
Challenges to Use Machine Learning in Agricultural Big Data: A Systematic Literature Review





Abstract
:1. Introduction
2. Background
2.1. Machine Learning
2.2. Big Data
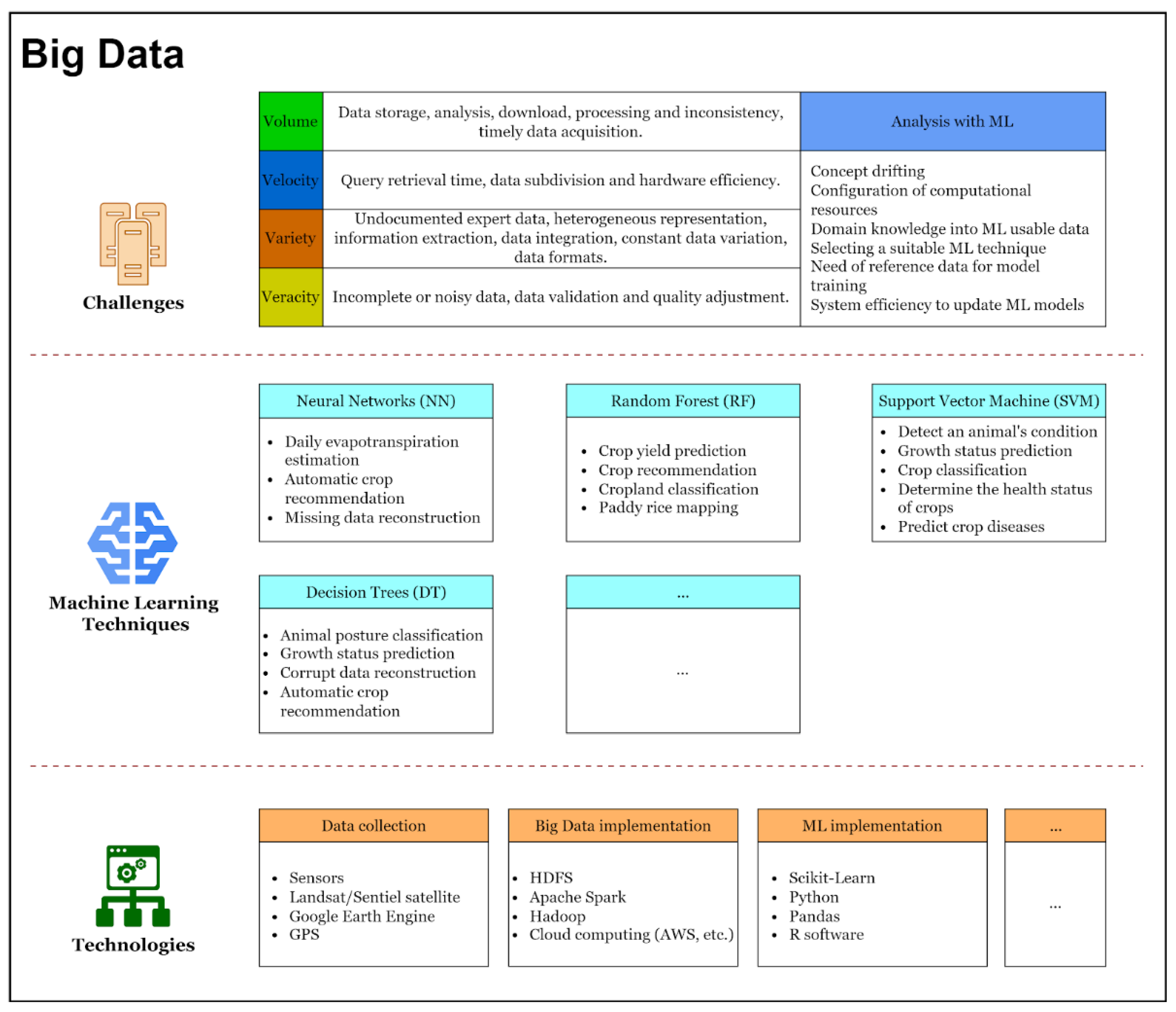
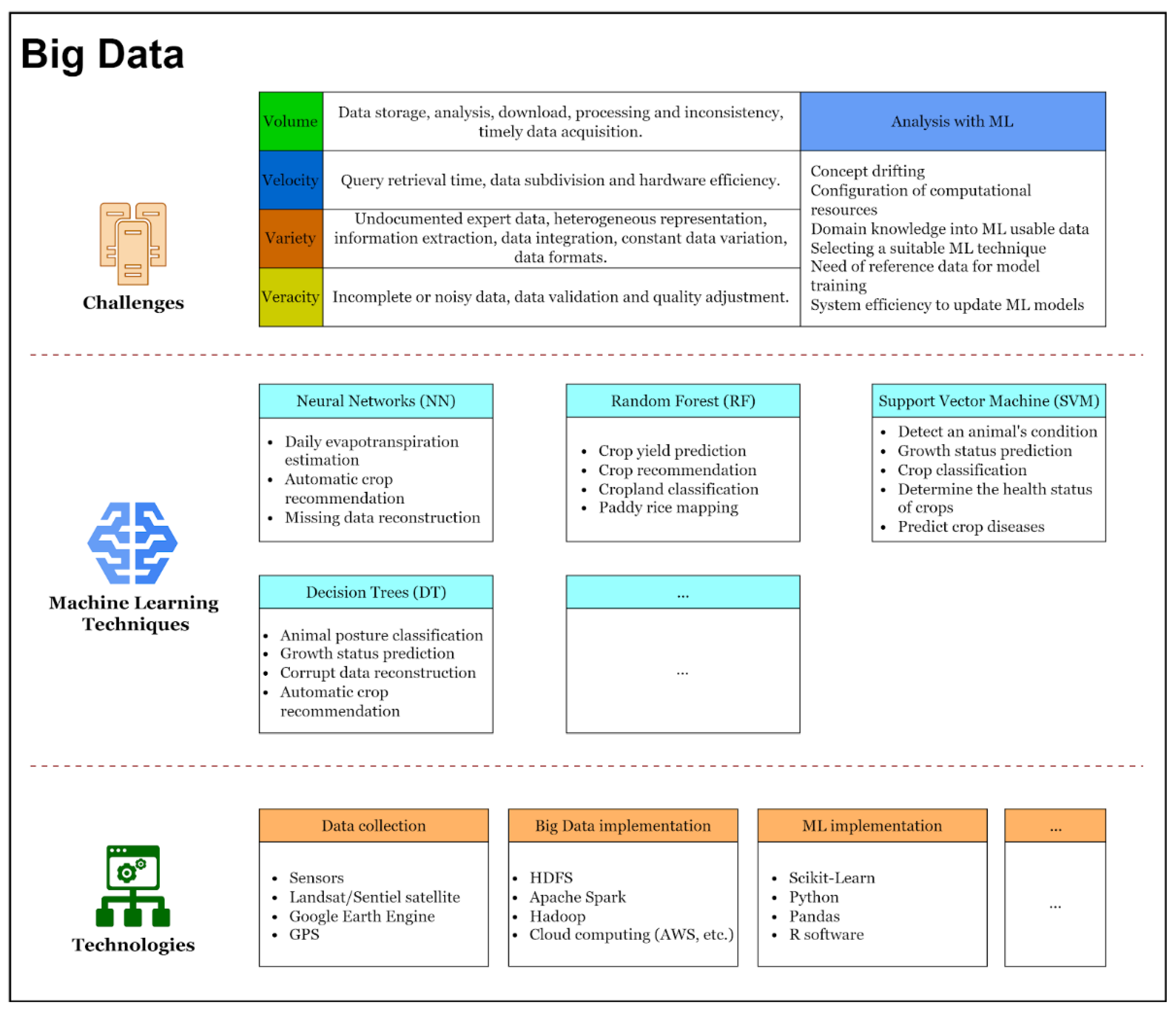
2.3. Challenges in Agricultural Big Data and ML
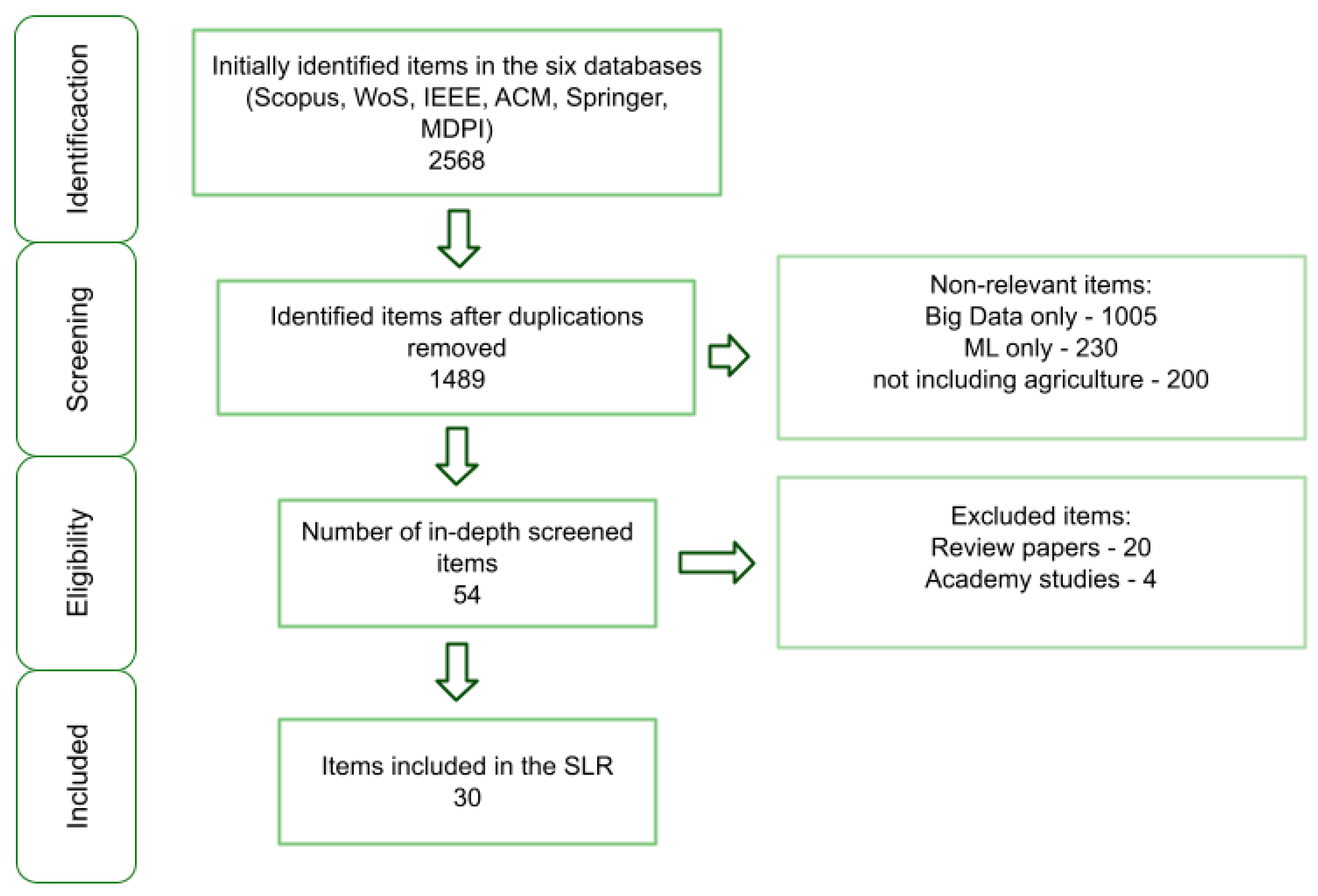
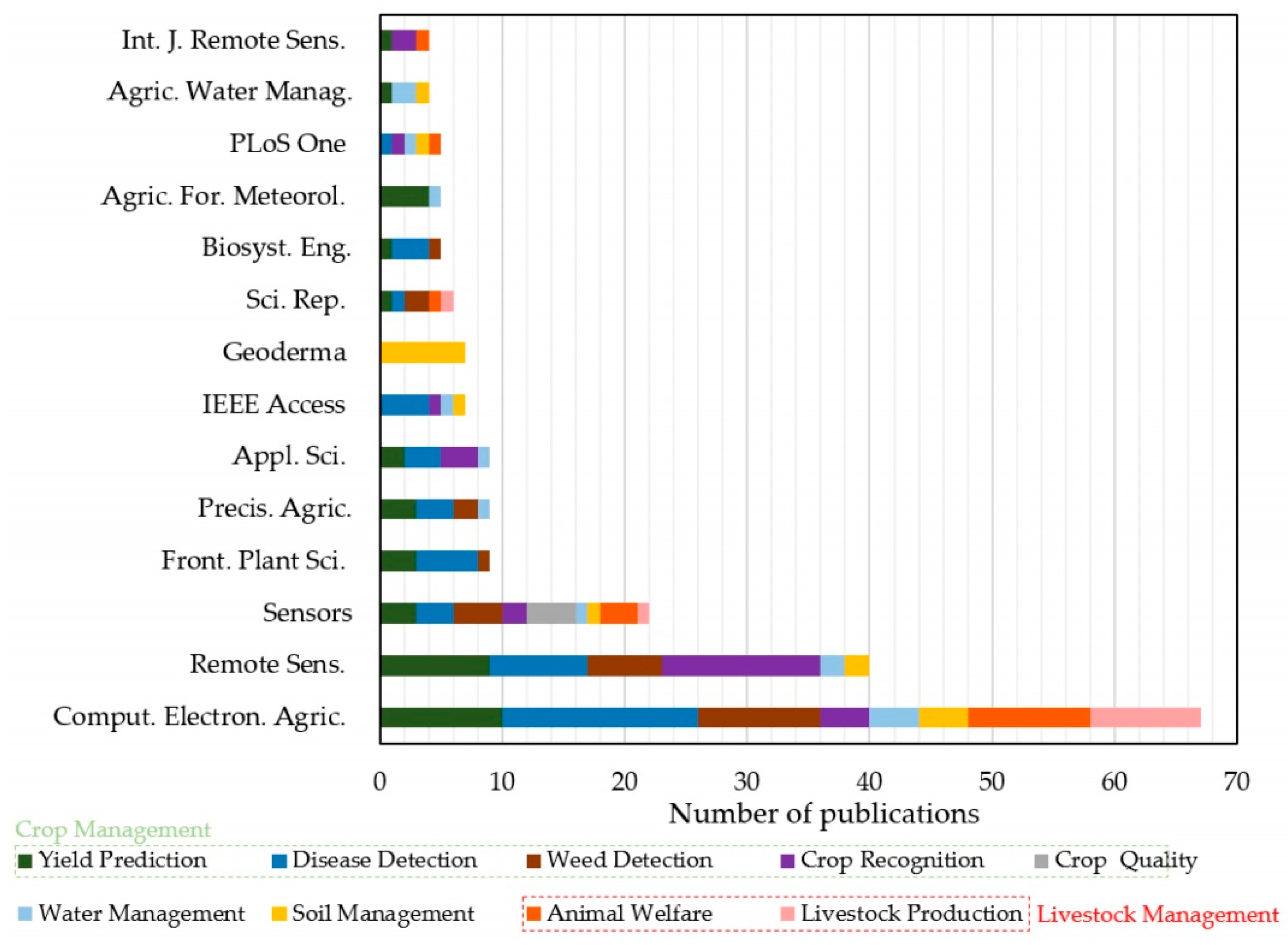
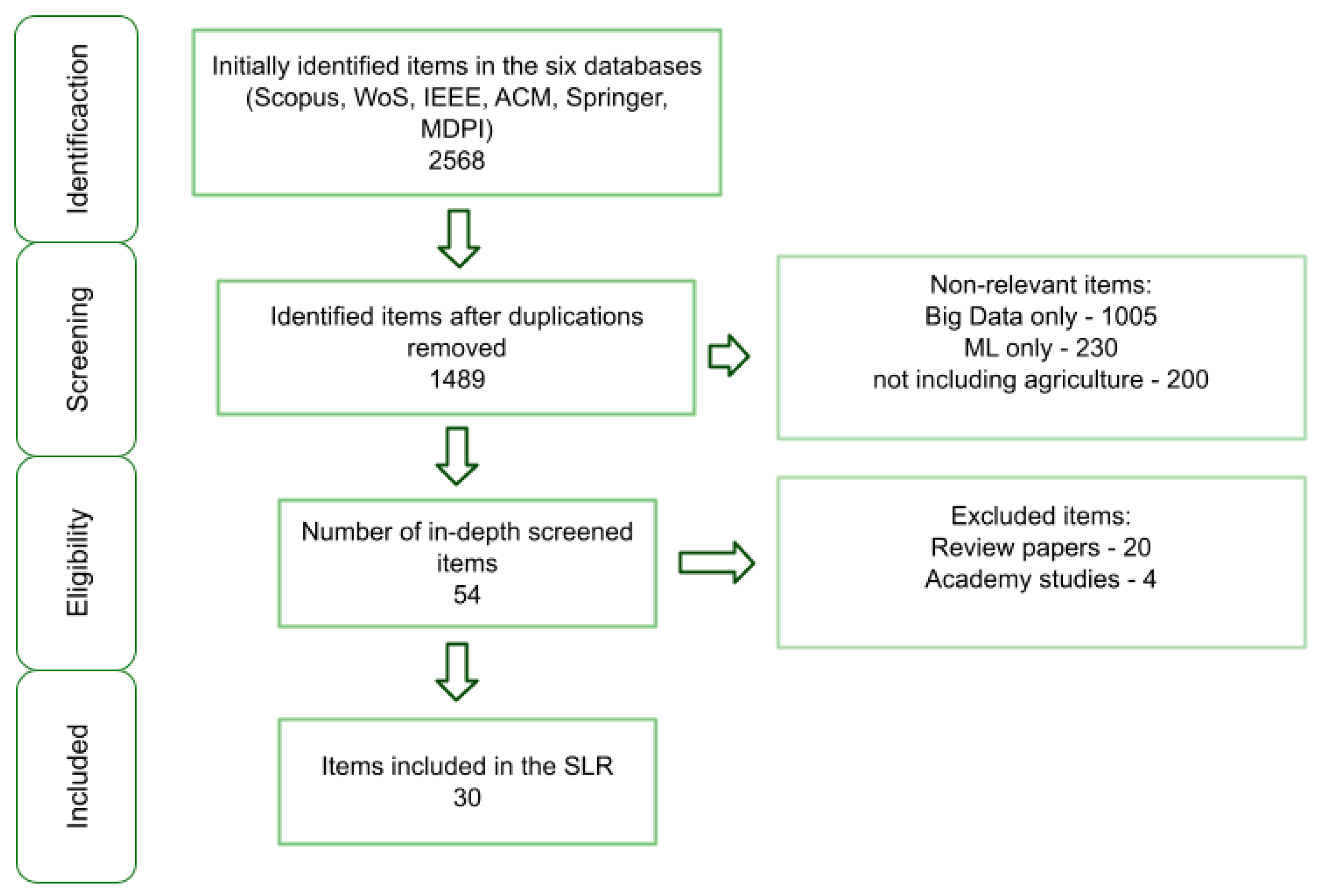
3. Methodology
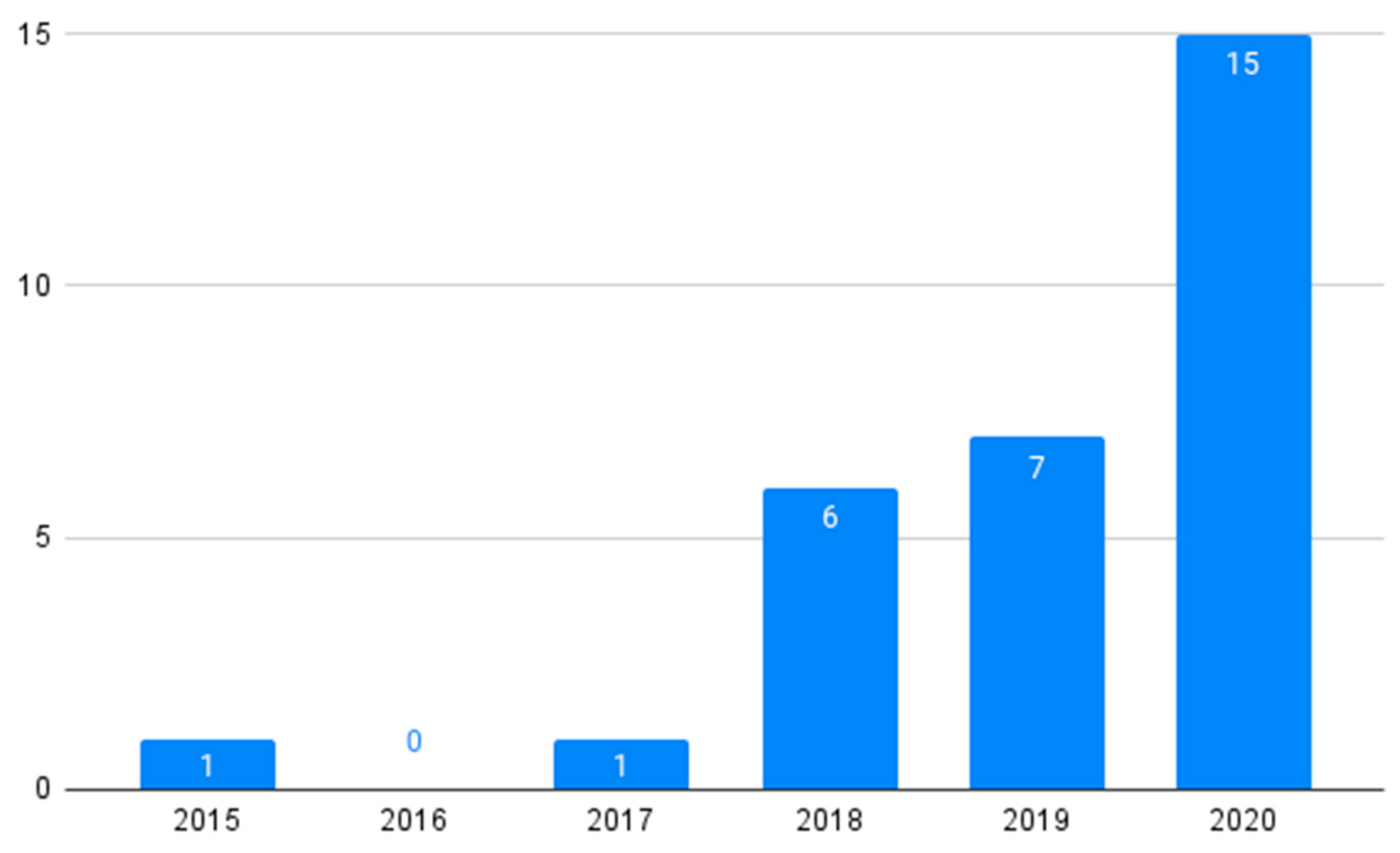
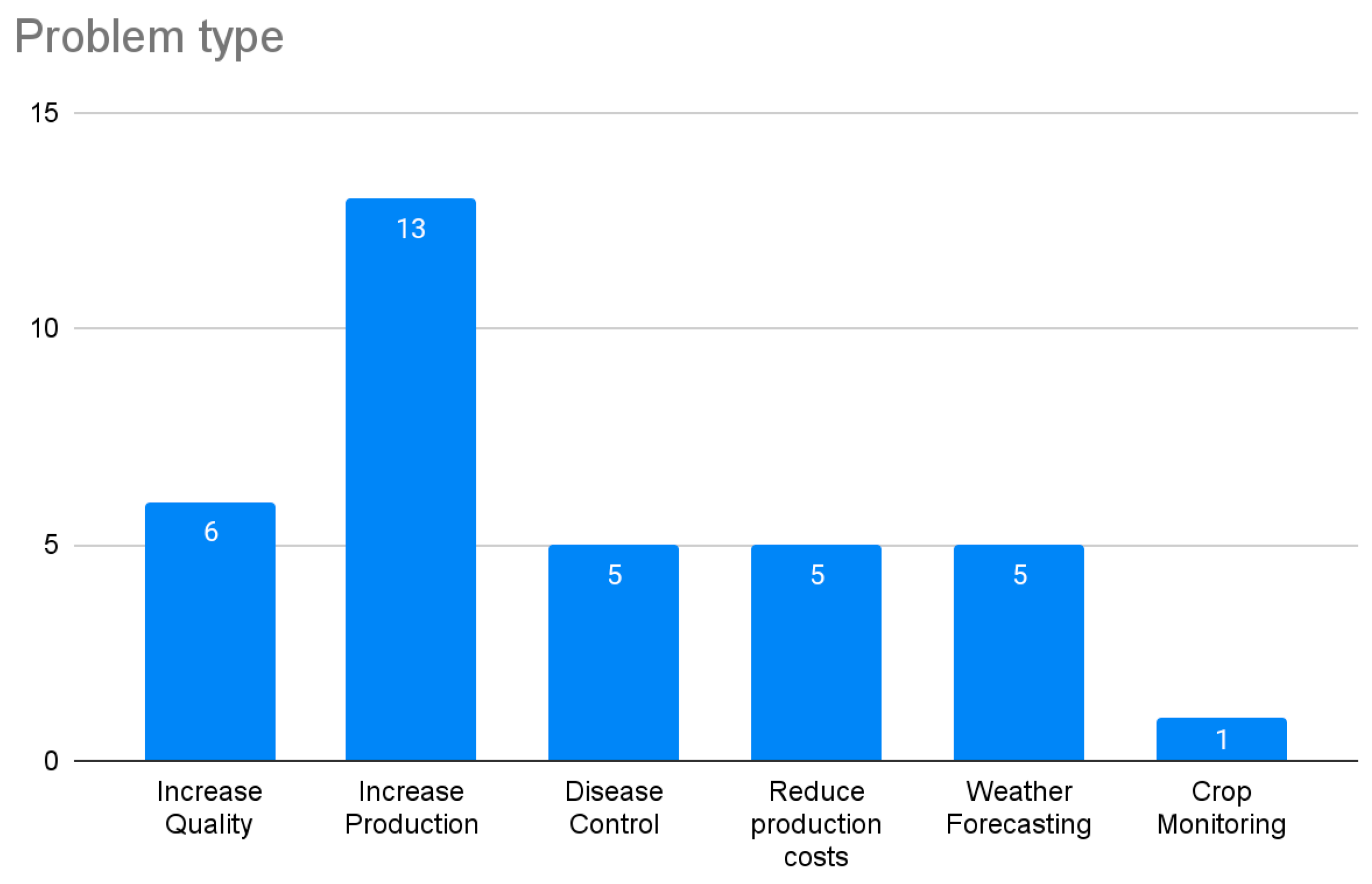
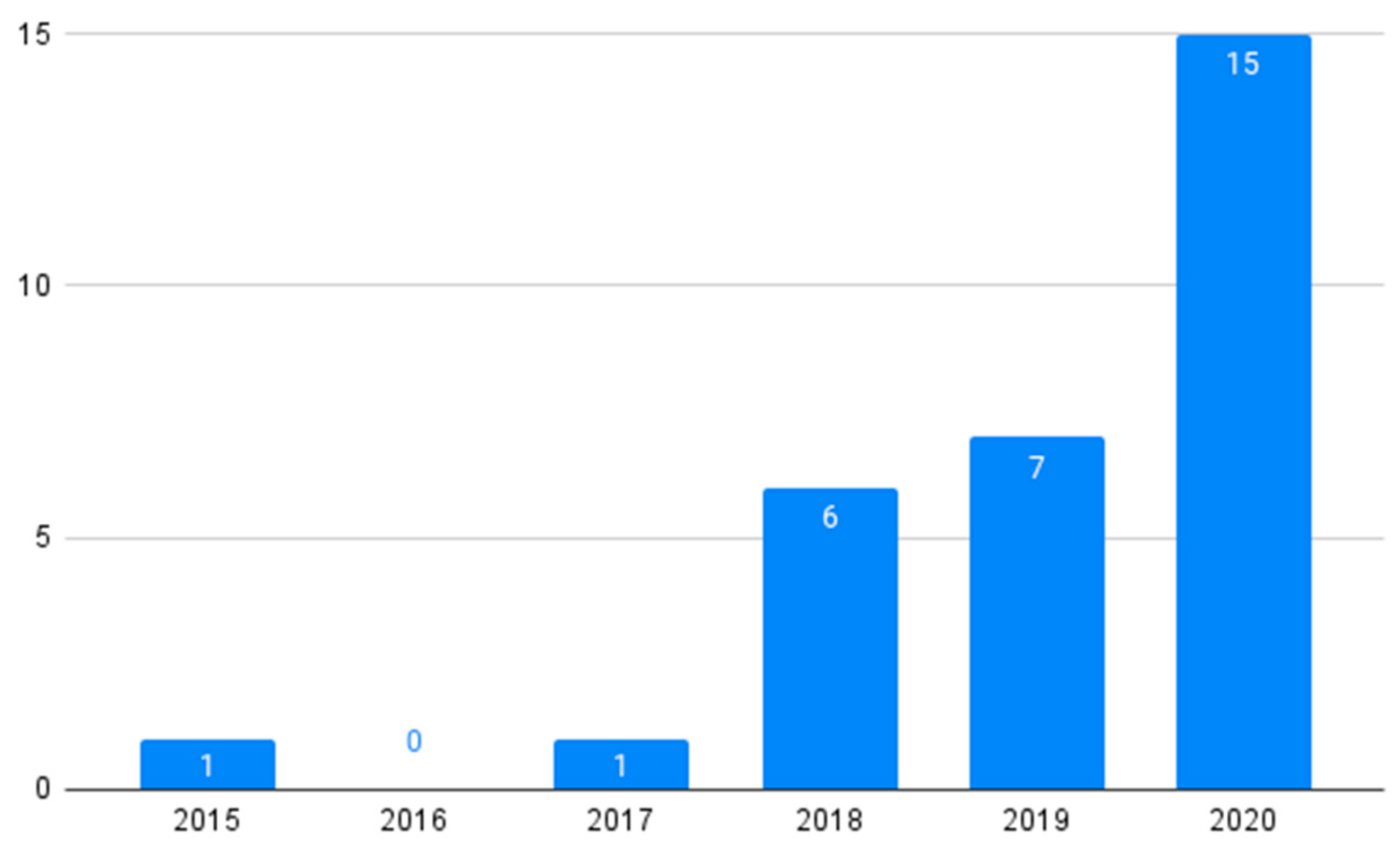
4. Results
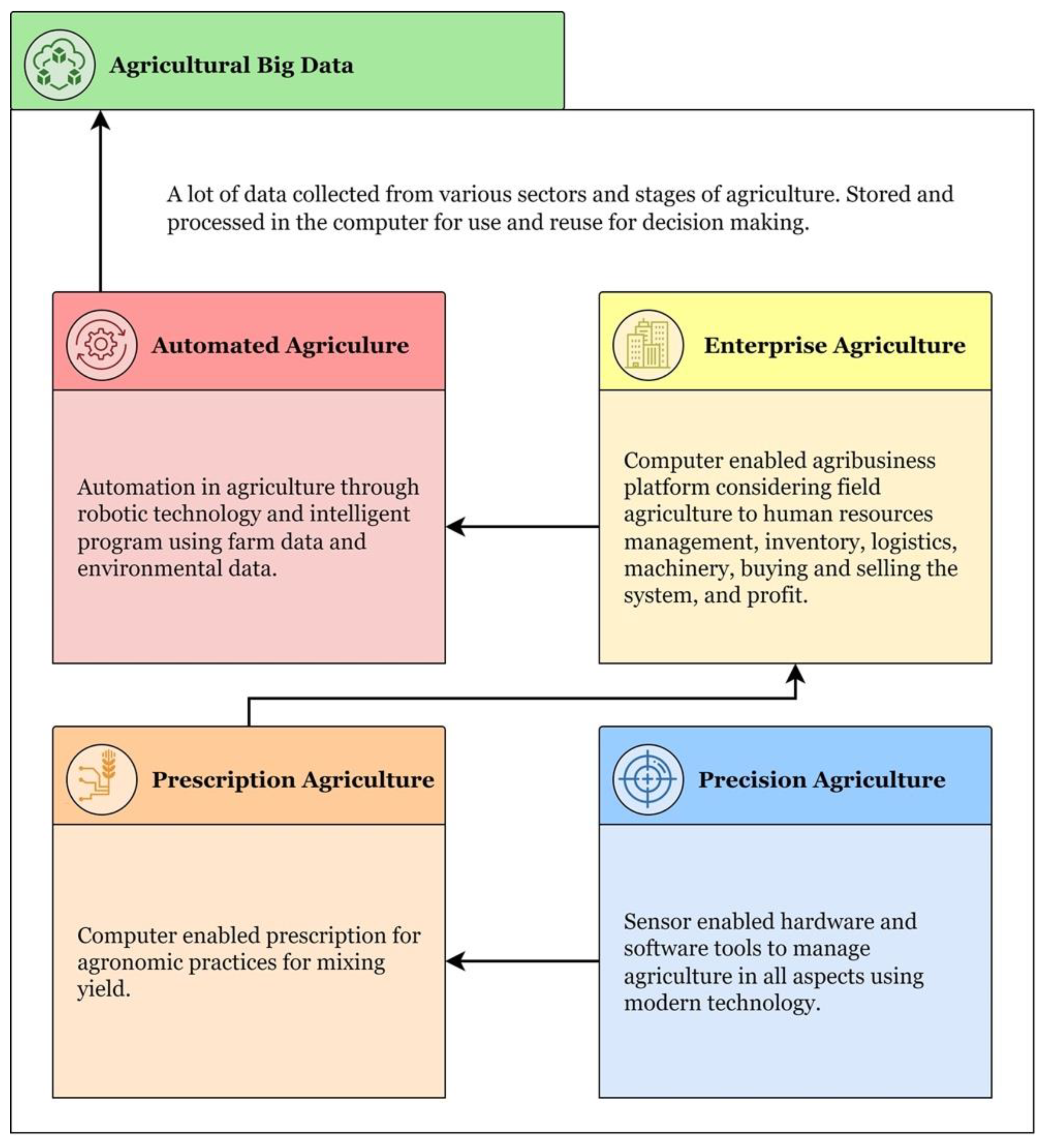
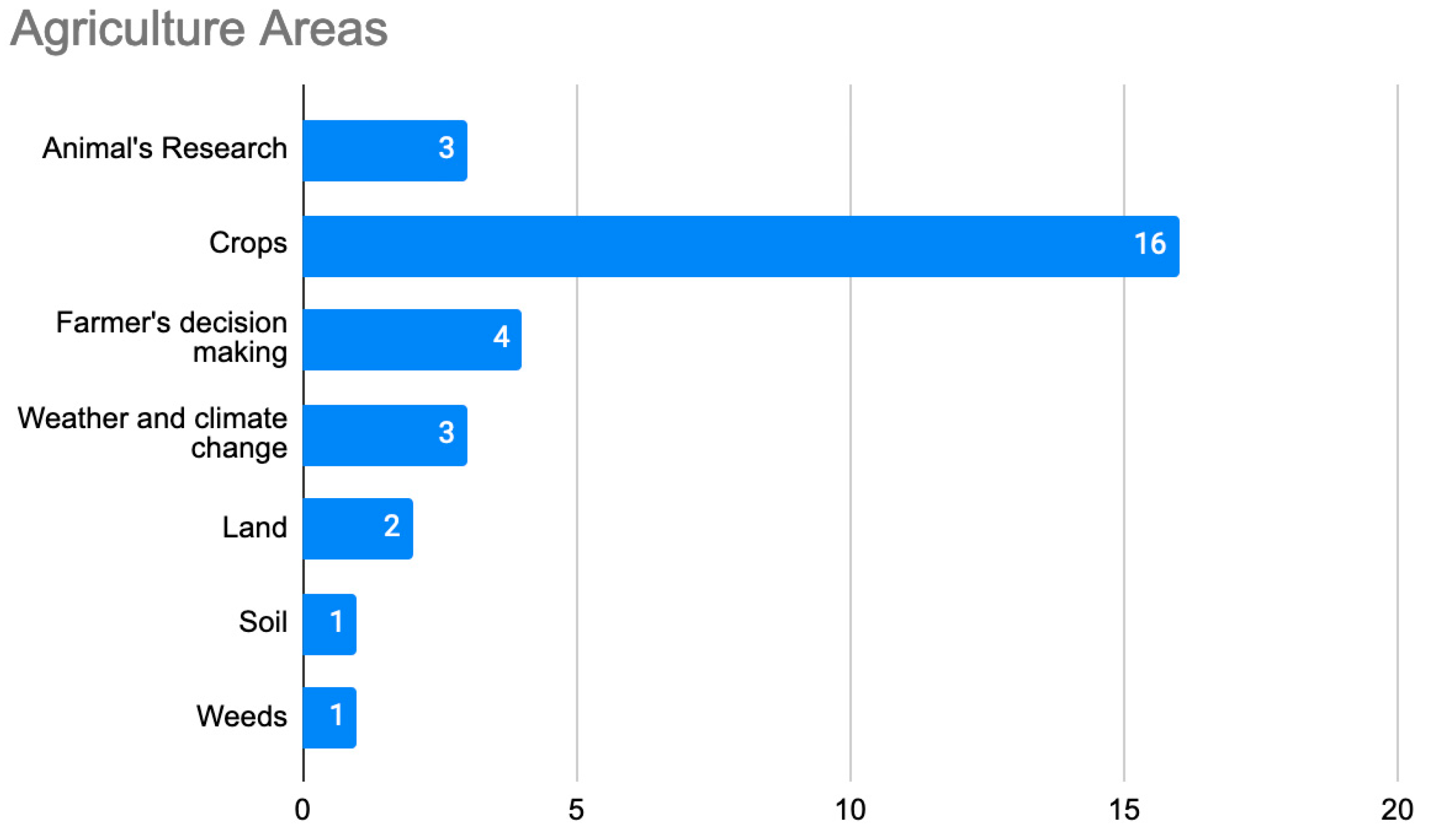
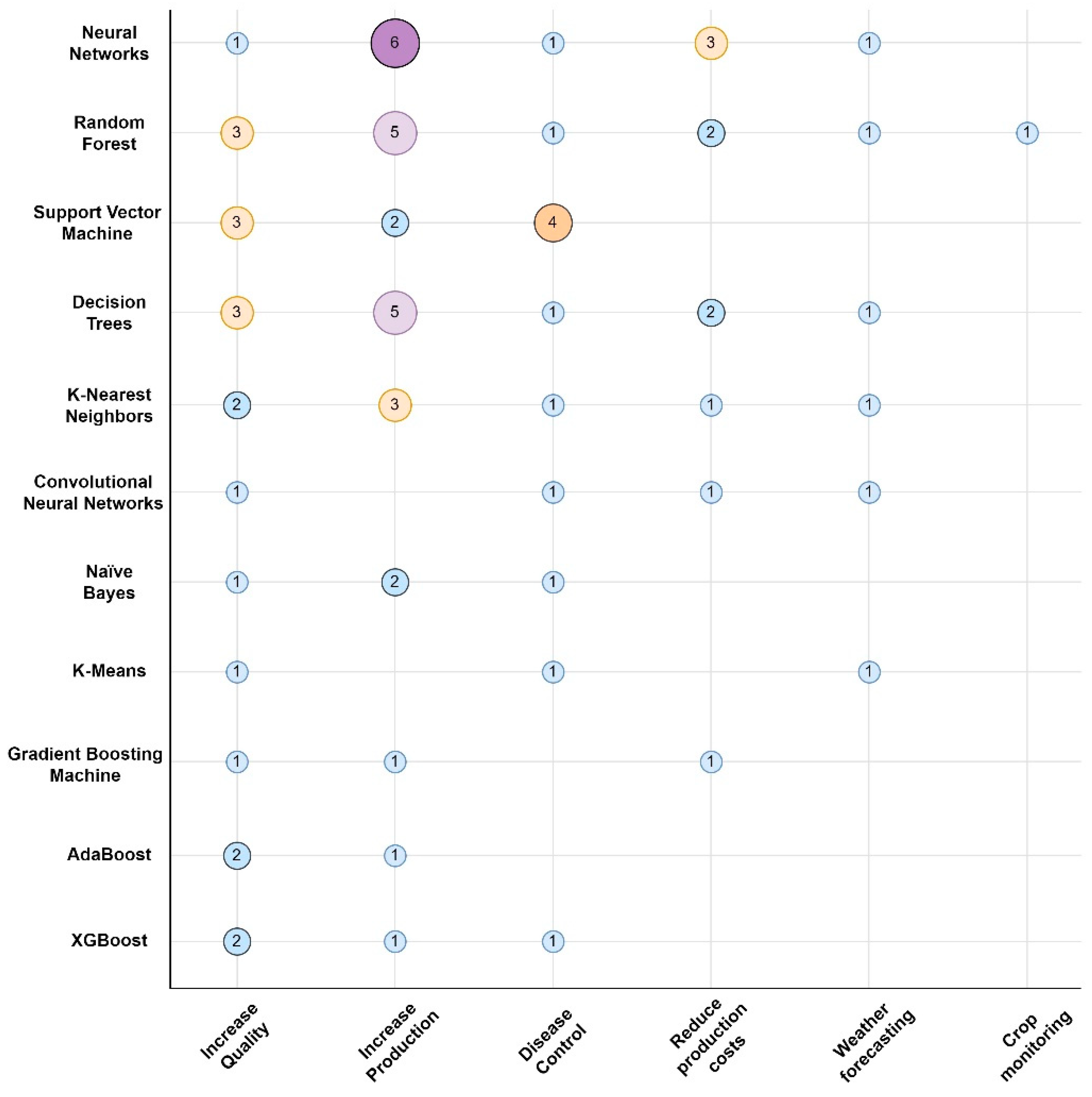
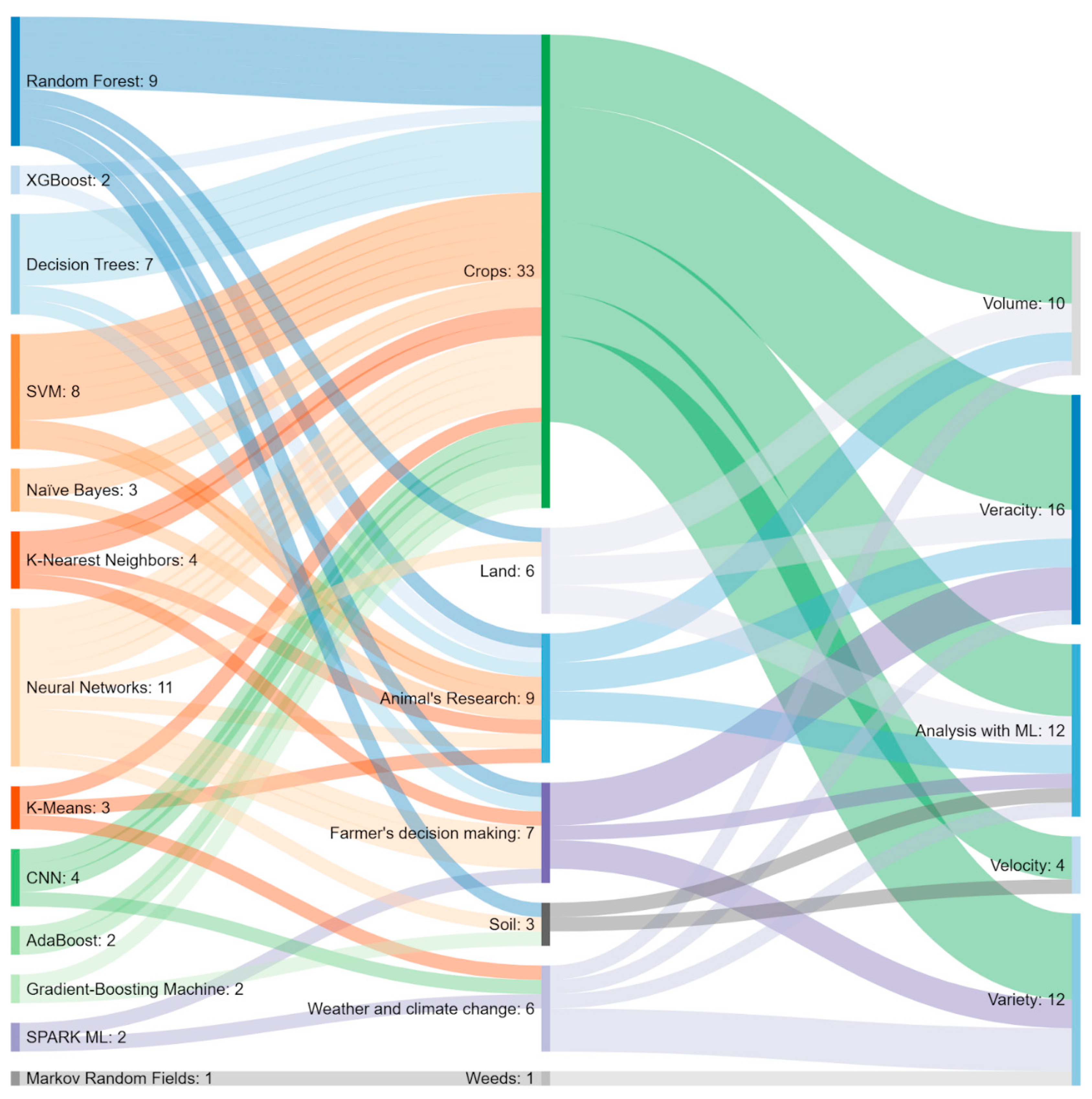
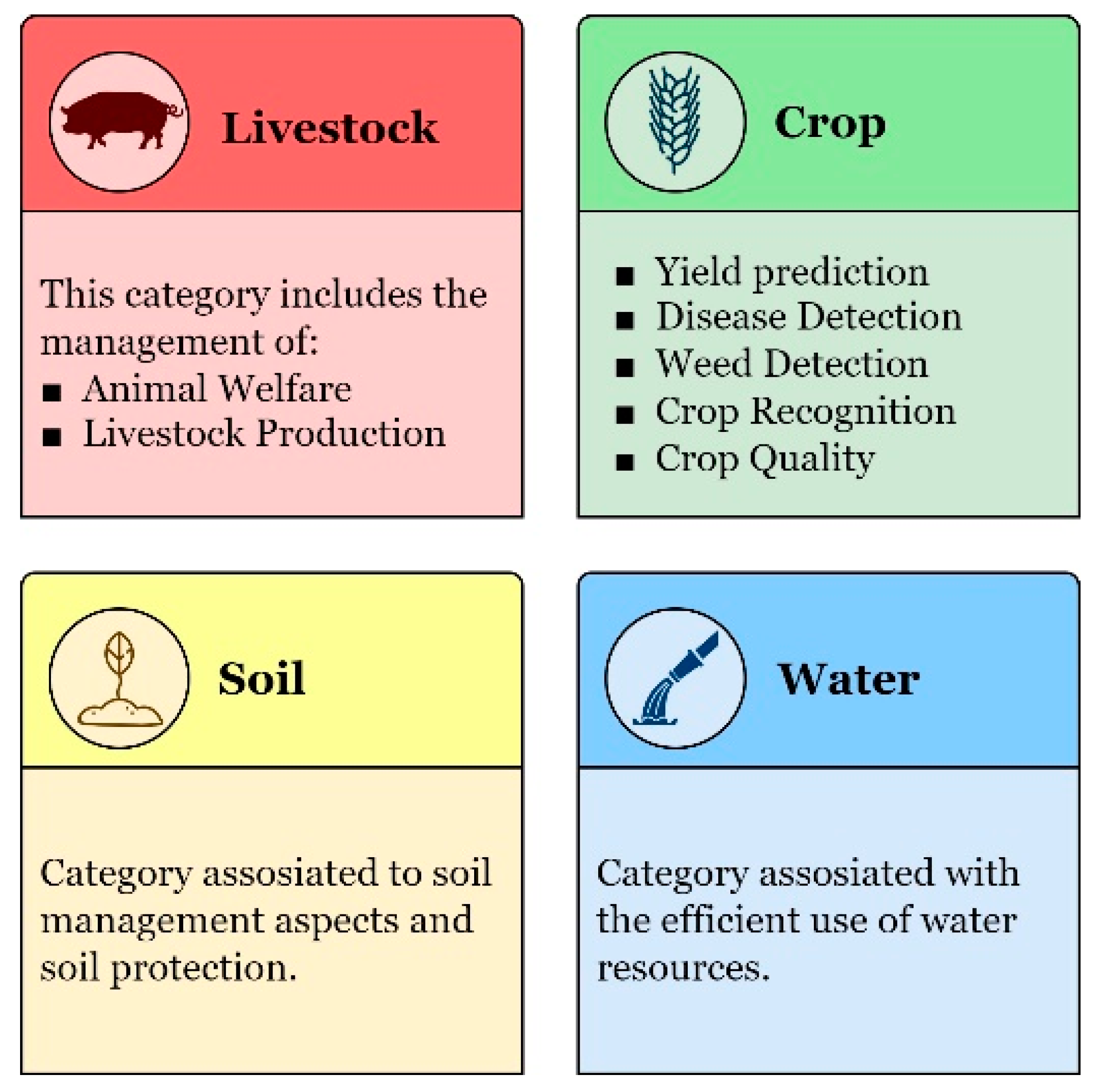
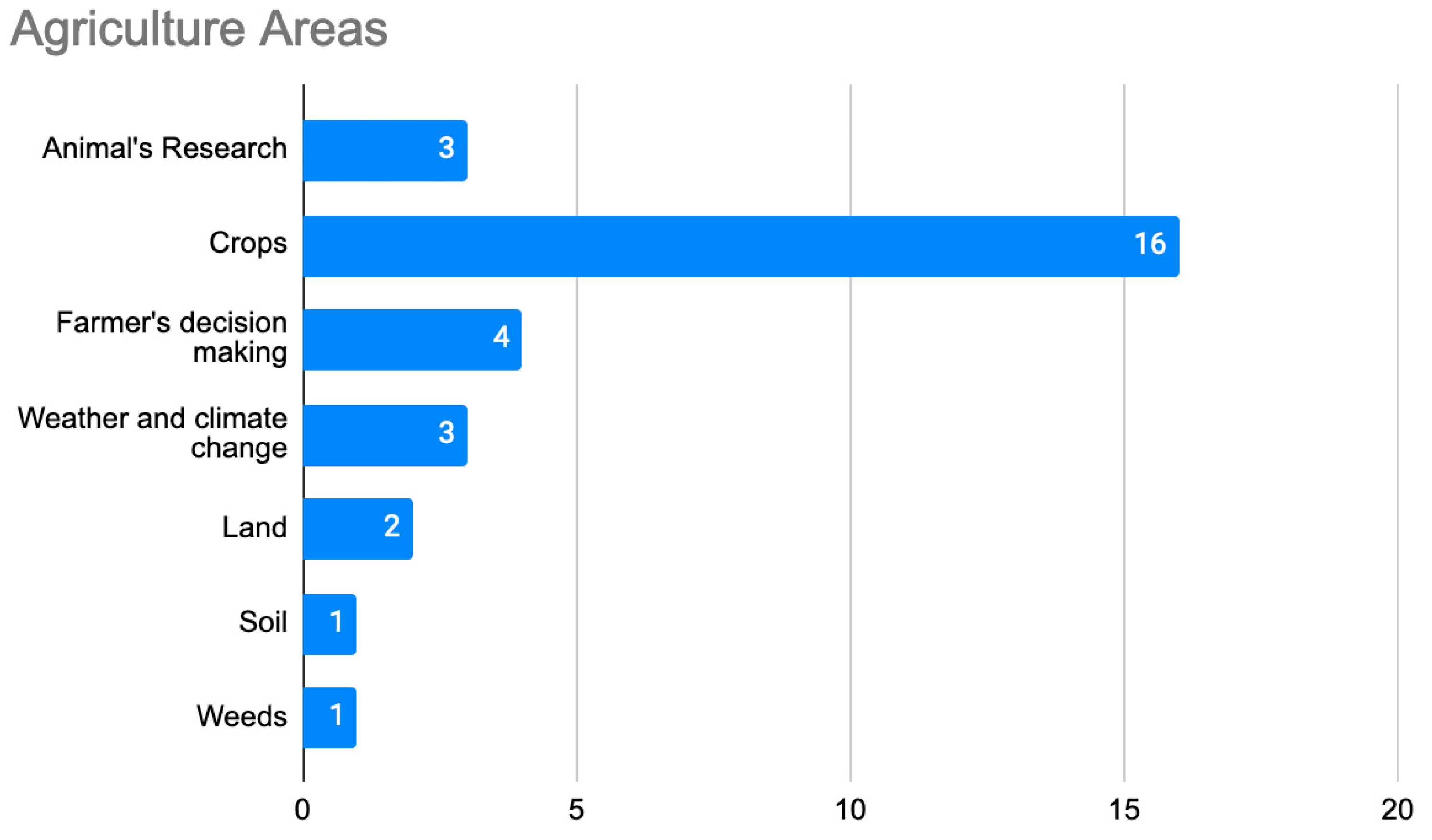
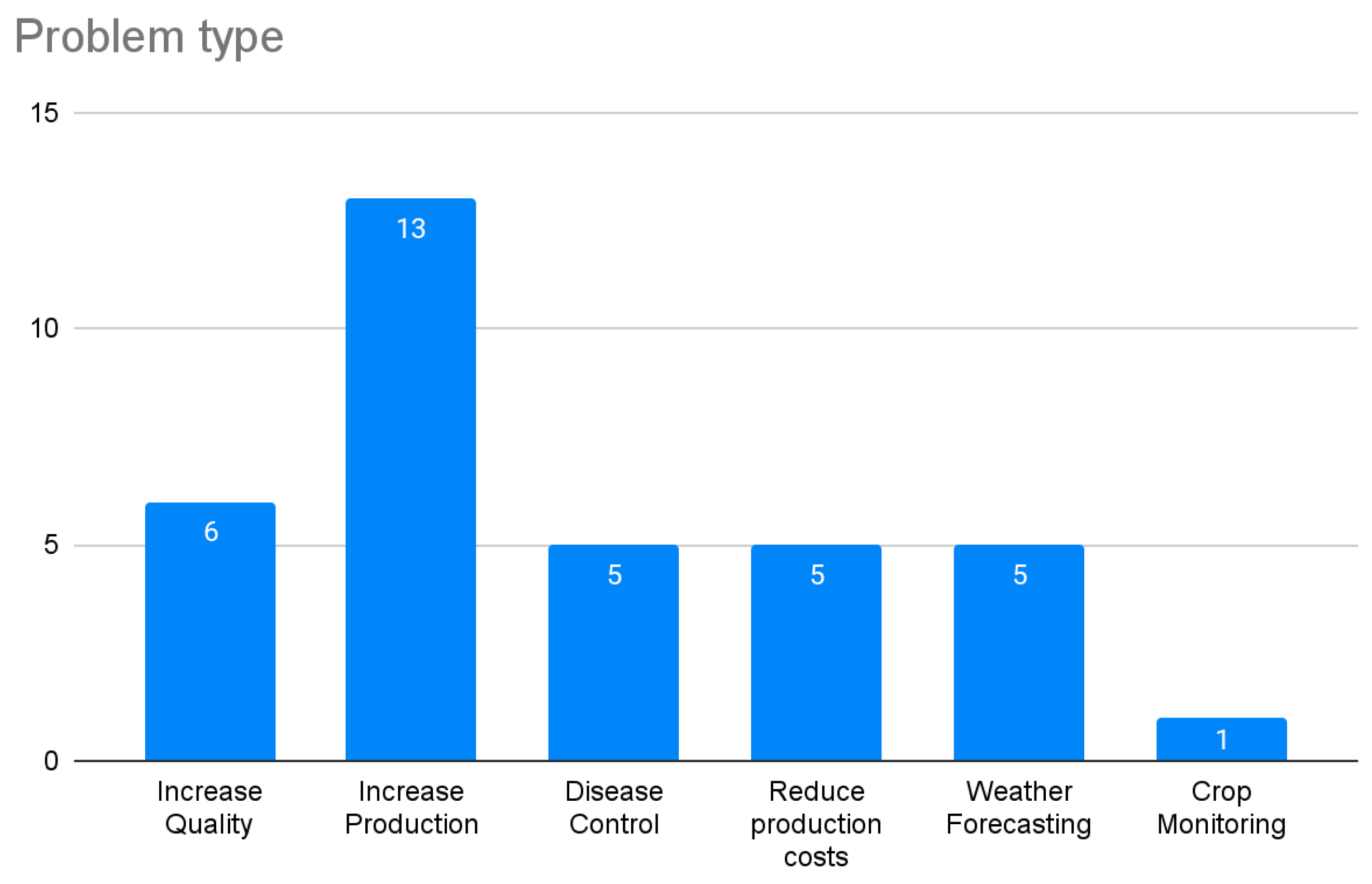
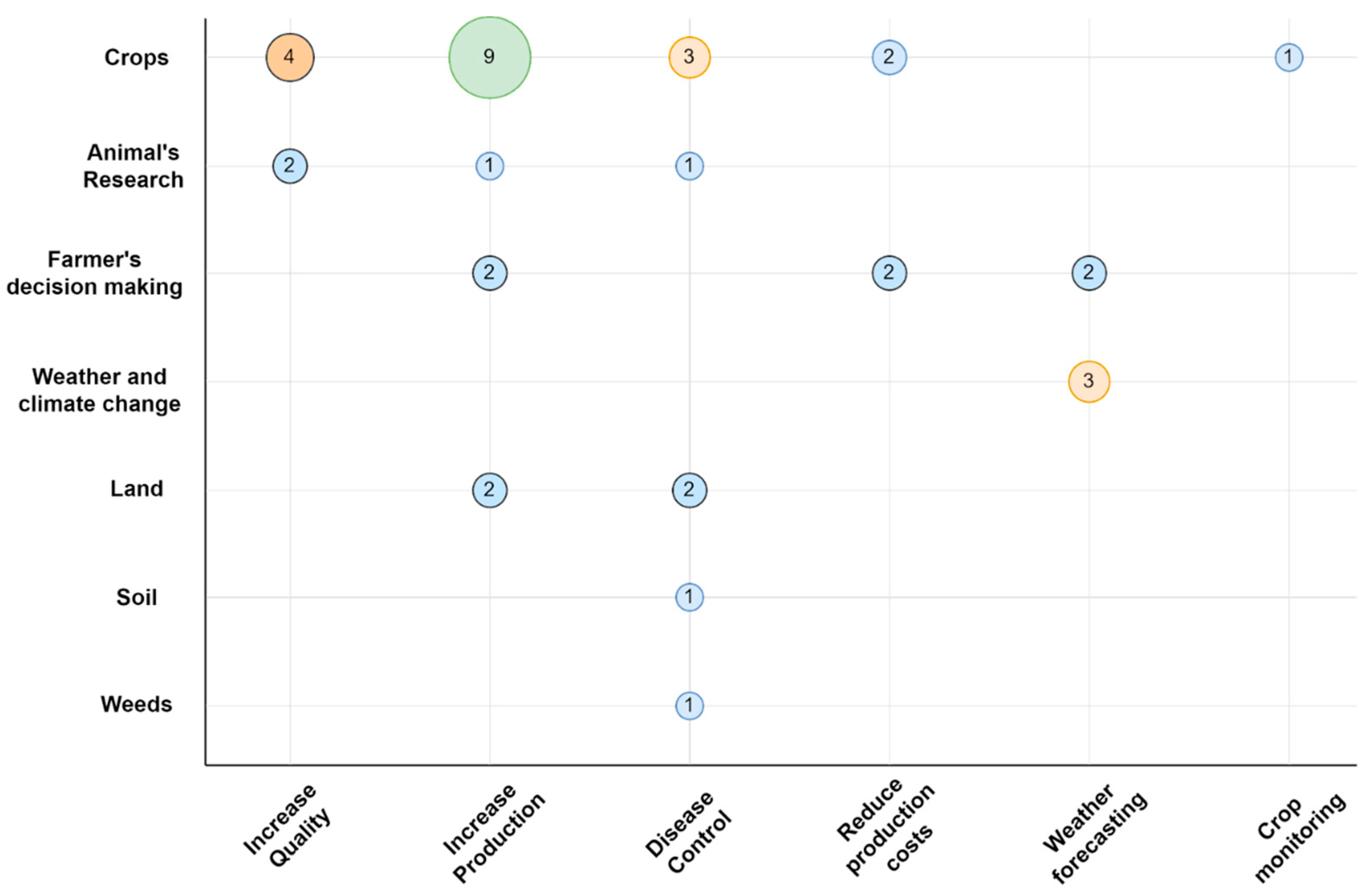
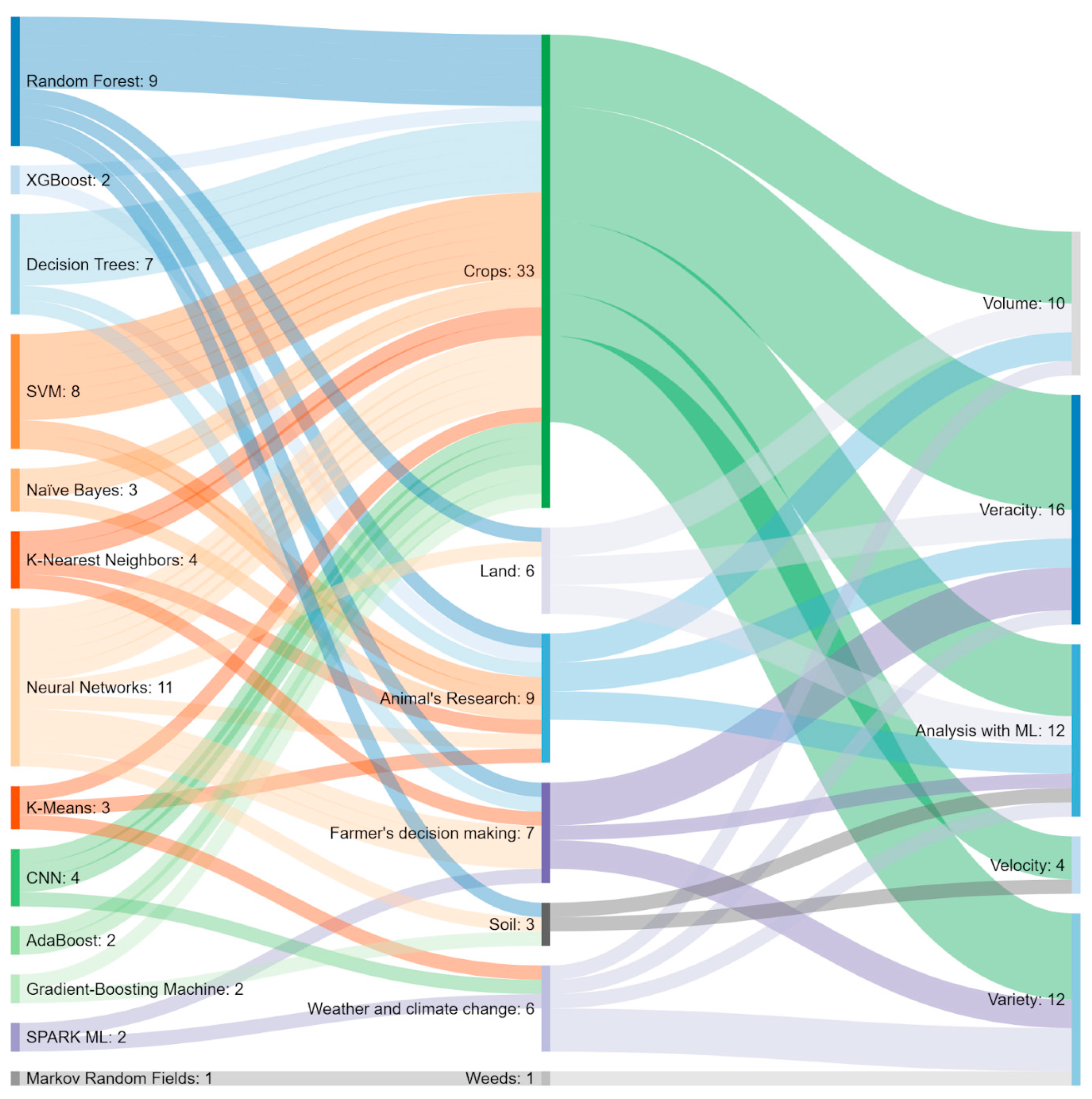
4.1. Solutions in Agricultural Big Data
4.1.1. Farmers’ Decision Making
4.1.2. Crops
4.1.3. Animal Research
4.1.4. Land
4.1.5. Weather and Climate Change
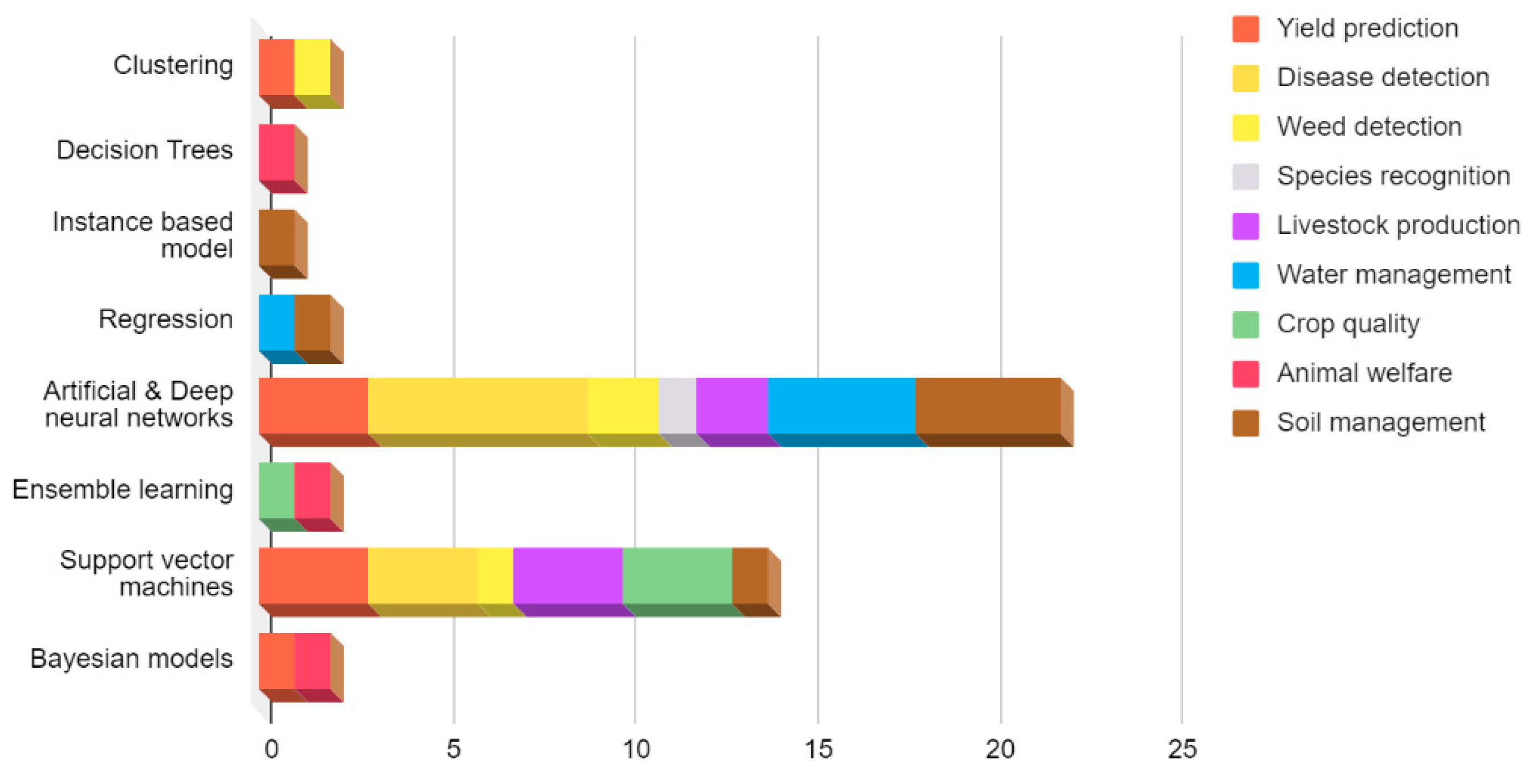
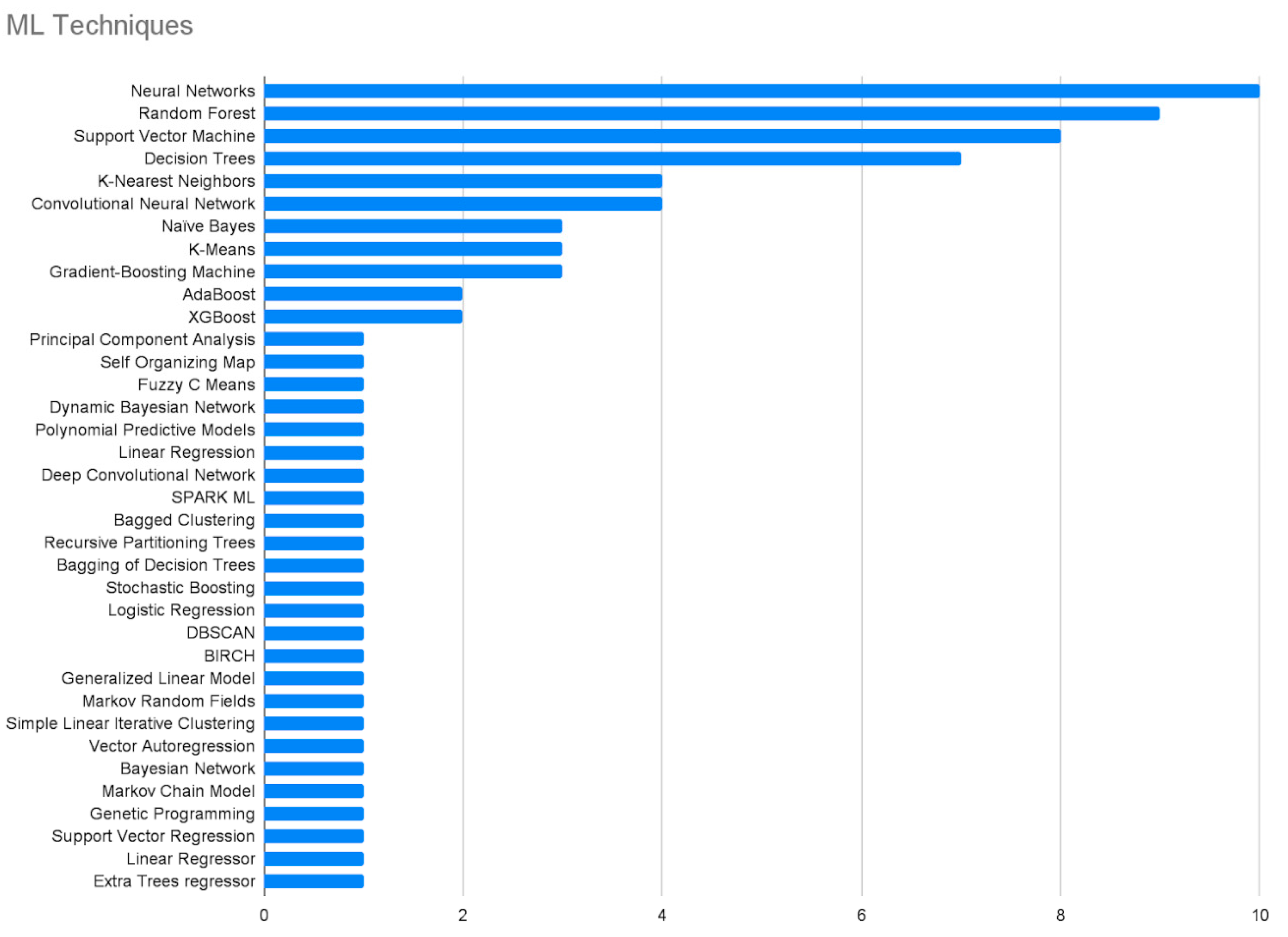
