Comparison of Bottom-Up and Top-Down Procedures for Water Demand Reconstruction





Abstract
1. Introduction
2. Materials and Methods
2.1. Top-Down Procedure
2.2. Bottom-Up Procedure
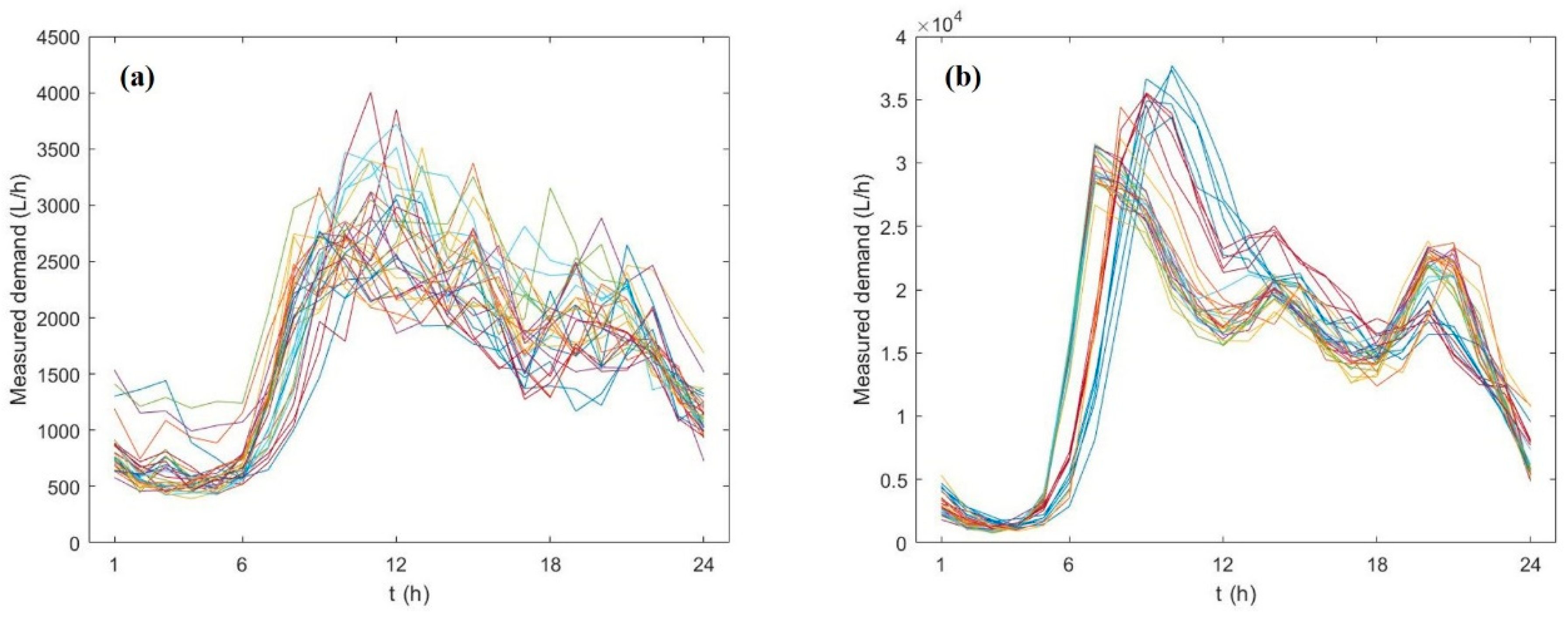
2.3. Case Studies
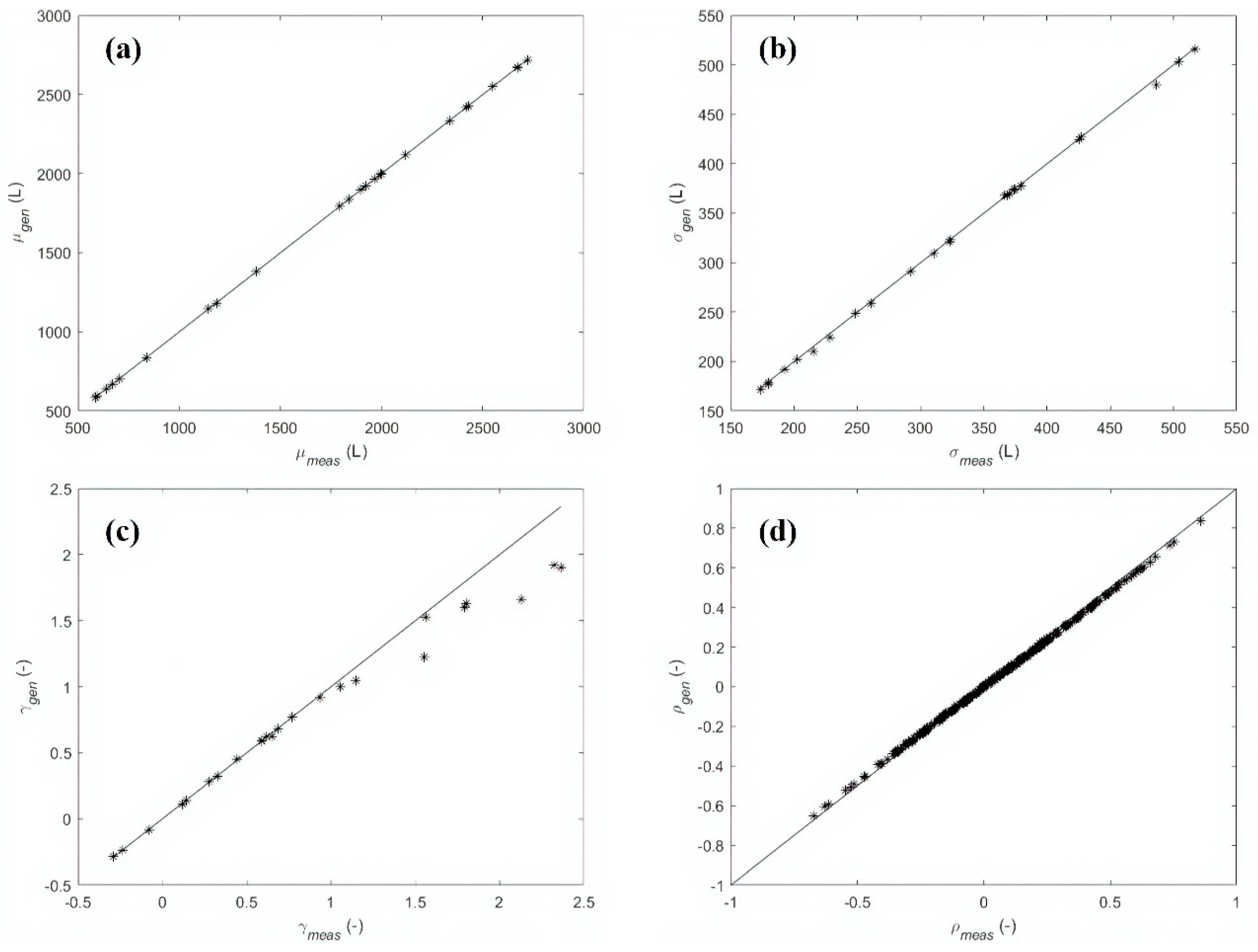
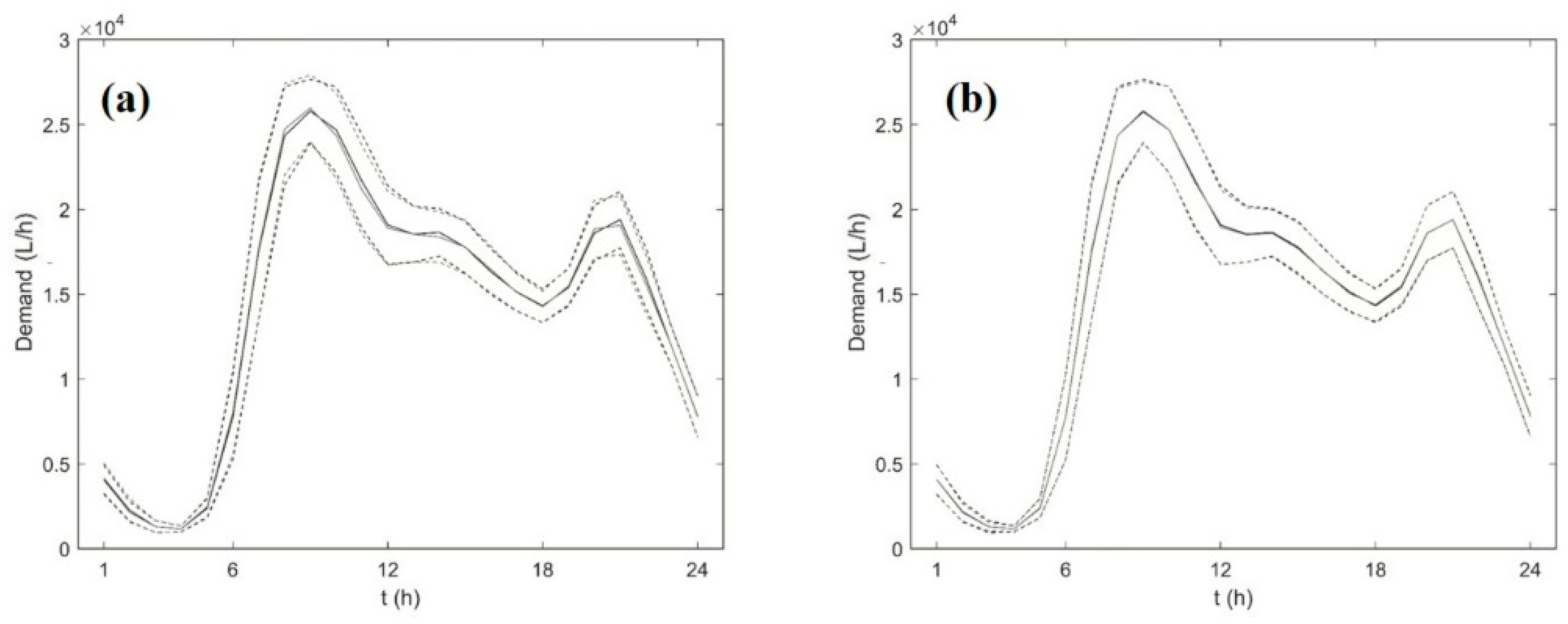
3. Results
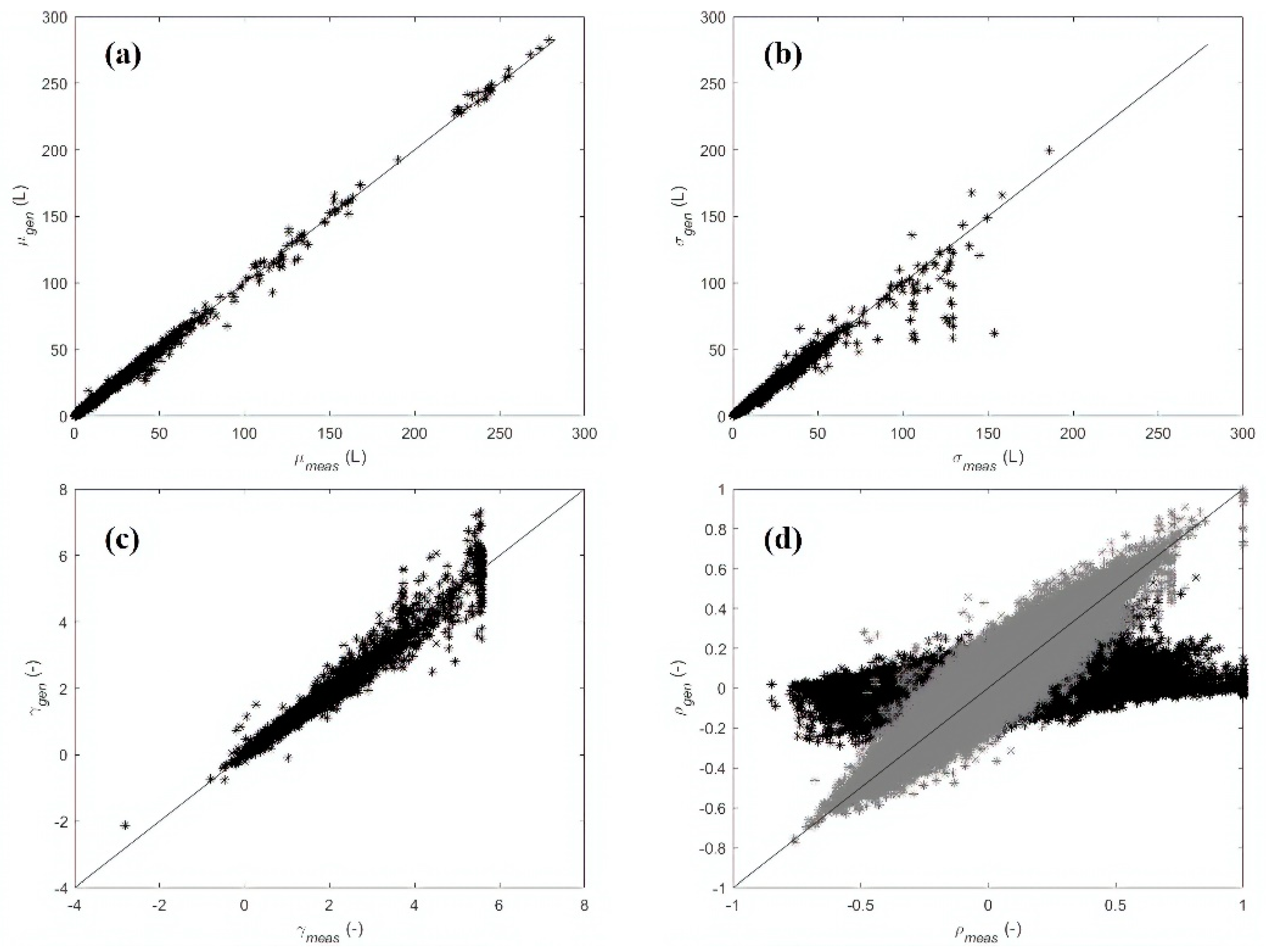
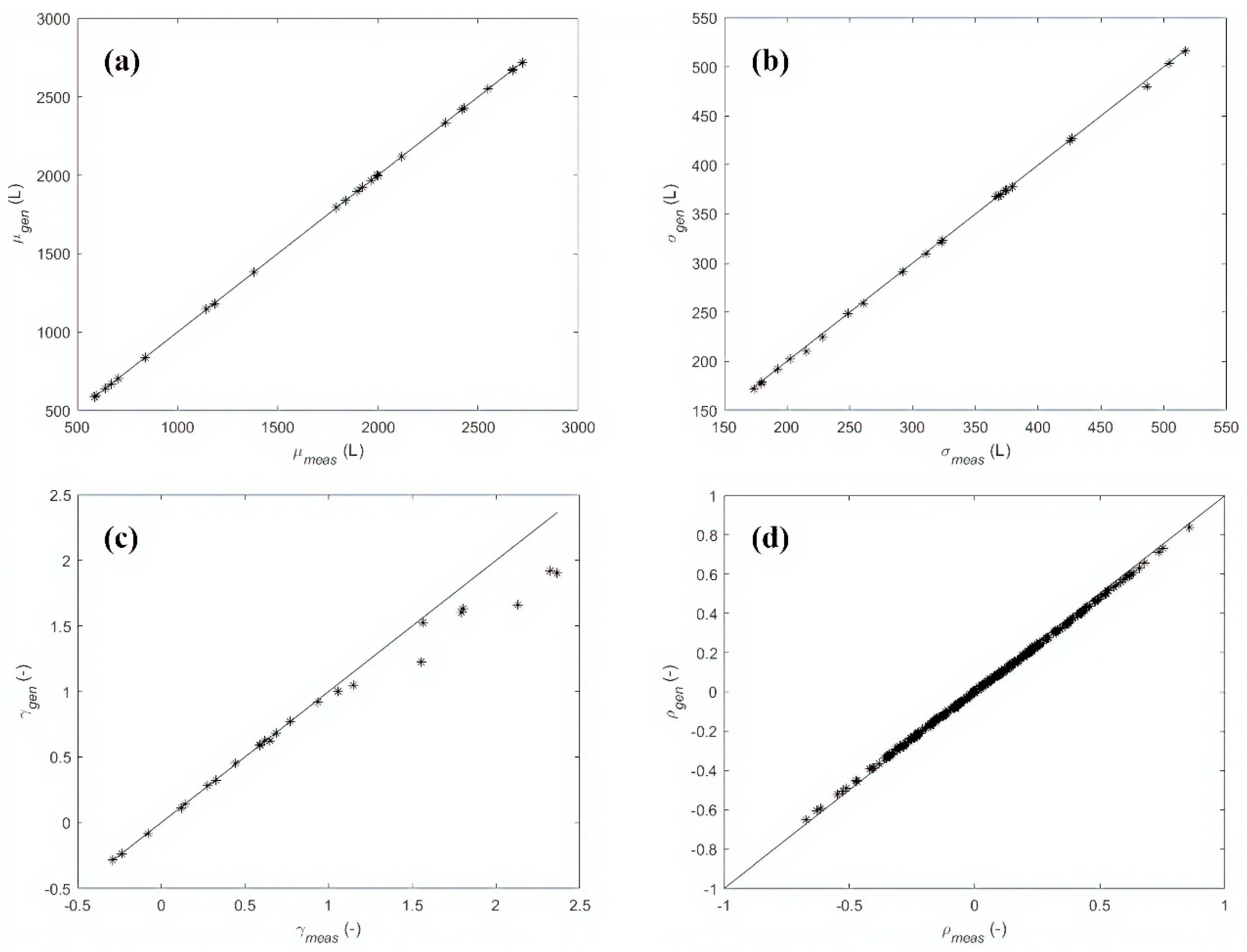
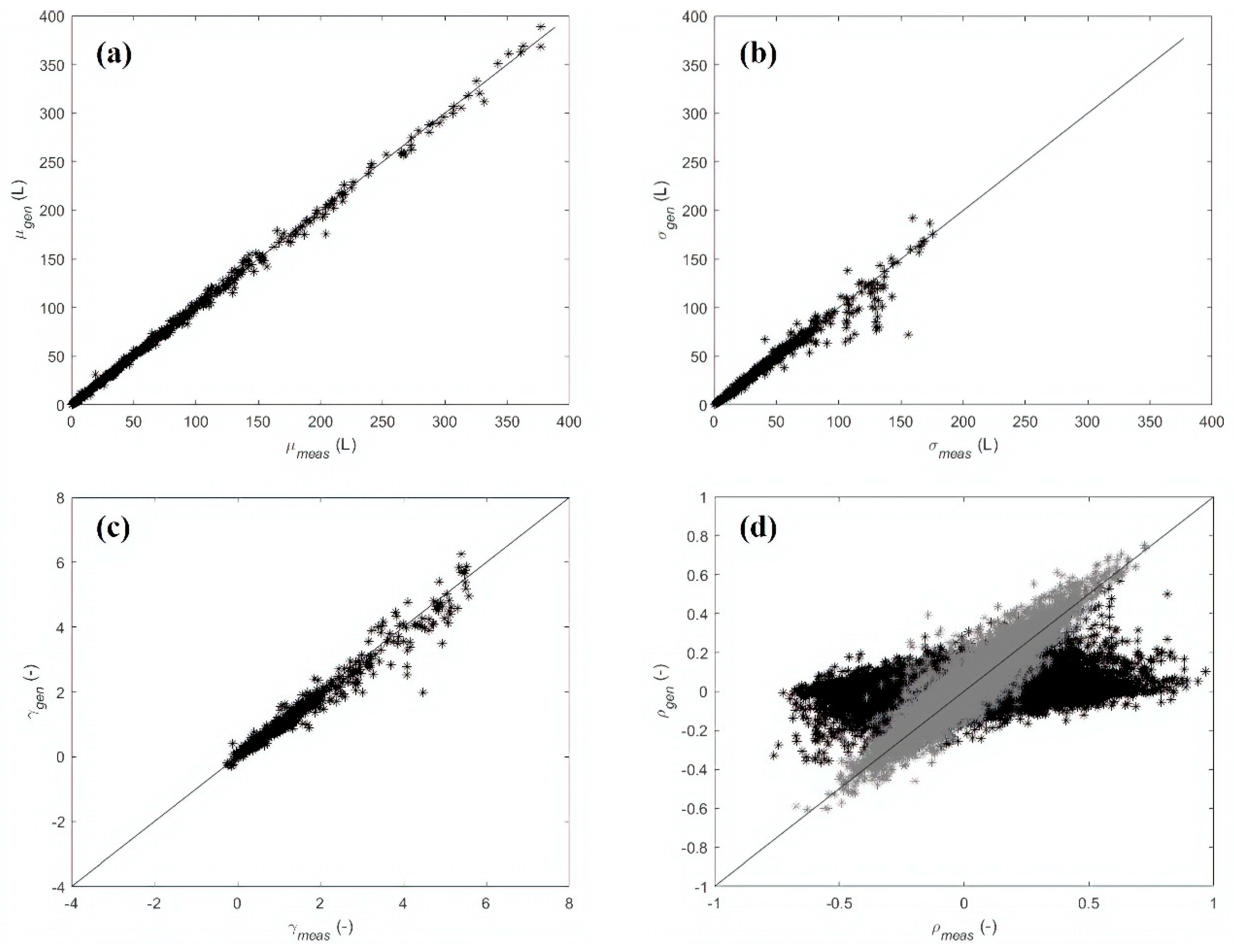
3.1. Results—Case Study 1
3.2. Results—Case Study 2
4. Discussion
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Creaco, E.; Pezzinga, G.; Savic, D. On the choice of the demand and hydraulic modeling approach to WDN real-time simulation. Water Resour. Res. 2017, 53, 6159–6177. [Google Scholar] [CrossRef]
- Walski, T.M.; Chase, D.V.; Savic, D.A.; Grayman, W.; Beckwith, S.; Koelle, E. Advanced Water Distribution Modeling and Management; Haestad Press: Waterbury, CT, USA, 2003. [Google Scholar]
- Filion, Y.R.; Karney, B.W.; Adams, B.J. Stochasticity of demand and probabilistic performance of water networks. In World Water Congress 2005: Impacts of Global Climate Change, Proceedings of the 2005 World Water and Environmental Resources Congress, Anchorage, AK, USA, 15–19 May 2005; American Society of Civil Engineers: Reston, VA, USA, 2005. [Google Scholar]
