
Combination of Machine Learning and Raman Spectroscopy for Determination of the Complex of Whey Protein Isolate with Hyaluronic Acid


Abstract

1. Introduction
2. Materials and Methods
2.1. Materials
2.2. Preparation of WPI-HA Conjugates
2.3. Raman Scattering Measurements
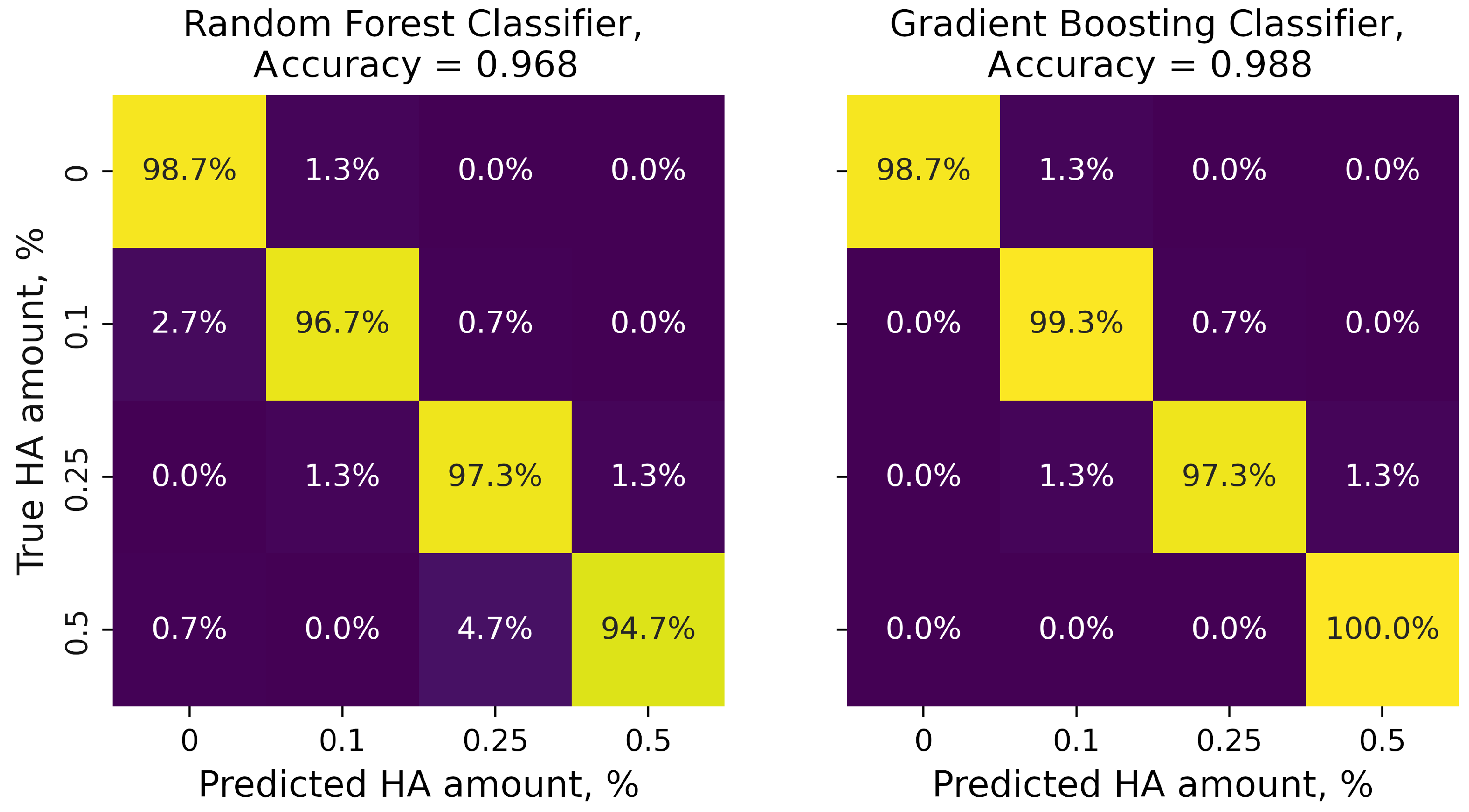
2.4. Data Analysis
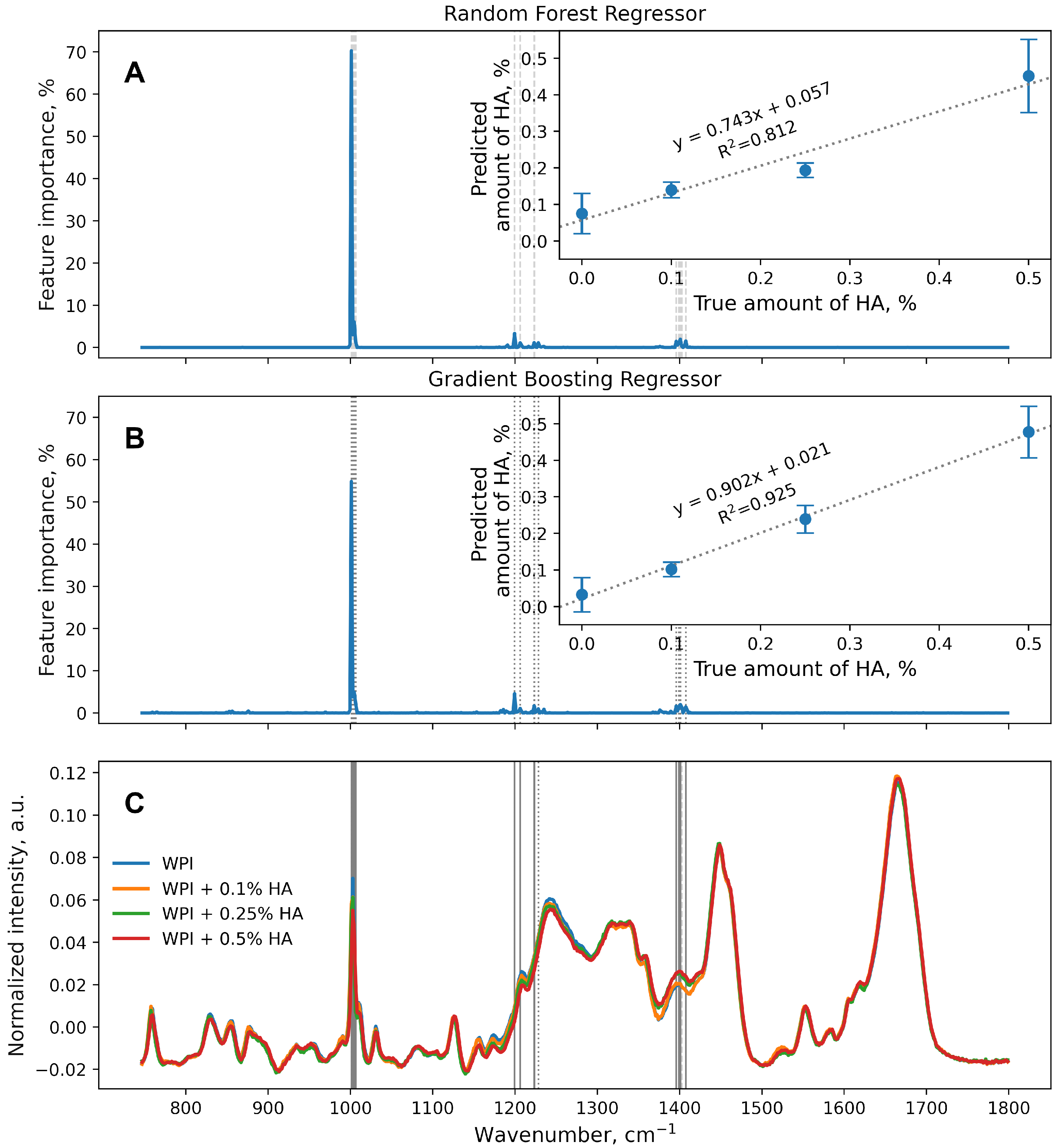
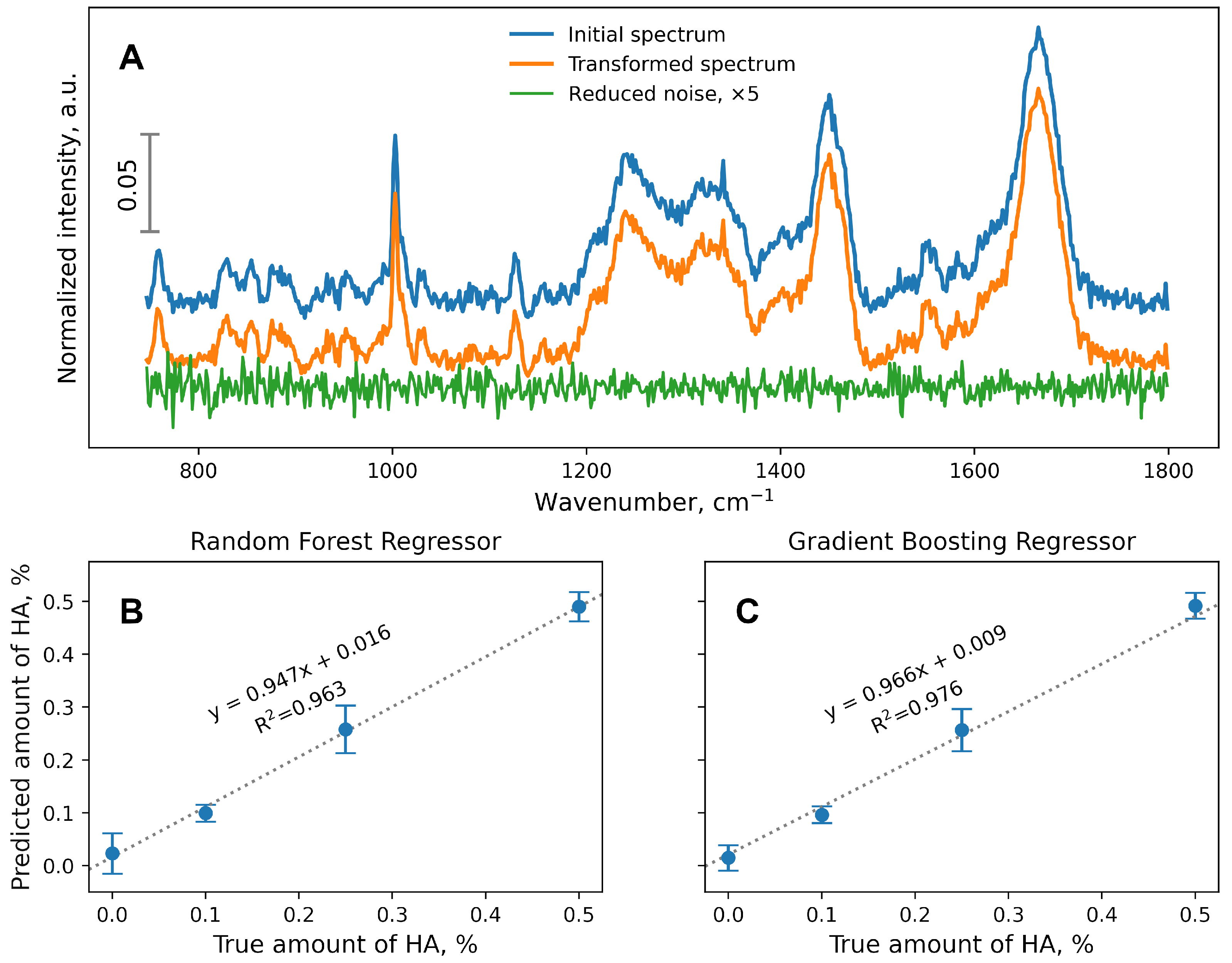
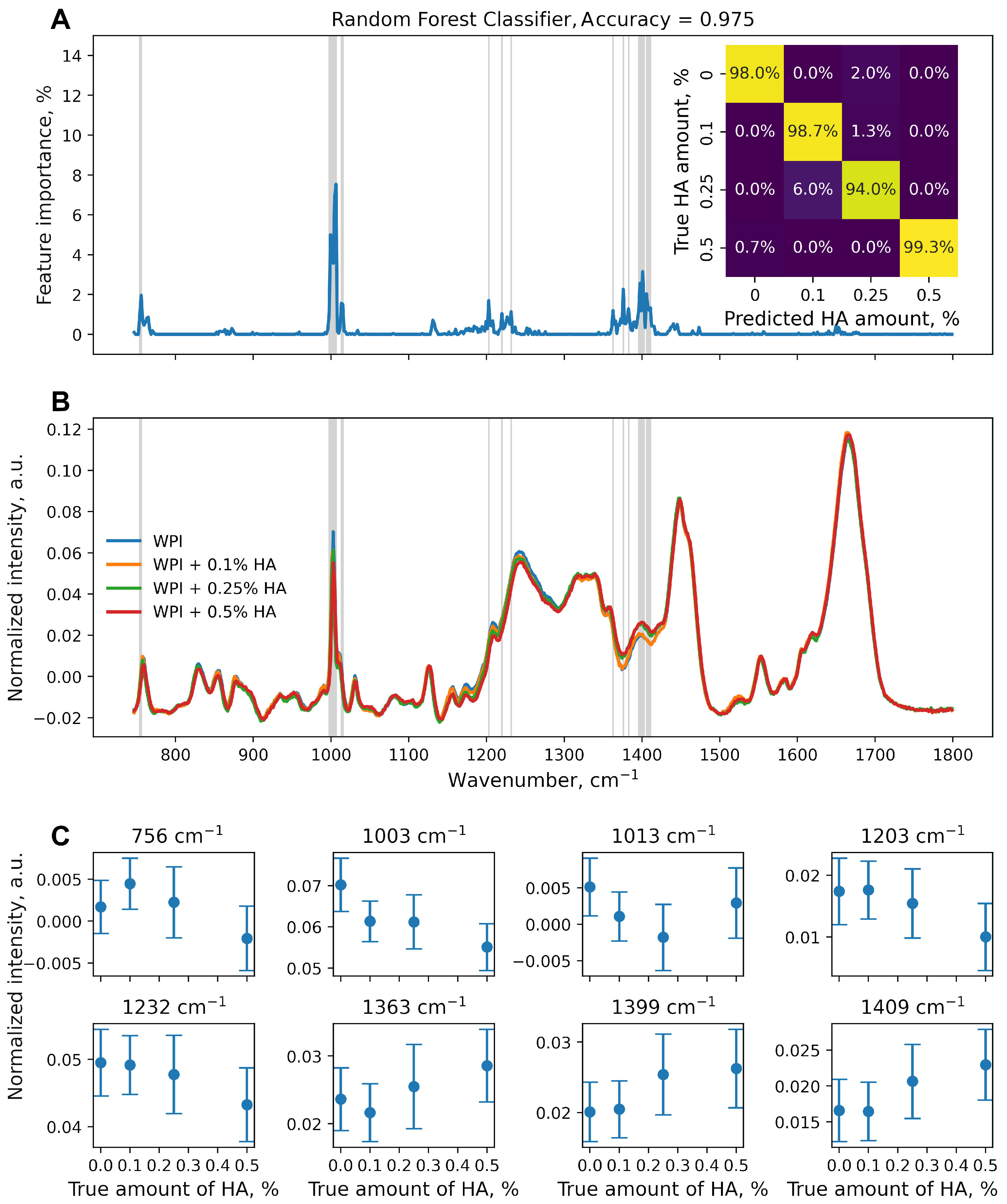
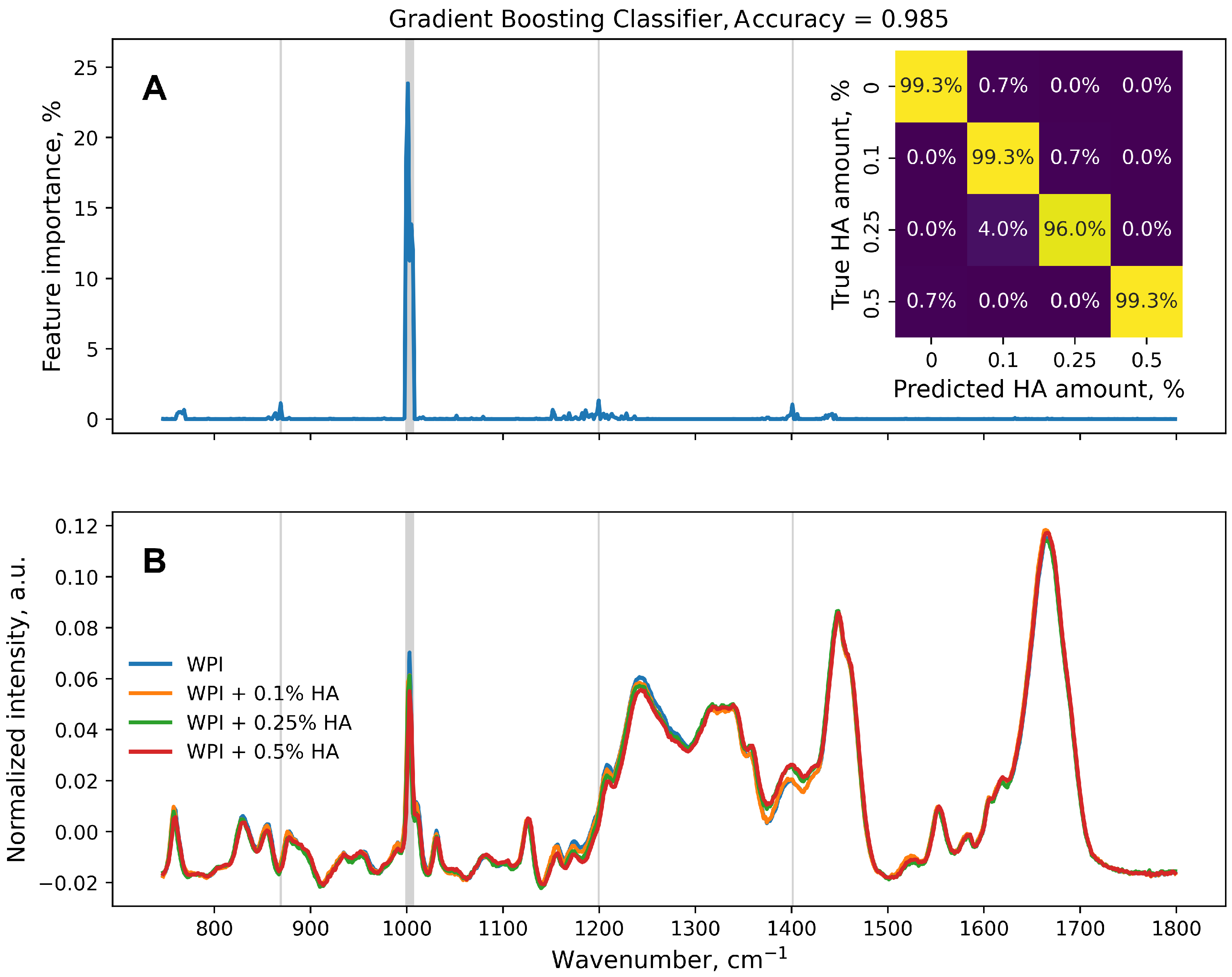
3. Results and Discussion
4. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| WPI | whey protein isolate |
| HA | hyaluronic acid |
| RF | random forest |
| GB | gradient boosting |
| PCA | principal component analysis |
| FTIR | Fourier-transform infrared spectroscopy |
References
- Tran, C.D.; Mututuvari, T.M. Cellulose, Chitosan, and Keratin Composite Materials. Controlled Drug Release. Langmuir 2015, 31, 1516–1526. [Google Scholar] [CrossRef]
- Raj, V.; Prabha, G. Synthesis, characterization and in vitro drug release of cisplatin loaded Cassava starch acetate–PEG/gelatin nanocomposites. J. Assoc. Arab. Univ. Basic Appl. Sci. 2016, 21, 10–16. [Google Scholar] [CrossRef]
- Cong, Z.; Shi, Y.; Wang, Y.; Wang, Y.; Niu, J.; Chen, N.; Xue, H. A novel controlled drug delivery system based on alginate hydrogel/chitosan micelle composites. Int. J. Biol. Macromol. 2018, 107, 855–864. [Google Scholar] [CrossRef] [PubMed]
- Tahmasbi Rad, A.; Ali, N.; Kotturi, H.S.R.; Yazdimamaghani, M.; Smay, J.; Vashaee, D.; Tayebi, L. Conducting scaffolds for liver tissue engineering. J. Biomed. Mater. Res. Part A 2014, 102, 4169–4181. [Google Scholar] [CrossRef] [PubMed]
