
Interpretable Machine Learning Framework to Predict the Glass Transition Temperature of Polymers


Abstract
1. Introduction
- To evaluate the effectiveness of various machine learning algorithms on polymer data.
- To implement feature representation techniques for polymers.
- To rank and identify significant features associated with polymers.
- To propose an interpretable machine learning framework to predict the glass transition temperature of polymers.
- To implement the SHAP technique to demonstrate the effects of specific features on the model’s output.
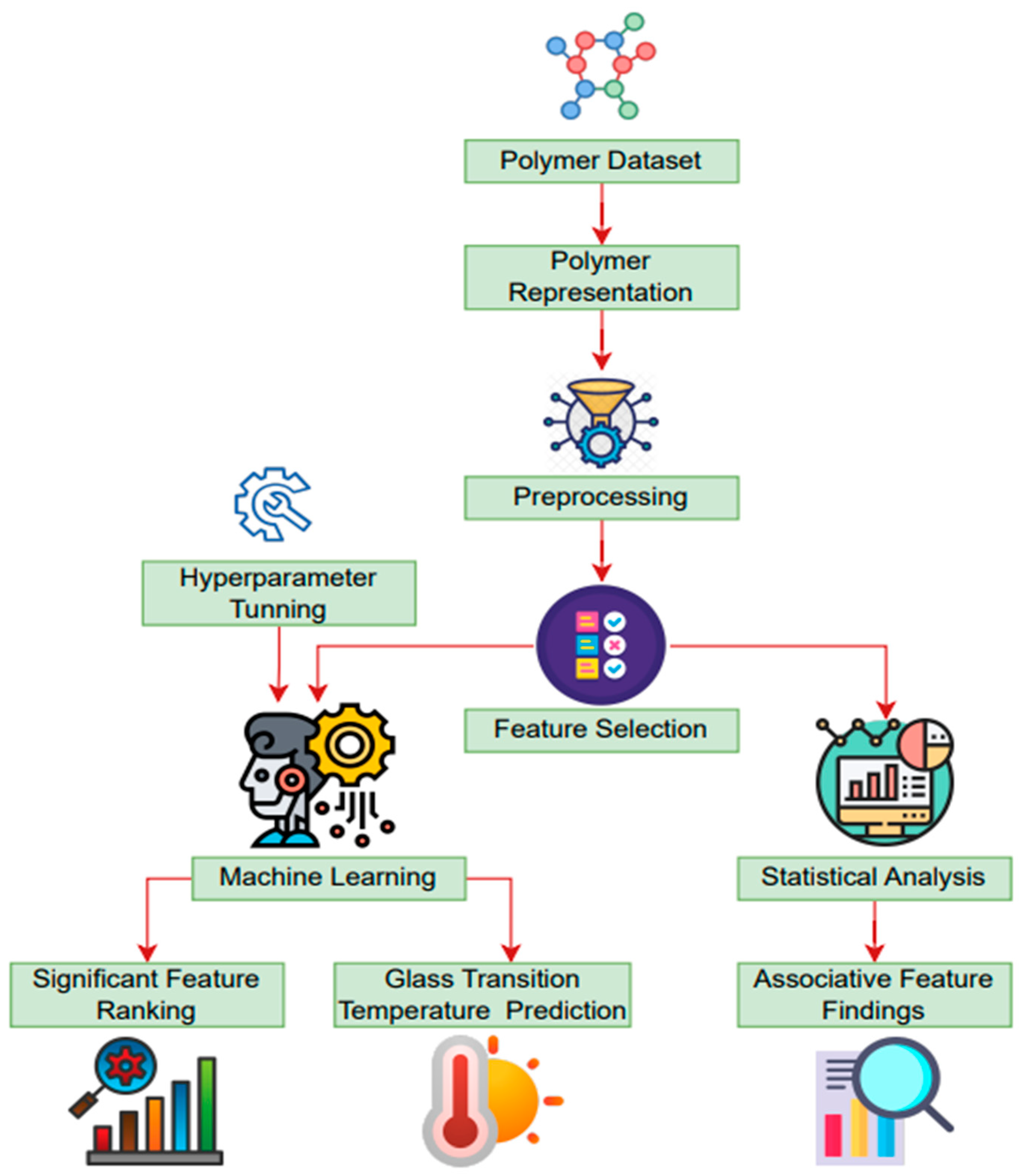
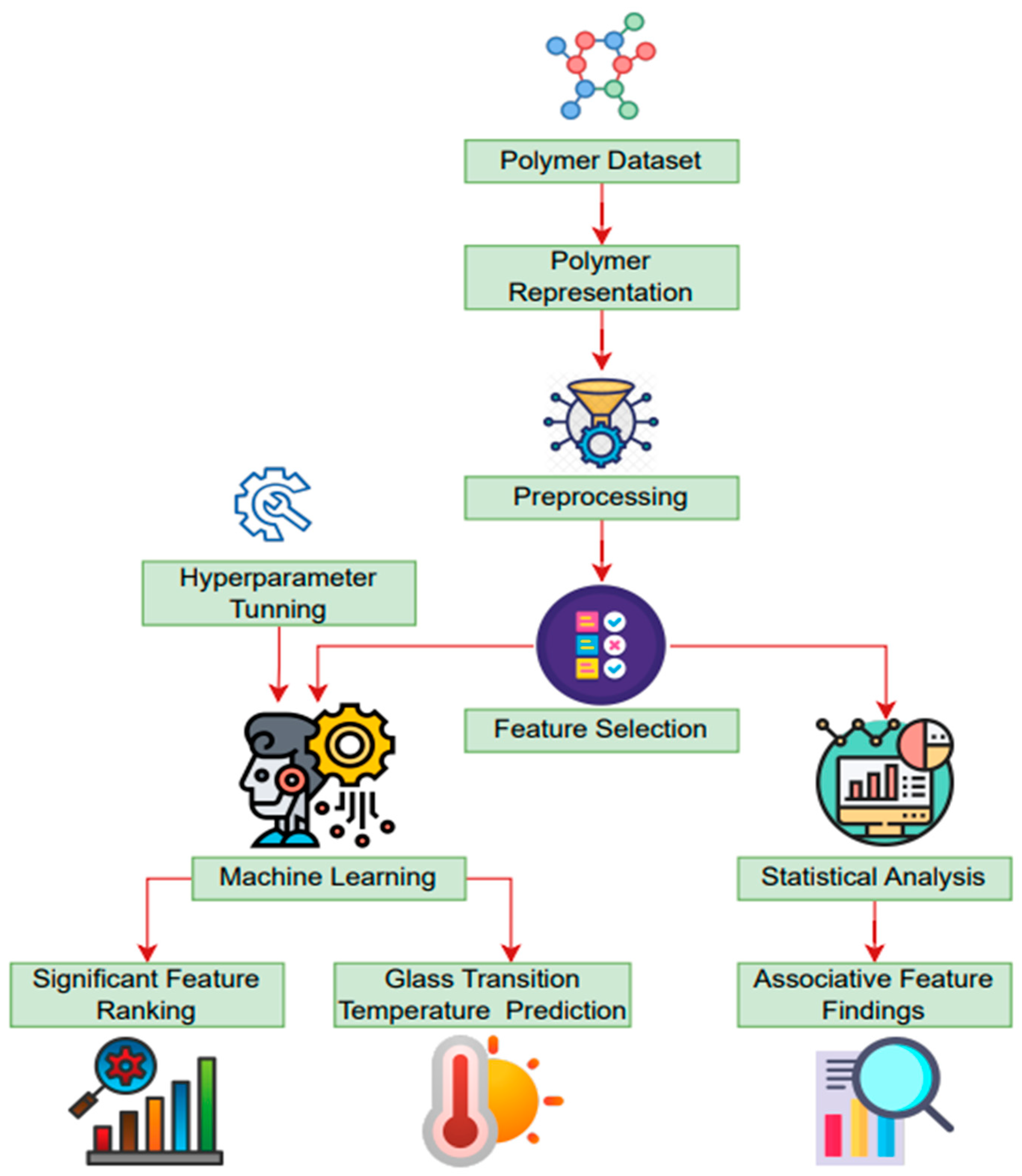
2. Materials and Methods
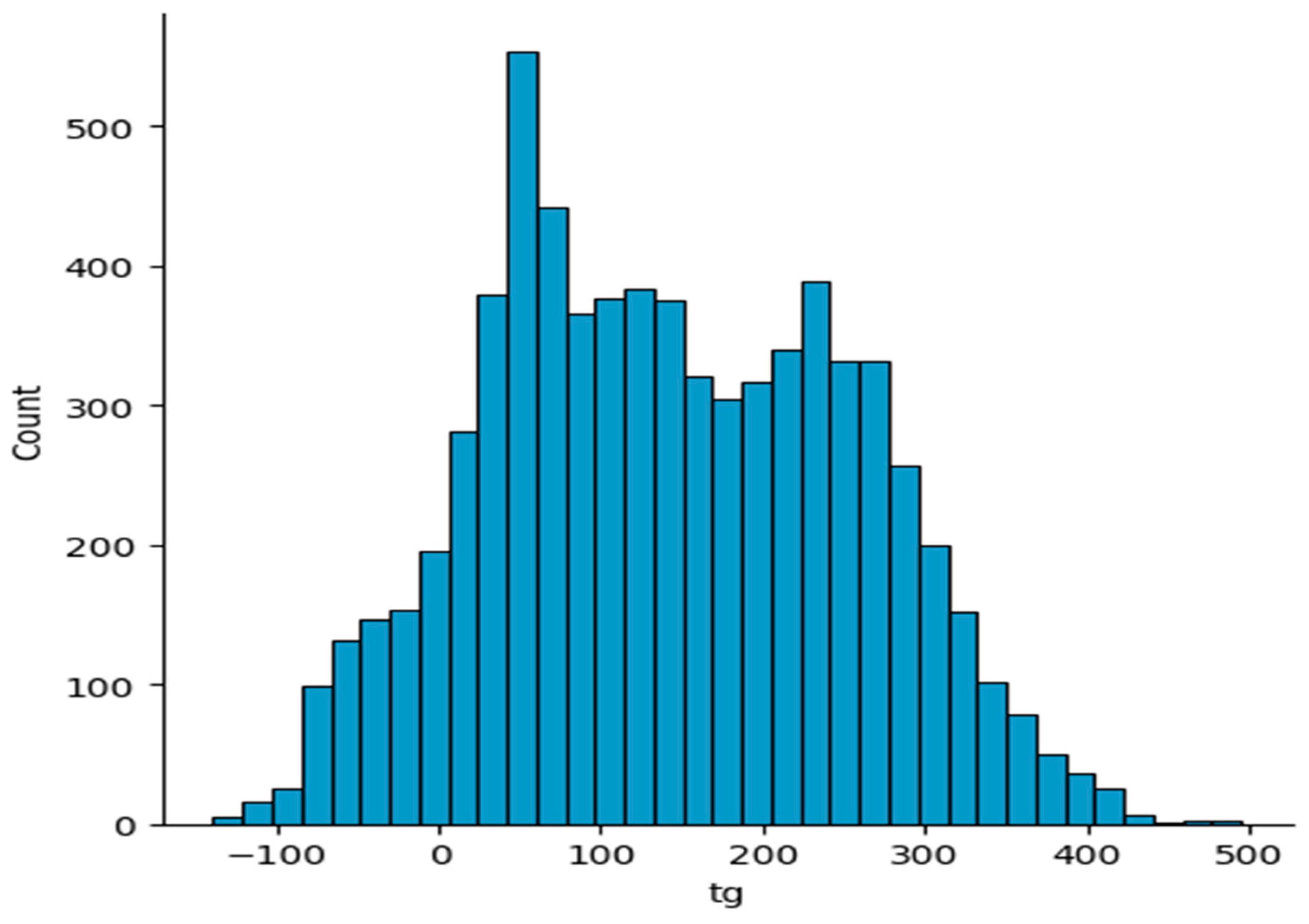
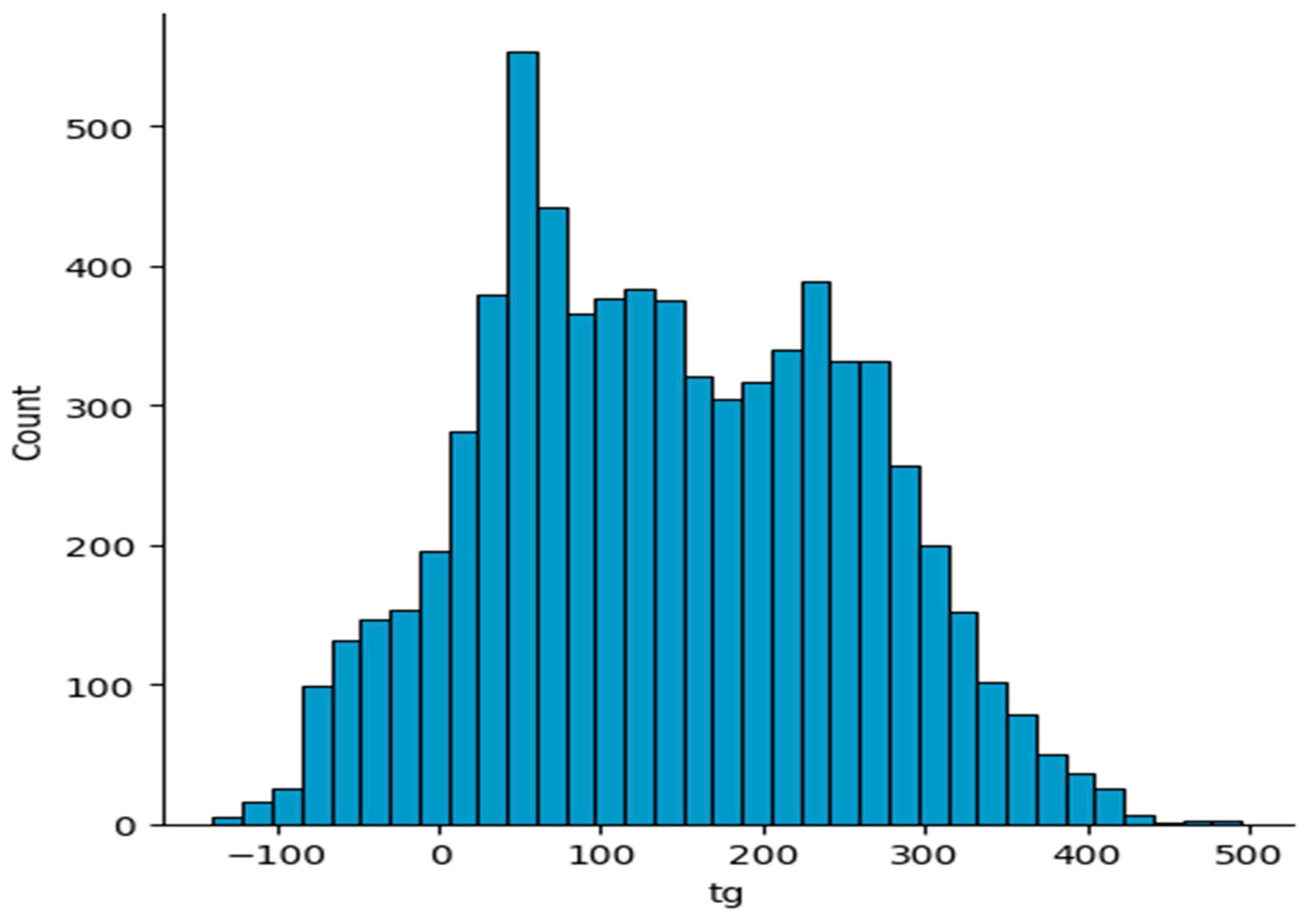
2.1. Polymer Dataset
2.2. Data Preprocessing
2.3. Polymer Representation
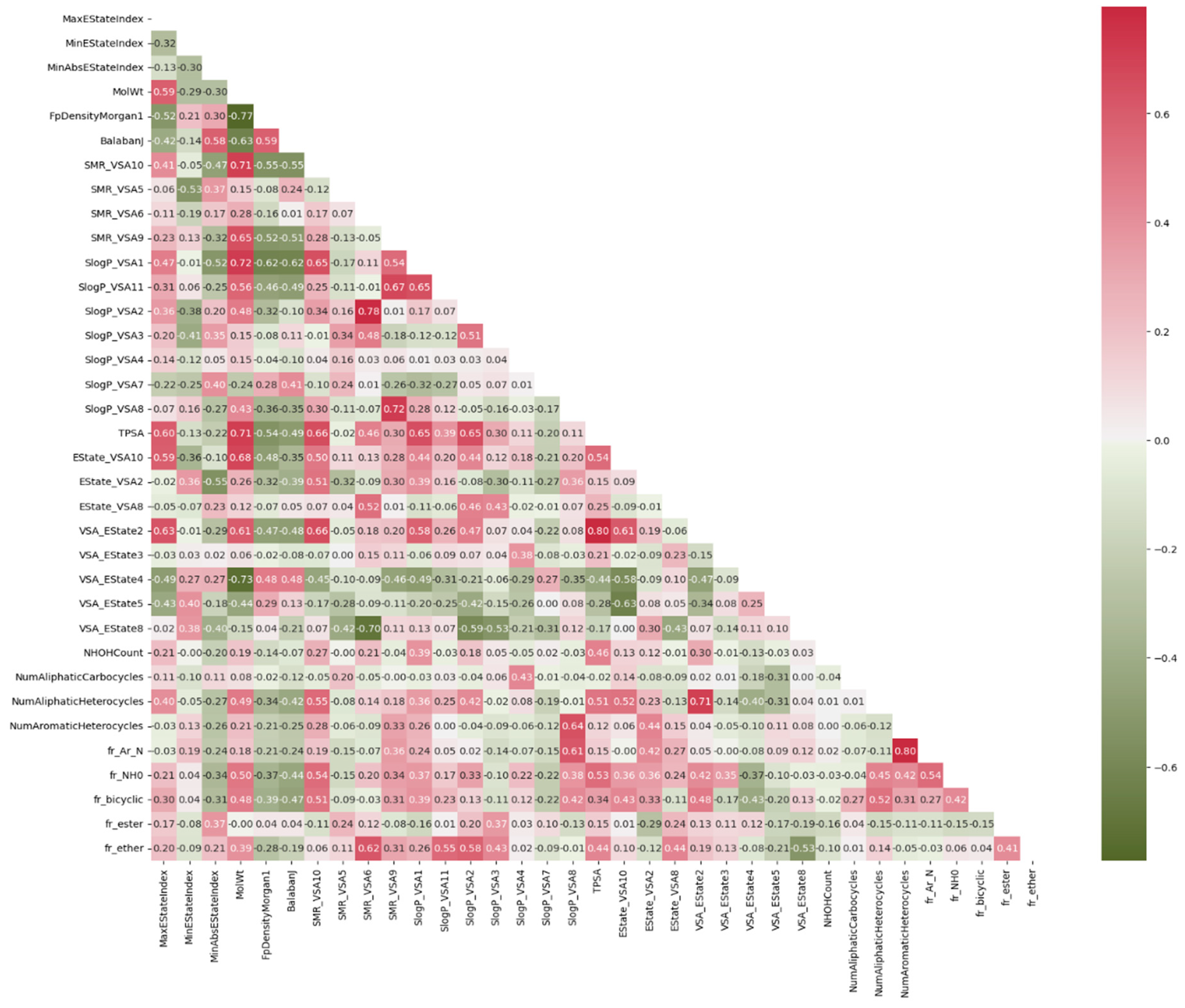
2.4. Feature Selection Method
2.5. Feature Ranking Technique
2.6. Statistical Analysis
2.7. Machine Learning Model
2.8. Hyperparameter Optimization Technique
2.9. Shapley Additive Explanations (SHAP)
2.10. Performance Evaluation Metrics
3. Experimental Results
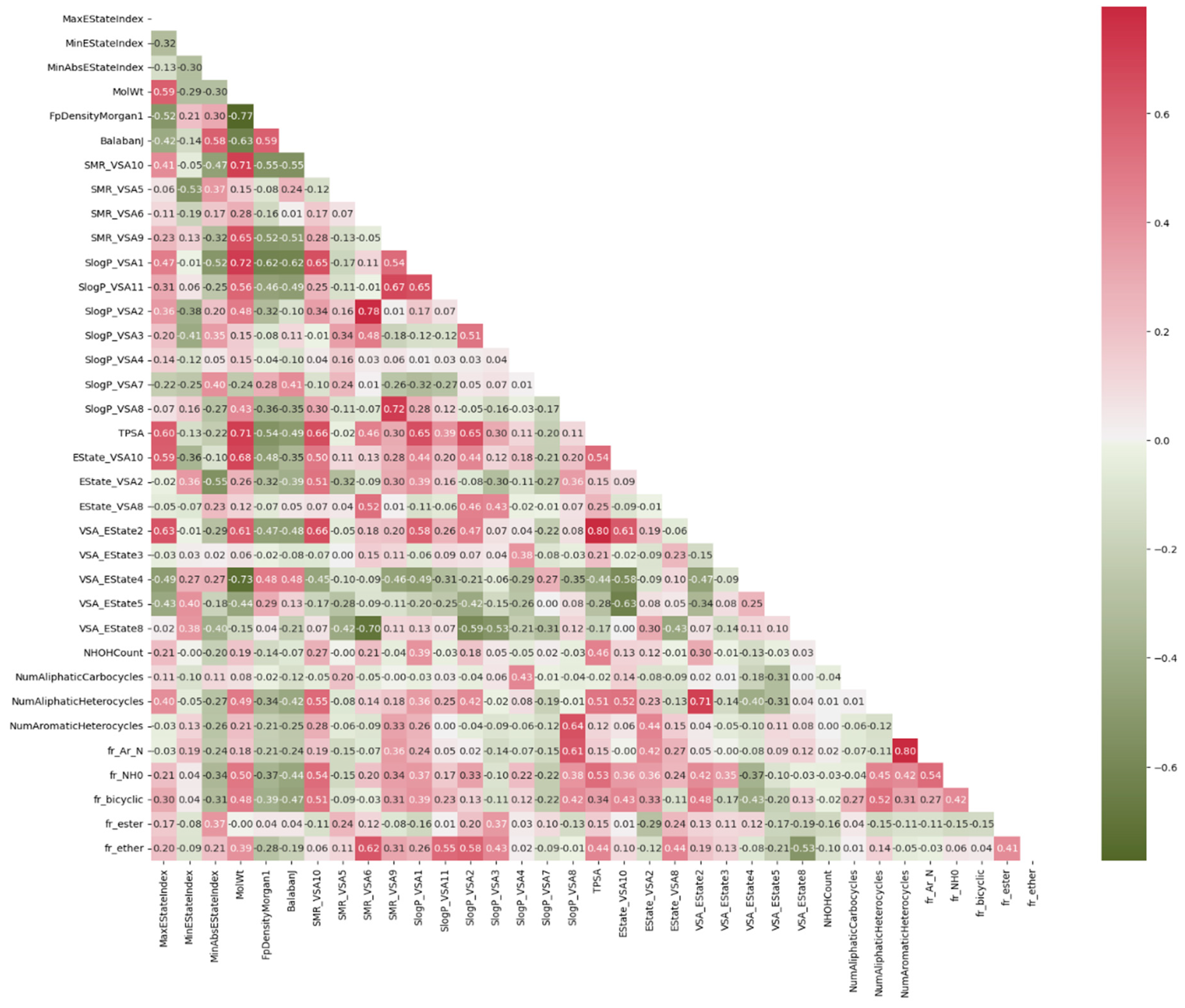
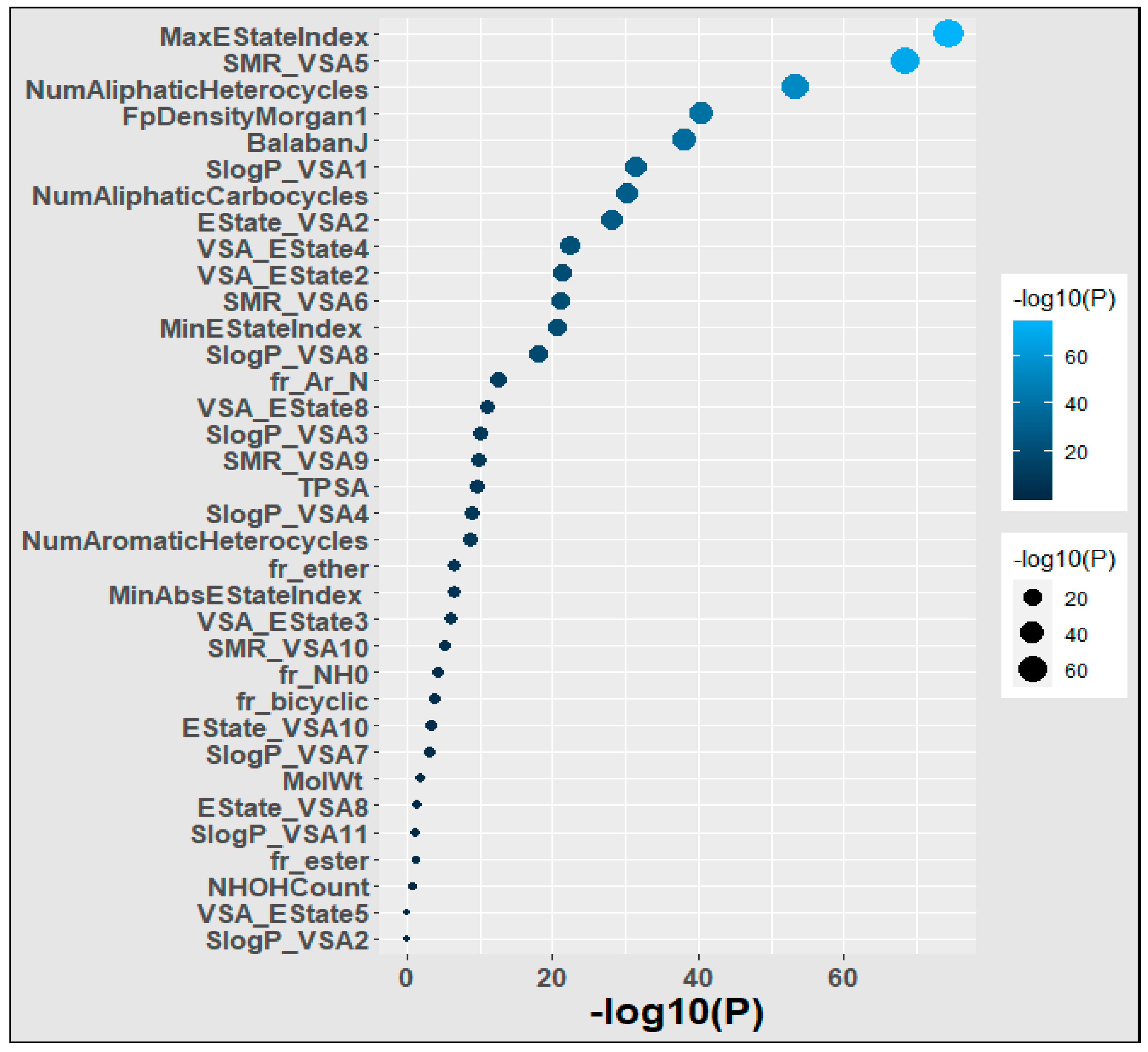
3.1. Finding Significantly Associated Features Using Statistical Methods
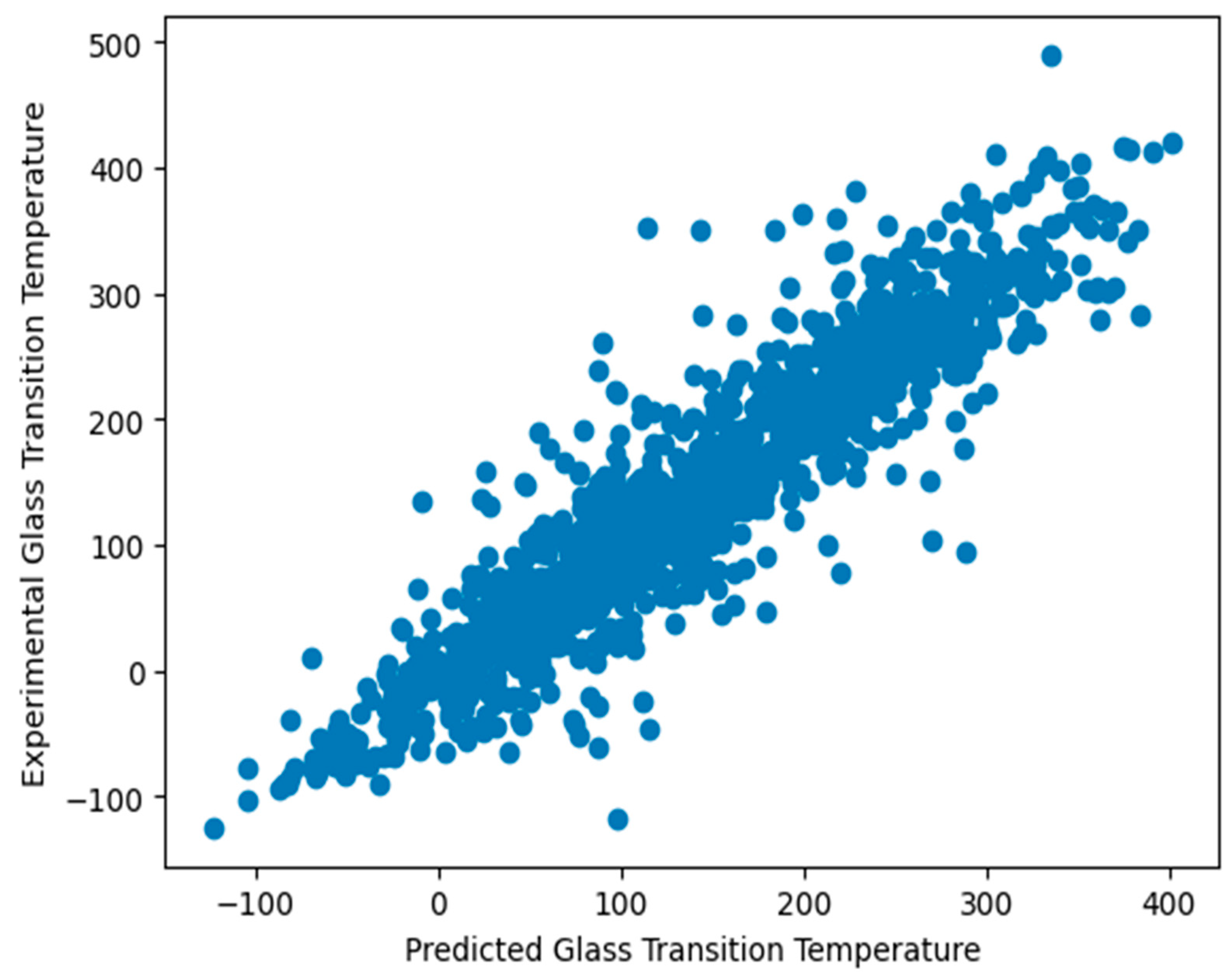
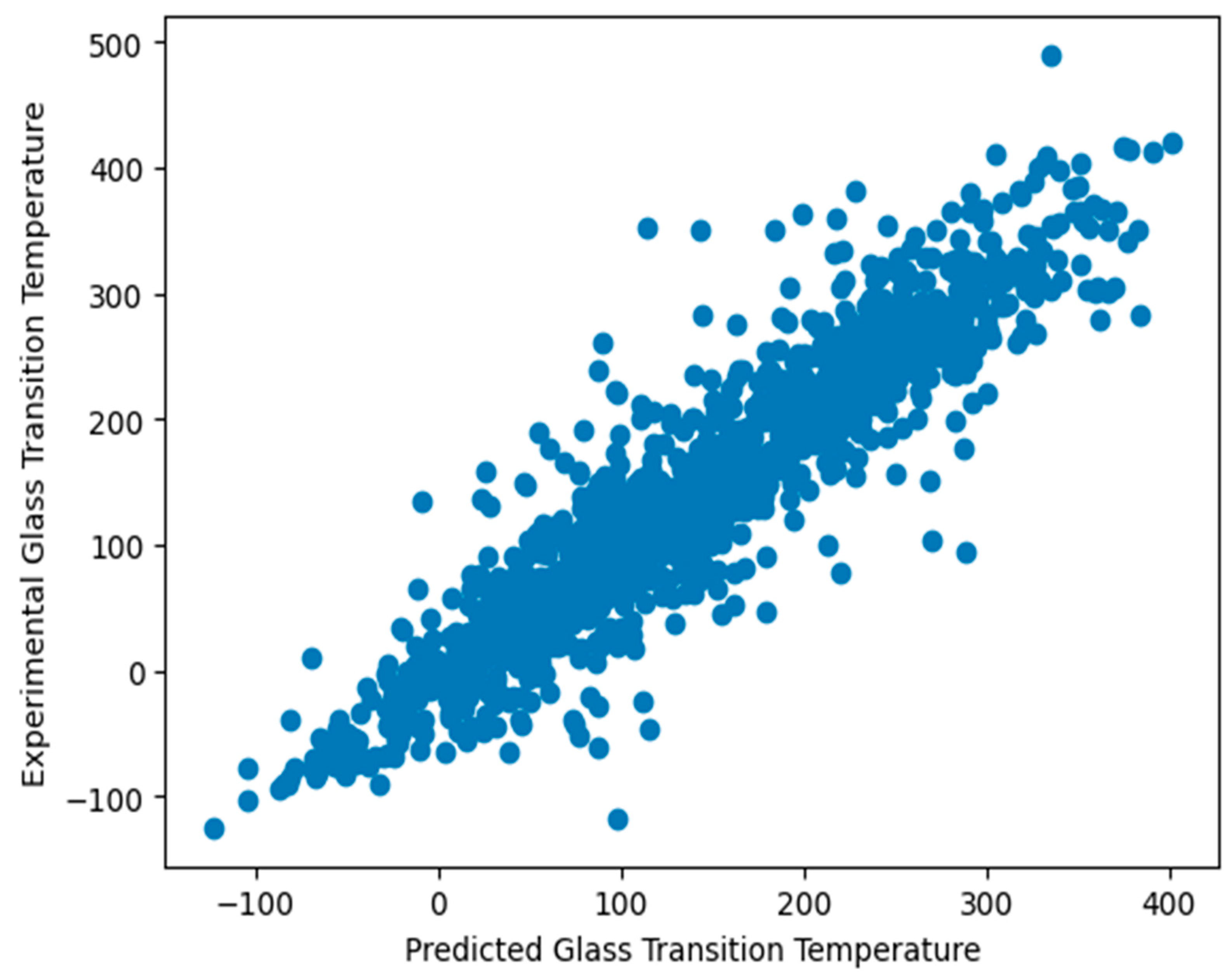
3.2. Prediction of Glass Transition Temperature Using Machine Learning Techniques
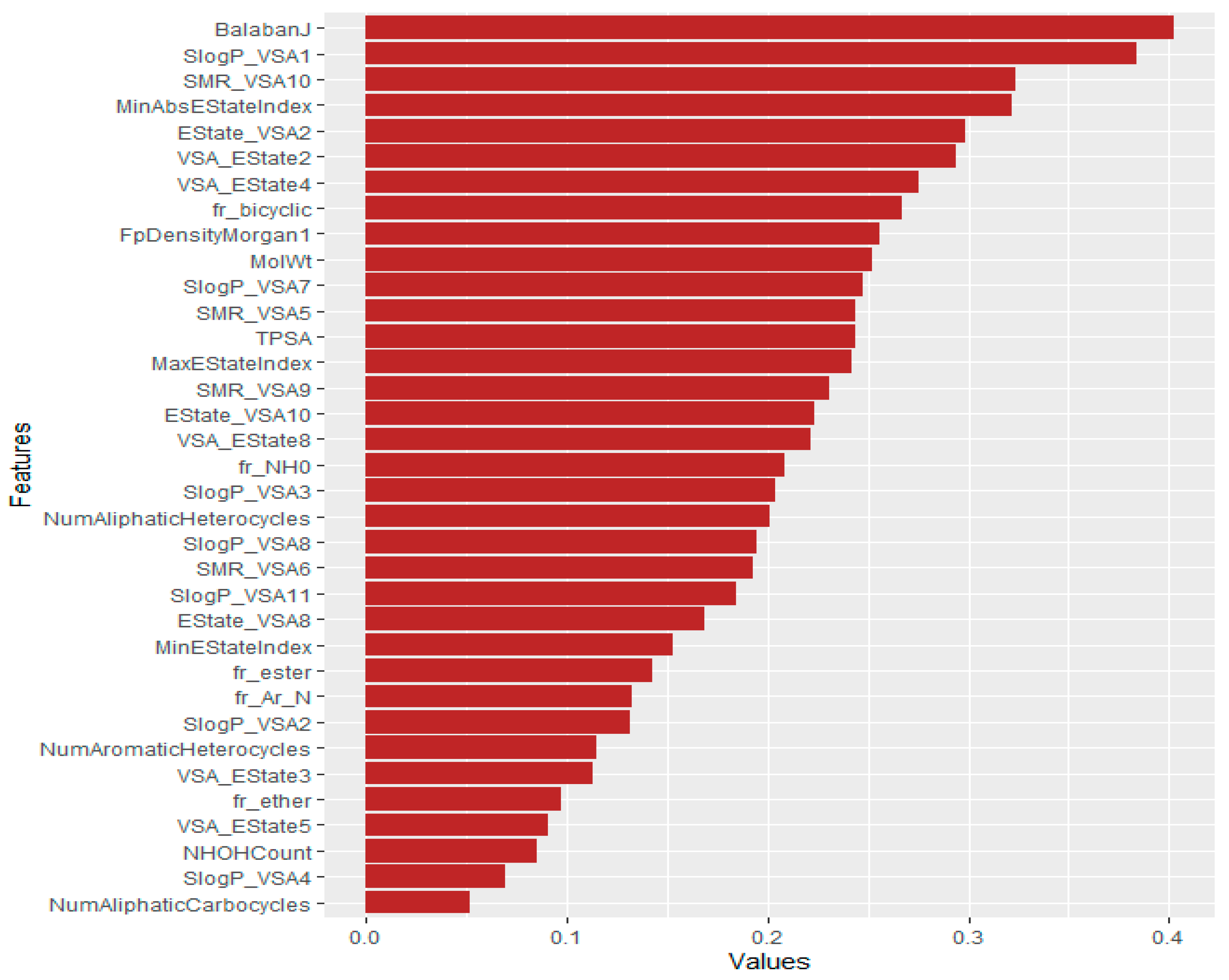
3.3. Feature Ranking Using Machine Learning Techniques
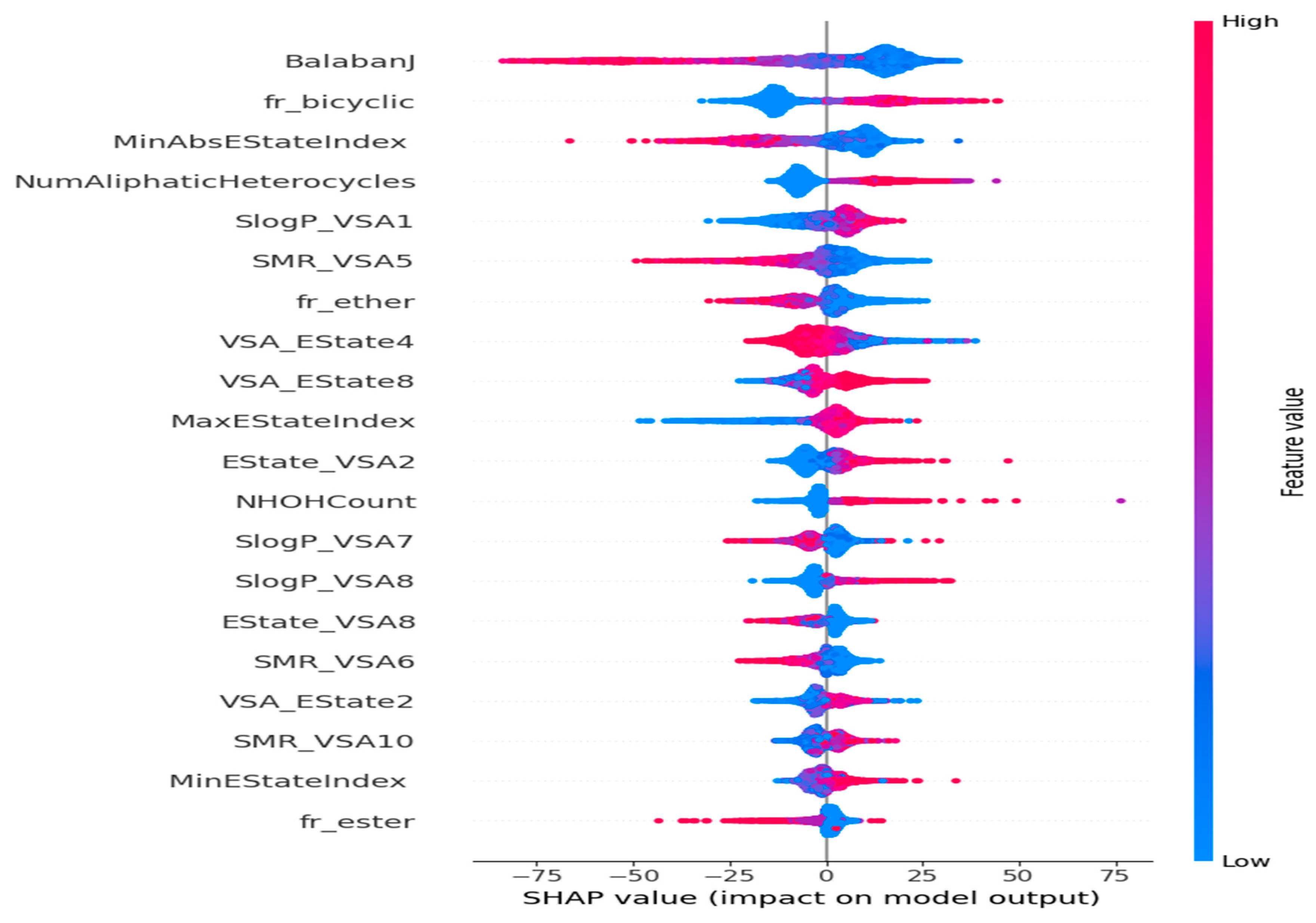
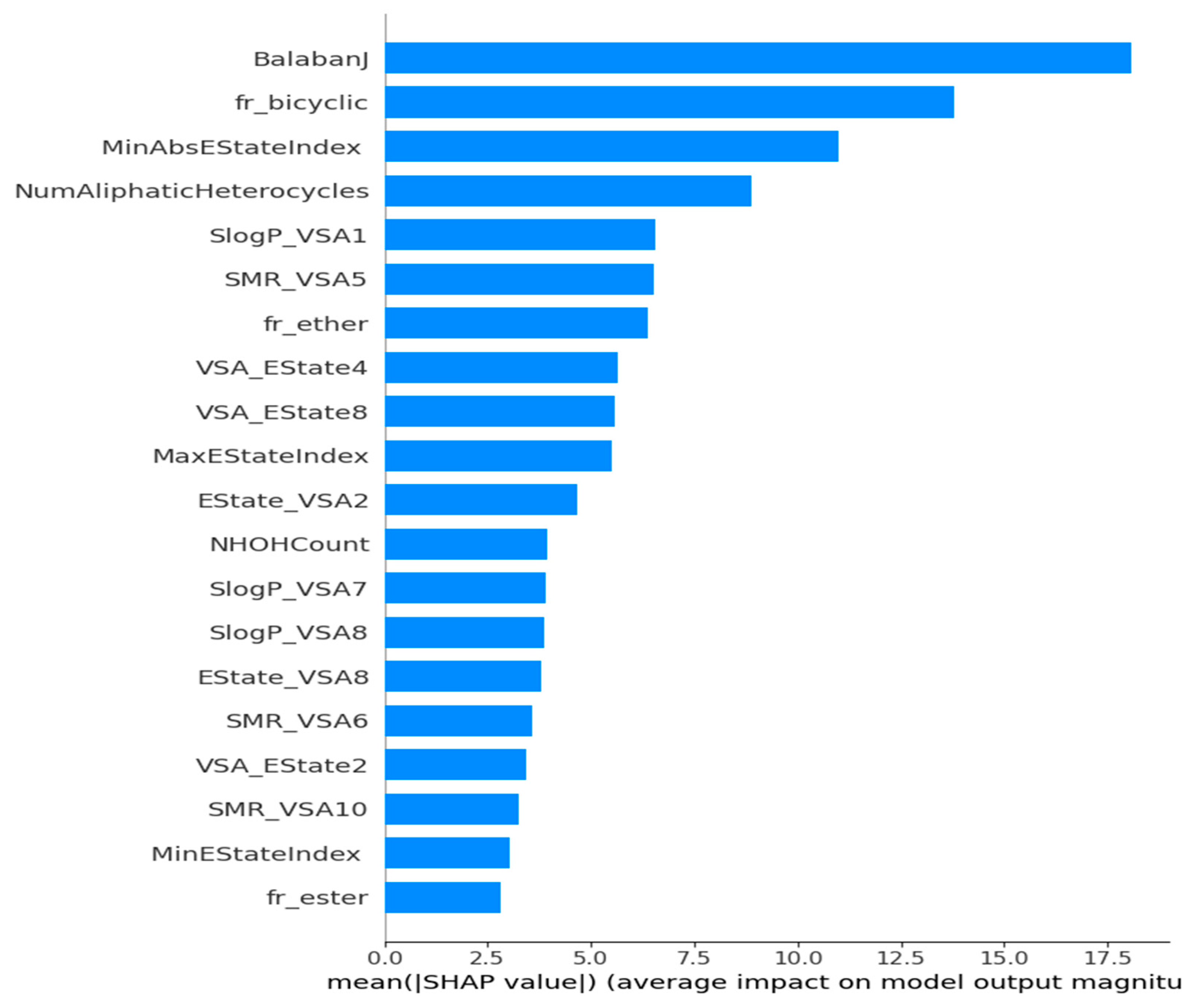
3.4. Analysis of the Significance of Features on Model Output
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Conflicts of Interest
References
- Kim, C.; Chandrasekaran, A.; Huan, T.D.; Das, D.; Ramprasad, R. Polymer Genome: A Data-Powered Polymer Informatics Platform for Property Predictions. J. Phys. Chem. C 2018, 122, 17575–17585. [Google Scholar] [CrossRef]
- Kim, C.; Batra, R.; Chen, L.; Tran, H.; Ramprasad, R. Polymer design using genetic algorithm and machine learning. Comput. Mater. Sci. 2021, 186, 110067. [Google Scholar] [CrossRef]
- Kazemi-Khasragh, E.; Blázquez, J.P.F.; Gómez, D.G.C.; González, C.; Haranczyk, M. Facilitating polymer property prediction with machine learning and group interaction modelling methods. Int. J. Solids Struct. 2024, 286, 112547. [Google Scholar] [CrossRef]
