Towards Improving the Efficiency of Bayesian Model Averaging Analysis for Flow in Porous Media via the Probabilistic Collocation Method


Abstract
:1. Introduction
2. Methods
2.1. Governing Equations of Groudnwater Flow System
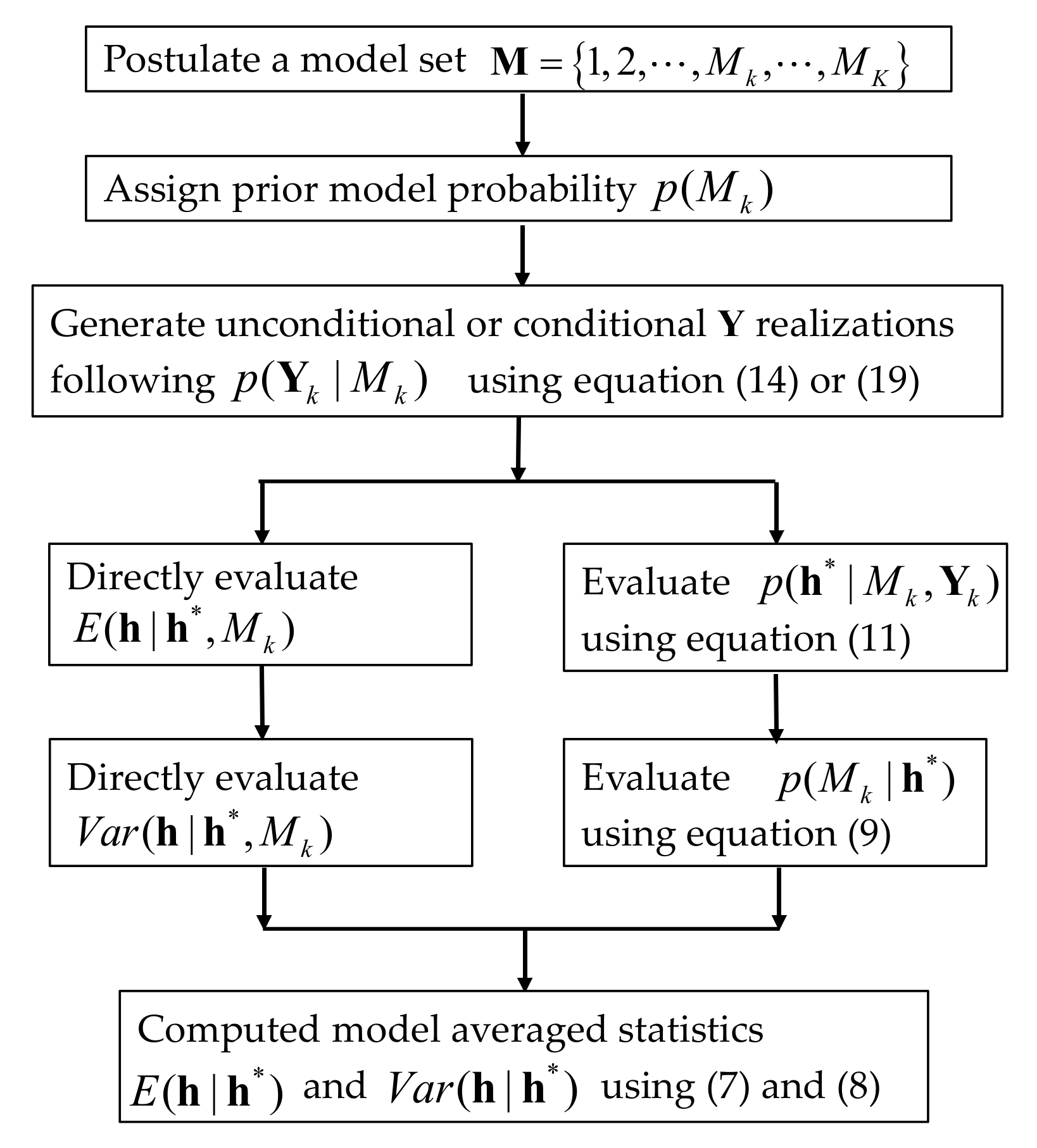
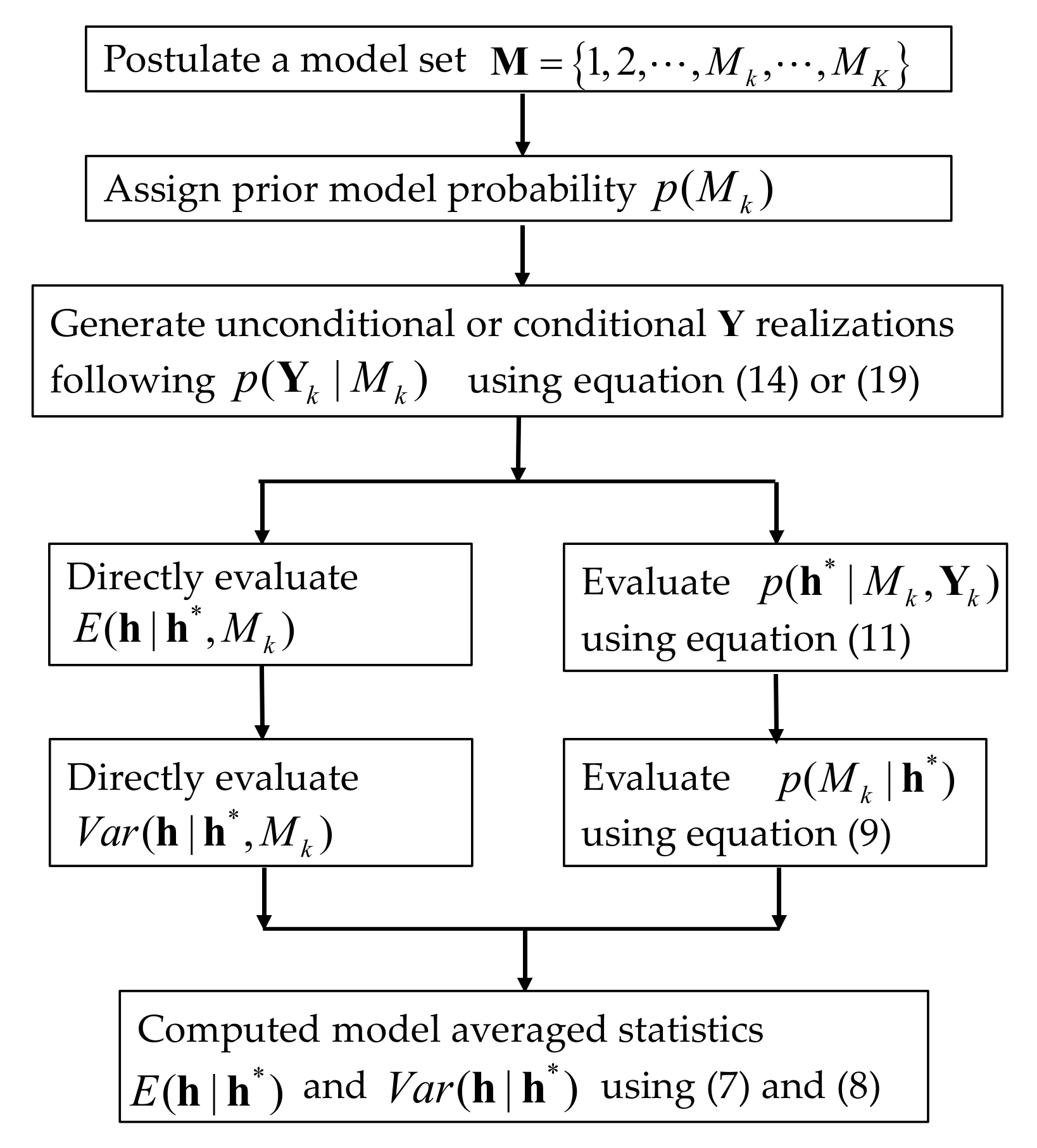
2.2. Bayesian Model Averaging Method
2.3. Unconditional and Conditional Karhunen–Loeve Expansion Methods
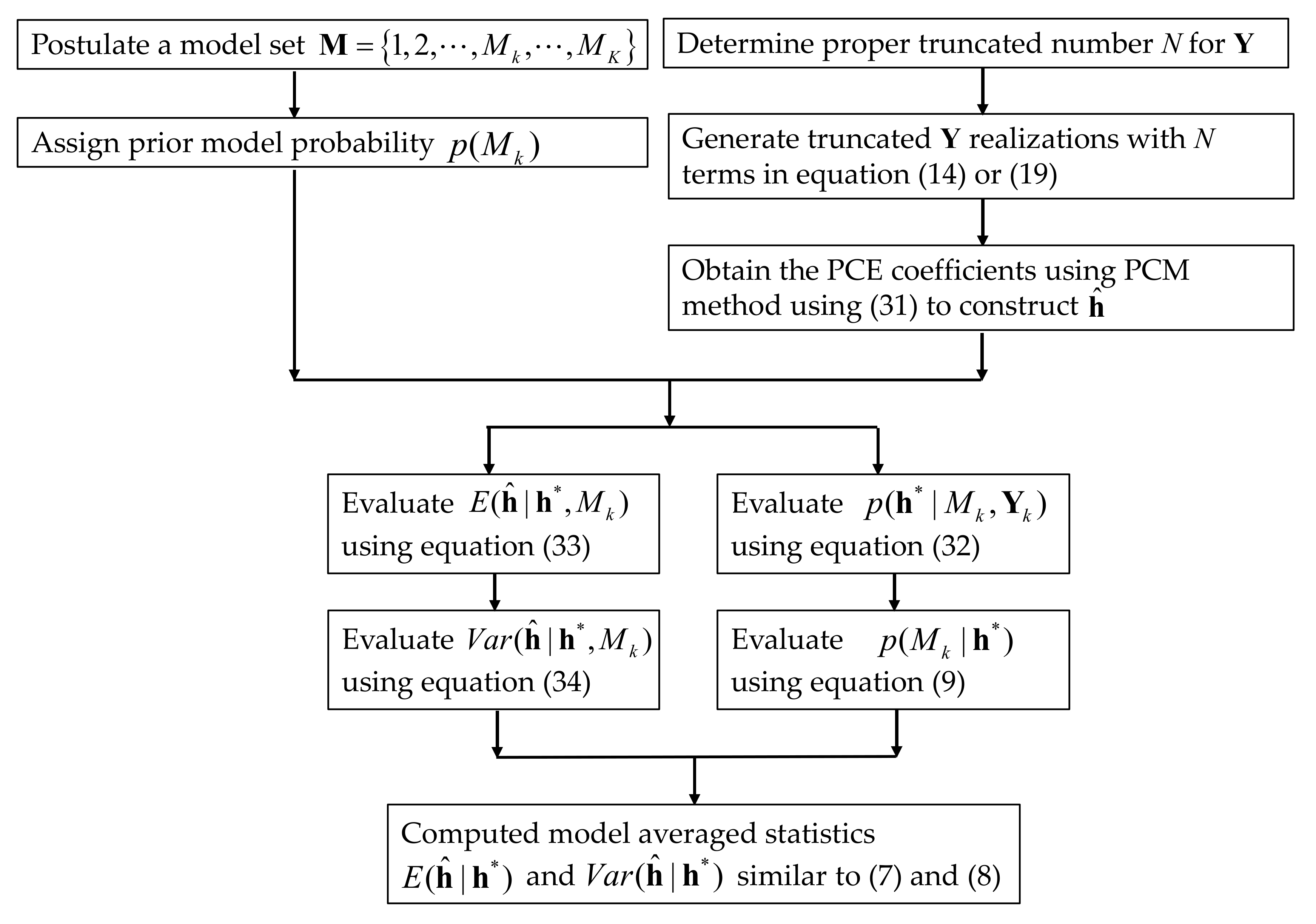
2.4. Polynomial Chaos Expansion Method
2.5. Probabilistic Collocation Method
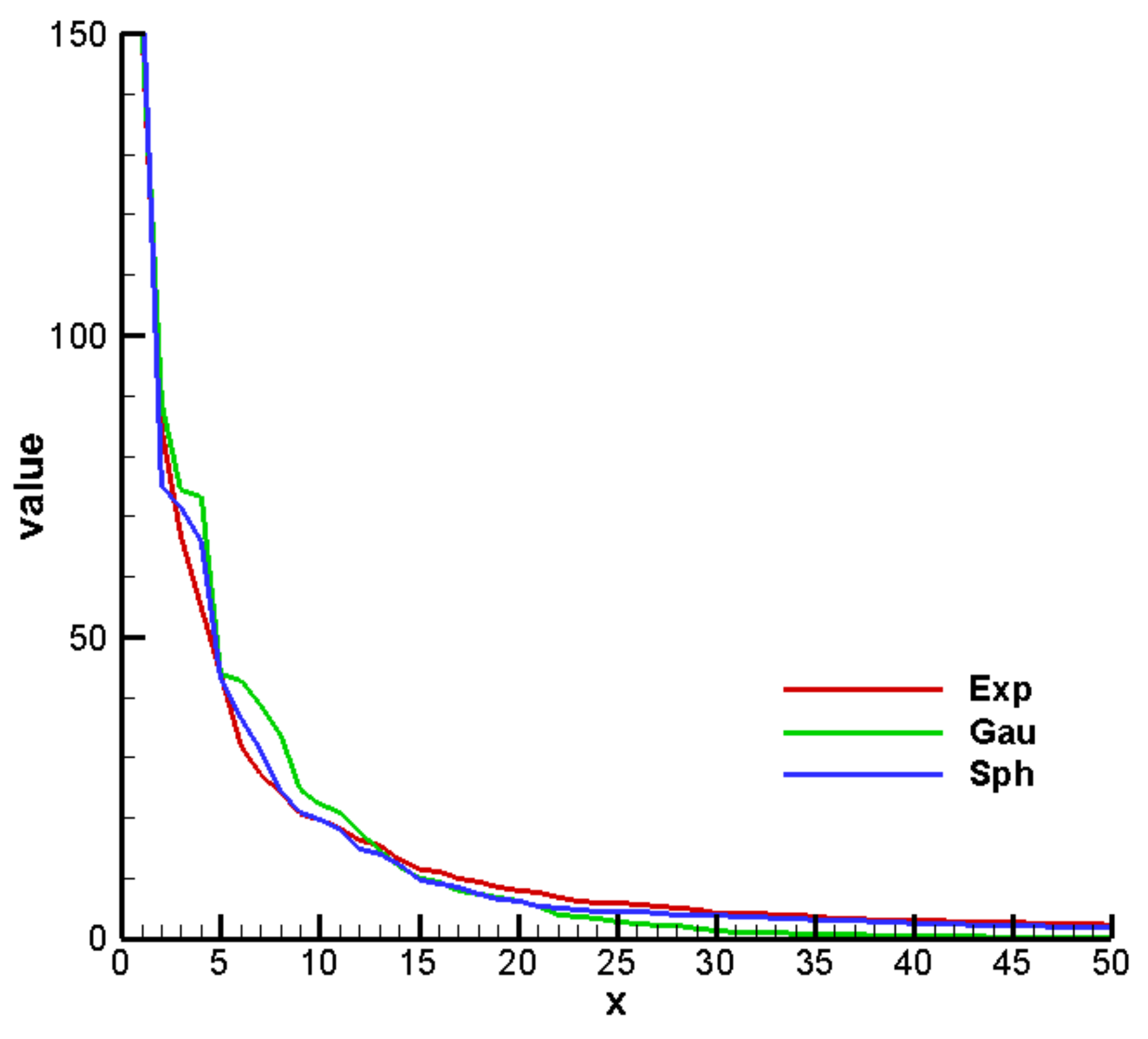
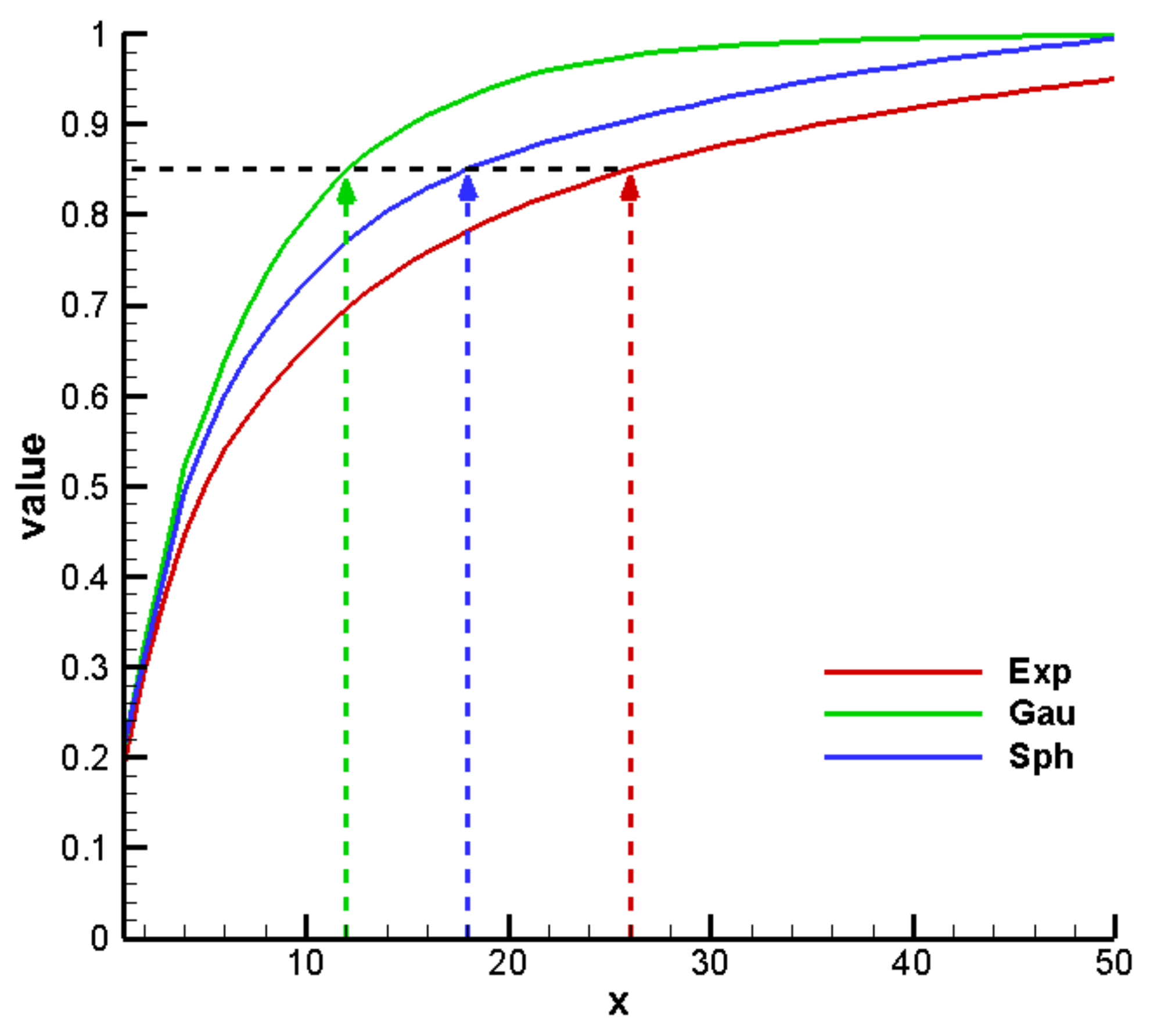
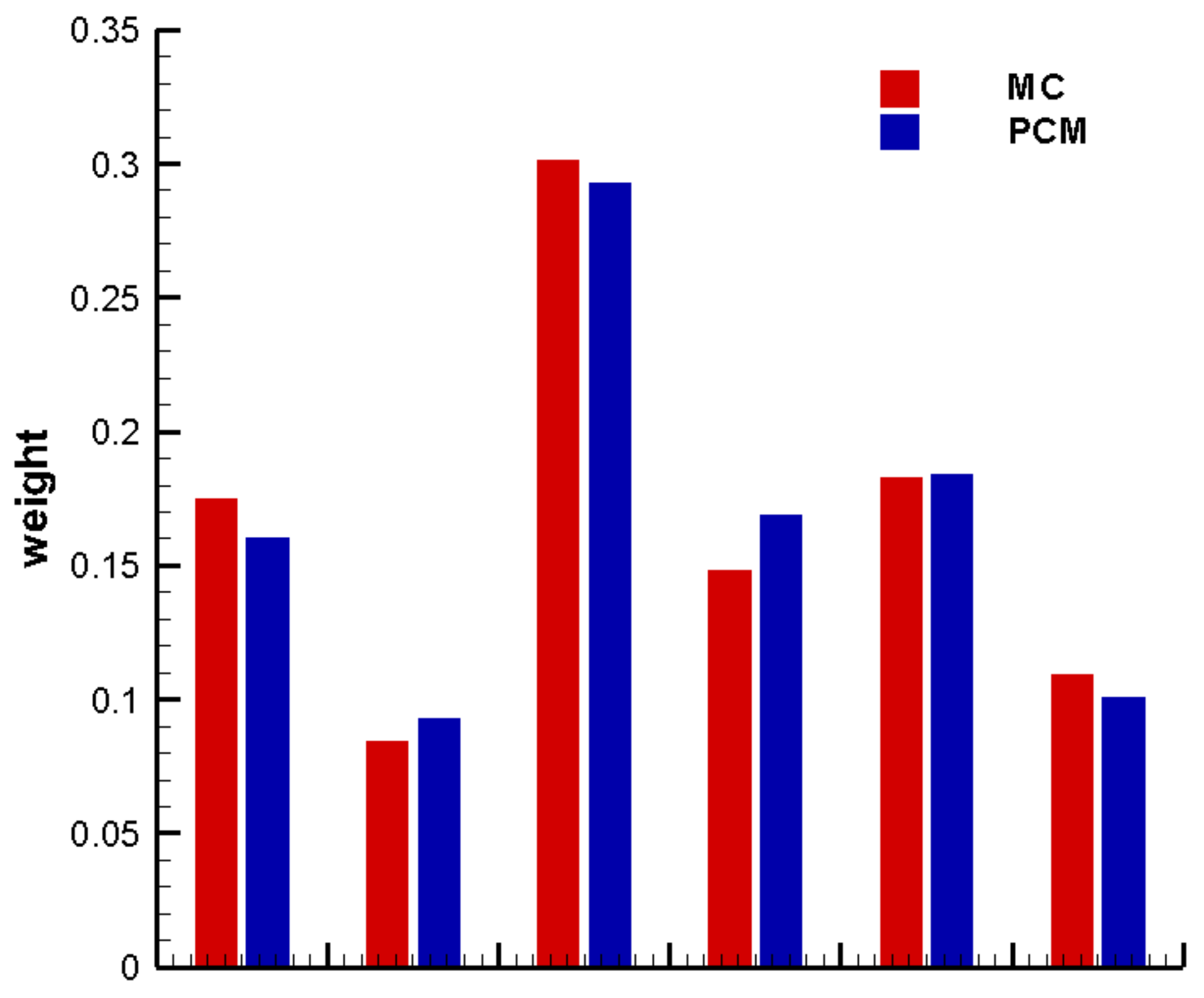
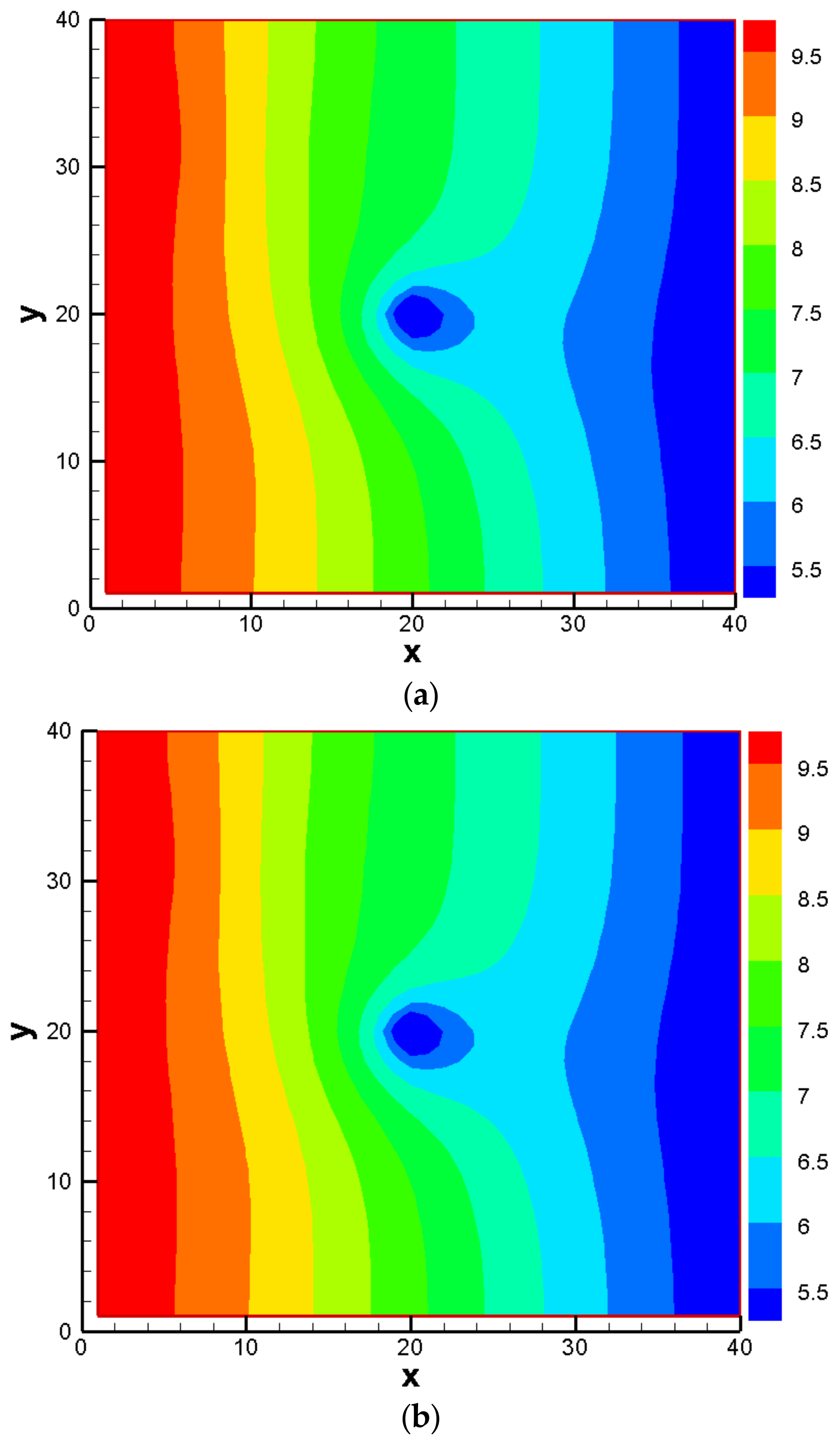
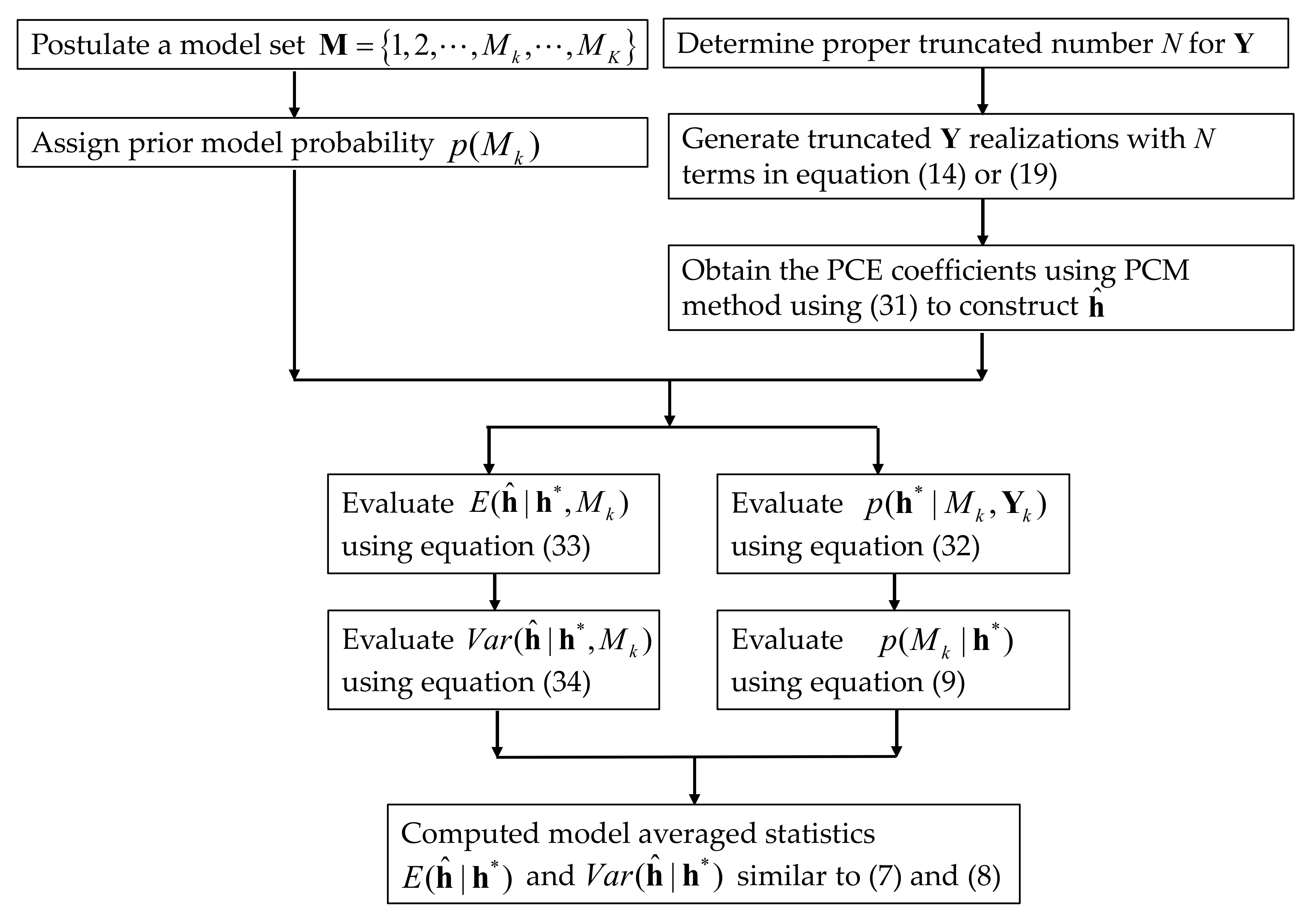
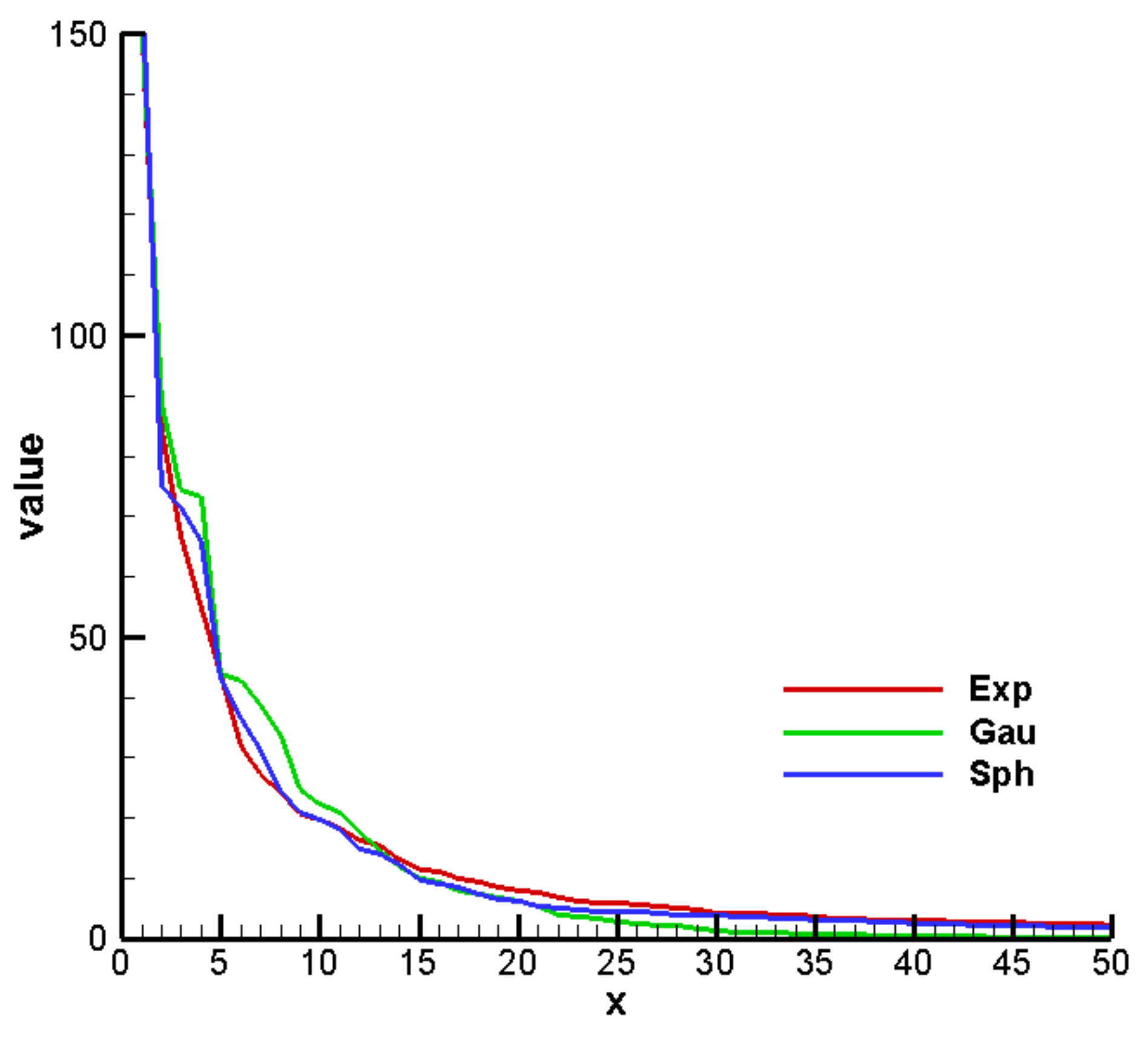
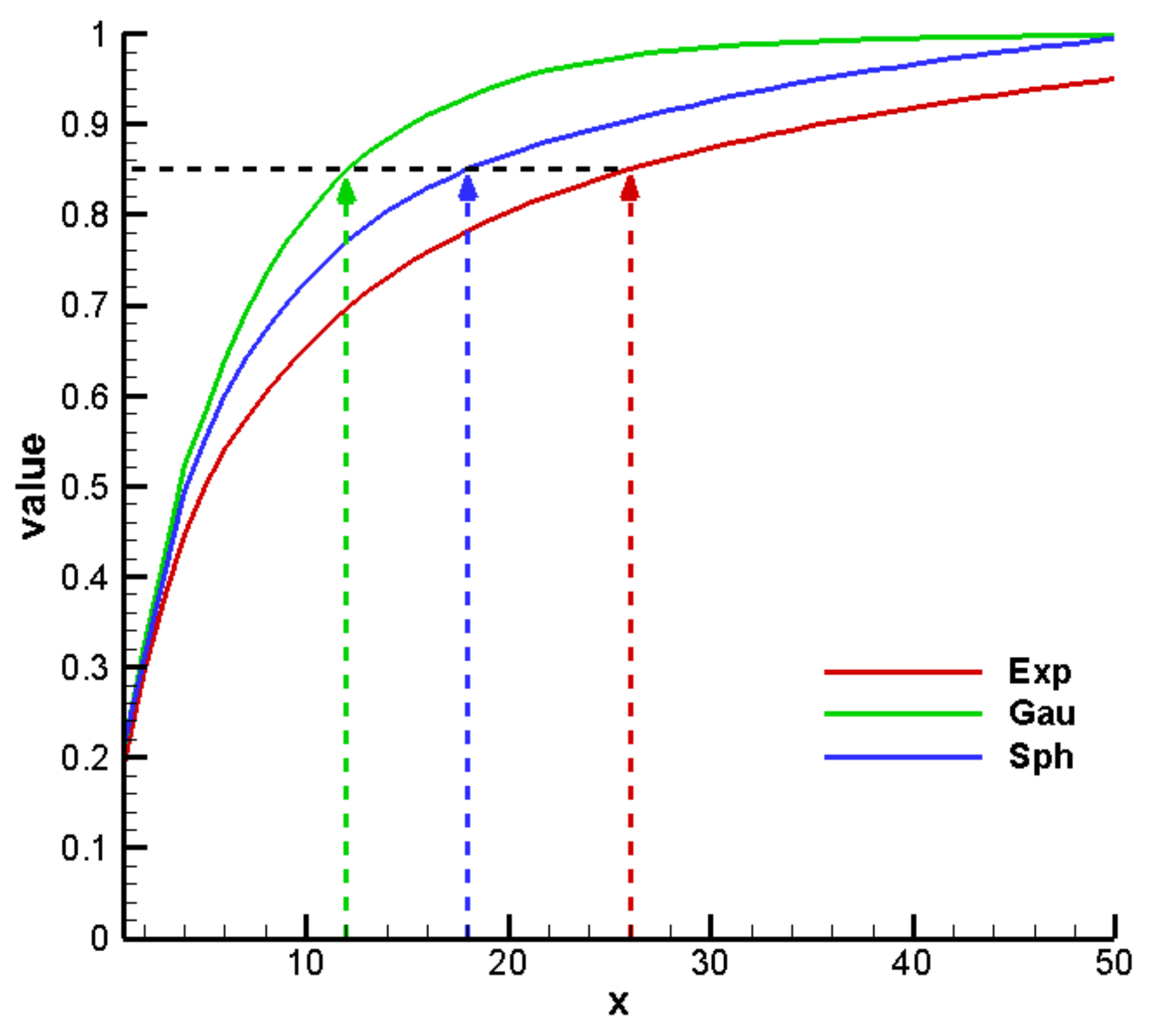
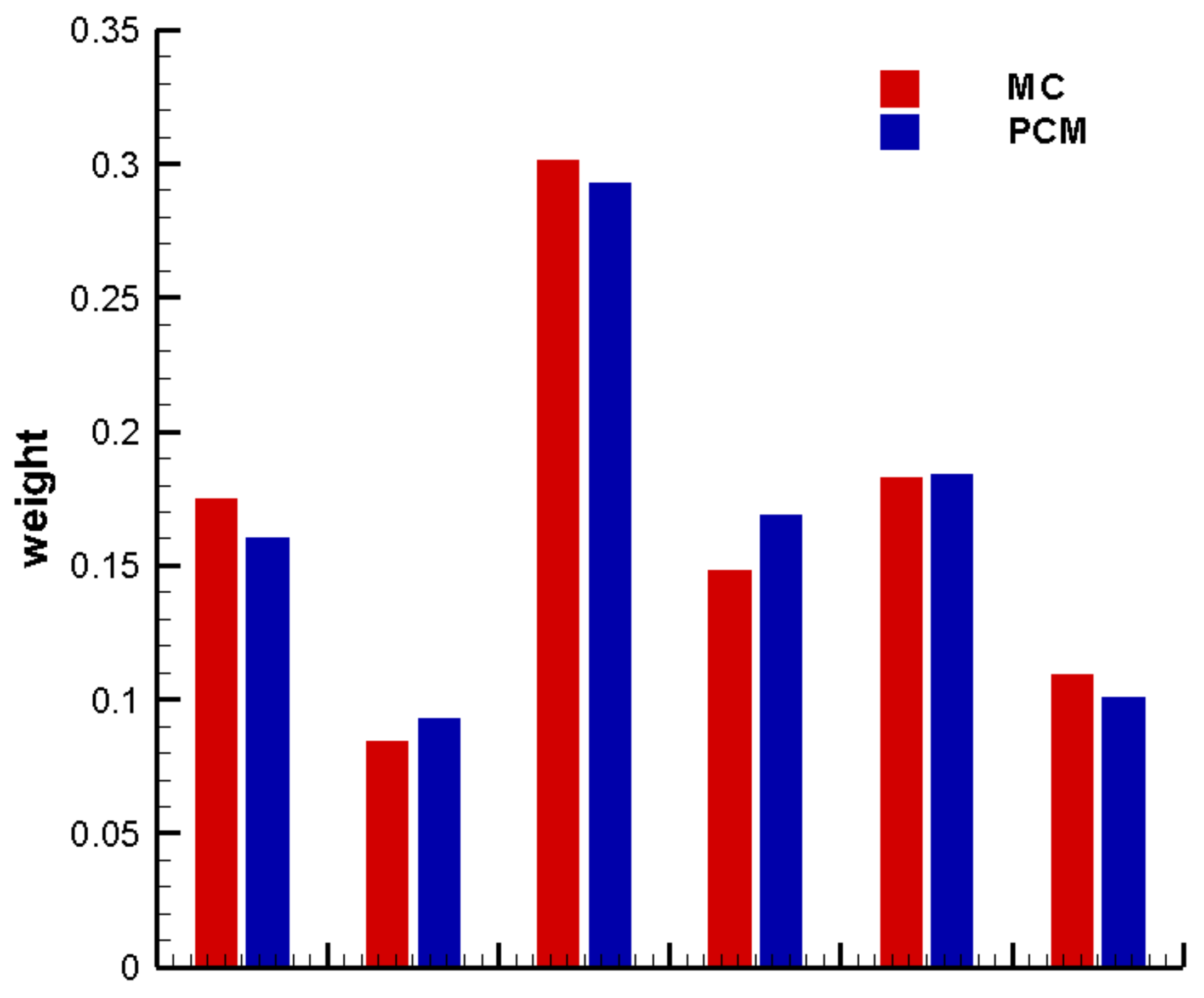
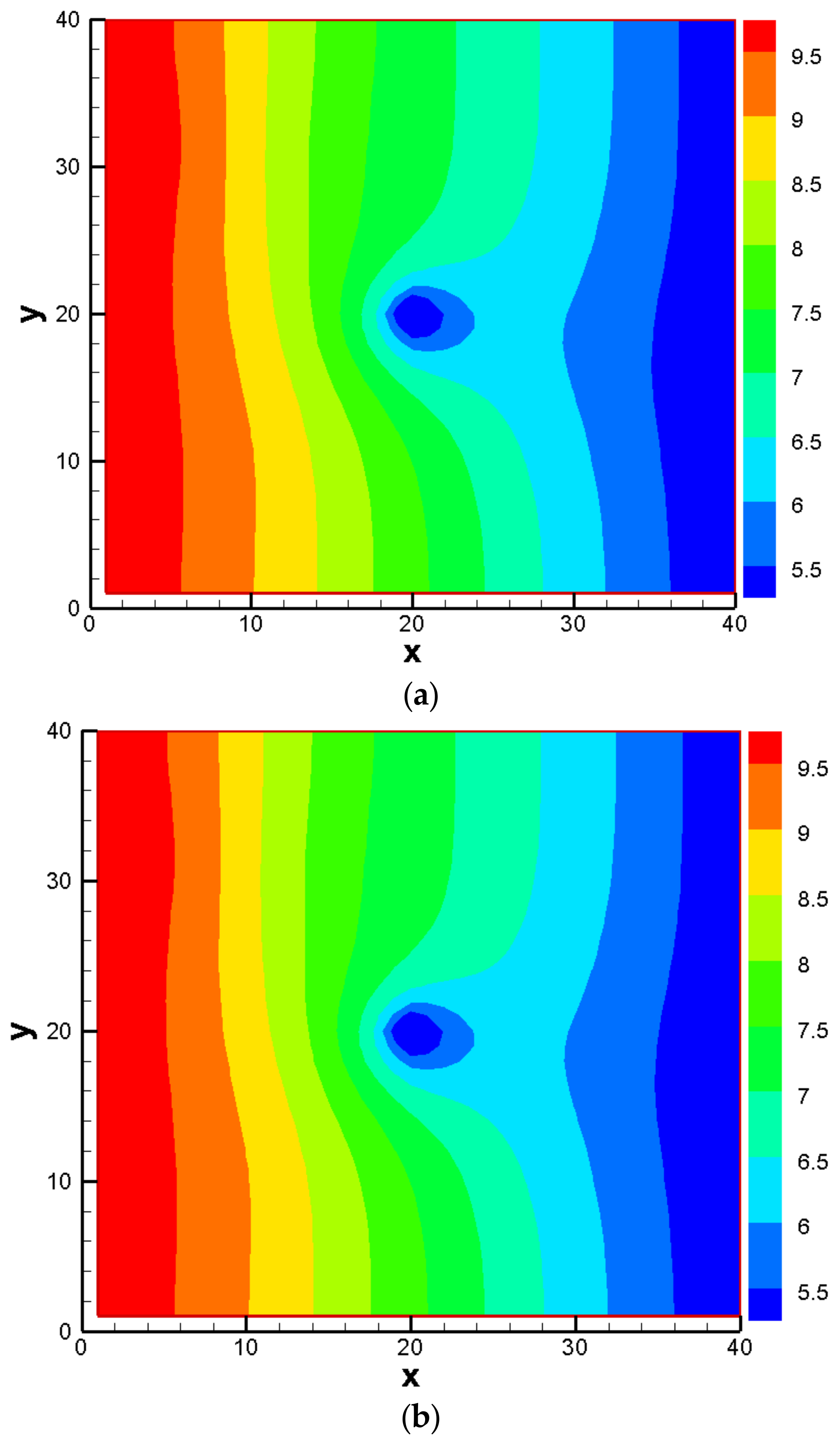
3. Results and Discussion
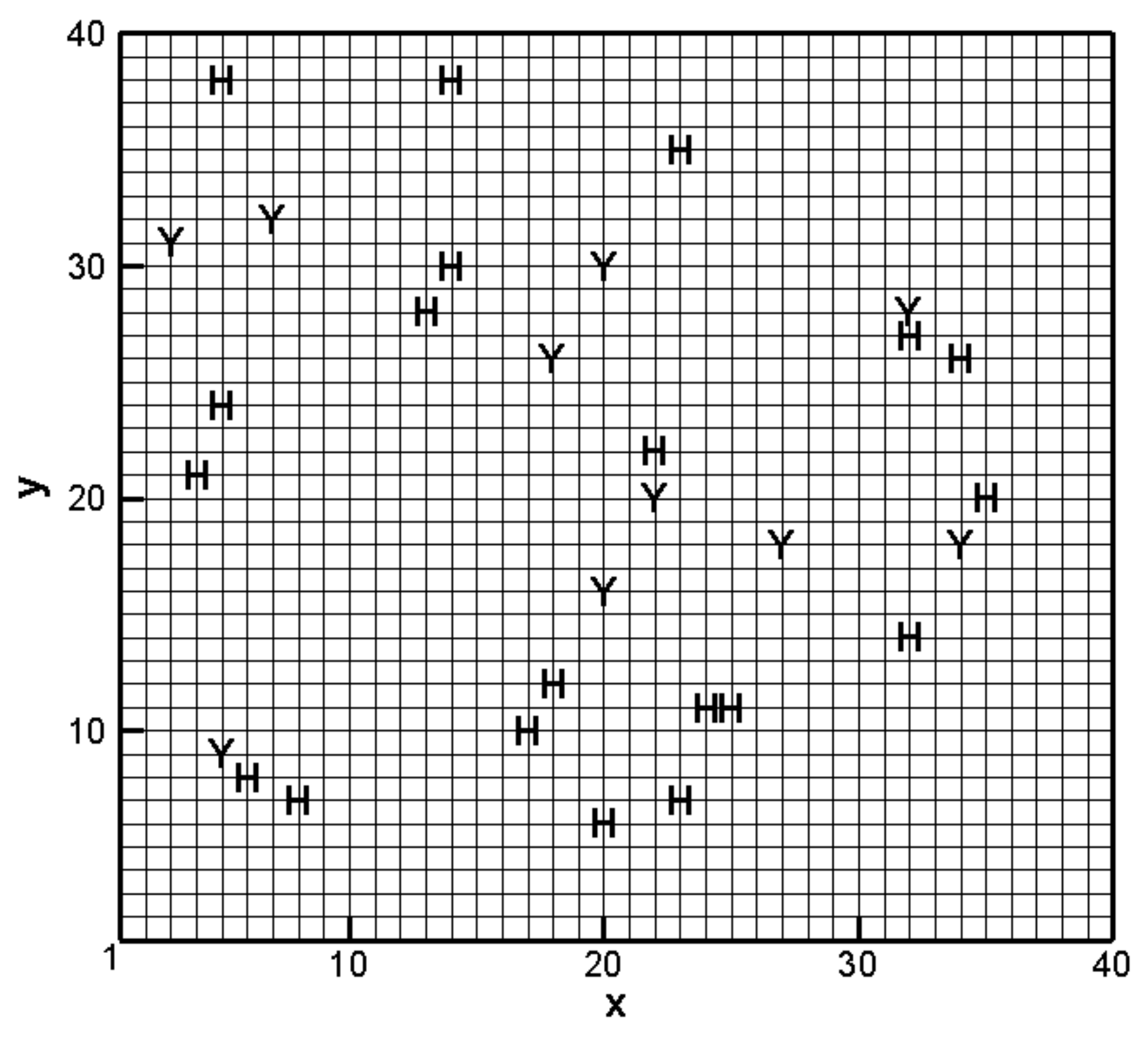
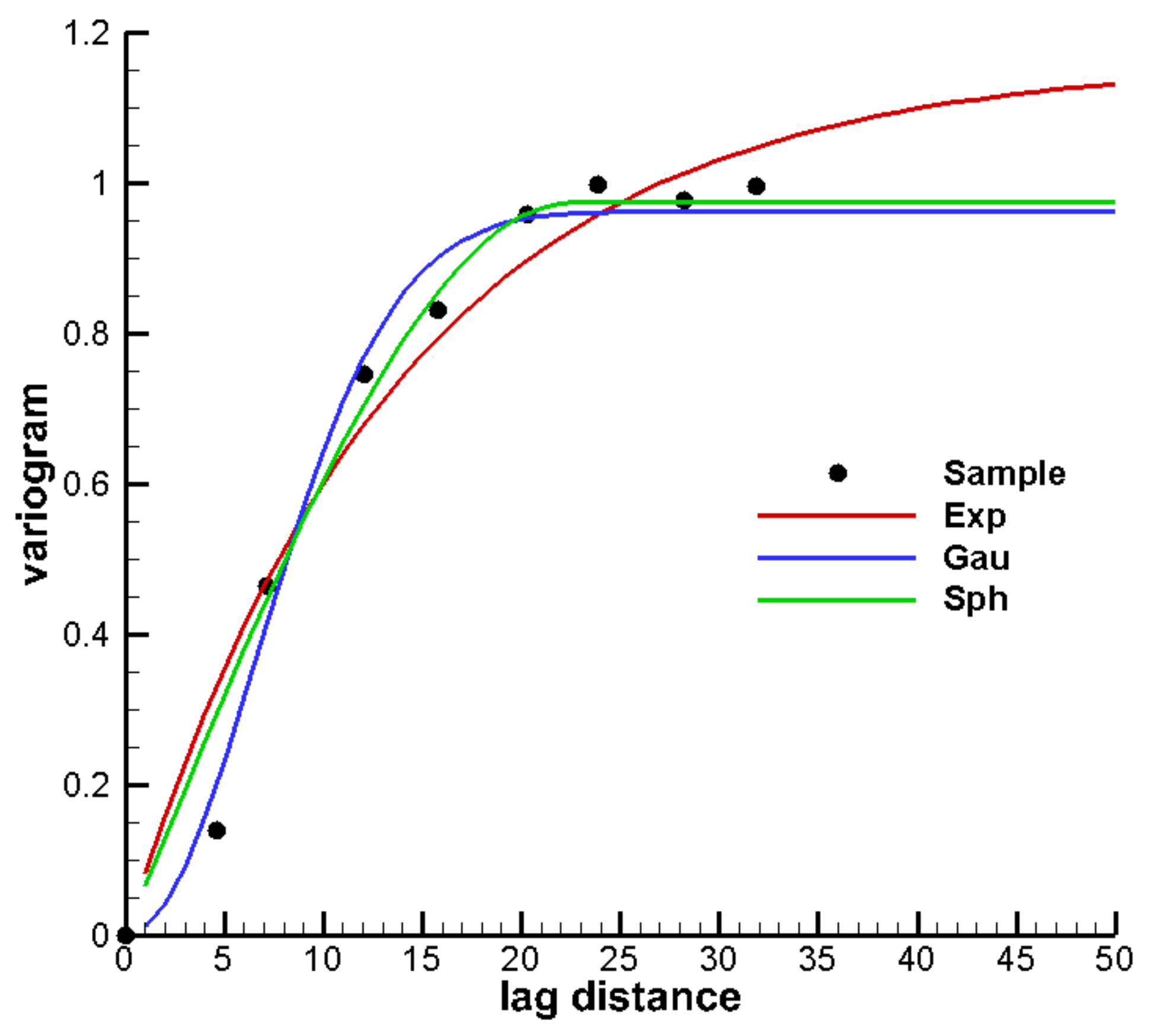
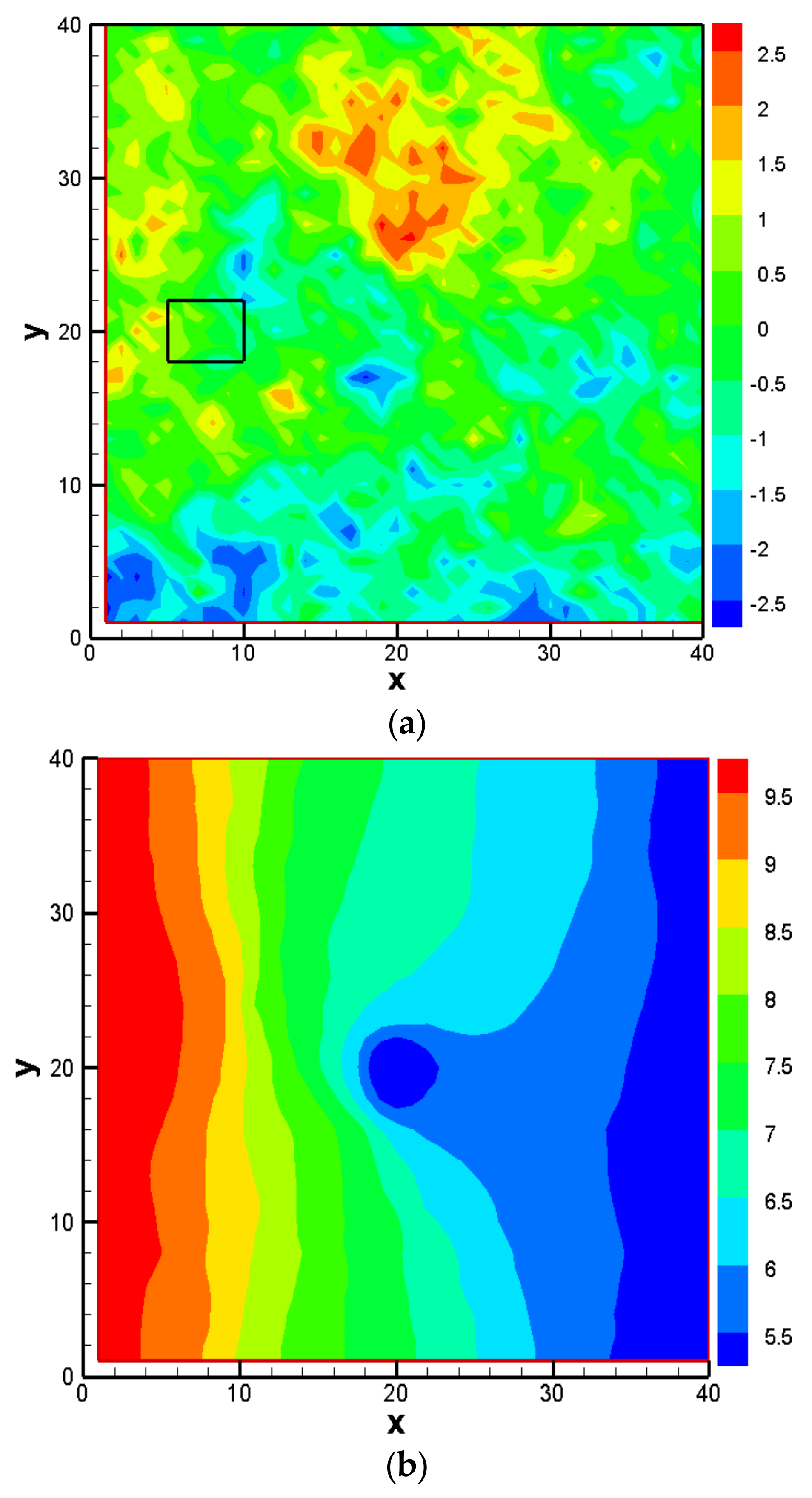
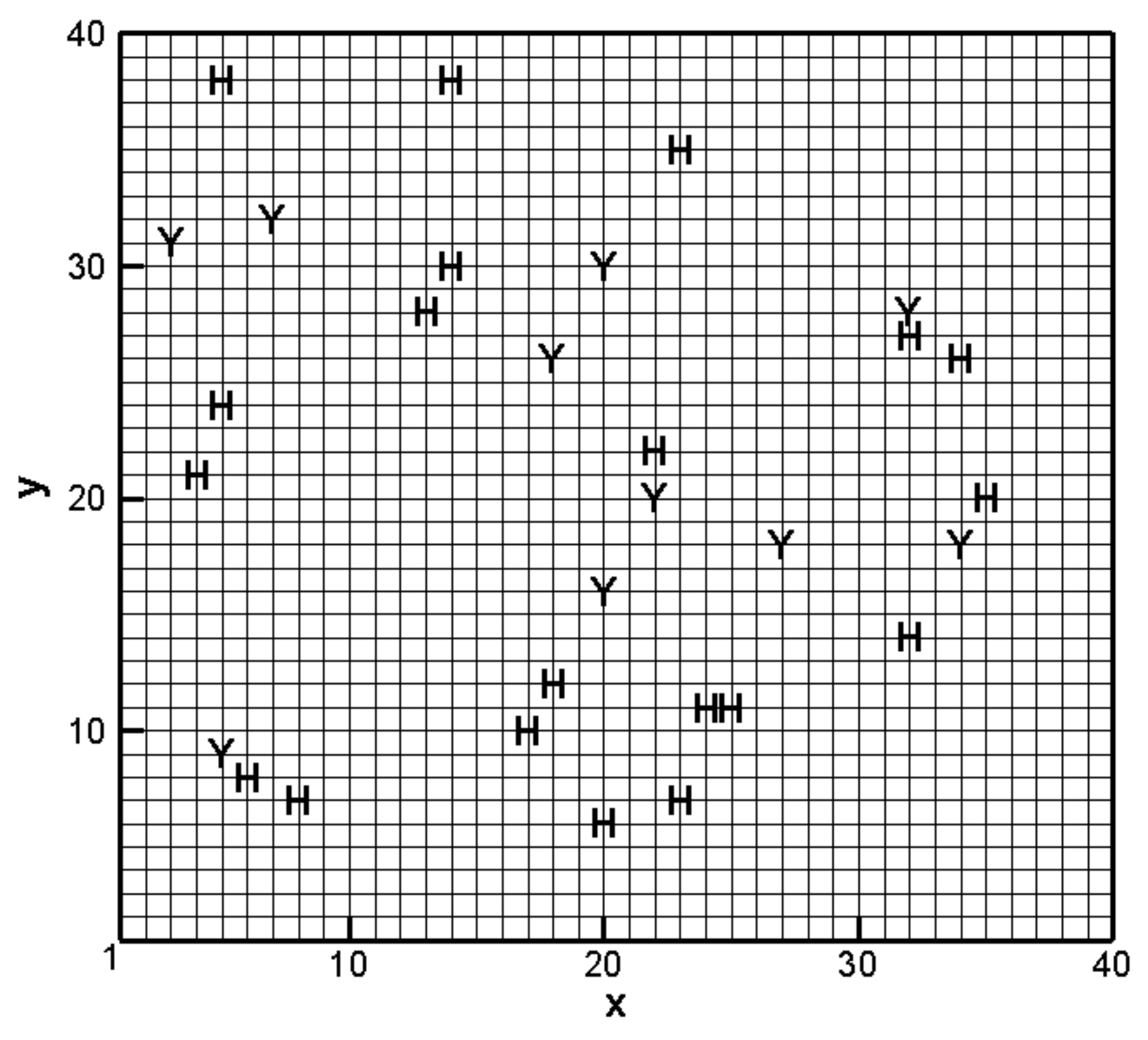
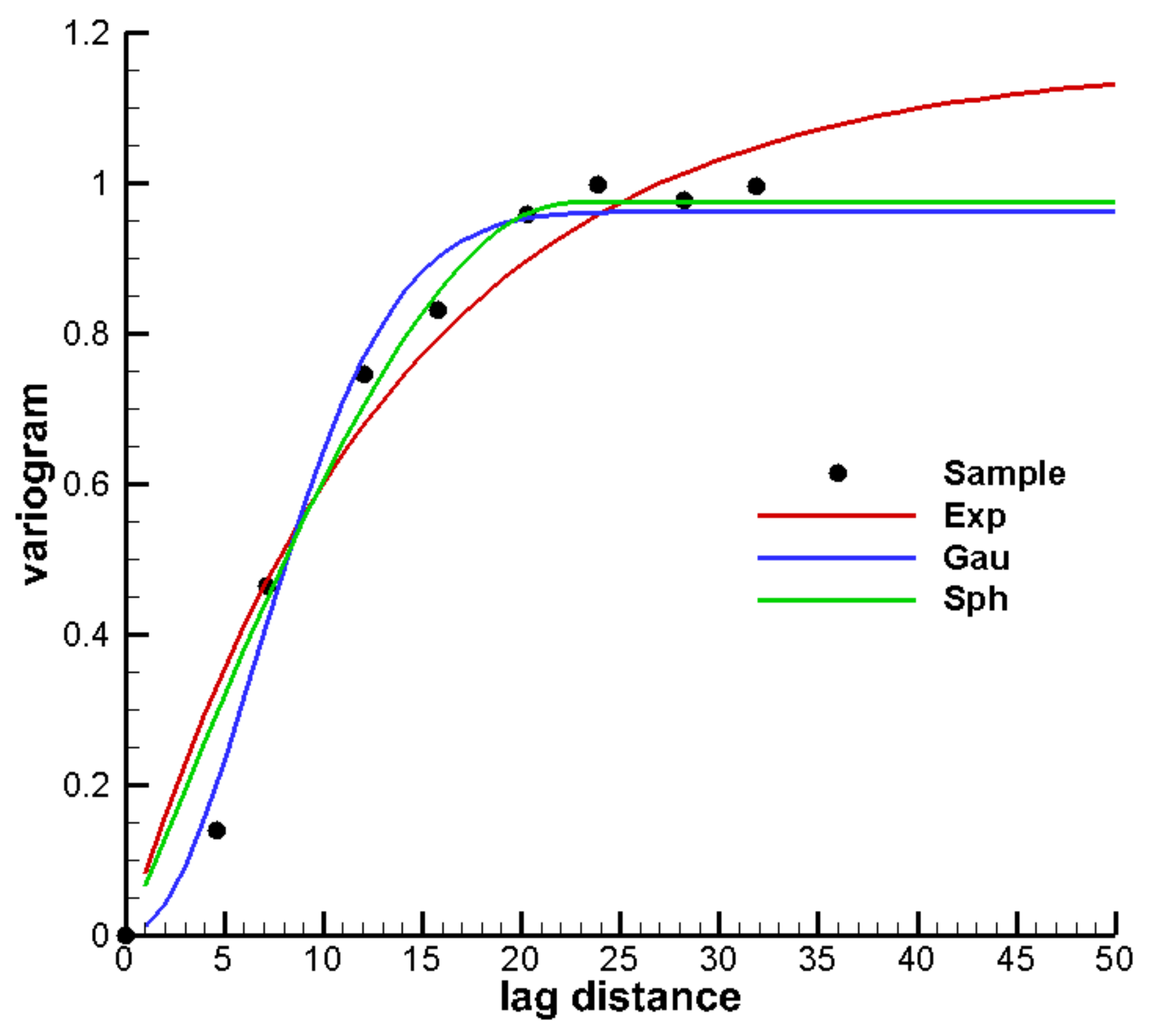
3.1. Establishment of the Reference Model and Alternative Model Set
3.2. Construction of PCM-Based Response Surface Model in BMA Multi-Model Analysis
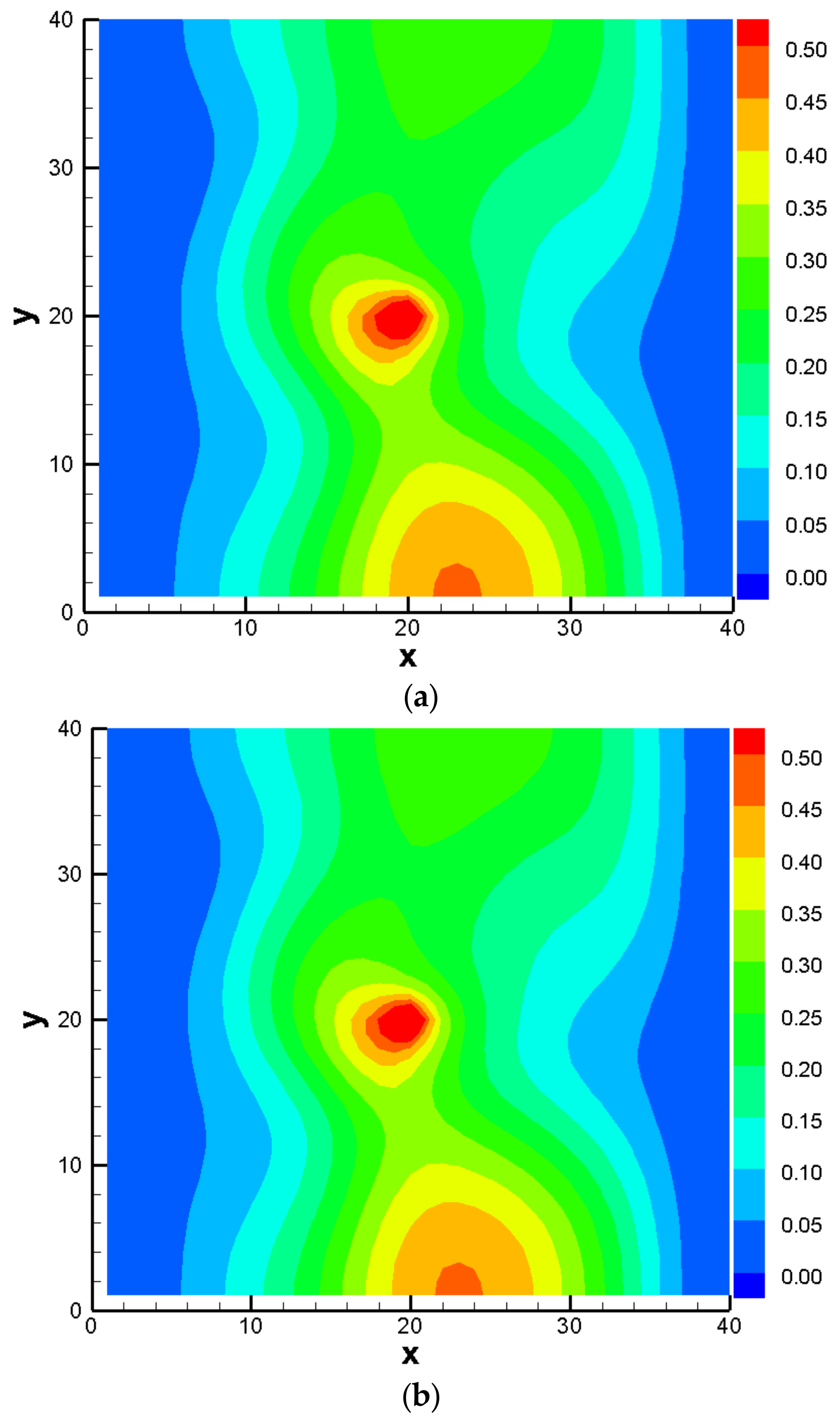
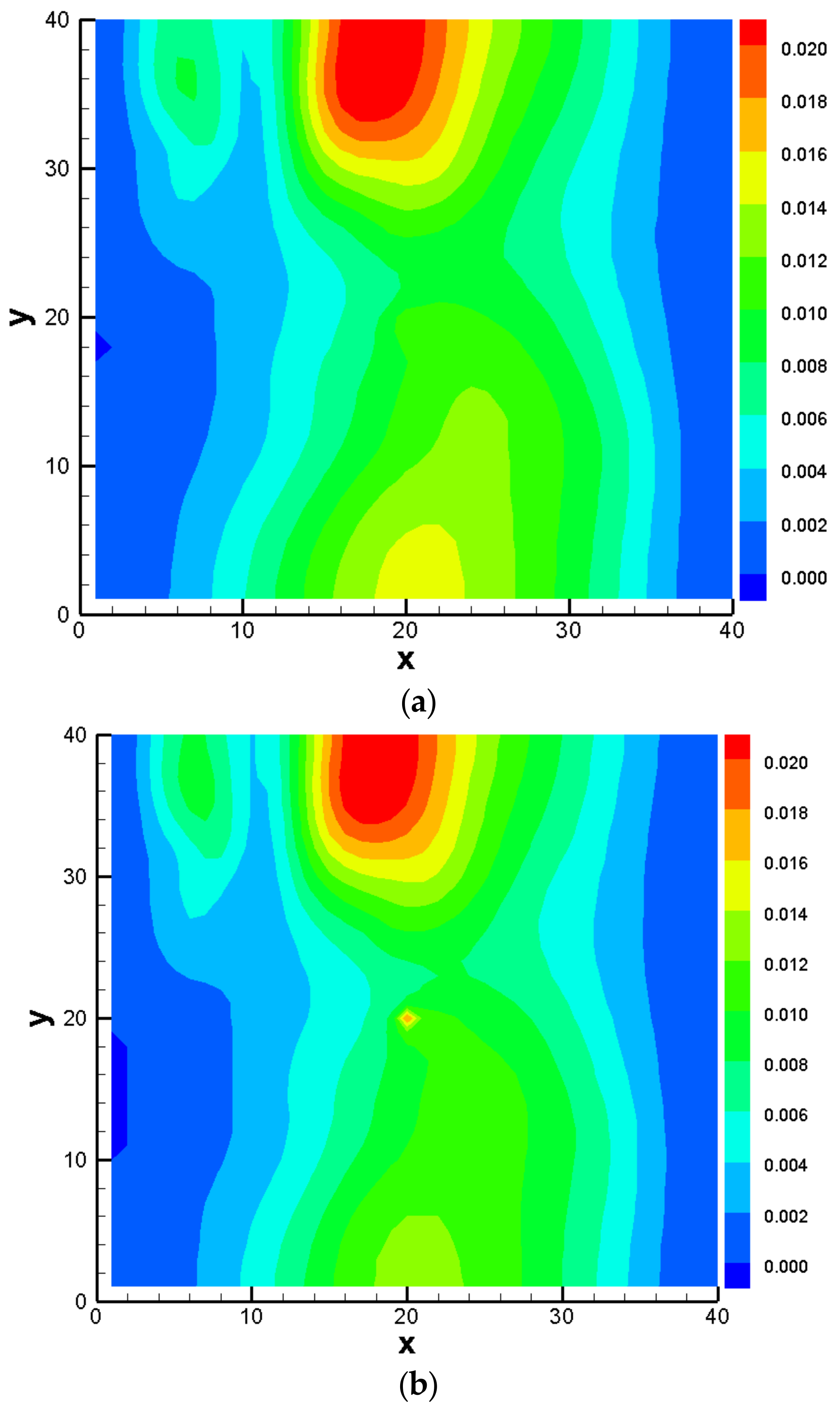
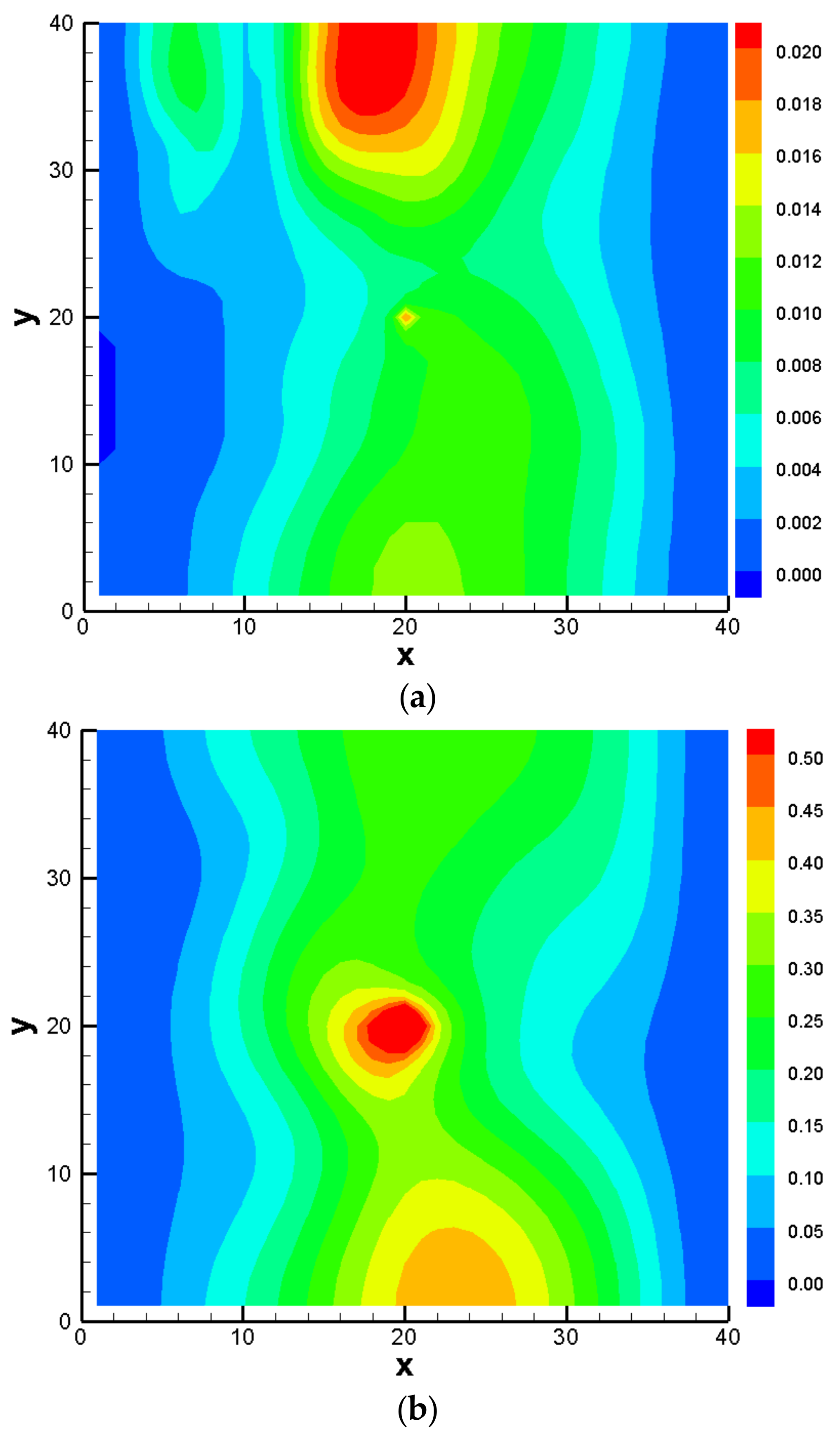
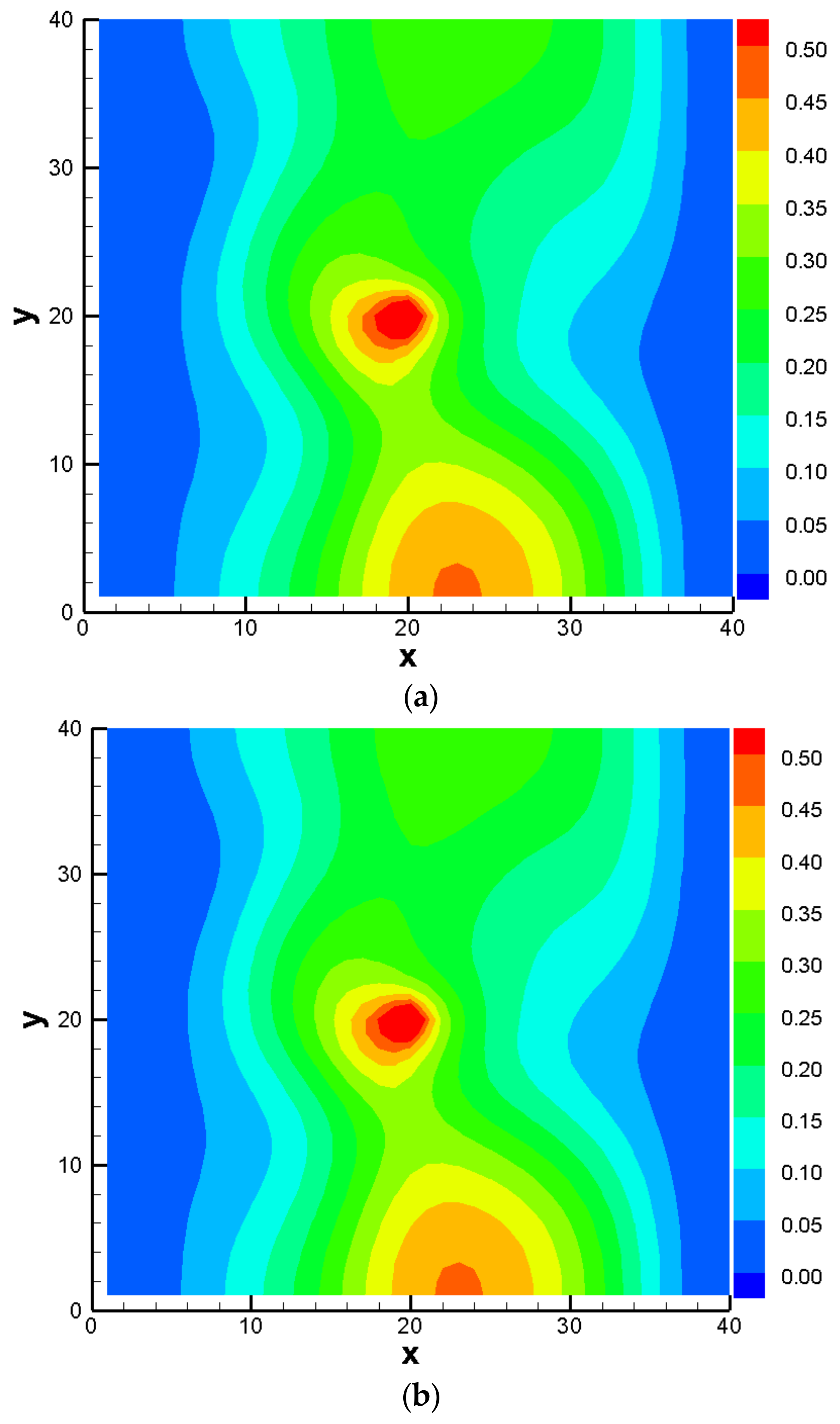
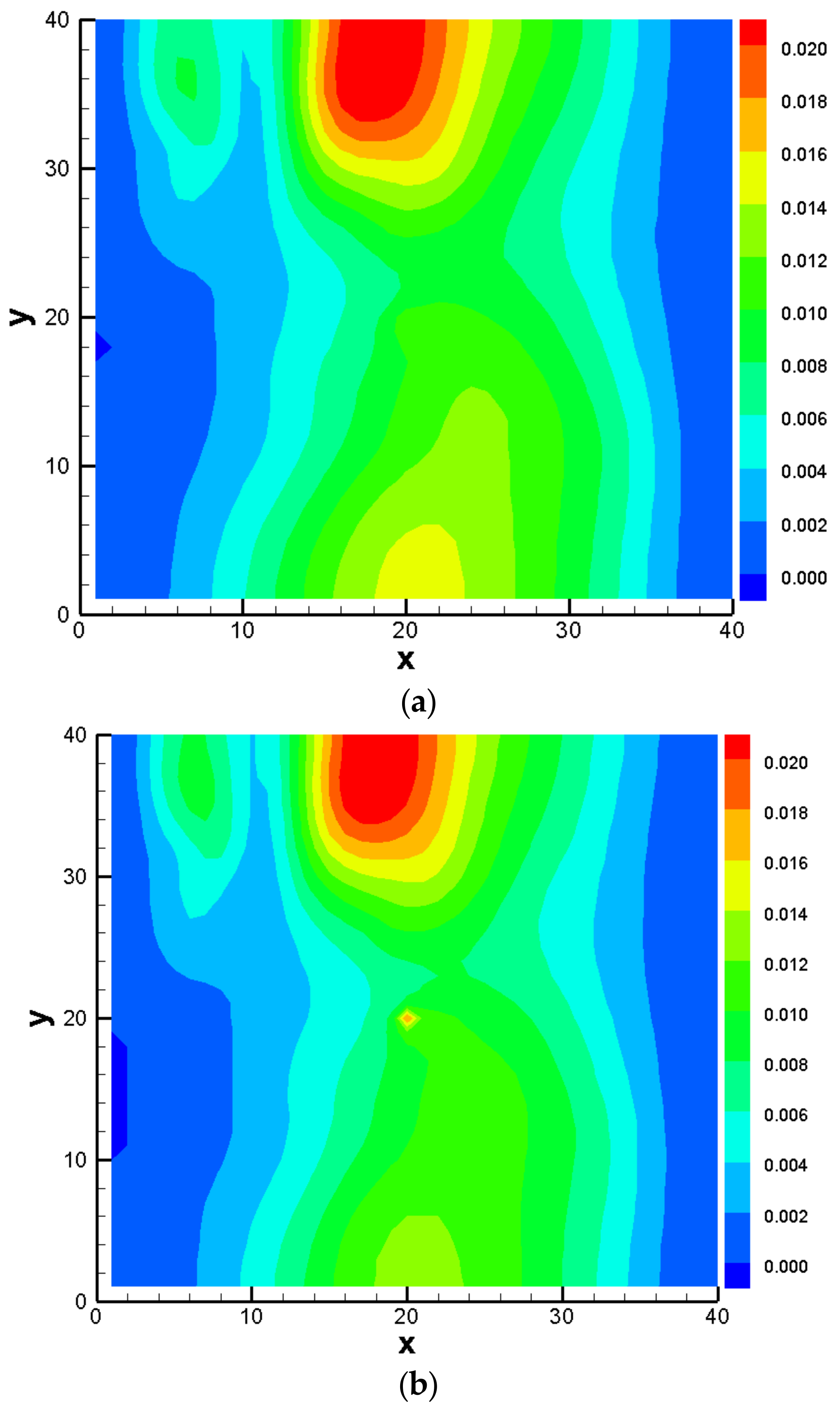
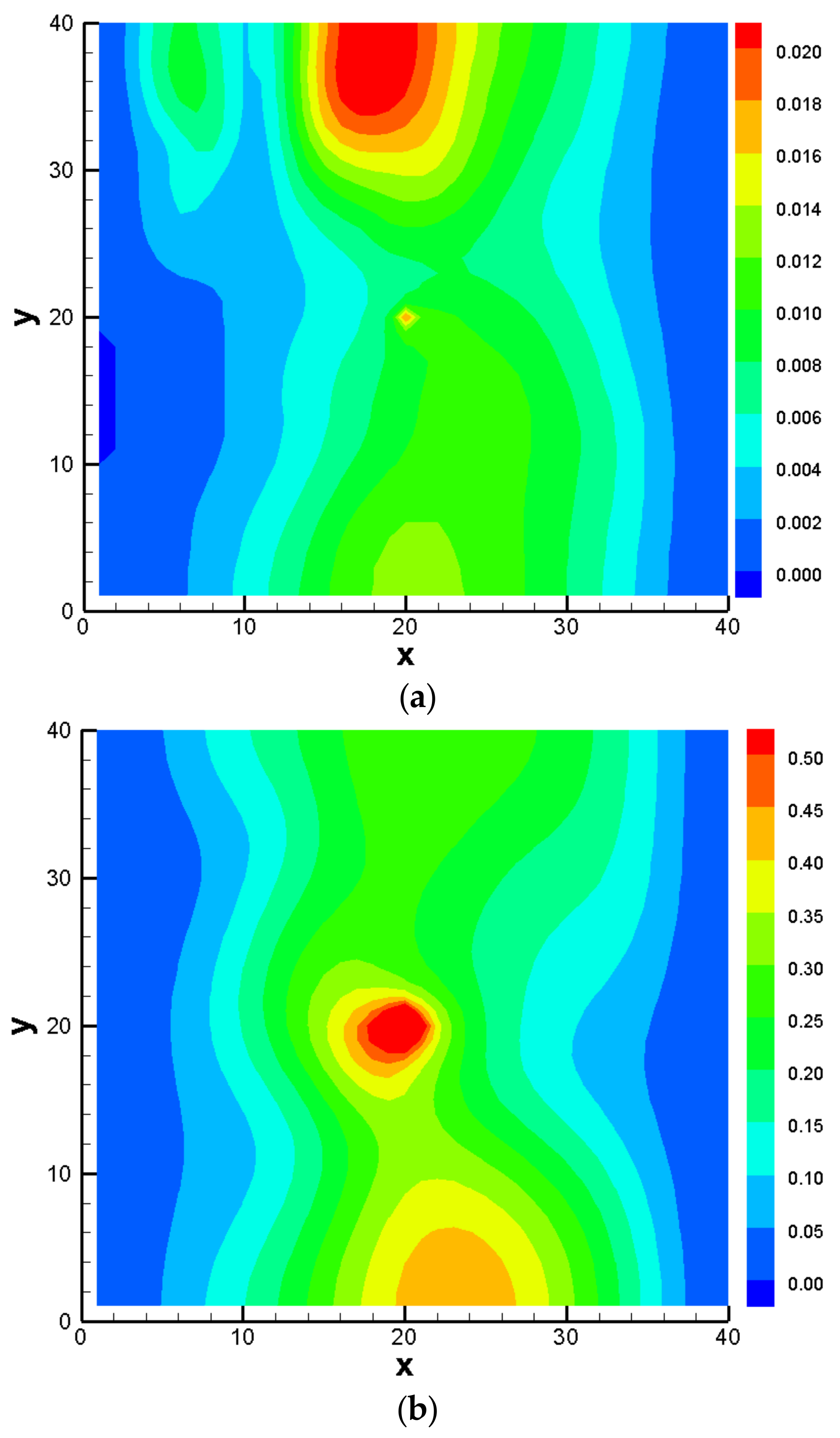
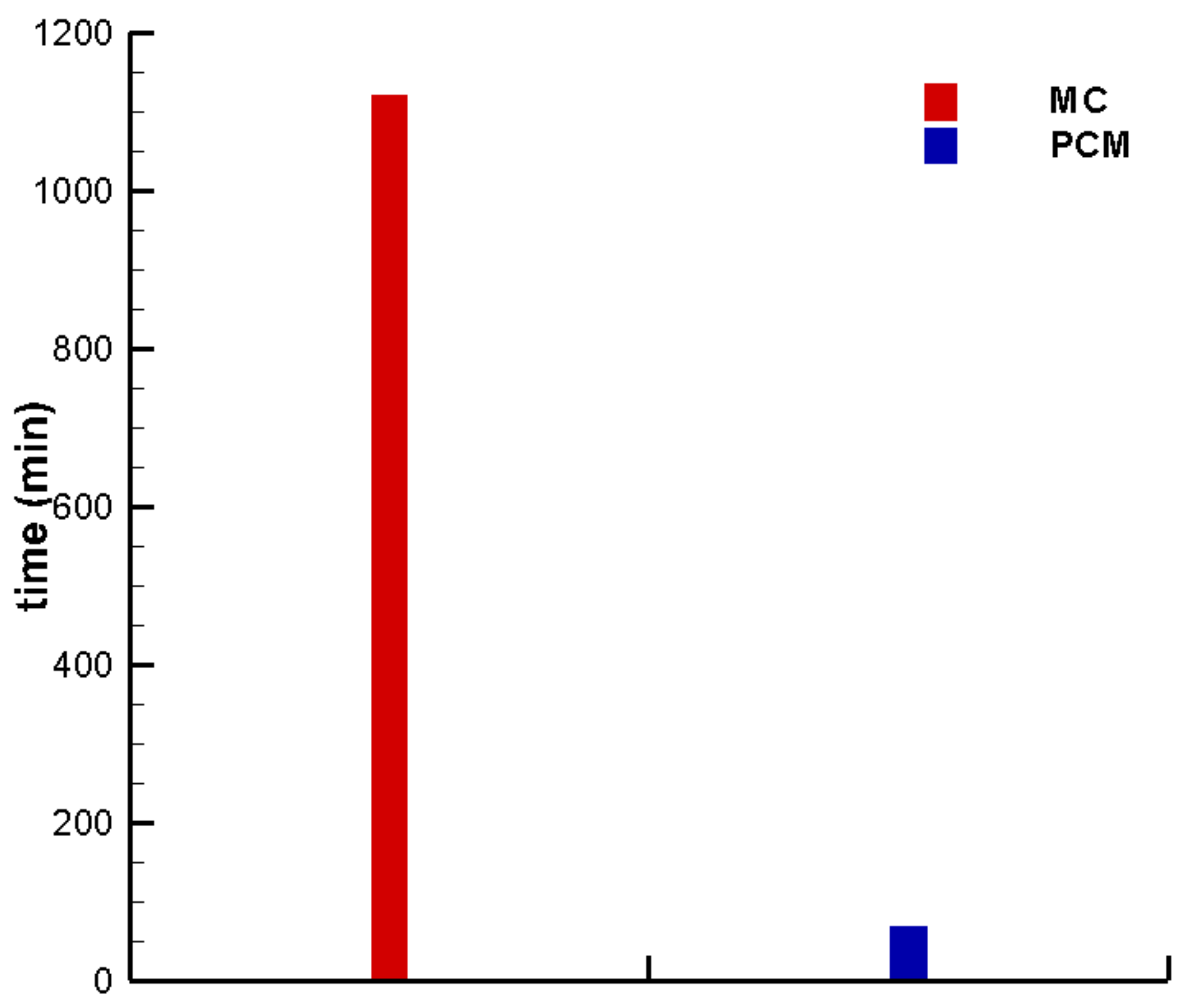
3.3. Comparison Results
4. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Gelhar, L.W. Stochastic subsurface hydrology from theory to applications. Water Resour. Res. 1986, 22, 135S–145S. [Google Scholar] [CrossRef]
- Zhang, D. Stochastic Methods for Flow in Porous Media: Coping with Uncertainties; Academic Press: Cambridge, MA, USA, 2001. [Google Scholar]
- Dagan, G.; Neuman, S.P. Subsurface Flow and Transport: A Stochastic Approach; Cambridge University Press: Cambridge, UK, 2005. [Google Scholar]
- Refsgaard, J.C.; Christensen, S.; Sonnenborg, T.O.; Seifert, D.; Højberg, A.L.; Troldborg, L. Review of strategies for handling geological uncertainty in groundwater flow and transport modeling. Adv. Water Res. 2012, 36, 36–50. [Google Scholar] [CrossRef]
- Gong, W.; Gupta, H.V.; Yang, D.; Sricharan, K., III; Hero, A.O. Estimating epistemic and aleatory uncertainties during hydrologic modeling: An information theoretic approach. Water Resour. Res. 2013, 49, 2253–2273. [Google Scholar] [CrossRef]
- Ross, J.L.; Ozbek, M.M.; Pinder, G.F. Aleatoric and epistemic uncertainty in groundwater flow and transport simulation. Water Resour. Res. 2009, 45, 641–648. [Google Scholar] [CrossRef]
- Sun, S.; Fu, G.; Djordjević, S.; Khu, S.T. Separating aleatory and epistemic uncertainties: Probabilistic sewer flooding evaluation using probability box. J. Hydrol. 2012, 420, 360–372. [Google Scholar] [CrossRef]
- Srinivasan, G.; Tartakovsky, D.M.; Robinson, B.A.; Aceves, A.B. Quantification of uncertainty in geochemical reactions. Water Resour. Res. 2007, 43, 497–507. [Google Scholar] [CrossRef]
- Sun, N.-Z. Inverse Problems in Groundwater Modeling; Springer: New York, NY, USA, 2013; Volume 6. [Google Scholar]
