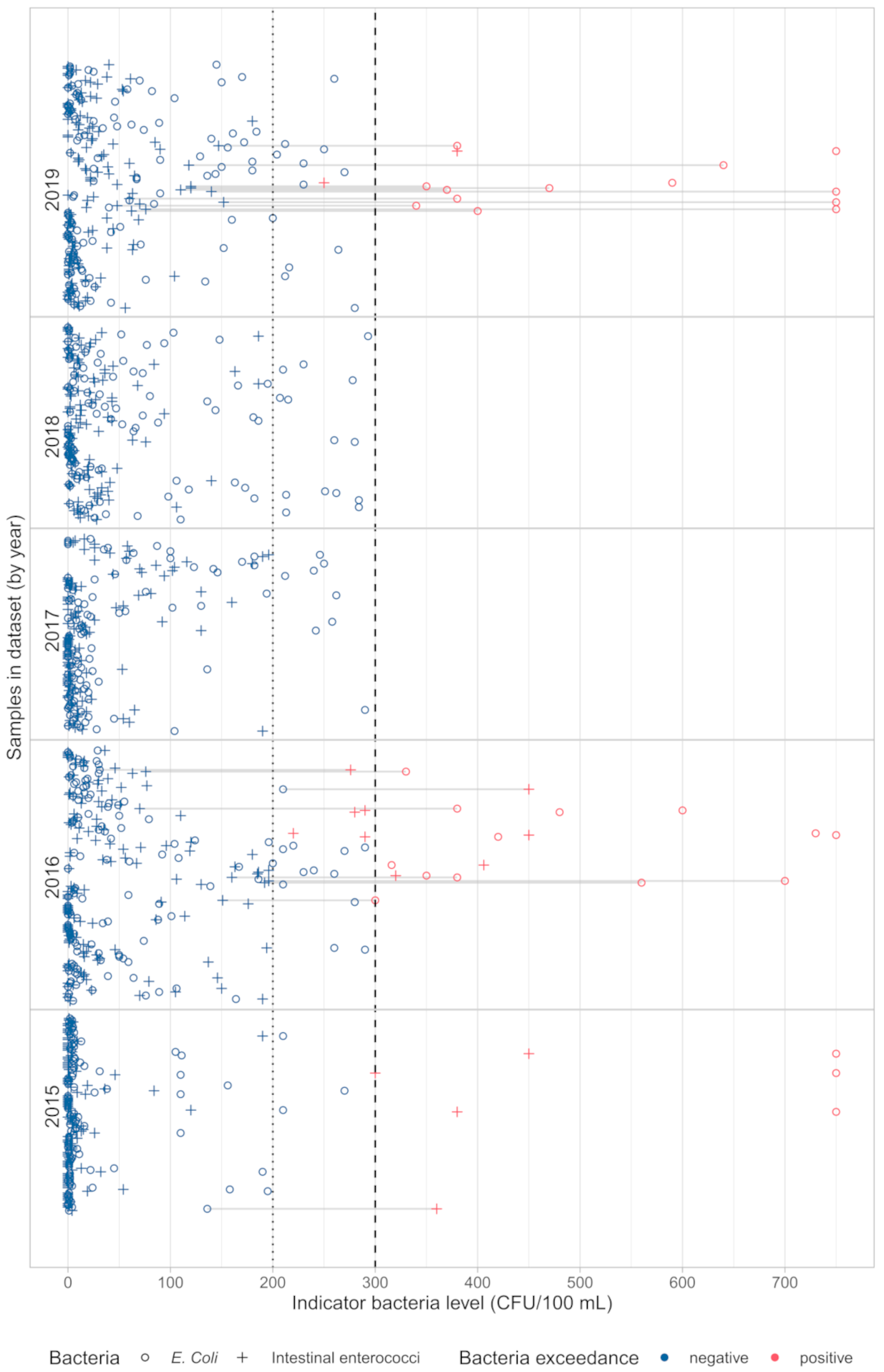
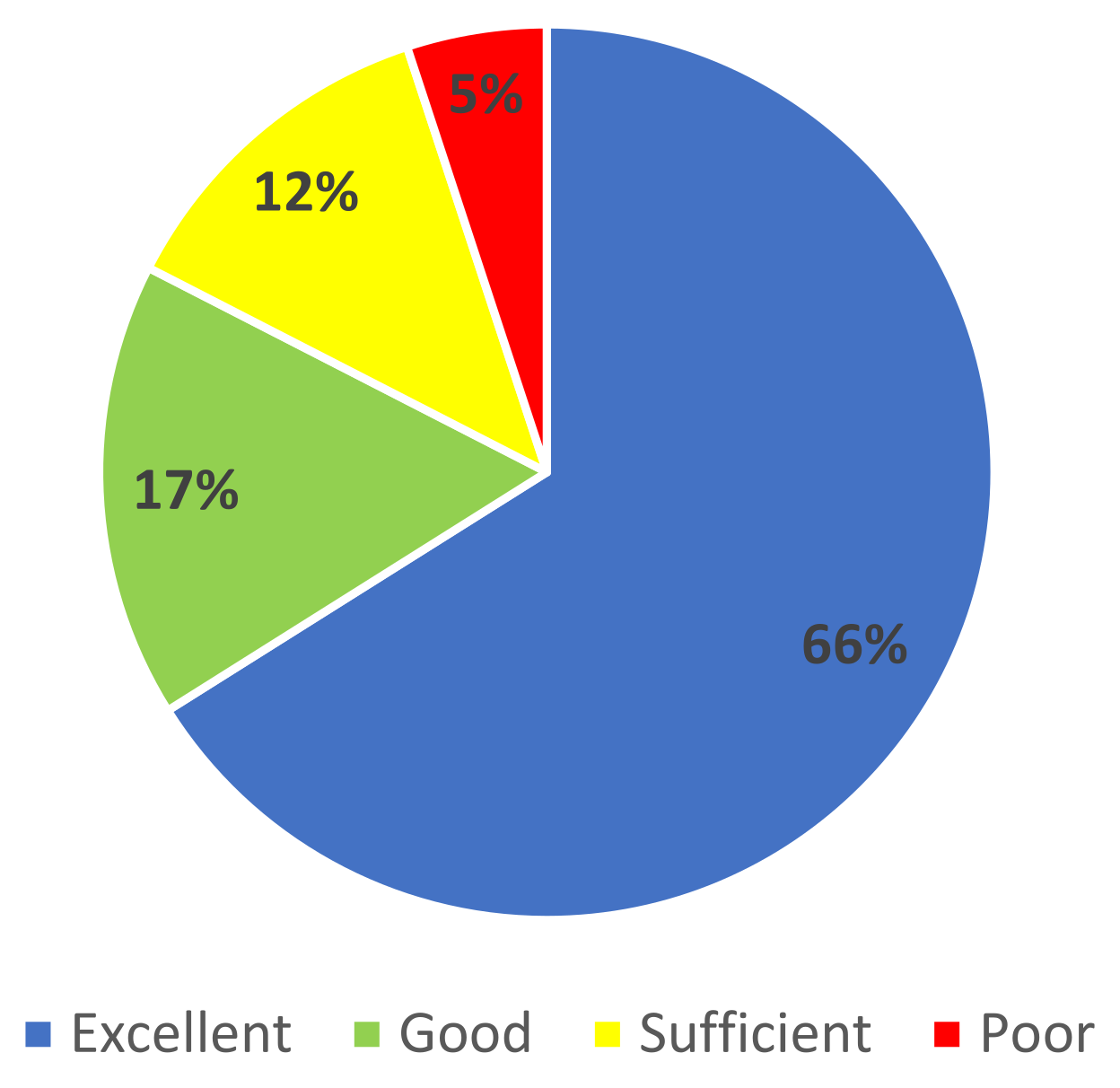
Out of 612 seawater samples collected, 31 (5%) were of poor quality (
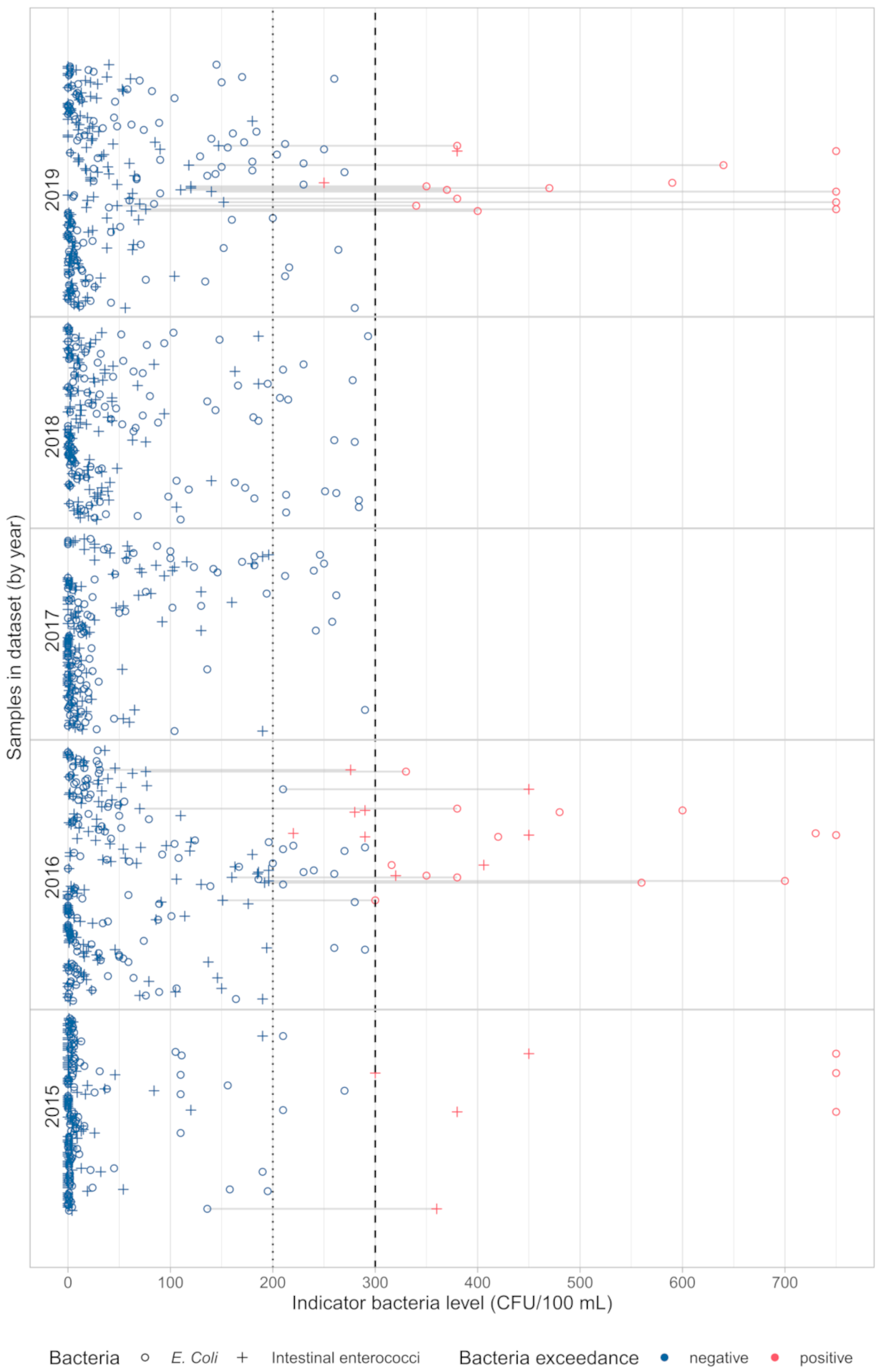
Figure 5). Most samples (16) had only exceedance of
