
Boosting-Based Machine Learning Applications in Polymer Science: A Review

 ,
,  , , and
, , and
Abstract
1. Introduction
2. Theoretical Background of Boosting Methods
2.1. Gradient Boosting (GB)
- -
- is the actual target value,
- -
- is the predicted value from the previous model,
- -
- is the new decision tree that is fitted to the residuals (errors) from ,
- -
- is the learning rate, which controls the contribution of each tree.
- -
- is the loss function that measures the error of the model’s prediction,
- -
- is the regularization term that penalizes overly complex trees, often given by:
2.2. AdaBoost
- -
- is the weak classifier,
- -
- is the weight of the i-th instance,
- -
- is the true label for the i-th instance.
- -
- is the weight of the t-th classifier, computed as:
- -
- T is the total number of weak classifiers,
- -
- is the weight (coefficient) assigned to each weak classifier based on its performance.
2.3. CatBoost
- -
- is the set of observations corresponding to the category ,
- -
- is the average target value for the categorical feature.
- -
- is the previous model’s prediction,
- -
- is the learning rate, and
- -
- is the decision tree model trained on the residuals.
- -
- T is the number of leaves in the tree,
- -
- is the weight of each leaf node,
- -
- and are regularization parameters that control the complexity of the trees.
2.4. LightGBM
- -
- is the value of the continuous feature,
- -
- is the binning step size (which determines the size of the bins), and
- -
- represents the bin index that the value falls into.
- -
- is the prediction from the previous model,
- -
- is the learning rate,
- -
- is the prediction of the new decision tree at the t-th step.
- -
- N is the total number of instances,
- -
- L and R represent the left and right child nodes after the split,
- -
- is the gradient of the loss with respect to the feature values.
- -
- T is the number of leaves in the tree,
- -
- is the weight of the j-th leaf node,
- -
- and are regularization parameters.
- -
- is the initial model, typically the mean of the target values,
- -
- is the learning rate,
- -
- is the t-th decision tree model.
2.5. XGBoost
- -
- is the true label for instance i,
- -
- is the model’s prediction for instance i at the previous step,
- -
- is the prediction of the new decision tree at the t-th step,
- -
- is the learning rate.
- -
- T is the number of leaves in the tree,
- -
- is the weight of the j-th leaf,
- -
- is a regularization parameter controlling the number of leaves in the tree,
- -
- is a regularization parameter controlling the size of the weights.
- -
- is the loss function that measures the difference between the true label and the predicted value ,
- -
- is the regularization term as defined earlier.
- -
- and are the gradient and Hessian of the loss function (first and second derivatives),
- -
- L, R, and S are the left, right, and split node, respectively.
- -
- is the initial model (often the mean value of the target),
- -
- is the learning rate,
- -
- is the prediction from the t-th tree.
3. Case Studies
3.1. Concrete and Geopolymer Composites
3.2. FRP and Reinforced Concrete Systems
3.3. Material Properties Prediction
3.4. Advanced Manufacturing and Processing
3.5. Sustainability, Environmental, and Structural Performance
4. Review Outlook
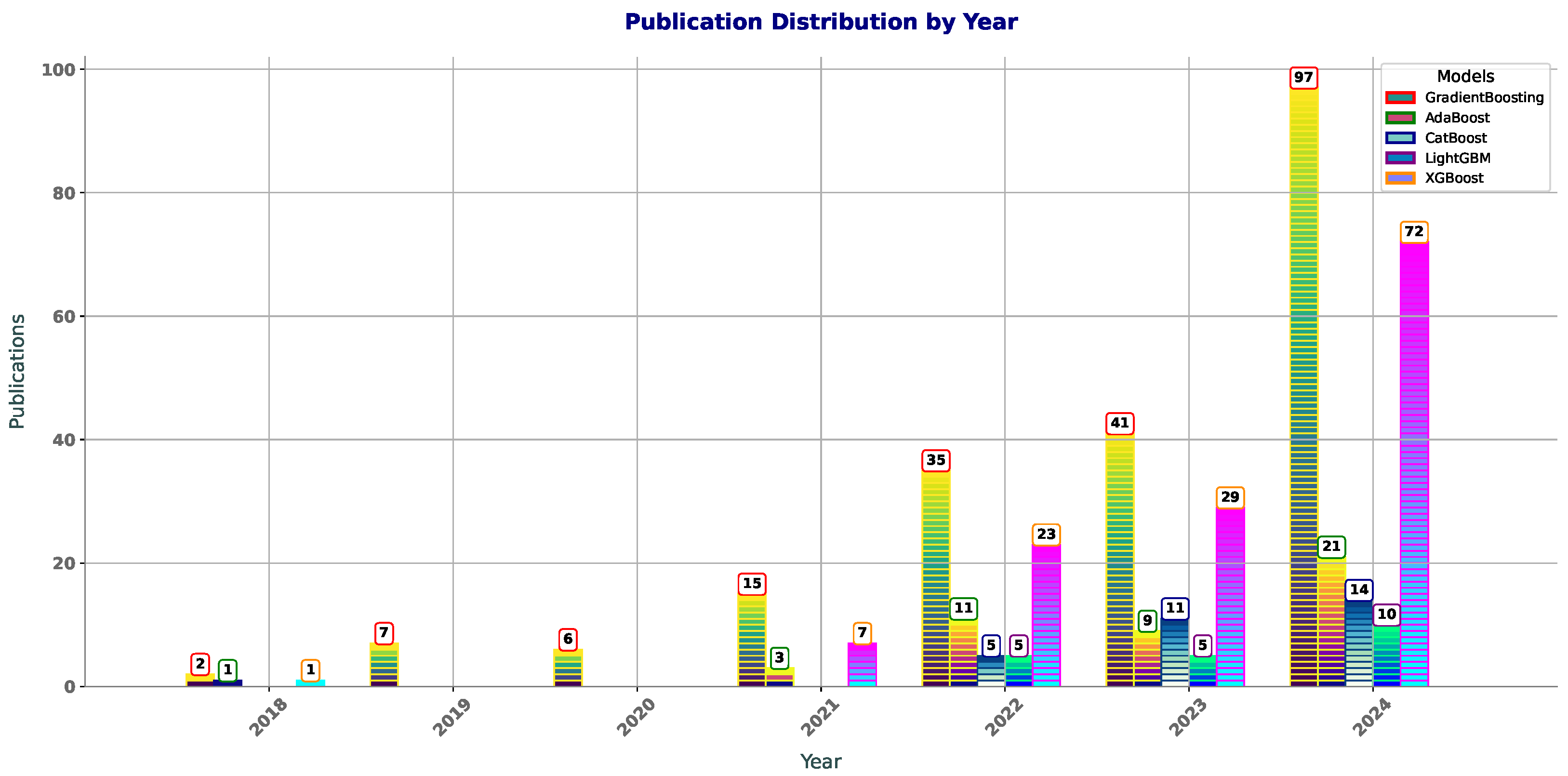
4.1. Analysis
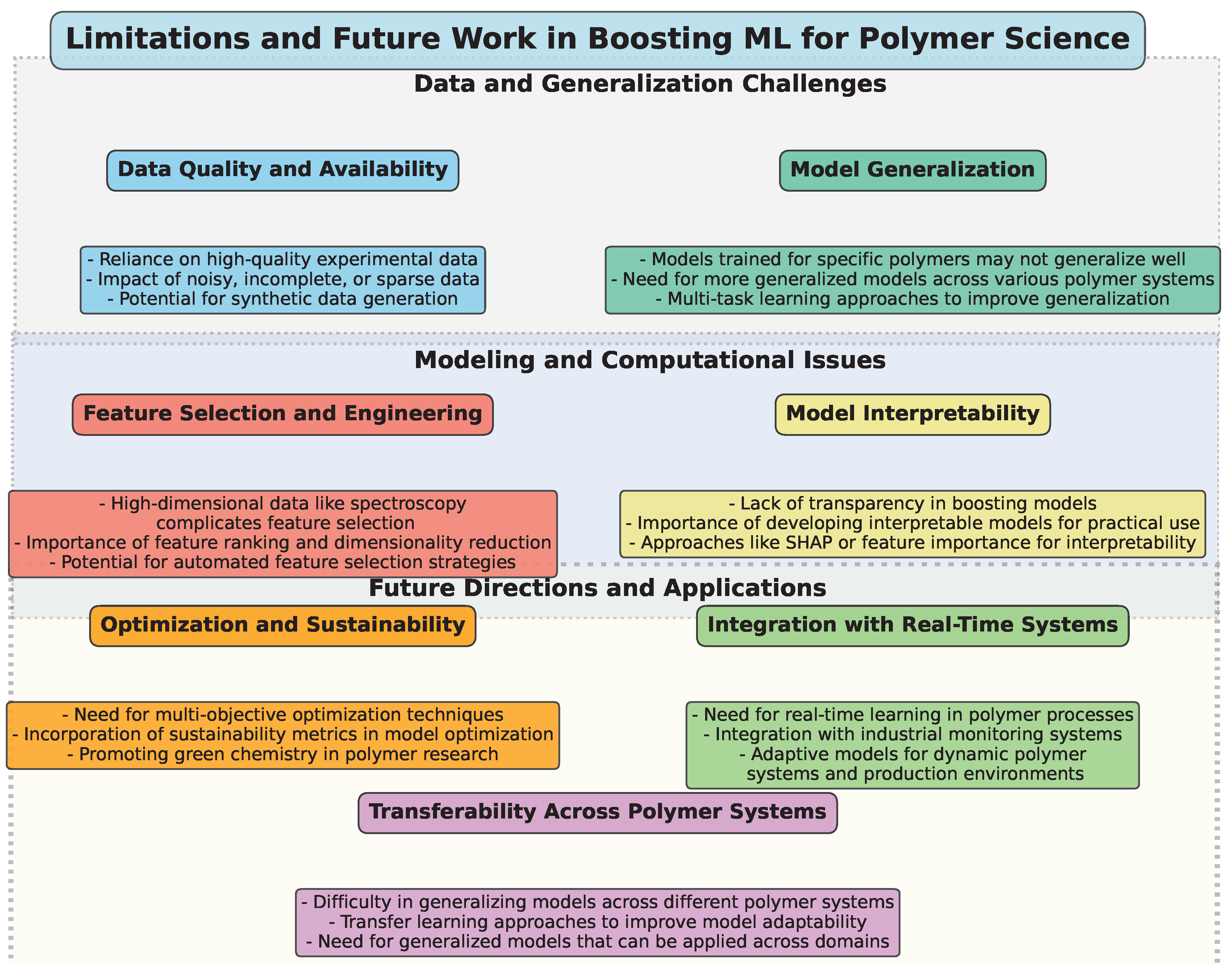
4.2. Limitations
4.3. Future Work
Author Contributions
Funding
Conflicts of Interest
References
- Broda, M.; Yelle, D.J.; Serwańska-Leja, K. Biodegradable Polymers in Veterinary Medicine—A Review. Molecules 2024, 29, 883. [Google Scholar] [CrossRef] [PubMed]
- Huang, B.; Yang, M.; Kou, Y.; Jiang, B. Absorbable implants in sport medicine and arthroscopic surgery: A narrative review of recent development. Bioact. Mater. 2024, 31, 272–283. [Google Scholar] [CrossRef] [PubMed]
- Kuperkar, K.; Atanase, L.I.; Bahadur, A.; Crivei, I.C.; Bahadur, P. Degradable polymeric bio (nano) materials and their biomedical applications: A comprehensive overview and recent updates. Polymers 2024, 16, 206. [Google Scholar] [CrossRef] [PubMed]
- Kim, H.C.; Tu, R.; Sodano, H.A. Room temperature 3D printing of high-temperature engineering polymer and its nanocomposites with porosity control for multifunctional structures. Compos. Part B Eng. 2024, 279, 111444. [Google Scholar] [CrossRef]
- Sabet, M. Unveiling advanced self-healing mechanisms in graphene polymer composites for next-generation applications in aerospace, automotive, and electronics. Polym.-Plast. Technol. Mater. 2024, 63, 2032–2059. [Google Scholar] [CrossRef]
- Silva, N.C.; Chevigny, C.; Domenek, S.; Almeida, G.; Assis, O.B.G.; Martelli-Tosi, M. Nanoencapsulation of active compounds in chitosan by ionic gelation: Physicochemical, active properties and application in packaging. Food Chem. 2025, 463, 141129. [Google Scholar] [CrossRef]
- Bharati, S.; Gaikwad, V.L. Biodegradable Polymers in Food Packaging. In Handbook of Biodegradable Polymers; Jenny Stanford Publishing: Singapore, 2025; pp. 683–743. [Google Scholar]
- Ngasotter, S.; Xavier, K.M.; Sagarnaik, C.; Sasikala, R.; Mohan, C.; Jaganath, B.; Ninan, G. Evaluating the reinforcing potential of steam-exploded chitin nanocrystals in chitosan-based biodegradable nanocomposite films for food packaging applications. Carbohydr. Polym. 2025, 348, 122841. [Google Scholar] [CrossRef] [PubMed]
- Zhang, Z.; Lu, L.; Hong, B.; Ye, Q.; Guo, L.; Yuan, C.; Liu, B.; Cui, B. Starch/polyacrylamide hydrogels with flexibility, conductivity and sensitivity enhanced by two imidazolium-based ionic liquids for wearable electronics: Effect of anion structure. Carbohydr. Polym. 2025, 347, 122783. [Google Scholar] [CrossRef] [PubMed]
- Zhang, Y.; Yu, Y.; Wang, Y.; Xia, C.; He, L.; Xia, Y.; Wang, Z. Self-recovery and self-conducting epoxy-based shape memory polymer microactuator. Sens. Actuators B Chem. 2025, 422, 136562. [Google Scholar] [CrossRef]
- Sun, Y.; Liang, F.; Chen, J.; Tang, H.; Yuan, W.; Zhang, S.; Tang, Y.; Chua, K.J. Ultrathin flexible heat pipes with heat transfer performance and flexibility optimization for flexible electronic devices. Renew. Sustain. Energy Rev. 2025, 208, 115064. [Google Scholar] [CrossRef]
- Tao, W.; Sun, Z.; Yang, Z.; Liang, B.; Wang, G.; Xiao, S. Transformer fault diagnosis technology based on AdaBoost enhanced transferred convolutional neural network. Expert Syst. Appl. 2025, 264, 125972. [Google Scholar] [CrossRef]