- Rosellini, E.; Zhang, Y.S.; Migliori, B.; Barbani, N.; Lazzeri, L.; Shin, S.R.; Dokmeci, M.R.; Cascone, M.G. Protein/polysaccharide-based scaffolds mimicking native extracellular matrix for cardiac tissue engineering applications. J. Biomed. Mater. Res. Part A 2018, 106, 769–781. [Google Scholar] [CrossRef] [PubMed]
- van den Berg, L.; Rosenberg, Y.; van Boekel, M.A.; Rosenberg, M.; van de Velde, F. Microstructural features of composite whey protein/polysaccharide gels characterized at different length scales. Food Hydrocoll. 2009, 23, 1288–1298. [Google Scholar] [CrossRef]
- Wang, L.; Wu, M.; Liu, H.M. Emulsifying and physicochemical properties of soy hull hemicelluloses-soy protein isolate conjugates. Carbohydr. Polym. 2017, 163, 181–190. [Google Scholar] [CrossRef] [PubMed]
- Cialla-May, D.; Krafft, C.; Rösch, P.; Deckert-Gaudig, T.; Frosch, T.; Jahn, I.J.; Pahlow, S.; Stiebing, C.; Meyer-Zedler, T.; Bocklitz, T.; et al. Raman Spectroscopy and Imaging in Bioanalytics. Anal. Chem. 2022, 94, 86–119. [Google Scholar] [CrossRef]
- Selvarajan, P.; Chandra, G.; Bhattacharya, S.; Sil, S.; Vinu, A.; Umapathy, S. Potential of Raman spectroscopy towards understanding structures of carbon-based materials and perovskites. Emergent Mater. 2019, 2, 417–439. [Google Scholar] [CrossRef]
- Kuhar, N.; Sil, S.; Verma, T.; Umapathy, S. Challenges in application of Raman spectroscopy to biology and materials. RSC Adv. 2018, 8, 25888–25908. [Google Scholar] [CrossRef]
