
Simulation Model for Time to Flowering with Climatic and Genetic Inputs for Wild Chickpea

 ,
,  ,
,
Abstract
1. Introduction
2. Materials and Methods
2.1. The Overview
2.2. Data Set of Wild Chickpeas
2.3. Climate Data
- 1.
- D is day length.
- 2.
- is minimal temperature.
- 3.
- is maximal temperature.
- 4.
- P is precipitation.
- 5.
- S is solar radiation.
2.4. A Model with Climatic Factors
2.5. Genotype-to-Climatic Factors Interactions
2.6. Analytic Form of the Control Function
2.7. Model Adaptation
2.8. Model Cross-Validation and Negative Control
2.9. Estimation of Impacts of Climatic Factors and Genotype Information to the Model
2.10. Model Ensemble with Defined Interactions for Forecasting
2.11. Synthetic Weather Generation and Time to Flowering Forecast
3. Results
3.1. A Model with Climatic Factors
3.2. Impacts of Different Factors to the Model
3.3. Comparison of Genotypes
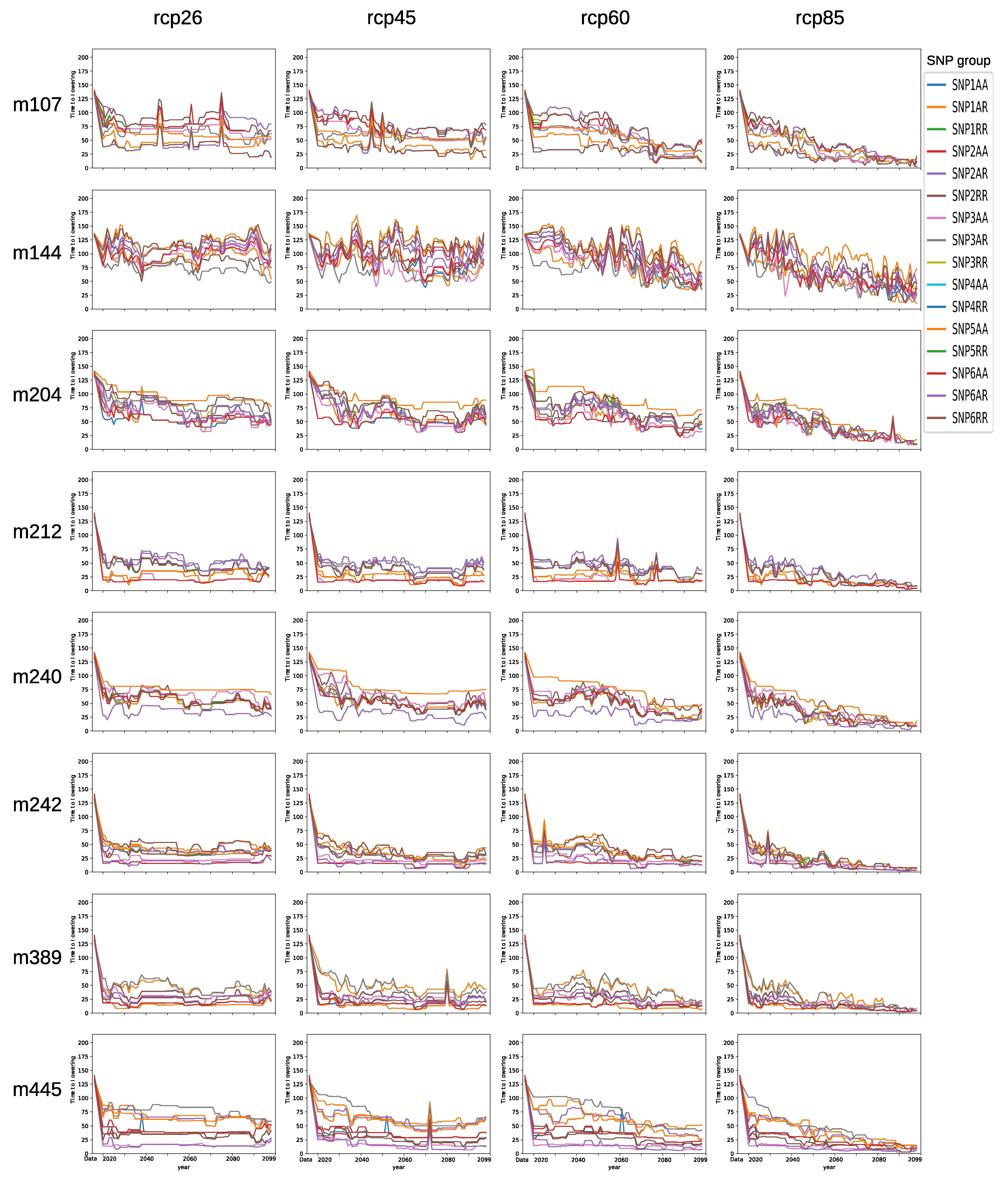
3.4. Comparison of SNP Groups
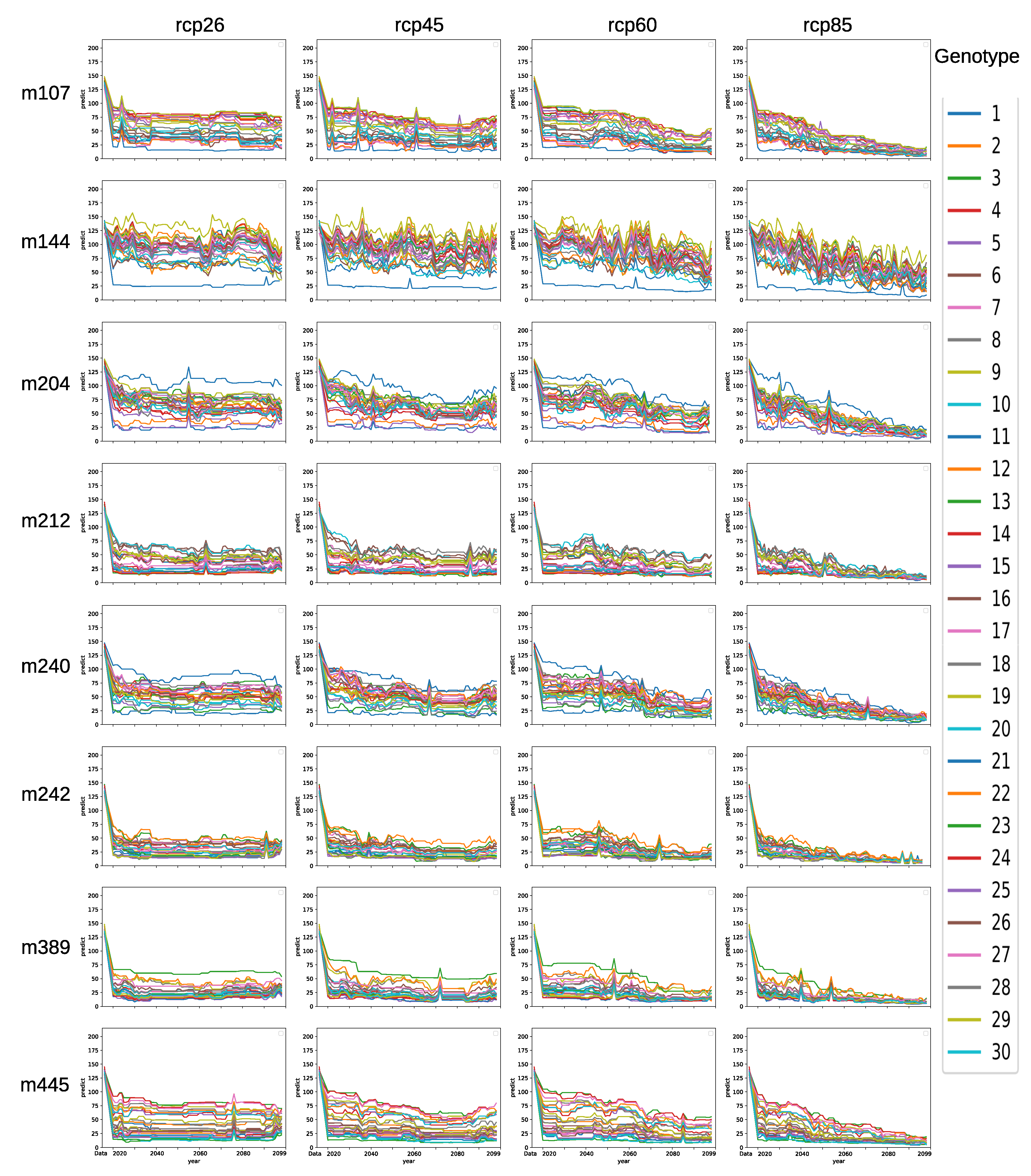
3.5. Model Ensemble with Genotype-to-Climatic Factors Interactions
3.6. Forecasting
4. Discussion
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Gaur, P.M.; Samineni, S.; Thudi, M.; Tripathi, S.; Sajja, S.B.; Jayalakshmi, V.; Mannur, D.M.; Vijayakumar, A.G.; Gangarao, N.V.P.R.; Ojiewo, C.; et al. Integrated breeding approaches for improving drought and heat adaptation in chickpea (CicerArietinum L.). Plant Breed. 2018, 138, 389–400. [Google Scholar] [CrossRef]
- Ridge, S.; Deokar, A.; Lee, R.; Daba, K.; Macknight, R.C.; Weller, J.L.; Tar’an, B. The Chickpea Early Flowering 1 (Efl1) Locus Is an Ortholog of Arabidopsis ELF3. Plant Physiol. 2017, 175, 802–815. [Google Scholar] [CrossRef] [PubMed]
- Varshney, R.K.; Song, C.; Saxena, R.; Azam, S.; Yu, C.; Sharpe, A.G.; Cannon, S.; Baek, J.; Rosen, B.D.; Tar’an, B.; et al. Draft genome sequence of chickpea (Cicer arietinum) provides a resource for trait improvement. Nat. Biotechnol. 2013, 31, 9. [Google Scholar] [CrossRef] [PubMed]
- Abbo, S.; Berger, J.; Turner, N. Evolution of cultivated chickpea: Four bottlenecks limit diversity and constrain adaptation. Funct. Plant Biol. 2003, 30, 1081–1087. [Google Scholar] [CrossRef]
- Smithson, J.; Thompson, J.; Summerfield, R. Chickpea (Cicerarietinum L.). In Grain Legume Crops; Summerfield, R., Roberts, R., Eds.; Collins: London, UK, 1985; pp. 312–390. [Google Scholar]
- Kumar, J.; Abbo, S. Genetics of flowering time in chickpea and its bearing on productivity in the semi-arid environments. Adv. Agron. 2001, 72, 107–138. [Google Scholar]
- Roberts, E.; Hadley, P.; Summerfield, R. Effects of temperature and photoperiod on flowering in chickpeas (CicerArietinum L.). Ann. Bot. 1985, 55, 881–892. [Google Scholar] [CrossRef]
- Berger, J.; Milroy, S.; Turner, N.; Siddique, K.; Imtiaz, M.; Malhotra, R. Chickpea evolution has selected for contrasting phenological mechanisms among different habitats. Euphytica 2011, 180, 1–15. [Google Scholar] [CrossRef]