- Carrera, J.; Neuman, S.P. Estimation of aquifer parameters under transient and steady state conditions: 1. Maximum likelihood method incorporating prior information. Water Resour. Res. 1986, 22, 199–210. [Google Scholar] [CrossRef]
- Marsily, G.D.; Delay, F.; Gonçalvès, J.; Renard, P.; Teles, V.; Violette, S. Dealing with spatial heterogeneity. Hydrogeol. J. 2005, 13, 161–183. [Google Scholar] [CrossRef]
- Alcolea, A.; Carrera, J.; Medina, A. Pilot points method incorporating prior information for solving the groundwater flow inverse problem. Adv. Water Res. 2006, 29, 1678–1689. [Google Scholar] [CrossRef]
- Medina, A.; Carrera, J. Geostatistical inversion of coupled problems: Dealing with computational burden and different types of data. J. Hydrol. 2003, 281, 251–264. [Google Scholar] [CrossRef]
- Oliver, D.S.; Cunha, L.B.; Reynolds, A.C. Markov chain monte carlo methods for conditioning a permeability field to pressure data. Math. Geol. 1997, 29, 61–91. [Google Scholar] [CrossRef]
- Vrugt, J.A. Dream(d): An adaptive markov chain monte carlo simulation algorithm to solve discrete, noncontinuous, posterior parameter estimation problems. Hydrol. Earth Syst. Sci. 2011, 8, 3701–3713. [Google Scholar] [CrossRef]
- Chen, Y.; Zhang, D. Data assimilation for transient flow in geologic formations via ensemble kalman filter. Adv. Water Res. 2006, 29, 1107–1122. [Google Scholar] [CrossRef]
- Erdal, D.; Cirpka, O.A. Joint inference of groundwater-recharge and hydraulic-conductivity fields from head data using the ensemble kalman filter. Hydrol. Earth Syst. Sci. 2015, 12, 5565–5599. [Google Scholar] [CrossRef]
