
Bidimensional and Multidimensional Principal Component Analysis in Long Term Atmospheric Monitoring



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
2. Experiments
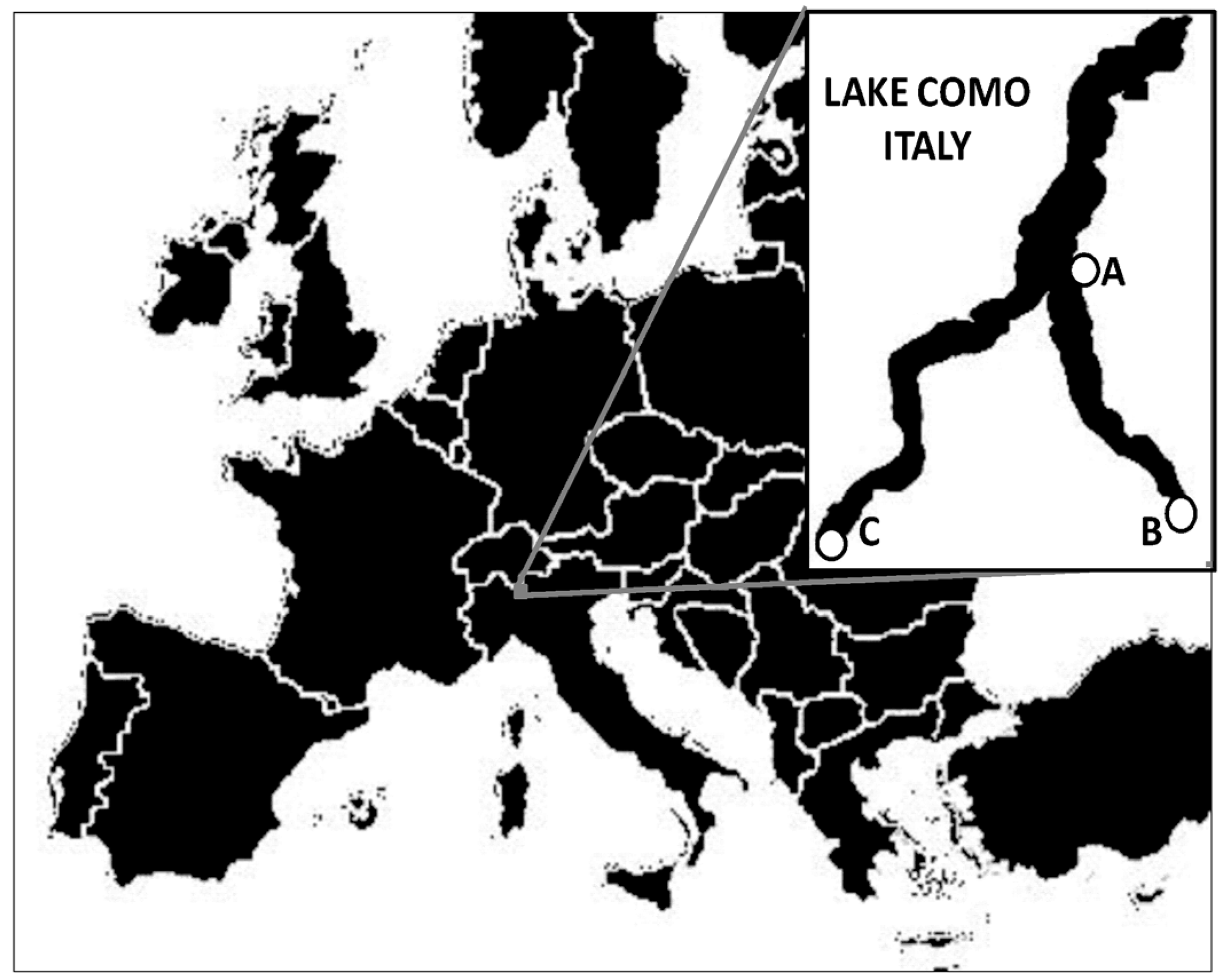
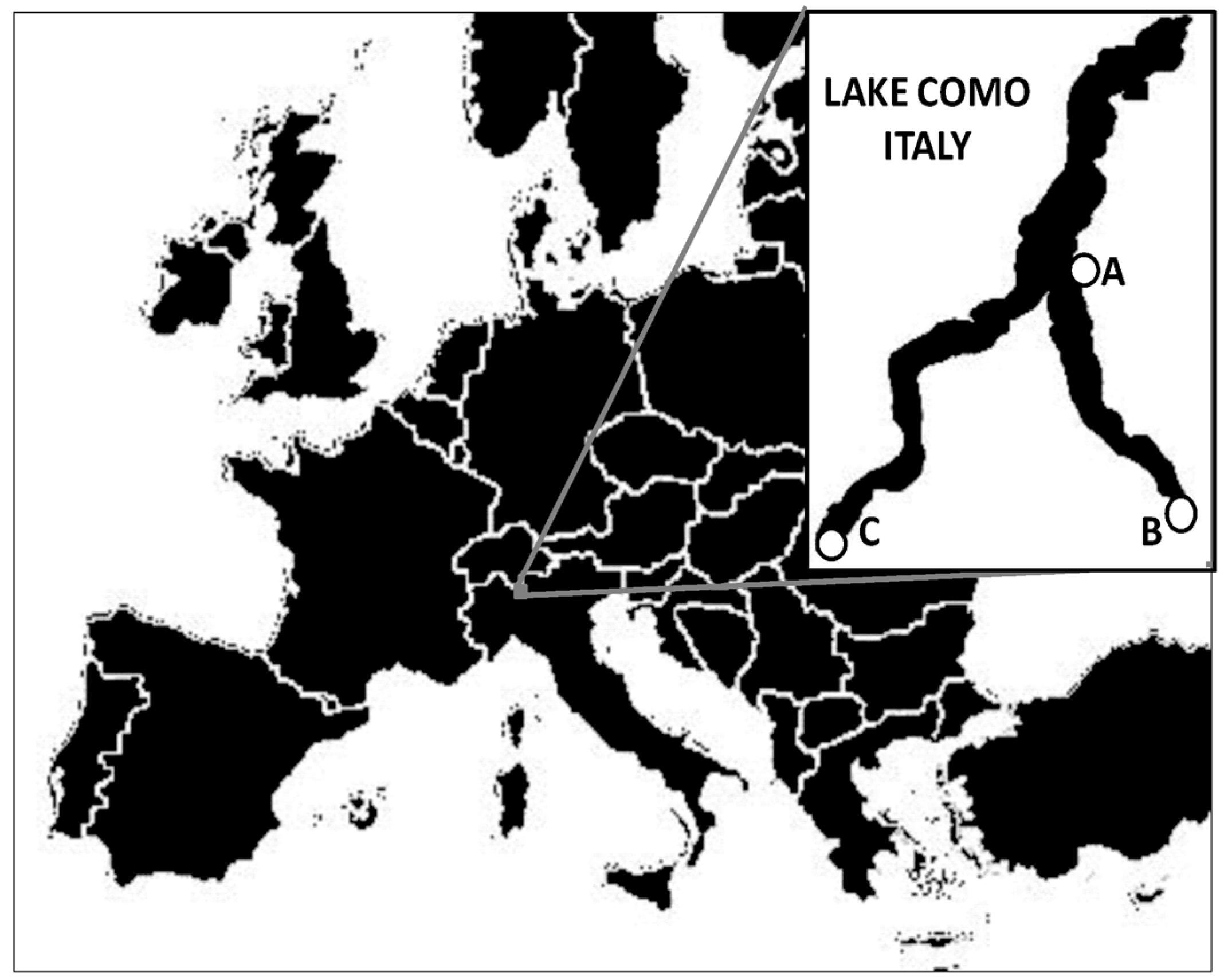
2.1. Case of Study
2.2. Theory
2.2.1. Raw Data: Transformation and Preprocessing
- AverageThe models were built on averaged data, according to the information to be emphasized, as described in following sections. Average values were calculated only if 75% of the data were available (following the criteria used from the troposphere analyzer), any datum that did not meet this criteria was coded as missing value.