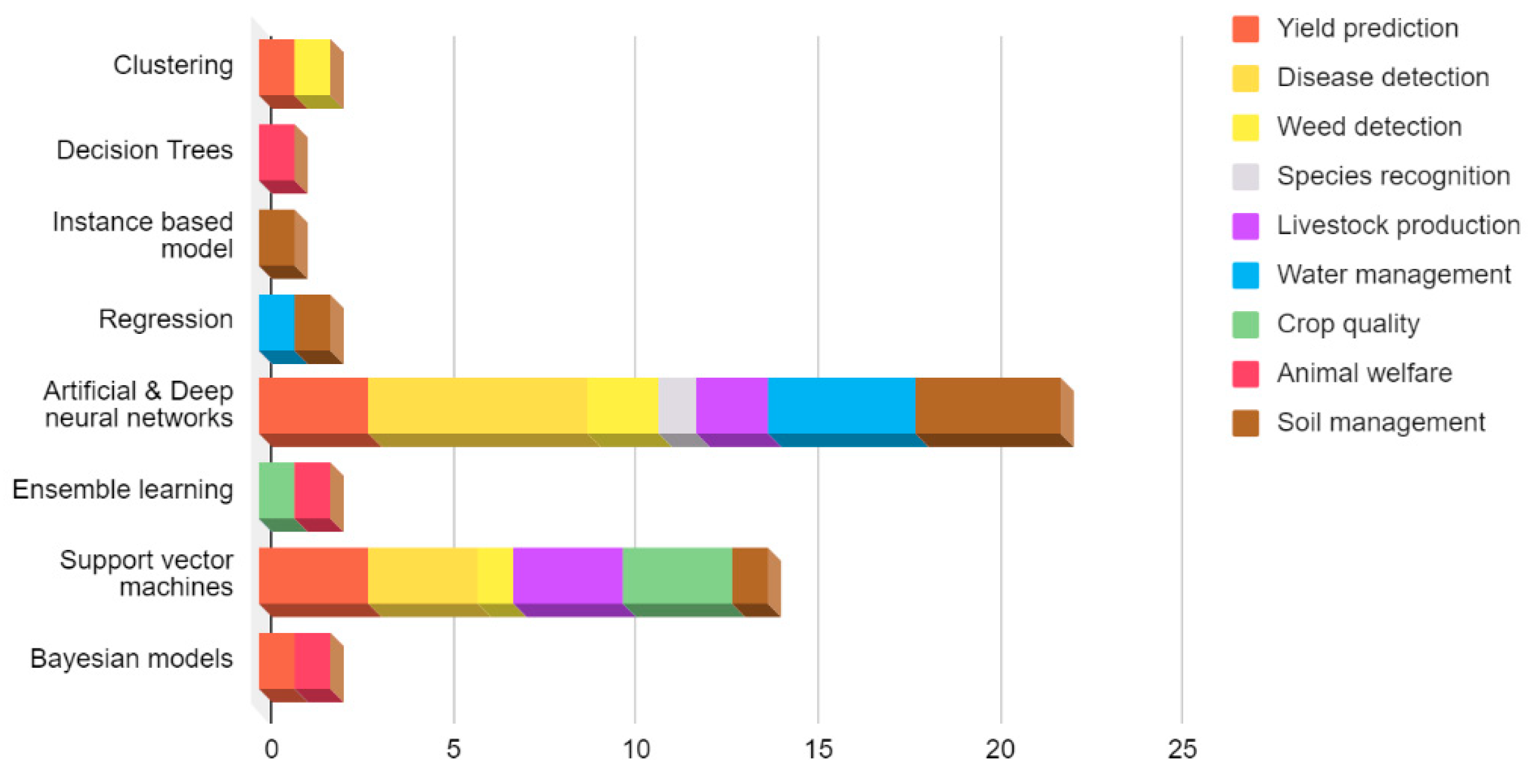
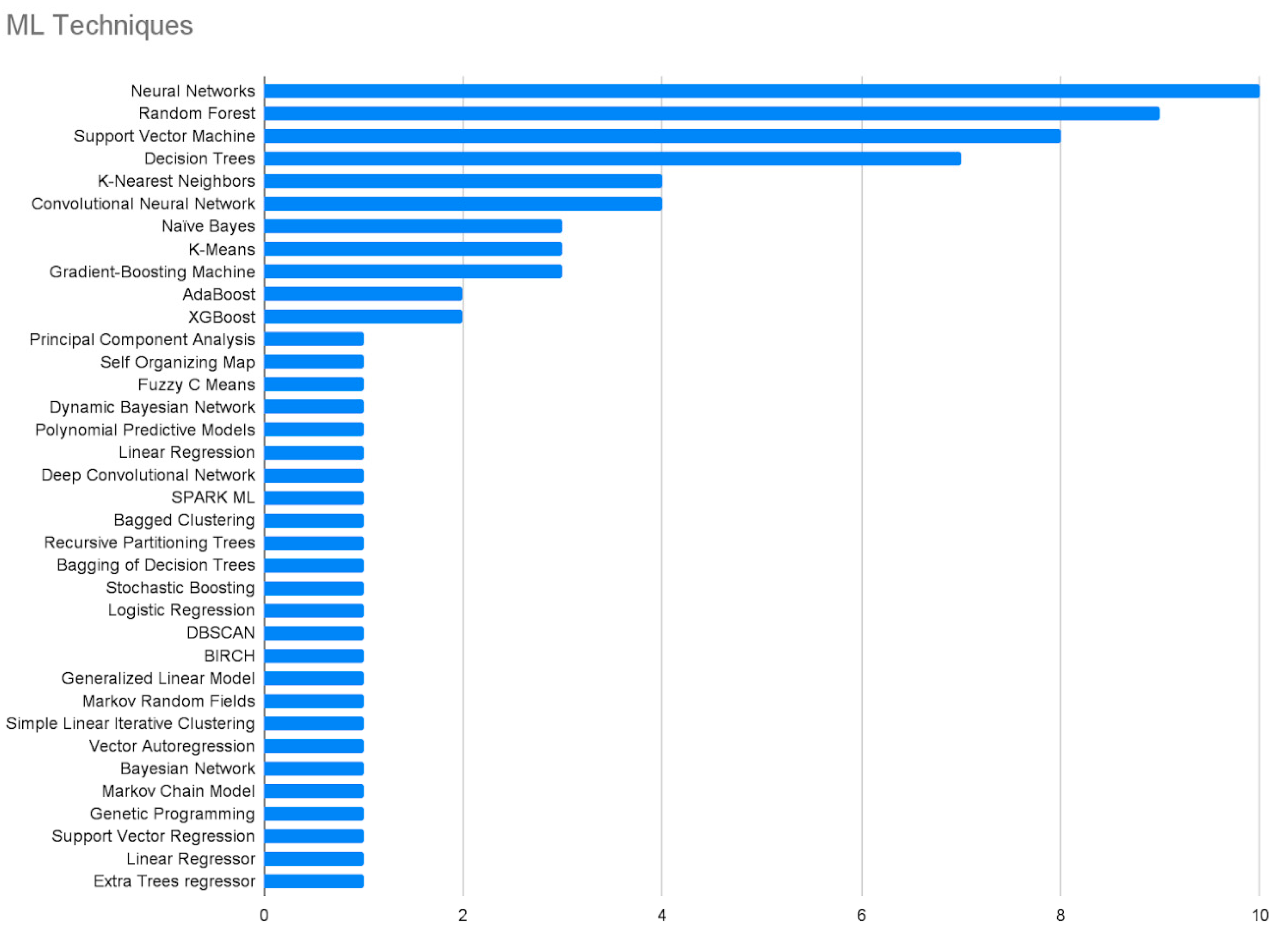
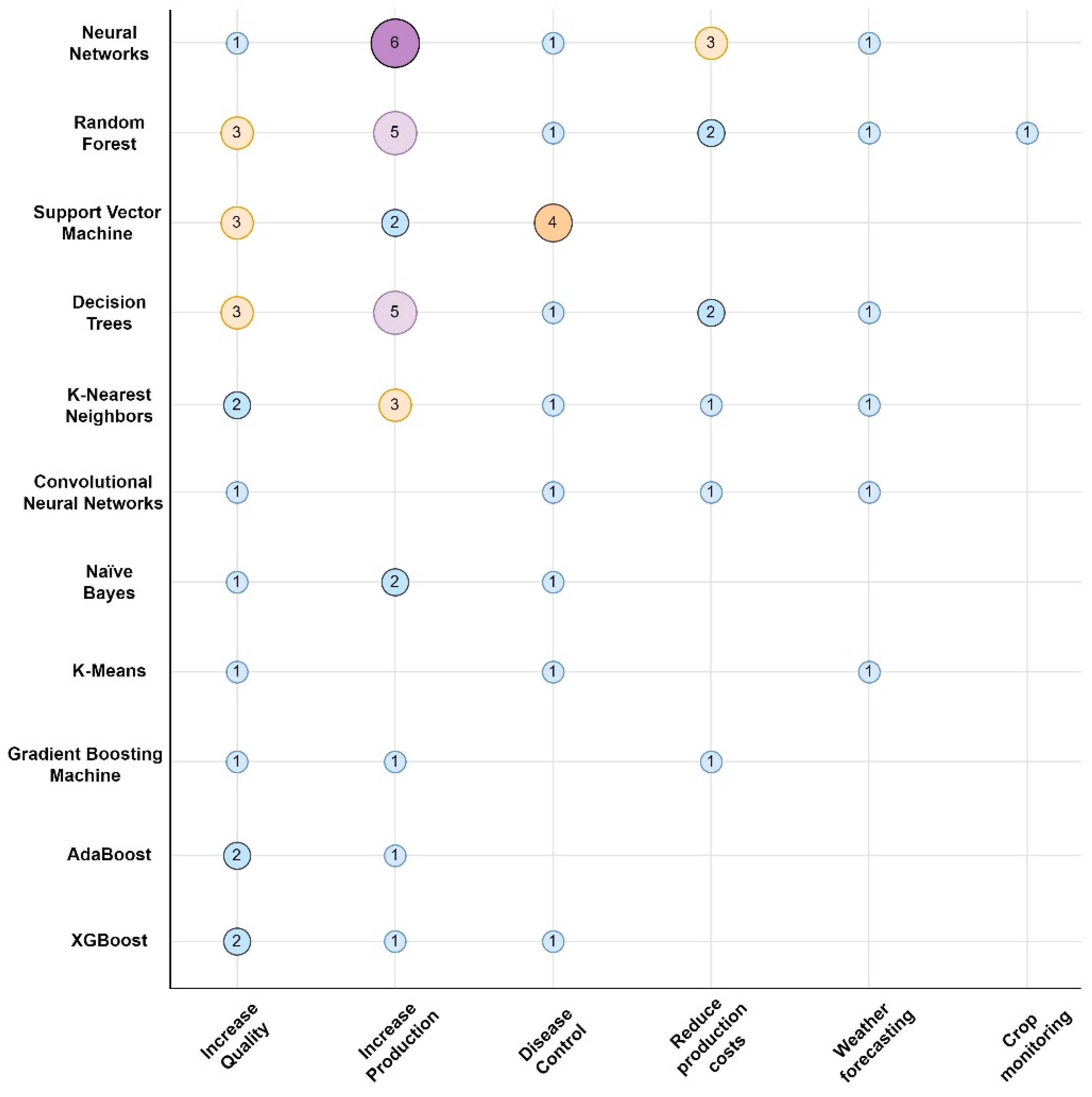
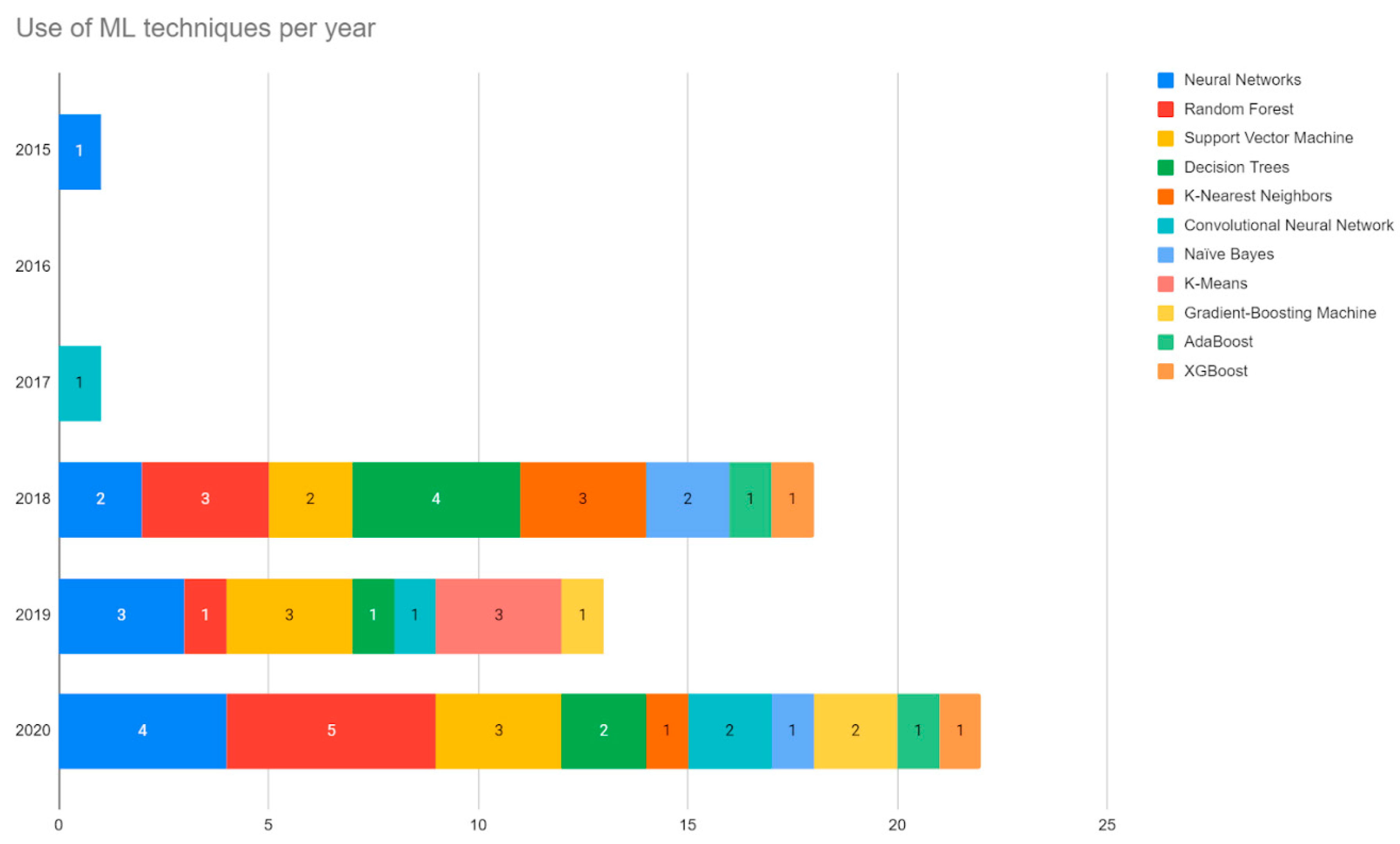
4.2. ML Techniques in Agricultural Big Data
4.2.1. Neural Networks
4.2.2. Random Forest
4.2.3. Support Vector Machine
4.2.4. Decision Tree
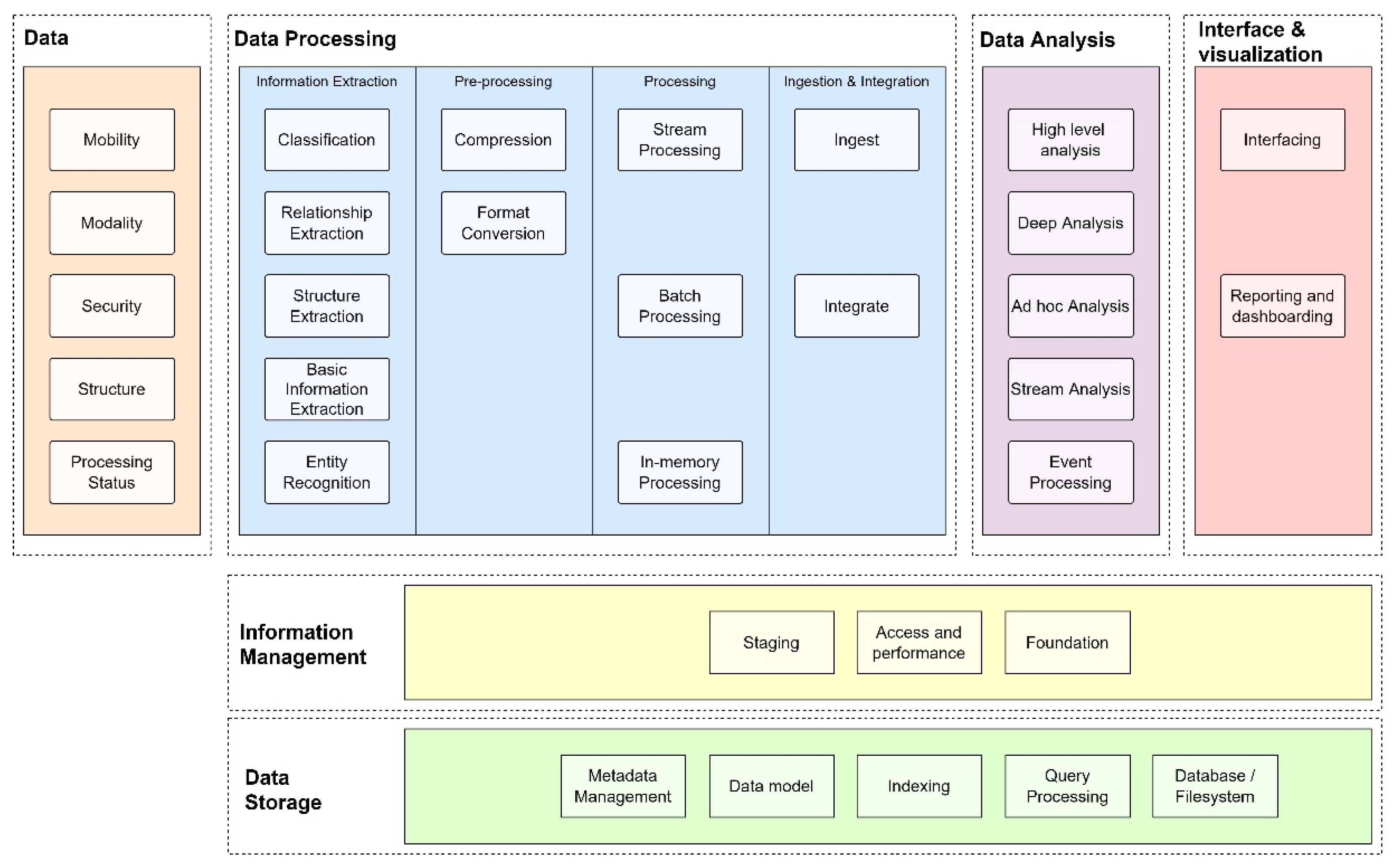
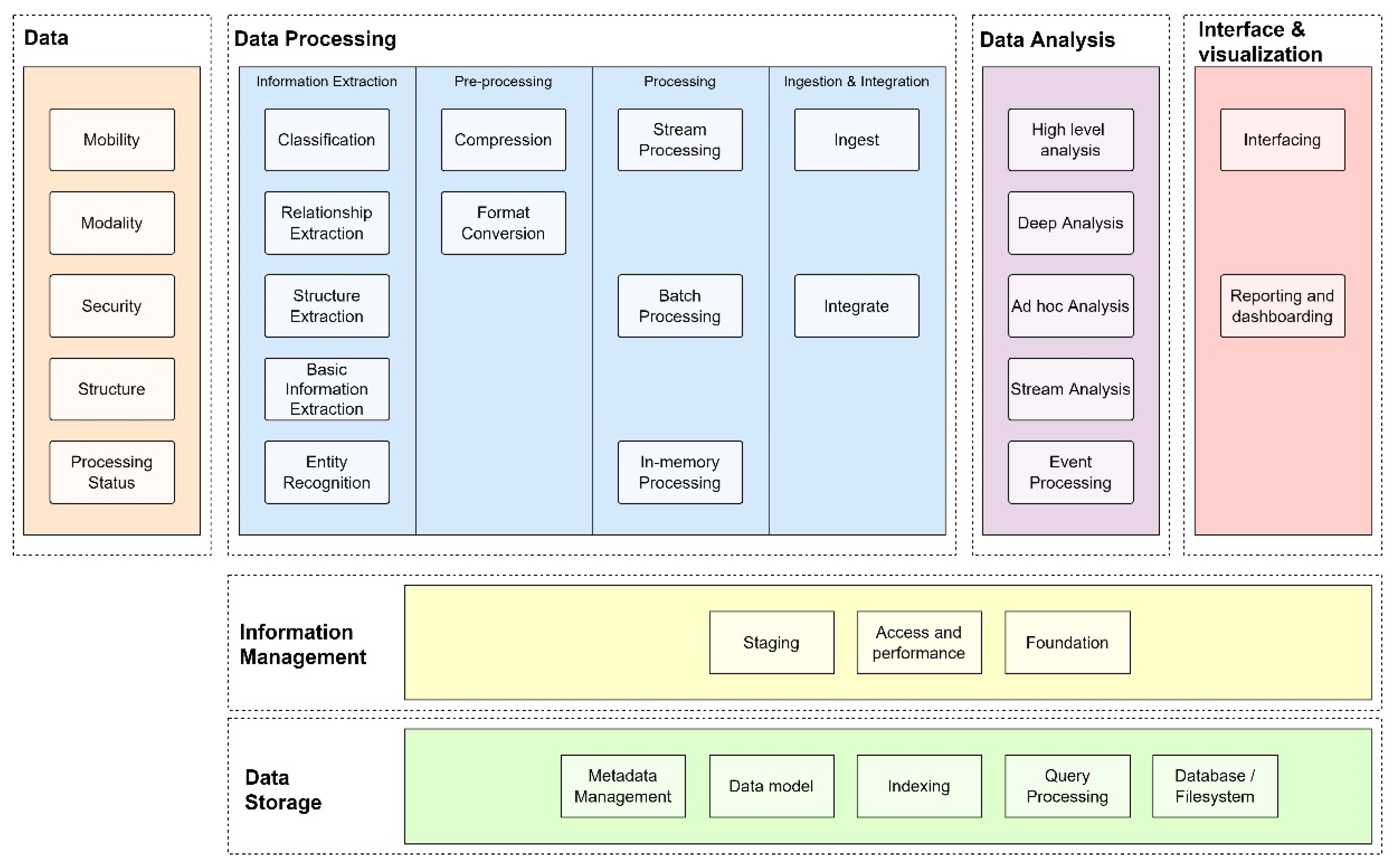
4.3. Agricultural Big Data Technologies
4.4. Challenges in the Use of ML in Agricultural Big Data
4.4.1. Volume
4.4.2. Variety
4.4.3. Velocity
4.4.4. Veracity
4.4.5. Analysis with ML
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Conflicts of Interest
References
- Hunter, M.C.; Smith, R.G.; Schipanski, M.E.; Atwood, L.W.; Mortensen, D.A. Agriculture in 2050: Recalibrating Targets for Sustainable Intensification. Bioscience 2017, 67, 386–391. [Google Scholar] [CrossRef] [Green Version]
- White, E.L.; Thomasson, J.A.; Auvermann, B.; Kitchen, N.R.; Pierson, L.S.; Porter, D.; Baillie, C.; Hamann, H.; Hoogenboom, G.; Janzen, T.; et al. Report from the conference, ‘identifying obstacles to applying Big Data in agriculture’. Precis. Agric. 2021, 22, 306–315. [Google Scholar] [CrossRef]
