
Machine Learning-Based Process Control for Injection Molding of Recycled Polypropylene

 and
and 
Abstract
1. Introduction
2. Materials and Methods
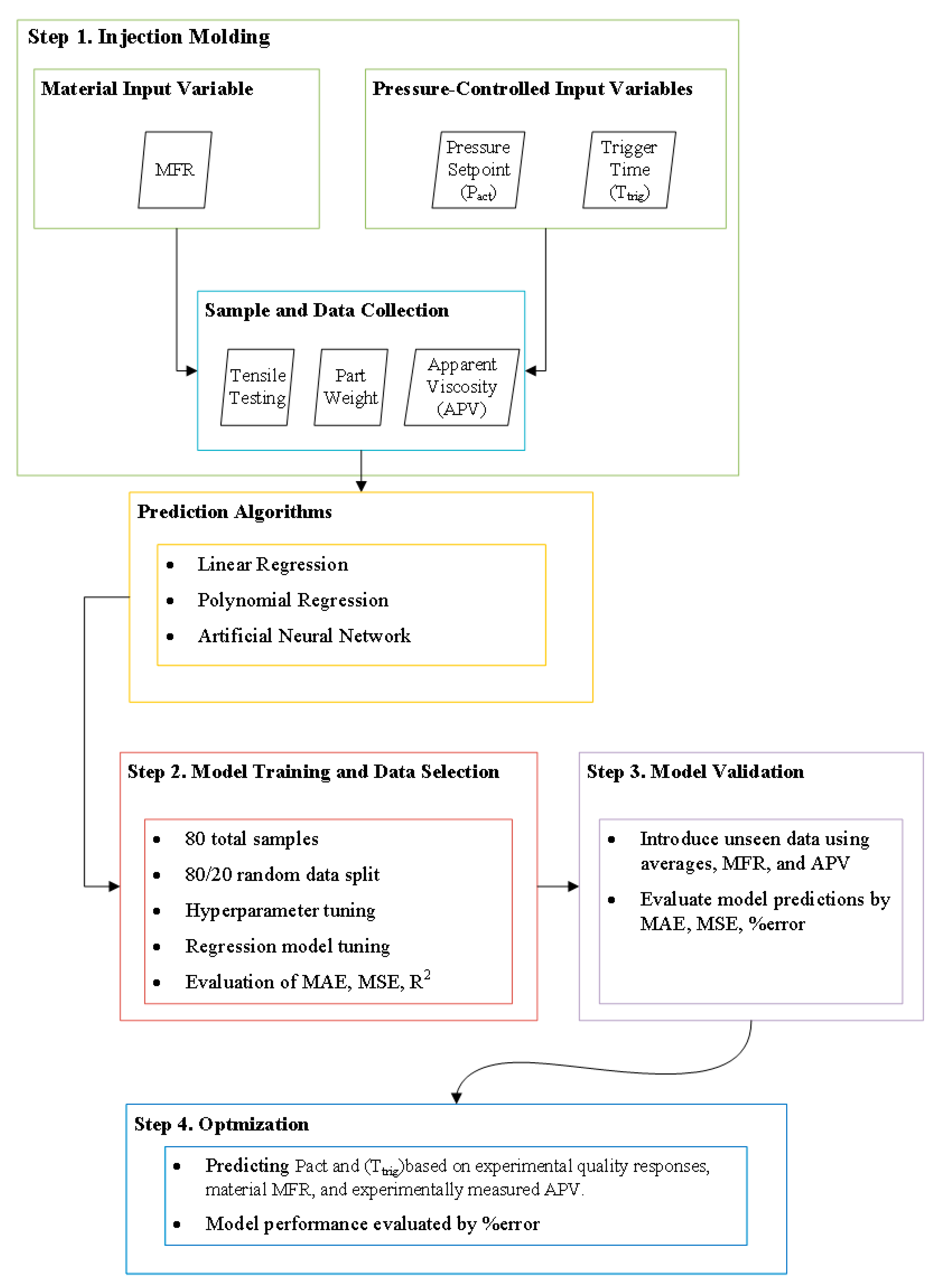
2.1. Process Control Approach
- Data collection from injection molding experiments and testing of the experiment specimens;
- Model setup, hyperparameter tuning, and training of each of the prediction models;
- Model validation is conducted by introducing hold-out data and evaluating each model’s ability to predict quality responses;
- Process optimization to predict the processing parameters associated with each quality response input;
- All machine learning algorithms were coded using Python version 3.10.12, with Scikit-learn version 1.3.2 used for the implementation of regression models.