- Butler, H.J.; Ashton, L.; Bird, B.; Cinque, G.; Curtis, K.; Dorney, J.; Esmonde-White, K.; Fullwood, N.J.; Gardner, B.; Martin-Hirsch, P.L.; et al. Using Raman spectroscopy to characterize biological materials. Nat. Protoc. 2016, 11, 664–687. [Google Scholar] [CrossRef] [PubMed]
- Lussier, F.; Thibault, V.; Charron, B.; Wallace, G.Q.; Masson, J.F. Deep learning and artificial intelligence methods for Raman and surface-enhanced Raman scattering. TrAC Trends Anal. Chem. 2020, 124, 115796. [Google Scholar] [CrossRef]
- Ralbovsky, N.M.; Lednev, I.K. Towards development of a novel universal medical diagnostic method: Raman spectroscopy and machine learning. Chem. Soc. Rev. 2020, 49, 7428–7453. [Google Scholar] [CrossRef] [PubMed]
- Guo, S.; Popp, J.; Bocklitz, T. Chemometric analysis in Raman spectroscopy from experimental design to machine learning–based modeling. Nat. Protoc. 2021, 16, 5426–5459. [Google Scholar] [CrossRef] [PubMed]
- Alizadeh-Pasdar, N.; Nakai, S.; Li-Chan, E.C.Y. Principal Component Similarity Analysis of Raman Spectra To Study the Effects of pH, Heating, and κ-Carrageenan on Whey Protein Structure. J. Agric. Food Chem. 2002, 50, 6042–6052. [Google Scholar] [CrossRef] [PubMed]
- Noothalapati, H.; Iwasaki, K.; Yamamoto, T. Biological and Medical Applications of Multivariate Curve Resolution Assisted Raman Spectroscopy. Anal. Sci. 2017, 33, 15–22. [Google Scholar] [CrossRef] [PubMed]
- Chan, J.; Fore, S.; Wachsmann-Hogiu, S.; Huser, T. Raman spectroscopy and microscopy of individual cells and cellular components. Laser Photonics Rev. 2008, 2, 325–349. [Google Scholar] [CrossRef]
