Application of Artificial Neural Networks to Rainfall Forecasting in the Geum River Basin, Korea


Abstract
1. Introduction
2. Data
2.1. Rainfall Data
2.2. Climate Indices
3. Methodology
3.1. Artificial Neural Network
3.2. ANN Model Development
- (1)
- The products Pij are obtained by multiplying the input-hidden connection weight and the hidden-output connection weight for each hidden neuron i and repeating this for each input neuron j;
- (2)
- Scaled products Qij are obtained by dividing the absolute values of Pij by the sum for all input variables for each hidden neuron i;
- (3)
- The product Sj is obtained by summing Qij for each input neuron; and
- (4)
- Relative importance values RIj (%) are obtained by dividing Sj by the sum for all the input variables and expressing the figure as a percentage.
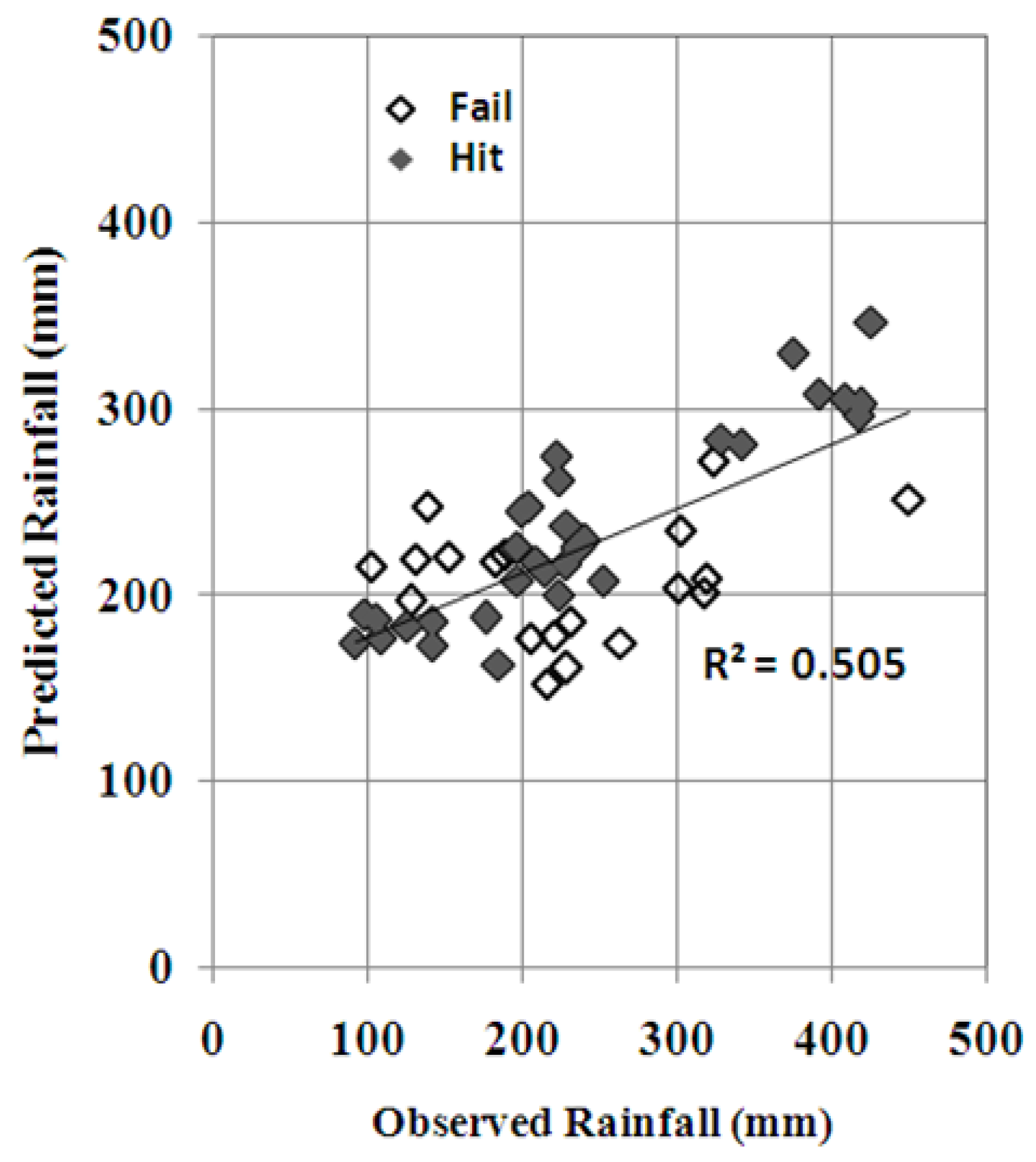
4. Results and Discussion
4.1. Preliminary ANN Model for Rainfall Forecasting
4.2. Quantification of Relative Importance of Input Variables
4.3. Best ANN Model for Rainfall Forecasting
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Nayak, R.D.; Mahapatra, A.; Mishra, P. A survey on rainfall prediction using artificial neural network. Int. J. Comput. Appl. 2013, 72, 32–40. [Google Scholar]
- Adamowski, J.; Sun, K. Development of a coupled wavelet transform and neural network method for flow forecasting of non-perennial rivers in semi-arid watersheds. J. Hydrol. 2010, 390, 85–91. [Google Scholar] [CrossRef]
- Bodri, L.; Cermak, V. Prediction of extreme precipitation using a neural network: Application to summer flood occurrence in Moravia. Adv. Eng. Softw. 2000, 31, 311–321. [Google Scholar] [CrossRef]
- Bodri, L.; Cermak, V. Neural network prediction of monthly precipitation: Application to summer flood occurrence in two regions of central Europe. Stud. Geophys. Geod. 2001, 45, 155–167. [Google Scholar] [CrossRef]
- Wu, X.; Hongxing, C. Forecasting monsoon precipitation using artificial neural networks. Adv. Atmos. Sci. 2001, 18, 950–958. [Google Scholar]
- Philip, N.S.; Joseph, K.B. A neural network tool for analyzing trends in rainfall. Comput. Geosci. 2003, 29, 215–223. [Google Scholar] [CrossRef]
- Chakraverty, S.; Gupta, P. Comparison of neural network configurations in the long-range forecast of southwest monsoon rainfall over India. Neural Comput. Appl. 2008, 17, 187–192. [Google Scholar] [CrossRef]
- Chattopadhyay, S.; Chattopadhyay, G. Comparative study among different neural net learning algorithms applied to rainfall time series. Meteorol. Appl. 2008, 15, 273–280. [Google Scholar] [CrossRef]
- Gholizadeh, M.H.; Darand, M. Forecasting precipitation with artificial neural networks (Case Study: Tehran). J. Appl. Sci. 2009, 9, 1786–1790. [Google Scholar] [CrossRef]
- Aksoy, H.; Dahamsheh, A. Artificial neural network models for forecasting monthly precipitation in Jordan. Stoch. Environ. Res. Risk Assess. 2009, 23, 917–931. [Google Scholar] [CrossRef]
- Bilgili, M.; Sahin, B. Prediction of long-term monthly temperature and rainfall in Turkey. Energy Sour. Part A 2010, 32, 60–71. [Google Scholar] [CrossRef]