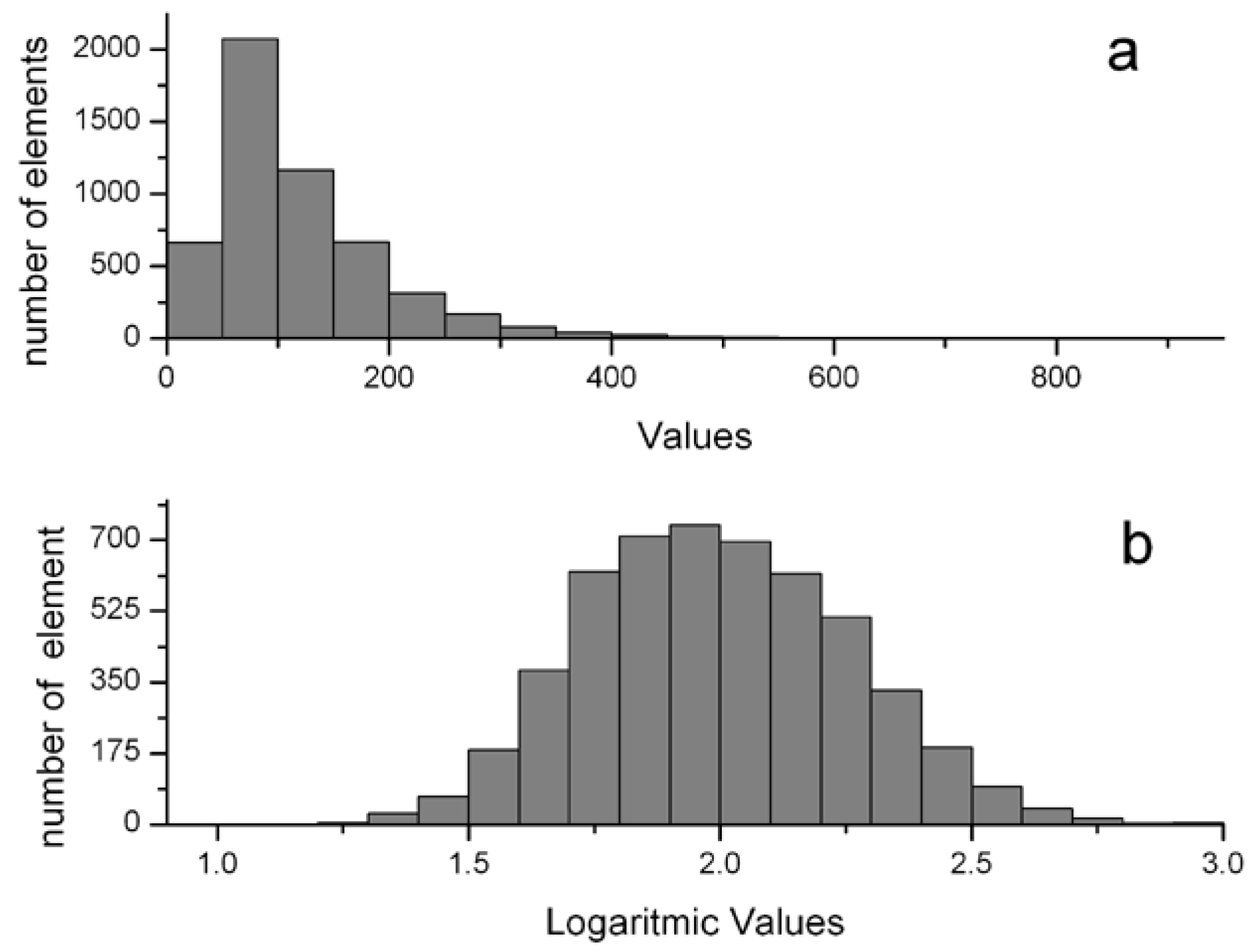
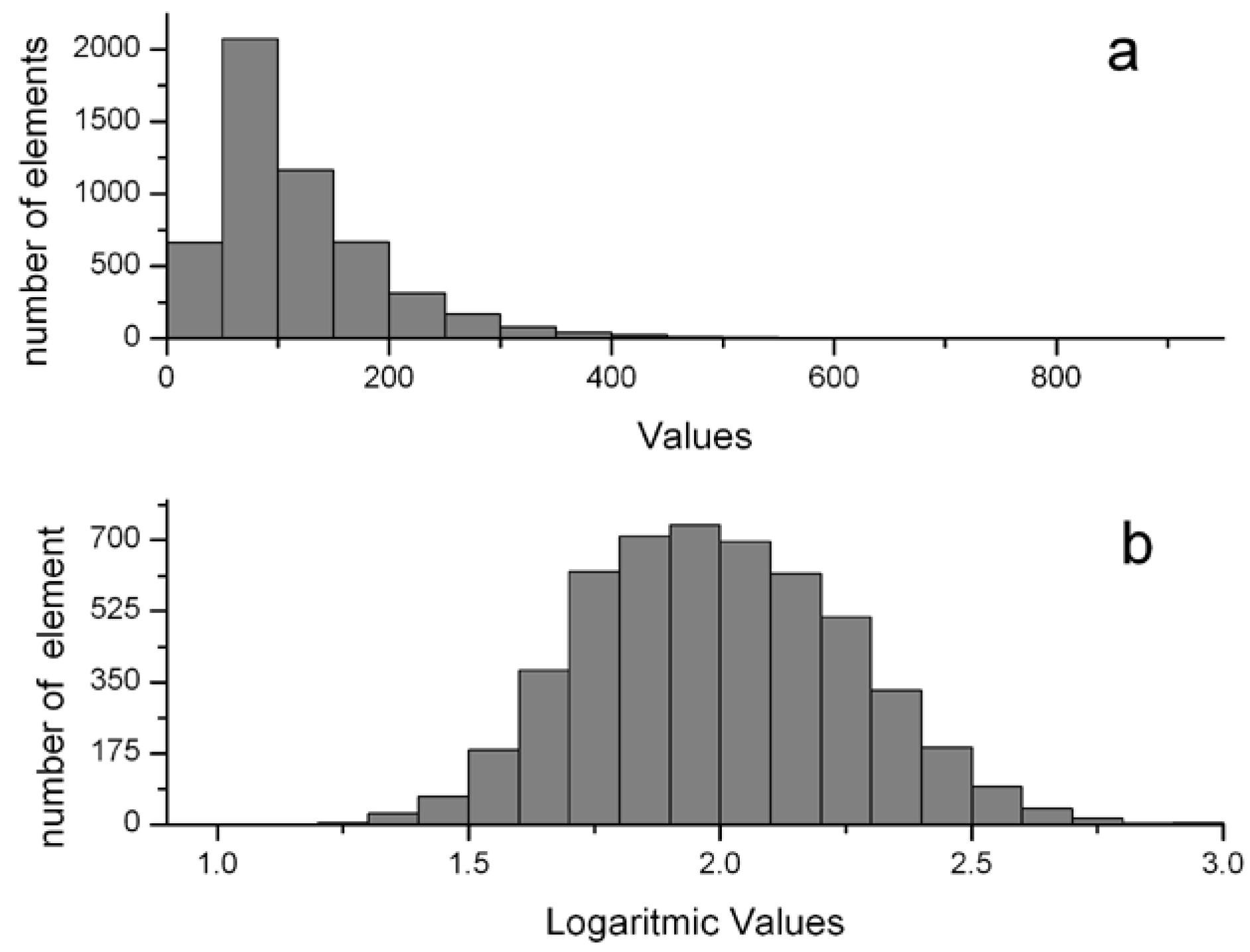
- Logarithmic transformationVariables box plots and histogram plots were analyzed to check non-linearities. An example of a highly asymmetrical variable is shown in Figure 2a. In such cases, a data logarithmic transformation, or a square root in the case of slight asymmetry, was applied to make the distribution more symmetrical. Figure 2b shows the same variable distribution after a logarithmic transformation.
- AutoscalingThis preprocessing technique is required when variables expressed in different units and/or showing different variation ranges have to be compared. It gives all variables the same chance to influence the estimation of the components. Autoscaling results from performing the mean centering and the standardization transformations:
- J-scalingJ-scaling is the autoscaling in the variable (columns) direction in multi-way modeling [8,19]: the objects with all the other information are arranged in the rows. This pretreatment removes the differences between the variables arising from different ranges and magnitudes giving all of the variables the same chance to contribute to the model. This method retains the differences between the objects.
