The Impact of Training Data Sequence on the Performance of Neuro-Fuzzy Rainfall-Runoff Models with Online Learning




Abstract
1. Introduction
2. Materials and Methods
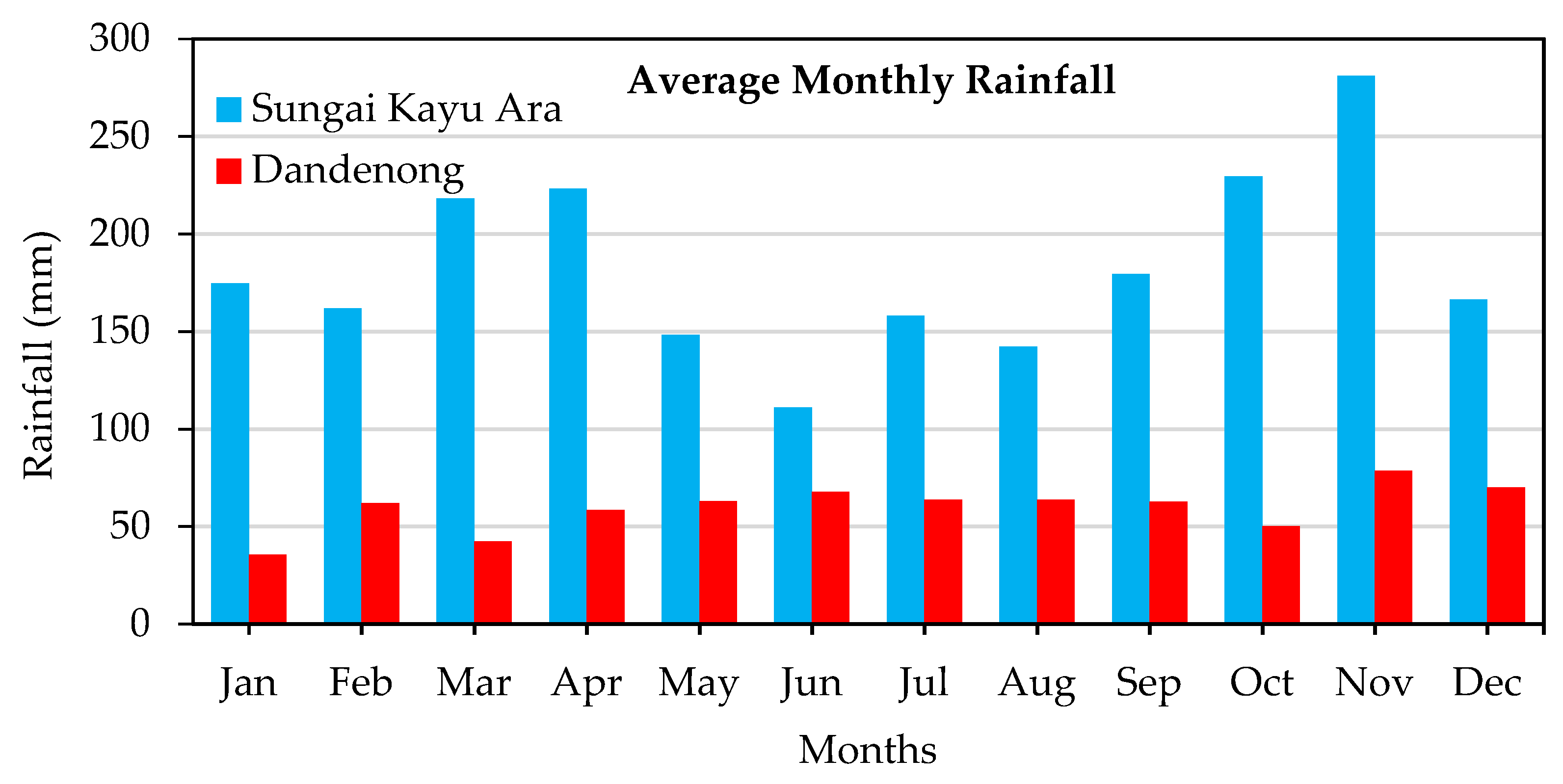
2.1. Study Sites
2.2. Dynamic Evolving Neural-Fuzzy Inference System (DENFIS)
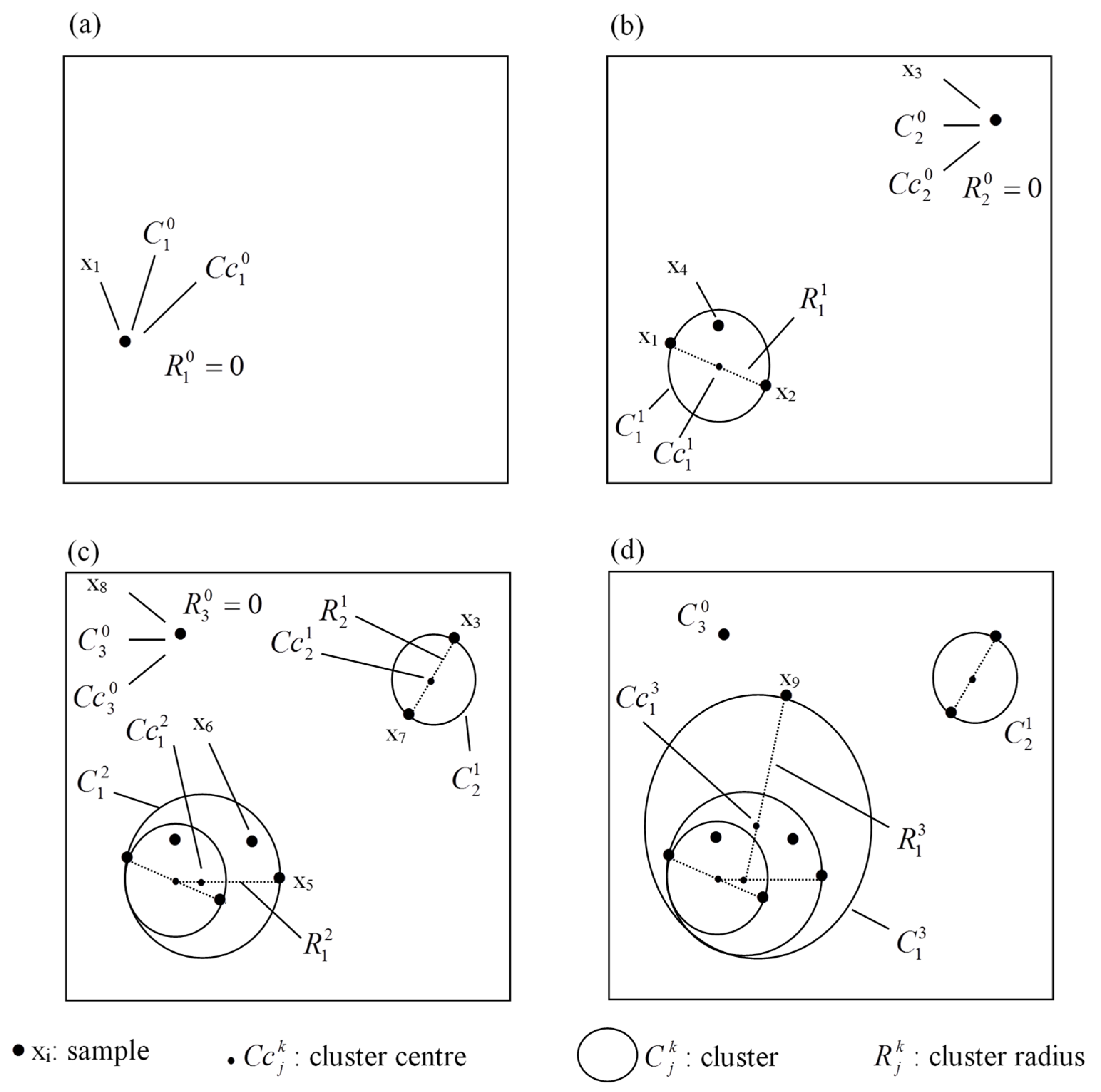
- Step 1.