2.2. Model Training and Validation
2.3. Data Collection
2.4. Multivariate Regression Model
2.5. Artificial Neural Networks
3. Results and Discussion
3.1. Experimental Results
3.2. Multivariate Regression Model Creation and Evaluation
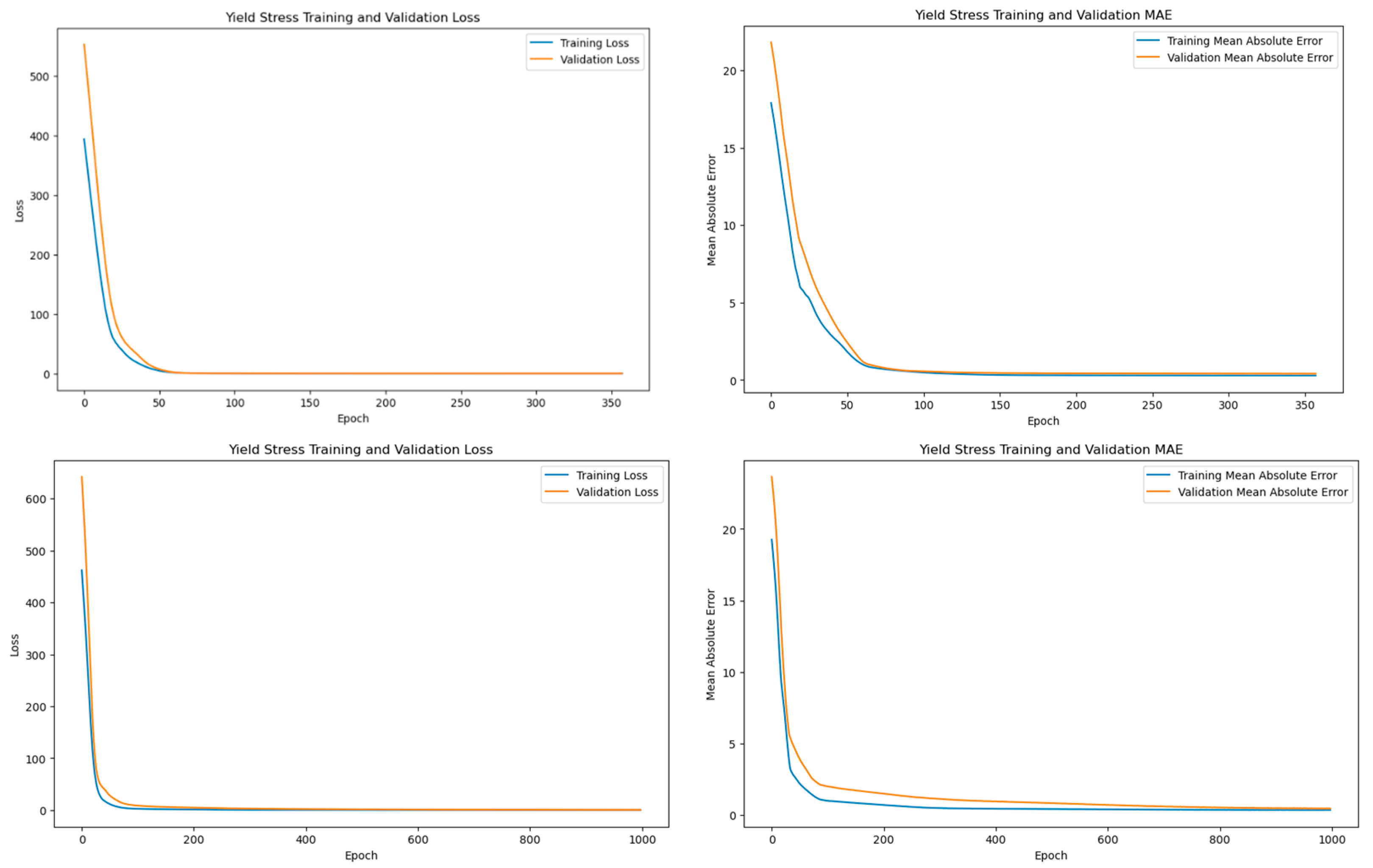
3.3. Artificial Neural Network Setup and Evaluation
3.4. Validation of the Models
3.4.1. Multivariate Regression Models
3.4.2. Artificial Neural Network
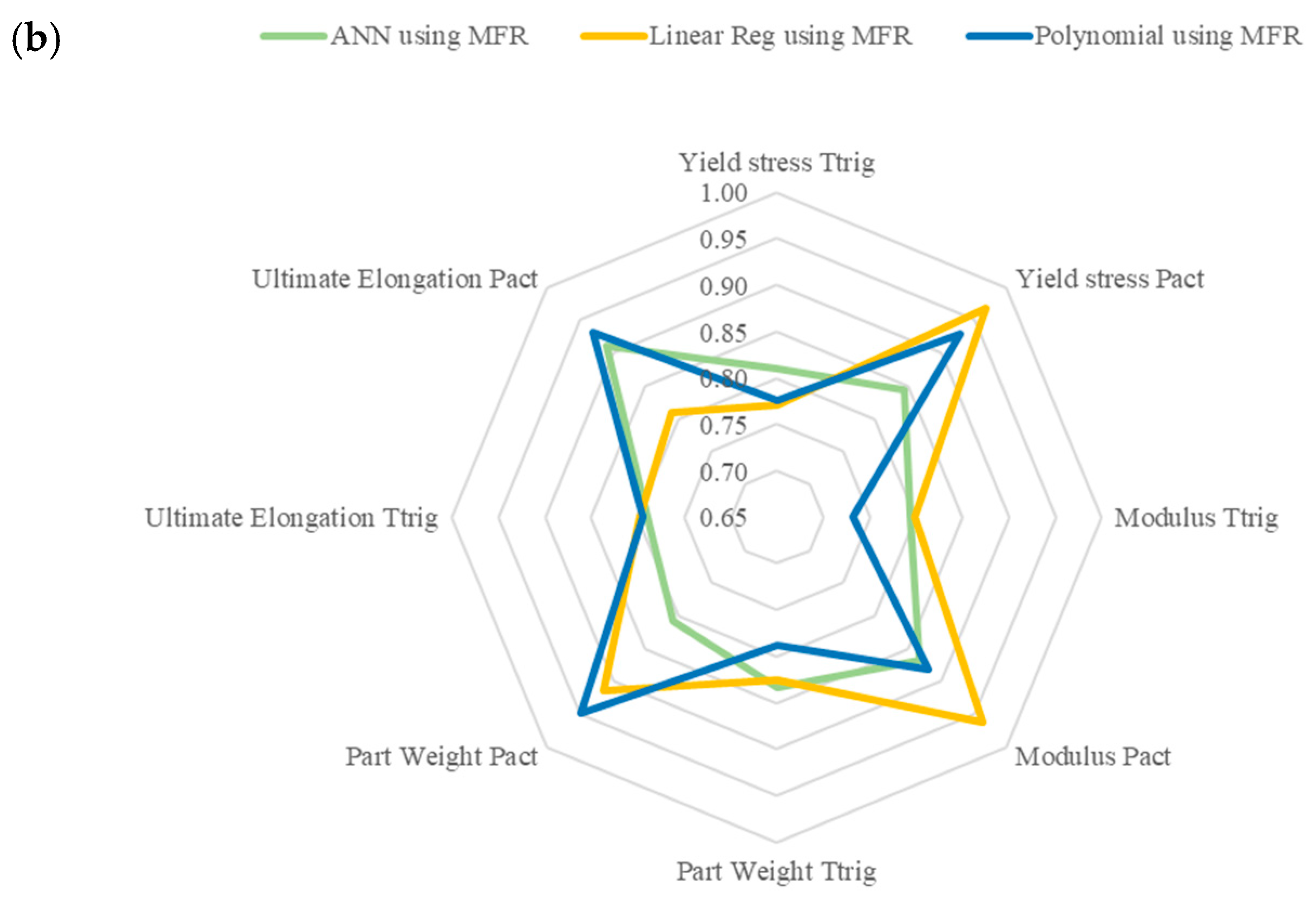
3.4.3. Comparison Between Models
3.5. Process Input Optimization
3.6. Validation of Input Prediction
4. Conclusions
- Processing inputs were predicted based on material properties and quality responses for a P-Ctrl injection molding process using 5 blends of recycled polypropylene;
- The work focused on the training, validation, and optimization of these models and the ability of each of the models to predict different outputs based on complex material and processing relationships;
- The research explored tuning of the models is important to optimize the prediction of the behavior of challenging recycled materials. The proposed strategy could lead to an increase in their usage across different industries;
- Models created could accurately predict the yield stress, ultimate elongation, and part weight to within 5% error for the linear and polynomial models and 10% error for the ANN with the Trig2 run;
- The predictions for the modulus were far less accurate with a % error of ~11% for the ANN and the linear regression models and of ~40% for the polynomial model. The modulus, as shown in the data, is a property that tends to show high variation across and within each of the runs. Therefore, the models struggle to find the proper trends, leading to larger errors in the predicted data;
- The differences between models’ performances can be attributed to data variability across different features. Future work will focus on expanding the analysis for different materials to allow more in-depth analysis of the sources of error;
- The optimization problem results showed no single methodology to be superior for all responses, as specific models performed better for particular ones. However, the overall results of predicting the processing inputs, Ttrig and Pact, were much worse, with errors between 3–25% depending on the response and the model;
- Future work will focus on adding a feature reassessment to identify other combinations of inputs that could better capture the complex relationships seen during the process. Additionally, alternative machine learning methodologies will be evaluated, including ensemble methods, such as Random Forest and Gradient Boosting, which could improve generalization and better capture the complex relationships in the data.
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Conflicts of Interest
Appendix A. Sample Python Script

Appendix B. Raw Data

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Material MFR (g/10 min) | Trigger Time (s) | Actual Pressure (bar) | Ultimate Elongation (%) | Yield Stress (MPa) | Modulus (MPa) | Part Weight (g) | APV (Pa-s) |
|---|---|---|---|---|---|---|---|
| 5 | 2 | 624 | 334.36 | 32.64 | 1361.83 | 13.21 | 275.48 |
| 5 | 2 | 624 | 353.54 | 32.66 | 1353.72 | 13.22 | 276.97 |
| 5 | 2 | 624 | 335.73 | 32.23 | 1323.97 | 13.21 | 277.46 |
| 5 | 2 | 624 | 326.65 | 32.51 | 1320.19 | 13.21 | 275.17 |
| 5 | 2 | 624 | 347.85 | 32.66 | 1332.20 | 13.20 | 277.23 |
| 5 | 2 | 624 | 321.91 | 32.77 | 1320.84 | 13.21 | 274.91 |
| 5 | 2 | 624 | 339.89 | 32.90 | 1334.81 | 13.22 | 274.12 |
| 5 | 2 | 624 | 335.37 | 32.52 | 1318.86 | 13.21 | 277.72 |
| 5 | 2 | 624 | 335.93 | 32.75 | 1319.47 | 13.21 | 282.95 |
| 5 | 2 | 624 | 368.35 | 32.10 | 1275.79 | 13.22 | 276.37 |
| 5 | 3 | 598 | 332.31 | 33.07 | 1342.81 | 13.19 | 509.84 |