2.2.2. Bidimensional Modeling: Principal Component Analysis
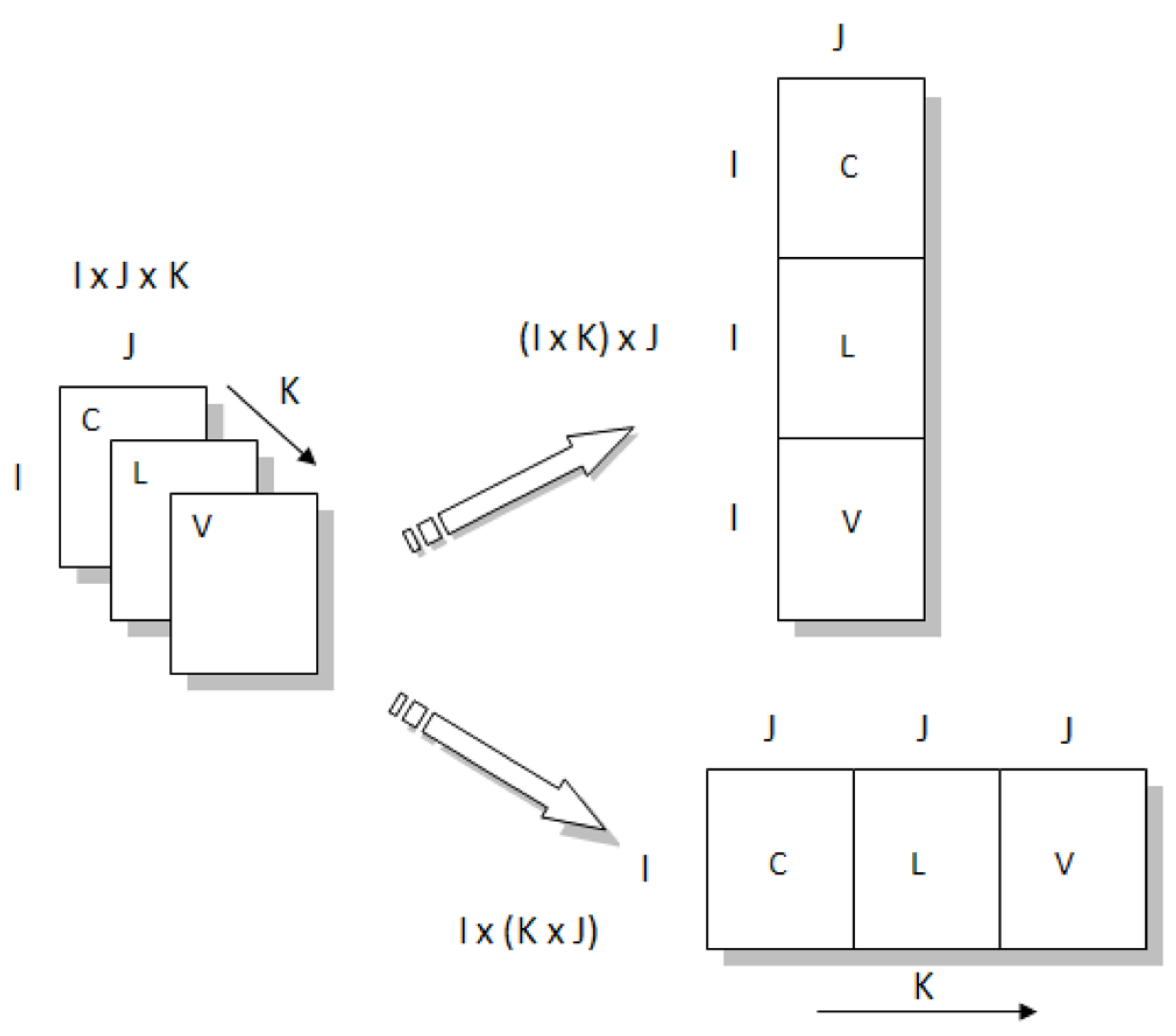
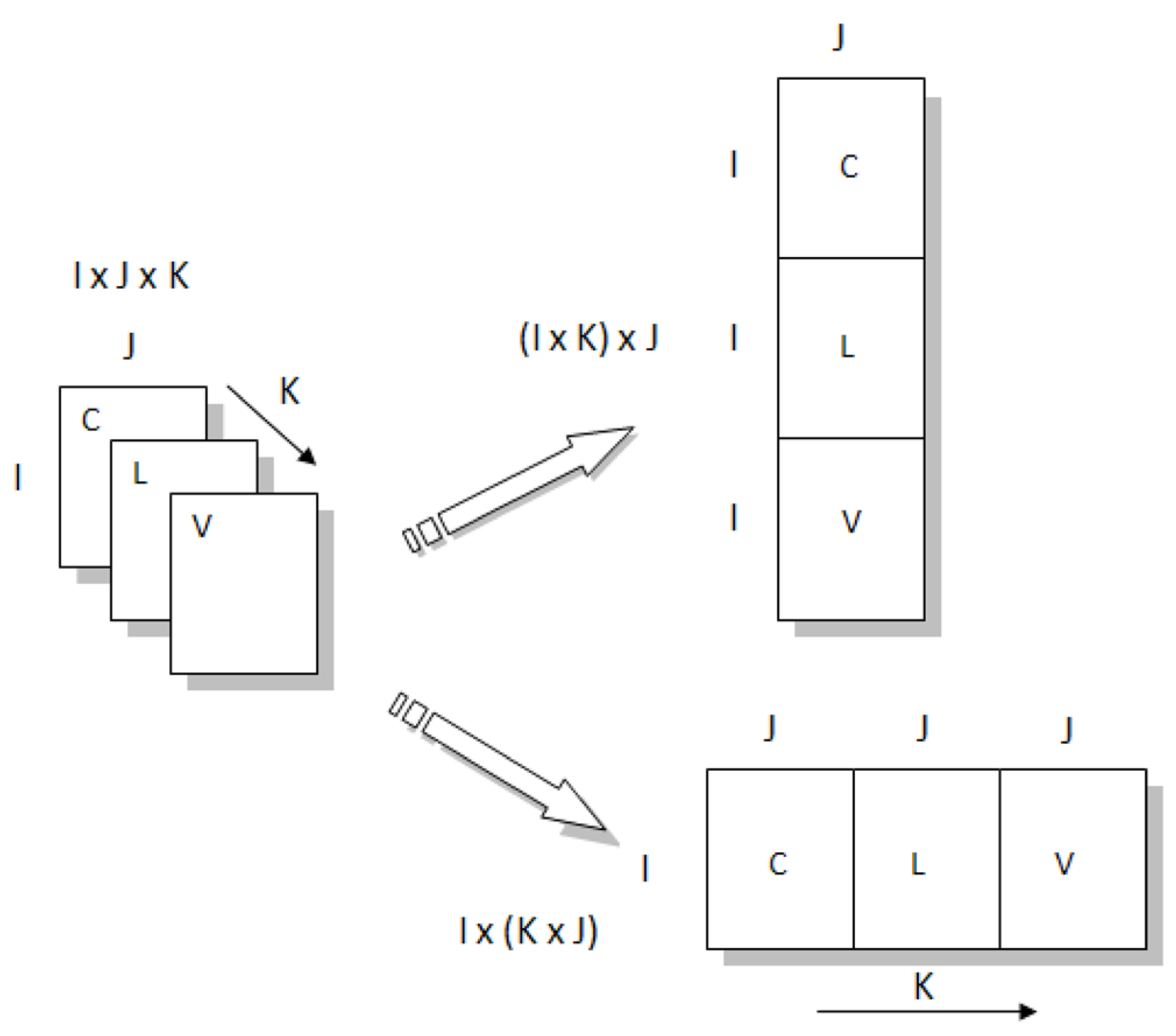
- Unfold-PCAAs mentioned above, PCA can be also used with satisfying results when data have an intrinsically multidimensional structure, but a transformation of the array is necessary to obtain a bidimensional data matrix. This will lead to information mixing in at least one of the two dimensions of the data matrix.For a three-dimensional array X (I × J × K), where I represents the samples, J the variables, and K the conditions (in this article I = time, J = chemical variables, and K = sampling sites), different unfolding schemes could be applied, depending on the modeling purpose (Figure 3). Two strategies were considered in this article:
- -
- mixing the information of samples and conditions in a matrix (I × K) × J, with the goal of investigating sample variations in time;
- -
- mixing the information of samples and variables in a matrix I × (K × J), to study the relationships between the variables and the average changes of the investigated sites in time.
