Gene Expression Programming Coupled with Unsupervised Learning: A Two-Stage Learning Process in Multi-Scale, Short-Term Water Demand Forecasts

Abstract
:1. Introduction
- Evaluation of GEP as an alternative to other black-box models used in the literature that have not been explored by other researchers in the field of short-term water demand forecasting
- Investigation of coupling time series clustering with GEP in short-term water demand forecasts to reduce the adverse effect of seasonality and holidays/working days on performance of proposed forecast models
- Proposing a suitable sampling frequency for WDS operators through a time-scale modeling process
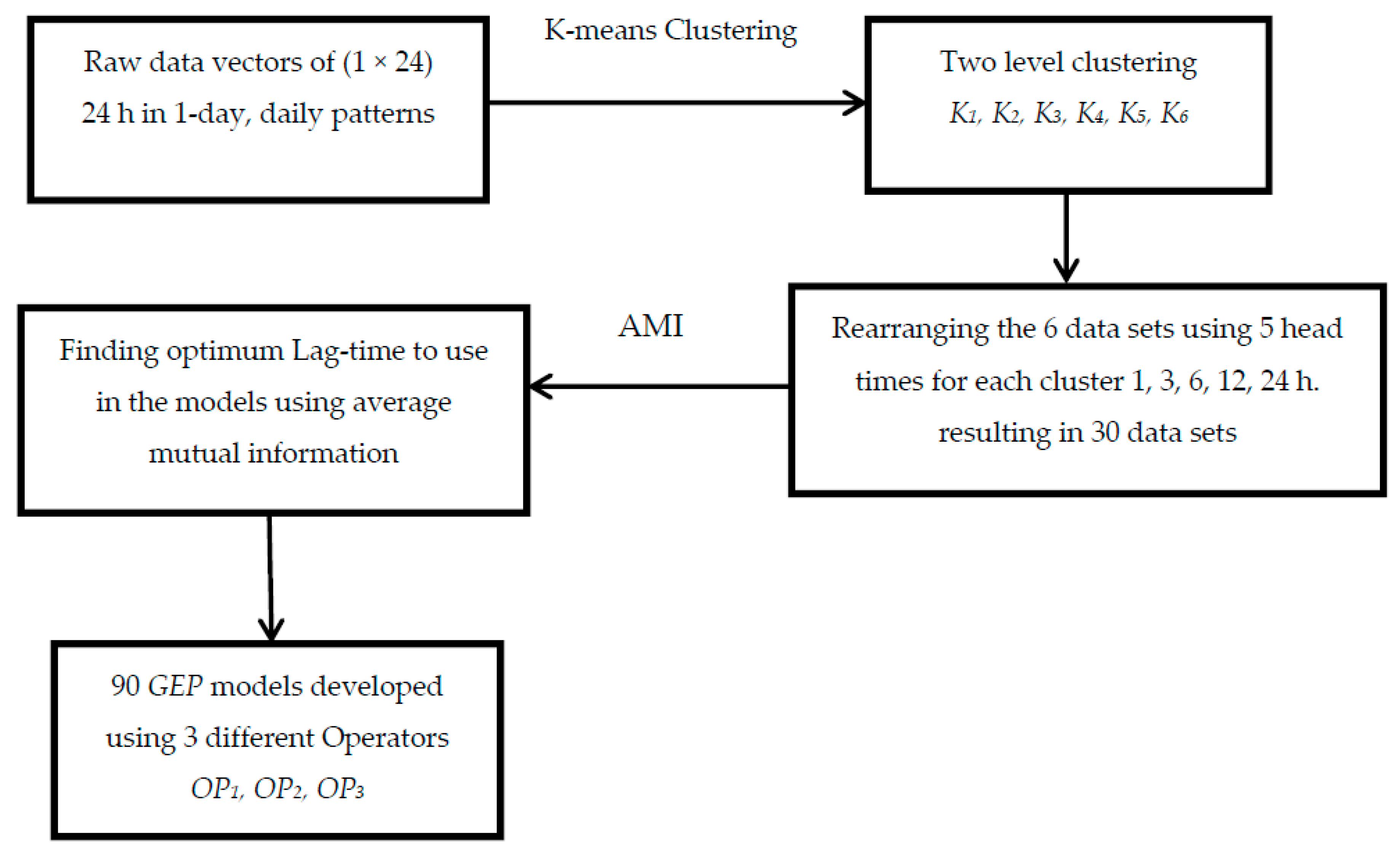
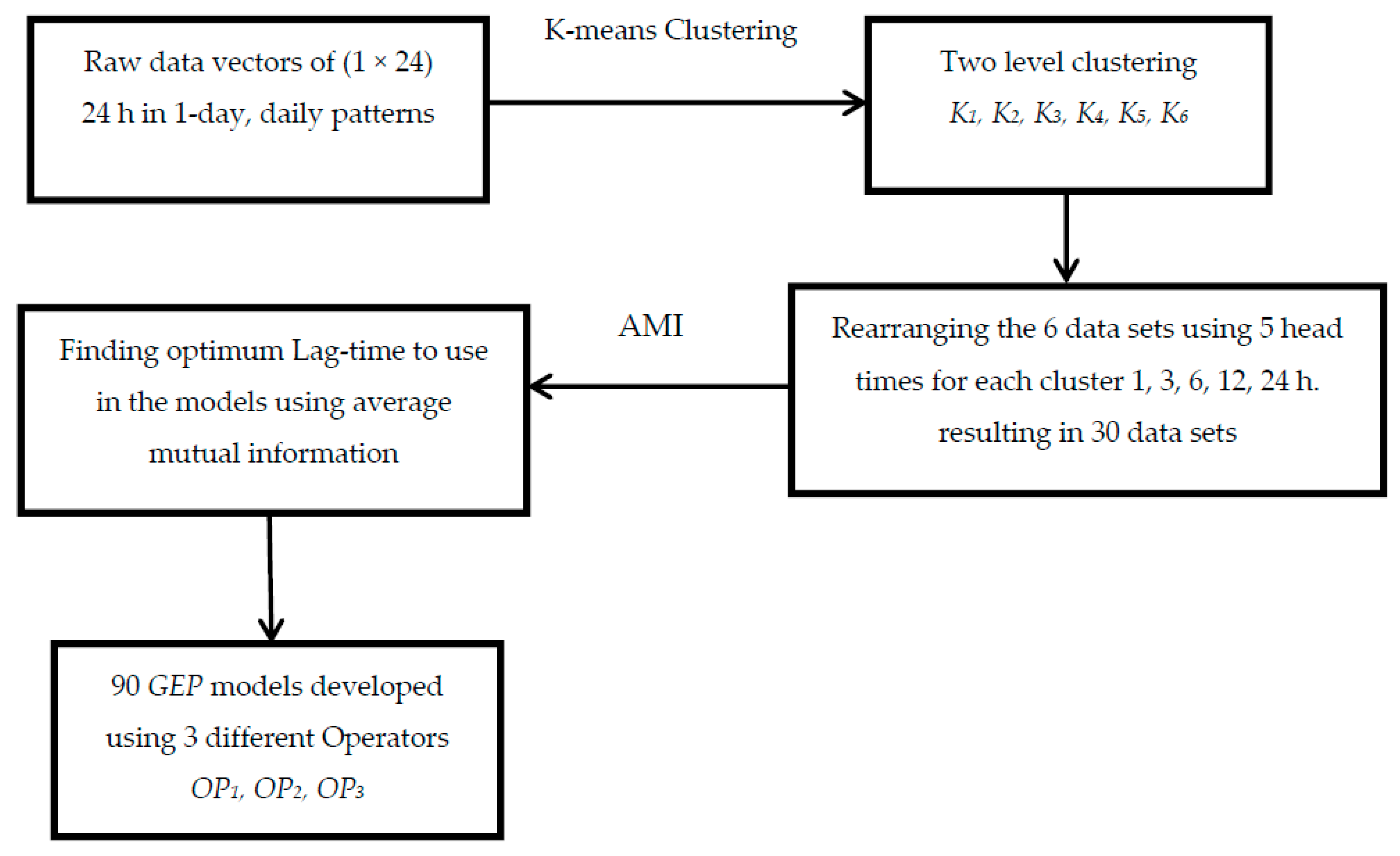
2. Model Development
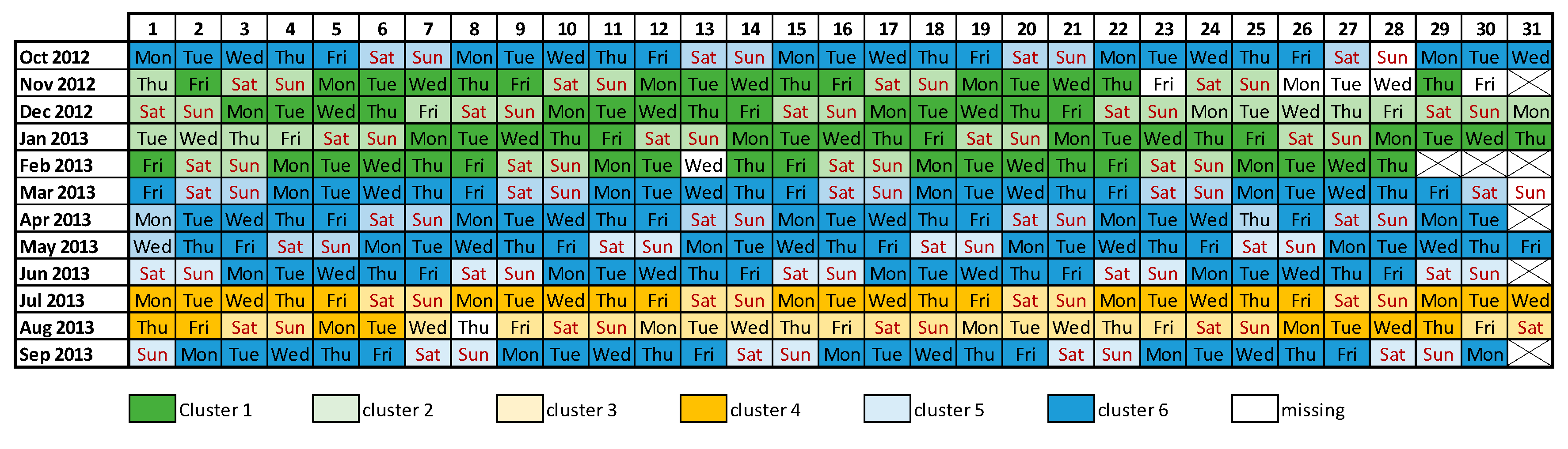
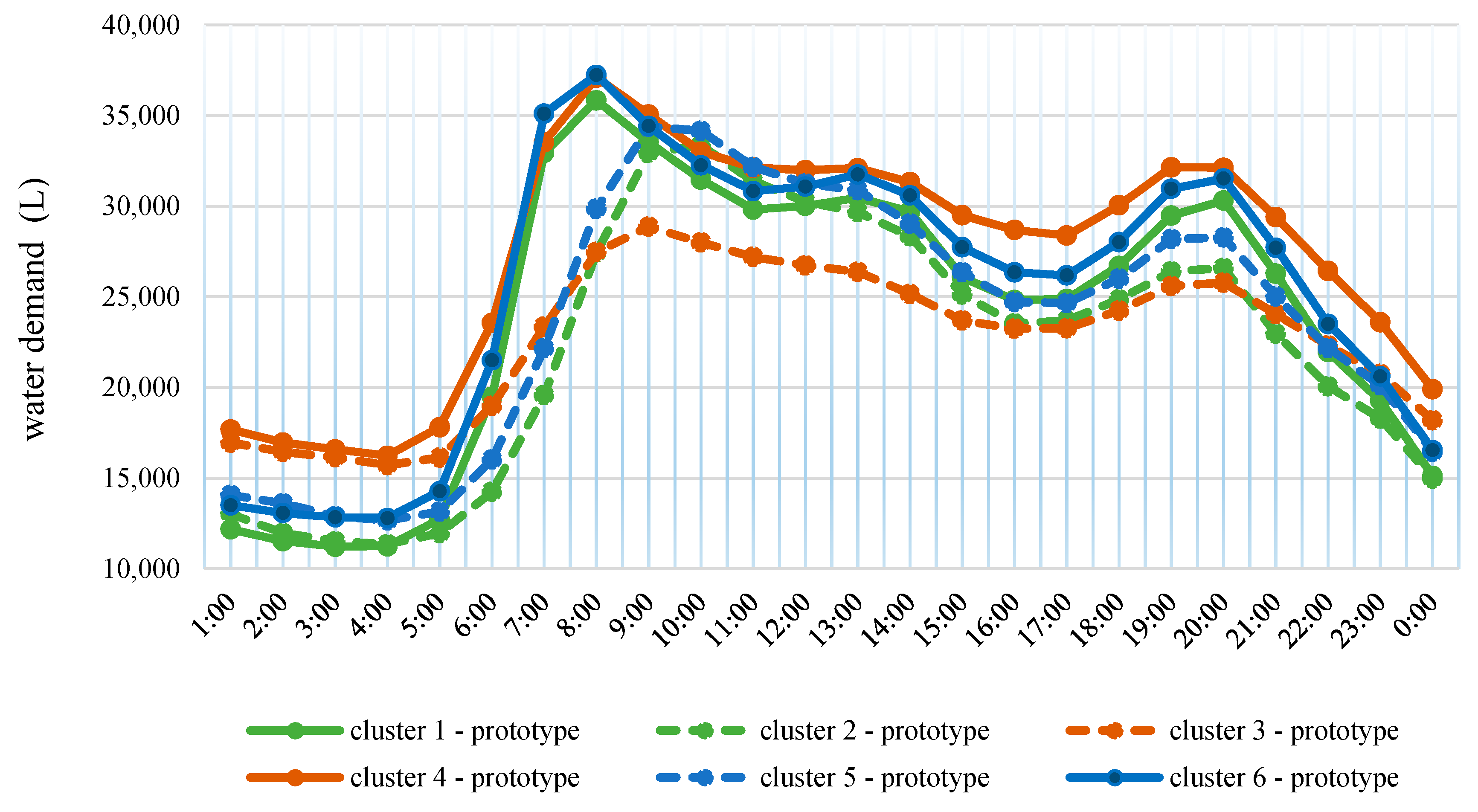
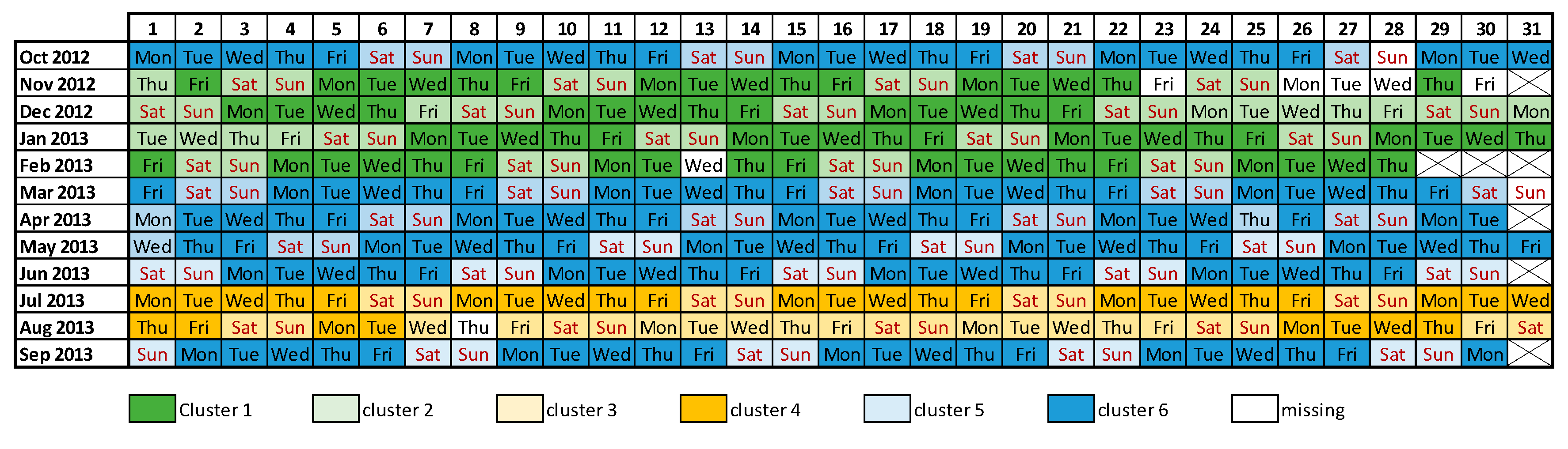
2.1. Unsupervised Learning: K-Means Clusters
2.2. Average Mutual Information
2.3. Gene Expression Programing
- Creating a random initial population of chromosomes
- Expressing chromosomes in a tree diagram with subsets
- Comparing the new offspring solutions based on fitness criteria
- Keeping the best solution, followed by reproduction methods like replication, mutation, recombination, etc.
