
Interpolation of Temperature in a Mountainous Region Using Heterogeneous Observation Networks


Abstract
1. Introduction
2. Data and Methods
2.1. Data
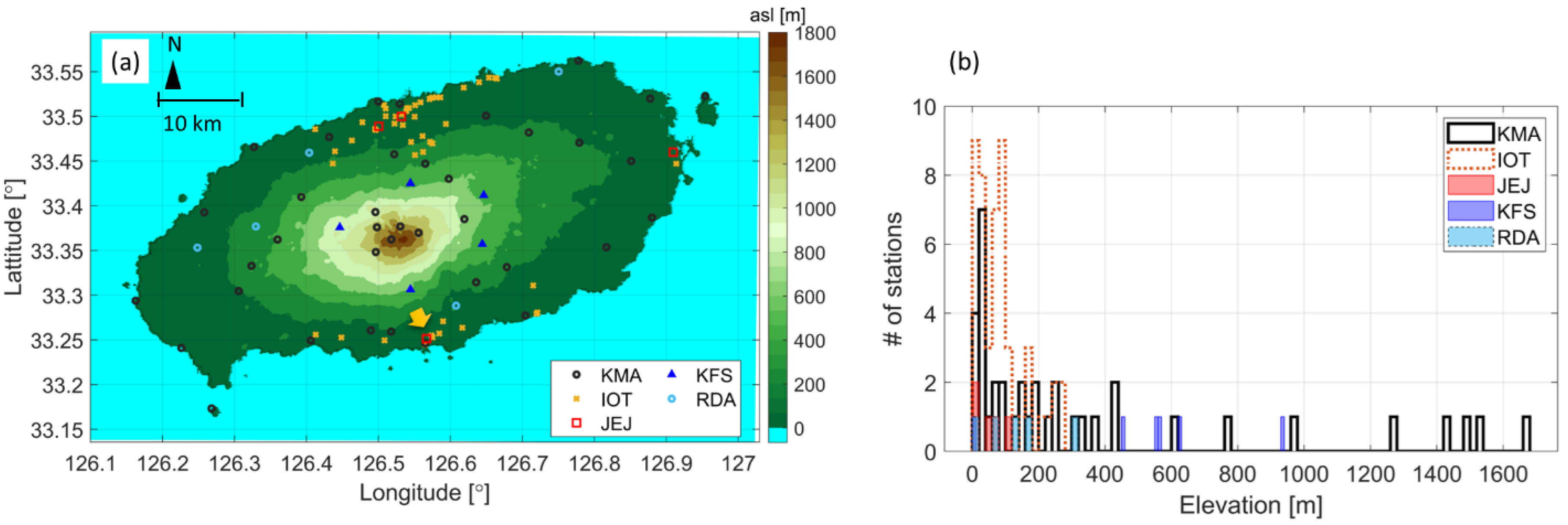
2.1.1. Study Area
2.1.2. Dataset
2.2. Methods
2.2.1. Interpolation Methods
2.2.2. Harmonization Using a Reference Network
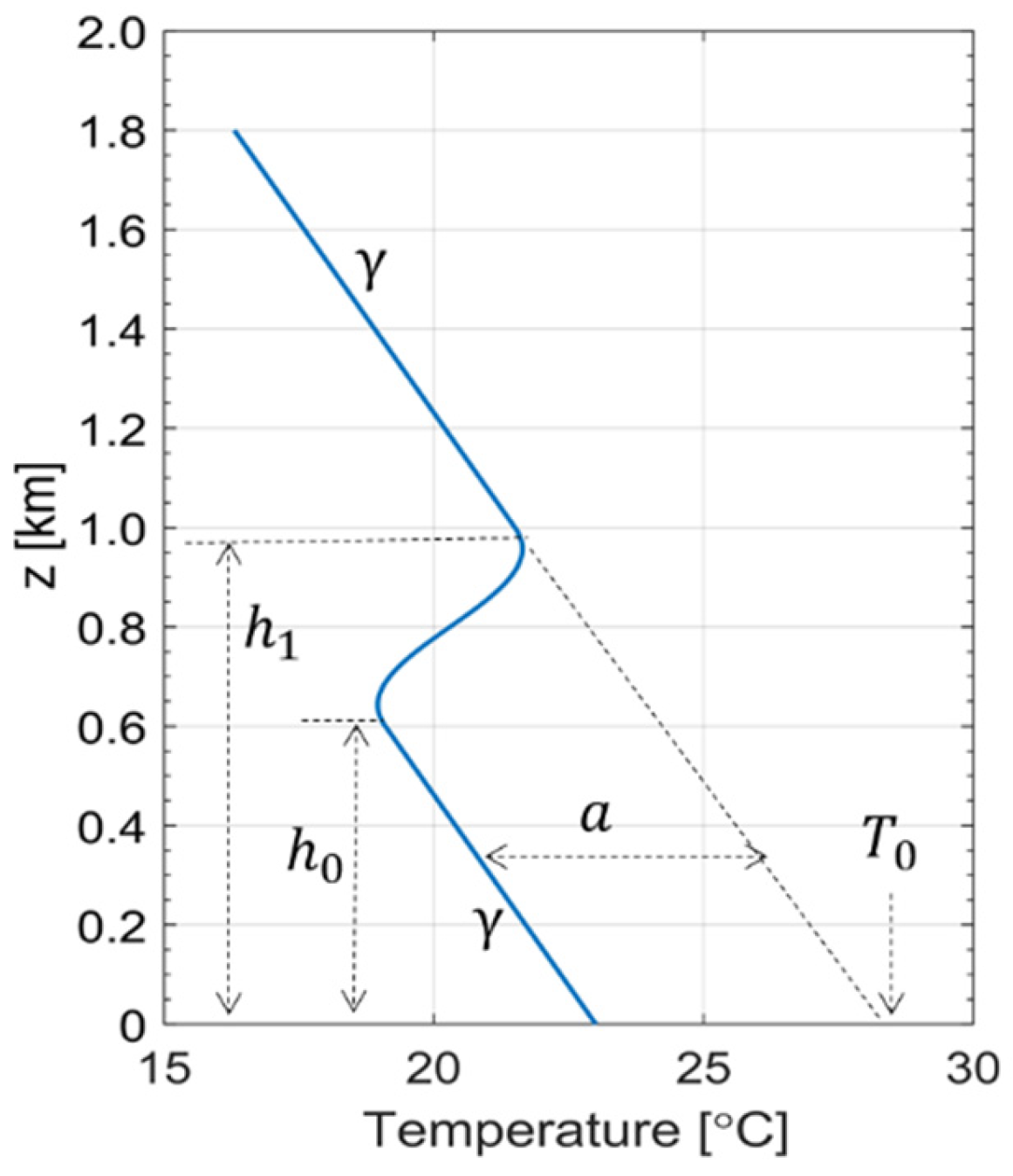
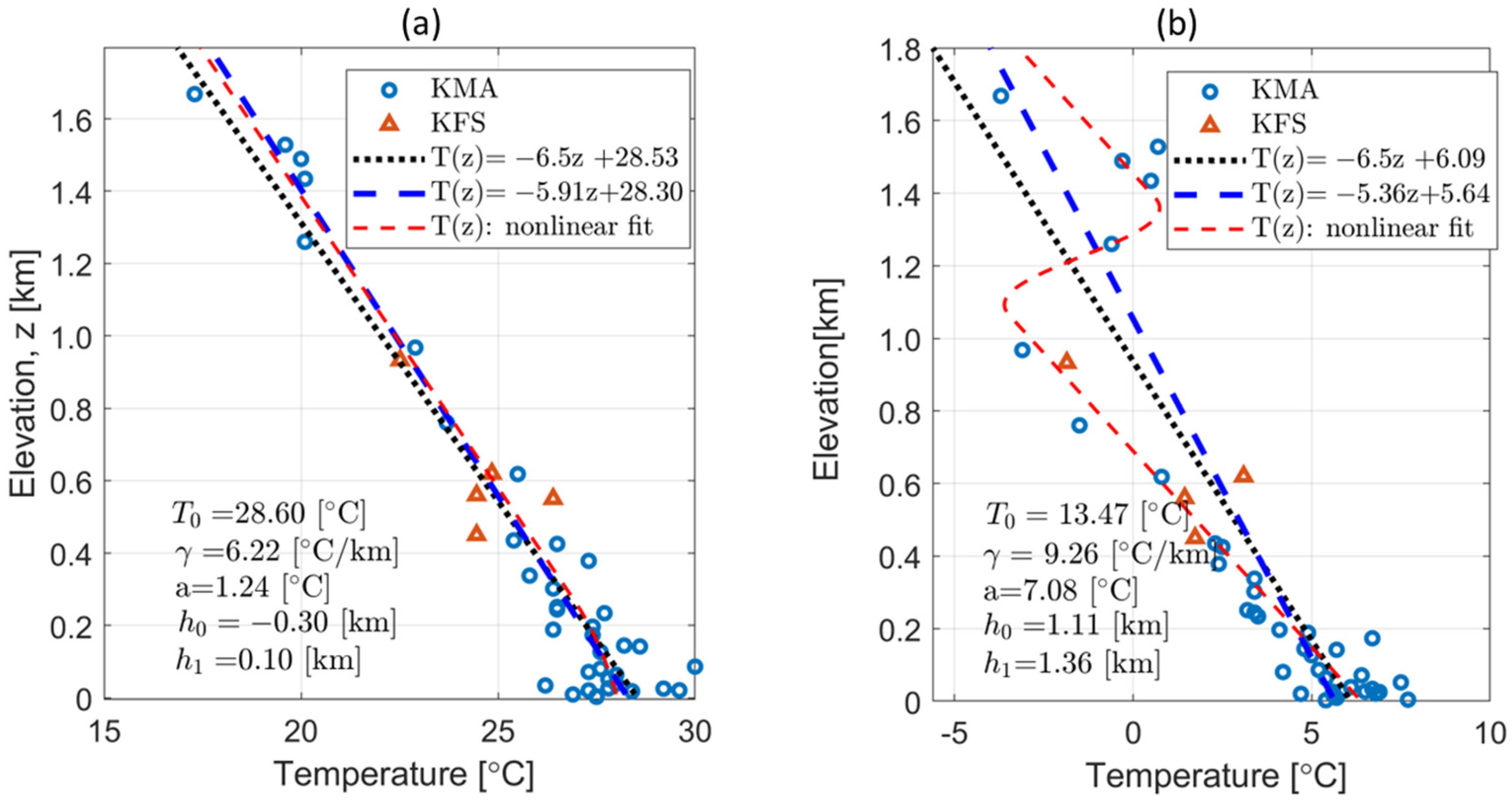
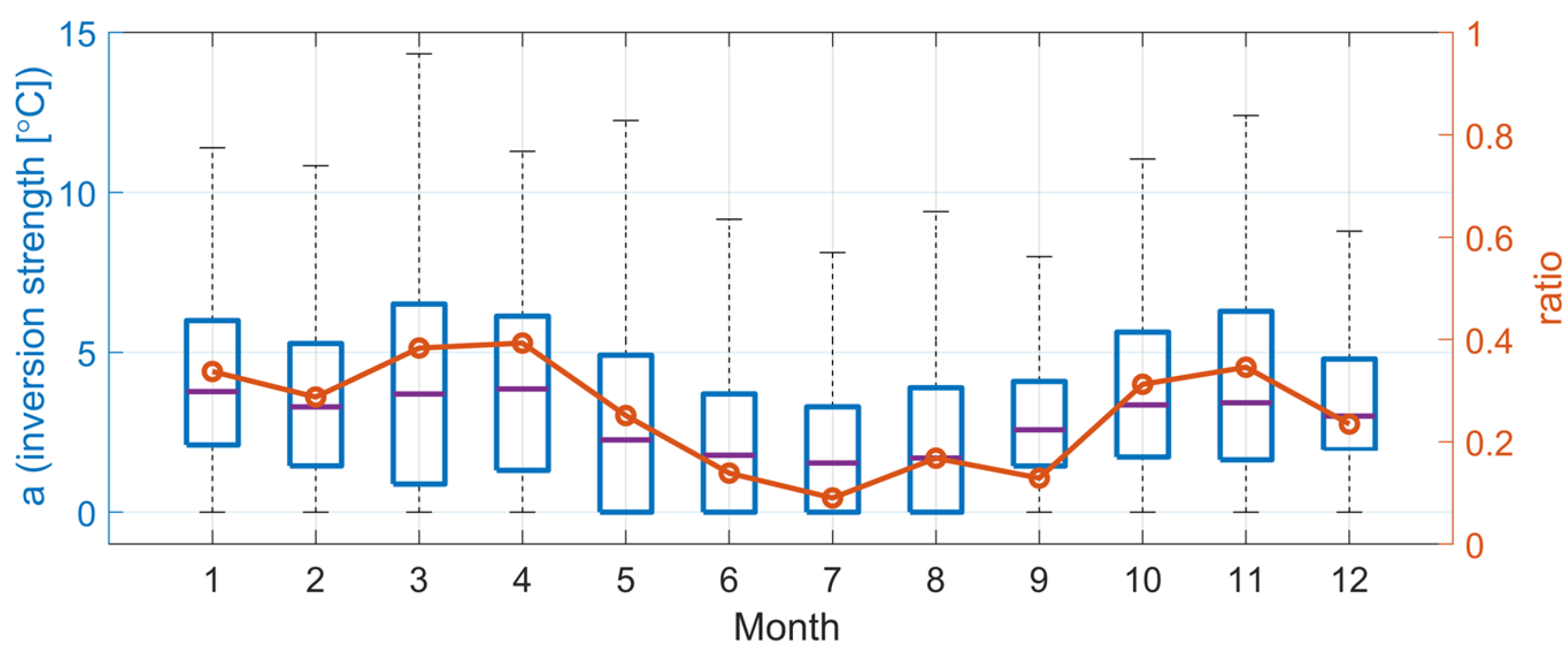
2.2.3. Computation of Vertical Temperature Profiles
2.2.4. RBF Interpolation Using Real Time Vertical Temperature Profile
3. Results
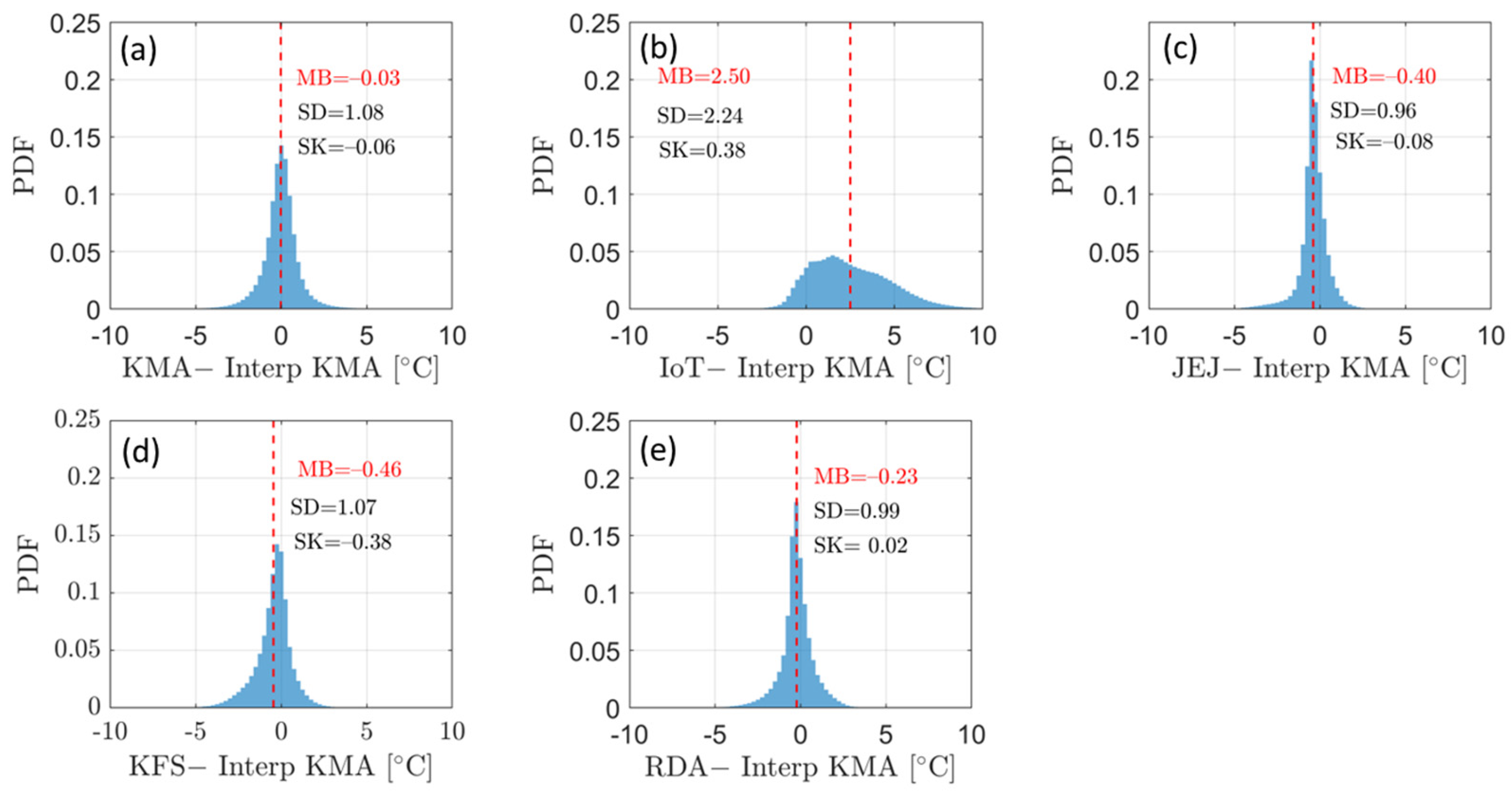
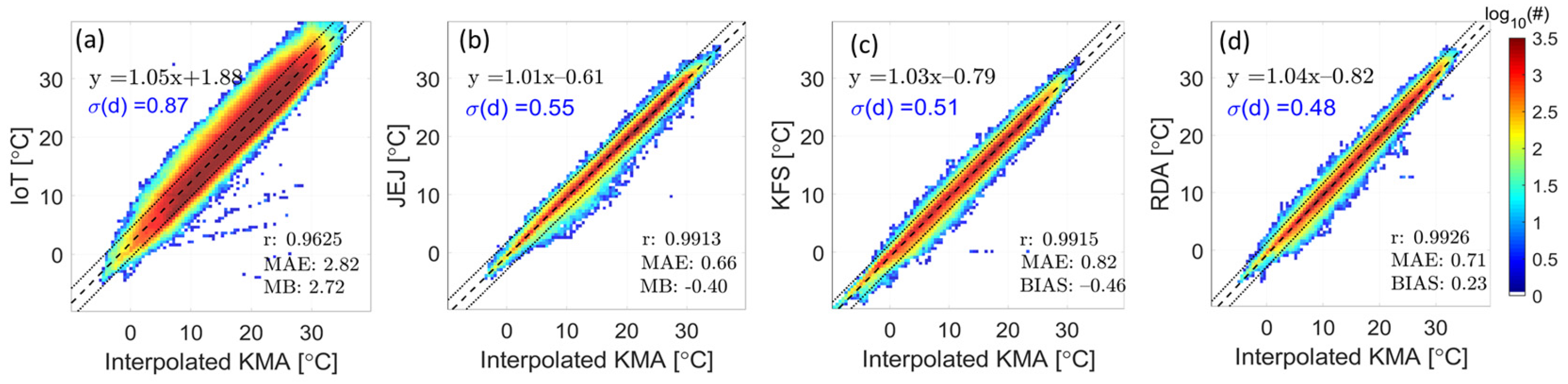
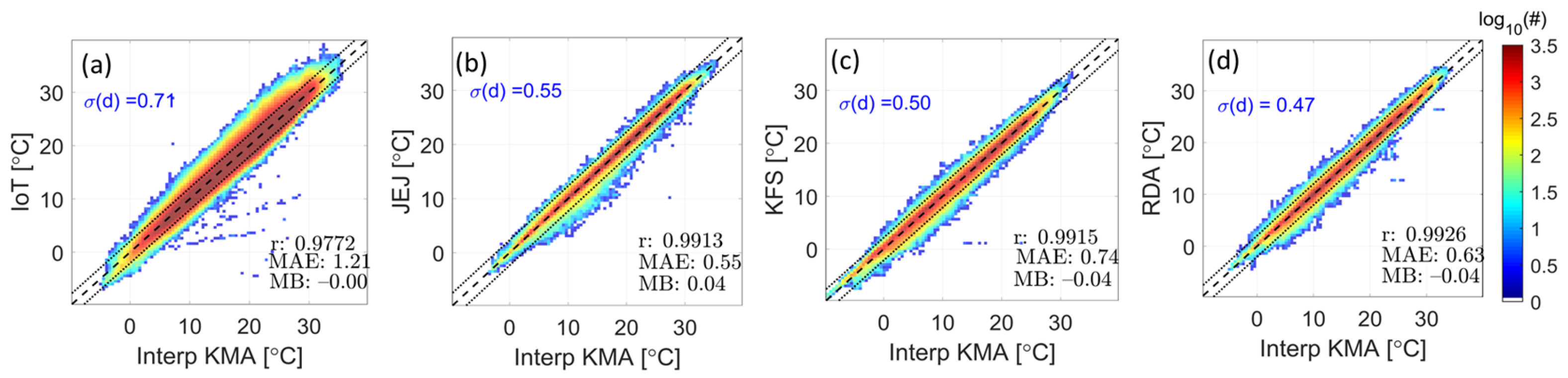
3.1. Data Harmonization (Removal and Adjustment of Heterogeneous Data)
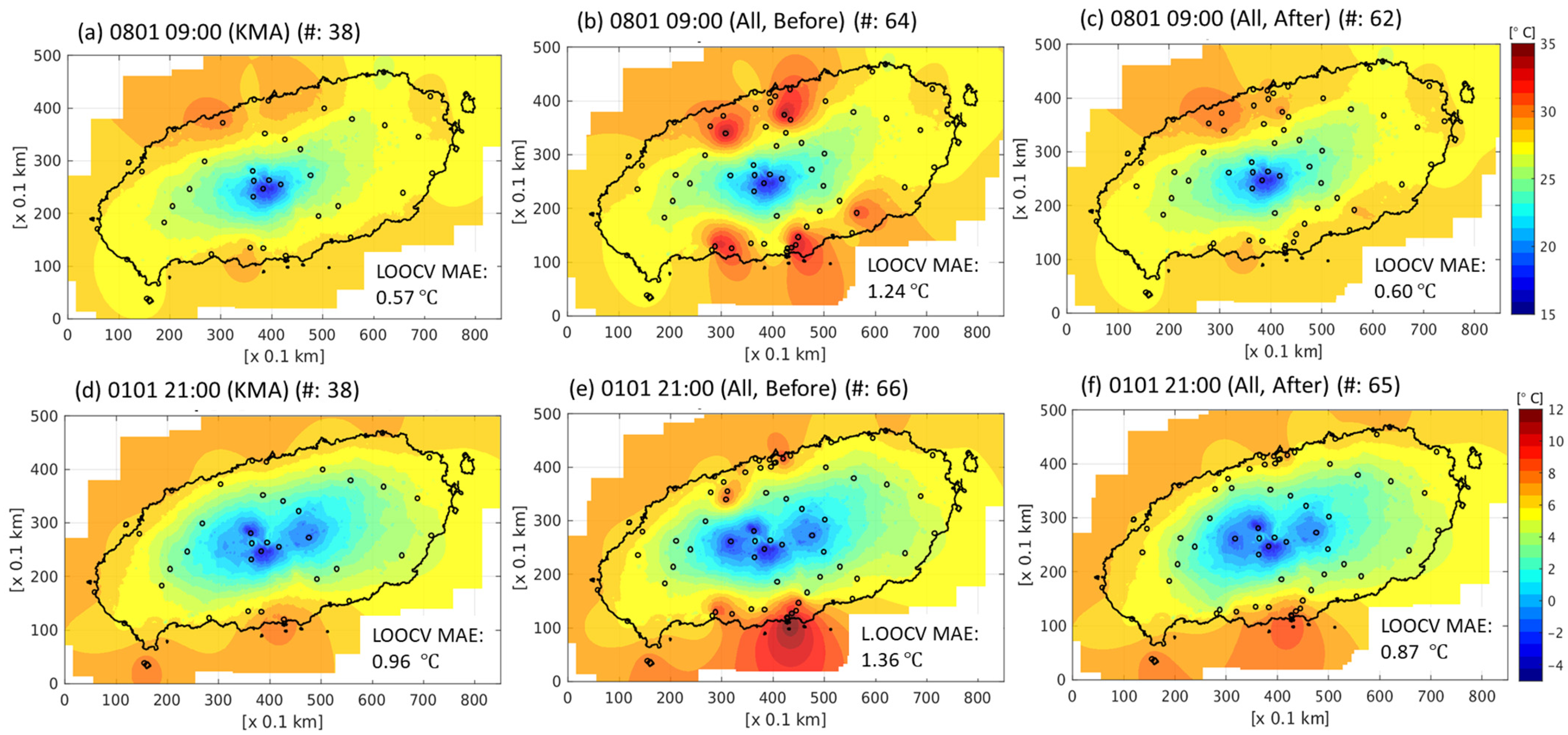
3.2. Verification of Effect of Merging Harmonized Data
3.2.1. Examples of Interpolation Results
3.2.2. Verification Using 2020 Data
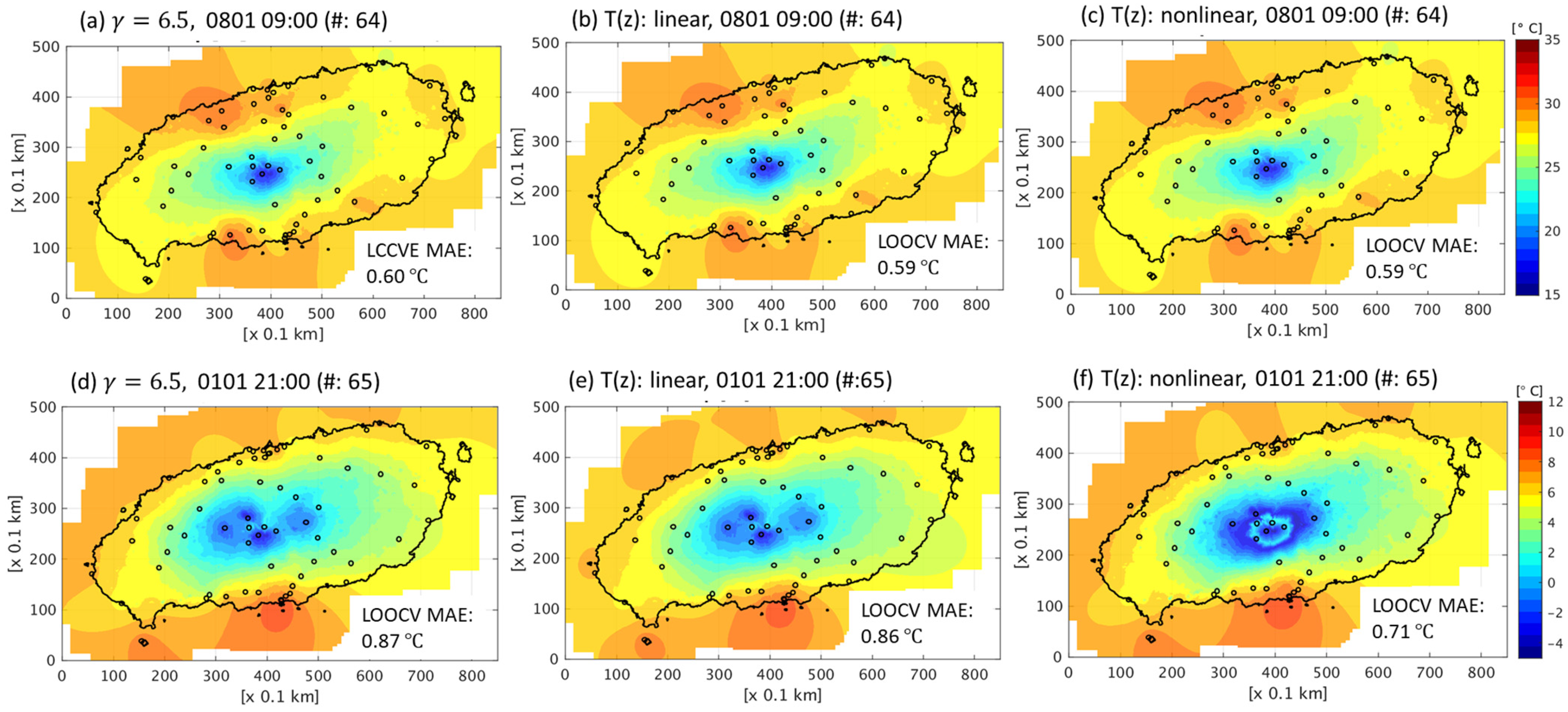
3.3. Interpolation Results for Different Temperature Profiles
3.3.1. Examples of Interpolation Results
3.3.2. Verification Using 2020 Data
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A
- Exponential (or Matern):
- Gaussian:
- Multiquadric:
- Inverse multiquadric:
- Radial power:
- Thin-plate spline:

References
- Gentine, P.; Chhang, A.; Rigden, A.; Salvucci, G. Evaporation estimates using weather station data and boundary layer theory. Geophys. Res. Lett. 2016, 43, 11661–11670. [Google Scholar] [CrossRef]
- Sexstone, G.A.; Clow, D.W.; Fassnacht, S.R.; Liston, G.E.; Hiemstra, C.A.; Knowles, J.F.; Penn, C.A. Snow Sublimation in Mountain Environments and Its Sensitivity to Forest Disturbance and Climate Warming. Water Resour. Res. 2018, 54, 1191–1211. [Google Scholar] [CrossRef]
