
A Study of Kale Recognition Based on Semantic Segmentation

Abstract
1. Introduction
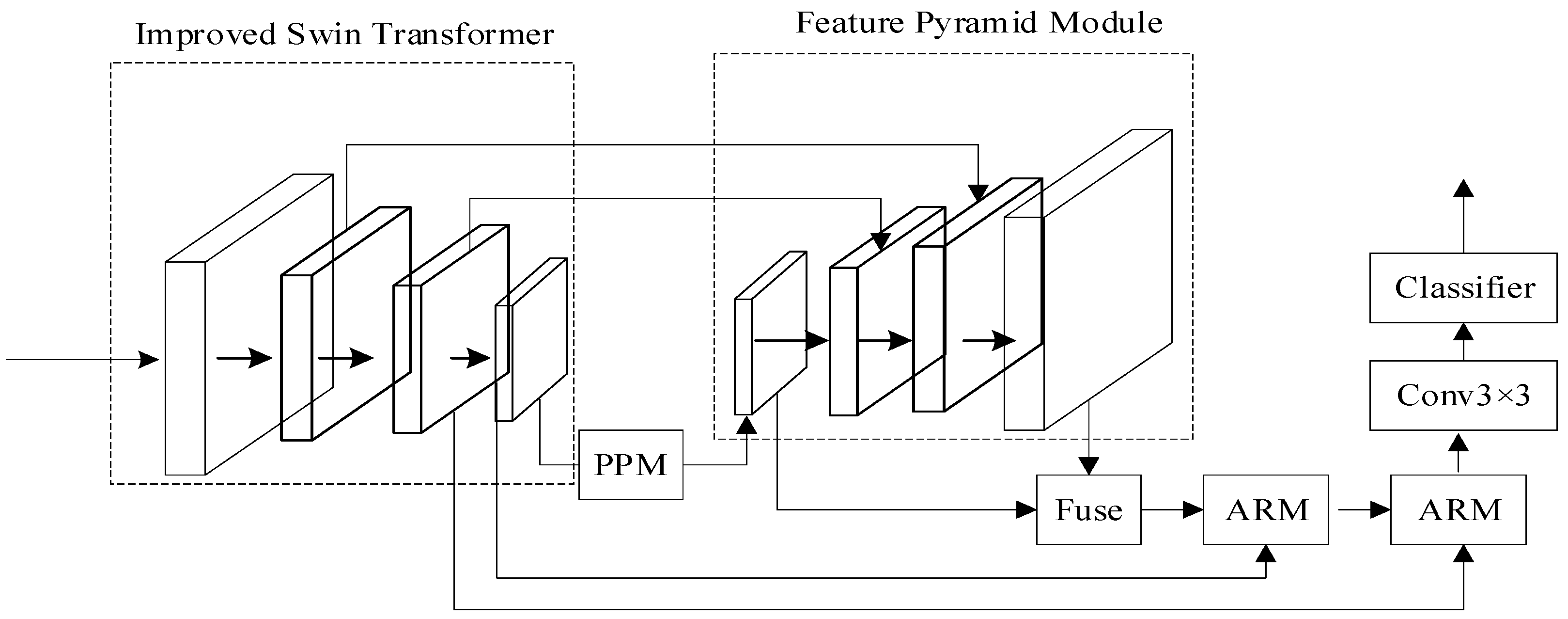
- Building upon the UperNet architecture, a tailored semantic segmentation framework is developed that considers the specific growth characteristics of kale leaves.
- By adopting the Swin transformer as our backbone network, the channel attention module (CAM) is introduced to significantly improve the network’s ability to represent and extract information about the kale’s outer leaves and leaf bulb.
- An ARM within the decoding part of the framework is designed to refine the edge detection accuracy of kale’s target areas.
- The issue of class imbalance is addressed by modifying the optimizer and loss function during the network training phase, ensuring a more balanced class distribution and improved learning dynamics.