- Filion, Y.; Adams, B.; Karney, B. Cross correlation of demands in water distribution network design. J. Water Resour. Plan. Manag. 2007, 133, 137–144. [Google Scholar] [CrossRef]
- Blokker, E.J.M.; Vreeburg, J.H.G.; Buchberger, S.G.; Van Dijk, J.C. Importance of demand modelling in network water quality models: A review. Drink. Water Eng. Sci. 2008, 1, 27–38. [Google Scholar] [CrossRef]
- Blokker, E.J.M.; Beverloo, H.; Vogelaar, A.J.; Vreeburg, J.H.G.; Van Dijk, J.C. A bottom-up approach of stochastic demand allocation in a hydraulic network model: A sensitivity study of model parameters. J. Hydroinformatics 2011, 13, 714–728. [Google Scholar] [CrossRef]
- Koutsoyiannis, D.; Manetas, A. Simple disaggregation by accurate adjusting procedures. Water Resour. Res. 1996, 32, 2105–2117. [Google Scholar] [CrossRef]
- Kumar, D.N.; Lall, U.; Petersen, M.R. Multisite disaggregation of monthly to daily streamflow. Water Resour. Res. 2000, 36, 1823–1833. [Google Scholar] [CrossRef]
- Deidda, R.; Badas, M.G.; Piga, E. Space-time scaling in high-intensity Tropical Ocean Global Atmosphere Coupled Ocean-Atmosphere Response Experiment (TOGA-COARE) storms. Water Resour. Res. 2004, 40, W02506. [Google Scholar] [CrossRef]
- Onibon, H.; Lebel, T.; Afouda, A.; Guillot, G. Gibbs sampling for conditional spatial disaggregation of rain fields. Water Resour. Res. 2004, 40, W08401. [Google Scholar] [CrossRef]
- Mejia, J.M.; Rousselle, J. Disaggregation models in hydrology revisited. Water Resour. Res. 1976, 12, 185–186. [Google Scholar] [CrossRef]
- Todini, E. The preservation of skewness in linear disaggregation schemes. J. Hydrol. 1980, 47, 199–214. [Google Scholar] [CrossRef]
- Santos, E.G.; Salas, J.D. Stepwise disaggregation scheme for synthetic hydrology. J. Hydraul. Eng. 1992, 118, 765–784. [Google Scholar] [CrossRef]
- Tarboton, D.G.; Sharma, A.; Lall, U. Disaggregation procedures for stochastic hydrology based on nonparametric density estimation. Water Resour. Res. 1998, 34, 107–119. [Google Scholar] [CrossRef]
- Lee, T.; Salas, J.D.; Prairie, J. An enhanced nonparametric streamflow disaggregation model with genetic algorithm. Water Resour. Res. 2010, 46, W08529. [Google Scholar] [CrossRef]