- Barnhart, T.B.; Molotch, N.P.; Livneh, B.; Harpold, A.A.; Knowles, J.F.; Schneider, D. Snowmelt rate dictates streamflow. Geophys. Res. Lett. 2016, 43, 8006–8016. [Google Scholar] [CrossRef]
- Ceppi, P.; Scherrer, S.C.; Fischer, A.M.; Appenzeller, C. Revisiting Swiss temperature trends 1959–2008. Int. J. Climatol. 2012, 32, 203–213. [Google Scholar] [CrossRef]
- Van der Schrier, G.; van den Besselaar, E.J.M.; Tank, A.M.G.K.; Verver, G. Monitoring European average temperature based on the E-OBS gridded data set. J. Geophys. Res-Atmos. 2013, 118, 5120–5135. [Google Scholar] [CrossRef]
- Monestiez, P.; Courault, D.; Allard, D.; Ruget, F. Spatial interpolation of air temperature using environmental context: Application to a crop model. Environ. Ecol. Stat. 2001, 8, 297–309. [Google Scholar] [CrossRef]
- Van der Schrier, G.; Efthymiadis, D.; Briffa, K.R.; Jones, P.D. European Alpine moisture variability for 1800–2003. Int. J. Climatol. 2007, 27, 415–427. [Google Scholar] [CrossRef]
- Viviroli, D.; Zappa, M.; Schwanbeck, J.; Gurtz, J.; Weingartner, R. Continuous simulation for flood estimation in ungauged mesoscale catchments of Switzerland—Part I: Modelling framework and calibration results. J. Hydrol. 2009, 377, 191–207. [Google Scholar] [CrossRef]
- Plavcova, E.; Kysely, J. Evaluation of daily temperatures in Central Europe and their links to large-scale circulation in an ensemble of regional climate models. Tellus A Dyn. Meteorol. Oceanogr. 2011, 63, 1052–1054. [Google Scholar]