- Chang, S.-Y.; Chowhan, T.; Latif, S. State and parameter estimation with an sir particle filter in a three-dimensional groundwater pollutant transport model. J. Environ. Eng. 2012, 138, 1114–1121. [Google Scholar] [CrossRef]
- Zhou, H.; Gómez-Hernández, J.J.; Li, L. Inverse methods in hydrogeology: Evolution and recent trends. Adv. Water Res. 2014, 63, 22–37. [Google Scholar] [CrossRef]
- Beven, K.; Binley, A. The future of distributed models—Model calibration and uncertainty prediction. Hydrol. Process. 2010, 6, 279–298. [Google Scholar] [CrossRef]
- Neuman, S.P. Maximum likelihood bayesian averaging of uncertain model predictions. Stoch. Environ. Res. Risk Assess. 2003, 17, 291–305. [Google Scholar] [CrossRef]
- Beven, K.; Freer, J. Equifinality, data assimilation, and uncertainty estimation in mechanistic modelling of complex environmental systems using the glue methodology. J. Hydrol. 2001, 249, 11–29. [Google Scholar] [CrossRef]
- Binley, A.; Beven, K. Vadose zone flow model uncertainty as conditioned on geophysical data. Ground Water 2003, 41, 119–127. [Google Scholar] [CrossRef] [PubMed]
- Morse, B.S.; Pohll, G.; Huntington, J.; Castillo, R.R. Stochastic capture zone analysis of an arsenic-contaminated well using the generalized likelihood uncertainty estimator (glue) methodology. Water Resour. Res. 2003, 39, 377–380. [Google Scholar] [CrossRef]
- Montanari, A. Large sample behaviors of the generalized likelihood uncertainty estimation (glue) in assessing the uncertainty of rainfall-runoff simulations. Water Resour. Res. 2005, 41, 224–236. [Google Scholar] [CrossRef]
- Beven, K.J.; Smith, P.J.; Freer, J.E. So just why would a modeller choose to be incoherent? J. Hydrol. 2008, 354, 15–32. [Google Scholar] [CrossRef]