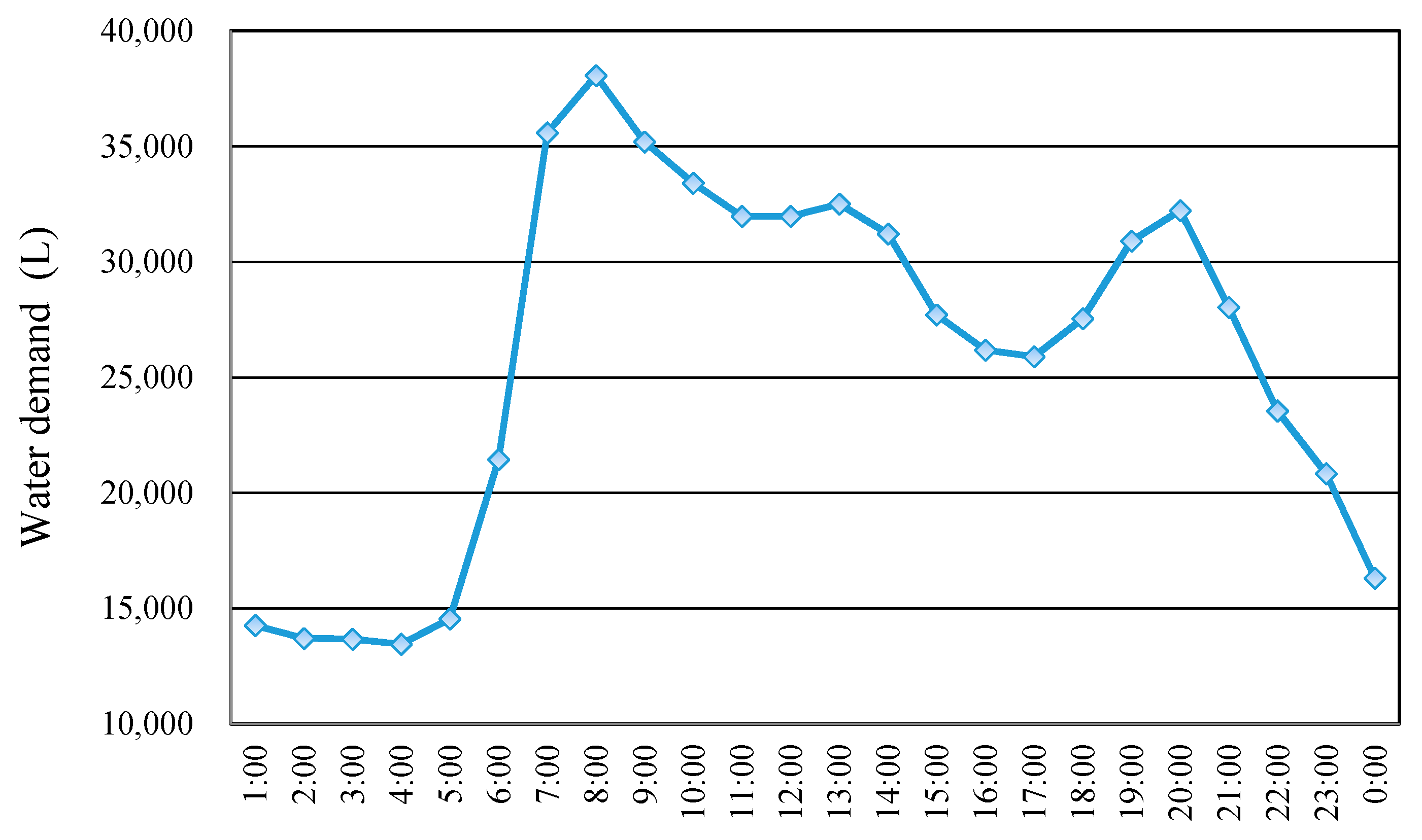
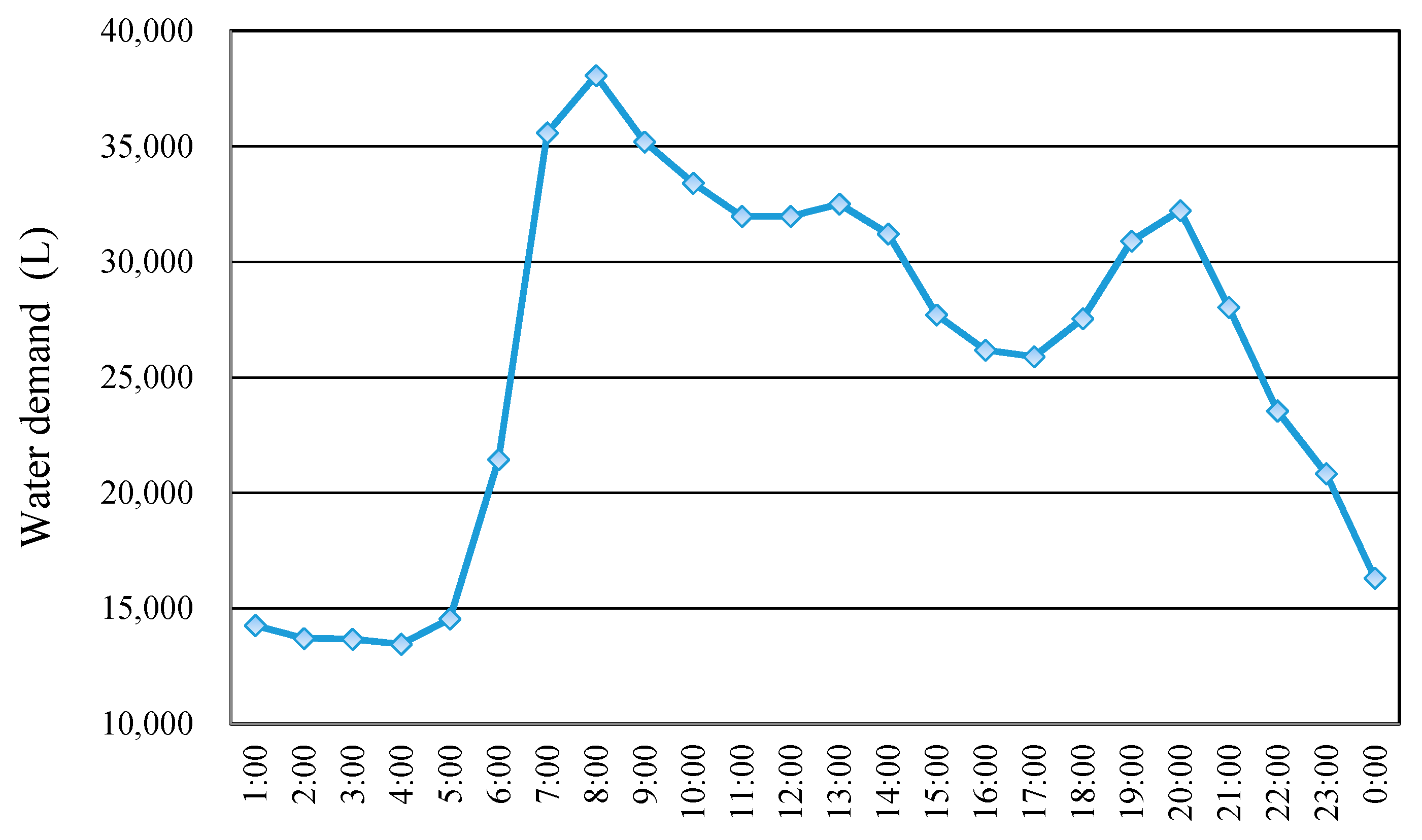
3. Study Area and Data Collection
- 149,639 junctions
- 118,950 pipes
- 26 pumping stations
- 501 wells and well pumps
- 33 storage tanks
- 95 booster pumps
- 36,295 valves
- 602 check valves
- Total base demand 7.5 ± 4.2 (m3/s)
4. Results
5. Conclusions
Supplementary Materials
Acknowledgments
Author Contributions
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
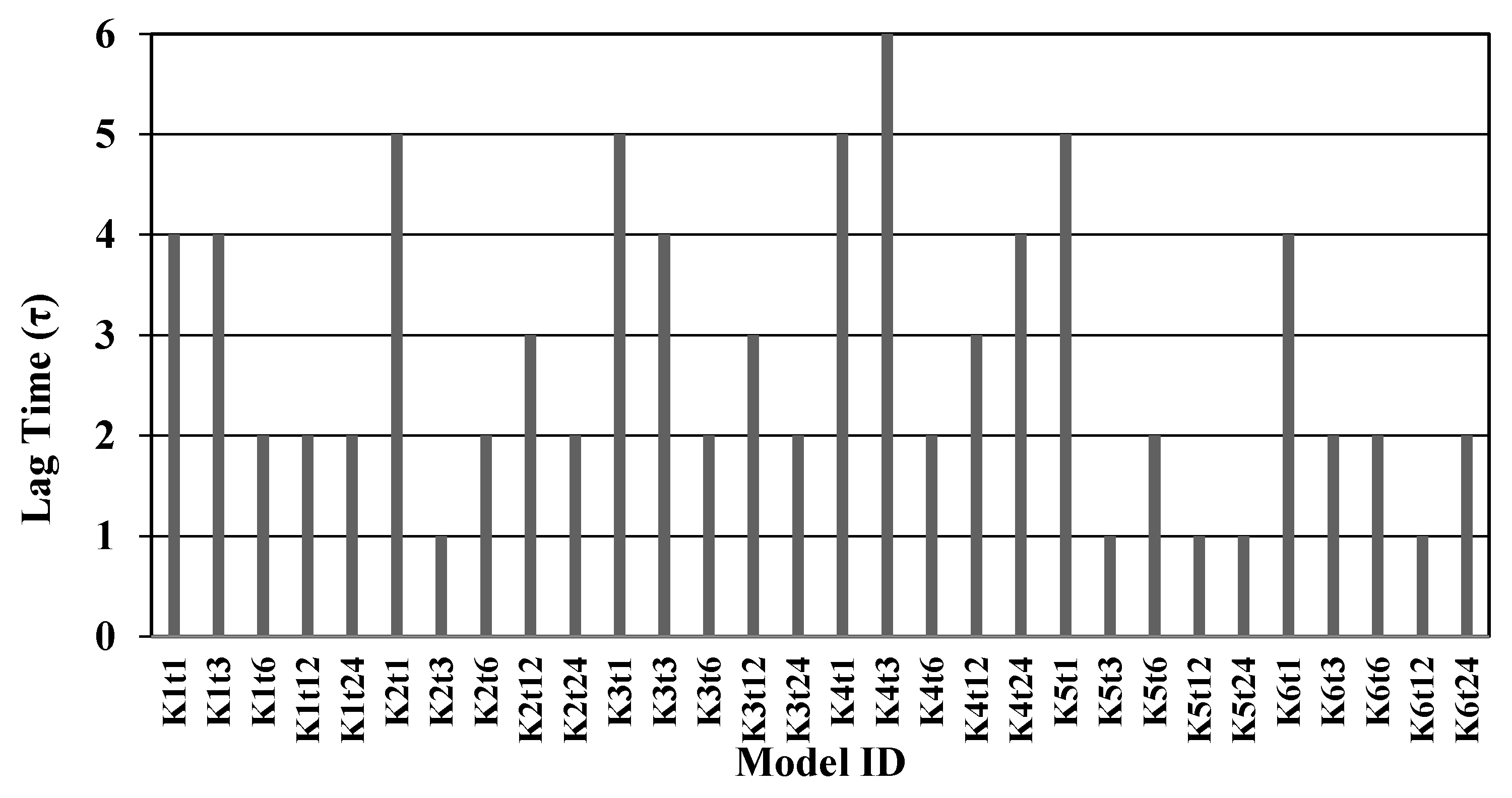{kind=link}
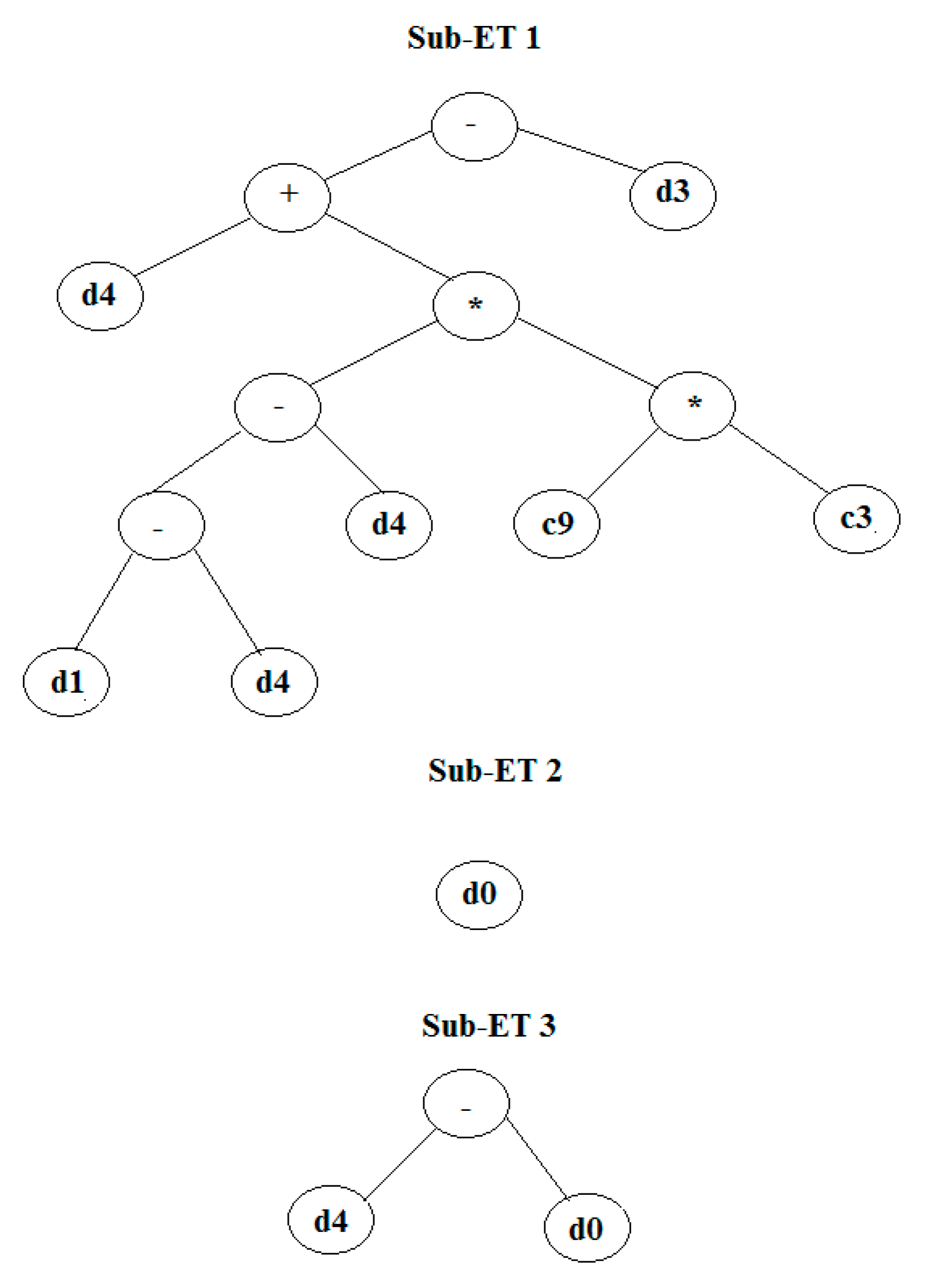{kind=link}
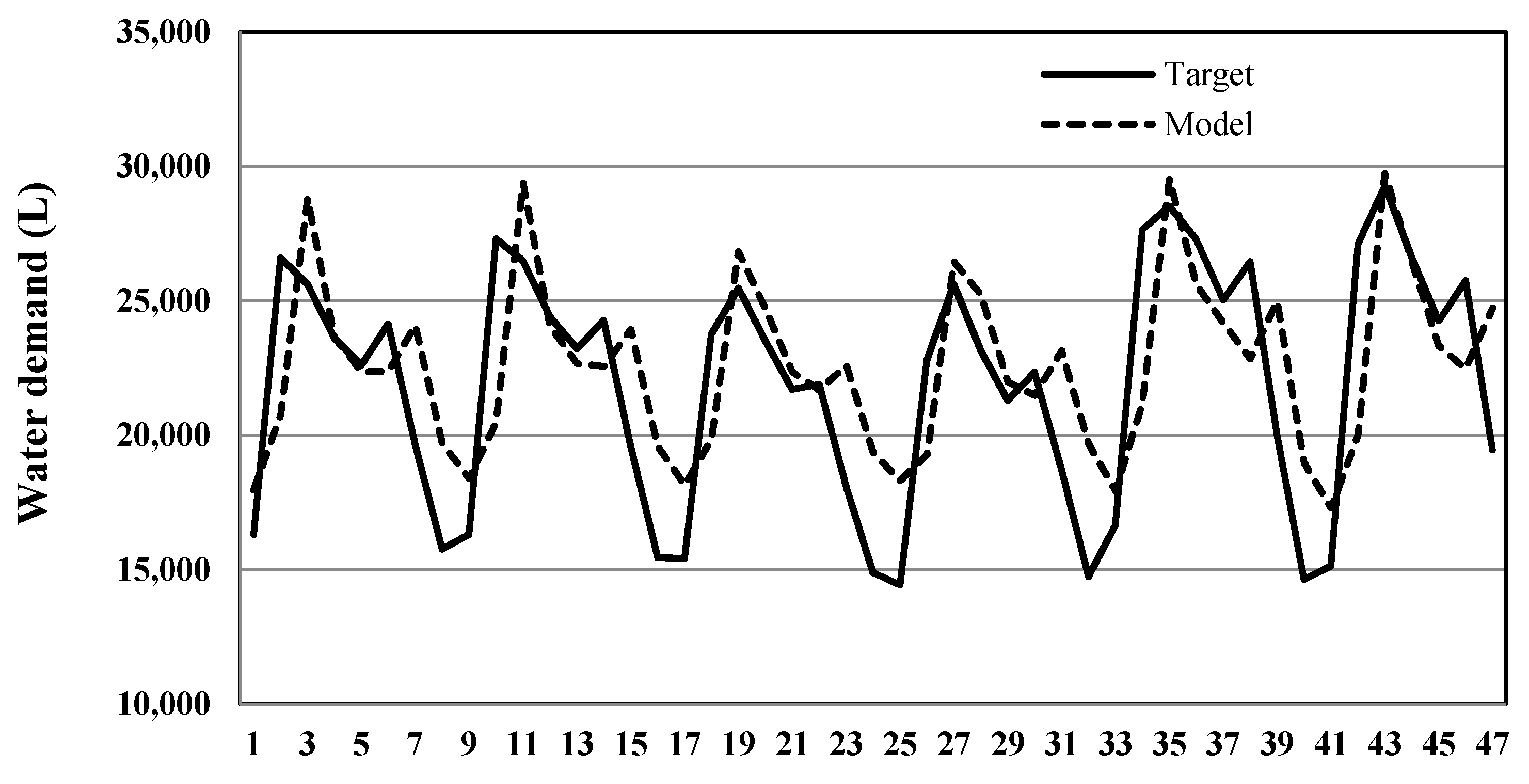{kind=link}
| Model ID | Training | Test | Model ID | Training | Test | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| MAE | RMSE | R2 | MAE | RMSE | R2 | MAE | RMSE | R2 | MAE | RMSE | R2 | ||
| K1HT1OP1 | 0.27 | 0.36 | 0.88 | 0.27 | 0.33 | 0.91 | K4HT1OP1 | 0.20 | 0.29 | 0.92 | 0.25 | 0.35 | 0.84 |
| K1HT1OP2 | 0.31 | 0.42 | 0.84 | 0.29 | 0.38 | 0.86 | K4HT1OP2 | 0.23 | 0.32 | 0.90 | 0.25 | 0.36 | 0.82 |
| K1HT1OP3 | 0.35 | 0.52 | 0.75 | 0.32 | 0.48 | 0.78 | K4HT1OP3 | 0.31 | 0.41 | 0.84 | 0.25 | 0.31 | 0.90 |
| K1HT3OP1 | 0.50 | 0.64 | 0.64 | 0.53 | 0.40 | 0.65 | K4HT3OP1 | 0.47 | 0.55 | 0.70 | 1.63 | 1.48 | 0.38 |
| K1HT3OP2 | 0.54 | 0.68 | 0.67 | 0.55 | 0.72 | 0.62 | K4HT3OP2 | 0.61 | 0.73 | 0.49 | 1.52 | 1.53 | 0.32 |
| K1HT3OP3 | 0.41 | 0.51 | 0.74 | 0.44 | 0.52 | 0.75 | K4HT3OP3 | 0.46 | 0.56 | 0.69 | 1.01 | 1.41 | 0.24 |
| K1HT6OP1 | 0.23 | 0.30 | 0.91 | 0.29 | 0.36 | 0.89 | K4HT6OP1 | 0.42 | 0.49 | 0.76 | 1.28 | 1.75 | 0.13 |
| K1HT6OP2 | 0.32 | 0.40 | 0.84 | 0.28 | 0.33 | 0.91 | K4HT6OP2 | 0.38 | 0.46 | 0.81 | 0.58 | 0.76 | 0.28 |
| K1HT6OP3 | 0.17 | 0.23 | 0.95 | 0.22 | 0.28 | 0.93 | K4HT6OP3 | 0.27 | 0.35 | 0.88 | 1.01 | 1.28 | 0.07 |
| K1HT12OP1 | 0.30 | 0.42 | 0.82 | 0.22 | 0.33 | 0.88 | K4HT12OP1 | 0.30 | 0.44 | 0.80 | 1.02 | 1.18 | 0.09 |
| K1HT12OP2 | 0.34 | 0.49 | 0.77 | 0.29 | 0.38 | 0.84 | K4HT12OP2 | 0.35 | 0.48 | 0.76 | 0.56 | 0.62 | 0.55 |
| K1HT12OP3 | 0.31 | 0.45 | 0.79 | 0.28 | 0.37 | 0.84 | K4HT12OP3 | 0.35 | 0.50 | 0.75 | 0.83 | 1.03 | 0.15 |
| K1HT24OP1 | 0.54 | 0.73 | 0.47 | 0.55 | 0.66 | 0.38 | K4HT24OP1 | 0.40 | 0.52 | 0.72 | 1.12 | 1.82 | 0.26 |
| K1HT24OP2 | 0.51 | 0.72 | 0.48 | 0.54 | 0.66 | 0.25 | K4HT24OP2 | 0.41 | 0.48 | 0.78 | 1.35 | 1.88 | 0.14 |
| K1HT24OP3 | 0.56 | 0.75 | 0.43 | 0.71 | 0.54 | 0.11 | K4HT24OP3 | 0.36 | 0.44 | 0.80 | 1.30 | 1.88 | 0.27 |
| K2HT1OP1 | 0.20 | 0.29 | 0.93 | 0.22 | 0.27 | 0.94 | K5HT1OP1 | 0.28 | 0.35 | 0.89 | 0.23 | 0.28 | 0.90 |
| K2HT1OP2 | 0.18 | 0.27 | 0.93 | 0.19 | 0.24 | 0.95 | K5HT1OP2 | 0.24 | 0.31 | 0.91 | 0.20 | 0.24 | 0.92 |