- Singh, P.; Virmani, S. Modelling growth and yield of chickpea (Cicer Arietinum L.). Field Crops Res. 1996, 46, 41–59. [Google Scholar] [CrossRef]
- Ellis, R.H.; Lawn, R.J.; Summerfield, R.J.; Qi, A.; Roberts, E.H.; Chay, P.M.; Brouwer, J.B.; Rose, J.L.; Yeates, S.J.; Sandover, S.; et al. Towards the Reliable Prediction of Time to Flowering in Six Annual Crops. V. Chickpea (CicerArietinum). Exp. Agric. 1994, 30, 271–282. [Google Scholar] [CrossRef]
- Kumar, V.; Singh, A.; Mithra, S.V.A.; Krishnamurthy, S.L.; Parida, S.K.; Jain, S.; Tiwari, K.K.; Kumar, P.; Rao, A.R.; Sharma, S.K.; et al. Genome-wide association mapping of salinity tolerance in rice (OryzaSativa). DNA Res. 2015, 22, 133–145. [Google Scholar] [CrossRef]
- Upadhyaya, H.D.; Bajaj, D.; Das, S.; Saxena, M.S.; Badoni, S.; Kumar, V.; Tripathi, S.; Gowda, C.L.L.; Sharma, S.; Tyagi, A.K.; et al. A genome-scale integrated approach aids in genetic dissection of complex flowering time trait in chickpea. Plant Mol. Biol. 2015, 89, 403–420. [Google Scholar] [CrossRef] [PubMed]
- Soltani, A.; Hammer, G.; Torabi, B.; Robertson, M.; Zeinali, E. Modeling chickpea growth and development: Phenological development. Field Crops Res. 2006, 99, 1–13. [Google Scholar] [CrossRef]
- Vadez, V.; Soltani, A.; Sinclair, T. Modelling possible benefits of root related traits to enhance terminal drought adaptation of chickpea. Field Crops Res. 2012, 137, 108–115. [Google Scholar] [CrossRef]
- Vadez, V.; Soltani, A.; Sinclair, T. Crop simulation analysis of phenological adaptation of chickpea to different latitudes of India. Field Crops Res. 2013, 146, 1–9. [Google Scholar] [CrossRef]
- Soltani, A.; Robertson, M.; Mohammad-Nejad, Y.; Rahemi-Karizaki, A. Modeling chickpea growth and development: Leaf production and senescence. Field Crops Res. 2006, 99, 14–23. [Google Scholar] [CrossRef]
- Zhang, X.; Cai, X. Climate change impacts on global agricultural land availability. Environ. Res. Lett. 2011, 6, 014014. [Google Scholar] [CrossRef]
- Foley, J.A.; Ramankutty, N.; Brauman, K.A.; Cassidy, E.S.; Gerber, J.S.; Johnston, M.; Mueller, N.D.; O’Connell, C.; Ray, D.K.; West, P.C.; et al. Solutions for a cultivated planet. Nature 2011, 478, 337–342. [Google Scholar] [CrossRef] [PubMed]
- Laurent, R.; Cai, X. A maximum entropy method for combining AOGCMs for regional intra-year climate change assessment. Clim. Chang. 2007, 82, 411–435. [Google Scholar] [CrossRef]
- Deb, P.; Shrestha, S.; Babel, M.S. Forecasting climate change impacts and evaluation of adaptation options for maize cropping in the hilly terrain of Himalayas: Sikkim, India. Theor. Appl. Climatol. 2015, 121, 649–667. [Google Scholar] [CrossRef]
- Shrestha, S.; Deb, P.; Bui, T.T.T. Adaptation strategies for rice cultivation under climate change in Central Vietnam. Mitig. Adapt. Strateg. Glob. Chang. 2016, 21, 15–37. [Google Scholar] [CrossRef]
