Abstract
Skewed X chromosome inactivation (XCI-S) has been reported to be associated with some X-linked diseases, and currently several methods have been proposed to estimate the degree of the XCI-S (denoted as ) for a single locus. However, no method has been available to estimate for genes. Therefore, in this paper, we first propose the point estimate and the penalized point estimate of for genes, and then derive its confidence intervals based on the Fieller’s and penalized Fieller’s methods, respectively. Further, we consider the constraint condition of and propose the Bayesian methods to obtain the point estimates and the credible intervals of , where a truncated normal prior and a uniform prior are respectively used (denoted as GBN and GBU). The simulation results show that the Bayesian methods can avoid the extreme point estimates (0 or 2), the empty sets, the noninformative intervals () and the discontinuous intervals to occur. GBN performs best in both the point estimation and the interval estimation. Finally, we apply the proposed methods to the Minnesota Center for Twin and Family Research data for their practical use. In summary, in practical applications, we recommend using GBN to estimate of genes.
1. Introduction
X chromosome inactivation (XCI) is an important epigenetic phenomenon. Under the XCI, one of two X chromosomes in females is silenced in the early stage of embryonic development to ensure that the transcriptional dosage of X chromosomes in females and that in males are balanced [1]. Generally, there are three patterns of the XCI [2], random X chromosome inactivation (XCI-R), skewed X chromosome inactivation (XCI-S) [3,4,5,6], and escape from X chromosome inactivation (XCI-E) [7,8]. The XCI-R means that the paternal and maternal X chromosomes in females have the same probabilities to be inactive, i.e., for a locus on the X chromosome, approximately 50% of the cells inactivate one of the alleles, while the remaining 50% of the cells keep the other allele inactive. Under the XCI-E, the alleles on both the X chromosomes in females are expressed, which are similar to those at an autosomal locus. For humans, about 15-30% of the X-linked genes have been reported to undergo the XCI-E [7]. Finally, the XCI-S is defined as more than 75% of the cells in females inactivating the same allele [9]. For some extreme skewed cases, it is possible that more than 90% of the cells keep the same allele silenced [9,10]. As such, the difference in the number of the X chromosomes in females and males and the complexity of the XCI make the association tests for the X chromosomes more complicated than those for the autosomes.
The skewness of the XCI can reflect, or cause, biological consequences for females [9]. The clonal expansion of a somatic cell in females may lead to a cell population with extremely skewed XCI [9]. For some X-linked disorders, there is strong selection of the cells which keep the mutant allele inactive in the heterozygous carriers and, hence, assessing the degree of the skewness of the XCI is helpful in terms of being indicative of the carrier’s disease status [11]. Further, the degree of the skewness of the XCI can determine the severity of certain X-linked diseases, such as haemophilia B [12,13]. On the other hand, even for the same mutant allele, the XCI-S in different tissues or cells may result in different clinical consequences. For example, in heterozygous females with a mutant FoxP3 allele, the XCI-S against the mutant allele in specific tissues can prevent autoimmune disease, while the XCI-S skewed towards the mutant allele in breast epithelial cells can cause breast cancer [14]. Besides this, studies have shown that some diseases, such as ovarian cancer, Rett syndrome, Duchenne muscular dystrophy and recurrent miscarriage, are also related to the XCI-S [15,16,17,18]. Therefore, in recent years, researchers have proposed some methods to test the association between the alleles at an X-chromosomal single nucleotide polymorphism (SNP) locus and traits [19,20,21,22,23,24,25,26]. For example, Wang et al. [23] developed a permutation-based test statistic which considers all the XCI patterns. For the XCI-R and the XCI-S, this method respectively codes three female genotypes (, and ) as 0, and 2 at an X-chromosomal SNP, with the major allele and the minor allele , where is an unknown genotypic value for heterozygous females, and respectively codes two male genotypes ( and ) as 0 and 2. Here, can be used to measure the degree of the XCI skewing. For instance, is indicative of the XCI-S skewed towards the minor allele , means that the XCI pattern is the XCI-R, and indicates the XCI-S skewed towards the major allele . For the XCI-E, three female genotypes are coded as 0, 1 and 2, and two male genotypes are coded as 0 and 1, respectively. However, the X-chromosomal association tests mentioned above are only applicable to a single SNP and common variants, and are not suitable for genetic regions or genes with multiple SNPs and rare variants. Rare variants refer to the variants with a minor allele frequency (MAF) less than 1%, and those with MAF are called common variants [27,28]. Over the past few years, genome-wide association studies have identified many common variants associated with complex traits, but these variants usually explain only a small part of the estimated heritability for a given trait. On the other hand, it has been shown that rare variants play a key role in influencing traits [29]. Single-variant tests often have low test power when applied to the rare variants. Therefore, many statistical methods had been presented, which focus on testing the cumulative effect of rare variants in genetic regions or SNP sets (such as genes), including the burden test and the variance-component tests [27,30,31,32,33]. The burden test collapses all the rare variants in a genetic region into a single burden variable, and then regresses the trait on the burden variable to test the cumulative effect of the rare variants in that region [27]. The variance-component tests, such as the sequence kernel association test (SKAT), do not directly aggregate the variants in the modeling process, but aggregate the association between the variants and the trait through a kernel matrix [33]. Another method, SKAT-O, proposed by Lee et al. [34], has the advantages of both the burden and SKAT tests, but the time cost is higher than the previous two methods. All these methods have one thing in common, i.e., increasing the weights of rare variants’ contributions and decreasing the weights of common variants’ contributions. However, for a trait-related gene, the relative influence of rare and common variants is not known [35]. Therefore, Iuliana et al. [35] put forward several multi-locus association tests, such as the adaptive sum test, which consider the effects of both common and rare variants on the trait, and these methods are more powerful when the genes simultaneously contain rare and common variants. Note that these multi-locus association tests are all based on genetic regions or genes on autosomes, and may not be directly applied to the X chromosomes. Therefore, Clement et al. [36] improved the traditional burden test, SKAT and SKAT-O methods and suggested three gene-based X-chromosomal association tests. However, these methods only take account of the XCI-R and XCI-E patterns. What is more, the FxSKAT method, proposed by Asuman et al. [37], is not only applicable to pedigree data, but also takes the XCI-E into account during the analysis process.
Except for testing the association between the genes on the X chromosome and the traits under study, it is also important to develop methods to measure the corresponding degree of the skewness of the XCI (denoted as ). At present, researchers have put forward several methods to estimate for a single SNP, which can simultaneously get the point estimates and the confidence intervals (CIs) of . Specifically, Xu et al. [38] proposed a statistical index for estimating based on family trios (both parents and their daughter), which can be represented as the ratio of two relative risks in females, and derived the corresponding CI with the likelihood ratio (LR) test. Wang et al. [39] used the ratio of two regression coefficients of a logistic regression to estimate , and obtained the CIs with the LR, Fieller’s and delta methods, respectively. Li et al. [40] further extended the methods of Wang et al. so that they can accommodate quantitative traits. However, the above-mentioned methods are all constructed for a single SNP, and are not suitable for genetic regions or genes containing multiple SNPs. Furthermore, when applied to rare variants, they perform poorly. In addition, it should be noted that the delta method cannot control the coverage probability (CP) well, and the LR and Fieller’s methods have similar performance in the interval estimation, while the Fieller’s method is computationally efficient. Thus, the Fieller’s method is recommended in practice. However, both the LR and Fieller’s methods may yield unbounded CIs when the denominators in the ratios used to estimate are close to 0. Fortunately, the penalized Fieller’s (PF) method, which was proposed by Wang et al. [41], can be used to conduct the ratio estimation and always get the bounded CIs by choosing an appropriate penalty parameter. However, it has not been applied to the estimation of the degree of the skewness of the XCI yet. On the other hand, the above-mentioned methods do not consider the constraint condition of , and simply cut off the point estimates and the CIs within , which may result in extreme point estimates (0 or 2) and empty sets or noninformative CIs (i.e., ). In contrast, the Bayesian methods can effectively utilize the prior information of each unknown parameter in the analysis, and have been widely used in statistical genetics [42].
Therefore, in this paper, we borrow the idea of the burden test, aggregate all the variants in a gene under study into a burden variable by selecting the appropriate weights, and then estimate the mean degree of the skewness of the XCI over all the SNPs in the gene based on the burden variable. We first propose the point estimate and the penalized point estimate of for the gene, and then derive its CIs based on the Fieller’s and PF methods, respectively. Then, by considering the constraint condition of , we propose the Bayesian methods to obtain the point estimates and the credible intervals of . Specifically, after getting enough samples drawn from the posterior distribution of , we calculate the mode of the samples as the point estimate of and the highest posterior density interval (HPDI) as the credible interval of [43]. We conduct extensive simulation studies to compare the performances of the proposed point estimation methods and the interval estimation methods for . Finally, we demonstrate the practical utility of the proposed methods by applying them to the Minnesota Center for Twin and Family Research (MCTFR) data.
2. Materials and Methods
2.1. Notations
Suppose that we only collect female subjects, because male subjects provide no information on the XCI skewing. Consider an X-linked trait (quantitative or qualitative) and let represent the trait value of the female (), then is the vector of the trait values for all the females. Assume that a gene which contains SNPs is associated with this trait, and let and denote the major allele and the minor allele at the SNP (), respectively. Let be the genotype at the SNP of the female (i.e., or ). If we use to measure the mean degree of the skewness of the XCI for all the SNPs in the gene, then and can be used to denote the genotypic values for genotypes , and , respectively. As such, is the vector of the genotypic values at the SNPs of the female. Therefore, we consider the association between the gene and the trait based on the following generalized linear model
where is a link function; is the vector of covariates of the female, which are needed to be adjusted, and is an covariate matrix; is the conditional mean of the female’s trait value given and ; is the intercept, is the vector of the regression coefficients of , and is an vector of the regression coefficients of .
