
Transfer Learning with Convolutional Neural Networks for Cider Apple Varieties Classification

 , , and
, , and
Abstract
1. Introduction
2. Materials and Methods
2.1. Study Area
2.2. Apple Image Data
2.3. Convolutional Neural Networks: Architecture and Training
2.4. Transfer Learning
3. Results
3.1. Experiment A: Determining the Best Architectures for Transfer Learning
3.2. Experiment B: Refining Our Models
3.2.1. InceptionV3
3.2.2. MobileNetV2
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Dapena-Fuente, E.; Blázquez Nogueiro, M.D. Descripción De Las Variedades De Manzana De La D.O.P. Sidra De Asturias; Serida: Villaviciosa, Asturias, Spain, 2009; pp. 11–56. [Google Scholar]
- Bhargava, A.; Bansal, A. Fruits and Vegetables Quality Evaluation Using Computer Vision: A Review. J. King Saud Univ.Comput. Inf. Sci. 2021, 33, 243–257. [Google Scholar] [CrossRef]
- Hossain, M.S.; Al-Hammadi, M.; Muhammad, G. Automatic Fruit Classification Using Deep Learning for Industrial Applications. IEEE Trans. Ind. Informatics 2019, 15, 1027–1034. [Google Scholar] [CrossRef]
- Li, Y.; Feng, X.; Liu, Y.; Han, X. Apple Quality Identification and Classification by Image Processing Based on Convolutional Neural Networks. Sci. Rep. 2021, 11, 16618. [Google Scholar] [CrossRef] [PubMed]
- Zuñiga, E.N.; Gordillo, S.; Martínez, F.H. Approaches to Deep Learning-Based Apple Classification Scheme Selection. Int. J. Eng. Res. Technol. 2021, 14, 510–515. [Google Scholar]
- Shi, X.; Chai, X.; Yang, C.; Xia, X.; Sun, T. Vision-Based Apple Quality Grading with Multi-View Spatial Network. Comput. Electron. Agric. 2022, 195, 106793. [Google Scholar] [CrossRef]
- Alhawas, N.; Tüfekci, Z. The Effectiveness of Transfer Learning and Fine-Tuning Approach for Automated Mango Variety Classification. Eur. J. Sci. Technol. 2022, 34, 344–353. [Google Scholar] [CrossRef]
- Ghazi, M.; Yanikoglu, B.; Aptoula, E. Plant Identification Using Deep Neural Networks via Optimization of Transfer Learning Parameters. Neurocomputing 2017, 235, 228–235. [Google Scholar] [CrossRef]
- Joseph, J.L.; Kumar, V.A.; Mathew, S.P. Fruit Classification Using Deep Learning BT—Innovations in Electrical and Electronic Engineering; Mekhilef, S., Favorskaya, M., Pandey, R.K., Shaw, R.N., Eds.; Springer: Singapore, 2021; pp. 807–817. [Google Scholar]
- Apolo-Apolo, O.E.; Martínez-Guanter, J.; Egea, G.; Raja, P.; Pérez-Ruiz, M. Deep Learning Techniques for Estimation of the Yield and Size of Citrus Fruits Using a UAV. Eur. J. Agron. 2020, 115, 126030. [Google Scholar] [CrossRef]
- Yu, J.; Sharpe, S.M.; Schumann, A.W.; Boyd, N.S. Deep Learning for Image-Based Weed Detection in Turfgrass. Eur. J. Agron. 2019, 104, 78–84. [Google Scholar] [CrossRef]
- Dias, P.A.; Tabb, A.; Medeiros, H. Apple Flower Detection Using Deep Convolutional Networks. Comput. Ind. 2018, 99, 17–28. [Google Scholar] [CrossRef]
- Xia, X.; Chai, X.; Zhang, N.; Sun, T. Visual Classification of Apple Bud-Types via Attention-Guided Data Enrichment Network. Comput. Electron. Agric. 2021, 191, 106504. [Google Scholar] [CrossRef]
- ImageNet. Available online: https://www.image-net.org/about.php (accessed on 25 April 2022).
- Watts, S.; Migicovsky, Z.; Myles, S. Cider and Dessert Apples: What Is the Difference? Plants People Planet 2022, 4, 593–598. [Google Scholar]
- Miles, C.; Peck, G.; Beltsville, M.B.U.; Geneva, T.C.U.; Miles, C.; State, W.; Nwrec, V.; Vernon, M.; Merwin, I.; Diamond, B.; et al. Importing European Cider Cultivars into the US. In Proceedings of the CiderCon 2016, Portland, OR, USA, 2–6 February 2016. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2014. [CrossRef]
- Chollet, F. Keras. Available online: https://github.com/keras-team/keras (accessed on 21 December 2021).
