Insights into Mobile Genetic Elements of the Biocide-Degrading Bacterium Pseudomonas nitroreducens HBP-1

Abstract
1. Introduction
2. Materials and Methods
2.1. Culture Conditions
2.2. DNA Isolation, Sequencing and Assembly
2.3. Annotation
2.4. In Silico Analyses of Genomic Islands, ICEs and Prophages
2.5. Characterization of ICE Attachment Sites
2.6. ICE Transfer Assays
2.7. Database Submission
3. Results and Discussion
3.1. Genome of Pseudomonas Nitroreducens HBP-1
3.2. Genomic Insight into Plasmids of P. nitroreducens
3.3. Genomic Islands in the Genome of P. nitroreducens
3.4. Defining the Borders of ICEPni1 and ICEPni2
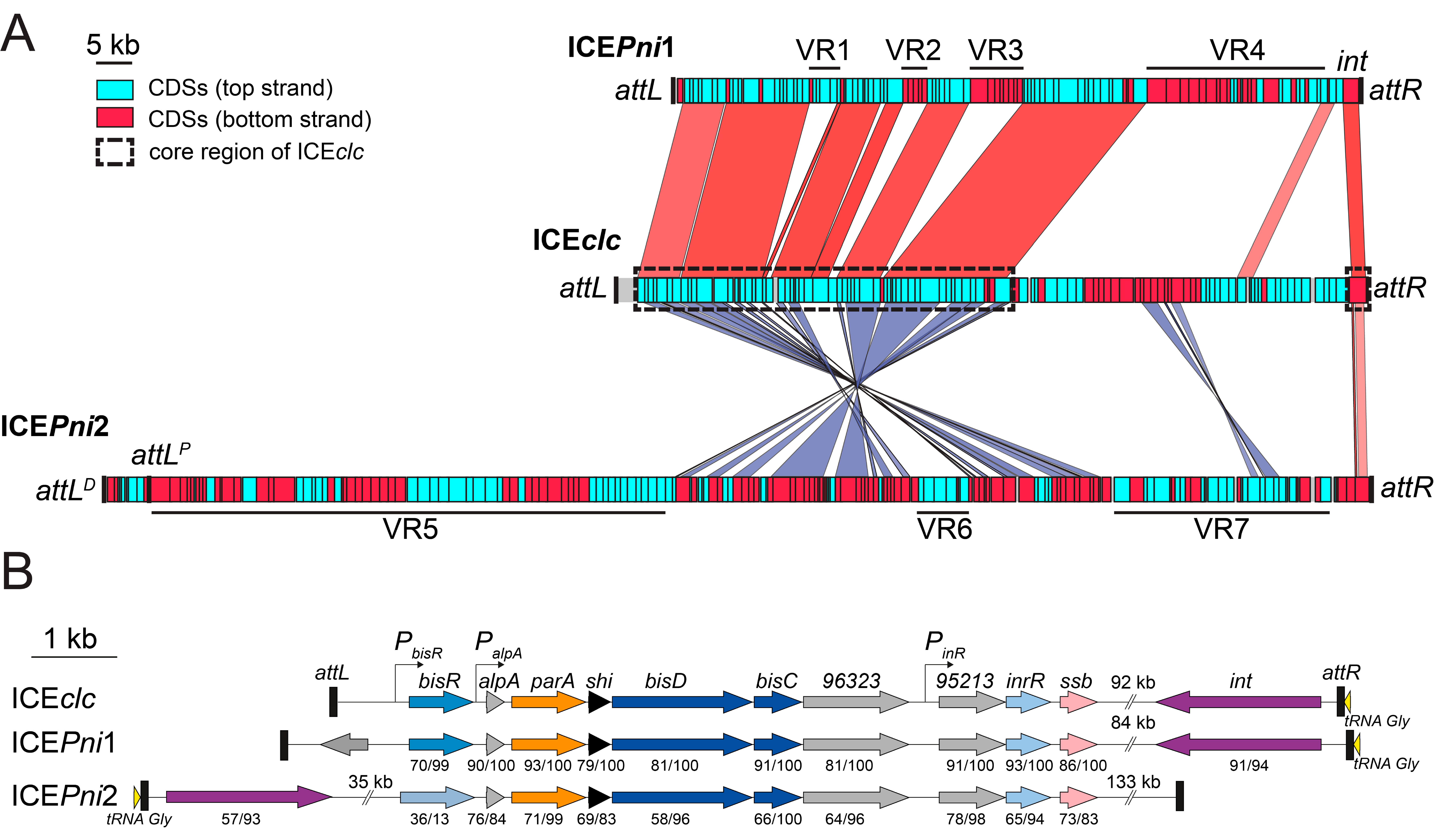
3.5. ICEPni1 and ICEPni2 Are Related to ICEclc
3.6. ICEPni1 Encodes Mercury, Arsenic and Formaldehyde Detoxification and a Bacteriophage Defense System
3.7. ICEPni2 Encodes Metabolism of Aromatic Compounds and Fatty Acids
3.8. ICEPni1 Can Excise and Transfer to P. putida, and Integrates into One of Four tRNAGly Gene Targets
3.9. ICEPni2 Is also a Functional ICE
4. Concluding Remarks
Supplementary Materials
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Atashgahi, S.; Sánchez-Andrea, I.; Heipieper, H.J.; van der Meer, J.R.; Stams, A.J.M.; Smidt, H. Prospects for harnessing biocide resistance for bioremediation and detoxification. Science 2018, 360, 743–746. [Google Scholar] [CrossRef] [PubMed]
- Megharaj, M.; Ramakrishnan, B.; Venkateswarlu, K.; Sethunathan, N.; Naidu, R. Bioremediation approaches for organic pollutants: A critical perspective. Environ. Int. 2011, 37, 1362–1375. [Google Scholar] [CrossRef] [PubMed]
- Mrozik, A.; Miga, S.; Piotrowska-Seget, Z. Enhancement of phenol degradation by soil bioaugmentation with Pseudomonas sp. JS150. J. Appl. Microbiol. 2011, 111, 1357–1370. [Google Scholar] [CrossRef] [PubMed]
- Miyazaki, R.; Bertelli, C.; Benaglio, P.; Canton, J.; De Coi, N.; Gharib, W.H.; Gjoksi, B.; Goesmann, A.; Greub, G.; Harshman, K.; et al. Comparative genome analysis of Pseudomonas knackmussii B13, the first bacterium known to degrade chloroaromatic compounds. Environ. Microbiol. 2015, 17, 91–104. [Google Scholar] [CrossRef]
- Morales, M.; Sentchilo, V.; Bertelli, C.; Komljenovic, A.; Kryuchkova-Mostacci, N.; Bourdilloud, A.; Linke, B.; Goesmann, A.; Harshman, K.; Segers, F.; et al. The genome of the toluene-degrading Pseudomonas veronii strain 1YdBTEX2 and its differential gene expression in contaminated sand. PLoS ONE 2016, 11, e0165850. [Google Scholar] [CrossRef]
- Kohler, H.P.; Kohler-Staub, D.; Focht, D.D. Degradation of 2-hydroxybiphenyl and 2,2′-dihydroxybiphenyl by Pseudomonas sp. strain HBP1. Appl. Environ. Microbiol. 1988, 54, 2683–2688. [Google Scholar] [CrossRef]