- Mcconnell, P. Hydrological forecasting uncertainty assessment: Incoherence of the glue methodology. J. Hydrol. 2006, 330, 368–381. [Google Scholar]
- Draper, D. Assessment and propagation of model uncertainty. J. R. Stat. Soc. Ser. B (Methodol.) 1995, 57, 45–97. [Google Scholar]
- Hoeting, J.A.; Madigan, D.; Raftery, A.E.; Volinsky, C.T. Bayesian model averaging: A tutorial. Stat. Sci. 1999, 14, 382–401. [Google Scholar]
- Poeter, E.; Anderson, D. Multimodel ranking and inference in ground water modeling. Ground Water 2005, 43, 597–605. [Google Scholar] [CrossRef] [PubMed]
- Nowak, W.; Barros, F.P.J.D.; Rubin, Y. Bayesian geostatistical design: Task-driven optimal site investigation when the geostatistical model is uncertain. Water Resour. Res. 2010, 46, 374–381. [Google Scholar] [CrossRef]
- Xue, L.; Zhang, D. A multimodel data assimilation framework via the ensemble kalman filter. Water Resour. Res. 2014, 50, 4197–4219. [Google Scholar] [CrossRef]
- Xue, L. Application of the multimodel ensemble kalman filter method in groundwater system. Water 2015, 7, 528–545. [Google Scholar] [CrossRef]
- Xue, L.; Zhang, D.; Guadagnini, A.; Neuman, S.P. Multimodel bayesian analysis of groundwater data worth. Water Resour. Res. 2015, 50, 8481–8496. [Google Scholar] [CrossRef]
- Rojas, R.; Feyen, L.; Dassargues, A. Conceptual model uncertainty in groundwater modeling: Combining generalized likelihood uncertainty estimation and bayesian model averaging. Water Resour. Res. 2008, 44, W12418. [Google Scholar] [CrossRef]
- Razavi, S.; Tolson, B.A.; Burn, D.H. Review of surrogate modeling in water resources. Water Resour. Res. 2012, 48, 7401. [Google Scholar] [CrossRef]