| K2HT1OP3 | 0.22 | 0.30 | 0.91 | 0.22 | 0.28 | 0.93 | K5HT1OP3 | 0.22 | 0.30 | 0.92 | 0.22 | 0.28 | 0.92 |
| K2HT3OP1 | 0.70 | 0.82 | 0.32 | 0.77 | 0.87 | 0.30 | K5HT3OP1 | 0.71 | 0.83 | 0.30 | 0.62 | 0.74 | 0.25 |
| K2HT3OP2 | 0.69 | 0.81 | 0.34 | 0.74 | 0.86 | 0.33 | K5HT3OP2 | 0.71 | 0.84 | 0.32 | 0.63 | 0.75 | 0.26 |
| K2HT3OP3 | 0.63 | 0.75 | 0.43 | 0.67 | 0.79 | 0.43 | K5HT3OP3 | 0.71 | 0.83 | 0.30 | 0.62 | 0.73 | 0.27 |
| K2HT6OP1 | 0.43 | 0.51 | 0.74 | 0.45 | 0.55 | 0.72 | K5HT6OP1 | 0.49 | 0.60 | 0.64 | 0.52 | 0.59 | 0.63 |
| K2HT6OP2 | 0.34 | 0.45 | 0.80 | 0.35 | 0.43 | 0.87 | K5HT6OP2 | 0.45 | 0.55 | 0.71 | 0.44 | 0.51 | 0.66 |
| K2HT6OP3 | 0.36 | 0.45 | 0.80 | 0.34 | 0.42 | 0.89 | K5HT6OP3 | 0.34 | 0.48 | 0.77 | 0.34 | 0.46 | 0.80 |
| K2HT12OP1 | 0.40 | 0.53 | 0.72 | 0.34 | 0.45 | 0.78 | K5HT12OP1 | 0.70 | 0.78 | 0.35 | 0.64 | 0.80 | 0.35 |
| K2HT12OP2 | 0.43 | 0.56 | 0.69 | 0.45 | 0.54 | 0.80 | K5HT12OP2 | 0.70 | 0.78 | 0.35 | 0.64 | 0.80 | 0.35 |
| K2HT12OP3 | 0.45 | 0.59 | 0.65 | 0.40 | 0.46 | 0.81 | K5HT12OP3 | 0.68 | 0.72 | 0.38 | 0.58 | 0.75 | 0.44 |
| K2HT24OP1 | 0.57 | 0.82 | 0.34 | 0.50 | 0.63 | 0.13 | K5HT24OP1 | 0.63 | 0.81 | 0.33 | 0.81 | 0.95 | 0.08 |
| K2HT24OP2 | 0.58 | 0.80 | 0.34 | 0.41 | 0.52 | 0.12 | K5HT24OP2 | 0.64 | 0.83 | 0.29 | 0.78 | 1.05 | 0.06 |
| K2HT24OP3 | 0.58 | 0.80 | 0.34 | 0.41 | 0.52 | 0.13 | K5HT24OP3 | 0.67 | 0.79 | 0.36 | 0.80 | 1.05 | 0.08 |
| K3HT1OP1 | 0.19 | 0.24 | 0.95 | 0.18 | 0.23 | 0.93 | K6HT1OP1 | 0.33 | 0.43 | 0.81 | 0.30 | 0.38 | 0.82 |
| K3HT1OP2 | 0.21 | 0.28 | 0.93 | 0.21 | 0.27 | 0.92 | K6HT1OP2 | 0.29 | 0.39 | 0.85 | 0.25 | 0.34 | 0.86 |
| K3HT1OP3 | 0.19 | 0.25 | 0.94 | 0.20 | 0.25 | 0.93 | K6HT1OP3 | 0.26 | 0.36 | 0.88 | 0.22 | 0.28 | 0.91 |
| K3HT3OP1 | 0.60 | 0.73 | 0.46 | 0.55 | 0.67 | 0.45 | K6HT3OP1 | 0.42 | 0.57 | 0.67 | 0.41 | 0.55 | 0.64 |
| K3HT3OP2 | 0.60 | 0.75 | 0.46 | 0.56 | 0.69 | 0.45 | K6HT3OP2 | 0.45 | 0.58 | 0.70 | 0.48 | 0.60 | 0.63 |
| K3HT3OP3 | 0.47 | 0.56 | 0.74 | 0.43 | 0.53 | 0.73 | K6HT3OP3 | 0.45 | 0.59 | 0.66 | 0.46 | 0.59 | 0.61 |
| K3HT6OP1 | 0.71 | 0.87 | 0.33 | 0.62 | 0.87 | 0.52 | K6HT6OP1 | 0.33 | 0.43 | 0.81 | 0.40 | 0.52 | 0.84 |
| K3HT6OP2 | 0.58 | 0.69 | 0.54 | 0.50 | 0.62 | 0.58 | K6HT6OP2 | 0.45 | 0.55 | 0.70 | 0.47 | 0.51 | 0.77 |
| K3HT6OP3 | 0.58 | 0.73 | 0.50 | 0.61 | 0.78 | 0.35 | K6HT6OP3 | 0.38 | 0.48 | 0.79 | 0.40 | 0.45 | 0.89 |
| K3HT12OP1 | 0.48 | 0.59 | 0.65 | 0.36 | 0.49 | 0.24 | K6HT12OP1 | 0.68 | 0.92 | 0.14 | 0.66 | 0.89 | 0.19 |
| K3HT12OP2 | 0.41 | 0.50 | 0.75 | 0.38 | 0.47 | 0.37 | K6HT12OP2 | 0.73 | 0.94 | 0.12 | 0.73 | 0.92 | 0.17 |
| K3HT12OP3 | 0.40 | 0.50 | 0.75 | 0.35 | 0.47 | 0.27 | K6HT12OP3 | 0.65 | 0.89 | 0.22 | 0.73 | 0.95 | 0.12 |
