Prediction of Water Utility Performance: The Case of the Water Efficiency Rate


Abstract
:1. Introduction
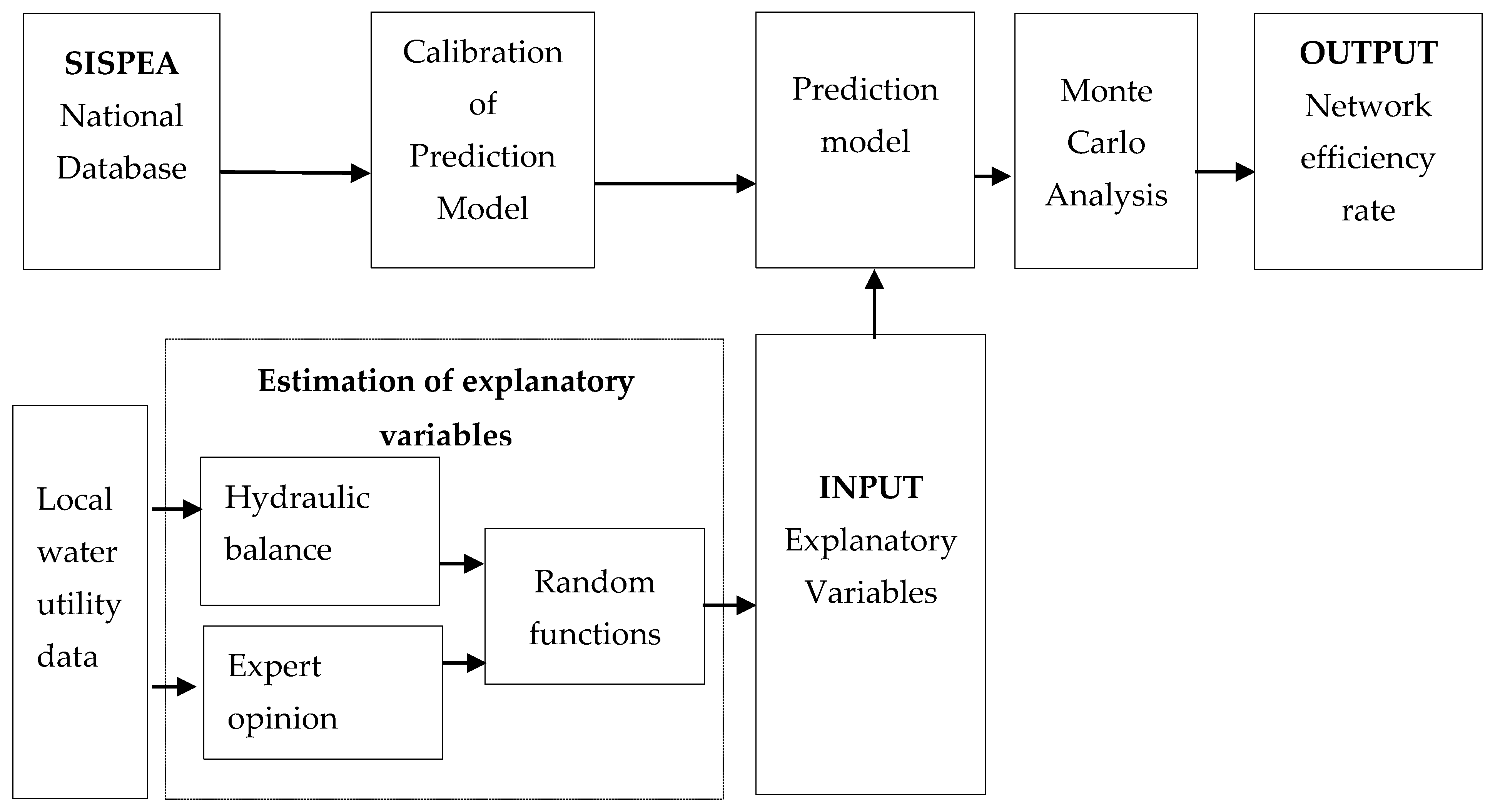
- National analysis trend by training ANN and MRA on a set of mandatory performance indicators of more than 12,000 water utilities for the last decade (2006–2016) gathered into a national French database “SISPEA”. Performance indicators are considered as inputs to predict efficiency. Several simulations are required to define the number of layers, neurons of the ANN and to match the effective set of input indicator that increases the accuracy of the prediction model both for ANN and MRA.
- Local analysis by estimating the trend of performance indicators considered as inputs in the previous analysis. Estimation of inputs is done by dedicated mathematical functions and using Monte Carlo analysis involving expert opinion for a specific set of parameters.
