1. Introduction
The track record of multivariate quantiles in hydrology is long and started with the papers by [
1,
2,
3]. Quickly, a growing amount of literature on this topic with an application focus arose (see, e.g., [
4,
5,
6]). A thorough overview of the current state of the art can be found in [
7]. The notion of multivariate quantile we use in this paper is based on copulas. It has the nice feature that a
multivariate quantile separates the copula domain into two sets, one comprising
p, the other comprising
of the total probability mass. Some theoretical aspects can be found in e.g., [
8,
9,
10].
Not only the estimation of multivariate quantiles is important, but also an assessment of the estimation uncertainty. Confidence regions can be an essential tool for doing this. In contrast to pointwise confidence bands, confidence regions provide a holistic precision analysis of multivariate quantiles. For example, Refs. [
11,
12] construct confidence regions for multivariate quantiles based on highest density regions [
13]. However, in principle, any approach for constructing confidence regions of level sets is applicable since the multivariate quantiles considered are specific level sets.
We attempt to fill this research gap and contribute to the existing literature on multivariate quantiles in several ways. First, we extend two recently developed approaches for construction of level set confidence regions by Mammen and Polonik [
14] and Chen et al. [
15] to the estimation problem at hand. Note that the multivariate quantiles considered here are level sets at specific levels of the copula. However, in contrast to the cited works, where the levels are known and fixed in advance, the level of the multivariate quantile has to be estimated. Second, we check the coverage probabilities of the extended methods by a simulation study in order to investigate their reliability. Finally, we apply the methods on a small sample of flood data to gain further insights.
The paper is structured as follows: The next section introduces copulas and the notion of multivariate quantiles used here. The confidence region approaches by Mammen and Polonik [
14] and Chen et al. [
15] are discussed in
Section 3. Moreover, they are extended to multivariate quantile estimation. In
Section 4, a simulation study is conducted in order to explore the strengths and weaknesses of the considered methods. The paper is concluded by an application on a small sample of flood data and a discussion of some further aspects.
2. Copulas and Multivariate Quantiles
This section introduces both copulas and the notion of multivariate quantiles we use throughout the paper. Additionally, the notation and some preliminaries are covered. According to Sklar’s theorem [
16], every distribution function
F of a continuous
d-variate random variable
can be decomposed into a copula
C and its univariate marginal distributions
by
This allows for separating the marginal distributions and the overall dependence structure of
. The copula itself is a distribution function of the random variable
. Note that the univariate components of
are uniformly distributed. A good theoretical introduction to copulas can be found, e.g., in [
17,
18,
19]. An introduction for practical purposes can be found, e.g., in [
8,
20].
Let
be an i.i.d. sample of a random vector
and let
be the
ith component of the vector
. The copula
C of
may be estimated based on the so called pseudo observations
,
. These can be obtained either by estimation of the marginal distributions
, i.e.,
or by rank transformation of the data, i.e.,
Note that estimation of the marginal distributions is prone to model misspecification [
20]. Hence, a rank transformation is often preferable.
Using the pseudo observations
,
, the copula can be estimated in different fashions. The estimator
is called empirical copula and obtained by the empirical distribution of the pseudo observations
A second estimator
that we use later on is based on kernel estimation. It is obtained by
where
is the scaled version of a suitable multivariate kernel
and
is the inverse standard normal cumulative distribution function (CDF) applied component-wise. Using a multiplicative kernel, this estimator is investigated in [
21]. The transformation
circumvents potential boundary issues that can arise in the copula domain
. It is also recommended in [
18]. Apart from choosing a kernel, the estimator also requires a bandwidth parameter
h. in this paper, we choose
to be a multiplicative multivariate Gaussian kernel and
, which is Silverman’s rule of thumb [
22]. As will become clear later, these choices are particularly easy to work with and let us generate confidence regions in the original copula domain.
The Kendall distribution function
[
23,
24,
25] gives the probability that the copula
C stays at or below a given level
p, i.e.,
Barbe et al. [
23] show that the Kendall distribution function can be estimated non-parametrically from a sample of size
n by
where
. In addition to that, we need an estimator of the inverse of
. For
, this is obtained by
Furthermore, we define
and
. Let
denote convergence in probability. It can be shown that not only
for
[
23], but also
for
[
26]. Moreover,
is strongly consistent [
27].