| K3HT24OP1 | 0.42 | 0.52 | 0.73 | 0.46 | 0.54 | 0.37 | K6HT24OP1 | 0.30 | 0.44 | 0.80 | 0.26 | 0.36 | 0.68 |
| K3HT24OP2 | 0.53 | 0.63 | 0.63 | 0.40 | 0.56 | 0.10 | K6HT24OP2 | 0.32 | 0.46 | 0.78 | 0.26 | 0.37 | 0.67 |
| K3HT24OP3 | 0.42 | 0.52 | 0.72 | 0.37 | 0.51 | 0.37 | K6HT24OP3 | 0.31 | 0.45 | 0.80 | 0.28 | 0.39 | 0.67 |
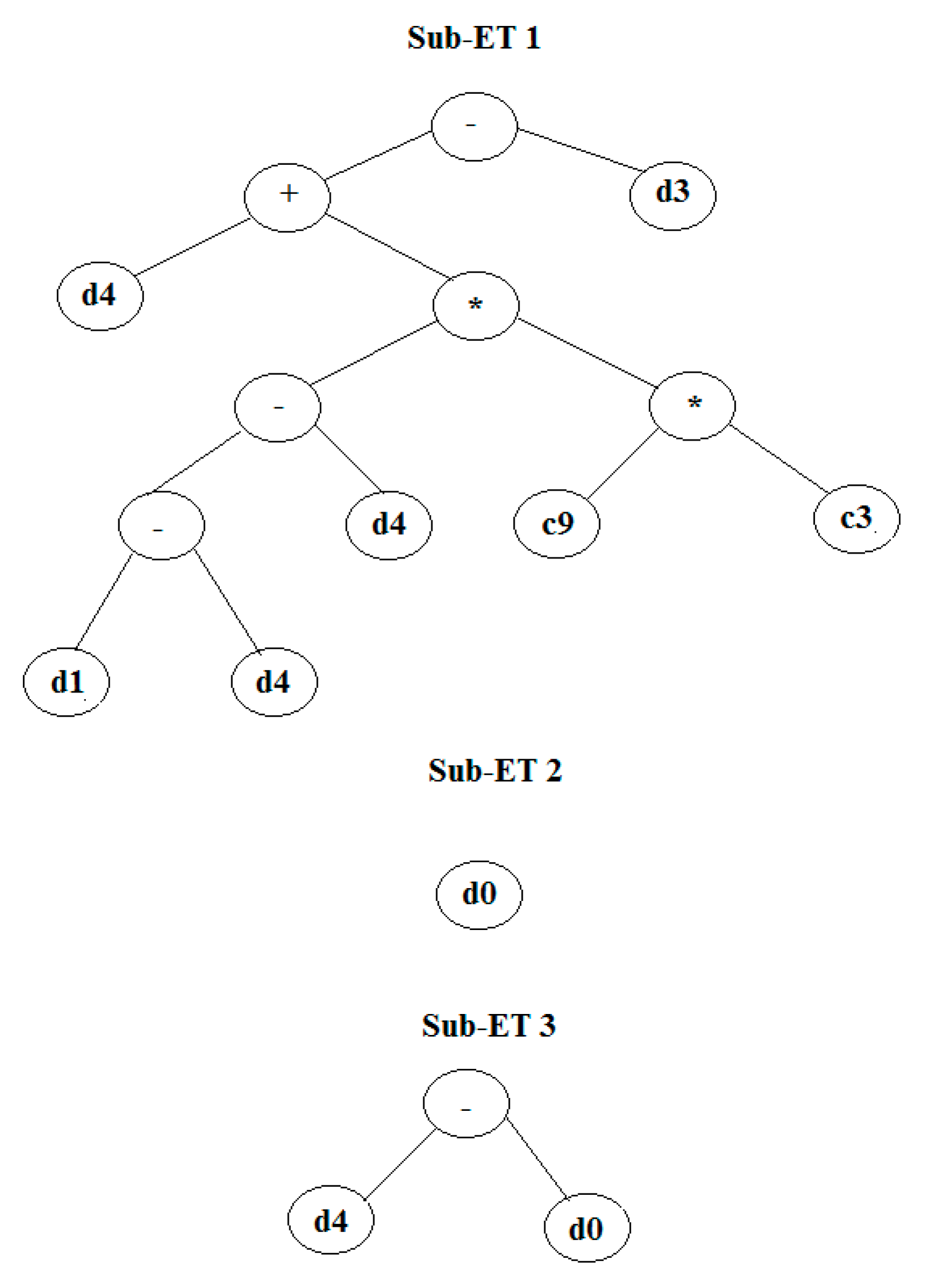
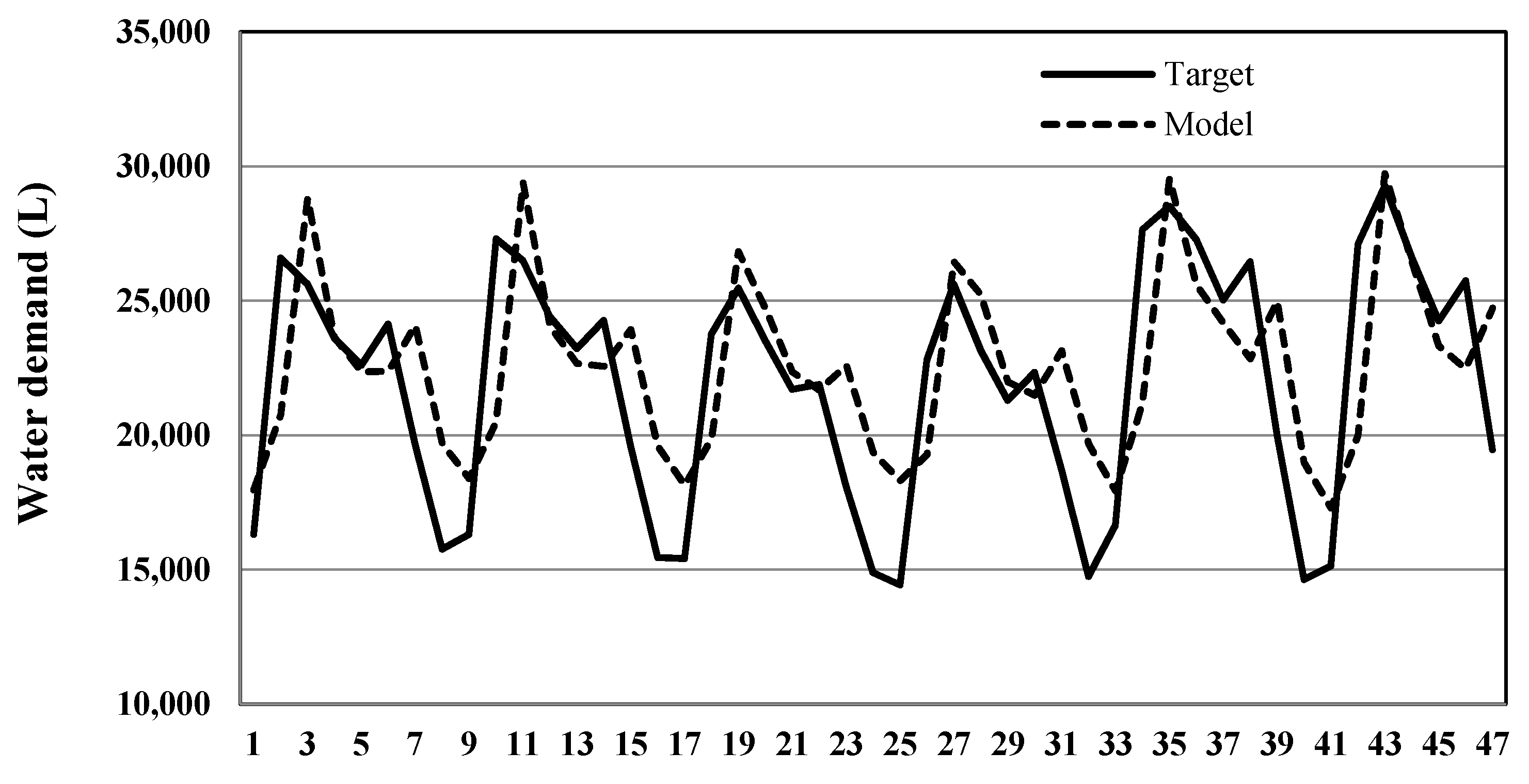
References
- Gleick, P.H. The World’s Water Volume 7: The Biennial Report on Freshwater; Island Press: Washington, DC, USA, 2011. [Google Scholar]
- Mamo, T.G.; Juran, I.; Shahrour, I. Urban water demand forecasting using the stochastic nature of short term historical water demand and supply pattern. J. Water Resour. Hydraul. Eng. 2013, 2, 92–103. [Google Scholar]
- Ghiassi, M.; Zimbra, D.; Saidane, H. Urban water demand forecasting with a dynamic artificial neural network model. J. Water Resour. Plan. Manag. 2008, 134, 138–146. [Google Scholar] [CrossRef]
- Cao, L. Data science: A comprehensive overview. ACM Comput. Surv. (CSUR) 2017, 50, 43. [Google Scholar] [CrossRef]
- Gupta, A.; Mishra, S.; Bokde, N.; Kulat, K. Need of smart water systems in India. Int. J. Appl. Eng. Res. 2016, 11, 2216–2223. [Google Scholar]
- Bougadis, J.; Adamowski, K.; Diduch, R. Short-term municipal water demand forecasting. Hydrol. Process. 2005, 19, 137–148. [Google Scholar] [CrossRef]
- Jain, A.; Ormsbee, L.E. Short-term water demand forecast modeling techniques—Conventional methods versus AI. J. Am. Water Works Assoc. 2002, 94, 64–72. [Google Scholar]
- Adamowski, J.F. Peak daily water demand forecast modeling using artificial neural networks. J. Water Resour. Plan. Manag. 2008, 134, 119–128. [Google Scholar] [CrossRef]
- Gato, S.; Jayasuriya, N.; Roberts, P. Temperature and rainfall thresholds for base use urban water demand modelling. J. Hydrol. 2007, 337, 364–376. [Google Scholar] [CrossRef]
- Shabani, S.; Yousefi, P.; Adamowski, J.; Naser, G. Intelligent soft computing models in water demand forecasting. In Water Stress in Plants; InTech: London, UK, 2016. [Google Scholar]
- Bakker, M.; Van Duist, H.; Van Schagen, K.; Vreeburg, J.; Rietveld, L. Improving the performance of water demand forecasting models by using weather input. Procedia Eng. 2014, 70, 93–102. [Google Scholar] [CrossRef]
- Maidment, D.; Parzen, E. Monthly water use and its relationship to climatic variables in Texas. Water Resour. Bull. 1984, 19, 409–418. [Google Scholar]
- Brekke, L.; Larsen, M.D.; Ausburn, M.; Takaichi, L. Suburban water demand modeling using stepwise regression. J. Am. Water Works Assoc. 2002, 94, 65. Available online: https://search.proquest.com/openview/bdbe337b223db024059c1efb7c6028f4/1?pq-origsite=gscholar&cbl=25142 (accessed on 31 July 2017).