- Laloy, E.; Rogiers, B.; Vrugt, J.A.; Mallants, D.; Jacques, D. Efficient posterior exploration of a high-dimensional groundwater model from two-stage markov chain monte carlo simulation and polynomial chaos expansion. Water Resour. Res. 2013, 49, 2664–2682. [Google Scholar] [CrossRef]
- Li, W.; Oyerinde, A.; Stern, D.; Wu, X.H.; Zhang, D. Probabilistic collocation based kalman filter for assisted history matching—A case study. In Proceedings of the SPE Reservoir Simulation Symposium, The Woodlands, TX, USA, 21–23 February 2011. [Google Scholar]
- Dai, C.; Xue, L.; Zhang, D.; Guadagnini, A. Data-worth analysis through probabilistic collocation-based ensemble kalman filter. J. Hydrol. 2016, 540, 488–503. [Google Scholar] [CrossRef]
- Oladyshkin, S.; Class, H.; Nowak, W. Bayesian updating via bootstrap filtering combined with data-driven polynomial chaos expansions: Methodology and application to history matching for carbon dioxide storage in geological formations. Comput. Geosci. 2013, 17, 671–687. [Google Scholar] [CrossRef]
- Deutsch, C.; Journel, A. Gslib: Geostatistical Software Library and User’s Guide, 2nd ed.; Oxford University Press: Oxford, UK, 1998. [Google Scholar]
- Sarma, P.; Durlofsky, L.J.; Aziz, K.; Chen, W.H. Efficient real-time reservoir management using adjoint-based optimal control and model updating. Comput. Geosci. 2006, 10, 3–36. [Google Scholar] [CrossRef]
- Ghanem, R.G.; Spanos, P.D. Stochastic Finite Elements: A Spectral Approach; Springer: Berlin, Gremany, 1991; p. 224. [Google Scholar]
- Tatang, M.A.; Pan, W.; Prinn, R.G.; Mcrae, G.J. An efficient method for parametric uncertainty analysis of numerical geophysical models. J. Geophys. Res. Atmos. 1997, 102, 21925–21932. [Google Scholar] [CrossRef]