| 5 | 3 | 598 | 335.70 | 33.40 | 1341.64 | 13.19 | 494.71 |
| 5 | 3 | 598 | 349.49 | 31.15 | 1303.58 | 13.19 | 473.78 |
| 5 | 3 | 598 | 306.55 | 34.08 | 1402.71 | 13.19 | 500.30 |
| 5 | 3 | 598 | 331.19 | 32.60 | 1330.13 | 13.18 | 496.31 |
| 5 | 3 | 598 | 337.84 | 31.89 | 1338.42 | 13.19 | 497.07 |
| 5 | 3 | 598 | 324.93 | 32.91 | 1379.63 | 13.18 | 500.34 |
| 5 | 3 | 598 | 320.70 | 33.14 | 1349.97 | 13.18 | 501.40 |
| 5 | 3 | 598 | 297.53 | 33.08 | 1378.71 | 13.19 | 498.53 |
| 5 | 3 | 598 | 336.11 | 32.80 | 1367.48 | 13.18 | 493.08 |
| 8 | 2 | 563 | 347.15 | 28.42 | 1128.57 | 13.22 | 229.50 |
| 8 | 2 | 563 | 318.19 | 28.55 | 1147.12 | 13.21 | 232.38 |
| 8 | 2 | 563 | 327.12 | 28.51 | 1115.59 | 13.21 | 223.12 |
| 8 | 2 | 563 | 334.80 | 28.54 | 1155.11 | 13.21 | 226.64 |
| 8 | 2 | 563 | 341.88 | 27.72 | 1121.72 | 13.22 | 244.75 |
| 8 | 2 | 563 | 306.98 | 30.17 | 1284.43 | 13.21 | 241.79 |
| 8 | 2 | 563 | 315.01 | 29.80 | 1245.28 | 13.21 | 232.20 |
| 8 | 2 | 563 | 296.44 | 29.63 | 1217.40 | 13.21 | 227.24 |
| 8 | 2 | 563 | 291.60 | 30.72 | 1303.36 | 13.21 | 243.21 |
| 8 | 2 | 563 | 310.26 | 29.94 | 1264.10 | 13.21 | 231.96 |
| 8 | 3 | 538 | 304.85 | 30.10 | 1284.07 | 13.19 | 419.12 |
| 8 | 3 | 538 | 289.77 | 30.85 | 1280.18 | 13.19 | 442.14 |
| 8 | 3 | 538 | 320.12 | 29.82 | 1246.01 | 13.19 | 447.77 |
| 8 | 3 | 538 | 286.17 | 30.36 | 1303.06 | 13.19 | 402.20 |
| 8 | 3 | 538 | 278.10 | 30.47 | 1289.62 | 13.20 | 441.22 |
| 8 | 3 | 538 | 341.33 | 27.45 | 1047.07 | 13.18 | 969.45 |
| 8 | 3 | 538 | 339.06 | 28.16 | 1076.78 | 13.19 | 974.48 |
| 8 | 3 | 538 | 333.76 | 27.29 | 1049.93 | 13.19 | 959.64 |
| 8 | 3 | 538 | 343.27 | 26.86 | 1035.26 | 13.18 | 1091.14 |
| 8 | 3 | 538 | 351.63 | 26.96 | 1022.20 | 13.18 | 653.57 |
| 14 | 2 | 483 | 356.87 | 20.59 | 762.45 | 13.21 | 184.68 |
| 14 | 2 | 483 | 345.65 | 20.12 | 750.41 | 13.21 | 182.21 |
| 14 | 2 | 483 | 368.24 | 20.04 | 747.24 | 13.22 | 183.65 |
| 14 | 2 | 483 | 345.34 | 20.53 | 770.93 | 13.22 | 190.12 |
| 14 | 2 | 483 | 349.34 | 21.10 | 776.26 | 13.22 | 186.66 |
| 14 | 2 | 483 | 344.47 | 20.64 | 776.86 | 13.21 | 181.36 |
| 14 | 2 | 483 | 365.18 | 19.93 | 737.49 | 13.21 | 177.64 |
| 14 | 2 | 483 | 369.39 | 19.56 | 722.31 | 13.22 | 177.65 |
| 14 | 2 | 483 | 355.92 | 20.04 | 730.33 | 13.21 | 186.52 |
| 14 | 2 | 483 | 379.80 | 19.60 | 729.58 | 13.21 | 194.29 |
| 14 | 3 | 457 | 359.06 | 20.26 | 755.07 | 13.20 | 319.25 |
| 14 | 3 | 457 | 369.96 | 19.88 | 743.02 | 13.20 | 335.31 |
| 14 | 3 | 457 | 347.07 | 20.21 | 758.87 | 13.20 | 314.59 |
| 14 | 3 | 457 | 330.97 | 19.90 | 730.88 | 13.19 | 338.14 |
| 14 | 3 | 457 | 365.56 | 19.82 | 725.93 | 13.20 | 304.05 |
| 14 | 3 | 457 | 372.34 | 20.63 | 762.41 | 13.20 | 407.50 |
| 14 | 3 | 457 | 361.73 | 19.33 | 684.55 | 13.19 | 378.87 |
| 14 | 3 | 457 | 343.82 | 19.53 | 711.29 | 13.20 | 325.27 |
| 14 | 3 | 457 | 374.85 | 20.19 | 744.37 | 13.20 | 320.52 |
| 14 | 3 | 457 | 372.21 | 19.25 | 710.97 | 13.19 | 348.57 |
| 32 | 2 | 415 | 397.97 | 13.58 | 374.46 | 13.21 | 135.84 |
| 32 | 2 | 415 | 398.13 | 12.91 | 337.80 | 13.21 | 132.26 |
| 32 | 2 | 415 | 395.81 | 11.92 | 288.90 | 13.21 | 130.55 |
| 32 | 2 | 415 | 375.94 | 12.34 | 300.99 | 13.20 | 139.71 |
| 32 | 2 | 415 | 395.87 | 13.05 | 331.82 | 13.20 | 144.78 |
| 32 | 2 | 415 | 385.01 | 12.77 | 344.96 | 13.20 | 138.48 |
| 32 | 2 | 415 | 408.92 | 12.77 | 336.38 | 13.21 | 130.93 |
| 32 | 2 | 415 | 410.16 | 12.74 | 333.87 | 13.20 | 139.93 |
| 32 | 2 | 415 | 386.21 | 12.99 | 349.26 | 13.21 | 130.07 |
| 32 | 2 | 415 | 397.15 | 12.44 | 327.58 | 13.20 | 127.63 |
| 32 | 3 | 383 | 380.97 | 13.87 | 398.49 | 13.18 | 238.31 |
| 32 | 3 | 383 | 387.53 | 13.36 | 370.07 | 13.18 | 261.67 |
| 32 | 3 | 383 | 385.43 | 13.19 | 362.70 | 13.18 | 230.65 |
| 32 | 3 | 383 | 418.18 | 13.03 | 340.46 | 13.18 | 245.37 |