- Bhat, S.A.; Huang, N.F. Big Data and AI Revolution in Precision Agriculture: Survey and Challenges. IEEE Access 2021, 9, 110209–110222. [Google Scholar] [CrossRef]
- Maya-Gopal, P.S.; Chintala, B.R. Others Big Data challenges and opportunities in agriculture. Int. J. Agric. Environ. Inf. Syst. 2020, 11, 48–66. [Google Scholar] [CrossRef]
- Torky, M.; Hassanein, A.E. Integrating blockchain and the internet of things in precision agriculture: Analysis, opportunities, and challenges. Comput. Electron. Agric. 2020, 178, 105476. [Google Scholar] [CrossRef]
- Hongyan, L.; Ziyi, C.; Haitong, W. Research of Agricultural Big Data. E3S Web. Conf. 2020, 214, 1011. [Google Scholar]
- Lassoued, R.; Macall, D.M.; Smyth, S.J.; Phillips, P.W.B.; Hesseln, H. Expert Insights on the Impacts of, and Potential for, Agricultural Big Data. Sustainability 2021, 13, 2521. [Google Scholar] [CrossRef]
- Tibbetts, J.H. The Frontiers of Artificial Intelligence. Bioscience 2018, 68, 5–10. [Google Scholar] [CrossRef]
- Liakos, K.; Busato, P.; Moshou, D.; Pearson, S.; Bochtis, D. Machine Learning in Agriculture: A Review. Sensors 2018, 18, 2674. [Google Scholar] [CrossRef] [Green Version]