Using the previous concepts of copulas and the Kendall distribution function, we can now define the notion of multivariate quantiles we use in this paper. It has been used previously in, e.g., [
7,
9] and in a similar fashion in [
10]. in the following, let
denote the class of copulas for which
is strictly increasing and continuous.
Definition 1 ([
9])
. For a copula and a multivariate quantile is defined as We can now write
. Hence, the boundary of the
multivariate quantile partitions the copula domain into a set comprising probability mass
p and a set comprising probability mass
, which is a nice feature of this particular definition. Furthermore, the shape of the boundary is determined by the shape of the level curve of the copula. The level curve reflects the distribution of the probability mass and the strength of dependence between the involved variables (see, e.g., [
28]) which transfers to the quantile definition here. For further motivation and theoretical considerations of this approach, see [
7,
10]. Note that, because
,
has no total ordering, there are many other notions of multivariate quantiles (see, e.g., [
4,
29,
30,
31,
32]). However, we do not consider these further here.
can be estimated either by
or by
where
is as defined in Equation (
4),
is the empirical copula (
1), and
is the kernel estimated copula (
2). The estimator
is consistent [
10]. An algorithm to construct the estimator on a given bivariate copula sample can be found in [
10].
We want to point out that the estimators (
5) and (
6) can be used for cases three and four in [
7]. in addition, the estimators cover the multivariate quantiles used in [
10]. Furthermore, note that we use a non-parametric approach for multivariate quantile estimation here. Parametric and semi-parametric estimators can be found, e.g., in [
8,
9].
A further concept we employ is the Hausdorff distance
. It plays a key role in one of the approaches to construct confidence regions (see
Section 3.2). Let the Euclidean distance between two points
be denoted by
. We can then define the distance between a point
and a set
as
. If the set