| 32 | 3 | 383 | 395.07 | 13.53 | 380.87 | 13.18 | 271.56 |
| 32 | 3 | 383 | 392.74 | 13.25 | 365.19 | 13.18 | 265.16 |
| 32 | 3 | 383 | 411.57 | 12.63 | 322.07 | 13.18 | 261.61 |
| 32 | 3 | 383 | 402.72 | 12.99 | 348.56 | 13.18 | 269.48 |
| 32 | 3 | 383 | 406.46 | 13.07 | 350.22 | 13.19 | 299.13 |
| 32 | 3 | 383 | 386.96 | 12.69 | 330.30 | 13.18 | 288.72 |
| 50 | 2 | 367 | 209.39 | 11.45 | 289.17 | 13.18 | 103.64 |
| 50 | 2 | 367 | 354.55 | 11.79 | 297.29 | 13.19 | 100.79 |
| 50 | 2 | 367 | 353.27 | 11.69 | 290.74 | 13.19 | 105.12 |
| 50 | 2 | 367 | 372.53 | 11.23 | 260.94 | 13.19 | 101.98 |
| 50 | 2 | 367 | 369.58 | 11.40 | 276.97 | 13.19 | 106.23 |
| 50 | 2 | 367 | 372.72 | 11.91 | 305.30 | 13.19 | 100.50 |
| 50 | 2 | 367 | 371.66 | 11.87 | 300.16 | 13.19 | 99.93 |
| 50 | 2 | 367 | 354.12 | 11.63 | 279.09 | 13.18 | 100.76 |
| 50 | 2 | 367 | 338.49 | 11.60 | 282.68 | 13.19 | 104.05 |
| 50 | 2 | 367 | 376.09 | 11.70 | 284.47 | 13.18 | 100.14 |
| 50 | 3 | 336 | 348.24 | 11.80 | 299.26 | 13.18 | 175.92 |
| 50 | 3 | 336 | 362.97 | 11.58 | 288.62 | 13.17 | 174.99 |
| 50 | 3 | 336 | 388.54 | 12.19 | 319.45 | 13.16 | 180.95 |
| 50 | 3 | 336 | 380.54 | 11.92 | 303.80 | 13.17 | 179.36 |
| 50 | 3 | 336 | 390.18 | 11.72 | 289.86 | 13.17 | 179.80 |
| 50 | 3 | 336 | 385.02 | 11.92 | 302.17 | 13.17 | 180.70 |
| 50 | 3 | 336 | 357.50 | 12.16 | 316.57 | 13.16 | 181.50 |
| 50 | 3 | 336 | 330.23 | 11.94 | 296.02 | 13.17 | 185.16 |
| 50 | 3 | 336 | 377.34 | 11.84 | 288.48 | 13.16 | 185.46 |
| 50 | 3 | 336 | 382.42 | 12.13 | 312.36 | 13.17 | 181.63 |
References
- Párizs, R.D.; Török, D.; Ageyeva, T.; Kovács, J.G. Machine Learning in Injection Molding: An Industry 4.0 Method of Quality Prediction. Sensors 2022, 22, 2704. [Google Scholar] [CrossRef]
- Ageyeva, T.; Horváth, S.; Kovács, J.G. In-Mold Sensors for Injection Molding: On the Way to Industry 4.0. Sensors 2019, 19, 3551. [Google Scholar] [CrossRef]
- Ademujimi, T.T.; Brundage, M.P.; Prabhu, V.V. A Review of Current Machine Learning Techniques Used in Manufacturing Diagnosis. In Proceedings of the IFIP International Conference on Advances in Production Management Systems (APMS), Hamburg, Germany, 3–7 September 2017; pp. 407–415. [Google Scholar]
- Aminabadi, S.S.; Tabatabai, P.; Steiner, A.; Gruber, D.P.; Friesenbichler, W.; Habersohn, C.; Berger-Weber, G. Industry 4.0 In-Line AI Quality Control of Plastic Injection Molded Parts. Polymers 2022, 14, 3551. [Google Scholar] [CrossRef]
- Kurt, M.; Kaynak, Y.; Kamber, O.S.; Mutlu, B.; Bakir, B.; Koklu, U. Influence of molding conditions on the shrinkage and roundness of injection molded parts. Int. J. Adv. Manuf. Technol. 2009, 46, 571–578. [Google Scholar] [CrossRef]
- Huang, M.; Nian, S.; Lin, G. Influence of V/P switchover point, injection speed, and holding pressure on quality consistency of injection-molded parts. J. Appl. Polym. Sci. 2021, 138, 51223. [Google Scholar] [CrossRef]
- Chen, Z.; Turng, L. A review of current developments in process and quality control for injection molding. Adv. Polym. Technol. 2005, 24, 165–182. [Google Scholar] [CrossRef]
- Sykes, A.O. An Introduction to Regression Analysis. Law and Economics, no. 20, 1993. Available online: https://chicagounbound.uchicago.edu/law_and_economics (accessed on 1 April 2024).
- Yang, Y.; Gao, F. Injection molding product weight: Online prediction and control based on a nonlinear principal component regression model. Polym. Eng. Sci. 2006, 46, 540–548. [Google Scholar] [CrossRef]
- Zhang, Y.; Mao, T.; Huang, Z.; Gao, H.; Li, D. A statistical quality monitoring method for plastic injection molding using machine built-in sensors. Int. J. Adv. Manuf. Technol. 2015, 85, 2483–2494. [Google Scholar] [CrossRef]