- Polebitski, A.S.; Palmer, R.N.; Waddell, P. Evaluating water demands under climate change and transitions in the urban environment. J. Water Resour. Plan. Manag. 2010, 137, 249–257. [Google Scholar] [CrossRef]
- Alvisi, S.; Franchini, M.; Marinelli, A. A short-term, pattern-based model for water-demand forecasting. J. Hydroinform. 2007, 9, 39–50. [Google Scholar] [CrossRef]
- Bakker, M.; Vreeburg, J.H.G.; Schagen, K.M.V.; Rietveld, L.C. A fully adaptive forecasting model for short-term drinking water demand. Environ. Model. Softw. 2013, 48, 141–151. [Google Scholar] [CrossRef]
- Al-Zahrani, M.A.; Abo-Monasar, A. Urban residential water demand prediction based on artificial neural networks and time series models. Water Resour. Manag. 2015, 29, 3651–3662. [Google Scholar] [CrossRef]
- Tiwari, M.K.; Adamowski, J. Urban water demand forecasting and uncertainty assessment using ensemble wavelet-bootstrap-neural network models. Water Resour. Res. 2013, 49, 6486–6507. [Google Scholar] [CrossRef]
- Firat, M.; Yurdusev, M.A.; Turan, M.E. Evaluation of artificial neural network techniques for municipal water consumption modeling. Water Resour. Manag. 2009, 23, 617–632. [Google Scholar] [CrossRef]
- Tiwari, M.K.; Adamowski, J.F. Medium-term urban water demand forecasting with limited data using an ensemble wavelet–bootstrap machine-learning approach. J. Water Resour. Plan. Manag. 2014, 141. [Google Scholar] [CrossRef]
- Odan, F.K.; Reis, L.F. Hybrid water demand forecasting model associating artificial neural network with Fourier series. J. Water Resour. Plan. Manag. 2012, 138, 245–256. [Google Scholar] [CrossRef]
- Huang, L.; Zhang, C.; Peng, Y.; Zhou, H. Application of a combination model based on wavelet transform and KPLS-ARMA for urban annual water demand forecasting. J. Water Resour. Plan. Manag. 2013, 140. [Google Scholar] [CrossRef]
- Herrera, M.; Torgo, L.; Izquierdo, J.; Pérez-García, R. Predictive models for forecasting hourly urban water demand. J. Hydrol. 2010, 387, 141–150. [Google Scholar] [CrossRef]
- Shabani, S.; Yousefi, P.; Naser, G. Support Vector Machines in Urban Water Demand Forecasting Using Phase Space Reconstruction. Procedia Eng. 2017, 186, 537–543. [Google Scholar] [CrossRef]
- Goyal, M.K.; Bharti, B.; Quilty, J.; Adamowski, J.; Pandey, A. Modeling of daily pan evaporation in sub-tropical climates using ANN, LS-SVR, Fuzzy Logic, and ANFIS. Expert Syst. Appl. 2014, 41, 5267–5276. [Google Scholar] [CrossRef]