A is closed, min instead of inf can be used. The Hausdorff distance
can then be defined as follows.
Definition 2. For non-empty subsets the Hausdorff distance is defined by In general, the Hausdorff distance may be infinite. However, since we consider only subsets of the compact set , the Hausdorff distance is always finite. in the next section, we introduce two approaches to construct confidence regions for level set estimation and extend them to multivariate quantiles.
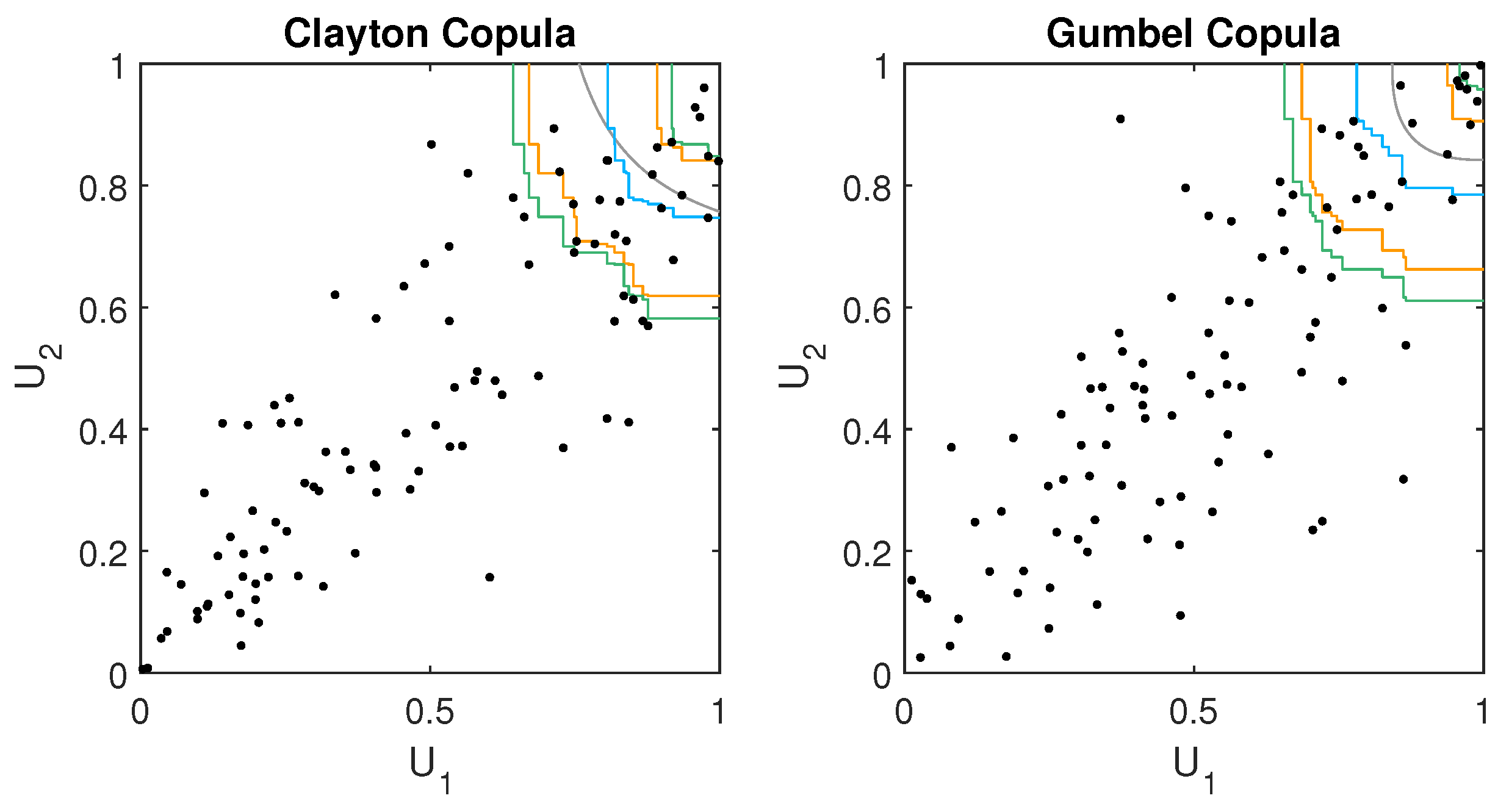
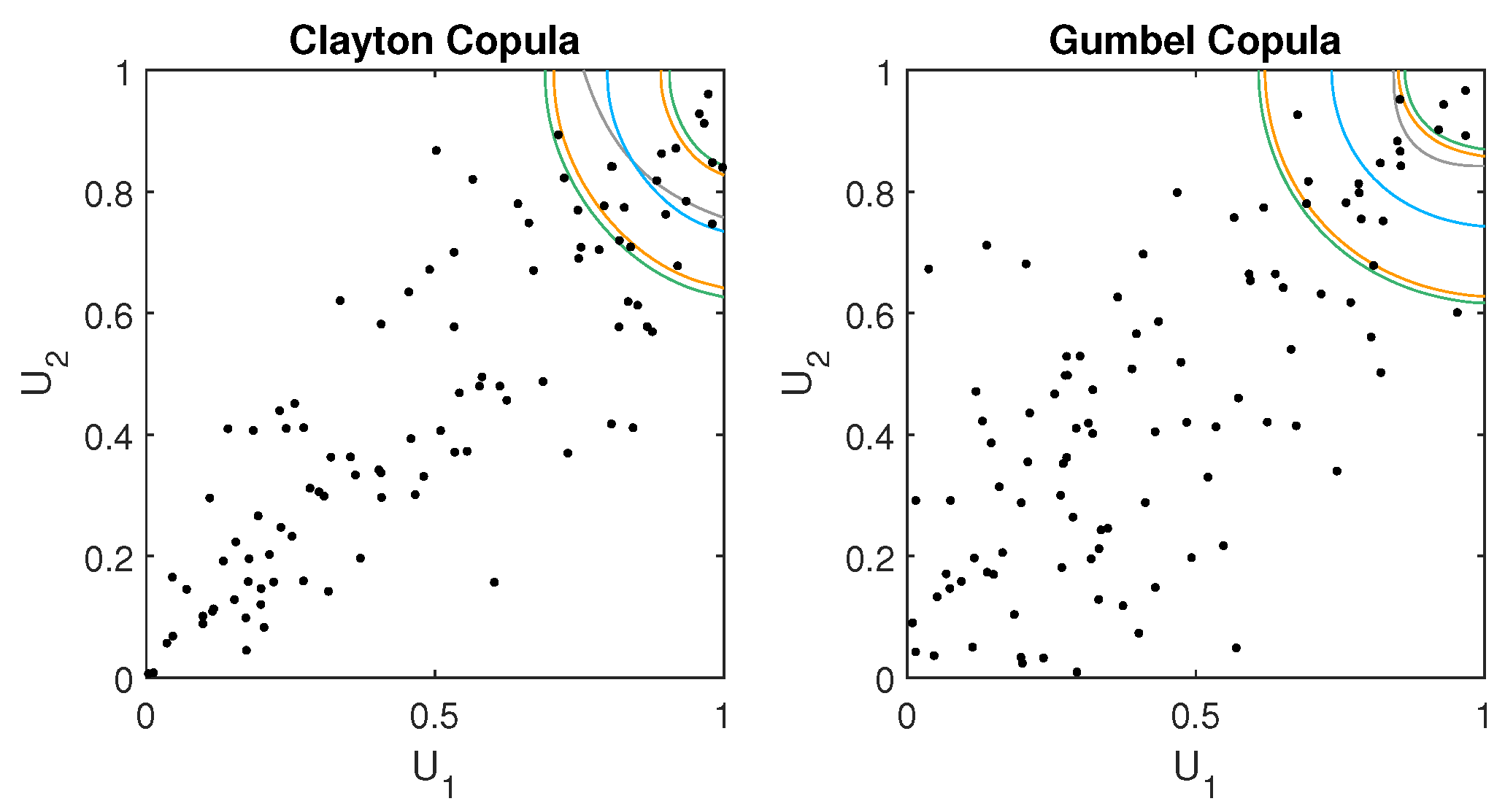
4. Simulation Study
We investigate in a simulation study whether the extended approaches introduced in
Section 3.1 and
Section 3.2 hold their proposed confidence level
via coverage probabilities. In particular, we focus on small sample sizes as they are found in hydrology applications. For both approaches, we consider the same simulation settings. We simulate samples of sizes
from Gauss, Clayton, and Gumbel copulas, where we restrict ourselves to the bivariate case. The Gauss copula has a parameter
corresponding to a Kendall’s
of
, whereas, for the Clayton and the Gumbel copula settings, the parameters correspond to a Kendall’s
of
. Note that in the Gauss case a Kendall’s
of 0 corresponds to independence.
For each setting, we estimate confidence regions for the
multivariate quantile to get a better picture of the performance on the whole copula domain. Confidence regions are estimated at the
and
confidence levels. For this, we use 1000 bootstraps for the Mammen and Polonik [
14] approach and 200 bootstraps for the Chen et al. [
15] approach, due to the high computation times of the latter. Each simulation setting is repeated 1000 times to obtain reliable results. The coverage probability is calculated by checking whether the theoretical multivariate quantile boundary lies within the estimated confidence region in each simulation run. For example,
Figure 1 and
Figure 2 show cases where the theoretical multivariate quantile is covered by the confidence region.
The coverage probabilities for the extended Mammen and Polonik [