- Yuan, F.; Berndtsson, R.; Uvo, C.B.; Zhang, L.; Jiang, P. Summer precipitation prediction in the source region of the Yellow River using climate indices. Hydrol. Res. 2016, 47, 847–856. [Google Scholar] [CrossRef]
- Jiang, P.; Gautam, M.R.; Zhu, J.; Yu, Z. How well do the GCMs/RCMs capture the multi-scale temporal variability of precipitation in the Southwestern United States? J. Hydrol. 2013, 479, 75–85. [Google Scholar] [CrossRef]
- Leathers, D.J.; Yarnal, B.; Palecki, M.A. The Pacific North-American teleconnection pattern and United-States climate 1. Regional temperature and precipitation associations. J. Clim. 1991, 4, 517–528. [Google Scholar] [CrossRef]
- Silverman, D.; Dracup, J.A. Artificial neural networks and long-range precipitation in California. J. Appl. Meteorol. 2000, 39, 57–66. [Google Scholar] [CrossRef]
- Kumar, D.N.; Reddy, M.J.; Maity, R. Regional rainfall forecasting using large scale climate teleconnections and artificial intelligence techniques. J. Intell. Syst. 2007, 16, 307–322. [Google Scholar]
- Iseri, Y.; Dandy, G.C.; Maier, H.R.; Kawamura, A.; Jinno, K. Medium term forecasting of rainfall using artificial neural networks. In Proceedings of the International Congress on Modelling and Simulation, Melbourne, Australia, 12–15 December 2005; pp. 1834–1840. [Google Scholar]
- Hartmann, H.; Becker, S.; King, L. Predicting summer rainfall in the Yangtze River basin with neural networks. Int. J. Climatol. 2008, 28, 925–936. [Google Scholar] [CrossRef]
- Abbot, J.; Marohasy, J. Application of artificial neural networks to rainfall forecasting in Queensland. Australia. Adv. Atmos. Sci. 2012, 29, 717–730. [Google Scholar] [CrossRef]
- Abbot, J.; Marohasy, J. Application of artificial neural networks to forecasting monthly rainfall one year in advance for locations within the Murray Darling basin, Australia. Int. J. Sustain. Dev. Plan. 2017, 12, 1282–1298. [Google Scholar] [CrossRef]
- Badr, H.S.; Zaitchik, B.F.; Guikema, S.D. Application of statistical models to the prediction of seasonal rainfall anomalies over the Sahel. J. Appl. Meteorol. Climatol. 2013, 53, 614–636. [Google Scholar] [CrossRef]
- Rasel, H.M.; Imteaz, M.A.; Hossain, I.; Mekanki, F. Comparative study between linear and non-linear modelling techniques in rainfall forecasting for South Australia. In Proceedings of the International Congress on Modelling and Simulation, Gold Coast, Australia, 29 November–4 December 2015; pp. 2012–2018. [Google Scholar]
- Hong, I.; Lee, J.H.; Cho, H.S. National drought management framework for drought preparedness in Korea (lessons from the 2014–2015 drought). Water Policy 2016, 18, 89–106. [Google Scholar] [CrossRef]
- Peres, D.J.; Iuppa, C.; Cavallaro, L.; Cancelliere, A.; Foti, E. Significant wave height record extension by neural networks and reanalysis wind data. Ocean Model. 2015, 94, 128–140. [Google Scholar] [CrossRef]
- Dawson, C.W.; Wilby, R.L. Hydrological modelling using artificial neural networks. Prog. Phys. Geogr. 2001, 25, 80–108. [Google Scholar] [CrossRef]