2. Materials and Methods
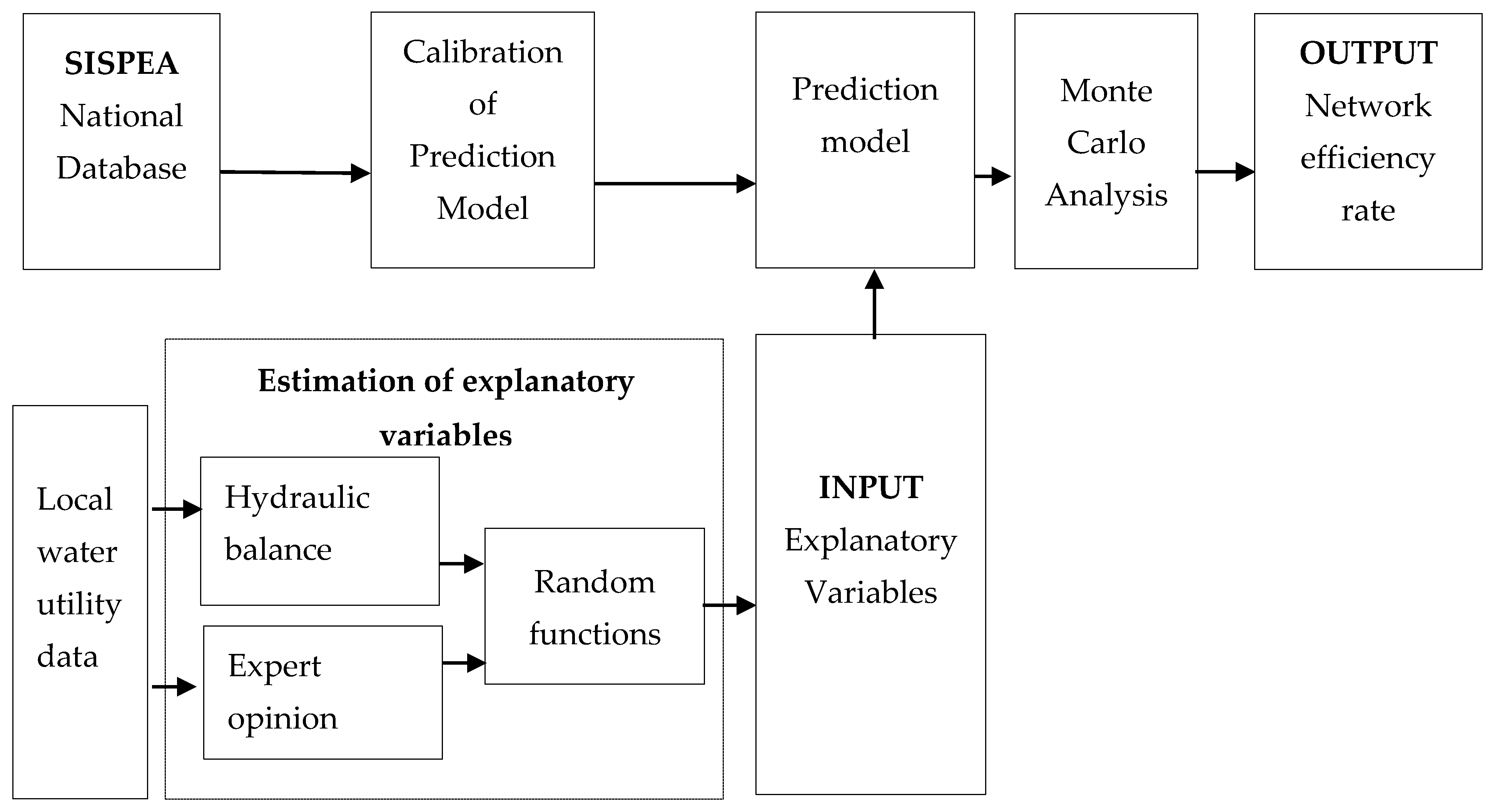
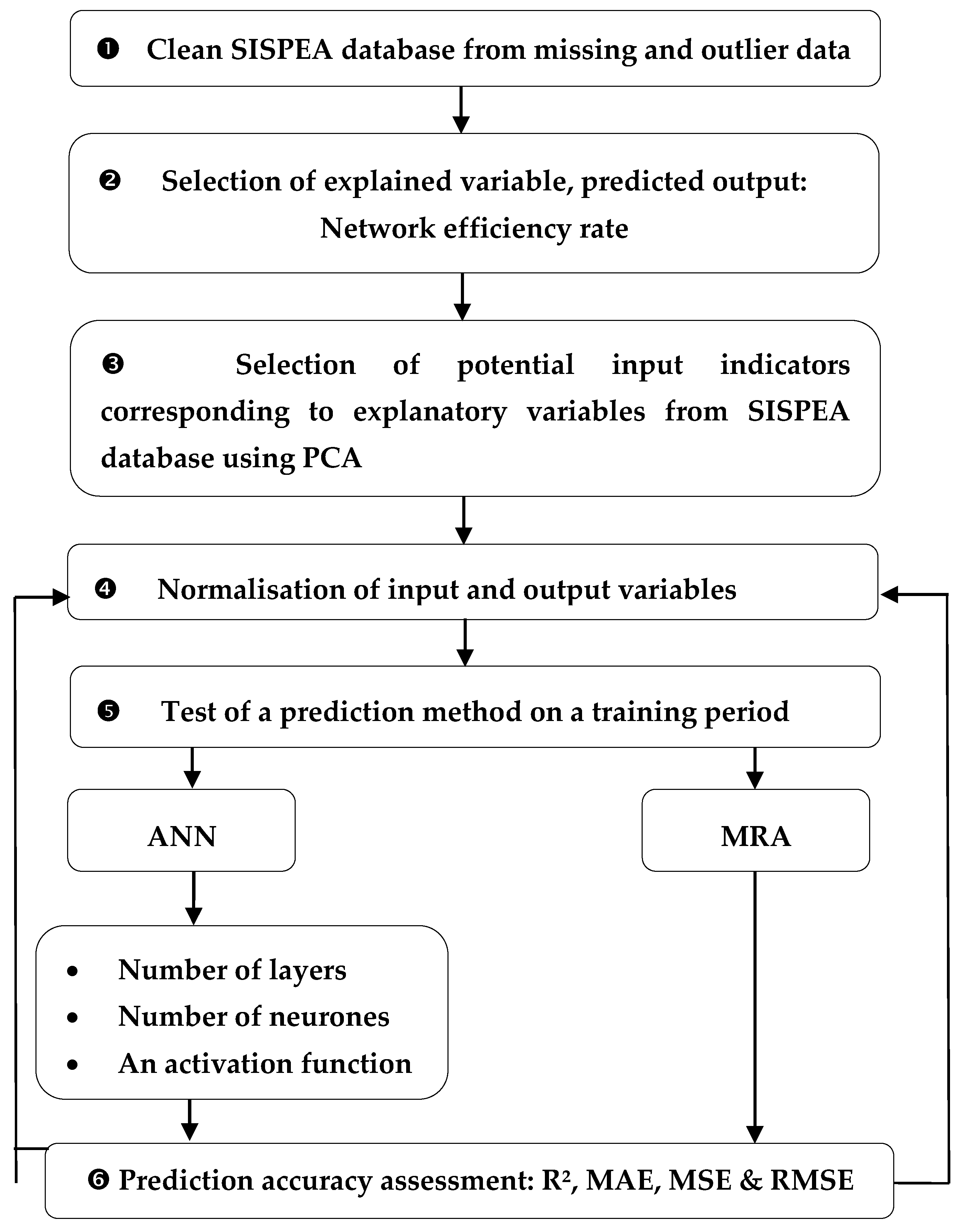
2.1. Calibration of the Prediction Model: National Analysis
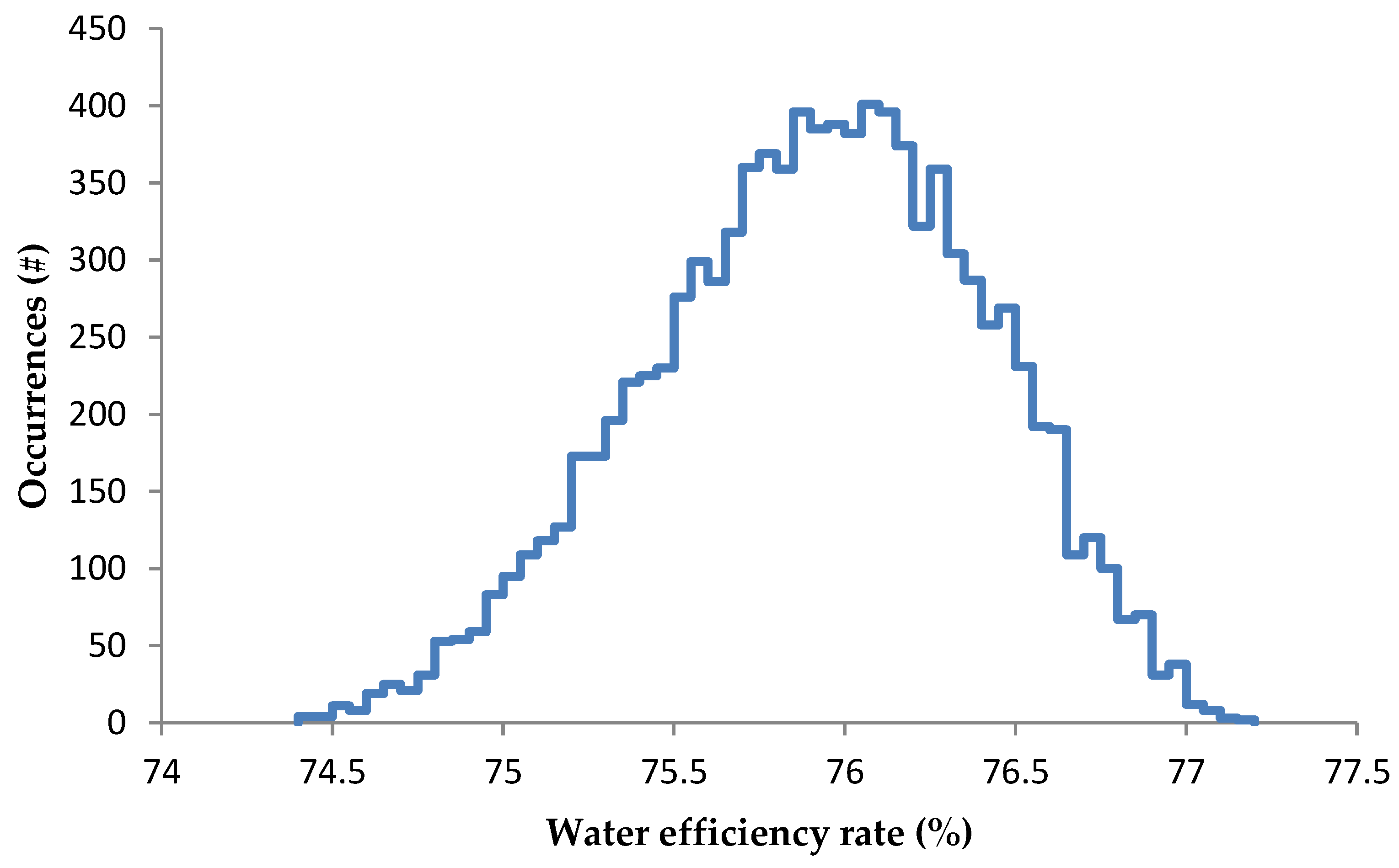
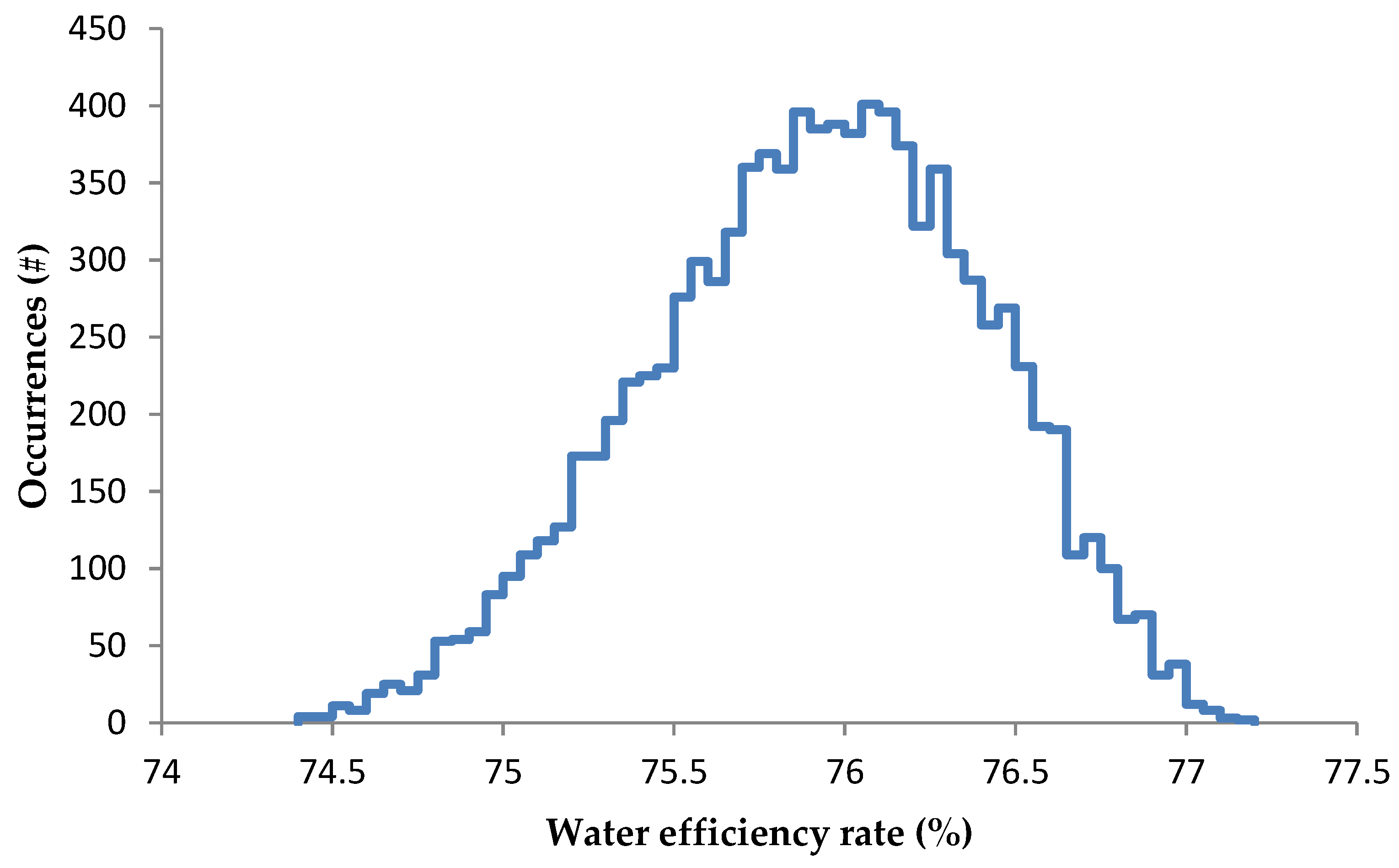
2.1.1. Predicted Output: The Water Efficiency Rate
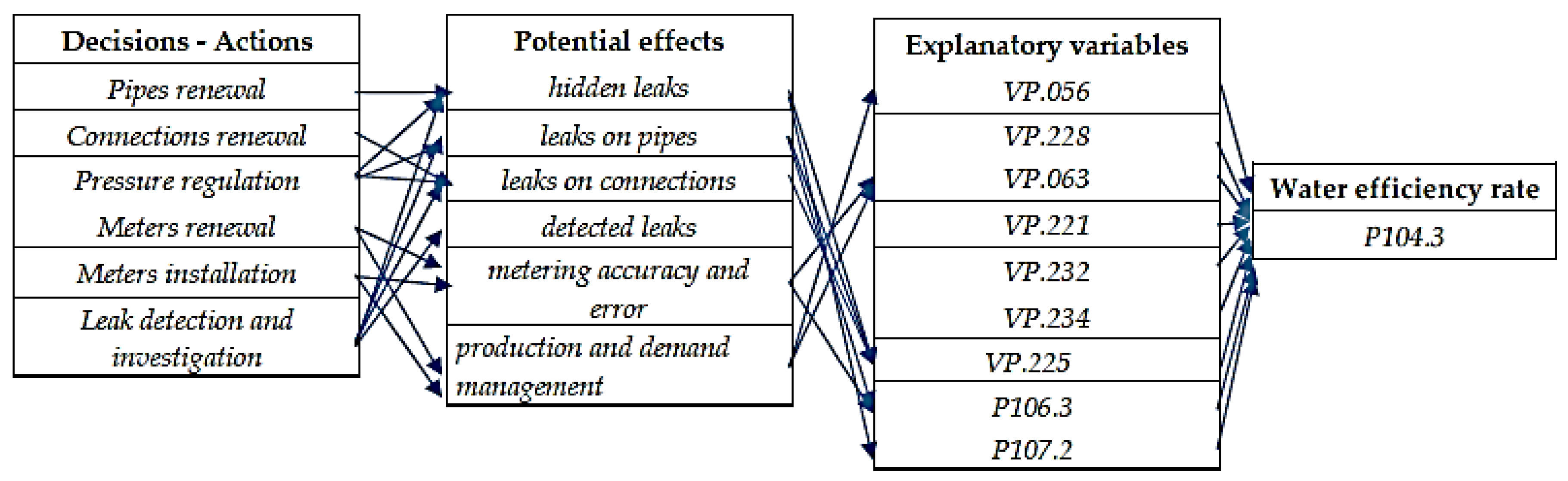
2.1.2. Selection of Explanatory Variables
- Crep: unit cost of a leak reparation in € per unit.
- Cdet: unit cost in € per km
- nc: number of leaks on connections per year
- np: number of leaks on pipes per year
- nd: number of leaks detected by leak detection
- Ccon: unit cost of a connection renewal in € per unit
- Cp: unit cost of pipe renewal in € per km
- lnet: length of the network