- Uboldi, F.; Lussana, C.; Salvati, M. Three-dimensional spatial interpolation of surface meteorological observations from high-resolution local networks. Francesco Uboldi, Cristian Lussana and Marta Salvati. Meteorol. Appl. 2008, 15, 537. [Google Scholar] [CrossRef]
- Lussana, C.; Uboldi, F.; Salvati, M.R. A spatial consistency test for surface observations from mesoscale meteorological networks. Q. J. Roy. Meteor. Soc. 2010, 136, 1075–1088. [Google Scholar] [CrossRef]
- Lussana, C.; Tveito, O.E.; Uboldi, F. Three-dimensional spatial interpolation of 2m temperature over Norway. Q. J. Roy. Meteor. Soc. 2018, 144, 344–364. [Google Scholar] [CrossRef]
- Haggmark, L.; Ivarsson, K.I.; Gollvik, S.; Olofsson, R.O. Mesan, an operational mesoscale analysis system. Tellus A Dyn. Meteorol. Oceanogr. 2000, 52, 2–20. [Google Scholar] [CrossRef]
- Daly, C.; Halbleib, M.; Smith, J.I.; Gibson, W.P.; Doggett, M.K.; Taylor, G.H.; Curtis, J.; Pasteris, P.P. Physiographically sensitive mapping of climatological temperature and precipitation across the conterminous United States. Int. J. Climatol. 2008, 28, 2031–2064. [Google Scholar] [CrossRef]
- McGuire, C.R.; Nufio, C.R.; Bowers, M.D.; Guralnick, R.P. Elevation-Dependent Temperature Trends in the Rocky Mountain Front Range: Changes over a 56-and 20-Year Record. PLoS ONE 2012, 7, e44370. [Google Scholar] [CrossRef]
- Brunetti, M.; Maugeri, M.; Nanni, T.; Simolo, C.; Spinoni, J. High-resolution temperature climatology for Italy: Interpolation method intercomparison. Int. J. Climatol. 2014, 34, 1278–1296. [Google Scholar] [CrossRef]
- Um, M.J.; Kim, Y. Spatial variations in temperature in a mountainous region of Jeju Island, South Korea. Int. J. Climatol. 2017, 37, 2413–2423. [Google Scholar] [CrossRef]