Based on the idea of the burden test [27], we aggregate all the SNPs in the gene into a burden variable and let , where is a weight for the SNP. Here we assume that is a function with respect to the MAF at the SNP (denoted as ), i.e., [35]. So, model (1) can be rewritten as
where is the regression coefficient of . Next, we consider two variables and , where is the indicator function. Thus, means that the female contains at least one minor allele at the SNP, and denotes that the female is a homozygote at the SNP. Through simple transformations, we can get , and can be expressed as , where and . Further, let and . To estimate the mean degree of the XCI skewing for the gene (i.e., ), we substitute into model (2) and get
For quantitative traits, is the identity function, and model (3) can be written as , where is the random error and follows . In this case, the unknown parameters are , and the corresponding likelihood function of the sample is
As for qualitative traits, is the logit function, and model (3) is written as =. The unknown parameters are and the likelihood function is
where and 0 respectively indicate that the female is a case and a control, and . Let and , and we have
As such, we obtain and can be expressed as
By assuming that the degree of the skewness of the XCI at the SNP is , satisfies, under a certain condition (the proof is given in Appendix A),
where is the number of the females who contain at least one minor allele at the SNP, and is the number of the females whose genotypes at the SNP are . So, is the weighted mean of the ’s for all the SNPs in the gene with the weights being . When there are rare variants at some SNPs or when the variation of the ’s in the gene is large, is still well defined for the whole gene. On the other hand, from Equation (5), can be well defined if there is an association between the gene and the trait (i.e., ). Further, if and only if and , which means that all the ’s are 0 and the XCI-S is completely skewed towards the minor allele for each SNP, and only when and , indicating that all the ’s are 2 and the XCI-S is completely skewed towards the major allele for each SNP. However, means that on the average, the gene undergoes the XCI-R or the XCI-E. After obtaining the estimates of and , respectively denoted by and which can be derived by the maximum likelihood method, the point estimate of can be expressed as .
2.2. Point Estimate and CI of by Fieller’s Method
Note that should take the possible values from the interval . So, the original estimate needs to be cut off in and the resulting estimate is denoted by . Further, we utilize the Fieller’s method to get the CI of . Specifically, borrowing the idea of Wang et al. [39], we have , and . To construct the CI of , we first establish a Wald test under the null hypothesis , where is a pre-specified value (e.g., 1, which means that on the average, the gene undergoes the XCI-R or the XCI-E). As such, we have , and the Wald test statistic is
Therefore, the CI of can be derived by solving the following equation
where is the upper quantile of the standard normal distribution. Rearrange the above equation with respect to into a quadratic equation
where , and . When or , the CI of will degenerate to be a point. The CI of for other cases is as follows
It should be noted that even in the case of , the CI of obtained by the Fieller’s method may still be an empty set. And in the case of and , the CI may be composed of two parts, which is the discontinuous interval.
2.3. Penalized Point Estimate and CI of by PF Method
As mentioned above, we construct as the point estimate of , where . However, if the denominator is very close to 0, will tend to the infinity. The CI of based on the Fieller’s method before the truncation is usually unbounded. To deal with this issue in the ratio estimate and borrow the idea of Wang et al. [41], we propose the following PF method to obtain the penalized point estimate of and the corresponding CI. Consider the penalized log-likelihood function of as follows: , where is a penalty parameter and is taken to be as suggested by Wang et al. [41] because the CI obtained by the PF method is always bounded with . By maximizing the function , we have the penalized denominator , where is the signum function. Further, we can get , where . If we replace by to obtain the point estimate , then is a biased estimate of . To reduce this bias, we need to correct the numerator by . Correspondingly, we can get and . After obtaining the corrected denominator and the corrected numerator , truncated by is the penalized point estimate of , which is denoted by . The construction process of the corresponding CI of is the same as the Fieller’s method, except for respectively replacing , , , and by , , , and in Equation (6). However, it should be noted that although the CI of based on the PF method is always bounded when , it may be out of and we need to truncate it by .
2.4. Point Estimate and Credible Interval of by Bayesian Method
Note that the point estimates ( and ), and the corresponding CIs mentioned above, are cut off in the interval and cannot directly incorporate the information on . Therefore, in this subsection, we introduce the Bayesian method to give the point estimate and the credible interval of by considering the prior information of . Specifically, we have the posterior distribution of the unknown parameter as follows
where is the joint prior distribution of ; when the traits are quantitative, and ; when the traits are qualitative, and . However, in general, we cannot get the analytical solutions of . Therefore, it is not feasible to directly sample from the posterior distribution. Fortunately, there are several algorithms for sampling from an approximate distribution of the posterior distribution, such as the Hamiltonian Monte Carlo (HMC) algorithm which can be implemented by the “rstan” package in R [43]. On the other hand, according to Annis et al. [43], the correlation between the parameters has little influence on the HMC algorithm. To simplify the operations, and improve the sampling efficiency, we assume that the unknown parameters in are independent of each other, and use the HMC algorithm to sample from the approximate posterior distribution of . In other words, we choose the prior distribution for each unknown parameter separately.
The prior distributions of the parameters in are selected as follows. To reduce the influence of the selection of the prior distributions on the results, for nuisance parameters , and (there is an additional nuisance parameter when the trait is quantitative), we choose the weak prior distributions [44]. Specifically, we assume that the prior distributions of and are both , and that of is . For quantitative traits, we also specify the prior distribution of to be an exponential distribution, i.e., . As for the parameter of interest, which is used to measure the mean degree of the skewness of the XCI over all the SNPs in the gene and satisfies the constraint condition of , we consider two possible prior distributions. The first one is the truncated normal distribution, with both parameters being 1 and the values ranging from 0 to 2, and the probability density function of the prior distribution is
where is the probability density function of the standard normal distribution. In this way, not only satisfies the constraint condition of , but also the probability of being close to 1 is the highest, which is consistent with the literature [2], i.e., most of the SNPs on the X chromosome undergo the XCI-R. Meanwhile, the selected truncated normal distribution of also avoids that the probability of taking the extreme value (0 or 2) is too low, which may be more suitable for practical applications. The second prior distribution of is a uniform distribution, i.e., .
After specifying the prior distributions of all the unknown parameters, we can get enough samples of through the HMC algorithm, and then calculate the mode of the samples as the point estimate of , and the highest posterior density interval (HPDI) as the credible interval of . Here, we denote the Bayesian methods with the truncated normal prior and the uniform prior as GBN and GBU, and the point estimates obtained by these two methods are denoted as and , respectively.
3. Results
3.1. Simulation Settings
We conducted extensive simulation studies to evaluate the performances of the proposed point estimation and interval estimation methods. The number of female subjects (i.e., the sample size ) is set to be 500 and 2000. Consider a gene associated with the trait under study and the number of the SNPs in the gene (i.e., ) is fixed at 100, i.e., we assume that all the 100 SNPs are associated with the trait. Meanwhile, we define as the proportion of rare variants among the 100 SNPs. To explore the effect of on the proposed methods, we set , 0.4 and 1, which correspond to the cases of all the 100 SNPs only including common variants, the 100 SNPs simultaneously containing common and rare variants, and all the 100 SNPs only consisting of rare variants, respectively. Among them, the MAFs for common variants are sampled from , while the MAFs for rare variants are randomly simulated from [45,46,47]. We generate the genotypes of female subjects by referring to the ideas of Wang et al. [45], Basu et al. [46], and Turkmen et al. [47]. We first generate a latent vector from the multivariate normal distribution with the mean vector being and the elements of the variance-covariance matrix satisfying and () [45,47], where the linkage disequilibrium among the SNPs is taken into consideration. For simplicity, we set in our simulation studies. Once is generated, it is then transformed to 0 (major allele) or 1 (minor allele) determined by the corresponding MAFs. This process is repeated twice, and two simulated vectors of length 100 are put together to form the genotypes at the 100 SNPs for a female subject. After simulating the genotypes of female subjects, we have an genotypic value matrix with the elements being 0, 1 or 2, and then we replace the elements of equal to 1 with to simulate the information on the XCI-S. Note that to simplify the simulation and better evaluate the performances of our proposed methods (e.g., the calculation of the mean squared errors (MSEs) of the point estimates requires a single true value of for each replicate; the details are given later), we set the degrees of the XCI skewing ’s at all the 100 SNPs to be the same in the simulation study (i.e., ).
We only consider a covariate , which is generated from the standard normal distribution. For the quantitative trait, we simulate the trait value of the th female according to the following model
where is the random error, which is generated from the standard normal distribution; is the intercept and is the regression coefficient of the covariate , and both the parameters are set to be 0.5 [36]; is the regression coefficient of the genotypic value at the SNP [33,34,36], where is the tuning parameter and is used to avoid the effect of a SNP being too large or too small [36]. To highlight the effects of rare variants on the trait, we set when the SNP has a rare variant, otherwise. Further, notice that the directions of the effects of different SNPs on the trait may be different. Therefore, we consider the proportion of the SNPs with positive effects among the 100 SNPs (denoted by ) and set to be 0.6 and 1, indicating that the effect directions of some SNPs are positive and some are negative, and all the SNP effects are positive, respectively. We do not simulate the case of (i.e., all the SNP effects are negative) because the results with are similar to those with . As for the qualitative trait, the model for generating the affection status of the th female is as follows
All of the parameters are the same as when simulating the quantitative trait, except that we need to set the case-control ratio to be 1:1.
After simulating the genotypes and the trait values, we use model (4) to obtain the estimates of and , where , , , and is the estimate of the MAF at the SNP. Then, we get the point estimate , the penalized point estimate , and the CIs of derived by the Fieller’s and the PF methods. As for the Bayesian methods, the HMC algorithm is implemented through the “sampling” function in the R package “rstan”. We set 8 chains for the parallel sampling in the simulation. For each chain, we extract 10,000 samples, and the first 5000 are used for warm-up. So, we finally get 40,000 samples. To ensure the convergence, the target acceptance rate is set to be 0.99.
