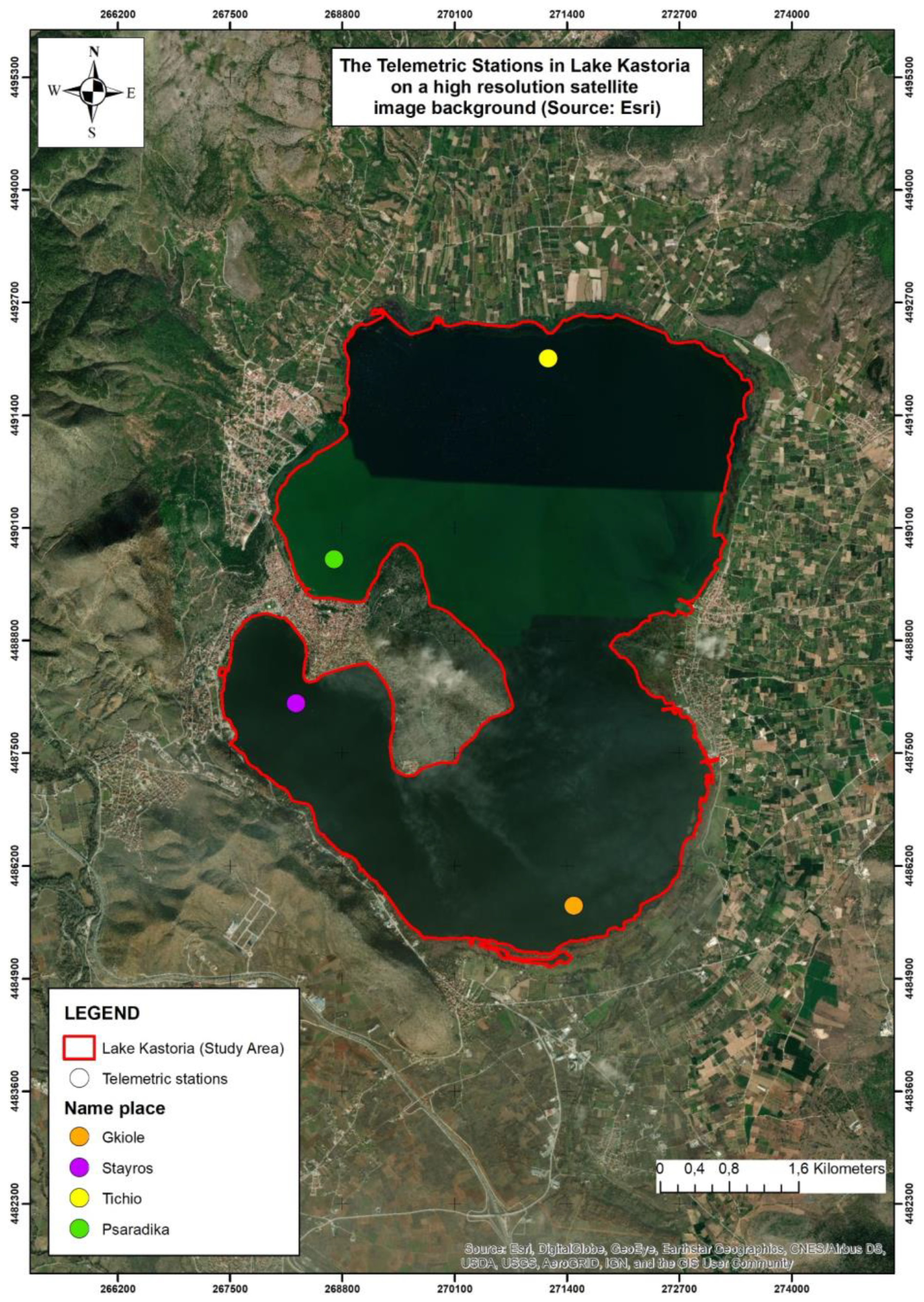
2.1. Study Area
2.2. Programming Language
2.3. Tools and Platforms
2.4. Graphical User Interface
2.5. Libraries
2.6. Input and Output Data
2.7. Number of Hidden Layers
2.8. Number of Nodes in the Hidden Layer
2.9. Training Epochs
2.10. Activation Function
2.11. Learning Rate
2.12. Optimization Algorithm
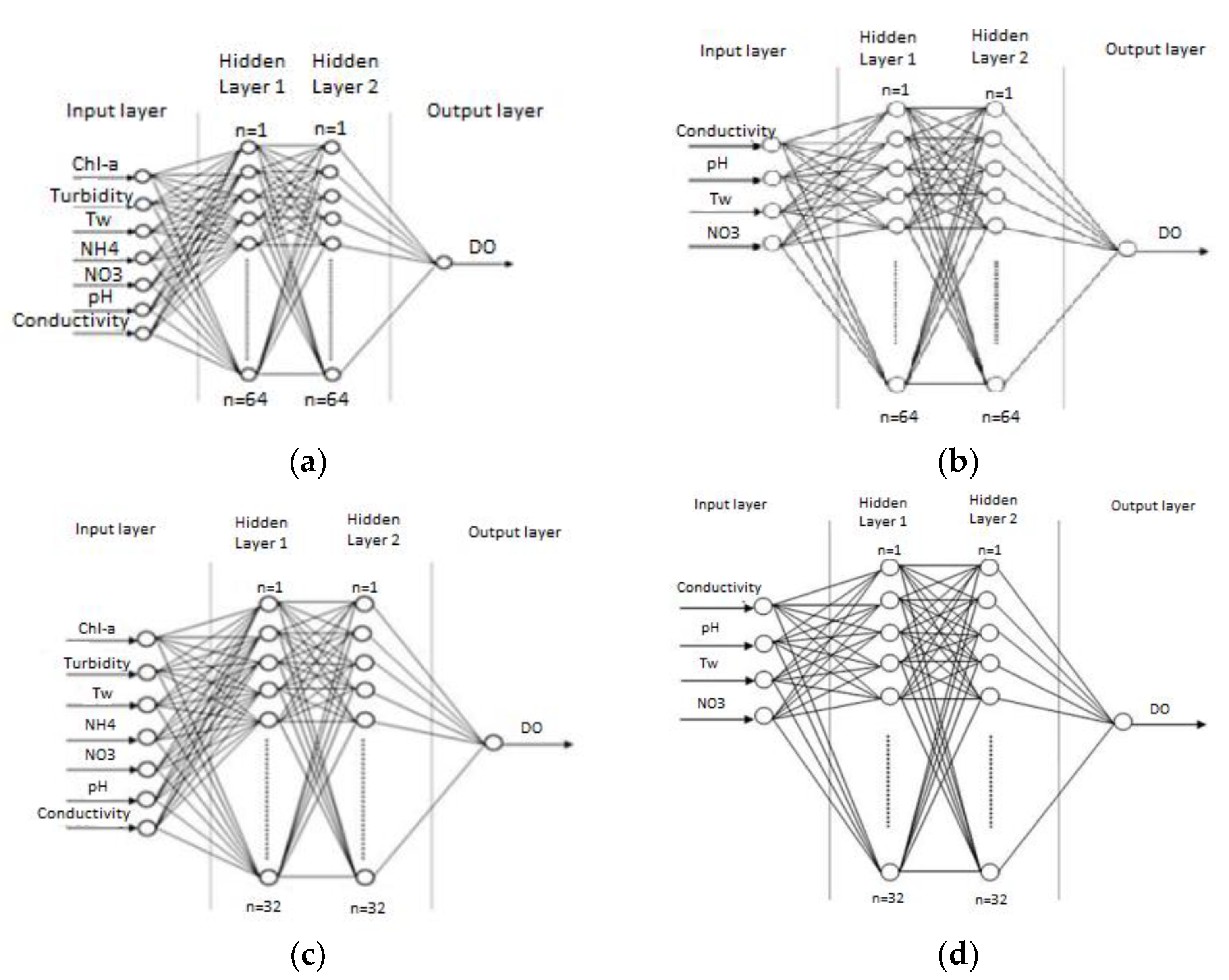
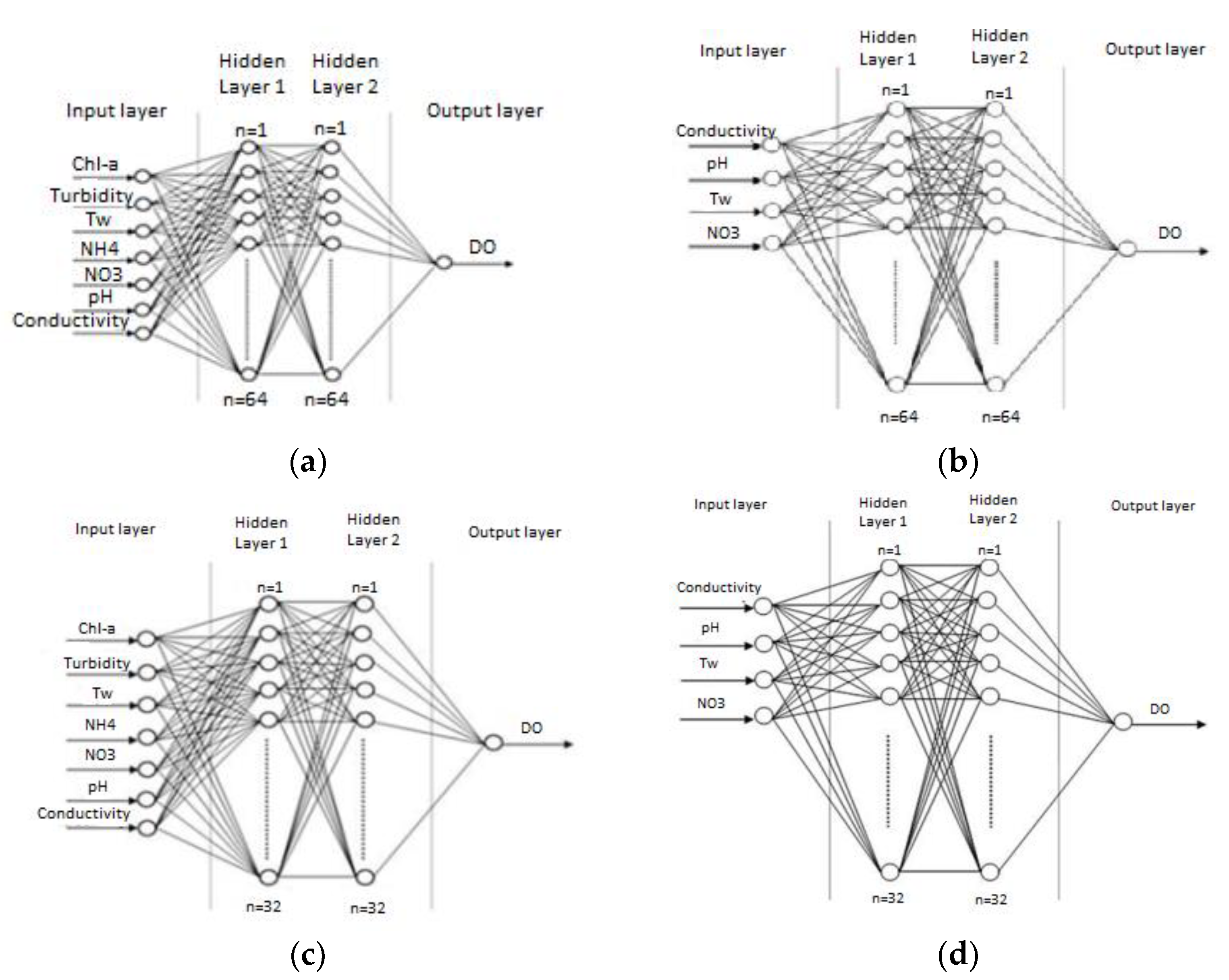
2.13. The Structures
- an input layer of quality parameters, depending on the investigated structure;
- two densely connected hidden layers, consisting of 64 or 32 units/nodes each, depending on the investigated structure; and
- an output layer of DO quality parameter.