- Kohler, H.P.; Schmid, A.; van der Maarel, M. Metabolism of 2,2′-dihydroxybiphenyl by Pseudomonas sp. strain HBP1: Production and consumption of 2,2′,3-trihydroxybiphenyl. J. Bacteriol. 1993, 175, 1621–1628. [Google Scholar] [CrossRef]
- Kohler, H.P.; van der Maarel, M.J.; Kohler-Staub, D. Selection of Pseudomonas sp. strain HBP1 Prp for metabolism of 2-propylphenol and elucidation of the degradative pathway. Appl. Environ. Microbiol. 1993, 59, 860–866. [Google Scholar] [CrossRef]
- Reichlin, F.; Kohler, H.P. Pseudomonas sp. strain HBP1 Prp degrades 2-isopropylphenol (ortho-cumenol) via meta cleavage. Appl. Environ. Microbiol. 1994, 60, 4587–4591. [Google Scholar] [CrossRef]
- Suske, W.A.; Held, M.; Schmid, A.; Fleischmann, T.; Wubbolts, M.G.; Kohler, H.P. Purification and characterization of 2-hydroxybiphenyl 3-monooxygenase, a novel NADH-dependent, FAD-containing aromatic hydroxylase from Pseudomonas azelaica HBP1. J. Biol. Chem. 1997, 272, 24257–24265. [Google Scholar] [CrossRef][Green Version]
- Suske, W.A.; van Berkel, W.J.; Kohler, H.P. Catalytic mechanism of 2-hydroxybiphenyl 3-monooxygenase, a flavoprotein from Pseudomonas azelaica HBP1. J. Biol. Chem. 1999, 274, 33355–33365. [Google Scholar] [CrossRef] [PubMed]
- Jaspers, M.C.; Suske, W.A.; Schmid, A.; Goslings, D.A.; Kohler, H.P.; van der Meer, J.R. HbpR, a new member of the XylR/DmpR subclass within the NtrC family of bacterial transcriptional activators, regulates expression of 2-hydroxybiphenyl metabolism in Pseudomonas azelaica HBP1. J. Bacteriol. 2000, 182, 405–417. [Google Scholar] [CrossRef] [PubMed]
- Jaspers, M.C.; Sturme, M.; van der Meer, J.R. Unusual location of two nearby pairs of upstream activating sequences for HbpR, the main regulatory protein for the 2-hydroxybiphenyl degradation pathway of Pseudomonas azelaica HBP1. Microbiol. Read. Engl. 2001, 147, 2183–2194. [Google Scholar] [CrossRef] [PubMed][Green Version]
- Jaspers, M.C.; Schmid, A.; Sturme, M.H.; Goslings, D.A.; Kohler, H.P.; Roelof Van Der Meer, J. Transcriptional organization and dynamic expression of the hbpCAD genes, which encode the first three enzymes for 2-hydroxybiphenyl degradation in Pseudomonas azelaica HBP1. J. Bacteriol. 2001, 183, 270–279. [Google Scholar] [CrossRef]
- García, J.L.; Rozas, D.; Del Cerro, C.; Nogales, J.; El-Said Mohamed, M.; Díaz, E. Genome sequence of Pseudomonas azelaica HBP1, which catabolizes 2-hydroxybiphenyl fungicide. Genome Announc. 2014, 2. [Google Scholar] [CrossRef]
- El-Said Mohamed, M.; García, J.L.; Martínez, I.; Del Cerro, C.; Nogales, J.; Díaz, E. Genome sequence of Pseudomonas azelaica strain Aramco J. Genome Announc. 2015, 3. [Google Scholar] [CrossRef]
- Garbisu, C.; Garaiyurrebaso, O.; Epelde, L.; Grohmann, E.; Alkorta, I. Plasmid-mediated bioaugmentation for the bioremediation of contaminated soils. Front. Microbiol. 2017, 8, 1966. [Google Scholar] [CrossRef]