- Schapire, R.E. Explaining adaboost. In Empirical Inference: Festschrift in Honor of Vladimir N. Vapnik; Springer: Berlin/Heidelberg, Germany, 2013; pp. 37–52. [Google Scholar]
- Bentéjac, C.; Csörgo, A.; Martínez-Muñoz, G. A comparative analysis of gradient boosting algorithms. Artif. Intell. Rev. 2021, 54, 1937–1967. [Google Scholar] [CrossRef]
- Chen, H.; Cheng, Y.; Du, T.; Wu, X.; Cao, Y.; Liu, Y. Enhancing the performance of recycled aggregate green concrete via a Bayesian optimization light gradient boosting machine and the nondominated sorting genetic algorithm-III. Constr. Build. Mater. 2025, 458, 139527. [Google Scholar] [CrossRef]
- Meng, S.; Shi, Z.; Xia, C.; Zhou, C.; Zhao, Y. Exploring LightGBM-SHAP: Interpretable predictive modeling for concrete strength under high temperature conditions. In Structures; Elsevier: Amsterdam, The Netherlands, 2025; Volume 71, p. 108134. [Google Scholar]
- Ke, G.; Meng, Q.; Finley, T.; Wang, T.; Chen, W.; Ma, W.; Ye, Q.; Liu, T.Y. Lightgbm: A highly efficient gradient boosting decision tree. Adv. Neural Inf. Process. Syst. 2017, 30, 52. [Google Scholar]
- Hancock, J.T.; Khoshgoftaar, T.M. CatBoost for big data: An interdisciplinary review. J. Big Data 2020, 7, 94. [Google Scholar] [CrossRef] [PubMed]
- Wei, C.; Li, Z.; Zhu, D.; Xu, T.; Liang, Z.; Liu, Y.; Zhao, N. Regulation of the physicochemical properties of nutrient solution in hydroponic system based on the CatBoost model. Comput. Electron. Agric. 2025, 229, 109729. [Google Scholar] [CrossRef]
- Wang, R.; Zhang, M.; Gong, F.; Wang, S.; Yan, R. Improving port state control through a transfer learning-enhanced XGBoost model. Reliab. Eng. Syst. Saf. 2025, 253, 110558. [Google Scholar] [CrossRef]
- Chen, T.; Guestrin, C. Xgboost: A scalable tree boosting system. In Proceedings of the 22nd ACM Sigkdd International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 785–794. [Google Scholar]
- Sarkis-Onofre, R.; Catalá-López, F.; Aromataris, E.; Lockwood, C. How to properly use the PRISMA Statement. Syst. Rev. 2021, 10, 1–3. [Google Scholar] [CrossRef]
- Demir, S.; Sahin, E.K. An investigation of feature selection methods for soil liquefaction prediction based on tree-based ensemble algorithms using AdaBoost, gradient boosting, and XGBoost. Neural Comput. Appl. 2023, 35, 3173–3190. [Google Scholar] [CrossRef]
- Zhang, C.; Zhang, Y.; Shi, X.; Almpanidis, G.; Fan, G.; Shen, X. On incremental learning for gradient boosting decision trees. Neural Process. Lett. 2019, 50, 957–987. [Google Scholar] [CrossRef]
- Sobolewski, R.A.; Tchakorom, M.; Couturier, R. Gradient boosting-based approach for short-and medium-term wind turbine output power prediction. Renew. Energy 2023, 203, 142–160. [Google Scholar] [CrossRef]
- Phankokkruad, M.; Wacharawichanant, S. Prediction of mechanical properties of polymer materials using extreme gradient boosting on high molecular weight polymers. In Complex, Intelligent, and Software Intensive Systems, Proceedings of the 12th International Conference on Complex, Intelligent, and Software Intensive Systems (CISIS-2018), Matsue, Japan, 4–6 July 2018; Springer: Berlin/Heidelberg, Germany, 2019; pp. 375–385. [Google Scholar]
- Park, H.; Joo, C.; Lim, J.; Kim, J. Novel natural gradient boosting-based probabilistic prediction of physical properties for polypropylene-based composite data. Eng. Appl. Artif. Intell. 2024, 135, 108864. [Google Scholar] [CrossRef]
- Kavzoglu, T.; Teke, A. Predictive Performances of ensemble machine learning algorithms in landslide susceptibility mapping using random forest, extreme gradient boosting (XGBoost) and natural gradient boosting (NGBoost). Arab. J. Sci. Eng. 2022, 47, 7367–7385. [Google Scholar] [CrossRef]
- Shahraki, A.; Abbasi, M.; Haugen, ∅. Boosting algorithms for network intrusion detection: A comparative evaluation of Real AdaBoost, Gentle AdaBoost and Modest AdaBoost. Eng. Appl. Artif. Intell. 2020, 94, 103770. [Google Scholar] [CrossRef]
- Hussain, S.S.; Zaidi, S.S.H. AdaBoost Ensemble Approach with Weak Classifiers for Gear Fault Diagnosis and Prognosis in DC Motors. Appl. Sci. 2024, 14, 3105. [Google Scholar] [CrossRef]
- Zhang, L.; Jánošík, D. Enhanced short-term load forecasting with hybrid machine learning models: CatBoost and XGBoost approaches. Expert Syst. Appl. 2024, 241, 122686. [Google Scholar] [CrossRef]
- Mesghali, H.; Akhlaghi, B.; Gozalpour, N.; Mohammadpour, J.; Salehi, F.; Abbassi, R. Predicting maximum pitting corrosion depth in buried transmission pipelines: Insights from tree-based machine learning and identification of influential factors. Process Saf. Environ. Prot. 2024, 187, 1269–1285. [Google Scholar] [CrossRef]
- Osman, M.; He, J.; Mokbal, F.M.M.; Zhu, N.; Qureshi, S. Ml-lgbm: A machine learning model based on light gradient boosting machine for the detection of version number attacks in rpl-based networks. IEEE Access 2021, 9, 83654–83665. [Google Scholar] [CrossRef]
- Dhaliwal, S.S.; Nahid, A.A.; Abbas, R. Effective intrusion detection system using XGBoost. Information 2018, 9, 149. [Google Scholar] [CrossRef]
- Thongsuwan, S.; Jaiyen, S.; Padcharoen, A.; Agarwal, P. ConvXGB: A new deep learning model for classification problems based on CNN and XGBoost. Nucl. Eng. Technol. 2021, 53, 522–531. [Google Scholar] [CrossRef]
- Zabin, R.; Haque, K.F.; Abdelgawad, A. PredXGBR: A Machine Learning Framework for Short-Term Electrical Load Prediction. Electronics 2024, 13, 4521. [Google Scholar] [CrossRef]
- Tian, J.; Tsai, P.W.; Zhang, K.; Cai, X.; Xiao, H.; Yu, K.; Zhao, W.; Chen, J. Synergetic focal loss for imbalanced classification in federated xgboost. IEEE Trans. Artif. Intell. 2023, 5, 647–660. [Google Scholar] [CrossRef]
- Alsulamy, S. Predicting construction delay risks in Saudi Arabian projects: A comparative analysis of CatBoost, XGBoost, and LGBM. Expert Syst. Appl. 2025, 268, 126268. [Google Scholar] [CrossRef]
- Zhuo, H.; Li, T.; Lu, W.; Zhang, Q.; Ji, L.; Li, J. Prediction model for spontaneous combustion temperature of coal based on PSO-XGBoost algorithm. Sci. Rep. 2025, 15, 2752. [Google Scholar] [CrossRef] [PubMed]
- Ueki, Y.; Seko, N.; Maekawa, Y. Machine learning approach for prediction of the grafting yield in radiation-induced graft polymerization. Appl. Mater. Today 2021, 25, 101158. [Google Scholar] [CrossRef]
- Zhao, Y.; Chen, Z.; Jian, X. A High-Generalizability Machine Learning Framework for Analyzing the Homogenized Properties of Short Fiber-Reinforced Polymer Composites. Polymers 2023, 15, 3962. [Google Scholar] [CrossRef]