- Youssef, A.H.; Madhuranthakam, C.M.R.; Elkamel, A.; Mittal, V. Optimizing mechanical properties of injection-molded long fiber-reinforced polypropylene. J. Thermoplast. Compos. Mater. 2014, 28, 849–862. [Google Scholar] [CrossRef]
- Shie, J. Optimization of injection-molding process for mechanical properties of polypropylene components via a generalized regression neural network. Polym. Adv. Technol. 2007, 19, 73–83. [Google Scholar] [CrossRef]
- Alexander, M.T.; Montgomery, D.C.; Runger, G. Applied Statistics and Probability for Engineers. Technometrics 1995, 37, 455. [Google Scholar] [CrossRef]
- Tsai, K.-M.; Hsieh, C.-Y.; Lo, W.-C. A study of the effects of process parameters for injection molding on surface quality of optical lenses. J. Mech. Work. Technol. 2008, 209, 3469–3477. [Google Scholar] [CrossRef]
- Deanin, R. Polymer Structure and Practical Properties; Cahners Books Publishing: Boston, MA, USA, 1972. [Google Scholar]
- Yin, F.; Mao, H.; Hua, L.; Guo, W.; Shu, M. Back Propagation neural network modeling for warpage prediction and optimization of plastic products during injection molding. Mater. Des. 2010, 32, 1844–1850. [Google Scholar] [CrossRef]
- Lee, C.; Na, J.; Park, K.; Yu, H.; Kim, J.; Choi, K.; Park, D.; Park, S.; Rho, J.; Lee, S. Development of Artificial Neural Network System to Recommend Process Conditions of Injection Molding for Various Geometries. Adv. Intell. Syst. 2020, 2, 2000037. [Google Scholar] [CrossRef]
- Xu, Y.; Zhang, Q.; Zhang, W.; Zhang, P. Optimization of injection molding process parameters to improve the mechanical performance of polymer product against impact. Int. J. Adv. Manuf. Technol. 2014, 76, 2199–2208. [Google Scholar] [CrossRef]
- Yousef, B.F.; Mourad, A.-H.I.; Hilal-Alnaqbi, A. Prediction of the Mechanical Properties of PE/PP Blends Using Artificial Neural Networks. Procedia Eng. 2011, 10, 2713–2718. [Google Scholar] [CrossRef]
- Ozcelik, B.; Erzurumlu, T. Comparison of the warpage optimization in the plastic injection molding using ANOVA, neural network model and genetic algorithm. J. Mech. Work. Technol. 2005, 171, 437–445. [Google Scholar] [CrossRef]
- Kenig, S.; Ben-David, A.; Omer, M.; Sadeh, A. Control of properties in injection molding by neural networks. Eng. Appl. Artif. Intell. 2001, 14, 819–823. [Google Scholar] [CrossRef]
- Heinisch, J.; Lockner, Y.; Hopmann, C. Comparison of design of experiment methods for modeling injection molding experiments using artificial neural networks. J. Manuf. Process. 2021, 61, 357–368. [Google Scholar] [CrossRef]
- Haykin, S. Neural Networks: A Comprehensive Foundation, 2nd ed.; Prentice Hall: Hoboken, NJ, USA, 1998. [Google Scholar]
- Lockner, Y.; Hopmann, C.; Zhao, W. Transfer learning with artificial neural networks between injection molding processes and different polymer materials. J. Manuf. Process. 2022, 73, 395–408. [Google Scholar] [CrossRef]
- Liao, L.; Li, H.; Shang, W.; Ma, L. An Empirical Study of the Impact of Hyperparameter Tuning and Model Optimization on the Performance Properties of Deep Neural Networks. ACM Trans. Softw. Eng. Methodol. 2022, 31, 1–40. [Google Scholar] [CrossRef]
- Roy, U.; Li, Y. Sustainability Assessment of the Injection Molding Process and the Effects of Material Selection. In Proceedings of the ASME Design Engineering Technical Conference, Buffalo, NY, USA, 17–20 August 2014; Volume 4, pp. 1–10. [Google Scholar] [CrossRef]
- Dangelico, R.M.; Pujari, D. Mainstreaming Green Product Innovation: Why and How Companies Integrate Environmental Sustainability. J. Bus. Ethic 2010, 95, 471–486. [Google Scholar] [CrossRef]
- Malloy, R. Plastic Part Design for Injection Molding—An Introduction, 2nd ed.; Hanser Publishers: Munich, Germany, 2010; Available online: https://app.knovel.com/web/toc.v/cid:kpPPDIMAI2/viewerType:toc//root_slug:plastic-part-design-injection/url_slug:linear-mold-shrinkage?b-q=malloy&include_synonyms=no&issue_id=kt011Q5BD4&hierarchy= (accessed on 9 November 2021).