14] approach can be found in
Table 1. The first sanity check which can be made is that the
confidence region exhibits higher coverage probabilities than the
confidence region, which is the case throughout. Most of the settings for the
and
multivariate quantiles show more conservative coverage probabilities than the respective confidence level would suggest. In contrast to that, particularly the negative dependence settings for
exhibit too low coverage probabilities. Too high and too low coverage probabilities could be due to the estimation uncertainty of
and the bounded copula domain. The results over the different sample sizes are very similar. We conclude from this that the estimator works quite well for small sample sizes. Overall, the results for the Mammen and Polonik [
14] approach are reasonable.
The results of the extended Chen et al. [
15] approach can be found in
Table 2. Most of the coverage probabilities are too low. In particular, confidence regions for high dependence seem to be problematic. In contrast to that, the results are reasonable for low to medium strong dependence, i.e.,
. This could be due to several effects. First, the bounded copula domain could be an issue. Second, the original approach by Chen et al. [
15] was developed for densities and not for copulas which are distribution functions. In addition, the estimation of
is present in the approach. However, we do not think that the latter plays an important role since the results for the Mammen and Polonik [
14] approach are good where estimation of
is also necessary. Finally, we calculate the coverage probabilities by checking whether the level curve at level
of the underlying copula
C is within the boundaries of the constructed confidence set since we are actually interested in the level curves of the copula
C. In contrast to that, the approach of Chen et al. [
15] aims to estimate confidence regions for the level curves of a convolution of the copula
C and the kernel
, whereby a certain smoothness and limit behavior of the results in ensured. This could lead to the biased coverage probabilities in our case.