- Nowak, K.; Prairie, J.; Rajagopalan, B.; Lall, U. A nonparametric stochastic approach for multisite disaggregation of annual to daily streamflow. Water Resour. Res. 2010, 46, W08529. [Google Scholar] [CrossRef]
- Creaco, E.; Blokker, M.; Buchberger, S. Models for generating household water demand pulses: Literature review and comparison. J. Water Resour. Plan. Manag. 2017, 143, 1–11. [Google Scholar] [CrossRef]
- Buchberger, S.G.; Carter, J.T.; Lee, Y.; Schade, T.G. Random Demands, Travel Times and Water Quality in Deadends; AWWA Research Foundation: Denver, CO, USA, 2003. [Google Scholar]
- Blokker, M.; Agudelo-Vera, C.; Moerman, A.; Van Thienen, P.; Pieterse-Quirijns, I. Review of applications for SIMDEUM, a stochastic drinking water demand model with a small temporal and spatial scale. Drink. Water Eng. Sci. 2017, 10, 1–12. [Google Scholar] [CrossRef]
- Gargano, R.; Di Palma, F.; de Marinis, G.; Granata, F.; Greco, R. A stochastic approach for the water demand of residential end users. Urban Water J. 2016, 13, 569–582. [Google Scholar] [CrossRef]