- Li, H.; Zhang, D. Probabilistic collocation method for flow in porous media: Comparisons with other stochastic methods. Water Resour. Res. 2007, 43, 6627–6632. [Google Scholar] [CrossRef]
- Liao, Q.; Zhang, D. Probabilistic collocation method for strongly nonlinear problems: 1. Transform by location. Water Resour. Res. 2013, 49, 7911–7928. [Google Scholar] [CrossRef]
- Chang, H.; Zhang, D. A comparative study of stochastic collocation methods for flow in spatially correlated random fields. Commun. Comput. Phys. 2009, 6, 509–535. [Google Scholar]
- Xiu, D.; Karniadakis, G.E. Modeling uncertainty in steady state diffusion problems via generalized polynomial chaos. Comput. Methods Appl. Mech. Eng. 2002, 191, 4927–4948. [Google Scholar] [CrossRef]
- Di Federico, V.; Neuman, S.P. Scaling of random fields by means of truncated power variograms and associated spectra. Water Resour. Res. 1997, 33, 1075–1085. [Google Scholar] [CrossRef]
- Ballio, F.; Guadagnini, A. Convergence assessment of numerical monte carlo simulations in groundwater hydrology. Water Resour. Res. 2004, 40, 285. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Value |
|---|---|
| Discretization | |
| Row | 40 |
| Column | 40 |
| Grid spacing | 1 |
| Stress period | 1 |
| Time step | 20 |
| Reference geostatistical model | |
| Type | TpvG |
| A | 0.1 |
| H | 0.25 |
| λu | 25 |
| Reference flow condition | |
| Prescribed head on left boundary | 10 |
| Prescribed head on right boundary | 5 |
| Impervious upper and bottom boundaries | 0 |
| Pumping rate | 5 |
| Recharge rate | 0.01 |