- rc: annual connections renewal rate in percentage per year
- rp: annual renewal rate in percentage of length renewed per year
2.1.3. Normalization of Variables
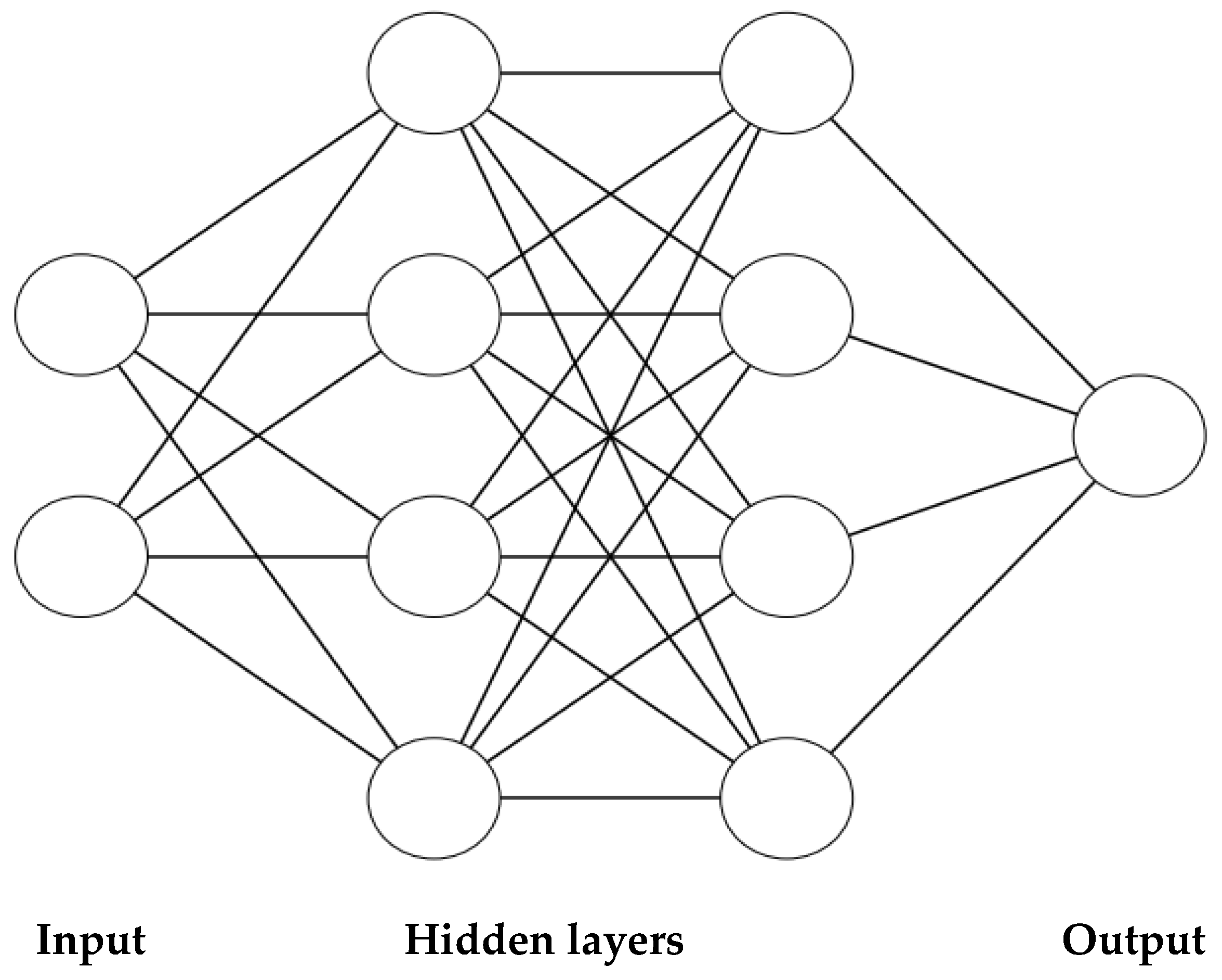
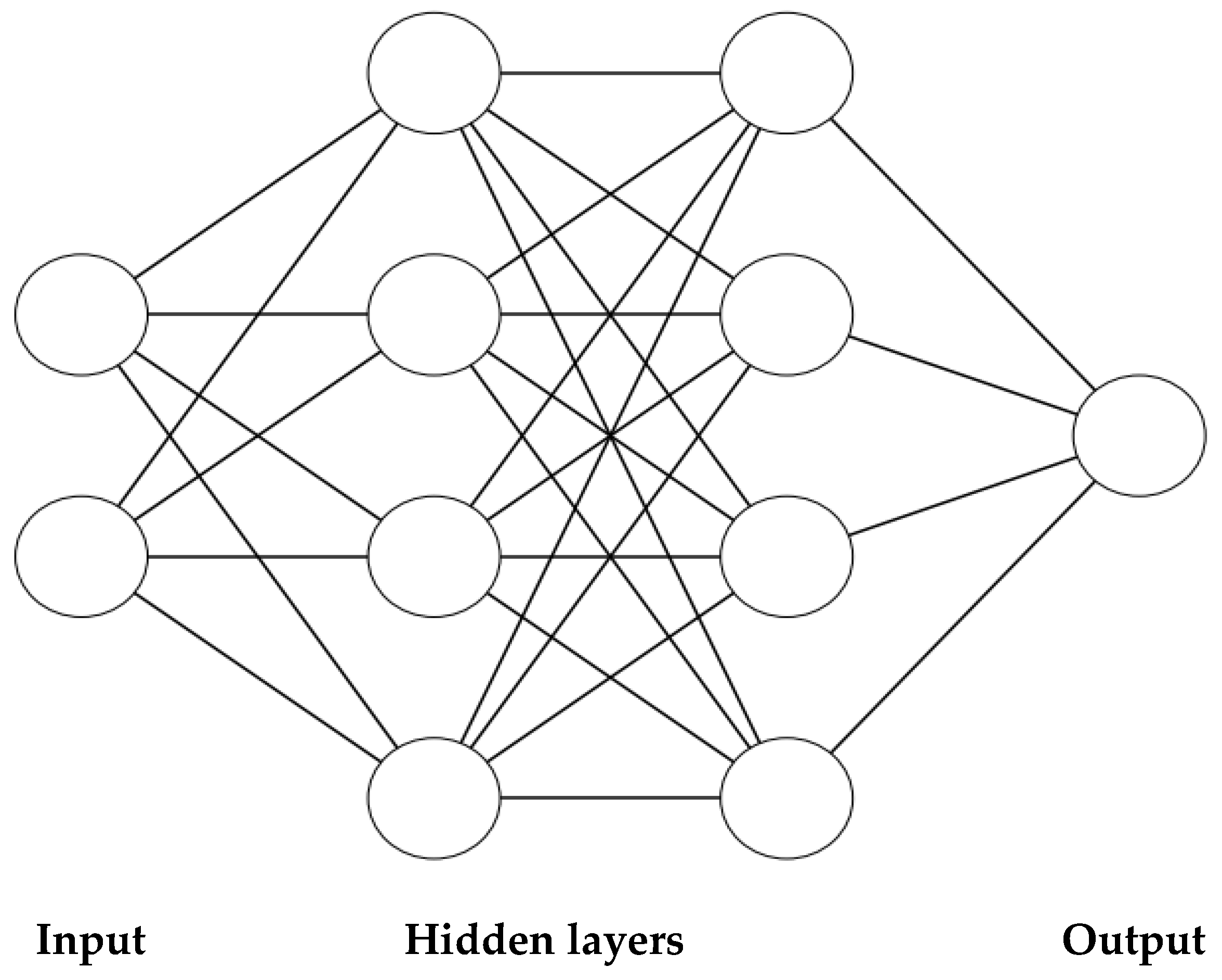
2.1.4. Prediction Method: Multiple Regression Analysis (MRA) and Artificial Neural Network (ANN)
- Y: vector of explained variables (output);
- X: vector of explanatory variables (input);
- β: variables coefficients;
- ε0: vector of error estimation.
- The assumption that no variables are explanatory for the regression. This hypothesis is tested with an F-test. The F value must exceed a critical value in order to reject the hypothesis.
- The assumption that the true coefficient of an explanatory variable is zero. This hypothesis is tested by computing the p-value. If p-value is greater than 0.05, the hypothesis is rejected and therefore the variable has an explanatory effect.