- 7-64-64-1 for Gkiole, Psaradika, and Toichio stations (Figure 2a) and 6-64-64-1 for Stavros station, where NH4 parameter is not available;
- 4-64-64-1 for all stations (Figure 2b);
- 7-32-32-1 for Gkiole, Psaradika, and Toichio stations (Figure 2c) and 6-32-32-1 for Stavros station where NH4 parameter is not available; and
- 4-32-32-1 for all stations (Figure 2d).
2.14. Preparation of the Dataset
2.15. Statistical Descriptors
3. Results
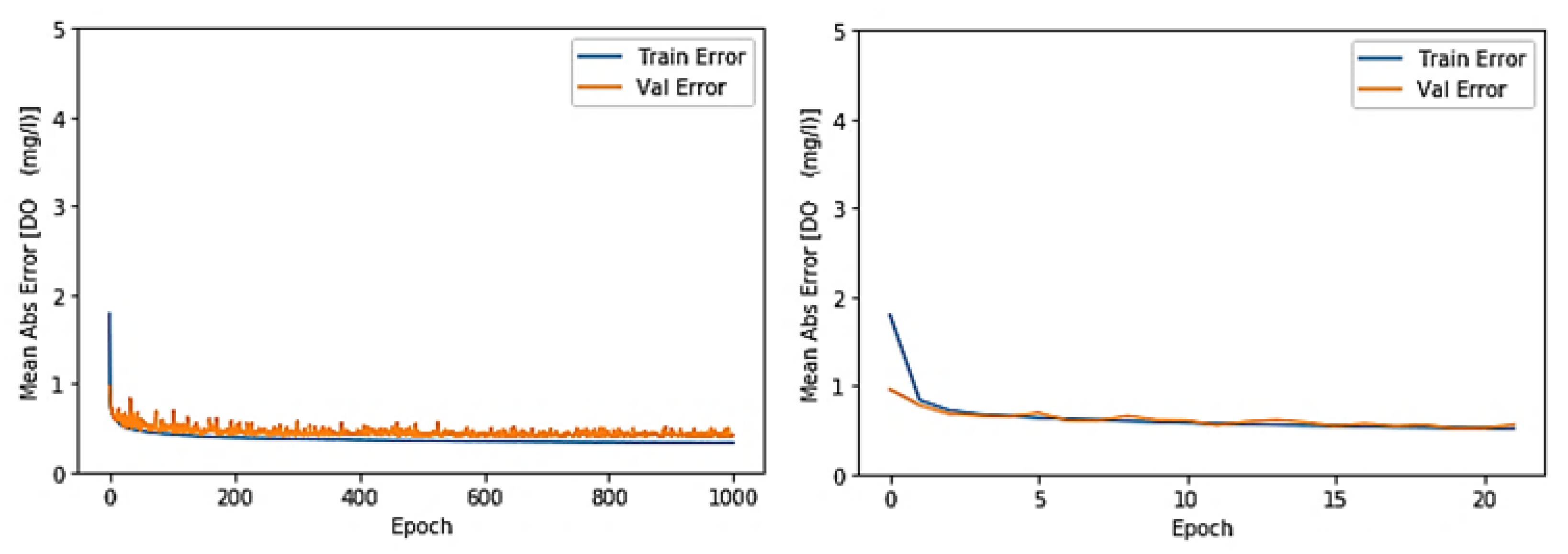
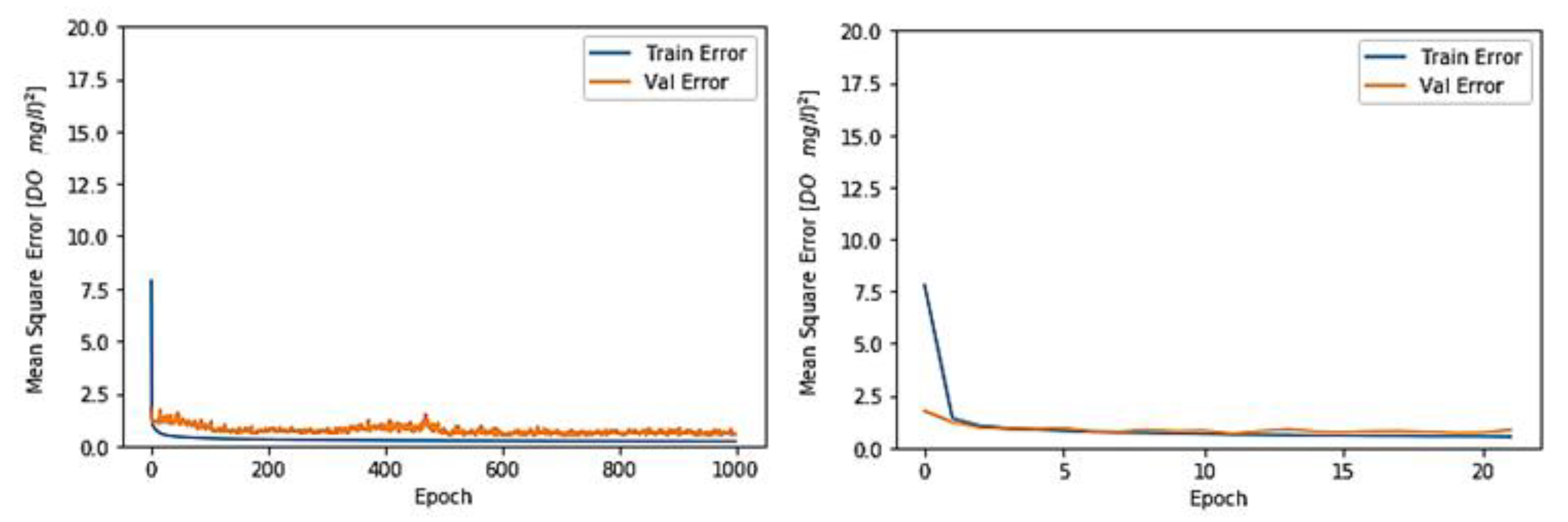
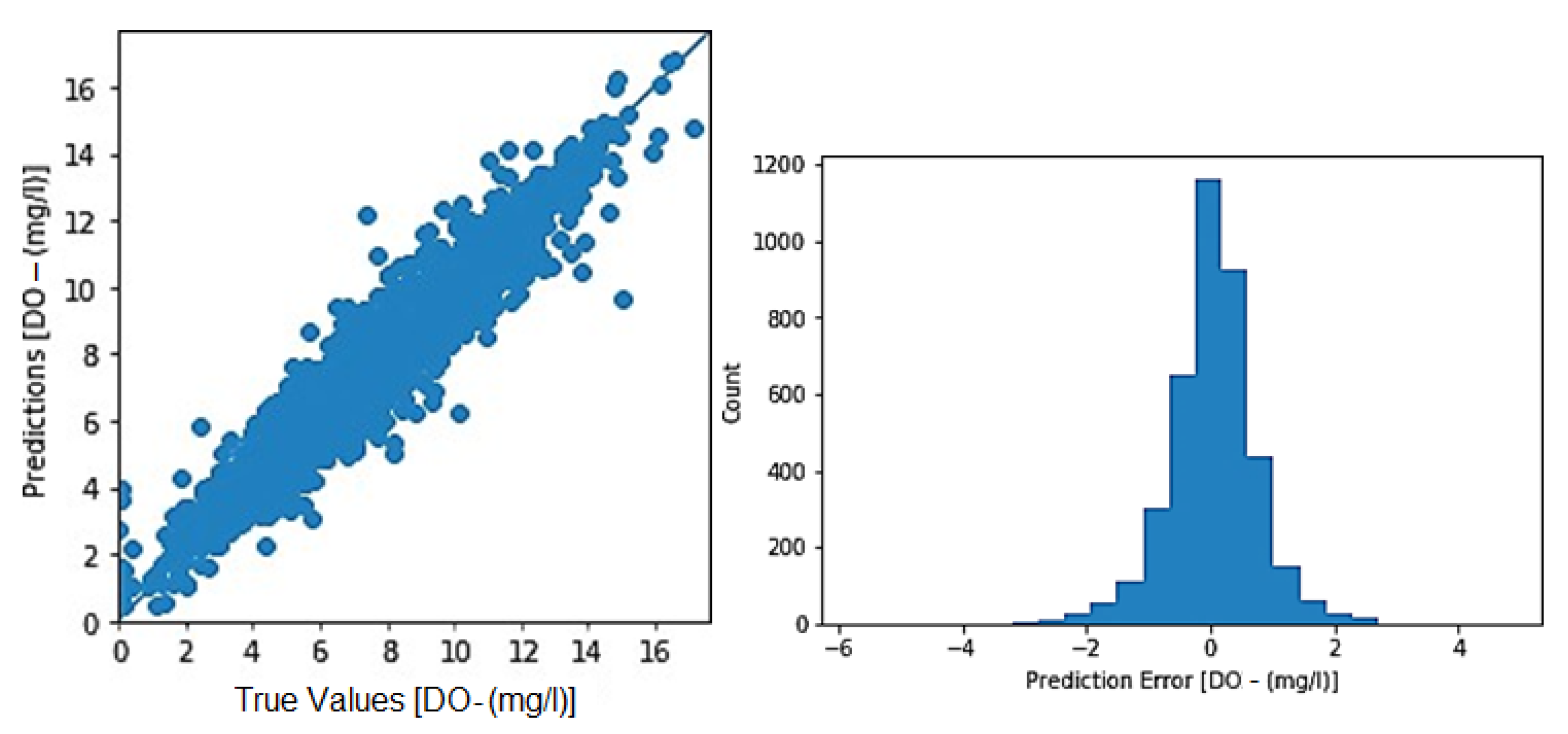
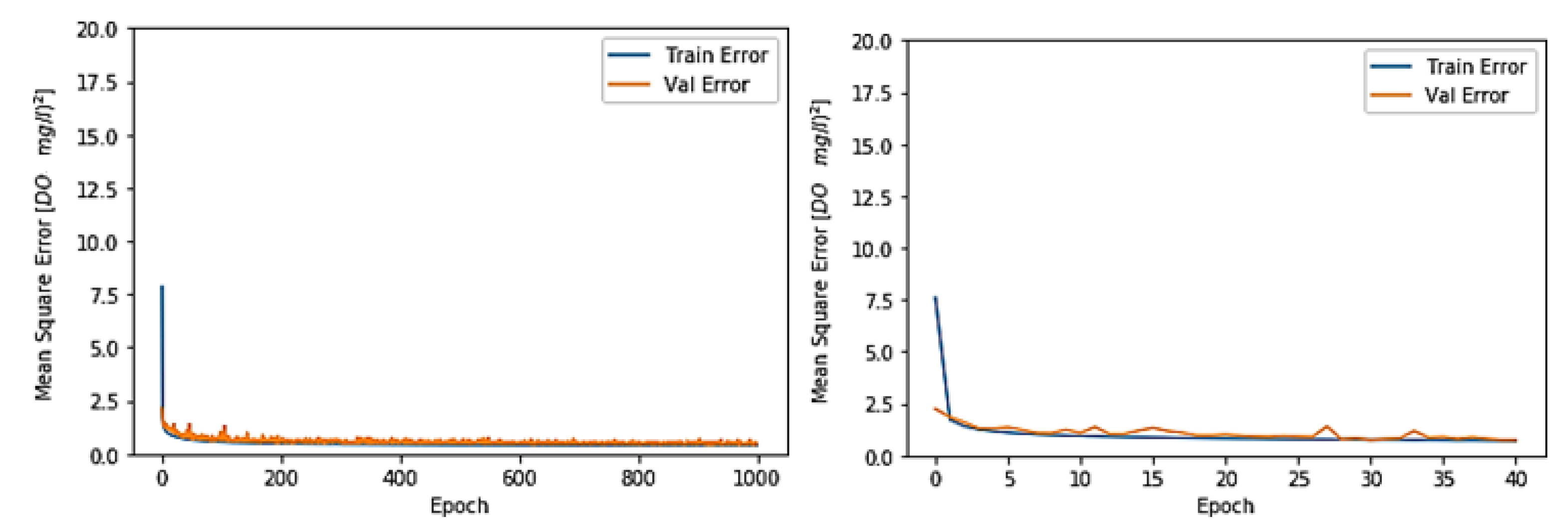
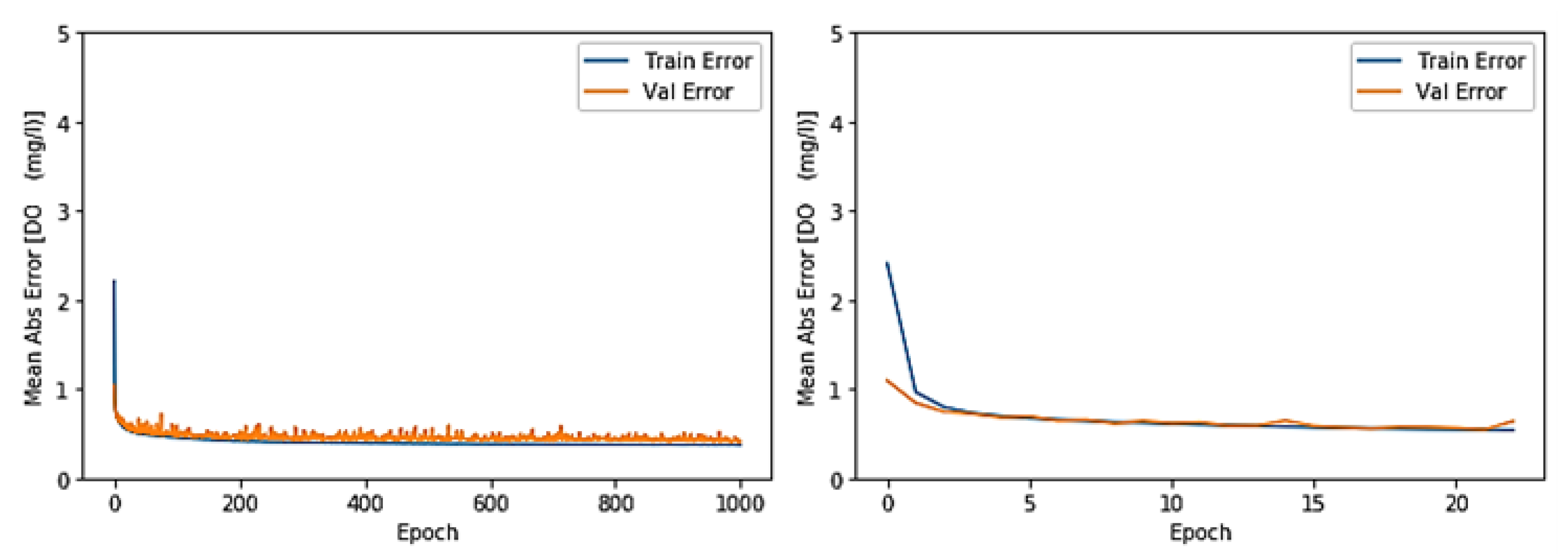
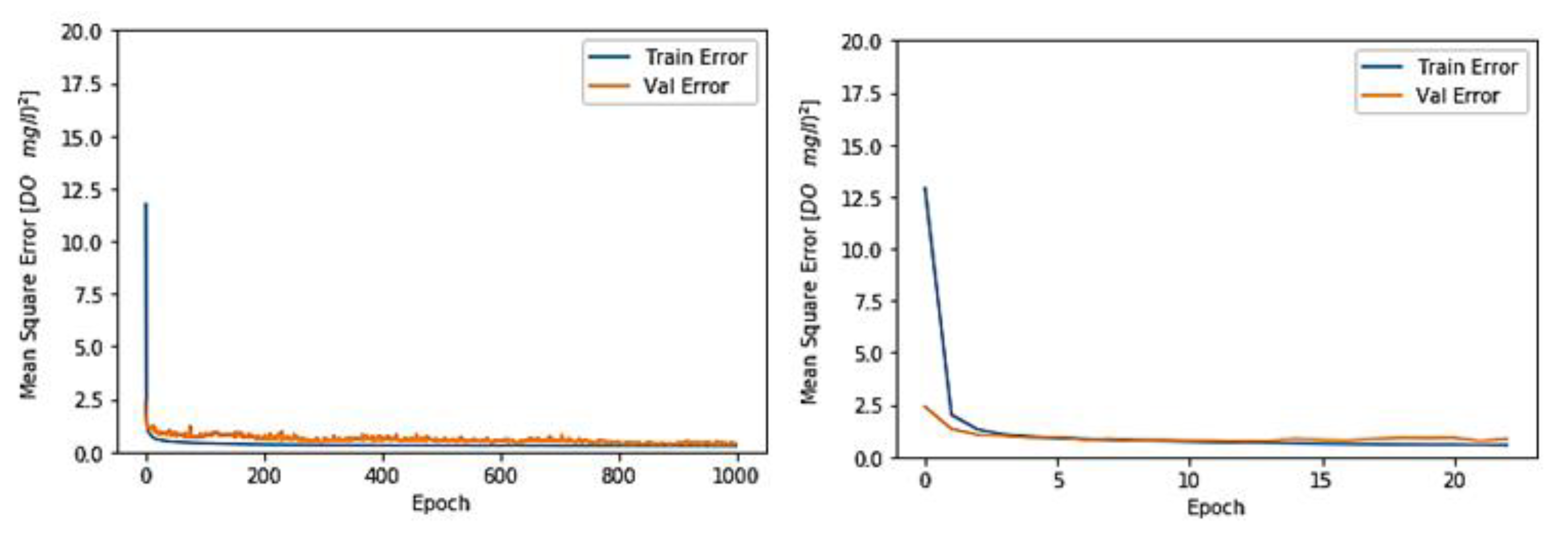
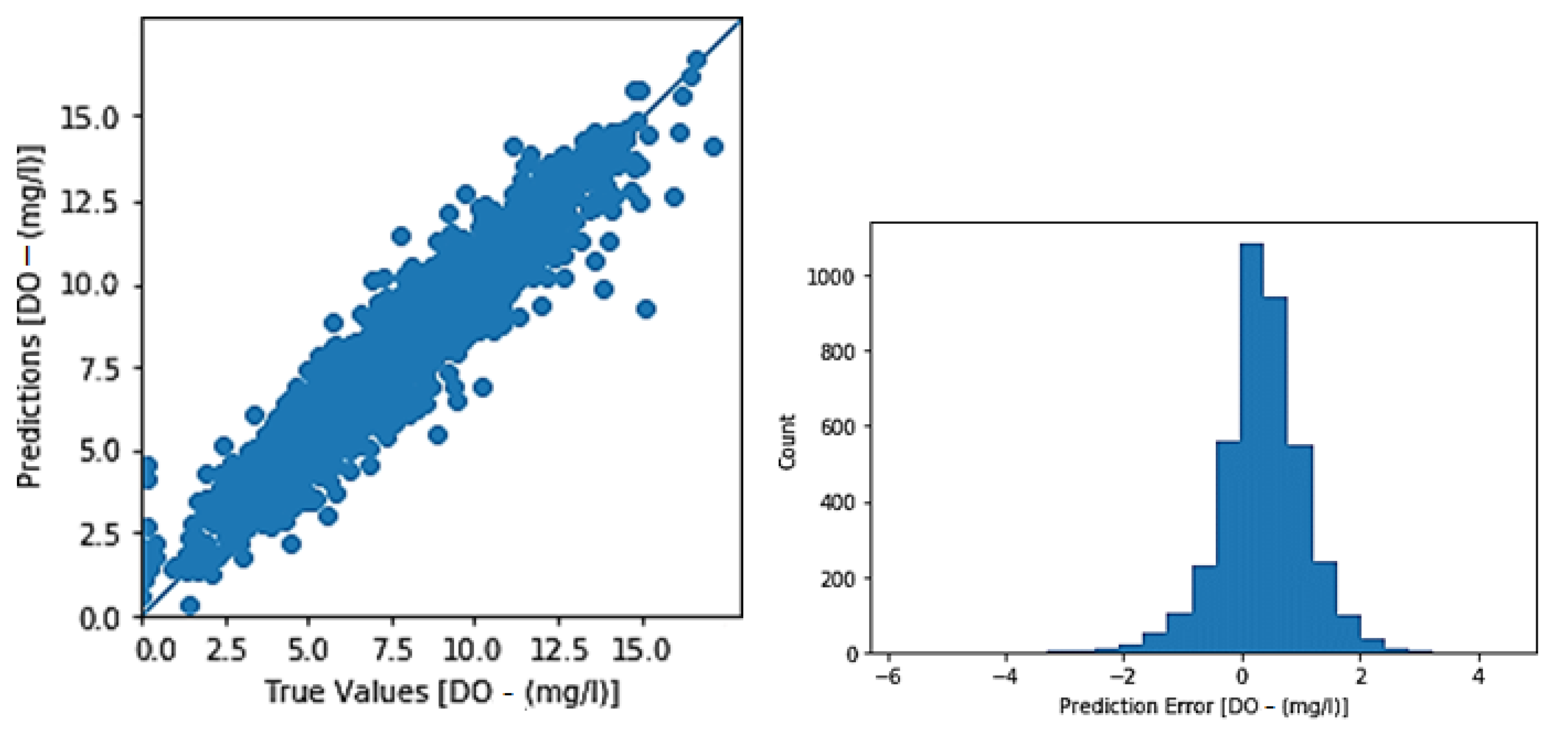
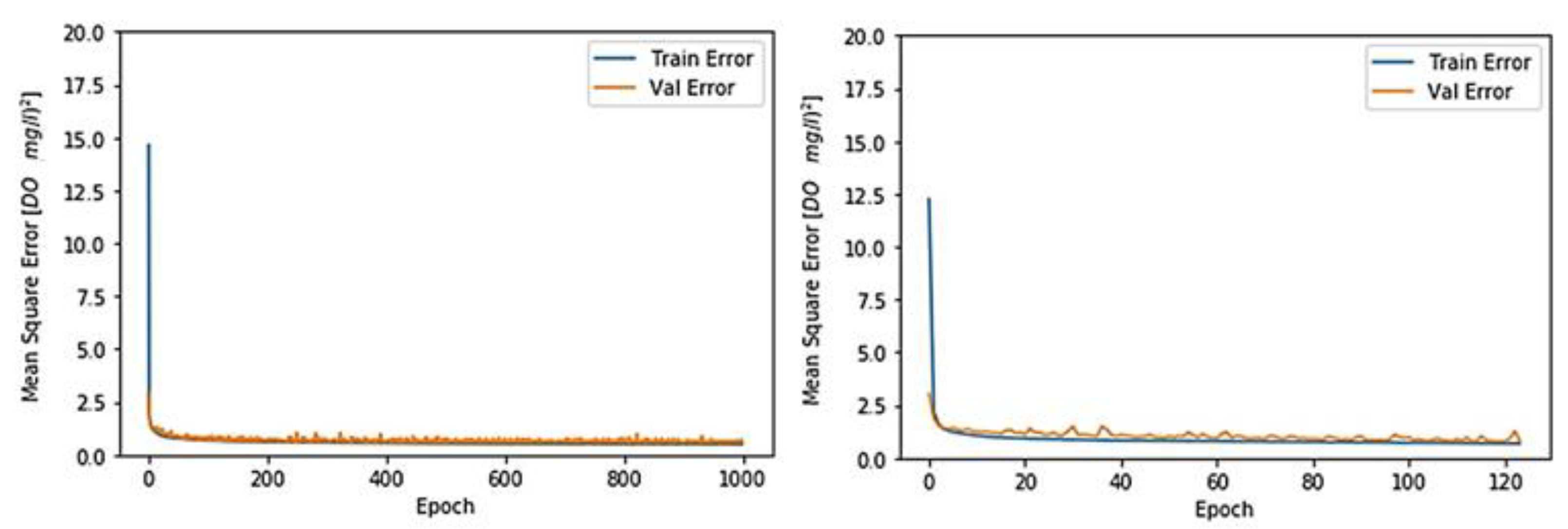
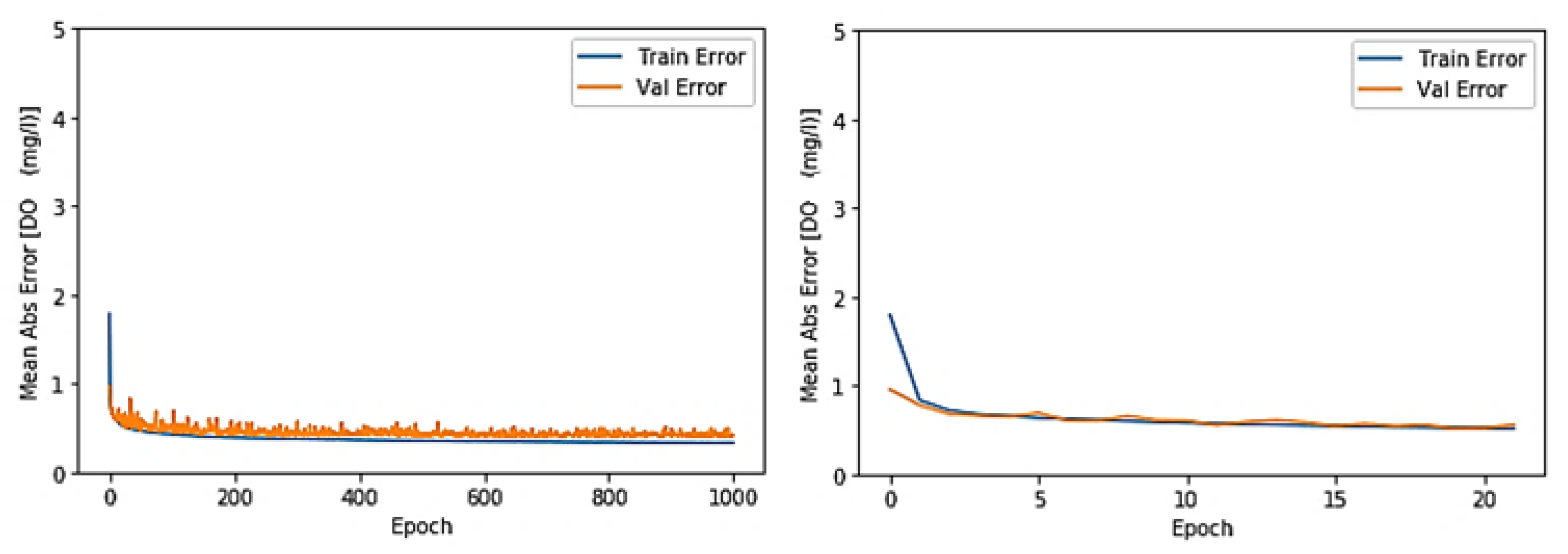