E. coli, three samples had only exceedance of intestinal enterococci, and 12 had exceedance of both FIB. This can be seen in both
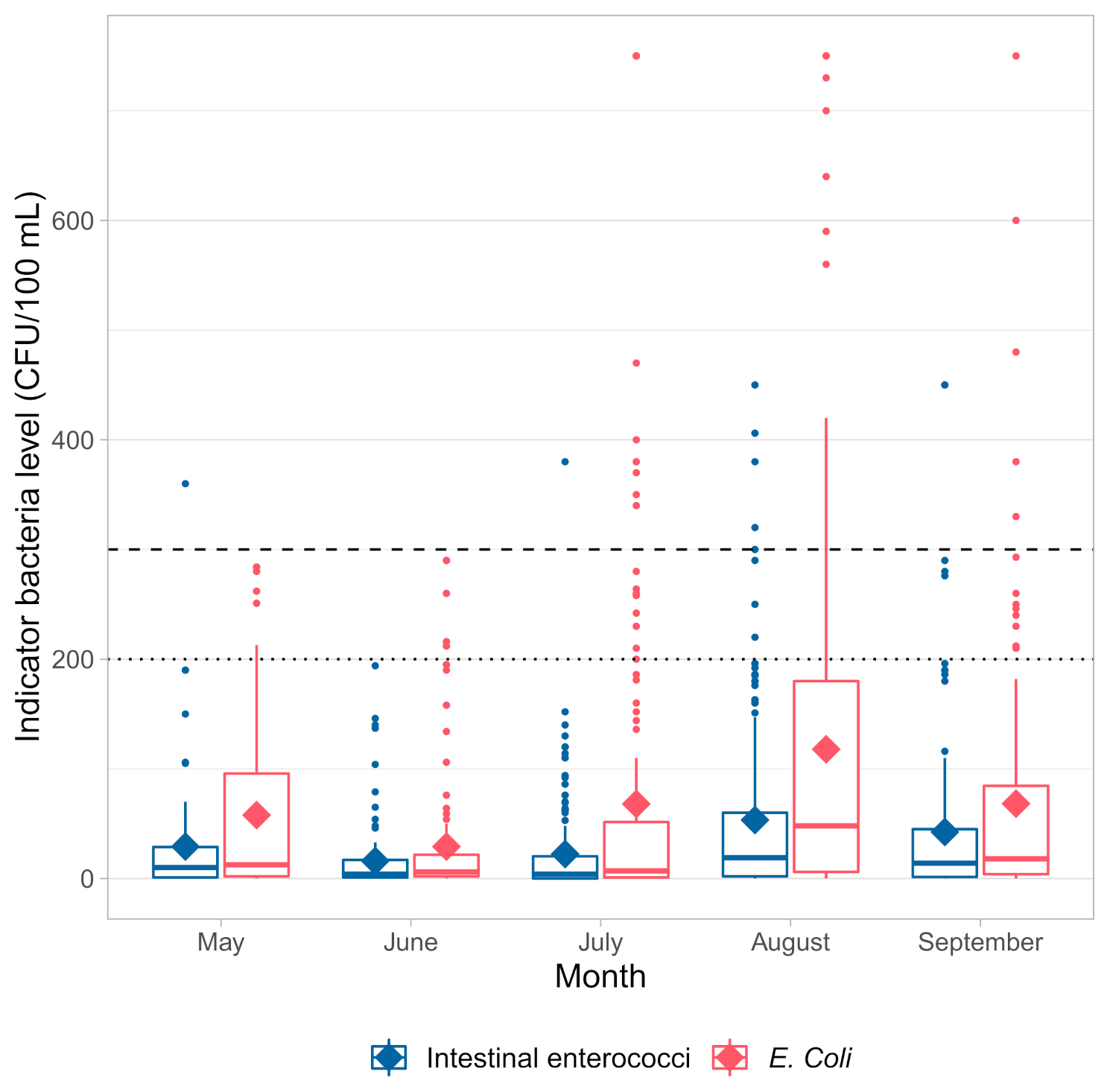
Figure 6 and
Figure 7.