- Andrés, F.; Coupland, G. The genetic basis of flowering responses to seasonal cues. Nat. Rev. Genet. 2012, 13, 627–639. [Google Scholar] [CrossRef]
- Srikanth, A.; Schmid, M. Regulation of flowering time: All roads lead to Rome. Cell. Mol. Life Sci. 2011, 68, 2013–2037. [Google Scholar] [CrossRef] [PubMed]
- Gursky, V.V.; Kozlov, K.N.; Nuzhdin, S.V.; Samsonova, M.G. Dynamical Modeling of the Core Gene Network Controlling Flowering Suggests Cumulative Activation From the FLOWERING LOCUS T Gene Homologs in Chickpea. Front. Genet. 2018, 9, 547. [Google Scholar] [CrossRef] [PubMed]
- Boote, K.J.; Jones, J.W.; White, J.W.; Asseng, S.; Lizaso, J.I. Putting Mechanisms into Crop Production Models. Plant Cell Environ. 2013, 36, 1658–1672. [Google Scholar] [CrossRef]
- Boote, J.K.; Jones, J.; Pickering, N. Potential Uses and Limitations of Crop Models. Agron. J. 1996, 88, 704–716. [Google Scholar] [CrossRef]
- Jones, J.; Hoogenboom, G.; Porter, C.; Boote, K.; Batchelor, W.; Hunt, L.; Wilkens, P.; Singh, U.; Gijsman, A.; Ritchie, J. The DSSAT cropping system model. Eur. J. Agron. 2003, 18, 235–265. [Google Scholar] [CrossRef]
- Jones, J.W.; Antle, J.M.; Basso, B.; Boote, K.J.; Conant, R.T.; Foster, I.; Godfray, H.C.J.; Herrero, M.; Howitt, R.E.; Janssen, S.; et al. Brief history of agricultural systems modeling. Agric. Syst. 2016, 155, 240–254. [Google Scholar] [CrossRef]
- Jones, J.W.; Antle, J.M.; Basso, B.; Boote, K.J.; Conant, R.T.; Foster, I.; Godfray, H.C.J.; Herrero, M.; Howitt, R.E.; Janssen, S.; et al. Toward a new generation of agricultural system data, models, and knowledge products: State of agricultural systems science. Agric. Syst. 2017, 155, 269–288. [Google Scholar] [CrossRef]
- Keating, B.; Carberry, P.; Hammer, G.; Probert, M.; Robertson, M.; Holzworth, D.; Huth, N.; Hargreaves, J.; Meinke, H.; Hochman, Z.; et al. An overview of APSIM, a model designed for farming systems simulation. Eur. J. Agron. 2003, 18, 267–288. [Google Scholar] [CrossRef]
- Battisti, R.; Sentelhas, P.C.; Boote, K.J. Sensitivity and requirement of improvements of four soybean crop simulation models for climate change studies in Southern Brazil. Int. J. Biometeorol. 2018, 62, 823–832. [Google Scholar] [CrossRef]
- Williams, J.R.; Jones, C.A.; Kiniry, J.R.; Spanel, D.A. The EPIC Crop Growth Model. Trans. ASAE 1989, 32, 497–511. [Google Scholar] [CrossRef]
- Sousa-Ortega, C.; Royo-Esnal, A.; Urbano, J.M. Predicting Seedling Emergence of Three Canarygrass (Phalaris) Species under Semi-Arid Conditions Using Parametric and Non-Parametric Models. Agronomy 2021, 11, 893. [Google Scholar] [CrossRef]
- Wilkerson, G.; Jones, J.; Boote, K.; Ingram, K.; Mishoe, J. Modeling soybean growth for crop management. Trans. Am. Soc. Agric. Eng. 1983, 26, 63–73. [Google Scholar] [CrossRef]