- Fei, N.C.; Kamaruddin, S.; Siddiquee, A.N.; Khan, Z.A. Experimental Investigation on the Recycled HDPE and Optimization of Injection Moulding Process Parameters via Taguchi Method. 2011. Available online: https://www.researchgate.net/publication/215594743 (accessed on 1 March 2024).
- Altonen, M.; McConell, N.; Breidenbach, S.; Gergov, G. Injection Molding Machines and Methods for Accounting for Changes in Material Properties During Injection Molding Runs. CA2919376C, 5 February 2015. [Google Scholar]
- Altonen, G.; Neufarth, R.; Schiller, G.; Berg, C. Alternative Pressure Control For An Injection Molding Apparatus. U.S. Patent US9289933B2, 22 March 2016. [Google Scholar]
- Krantz, J.; Nieduzak, Z.; Kazmer, E.; Licata, J.; Ferki, O.; Gao, P.; Sobkowicz, M.J.; Masato, D. Investigation of pressure-controlled injection molding on the mechanical properties and embodied energy of recycled high-density polyethylene. Sustain. Mater. Technol. 2023, 36, e00651. [Google Scholar] [CrossRef]
- Krantz, J.; Nieduzak, Z.; Licata, J.; O’Meara, S.; Gao, P.; Masato, D. In-mold rheology and automated process control for injection molding of recycled polypropylene. Polym. Eng. Sci. 2024, 64, 4112–4127. [Google Scholar] [CrossRef]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine Learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Lee, J.; Yang, D.; Yoon, K.; Kim, J. Effects of Input Parameter Range on the Accuracy of Artificial Neural Network Prediction for the Injection Molding Process. Polymers 2022, 14, 1724. [Google Scholar] [CrossRef]
- ASTM D638-14; Standard Test Method for Tensile Properties of Plastics. American Society for Testing and Materials: West Conshohocken, PA, USA, 1998.


| Reference | Machine Learning Technique | Input Variables | Quality Metric |
|---|---|---|---|
| Heinisch et al. [22] | ANN | Simulation based, injection time, cooling time, packing pressure, packing time, melt and mold temperature | Length, width, weight |
| Yin et al. [16] | BP neural network | Mold and melt temperature, packing pressure, packing time, cooling time | Warpage |
| Lee et al. [17] | ANN, transfer learning | Combination of experimental and simulation based, geometric features and processing features | Weight |
| Xu et al. [18] | ANN combined with particle swarm optimization | Simulation based, mold and melt temperature, injection velocity, compression distance, force, velocity and waiting time | Impact performance (von mises stresses) |
| Yousef et al. [19] | ANN | Strain, blending ratio | Tensile performance and curves |
| Ozcelik, et al. [20] | ANN, ANOVA, genetic algorithm | Simulation based, mold and melt temperature, packing pressure, packing time, gate type, and gate location | Warpage |
| Kenig et al. [21] | ANN, multivariate regression | Melt and mold temperature, packing pressure, injection time, cooling time | Tensile modulus |
| Youssef, et al. [11] | Polynomial regression | Mechanical properties | Prediction accuracy, cost |
| Material | Non-Woven (%) | BOPP (%) | MFR (g/10 min) |
|---|---|---|---|
| Material A | 80 | 20 | 32 |
| Material B | 50 | 50 | 14 |
| Material C | 20 | 80 | 8 |
| Material D | 100 | 0 | 50 |
| Material E | 0 | 100 | 5 |
| Run | Melt Flow Rate (g/10 min) | Ttrig (s) | Pact (bar) |
|---|---|---|---|
| 1 | 32 | 2 | 415 |
| 2 | 32 | 3 | 382 |
| 3 | 8 | 2 | 563 |
| 4 | 8 | 3 | 538 |
| 5 | 50 | 2 | 367 |
| 6 | 50 | 3 | 336 |
| 7 | 5 | 2 | 624 |
| 8 | 5 | 3 | 598 |
| Run | MFR (g/10 min)/APV (Pa-s) | Ttrig (s) | Pact (bar) |
|---|---|---|---|
| Trig2 | 14/184 | 2 | 483 |
| 14/182 | 2 | ||
| 14/183 | 2 | ||
| 14/190 | 2 | ||
| 14/186 | 2 | ||
| 14/181 | 2 | ||