- Receiving a new data point xi, its distance with the centers of all n existing clusters (created previously) need to be calculated using for where j is the cluster index and CCj is the center of the jth cluster. If all examples of the data stream have been presented, the algorithm is complete.
- Step 2.
- The calculated distance Dij will be compared against all existing cluster radius Rj. If any radius satisfies the condition , then xi belongs to the closest cluster (denoted as Cm) with the minimum distance of for . In this case, the new data point is adopted by an existing rule; therefore, no new cluster is created, and no existing cluster gets updated (the cases of x4 and x6 in Figure 4b,c). At this stage, the algorithm returns to Step 1. If Dij > Rj, the algorithm continues to the next step.
- Step 3.
- For all n existing cluster centers, the parameter Sij will be calculated for input data xi and clusters j = 1, 2, …, n, using Sij = Dij + Rij. The cluster that gives the minimum Sij will be denoted as cluster Ca with center CCa and parameter Sia. Then algorithm goes to the next step.
- Step 4.
- If Sia > 2 × Dthr, the input data xi does not belong to any existing clusters and a new cluster needs to be created similar to step 0 (the cases of x3 and x8 in Figure 4) and then the algorithm then returns to step 1. Else (i.e., Sia ≤ 2× Dthr), algorithm goes to the next step.
- Step 5.