- Roorkiwal, M.; Rathore, A.; Das, R.R.; Singh, M.K.; Jain, A.; Srinivasan, S.; Gaur, P.M.; Chellapilla, B.; Tripathi, S.; Li, Y.; et al. Genome-Enabled Prediction Models for Yield Related Traits in Chickpea. Front. Plant Sci. 2016, 7, 1666. [Google Scholar] [CrossRef] [PubMed]
- Hoogenboom, G.; White, J.; Jones, J.; Boote, K. BEANGRO: A process-oriented dry bean model with a versatile user interface. Agon. J. 1994, 86, 186–190. [Google Scholar] [CrossRef]
- Ilkaee, M.N.; Paknejad, F.; Golzardi, F.; Tookalloo, M.R.; Habibi, D.; Tohidloo, G.; Pazoki, A.; Agayari, F.; Rezaee, M.; Rika, Z.F. Simulation of some of important traits in chickpea cultivars under different sowing date using CROPGRO-Pea model. Int. J. Biosci. 2014, 4, 84–92. [Google Scholar]
- Jones, J.; Keating, B.; Porter, C. Approaches to modular model development. Agric. Syst. 2001, 70, 421–443. [Google Scholar] [CrossRef]
- Wajid, A.; Rahman, M.H.U.; Ahmad, A.; Khaliq, T.; Mahmood, N.; Rasul, F.; Bashir, M.U.; Awais, M.; Hussain, J.; Hoogeboom, G. Simulating the Interactive Impact of Nitrogen and Promising Cultivars on Yield of Lentil (Lens Culinaris) Using CROPGRO-Legume Model. Int. J. Agric. Biol. 2013, 15, 1331–1336. [Google Scholar]
- Soltani, A.; Sinclair, T.R. A simple model for chickpea development, growth and yield. Field Crops Res. 2011, 124, 252–260. [Google Scholar] [CrossRef]
- Chung, U.; Yu, K.; Bs, S.; Mc, S. Evaluation of Variation and Uncertainty in the Potential Yield of Soybeans in South Korea Using Multi-model Ensemble Climate Change Scenarios. Agrotechnology 2017, 6, 1000158. [Google Scholar]
- Lal, M.; Singh, K.; Srinivasan, G.; Rathore, L.; Naidu, D.; Tripathi, C. Growth and yield responses of soybean in Madhya Pradesh, India to climate variability and change. Agric. For. Meteorol. 1999, 93, 53–70. [Google Scholar] [CrossRef]
- Mohammed, A.; Tana, T.; Singh, P.; Molla, A.; Seid, A. Identifying best crop management practices for chickpea (CicerArietinum L.) in Northeastern Ethiopia under climate change condition. Agric. Water Manag. 2017, 194, 68–77. [Google Scholar] [CrossRef]
- Patil, D.; Patel, H. Calibration and validation of cropgro (DSSAT 4.6) model for chickpea under middle gujarat agroclimatic region. Int. J. Agric. Sci. 2017, 9, 4342–4344. [Google Scholar]
- Urgaya, M. Modeling the Impacts of Climate Change on Chickpea Production in Adaa Woreda (East Showa Zone) in the Semi-Arid Central Rift Valley of Ethiopia. J. Pet Environ. Biotechnol. 2016, 7, 288. [Google Scholar]
- Bhosale, S.U.; Stich, B.; Rattunde, H.F.W.; Weltzien, E.; Haussmann, B.I.; Hash, C.T.; Ramu, P.; Cuevas, H.E.; Paterson, A.H.; Melchinger, A.E.; et al. Association analysis of photoperiodic flowering time genes in west and central African sorghum [SorghumBicolor (L.) Moench]. BMC Plant Biol. 2012, 12, 32. [Google Scholar] [CrossRef]