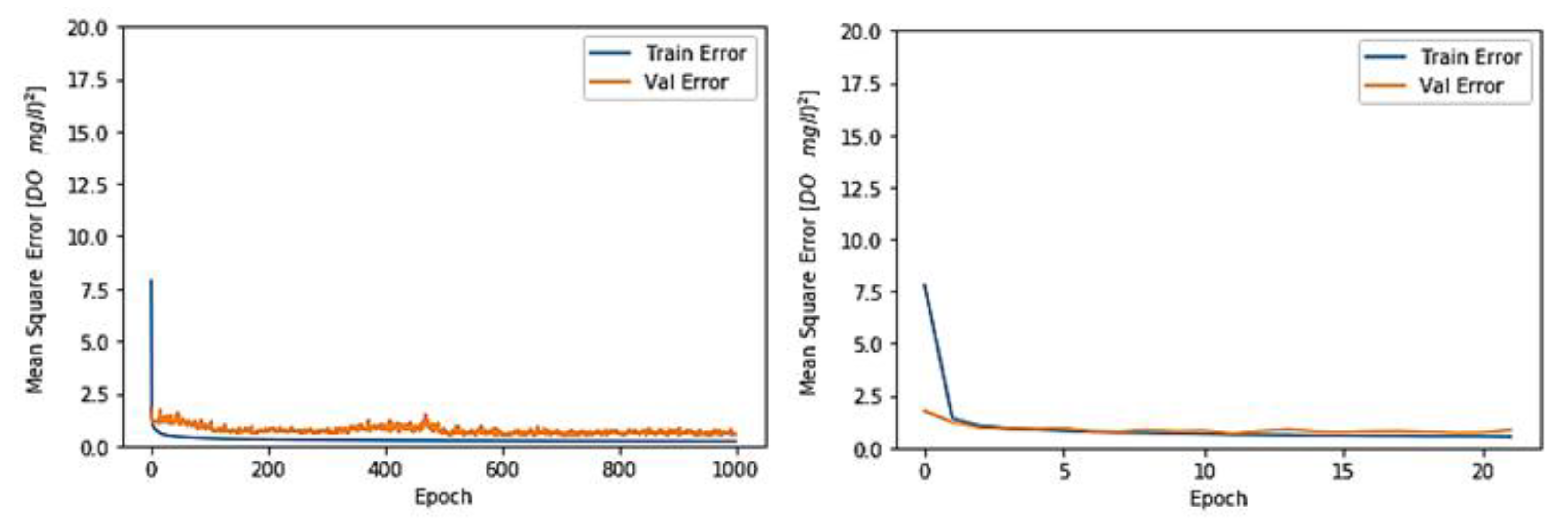
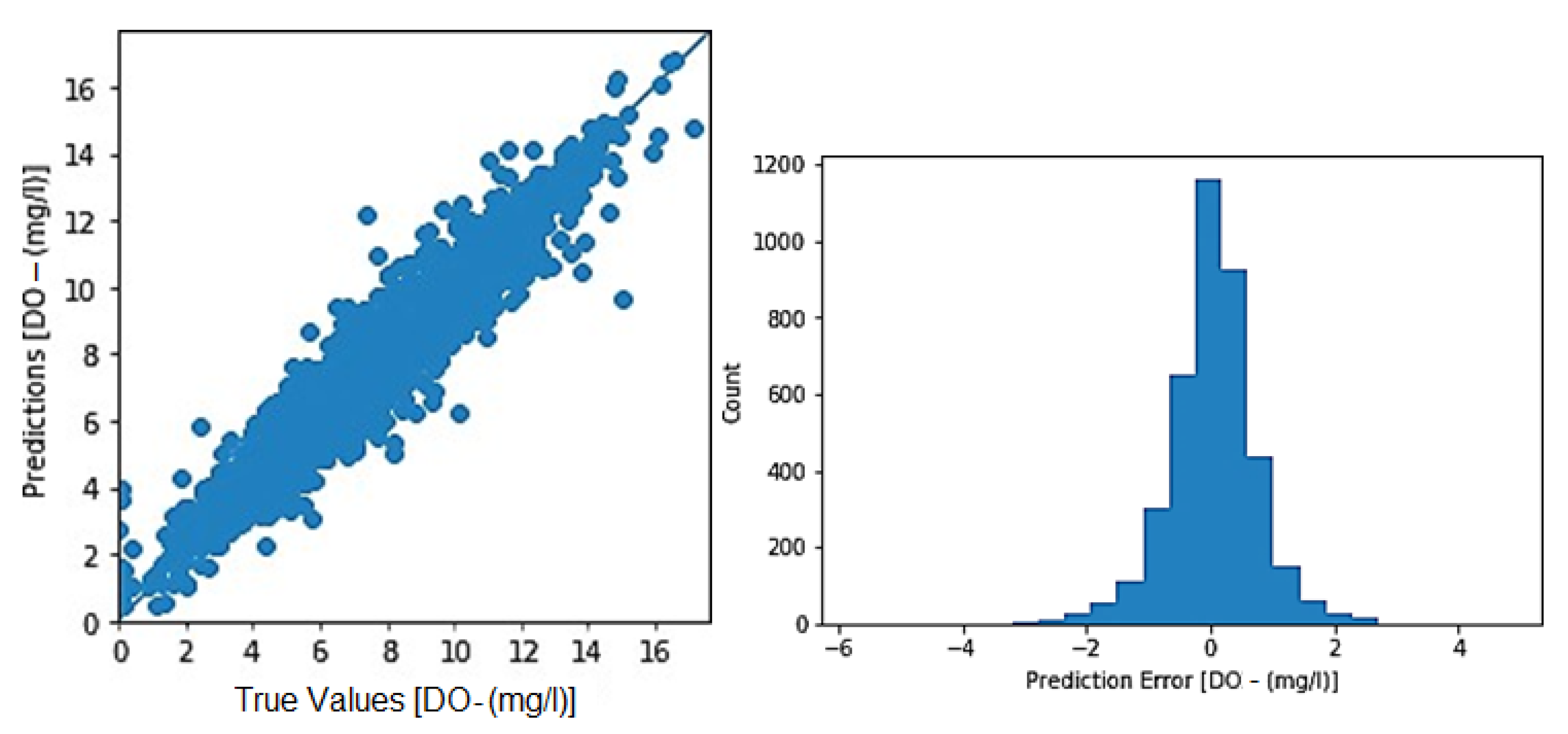
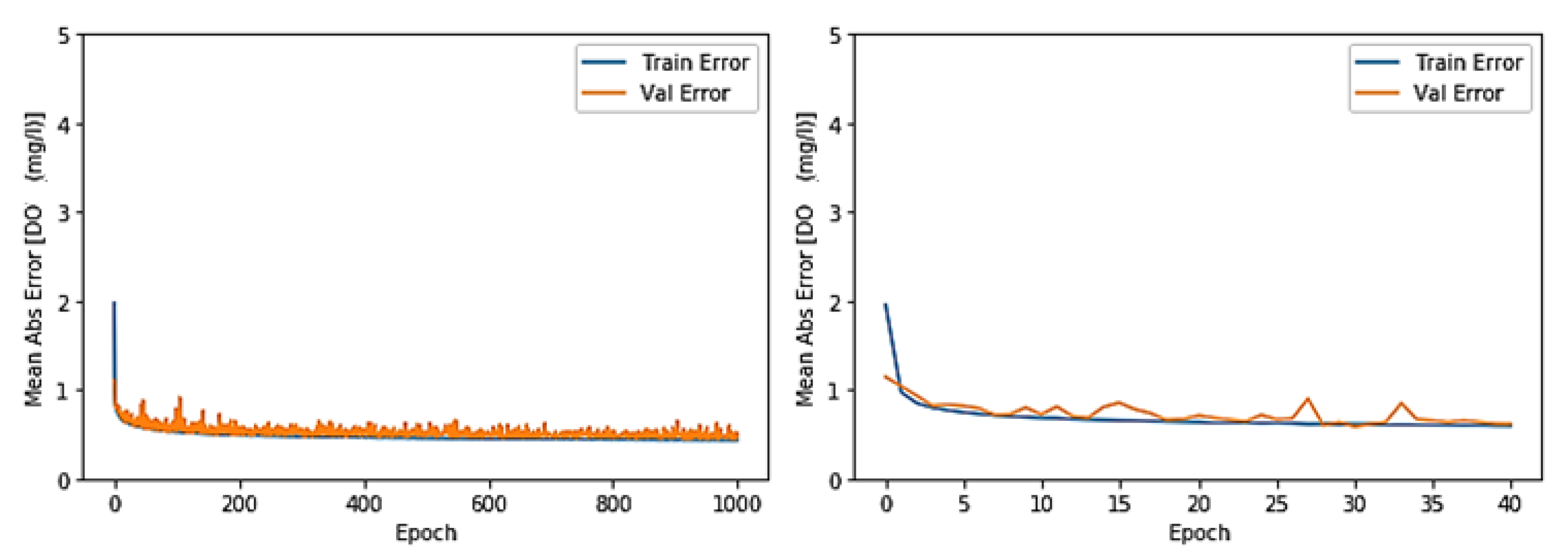
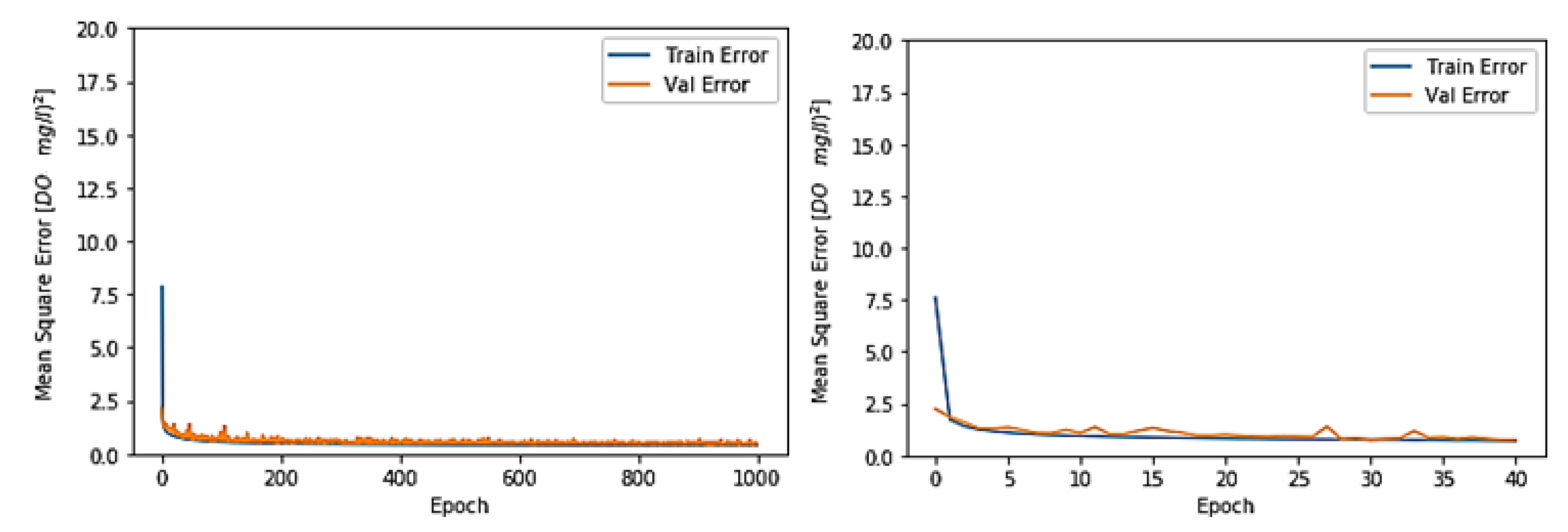
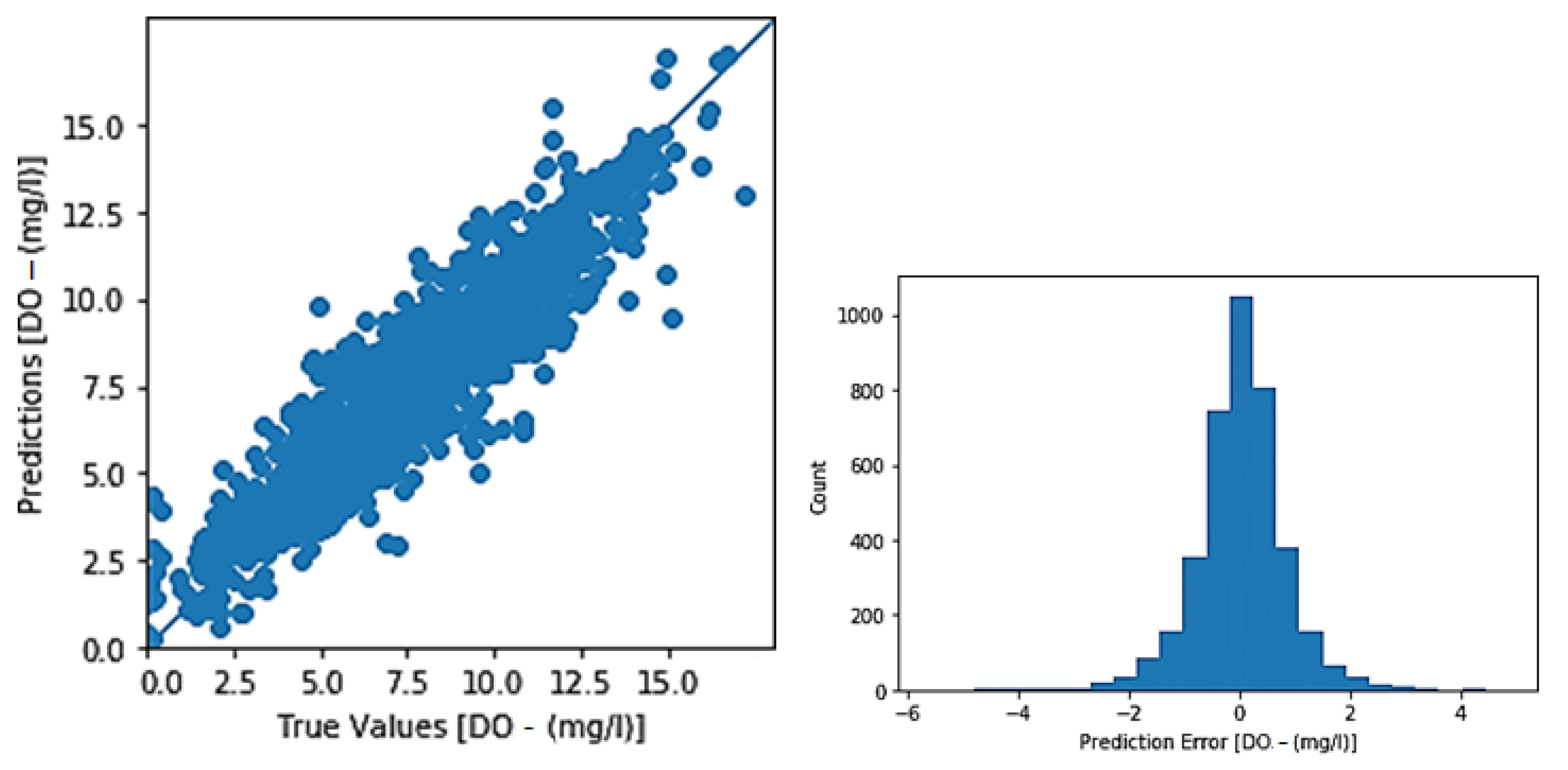
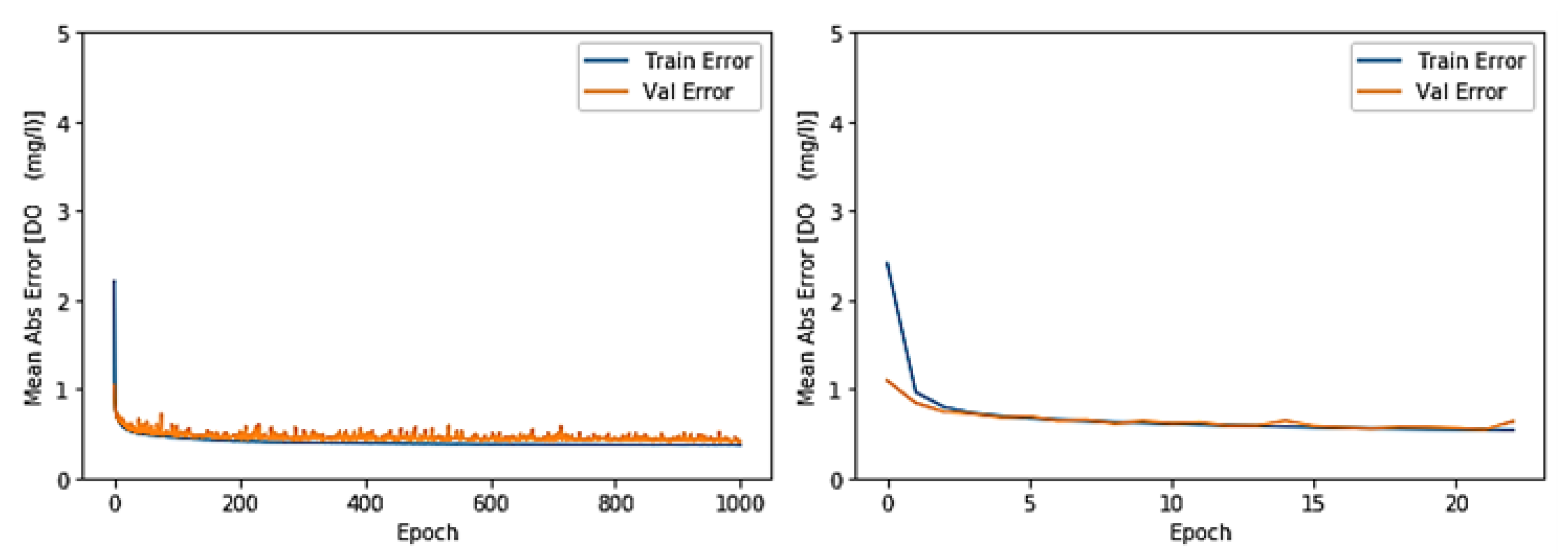
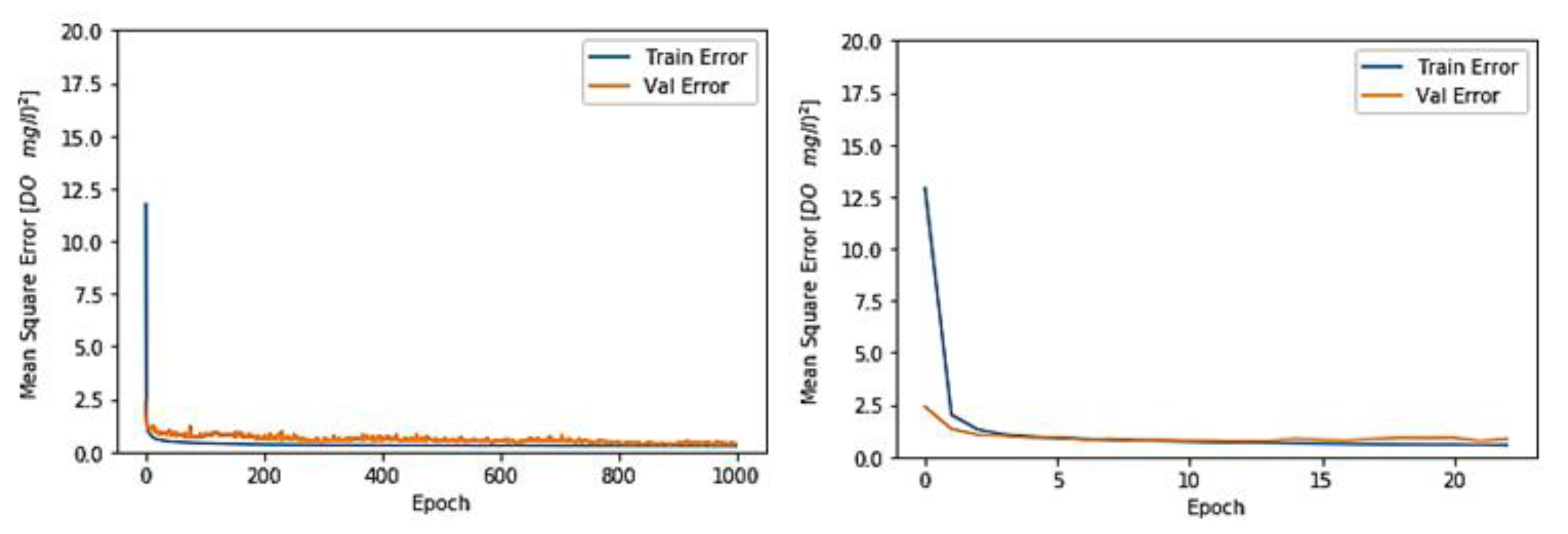
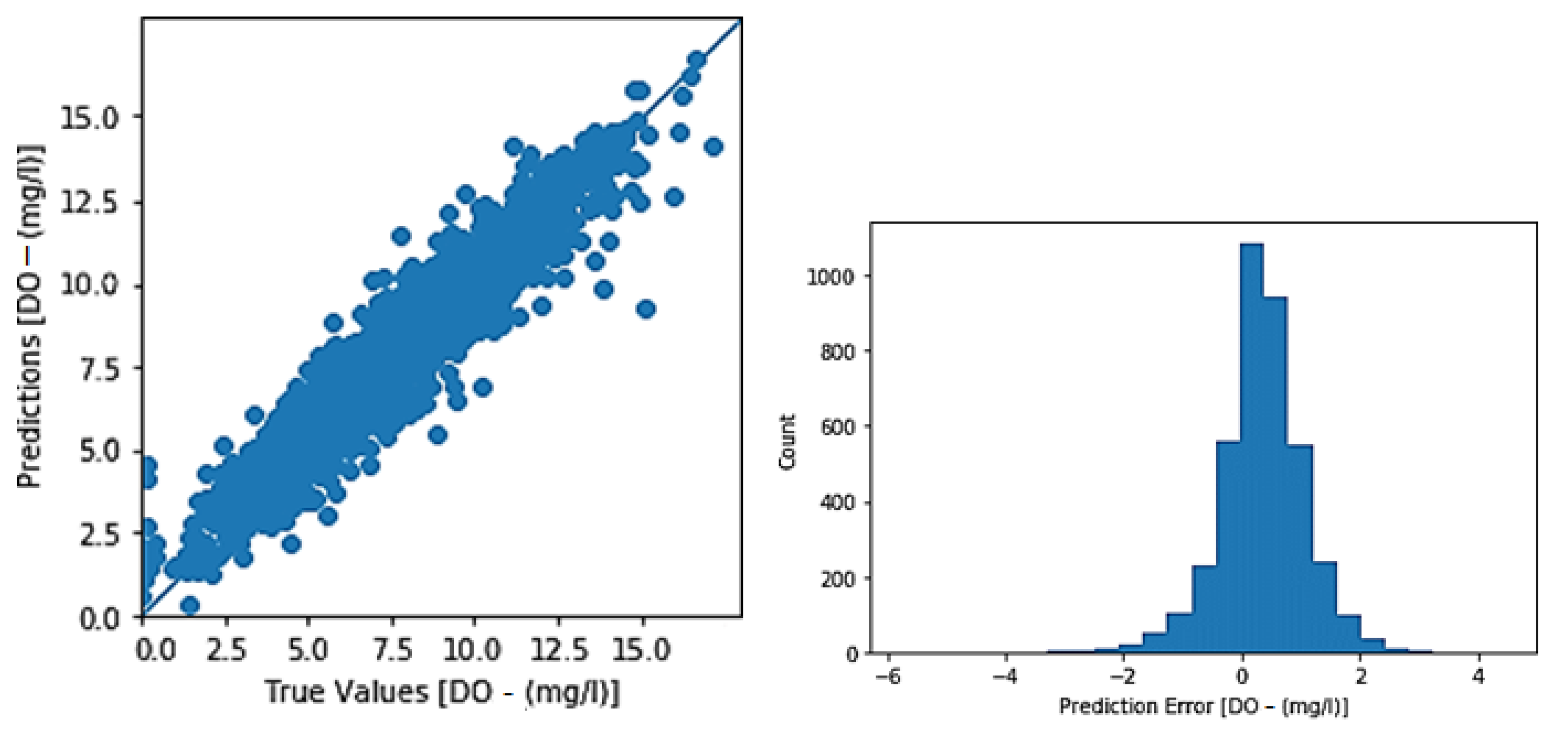
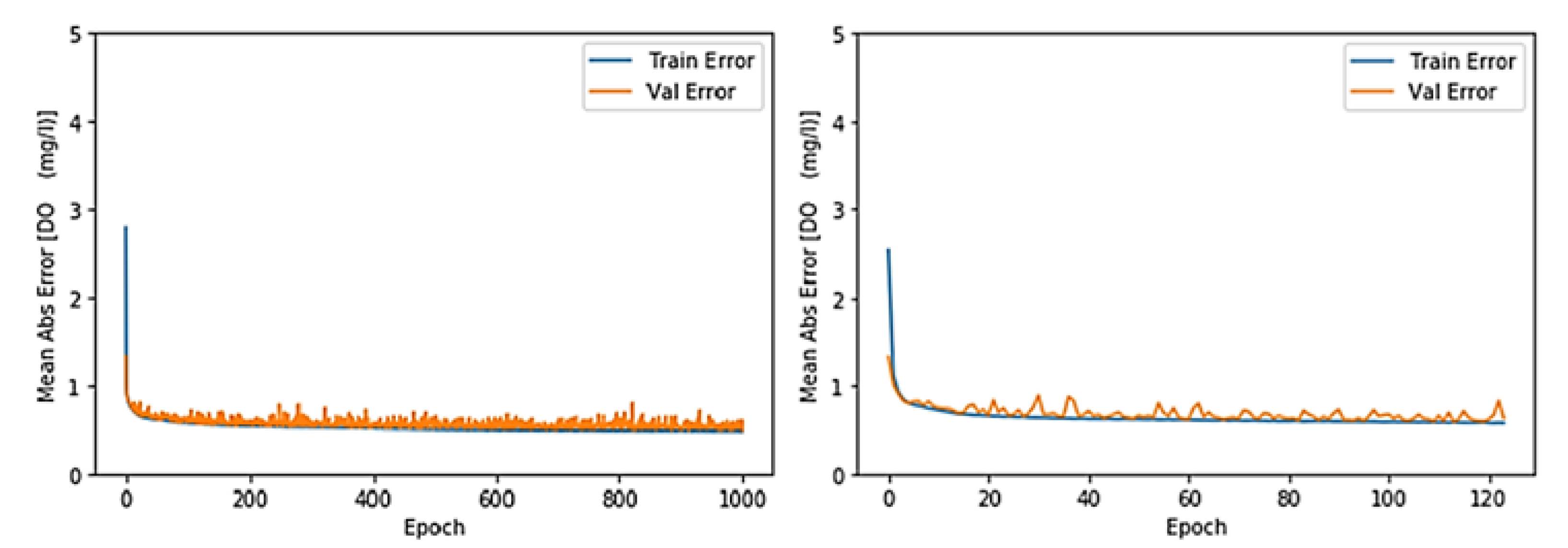