2. Materials and Methods
2.1. Experimental Data
2.2. Experimental Methods
2.2.1. An Improved Semantic Segmentation Model
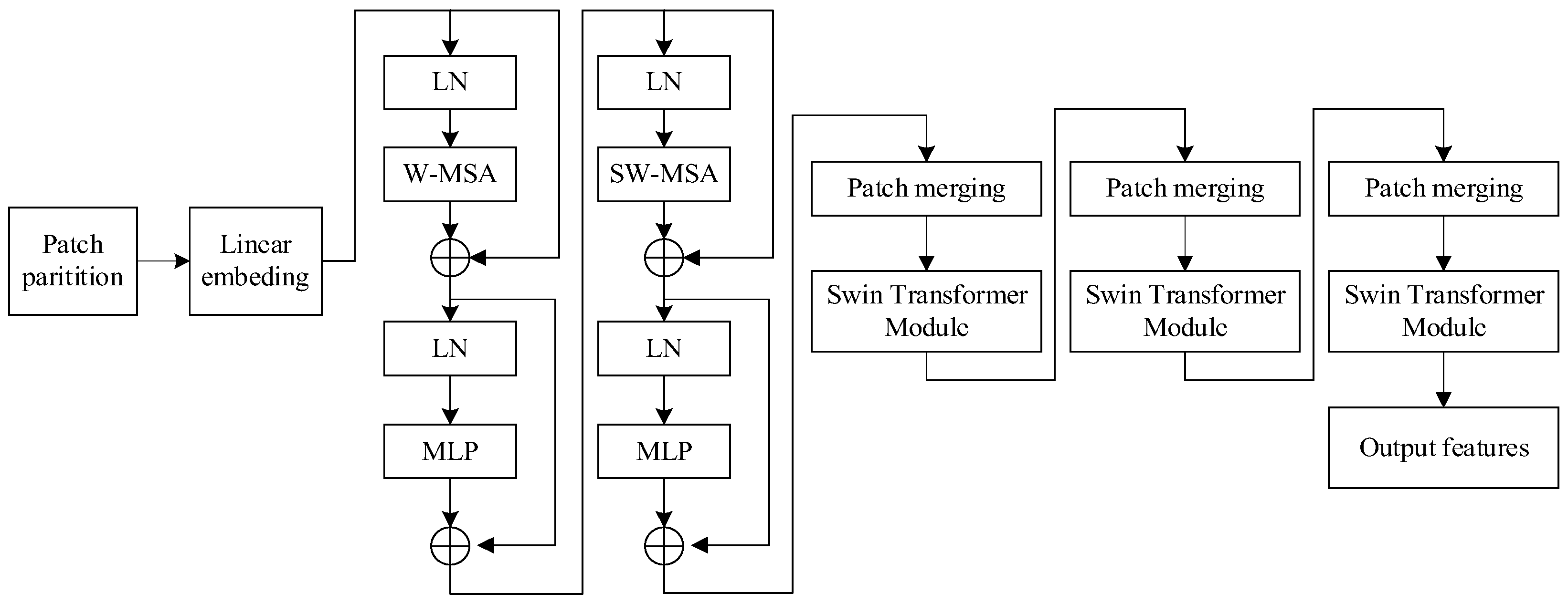
2.2.2. Swin Transformer
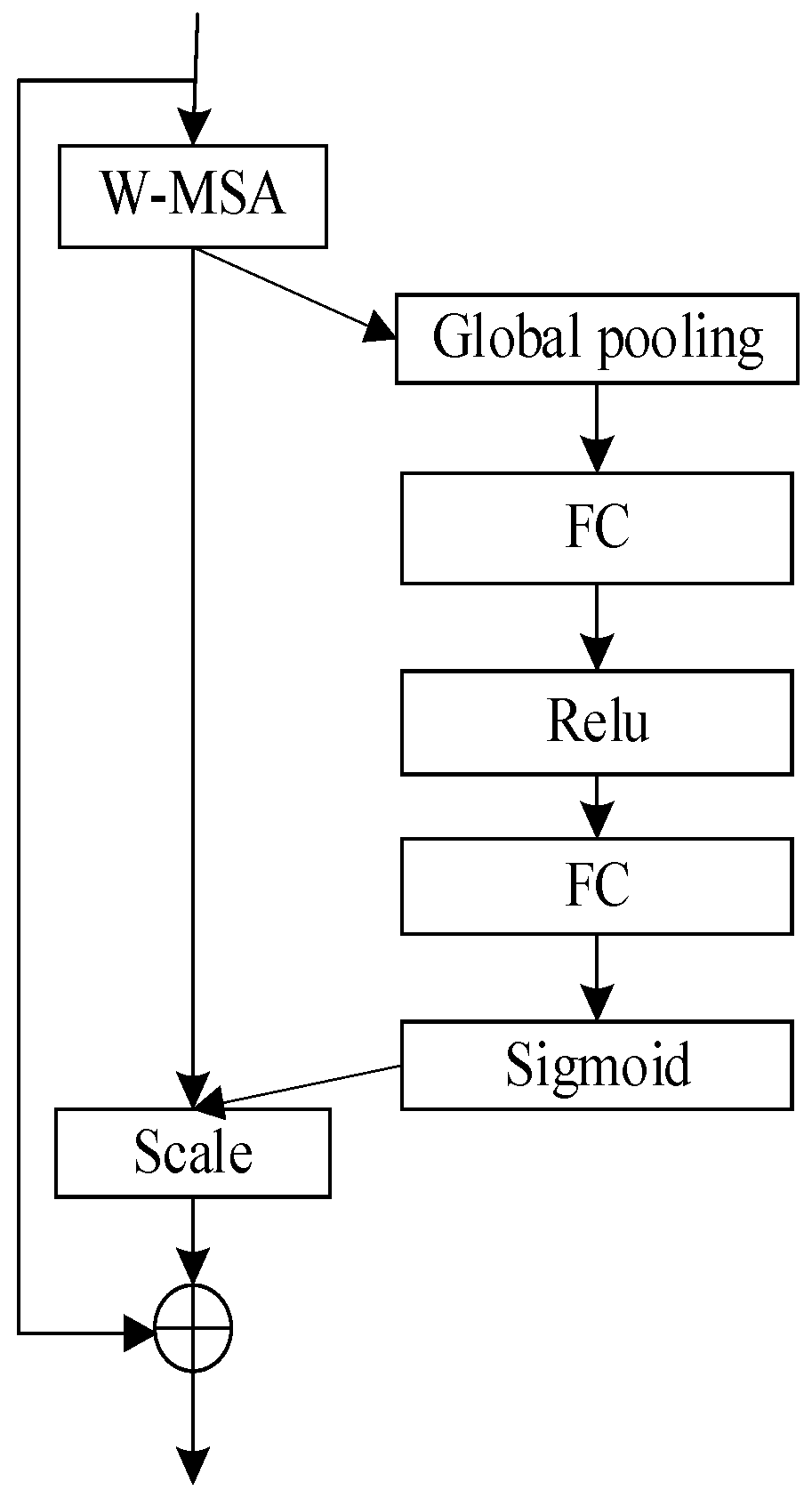
2.2.3. Channel Attention Module (CAM)
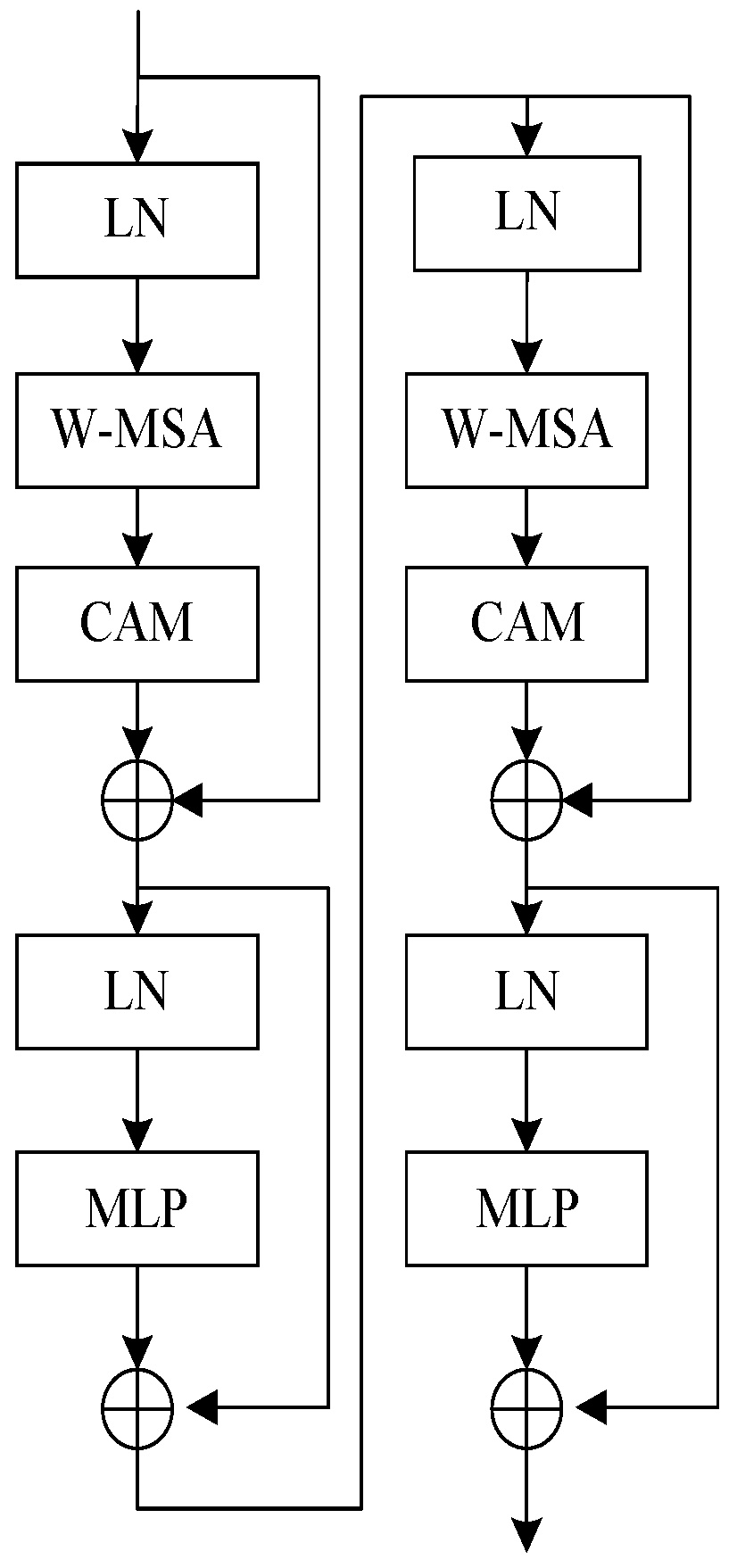
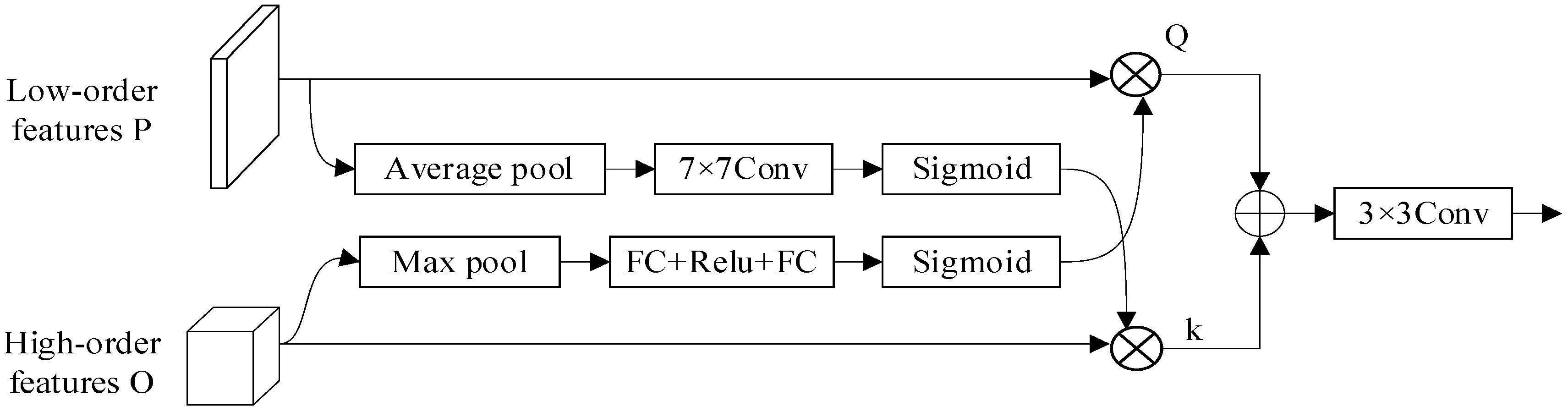
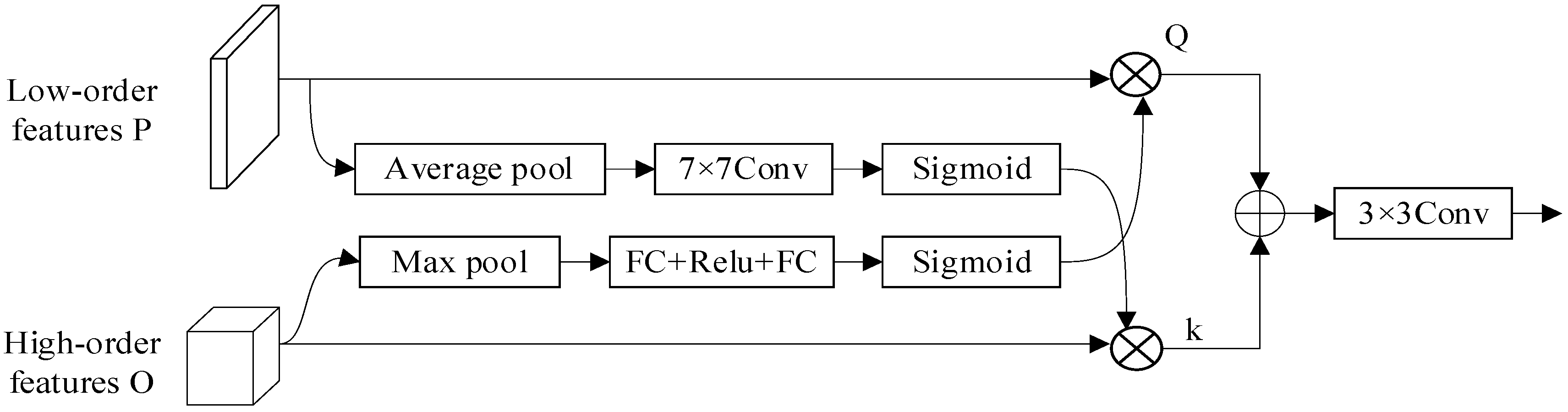
2.2.4. Attention Refinement Module (ARM)
3. Model Training and Performance Evaluation
3.1. Test Platform Configuration
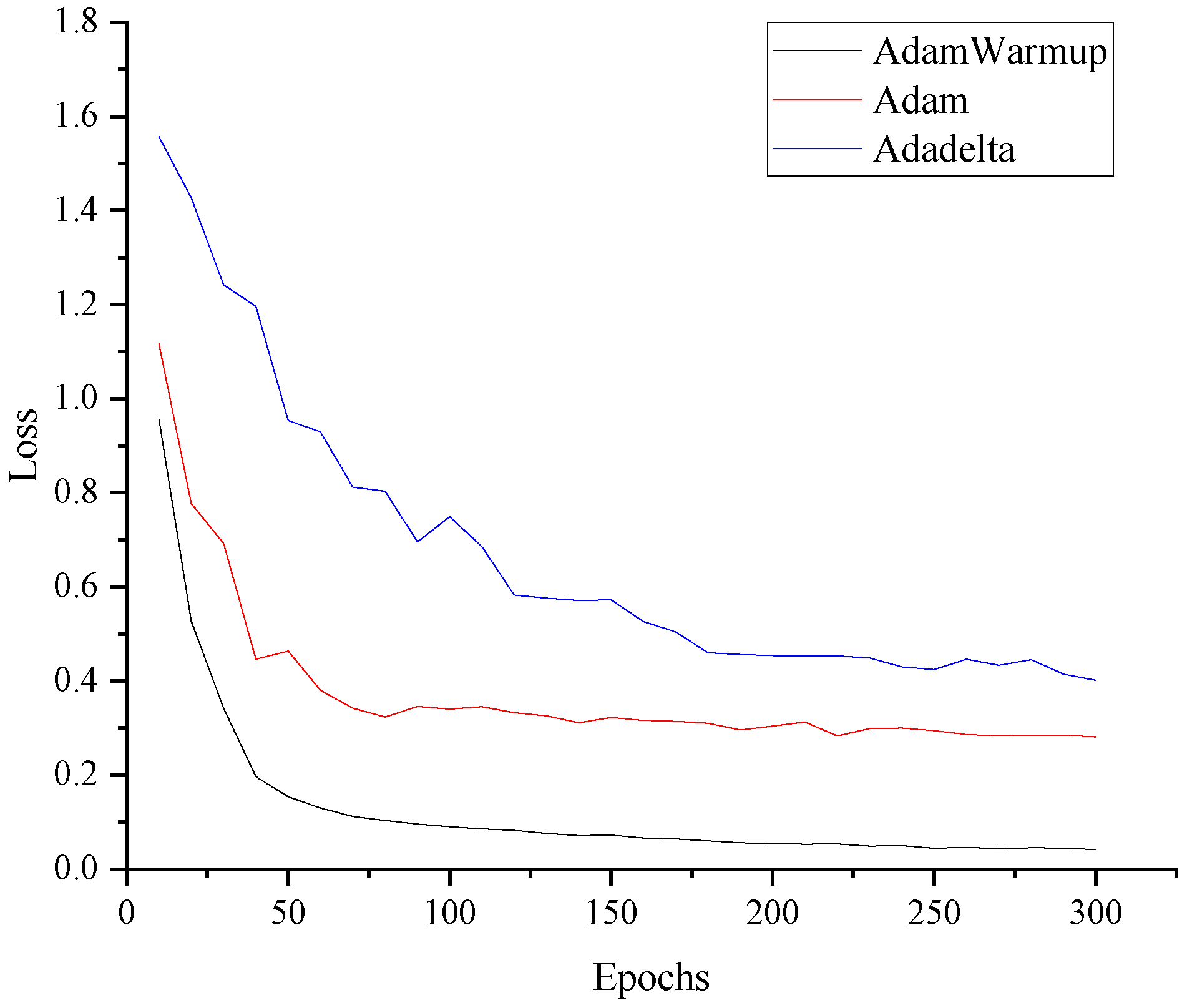
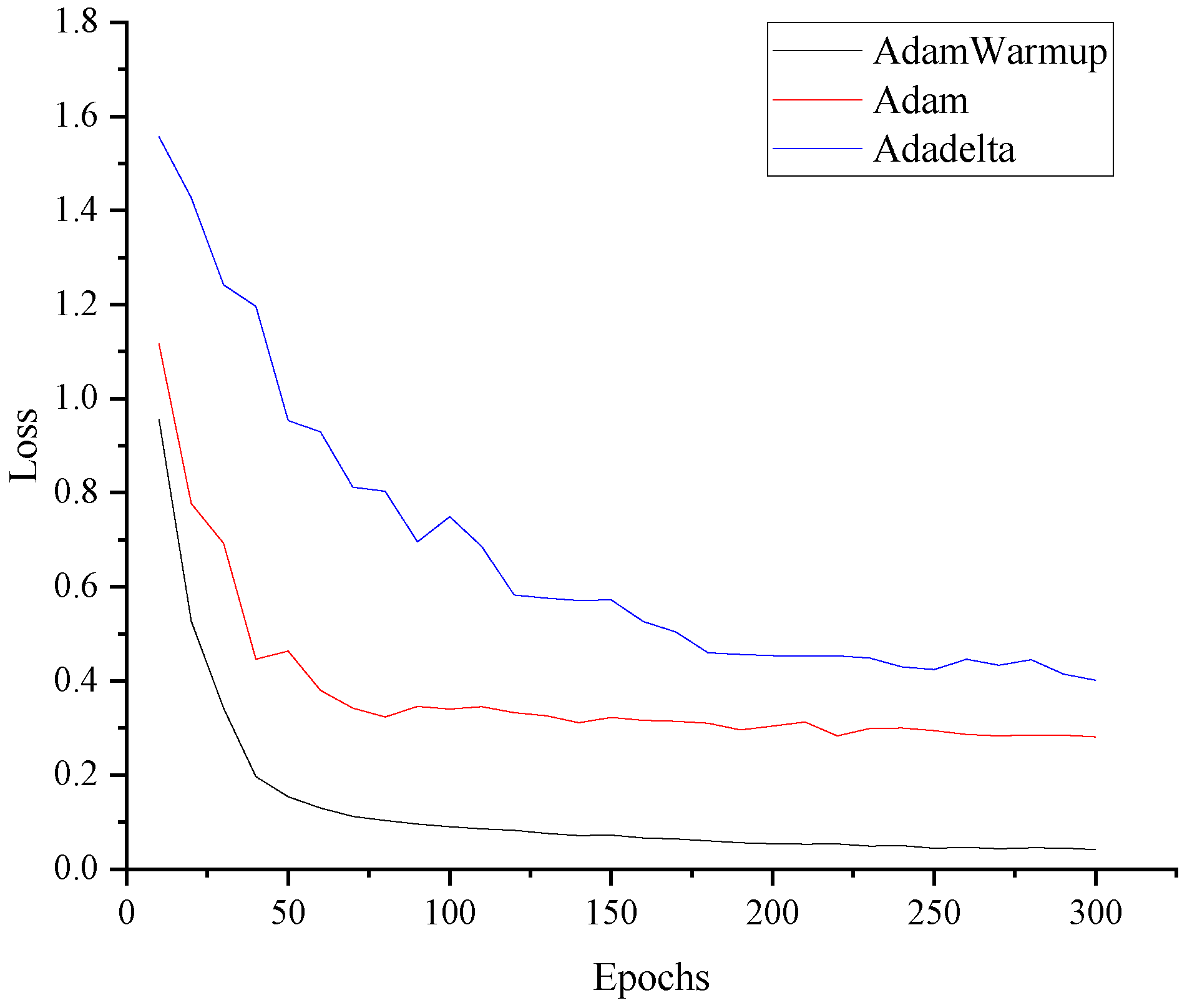
3.2. Model Training Strategies
3.3. Indicators for Model Evaluation
4. Results and Analysis
4.1. Ablation Experiment
4.2. Comparison of Segmentation Recognition Effect of Different Models
4.3. Visualization and Analysis
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Huang, L.; He, M.; Tan, C.; Jiang, D.; Li, G.; Yu, H. Jointly network image processing: Multi-task image semantic segmentation of indoor scene based on CNN. IET Image Process. 2020, 14, 3689. [Google Scholar] [CrossRef]