- Visioni, A.; Tondelli, A.; Francia, E.; Pswarayi, A.; Malosetti, M.; Russell, J.; Thomas, W.; Waugh, R.; Pecchioni, N.; Romagosa, I.; et al. Genome-wide association mapping of frost tolerance in barley (Hordeum Vulgare L.). BMC Genom. 2013, 14, 424. [Google Scholar] [CrossRef]
- Tian, F.; Bradbury, P.J.; Brown, P.J.; Hung, H.; Sun, Q.; Flint-Garcia, S.; Rocheford, T.R.; McMullen, M.D.; Holl, J.B.; Buckler, E.S. Genome-wide association study of leaf architecture in the maize nested association mapping population. Nat. Genet. 2011, 43, 159–162. [Google Scholar] [CrossRef]
- Kump, K.L.; Bradbury, P.J.; Wisser, R.J.; Buckler, E.S.; Belcher, A.R.; Oropeza-Rosas, M.A.; Zwonitzer, J.C.; Kresovich, S.; McMullen, M.D.; Ware, D.; et al. Genome-wide association study of quantitative resistance to southern leaf blight in the maize nested association mapping population. Nat. Genet. 2011, 43, 163–168. [Google Scholar] [CrossRef] [PubMed]
- Yang, W.; Guo, Z.; Huang, C.; Duan, L.; Chen, G.; Jiang, N.; Fang, W.; Feng, H.; Xie, W.; Lian, X.; et al. Combining high-throughput phenotyping and genome-wide association studies to reveal natural genetic variation in rice. Nat. Commun. 2014, 5, 5087. [Google Scholar] [CrossRef] [PubMed]
- Lasky, J.R.; Upadhyaya, H.D.; Ramu, P.; Deshpande, S.; Hash, C.T.; Bonnette, J.; Juenger, T.E.; Hyma, K.; Acharya, C.; Mitchell, S.E.; et al. Genome-environment associations in sorghum landraces predict adaptive traits. Sci. Adv. 2015, 1, e1400218. [Google Scholar] [CrossRef]
- Hwang, C.; Correll, M.; Gezan, S.; Zhang, L.; Bhakta, M.; Vallejos, C.; Boote, K.; Clavijo-Michelangeli, J.; Jones, J. Next generation crop models: A modular approach to model early vegetative and reproductive development of the common bean (PhaseolusVulgaris L). Agric. Syst. 2017, 155, 225–239. [Google Scholar] [CrossRef] [PubMed]
- Hatfield, J.; Walthall, C. Meeting Global Food Needs: Realizing the Potential via Genetics x Environment x Management Interactions. Agron. J. 2015, 107, 1215–1226. [Google Scholar] [CrossRef]
- Tardieu, F.; Tuberosa, R. Dissection and modelling of abiotic stress tolerance in plants. Curr. Opin. Plant Biol. 2010, 13, 206–212. [Google Scholar] [CrossRef] [PubMed]
- Asseng, S.; Ewert, F.; Rosenzweig, C.; Jones, J.W.; Hatfield, J.L.; Ruane, A.C.; Boote, K.J.; Thorburn, P.J.; Rötter, R.P.; Cammarano, D.; et al. Uncertainty in simulating wheat yields under climate change. Nat. Clim. Chang. 2013, 3, 827–832. [Google Scholar] [CrossRef]
- Rosenzweig, C.; Jones, J.; Hatfield, J.; Ruane, A.; Boote, K.; Thorburn, P.; Antle, J.; Nelson, G.; Porter, C.; Janssen, S.; et al. The Agricultural Model Intercomparison and Improvement Project (AgMIP): Protocols and pilot studies. Agric. For. Meteorol. 2013, 170, 166–182. [Google Scholar] [CrossRef]
- Asseng, S.; Ewert, F.; Martre, P.; Rötter, R.P.; Lobell, D.B.; Cammarano, D.; Kimball, B.A.; Ottman, M.J.; Wall, G.W.; White, J.W.; et al. Rising temperatures reduce global wheat production. Nat. Clim. Chang. 2015, 5, 143–147. [Google Scholar] [CrossRef]