- Since Sia ≤ 2× Dthr, the cluster Ca needs to be updated by revising the center location and increasing the cluster radius. In this process, the new radius will be set as Ra (new) = Sia/2 while the new center will be located at the point on the line connecting xi and CCa with a distance of Ra (new) from point xi (the cases of x2, x5, x7 and x9 in Figure 4). The algorithm proceeds to the step 1.
2.3. Benchmark Models
2.3.1. Hydrologic Engineering Center–Hydrologic Modelling System (HEC–HMS)
2.3.2. Storm Water Management Model (SWMM)
2.3.3. Autoregressive Model with Exogenous Inputs (ARX)
2.4. Input Data Selection and Model Development
2.5. Performance Criteria
3. Result and Discussions
3.1. Input Selection Results
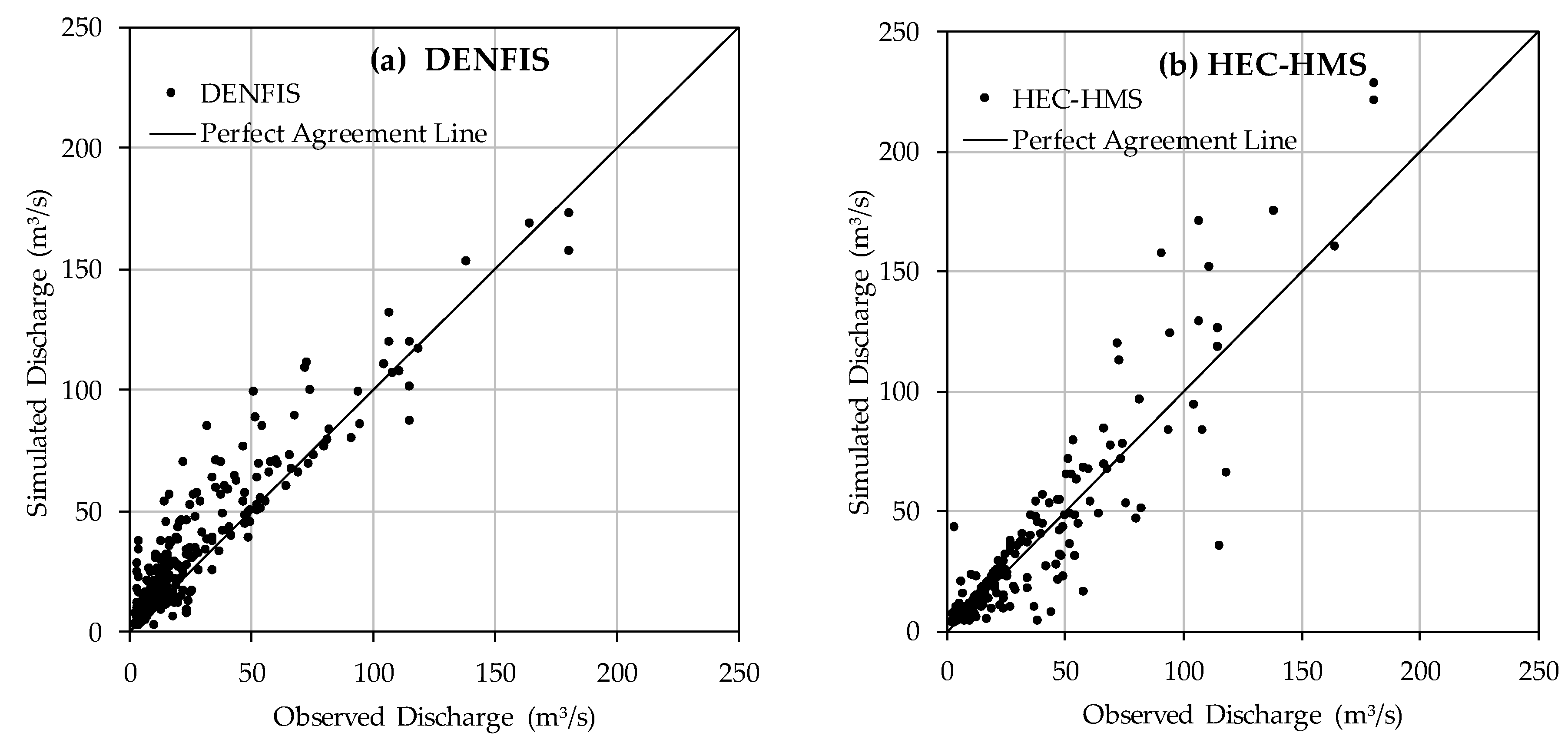
3.2. DENFIS Performance on Event-Based R-R Modelling in Sungai Kayu Ara Catchment
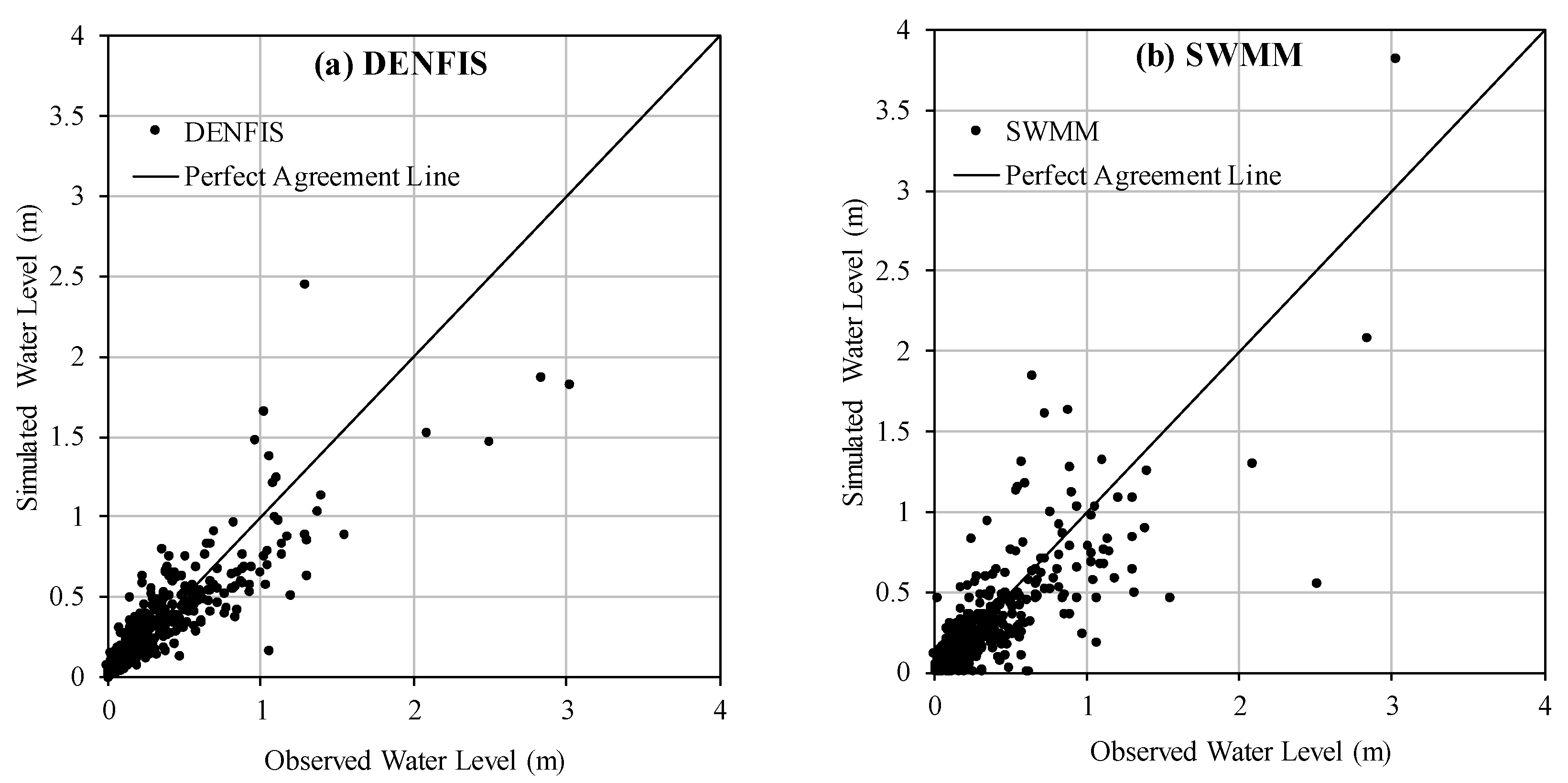
3.3. DENFIS Performance on Continuous R-R Data Modelling in Dandenong Catchment
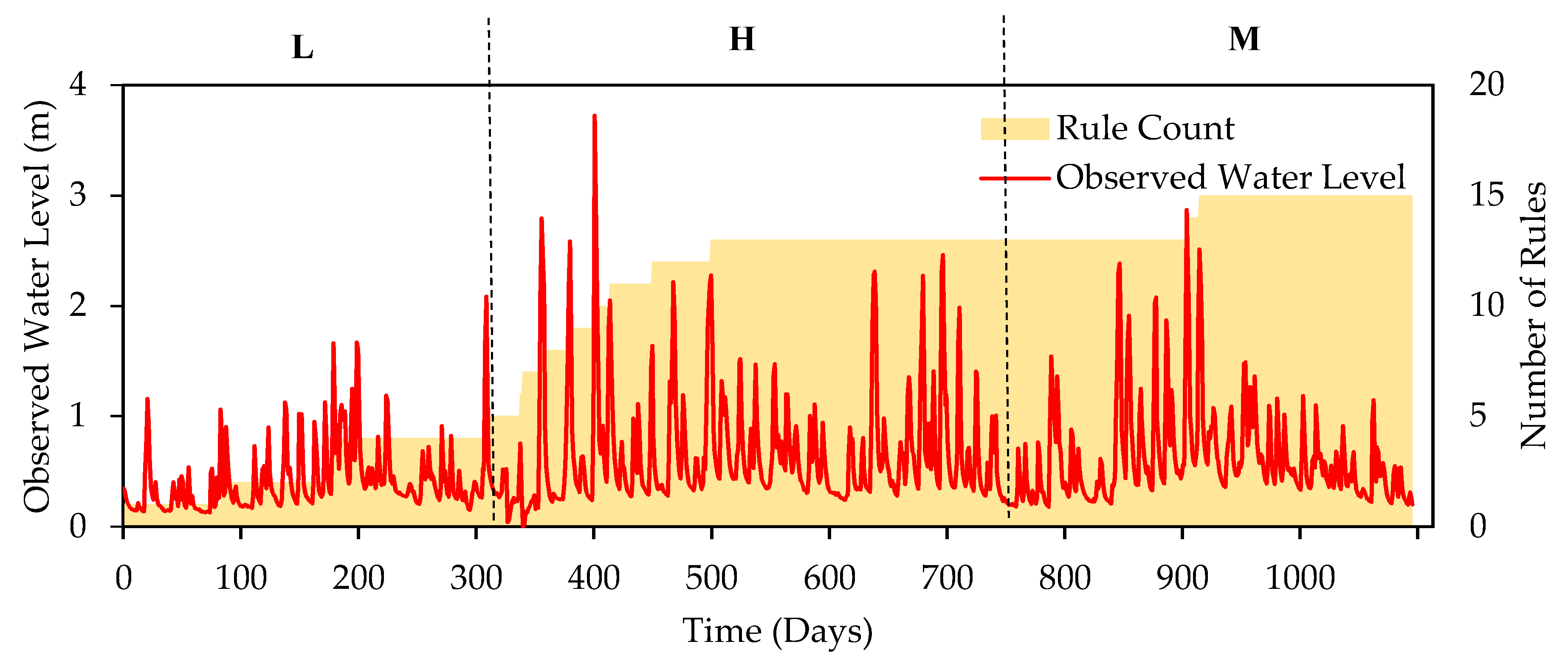
3.4. Impact of Training Data Sequence on DENFIS Performance
3.5. Study Limitations and Future Research Direction
4. Conclusions
- DENFIS performed well in both event-based rainfall-runoff modelling (Sungai Kayu Ara catchment) and continuous rainfall-river stage simulation (Dandenong catchment) in terms of several goodness-of-fit criteria including CE, R2, RMSE, and MAE. Its results were significantly superior to those obtained from the benchmark model ARX (e.g., in Sungai Kayu Ara catchment, DENFIS result of CE = 0.876 was significantly higher than CE = 0.175 obtained by ARX) and were moderately better than the ones obtained by physically-based benchmark models HEC–HMS and SWMM in Sungai Kayu Ara and Dandenong catchments, respectively.