- Akinpelu, S.; Abolade, S.; Okafor, E.; Obada, D.; Ukpong, A.; Healy, J.; Akande, A. Interpretable machine learning methods to predict the mechanical properties of ABX3 perovskites. Results Phys. 2024, 65, 107978. [Google Scholar] [CrossRef]
- Liu, Z.; Wang, T.; Jin, L.; Zeng, J.; Dong, S.; Wang, F.; Wang, F.; Dong, J. Towards high stiffness and ductility-The Mg-Al-Y alloy design through machine learning. J. Mater. Sci. Technol. 2024, 221, 194–203. [Google Scholar] [CrossRef]
- Zhang, J.G.; Yang, G.C.; Ma, Z.H.; Zhao, G.L.; Song, H.Y. A stacking-CRRL fusion model for predicting the bearing capacity of a steel-reinforced concrete column constrained by carbon fiber-reinforced polymer. In Structures; Elsevier: Amsterdam, The Netherlands, 2023; Volume 55, pp. 1793–1804. [Google Scholar]
- Zhao, J.; Wang, A.; Zhu, Y.; Dai, J.G.; Xu, Q.; Liu, K.; Hao, F.; Sun, D. Manufacturing ultra-high performance geopolymer concrete (UHPGC) with activated coal gangue for both binder and aggregate. Compos. Part B Eng. 2024, 284, 111723. [Google Scholar] [CrossRef]
- Katlav, M.; Ergen, F.; Donmez, I. AI-driven design for the compressive strength of ultra-high performance geopolymer concrete (UHPGC): From explainable ensemble models to the graphical user interface. Mater. Today Commun. 2024, 40, 109915. [Google Scholar] [CrossRef]
- Wang, Q.; Ahmad, W.; Ahmad, A.; Aslam, F.; Mohamed, A.; Vatin, N.I. Application of Soft Computing Techniques to Predict the Strength of Geopolymer Composites. Polymers 2022, 14, 74. [Google Scholar] [CrossRef]
- Khan, K.; Ahmad, W.; Amin, M.N.; Ahmad, A.; Nazar, S.; Al-Faiad, M.A. Assessment of Artificial Intelligence Strategies to Estimate the Strength of Geopolymer Composites and Influence of Input Parameters. Polymers 2022, 14, 2509. [Google Scholar] [CrossRef]
- Zhou, J.; Tian, Q.; Ahmad, A.; Huang, J. Compressive and tensile strength estimation of sustainable geopolymer concrete using contemporary boosting ensemble techniques. Rev. Adv. Mater. Sci. 2024, 63, 20240014. [Google Scholar] [CrossRef]
- Amin, M.N.; Iqbal, M.; Khan, K.; Qadir, M.G.; Shalabi, F.I.; Jamal, A. Ensemble Tree-Based Approach towards Flexural Strength Prediction of FRP Reinforced Concrete Beams. Polymers 2022, 14, 1303. [Google Scholar] [CrossRef] [PubMed]
- Zadkarami, M.; Shahbazian, M.; Salahshoor, K. Pipeline leakage detection and isolation: An integrated approach of statistical and wavelet feature extraction with multi-layer perceptron neural network (MLPNN). J. Loss Prev. Process Ind. 2016, 43, 479–487. [Google Scholar] [CrossRef]
- Shamim Ansari, S.; Muhammad Ibrahim, S.; Danish Hasan, S. Conventional and Ensemble Machine Learning Models to Predict the Compressive Strength of Fly Ash Based Geopolymer Concrete. Mater. Today Proc. 2023. [Google Scholar] [CrossRef]
- Dodo, Y.; Arif, K.; Alyami, M.; Ali, M.; Najeh, T.; Gamil, Y. Estimation of compressive strength of waste concrete utilizing fly ash/slag in concrete with interpretable approaches: Optimization and graphical user interface (GUI). Sci. Rep. 2024, 14, 4598. [Google Scholar] [CrossRef]
- Sidhu, J.; Kumar, P. Experimental investigation on the effect of integral hydrophobic modification on the properties of fly ash-slag based geopolymer concrete. Constr. Build. Mater. 2024, 452, 138818. [Google Scholar] [CrossRef]
- Wudil, Y.S.; Al-Fakih, A.; Al-Osta, M.A.; Gondal, M. Effective carbon footprint assessment strategy in fly ash geopolymer concrete based on adaptive boosting learning techniques. Environ. Res. 2025, 266, 120570120570. [Google Scholar] [CrossRef] [PubMed]
- Kim, B.; Lee, D.E.; Hu, G.; Natarajan, Y.; Preethaa, S.; Rathinakumar, A.P. Ensemble Machine Learning-Based Approach for Predicting of FRP–Concrete Interfacial Bonding. Mathematics 2022, 10, 231. [Google Scholar] [CrossRef]
- Kumarawadu, H.; Weerasinghe, P.; Perera, J.S. Evaluating the Performance of Ensemble Machine Learning Algorithms over Traditional Machine Learning Algorithms for Predicting Fire Resistance in FRP Strengthened Concrete Beams. Electron. J. Struct. Eng. 2024, 24, 47–53. [Google Scholar] [CrossRef]
- Wang, C.; Zou, X.; Sneed, L.H.; Zhang, F.; Zheng, K.; Xu, H.; Li, G. Shear strength prediction of FRP-strengthened concrete beams using interpretable machine learning. Constr. Build. Mater. 2023, 407, 133553. [Google Scholar] [CrossRef]
- Mahmoudian, A.; Tajik, N.; Taleshi, M.M.; Shakiba, M.; Yekrangnia, M. Ensemble machine learning-based approach with genetic algorithm optimization for predicting bond strength and failure mode in concrete-GFRP mat anchorage interface. Structures 2023, 57, 105173. [Google Scholar] [CrossRef]
- Mahmoudian, A.; Bypour, M.; Kioumarsi, M. Explainable Boosting Machine Learning for Predicting Bond Strength of FRP Rebars in Ultra High-Performance Concrete. Computation 2024, 12, 202. [Google Scholar] [CrossRef]
- Wang, S.; Fu, Y.; Ban, S.; Duan, Z.; Su, J. Genetic evolutionary deep learning for fire resistance analysis in fibre-reinforced polymers strengthened reinforced concrete beams. Eng. Fail. Anal. 2024, 169, 109149. [Google Scholar] [CrossRef]
- Hu, H.; Wei, Q.; Wang, T.; Ma, Q.; Jin, P.; Pan, S.; Li, F.; Wang, S.; Yang, Y.; Li, Y. Experimental and Numerical Investigation Integrated with Machine Learning (ML) for the Prediction Strategy of DP590/CFRP Composite Laminates. Polymers 2024, 16, 1589. [Google Scholar] [CrossRef] [PubMed]
- Aydın, F.; Karaoğlan, K.M.; Pektürk, H.Y.; Demir, B.; Karakurt, V.; Ahlatçı, H. The comparative evaluation of the wear behavior of epoxy matrix hybrid nano-composites via experiments and machine learning models. Tribol. Int. 2025, 204, 110451. [Google Scholar] [CrossRef]
- Li, B.; Zhang, J.; Qu, Y.; Chen, D.; Chen, F. Data-driven predicting of bond strength in corroded BFRP concrete structures. Case Stud. Constr. Mater. 2024, 21, e03638. [Google Scholar] [CrossRef]
- Khodadadi, N.; Roghani, H.; De Caso, F.; El-kenawy, E.S.M.; Yesha, Y.; Nanni, A. Data-driven PSO-CatBoost machine learning model to predict the compressive strength of CFRP- confined circular concrete specimens. Thin-Walled Struct. 2024, 198, 111763. [Google Scholar] [CrossRef]
- Luo, T.; Xie, J.; Zhang, B.; Zhang, Y.; Li, C.; Zhou, J. An improved levy chaotic particle swarm optimization algorithm for energy-efficient cluster routing scheme in industrial wireless sensor networks. Expert Syst. Appl. 2024, 241, 122780. [Google Scholar] [CrossRef]
- Gong, C.; Zhou, N.; Xia, S.; Huang, S. Quantum particle swarm optimization algorithm based on diversity migration strategy. Future Gener. Comput. Syst. 2024, 157, 445–458. [Google Scholar] [CrossRef]