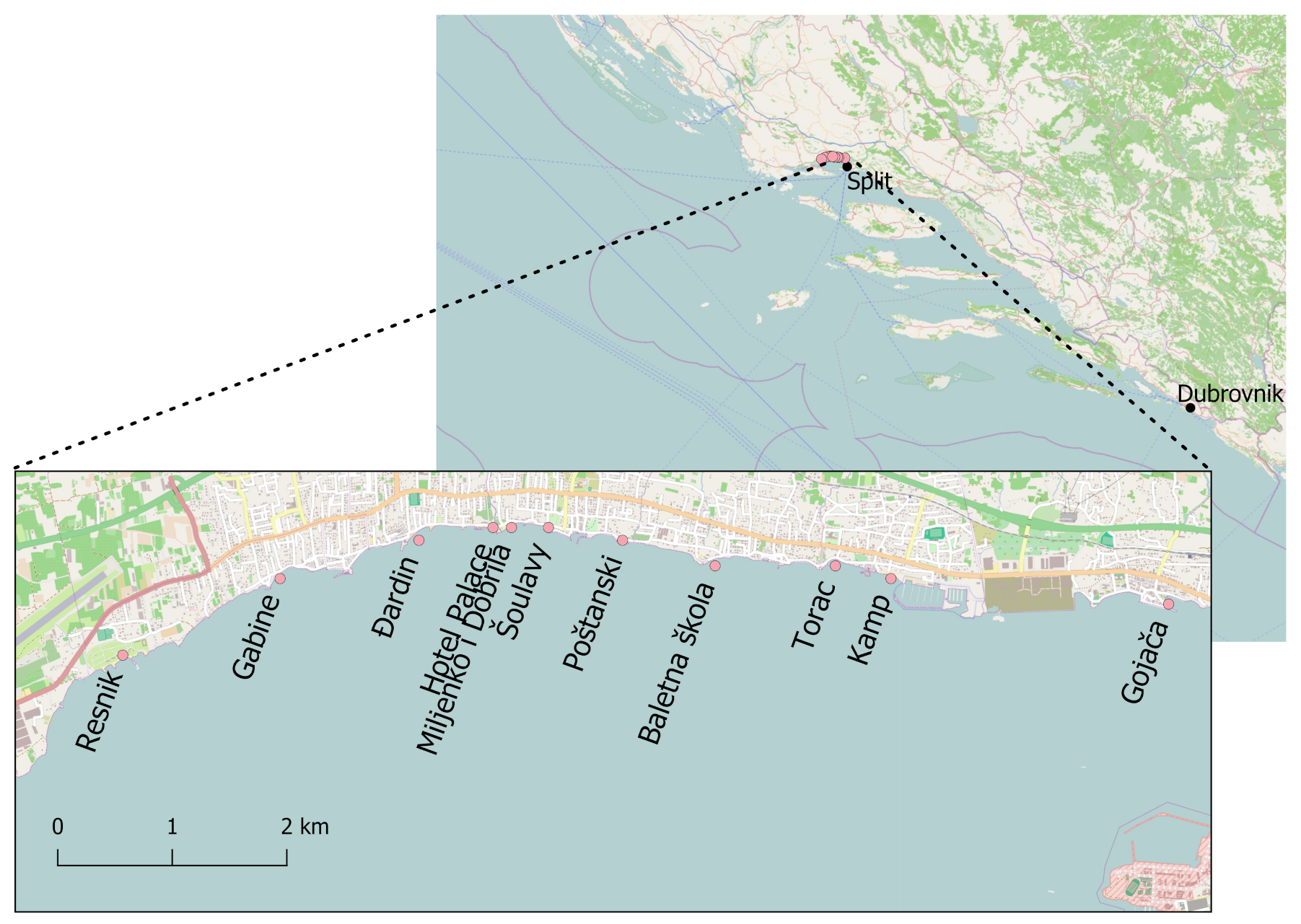
Figure 6 depicts variation of both bacteria by months from May to September in the period from 2015 to 2019 for 11 beaches in Kastela. Poor quality is recorded mainly in July, August, and September.
Figure 7 shows the variation across years for each sample and also the samples with poor water quality where only one indicator bacteria exceeded the threshold (marked with grey lines).
Of all the poor quality samples, most (23) came from the bathing sites in the eastern part of Kaštela, namely Torac, Kamp and Gojača, indicating that this part of the bay is still subject to higher pollution pressure. Of the 76 (12.4%) samples that showed sufficient quality, 61 (80%) samples showed the exceedance of only one indicator bacteria. Although the bacterial levels are correlated, as expected, it is not uncommon for only one indicator bacteria to exceed the threshold and the other not. One of the main reasons for this is probably the stricter criteria for upper limits for
E. coli in Croatian Regulation on Sea Bathing Water Quality [
22] compared to the values recommended by European Union Bathing water Dirrective (BWD) [
4]. Accordingly, the exceedances are mainly due to increased
E. coli levels. This is in line with the results of the analysis 30,000 data collected during the official monitoring of bathing water quality at all Croatian coastal bathing sites in 2015–2018. Of the 779 bathing water samples that were classified in a lower category based on the counts of only one indicator, 59% were classified based on
E. coli and 41% based on the counts of intestinal enterococci [