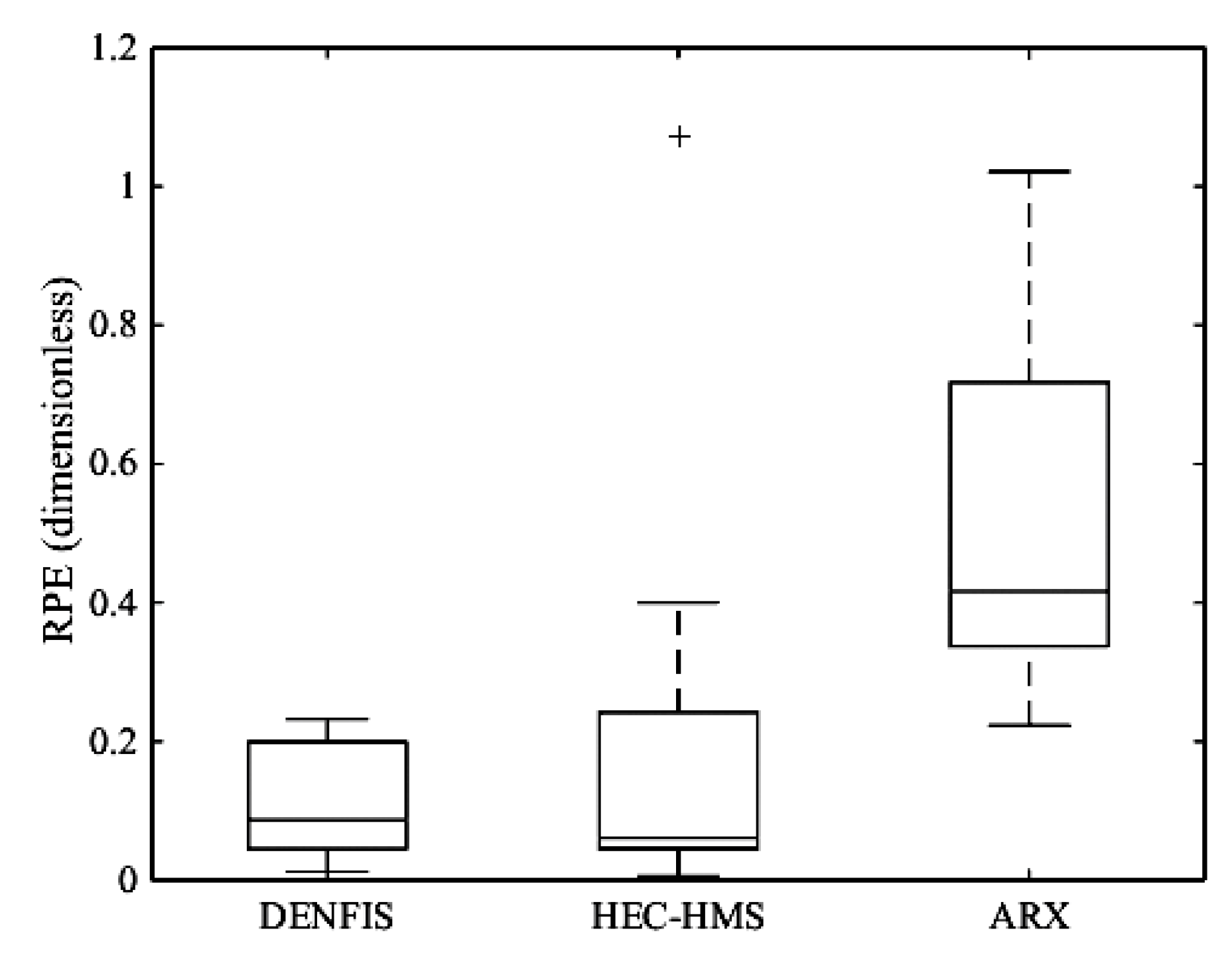
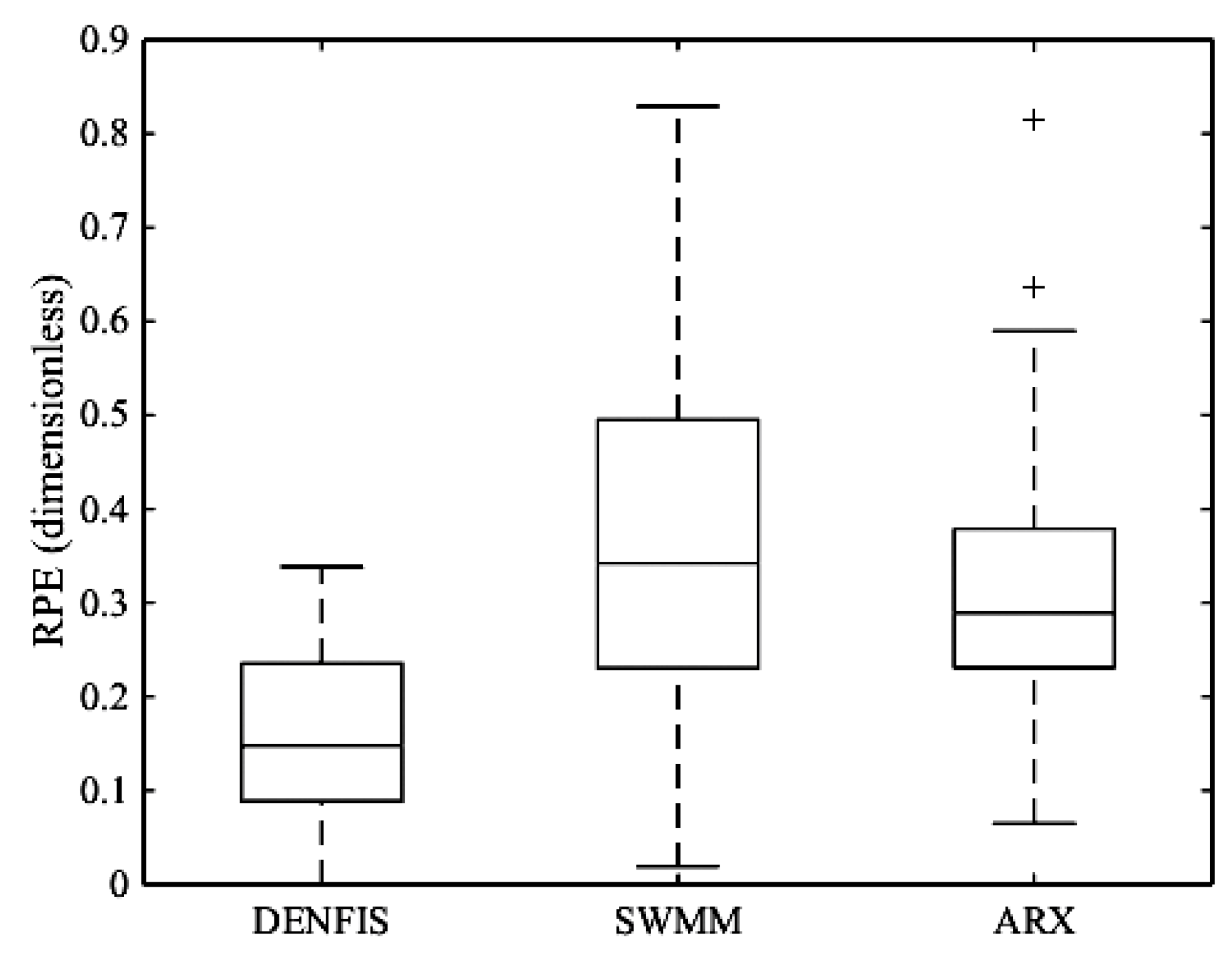
- In peak estimation in the Sungai Kayu Ara catchment, DENFIS produced comparable results in terms of RPE against HEC–HMS model (RPE = 0.113 for DENFIS against RPE = 0.179 for HEC–HMS); however, HEC–HMS had more scattered RPE values with few outliers. In Dandenong catchment, DENFIS (RPE = 0.159) significantly outperformed SWMM (RPE = 0.363) in peak estimation.
- The systematic investigation on the impact of data sequence with low (L), medium (M), and high (H) categories of output data showed that data category of high values, H, contributes to generation of more number of rules in both catchments. Moreover, in the Dandenong catchment, the combinations starting with contrasting categories (i.e., LH or HL) found to be successful in improving the model performance. This was attributed to the fact that the available contrasting data in early stage of training can result in an appropriate initialization of the model parameters. Moreover, this can contribute to generating more diverse rules in the rule-base which can eventually improve the model performance. This finding can be very useful when users choose the training data set.
- The findings of this study suggest the need for running sensitivity analysis on the training dataset during the development of NFS models with local learning. Moreover, the promising results of the proposed AI-based data-driven model, DENFIS, shows the potential advantages of this model in catchments with limited hydrological data.
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Sungai Kayu Ara | |||||
| Station No. | Stations ID | Station Name | Start Date | End Date | Coeff. of Variation |
| R1 | 3110004 | Balai Polis Sea Park | 1-March-1996 | 31-July-2004 | 4.07 |
| R2 | 3110006 | Tmn. Bukit Mayang Mas | 1-March-1996 | 31-July-2004 | 3.24 |
| R3 | 3110007 | Sek. Ren. China Yuk Chai | 1-March-1996 | 31-July-2004 | 3.25 |
| R4 | 3110009 | Tropicana Golf Resort | 1-March-1996 | 31-July-2004 | 3.68 |
| R5 | 3110010 | Balai Polis TTDI | 1-March-1996 | 31-July-2004 | 3.48 |