- Cravero, A.; Sepúlveda, S. Use and Adaptations of Machine Learning in Big Data—Applications in Real Cases in Agriculture. Electronics 2021, 10, 552. [Google Scholar] [CrossRef]
- Bilali, H.E.; Allahyari, M.S. Transition towards sustainability in agriculture and food systems: Role of information and communication technologies. Inf. Process. Agric. 2018, 5, 456–464. [Google Scholar] [CrossRef]
- Moher, D.; Liberati, A.; Tetzlaff, J.; Altman, D.G.; Group, P. Preferred reporting items for systematic reviews and meta-analyses: The PRISMA statement. PLoS Med. 2009, 6, e1000097. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Cherkassky, V.; Mulier, F. Learning from Data: Concepts, Theory, and Methods; John Wiley & Sons: Hoboken, NJ, USA, 2007. [Google Scholar]
- Rudin, C.; Wagstaff, K. Machine learning for science and society. Mach. Learn. 2014, 95, 1–9. [Google Scholar] [CrossRef] [Green Version]
- Qiu, J.; Wu, Q.; Ding, G.; Xu, Y.; Feng, S. A survey of machine learning for Big Data processing. EURASIP J. Adv. Signal Process. 2016, 1, 1–16. [Google Scholar]
- Benos, L.; Tagarakis, A.C.; Dolias, G.; Berruto, R.; Kateris, D.; Bochtis, D. Machine Learning in Agriculture: A Comprehensive Updated Review. Sensors 2021, 21, 3758. [Google Scholar] [CrossRef]