32]. Another likely reason is the timing of sampling. Seawater samples for official monitoring are usually collected in the morning so that the samples can be taken to the laboratory and processed the same day. At this time of day, solar radiation, which is the most important factor in reducing FIB, is weaker than during the rest of the day, so it does not have much effect on FIB die-off rates. This is especially true for
E. coli, as it is known that this bacteria, like other coliform bacteria, is much more sensitive than intestinal enterococci to the negative effects of environmental factors, especially solar radiation [
33,
34,
35]. If sampling had been conducted in the afternoon, the number of
E. coli would likely have decreased more than intestinal enterococci, so water quality exceedances would have been more likely due to increased numbers of intestinal enterococci. This was the motivation to observe faecal indicators separately and to train separate ML models.
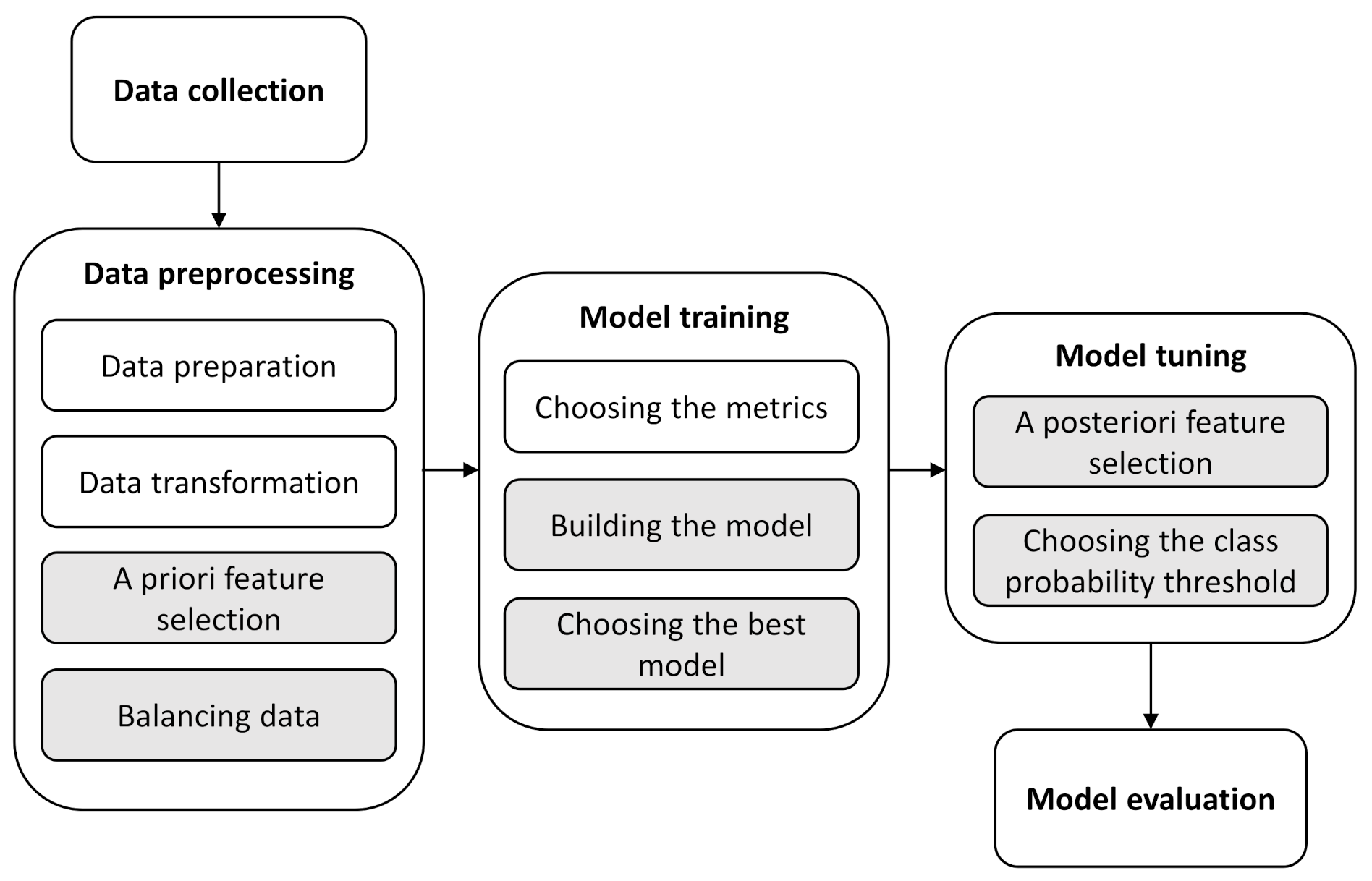
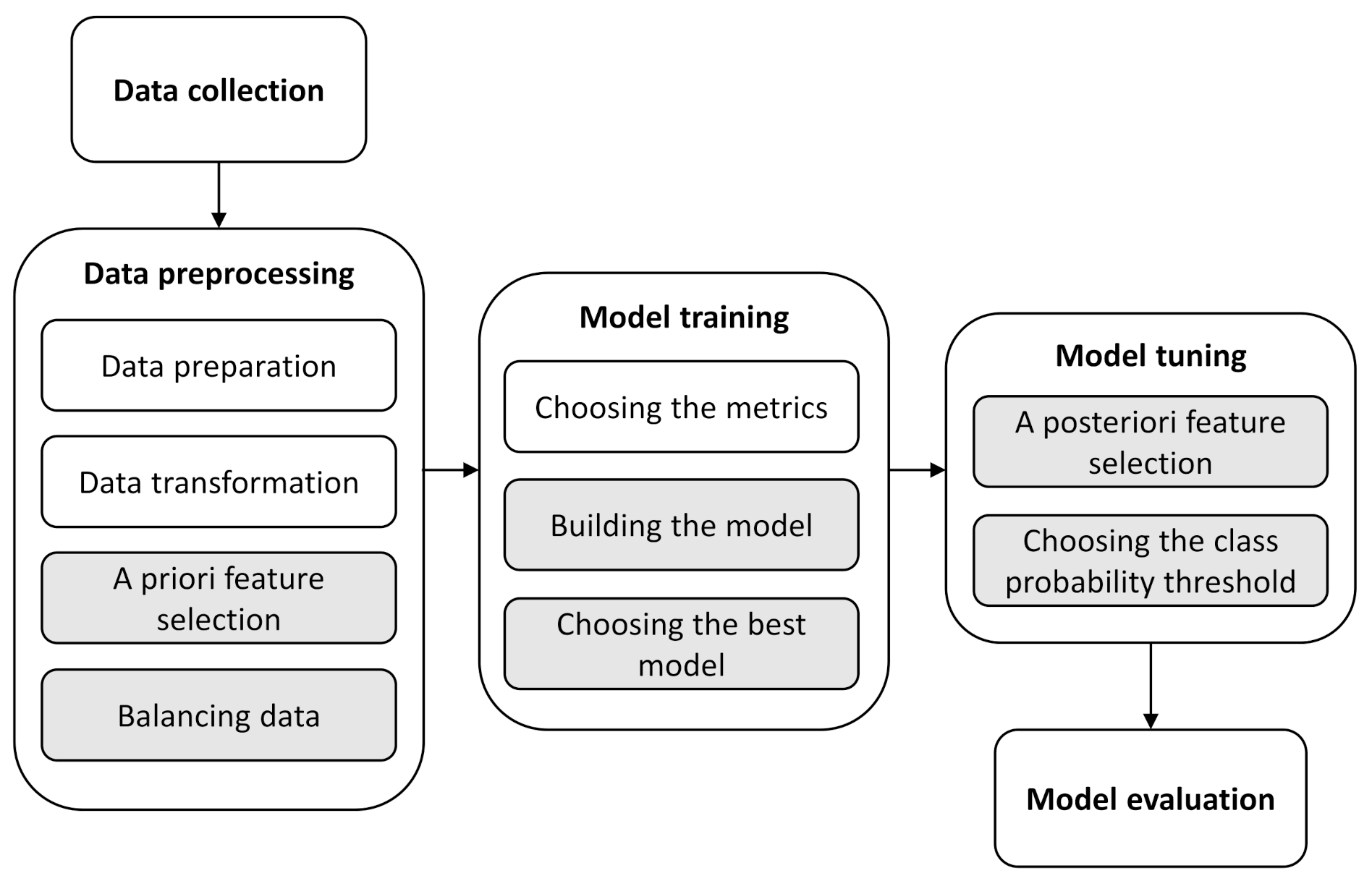
3.1. Building the Predictive Models
Of the 612 samples collected, 139 are from 2019 and are left as a holdout set, leaving 473 samples for training. It can be seen from
Figure 7 that, among all samples in 2019, 13 of them are of poor quality. Only two exceedances of intestinal enterococci are reported, which could affect the results of the evaluation, but still the results of the cross-validation on the training set can give information about the model performance.
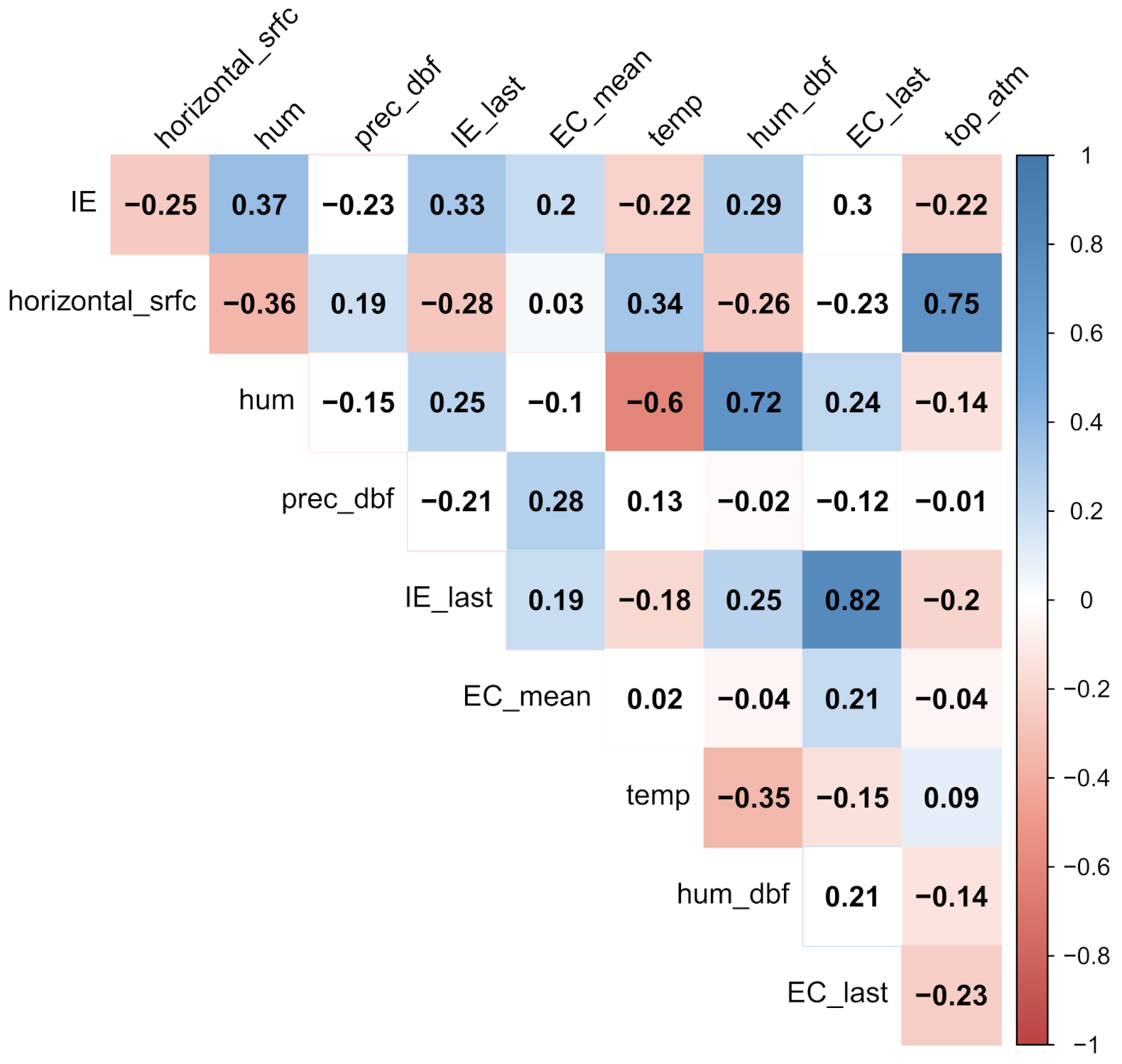