The above simulation steps are all implemented in the R software (version 4.1.1, http://r-project.org, accessed on 5 January 2022). For each simulation setting, the number of the replicates is fixed to be 500, and for each replicate, the true value of is sampled from the uniform distribution . To evaluate the accuracy and the robustness of , , and , we calculate the MSEs of these point estimates. Here, , where represents the true value of and is the point estimate in the th replicate (). Note that and are always between 0 and 2, so we only compute the proportions of and taking the extreme values (0 or 2), respectively. Meanwhile, scatter plots are used to show the relationship between the four point estimates and the true values of . To compare the performances of the GBN, GBU, PF and Fieller’s methods in the interval estimation, we calculate the CP as well as the mean, the median, the standard deviation and the interquartile range of the widths of the 95% HPDIs or CIs (denoted by , , and ), respectively. For the PF and Fieller’s methods, we also compute the proportions of the empty sets (EP), the noninformative intervals (NP), and the discontinuous intervals (DP) to further compare the effectiveness of these two methods, where the noninformative interval means the CI being . However, it should be noted that the GBN and GBU methods avoid the cases of empty sets, noninformative intervals, and discontinuous intervals occurring. In addition, we draw the scatter plots between the interval widths of the four proposed methods and the true values of .
3.2. Simulation Results
The proportions of the extreme values (0 or 2) for and are shown in Table 1. It can be seen from the table that the proportions of the point estimates equal to 0 are the same for both and , while the proportion of the point estimates equal to 2 for is reduced. This is because before the truncation, both and always have the same sign, and is bounded. Specifically, when and are negative, and are both 0. On the other hand, when and are positive, compared with , the proportion of being greater than 2 decreases. Further, from Table 1, with the increase of the sample size or the trait changing from qualitative to quantitative, the proportions of the extreme values for and both become less. Next, let us take a look at the effects of the proportion of the rare variants () and the proportion of the SNPs with the positive effects () among all the SNPs on the proportions of the extreme values for and . Under the situation that the trait is quantitative and (i.e., the effect directions of some SNPs are positive and some are negative), the proportions of the extreme values (0 and 2) for and with (all the SNPs only include common variants) are less than those with (all the SNPs only consist of rare variants), irrespective of the sample size (). As for the qualitative trait, when and , the proportion of the extreme values equal to 0 for and the proportions of the extreme values (0 and 2) for with are smaller than those with , while the proportion of the extreme values equal to 2 for with (12.8%) is larger than that with (10.4%). When the trait is qualitative, and , the results are similar to those with , except that the proportion of the extreme values equal to 2 for with (20.0%) and that with (19.2%) are very close to each other. In addition, the proportions of the extreme values (0 or 2) for and . have no obvious trends for other cases of different values of and .

Table 1.
Proportions (%) of extreme values of and among 500 replications.
The MSEs of the four point estimates (, , and ) are listed in Table 2. From Table 2, we can see that the MSEs of and are smaller than those of and , and the MSE of is the smallest. When the sample size increases or the trait turns from qualitative to quantitative, the MSEs of these four point estimates decrease significantly. In general, the MSEs of the four point estimates gradually become larger when changes from 0, 0.4 to 1 (i.e., higher proportion of rare variants) and other parameters are kept unchanged, except for the case when the trait is quantitative, and . On the other hand, the MSEs of the four point estimates with (i.e., the effect directions of some SNPs are positive and some are negative) are smaller than those with (i.e., all the SNP effects are positive), when other parameters are fixed.
Table 2.
Mean squared errors of , , and among 500 replications.
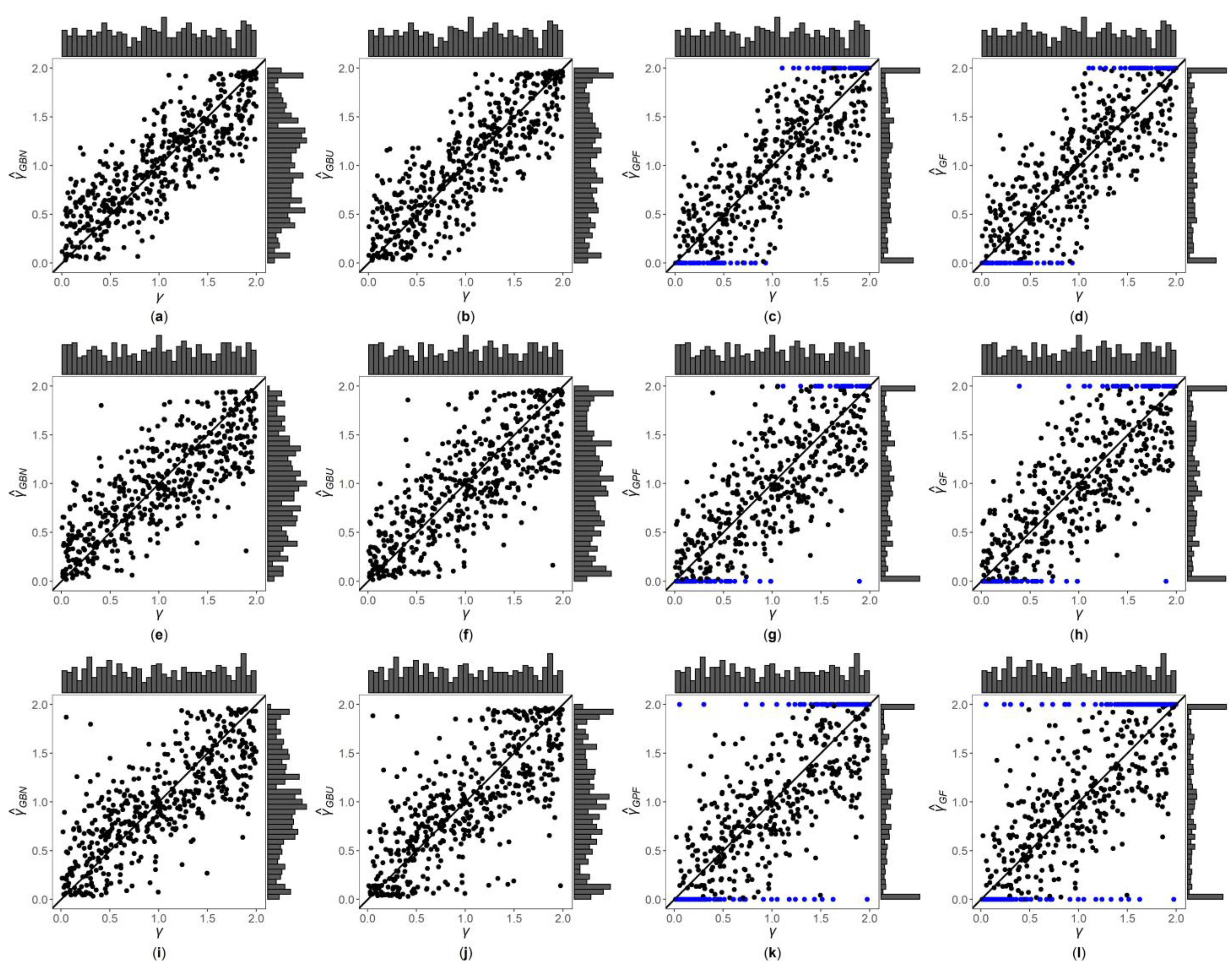
Figure 1, Figure 2 and Figures S1–S6 are the scatter plots of the four point estimates against the true values of under different simulation settings. These figures can more intuitively compare the performances of the four point estimates. For example, Figure 1 and Figure 2 are the scatter plots of the four point estimates against the true values of for the quantitative trait with , and and 1, respectively. In each figure, subplots (a)–(d) (four subplots in the first row) are respectively the scatter plots of , , and with ; subplots (e)–(h) (four subplots in the second row) and subplots (i)–(l) (four subplots in the third row) are the corresponding scatter plots with and 1, respectively. By comparing the four subplots in the same row of each figure, we find that the two point estimates ( and ) obtained by the Bayesian methods are closer to the true values of , and both perform better than and . On the other hand, note that the distribution of the true value of is , and it can be seen from the figures that the distributions of and are more uniform, while the distributions of and are skewed towards the extreme values (0 and 2). Meanwhile, by respectively comparing subplots (a), (e) and (i) for with subplots (b), (f) and (j) for , there is a little greater dispersion for than . In addition, from subplots (c), (g) and (k) for and subplots (d), (h) and (l) for , we observe that there exist many extreme point estimates for and (represented by the blue points). Moreover, the scatter plots for and provide the additional information that most of the extreme point estimates generally occur when the true values of are less than 0.5 or greater than 1.5. Further, by comparing the subplots in different rows of each figure when (Figure 1, Figures S1, S3 and S5), i.e., changing from 0, 0.4 to 1, the dispersions of the four point estimates generally increase, indicating that, in general, the MSEs of the four point estimates become larger, which are consistent with the results in Table 2. The numbers of the blue points in subplots (c) and (d) with are much less than those in subplots (k) and (l) with , respectively. However, for those figures with (Figure 2, Figure S2, S4 and S6), there is no obvious trend for the number of the blue points. Compared to Figure 1 (), the agreements between the four point estimates and the true values of in Figure 2 () are worse, which can also be seen in other figures (Figures S1, S3 and S5 vs. Figures S2, S4 and S6, respectively). Observing Figure 2, we find that the four point estimation methods may underestimate when . Finally, these four point estimation methods perform better for the quantitative trait than for the qualitative trait (Figure 1, Figure 2, Figures S1 and S2 vs. Figures S3–S6, respectively), and when the sample size increases (Figures S1, S2, S5 and S6 vs. Figure 1, Figure 2, Figures S3 and S4, respectively).
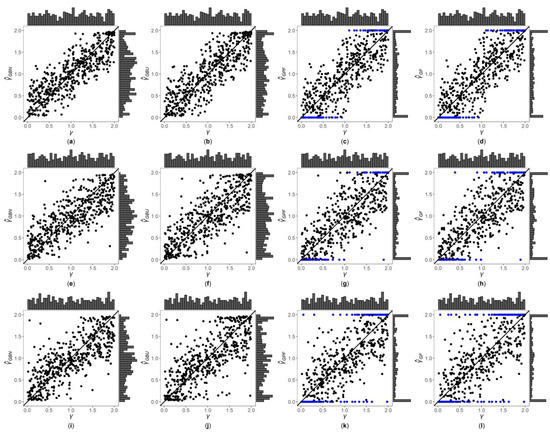
Figure 1.