- Zhao, E.; Dong, L.; Dai, H. Infrared maritime target detection based on edge dilation segmentation and multiscale local saliency of image details. Infrared Phys. Technol. 2023, 133, 104852. [Google Scholar] [CrossRef]
- Machado, G.R.; Silva, E.; Goldschmidt, R.R. Adversarial Machine Learning in Image Classification: A Survey Toward the Defender’s Perspective. ACM Comput. Surv. 2023, 55, 1–38. [Google Scholar] [CrossRef]
- Long, J.; Shelhamer, E.; Darrell, T. Fully Convolutional Networks for Semantic Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; IEEE: Piscataway, NJ, USA, 2015. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015. [Google Scholar]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid Scene Parsing Network. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; IEEE: Piscataway, NJ, USA, 2017. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Schroff, F.; Adam, H. Rethinking Atrous Convolution for Semantic Image Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Chen, L.C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation. In Proceedings of the Computer Vision—ECCV 2018, Berlin, Germany, 8–14 September 2018; Springer International Publishing: Berlin/Heidelberg, Germany, 2018. [Google Scholar]
- Xue, J.; Wang, Y.; Qu, A.; Zhang, J.; Sun, H. Image segmentation method for Lingwu long jujube based on improved FCN-8s. J. Agric. Eng. 2021, 37, 191–197. [Google Scholar] [CrossRef]
- Song, Z.; Zhou, Z.; Wang, W.; Gao, F.; Fu, L.; Li, R.; Cui, Y. Canopy segmentation and wire reconstruction for kiwifruit robotic harvesting. Comput. Electron. Agric. 2021, 181, 105933. [Google Scholar] [CrossRef]
- Ren, H.J.; Liu, P.; Dai, C.; Shi, J.C. Crop Segmentation Method of Remote Sensing Image Based on Improved DeepLabv3+ Network. Comput. Eng. Appl. 2022, 58, 215. [Google Scholar]