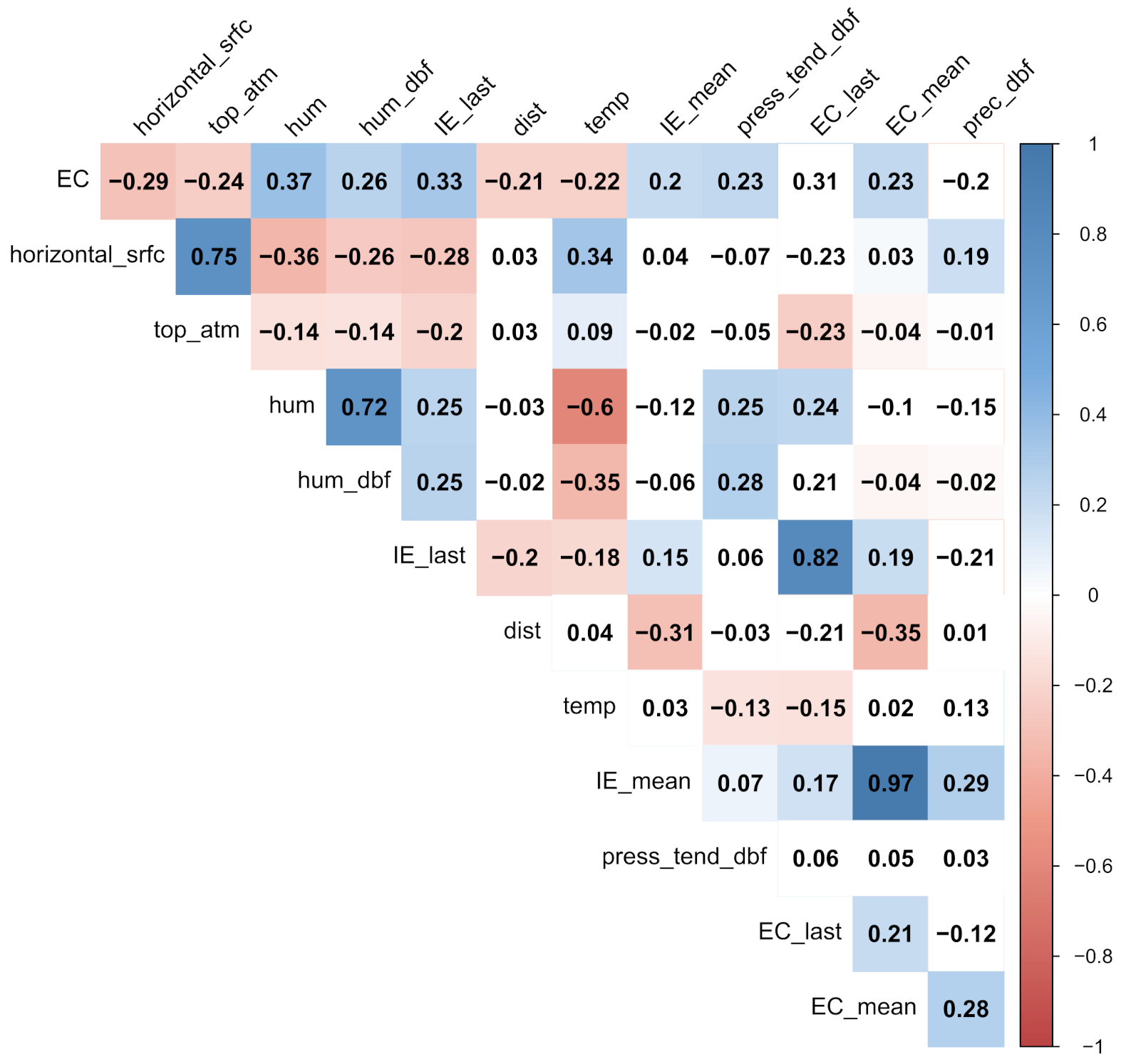
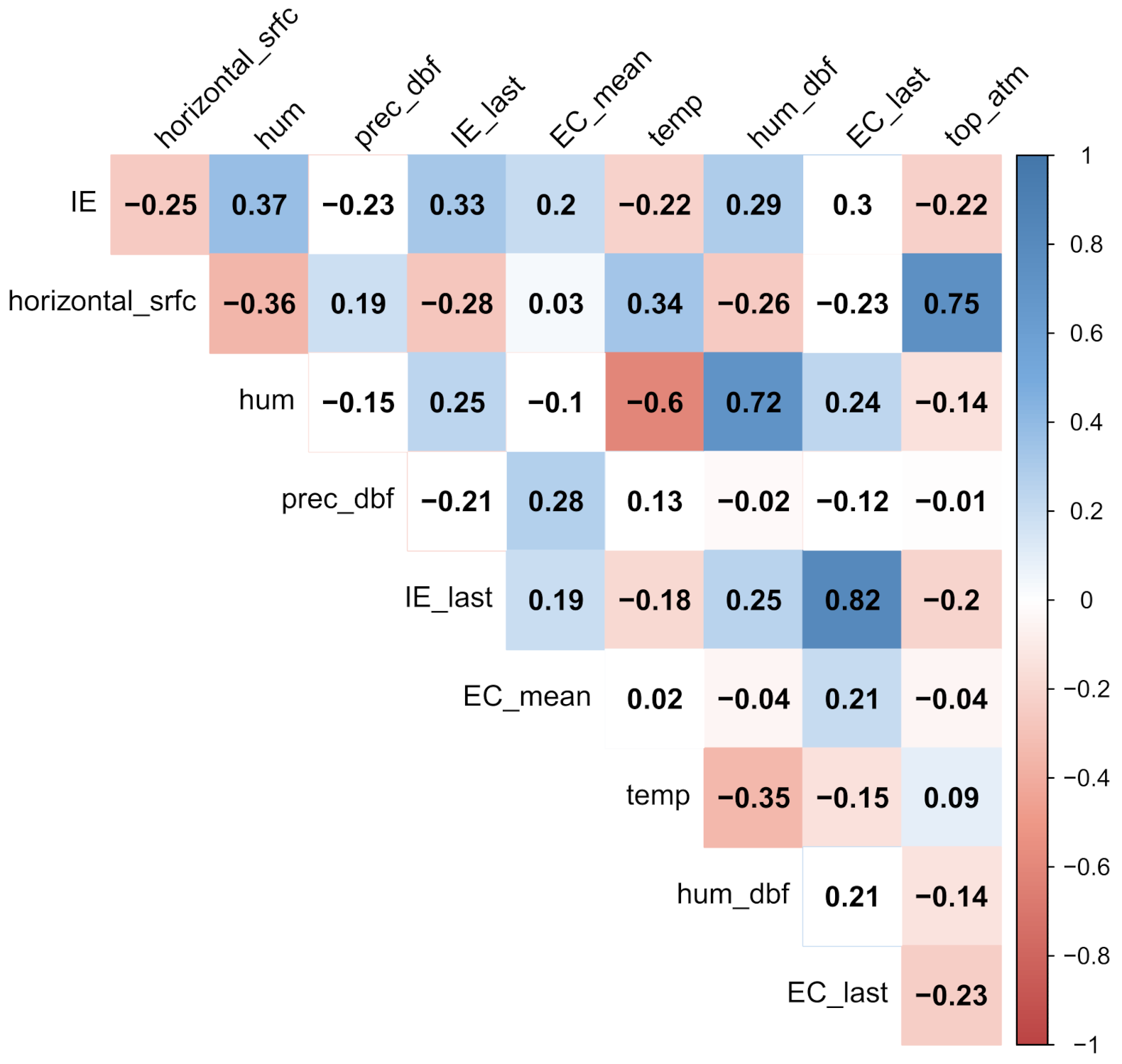
The number of independent parameters is relatively large compared to the size of the dataset, which generally leads to unstable learning. To reduce the number of independent parameters, the correlation with the FIB level on the training set is observed and those with a correlation coefficient (Spearman correlation coefficient [
25]) below 0.2 are considered weak and discarded [
25,
38]. This is done separately for each indicator bacteria, resulting in 12 independent variables for predicting exceedance of
E. coli (air temperature—
temp, insolation on horizontal surface—
horizontal_srfc, top-of-atmosphere insolation—
top_atm, pressure tendency on day before—
press_tend_dbf, precipitation on day before—
prec_dbf, humidity—
hum, humidity on day before—
hum_dbf, both intestinal enterococci and
E. coli count in last sampling—
IE_last and
EC_last, both the mean number of intestinal enterococci and the mean number of
E. coli in the last season—
IE_mean and
EC_mean and distance to sewage outlet—
dist) and nine independent variables for intestinal enterococci (insolation on horizontal surface—
horizontal_srfc, top-of- atmosphere insolation—
top_atm, precipitation on day before—
prec_dbf, humidity—
hum, humidity on day before—
hum_dbf, both intestinal enterococci and
E. coli count in last sampling—
IE_last and
EC_last, and mean number of
E. coli in the last season—
EC_mean). Correlation plots of the correlation of 12 features for
E. coli and nine for intestinal enterococci are shown in
Figure 8 and
Figure 9.