- Alvisi, S.; Ansaloni, N.; Franchini, M. Generation of synthetic water demand time series at different temporal and spatial aggregation levels. Urban Water J. 2014, 11, 297–310. [Google Scholar] [CrossRef]
- Blokker, E.J.M. Stochastic Water Demand Modelling for a Better Understanding of Hydraulics in Water Distribution Networks; Water Management Academic Press: Delft, The Netherlands, 2010; ISBN 9789089570154. [Google Scholar]
- Sheng, Z.; Jia, S.; Michelsen, A.; Abudu, S. Lessons learned from long term water resources plans: Top town vs. bottom up. In International Water Resources Association (IWRA), Proceedings of the XVIth World Water Congress “Bridging Science and Policy”, Cancun, Mexico, 29 May–2 June 2017; International Water Resources Association: Paris, France, 2017; pp. 1–8. [Google Scholar]
- Mamade, A.; Loureiro, D.; Alegre, H.; Covas, D. Top-down and bottom-up approaches for water-energy balance in Portuguese supply systems. Water 2018, 10, 577. [Google Scholar] [CrossRef]
- Creaco, E.; De Paola, F.; Fiorillo, D.; Giugni, M. Bottom-Up Generation of Water Demands to Preserve Basic Statistics and Rank Cross-Correlations of Measured Time Series. J. Water Resour. Plan. Manag. 2020, 146, 1–9. [Google Scholar] [CrossRef]