- Mohit, H.; Sanjay, M.R.; Siengchin, S.; Kanaan, B.; Ali, V.; Alarifi, I.M.; El-Bagory, T.M.A.A. Machine learning-based prediction of mechanical and thermal properties of nickel/cobalt/ferrous and dried leaves fiber-reinforced polymer hybrid composites. Polym. Compos. 2024, 45, 489–506. [Google Scholar] [CrossRef]
- Mysona, J.A.; Nealey, P.F.; de Pablo, J.J. Machine Learning Models and Dimensionality Reduction for Prediction of Polymer Properties. Macromolecules 2024, 57, 1988–1997. [Google Scholar] [CrossRef]
- Champa-Bujaico, E.; Díez-Pascual, A.M.; Redondo, A.L.; Garcia-Diaz, P. Optimization of mechanical properties of multiscale hybrid polymer nanocomposites: A combination of experimental and machine learning techniques. Compos. Part. B: Eng. 2024, 269, 111099. [Google Scholar] [CrossRef]
- Albuquerque, R.Q.; Rothenhäusler, F.; Ruckdäschel, H. Designing formulations of bio-based, multicomponent epoxy resin systems via machine learning. MRS Bull. 2024, 49, 59–70. [Google Scholar] [CrossRef]
- Li, D.; Ru, Y.; Liu, J. GATBoost: Mining graph attention networks-based important substructures of polymers for a better property prediction. Mater. Today Commun. 2024, 38, 107577. [Google Scholar] [CrossRef]
- Jeon, J.; Rhee, B.; Gim, J. Melt Temperature Estimation by Machine Learning Model Based on Energy Flow in Injection Molding. Polymers 2022, 14, 5548. [Google Scholar] [CrossRef]
- Babbar, A.; Ragunathan, S.; Mitra, D.; Dutta, A.; Patra, T.K. Explainability and extrapolation of machine learning models for predicting the glass transition temperature of polymers. J. Polym. Sci. 2024, 62, 1175–1186. [Google Scholar] [CrossRef]
- Miccio, L.A.; Borredon, C.; Schwartz, G.A. A glimpse inside materials: Polymer structure–Glass transition temperature relationship as observed by a trained artificial intelligence. Comput. Mater. Sci. 2024, 236, 112863. [Google Scholar] [CrossRef]
- Wang, S.; Yang, H.; Stratford, T.; He, J.; Li, B.; Su, J. Evaluating the effect of curing conditions on the glass transition of the structural adhesive using conditional tabular generative adversarial networks. Eng. Appl. Artif. Intell. 2024, 130, 107796. [Google Scholar] [CrossRef]
- Liu, C.; Wang, X.; Cai, W.; He, Y.; Su, H. Machine Learning Aided Prediction of Glass-Forming Ability of Metallic Glass. Processes 2023, 11, 2806. [Google Scholar] [CrossRef]
- Qu, T.; Nan, G.; Ouyang, Y.; Bieketuerxun, B.; Yan, X.; Qi, Y.; Zhang, Y. Structure–Property Relationship, Glass Transition, and Crystallization Behaviors of Conjugated Polymers. Polymers 2023, 15, 4268. [Google Scholar] [CrossRef]