The standard data balancing to ratio 50:50 for positive:negative samples leads to a very small dataset in our case (about 40 samples), especially when compared to the dimensionality of the feature space (as many as 12 features for
E. coli). Therefore, undersampling is used to bring the dataset to a moderate 10:90 imbalance, as defined by [
39]. Furthermore, the metrics of AUC and informedness are used to penalize the majority class preference [
16,
40]. In addition, at the end, by knowing that dataset is still imbalanced and that all of the models we used are sensitive to it, we adjusted the classification threshold, which is also one of the methods to deal with imbalanced datasets [
16].
Each of the models—artificial neural network (ANN), random forest (RF), and support vector machines (SVM)—is validated. Each model is validated by varying the parameters of the model: decay and size for ANN, mtry for RF and degree, and scale and C for SVM as shown in
Table 4.
To decide on the best model, the AUC metric is used. For EC_class, the best ANN is obtained for decay = 0.1 and size = 5, the best RF is obtained for mtry = 2, and the best SVM is obtained for degree = 2, scale = 0.1, and C = 1. For IE_class, the best ANN is achieved for decay = 0.1 and size = 5, the best RF for mtry = 2 and the best SVM for degree = 1, scale = 0.001 and C = 0.5.
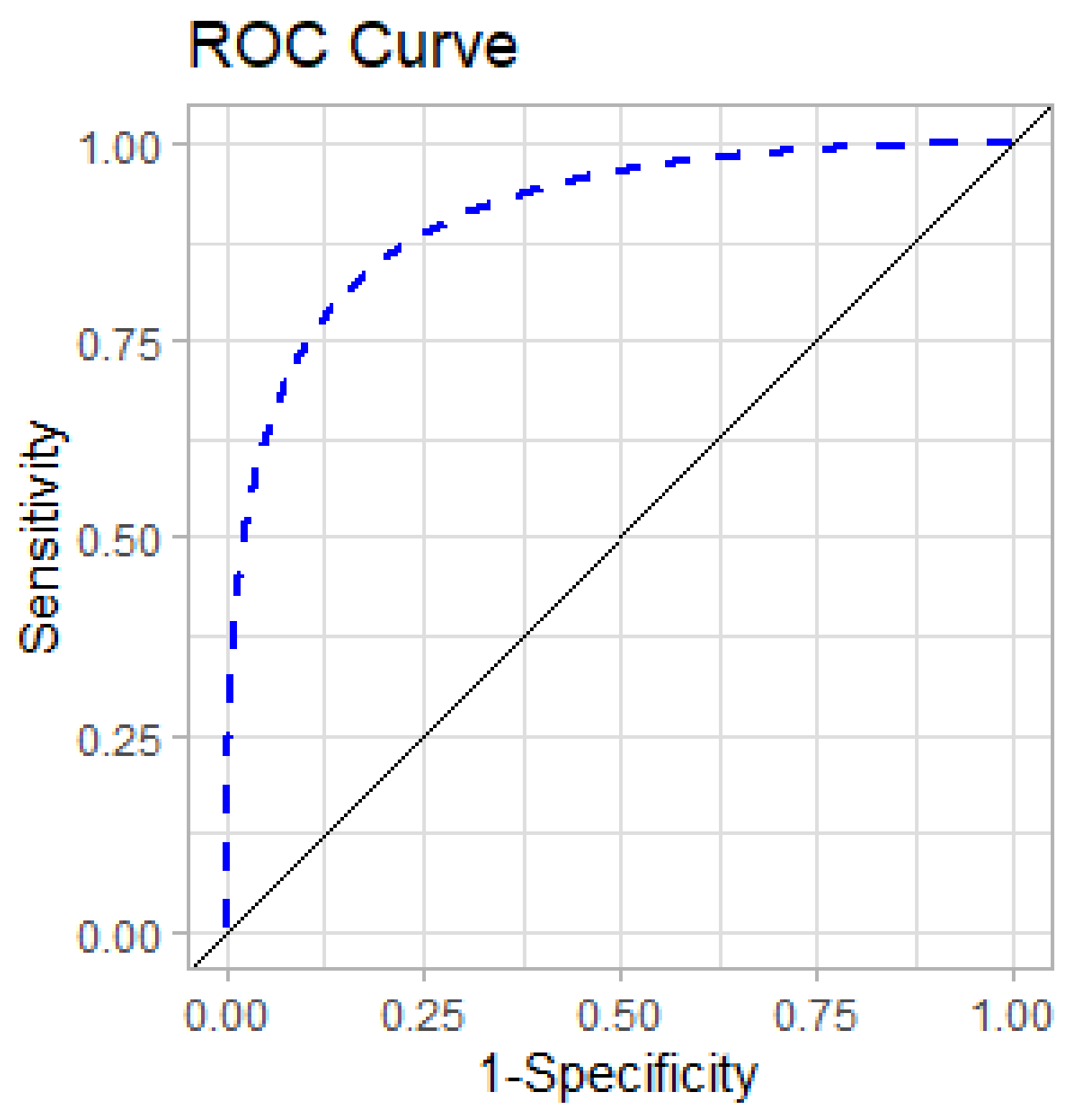
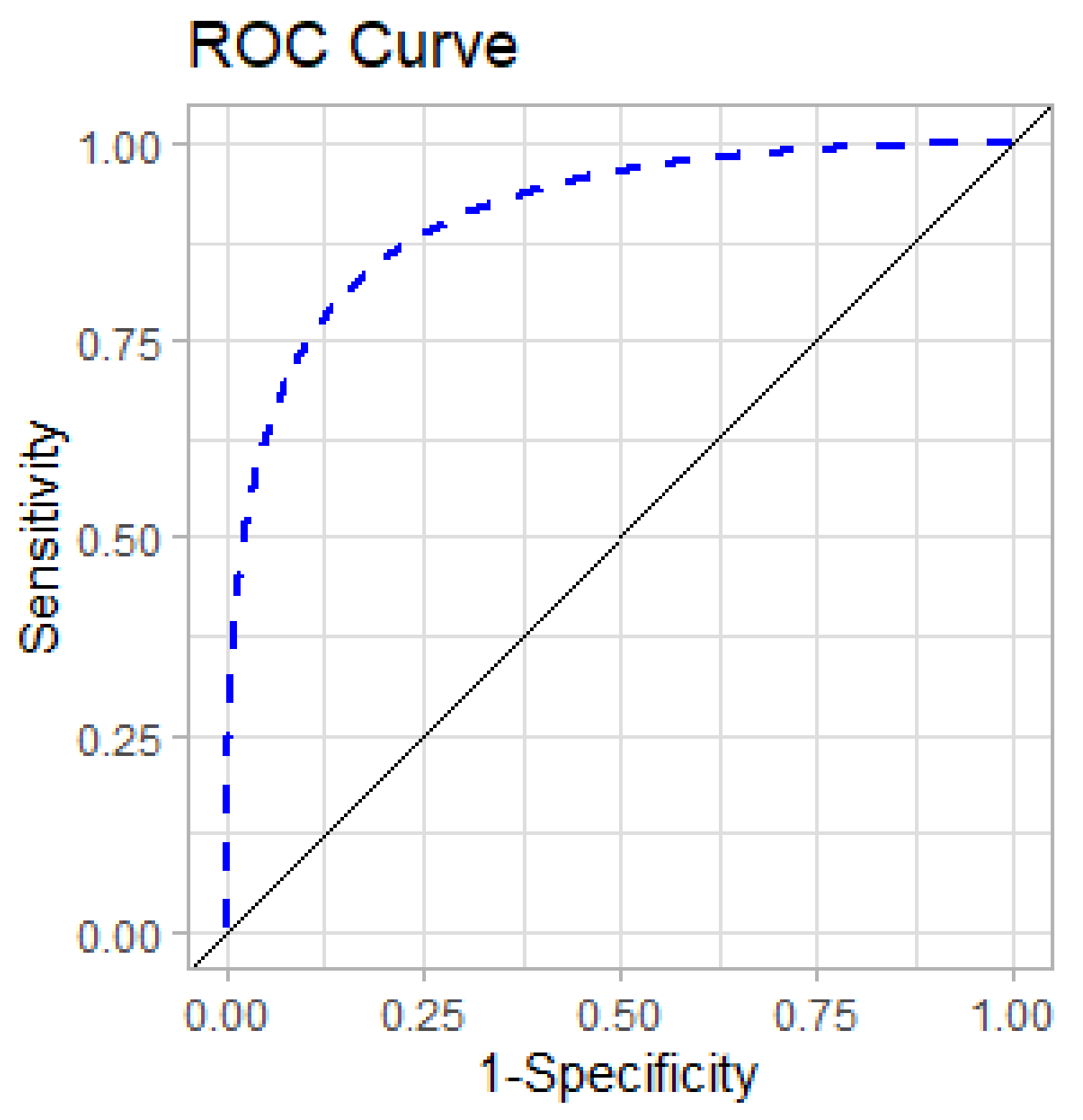
The
ROC for the best models are shown in
Figure 10. The
ROC represents the overall performance of each model (through different thresholds).