- Fatih, B.A.L.; Kayaalp, F. Review of machine learning and deep learning models in agriculture. Int. Adv. Res. Eng. J. 2021, 5, 309–323. [Google Scholar]
- Santos, M.; e Sá, J.; Costa, C.; Galváo, J.; Andrade, C.; Martinho, B.; Lima, F.; Costa, E. A Big Data analytics architecture for industry 4.0. In World Conference on Information Systems and Technologies; Springer: Berlin/Heidelberg, Germany, 2017; pp. 175–184. [Google Scholar]
- Sassi, I.; Ouaftouh, S.; Anter, S. Adaptation of Classical Machine Learning Algorithms to Big Data Context: Problems and Challenges. In Proceedings of the 2019 1st International Conference on Smart Systems and Data Science (ICSSD), Rabat, Morocco, 3–4 October 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 1–7. [Google Scholar]
- Gupta, D.; Rani, R. A study of Big Data evolution and research challenges. J. Inf. Sci. 2019, 45, 322–340. [Google Scholar] [CrossRef]
- Elshawi, R.; Sakr, S.; Talia, D.; Trunfio, P. Big Data Systems Meet Machine Learning Challenges: Towards Big Data Science as a Service. Big Data Res. 2018, 14, 1–11. [Google Scholar] [CrossRef] [Green Version]