Scatter plots of point estimates of against true values of for quantitative trait with and . The blue points represent the extreme values (0 or 2). (a) with ; (b) with ; (c) with ; (d) with ; (e) with ; (f) with ; (g) with ; (h) with ; (i) with ; (j) with ; (k) with ; (l) with .
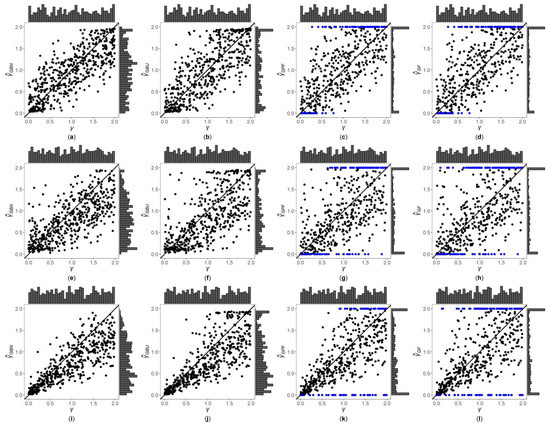
Figure 2.
Scatter plots of point estimates of against true values of for quantitative trait with and . The blue points represent the extreme values (0 or 2). (a) with ; (b) with ; (c) with ; (d) with ; (e) with ; (f) with ; (g) with ; (h) with ; (i) with ; (j) with ; (k) with ; (l) with .
Table 3 displays the EPs, NPs and DPs of the PF and Fieller’s methods. From Table 3, we observe that the EPs of the PF method are generally smaller than, or equal to, those of the Fieller’s method, except for the quantitative trait with , or 1, and , and the qualitative trait with or , or 1, and . However, the NPs of the PF method are always smaller than, or equal to, those of the Fieller’s method. Note that when we use the PF and Fieller’s methods to calculate the CIs of , we need to truncate the CIs by the interval . As such, compared to the Fieller’s method, the PF method can get shorter CIs, which means that the PF method reduces the possibility of the truncated CIs being the noninformative intervals. On the other hand, if the CIs before the truncation are disjoint from the interval , the PF method will increase the possibility that the truncated CIs are empty sets, which is the reason why the PF method may have bigger EPs than the Fieller’s method in some scenarios. In addition, all the DPs of the PF method are equal to 0. This is because we consider the penalty parameter , and the CIs derived by the PF method are always continuous. With increase of the sample size, the NPs of the PF and Fieller’s methods and the DPs of the Fieller’s method become smaller. Moreover, under the same simulation settings, the NPs of both methods, and the DPs of the Fieller’s method, for the quantitative trait are less than those for the qualitative trait. Under the situation that , when changes from 0, 0.4 to 1 and other parameters are kept unchanged, the EPs of both methods have no obvious trends, while the NPs of both methods and the DPs of the Fieller’s method generally become larger. As for , when changing from 0, 0.4 to 1 and other parameters being fixed, the EPs of the PF method appear larger except for the quantitative trait and , while the DPs of the Fieller’s method are relatively stable, and the NPs of the PF and Fieller’s methods show a trend of first increasing and then decreasing on most occasions. On the other hand, when other parameters are fixed, the EPs and NPs of the PF and Fieller’s methods with are smaller than those with in most cases, and the DPs of the Fieller’s method with are larger than or equal to those with .
Table 3.
Proportions (%) of empty sets (EPs), noninformative intervals (NPs), and discontinuous intervals (DPs) of PF and Fieller’s methods among 500 replications.
The CPs, and of the GBN, GBU, PF and Fieller’s methods are displayed in Table 4, and the corresponding and are given in Table 5. Table 4 demonstrates that, for the quantitative trait, the CPs of the GBN, GBU and Fieller’s methods are controlled around 95%. However, when , and , the CP of the PF method is underestimated (87.8%). As the sample size increases to 2000 and other parameters remain unchanged, the CP of the PF method is 96.6%. For the qualitative trait, when , the CPs of the GBN, GBU and PF methods are underestimated in most situations. With the increase of the sample size to 2000, the CPs of these three methods generally increase to be around 95%, but the CPs when and are still underestimated. Thus, for this simulation setting, we conduct an additional simulation study with larger sample sizes (3000 and 4000), and the corresponding results are presented in Table S1. It is shown in Table S1 that the CPs of these three methods are closer to 95% when the sample size continues to increase. This is explainable by the fact that qualitative traits generally require larger samples to achieve the same CPs than quantitative traits. In addition, we can see from Table 4 that the Fieller’s method has higher CPs under various simulation settings for the qualitative trait. However, according to Table 3, when the trait is qualitative, the NPs of the Fieller’s method are relatively high, which means that many CIs obtained by the Fieller’s method are the noninformative intervals (i.e., ). This may explain why the CPs of the Fieller’s method are on the high side. Further, from Table 4 and Table 5, the , , and of the GBN and GBU methods are smaller than those of the PF and Fieller’s methods in most situations. The GBN method has the smallest , and in most cases, and it also has the smallest under all the simulated settings. As can be seen from Table 4, when the trait is qualitative and , the ’s of the Fieller’s method are all 2, which indicates that in this case, more than half of the CIs based on the Fieller’s method are the noninformative intervals. This is consistent with the results of the NPs in Table 3. When the sample size increases, or the trait turns from qualitative into quantitative, the ’s and ’s of the four interval estimation methods greatly decrease. However, for the and , there are different trends in some situations. For example, when the trait is qualitative, the ’s and ’s of the four methods become larger in most cases as the sample size increases. Note that the widths of the intervals obtained by the four methods are closer to 2 and the corresponding variation will be smaller when . With the sample size increasing, the widths of the intervals gradually decrease and the corresponding variation appears larger, which may cause the bigger and .
Table 4.
Coverage probability (CP, in %), and of GBN, GBU, PF and Fieller’s methods among 500 replications.
Table 5.
and of GBN, GBU, PF and Fieller’s methods among 500 replications.
In the case of , the four methods have larger ’s and ’s in most cases when changes from 0, 0.4 to 1, while for the scenario of , the four methods show a trend of first increasing and then decreasing on most occasions, except that the ’s and ’s of the Fieller’s method are gradually larger for the qualitative trait. When the trait is quantitative and , the ’s and ’s of the four methods become larger with increasing from 0, 0.4 to 1, irrespective of the sample size. When the trait is qualitative, and , as is bigger, the ’s and ’s of the four methods generally are smaller, while when , the ’s of the four methods and the ’s of the GBN and GBU methods are relatively stable, and the ’s of the PF and Fieller’s methods generally become larger. For the quantitative trait with and , with the increase of , the ’s and ’s of the GBN, GBU and Fieller’s methods appear smaller and those of the PF method are larger in most situations, while in the case of , the four methods usually have larger ’s and ’s. When the trait is qualitative and , with increasing, the ’s and ’s of the GBN and GBU methods present a tendency of first decreasing and then increasing on most occasions, while those of the PF method are larger in most cases, and those of the Fieller’s method become smaller, irrespective of the sample size. On the other hand, when other parameters are fixed, the ’s and ’s of the four methods with are smaller than those with , except for the ’s of the GBN, GBU and PF methods and the ’s of the GBN and GBU methods for the quantitative trait with and , and those for the qualitative trait with or , and . Under the scenarios where is kept unchanged, the ’s and ’s of the GBN, GBU and Fieller’s methods with are generally larger than those with for the quantitative trait with , and the qualitative trait with or , while there are different trends for the quantitative trait with . In addition, the ’s and ’s of the PF method with generally are smaller than those with , when other parameters are fixed.