- The logistic function that is often preferred with Equation (8):
- The hyperbolic tangent function (tanh) that can sometimes lead to better results than the logistic function [15] with Equation (8):
- The rectified linear unit function (ReLU), the expression of which is given by Equation (10):
- The identity function, the expression of which is defined by Equation (11):
- n the number of input values;
- the value of input i;
- the mean of the input values.
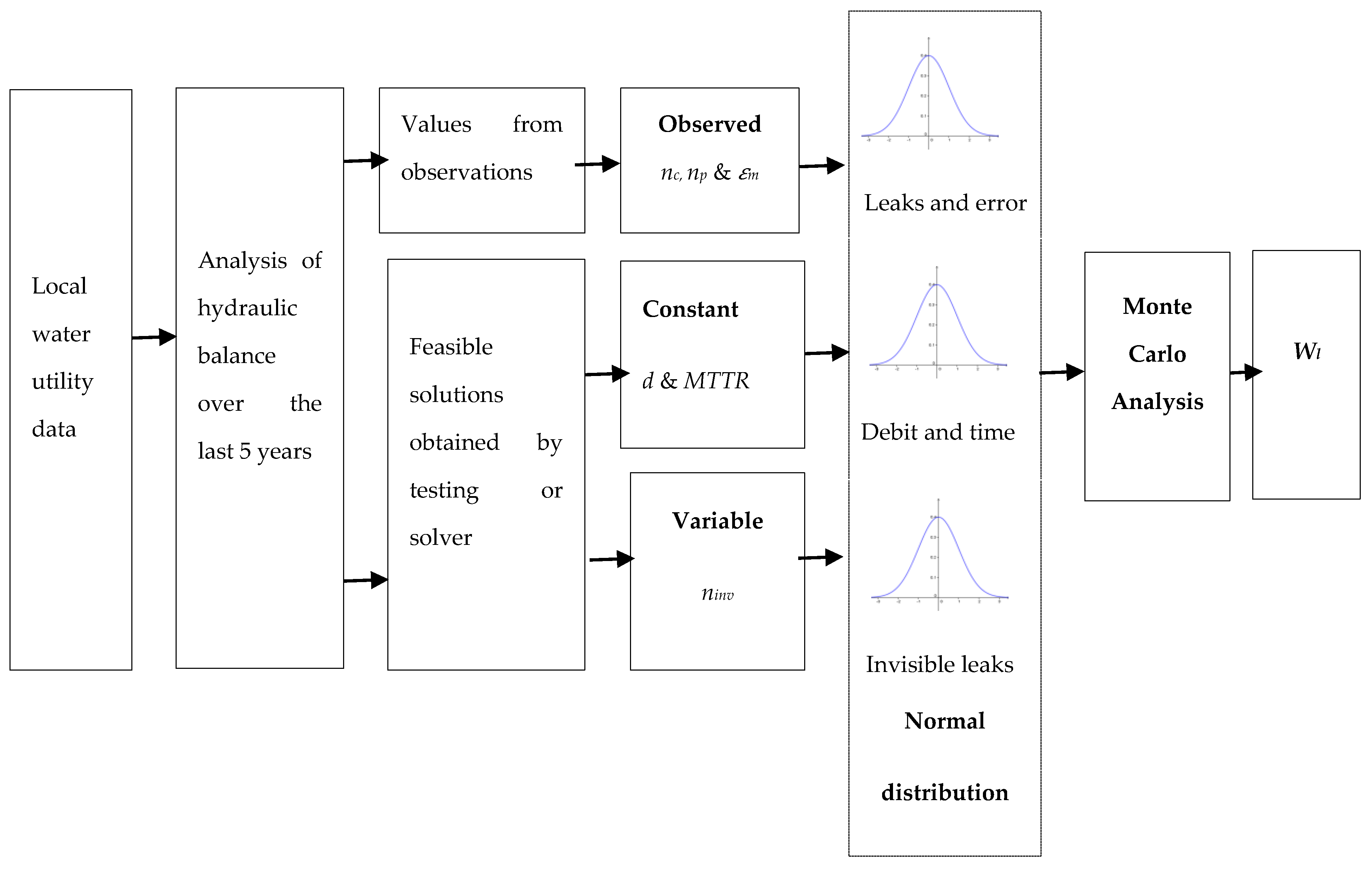
2.2. Estimation of Explanatory Variables
2.2.1. Random Generation
2.2.2. Hydraulic Balance
- Real losses are due to visible leaks observed on pipes, connections and other hydraulic components. Hidden leaks are detected with leaks detection techniques.