In conclusion, the simulation study shows a reasonable performance of the extended Mammen and Polonik [
14] method. On the other hand, results for the extended Chen et al. [
15] method are mixed. They are, however, reasonably precise for low to medium strong dependence. In summary, we advise practitioners to use the Mammen and Polonik [
14] approach for construction of multivariate quantile confidence regions. In the next section, we apply the introduced methods on a small hydrology related data set to gain further insights.
5. Application
We apply the two confidence region approaches on a small data set with a hydrology context. The data can be found in [
35]. It comprises 33 yearly maximum values of flood peak and flood volume of the Ashuapmushuan basin in Quebec, Canada. The observations were collected in the period 1963–1995. In a first step, we rank-transform the data to obtain the pseudo observations in the copula domain
.
Figure 3 shows a scatterplot of the original data and the rank-transformed data. The data exhibit positive dependence with a Kendall’s
of approximately
.
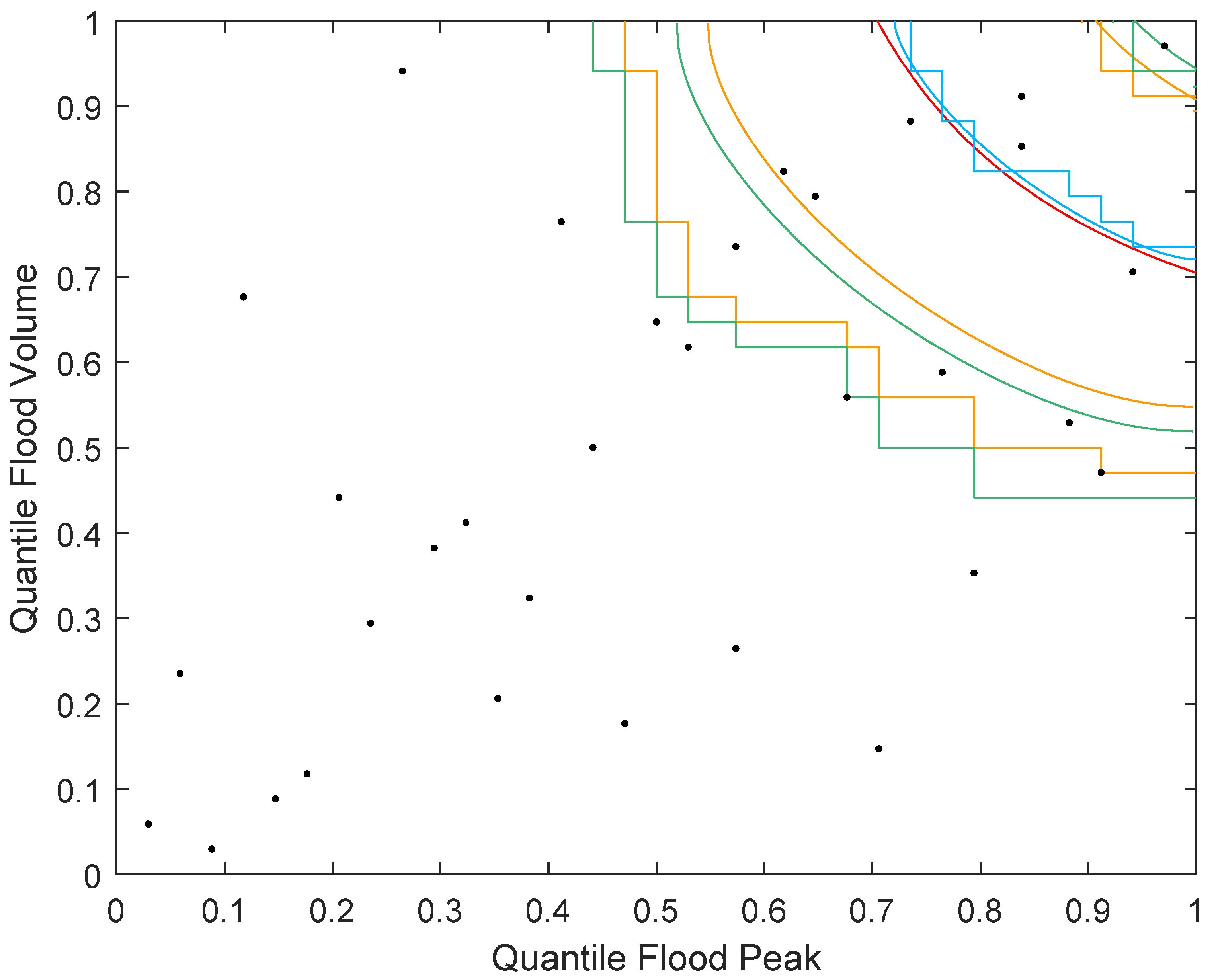
In a second step, we estimate the
(i.e.,
) multivariate quantile with the two estimators
and
. The estimation results are shown in
Figure 4. As can be seen, the two estimated boundaries nicely overlap. For comparison purposes, we additionally estimate a parametric copula model. A Clayton copula with parameter
≈ 1.4 fits the data best among Gumbel, Frank, Gauss-, and t-copulas. The estimated boundary is shown in
Figure 4 as a red line and is close to the non-parametric estimates.
In a third step, we apply the extended method of Mammen and Polonik [
14] as introduced in
Section 3.1 to the data. The result of this can be seen in
Figure 4. The orange and green step curves depict the confidence region boundaries for confidence levels
and
, respectively. Recall that the boundary of the
multivariate quantile partitions the copula domain into a set comprising
of the probability mass, which lies to the upper right of the boundary, and a set comprising
of the probability mass, which lies to the lower left of the boundary. Counting the points within the confidence region boundaries, we obtain between
and
of the points for the
confidence region and between
and
of the points for the
confidence region. Thus, the confidence regions seem wide, which has to be related to the small sample size though.
Next, we also apply the extended method of Chen et al. [
15] as introduced in
Section 3.2.
Figure 4 shows the results. The orange and green smooth lines depict the confidence region boundaries for confidence levels