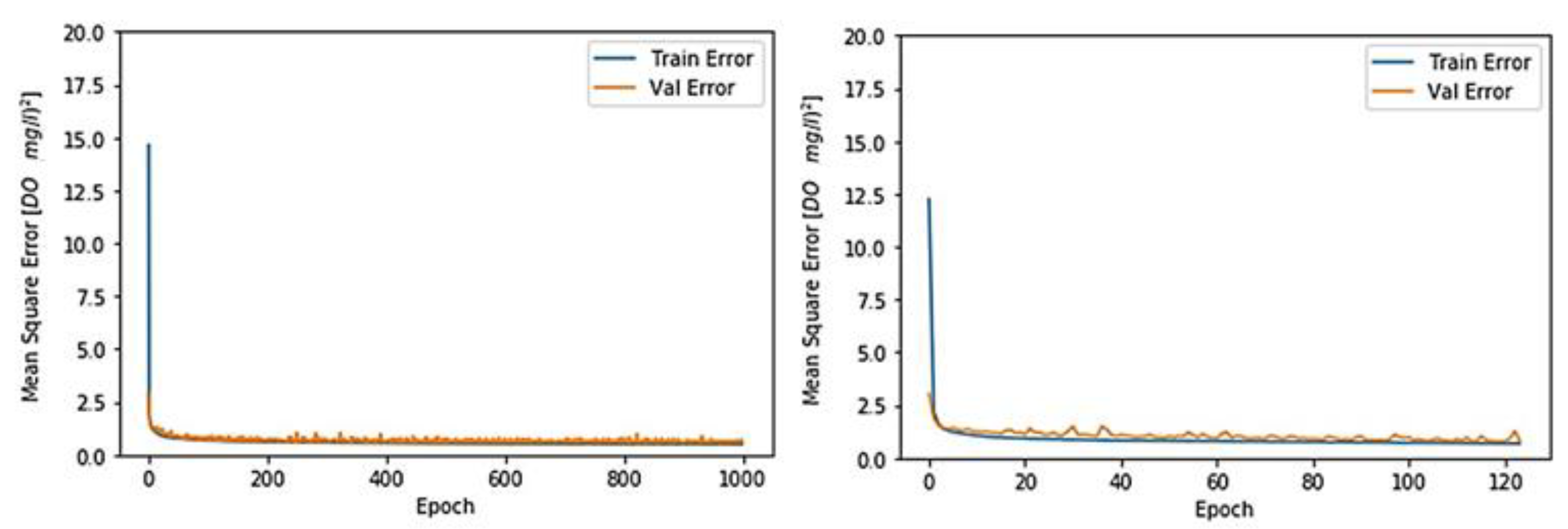
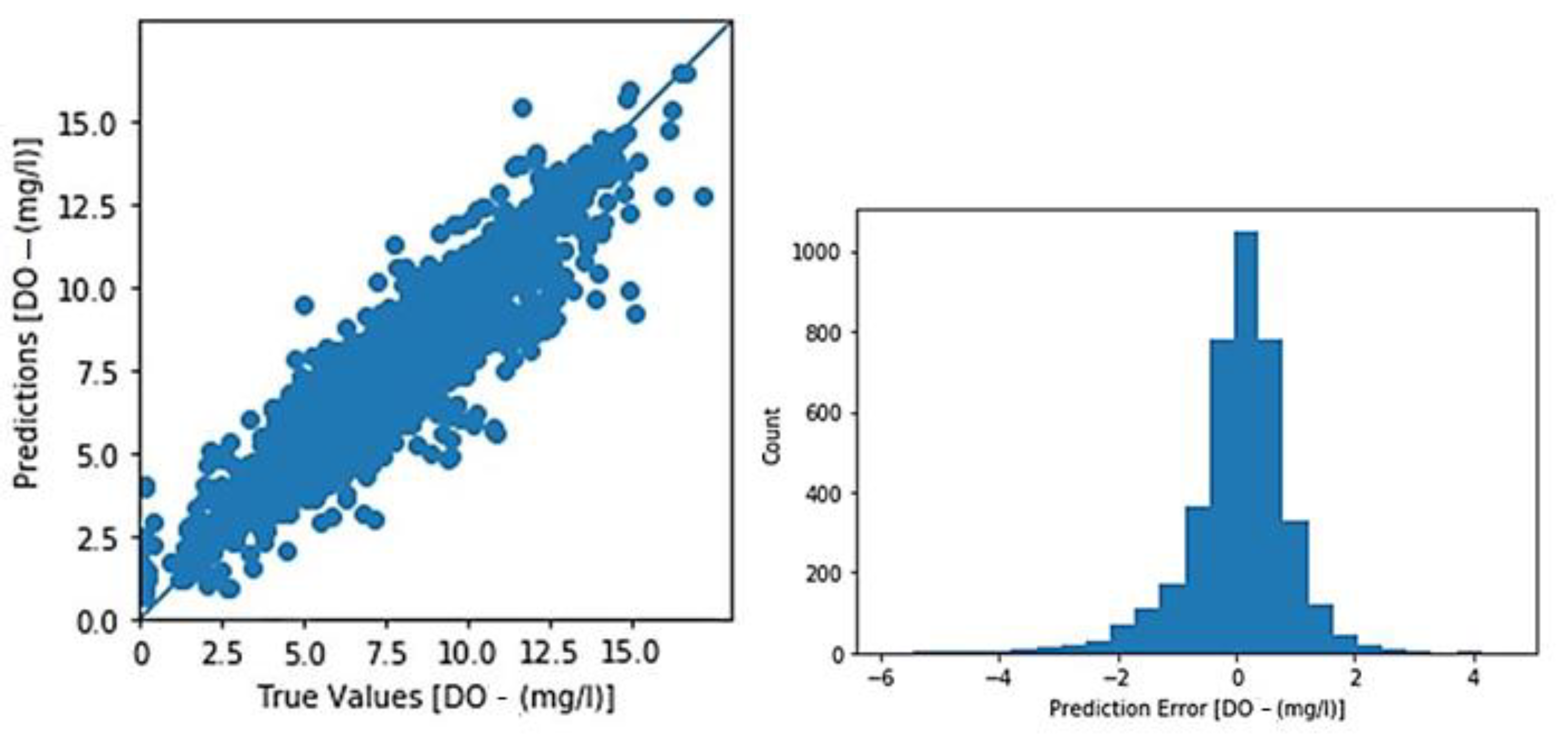
3.1. Toichio Station
3.1.1. Structure: 7-64-64-1
3.1.2. Structure: 4-64-64-1
3.1.3. Structure: 7-32-32-1
3.1.4. Structure: 4-32-32-1
3.2. All Stations/Structure
4. Discussion
- Use additional information captured from a modern drone (uncrewed aerial vehicle) equipped with a multispectral camera as ground-truth information to calibrate satellite imagery in order to improve quantification of the specific quality parameters of the water from the study area. The additional information could also be enhanced by using data (ground data collection) derived from field work (targeted area samplings) in the study area. The existing operational algorithms could be tested, or maybe new ones could be created in order to find the best fit of the band ratio.
- Use more complex machine learning methods (such as convolutional neural networks (CNNs)), not only for Lake Kastoria but also for other national and international lakes, mainly in neighboring countries with cross-border water resources.
- Use the same methodology in order to test the adequacy of the proposed models for other national and international lakes.