2.2.3. Multidimensional Modeling: Tucker3
2.3. Experimental
Dealing with Missing Data
3. Results and Discussion
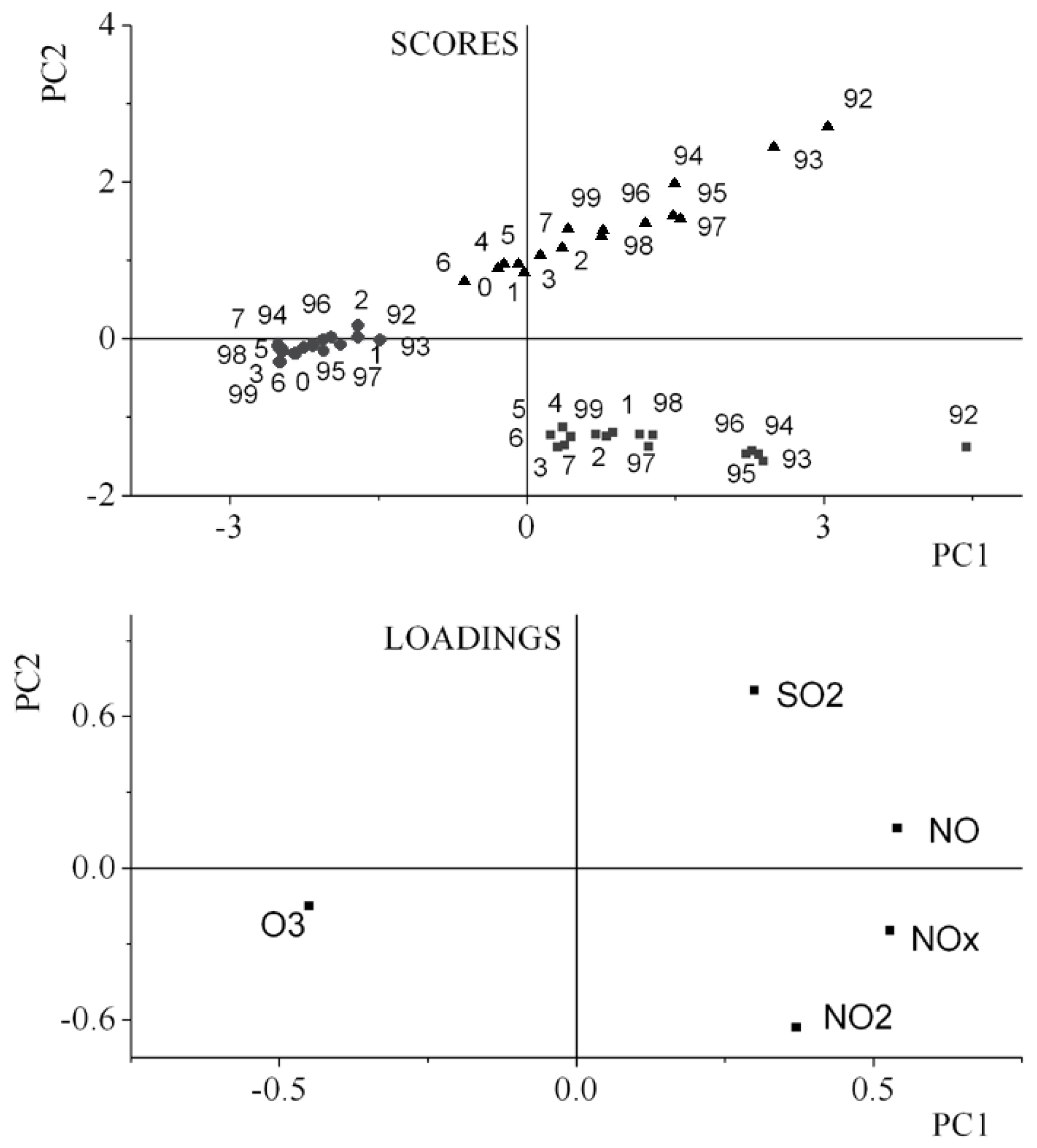
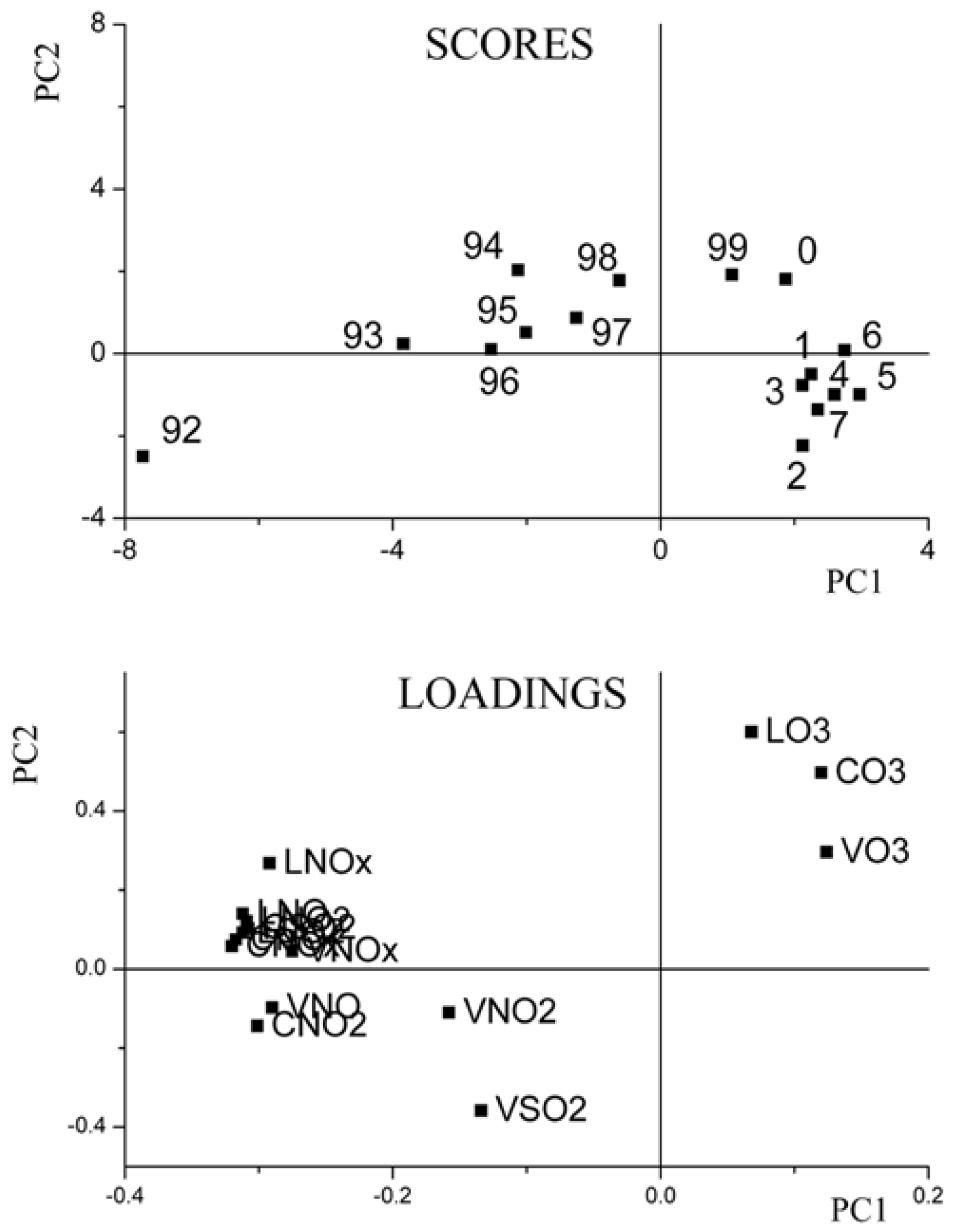
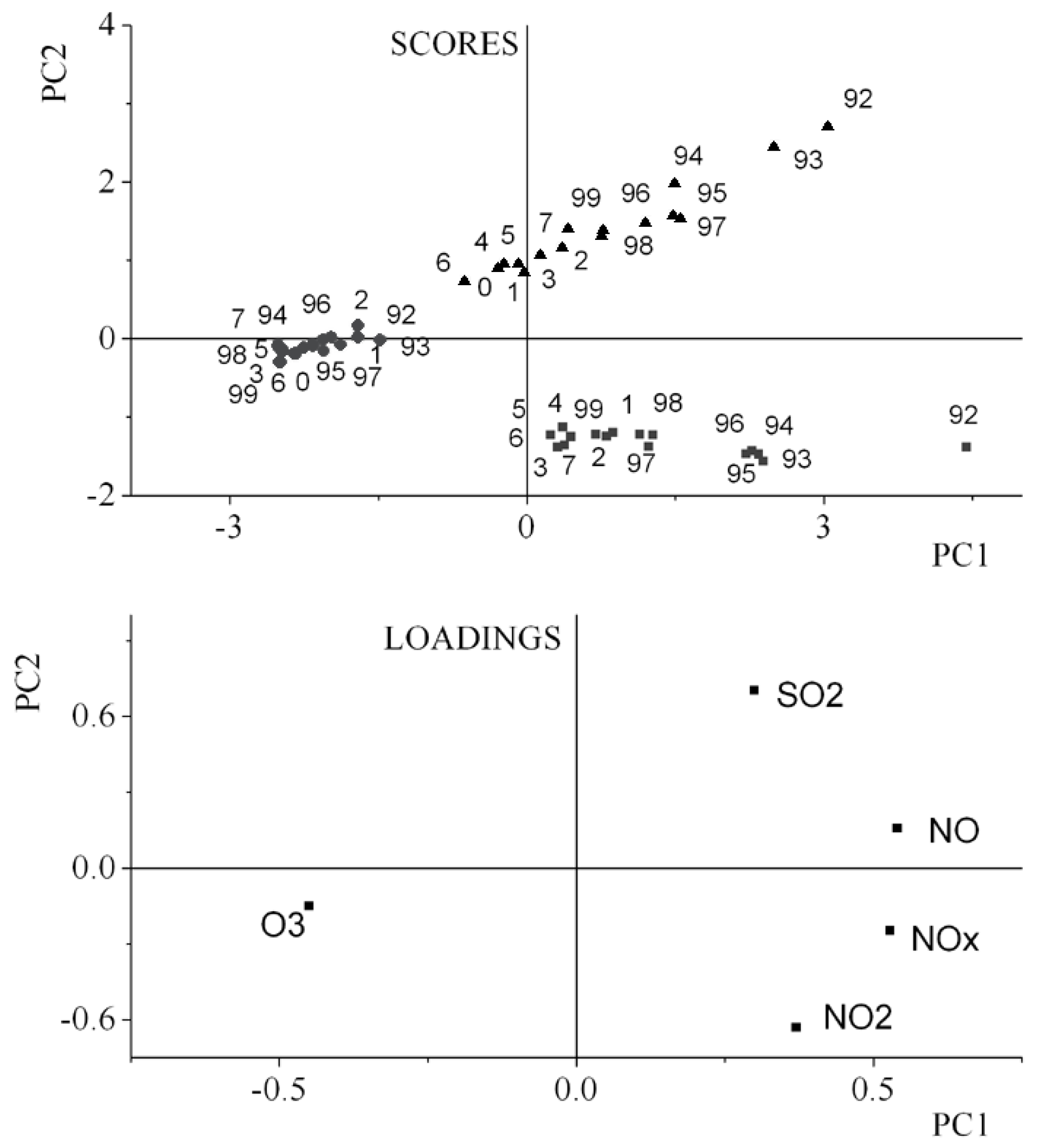
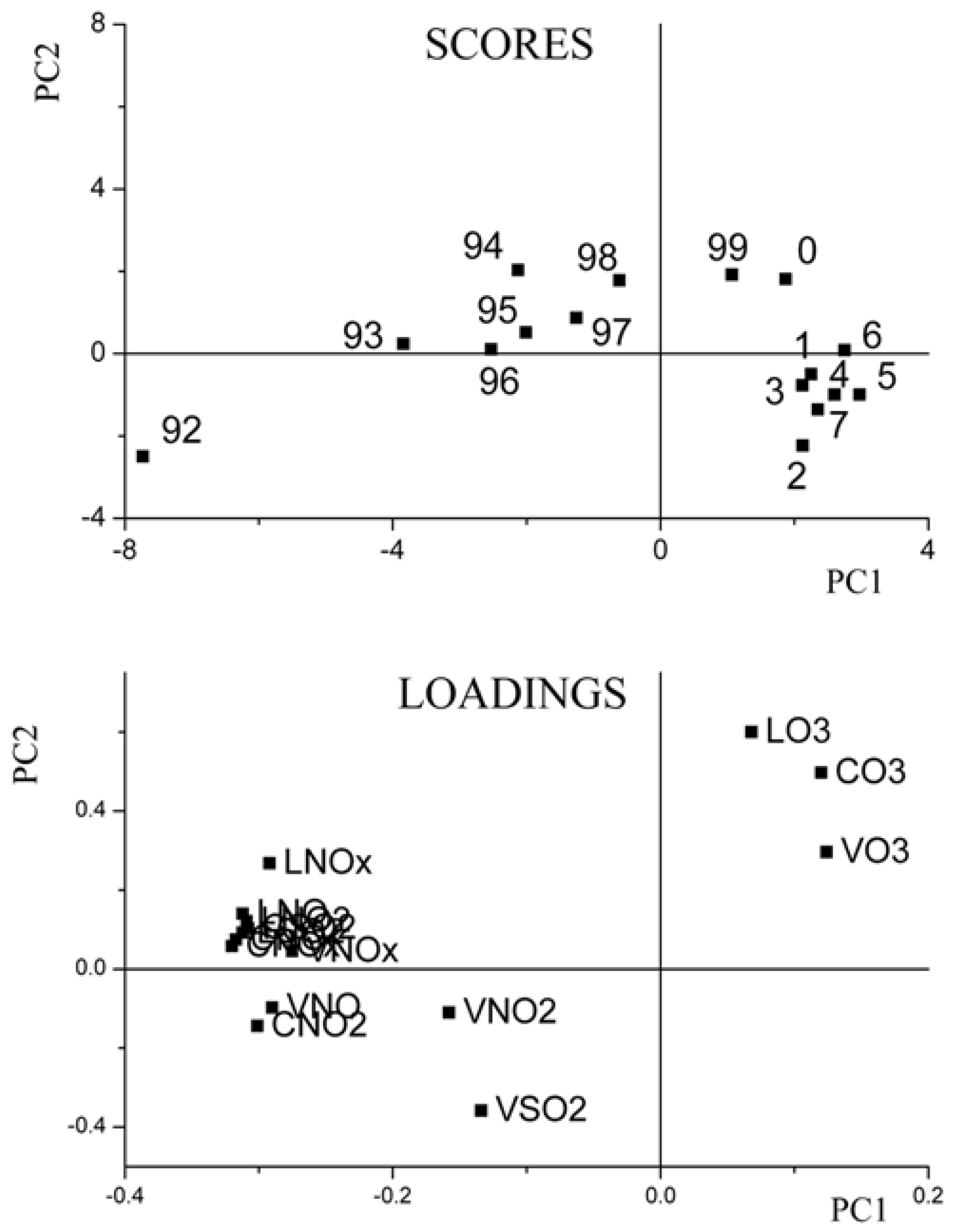
3.1. Unfold-Principal Component Analysis
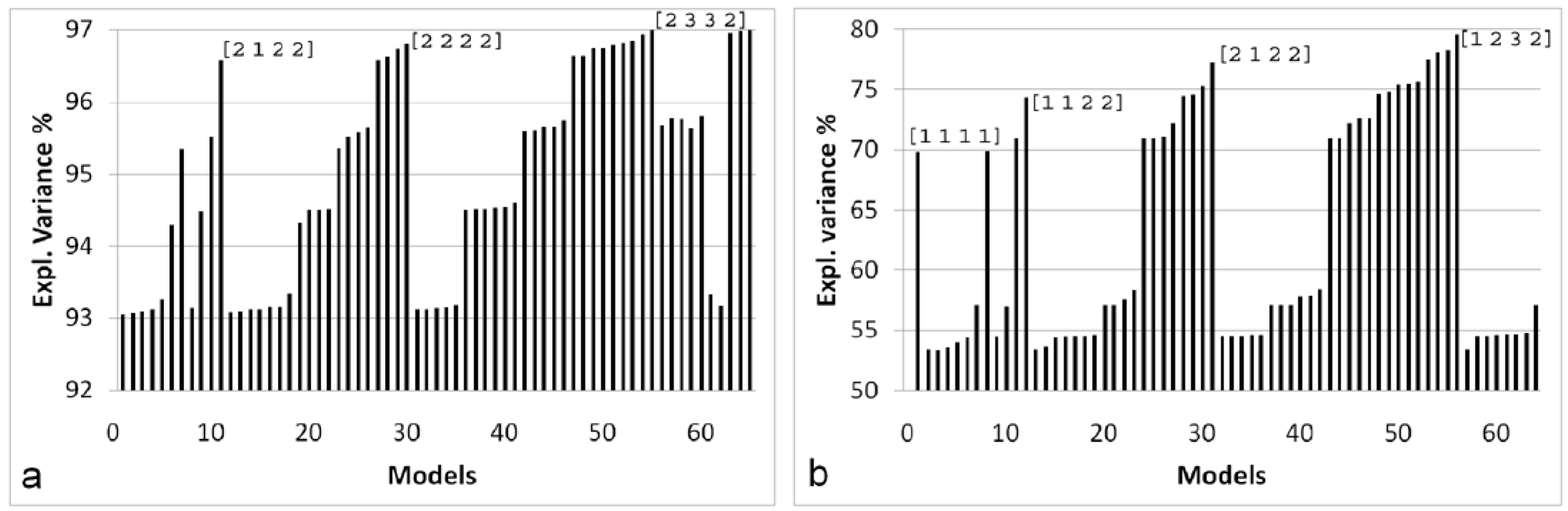
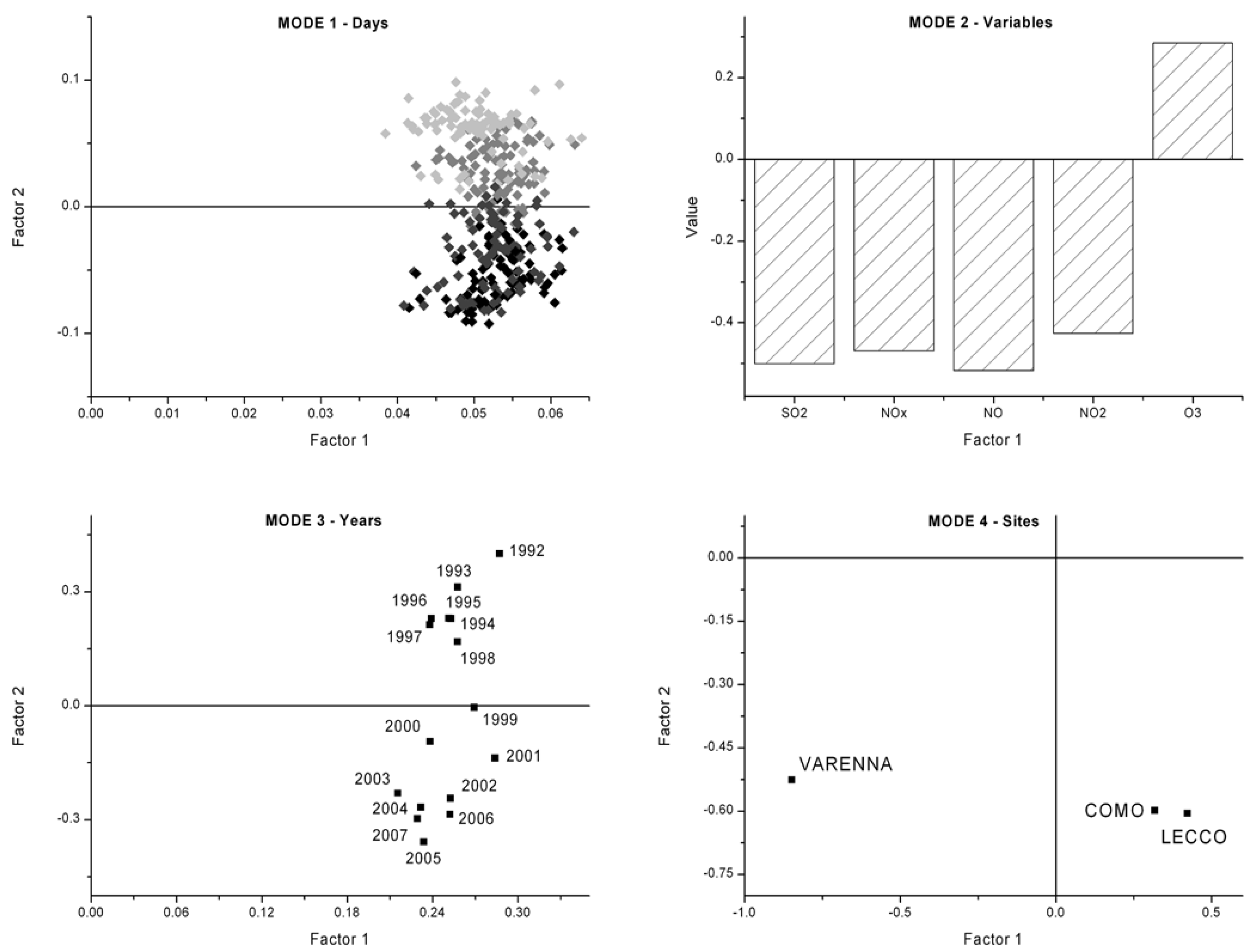
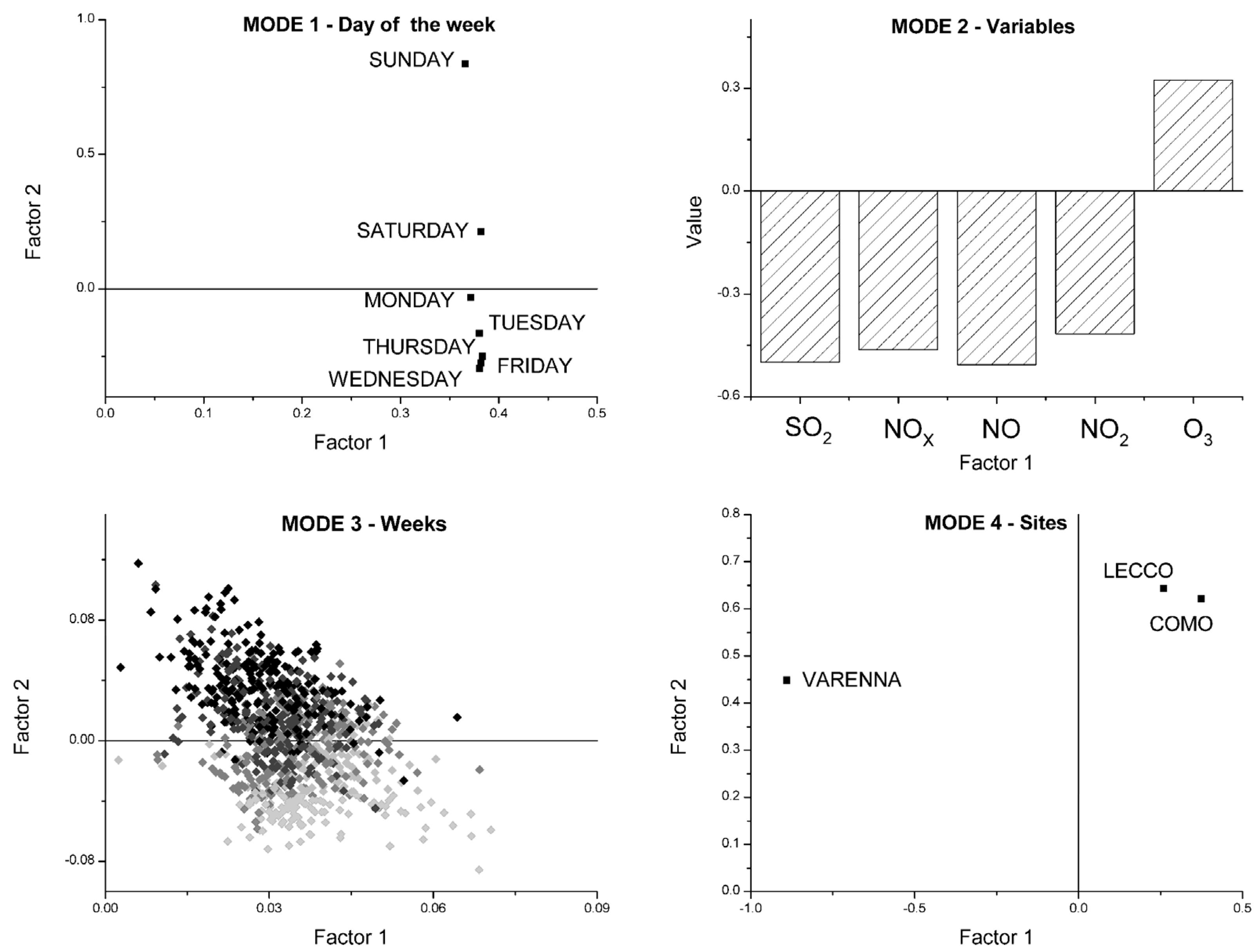
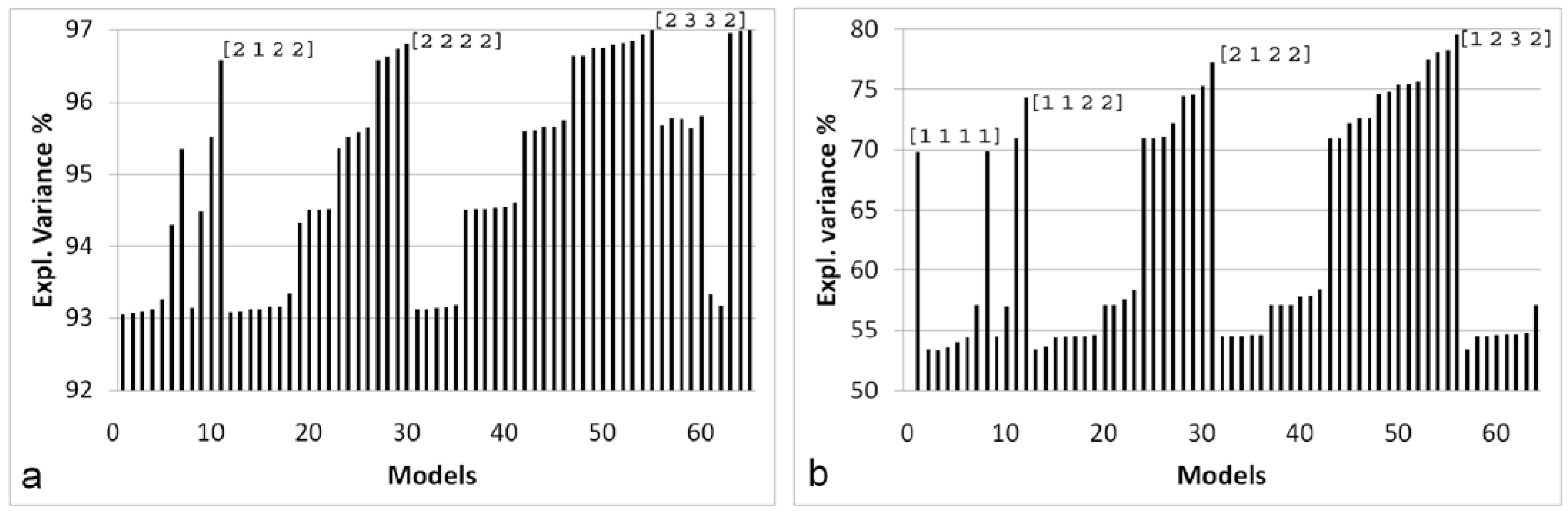
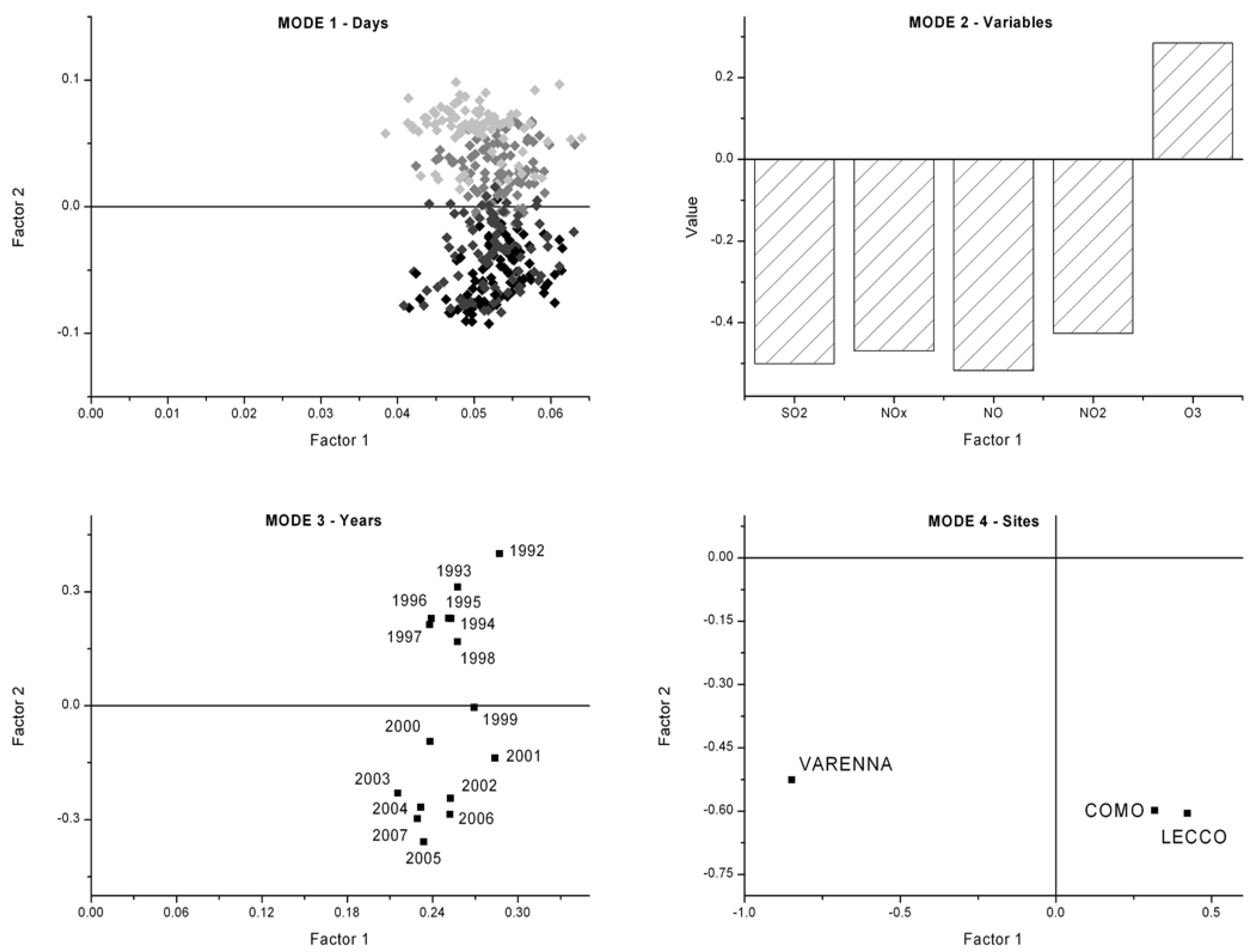
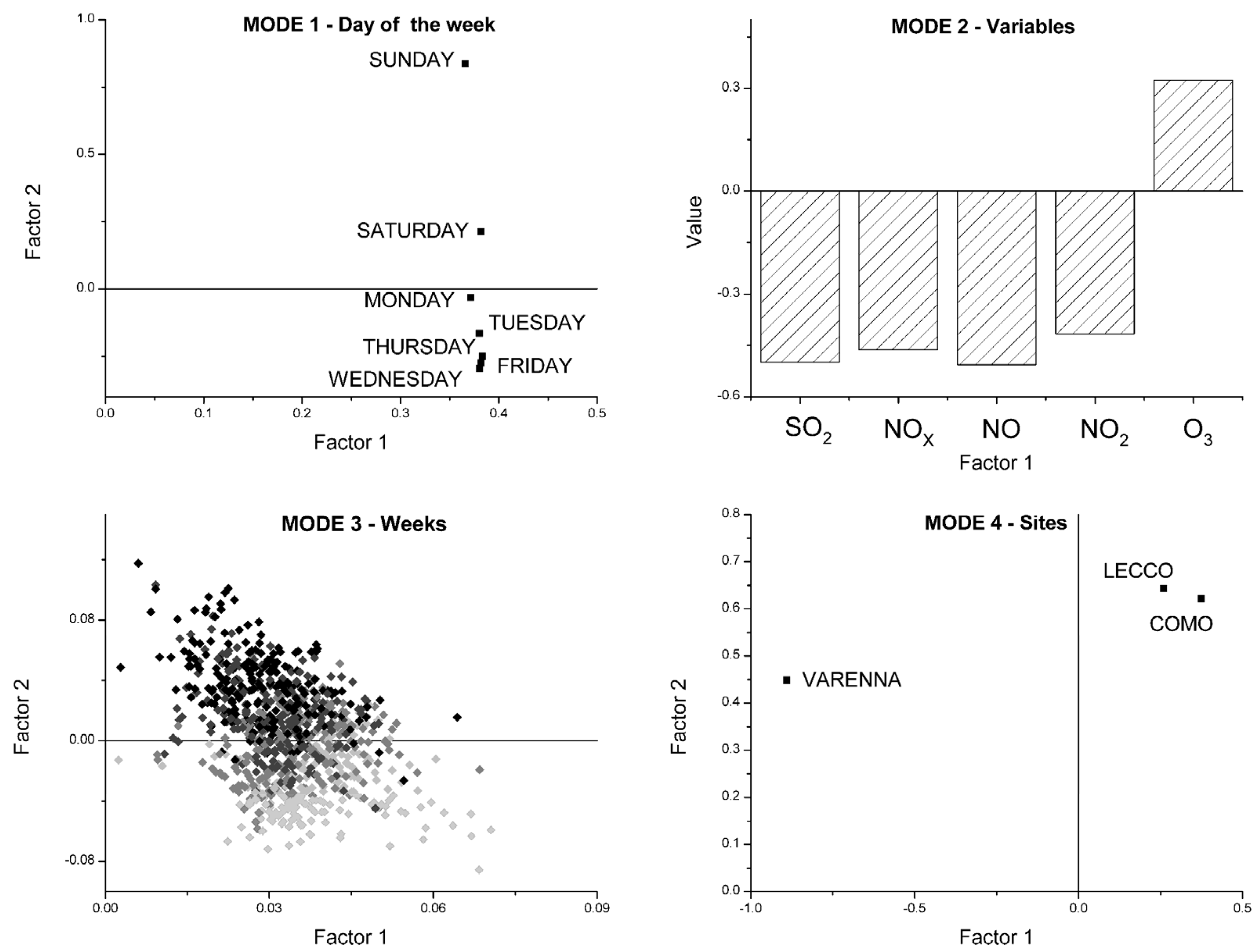
3.2. Four-Way Tucker3 Model
4. Conclusions
Supplementary Materials
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Brunekreef, B.; Holgate, S.T. Air pollution and health. Lancet 2002, 360, 1233–1242. [Google Scholar] [CrossRef]
- Henry, R.C.; Hidy, G.M. Multivariate analysis of particulate sulfate and other air quality variables by principal component analysis—Part I: Annual data from Los Angeles and New York. Atmos. Environ. 1979, 13, 1581–1596. [Google Scholar] [CrossRef]
- Henry, R.C.; Hidy, G.M. Multivariate analysis of particulate sulfate and other air quality variables by principal component analysis—Part II: Salt Lake City, Utah and St. Louis, Missuri. Atmos. Environ. 1979, 13, 1581–1596. [Google Scholar] [CrossRef]
- Han, Y.M.; Du, P.X.; Cao, J.J.; Posmentier, E.S. Multivariate analysis of heavy metal contamination in urban dusts of Xi’an, Central China. Sci. Total Environ. 2006, 355, 176–186. [Google Scholar]
- Pires, J.C.M.; Pereira, M.C.; Alvim-Ferraz, M.C.M.; Martins, F.G. Identification of redundant air quality measurements through the use of principal component analysis. Atmos. Environ. 2009, 43, 3837–3842. [Google Scholar] [CrossRef]