- Debit for visible leak is higher than for hidden leak
- Renewal, maintenance and reparation actions contribute to water loss reduction
- Metering error should be considered in the hydraulic balance because it artificially increases water losses.
- Water losses depend highly on hidden leaks that should be estimated
- Mean time to repair (MTTR) is considered as one of the key parameters for water loss reduction.
3. Case Study
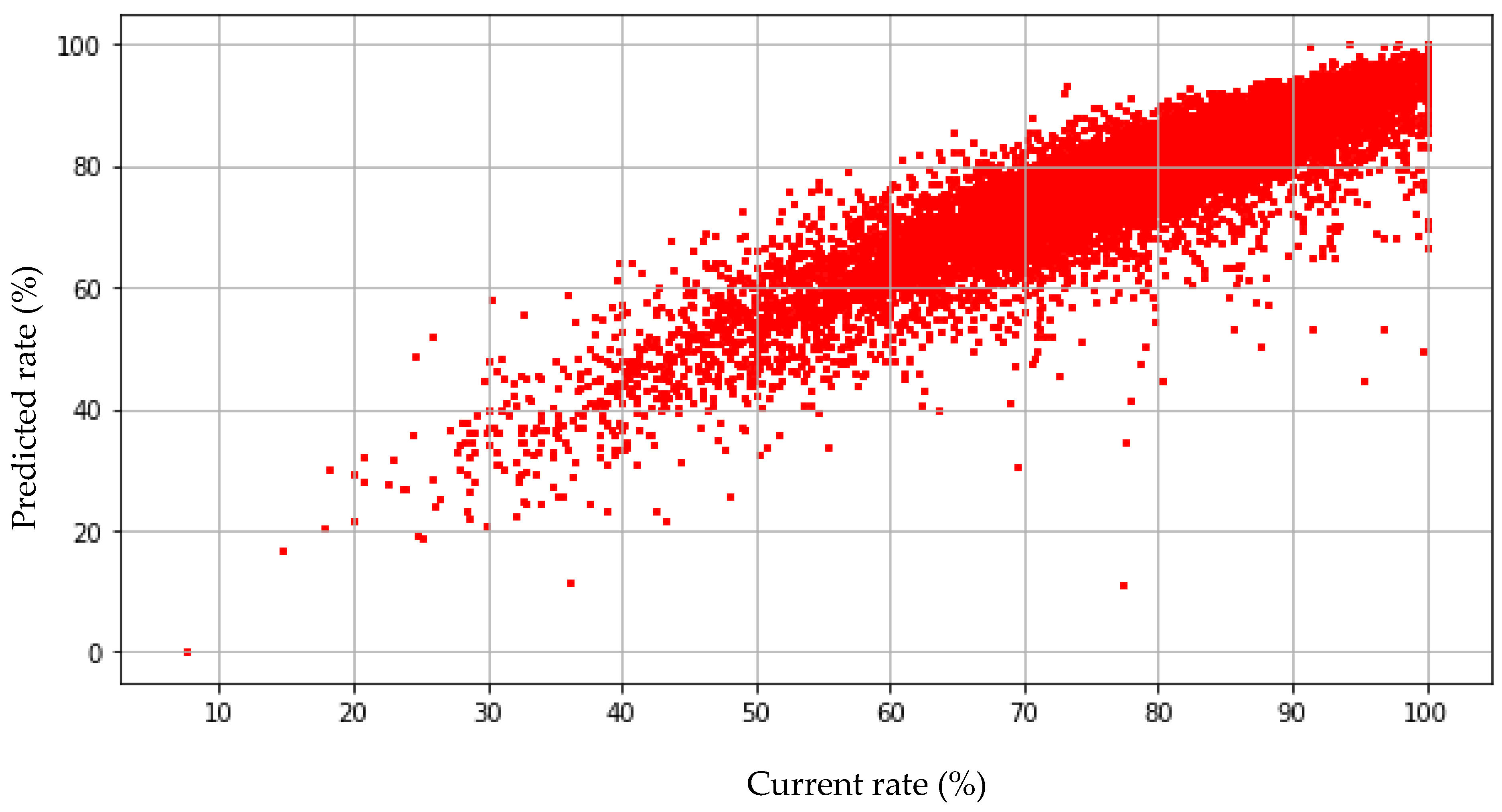
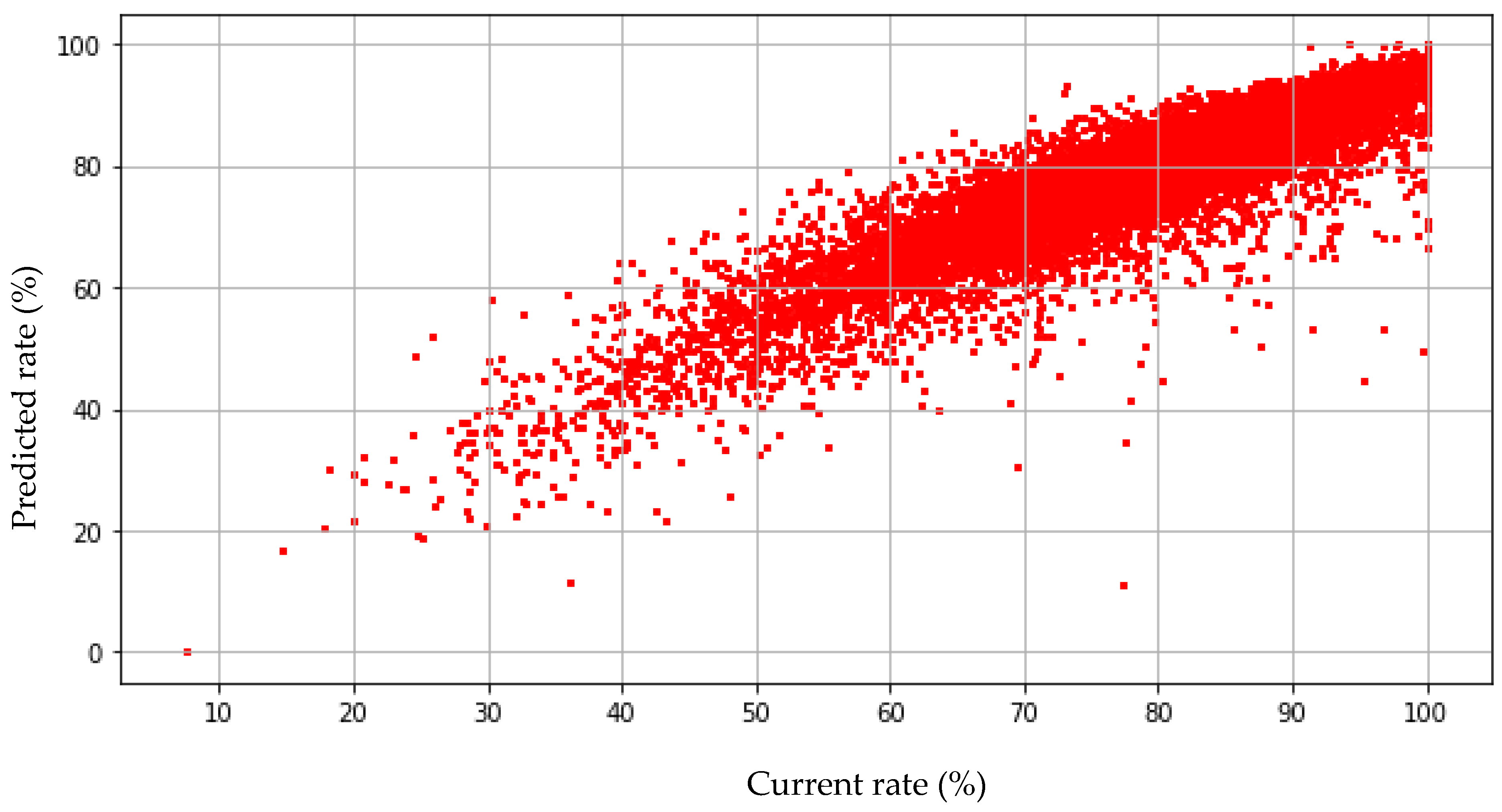
3.1. Multiple Regression Analysis
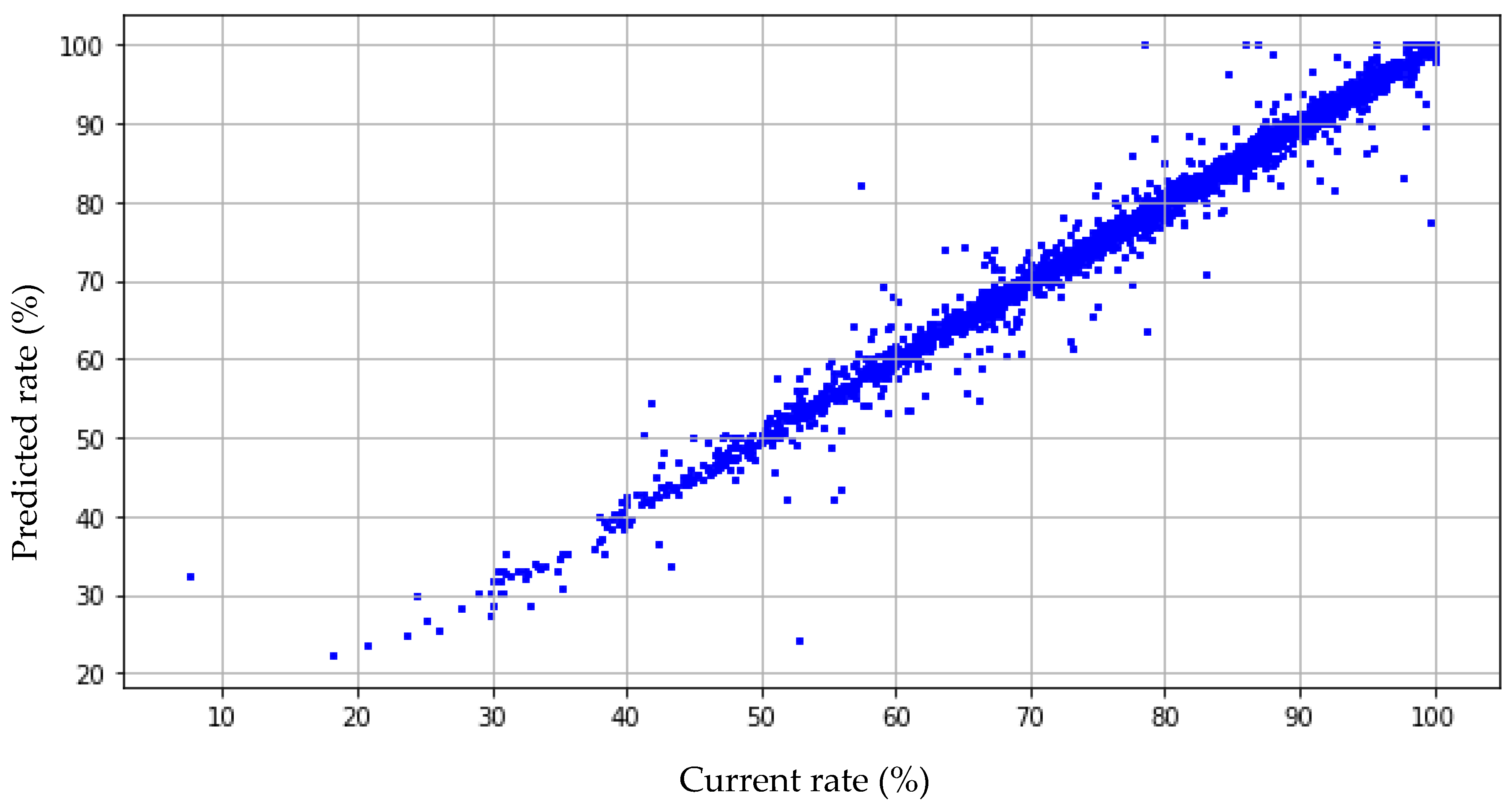
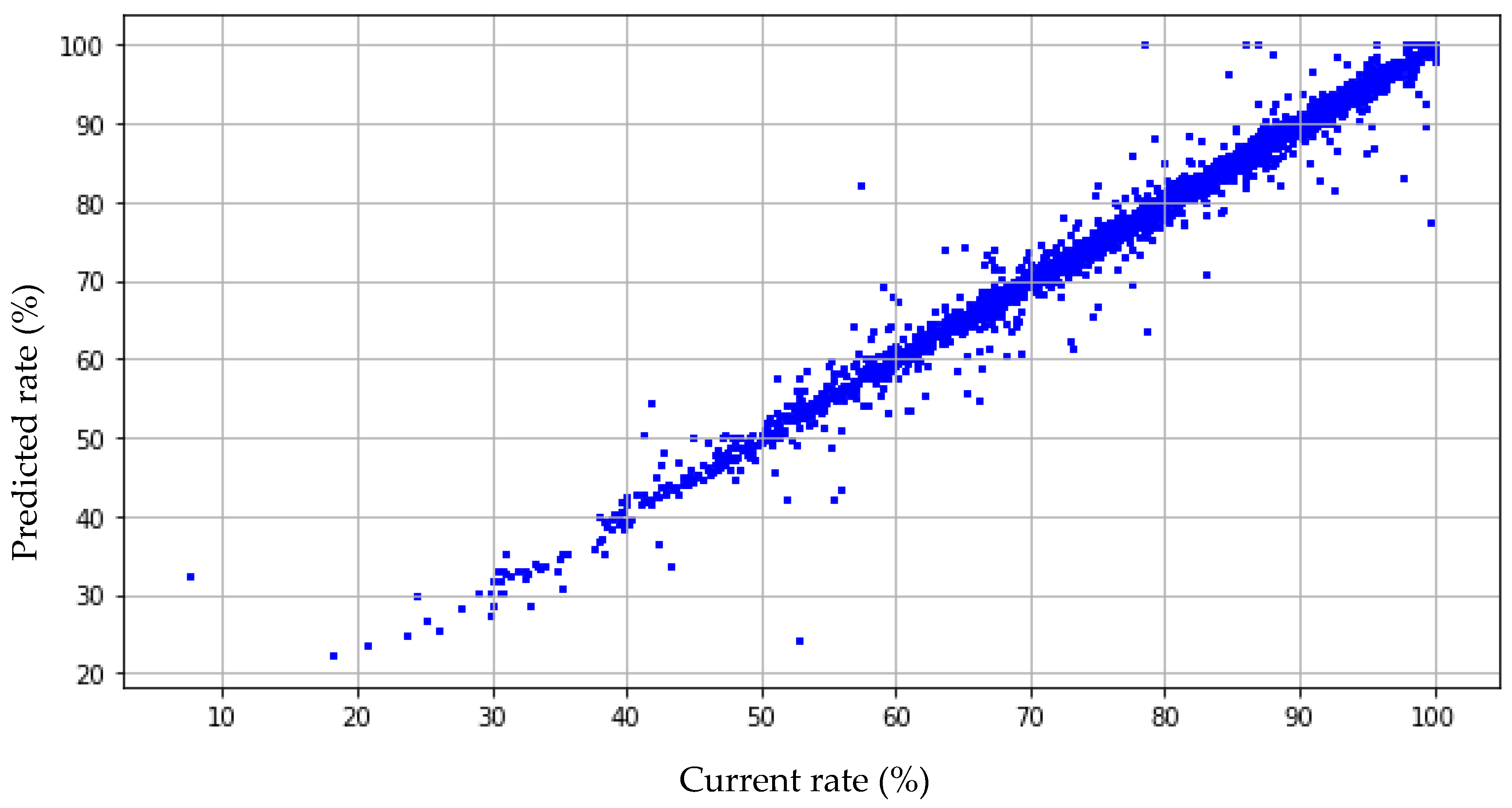
3.2. Artificial Neural Network Calibration
3.3. Estimation of Explanatory Variables
4. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Adedeji, K.; Hamam, Y.; Abe, B.; Abu-Mahfouz, A. Leakage Detection and Estimation Algorithm for Loss Reduction in Water Piping Networks. Water 2017, 9, 773. [Google Scholar] [CrossRef]
- Colombo, A.; Karney, B. Energy and Costs of Leaky Pipes: Toward Comprehensive Picture. J. Water Resour. Plan. Manag. 2002, 128, 441–450. [Google Scholar] [CrossRef]
- Salvetti, M. The network efficiency rate: A key performance indicator for water services asset management? In Proceedings of the 7th IWA International Conference on Efficient Use and Management of Water (Efficient 2013), Paris, France, 22–25 October 2013. [Google Scholar]
- Candelieri, A.; Archetti, F.; Messina, E. Improving leakage management in urban water distribution networks through data analytics and hydraulic simulation. WIT Trans. Ecol. Environ. 2013, 171, 107–117. [Google Scholar] [Green Version]
- Xin, K.; Tao, T.; Lu, Y.; Xiong, X.; Li, F. Apparent Losses Analysis in District Metered Areas of Water Distribution Systems. Water Resour. Manag. 2014, 28, 683–696. [Google Scholar] [CrossRef]
- Jang, D.; Choi, G. Estimation of Non-Revenue Water Ratio Using MRA and ANN in Water Distribution Networks. Water 2017, 10, 2. [Google Scholar] [CrossRef]
- Jang, D.; Park, H.; Choi, G. Estimation of Leakage Ratio Using Principal Component Analysis and Artificial Neural Network in Water Distribution Systems. Sustainability 2018, 10, 750. [Google Scholar] [CrossRef]
- Shirzad, A.; Tabesh, M.; Farmani, R. A comparison between performance of support vector regression and artificial neural network in prediction of pipe burst rate in water distribution networks. KSCE J. Civ. Eng. 2014, 18, 941–948. [Google Scholar] [CrossRef]
- Jafar, R.; Shahrour, I.; Juran, I. Application of Artificial Neural Networks (ANN) to model the failure of urban water mains. Math. Comput. Model. 2010, 51, 1170–1180. [Google Scholar] [CrossRef]
- Tabesh, M.; Soltani, J.; Farmani, R.; Savic, D. Assessing pipe failure rate and mechanical reliability of water distribution networks using data-driven modeling. J. Hydroinform. 2009, 11, 1–17. [Google Scholar] [CrossRef] [Green Version]
- Nishiyama, M.J. Forecasting Water Main Failures in the City of Kingston Using Artificial Neural Networks; Department of Civil Engineering, Queen’s University: Kingston, ON, Canada, 2013; 105p. [Google Scholar]
- Kutylowska, M. Prediction of failure frequency of water-pipe network in the selected city. Period. Polytech. Civ. Eng. 2017, 61, 548–553. [Google Scholar] [CrossRef]
- Kamiński, K.; Kamiński, W.; Mizerski, T. Application of Artificial Neural Networks to the Technical Condition Assessment of Water Supply Systems. Ecol. Chem. Eng. S 2017, 24, 31–40. [Google Scholar] [CrossRef] [Green Version]
- Rojek, I.; Studziński, J. Comparison of different types of neuronal nets for failures location within water-supply networks. Maint. Reliab. 2014, 16, 42–47. [Google Scholar]
- Gholami, V.; Sebghati, M.; Yousefi, Z. Integration of artificial neural network and geographic information system applications in simulating groundwater quality. Environ. Health Eng. Manag. J. 2016, 3, 173–182. [Google Scholar] [CrossRef] [Green Version]