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Williamson, C.E.; Saros, J.E.; Vincent, W.F.; Smol, J.P. Lakes and reservoirs as sentinels, integrators, and regulators of climate change. Limnol. Oceanogr. 2009, 54, 2273–2282. [Google Scholar] [CrossRef]
- Jeppesen, E.; Kronvang, B.; Meerhoff, M.; Søndergaard, M.; Hansen, K.M.; Andersen, H.E.; Lauridsen, T.L.; Liboriussen, L.; Beklioglu, M.; Özen, A.; et al. Climate change effects on runoff, catchment phosphorus loading and lake ecological state, and potential adaptations. J. Environ. Qual. 2009, 38, 1930–1941. [Google Scholar] [CrossRef]
- Psilovikos, A. The Contribution of Monitoring to the Rational Management and Prevention of Environmental Risks on the Nestos Transboundary River. The perspective for the implementation of Directive 2000/60. Hydrotechnica 2005, l15, 87–102. [Google Scholar]
- Mantzafleri, N.; Psilovikos, A.; Mplanta, A. Water quality monitoring and modeling in Lake Kastoria, using GIS. Assessment and management of pollution sources. Water Resour. Manag. 2009, 23, 3221–3254. [Google Scholar] [CrossRef]
- Sammut, C.; Webb, G.I. Encyclopedia of Machine Learning and Data Mining; Springer Publishing Company: Berlin/Heidelberg, Germany, 2017; Volume 32. [Google Scholar]
- Liakos, K.G.; Busato, P.; Moshou, D.; Pearson, S.; Bochtis, D. Machine Learning in agriculture: A review. Sensors 2018, 18, 2674. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Diamantopoulou, M.J.; Papamichail, D.M.; Antonopoulos, V.Z. The use of a Neural Network technique for the prediction of Water Quality parameters. Oper. Res. 2005, 5, 115–125. [Google Scholar] [CrossRef]
- Alizadeh, M.J.; Kavianpour, M.R. Development of wavelet-ANN models to predict water quality parameters in Hilo Bay, Pacific Ocean. Mar. Pollut. Bull. 2015, 98, 171–178. [Google Scholar] [CrossRef] [PubMed]
- Karamoutsou, L.; Psilovikos, A. The Use of Artificial Neural Networks in Predicting the Water Quality of Lake Kastoria. In Proceedings of the 14th Conference of the Hellenic Hydrotechnical Association (EYE), Volos, Greece, 16–17 May 2019. [Google Scholar]
- Sentas, A.; Karamoutsou, L.; Charizopoulos, N.; Psilovikos, T.; Psilovikos, A.; Loukas, A. The use of Stochastic Models for short term predictions of Water Parameters of the Thesaurus Dam, Nestos River, Greece. In Proceedings of the 3rd EWaS International Conference, Lefkada, Greece, 27–30 June 2018. [Google Scholar]
- Zhang, Y.; Fitch, P.; Thorburn, P.; Vilas, M.D.L.P. Applying multi-layer artificial neural network and mutual information to the prediction of trends in dissolved oxygen. Front. Environ. Sci. 2019, 7, 46. [Google Scholar] [CrossRef]
- Lek, S.; Delacoste, M.; Baran, P.; Dimopoulos, I.; Lauga, J.; Aulagnier, S. Application of Neural Networks to modelling nonlinear relationships in ecology. Ecol. Model. 1996, 90, 36–52. [Google Scholar] [CrossRef]
- Chen, J.; Wang, Y. Comparing Activation Functions in Modeling Shoreline Variation Using Multilayer Perceptron Neural Network. Water 2020, 12, 1281. [Google Scholar] [CrossRef]
- Mellios, N.; Moe, S.; Laspidou, C. Machine Learning Approaches for Predicting Health Risk of Cyanobacterial Blooms in Northern European Lakes. Water 2020, 12, 1191. [Google Scholar] [CrossRef] [Green Version]
- Ranković, V.; Radulović, J.; Radojević, I.; Ostojić, A.; Čomić, L. Neural network modeling of dissolved oxygen in the Gruža reservoir, Serbia. Ecol. Model. 2010, 221, 1239–1244. [Google Scholar] [CrossRef]
- Akkoyunlu, A.; Altun, H.; Cigizoglu, H.K. Depth-integrated estimation of Dissolved Oxygen in a lake. J. Environ. Eng. 2011, 137, 961–967. [Google Scholar] [CrossRef]
- Ay, M.; Kisi, O. Modeling of dissolved oxygen concentration using different neural network techniques in Foundation Creek, El Paso County, Colorado. J. Environ. Eng. 2012, 138, 654–662. [Google Scholar] [CrossRef]
- Han, H.G.; Qiao, J.F.; Chen, Q.L. Model predictive control of dissolved oxygen concentration based on a self-organizing RBF neural network. Control Eng. Pract. 2012, 20, 465–476. [Google Scholar] [CrossRef]
- Wen, X.; Fang, J.; Diao, M.; Zhang, C. Artificial neural network modeling of dissolved oxygen in the Heihe River, Northwestern China. Environ. Monit. Assess. 2013, 185, 4361–4371. [Google Scholar] [CrossRef] [PubMed]
- Kuo, J.T.; Hsieh, M.H.; Lung, W.S.; She, N. Using Artificial Neural Network for reservoir eutrophication prediction. Ecol. Model. 2007, 200, 171–177. [Google Scholar] [CrossRef]
- French, M.; Recknagel, F. Modeling algal blooms in freshwaters using artificial neural networks. In Computer Techniques in Environmental Studies V, Vol. II: Environment Systems; Zanetti, P., Ed.; Computational Mechanics Publications: Boston, MA, USA, 1994; pp. 87–94. [Google Scholar]
- Cho, S.; Lim, B.; Jung, J.; Kim, S.; Chae, H.; Park, J.; Park, S.; Park, J.K. Factors affecting algal blooms in a man-made lake and prediction using an Artificial Neural Network. Measurement 2014, 53, 224–233. [Google Scholar] [CrossRef]
- Karul, C.; Soyupak, S.; Cilesiz, A.F.; Akbay, N.; Germen, E. Case studies on the use of neural networks in eutrophication modelling. Ecol. Model. 2000, 134, 145–152. [Google Scholar] [CrossRef]
- Lek, S.; Guean, J.F. Artificial Neural Networks as a tool in ecological modeling, an introduction. Ecol. Model. 1999, 120, 65–73. [Google Scholar] [CrossRef]
- Yabunaka, K.-I.; Hosomi, M.; Murakami, A. Novel application of a backpropagation artificial neural network model formulated to predict algal bloom. Water Sci. Technol. 1997, 36, 89–97. [Google Scholar] [CrossRef]
- Lu, F.; Zhang, H.; Liu, W. Development and application of a GIS-based artificial neural network system for water quality prediction: A case study at the Lake Champlain area. J. Oceanol. Limnol. 2020, 38, 1835–1845. [Google Scholar] [CrossRef]
- Hosseini, N.; Johnston, J.; Lindenschmidt, K.E. Impacts of climate change on the water quality of a regulated prairie river. Water 2017, 9, 199. [Google Scholar] [CrossRef] [Green Version]
- Abadi, M.; Barham, P.; Chen, J.; Chen, Z.; Davis, A.; Dean, J.; Devin, M.; Ghemawat, S.; Irving, G.; Isard, M.; et al. Tensorflow: A system for large-scale machine learning. In Proceedings of the 12th (USENIX) Symposium on Operating Systems Design and Implementation, Savannah, GA, USA, 2–4 November 2016. [Google Scholar]
- Deep Learning. Available online: https://developer.nvidia.com/deep-learning (accessed on 15 January 2020).
- Spyder. The scientific Python Development Environment. Available online: https://www.spyder-ide.org/ (accessed on 15 January 2020).
- Tensorflow. Available online: https://www.tensorflow.org/overview (accessed on 15 January 2020).
- Smithson, S.C.; Yang, G.; Gross, W.J.; Meyer, B.H. Neural networks designing neural networks: Multi-objective hyper-parameter optimization. In Proceedings of the 35th International Conference on Computer-Aided Design, Austin, TX, USA, 7–10 November 2016. [Google Scholar]
- Gaya, M.S.; Zango, M.U.; Yusuf, L.A.; Mustapha, M.; Muhammad, B.; Sani, A.; Tijjani, A.; Wahab, N.A.; Khairi, M.T.M. Estimation of turbidity in water treatment plant using Hammerstein-Wiener and neural network technique. Indones. J. Electr. Eng. Comput. Sci. 2017, 5, 666–672. [Google Scholar] [CrossRef]
- Kriegeskorte, N.; Golan, T. Neural network models and deep learning. Curr. Biol. 2019, 29, 231–236. [Google Scholar] [CrossRef] [PubMed]
- Hossen, T.; Plathottam, S.J.; Angamuthu, R.K.; Ranganathan, P.; Salehfar, H. Short-term load forecasting using deep neural networks (DNN). In Proceedings of the 2017 North American Power Symposium (NAPS), IEEE, Morgantown, WV, USA, 17–19 September 2017. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Station | Number of Data/Parameter |
|---|---|
| Gkiole | 16,922 |
| Toichio | 19,763 |
| Psaradika | 16,574 |
| Stavros | 19,154 |
| Variables | Unit | Mean | Std Dev | Min | 25% | 50% | 75% | Max |
|---|---|---|---|---|---|---|---|---|
| Chlorophyll-a | μg/L | 11.74 | 11.48 | 0.30 | 5.40 | 8.40 | 14.10 | 453.30 |
| Conductivity | μS/cm | 316.18 | 25.26 | 239.00 | 307.00 | 318.00 | 331.00 | 369.00 |
| pH | - | 8.41 | 0.35 | 5.40 | 8.10 | 8.40 | 8.60 | 9.80 |
| Turbidity | NTU | 20.87 | 52.28 | 0.10 | 0.00 | 1.80 | 49.00 | 3000.00 |
| Temperature | oC | 14.33 | 7.83 | 0.80 | 6.80 | 13.80 | 21.80 | 30.40 |
| NH4 | mg/L | 0.56 | 1.14 | 0.10 | 0.00 | 0.10 | 0.60 | 19.70 |
| NO3 | mg/L | 1.30 | 0.74 | 0.01 | 0.83 | 1.24 | 1.70 | 3.72 |
| DO | mg/L | 8.10 | 2.60 | 0.01 | 6.34 | 8.29 | 9.73 | 18.27 |
| Station | Structure | Training | Test | ||||
|---|---|---|---|---|---|---|---|
| MAE | MSE | NSE | MAE | MSE | NSE | ||
| Gkiole | 7-64-64-1 | 0.69 | 0.89 | 0.81 | 0.71 | 0.92 | 0.79 |
| 4-64-64-1 | 0.58 | 0.83 | 0.84 | 0.61 | 0.85 | 0.82 | |
| 7-32-32-1 | 0.54 | 0.65 | 0.89 | 0.55 | 0.68 | 0.86 | |
| 4-32-32-1 | 0.64 | 0.84 | 0.82 | 0.67 | 0.94 | 0.81 | |
| Toichio | 7-64-64-1 | 0.48 | 0.52 | 0.92 | 0.49 | 0.51 | 0.93 |
| 4-64-64-1 | 0.62 | 0.70 | 0.89 | 0.62 | 0.72 | 0.91 | |
| 7-32-32-1 | 0.50 | 0.54 | 0.91 | 0.54 | 0.57 | 0.92 | |
| 4-32-32-1 | 0.58 | 0.76 | 0.90 | 0.62 | 0.77 | 0.91 | |
| Psaradika | 7-64-64-1 | 0.60 | 0.77 | 0.88 | 0.63 | 0.80 | 0.90 |
| 4-64-64-1 | 0.57 | 0.65 | 0.91 | 0.58 | 0.68 | 0.92 | |
| 7-32-32-1 | 0.57 | 0.70 | 0.89 | 0.58 | 0.72 | 0.90 | |
| 4-32-32-1 | 0.58 | 0.69 | 0.89 | 0.60 | 0.71 | 0.90 | |
| Stavros | 6-64-64-1 | 0.73 | 1.02 | 0.87 | 0.74 | 1.08 | 0.86 |
| 4-64-64-1 | 0.69 | 1.07 | 0.88 | 0.72 | 1.11 | 0.86 | |
| 6-32-32-1 | 0.69 | 0.98 | 0.91 | 0.70 | 1.01 | 0.90 | |
| 4-32-32-1 | 0.73 | 1.23 | 0.86 | 0.78 | 1.30 | 0.85 | |
| Station | Structure | Training | Test | ||||
|---|---|---|---|---|---|---|---|
| MAE | MSE | NSE | MAE | MSE | NSE | ||
| Gkiole | 7-32-32-1 | 0.54 | 0.65 | 0.89 | 0.55 | 0.68 | 0.86 |
| Toichio | 7-64-64-1 | 0.48 | 0.52 | 0.92 | 0.49 | 0.51 | 0.93 |
| Psaradika | 4-64-64-1 | 0.57 | 0.65 | 0.91 | 0.58 | 0.68 | 0.92 |
| Stavros | 6-32-32-1 | 0.69 | 0.98 | 0.91 | 0.70 | 1.05 | 0.90 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Karamoutsou, L.; Psilovikos, A. Deep Learning in Water Resources Management: Τhe Case Study of Kastoria Lake in Greece. Water 2021, 13, 3364. https://doi.org/10.3390/w13233364
Karamoutsou L, Psilovikos A. Deep Learning in Water Resources Management: Τhe Case Study of Kastoria Lake in Greece. Water. 2021; 13(23):3364. https://doi.org/10.3390/w13233364
Chicago/Turabian StyleKaramoutsou, Lina, and Aris Psilovikos. 2021. "Deep Learning in Water Resources Management: Τhe Case Study of Kastoria Lake in Greece" Water 13, no. 23: 3364. https://doi.org/10.3390/w13233364
APA StyleKaramoutsou, L., & Psilovikos, A. (2021). Deep Learning in Water Resources Management: Τhe Case Study of Kastoria Lake in Greece. Water, 13(23), 3364. https://doi.org/10.3390/w13233364