| 14/177 | 2 | ||
| 14/177 | 2 | ||
| 14/186 | 2 | ||
| 14/194 | 2 | ||
| Trig3 | 14/319 | 3 | 457 |
| 14/335 | 3 | ||
| 14/314 | 3 | ||
| 14/338 | 3 | ||
| 14/304 | 3 | ||
| 14/407 | 3 | ||
| 14/378 | 3 | ||
| 14/325 | 3 | ||
| 14/320 | 3 | ||
| 14/348 | 3 |
| Material MFR (g/10 min) | Trigger Time (s) | APV (Pa-s) | Yield Stress (MPa) | Modulus (MPa) | Ultimate Elongation (%) | Part Weight (g) |
|---|---|---|---|---|---|---|
| 5 | 2 | 277 ± 1.2 | 32.57 ± 0.12 | 1326 ± 11 | 340 ± 7.5 | 13.21 ± 0.003 |
| 5 | 3 | 497 ± 4.4 | 32.81 ± 0.38 | 1353 ± 14 | 327 ± 8 | 13.19 ± 0.002 |
| 8 | 2 | 233 ± 3.5 | 29.2 ± 0.45 | 1198 ± 35 | 319 ± 9 | 13.21 ± 0.002 |
| 8 | 3 | 680 ± 270 | 28.8 ± 0.77 | 1163 ± 59 | 319 ± 13 | 13.18 ± 0.003 |
| 32 | 2 | 135 ± 2.6 | 12.7 ± 0.22 | 333 ± 12 | 395 ± 5 | 13.21 ± 0.003 |
| 32 | 3 | 263 ± 10 | 13.2 ± 0.18 | 357 ± 11 | 397 ± 6 | 13.18 ± 0.002 |
| 50 | 2 | 102 ± 1.1 | 11.62 ± 0.1 | 287 ± 6 | 347 ± 24 | 13.19 ± 0.002 |
| 50 | 3 | 181 ± 1.5 | 11.92 ± 0.09 | 302 ± 14 | 370 ± 10 | 13.17 ± 0.003 |
| Material MFR (g/10 min) | Trigger Time (s) | APV (Pa-s) | Yield Stress (MPa) | Modulus (MPa) | Ultimate Elongation (%) | Part Weight (g) |
|---|---|---|---|---|---|---|
| 5 | 2 | 277 ± 1.2 | 32.57 ± 0.12 | 1326 ± 11 | 340 ± 7.5 | 13.21 ± 0.003 |
| 5 | 3 | 497 ± 4.4 | 32.81 ± 0.38 | 1353 ± 14 | 327 ± 8 | 13.19 ± 0.002 |
| 8 | 2 | 233 ± 3.5 | 29.2 ± 0.45 | 1198 ± 35 | 319 ± 9 | 13.21 ± 0.002 |
| 8 | 3 | 680 ± 270 | 28.8 ± 0.77 | 1163 ± 59 | 319 ± 13 | 13.18 ± 0.003 |
| 32 | 2 | 135 ± 2.6 | 12.7 ± 0.22 | 333 ± 12 | 395 ± 5 | 13.21 ± 0.003 |
| 32 | 3 | 263 ± 10 | 13.2 ± 0.18 | 357 ± 11 | 397 ± 6 | 13.18 ± 0.002 |
| 50 | 2 | 102 ± 1.1 | 11.62 ± 0.1 | 287 ± 6 | 347 ± 24 | 13.19 ± 0.002 |
| 50 | 3 | 181 ± 1.5 | 11.92 ± 0.09 | 302 ± 13 | 370 ± 10 | 13.17 ± 0.003 |
| Response | MFR Model | APV Model | ||
|---|---|---|---|---|
| R2 | R2/Degree | R2 | R2/Degree | |
| Linear Regression | Polynomial Regression | Linear Regression | Polynomial Regression | |
| Yield Stress | 95.6 | 98.2/4 | 96.5 | 98.9/3 |
| Modulus | 93.5 | 96.5/4 | 94.8 | 98.9/3 |
| Ultimate Elongation | 12.3 | 55.3/3 | 44.8 | 69.6/3 |
| Part Weight | 58.1 | 54.9/2 | 56.7 | 58.2/2 |
| Response | Training/Validation | MFR Model | APV Model | ||
|---|---|---|---|---|---|
| Final MAE | Final Loss | Final MAE | Final Loss | ||
| Yield Stress | Training | 0.432 | 0.387 | 0.348 | 0.208 |
| Validation | 0.756 | 1.34 | 0.451 | 0.523 | |
| Modulus | Training | 31.1 | 2187 | 22.46 | 1016 |
| Validation | 54.55 | 6609 | 38.68 | 2824 | |
| Ultimate Elongation | Training | 15.01 | 560 | 19.48 | 915 |
| Validation | 17.03 | 448 | 21.7 | 637 | |
| Part Weight | Training | 0.0043 | 0.00003 | 0.027 | 0.0016 |
| Validation | 0.0057 | 0.00005 | 0.128 | 0.06 | |
| Linear Model | Polynomial Model | ||||
|---|---|---|---|---|---|
| Run | Response | Model | % Error | Model | % Error |
| Trig2 | Yield Stress | APV | 2.38 | APV | 2.48 |
| MFR | 5.85 | MFR | 2.09 | ||
| Modulus | APV | 1.06 | APV | 5.28 | |
| MFR | 11.59 | MFR | 31.8 | ||
| Ultimate Elongation | APV | 1.43 | APV | 3.76 | |
| MFR | 5.81 | MFR | 2.45 | ||
| Part Weight | APV | 0.07 | APV | 0.01 | |
| MFR | 0.02 | MFR | 0.22 | ||
| Run | Response | Model | % Error | Model | % Error |
| Trig3 | Yield Stress | APV | 2.75 | APV | 1.56 |
| MFR | 5.54 | MFR | 2.52 | ||
| Modulus | APV | 0.68 | APV | 8.5 | |
| MFR | 11.34 | MFR | 44.09 | ||
| Ultimate Elongation | APV | 1.28 | APV | 2.54 | |
| MFR | 5.9 | MFR | 5.32 | ||
| Part Weight | APV | 0.08 | APV | 0.02 | |
| MFR | 0.01 | MFR | 0.22 | ||
| Run | Response | Model | % Error |
|---|---|---|---|
| Trig2 | Yield Stress | APV | 3.37 |
| MFR | 5.02 | ||
| Modulus | APV | 10.78 | |
| MFR | 5.02 | ||
| Ultimate Elongation | APV | 5.17 | |
| MFR | 5.74 | ||