- Sangkhawasi, M.; Remsungnen, T.; Vangnai, A.S.; Maitarad, P.; Rungrotmongkol, T. Prediction of the Glass Transition Temperature in Polyethylene Terephthalate/Polyethylene Vanillate (PET/PEV) Blends: A Molecular Dynamics Study. Polymers 2022, 14, 2858. [Google Scholar] [CrossRef] [PubMed]
- Krupka, J.; Dockal, K.; Krupka, I.; Hartl, M. Elastohydrodynamic Lubrication of Compliant Circular Contacts near Glass-Transition Temperature. Lubricants 2022, 10, 155. [Google Scholar] [CrossRef]
- Hu, A.; Huang, Y.; Chen, Q.; Huang, W.; Wu, X.; Cui, L.; Dong, Y.; Liu, J. Glass transition of amorphous polymeric materials informed by machine learning. APL Mach. Learn. 2023, 1, 026111. [Google Scholar] [CrossRef]
- Karuth, A.; Alesadi, A.; Xia, W.; Rasulev, B. Predicting glass transition of amorphous polymers by application of cheminformatics and molecular dynamics simulations. Polymer 2021, 218, 123495. [Google Scholar] [CrossRef]
- Alesadi, A.; Cao, Z.; Li, Z.; Zhang, S.; Zhao, H.; Gu, X.; Xia, W. Machine learning prediction of glass transition temperature of conjugated polymers from chemical structure. Cell Rep. Phys. Sci. 2022, 3, 100911. [Google Scholar] [CrossRef]
- Zhao, Y.; Mulder, R.J.; Houshyar, S.; Le, T.C. A review on the application of molecular descriptors and machine learning in polymer design. Polym. Chem. 2023, 14, 3325–3346. [Google Scholar] [CrossRef]
- Cassar, D.R.; de Carvalho, A.C.; Zanotto, E.D. Predicting glass transition temperatures using neural networks. Acta Mater. 2018, 159, 249–256. [Google Scholar] [CrossRef]
- Alcobaça, E.; Mastelini, S.M.; Botari, T.; Pimentel, B.A.; Cassar, D.R.; De Carvalho, A.C.; Zanotto, E.D. Explainable Machine Learning Algorithms for Predicting Glass Transition Temperatures. Acta Mater. 2020, 188, 92–100. [Google Scholar] [CrossRef]
- Zhang, Y.; Xu, X. Machine learning glass transition temperature of polymers. Heliyon 2020, 6, e05055. [Google Scholar] [CrossRef] [PubMed]
- Yan, C.; Feng, X.; Wick, C.; Peters, A.; Li, G. Machine learning assisted discovery of new thermoset shape memory polymers based on a small training dataset. Polymer 2021, 214, 123351. [Google Scholar] [CrossRef]
- Zhang, Y.; Xu, X. Machine learning glass transition temperature of styrenic random copolymers. J. Mol. Graph. Model. 2021, 103, 107796. [Google Scholar] [CrossRef] [PubMed]