AUC values for
EC_class prediction for ANN is 0.77, for RF is 0.75, and for SVM is 0.7.
AUC values for
IE_class prediction for ANN is 0.76, for RF is 0.88, and for SVM is 0.72. Therefore, the best model for
EC_class prediction is ANN with decay = 0.1 and size = 5, while the best model for
IE_class is RF with mtry = 2. Other metrics can be found in
Table 5.
Additional feature selection was performed for the best models for each bacteria. For the ANN model for
EC_class, the less important features (according to feature importance—see
Table 6a) are discarded one by one and the results (AUC) of the ANNs are compared. The best performance was obtained for ANN with the six most important features (insolation on horizontal surface—
horizontal_srfc, top-of-atmosphere insolation—
top_atm, humidity—
hum, humidity on day before—
hum_dbf, intestinal enterococci count in last sampling—
IE_last, distance to sewage outlet—
dist). For the RF model for
IE_class, we manually selected five features by eliminating the least important features that are correlated with other features, since RF is very sensitive to intercorrelations [
28]. The RF model with five features (humidity—
hum, precipitation on day before—
prec_dbf, mean
E. coli count in the last season—
EC_mean, insolation on horizontal surface—
horizontal_srfc, and intestinal enterococci count in last sampling—
IE _last) is compared with the model with all features, and it performed better on the training data (see
Table 6b).
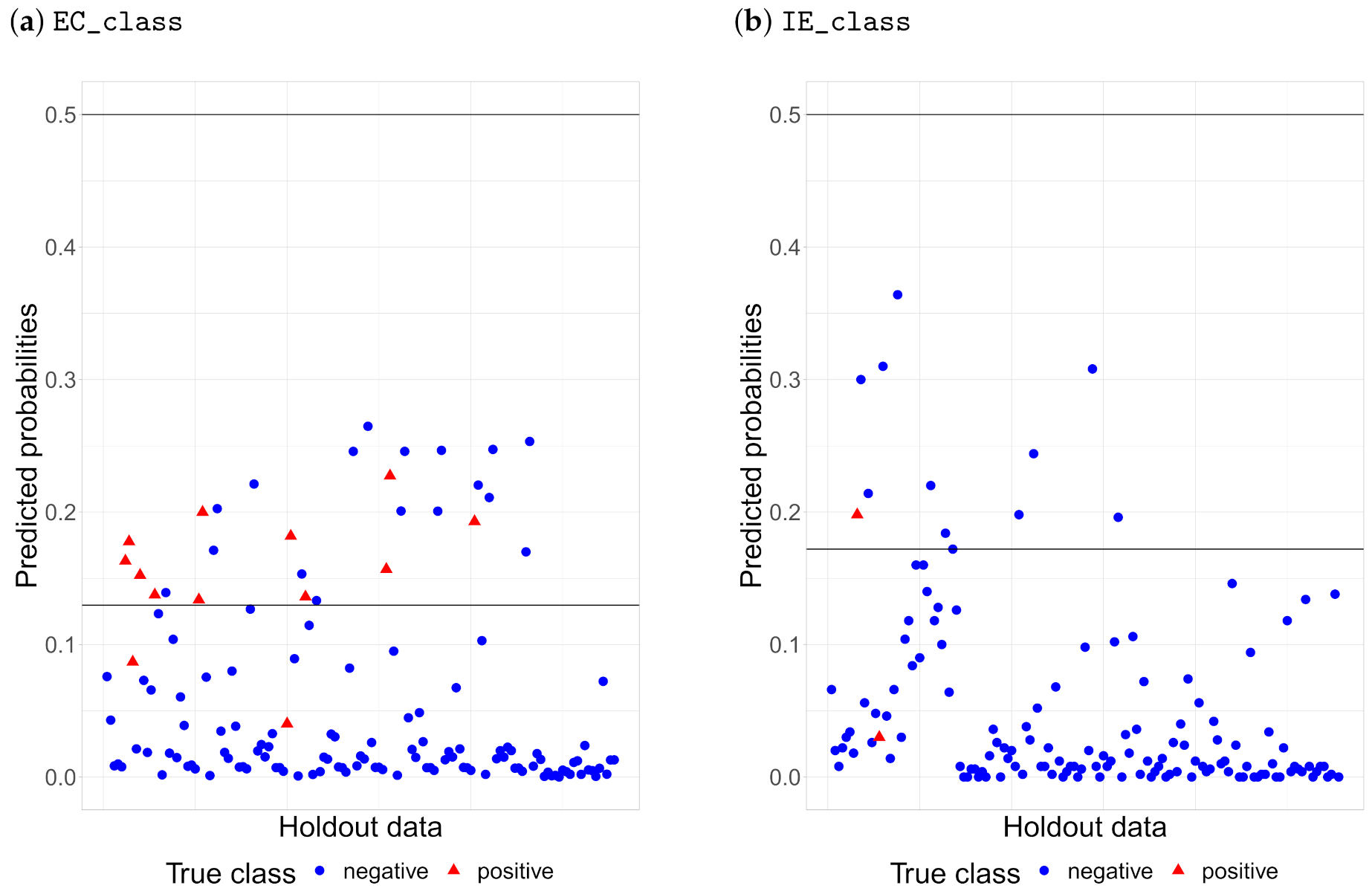
The default threshold for the class probability threshold is 0.5, but this threshold needs to be adjusted to account for the imbalance in the data that still exist after under-sampling (as described earlier). The trained model is biased towards the negative class, which means that the predicted probability of a positive case is underrated. Therefore, the default threshold for classification by probability is not applicable here.
The threshold with the highest
Informedness is taken for each indicator bacteria. For the
EC_class, the best threshold is 0.130 and for
IE_class 0.172. The cross-validation results for the best models can be found in
Table 7.
3.2. Evaluation
The selected models were tested on holdout data using adjusted thresholds. The results of the evaluation on holdout data can be found in
Table 8 and
Table 9.
The confusion matrix for
EC_class (given in the first section of
Table 8) shows that the model correctly predicts 11 out of 13
EC_class positives. The model also correctly predicts 109 out of 126 negatives.
EC_class is predicted with
Informedness 71.1% and F-score 53.7%.