- Yonemura, S.; Kawashima, S.; Matsueda, H.; Sawa, Y.; Inoue, S.; Tanimoto, H. Temporal variations in ozone concentrations derived from PCA. Theor. Appl. Climatol. 2008, 92, 47–58. [Google Scholar] [CrossRef]
- Merino, A.; Wu, X.; Gascón, E.; Berthet, C.; García-Ortega, E.; Dessens, J. Hailstorms in southwestern France: Incidence and atmospheric characterization. Atmos. Res. 2014, 140–141, 61–75. [Google Scholar] [CrossRef]
- Leardi, R.; Armanino, C.; Lanteri, S.; Alberotanza, L. Three-mode principal component analysis of monitoring data from Venice lagoon. J. Chemometr. 2000, 14, 187–195. [Google Scholar] [CrossRef]
- Barbieri, P.; Adami, G.; Piselli, P.; Gemiti, F.; Reisenhofer, E. A three-way principal factor analysis for assessing the time variability of freshwaters related to a municipal water supply. Chemom. Intell. Lab. Syst. 2002, 62, 89–100. [Google Scholar] [CrossRef]
- Stanimirova, I.; Kita, A.; Malkowski, E.; John, E.; Walczak, B. Nway exploration of environmental data obtained from sequential extraction procedure. Chemom. Intell. Lab. Syst. 2009, 96, 203–209. [Google Scholar] [CrossRef]
- Engle, M.A.; Gallo, M.; Schroeder, K.T.; Geboy, N.J.; Zupancic, J.W. Three-way compositional analysis of water quality monitoring data. Environ. Ecol. Stat. 2014, 21, 565–581. [Google Scholar] [CrossRef]
- Giussani, B.; Monticelli, D.; Gambillara, R.; Pozzi, A.; Dossi, C. Three-way principal component analysis of chemical data from Lake Como watershed. Microchem. J. 2008, 88, 160–166. [Google Scholar] [CrossRef]