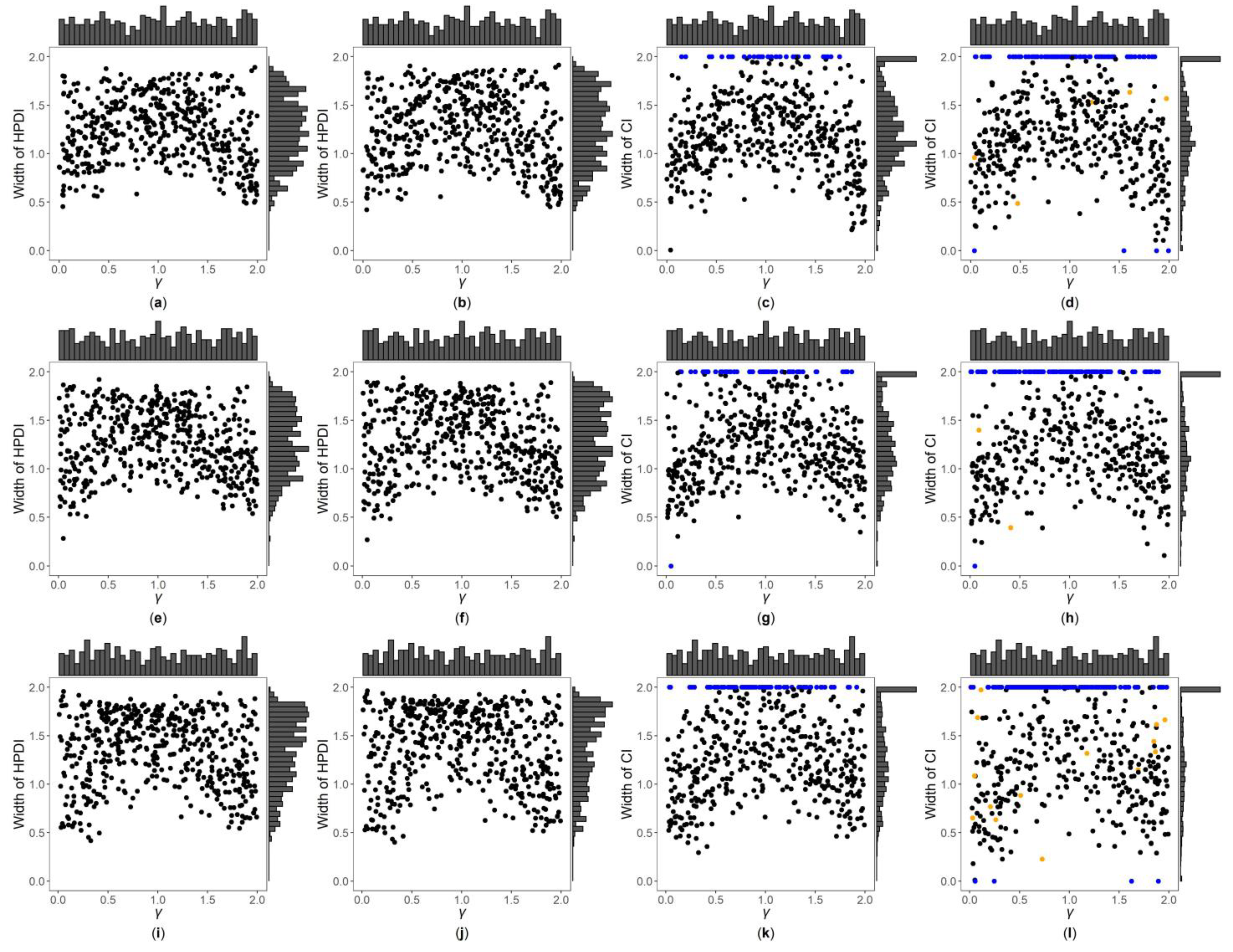
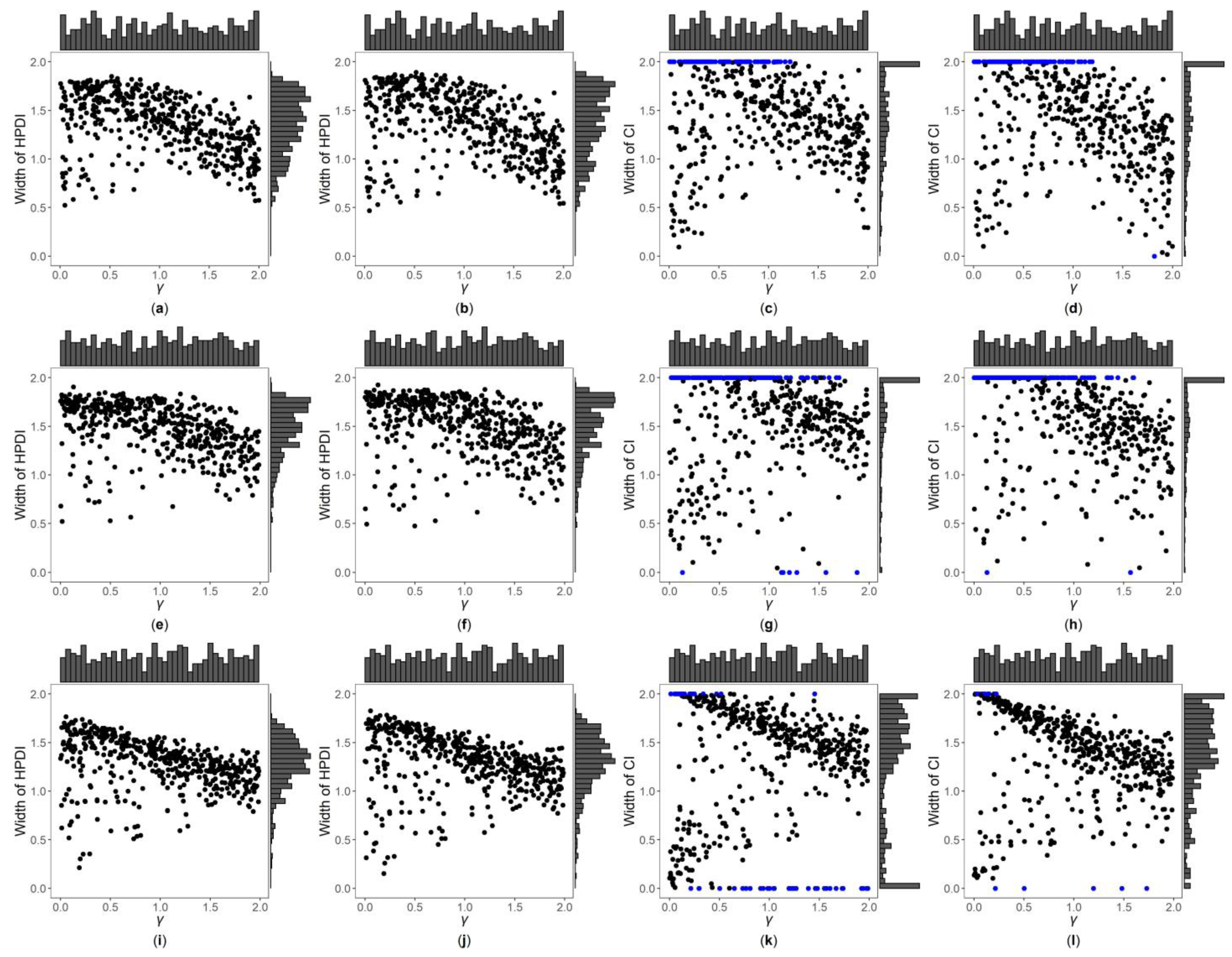
Figure 3, Figure 4 and Figures S7–S12 are the scatter plots of the widths of the 95% HPDIs or CIs obtained by the four interval estimation methods (GBN, GBU, PF and Fieller) against the true values of under different simulation settings. We can clearly observe the distributions of the widths of the HPDIs or CIs through these figures. For example, Figure 3 and Figure 4 are the scatter plots of the widths of the HPDIs or CIs against the true values of for the quantitative trait with , and and 1, respectively. In each figure, subplots (a)–(d) (four subplots in the first row) are respectively the scatter plots for the GBN, GBU, PF and Fieller’s methods with ; subplots (e)–(h) (four subplots in the second row) and subplots (i)-(l) (four subplots in the third row) are the corresponding scatter plots with and 1, respectively. It can be seen from the four subplots in the same row of each figure that the distributions of the widths of the HPDIs for the GBN and GBU methods are similar, and both have smaller dispersions than those of the CIs for the PF and Fieller’s methods. Furthermore, these figures display that the distributions of the interval widths for the PF and Fieller’s methods are greatly more skewed towards 2 than the GBN and GBU methods. We respectively compare subplots (a), (e) and (i) for the GBN method with subplots (b), (f) and (j) for the GBU method and find that the dispersions of the widths of the HPDIs for the GBN method are slightly smaller than the GBU method. Additionally, subplots (c), (g) and (k) for the PF method, and subplots (d), (h) and (l) for the Fieller’s method, show that the PF and Fieller’s methods may yield empty sets or noninformative intervals (displayed by the blue points), and the Fieller’s method may also get discontinuous intervals (shown by the orange points). By comparing the subplots in different rows of each figure (Figure 3 and Figure S7) when the trait is quantitative and , the dispersions of the widths of the HPDIs or CIs become slightly larger as changing from 0, 0.4 to 1, and it can also be seen from Figure 3 that the distributions of the interval widths are a little more skewed towards 2. On the other hand, when the trait is qualitative with (Figures S9 and S11), there are no obvious trends in the dispersions of the interval widths, except that their distributions are more skewed towards 2. However, under the situation that (Figure 4, Figures S8, S10 and S12), the points in these figures become less discrete in most cases when increases, and the overall widths of the four interval estimation methods also somewhat decrease, except for the scenarios where the trait is quantitative and , and the trait is qualitative and . Further, by comparing the figures for different values of (Figure 3, Figures S7, S9 and S11 vs. Figure 4, Figures S8, S10 and S12, respectively), it can be found that the overall widths of the HPDIs or the CIs obtained by the four interval estimation methods with are generally smaller than those with , except for those with . Lastly, as the trait turns from qualitative into quantitative (Figures S9–S12 vs. Figure 3, Figure 4, Figures S7 and S8, respectively) or the sample size increases (Figure 3, Figure 4, Figures S9 and S10 vs. Figures S7, S8, S11 and S12, respectively), the performances of the four interval estimation methods are greatly improved.
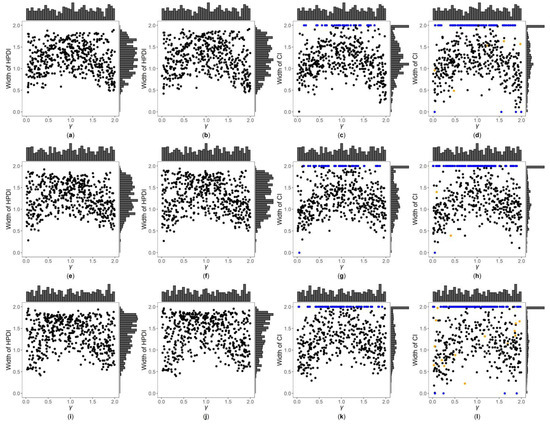
Figure 3.
Widths of highest posterior density intervals (HPDIs) or confidence intervals (CIs) of GBN, GBU, PF and Fieller’s methods against true values of for quantitative trait with and . The blue points represent the widths of the empty sets or the noninformative intervals, and the orange points represent the widths of the discontinuous intervals. (a) GBN with ; (b) GBU with ; (c) PF with ; (d) Fieller with ; (e) GBN with ; (f) GBU with ; (g) PF with ; (h) Fieller with ; (i) GBN with ; (j) GBU with ; (k) PF with ; (l) Fieller with .
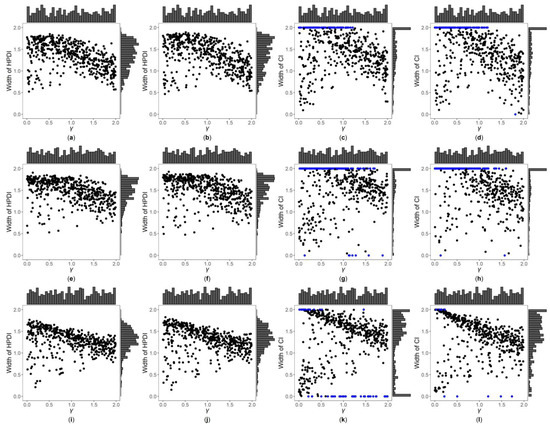
Figure 4.