- Alizamir, M.; Gholampour, A.; Kim, S.; Keshtegar, B.; Jung, W.T. Designing a reliable machine learning system for accurately estimating the ultimate condition of FRP-confined concrete. Sci. Rep. 2024, 14, 20466. [Google Scholar] [CrossRef] [PubMed]
- Khan, K.; Iqbal, M.; Salami, B.A.; Amin, M.N.; Ahamd, I.; Alabdullah, A.A.; Arab, A.M.A.; Jalal, F.E. Estimating flexural strength of FRP reinforced beam using artificial neural network and random forest prediction models. Polymers 2022, 14, 2270. [Google Scholar] [CrossRef]
- Amin, M.N.; Salami, B.A.; Zahid, M.; Iqbal, M.; Khan, K.; Abu-Arab, A.M.; Alabdullah, A.A.; Jalal, F.E. Investigating the bond strength of FRP laminates with concrete using LIGHT GBM and SHAPASH analysis. Polymers 2022, 14, 4717. [Google Scholar] [CrossRef] [PubMed]
- Tian, L.; Wang, L.; Xian, G. Machine learning prediction of interfacial bond strength of FRP bars with different surface characteristics to concrete. Case Stud. Constr. Mater. 2024, 21, e03984. [Google Scholar] [CrossRef]
- Cheng, G.; Xiang, C.; Guo, F.; Wen, X.; Jia, X. Prediction of the tribological properties of a polymer surface in a wide temperature range using machine learning algorithm based on friction noise. Tribol. Int. 2023, 180, 108213. [Google Scholar] [CrossRef]
- Fatriansyah, J.F.; Linuwih, B.D.P.; Andreano, Y.; Sari, I.S.; Federico, A.; Anis, M.; Surip, S.N.; Jaafar, M. Prediction of Glass Transition Temperature of Polymers Using Simple Machine Learning. Polymers 2024, 16, 2464. [Google Scholar] [CrossRef] [PubMed]
- Ascencio-Medina, E.; He, S.; Daghighi, A.; Iduoku, K.; Casanola-Martin, G.M.; Arrasate, S.; González-Díaz, H.; Rasulev, B. Prediction of Dielectric Constant in Series of Polymers by Quantitative Structure-Property Relationship (QSPR). Polymers 2024, 16, 2731. [Google Scholar] [CrossRef] [PubMed]
- Danesh, T.; Ouaret, R.; Floquet, P.; Negny, S. Interpretability of neural networks predictions using Accumulated Local Effects as a model-agnostic method. In Computer Aided Chemical Engineering; Elsevier: Amsterdam, The Netherlands, 2022; Volume 51, pp. 1501–1506. [Google Scholar]
- Katić, D.; Krstić, H.; Otković, I.I.; Juričić, H.B. Comparing multiple linear regression and neural network models for predicting heating energy consumption in school buildings in the Federation of Bosnia and Herzegovina. J. Build. Eng. 2024, 97, 110728. [Google Scholar] [CrossRef]
- Helmer, M.; Warrington, S.; Mohammadi-Nejad, A.R.; Ji, J.L.; Howell, A.; Rosand, B.; Anticevic, A.; Sotiropoulos, S.N.; Murray, J.D. On the stability of canonical correlation analysis and partial least squares with application to brain-behavior associations. Commun. Biol. 2024, 7, 217. [Google Scholar] [CrossRef] [PubMed]
- Goh, K.L.; Goto, A.; Lu, Y. LGB-Stack: Stacked Generalization with LightGBM for Highly Accurate Predictions of Polymer Bandgap. ACS Omega 2022, 7, 29787–29793. [Google Scholar] [CrossRef] [PubMed]
- Amrihesari, M.; Kern, J.; Present, H.; Moreno Briceno, S.; Ramprasad, R.; Brettmann, B. Machine Learning Models for Predicting Polymer Solubility in Solvents across Concentrations and Temperatures. J. Phys. Chem. B 2024, 128, 12786–12797. [Google Scholar] [CrossRef] [PubMed]
- Rajaee, P.; Ghasemi, F.A.; Rabiee, A.H.; Fasihi, M.; Kakeh, B.; Sadeghi, A. Predicting tensile and fracture parameters in polypropylene-based nanocomposites using machine learning with sensitivity analysis and feature impact evaluation. Compos. Part C Open Access 2024, 15, 100535. [Google Scholar] [CrossRef]
- Mishra, J.K.; Hwang, K.J.; Ha, C.S. Preparation, mechanical and rheological properties of a thermoplastic polyolefin (TPO)/organoclay nanocomposite with reference to the effect of maleic anhydride modified polypropylene as a compatibilizer. Polymer 2005, 46, 1995–2002. [Google Scholar] [CrossRef]
- Abdi, J.; Hadipoor, M.; Hadavimoghaddam, F.; Hemmati-Sarapardeh, A. Estimation of tetracycline antibiotic photodegradation from wastewater by heterogeneous metal-organic frameworks photocatalysts. Chemosphere 2022, 287, 132135. [Google Scholar] [CrossRef]
- Abánades Lázaro, I.; Chen, X.; Ding, M.; Eskandari, A.; Fairen-Jimenez, D.; Giménez-Marqués, M.; Gref, R.; Lin, W.; Luo, T.; Forgan, R.S. Metal–organic frameworks for biological applications. Nat. Rev. Methods Prim. 2024, 4, 42. [Google Scholar] [CrossRef]
- Chen, D.; Zheng, Y.T.; Huang, N.Y.; Xu, Q. Metal-organic framework composites for photocatalysis. EnergyChem 2024, 6, 100115. [Google Scholar] [CrossRef]
- Okada, M.; Amamoto, Y.; Kikuchi, J. Designing Sustainable Hydrophilic Interfaces via Feature Selection from Molecular Descriptors and Time-Domain Nuclear Magnetic Resonance Relaxation Curves. Polymers 2024, 16, 824. [Google Scholar] [CrossRef] [PubMed]
- Salehi, S.; Arashpour, M.; Golafshani, E.M.; Kodikara, J. Prediction of rheological properties and ageing performance of recycled plastic modified bitumen using Machine learning models. Constr. Build. Mater. 2023, 401, 132728. [Google Scholar] [CrossRef]
- Nizamuddin, S.; Jamal, M.; Biligiri, K.P.; Giustozzi, F. Effect of various compatibilizers on the storage stability, thermochemical and rheological properties of recycled plastic-modified bitumen. Int. J. Pavement Res. Technol. 2024, 17, 854–867. [Google Scholar] [CrossRef]
- Gairola, S.; Sinha, S.; Singh, I. Improvement of flame retardancy and anti-dripping properties of polypropylene composites via ecofriendly borax cross-linked lignocellulosic fiber. Compos. Struct. 2024, 354, 118822. [Google Scholar] [CrossRef]
- Chonghyo, J.; Hyundo, P.; Scokyoung, H.; Jongkoo, L.; Insu, H.; Hyungtae, C.; Junghwan, K. Prediction for heat deflection temperature of polypropylene composite with Catboost. In Computer Aided Chemical Engineering; Elsevier: Amsterdam, The Netherlands, 2022; Volume 49, pp. 1801–1806. [Google Scholar]
- Chepurnenko, A.; Kondratieva, T.; Deberdeev, T.; Akopyan, V.; Avakov, A.; Chepurnenko, V. Prediction of Rheological Parameters of Polymers Using the CatBoost Gradient Boosting Algorithm. Polym. Sci. Ser. D 2024, 17, 121–128. [Google Scholar] [CrossRef]
- Hofmann, J.; Li, Z.; Taphorn, K.; Herzen, J.; Wudy, K. Porosity prediction in laser-based powder bed fusion of polyamide 12 using infrared thermography and machine learning. Addit. Manuf. 2024, 85, 104176. [Google Scholar] [CrossRef]