- Sillmann, S. The relation between ozone, NOx and hydrocarbons in urban and polluted rural environments. Atmos. Environ. 1999, 33, 1821–1845. [Google Scholar] [CrossRef]
- Jenkin, M.E.; Clemitshaw, K.C. Ozone and other secondary photochemical pollutants: Chemical processes governing their formation in the planetary boundary layer. Atmos. Environ. 2000, 34, 2499–2527. [Google Scholar] [CrossRef]
- Zeng, Y.; Hopke, P.K. Methodological study applying three-mode factor analysis to three-way chemical data sets. Chemom. Intell. Lab. Syst. 1990, 7, 237–250. [Google Scholar] [CrossRef]
- Malik, A.; De Juan, A.; Tauler, R. Multivariate curve resolution: A different way to examine chemical data. In 40 Years of Chemometrics—From Bruce Kowalski to the Future; ACS Symposium Series: Washington, DC, USA, 2015; Volume 1199, pp. 95–128. [Google Scholar]
- Bro, R. PARAFAC. Tutorial and applications. Chemom. Intell. Lab. Syst. 1997, 38, 149–171. [Google Scholar] [CrossRef]
- De Noord, O.E. The influence of data preprocessing on the robustness and parsimony of multivariate calibration models. Chemom. Intell. Lab. Syst. 1994, 23, 65–70. [Google Scholar] [CrossRef]
- Kroonenberg, P.M. Three-Mode Principal Component Analysis; DSWO Press: Leiden, The Netherlands, 1983. [Google Scholar]
- Wold, S.; Esbensen, K.; Geladi, P. Principal component analysis. Chemom. Intell. Lab. Syst. 1987, 2, 37–52. [Google Scholar] [CrossRef]
- Brereton, R. Applied Chemometrics for Scientists; Wiley: Hoboken, NJ, USA, 2007. [Google Scholar]
- Tucker, L.R. Some mathematical notes on three-mode factor analysis. Psychometrika 1966, 31, 279–311. [Google Scholar] [CrossRef] [PubMed]