| R6 | 3110011 | Sungai Penchala Upstream | 1-March-1996 | 31-July-2004 | 3.42 |
| R7 | 3110012 | Masjid Jamek Sg.Penchala | 1-March-1996 | 31-July-2004 | 3.52 |
| R8 | 3110013 | TNB Bandar Utama | 1-March-1996 | 31-July-2004 | 4.40 |
| R9 | 3110014 | Sek. Men. Damansara Jaya | 1-March-1996 | 31-July-2004 | 3.11 |
| R10 | 3110015 | SRK BDR Sri Damansara | 1-March-1996 | 31-July-2004 | 3.64 |
| Q | 3111404 | Sungai Kayu Ara | 1-March-1996 | 31-July-2004 | 1.39 |
| Dandenong | |||||
| Station No. | Stations ID | Station Name | Start Date | End Date | |
| RD | 228204C | Dandenong | 1-January-2005 | 31-December-2015 | 2.74 |
| RR | 228368A | Rowville | 1-January-2005 | 31-December-2015 | 3.01 |
| RH | 228357A | Heathmont | 1-January-2005 | 31-December-2015 | 3.04 |
| RSD | DADAN0322 | Dandenong | 1-January-2005 | 31-December-2015 | 2.49 |
| RSR | DADAN0235 | Rowville | 1-January-2005 | 31-December-2015 | 2.92 |
| RSH | DADAN0077 | Heathmont | 1-January-2005 | 31-December-2015 | 2.50 |
References
- Cheng, X.; Noguchi, M. Rainfall-raunoff modelling by neural network approach. In Proceedings of the International Conference on Water Resources & Environment Research, Kyoto, Japan, 29–31 October 1996; pp. 143–150. [Google Scholar]
- Keesstra, S.; Nunes, J.P.; Saco, P.; Parsons, T.; Poeppl, R.; Masselink, R.; Cerdà, A. The way forward: Can connectivity be useful to design better measuring and modelling schemes for water and sediment dynamics? Sci. Total Environ. 2018, 644, 1557–1572. [Google Scholar] [CrossRef]
- Masselink, R.J.H.; Temme, A.J.A.M.; Giménez, R.; Casalí, J.; Keesstra, S.D. Assessing hillslope-channel connectivity in an agricultural catchment using rare-earth oxide tracers and random forests models. Cuad. Investig. Geogr. 2017, 43, 19–39. [Google Scholar] [CrossRef]
- May, D.B.; Sivakumar, M. Prediction of urban stormwater quality using artificial neural networks. Environ. Modell. Softw. 2009, 24, 296–302. [Google Scholar] [CrossRef]
- Rossman, L.A. Storm Water Management Model User’s Manual, Version 5.0; National Risk Management Research Laboratory, Office of Research and Development, US Environmental Protection Agency: Cincinnati, OH, USA, 2010.