- Breunig, M.; Al-Doori, M.; Butwilowski, E.; Kuper, P.V.; Benner, J.; Haefele, K.-H. Proceedings of the 9th 3DGeoInfo Conference 2014, Dubai, United Arab Emirates, 11–13 November 2014; The Conference Chairs of 3DGeoInfo: Karlsruhe, Germany, 2014. [Google Scholar]
- Chollet, F. Keras Documentation. 2015. Available online: https://keras.io/api (accessed on 11 April 2022).
- Chollet, F. Deep Learning with Python; Manning Publications: Shelter Island, NY, USA, 2021; ISBN 9781617296864. [Google Scholar]
- Tan, M.; Le, Q. EfficientNetV2: Smaller Models and Faster Training. arXiv 2021. [Google Scholar] [CrossRef]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L. MobileNetV2: Inverted Residuals and Linear Bottlenecks. arXiv 2018. [Google Scholar] [CrossRef]
- Szegedy, C.; Ioffe, S.; Vanhoucke, V.; Alemi, A. Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning. In Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence, Phoenix, AZ, USA, 12–17 February 2016. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going Deeper with Convolutions. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar] [CrossRef]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the Inception Architecture for Computer Vision. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 2818–2826. [Google Scholar] [CrossRef]
- ILSRVC. ImageNet Large Scale Visual Recognition Challenge. Available online: https://www.image-net.org/challenges/LSVRC/index.php (accessed on 25 April 2022).
- Bhadouria, V.S. Explaining Accuracy, Precision, Recall, and F1 Score. Available online: https://medium.com/swlh/explaining-accuracy-precision-recall-and-f1-score-f29d370caaa8 (accessed on 12 July 2022).