- Andersson, C.A.; Bro, R. Improving the speed of multi-way algorithms: Part I. Tucker3. Chemom. Intell. Lab. Syst. 1998, 42, 93–103. [Google Scholar] [CrossRef]
- Andersson, C.A.; Bro, R. The N-way toolbox for MATLAB. Chemom. Intell. Lab. Syst. 2000, 52, 1–4. [Google Scholar] [CrossRef]
- Alier, M.; Felipe-Sotelo, M.; Hernàndez, I.; Tauler, R. Variation patterns of nitric oxide in Catalonia during the period from 2001 to 2006 using multivariate data analysis methods. Anal. Chim. Acta 2009, 642, 77–88. [Google Scholar] [CrossRef] [PubMed]
- Dempster, A.P.; Laird, N.M.; Rubin, D.B. Maximum likelihood for incomplete data via the EM algorithm. J. R. Stat. Soc. B 1977, 39, 1–38. [Google Scholar]
- Walczak, B.; Massart, D.L. Dealing with missing data: Part I. Chemom. Intell. Lab. Syst. 2001, 58, 15–27. [Google Scholar] [CrossRef]
- Walczak, B.; Massart, D.L. Dealing with missing data: Part II. Chemom. Intell. Lab. Syst. 2001, 58, 29–42. [Google Scholar] [CrossRef]
- Zhang, L.; Marron, J.S.; Shen, H.P.; Zhu, Z. Singular value decomposition and its visualization. J. Comput. Graph. Stat. 2007, 16, 833–854. [Google Scholar] [CrossRef]
- Zhu, M.; Ghodsi, A. Automatic dimensionality selection from the scree plot via the use of profile likelihood. Comput. Stat. Data Anal. 2006, 51, 918–930. [Google Scholar] [CrossRef]
- Caserini, S.; Giuliano, M.; Pastorello, C. Traffic emission scenarios in Lombardy region in 1998–2015. Sci. Total Environ. 2008, 389, 453–465. [Google Scholar] [CrossRef] [PubMed]
- Liu, C.M.; Huang, C.Y.; Shield, S.L.; Wu, C.C. Important meteorological parameters for ozone episodes experienced in the Taipei basin. Atmos. Environ. 1994, 28, 159–173. [Google Scholar] [CrossRef]