- Bergstrom, S.; Forsman, A. Development of a conceptual deterministic rainfall-runoff model. Nord. Hydrol. 1973, 4, 240–253. [Google Scholar] [CrossRef]
- Chen, X.Y.; Chau, K.W.; Wang, W.C. A novel hybrid neural network based on continuity equation and fuzzy pattern-recognition for downstream daily river discharge forecasting. J. Hydroinform. 2015, 17, 733–744. [Google Scholar] [CrossRef]
- Nourani, V.; Tahershamsi, A.; Abbaszadeh, P.; Shahrabi, J.; Hadavandi, E. A new hybrid algorithm for rainfall-runoff process modeling based on the wavelet transform and genetic fuzzy system. J. Hydroinform. 2014, 16, 1004–1024. [Google Scholar] [CrossRef]
- Maheswaran, R.; Khosa, R. Wavelets-based non-linear model for real-time daily flow forecasting in Krishna River. J. Hydroinform. 2013, 15, 1022–1041. [Google Scholar] [CrossRef]
- Jain, A.; Kumar, A.M. Hybrid neural network models for hydrologic time series forecasting. Appl. Soft Comput. J. 2007, 7, 585–592. [Google Scholar] [CrossRef]
- Shamseldin, A.Y. Artificial neural network model for river flow forecasting in a developing country. J. Hydroinform. 2010, 12, 22–35. [Google Scholar] [CrossRef]
- Asadnia, M.; Chua, L.H.; Qin, X.S.; Talei, A. Improved particle swarm optimization-based artificial neural network for rainfall-runoff modeling. J. Hydrol. Eng. 2014, 19, 1320–1329. [Google Scholar] [CrossRef]
- Meng, C.; Zhou, J.; Tayyab, M.; Zhu, S.; Zhang, H. Integrating artificial neural networks into the VIC model for rainfall-runoff modeling. Water 2016, 8, 407. [Google Scholar] [CrossRef]
- Semiromi, M.T.; Omidvar, S.; Kamali, B. Reducing computational costs of automatic calibration of rainfall-runoff models: Meta-models or high-performance computers? Water 2018, 10, 1440. [Google Scholar] [CrossRef]
- Cho, S.Y.; Quek, C.; Seah, S.X.; Chong, C.H. HebbR2-Taffic: A novel application of neuro-fuzzy network for visual based traffic monitoring system. Expert Syst. Appl. 2009, 36 Pt 2, 6343–6356. [Google Scholar] [CrossRef]
- Alilou, H.; Rahmati, O.; Singh, V.P.; Choubin, B.; Pradhan, B.; Keesstra, S.; Ghiasi, S.S.; Sadeghi, S.H. Evaluation of watershed health using Fuzzy-ANP approach considering geo-environmental and topo-hydrological criteria. J. Environ. Manag. 2019, 232, 22–36. [Google Scholar] [CrossRef] [PubMed]
- Keesstra, S.D.; Temme, A.J.A.M.; Schoorl, J.M.; Visser, S.M. Evaluating the hydrological component of the new catchment-scale sediment delivery model LAPSUS-D. Geomorphology 2014, 212, 97–107. [Google Scholar] [CrossRef]
- Mamdani, E.H.; Assilian, S. Experiment in linguistic synthesis with a fuzzy logic controller. Int. J. Man-Mach. Stud. 1975, 7, 1–13. [Google Scholar] [CrossRef]
- Takagi, T.; Sugeno, M. Fuzzy identification of systems and its applications to modeling and control. IEEE Trans. Syst. Man Cybern. 1985, 1, 116–132. [Google Scholar] [CrossRef]
- Sugeno, M.; Kang, G. Structure identification of fuzzy model. Fuzzy Sets Syst. 1988, 28, 15–33. [Google Scholar] [CrossRef]
- Jang, J.-S.R. ANFIS: Adaptive-network-based fuzzy inference system. IEEE Trans. Syst. Man Cybern. 1993, 23, 665–685. [Google Scholar] [CrossRef]
- Nayak, P.C.; Sudheer, K.P.; Rangan, D.M.; Ramasastri, K.S. A neuro-fuzzy computing technique for modeling hydrological time series. J. Hydrol. 2004, 291, 52–66. [Google Scholar] [CrossRef]
- Nayak, P.; Sudheer, K.P.; Rangan, D.M.; Ramasastri, K.S. Short-term flood forecasting with a neurofuzzy model. Water Resour. Res. 2005, 41. [Google Scholar] [CrossRef]
- Remesan, R.; Shamim, M.A.; Han, D.; Mathew, J. Runoff prediction using an integrated hybrid modelling scheme. J. Hydrol. 2009, 372, 48–60. [Google Scholar] [CrossRef]
- Mukerji, A.; Chatterjee, C.; Raghuwanshi, N.S. Flood forecasting using ANN, neuro-fuzzy, and neuro-GA models. J. Hydrol. Eng. 2009, 14, 647–652. [Google Scholar] [CrossRef]
- Talei, A.; Chua, L.H.C.; Wong, T.S. Evaluation of rainfall and discharge inputs used by Adaptive Network-based Fuzzy Inference Systems (ANFIS) in rainfall–runoff modeling. J. Hydrol. 2010, 391, 248–262. [Google Scholar] [CrossRef]
- Talei, A.; Chua, L.H.C.; Quek, C. A novel application of a neuro-fuzzy computational technique in event-based rainfall–runoff modeling. Expert Syst. Appl. 2010, 37, 7456–7468. [Google Scholar] [CrossRef]
- Bartoletti, N.; Casagli, F.; Marsili-Libelli, S.; Nardi, A.; Palandri, L. Data-driven rainfall/runoff modelling based on a neuro-fuzzy inference system. Environ. Modell. Softw. 2018, 106, 35–47. [Google Scholar] [CrossRef]
- Zakhrouf, M.; Bouchelkia, H.; Stamboul, M. Neuro-Wavelet (WNN) and Neuro-Fuzzy (ANFIS) systems for modeling hydrological time series in arid areas. A case study: The catchment of Aïn Hadjadj (Algeria). Desalin. Water Treat. 2016, 57, 17182–17194. [Google Scholar] [CrossRef]
- Chang, T.K.; Talei, A.; Alaghmand, S.; Ooi, M.P.L. Choice of rainfall inputs for event-based rainfall-runoff modeling in a catchment with multiple rainfall stations using data-driven techniques. J. Hydrol. 2017, 545, 100–108. [Google Scholar] [CrossRef]
- Mosavi, A.; Ozturk, P.; Chau, K.W. Flood prediction using machine learning models: Literature review. Water 2018, 10, 1536. [Google Scholar] [CrossRef]
- Kasabov, N.K.; Song, Q. DENFIS: Dynamic evolving neural-fuzzy inference system and its application for time-series prediction. IEEE Trans. Fuzzy Syst. 2002, 10, 144–154. [Google Scholar] [CrossRef]
- Hong, Y.-S.T.; White, P.A. Hydrological modeling using a dynamic neuro-fuzzy system with on-line and local learning algorithm. Adv. Water Resour. 2009, 32, 110–119. [Google Scholar] [CrossRef]
- Chang, T.K.; Talei, A.; Quek, C.; Pauwels, V.R. Rainfall-runoff modelling using a self-reliant fuzzy inference network with flexible structure. J. Hydrol. 2018, 564, 1179–1193. [Google Scholar] [CrossRef]
- Luna, I.; Soares, S.; Ballini, R. An adaptive hybrid model for monthly streamflow forecasting. In Proceedings of the Fuzzy Systems Conference, London, UK, 23–26 July 2007; FUZZ-IEEE 2007. IEEE International: Piscataway, NJ, USA, 2007. [Google Scholar]
- Hong, Y.-S.T. Dynamic nonlinear state-space model with a neural network via improved sequential learning algorithm for an online real-time hydrological modeling. J. Hydrol. 2012, 468, 11–21. [Google Scholar] [CrossRef]
- Talei, A.; Chua, L.H.C.; Quek, C.; Jansson, P.E. Runoff forecasting using a Takagi–Sugeno neuro-fuzzy model with online learning. J. Hydrol. 2013, 488, 17–32. [Google Scholar] [CrossRef]
- Nguyen, P.K.-T.; Chua, L.H.C.; Talei, A.; Chai, Q.H. Water level forecasting using neuro-fuzzy models with local learning. Neural Comput. Appl. 2016, 30, 1877–1887. [Google Scholar] [CrossRef]
- Ashrafi, M.; Chua, L.H.C.; Quek, C.; Qin, X. A fully-online Neuro-Fuzzy model for flow forecasting in basins with limited data. J. Hydrol. 2017, 545, 424–435. [Google Scholar] [CrossRef]
- U S Army Corps of Engineers (USACE). Hydrologic Modeling System: Technical Reference Manual; U.S. Army Corps of Engineers, Hydrologic Engineering Center: Davis, CA, USA, 2000.