- Martre, P.; Wallach, D.; Asseng, S.; Ewert, F.; Jones, J.W.; Rötter, R.P.; Boote, K.J.; Ruane, A.C.; Thorburn, P.J.; Cammarano, D.; et al. Multimodel ensembles of wheat growth: Many models are better than one. Glob. Chang. Biol. 2015, 21, 911–925. [Google Scholar] [CrossRef]
- Ahmed, M.; Stöckle, C.O.; Nelson, R.; Higgins, S.; Ahmad, S.; Raza, M.A. Novel multimodel ensemble approach to evaluate the sole effect of elevated CO2 on winter wheat productivity. Sci. Rep. 2019, 9, 7813. [Google Scholar] [CrossRef]
- Kozlov, K.; Sokolkova, A.; Lee, C.-R.; Ting, C.-T.; Schafleitner, R.; Bishop-von Wettberg, E.; Nuzhdin, S.; Samsonova, M. Dynamical climatic model for time to flowering in Vigna radiata. BMC Plant Biol. 2020, 18. [Google Scholar] [CrossRef]
- Kozlov, K.; Singh, A.; Berger, J.; Wettberg, E.B.V.; Kahraman, A.; Aydogan, A.; Cook, D.; Nuzhdin, S.; Samsonova, M. Non-linear regression models for time to flowering in wild chickpea combine genetic and climatic factors. BMC Plant Biol. 2019, 19, 94. [Google Scholar] [CrossRef]
- von Wettberg, E.J.; Chang, P.L.; Başdemir, F.; Carrasquila-Garcia, N.; Korbu, L.B.; Moenga, S.M.; Bedada, G.; Greenlon, A.; Moriuchi, K.S.; Singh, V.; et al. Ecology and genomics of an important crop wild relative as a prelude to agricultural innovation. Nat. Commun. 2018, 9, 1–13. [Google Scholar] [CrossRef] [PubMed]
- Berger, J. Analysis of Phenotyping of Wild Chickpea in Diverse Environments; Commonwealth Scientific and Industrial Research Organization (CSIRO), Agriculture and Food: Perth, WA, Australia, 2021. [Google Scholar]
- Singh, A. Genome-wide association studies in wild chickpea. In Program Molecular and Computation Biology; University of California: Los-Angeles, CA, USA, 2021. [Google Scholar]
- Stackhouse, P.W.; Perez, R.; Sengupta, M.; Knapp, K.; Mikovitz, J.C.; Schlemmer, J.; Scarino, B.; Zhang, T.; Cox, S.J. An Assessment of New Satellite Data Products for the Development of a Long-term Global Solar Resource At 10–100 km. In Proceedings of the Solar 2016 Conference, San Francisco, CA, USA, 10–14 July 2016; pp. 1–6. [Google Scholar]
- Noorian, F.; de, Silva, A.M.; Leong, P.H.W. gramEvol: Grammatical Evolution in R. J. Stat. Softw. 2016, 71, 1–26. [Google Scholar] [CrossRef]
- O’Neill, M.; Ryan, C. Grammatical evolution. IEEE Trans. Evol. Comput. 2001, 5, 349–358. [Google Scholar] [CrossRef]
- Kozlov, K.; Samsonov, A. DEEP–Differential Evolution Entirely Parallel Method for Gene Regulatory Networks. J. Supercomput. 2011, 57, 172–178. [Google Scholar] [CrossRef]
- Kozlov, K.; Samsonov, A.M.; Samsonova, M. A software for parameter optimization with Differential Evolution Entirely Parallel method. PeerJ Comput. Sci. 2016, 2, e74. [Google Scholar] [CrossRef]