- Hudson, G.; Wackernagel, H. Mapping Temperature Using Kriging with External Drift—Theory and an Example from Scotland. Int. J. Climatol. 1994, 14, 77–91. [Google Scholar] [CrossRef]
- Tadic, M.P. Gridded Croatian climatology for 1961–1990. Theor. Appl. Climatol. 2010, 102, 87–103. [Google Scholar] [CrossRef]
- Krahenmann, S.; Bissolli, P.; Rapp, J.; Ahrens, B. Spatial gridding of daily maximum and minimum temperatures in Europe. Meteorol. Atmos. Phys. 2011, 114, 151–161. [Google Scholar] [CrossRef]
- Hengl, T.; Heuvelink, G.B.M.; Tadic, M.P.; Pebesma, E.J. Spatio-temporal prediction of daily temperatures using time-series of MODIS LST images. Theor. Appl. Climatol. 2012, 107, 265–277. [Google Scholar] [CrossRef]
- Stewart, S.B.; Nitschke, C.R. Improving temperature interpolation using MODIS LST and local topography: A comparison of methods in south east Australia. Int. J. Climatol. 2017, 37, 3098–3110. [Google Scholar] [CrossRef]
- Zink, M.; Mai, J.; Cuntz, M.; Samaniego, L. Conditioning a Hydrologic Model Using Patterns of Remotely Sensed Land Surface Temperature. Water Resour. Res. 2018, 54, 2976–2998. [Google Scholar] [CrossRef]
- Collados-Lara, A.J.; Fassnacht, S.R.; Pardo-Iguzquiza, E.; Pulido-Velazquez, D. Assessment of High Resolution Air Temperature Fields at Rocky Mountain National Park by Combining Scarce Point Measurements with Elevation and Remote Sensing Data. Remote Sens. 2021, 13, 113. [Google Scholar] [CrossRef]
- Appelhans, T.; Mwangomo, E.; Hardy, D.R.; Hemp, A.; Nauss, T. Evaluating machine learning approaches for the interpolation of monthly air temperature at Mt. Kilimanjaro, Tanzania. Spat. Stat. 2015, 14, 91–113. [Google Scholar] [CrossRef]