- Desa, M.; Niemczynowicz, J. Spatial variability of rainfall in Kuala Lumpur, Malaysia: Long and short term characteristics. Hydrol. Sci. J. 1996, 41, 345–362. [Google Scholar] [CrossRef]
- Desa, M.; Munira, M.N.; Akhmal, H.; Kamsiah, A.W. Capturing extreme rainfall events in Kerayong catchment. In Proceedings of the 10th International Conference on Urban Drainage, Copenhagen, Denmark, 21–26 August 2005. [Google Scholar]
- Talei, A.; Chua, L.H. Influence of lag time on event-based rainfall–runoff modeling using the data driven approach. J. Hydrol. 2012, 438, 223–233. [Google Scholar] [CrossRef]
- Onyutha, C. On Rigorous Drought Assessment Using Daily Time Scale: Non-Stationary Frequency Analyses, Revisited Concepts, and a New Method to Yield Non-Parametric Indices. Hydrology 2017, 4, 48. [Google Scholar] [CrossRef]
- Maier, H.R.; Dandy, G.C. Neural networks for the prediction and forecasting of water resources variables: A review of modelling issues and applications. Environm. Modell. Softw. 2000, 15, 101–124. [Google Scholar] [CrossRef]
- Mekanik, F.; Imteaz, M.; Talei, A. Seasonal rainfall forecasting by adaptive network-based fuzzy inference system (ANFIS) using large scale climate signals. Clim. Dyn. 2016, 46, 3097–3111. [Google Scholar] [CrossRef]
- Chau, K.; Wu, C. A hybrid model coupled with singular spectrum analysis for daily rainfall prediction. J. Hydroinform. 2010, 12, 458–473. [Google Scholar] [CrossRef]
- Alizadeh, M.J.; Kavianpour, M.R.; Kisi, O.; Nourani, V. A new approach for simulating and forecasting the rainfall-runoff process within the next two months. J. Hydrol. 2017, 548, 588–597. [Google Scholar] [CrossRef]
- Elshorbagy, A.; Corzo, G.; Srinivasulu, S.; Solomatine, D.P. Experimental investigation of the predictive capabilities of data driven modeling techniques in hydrology-Part 2: Application. Hydrol. Earth Syst. Sci. 2010, 14, 1943–1961. [Google Scholar] [CrossRef]
- He, J.; Valeo, C.; Chu, A.; Neumann, N.F. Prediction of event-based stormwater runoff quantity and quality by ANNs developed using PMI-based input selection. J. Hydrol. 2011, 400, 10–23. [Google Scholar] [CrossRef]
- Da Costa Couto, M.P. Review of input determination techniques for neural network models based on mutual information and genetic algorithms. Neural Comput. Appl. 2009, 18, 891–901. [Google Scholar] [CrossRef]
- Legates, D.R.; McCabe, G.J., Jr. Evaluating the use of ‘goodness-of-fit’ measures in hydrologic and hydroclimatic model validation. Water Resour. Res. 1999, 35, 233–241. [Google Scholar] [CrossRef]
- Boscarello, L.; Ravazzani, G.; Cislaghi, A.; Mancini, M. Regionalization of flow-duration curves through catchment classification with streamflow signatures and physiographic-climate indices. J. Hydrol. Eng. 2016, 21, 05015027. [Google Scholar] [CrossRef]
- Castellarin, A.; Galeati, G.; Brandimarte, L.; Montanari, A.; Brath, A. Regional flow-duration curves: Reliability for ungauged basins. Adv. Water Resour. 2004, 27, 953–965. [Google Scholar] [CrossRef]
- Massari, C.; Brocca, L.; Ciabatta, L.; Moramarco, T.; Gabellani, S.; Albergel, C.; De Rosnay, P.; Puca, S.; Wagner, W. The Use of H-SAF Soil Moisture Products for Operational Hydrology: Flood Modelling over Italy. Hydrology 2015, 2, 2–22. [Google Scholar] [CrossRef]
- Masseroni, D.; Galeati, G.; Brandimarte, L.; Montanari, A.; Brath, A. A reliable rainfall-runoff model for flood forecasting: Review and application to a semi-urbanized watershed at high flood risk in Italy. Hydrol. Res. 2017, 48, 726–740. [Google Scholar] [CrossRef]
- Abrahart, R.; Kneale, P.E.; See, L.M. Neural Networks for Hydrological Modeling; CRC Press: Boca Raton, FL, USA, 2004. [Google Scholar]
- Dawson, C.W.; See, L.M.; Abrahart, R.J.; Heppenstall, A.J. Symbiotic adaptive neuro-evolution applied to rainfall–runoff modelling in northern England. Neural Netw. 2006, 19, 236–247. [Google Scholar] [CrossRef] [PubMed]
- Brocca, L.; Melone, F.; Moramarco, T.; Morbidelli, R. Spatial-temporal variability of soil moisture and its estimation across scales. Water Resour. Res. 2010, 46. [Google Scholar] [CrossRef]
- Kisi, O.; Shiri, J.; Tombul, M. Modeling rainfall-runoff process using soft computing techniques. Comput. Geosci. 2013, 51, 108–117. [Google Scholar] [CrossRef]
- Alaghmand, S.; Bin Abdullah, R.; Abustan, I.; Vosoogh, B. GIS-based river flood hazard mapping in urban area (a case study in Kayu Ara River Basin, Malaysia). Int. J. Eng. Technol. 2010, 2, 488–500. [Google Scholar]