- Han, K.; Wang, Y.; Chen, H.; Chen, X.; Guo, J.; Liu, Z.; Tang, Y.; Xiao, A.; Xu, C.; Xu, Y.; et al. A Survey on Vision Transformer. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 45, 87–110. [Google Scholar] [CrossRef] [PubMed]
- Trappey, A.J.; Chang, A.C.; Trappey, C.V.; Chien, J.Y.C. Intelligent RFQ Summarization Using Natural Language Processing, Text Mining, and Machine Learning Techniques. J. Glob. Inf. Manag. 2022, 30, 1–26. [Google Scholar] [CrossRef]
- Liu, Z.; Lin, Y.T.; Cao, Y.; Hu, H.; Wei, Y.X.; Zhang, Z.; Lin, S.; Guo, B.N. Swin Transformer: Hierarchical Vision Transformer using Shifted Windows. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Montreal, BC, Canada, 11–17 October 2021. [Google Scholar]
- Hahn, C.; Howard, N.P.; Albach, D.C. Different Shades of Kale—Approaches to Analyze Kale Variety Interrelations. Genes 2022, 13, 232. [Google Scholar] [CrossRef] [PubMed]
- Khan, H.; Hussain, T.; Khan, S.U.; Khan, Z.A.; Baik, S.W. Deep multi-scale pyramidal features network for supervised video summarization. Expert Syst. Appl. 2024, 237, 121288. [Google Scholar] [CrossRef]