- De Vos, N.J.; Rientjes, T.H.M. Constraints of artificial neural networks for rainfall-runoff modelling: Trade-offs in hydrological state representation and model evaluation. Hydrol. Earth Syst. Sci. 2005, 9, 111–126. [Google Scholar] [CrossRef]
- Sumi, S.M.; Zaman, M.F.; Hirose, H. A rainfall forecasting method using machine learning models and its application to the Fukuoka city case. Int. J. Appl. Math. Comput. Sci. 2012, 22, 841–854. [Google Scholar] [CrossRef]
- Singh, S.K.; Jain, S.K.; Bárdossy, A. Training of artificial neural networks using information-rich data. Hydrology 2014, 1, 40–62. [Google Scholar] [CrossRef]
- Kim, T.W.; Valdes, J.B. Nonlinear model for drought forecasting based on a conjunction of wavelet transforms and neural networks. J. Hydrol. Eng. 2003, 8, 319–328. [Google Scholar] [CrossRef]
- Sung, J.Y.; Lee, J.; Chung, I.M.; Heo, J.H. Hourly water level forecasting at tributary affected by main river condition. Water 2017, 9, 644. [Google Scholar] [CrossRef]
- Rumelhart, D.E.; McClenlland, J.L. Foundations. In Parallel Distributed Processing: Explorations in the Microstructure of Cognition; MIT Press: Cambridge, MA, USA, 1986; Volume 1. [Google Scholar]
- Supharatid, S. Application of a neural network model in establishing a stage-discharge relationship for a tidal river. Hydrol. Process. 2003, 17, 3085–3099. [Google Scholar] [CrossRef]
- Stone, M. Cross-validatory choice and assessment of statistical predictions. J. R. Stat. Soc. Ser. B 1974, 36, 111–147. [Google Scholar]
- Rodriguez, J.D.; Perez, A.; Lozano, J.A. Sensitivity analysis of k-fold cross validation in prediction error estimation. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 32, 569–575. [Google Scholar] [CrossRef] [PubMed]
- Garson, G.D. Interpreting neural-network connection weights. AI Expert 1991, 6, 47–51. [Google Scholar]
- Olden, J.D.; Jackson, D.A. Illuminating the ‘‘black box’’: A randomization approach for understanding variable contributions in artificial neural networks. Ecol. Model. 2002, 154, 135–150. [Google Scholar] [CrossRef]
- Pentos, K. The methods of extracting the contribution of variables in artificial neural network models-Comparison of inherent instability. Comput. Electron. Agric. 2016, 127, 141–146. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Climate Index | Description | Time Lag (months) | Correlation Coefficient |
|---|---|---|---|
| AO | The first leading mode from the Empirical Orthogonal Function (EOF) analysis of monthly mean height anomalies at 1000-hPa | 10 | 0.196 |
| EP/NP | A Spring–Summer–Fall pattern with three main anomaly centers | 6 | 0.326 |
| EA | The second prominent mode of low-frequency variability over the North Atlantic, and appears as a leading mode in all months | 7 | −0.294 |
| NAO | One of the most prominent teleconnection patterns in all seasons is the North Atlantic Oscillation | 5 | −0.375 |
| NTA | The timeseries of SST anomalies averaged over 60W to 20W, 6N to 18N and 20W to 10W, 6N to 10N | 4 | 0.255 |
| TNA | Anomaly of the average of the monthly SST from 5.5N to 23.5N and 15W to 57.5W | 10 | 0.225 |
| WP | A primary mode of low-frequency variability over the North Pacific in all months | 4 | −0.202 |