- Brentan, B.M.; Luvizotto, E., Jr.; Herrera, M.; Izquierdo, J.; Pérez-García, R. Hybrid regression model for near real-time urban water demand forecasting. J. Comput. Appl. Math. 2017, 309, 532–541. [Google Scholar] [CrossRef]
- Ferreira, C. What Is Gene Expression Programming? Idea Group Publishing: London, UK, 2008. [Google Scholar]
- Shiri, J.; Marti, P.; Singh, V.P. Evaluation of gene expression programming approaches for estimating daily evaporation through spatial and temporal data scanning. Hydrol. Process. 2014, 28, 1215–1225. [Google Scholar] [CrossRef]
- Fernando, A.K.; Shamseldin, A.Y.; Abrahart, R.J. Use of gene expression programming for multimodel combination of rainfall-runoff models. J. Hydrol. Eng. 2011, 17, 975–985. [Google Scholar] [CrossRef]
- Stull, R. Wet-bulb temperature from relative humidity and air temperature. J. Appl. Meteorol. Climatol. 2011, 50, 2267–2269. [Google Scholar] [CrossRef]
- Kisi, O.; Shiri, J. Precipitation forecasting using wavelet-genetic programming and wavelet-neuro-fuzzy conjunction models. Water Resour. Manag. 2011, 25, 3135–3152. [Google Scholar] [CrossRef]
- Fu, T.C. A review on time series data mining. Eng. Appl. Artif. Intell. 2011, 24, 164–181. [Google Scholar] [CrossRef]
- Candelieri, A. Clustering and Support Vector Regression for Water Demand Forecasting and Anomaly Detection. Water 2017, 9, 224. [Google Scholar] [CrossRef]
- Arbelaitz, O.; Gurrutxaga, I.; Muguerza, J.; Pérez, J.M.; Perona, I. An extensive comparative study of cluster validity indices. Pattern Recognit. 2013, 46, 243–256. [Google Scholar] [CrossRef]
- Fraser, A.M.; Swinney, H.L. Independent coordinates for strange attractors from mutual information. Phys. Rev. A 1986, 33, 1134–1140. [Google Scholar] [CrossRef]
- Holzfuss, J.; Mayer, G. An approach to error-estimation in the application of dimension algorithms. In Dimensions and Entropies in Chaotic Systems; Mayer-Kress, G., Ed.; Springer: New York, NY, USA, 1986; pp. 114–122. [Google Scholar]
- Hegger, R.; Kantza, B.; Schreiber, T. Practical implementation of nonlinear time series methods: The TISEAN package. Chaos 1999, 9, 413–435. [Google Scholar] [CrossRef] [PubMed]
- Khatibi, R.; Sivakumar, B.; Ghorbani, M.A.; Kisi, O.; Kocak, K.; Zadeh, D.F. Investigation chaos in river stage and discharge time series. J. Hydrol. 2012, 414–415, 108–117. [Google Scholar] [CrossRef]

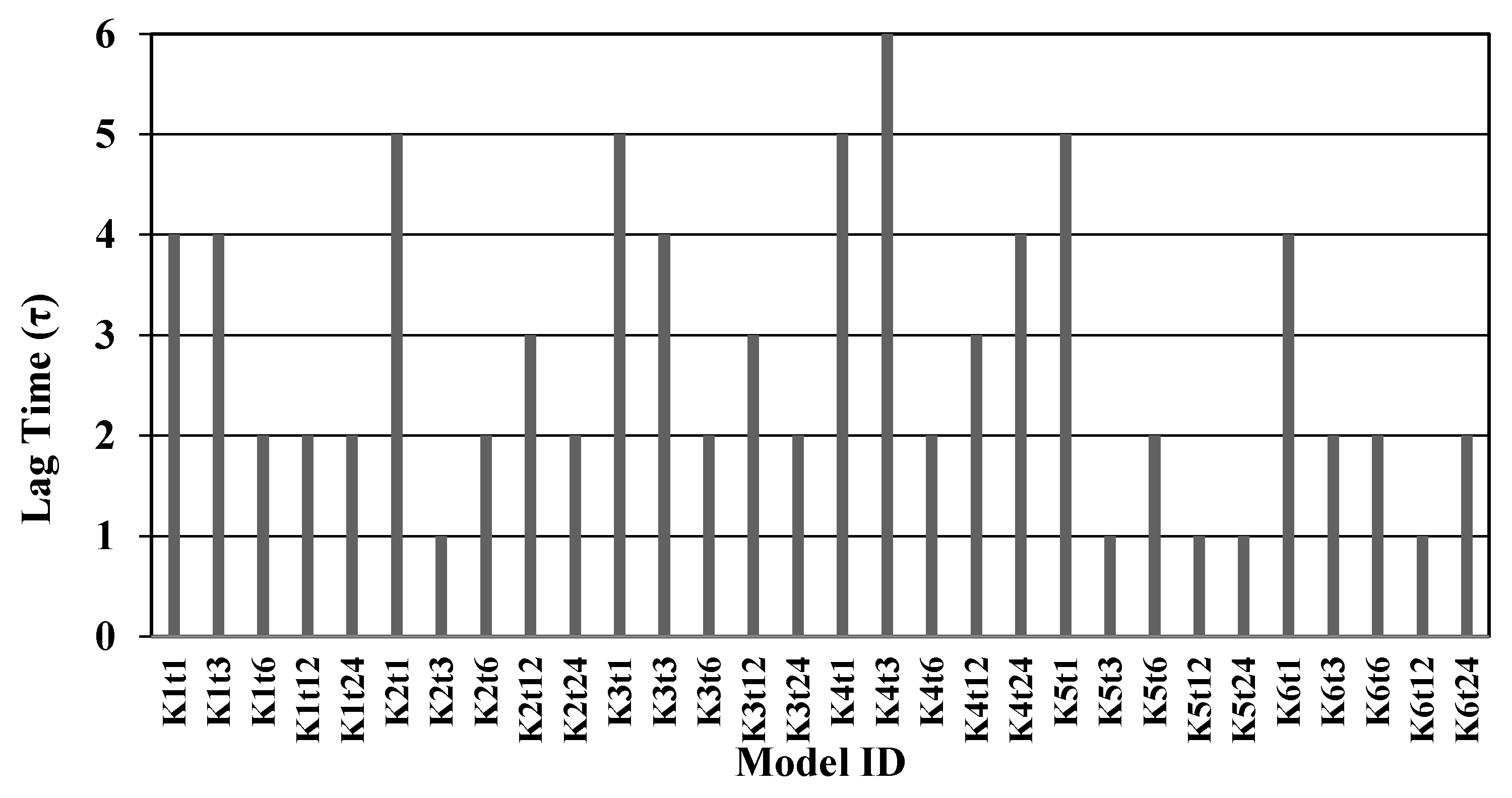
| (a). MAE * (Mean ± Standard Deviation) | |||||
| Operator | Head Time = 1 | Head Time = 3 | Head Time = 6 | Head Time = 12 | Head Time = 24 |
| GEP-operator_1 | 0.2409 ± 0.0388 | 0.7497 ± 0.4449 | 0.5943 ± 0.3548 | 0.5399 ± 0.2932 | 0.6163 ± 0.3039 |
| GEP-operator_2 | 0.2319 ± 0.0391 | 0.7448 ± 0.3885 | 0.4386 ± 0.1096 | 0.5061 ± 0.1660 | 0.6242 ± 0.3952 |