- Miyazaki, R.; van der Meer, J.R. A dual functional origin of transfer in the ICEclc genomic island of Pseudomonas knackmussii B13. Mol. Microbiol. 2011, 79, 743–758. [Google Scholar] [CrossRef]
- Gerhardt, P.; Murray, R.G.E.; Costilow, R.N.; Nester, E.W.; Wood, W.A.; Kreig, N.R.; Briggs Phillips, G. Manual of methods for general bacteriology. J. Clin. Pathol. 1981, 34, 1069. [Google Scholar]
- Chin, C.-S.; Alexander, D.H.; Marks, P.; Klammer, A.A.; Drake, J.; Heiner, C.; Clum, A.; Copeland, A.; Huddleston, J.; Eichler, E.E.; et al. Nonhybrid, finished microbial genome assemblies from long-read SMRT sequencing data. Nat. Methods 2013, 10, 563–569. [Google Scholar] [CrossRef]
- Langmead, B.; Salzberg, S.L. Fast gapped-read alignment with Bowtie 2. Nat. Methods 2012, 9, 357–359. [Google Scholar] [CrossRef] [PubMed]
- Li, H.; Handsaker, B.; Wysoker, A.; Fennell, T.; Ruan, J.; Homer, N.; Marth, G.; Abecasis, G.; Durbin, R.; 1000 Genome Project Data Processing Subgroup. The Sequence Alignment/Map format and SAMtools. Bioinformatics 2009, 25, 2078–2079. [Google Scholar] [CrossRef] [PubMed]
- García-Alcalde, F.; Okonechnikov, K.; Carbonell, J.; Cruz, L.M.; Götz, S.; Tarazona, S.; Dopazo, J.; Meyer, T.F.; Conesa, A. Qualimap: Evaluating next-generation sequencing alignment data. Bioinformatics 2012, 28, 2678–2679. [Google Scholar] [CrossRef] [PubMed]
- Okonechnikov, K.; Conesa, A.; García-Alcalde, F. Qualimap 2: Advanced multi-sample quality control for high-throughput sequencing data. Bioinformatics 2016, 32, 292–294. [Google Scholar] [CrossRef] [PubMed]
- Tatusova, T.; DiCuccio, M.; Badretdin, A.; Chetvernin, V.; Nawrocki, E.P.; Zaslavsky, L.; Lomsadze, A.; Pruitt, K.D.; Borodovsky, M.; Ostell, J. NCBI prokaryotic genome annotation pipeline. Nucleic Acids Res. 2016, 44, 6614–6624. [Google Scholar] [CrossRef] [PubMed]
- Haft, D.H.; DiCuccio, M.; Badretdin, A.; Brover, V.; Chetvernin, V.; O’Neill, K.; Li, W.; Chitsaz, F.; Derbyshire, M.K.; Gonzales, N.R.; et al. RefSeq: An update on prokaryotic genome annotation and curation. Nucleic Acids Res. 2018, 46, D851–D860. [Google Scholar] [CrossRef]
- Aziz, R.K.; Bartels, D.; Best, A.A.; DeJongh, M.; Disz, T.; Edwards, R.A.; Formsma, K.; Gerdes, S.; Glass, E.M.; Kubal, M.; et al. The RAST Server: Rapid annotations using subsystems technology. BMC Genom. 2008, 9, 75. [Google Scholar] [CrossRef]
- Seemann, T. Prokka: Rapid prokaryotic genome annotation. Bioinformatics 2014, 30, 2068–2069. [Google Scholar] [CrossRef]
- Caspi, R.; Billington, R.; Keseler, I.M.; Kothari, A.; Krummenacker, M.; Midford, P.E.; Ong, W.K.; Paley, S.; Subhraveti, P.; Karp, P.D. The MetaCyc database of metabolic pathways and enzymes—A 2019 update. Nucleic Acids Res. 2020, 48, D445–D453. [Google Scholar] [CrossRef]