- Grimbergen, M.C.M.; van Swol, C.F.P.; Kendall, C.; Verdaasdonk, R.M.; Stone, N.; Bosch, J.L.H.R. Signal-to-Noise Contribution of Principal Component Loads in Reconstructed Near-Infrared Raman Tissue Spectra. Appl. Spectrosc. 2010, 64, 8–14. [Google Scholar] [CrossRef]
- Lima, A.M.F.; Daniel, C.R.; Pacheco, M.T.T.; de Brito, P.L.; Silveira, L. Discrimination of leukemias and non-leukemic cancers in blood serum samples of children and adolescents using a Raman spectral model. Lasers Med. Sci. 2022, 38, 22. [Google Scholar] [CrossRef]
- Yanina, I.Y.; Svenskaya, Y.I.; Prikhozhdenko, E.S.; Bratashov, D.N.; Lomova, M.V.; Gorin, D.A.; Sukhorukov, G.B.; Tuchin, V.V. Optical monitoring of adipose tissue destruction under encapsulated lipase action. J. Biophotonics 2018, 11, e201800058. [Google Scholar] [CrossRef]
- Rapport, M.; Weissmann, B.; Linker, A.; Meyer, K. Isolation of a Crystalline Disaccharide, Hyalobiuronic Acid, from Hyaluronic Acid. Nature 1951, 168, 996–997. [Google Scholar] [CrossRef] [PubMed]
- Haylock, D.N.; Nilsson, S.K. The role of hyaluronic acid in hemopoietic stem cell biology. Regen. Med. 2006, 1, 437–445. [Google Scholar] [CrossRef]
- Huang, H.; Huang, G. Application of hyaluronic acid as carriers in drug delivery. Drug Deliv. 2018, 25, 766–772. [Google Scholar] [CrossRef] [PubMed]
- Park, K.Y.; Kim, H.K.; Kim, B.J. Comparative study of hyaluronic acid fillers by in vitro and in vivo testing. J. Eur. Acad. Dermatol. Venereol. 2014, 28, 565–568. [Google Scholar] [CrossRef] [PubMed]
- Liu, Y.; Chen, D.; Zhang, A.; Xiao, M.; Li, Z.; Luo, W.; Pan, Y.; Qu, W.; Xie, S. Composite inclusion complexes containing hyaluronic acid/chitosan nanosystems for dual responsive enrofloxacin release. Carbohydr. Polym. 2021, 252, 117162. [Google Scholar] [CrossRef]