- Gadagi, A.; Sivaprakash, B.; Adake, C.; Deshannavar, U.; Hegde, P.G.; Santhosh, P.; Rajamohan, N.; Osman, A.I. Epoxy composite reinforced with jute/basalt hybrid—Characterisation and performance evaluation using machine learning techniques. Compos. Part C Open Access 2024, 14, 100453. [Google Scholar] [CrossRef]
- Wang, Q.; Qi, J.; Hosseini, S.; Rasekh, H.; Huang, J. ICA-LightGBM Algorithm for Predicting Compressive Strength of Geo-Polymer Concrete. Buildings 2023, 13, 2278. [Google Scholar] [CrossRef]
- Ncir, N.; El Akchioui, N. An advanced intelligent MPPT control strategy based on the imperialist competitive algorithm and artificial neural networks. Evol. Intell. 2024, 17, 1437–1461. [Google Scholar] [CrossRef]
- Abbasi, M.; Sadough, F.; Mahmoudi, A. Solving the fuzzy p-hub center problem using imperialist competitive algorithm. Int. J. Mach. Learn. Cybern. 2024, 15, 6163–6183. [Google Scholar] [CrossRef]
- Ahmad, A.; Ahmad, W.; Chaiyasarn, K.; Ostrowski, K.A.; Aslam, F.; Zajdel, P.; Joyklad, P. Prediction of geopolymer concrete compressive strength using novel machine learning algorithms. Polymers 2021, 13, 3389. [Google Scholar] [CrossRef] [PubMed]
- Asadi, B.; Hajj, R. Prediction of asphalt binder elastic recovery using tree-based ensemble bagging and boosting models. Constr. Build. Mater. 2024, 410, 134154. [Google Scholar] [CrossRef]
- Fares, M.Y.; Marini, S.; Lanotte, M. Multiple Stress Creep Recovery of High-Polymer Modified Binders: Consideration of Temperature and Stress Sensitivity for Quality Assurance/Quality Control Policy Development. Transp. Res. Rec. 2024, 03611981241240765. [Google Scholar] [CrossRef]
- Shen, Y.; Sun, J.; Liang, S. Interpretable Machine Learning Models for Punching Shear Strength Estimation of FRP Reinforced Concrete Slabs. Crystals 2022, 12, 259. [Google Scholar] [CrossRef]
- Hamilton, R.I.; Papadopoulos, P.N. Using SHAP values and machine learning to understand trends in the transient stability limit. IEEE Trans. Power Syst. 2023, 39, 1384–1397. [Google Scholar] [CrossRef]
- Rahman, J.; Arafin, P.; Billah, A.M. Machine learning models for predicting concrete beams shear strength externally bonded with FRP. In Structures; Elsevier: Amsterdam, The Netherlands, 2023; Volume 53, pp. 514–536. [Google Scholar]
- Biruk-Urban, K.; Bere, P.; Józwik, J. Machine Learning Models in Drilling of Different Types of Glass-Fiber-Reinforced Polymer Composites. Polymers 2023, 15, 4609. [Google Scholar] [CrossRef] [PubMed]
- Jalali, S.; Baniadam, M.; Maghrebi, M. Impedance value prediction of carbon nanotube/polystyrene nanocomposites using tree-based machine learning models and the Taguchi technique. Results Eng. 2024, 24, 103599. [Google Scholar] [CrossRef]
- Ma, L.; Zhou, C.; Lee, D.; Zhang, J. Prediction of axial compressive capacity of CFRP-confined concrete-filled steel tubular short columns based on XGBoost algorithm. Eng. Struct. 2022, 260, 114239. [Google Scholar] [CrossRef]
- Gao, W.; Jiang, Q.; Guan, Y.; Huang, H.; Liu, S.; Ling, S.; Zhou, L. Transfer learning improves predictions in lignin content of Chinese fir based on Raman spectra. Int. J. Biol. Macromol. 2024, 269, 132147. [Google Scholar] [CrossRef]
- Dong, Z.; Fang, Y.; Wang, X.; Zhao, Y.; Wang, Q. Hydrophobicity classification of polymeric insulators based on embedded methods. Mater. Res. 2015, 18, 127–137. [Google Scholar] [CrossRef]
- Kong, Q.; He, C.; Liao, L.; Xu, J.; Yuan, C. Hyperparameter optimization for interfacial bond strength prediction between fiber-reinforced polymer and concrete. Structures 2023, 51, 573–601. [Google Scholar] [CrossRef]
- Alanazi, J.; Algahtani, M.M.; Alanazi, M.; Alharby, T.N. Application of different mathematical models based on artificial intelligence technique to predict the concentration distribution of solute through a polymeric membrane. Ecotoxicol. Environ. Saf. 2023, 262, 115183. [Google Scholar] [CrossRef]
- Hai, T.; Basem, A.; Alizadeh, A.a.; Sharma, K.; Jasim, D.J.; Rajab, H.; Ahmed, M.; Kassim, M.; Singh, N.S.S.; Maleki, H. Optimizing Gaussian process regression (GPR) hyperparameters with three metaheuristic algorithms for viscosity prediction of suspensions containing microencapsulated PCMs. Sci. Rep. 2024, 14, 20271. [Google Scholar] [CrossRef]
- Tahir, M.H.; Farrukh, A.; Alqahtany, F.Z.; Badshah, A.; Shaaban, I.A.; Assiri, M.A. Accelerated discovery of polymer donors for organic solar cells through machine learning: From library creation to performance forecasting. Spectrochim. Acta Part A Mol. Biomol. Spectrosc. 2025, 326, 125298. [Google Scholar] [CrossRef]
- Jiang, J.; Lu, A.; Ma, X.; Ouyang, D.; Williams, R.O. The applications of machine learning to predict the forming of chemically stable amorphous solid dispersions prepared by hot-melt extrusion. Int. J. Pharm. X 2023, 5, 100164. [Google Scholar] [CrossRef] [PubMed]
- Burke, A.J. Asymmetric organocatalysis in drug discovery and development for active pharmaceutical ingredients. Expert Opin. Drug Discov. 2023, 18, 37–46. [Google Scholar] [CrossRef] [PubMed]
- Pang, J.; Zhao, Z. Real-time Monitoring of Fluidized Bed Agglomerating based on Improved Adaboost Algorithm. J. Physics Conf. Ser. 2021, 1924, 012026. [Google Scholar] [CrossRef]
- Chan, R.K.; Wang, B.X. Do long-term acoustic-phonetic features and mel-frequency cepstral coefficients provide complementary speaker-specific information for forensic voice comparison? Forensic Sci. Int. 2024, 363, 112199. [Google Scholar] [CrossRef] [PubMed]
- Fiosina, J.; Sievers, P.; Drache, M.; Beuermann, S. Polymer reaction engineering meets explainable machine learning. Comput. Chem. Eng. 2023, 177, 108356. [Google Scholar] [CrossRef]
- Correia, J.S.; Mirón-Barroso, S.; Hutchings, C.; Ottaviani, S.; Somuncuoğlu, B.; Castellano, L.; Porter, A.E.; Krell, J.; Georgiou, T.K. How does the polymer architecture and position of cationic charges affect cell viability? Polym. Chem. 2023, 14, 303–317. [Google Scholar] [CrossRef] [PubMed]
- Deshpande, A.R.; Kulkarni, A.P.; Wasatkar, N.; Gajalkar, V.; Abdullah, M. Prediction of Wear Rate of Glass-Filled PTFE Composites Based on Machine Learning Approaches. Polymers 2024, 16, 2666. [Google Scholar] [CrossRef] [PubMed]
- Huang, D.; Li, Z.; Wang, K.; Zhou, H.; Zhao, X.; Peng, X.; Zhang, R.; Wu, J.; Liang, J.; Zhao, L. Probing the Effect of Photovoltaic Material on Voc in Ternary Polymer Solar Cells with Non-Fullerene Acceptors by Machine Learning. Polymers 2023, 15, 2954. [Google Scholar] [CrossRef]