- Giustolisi, O.; Simeone, V. Optimal design of artificial neural networks by a multi-objective strategy: Groundwater level predictions. Hydrol. Sci. J. 2006, 51, 502–523. [Google Scholar] [CrossRef]
- Rahmati, S.H.; Haddad, O.B.; Sedghi, H. and Babazadeh, H. A comparison of anfis, ann, arma & multivariable regression methods for urban water-consumption forecasting, considering impacts of climate change: A case study on Tehran mega city. Indian J. Sci. Res. 2014, 7, 870–880. [Google Scholar]
- Makaya, E.; Hensel, O. Modelling flow dynamics in water distribution networks using artificial neural networks—A leakage detection technique. Int. J. Eng. Sci. Technol. 2016, 7, 33–43. [Google Scholar] [CrossRef]
- Berg, S.; Padowski, J.C. Overview of Water Utility Benchmarking Methodologies: From Indicators to Incentives; Public Utility Research Center, University of Florida: Gainesville, FL, USA, 2007; Available online: http://warrington.ufl.edu/centers/purc/purcdocs/papers/0712_Berg_Overview_of_Water.pdf (accessed on September 2018).
- Osmo, T.S. Performance benchmarking in Nordic water utilities. Procedia Econ. Financ. 2015, 21, 399–406. [Google Scholar] [CrossRef]
- Nafi, A.; Tcheng, J.; Beau, P. Comprehensive Methodology for Overall Performance Assessment of Water Utilities. Water Resour. Manag. 2015, 29, 5429–5450. [Google Scholar] [CrossRef]
- Hornik, K.; Stinchcombe, M.; White, H. Multilayer feedforward networks are universal approximators. Neural Netw. 1989, 2, 359–366. [Google Scholar] [CrossRef]
- Hsu, K.; Gupta, H.V.; Sorooshian, S. Artificial Neural Network Modeling of the Rainfall-Runoff Process. Water Resour. Res. 1995, 31, 2517–2530. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Leakage Management Actions | SISPEA Code | Explanatory Variables—Indicators | Explained Variable—Target |
|---|---|---|---|
| Metering and metering error | VP.056 | Number of users | Network efficiency rate (P104.3) |
| VP.228 | Linear density of users | ||
| VP.063 | Billed metered domestic consumption | ||
| VP.221 | Volume of unmetered consumption | ||
| VP.232 | Billed metered consumption | ||
| VP.234 | Volume produced + Volume imported | ||
| Leakage and water losses | VP.225 | Average network efficiency rate over 3 last years | |
| P106.3 | Linear leakage index on distribution mains | ||
| Pipes renewal | P107.2 | Average renewal rate of water mains over the 5 last years |
| SISPEA Code | Explanatory Variables—Indicators | Function | Type | Unit | Range of Variation |
|---|---|---|---|---|---|
| VP.056 | Number of users | Uniform | Discrete | # | Depends on past trend and potential evolution of the demand and water uses |
| VP.228 | Linear density of users | Ratio | Continuous | #/km | |
| VP.063 | Billed metered domestic consumption | Uniform | Continuous | m3 | Depends on past trend and potential evolution of the demand and water uses |
| VP.221 | Volume of unmetered consumption | Uniform | Continuous | m3 | Depends on the improvement or decrease of metering accuracy, actions in terms of leakage management or meters renewal or installation. |
| VP.232 | Billed metered consumption | Uniform | Continuous | m3 | Depends on past trend and potential evolution of the demand and water uses |
| VP.234 | Volume produced + Volume imported | Uniform | Continuous | m3 | Depends on production capacities, demand evolution and water importation evolution |
| VP.225 | Average network efficiency rate over 3 last years | Mean ratio | Continuous | % | Observation over the last 3 years |
| P107.2 | Average renewal rate of water mains over the 5 last years | Mean ratio | Continuous | % | Observation over the last 5 years |
| Symbol | Definition of the Variable | Unit |