- Siddiqi, R. Effectiveness of Transfer Learning and Fine Tuning in Automated Fruit Image Classification. In Proceedings of the 2019 3rd International Conference on Deep Learning Technologies, Xiamen, China, 5–7 July 2019; pp. 91–100. [Google Scholar] [CrossRef]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
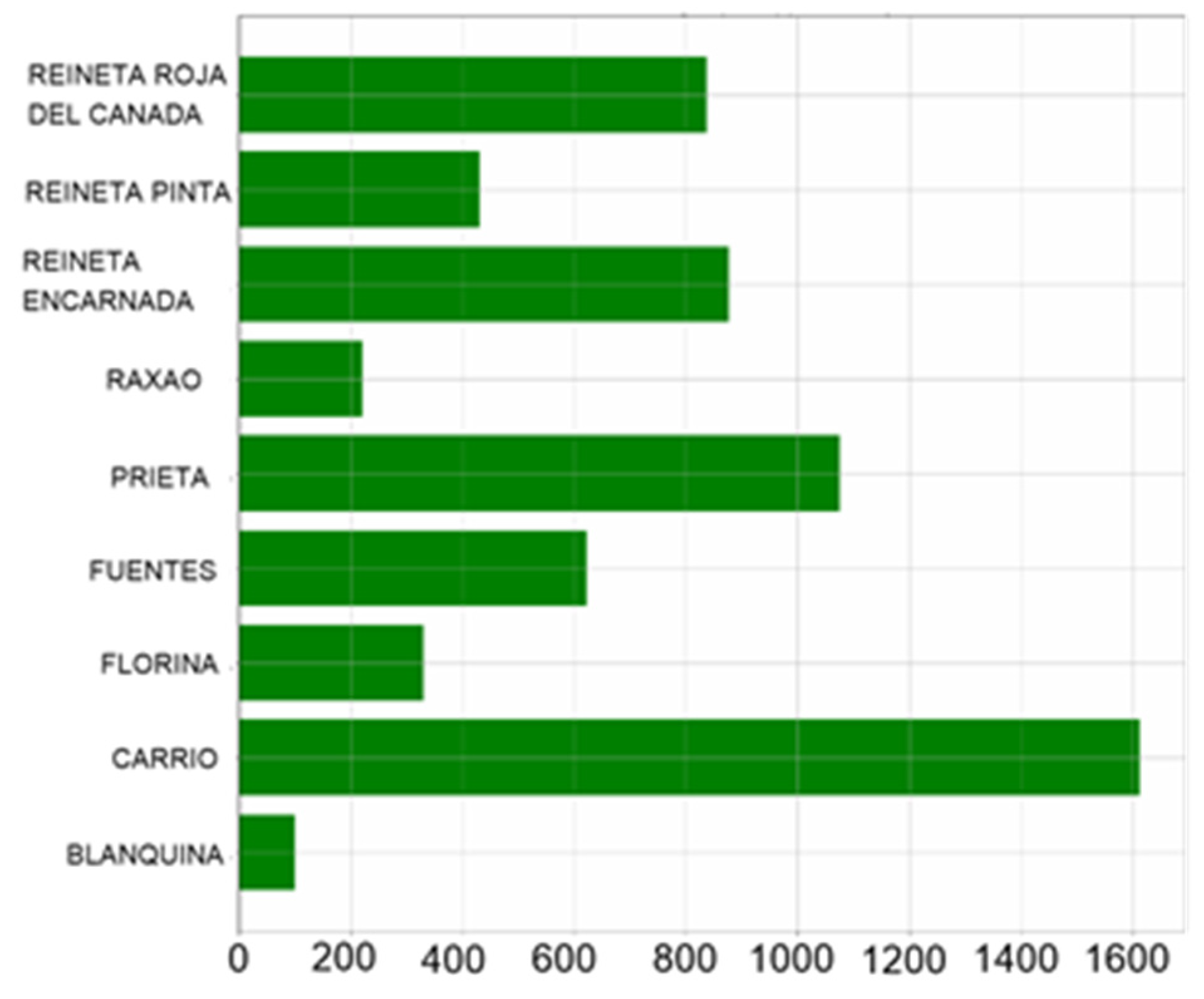{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
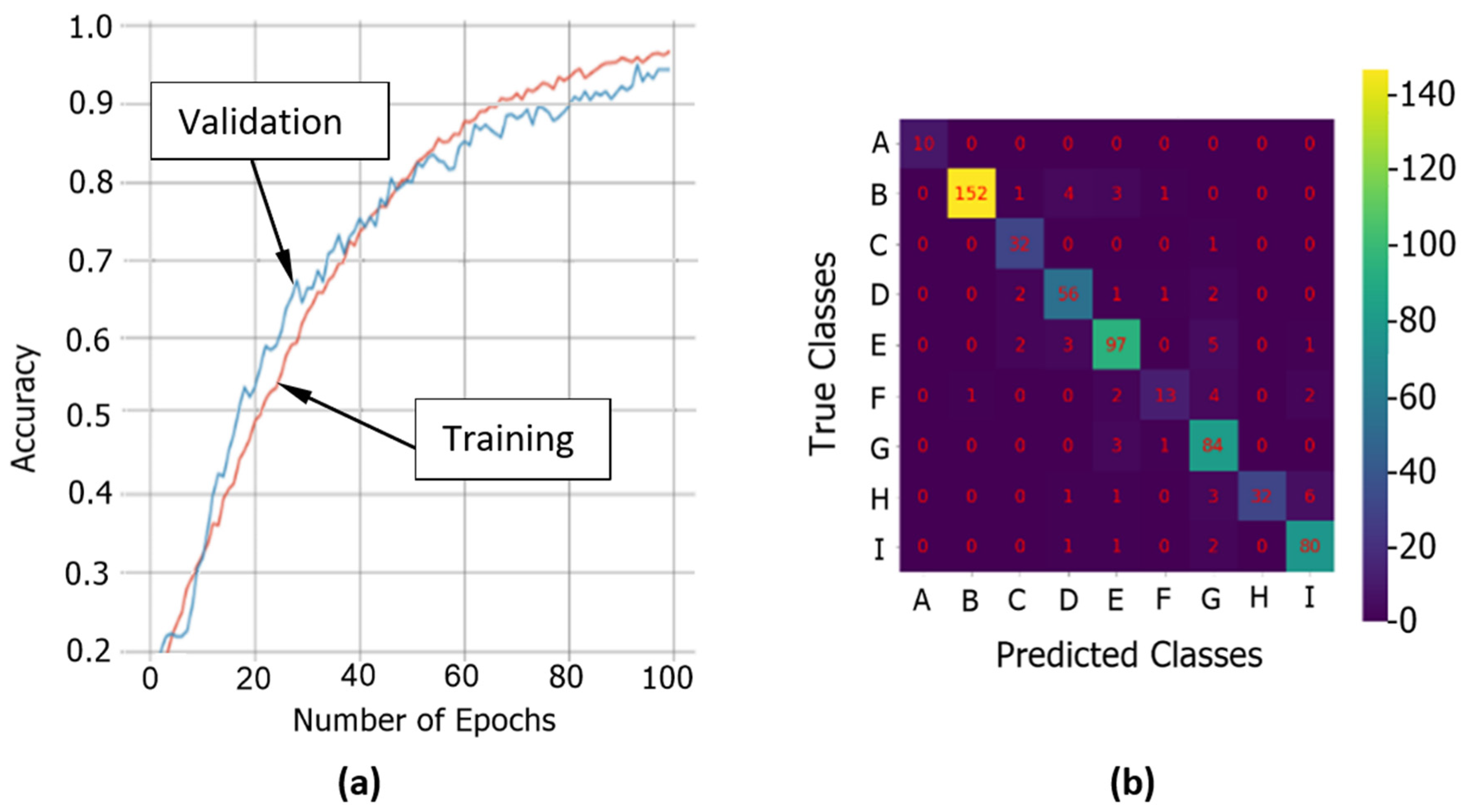{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Execution Type | Validation Accuracy | Test Accuracy | Training Accuracy | Execution Time (Hours) | Number of Trainable Parameters |
|---|---|---|---|---|---|
| One step | 97.87% (98.69% epoch 162) | 97.55% | 99.71% | 2:43 h | 22,039,849 |
| Two steps | 98.20% (98.20% epoch 185) | 97.22% | 99.43% | 2:50 h | 22,039,849 |
| Name | Validation Accuracy | Batch Size | Final Test Accuracy (100th Epoch) |
|---|---|---|---|
| MobileNetV2 | 94.920 (epoch 94) | 24 | 91.00% |
| InceptionV3 | 98.693 (epoch 93) | 24 | 92.96% |
| VGG16 | 84.943 (epoch 99) | 24 | 53.68% |
| EfficientNetV2M | 80.54(epoch 99) | 24 | 70.54% |
| InceptionResnetV2 | 97.218 (epoch 85) | 12 | 94.76% |
| Our-CNN (6 blocks: Conv + Maxpool layer) | 73.977(epoch 78) | 12 | 37.64% |
| CNN Architecture | Test Accuracy | F1 Score | Number of Pars: | Training Time: |
|---|---|---|---|---|
| VGG16 | 69.89% | 0.688 | 14,789,577 | 1:39 h |
| EfficientNetV2M | 70.54% | 0.675 | 53,031,549 | 4:02 h |
| MobileNetV2 | 91.00% | 0.890 | 2,431,561 | 1:23 h |
| InceptionV3 | 92.96% | 0.929 | 22,039,849 | 1:27 h |
| Data Set | Accuracy | Precision | Recall | F1 |
|---|---|---|---|---|
| Training | 99.71% | |||
| Validation | 97.05% (98.20% epoch 181) | 97.52% | 96.52% | 0.970 |
| Test | 98.04% | 98.41% | 97.76% | 0.980 |
| Class Name | Precision | Recall | F1 | Support 1 |
|---|---|---|---|---|