- Haig, B.D. Big Data Science: A Philosophy of Science Perspective; American Psychological Association: Washington, DC, USA, 2020. [Google Scholar]
- De Mauro, A.; Greco, M.; Grimaldi, M. A formal definition of Big Data based on its essential features. Libr. Rev. 2016, 65, 122–135. [Google Scholar] [CrossRef]
- Demchenko, Y.; De-Laat, C.; Membrey, P. Defining architecture components of the Big Data Ecosystem. Collab. Technol. Syst. Int. Conf. 2014, 104–112. [Google Scholar]
- Salma, C.A.; Tekinerdogan, B.; Athanasiadis, I.N. Chapter 4—Domain-Driven Design of Big Data Systems Based on a Reference Architecture. In Software Architecture for Big Data and the Cloud; Morgan Kaufmann: Burlington, MA, USA, 2017; pp. 49–68. [Google Scholar]
- Sowmya, R.; Suneetha, K. Data mining with Big Data. IEEE Trans. Knowl. Data Eng. 2017, 26, 246–250. [Google Scholar]
- Song, I.-Y.; Zhu, Y. Big Data and data science: What should we teach? Expert Syst. Wiley Online Libr. 2016, 33, 364–373. [Google Scholar] [CrossRef]
- Sarker, M.N.I.; Islam, M.S.; Ali, M.A.; Islam, M.S.; Salam, M.A.; Mahmud, S.H. Promoting digital agriculture through Big Data for sustainable farm management. Int. J. Innov. Appl. Stud. 2019, 25, 1235–1240. [Google Scholar]