|---|---|---|
| Wd | Annual volume of distributed water | m3 |
| Wb | Annual volume of billed water | m3 |
| Wl | Annual volume of water loss (real) | m3 |
| Wp | Annual volume of produced water | m3 |
| Wimp | Annual volume of imported water | m3 |
| Wexp | Annual volume of exported water | m3 |
| Waut | Annual volume of authorized unbilled consumption | m3 |
| Wser | Annual Volume of unbilled water for service | m3 |
| Wnon aut | Annual volume of unauthorized water | m3 |
| np | Number of breaks/leaks on pipes per year | # |
| nc | Number of breaks/leaks on connections per year | # |
| Lnet | Network length (without length of connections) | # |
| nc | Number of connections | |
| ninv | Number of hidden leaks per year | # |
| dp | Average debit for a leak on pipe | L/s |
| dc | Average debit for leak on connection | L/s |
| d | Average debit for hidden leak | L/s |
| MTTRvl | Mean Time to repair visible leak | S |
| MTTRinv | Mean time to repair hidden leaks | S |
| rd | Efficiency ratio of leak detection (number of detected leaks per km) | #/km of investigation |
| rp | Water pipes annual renewal rate | % |
| rc | Connections annual renewal rate | % |
| rb | Pipes breakage rate | #/km |
| Crep | Cost of pipe or connection reparation | € per reparation |
| Cp | Cost of pipe renewal | €/km |
| Cc | Cost of connection reparation | € per reparation |
| Cdet | Cost of leak detection | € /km of leak detection |
| εm | Metering error in percentage or in volume | % or m3 |
| Variables | Mean | Standard Deviation |
|---|---|---|
| VP.056 | 5.28 × 105 | 3.26 × 106 |
| VP.228 | 8.33 × 105 | 4.50 × 106 |
| VP.063 | 5.36 × 104 | 4.43 × 105 |
| VP.221 | 2.49 × 102 | 7.07 × 103 |
| VP.232 | 4.00 × 103 | 1.66 × 104 |
| VP.234 | 3.08 × 10 | 2.16 × 10 |
| VP.225 | 5.82 × 105 | 3.51 × 106 |
| P106.3 | 0.35 × 10 | 0.48 × 10 |
| Accuracy Indicator | MAE | MSE | R2 |
|---|---|---|---|
| MRA | 3.921 | 31.101 | 0.805 |
| Activation Function | Hidden Layer | Number of Neurons | MAE | MSE | R2 |
|---|---|---|---|---|---|
| Identity | Single layer | 18 | 4.038 | 32.771 | 0.798 |
| Rectified linear unit | Single layer | 18 | 2.035 | 9.470 | 0.942 |
| Hyperbolic tangent | Single layer | 18 | 1.312 | 6.879 | 0.958 |
| Logistic | Single layer | 18 | 1.382 | 6.695 | 0.959 |
| Hidden Layer | Number of Neurons | MAE | MSE | R2 |
|---|---|---|---|---|
| Single layer | 9 | 1.689 | 7.719 | 0.952 |
| Single layer | 18 | 1.382 | 6.695 | 0.959 |
| Single layer | 36 | 1.215 | 5.764 | 0.965 |
| Single layer | 72 | 1.269 | 6.738 | 0.959 |
| Multiple layer | (9, 9) | 1.200 | 4.334 | 0.973 |
| Multiple layer | (18, 18) | 1.027 | 3.575 | 0.978 |
| Multiple layer | (36, 36) | 0.775 | 3.025 | 0.981 |
| Multiple layer | (72, 72) | 0.810 | 4.614 | 0.972 |
| Multiple layer | (18, 9) | 0.910 | 3.320 | 0.980 |
| Multiple layer | (9, 18) | 1.116 | 4.314 | 0.973 |
| Multiple layer | (36, 18) | 0.808 | 3.322 | 0.980 |
| Multiple layer | (18, 36) | 0.848 | 5.120 | 0.968 |
| Multiple layer | (72, 36) | 0.859 | 6.691 | 0.980 |
| Multiple layer | (36, 72) | 0.835 | 5.268 | 0.968 |
| Year | Observed (%) | Predicted-MRA (%) | Predicted-ANN (%) |
|---|---|---|---|
| 2010 | 65.9 | 63.0 | 65.7 |
| 2011 | 63.2 | 61.7 | 62.4 |
| 2012 | 61.4 | 60.2 | 60.7 |
| 2013 | 75.0 | 67.6 | 75.1 |
| 2014 | 75.1 | 71.2 | 75.1 |
| 2015 | 76.9 | 75.6 | 76.8 |
| 2016 | 76.6 | 76.5 | 76.6 |
| Accuracy Indicators | MRA | ANN |
|---|---|---|
| R2 | 0.745 | 0.991 |
| MAE | 2.185 | 0.407 |
| MSE | 10.030 | 0.339 |
| RMSE | 3.167 | 0.582 |
| Variables | Year N | Past Trend | Expert Opinion | Estimation |
|---|---|---|---|---|
| np | 10 | +20% | [−20%; +20%] | Uniform distribution (Discrete) |
| nc | 18 | −6% | [−15%; +20%] | Uniform distribution (Discrete) |
| dp | 5 m3/h | +1% | [−10%; +10%] | Uniform distribution (Continuous) |