- Qian, H.; Huang, Z.; Xu, Y.; Zhou, Q.; Wang, J.; Shen, J.; Shen, Z. Very high cycle fatigue life prediction of Ti60 alloy based on machine learning with data enhancement. Eng. Fract. Mech. 2023, 289, 109431. [Google Scholar] [CrossRef]
- Ke, X.; Li, J. U-FPNDet: A one-shot traffic object detector based on U-shaped feature pyramid module. IET Image Process. 2021, 15, 2146–2156. [Google Scholar] [CrossRef]
- Kumar, P.; Hati, A.S. Convolutional neural network with batch normalisation for fault detection in squirrel cage induction motor. IET Electr. Power Appl. 2021, 15, 39–50. [Google Scholar] [CrossRef]
- Shen, Z.; Yang, H.; Zhang, S. Optimal approximation rate of ReLU networks in terms of width and depth. J. Math. Pures Appl. 2022, 157, 101–135. [Google Scholar] [CrossRef]
- Sekharamantry, P.K.; Melgani, F.; Malacarne, J. Deep learning-based apple detection with attention module and improved loss function in YOLO. Remote Sens. 2023, 15, 1516. [Google Scholar] [CrossRef]
- Sekharamantry, P.K.; Melgani, F.; Malacarne, J.; Ricci, R.; de Almeida Silva, R.; Marcato Junior, J. A Seamless Deep Learning Approach for Apple Detection, Depth Estimation, and Tracking Using YOLO Models Enhanced by Multi-Head Attention Mechanism. Computers 2024, 13, 83. [Google Scholar] [CrossRef]
- Touvron, H.; Cord, M.; Douze, M.; Massa, F.; Sablayrolles, A.; Jégou, H. Training data-efficient image transformers & distillation through attention. In Proceedings of the International Conference on Machine Learning, Virtual, 18–24 July 2021; PMLR: New York, NY, USA, 2021; pp. 10347–10357. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Programs | mPA (%) | mIOU (%) | |||
|---|---|---|---|---|---|
| ResNet | Swin Transformer | CAM | ARM | ||
| √ | × | × | × | 87.8 | 85.9 |
| × | √ | × | × | 90.5 | 89.1 |
| × | √ | √ | × | 93.3 | 90.7 |
| × | √ | × | √ | 91.7 | 90.0 |
| × | √ | √ | √ | 95.2 | 91.2 |
| Module | Backbone | mPA/% | mIoU/% |
|---|---|---|---|