| BLANQUINA | 1.00 | 1.00 | 1.00 | 10 |
| CARRIO | 0.99 | 0.99 | 0.99 | 161 |
| FLORINA | 0.86 | 0.97 | 0.91 | 33 |
| FUENTES | 0.98 | 0.94 | 0.96 | 62 |
| PRIETA | 0.99 | 0.97 | 0.98 | 108 |
| RAXAO | 1.00 | 1.00 | 1.00 | 22 |
| REINETA ENCARNADA | 0.96 | 1.00 | 0.98 | 88 |
| REINETA PINTA | 0.97 | 0.91 | 0.94 | 43 |
| REINETA ROJA DEL CANADA | 0.99 | 0.98 | 0.98 | 84 |
| accuracy | 0.99 | 0.98 | 0.98 | 611 |
| macro avg. | 0.97 | 0.97 | 0.97 | 611 |
| Support-weighted avg. | 0.98 | 0.98 | 0.98 | 611 |
| Data Set | Accuracy | Precision | Recall | F1 |
|---|---|---|---|---|
| Training | 99.80% | |||
| Validation | 93.29% (96.72% epoch 188) | 95.93% | 91.66% | 0.933 |
| Test | 93.13% | 96.12% | 91.26% | 0.931 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
García Cortés, S.; Menéndez Díaz, A.; Oliveira Prendes, J.A.; Bello García, A. Transfer Learning with Convolutional Neural Networks for Cider Apple Varieties Classification. Agronomy 2022, 12, 2856. https://doi.org/10.3390/agronomy12112856
García Cortés S, Menéndez Díaz A, Oliveira Prendes JA, Bello García A. Transfer Learning with Convolutional Neural Networks for Cider Apple Varieties Classification. Agronomy. 2022; 12(11):2856. https://doi.org/10.3390/agronomy12112856
Chicago/Turabian StyleGarcía Cortés, Silverio, Agustín Menéndez Díaz, José Alberto Oliveira Prendes, and Antonio Bello García. 2022. "Transfer Learning with Convolutional Neural Networks for Cider Apple Varieties Classification" Agronomy 12, no. 11: 2856. https://doi.org/10.3390/agronomy12112856
APA StyleGarcía Cortés, S., Menéndez Díaz, A., Oliveira Prendes, J. A., & Bello García, A. (2022). Transfer Learning with Convolutional Neural Networks for Cider Apple Varieties Classification. Agronomy, 12(11), 2856. https://doi.org/10.3390/agronomy12112856