- Liu, Y.; Chen, D.; Zhang, A.; Xiao, M.; Li, Z.; Luo, W.; Pan, Y.; Qu, W.; Xie, S. The Application of Hyaluronic Acid-Based Hydrogels in Bone and Cartilage Tissue Engineering. Adv. Mater. Sci. Eng. 2019, 2019, 3027303. [Google Scholar] [CrossRef]
- Du, X.; Dubin, P.L.; Hoagland, D.A.; Sun, L. Protein-Selective Coacervation with Hyaluronic Acid. Biomacromolecules 2014, 15, 726–734. [Google Scholar] [CrossRef]
- Guo, M. (Ed.) Whey Protein Production, Chemistry, Functionality, and Applications; Wiley: Hoboken, NJ, USA, 2019. [Google Scholar] [CrossRef]
- Hsein, H.; Garrait, G.; Beyssac, E.; Hoffart, V. Whey protein mucoadhesive properties for oral drug delivery: Mucin–whey protein interaction and mucoadhesive bond strength. Colloids Surf. B Biointerfaces 2015, 136, 799–808. [Google Scholar] [CrossRef]
- Zhu, D.; Damodaran, S.; Lucey, J.A. Physicochemical and Emulsifying Properties of Whey Protein Isolate (WPI)-Dextran Conjugates Produced in Aqueous Solution. J. Agric. Food Chem. 2010, 58, 2988–2994. [Google Scholar] [CrossRef]
- de Castro, R.J.S.; Domingues, M.A.F.; Ohara, A.; Okuro, P.K.; dos Santos, J.G.; Brexó, R.P.; Sato, H.H. Whey protein as a key component in food systems: Physicochemical properties, production technologies and applications. Food Struct. 2017, 14, 17–29. [Google Scholar] [CrossRef]
- Llamas-Unzueta, R.; Suárez, M.; Fernández, A.; Díaz, R.; Montes-Morán, M.A.; Menéndez, J.A. Whey-Derived Porous Carbon Scaffolds for Bone Tissue Engineering. Biomedicines 2021, 9, 1091. [Google Scholar] [CrossRef] [PubMed]