Widths of HPDIs or CIs of GBN, GBU, PF and Fieller’s methods against true values of for quantitative trait with and . The blue points represent the widths of the empty sets or the noninformative intervals. (a) GBN with ; (b) GBU with ; (c) PF with ; (d) Fieller with ; (e) GBN with ; (f) GBU with ; (g) PF with ; (h) Fieller with ; (i) GBN with ; (j) GBU with ; (k) PF with ; (l) Fieller with .
3.3. Application to MCTFR Data
The MCTFR Genome-Wide Association Study of Behavioral Disinhibition is a family-based epidemiological study of substance abuse and related psychopathology. The dataset can be made available from the database of Genotypes and Phenotypes with accession numbers 86747-6 and 95621-5 (https://www.ncbi.nlm.nih.gov/projects/gap/cgi-bin/study.cgi?study_id=phs000620.v1.p1, accessed on 5 January 2022). The dataset includes 2183 families and 7377 participants (3831 female subjects and 3546 male subjects). Among them, only 5960 subjects have both the phenotypic and genotypic data, while others do not have phenotypic data or do not have genotypic data. There are five quantitative traits included in this dataset: the nicotine composite score, the alcohol consumption composite score, the alcohol dependence composite score, the illicit drug composite score and the non-substance use related behavioral disinhibition composite score. To avoid the influence of family structure on the results, we exclude offspring from the real data application. At the same time, we only need the information of female subjects, so we also exclude male subjects from the analysis. Meanwhile, 12,354 SNPs on the X chromosome are included in the dataset. We use the following quality control criteria to filter the SNPs [48,49]: (1) genotype call rate being less than 99%, (2) MAF being smaller than , (3) individual call rate being below 99%, and (4) the p value of the Hardy–Weinberg equilibrium test being less than . Finally, 1994 female subjects and 12,342 SNPs on the X chromosome are utilized to conduct real data analysis. Since we estimate the degree of the skewness of the XCI based on genes, we first need to find the genes which each SNP belongs to. Based on the GRCH38 (Genome Reference Consortium Human Genome Build 38, https://uswest.ensembl.org/, accessed on 25 February 2022) reference, we use the “getBM” function in the R package “biomaRt” to match the SNPs to the genes on the X chromosome [45]. As such, we find 733 matched genes, while there are some genes containing only a single SNP in the dataset. As there have been several methods available to estimate the degree of the skewness of the XCI for a single SNP, we exclude genes consisting of only one SNP. Therefore, only 493 genes are included in the subsequent analysis.
Note that estimating requires the genes on the X chromosome to be associated with the traits. So, we need to test if the associations between the genes and the traits exist before using our proposed methods to estimate the degree of skewness of the XCI. Notice that the five traits in the MCTFR dataset do not follow normal distributions; therefore, we use the rank-based inverse normal transformation to transform the trait data [50]. Further, to adjust the effects of other variables, we incorporate two covariates, age and year of birth, into the application [48]. Due to the fact that we only use female subjects, we still apply the adaptive sum test proposed by Iuliana et al. [35] to test for the association between each gene and each trait. Unlike other multi-locus association analysis methods, when there are both rare and common variants in a gene, the adaptive sum test still maintains high test power. We set the significance level to be based on the Bonferroni correction. After identifying the genes associated with the traits, we calculate the four point estimates of (, , and ), and then use the GBN, GBU, PF and Fieller’s methods to obtain the corresponding HPDIs or CIs.
We finally identify only one gene, TMEM47, statistically significantly associated with the alcohol dependence composite score (p value ). There are two SNPs (rs10522027 and rs5928615) included in the gene. The estimated MAFs of these two SNPs are 0.1407 and 0.0998, respectively, which means that both SNPs only contain common variants. It has been confirmed that TMEM47 is located in the NC_000023.11 region and includes three exons. Studies have shown that the gene is expressed in the bladder, adipose and 23 other tissues and found that the overexpression of TMEM47 may induce resistance in patients to certain chemotherapy drugs [51,52]. The four point estimates (, , and ) of for the gene are 0.4703, 0.4547, 0.4816 and 0.4847, and the 95% HPDIs or CIs derived by the GBN, GBU, PF and Fieller’s methods are , , and , respectively. That is to say, the point estimates are all less than 0.5, while the 95% HPDIs or CIs all contain 1, which means that the XCI pattern for TMEM47 on the alcohol dependence composite score may be the XCI-R or the XCI-E. By comparing the interval widths of these four interval estimation methods, we find that the width of the CI obtained by the PF method is the shortest, followed by the HPDI obtained by the GBN method, and the longest is the CI yielded by the Fieller’s method.
4. Discussion
In this paper, we propose four point estimates (, , and ) and four interval estimation methods (GBN, GBU, PF and Fieller) of the degree of the skewness of the XCI for a gene (i.e., ). Among the point estimates, is constructed by truncating the ratio of the two regression coefficients by the interval . And, is obtained by choosing the penalty parameter , and respectively correcting the denominator and the numerator, which is also truncated by . Both the and are developed, based on the Bayesian theory, by considering the prior information of , and the corresponding prior distributions of are respectively a truncated normal distribution and a uniform distribution. Use of and can avoid the extreme point estimates of (0 or 2) occurring. Among the interval estimation methods, the Fieller’s method has been widely used to construct the CIs of a ratio estimate. The PF method can always get the bounded CIs by choosing an appropriate penalty parameter. The GBN and GBU methods calculate the HPDIs of the samples randomly chosen from the approximate posterior distributions of as the credible intervals, which can avoid empty sets, noninformative intervals (i.e., ) and discontinuous intervals to occur. We conducted extensive simulation studies to compare their performances, by simulating different types of traits (quantitative and qualitative), different sample sizes ( and 2000), different proportions of rare variants among all the SNPs considered (, 0.4 and 1), and different proportions of the SNPs with positive effects among all the SNPs considered ( and 1). The simulation results showed that there may exist some extreme point estimates for and , especially when the sample size is small or the proportion of rare variants is high. The least MSE, in most situations, is derived from , and the MSEs of and are smaller than those of and . As for the interval estimation, the CIs derived by the Fieller’s method may be empty sets, noninformative intervals and discontinuous intervals. Although the PF method can avoid discontinuous intervals, the resulting CIs can be empty sets and noninformative intervals. In addition, most of the CPs of the GBN and GBU methods can be controlled around 95%, and a larger sample size is required only when the trait is qualitative and all the SNPs are rare variants. For qualitative traits, the CPs of the PF method appear a little low when the sample size is relatively small. However, the CPs of the Fieller’s method seem to be well controlled, which is due to the large proportion of noninformative intervals. The GBN method has the smallest , and in most situations, and the least under all the simulation settings. Therefore, we recommend using and the GBN method to estimate the degree of the XCI skewing in practical applications.
On the other hand, concerning the simulation settings and the simulation results, we further discuss the following issues. Firstly, we consider the influence of the proportion of rare variants () and the proportion of the SNPs with positive effects () among all the SNPs in the gene under study on the estimation results. When and other parameters are fixed, the proportions of the extreme values (0 and 2) for and with are generally less than those with , while they have no obvious trends for other cases of different values of and . In general, the MSEs of the four point estimates generally become larger as changes from 0, 0.4 to 1 and other parameters are kept unchanged. The four point estimates with always have smaller MSEs than . The changing trends of the EPs, NPs and DPs of the PF and Fieller’s methods with the increase of are related to . Furthermore, the EPs and NPs of the PF and Fieller’s methods with generally are smaller than , while the DPs of the Fieller’s method with are larger than or equal to those with . On the other hand, in the case of , the four interval estimation methods have larger ’s and ’s in most cases with changing from 0, 0.4 to 1, while for the scenario of , those of the four methods show a trend of first increasing and then decreasing on most occasions. The changing tendencies of the ’s and ’s of the four methods, with increasing, are affected by the trait type, and . When other parameters are kept unchanged, the ’s and ’s of the four methods with are smaller than those with in most cases. Besides this, the findings, by comparing the ’s and ’s of the GBN, GBU and Fieller’s methods for with those for are related to the trait type and , while the ’s and ’s of the PF method with are generally smaller than those with . Secondly, to better evaluate the performances of the proposed methods, we set the degrees of the XCI skewing at all the SNPs in the gene to be the same in our simulation studies. For example, when we calculate the MSEs of the point estimates and the CPs of the HPDIs or the CIs, a single true value of for each replicate is required. However, note that there may be different degrees of the XCI skewing at different SNPs, and, actually, we can also consider this issue in our simulation studies, although we have no appropriate evaluation indexes to assess the performances of the proposed methods for this situation. Finally, when we simulate quantitative traits, the random error is generated from the standard normal distribution, where the standard deviation () is equal to 1. To further illustrate the effect of different values of on the estimation results, we conducted additional simulation studies with and assume that follows , where . The corresponding results are presented in Tables S2–S4 and Figures S13–S16. As can be seen from these tables and figures, the Bayesian methods still have obvious advantages in both the point estimation and the interval estimation. Further, the four point estimation methods, and the four interval estimation methods with , perform worse than .
We applied the proposed methods to the MCTFR data and identified a gene, TMEM47, which is statistically significantly associated with the alcohol dependence composite score. However, although the four point estimates of for the gene TMEM47 on the alcohol dependence composite score are all smaller than 0.5, the corresponding 95% HPDIs or CIs all contain 1, which means that the XCI pattern for this gene may not be the XCI-S. Further, we observed that the width of the CI obtained by the PF method is the shortest, followed by the HPDI obtained by the GBN method, and the longest was the CI yielded by the Fieller’s method. However, it should be noted that the PF method may not control the CP well (e.g., Table S3).