- Bertelli, C.; Laird, M.R.; Williams, K.P.; Simon Fraser University Research Computing Group; Lau, B.Y.; Hoad, G.; Winsor, G.L.; Brinkman, F.S.L. IslandViewer 4: Expanded prediction of genomic islands for larger-scale datasets. Nucleic Acids Res. 2017, 45, W30–W35. [Google Scholar] [CrossRef]
- Arndt, D.; Grant, J.R.; Marcu, A.; Sajed, T.; Pon, A.; Liang, Y.; Wishart, D.S. PHASTER: A better, faster version of the PHAST phage search tool. Nucleic Acids Res. 2016, 44, W16–W21. [Google Scholar] [CrossRef] [PubMed]
- Carver, T.J.; Rutherford, K.M.; Berriman, M.; Rajandream, M.-A.; Barrell, B.G.; Parkhill, J. ACT: The Artemis Comparison Tool. Bioinformatics 2005, 21, 3422–3423. [Google Scholar] [CrossRef]
- Carver, T.; Thomson, N.; Bleasby, A.; Berriman, M.; Parkhill, J. DNAPlotter: Circular and linear interactive genome visualization. Bioinformatics 2009, 25, 119–120. [Google Scholar] [CrossRef] [PubMed]
- Sentchilo, V.; Czechowska, K.; Pradervand, N.; Minoia, M.; Miyazaki, R.; van der Meer, J.R. Intracellular excision and reintegration dynamics of the ICEclc genomic island of Pseudomonas knackmussii sp. strain B13. Mol. Microbiol. 2009, 72, 1293–1306. [Google Scholar] [CrossRef] [PubMed]
- Moscoso, M.; Eritja, R.; Espinosa, M. Initiation of replication of plasmid pMV158: Mechanisms of DNA strand-transfer reactions mediated by the initiator RepB protein. J. Mol. Biol. 1997, 268, 840–856. [Google Scholar] [CrossRef]
- Carraro, N.; Rivard, N.; Burrus, V.; Ceccarelli, D. Mobilizable genomic islands, different strategies for the dissemination of multidrug resistance and other adaptive traits. Mob. Genet. Elem. 2017, 7, 1–6. [Google Scholar] [CrossRef] [PubMed]
- Nies, D.H. Efflux-mediated heavy metal resistance in prokaryotes. FEMS Microbiol. Rev. 2003, 27, 313–339. [Google Scholar] [CrossRef]
- Chevalier, S.; Bouffartigues, E.; Bodilis, J.; Maillot, O.; Lesouhaitier, O.; Feuilloley, M.G.J.; Orange, N.; Dufour, A.; Cornelis, P. Structure, function and regulation of Pseudomonas aeruginosa porins. FEMS Microbiol. Rev. 2017, 41, 698–722. [Google Scholar] [CrossRef]
- Perron, K.; Caille, O.; Rossier, C.; Van Delden, C.; Dumas, J.-L.; Köhler, T. CzcR-CzcS, a two-component system involved in heavy metal and carbapenem resistance in Pseudomonas aeruginosa. J. Biol. Chem. 2004, 279, 8761–8768. [Google Scholar] [CrossRef]
- Christie, G.E.; Calendar, R. Interactions between satellite bacteriophage P4 and its helpers. Annu. Rev. Genet. 1990, 24, 465–490. [Google Scholar] [CrossRef]
- Taylor, N.M.I.; van Raaij, M.J.; Leiman, P.G. Contractile injection systems of bacteriophages and related systems. Mol. Microbiol. 2018, 108, 6–15. [Google Scholar] [CrossRef] [PubMed]