| dc | 3 m3/h | −5% | [−10%; +10%] | Uniform distribution (Continuous) |
| MTTRvl | 24 h | −43% | [−50%; −10%] | Uniform distribution (Continuous) |
| Leakage Management Actions | SISPEA Code | Explanatory Variables—Indicators | Average | Expert Opinion | Estimation |
|---|---|---|---|---|---|
| Metering and metering error | VP.056 | Number of users | 6377 | [0%; +1%] | Uniform distribution function |
| VP.228 | Linear density of users | 78.53 | [−5%; 0%] | Uniform distribution function | |
| VP.063 | Billed metered domestic consumption | 660,831 | [−10%; −5%] | Uniform distribution function | |
| VP.221 | Volume of unmetered consumption | 1511 | [−20%; −15%] | Uniform distribution function | |
| VP.232 | Billed metered consumption | 687,259 | [0%; 10%] | Uniform distribution function | |
| VP.234 | Volume produced + Volume imported | 1,047,827 | [0%; +20%] | Uniform distribution function | |
| Leakage and water losses | VP.225 | Average network efficiency rate over the last 3 years. | 75.67% | Average value | |
| P106.3 | Linear leakage index on distribution mains | 7.64 | [−10%; −5%] | Uniform distribution function | |
| Pipes renewal | P107.2 | Average renewal rate of water mains over the last 5 years | 0.71% | [−100%; −90%] | Uniform distribution function |
| Decisions | Cost and Benefit | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| Leak Detection | Pipe Renewal | Connections Renewal Rate | Efficiency Rate (Benefit) | Total Cost (€) | CAPEX | OPEX | Cost Variation | Performance Variation | GE |
| 100% | 0.70% | 2% | 75.73% | 560,503 | 70% | 30% | |||
| 150% | 0.70% | 2% | 76.93% | 614,907 | 64% | 36% | +10% | +1.58% | 16.33% |
| 200% | 0.70% | 2% | 78.13% | 669,311 | 59% | 41% | +19% | +3.17% | 16.33% |
| 250% | 0.70% | 2% | 79.92% | 723,715 | 54% | 46% | +29% | +5.53% | 19.00% |
| 300% | 0.70% | 2% | 80.52% | 778,119 | 50% | 50% | +39% | +6.33% | 16.29% |
| Decisions | Cost and Benefit | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| Leak Detection | Pipe Renewal | Connections Renewal Rate | Efficiency Rate (Benefit) | Total Cost (€) | CAPEX | OPEX | Cost Variation | Performance Variation | GE |
| 100% | 0.70% | 2% | 75.73% | 560,503 | 70% | 30% | |||
| 100% | 1.05% | 2% | 75.74% | 645,683 | 74% | 26% | +15% | 0% | 0% |
| 100% | 1.40% | 2% | 75.74% | 730,864 | 77% | 23% | +30% | 0% | 0% |
| 100% | 1.75% | 2% | 75.75% | 816,044 | 79% | 21% | +46% | 0% | 0% |
| 100% | 2.10% | 2% | 75.75% | 901,224 | 81% | 19% | +61% | 0% | 0% |
| Decisions | Cost and Benefit | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| Leak Detection | Pipe Renewal | Connections Renewal Rate | Efficiency Rate (Benefit) | Total Cost (€) | CAPEX | OPEX | Cost Variation | Performance Variation | GE |
| 100% | 0.70% | 2% | 75.73% | 560,503 | 70% | 30% | |||
| 100% | 0.70% | 3% | 75.80% | 670,173 | 75% | 25% | +20% | +0.09% | 0.47% |
| 100% | 0.70% | 4% | 75.86% | 781,837 | 79% | 21% | +39% | +0.17% | 0.43% |
| 100% | 0.70% | 5% | 75.92% | 892,504 | 81% | 19% | +59% | +0.25% | 0.42% |
| 100% | 0.70% | 6% | 75.98% | 1,003,171 | 83% | 17% | +79% | +0.33% | 0.41% |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Nafi, A.; Brans, J. Prediction of Water Utility Performance: The Case of the Water Efficiency Rate. Water 2018, 10, 1443. https://doi.org/10.3390/w10101443
Nafi A, Brans J. Prediction of Water Utility Performance: The Case of the Water Efficiency Rate. Water. 2018; 10(10):1443. https://doi.org/10.3390/w10101443
Chicago/Turabian StyleNafi, Amir, and Jonathan Brans. 2018. "Prediction of Water Utility Performance: The Case of the Water Efficiency Rate" Water 10, no. 10: 1443. https://doi.org/10.3390/w10101443
APA StyleNafi, A., & Brans, J. (2018). Prediction of Water Utility Performance: The Case of the Water Efficiency Rate. Water, 10(10), 1443. https://doi.org/10.3390/w10101443