| FCN | ResNet | 81.6 | 80.2 |
| UNet | ResNet | 85.9 | 84.3 |
| PSPNet | ResNet | 82.3 | 79.1 |
| DeepLabv3+ | ResNet | 88.4 | 86.5 |
| UperNet | ResNet | 87.8 | 85.9 |
| UperNet | Swin transformer | 90.5 | 89.1 |
| proposed | Swin transformer + ECA | 95.2 | 91.2 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wu, H.; Guo, W.; Liu, C.; Sun, X. A Study of Kale Recognition Based on Semantic Segmentation. Agronomy 2024, 14, 894. https://doi.org/10.3390/agronomy14050894
Wu H, Guo W, Liu C, Sun X. A Study of Kale Recognition Based on Semantic Segmentation. Agronomy. 2024; 14(5):894. https://doi.org/10.3390/agronomy14050894
Chicago/Turabian StyleWu, Huarui, Wang Guo, Chang Liu, and Xiang Sun. 2024. "A Study of Kale Recognition Based on Semantic Segmentation" Agronomy 14, no. 5: 894. https://doi.org/10.3390/agronomy14050894
APA StyleWu, H., Guo, W., Liu, C., & Sun, X. (2024). A Study of Kale Recognition Based on Semantic Segmentation. Agronomy, 14(5), 894. https://doi.org/10.3390/agronomy14050894