- Ruiz-Alvarez, M.; Alonso-Sarria, F.; Gomariz-Castillo, F. Interpolation of Instantaneous Air Temperature Using Geographical and MODIS Derived Variables with Machine Learning Techniques. ISPRS Int. J. Geo-Inf. 2019, 8, 382. [Google Scholar] [CrossRef]
- Cho, D.; Yoo, C.; Im, J.; Lee, Y.; Lee, J. Improvement of spatial interpolation accuracy of daily maximum air temperature in urban areas using a stacking ensemble technique. GIScience Remote Sens. 2020, 57, 633–649. [Google Scholar] [CrossRef]
- Lussana, C.; Seierstad, I.A.; Nipen, T.N.; Cantarello, L. Spatial interpolation of two-metre temperature over Norway based on the combination of numerical weather prediction ensembles and in situ observations. Q. J. Roy. Meteor. Soc. 2019, 145, 3626–3643. [Google Scholar] [CrossRef]
- Kumar, M.; Kosovic, B.; Nayak, H.; Porter, W.; Randerson, J.; Banerjee, T. Evaluating the performance of WRF in simulating winds and surface meteorology during a Southern California wildfire event. Front. Earth Sci. 2024, 11, 1305124. [Google Scholar] [CrossRef]
- Brinckmann, S.; Krähenmann, S.; Bissolli, P. High-resolution daily gridded data sets of air temperature and wind speed for Europe, Earth Syst. Sci. Data 2016, 8, 491–516. [Google Scholar] [CrossRef]
- Skøien, J.; Baume, O.; Pebesma, E.; Heuvelink, G.M. Identifying and removing heterogeneities between monitoring networks. Environmetrics Off. J. Int. Environmetrics Soc. 2010, 21, 66–84. [Google Scholar] [CrossRef]
- Delvaux, C.; Journee, M.; Bertrand, C. The FORBIO Climate data set for climate analyses. Adv. Sci. Res. 2015, 12, 103–109. [Google Scholar] [CrossRef]