- Storn, R.; Price, K. Differential Evolution–A Simple and Efficient Heuristic for Global Optimization over Continuous Spaces; Technical Report TR-95-012; International Computer Science Institute: Berkley, CA, USA, 1995. [Google Scholar]
- Kozlov, K.; Novikova, L.; Seferova, I.; Samsonova, M. Mathematical model of soybean development dependence on climatic factors. Biofizika 2018, 63, 175–176. [Google Scholar]
- Zaharie, D. Parameter Adaptation in Differential Evolution by Controlling the Population Diversity. In Proceedings of the 4th International Workshop on Symbolic and Numeric Algorithms for Scientific Computing, Timisoara, Romania, 1–4 September 2020; pp. 385–397. [Google Scholar]
- Efron, B.; Tibshirani, R. An Introduction to the Bootstrap; Number 57 in Monographs on Statistics and Applied Probability; Chapman & Hall: New York, NY, USA, 1993. [Google Scholar]
- Jones, P.; Thornton, P. Spatial and temporal variability of rainfall related to a third-order Markov model. Agric. For. Meteorol. 1997, 86, 127–138. [Google Scholar] [CrossRef]
- Jones, P.; Thornton, P. Fitting a third-order Markov rainfall model to interpolated climate surfaces. Agric. For. Meteorol. 1999, 97, 213–231. [Google Scholar] [CrossRef]
- Jones, P.G.; Thornton, P.K. MarkSim: Software to Generate Daily Weather Data for Latin America and Africa. Agron. J. 2000, 92, 9. [Google Scholar] [CrossRef]
- SrinivasaRao, M.; Swathi, P.; Ramarao, C.A.; Rao, K.V.; Raju, B.M.K.; Srinivas, K.; Manimanjari, D.; Maheswari, M. Model and Scenario Variations in Predicted Number of Generations of Spodoptera litura Fab. on Peanut during Future Climate Change Scenario. PLoS ONE 2015, 10, e0116762. [Google Scholar]
- van, Vuuren, D.P.; Edmonds, J.; Kainuma, M.; Riahi, K.; Thomson, A.; Hibbard, K.; Hurtt, G.C.; Kram, T.; Krey, V.; Lamarque, J.-F.; et al. The representative concentration pathways: An overview. Clim. Chang. 2011, 109, 5–31. [Google Scholar]
- Demircan, M.; Gürkan, H.; Eskioğlu, O.; Arabacı, H.; Coşkun, M. Climate Change Projections for Turkey: Three Models and Two Scenarios. Turk. J. Water Sci. Manag. 2017, 1, 22–43. [Google Scholar] [CrossRef]
- Dunne, J.P.; John, J.G.; Shevliakova, E.; Stouffer, R.J.; Krasting, J.P.; Malyshev, S.L.; Milly, P.C.D.; Sentman, L.T.; Adcroft, A.J.; Cooke, W.; et al. GFDL’s ESM2 Global Coupled Climate–Carbon Earth System Models. Part II: Carbon System Formulation and Baseline Simulation Characteristics. J. Clim. 2013, 26, 2247–2267. [Google Scholar] [CrossRef]
- Collins, W.; Bellouin, N.; Doutriaux-Boucher, M.; Gedney, N.; Halloran, P.; Hinton, T.; Hughes, J.; Jones, C.; Joshi, M.; Liddicoat, S.; et al. Development and evaluation of an Earth-System model–HadGEM2. Geosci. Model Dev. 2011, 4, 1051–1075. [Google Scholar] [CrossRef]
- Fanourakis, D.; Giday, H.; Milla, R.; Pieruschka, R.; Kjaer, K.H.; Bolger, M.; Vasilevski, A.; Nunes-Nesi, A.; Fiorani, F.; Ottosen, C.-O. Pore size regulates operating stomatal conductance, while stomatal densities drive the partitioning of conductance between leaf sides. Ann. Bot. 2015, 115, 555–565. [Google Scholar] [CrossRef]