- Kamilaris, A.; Kartakoullis, A.; Prenafeta-Boldú, F. A review on the practice of Big Data analysis in agriculture. Comput. Electron. Agric. 2017, 143, 23–37. [Google Scholar] [CrossRef]
- Wolfert, S.; Ge, L.; Verdouw, C.; Bogaardt, M.-J. Big Data in smart farming—A review. Agric. Syst. 2017, 153, 69–80. [Google Scholar] [CrossRef]
- Weersink, A.; Fraser, E.; Pannell, D.; Duncan, E.; Rotz, S. Opportunities and Challenges for Big Data in Agricultural and Environmental Analysis. Annu. Rev. Resour. Econ. 2018, 10, 19–37. [Google Scholar] [CrossRef]
- Coble, K.H.; Mishra, A.K.; Ferrell, S.; Griffin, T. Big Data in agriculture: A challenge for the future. Appl. Econ. Perspect. Policy 2018, 40, 79–96. [Google Scholar] [CrossRef] [Green Version]
- Misra, N.N.; Dixit, Y.; Al-Mallahi, A.; Bhullar, M.S.; Upadhyay, R.; Martynenko, A. IoT, Big Data and artificial intelligence in agriculture and food industry. IEEE Internet Things J. 2020, 1, 99. [Google Scholar] [CrossRef]
- Kitchenham, B.; Charters, S. Guidelines for Performing Systematic Literature Reviews in Software Engineering. Rep. EBSE´07. 2007. Available online: https://www.elsevier.com/__data/promis_misc/525444systematicreviewsguide.pdf (accessed on 1 February 2022).