- Alaghmand, S.; bin Abdullah, R.; Abustan, I.; Eslamian, S. Comparison between capabilities of HEC-RAS and MIKE11 hydraulic models in river flood risk modeling (a case study of Sungai Kayu Ara River basin, Malaysia). Int. J. Hydrol. Sci. Technol. 2012, 2, 270–291. [Google Scholar] [CrossRef]
- Choi, K.S.; Ball, J.E. Parameter estimation for urban runoff modelling. Urban Water 2002, 4, 31–41. [Google Scholar] [CrossRef]
- Akhter, M.S.; Hewa, G.A. The use of PCSWMM for assessing the impacts of land use changes on hydrological responses and performance of WSUD in managing the impacts at myponga catchment, South Australia. Water 2016, 8, 511. [Google Scholar] [CrossRef]
- Onyutha, C. Influence of Hydrological Model Selection on Simulation of Moderate and Extreme Flow Events: A Case Study of the Blue Nile Basin. Adv. Meteorol. 2016, 2016, 7148326. [Google Scholar] [CrossRef]










| Sungai Kayu Ara (10-min Interval Data) | ||||
| Rainfall (mm) | Discharge (m³/s) | |||
| Training | Testing | Training | Testing | |
| Minimum | 0 | 0 | 3.20 | 0.10 |
| Maximum | 26.5 | 48.0 | 135.00 | 180.90 |
| Mean | 0.7 | 0.6 | 17.81 | 12.33 |
| Standard Deviation | 2.2 | 2.5 | 21.85 | 22.15 |
| Skewness | 4.8 | 6.5 | 2.70 | 3.90 |
| Dandenong (Daily Data) | ||||
| Rainfall (mm) | River Stage (m) | |||
| Training | Testing | Training | Testing | |
| Minimum | 0 | 0 | 0 | 0 |
| Maximum | 149.0 | 84.0 | 6.80 | 3.00 |
| Mean | 2.0 | 1.9 | 0.18 | 0.16 |
| Standard Deviation | 6.0 | 5.1 | 0.44 | 0.27 |
| Skewness | 8.6 | 5.6 | 7.35 | 4.45 |
| Performance Criteria | Formula | Unit | Range |
|---|---|---|---|
| Nash-Sutcliffe Coefficient of Efficiency | Dimensionless | (−∞, 1] | |
| Coefficient of Determination | Dimensionless | [0, 1] | |
| Root Mean Square Error | m3s−1 | [0, +∞) | |
| Mean Absolute Error | m3s−1 | [0, +∞) | |
| Relative Peak Error | Dimensionless | [0, +∞) |
| Catchment | Selected Inputs |
|---|---|
| Sungai Kayu Ara | R2(t − 2), R7(t − 1), R9(t − 8), Q(t − 1) |
| Dandenong | RD(t − 1), RSR(t − 1), RSH(t − 1) |
| Model | CE (-) | R2 (-) | RMSE (m3/s) | MAE (m3/s) | RPE (-) |
|---|---|---|---|---|---|
| DENFIS | 0.876 | 0.899 | 5.056 | 2.100 | 0.113 |
| HEC–HMS | 0.595 | 0.876 | 7.218 | 4.261 | 0.179 |
| ARX | 0.175 | 0.545 | 10.032 | 7.401 | 0.451 |
| Model | CE (-) | R2 (-) | RMSE (m) | MAE (m) | RPE (-) |
|---|---|---|---|---|---|
| DENFIS | 0.803 | 0.808 | 0.121 | 0.056 | 0.159 |
| SWMM | 0.686 | 0.696 | 0.153 | 0.067 | 0.363 |
| ARX | 0.689 | 0.797 | 0.150 | 0.062 | 0.320 |
| Catchment | Data Category | ||
|---|---|---|---|
| Low | Moderate | High | |
| Sungai Kayu Ara (Events) | 1, 3, 4, 8, 9 | 2, 5, 7, 10 | 6, 11, 12 |
| Dandenong (Year) | 2007 | 2012 | 2011 |
| Parameters | Training Data Sequence | |||||
|---|---|---|---|---|---|---|
| LMH | LHM | MLH | MHL | HLM | HML | |
| Rules Count | 18 | 18 | 18 | 18 | 20 | 20 |
| Rules Distribution | 5, 3, 10 | 5, 10, 3 | 7, 4, 7 | 7, 11, 0 | 14, 0, 6 | 14, 6, 0 |
| CE | 0.805 | 0.779 | 0.810 | 0.781 | 0.845 | 0.819 |
| R2 | 0.842 | 0.817 | 0.839 | 0.833 | 0.868 | 0.857 |
| RMSE (m3/s) | 5.635 | 5.860 | 5.557 | 5.835 | 5.248 | 5.319 |
| MAE (m3/s) | 2.462 | 2.711 | 2.400 | 2.697 | 2.335 | 2.434 |
| Parameters | Training Data Sequence | |||||
|---|---|---|---|---|---|---|
| LMH | LHM | MLH | MHL | HLM | HML | |
| Rule Count | 15 | 15 | 14 | 13 | 15 | 14 |
| Rules Distribution | 5, 8, 2 | 5, 8, 2 | 8, 4, 2 | 8, 2, 3 | 9, 4, 2 | 9, 2, 3 |
| CE | 0.408 | 0.771 | 0.442 | 0.712 | 0.758 | 0.713 |
| R2 | 0.524 | 0.784 | 0.527 | 0.714 | 0.778 | 0.750 |
| RMSE (m) | 0.276 | 0.172 | 0.268 | 0.193 | 0.177 | 0.192 |
| MAE (m) | 0.199 | 0.088 | 0.185 | 0.117 | 0.093 | 0.143 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chang, T.K.; Talei, A.; Chua, L.H.C.; Alaghmand, S. The Impact of Training Data Sequence on the Performance of Neuro-Fuzzy Rainfall-Runoff Models with Online Learning. Water 2019, 11, 52. https://doi.org/10.3390/w11010052
Chang TK, Talei A, Chua LHC, Alaghmand S. The Impact of Training Data Sequence on the Performance of Neuro-Fuzzy Rainfall-Runoff Models with Online Learning. Water. 2019; 11(1):52. https://doi.org/10.3390/w11010052
Chicago/Turabian StyleChang, Tak Kwin, Amin Talei, Lloyd H. C. Chua, and Sina Alaghmand. 2019. "The Impact of Training Data Sequence on the Performance of Neuro-Fuzzy Rainfall-Runoff Models with Online Learning" Water 11, no. 1: 52. https://doi.org/10.3390/w11010052
APA StyleChang, T. K., Talei, A., Chua, L. H. C., & Alaghmand, S. (2019). The Impact of Training Data Sequence on the Performance of Neuro-Fuzzy Rainfall-Runoff Models with Online Learning. Water, 11(1), 52. https://doi.org/10.3390/w11010052