| PDO | Pacific Decadal Oscillation is the leading principal component (PC) of monthly SST anomalies in the North Pacific Ocean | 11 | 0.200 |
| SOI | The development and intensity of El Niño or La Niña events in the Pacific Ocean, calculated using the pressure differences between Tahiti and Darwin | 10 | 0.183 |
| SLP_D | Sea Level Pressure at Darwin | 10 | −0.209 |
| GEUM | Areal average monthly precipitation for the Geum River basin | 7 | −0.195 |
| Number of Hidden Nodes | RRMSE (%) | CC | ||||
|---|---|---|---|---|---|---|
| Training | Validation | Testing | Training | Validation | Testing | |
| 2 | 29.75 | 35.60 | 34.46 | 0.757 | 0.459 | 0.723 |
| 3 | 30.51 | 35.62 | 34.51 | 0.747 | 0.457 | 0.735 |
| 4 | 30.43 | 35.52 | 34.41 | 0.742 | 0.460 | 0.733 |
| 5 | 30.46 | 35.67 | 34.28 | 0.740 | 0.455 | 0.743 |
| 6 | 30.89 | 35.68 | 34.49 | 0.736 | 0.454 | 0.740 |
| 7 | 31.32 | 35.73 | 34.75 | 0.733 | 0.455 | 0.743 |
| 8 | 30.95 | 35.72 | 34.47 | 0.734 | 0.453 | 0.743 |
| 9 | 31.54 | 35.71 | 34.88 | 0.731 | 0.454 | 0.743 |
| 10 | 31.23 | 35.72 | 34.66 | 0.731 | 0.453 | 0.742 |
| Category | Below Normal | Near Normal | Above Normal | Total |
|---|---|---|---|---|
| Hit | 9 | 14 | 8 | 31 |
| Fail | 7 | 6 | 6 | 19 |
| Total | 16 | 20 | 14 | 50 |
| Hit Score (%) | 56.3 | 70.0 | 57.1 | 62.0 |
| Number of Hidden Nodes | RRMSE (%) | CC | ||||
|---|---|---|---|---|---|---|
| Training | Validation | Testing | Training | Validation | Testing | |
| 2 | 25.84 | 32.72 | 34.75 | 0.771 | 0.614 | 0.623 |
| 3 | 25.87 | 33.10 | 34.57 | 0.770 | 0.613 | 0.630 |
| 4 | 26.70 | 33.46 | 34.04 | 0.764 | 0.610 | 0.655 |
| 5 | 26.24 | 33.51 | 34.23 | 0.763 | 0.608 | 0.646 |
| 6 | 26.18 | 34.79 | 34.11 | 0.764 | 0.584 | 0.656 |
| 7 | 25.66 | 33.83 | 34.78 | 0.774 | 0.609 | 0.624 |
| 8 | 25.80 | 33.92 | 34.66 | 0.771 | 0.607 | 0.630 |
| 9 | 25.76 | 34.03 | 34.72 | 0.772 | 0.606 | 0.625 |
| 10 | 25.77 | 34.11 | 34.76 | 0.772 | 0.604 | 0.627 |
| Category | Below Normal | Near Normal | Above Normal | Total |
|---|---|---|---|---|
| Hit | 12 | 12 | 9 | 33 |
| Fail | 4 | 8 | 5 | 17 |
| Total | 16 | 20 | 14 | 50 |
| Hit Score (%) | 75.0 | 60.0 | 64.3 | 66.0 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lee, J.; Kim, C.-G.; Lee, J.E.; Kim, N.W.; Kim, H. Application of Artificial Neural Networks to Rainfall Forecasting in the Geum River Basin, Korea. Water 2018, 10, 1448. https://doi.org/10.3390/w10101448
Lee J, Kim C-G, Lee JE, Kim NW, Kim H. Application of Artificial Neural Networks to Rainfall Forecasting in the Geum River Basin, Korea. Water. 2018; 10(10):1448. https://doi.org/10.3390/w10101448
Chicago/Turabian StyleLee, Jeongwoo, Chul-Gyum Kim, Jeong Eun Lee, Nam Won Kim, and Hyeonjun Kim. 2018. "Application of Artificial Neural Networks to Rainfall Forecasting in the Geum River Basin, Korea" Water 10, no. 10: 1448. https://doi.org/10.3390/w10101448
APA StyleLee, J., Kim, C.-G., Lee, J. E., Kim, N. W., & Kim, H. (2018). Application of Artificial Neural Networks to Rainfall Forecasting in the Geum River Basin, Korea. Water, 10(10), 1448. https://doi.org/10.3390/w10101448