- Lee, F.L.; Park, J.; Goyal, S.; Qaroush, Y.; Wang, S.; Yoon, H.; Rammohan, A.; Shim, Y. Comparison of Machine Learning Methods towards Developing Interpretable Polyamide Property Prediction. Polymers 2021, 13, 3653. [Google Scholar] [CrossRef]
- Tao, L.; Varshney, V.; Li, Y. Benchmarking Machine Learning Models for Polymer Informatics: An Example of Glass Transition Temperature. J. Chem. Inf. Model. 2021, 61, 5395–5413. [Google Scholar] [CrossRef]
- Liu, G.; Zhao, T.; Xu, J.; Luo, T.; Jiang, M. Graph Rationalization with Environment-based Augmentations. In Proceedings of the 28th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, ser. KDD ’22, Washington, DC, USA, 14–18 August 2022; Association for Computing Machinery: New York, NY, USA, 2022; pp. 1069–1078. [Google Scholar]
- Nguyen, T.; Bavarian, M. A Machine Learning Framework for Predicting the Glass Transition Temperature of Homopolymers. Ind. Eng. Chem. Res. 2022, 61, 12690–12698. [Google Scholar] [CrossRef]
- Kabir, H.; Garg, N. Machine learning enabled orthogonal camera goniometry for accurate and robust contact angle measurements. Sci. Rep. 2023, 13, 1497. [Google Scholar] [CrossRef]
- Bolón-Canedo, V.; Remeseiro, B. Feature selection in image analysis: A survey. Artif. Intell. Rev. 2020, 53, 2905–2931. [Google Scholar] [CrossRef]
- Ibarra, D.S.; Mathews, J.; Li, F.; Lu, H.; Li, G.; Chen, J. Deep learning for predicting the thermomechanical behavior of shape memory polymers. Polymer 2022, 261, 125395. [Google Scholar] [CrossRef]
- Goswami, S.; Ghosh, R.; Neog, A.; Das, B. Deep learning based approach for prediction of glass transition temperature in polymers. Mater. Today Proc. 2021, 46, 5838–5843. [Google Scholar] [CrossRef]
- Ma, R.; Liu, Z.; Zhang, Q.; Liu, Z.; Luo, T. Evaluating Polymer Representations via Quantifying Structure–Property Relationships. J. Chem. Inf. Model. 2019, 59, 3110–3119. [Google Scholar] [CrossRef] [PubMed]
- Tao, L.; Chen, G.; Li, Y. Machine learning discovery of high-temperature polymers. Patterns 2021, 2, 100225. [Google Scholar] [CrossRef] [PubMed]
- Akter, T.; Satu, M.S.; Khan, M.I.; Ali, M.H.; Uddin, S.; Lió, P.; Quinn, J.M.W.; Moni, M.A. Machine Learning-Based Models for Early Stage Detection of Autism Spectrum Disorders. IEEE Access 2019, 7, 166509–166527. [Google Scholar] [CrossRef]
- Fang, G.; Xu, P.; Liu, W. Automated Ischemic Stroke Subtyping Based on Machine Learning Approach. IEEE Access 2020, 8, 118426–118432. [Google Scholar] [CrossRef]