- Hiebl, J.; Auer, I.; Bohm, R.; Schoner, W.; Maugeri, M.; Lentini, G.; Spinoni, J.; Brunetti, M.; Nanni, T.; Tadic, M.P.; et al. A high-resolution 1961-1990 monthly temperature climatology for the greater Alpine region. Meteorol. Z. 2009, 18, 507–530. [Google Scholar] [CrossRef]
- Frei, C. Interpolation of temperature in a mountainous region using nonlinear profiles and non-Euclidean distances. Int. J. Climatol. 2014, 34, 1585–1605. [Google Scholar] [CrossRef]
- Li, J.Y.; Luo, S.W.; Qi, Y.J.; Huang, Y.P. Numerical solution of elliptic partial differential equation using radial basis function neural networks. Neural Netw. 2003, 16, 729–734. [Google Scholar]
- Wei, C.C. RBF Neural Networks Combined with Principal Component Analysis Applied to Quantitative Precipitation Forecast for a Reservoir Watershed during Typhoon Periods. J. Hydrometeorol. 2012, 13, 722–734. [Google Scholar] [CrossRef]
- Safdari-Vaighani, A.; Larsson, E.; Heryudono, A. Radial Basis Function Methods for the Rosenau Equation and Other Higher Order PDEs. J. Sci. Comput. 2018, 75, 1555–1580. [Google Scholar] [CrossRef]
- Liu, Z.Y.; Xu, Q.Y. A Multiscale RBF Collocation Method for the Numerical Solution of Partial Differential Equations. Mathematics 2019, 7, 964. [Google Scholar] [CrossRef]
- Fasshauer, G.E. Meshfree Approximation Methods with MATLAB; World Scientific: Singapore, 2007. [Google Scholar]
- Roque, C.; Ferreira, A.J. Numerical experiments on optimal shape parameters for radial basis functions. Numer. Methods Partial. Differ. Equ. Int. J. 2010, 26, 675–689. [Google Scholar] [CrossRef]
- Mongillo, M. Choosing basis functions and shape parameters for radial basis function methods. SIAM Undergrad. Res. Online 2011, 4, 2–6. [Google Scholar] [CrossRef]