- Atkinson, R. Atmospheric chemistry of VOCs and NOx. Atmos. Environ. 2000, 34, 2063–2101. [Google Scholar] [CrossRef]
- Chang, S.C.; Lee, C.T. Evaluation of trend of air quality in Taipei, Taiwan from 1994 to 2003. Environ. Monit. Assess. 2007, 127, 87–96. [Google Scholar] [CrossRef] [PubMed]
- Chang, S.C.; Lee, C.T. Secondary aerosol formation through photochemical reactions estimated by using air quality monitoring data in Taipei City from 1994 to 2003. Atmos. Environ. 2007, 41, 4002–4017. [Google Scholar] [CrossRef]
© 2016 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC-BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Giussani, B.; Roncoroni, S.; Recchia, S.; Pozzi, A. Bidimensional and Multidimensional Principal Component Analysis in Long Term Atmospheric Monitoring. Atmosphere 2016, 7, 155. https://doi.org/10.3390/atmos7120155
Giussani B, Roncoroni S, Recchia S, Pozzi A. Bidimensional and Multidimensional Principal Component Analysis in Long Term Atmospheric Monitoring. Atmosphere. 2016; 7(12):155. https://doi.org/10.3390/atmos7120155
Chicago/Turabian StyleGiussani, Barbara, Simone Roncoroni, Sandro Recchia, and Andrea Pozzi. 2016. "Bidimensional and Multidimensional Principal Component Analysis in Long Term Atmospheric Monitoring" Atmosphere 7, no. 12: 155. https://doi.org/10.3390/atmos7120155
APA StyleGiussani, B., Roncoroni, S., Recchia, S., & Pozzi, A. (2016). Bidimensional and Multidimensional Principal Component Analysis in Long Term Atmospheric Monitoring. Atmosphere, 7(12), 155. https://doi.org/10.3390/atmos7120155