- Guglielmini, J.; Néron, B.; Abby, S.S.; Garcillán-Barcia, M.P.; de la Cruz, F.; Rocha, E.P.C. Key components of the eight classes of type IV secretion systems involved in bacterial conjugation or protein secretion. Nucleic Acids Res. 2014, 42, 5715–5727. [Google Scholar] [CrossRef] [PubMed]
- Burrus, V.; Roussel, Y.; Decaris, B.; Guédon, G. Characterization of a novel integrative element, ICESt1, in the lactic acid bacterium Streptococcus thermophilus. Appl. Environ. Microbiol. 2000, 66, 1749–1753. [Google Scholar] [CrossRef] [PubMed][Green Version]
- Toussaint, A.; Merlin, C. Mobile elements as a combination of functional modules. Plasmid 2002, 47, 26–35. [Google Scholar] [CrossRef]
- Carraro, N.; Richard, X.; Sulser, S.; Delavat, F.; Mazza, C.; van der Meer, J.R. An analog to digital converter controls bistable transfer competence of a widespread integrative and conjugative element. eLife 2020, 9. [Google Scholar] [CrossRef] [PubMed]
- Delavat, F.; Miyazaki, R.; Carraro, N.; Pradervand, N.; van der Meer, J.R. The hidden life of integrative and conjugative elements. FEMS Microbiol. Rev. 2017. [Google Scholar] [CrossRef]
- Minoia, M.; Gaillard, M.; Reinhard, F.; Stojanov, M.; Sentchilo, V.; van der Meer, J.R. Stochasticity and bistability in horizontal transfer control of a genomic island in Pseudomonas. Proc. Natl. Acad. Sci. USA 2008, 105, 20792–20797. [Google Scholar] [CrossRef]
- Chen, J.; Bhattacharjee, H.; Rosen, B.P. ArsH is an organoarsenical oxidase that confers resistance to trivalent forms of the herbicide monosodium methylarsenate and the poultry growth promoter roxarsone. Mol. Microbiol. 2015, 96, 1042–1052. [Google Scholar] [CrossRef]
- Yang, H.-C.; Rosen, B.P. New mechanisms of bacterial arsenic resistance. Biomed. J. 2016, 39, 5–13. [Google Scholar] [CrossRef]
- Lau, R.K.; Ye, Q.; Birkholz, E.A.; Berg, K.R.; Patel, L.; Mathews, I.T.; Watrous, J.D.; Ego, K.; Whiteley, A.T.; Lowey, B.; et al. Structure and mechanism of a cyclic trinucleotide-activated bacterial endonuclease mediating bacteriophage immunity. Mol. Cell 2020, 77, 723–733.e6. [Google Scholar] [CrossRef]
- Czechowska, K.; Reimmann, C.; van der Meer, J.R. Characterization of a MexAB-OprM efflux system necessary for productive metabolism of Pseudomonas azelaica HBP1 on 2-hydroxybiphenyl. Front. Microbiol. 2013, 4, 203. [Google Scholar] [CrossRef] [PubMed]
- Ippoliti, P.J.; Delateur, N.A.; Jones, K.M.; Beuning, P.J. Multiple strategies for translesion synthesis in bacteria. Cells 2012, 1, 799–831. [Google Scholar] [CrossRef] [PubMed]
- Erill, I.; Campoy, S.; Mazon, G.; Barbé, J. Dispersal and regulation of an adaptive mutagenesis cassette in the bacteria domain. Nucleic Acids Res. 2006, 34, 66–77. [Google Scholar] [CrossRef] [PubMed]