- Douglas, T.E.; Vandrovcová, M.; Kročilová, N.; Keppler, J.K.; Zárubová, J.; Skirtach, A.G.; Bačáková, L. Application of whey protein isolate in bone regeneration: Effects on growth and osteogenic differentiation of bone-forming cells. J. Dairy Sci. 2018, 101, 28–36. [Google Scholar] [CrossRef] [PubMed]
- Wang, N.; Zhao, X.; Jiang, Y.; Ban, Q.; Wang, W. Enhancing the stability of oil-in-water emulsions by non-covalent interaction between whey protein isolate and hyaluronic acid. Int. J. Biol. Macromol. 2023, 225, 1085–1095. [Google Scholar] [CrossRef] [PubMed]
- Zhong, W.; Li, C.; Diao, M.; Yan, M.; Wang, C.; Zhang, T. Characterization of interactions between whey protein isolate and hyaluronic acid in aqueous solution: Effects of pH and mixing ratio. Colloids Surf. B Biointerfaces 2021, 203, 111758. [Google Scholar] [CrossRef] [PubMed]
- Zhong, W.; Zhang, T.; Dong, C.; Li, J.; Dai, J.; Wang, C. Effect of sodium chloride on formation and structure of whey protein isolate/hyaluronic acid complex and its ability to loading curcumin. Colloids Surf. A Physicochem. Eng. Asp. 2022, 632, 127828. [Google Scholar] [CrossRef]
- Zhong, W.; Li, J.; Wang, C.; Zhang, T. Formation, stability and in vitro digestion of curcumin loaded whey protein/ hyaluronic acid nanoparticles: Ethanol desolvation vs. pH-shifting method. Food Chem. 2023, 414, 135684. [Google Scholar] [CrossRef] [PubMed]
- Du, X.; Wang, P.; Fu, L.; Liu, H.; Zhang, Z.; Yao, C. Determination of Chlorpyrifos in Pears by Raman Spectroscopy with Random Forest Regression Analysis. Anal. Lett. 2020, 53, 821–833. [Google Scholar] [CrossRef]