- Hasan, S.M.M.; Uddin, P.; Mamun, A.; Sharif, M.I.; Ulhaq, A.; Krishnamoorthy, G. A Machine Learning Framework for Early-Stage Detection of Autism Spectrum Disorders. IEEE Access 2023, 11, 15038–15057. [Google Scholar] [CrossRef]
- Uddin, M.J.; Ahamad, M.M.; Hoque, M.N.; Walid, M.A.A.; Aktar, S.; Alotaibi, N.; Alyami, S.A.; Kabir, M.A.; Moni, M.A. A Comparison of Machine Learning Techniques for the Detection of Type-2 Diabetes Mellitus: Experiences from Bangladesh. Information 2023, 14, 376. [Google Scholar] [CrossRef]
- Lakshmi, A.V.; Ghali, V.; Subhani, S.; Baloji, N.R. Automated quantitative subsurface evaluation of fiber reinforced polymers. Infrared Phys. Technol. 2020, 110, 103456. [Google Scholar] [CrossRef]
- Mahajan, A.; Bajoliya, S.; Khandelwal, S.; Guntewar, R.; Ruchitha, A.; Singh, I.; Arora, N. Comparison of ML algorithms for prediction of tensile strength of polymer matrix composites. Mater. Today Proc. 2022, in press. [Google Scholar] [CrossRef]
- Ahmad, A.; Ahmad, W.; Chaiyasarn, K.; Ostrowski, K.A.; Aslam, F.; Zajdel, P.; Joyklad, P. Prediction of Geopolymer Concrete Compressive Strength Using Novel Machine Learning Algorithms. Polymers 2021, 13, 3389. [Google Scholar] [CrossRef] [PubMed]
- Anjum, M.; Khan, K.; Ahmad, W.; Ahmad, A.; Amin, M.N.; Nafees, A. Application of Ensemble Machine Learning Methods to Estimate the Compressive Strength of Fiber-Reinforced Nano-Silica Modified Concrete. Polymers 2022, 14, 3906. [Google Scholar] [CrossRef] [PubMed]
- Goodarzi, B.V.; Bahramian, A.R. Applying machine learning for predicting thermal conductivity coefficient of polymeric aerogels. J. Therm. Anal. Calorim. 2022, 147, 6227–6238. [Google Scholar] [CrossRef]
- Daghigh, V.; Lacy, T.E.; Daghigh, H.; Gu, G.; Baghaei, K.T.; Horstemeyer, M.F.; Pittman, C.U. Heat deflection temperatures of bio-nano-composites using experiments and machine learning predictions. Mater. Today Commun. 2020, 22, 100789. [Google Scholar] [CrossRef]
- Zhu, M.-X.; Deng, T.; Dong, L.; Chen, J.-M.; Dang, Z.-M. Review of machine learningdriven design of polymer-based dielectrics. IET Nanodielectr. 2022, 5, 24–38. [Google Scholar] [CrossRef]
- Ueki, Y.; Seko, N.; Maekawa, Y. Machine learning approach for prediction of the grafting yield in radiation-induced graft polymerization. Appl. Mater. Today 2021, 25, 101158. [Google Scholar] [CrossRef]
- Gayathri, R.; Rani, S.U.; Cepová, L.; Rajesh, M.; Kalita, K. A Comparative Analysis of Machine Learning Models in Prediction of Mortar Compressive Strength. Processes 2022, 10, 1387. [Google Scholar] [CrossRef]