| Storage coefficient | 0.05 |
| Porosity | 0.15 |
| Sampling information | |
| Number of lnK measurements | 10 |
| Number of head measurements | 20 |
| Measurement error | 1% of the observed head value |
| Setting of multi-model analysis | |
| Number of postulated models | 6 |
| Exp0 | |
| Exp1 | |
| Labels of the postulated models | Gau0 |
| Gau1 | |
| Sph0 | |
| Sph1 | |
| Statistics | MC-Based | PCM-Based | Relative Error |
|---|---|---|---|
| Multi-model mean | 7.3546 | 7.3536 | 0.013% |
| Within-model variance | 0.1560 | 0.1585 | 1.586% |
| Between-model variance | 0.0066 | 0.0061 | 8.274% |
| Total variance | 0.1626 | 0.1645 | 1.182% |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xue, L.; Dai, C.; Wu, Y.; Wang, L. Towards Improving the Efficiency of Bayesian Model Averaging Analysis for Flow in Porous Media via the Probabilistic Collocation Method. Water 2018, 10, 412. https://doi.org/10.3390/w10040412
Xue L, Dai C, Wu Y, Wang L. Towards Improving the Efficiency of Bayesian Model Averaging Analysis for Flow in Porous Media via the Probabilistic Collocation Method. Water. 2018; 10(4):412. https://doi.org/10.3390/w10040412
Chicago/Turabian StyleXue, Liang, Cheng Dai, Yujuan Wu, and Lei Wang. 2018. "Towards Improving the Efficiency of Bayesian Model Averaging Analysis for Flow in Porous Media via the Probabilistic Collocation Method" Water 10, no. 4: 412. https://doi.org/10.3390/w10040412
APA StyleXue, L., Dai, C., Wu, Y., & Wang, L. (2018). Towards Improving the Efficiency of Bayesian Model Averaging Analysis for Flow in Porous Media via the Probabilistic Collocation Method. Water, 10(4), 412. https://doi.org/10.3390/w10040412