- Vadez, V.; Berger, J.D.; Warkentin, T.; Asseng, S.; Ratnakumar, P.; Rao, K.P.C.; Gaur, P.M.; Munier-Jolain, N.; Larmure, A.; Voisin, A.-S.; et al. Adaptation of grain legumes to climate change: A review. Agron. Sustain. Dev. 2012, 32, 31–44. [Google Scholar] [CrossRef]
- Singh, P.; Nedumaran, S.; Boote, K.; Gaur, P.; Srinivas, K.; Bantilan, M. Climate change impacts and potential benefits of drought and heat tolerance in chickpea in South Asia and East Africa. Eur. J. Agron. 2014, 52, 123–137. [Google Scholar] [CrossRef]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Error Type | Validation (Days) | Test (Days) |
|---|---|---|
| Mean | 5.0 | 6.085 |
| Median | 4.0 | 5.0 |
| Maximal | 24.0 | 19.0 |
| Minimal | 0.0 | 0.0 |
| Number of samples | 492 | 200 |
| S | D | |||
|---|---|---|---|---|
| Longitude | () () | () () | () () | () () |
| Latitude | () () | () () | () () | () () |
| Elevation | () () | () () | () () | () () |
| SNP1AA vs. SNP1AR | 0.193 |
| SNP1AA vs. SNP1RR | 0.387 |
| SNP1AR vs. SNP1RR | 0.118 |
| SNP2AA vs. SNP2AR | 0.448 |
| SNP2AA vs. SNP2RR | 0.001 |
| SNP2AR vs. SNP2RR | 0.016 |
| SNP3AA vs. SNP3AR | 0.363 |
| SNP3AA vs. SNP3RR | 0.017 |
| SNP3AR vs. SNP3RR | 0.058 |
| SNP4AA vs. SNP4RR | 0.096 |
| SNP5AA vs. SNP5RR | 0.115 |
| SNP6AA vs. SNP6AR | 0.292 |
| SNP6AA vs. SNP6RR | 0.351 |
| SNP6AR vs. SNP6RR | 0.359 |
| Model Name | SSD | MEAN | MED |
|---|---|---|---|
| m107 | 117,260.0 | 5.79 | 5.0 |
| m144 | 134,074.0 | 5.93 | 5.0 |
| m204 | 105,133.0 | 5.26 | 4.0 |
| m212 | 106,429.0 | 5.29 | 4.0 |
| m240 | 106,119.0 | 5.29 | 4.0 |
| m242 | 106,228.0 | 5.29 | 4.0 |
| m389 | 119,893.0 | 5.59 | 4.0 |
| m445 | 120,305.0 | 5.87 | 5.0 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ageev, A.; Aydogan, A.; Bishop-von Wettberg, E.; Nuzhdin, S.V.; Samsonova, M.; Kozlov, K. Simulation Model for Time to Flowering with Climatic and Genetic Inputs for Wild Chickpea. Agronomy 2021, 11, 1389. https://doi.org/10.3390/agronomy11071389
Ageev A, Aydogan A, Bishop-von Wettberg E, Nuzhdin SV, Samsonova M, Kozlov K. Simulation Model for Time to Flowering with Climatic and Genetic Inputs for Wild Chickpea. Agronomy. 2021; 11(7):1389. https://doi.org/10.3390/agronomy11071389
Chicago/Turabian StyleAgeev, Andrey, Abdulkadir Aydogan, Eric Bishop-von Wettberg, Sergey V. Nuzhdin, Maria Samsonova, and Konstantin Kozlov. 2021. "Simulation Model for Time to Flowering with Climatic and Genetic Inputs for Wild Chickpea" Agronomy 11, no. 7: 1389. https://doi.org/10.3390/agronomy11071389
APA StyleAgeev, A., Aydogan, A., Bishop-von Wettberg, E., Nuzhdin, S. V., Samsonova, M., & Kozlov, K. (2021). Simulation Model for Time to Flowering with Climatic and Genetic Inputs for Wild Chickpea. Agronomy, 11(7), 1389. https://doi.org/10.3390/agronomy11071389