- Alvisi, S.; Ansaloni, N.; Franchini, M. Comparison of parametric and nonparametric disaggregation models for the top-down generation of water demand time series. Civ. Eng. Environ. Syst. 2016, 33, 3–21. [Google Scholar] [CrossRef]
- Bras, R.L.; Rodriguez-Iturbe, I. Random Functions and Hydrology; Addison-Wesley: Boston, MA, USA, 1984. [Google Scholar]
- Lall, U.; Sharma, A. A nearest neighbor bootstrap for resampling hydrologic time series. Water Resour. Res. 1996, 32, 679–693. [Google Scholar] [CrossRef]
- Spearman, C. The Proof and Measurement of Association between Two Things. Am. J. Psychol. 1904, 15, 72–101. [Google Scholar] [CrossRef]
- Nelsen, R.B. An introduction to Copulas (Springer Series in Statistics); Springer: New York, NY, USA, 2006; ISBN 9780387286594. [Google Scholar]
- Moughton, L.J.; Buchberger, S.G.; Boccelli, D.L.; Filion, Y.R.; Karney, B.W. Effect of time step and data aggregation on cross correlation of residential demands. In Proceedings of the 8th Annual Water Distribution Systems Analysis Symposium 2006, Cincinnati, OH, USA, 27–30 August 2006. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Application—Procedure | Single Demand μ | Single Demand σ | Single Demand γ | Single Demand ρ | Single Demand | Aggregated Demand μ | Aggregated Demand σ | Aggregated Demand γ | Aggregated Demand ρ |
|---|---|---|---|---|---|---|---|---|---|
| Application 1—Top-down | 1 | 0.95 | 0.96 | 0 | 0.89 | 1 | 1 | 0.94 | 1 |
| Application 2—Top-down | 1 | 0.94 | 0.95 | 0 | 0.85 | 1 | 1 | 0.94 | 1 |
| Application 1—Bottom-up | 1 | 1 | 0.96 | 1 | - | 1 | 1 | 0.59 | 0.37 |
| Application 2—Bottom-up | 1 | 1 | 0.79 | 1 | - | 1 | 0.92 | 0.72 | 0.69 |
| Application | Single Demand μ | Single Demand σ | Single Demand γ | Single Demand ρ | Single Demand | Aggregated Demand μ | Aggregated Demand σ | Aggregated Demand γ | Aggregated Demand ρ |
|---|---|---|---|---|---|---|---|---|---|
| Application 1 | 1 | 0.99 | 0.94 | 0.54 | 0.92 | 1 | 1 | 0.98 | 1 |
| Application 2 | 1 | 0.98 | 0.92 | 0.00 | 0.90 | 1 | 1 | 0.98 | 1 |
| Application 3 | 1 | 0.97 | 0.92 | 0.00 | 0.88 | 1 | 1 | 0.98 | 1 |
| Application | Single Demand μ | Single Demand σ | Single Demand γ | Single Demand ρ | Aggregated Demand μ | Aggregated Demand σ | Aggregated Demand γ | Aggregated Demand ρ |