- Li, M.; Xu, Y.; Men, J.; Yan, C.; Tang, H.; Zhang, T.; Li, H. Hybrid variable selection strategy coupled with random forest (RF) for quantitative analysis of methanol in methanol-gasoline via Raman spectroscopy. Spectrochim. Acta Part A Mol. Biomol. Spectrosc. 2021, 251, 119430. [Google Scholar] [CrossRef]
- Huang, W.; Shang, Q.; Xiao, X.; Zhang, H.; Gu, Y.; Yang, L.; Shi, G.; Yang, Y.; Hu, Y.; Yuan, Y.; et al. Raman spectroscopy and machine learning for the classification of esophageal squamous carcinoma. Spectrochim. Acta Part A Mol. Biomol. Spectrosc. 2022, 281, 121654. [Google Scholar] [CrossRef]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Friedman, J.H. Greedy Function Approximation: A Gradient Boosting Machine. Ann. Stat. 2001, 29, 1189–1232. [Google Scholar] [CrossRef]
- Zhao, Y.; Ma, C.Y.; Yuen, S.N.; Phillips, D.L. Study of Succinylated Food Proteins by Raman Spectroscopy. J. Agric. Food Chem. 2004, 52, 1815–1823. [Google Scholar] [CrossRef]
- Liu, R.; Yan, X.; Liu, Z.; McClements, D.J.; Liu, F.; Liu, X. Fabrication and characterization of functional protein-polysaccharide-polyphenol complexes assembled from lactoferrin, hyaluronic acid and (–)-epigallocatechin gallate. Food Funct. 2019, 10, 1098–1108. [Google Scholar] [CrossRef]
- Silverstein, R.M.; Webster, F.X.; Kiemle, D.J.; Bryce, D.L. Spectrometric Identification of Organic Compounds, 8th ed.; John Wiley & Sons, Inc.: New York, NY, USA, 2015; pp. 71–126. ISBN 978-0-470-61637-6. [Google Scholar]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Wavenumber, cm−1 | Assignment |