and
, respectively. With the same calculations as above, both the
confidence region and the
confidence region enclose between
and
of the points. Thus, the confidence regions are tighter than those of the Mammen and Polonik [
14] method. This can also be seen in
Figure 4. Clearly, the approach of Chen et al. [
15] gives a tighter confidence region on the lower end, whereas the two approaches give similar results on the upper end. This has to be put in light of the simulation study, which shows too liberal coverage probabilities for the method of Chen et al. [
15] in the considered case
and moderate positive dependence.
Furthermore, we analyze the secondary return period as defined in [
36]. The estimated secondary return period given by the multivariate quantile is
years. For the Mammen and Polonik [
14] approach, the confidence regions suggest a secondary return period between 3 and 33 years and between
and 33 years for the
and
confidence levels, respectively. The confidence regions of the Chen et al. [
15] approach suggest a secondary return period between
and 33 years and between
and 33 years for the
and
confidence levels, respectively. Thus, the confidence regions can also be used to assess the precision of the implied secondary return period of the multivariate quantile.
Finally, we want to stress again the advantages of having confidence regions for multivariate quantiles in a hydrology context. Not only do confidence regions give a statistical insight into the estimation uncertainty present, e.g.,
Figure 4 shows that these are very wide and more data would be needed for a reliable estimate of the multivariate quantile, but they are also helpful to the design of infrastructures. Since the true multivariate quantile boundary lies within the confidence region boundaries at the specified confidence level, the points within the confidence region should be considered when planning, e.g., new dams. In particular, a point from within the region between the lower boundary of the confidence region and the multivariate quantile boundary could actually be a point with a (true) secondary return period of 10 years and thus would be rarer than the estimated multivariate quantile suggests. Conversely, a point from within the region between the upper boundary of the confidence regions and the multivariate quantile boundary could have a lower (true) secondary return period and thus would occur more often than might be expected from considering the estimated multivariate quantile boundary only.







{kind=link}
{kind=link}
{kind=link}
{kind=link}