| Part Weight | APV | 9.6 | |
| MFR | 5.72 | ||
| Run | Response | Model | % Error |
| Trig3 | Yield Stress | APV | 14.99 |
| MFR | 12.6 | ||
| Modulus | APV | 3.87 | |
| MFR | 10.6 | ||
| Ultimate Elongation | APV | 3.85 | |
| MFR | 7.61 | ||
| Part Weight | APV | 11.15 | |
| MFR | 4.23 |
| Ultimate Elongation (%) | Yield Stress (MPa) | Modulus (MPa) | Part Weight (g) | MFR (g/10 min)/Viscosity (Pa-s) |
|---|---|---|---|---|
| 356 | 20.59 | 762 | 13.21 | 14/184 |
| 345 | 20.12 | 750 | 13.21 | 14/182 |
| 368 | 20.04 | 747 | 13.22 | 14/183 |
| 345 | 20.53 | 770 | 13.22 | 14/190 |
| 349 | 21.10 | 776 | 13.22 | 14/186 |
| 344 | 20.64 | 776 | 13.21 | 14/181 |
| 365 | 19.93 | 737 | 13.21 | 14/177 |
| 369 | 19.56 | 722 | 13.22 | 14/177 |
| 355 | 20.04 | 730 | 13.21 | 14/186 |
| 379 | 19.60 | 729 | 13.21 | 14/194 |
| 359 | 20.26 | 755 | 13.20 | 14/319 |
| 369 | 19.88 | 743 | 13.20 | 14/335 |
| 347 | 20.21 | 758 | 13.20 | 14/314 |
| 330 | 19.90 | 730 | 13.19 | 14/338 |
| 365 | 19.82 | 725 | 13.20 | 14/304 |
| 372 | 20.63 | 762 | 13.20 | 14/407 |
| 361 | 19.33 | 684 | 13.19 | 14/378 |
| 343 | 19.53 | 711 | 13.20 | 14/325 |
| 374 | 20.19 | 744 | 13.20 | 14/320 |
| 372 | 19.25 | 710 | 13.19 | 14/348 |
| ANN Model | ||||||||
|---|---|---|---|---|---|---|---|---|
| Data Used | Yield Stress | Modulus | Ultimate Elongation | Part Weight | ||||
| Ttrig %error | Pact %error | Ttrig %error | Pact %error | Ttrig %error | Pact %error | Ttrig %error | Pact %error | |
| APV | 19.20% | 12.80% | 23.30% | 9.20% | 20.20% | 17.20% | 24.70% | 17.80% |
| MFR | 19% | 15.60% | 20.80% | 13.30% | 21.10% | 9.0% | 16.70% | 19.20% |
| Linear Model | ||||||||
| Data Used | Yield Stress | Modulus | Ultimate Elongation | Part Weight | ||||
| Ttrig %error | Pact %error | Ttrig %error | Pact %error | Ttrig %error | Pact %error | Ttrig %error | Pact %error | |
| APV | 22.10% | 3.60% | 16.80% | 2.60% | 21.80% | 14.00% | 12.00% | 18.24% |
| MFR | 23% | 3.20% | 20.10% | 3.70% | 17.40% | 8.7% | 20.30% | 19.00% |
| Polynomial Model | ||||||||
| Data Used | Yield Stress | Modulus | Ultimate Elongation | Part Weight | ||||
| Ttrig %error | Pact %error | Ttrig %error | Pact %error | Ttrig %error | Pact %error | Ttrig %error | Pact %error | |
| APV | 24.20% | 7.70% | 18.60% | 7.40% | 18.30% | 12.30% | 19.70% | 13.40% |
| MFR | 22.40% | 7.00% | 26.80% | 11.90% | 20.60% | 7% | 21.20% | 5.20% |
| Original | Predicted | |||
|---|---|---|---|---|
| Dataset | Trigger | Pressure | Trigger | Pressure |
| Viscosity | 2 | 483 | 2.5 | 512 |
| Viscosity | 3 | 457 | 2.6 | 522 |
| MFR | 2 | 483 | 2.46 | 455 |
| MFR | 3 | 457 | 2.55 | 468 |
| Yield Stress (MPa) | ||
|---|---|---|
| Dataset | Model Inputs | Actual Inputs |
| Viscosity | 19.06 | 20.22 |
| Viscosity | 18.79 | 19.9 |
| MFR | 19.02 | 20.22 |
| MFR | 19.79 | 19.9 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Krantz, J.; Licata, J.; Raju, M.A.; Gao, P.; Ma, R.; Masato, D. Machine Learning-Based Process Control for Injection Molding of Recycled Polypropylene. Polymers 2025, 17, 940. https://doi.org/10.3390/polym17070940
Krantz J, Licata J, Raju MA, Gao P, Ma R, Masato D. Machine Learning-Based Process Control for Injection Molding of Recycled Polypropylene. Polymers. 2025; 17(7):940. https://doi.org/10.3390/polym17070940
Chicago/Turabian StyleKrantz, Joshua, Juliana Licata, Muntaqim Ahmed Raju, Peng Gao, Ruizhe Ma, and Davide Masato. 2025. "Machine Learning-Based Process Control for Injection Molding of Recycled Polypropylene" Polymers 17, no. 7: 940. https://doi.org/10.3390/polym17070940
APA StyleKrantz, J., Licata, J., Raju, M. A., Gao, P., Ma, R., & Masato, D. (2025). Machine Learning-Based Process Control for Injection Molding of Recycled Polypropylene. Polymers, 17(7), 940. https://doi.org/10.3390/polym17070940