Last, but not least, there are still some issues in our proposed methods which need to be discussed. Firstly, we would like to further discuss the effect of the truncation by the interval on the point estimation and the interval estimation of . When we use the and to estimate , both of them are truncated by . If the point estimates before the truncation ( and ) lie outside , and become the extreme values (0 or 2). Correspondingly, when using the PF and Fieller’s methods to construct the CIs of , it is easy to obtain empty sets or noninformative intervals. On the contrary, the Bayesian methods can avoid extreme point estimates, empty sets and noninformative intervals by specifying the appropriate prior distributions of and making full use of the constraint condition of . In addition, the extreme point estimate of 0 (2) means that the XCI is completely skewed towards the minor alleles (major alleles) at all the SNPs in a gene. However, these phenomena are not common in practice [2]. Meanwhile, it should be noted that empty sets and noninformative intervals are not informative, and the discontinuous CIs are also not useful, because the discontinuous CIs cannot be clearly explained in practice. Secondly, since the XCI patterns at different SNPs may be different, our estimated is just the mean degree of the skewness of the XCI over all the SNPs in the gene under study, and we cannot obtain the degree of the skewness of the XCI for each SNP in this gene. Meanwhile, in the process of estimating , the target allele is the minor one at each SNP, and it is not possible to distinguish the disease allele from the normal allele at each SNP. Therefore, we can only identify whether or not the XCI of the gene is skewed towards the minor alleles, but it is not possible to know whether the XCI is skewed towards the disease alleles or the normal alleles. Thirdly, the proposed Bayesian methods need to specify the prior distributions of all the unknown parameters in advance, and the selection of the prior distributions may have a certain impact on the results. For simplicity, we only considered two possible prior distributions for , and one prior distribution for each of the other unknown parameters. However, the prior distributions of these parameters are usually unknown, and we cannot guarantee that the weak prior distributions we used are the most appropriate. We provide an R package named GEXCIS, which is publicly available at https://github.com/Meng-KaiLi/GEXCIS (accessed on 30 April 2022), and can be used to estimate the degree of the skewness of the XCI for genes through the proposed methods in this paper. This R package also allows researchers to specify the prior distribution of each unknown parameter from their own research backgrounds. Fourthly, the Bayesian methods use the HMC algorithm for the sampling, which is not affected by the correlation between unknown parameters. Therefore, to improve computational efficiency, we assumed that all the unknown parameters are independent. However, the Bayesian methods, taking the correlation between the parameters into account, should have better performance, which is our future work. Fifthly, if the HPDIs or CIs we get contain 1, which means that the XCI pattern for the gene is the XCI-R or the XCI-E, our proposed methods cannot distinguish them. Therefore, in our future study, we will consider including males’ information to distinguish the XCI-R from the XCI-E. Finally, the proposed methods are only applicable to independent female subjects, and we will extend them in future so that they could accommodate the family data.
5. Conclusions
We propose four point estimates and four interval estimation methods to estimate of genes. Among the four point estimates, may have the extreme point estimates, and can only reduce the occurrence of the extreme point estimates equal to 2, while and can avoid the extreme point estimates occurring. As for the four interval estimation methods, the Fieller’s method may derive empty sets, discontinuous intervals and noninformative intervals, and the PF method can avoid the occurrence of discontinuous intervals and get less noninformative intervals, while the GBN and GBU methods do not yield these three types of the intervals. However, it should be noted that through these proposed methods, we cannot obtain the degree of the skewness of the XCI for each SNP in the gene, and cannot know whether the XCI is skewed towards the disease alleles or the normal alleles. In summary, the point estimates obtained by the GBN method always have the least MSE, and the HPDIs of the GBN method generally have the shortest width and the lowest variation, so we recommend using the GBN method in practical applications.
Supplementary Materials
The following supporting information can be downloaded at: https://www.mdpi.com/article/10.3390/genes13050827/s1, Table S1: Results of point estimations and interval estimations for among 500 replications with = 3000 and 4000, , and for qualitative trait; Table S2: MSEs of , , and among 500 replications with and for quantitative trait; Table S3: CPs (%), and of GBN, GBU, PF and Fieller’s methods among 500 replications with and for quantitative trait; Table S4: and of GBN, GBU, PF and Fieller’s methods among 500 replications with and for quantitative trait; Figures S1–S6: Scatter plots of point estimates of against true values of for quantitative () or qualitative trait with and 2000, and and 1; Figures S7–S12: Widths of HPDIs or CIs of GBN, GBU, PF and Fieller’s methods against true values of for quantitative () or qualitative trait with and 2000, and and 1; Figures S13 and S14: Scatter plots of point estimates of against true values of for quantitative trait with , and 1, and ; Figures S15 and S16: Widths of HPDIs or CIs of GBN, GBU, PF and Fieller’s methods against true values of for quantitative trait with , and 1, and .
Author Contributions
Conceptualization, J.-Y.Z.; methodology, M.-K.L. and Y.-X.Y.; software, M.-K.L., Y.-X.Y. and J.-Y.Z.; validation, M.-K.L., Y.-X.Y., B.Z. and K.-W.W.; writing—original draft preparation, M.-K.L. and Y.-X.Y.; writing—review and editing, B.Z., K.-W.W., W.K.F. and J.-Y.Z.; supervision, W.K.F. and J.-Y.Z.; project administration, J.-Y.Z. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the National Natural Science Foundation of China, grant numbers 82173619 and 81773544, the Science and Technology Planning Project of Guangdong Province, grant number 2020B1212030008, and the Hong Kong Research Grants Council, grant number 17302919.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Publicly available datasets were analyzed in this study. This data can be found here: https://www.ncbi.nlm.nih.gov/projects/gap/cgi-bin/study.cgi?study_id=phs000620.v1.p1 (accessed on 5 January 2022).
Acknowledgments
A Minnesota Center for Twin and Family Research (MCTFR) was supported by the National Institute on Drug Abuse, grant number U01 DA024417. The sample ascertainment and data collection in MCTFR data were supported by the National Institute on Drug Abuse, grant numbers R37 DA05147 and R01 DA13240, the National Institute on Alcohol Abuse and Alcoholism, grant numbers R01 AA09367 and R01 AA11886, and the National Institute of Mental Health, grant number R01 MH66140.
Conflicts of Interest
The authors declare no conflict of interest.
Appendix A
We assume that is the mean degree of the skewness of the XCI for the gene under study. For the th female, we have . On the other hand, when supposing that the degree of the skewness of the XCI at the th SNP is , the genotypic values of genotypes , and at the SNP of the female are 0, and 2, respectively. Similar to the construction process of , we can get . Under the assumption of , we have
and
Then,
where and . Finally, we have
References
- Lyon, M.F. Gene action in the X-chromosome of the mouse (Mus musculus L.). Nature 1961, 190, 372–373. [Google Scholar] [CrossRef] [PubMed]
- Amos-Landgraf, J.M.; Cottle, A.; Plenge, R.M.; Friez, M.; Schwartz, C.E.; Longshore, J.; Willard, H.F. X chromosome-inactivation patterns of 1,005 phenotypically unaffected females. Am. J. Hum. Genet. 2006, 79, 493–499. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Plenge, R.M.; Stevenson, R.A.; Lubs, H.A.; Schwartz, C.E.; Willard, H.F. Skewed X-chromosome inactivation is a common feature of X-linked mental retardation disorders. Am. J. Hum. Genet. 2002, 71, 168–173. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Shvetsova, E.; Sofronova, A.; Monajemi, R.; Gagalova, K.; Draisma, H.; White, S.J.; Santen, G.; Chuva de Sousa Lopes, S.M.; Heijmans, B.T.; van Meurs, J.; et al. Skewed X-inactivation is common in the general female population. Eur. J. Hum. Genet. 2019, 27, 455–465. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Medema, R.H.; Burgering, B.M. The X factor: Skewing X inactivation towards cancer. Cell 2007, 129, 1253–1254. [Google Scholar] [CrossRef] [Green Version]
- Deng, X.; Berletch, J.B.; Nguyen, D.K.; Disteche, C.M. X chromosome regulation: Diverse patterns in development, tissues and disease. Nat. Rev. Genet. 2014, 15, 367–378. [Google Scholar] [CrossRef]
- Posynick, B.J.; Brown, C.J. Escape from X-chromosome inactivation: An evolutionary perspective. Front. Cell Dev. Biol. 2019, 7, 241. [Google Scholar] [CrossRef]
- Peeters, S.B.; Cotton, A.M.; Brown, C.J. Variable escape from X-chromosome inactivation: Identifying factors that tip the scales towards expression. Bioessays 2014, 36, 746–756. [Google Scholar] [CrossRef]
- Minks, J.; Robinson, W.P.; Brown, C.J. A skewed view of X chromosome inactivation. J. Clin. Invest. 2008, 118, 20–23. [Google Scholar] [CrossRef]
- Chabchoub, G.; Uz, E.; Maalej, A.; Mustafa, C.A.; Rebai, A.; Mnif, M.; Bahloul, Z.; Farid, N.R.; Ozcelik, T.; Ayadi, H. Analysis of skewed X-chromosome inactivation in females with rheumatoid arthritis and autoimmune thyroid diseases. Arthritis Res. Ther. 2009, 11, R106. [Google Scholar] [CrossRef] [Green Version]