- Bin Inqiad, W.; Javed, M.F.; Siddique, M.S.; Khan, N.M.; Alkhattabi, L.; Abuhussain, M.; Alabduljabbar, H. Comparison of boosting and genetic programming techniques for prediction of tensile strain capacity of Engineered Cementitious Composites (ECC). Mater. Today Commun. 2024, 39, 109222. [Google Scholar] [CrossRef]
- Nguyen, T.H.; Vuong, H.T.; Shiau, J.; Nguyen-Thoi, T.; Nguyen, D.H.; Nguyen, T. Optimizing flexural strength of RC beams with recycled aggregates and CFRP using machine learning models. Sci. Rep. 2024, 14, 28621. [Google Scholar] [CrossRef] [PubMed]
- Li, F.; Rana, M.S.; Qurashi, M.A. Advanced machine learning techniques for predicting concrete mechanical properties: A comprehensive review of models and methodologies. Multiscale Multidiscip. Model. Exp. Des. 2025, 8, 1–41. [Google Scholar] [CrossRef]
- Cheng, X. A Comprehensive Study of Feature Selection Techniques in Machine Learning Models. Insights Comput. Signals Syst. 2024, 1, 10–70088. [Google Scholar] [CrossRef]
- Sheng, K.; Jiang, G.; Du, M.; He, Y.; Dong, T.; Yang, L. Interpretable knowledge-guided framework for modeling reservoir water-sensitivity damage based on Light Gradient Boosting Machine using Bayesian optimization and hybrid feature mining. Eng. Appl. Artif. Intell. 2024, 133, 108511. [Google Scholar] [CrossRef]
- Subeshan, B.; Atayo, A.; Asmatulu, E. Machine learning applications for electrospun nanofibers: A review. J. Mater. Sci. 2024, 59, 14095–14140. [Google Scholar] [CrossRef]
- Hussain, S.; Mustafa, M.W.; Jumani, T.A.; Baloch, S.K.; Alotaibi, H.; Khan, I.; Khan, A. A novel feature engineered-CatBoost-based supervised machine learning framework for electricity theft detection. Energy Rep. 2021, 7, 4425–4436. [Google Scholar] [CrossRef]
- Nagassou, M.; Mwangi, R.W.; Nyarige, E. A hybrid ensemble learning approach utilizing light gradient boosting machine and category boosting model for lifestyle-based prediction of type-II diabetes mellitus. J. Data Anal. Inf. Process. 2023, 11, 480–511. [Google Scholar] [CrossRef]
- Yin, L.; Ma, P.; Deng, Z. JLGBMLoc—A novel high-precision indoor localization method based on LightGBM. Sensors 2021, 21, 2722. [Google Scholar] [CrossRef] [PubMed]
- Chen, C.; Zhang, Q.; Ma, Q.; Yu, B. LightGBM-PPI: Predicting protein-protein interactions through LightGBM with multi-information fusion. Chemom. Intell. Lab. Syst. 2019, 191, 54–64. [Google Scholar] [CrossRef]
- Jin, D.; Lu, Y.; Qin, J.; Cheng, Z.; Mao, Z. SwiftIDS: Real-time intrusion detection system based on LightGBM and parallel intrusion detection mechanism. Comput. Secur. 2020, 97, 101984. [Google Scholar]
- Han, R.; Fu, X.; Guo, H. Interpretable machine learning-assisted strategy for predicting the mechanical properties of hydroxyl-terminated polyether binders. J. Polym. Sci. 2024. [Google Scholar] [CrossRef]
- Ke, L.; Qiu, M.; Chen, Z.; Zhou, J.; Feng, Z.; Long, J. An interpretable machine learning model for predicting bond strength of CFRP-steel epoxy-bonded interface. Compos. Struct. 2023, 326, 117639. [Google Scholar] [CrossRef]
- Kalladi, A.J.; Ramesan, M.T. In-situ polymerized boehmite/cashew gum/polyvinyl alcohol/polypyrrole blend nanocomposites with tunable structural, electrical, and mechanical properties for enhanced energy storage applications. J. Mol. Struct. 2025, 1322, 140379. [Google Scholar] [CrossRef]
- Nayak, S.; Sharma, Y.K. A modified Bayesian boosting algorithm with weight-guided optimal feature selection for sentiment analysis. Decis. Anal. J. 2023, 8, 100289. [Google Scholar] [CrossRef]
- Zhao, X.; Liu, Y.; Zhao, Q. Improved LightGBM for extremely imbalanced data and application to credit card fraud detection. IEEE Access 2024, 12, 159316–159335. [Google Scholar] [CrossRef]
- Ghasem, N. Combining CFD and AI/ML Modeling to Improve the Performance of Polypropylene Fluidized Bed Reactors. Fluids 2024, 9, 298. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Study | Boosting Technique | Application | Materials/ Properties Predicted | Dataset | Model Performance (R2, MAE, RMSE) | Key Influencing Factors | Additional Techniques/ Analysis |
|---|---|---|---|---|---|---|---|
| Zhao et al. (2023) [41] | XGBoost, LightGBM, Extra Trees | Short FRP composites | Homogenized mechanical properties (e.g., Young’s modulus) | High fidelity composite datasets, experimental data | R2 of 0.988 (train), 0.952 (test) | Fiber orientation, fiber content, matrix Young’s modulus | SHAP analysis, micromechanical model integration |
| Zhang et al. (2023) [44] | CatBoost, RF, Ridge, LASSO | Steel-reinforced concrete columns (SRCCs) clad in CFRP | Axial compression load capacity | Sparse data, 12 features | High predictive accuracy, better than individual models | Load capacity factors | SMOTE for data balancing, SHAP analysis |
| Katlav et al. (2024) [46] | XGBoost, LightGBM, AdaBoost, RF | UHPGC | Compressive strength (CS) | 181 test results, 13 input features | R2 = 0.948 | Age, fiber content, water content | SHAP analysis, user interface for practical predictions |
| Wang et al. (2022) [47] | AdaBoost, RF | GPCs | CS | Experimental datasets | R2 = 0.90 | Fly ash, curing time, NaOH molarity | SHAP analysis |
| Khan et al. (2022) [48] | XGBoost, GB | GPCs | CS | 500+ mixes | R2 = 0.98 | GGBS, NaOH molarity, fly ash | SHAP analysis |
| Zhou et al. (2024) [49] | XGBoost, AdaBoost, Gradient Boosting | GPC | CS, STS | Experimental data | R2 > 0.90 | Blast furnace slag, curing duration, fine aggregate | K-fold analysis |
| Amin et al. (2022) [50] | AdaBoost, RF | GeoPC | CS | 481 mixes, 9 variables | R2 = 0.95 | Curing time, temperature, specimen age | Sensitivity analysis, k-fold validation |
| Ansari et al. (2023) [52] | AdaBoost | GPC with fly ash | CS | 154 datasets | R2 = 0.944, RMSE = 2.506, MAE = 1.259 | Fly ash content, water-to-binder ratio | Evaluation through R2, MAE, RMSE |
| Dodo et al. (2024) [53] | AdaBoost, Bagging with ANN | FASBGeoPC | CS | 156 data points | R2 = 0.914 | GGBS, NaOH molarity, temperature | SHAP analysis, ensemble methods |
| Wudil et al. (2025) [55] | AdaBoost | Fly ash GeoPC | Carbon dioxide footprint (CO2-FP) | Experimental data, material features | CC = 0.9665, NSE = 0.9343 | NaOH, curing temperature, fly ash content | SHAP analysis, IoT integration |
| Study | Boosting Technique | Application | Materials/ Properties Predicted | Dataset | Model Performance (R2, MAE, RMSE) | Key Influencing Factors | Additional Techniques/ Analysis |
|---|---|---|---|---|---|---|---|
| Kim et al. [56] | CatBoost | FRP-concrete bond strength | FRP bond strength | 855 shear test data | RMSE: 2.31, R2: 0.96 | Small dataset, categorical features | Compared with XGBoost, HGBoost, RF |