- Petticrew, M.; Roberts, H. Systematic Reviews in the Social Sciences: A Practical Guide; John Wiley & Sons: Hoboken, NJ, USA, 2008. [Google Scholar]
- Dutta, R.; Li, C.; Smith, D.; Das, A.; Aryal, J. Big Data Architecture for Environmental Analytics. In International Symposium on Environmental Software Systems; Springer: Berlin/Heidelberg, Germany, 2015; pp. 578–588. [Google Scholar]
- Doshi, Z.; Nadkarni, S.; Agrawal, R.; Shah, N. AgroConsultant: Intelligent Crop Recommendation System Using Machine Learning Algorithms. In Proceedings of the 2018 Fourth International Conference on Computing Communication Control and Automation (ICCUBEA), Pune, India, 16–18 August 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 1–6. [Google Scholar]
- Rehman, A.; Liu, J.; Keqiu, L.; Mateen, A.; Yasin, M.Q. Machine learning prediction analysis using IoT for smart farming. Int. J. Emerg. Trends Eng. Res. 2020, 8, 6482–6487. [Google Scholar]
- Hajji, O.J.T. Mohammed Big Data Analytics and Artificial Intelligence Serving Agriculture. In Advanced Intelligent Systems for Sustainable Development (AI2SD’2019); Ezziyyani, M., Ed.; Springer International Publishing: Berlin/Heidelberg, Germany, 2020; pp. 57–65. [Google Scholar]
- Balducci, F.; Impedovo, D.; Pirlo, G. Machine learning applications on agricultural datasets for smart farm enhancement. Machines 2018, 6, 38. [Google Scholar] [CrossRef] [Green Version]
- Choudhary, N.K.; Chukkapalli, S.S.L.; Mittal, S.; Gupta, M.; Abdelsalam, M.; Joshi, A. YieldPredict: A Crop Yield Prediction Framework for Smart Farms. In Proceedings of the 2020 IEEE International Conference on Big Data (Big Data), Atlanta, GA, USA, 10–13 December 2020; pp. 2340–2349. [Google Scholar]
- Gnanasankaran, N.; Ramaraj, E. The effective yield of paddy crop in Sivaganga district—An initiative for smart farming. Int. J. Sci. Technol. Res. 2020, 9, 6452–6455. [Google Scholar]
- Priya, R.; Ramesh, D.; Khosla, E. Crop Prediction on the Region Belts of India: A Naïve Bayes MapReduce Precision Agricultural Model. In Proceedings of the 2018 International Conference on Advances in Computing, Communications and Informatics (ICACCI), Bangalore, India, 19–22 September 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 99–104. [Google Scholar]
- Priya, R.; Ramesh, D. ML based sustainable precision agriculture: A future generation perspective. Sustain. Comput. Inform. Syst. 2020, 28, 100439. [Google Scholar] [CrossRef]
- Donzia, S.K.Y.; Kim, H. Architecture Design of a Smart Farm System Based on Big Data Appliance Machine Learning. In Proceedings of the 2020 20th International Conference on Computational Science and Its Applications (ICCSA), Cagliari, Italy, 1–4 July 2020; pp. 45–52. [Google Scholar]
- Shelestov, A.; Lavreniuk, M.; Vasiliev, V.; Shumilo, L.; Kolotii, A.; Yailymov, B.; Kussul, N.; Yailymova, H. Cloud Approach to Automated Crop Classification Using Sentinel-1 Imagery. IEEE Trans. Big Data 2020, 6, 572–582. [Google Scholar] [CrossRef]
- Yahata, S.; Onishi, T.; Yamaguchi, K.; Ozawa, S.; Kitazono, J.; Ohkawa, T.; Yoshida, T.; Murakami, N.; Tsuji, H. A hybrid machine learning approach to automatic plant phenotyping for smart agriculture. In Proceedings of the 2017 International Joint Conference on Neural Networks (IJCNN), Anchorage, AK, USA, 14–19 May 2017; pp. 1787–1793. [Google Scholar]
- Fenu, G.; Malloci, F.M. An Application of Machine Learning Technique in Forecasting Crop Disease. In Proceedings of the 2019 the 3rd International Conference on Big Data Research, Paris, France, 20–22 November 2019. [Google Scholar]
- Tombe, R. Computer Vision for Smart Farming and Sustainable Agriculture. In Proceedings of the 2020 IST-Africa Conference (IST-Africa), Kampala, Uganda, 18–22 May 2020; IEEE: Piscataway, NJ, USA, 2020. [Google Scholar]
- Nóbrega, L.; Tavares, A.; Cardoso, A.; Gonzalves, P. Animal monitoring based on IoT technologies. In Proceedings of the 2018 IoT Vertical and Topical Summit on Agriculture—Tuscany (IOT Tuscany), Tuscany, Italy, 8–9 May 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 1–5. [Google Scholar]
- Abbona, F.; Vanneschi, L.; Bona, M.; Giacobini, M. Towards modelling beef cattle management with Genetic Programming. Livest. Sci. 2020, 241, 104205. [Google Scholar] [CrossRef]
- Amani, M.; Kakooei, M.; Moghimi, A.; Ghorbanian, A.; Ranjgar, B.; Mahdavi, S.; Davidson, A.; Fisette, T.; Rollin, P.; Brisco, B.; et al. Application of Google Earth Engine Cloud Computing Platform, Sentinel Imagery, and Neural Networks for Crop Mapping in Canada. Remote Sens. 2020, 12, 3561. [Google Scholar] [CrossRef]
- Sathiaraj, D.; Huang, X.; Chen, J. Predicting climate types for the Continental United States using unsupervised clustering techniques. Environmetrics 2019, 30, e2524. [Google Scholar] [CrossRef]
- Amaechi, E.S.; Pham, H. Van Enhancement of Convolutional Neural Networks Classifier Performance in the Classification of IoT Big Data. In Proceedings of the 4th International Conference on Machine Learning and Soft Computing, Haiphong, Vietnam, 17–19 January 2020; Association for Computing Machinery: Haiphong, Vietnam, 2020; pp. 25–29. [Google Scholar]
- Saggi, M.K.; Jain, S. Reference evapotranspiration estimation and modeling of the Punjab Northern India using deep learning. Comput. Electron. Agric. 2019, 156, 387–398. [Google Scholar] [CrossRef]
- Ip, R.H.; Ang, L.M.; Seng, K.P.; Broster, J.C.; Pratley, J.E. Big Data and machine learning for crop protection. Comput. Electron. Agric. 2018, 151, 376–383. [Google Scholar] [CrossRef]
- Sitokonstantinou, V.; Drivas, T.; Koukos, A.; Papoutsis, I.; Kontoes, C. Scalable Distributed Random Forest Classification for Paddy Rice Mapping. 2020. Available online: https://zenodo.org/record/3662151 (accessed on 1 February 2022).
- Aiken, V.C.F.; Dórea, J.R.R.; Acedo, J.S.; de Sousa, F.G.; Dias, F.G.; de Magalhães Rosa, G.J. Record linkage for farm-level data analytics: Comparison of deterministic, stochastic and machine learning methods. Comput. Electron. Agric. 2019, 163, 104857. [Google Scholar] [CrossRef]
- Gumma, M.K.; Thenkabail, P.; Teluguntla, P.; Oliphant, A.; Xiong, J.; Giri, C.; Pyla, V.; Dixit, S.; Whitbread, A. Agricultural cropland extent and areas of South Asia derived using Landsat satellite 30-m time-series big-data using random forest machine learning algorithms on the Google Earth Engine cloud. GISci. Remote Sens. 2020, 57, 302–322. [Google Scholar] [CrossRef] [Green Version]
- Yang, J.; Liu, M.; Lu, J.; Miao, Y.; Hossain, M.A.; Alhamid, M.F. Botanical internet of things: Toward smart indoor farming by connecting people, plant, data and clouds. Mob. Netw. Appl. 2018, 23, 188–202. [Google Scholar] [CrossRef]
- Vasumathi, M.T.; Kamarasan, M. Fruit disease prediction using machine learning over Big Data. Int. J. Recent Technol. Eng. 2019, 7, 556–559. [Google Scholar]
- Wang, X.; Yang, K.; Liu, T. The Implementation of a Practical Agricultural Big Data System. In Proceedings of the 2019 IEEE 5th International Conference on Computer and Communications (ICCC), Chengdu, China, 6–9 December 2019; pp. 1955–1959. [Google Scholar]
- Pandya, A.; Odunsi, O.; Liu, C.; Cuzzocrea, A.; Wang, J. Adaptive and Efficient Streaming Time Series Forecasting with Lambda Architecture and Spark. In Proceedings of the 2020 IEEE International Conference on Big Data (Big Data), Atlanta, GA, USA, 10–13 December 2020; pp. 5182–5190. [Google Scholar]
- Zhou, L.; Pan, S.; Wang, J.; Vasilakos, A. Machine learning on Big Data: Opportunities and challenges. Neurocomputing 2017, 237, 350–361. [Google Scholar] [CrossRef] [Green Version]
- Ochoa, K.S.; Guo, Z. A framework for the management of agricultural resources with automated aerial imagery detection. Comput. Electron. Agric. 2019, 162, 53–69. [Google Scholar] [CrossRef]
- Cui, X.; Gao, Z. A Standard Architecture of Agricultural Big Data for Deep Learning. In Proceedings of the 2020 IEEE International Conference on Advances in Electrical Engineering and Computer Applications (AEECA), Dalian, China, 25–27 August 2020; pp. 908–911. [Google Scholar]
- L’heureux, A.; Grolinger, K.; Elyamany, H.; Capretz, M. Machine learning with Big Data: Challenges and approaches. IEEE Access 2017, 5, 7776–7797. [Google Scholar] [CrossRef]
- del Río, S.; López, V.; Benítez, J.M.; Herrera, F. On the use of MapReduce for imbalanced Big Data using Random Forest. Inf. Sci. 2014, 285, 112–137. [Google Scholar] [CrossRef]
- Wibowo, M.; Sulaiman, S.; Shamsuddin, S.M. Machine Learning in Data Lake for Combining Data Silos. In Proceedings of the International Conference on Data Mining and Big Data, Fukuoka, Japan, 27 July–1 August 2017; Springer: Berlin/Heidelberg, Germany, 2017; pp. 294–306. [Google Scholar]
- LaPlante, A.; Sharma, B. Architecting Data Lakes Data Management Architectures for Advanced Business Use Cases; O’Reilly Media Inc.: Sevastopol, CA, USA, 2016. [Google Scholar]
- Khine, P.P.; Wang, Z.S. Data lake: A new ideology in Big Data era. In Proceedings of the InITM Web of Conferences 2018, Wuhan, China, 15–17 December 2017; EDP Science: Ulys, France, 2018; Volume 17, p. 03025. [Google Scholar] [CrossRef]
- Grolinger, K.; Hayes, M.; Higashino, W.A.; L’Heureux, A.; Allison, D.; Capretz, M. Challenges for MapReduce in Big Data. In Proceedings of the 2014 IEEE World Congress on Services, Anchorage, AK, USA, 27 June–2 July 2014; pp. 182–189. [Google Scholar]
- Loaiza, J.; Carmona, M.; Giuliani, G.; Fiameni, G. Big-Data in Climate Change Models—A Novel Approach with Hadoop MapReduce. In Proceedings of the 2017 International Conference on High Performance Computing & Simulation (HPCS), Genoa, Italy, 17–21 July 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 45–50. [Google Scholar]
- Yang, C.; Huang, Q.; Li, Z.; Liu, K.; Hu, F. Big Data and cloud computing: Innovation opportunities and challenges. Int. J. Digit. Earth 2017, 10, 13–53. [Google Scholar] [CrossRef] [Green Version]
- Sukumar, S.R. Machine Learning in the Big Data Era: Are We There Yet? In Proceedings of the ACM Knowledge Discovery and Data Mining: Workshop on Data Science for Social Good, New York, NY, USA, 24–17 August 2014. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Abbreviation | Meaning |
|---|---|
| DL | Deep learning |
| ANN | Artificial neural networks |
| SVM | Support vector machines |
| DT | Decision trees |
| NN | Neural networks |
| RF | Random forest |
| CNN | Convolutional neural networks |
| RNN | Recurrent neural networks |
| RBN | Restricted Boltzmann machine |
| DBN | Deep belief network |
| SNIC | Simple non-iterative clustering |
| SLIC | Simple linear iterative clustering |
| KC | K-means clustering |
| BC | Bagged clustering |
| RPT | Recursive partition trees |
| BDT | Booster decision trees |
| BCT | Bootstrap classification trees |
| SB | Stochastic boosting |
| LR | Logistic regression |
| AR | Autoregression |
| ARIMA | Autoregressive integrated moving average |
| VAR | Vector autoregression |
| KNN | K-nearest neighbors |
| GLM | Generalized linear model |
| GBM | Gradient-boosting machine |
| Abbreviation | Meaning |
|---|---|
| PRISMA | Preferred Reporting Items for Systematic Reviews and Meta-Analyses |
| IoT | Internet of things |
| ML | Machine learning |
| SLR | Systematic literature review |
| DL | Deep learning |
| AI | Artificial intelligence |
| UAV | Unmanned aerial vehicle |
| ICT | Information and communications technology |
| NDVI | Normalized difference vegetation index |
| ACM | Association for Computing Machinery |
| IEEE | Institute of Electrical and Electronics Engineers |
| MDPI | Multidisciplinary Digital Publishing Institute |
| WoS | Web of Science |
| BDM | Big Data application machine learning-based smart farm system |
| AAFC | Agriculture and Agri-Food Canada |
| ET0 | Reference evapotranspiration |
| MLC | Multi-label classification |
| RBF | Radial basis function |
| AUC | Area under curve |
| GEE | Google Earth Engine |
| GPS | Global Positioning System |
| HDFS | Hadoop Distributed File System |
| TCP | Transmission Control Protocol |
| NASA | National Aeronautics and Space Administration |
| ESA | European Space Agency |
| CSV | Comma-separated values |
| CPU | Central processing unit |
| GIS | Geographic information systems |
| Classification Type | Supervised Learning | Unsupervised Learning | Reinforcement Learning |
|---|---|---|---|
| Data processing tasks | Estimation Classification Regression | Clustering Prediction | Decision making |
| Learning algorithms | Support vector machine Bayesian networks Neural networks Naïve Bayes Hidden Markov model | Dirichlet process mixture model X-means K-means Gaussian mixture model | TD-learning Sarsa learning Q-learning R-learning |
| Authors | Volume | Variety | Velocity | Veracity | Analysis with ML |
|---|---|---|---|---|---|
| Dutta et al. [36] | x | x | |||
| Balducci et al. [40] | x | ||||
| Tombe [49] | x | x | |||
| Priya et al. [43] | x | ||||
| Doshi et al. [37] | x | ||||
| Shelestov et al. [46] | x | x | |||
| Nóbrega et al. [50] | x | ||||
| Amani et al. [52] | x | x | x | ||
| Rehman et al. [38] | x | x | |||
| Gumma et al. [59] | x | x | |||
| Gnanasankaran and Ramaraj [42] | |||||
| Tarik and Mohammed [39] | x | ||||
| Wang et al. [62] | x | x | x | x | x |
| Fenu and Malloci [48] | x | ||||
| Aiken et al. [58] | x | x | x | ||
| Ochoa and Guo [65] | x | x | x | ||
| Sathiaraj et al. [53] | x | ||||
| Vasumathi et al. [61] | x | x | x | ||
| Saggi et al. [55] | x | x | |||
| Ryan et al. [56] | x | ||||
| Yang et al. [60] | x | ||||
| Yahata et al. [47] | x | ||||
| Pandya et al. [63] | x | ||||
| Priya et al. [44] | x | ||||
| Abbona et al. [51] | x | x | |||
| Sitokonstantinou et al. [57] | x | x | x | ||
| Donzia and Kim [45] | x | ||||
| Choudhary et al. [41] | x | ||||
| Amaechi and Pham [54] | x | x | x | ||
| Cui and Gao [66] | x | x |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cravero, A.; Pardo, S.; Sepúlveda, S.; Muñoz, L. Challenges to Use Machine Learning in Agricultural Big Data: A Systematic Literature Review. Agronomy 2022, 12, 748. https://doi.org/10.3390/agronomy12030748
Cravero A, Pardo S, Sepúlveda S, Muñoz L. Challenges to Use Machine Learning in Agricultural Big Data: A Systematic Literature Review. Agronomy. 2022; 12(3):748. https://doi.org/10.3390/agronomy12030748
Chicago/Turabian StyleCravero, Ania, Sebastian Pardo, Samuel Sepúlveda, and Lilia Muñoz. 2022. "Challenges to Use Machine Learning in Agricultural Big Data: A Systematic Literature Review" Agronomy 12, no. 3: 748. https://doi.org/10.3390/agronomy12030748
APA StyleCravero, A., Pardo, S., Sepúlveda, S., & Muñoz, L. (2022). Challenges to Use Machine Learning in Agricultural Big Data: A Systematic Literature Review. Agronomy, 12(3), 748. https://doi.org/10.3390/agronomy12030748