- Sun, Z.; Fan, J.; Wang, Y. X-chromosome inactivation and related diseases. Genet. Res. 2022, 2022, 1391807. [Google Scholar] [CrossRef] [PubMed]
- Okumura, K.; Fujimori, Y.; Takagi, A.; Murate, T.; Ozeki, M.; Yamamoto, K.; Katsumi, A.; Matsushita, T.; Naoe, T.; Kojima, T. Skewed X chromosome inactivation in fraternal female twins results in moderately severe and mild haemophilia B. Haemophilia 2008, 14, 1088–1093. [Google Scholar] [CrossRef] [PubMed]
- Garagiola, I.; Mortarino, M.; Siboni, S.M.; Boscarino, M.; Mancuso, M.E.; Biganzoli, M.; Santagostino, E.; Peyvandi, F. X chromosome inactivation: A modifier of factor VIII and IX plasma levels and bleeding phenotype in Haemophilia carriers. Eur. J. Hum. Genet. 2021, 29, 241–249. [Google Scholar] [CrossRef]
- Zuo, T.; Wang, L.; Morrison, C.; Chang, X.; Zhang, H.; Li, W.; Liu, Y.; Wang, Y.; Liu, X.; Chan, M.; et al. FOXP3 is an X-linked breast cancer suppressor gene and an important repressor of the HER-2/ErbB2 oncogene. Cell 2007, 129, 1275–1286. [Google Scholar] [CrossRef] [Green Version]
- Li, G.; Jin, T.; Liang, H.; Tu, Y.; Zhang, W.; Gong, L.; Su, Q.; Gao, G. Skewed X-chromosome inactivation in patients with esophageal carcinoma. Diagn. Pathol. 2013, 8, 55. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Simmonds, M.J.; Kavvoura, F.K.; Brand, O.J.; Newby, P.R.; Jackson, L.E.; Hargreaves, C.E.; Franklyn, J.A.; Gough, S.C. Skewed X chromosome inactivation and female preponderance in autoimmune thyroid disease: An association study and meta-analysis. J. Clin. Endocrinol. Metab. 2014, 99, E127–E131. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Giliberto, F.; Radic, C.P.; Luce, L.; Ferreiro, V.; de Brasi, C.; Szijan, I. Symptomatic female carriers of Duchenne muscular dystro-phy (DMD): Genetic and clinical characterization. J. Neurol. Sci. 2014, 336, 36–41. [Google Scholar] [CrossRef] [Green Version]
- Sangha, K.K.; Stephenson, M.D.; Brown, C.J.; Robinson, W.P. Extremely skewed X-chromosome inactivation is increased in women with recurrent spontaneous abortion. Am. J. Hum. Genet. 1999, 65, 913–917. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zhang, Y.; Xu, S.Q.; Liu, W.; Fung, W.K.; Zhou, J.Y. A robust test for X-chromosome genetic association accounting for X-chromosome inactivation and imprinting. Genet. Res. 2020, 102, e2. [Google Scholar] [CrossRef] [Green Version]
- Zhang, L.; Martin, E.R.; Morris, R.W.; Li, Y.J. Association test for X-linked QTL in family-based designs. Am. J. Hum. Genet. 2009, 84, 431–444. [Google Scholar] [CrossRef] [Green Version]
- Zheng, G.; Joo, J.; Zhang, C.; Geller, N.L. Testing association for markers on the X chromosome. Genet. Epidemiol. 2007, 31, 834–843. [Google Scholar] [CrossRef] [PubMed]
- Clayton, D. Testing for association on the X chromosome. Biostatistics 2008, 9, 593–600. [Google Scholar] [CrossRef] [PubMed]
- Wang, J.; Yu, R.; Shete, S. X-chromosome genetic association test accounting for X-inactivation, skewed X-inactivation, and escape from X-inactivation. Genet. Epidemiol. 2014, 38, 483–493. [Google Scholar] [CrossRef] [PubMed]
- Liu, W.; Wang, B.Q.; Liu-Fu, G.; Fung, W.K.; Zhou, J.Y. X-chromosome genetic association test incorporating X-chromosome inactivation and imprinting effects. J. Genet. 2019, 98, 99. [Google Scholar] [CrossRef] [PubMed]
- Ma, L.; Hoffman, G.; Keinan, A. X-inactivation informs variance-based testing for X-linked association of a quantitative trait. BMC Genomics 2015, 16, 241. [Google Scholar] [CrossRef] [Green Version]
- Gao, F.; Chang, D.; Biddanda, A.; Ma, L.; Guo, Y.; Zhou, Z.; Keinan, A. XWAS: A software toolset for genetic data analysis and association studies of the X chromosome. J. Hered. 2015, 106, 666–671. [Google Scholar] [CrossRef] [Green Version]
- Madsen, B.E.; Browning, S.R. A groupwise association test for rare mutations using a weighted sum statistic. PLoS Genet. 2009, 5, e1000384. [Google Scholar] [CrossRef] [Green Version]
- Li, B.; Leal, S.M. Methods for detecting associations with rare variants for common diseases: Application to analysis of sequence data. Am. J. Hum. Genet. 2008, 83, 311–321. [Google Scholar] [CrossRef] [Green Version]
- Schork, N.J.; Murray, S.S.; Frazer, K.A.; Topol, E.J. Common vs. rare allele hypotheses for complex diseases. Curr. Opin. Genet. Dev. 2009, 19, 212–219. [Google Scholar] [CrossRef] [Green Version]
- Han, F.; Pan, W. A data-adaptive sum test for disease association with multiple common or rare variants. Hum. Hered. 2010, 70, 42–54. [Google Scholar] [CrossRef] [Green Version]
- Ionita-Laza, I.; Buxbaum, J.D.; Laird, N.M.; Lange, C. A new testing strategy to identify rare variants with either risk or protective effect on disease. PLoS Genet. 2011, 7, e1001289. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Price, A.L.; Kryukov, G.V.; de Bakker, P.I.; Purcell, S.M.; Staples, J.; Wei, L.J.; Sunyaev, S.R. Pooled association tests for rare variants in exon-resequencing studies. Am. J. Hum. Genet. 2010, 86, 832–838. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wu, M.C.; Lee, S.; Cai, T.; Li, Y.; Boehnke, M.; Lin, X. Rare-variant association testing for sequencing data with the sequence kernel association test. Am. J. Hum. Genet. 2011, 89, 82–93. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Lee, S.; Emond, M.J.; Bamshad, M.J.; Barnes, K.C.; Rieder, M.J.; Nickerson, D.A.; NHLBI GO Exome Sequencing Project—ESP Lung Project Team; Christiani, D.C.; Wurfel, M.M.; Lin, X. Optimal unified approach for rare-variant association testing with application to small-sample case-control whole-exome sequencing studies. Am. J. Hum. Genet. 2012, 91, 224–237. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ionita-Laza, I.; Lee, S.; Makarov, V.; Buxbaum, J.D.; Lin, X. Sequence kernel association tests for the combined effect of rare and common variants. Am. J. Hum. Genet. 2013, 92, 841–853. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Ma, C.; Boehnke, M.; Lee, S.; GoT2D Investigators. Evaluating the calibration and power of three gene-based association tests of rare variants for the X chromosome. Genet. Epidemiol. 2015, 39, 499–508. [Google Scholar] [CrossRef] [PubMed]
- Turkmen, A.S.; Lin, S. Detecting X-linked common and rare variant effects in family-based sequencing studies. Genet. Epidemiol. 2021, 45, 36–45. [Google Scholar] [CrossRef]
- Xu, S.Q.; Zhang, Y.; Wang, P.; Liu, W.; Wu, X.B.; Zhou, J.Y. A statistical measure for the skewness of X chromosome inactivation based on family trios. BMC Genet. 2018, 19, 109. [Google Scholar] [CrossRef]
- Wang, P.; Zhang, Y.; Wang, B.Q.; Li, J.L.; Wang, Y.X.; Pan, D.; Wu, X.B.; Fung, W.K.; Zhoui, J.Y. A statistical measure for the skewness of X chromosome inactivation based on case-control design. BMC Bioinformatics 2019, 20, 11. [Google Scholar] [CrossRef]
- Li, B.H.; Yu, W.Y.; Zhou, J.Y. A statistical measure for the skewness of X chromosome inactivation for quantitative traits and its application to the MCTFR data. BMC Genom. Data 2021, 22, 24. [Google Scholar] [CrossRef]
- Wang, P.; Xu, S.; Wang, Y.X.; Wu, B.; Fung, W.K.; Gao, G.; Liang, Z.; Liu, N. Penalized Fieller’s confidence interval for the ratio of bivariate normal means. Biometrics 2021, 77, 1355–1368. [Google Scholar] [CrossRef] [PubMed]
- Stephens, M.; Balding, D.J. Bayesian statistical methods for genetic association studies. Nat. Rev. Genet. 2009, 10, 681–690. [Google Scholar] [CrossRef] [PubMed]
- Annis, J.; Miller, B.J.; Palmeri, T.J. Bayesian inference with Stan: A tutorial on adding custom distributions. Behav. Res. Methods 2017, 49, 863–886. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kruschke J., K. Bayesian data analysis. Wiley Interdiscip. Rev. Cogn. Sci. 2010, 1, 658–676. [Google Scholar] [CrossRef] [PubMed]
- Wang, C.; Deng, S.; Sun, L.; Li, L.; Hu, Y.Q. A nonparametric test for association with multiple loci in the retrospective case-control study. Stat. Methods Med. Res. 2020, 29, 589–602. [Google Scholar] [CrossRef]
- Basu, S.; Pan, W. Comparison of statistical tests for disease association with rare variants. Genet. Epidemiol. 2011, 35, 606–619. [Google Scholar] [CrossRef] [PubMed]
- Turkmen, A.S.; Yan, Z.; Hu, Y.Q.; Lin, S. Kullback-Leibler distance methods for detecting disease association with rare variants from sequencing data. Ann. Hum. Genet. 2015, 79, 199–208. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- McGue, M.; Zhang, Y.; Miller, M.B.; Basu, S.; Vrieze, S.; Hicks, B.; Malone, S.; Oetting, W.S.; Iacono, W.G. A genome-wide association study of behavioral disinhibition. Behav. Genet. 2013, 43, 363–373. [Google Scholar] [CrossRef] [Green Version]
- Asadollahi, H.; Vaez Torshizi, R.; Ehsani, A.; Masoudi, A.A. An association of CEP78, MEF2C, VPS13A and ARRDC3 genes with survivability to heat stress in an F2 chicken population. J. Anim. Breed. Genet. 2022. [Google Scholar] [CrossRef]
- McCaw, Z.R.; Lane, J.M.; Saxena, R.; Redline, S.; Lin, X. Operating characteristics of the rank-based inverse normal transformation for quantitative trait analysis in genome-wide association studies. Biometrics 2020, 76, 1262–1272. [Google Scholar] [CrossRef]
- Ng, K.T.; Yeung, O.W.; Liu, J.; Li, C.X.; Liu, H.; Liu, X.B.; Qi, X.; Ma, Y.Y.; Lam, Y.F.; Lau, M.Y.; et al. Clinical significance and functional role of transmembrane protein 47 (TMEM47) in chemoresistance of hepatocellular carcinoma. Int. J. Oncol. 2020, 57, 956–966. [Google Scholar] [CrossRef]
- Men, X.; Su, M.; Ma, J.; Mou, Y.; Dai, P.; Chen, C.; Cheng, X.A. Overexpression of TMEM47 induces tamoxifen resistance in human breast cancer cells. Technol. Cancer Res. Treat. 2021, 20, 15330338211004916. [Google Scholar] [CrossRef]
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).