| Kumarawadu et al. [57] | XGBoost, CatBoost | Fire resistance of FRP-strengthened RC beams | Fire resistance | 21,000 data points | Accuracy: >92% | Loading ratio, insulation depth, concrete cover | Bayesian optimization, SHAP analysis |
| Wang et al. [58] | XGBoost | Shear strength of FRP-RC beams | Shear strength | 442 RC beam data | High prediction accuracy | Effective height of FRP, shear span ratio | Isolation forest anomaly detection |
| Mahmoudian et al. [59] | Decision Tree, RF, AdaBoost, XGBoost | Flexural bond strength of GFRP | GFRP-concrete bond | Experimental data | Accuracy: 100% | Concrete type, GFRP bar properties | Hyperparameter tuning, SHAP analysis |
| Mahmoudian et al. [60] | AdaBoost, XGBoost, CatBoost, GB, Hist GB | Bond strength in FRP-UHPC | FRP-UHPC bond strength | Experimental dataset | R2: 0.95, RMSE: 2.21 | Tensile strength, elastic modulus, embedment length | Shapley values, Voting Regressor |
| Wang et al. [61] | LightGBM, Genetic Programming | Fire resistance of FRP-strengthened RC beams | Fire resistance, deflection | 20,000 data points | R2: 0.923 (Fire Resistance), 0.789 (Deflection) | Insulation thickness, reinforcement area | Genetic Algorithm, SHAP analysis |
| Hu et al. [62] | XGBoost, Gradient Boosting | CFRP/metal composite laminates’ mechanical properties | Tensile and bending strength | Experimental and simulation data | Best for tensile (XGBoost), bending (RF) | Laminate stacking sequence | Numerical and experimental integration |
| Aydın et al. [63] | DMLP, RF, GBR, LR, PR | Wear behavior of MWCNT-CFRP composites | Wear loss prediction | Experimental data | R2: 0.9726 | MWCNT content, load, sliding distance | SEM, EDS analysis |
| Li et al. [64] | RF, AdaBoost | Bond strength of BFRP-concrete in corrosive environments | BFRP-concrete bond strength | 355 samples | R2: 0.925, MAE: 0.0589 | Corrosion, concrete strength, BFRP properties | SHAP analysis |
| Khodadadi et al. [65] | PSO-CatBoost | Compressive strength of CFRP-confined concrete | CFRP-CC compressive strength | 916 experimental results | R2: 0.9572 | CFRP reinforcement ratio, unconfined CS | SHAP, PFI, Graphical interface |
| Alizamir et al. [68] | GBRT, RF, ANNMLP, ANNRBF | FRP-confinement in concrete strength | Concrete strength ratio | 765 specimens | RMSE reduction: 69.94% (GBRT) | Concrete type, specimen geometry | Advanced feature selection |
| Amin et al. [50] | DT, GBT | Flexural capacity of FRP-RC beams | Flexural strength | 60% training, 40% validation | R: 0.94 (GBT) | Beam depth, concrete CS | Sensitivity analysis |
| Amin et al. [70] | RF, XGBoost, LIGHT GBM | Bond strength of FRP on concrete prisms | Interfacial bond strength (IBS) | 70% training, 30% testing | R2: 0.942 (training), 0.865 (testing) | FRP thickness, elastic modulus | SHAP analysis |
| Tian et al. [71] | CatBoost | Bond strength of FRP bars to concrete | Bond strength | 158 pull-out test results | RMSE reduction: 58.3% | Rib spacing and width, concrete properties | Integration with traditional formulas |
| Study | Boosting Technique | Application | Materials/ Properties Predicted | Dataset | Model Performance (R2, MAE, RMSE) | Key Influencing Factors | Additional Techniques/ Analysis |
|---|---|---|---|---|---|---|---|
| Cheng et al. [72] | XGBoost, LightGBM, CatBoost | Friction coefficient of polymer–metal pairs | Friction coefficient, temperature range (−120 °C to 25 °C) | Various working conditions | RMSE: 0.0135, R2: 0.615 | Friction noise, temperature | Time-frequency feature analysis |
| Fatriansyah et al. [73] | XGBoost, ANN, RNN, KNN, SVR | Glass transition temperature (Tg) of polymers | Tg of polymers | SMILES descriptors | R2: 0.774, MAE: 9.76% deviation | SMILES descriptor length | One Hot Encoding vs NLP |
| Ascencio-Medina et al. [74] | GBR | Dielectric permittivity of polymers | Dielectric permittivity | 86 polymers | R2: 0.938 (train), 0.822 (test) | Electronic, ionic, dipolar polarization | Genetic algorithm, ALE analysis |
| Goh et al. [78] | LightGBM (LGB-Stack) | Polymer properties prediction | Various polymer properties | 4209 polymers | R2: 0.92, RMSE: 0.41 | Molecular fingerprints | Feature reduction, Recursive Feature Elimination |
| Rajaee et al. [80] | AdaBoost, Decision Tree | Mechanical | Tensile strength, Young’s modulus, elongation | Polypropylene nanocomposites | R2: 0.90 for Young’s modulus | TPO levels, nanoparticle content | Sensitivity analysis |
| Abdi et al. [82] | CatBoost | Photodegradation of tetracycline | TC degradation from wastewater | 374 data points | AAPRE: 1.19%, STD: 0.0431 | Catalyst dosage, pH, surface area | Outlier detection |
| Okada et al. [85] | GBM-RFE | Hydrophilicity of polymer coatings | Surface hydrophilicity | Polyacrylamide coatings | High accuracy in feature selection | Polymer chain dynamics | TD-NMR, Recursive Feature Elimination |
| Salehi et al. [86] | CatBoost, XGBoost, LightGBM, RF | Rheological properties of RPMB | Complex shear modulus, phase angle | Recycled plastic modified bitumen | R2: 0.98 (shear modulus) | Base bitumen, recycled plastic quantity | SHAP analysis |
| Chonghyo et al. [89] | CatBoost, XGBoost, MLR | Heat deflection temperature (HDT) of PPCs | Heat deflection temperature | Polypropylene composites | R2: 0.8965, RMSE: 7.3477 | Material composition | Novel dimensionless number “A” |
| Chepurnenko et al. [90] | CatBoost, Evolutionary algorithms | Rheological properties of polymers | Viscosity, velocity modulus | Epoxy binder | MAPE: 0.86, MSE: 0.001 | Stress relaxation | Data normalization, regularization |
| Hofmann et al. [91] | LightGBM | Local solidity in PBF-LB process | Porosity, solidity | Thermal and temporal features | High prediction accuracy | Peak temperature, reheating | Infrared thermography, X-ray micro-CT |
| Gadagi et al. [92] | XGBoost, AdaBoost, GBM | Surface roughness of composites | Surface roughness of epoxy composites | Jute/basalt composites | High accuracy in roughness prediction | Spindle speed, feed rate | Taguchi L27 array |
| Wang et al. [93] | ICA-LightGBM | Geo-polymer concrete CS prediction | Compressive strength (CS) of geo-polymer concrete | Geo-polymer concrete dataset | R2: 0.9871 (train), 0.9805 (test) | Hyperparameter optimization | Imperialist Competitive Algorithm optimization |
| Ahmad et al. [96] | Boosting, AdaBoost | Compressive strength of GPC | Compressive strength of GPC | High calcium fly-ash-based GPC | R2: 0.96 | Fly ash composition | Sensitivity analysis |