- Fasshauer, G.E.; Zhang, J.G. On choosing “optimal” shape parameters for RBF approximation. Numer. Algorithms 2007, 45, 345–368. [Google Scholar] [CrossRef]
- Katipoğlu, O.M.; Acar, R.; Şenocak, S. Spatio-temporal analysis of meteorological and hydrological droughts in the Euphrates Basin, Turkey. Water Supply 2021, 21, 1657–1673. [Google Scholar] [CrossRef]
- Ryu, S.; Song, J.J.; Kim, Y.; Jung, S.H.; Do, Y.; Lee, G. Spatial Interpolation of Gauge Measured Rainfall Using Compressed Sensing. Asia-Pac. J. Atmos. Sci. 2021, 57, 331–345. [Google Scholar] [CrossRef]
- Powell, M.J.D. Univariate Multiquadric Approximation—Reproduction of Linear Polynomials. Int. S. Num. M. 1990, 94, 227–240. [Google Scholar]
- Buhmann, M. Radial Basis Functions: Theory and Implementations; Cambridge University Press: Cambridge, UK, 2003. [Google Scholar]
- Hardy, R.L. Multiquadric equations of topography and other irregular surfaces. J. Geophys. Res. 1971, 76, 1905–1915. [Google Scholar] [CrossRef]
- Fornberg, B.; Wright, G. Stable computation of multiquadric interpolants for all values of the shape parameter. Comput. Math. Appl. 2004, 48, 853–867. [Google Scholar] [CrossRef]
- Chow, J.Y.J.; Regan, A.C.; Arkhipov, D.I. Faster Converging Global Heuristic for Continuous Network Design Using Radial Basis Functions. Transport. Res. Rec. 2010, 2196, 102–110. [Google Scholar] [CrossRef]
- Morse, B.S.; Yoo, T.S.; Rheingans, P.; Chen, D.T.; Subramanian, K.R. Interpolating implicit surfaces from scattered surface data using compactly supported radial basis functions. In ACM SIGGRAPH 2005 Courses; 2005; pp. 78–87. Available online: https://dl.acm.org/doi/abs/10.1145/1198555.1198645 (accessed on 25 March 2024).