The confusion matrix for
IE_class (in the second section of the
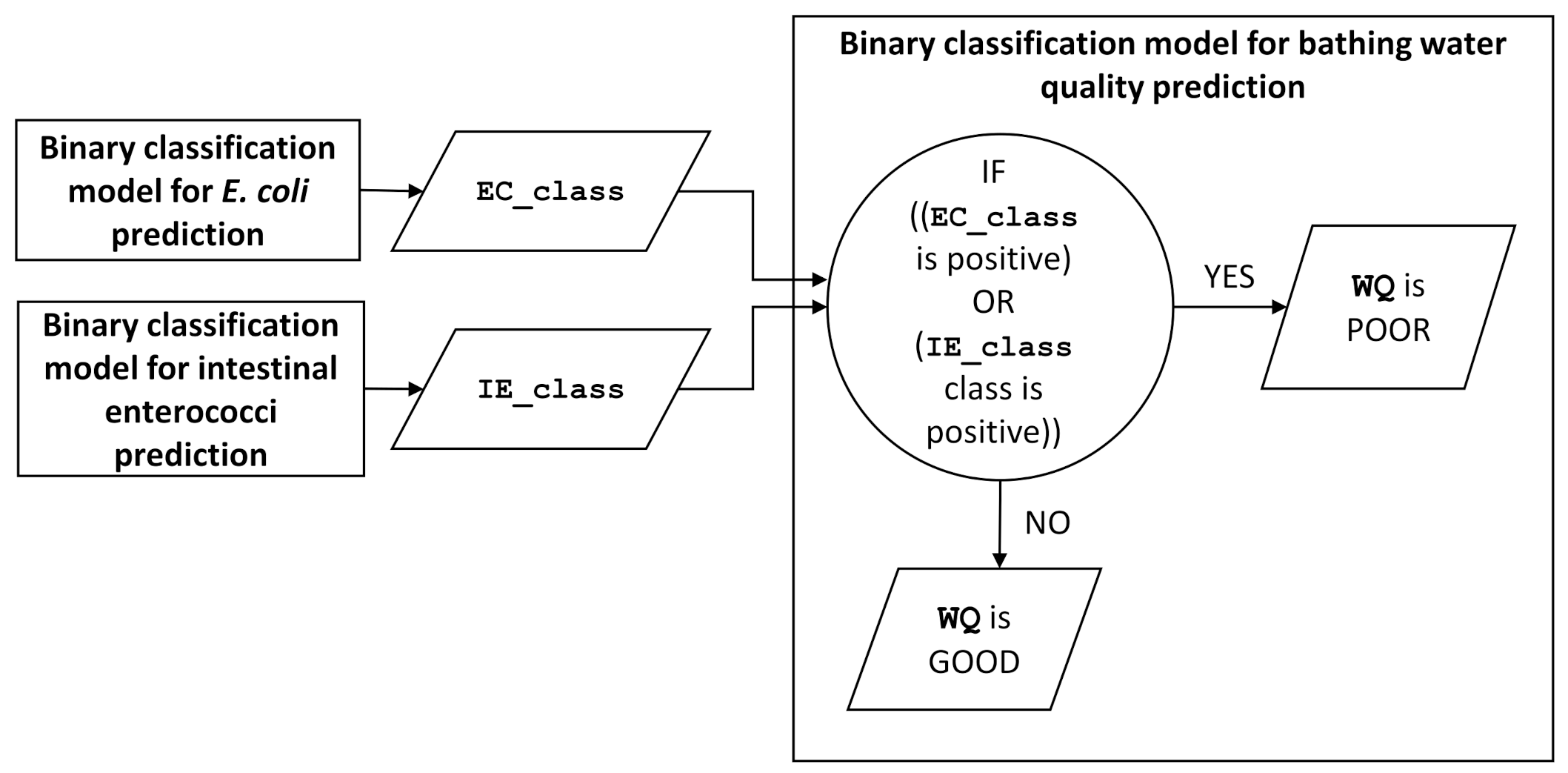
Table 8) shows that the model correctly predicts 1 out of 2 positives. The model also correctly predicts 127 out of 137 negatives. The confusion matrix for the combined model (in the third section of the
Table 8) shows that the model correctly predicts 12 of 13
WQ positives and correctly predicts 100 of 126 negatives.
IE _class is predicted with
Informedness 92.1% and F-score 15.4%. Combining these two models, the samples are predicted with
Informedness 71.7%, F-score 47.1% and an overall
Accuracy of 80.6%.
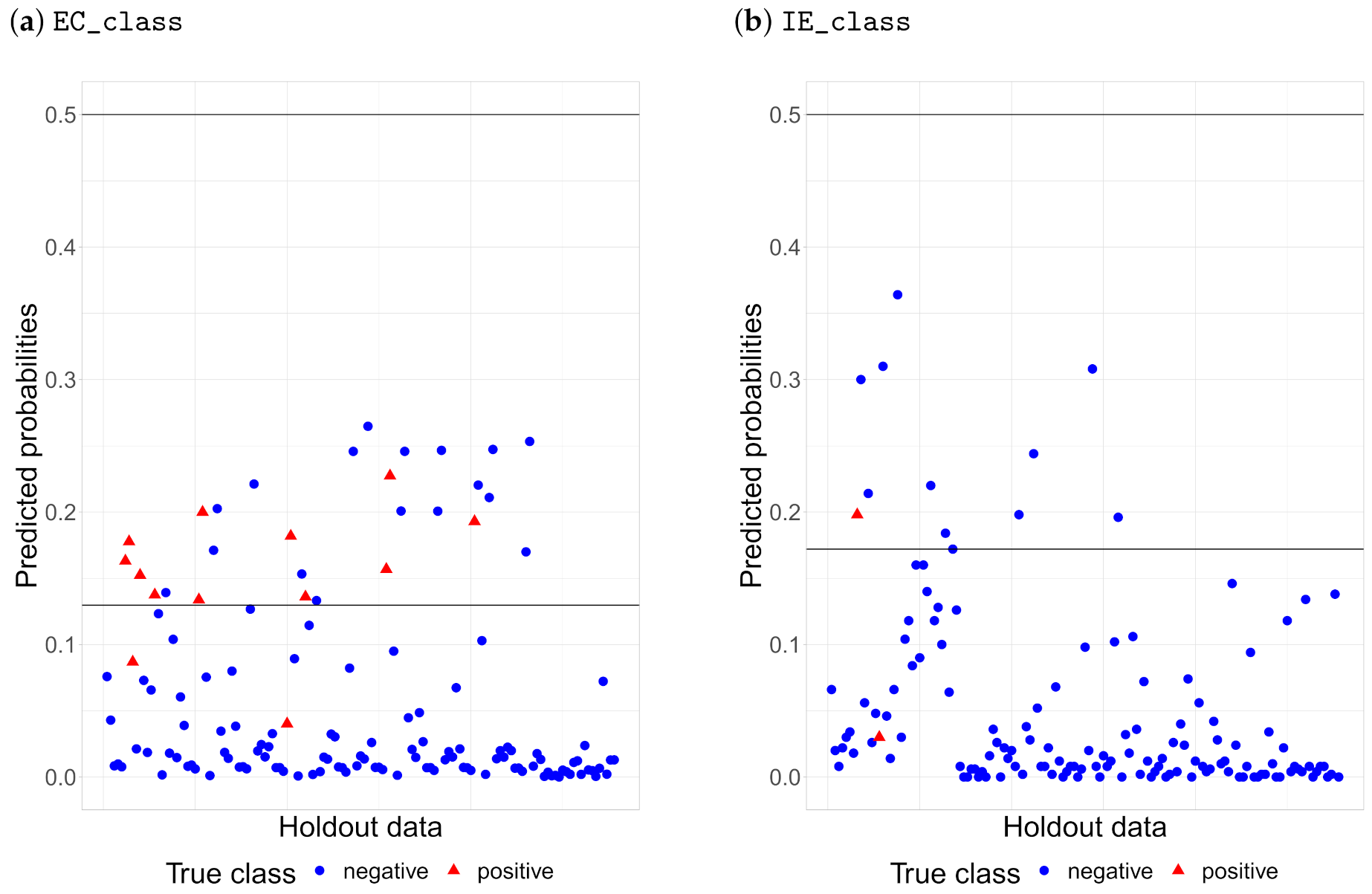
To illustrate the importance of the adjusting probability threshold, samples from the holdout set with default and selected thresholds are shown in
Figure 11 for each bacteria. It can be seen that the default threshold classifies all samples in the negative class, whereas the best threshold according to
Informedness seems to be a fair trade-off.
Measures of goodness of fit are given in a variety of ways in related work, and some of them are not even measurable for the models used in this paper (such as the measure of explained variance). However, when we compare the results presented in this paper with related works that are most similar to ours, we can see that the performance of our models is much better. Although related works report high specificity: 88% and 94% for [
11], from 85% up to 95% for [
12] and 98% [
13], they achieved very low sensitivity: 18% and 28% for [
11], from 37% up to 56% for [
12] and 11.2% [
13], meaning that a small amount of poor water quality is correctly classified as poor. Informedness calculated based on the Sensitivity and Specificity reported in related works are: 12% and 16% for [
11], from 22% up to 51% for [
12] and 0.92% [
13], which is much lower than the Informedness of 71.7% obtained by our approach.


 and
and 





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}