- Warner, D.F.; Ndwandwe, D.E.; Abrahams, G.L.; Kana, B.D.; Machowski, E.E.; Venclovas, C.; Mizrahi, V. Essential roles for imuA’- and imuB-encoded accessory factors in DnaE2-dependent mutagenesis in Mycobacterium tuberculosis. Proc. Natl. Acad. Sci. USA 2010, 107, 13093–13098. [Google Scholar] [CrossRef]
- Remigi, P.; Capela, D.; Clerissi, C.; Tasse, L.; Torchet, R.; Bouchez, O.; Batut, J.; Cruveiller, S.; Rocha, E.P.C.; Masson-Boivin, C. Transient hypermutagenesis accelerates the evolution of legume endosymbionts following horizontal gene transfer. PLoS Biol. 2014, 12, e1001942. [Google Scholar] [CrossRef]
- Carraro, N.; Burrus, V. The dualistic nature of integrative and conjugative elements. Mob. Genet. Elem. 2015, 5, 98–102. [Google Scholar] [CrossRef]
- Jayaram, M.; Ma, C.-H.; Kachroo, A.H.; Rowley, P.A.; Guga, P.; Fan, H.-F.; Voziyanov, Y. An overview of tyrosine site-specific recombination: From an Flp perspective. Microbiol. Spectr. 2015, 3. [Google Scholar] [CrossRef]
- Novick, R.P.; Christie, G.E.; Penadés, J.R. The phage-related chromosomal islands of Gram-positive bacteria. Nat. Rev. Microbiol. 2010, 8, 541–551. [Google Scholar] [CrossRef]
- Delavat, F.; Mitri, S.; Pelet, S.; van der Meer, J.R. Highly variable individual donor cell fates characterize robust horizontal gene transfer of an integrative and conjugative element. Proc. Natl. Acad. Sci. USA 2016, 113, E3375–E3383. [Google Scholar] [CrossRef]
- Meyer, F.; Goesmann, A.; McHardy, A.C.; Bartels, D.; Bekel, T.; Clausen, J.; Kalinowski, J.; Linke, B.; Rupp, O.; Giegerich, R.; et al. GenDB—An open source genome annotation system for prokaryote genomes. Nucleic Acids Res. 2003, 31, 2187–2195. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
| Name | Sequence (5′-3′) | Reference |
|---|---|---|
| pPaz2002_fw | CACAGGCGCTTTTGCTTGC | This work |
| pPaz2003_rev | CAGATGGTTGATGTAGCCGATAG | This work |
| pPazICE1_left_fw | GACTCGGGGCGATCCATTGAC | This work |
| pPazICE1_left_rev | CGCGACCCGTGCTCAAAC | This work |
| pPazICE1_merA_fw | ATCATGGCCGAGGCGATCAC | This work |
| pPazICE1_merA_rev | GCCAGGATGCCTTCGTACTTGG | This work |
| pPazICE2_right2_fw | GAACCGTGAGGTCTGAGAGCATG | This work |
| pPazICE2_right_rev | CCACTTCATCGACGTGGAACACA | This work |
| pPazICE2_LE_DisFw | CCTGACGCTGCCATCTGCCT | This work |
| pPazICE2_LE_DisRe | GAATGGCTGCAATCAGGAACGAC | This work |
| pICE2_LeftProxOut | CCGCCAGCACCCACAGAC | This work |
| pICE2_LeftProxIn | CATCTTGGAGTAAGAGCTGCGC | This work |
| pPazICE2_hbpA_fw | GGGTGCTGGTCCGGCTGG | This work |
| pPazICE2_hbpA_rev | CGGCGTTTTGCGCAACTAGC | This work |
| Pgly1fw | GCCCAAGCGTCGTGATGAATG | [34] |
| Pgly1rev | ACGTGAGCGGTGTTGATGGTGAT | [34] |
| Pgly2rev | TTGAAGCGGATCGGTGGGTAAT | [34] |