| GEP-operator_3 | 0.2387 ± 0.0444 | 0.6031 ± 0.2228 | 0.4854 ± 0.2857 | 0.5276 ± 0.2211 | 0.6433 ± 0.3808 |
| (b). RMSE * (Mean ± Standard Deviation) | |||||
| Operator | Head Time = 1 | Head Time = 3 | Head Time = 6 | Head Time = 12 | Head Time = 24 |
| GEP-operator_1 | 0.3087 ± 0.0563 | 0.7861 ± 0.3763 | 0.7731 ± 0.5048 | 0.6896 ± 0.3230 | 0.8272 ± 0.5226 |
| GEP-operator_2 | 0.3048 ± 0.0632 | 0.8595 ± 0.3398 | 0.5274 ± 0.1483 | 0.6215 ± 0.2052 | 0.8401 ± 0.5591 |
| GEP-operator_3 | 0.3116 ± 0.0842 | 0.7627 ± 0.3338 | 0.6104 ± 0.3661 | 0.6718 ± 0.2800 | 0.8149 ± 0.5710 |
| (c). R2 (Mean ± Standard Deviation) | |||||
| Operator | Head Time = 1 | Head Time = 3 | Head Time = 6 | Head Time = 12 | Head Time = 24 |
| GEP-operator_1 | 0.8900 ± 0.0498 | 0.4455 ± 0.1681 | 0.6221 ± 0.2732 | 0.4227 ± 0.3275 | 0.3174 ± 0.2151 |
| GEP-operator_2 | 0.8906 ± 0.0491 | 0.4332 ± 0.1593 | 0.6776 ± 0.2314 | 0.5131 ± 0.2665 | 0.2229 ± 0.2288 |
| GEP-operator_3 | 0.8962 ± 0.0569 | 0.5077 ± 0.2248 | 0.6551 ± 0.3585 | 0.4395 ± 0.3204 | 0.2727 ± 0.2255 |
| (d). MAPE % (Mean ± Standard Deviation) | |||||
| Operator | Head Time = 1 | Head Time = 3 | Head Time = 6 | Head Time = 12 | Head Time = 24 |
| GEP-operator_1 | 0.900 ± 0.0113 | 1.2067 ± 0.0080 | 2.1450 ± 0.0133 | 1.4267 ± 0.0098 | 2.0667 ± 0.0106 |
| GEP-operator_2 | 0.9400 ± 0.0110 | 1.4367 ±0.0113 | 2.3933 ± 0.0090 | 1.5950 ± 0.0012 | 2.0683 ± 0.0101 |
| GEP-operator_3 | 0.8850 ± 0.0089 | 1.2033 ± 0.0115 | 2.1867 ± 0.0084 | 1.4667 ± 0.0091 | 2.0917 ± 0.0010 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shabani, S.; Candelieri, A.; Archetti, F.; Naser, G. Gene Expression Programming Coupled with Unsupervised Learning: A Two-Stage Learning Process in Multi-Scale, Short-Term Water Demand Forecasts. Water 2018, 10, 142. https://doi.org/10.3390/w10020142
Shabani S, Candelieri A, Archetti F, Naser G. Gene Expression Programming Coupled with Unsupervised Learning: A Two-Stage Learning Process in Multi-Scale, Short-Term Water Demand Forecasts. Water. 2018; 10(2):142. https://doi.org/10.3390/w10020142
Chicago/Turabian StyleShabani, Sina, Antonio Candelieri, Francesco Archetti, and Gholamreza Naser. 2018. "Gene Expression Programming Coupled with Unsupervised Learning: A Two-Stage Learning Process in Multi-Scale, Short-Term Water Demand Forecasts" Water 10, no. 2: 142. https://doi.org/10.3390/w10020142
APA StyleShabani, S., Candelieri, A., Archetti, F., & Naser, G. (2018). Gene Expression Programming Coupled with Unsupervised Learning: A Two-Stage Learning Process in Multi-Scale, Short-Term Water Demand Forecasts. Water, 10(2), 142. https://doi.org/10.3390/w10020142