- Kong, Y.K.; Kurumisawa, K. Application of machine learning in predicting workability for alkali-activated materials. Case Stud. Constr. Mater. 2023, 18, e02173. [Google Scholar] [CrossRef]
- Post, A.; Lin, S.; Waas, A.M.; Ustun, I. Determining damage initiation of carbon fiber reinforced polymer composites using machine learning. Polym. Compos. 2023, 44, 932–953. [Google Scholar] [CrossRef]
- Shozib, I.A.; Ahmad, A.; Rahaman, M.S.A.; Abdul-Rani, A.M.; Alam, M.A.; Beheshti, M.; Taufiqurrahman, I. Modelling and optimization of microhardness of electroless Ni–P–TiO2 composite coating based on machine learning approaches and RSM. J. Mater. Res. Technol. 2021, 12, 1010–1025. [Google Scholar] [CrossRef]
- Armeli, G.; Peters, J.-H.; Koop, T. Machine-Learning-Based Prediction of the Glass Transition Temperature of Organic Compounds Using Experimental Data. ACS Omega 2023, 8, 12298–12309. [Google Scholar] [CrossRef]
- Lockner, Y.; Hopmann, C.; Zhao, W. Transfer learning with artificial neural networks between injection molding processes and different polymer materials. J. Manuf. Process. 2022, 73, 395–408. [Google Scholar] [CrossRef]
- Singla, S.; Mannan, S.; Zaki, M.; Krishnan, N.M.A. Accelerated design of chalcogenide glasses through interpretable machine learning for composition–property relationships. J. Phys. Mater. 2023, 6, 024003. [Google Scholar] [CrossRef]
- Alkadhim, H.A.; Amin, M.N.; Ahmad, W.; Khan, K.; Nazar, S.; Faraz, M.I.; Imran, M. Evaluating the Strength and Impact of Raw Ingredients of Cement Mortar Incorporating Waste Glass Powder Using Machine Learning and SHapley Additive ExPlanations (SHAP) Methods. Materials 2022, 15, 7344. [Google Scholar] [CrossRef] [PubMed]
- Sendek, A.D.; Ransom, B.; Cubuk, E.D.; Pellouchoud, L.A.; Nanda, J.; Reed, E.J. Machine Learning Modeling for Accelerated Battery Materials Design in the Small Data Regime. Adv. Energy Mater. 2022, 12, 2200553. Available online: https://onlinelibrary.wiley.com/doi/pdf/10.1002/aenm.202200553 (accessed on 29 June 2022). [CrossRef]
- Chang, Y.-J.; Jui, C.-Y.; Lee, W.-J.; Yeh, A.-C. Prediction of the Composition and Hardness of High-Entropy Alloys by Machine Learning. JOM 2019, 71, 3433–3442. [Google Scholar] [CrossRef]
- Wei, J.; Chu, X.; Sun, X.; Xu, K.; Deng, H.; Chen, J.; Wei, Z.; Lei, M. Machine learning in materials science. InfoMat 2019, 1, 338–358. Available online: https://onlinelibrary.wiley.com/doi/pdf/10.1002/inf2.12028 (accessed on 9 September 2019). [CrossRef]