| Pgly2fw | AATGTCATGCTGGGCTTCCTCAA | [34] |
| Pgly3fw | CAGTAATGCCAGCAGCGTGTCC | [34] |
| Pgly3rev | GTGCCGGAGAAACTGGAGCG | [34] |
| Pgly4fw | ATCGTGAGGTTCATGTTCTGGTGC | [34] |
| Pgly4rev | GCACCGCATAGACGCCACAGTA | [34] |
| Pgly5fw | TCACGCCGAACGTGGTAAAGC | [34] |
| Pgly5rev | GACCTCCGTGGAAGGCTGTAAATCT | [34] |
| Pgly6fw_SV 070933 | TCGCTAGAATGGCACCCATCAC | [34] |
| Pgly6rev 060353 | CGCCGCGTTGTGGTGTTTG | [34] |
| Pgly6fw 060354 | TCCTGCTCATTCCGTGCTTCATT | This work |
| Pgly6rev2 140309 | CGACTGAAACCTGTAGATC | This work |
| Recombination/Integration Site | Primer Pair | Amplicon Size (bp) |
|---|---|---|
| ICEPni1 in P. nitroreducens | ||
| attRICEPni1 | pPaz2002_fw/pPaz2003_rev | 1138 |
| attLICEPni1 | pPazICE1_left_fw/pPazICE1_left_rev | 984 |
| attPICEPni1 | pPaz2002_fw/pPazICE1_left_rev | 982 |
| ICEPni2 | ||
| attRICEPni2 | pPazICE2_right2_fw/pPazICE2_right_rev | 933 |
| attLPICEPni2 | pICE2_LeftProxOut/pICE2_LeftProxIn | 834 |
| attLDICEPni2 | pPazICE2_LE_DisFw/pPazICE2_LE_DisRe | 934 |
| attPPICEPni2 | pPazICE2_right2_fw/pICE2_LeftProxOut | 717 |
| attPDICEPni2 | pPazICE2_right2_fw/pPazICE2_LE_DisFw | 934 |
| attB Integration Sites in P. putida UWC1 a, tRNAGly | ||
| tRNAGly-1 PP_RS02330 | Pgly1fw/Pgly1fw | 985 |
| tRNAGly-2 PP_RS07265 | Pgly2fw/Pgly2rev | 401 |
| tRNAGly-3 PP_RS09655 | Pgly3fw/Pgly3rev | 185 |
| tRNAGly-4 PP_RS09665 | Pgly4fw/Pgly4rev | 225 |
| tRNAGly-5 PP_RS09670 | Pgly5fw/Pgly5rev | 135 |
| tRNAGly-6 PP_RS21295 | Pgly6fw/Pgly6rev | 803 |
| ICEPni1 Junctions in P. putida | ||
| ICEPni1-tRNAGly-3 (attR) | Pgly3fw/pPaz2002_fw | 553 |
| ICEPni1-tRNAGly-4 (attR) | Same as above | 800 |
| ICEPni1-tRNAGly-5 (attR) | Same as above | 962 |
| ICEPni1-tRNAGly-6 (attR) | Pgly6fw_SV/pPaz2002_fw | 482 |
| ICEPni1-tRNAGly-3 (attL) | pPaz2002_rev/Pgly3rev | 1039 |
| ICEPni1-tRNAGly-4 (attL) | pPaz2002_rev/Pgly3rev | 792 |
| ICEPni1-tRNAGly-5 (attL) | pPaz2002_rev/Pgly3rev | 637 |
| ICEPni1-tRNAGly-6 (attL) | pPaz2002_rev/Pgly6rev2 | 607 |
| ICEPni2 Junctions in P. putida | ||
| ICEPni2-tRNAGly-2 (attR) | pPazICE2_right2_fw/Pgly2fw | 536 |
| ICEPni2-tRNAGly-2 (attL) | pICE2_LeftProxOut/Pgly2rev | 579 |
| Replicon | Phage | Start-Stop (bp) | Size (kb) | Prediction a | Related Phage-Accession Number |
|---|---|---|---|---|---|
| Chromosome | P1 | 211,373–255,489 | 44.1 | intact | Stenotrophomas phage S1-NC_011589(5) |
| P2 | 654,715–672,064 | 17.3 | intact | Enterobacter phage Arya-NC_031048(6) | |
| P3 | 1,611,889–1,643,994 | 32.1 | incomplete | Pseudomonas phage FHA0480-NC_041851(8) | |
| P4 | 2,297,162–2,315,460 | 18.3 | incomplete | Pseudomonas phage YMC11/02/R656-NC_028657(7) | |
| P5 | 2,319,087–2,355,574 | 36.5 | questionable | Pseudomonas phage PAJU2-NC_011373(14) | |