|---|---|---|---|---|---|---|---|---|
| Application 1 | 1 | 1 | 0.90 | 1 | 1 | 0.97 | 0.64 | 0.96 |
| Application 2 | 1 | 1 | 0.88 | 1 | 1 | 0.98 | 0.40 | 0.94 |
| Application 3 | 1 | 1 | 0.90 | 1 | 1 | 0.98 | 0.34 | 0.93 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Fiorillo, D.; Creaco, E.; De Paola, F.; Giugni, M. Comparison of Bottom-Up and Top-Down Procedures for Water Demand Reconstruction. Water 2020, 12, 922. https://doi.org/10.3390/w12030922
Fiorillo D, Creaco E, De Paola F, Giugni M. Comparison of Bottom-Up and Top-Down Procedures for Water Demand Reconstruction. Water. 2020; 12(3):922. https://doi.org/10.3390/w12030922
Chicago/Turabian StyleFiorillo, Diana, Enrico Creaco, Francesco De Paola, and Maurizio Giugni. 2020. "Comparison of Bottom-Up and Top-Down Procedures for Water Demand Reconstruction" Water 12, no. 3: 922. https://doi.org/10.3390/w12030922
APA StyleFiorillo, D., Creaco, E., De Paola, F., & Giugni, M. (2020). Comparison of Bottom-Up and Top-Down Procedures for Water Demand Reconstruction. Water, 12(3), 922. https://doi.org/10.3390/w12030922