| Asadi et al. [97] | XGBoost, LightGBM, CatBoost, Extra Trees | Asphalt binder elastic recovery (ER) prediction | Elastic recovery (ER) from MSCR test results | Asphalt binders | R2: 0.852 (Extra Trees), 0.842 (XGBoost) | Stress recovery at 0.1, 3.2 kPa | Clustering analysis |
| Shen et al. [99] | AdaBoost | Punching shear strength of FRP RC slabs | Punching shear strength of FRP RC slabs | 121 experimental results | R2: 0.99, RMSE: 29.83, MAE: 23.00 | Effective depth, Young’s modulus of FRP | SHAP analysis |
| Rahman et al. [101] | CatBoost, XGBoost | Shear capacity of FRP RC beams | Shear capacity of FRP RC beams | 584 experimental results | R2: 0.9, MAE: 0.25 kN | FRP layer height, beam depth | SHAP analysis |
| Study | Boosting Technique | Application | Materials/ Properties Predicted | Dataset | Model Performance (R2, MAE, RMSE) | Key Influencing Factors | Additional Techniques/ Analysis |
|---|---|---|---|---|---|---|---|
| Biruk-Urban et al. [102] | GB | GFRP composites machinability | Cutting forces, delamination | Carbide diamond-coated drill data | High accuracy in delamination prediction | Drilling parameters, fiber type, weight fraction | Novel ink penetration method for delamination detection |
| Jalali et al. [103] | RF, CatBoost | MWCNT-polystyrene nanocomposites impedance | Impedance properties | Microwave-assisted synthesis data | R2 = 0.9880 (RF) | Microwave power, exposure time, frequency | Taguchi method, ANOVA for feature importance |
| Ma et al. [104] | XGBoost | CFRP-confined CFST short columns | Axial compressive capacity | 379 data points from literature | R2 = 0.9850 after hyperparameter optimization | Concrete, steel, CFRP strengths, cross-sectional area | Hyperparameter optimization for improved accuracy |
| Gao et al. [105] | XGBoost, LightGBM | Lignin content prediction in Chinese fir | Lignin content | Raman spectroscopy data | R2 = 0.93 (XGBoost) | Raman peaks, chemical structure differences | Transfer learning for model improvement |
| Donga et al. [106] | MultiBoost (AdaBoost + Bagging) | Hydrophobicity evaluation of insulated materials | Hydrophobicity properties | Image data from surface samples | High classification accuracy with MultiBoost | Illumination and surface irregularities | Image segmentation, DSP platform for real-time training |
| Kong [107] | CatBoost | FRP-concrete bond strength prediction | Bond strength | Experimental data | R2 = 0.9394, MAPE = 1.21% | Interfacial bond strength | Hyperparameter optimization, grid search |
| Alanazi et al. [108] | Adaboost | Membrane separation process in therapeutic agent purification | Solute concentration distribution | Over 8000 data points from experiments | R2 = 0.9853 (Boosted KNN) | Solute concentration, membrane parameters | Bat Algorithm for model optimization |
| Study | Boosting Technique | Application | Materials/ Properties Predicted | Dataset | Model Performance (R2, MAE, RMSE) | Key Influencing Factors | Additional Techniques/ Analysis |
|---|---|---|---|---|---|---|---|
| Gao et al. [105] | XGBoost, LightGBM | Lignin content prediction | Lignin content in Chinese fir | Raman spectroscopy data | Test R2 = 0.93 | Raman peak (2895 cm−1), chemical structure differences | Transfer learning; comparison of 9 algorithms |
| Tahir et al. [110] | Gradient Boosting Regressor | Design of polymer donors for OSCs | Predicted power conversion efficiency (PCE) | Mordred descriptors for 271 polymer donors | Molecular structure, synthetic accessibility | BRICS-based chemical library; RDKit similarity analysis | |
| Jiang et al. [111] | ECFP-LightGBM, ECFP-XGBoost | Hot-melt extrusion for ASDs | Amorphization and chemical stability | 760 formulation data points | Accuracy: 92.8% (amorphization), 96.0% (stability) | Barrel temperature, drug loading, API substructures | SHAP and information gain analyses |
| Pang et al. [113] | Improved AdaBoost | Real-time monitoring in FBR | Polymer agglomeration states | Acoustic emission signals (MFCC, LPCC) | Improved classification accuracy (F-score elevated) | Acoustic features affected by illumination | Cost factors and Gini index integration; DSP platform |
| Fiosina et al. [115] | XGBoost, CatBoost | Reverse engineering polymerization | Monomer concentration, molar masses, MMDs | Kinetic Monte Carlo simulator data | R2 > 0.96 for predictions; 0.68 for reverse engineering | Polymerization kinetics input variables | Multi-target regression; explainability techniques |
| Deshpande et al. [117] | Gradient Boosting (GB) | Wear rate prediction in composites | Specific wear rate of glass-filled PTFE | Pin-on-disc wear test data (L25 array) | R2 = 0.97 (GB model) | Sliding distance, applied load, sliding velocity | Pearson’s correlation analysis |
| Huang et al. [118] | XGBoost | OSC performance optimization | Open circuit voltage (Voc) of ternary PSCs | Data on polymer solar cells with NFAs | RMSE = 0.031, MAE = 0.022 | Doping concentration, HOMO/LUMO levels, MDs | Molecular descriptor and fingerprint analysis |
| Inqiad et al. [119] | XGBoost | ECC TSC prediction | TSC of ECC | Experimental ECC data | Correlation coefficient = 0.986, OF = 0.081 | Fiber content, age, water-to-binder ratio | Comparison with MEP and GEP; Shapley additive analysis |
| Nguyen et al. [120] | XGBoost, LightGBM, RF | Flexural behavior of RC beams | Flexural strength | 4851 experimental samples | RF achieved lowest MSE (highest accuracy) | Aggregate proportions, compressive strength, CFRP presence | Pareto optimization for hyperparameter tuning; sensitivity analysis |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Malashin, I.; Tynchenko, V.; Gantimurov, A.; Nelyub, V.; Borodulin, A. Boosting-Based Machine Learning Applications in Polymer Science: A Review. Polymers 2025, 17, 499. https://doi.org/10.3390/polym17040499
Malashin I, Tynchenko V, Gantimurov A, Nelyub V, Borodulin A. Boosting-Based Machine Learning Applications in Polymer Science: A Review. Polymers. 2025; 17(4):499. https://doi.org/10.3390/polym17040499
Chicago/Turabian StyleMalashin, Ivan, Vadim Tynchenko, Andrei Gantimurov, Vladimir Nelyub, and Aleksei Borodulin. 2025. "Boosting-Based Machine Learning Applications in Polymer Science: A Review" Polymers 17, no. 4: 499. https://doi.org/10.3390/polym17040499
APA StyleMalashin, I., Tynchenko, V., Gantimurov, A., Nelyub, V., & Borodulin, A. (2025). Boosting-Based Machine Learning Applications in Polymer Science: A Review. Polymers, 17(4), 499. https://doi.org/10.3390/polym17040499