|---|---|
| 760, 880, 1360 | Tryptophan, indole ring |
| 830, 855 | Tyrosine, Fermi resonance between ring fundamental and overtone |
| 1003 | Phenylalanine, ring breath |
| 1240 | Amide III, N–H in-plane bend, C–N stretch |
| 1400 | Aspartic and glutamic acids, C=O stretch of COO− |
| 1450, 1465 | Aliphatic residues, C–H bending |
| 1540 | Amide II, N–H deformation |
| 1667 | Amide I, amide C=O stretch, N–H wag |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mayorova, O.A.; Saveleva, M.S.; Bratashov, D.N.; Prikhozhdenko, E.S. Combination of Machine Learning and Raman Spectroscopy for Determination of the Complex of Whey Protein Isolate with Hyaluronic Acid. Polymers 2024, 16, 666. https://doi.org/10.3390/polym16050666
Mayorova OA, Saveleva MS, Bratashov DN, Prikhozhdenko ES. Combination of Machine Learning and Raman Spectroscopy for Determination of the Complex of Whey Protein Isolate with Hyaluronic Acid. Polymers. 2024; 16(5):666. https://doi.org/10.3390/polym16050666
Chicago/Turabian StyleMayorova, Oksana A., Mariia S. Saveleva, Daniil N. Bratashov, and Ekaterina S. Prikhozhdenko. 2024. "Combination of Machine Learning and Raman Spectroscopy for Determination of the Complex of Whey Protein Isolate with Hyaluronic Acid" Polymers 16, no. 5: 666. https://doi.org/10.3390/polym16050666
APA StyleMayorova, O. A., Saveleva, M. S., Bratashov, D. N., & Prikhozhdenko, E. S. (2024). Combination of Machine Learning and Raman Spectroscopy for Determination of the Complex of Whey Protein Isolate with Hyaluronic Acid. Polymers, 16(5), 666. https://doi.org/10.3390/polym16050666