- Lin, G.-F.; Chen, L.-H. A spatial interpolation method based on radial basis function networks incorporating a semivariogram model. J. Hydrol. 2004, 288, 288–298. [Google Scholar] [CrossRef]
- Ahmed, S.; De Marsily, G. Comparison of geostatistical methods for estimating transmissivity using data on transmissivity and specific capacity. Water Resour. Res. 1987, 23, 1717–1737. [Google Scholar] [CrossRef]
- Odeh, I.O.; McBratney, A.; Chittleborough, D. Further results on prediction of soil properties from terrain attributes: Heterotopic cokriging and regression-kriging. Geoderma 1995, 67, 215–226. [Google Scholar] [CrossRef]
- Wackernagel, H. Multivariate Geostatistics: An Introduction with Applications, 2nd ed.; Springer: Berlin, Germany, 1998. [Google Scholar]
- Chiles, J.-P.; Delfiner, P. Geostatistics: Modeling Spatial Uncertainty; John Wiley & Sons: Hoboken, NJ, USA, 2009; Volume 497. [Google Scholar]
- Mehta, P.; Bukov, M.; Wang, C.H.; Day, A.G.; Richardson, C.; Fisher, C.K.; Schwab, D.J. A high-bias, low-variance introduction to machine learning for physicists. Phys. Rep. 2019, 810, 1–124. [Google Scholar] [CrossRef] [PubMed]
- Stolbunov, V.; Nair, P.B. Sparse radial basis function approximation with spatially variable shape parameters. Appl. Math. Comput. 2018, 330, 170–184. [Google Scholar] [CrossRef]
- Sanyal, S.; Zhang, P. Improving quality of data: IoT data aggregation using device to device communications. IEEE Access 2018, 6, 67830–67840. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Site ID | (a, b) | Site ID | (a, b) | Site ID | (a, b) | Site ID | (a, b) | ||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | (1.10, −0.61) | 0.37, 0.36 | 12 | (0.97, 3.75) | 3.16, 0.59 | 24 | (1.04, 2.27) | 2.91, 0.95 | 36 | (1.16, −2.04) | 1.08, 0.68 |
| 1 | (1.08, −1.27) | 0.27, 0.43 | 13 | (1.04 2.49) | 3.30, 0.73 | 25 | (1.05, 2.60) | 3.41, 0.76 | 37 | (1.08, 0.82) | 2.45, 0.74 |
| 2 | (0.94, 4.73) | 3.47, 0.81 | 14 | (0.92, 4.55) | 2.89, 0.89 | 26 | (1.03, 0.40) | 0.88, 0.82 | 38 | (1.21, −4.39) | 1.05, 0.44 |
| 3 | (1.07, −0.51) | 0.74, 0.64 | 15 | (1.02, 3.31) | 3.68, 0.52 | 27 | (1.06, 2.69) | 3.59, 0.68 | 40 | (1.01, 1.95) | 2.12, 0.66 |
| 4 | (1.24, −2.85) | 3.04, 0.43 | 16 | (1.03, 4.13) | 4.71, 0.85 | 28 | (1.09, 2.17) | 3.48, 0.48 | 41 | (1.07, 2.62)) | 4.01, 0.77 |
| 5 | (1.15, −0.92) | 1.50, 0.68 | 17 | (1.14, 0.38) | 2.75, 0.71 | 29 | (0.98, 2.99) | 2.66, 0.74 | 42 | (1.03, 1.00) | 1.58, 0.63 |
| 6 | (0.90, 3.78) | 1.29, 0.55 | 18 | (1.10, 1.96) | 3.56, 0.80 | 30 | (0.99, 2.58) | 2.37, 0.71 | 43 | (1.08, −0.20) | 1.16, 0.69 |
| 7 | (1.29, −2.94) | 3.78, 0.69 | 19 | (1.09, 1.96) | 3.39, 0.70 | 31 | (1.15, −2.61) | 0.28, 0.48 | 44 | (1.19, −1.49) | 1.79, 0.99 |
| 8 | (0.95, 6.90) | 5.77, 0.71 | 20 | (0.99, 4.26) | 4.08, 0.77 | 32 | (1.07, −0.18) | 1.20, 0.29 | 45 | (1.09, 1.90) | 3.69, 0.96 |
| 9 | (1.07, 0.65) | 1.73, 0.76 | 21 | (1.00, 3.05) | 3.04, 0.66 | 33 | (1.09, 0.87) | 0.95, 0.64 | 46 | (1.09,0.40) | 1.90, 0.37 |
| 10 | (1.03, 0.75) | 1.26, 0.73 | 22 | (0.95, 3,32) | 2.15, 0.73 | 34 | (1.04, 1.55) | 2.29, 0.62 | 47 | (1.12,0.07) | 2.42, 0.59 |
| 11 | (0.99, 5.62,) | 5.54, 0.75 | 23 | (1.19, −1.98) | 1.63, 1.14 | 35 | (1.06, 1.24) | 2.27, 0.52 | 48 | (1.06, 1.70) | 2.84, 0.57 |
| IoT | JEJ | KFS | RDA | |
|---|---|---|---|---|
| (a, b) | * Individual Equation | (1.01, −0.61) | (1.03, −0.79) | (1.04, −0.82) |
| 0.71 | 0.55 | 0.51 | 0.48 | |
| Removal rate [%] | 17.74 | 2.82 | 5.27 | 4.83 |
| Data for Interpolation | Verification Network | LOOCV MVE [°C] | Mean Bias [°C] | ||
|---|---|---|---|---|---|
| Before | After | Before | After | ||
| KMA | KMA | 0.73 | −0.00 | ||
| All (KMA + IoT + JEJ + KFS + RDA) (Leave-one-out Cross-validation) | KMA | 1.00 | 0.70 | 0.37 | −0.00 |
| IoT | 2.21 | 0.78 | −1.52 | 0.01 | |
| JEJ | 1.05 | 0.59 | 0.56 | −0.08 | |
| KFS | 0.94 | 0.63 | 0.63 | 0.01 | |
| RDA | 1.12 | 0.53 | 0.88 | 0.01 | |
| All | 1.26 | 0.69 | 0.04 | −0.00 | |
| Network for Interpolation | Methods | |||||
|---|---|---|---|---|---|---|
| Regression-Based RBF | KED | RK | ||||
| Linear T(z) | Nonlinear T(z) | Linear T(z) | ||||
| KMA | 0.73 | 0.72 | 0.66 | 0.87 | 0.87 | 0.78 |
| All | 0.69 | 0.69 | 0.66 | 0.77 | 1.09 | 0.74 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ryu, S.; Song, J.J.; Lee, G. Interpolation of Temperature in a Mountainous Region Using Heterogeneous Observation Networks. Atmosphere 2024, 15, 1018. https://doi.org/10.3390/atmos15081018
Ryu S, Song JJ, Lee G. Interpolation of Temperature in a Mountainous Region Using Heterogeneous Observation Networks. Atmosphere. 2024; 15(8):1018. https://doi.org/10.3390/atmos15081018
Chicago/Turabian StyleRyu, Soorok, Joon Jin Song, and GyuWon Lee. 2024. "Interpolation of Temperature in a Mountainous Region Using Heterogeneous Observation Networks" Atmosphere 15, no. 8: 1018. https://doi.org/10.3390/atmos15081018
APA StyleRyu, S., Song, J. J., & Lee, G. (2024). Interpolation of Temperature in a Mountainous Region Using Heterogeneous Observation Networks. Atmosphere, 15(8), 1018. https://doi.org/10.3390/atmos15081018