- Parikh, N.; Karamta, M.; Yadav, N.; Tavakoli, M.M.; Prochowicz, D.; Akin, S.; Kalam, A.; Satapathi, S.; Yadav, P. Is machine learning redefining the perovskite solar cells? J. Energy Chem. 2022, 66, 74–90. [Google Scholar] [CrossRef]
- Ghosh, A.; Satvaya, P.; Kundu, P.K.; Sarkar, G. Calibration of RGB sensor for estimation of real-time correlated color temperature using machine learning regression techniques. Optik 2022, 258, 168954. [Google Scholar] [CrossRef]
- Chen, H.; Li, X.; Wu, Y.; Zuo, L.; Lu, M.; Zhou, Y. Compressive Strength Prediction of High-Strength Concrete Using Long Short-Term Memory and Machine Learning Algorithms. Buildings 2022, 12, 302. [Google Scholar] [CrossRef]
- Lu, H.-J.; Zou, N.; Jacobs, R.; Afflerbach, B.; Lu, X.-G.; Morgan, D. Error assessment and optimal cross-validation approaches in machine learning applied to impurity diffusion. Comput. Mater. Sci. 2019, 169, 109075. [Google Scholar] [CrossRef]
- Ali, S.F.; Fan, J. Capturing Dynamic Behaviors of a Rate Sensitive, Elastomer with Strain Energy Absorptions and Dissipation Effects. Int. J. Appl. Mech. 2021, 13, 2150104. [Google Scholar] [CrossRef]
- Ali, S.F.; Fan, J.T.; Feng, J.Q.; Wei, X.Q. A Macro-Mechanical Study for Capturing the Dynamic Behaviors of a Rate-Dependent Elastomer and Clarifying the Energy Dissipation Mechanisms at Various Strain Rates. Acta Mech. Solida Sin. 2021, 35, 228–238. [Google Scholar]
- Fan, J.; Weerheijm, J.; Sluys, L. High-strain-rate tensile mechanical response of a polyurethane elastomeric material. Polymer 2015, 65, 72–80. [Google Scholar] [CrossRef]
- Fan, J.T.; Weerheijm, J.; Sluys, L.J. Glass interface effect on high-strain-rate tensile response of a soft polyurethane elastomeric polymer material. Compos. Sci. Technol. 2015, 118, 55–62. [Google Scholar] [CrossRef]
- Ali, S.F.; Fan, J. Elastic-viscoplastic constitutive model for capturing the mechanical response of polymer composite at various strain rates. J. Mater. Sci. Technol. 2020, 57, 12–17. [Google Scholar]
- Fan, J.T. Strain rate dependent mechanical properties of a high-strength poly(methyl methacrylate). J. Appl. Polym. Sci. 2018, 135, 46189. [Google Scholar] [CrossRef]
- Fan, J.T.; Weerheijm, J.; Sluys, L.J. Compressive response of a glass–polymer system at various strain rates. Mech. Mater. 2016, 95, 49–59. [Google Scholar] [CrossRef]
- Fan, J.T.; Weerheijm, J.; Sluys, L.J. Compressive response of multiple-particles-polymer systems at various strain rates. Polymer 2016, 91, 62–73. [Google Scholar] [CrossRef]