| P6 | 2,525,149–2,570,649 | 45.5 | intact | Pseudomonas phage MD8-NC_031091(5) | |
| P7 | 2,562,995–2,608,469 | 45.5 | intact | Pseudomonas phage phiCTX-NC_003278(29) | |
| P8 | 2,935,034–2,974,747 | 39.7 | intact | Pseudomonas phage JBD25-NC_027992(34) | |
| P9 | 3,666,393–3,701,365 | 35.0 | intact | Salmonella phage SEN34-NC_028699(20) | |
| P10 | 3,714,527–3,770,149 | 55.6 | intact | Salmonella phage SEN34-NC_028699(19) | |
| P11 | 5,332,674–5,379,949 | 47.3 | intact | Pseudomonas phage YMC11/02/R656-NC_028657(9) | |
| pPniHBP1_1 | P12 | 144,536–158,207 | 13.7 | incomplete | Acinetobacter phage vB_AbaM_ME3-NC_041884(3) |
| P13 | 323,653–329,028 | 5.4 | incomplete | Pseudomonas phage MD8-NC_031091(2) | |
| P14 | 385,628–394,444 | 8.8 | incomplete | Halovirus HCTV5-NC_021327(2) | |
| pPniHBP1_2 | P15 | 51,522–65,829 | 14.3 | incomplete | Ralstonia phage p12J-NC_005131(2) |
| Attachment Site | Sequence (5′ to 3′) | Host |
|---|---|---|
| ICEPni1 | ||
| attL | GACTCGTTTCCCGCTCCA | P. nitroreducens |
| attR | GTCTCGTTTCCCGCTCCA | P. nitroreducens |
| attP | GACTCGTTTCCCGCTCCA | P. nitroreducens |
| attB | GTCTCGTTTCCCGCTCCA | P. nitroreducens |
| attB | GTCTCGTTTCCCGCTCCA | P. putida |
| attL | GACTCGTTTCCCGCTCCA | P. putida |
| attR | GTCTCGTTTCCCGCTCCA | P. putida |
| ICEPni2 | ||
| attL | TTCCCTTCGCCCGCTCCA | P. nitroreducens |
| attR | TTCCCTTCGCCCGCTCCA | P. nitroreducens |
| attP | TTCCCTTCGCCCGCTCCA | P. nitroreducens |
| attB | TTCCCTTCGCCCGCTCCA | P. nitroreducens |
| attB | TTCCCTCTACCCGCTCCA | P. putida |
| attL1 | TTCCCTCTACCCGCTCCA | P. putida |
| attL2 | TTCCCTTCGCCCGCTCCA | P. putida |
| attR1 | TTCCCTCTACCCGCTCCA | P. putida |
| attR2 | TTCCCTTCGCCCGCTCCA | P. putida |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Carraro, N.; Sentchilo, V.; Polák, L.; Bertelli, C.; van der Meer, J.R. Insights into Mobile Genetic Elements of the Biocide-Degrading Bacterium Pseudomonas nitroreducens HBP-1. Genes 2020, 11, 930. https://doi.org/10.3390/genes11080930
Carraro N, Sentchilo V, Polák L, Bertelli C, van der Meer JR. Insights into Mobile Genetic Elements of the Biocide-Degrading Bacterium Pseudomonas nitroreducens HBP-1. Genes. 2020; 11(8):930. https://doi.org/10.3390/genes11080930
Chicago/Turabian StyleCarraro, Nicolas, Vladimir Sentchilo, Lenka Polák, Claire Bertelli, and Jan Roelof van der Meer. 2020. "Insights into Mobile Genetic Elements of the Biocide-Degrading Bacterium Pseudomonas nitroreducens HBP-1" Genes 11, no. 8: 930. https://doi.org/10.3390/genes11080930
APA StyleCarraro, N., Sentchilo, V., Polák, L., Bertelli, C., & van der Meer, J. R. (2020). Insights into Mobile Genetic Elements of the Biocide-Degrading Bacterium Pseudomonas nitroreducens HBP-1. Genes, 11(8), 930. https://doi.org/10.3390/genes11080930