- Fan, J.T.; Wang, C. Dynamic compressive response of a developed polymer composite at different strain rates. Compos. Part B Eng. 2018, 152, 96–101. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| DT | SVR | AB | KNN | XGB | RF | LGB | HGB | ETR | |
|---|---|---|---|---|---|---|---|---|---|
| 0.686 | 0.684 | 0.620 | 0.8015 | 0.811 | 0.7981 | 0.7997 | 0.807 | 0.704 | |
| MAE | 40.953 | 47.604 | 54.300 | 35.719 | 33.865 | 34.317 | 36.016 | 35.128 | 40.242 |
| RMSE | 62.283 | 62.467 | 68.553 | 49.516 | 48.312 | 49.936 | 49.741 | 48.823 | 60.465 |
| DT | SVR | AB | KNN | XGB | RF | LGB | HGB | ETR | |
|---|---|---|---|---|---|---|---|---|---|
| 0.754 | 0.815 | 0.664 | 0.789 | 0.816 | 0.803 | 0.810 | 0.820 | 0.797 | |
| MAE | 39.204 | 32.979 | 51.195 | 35.325 | 33.291 | 35.506 | 34.072 | 33.032 | 37.105 |
| RMSE | 55.077 | 47.798 | 64.378 | 51.040 | 47.730 | 49.354 | 48.389 | 47.099 | 50.123 |
| DT | SVR | AB | KNN | XGB | RF | LGB | HGB | ETR | |
|---|---|---|---|---|---|---|---|---|---|
| 0.690 | 0.652 | 0.679 | 0.805 | 0.841 | 0.850 | 0.857 | 0.851 | 0.867 | |
| MAE | 41.668 | 50.165 | 50.172 | 34.615 | 30.922 | 29.898 | 30.325 | 31.018 | 27.960 |
| RMSE | 61.840 | 65.560 | 62.955 | 49.033 | 44.295 | 43.011 | 42.010 | 42.900 | 40.477 |
| DT | SVR | AB | KNN | XGB | RF | LGB | HGB | ETR | |
|---|---|---|---|---|---|---|---|---|---|
| 0.734 | 0.861 | 0.690 | 0.829 | 0.862 | 0.825 | 0.859 | 0.861 | 0.869 | |
| MAE | 41.774 | 28.057 | 49.570 | 30.779 | 28.882 | 33.971 | 29.696 | 28.937 | 27.895 |
| RMSE | 57.299 | 41.362 | 61.920 | 45.963 | 41.249 | 46.507 | 41.773 | 41.371 | 40.286 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Uddin, M.J.; Fan, J. Interpretable Machine Learning Framework to Predict the Glass Transition Temperature of Polymers. Polymers 2024, 16, 1049. https://doi.org/10.3390/polym16081049
Uddin MJ, Fan J. Interpretable Machine Learning Framework to Predict the Glass Transition Temperature of Polymers. Polymers. 2024; 16(8):1049. https://doi.org/10.3390/polym16081049
Chicago/Turabian StyleUddin, Md. Jamal, and Jitang Fan. 2024. "Interpretable Machine Learning Framework to Predict the Glass Transition Temperature of Polymers" Polymers 16, no. 8: 1049. https://doi.org/10.3390/polym16081049
APA StyleUddin, M. J., & Fan, J. (2024). Interpretable Machine Learning Framework to Predict the Glass Transition Temperature of Polymers. Polymers, 16(8), 1049. https://doi.org/10.3390/polym16081049