
Quality Classification of Injection-Molded Components by Using Quality Indices, Grading, and Machine Learning



Abstract

1. Introduction
2. Methodology
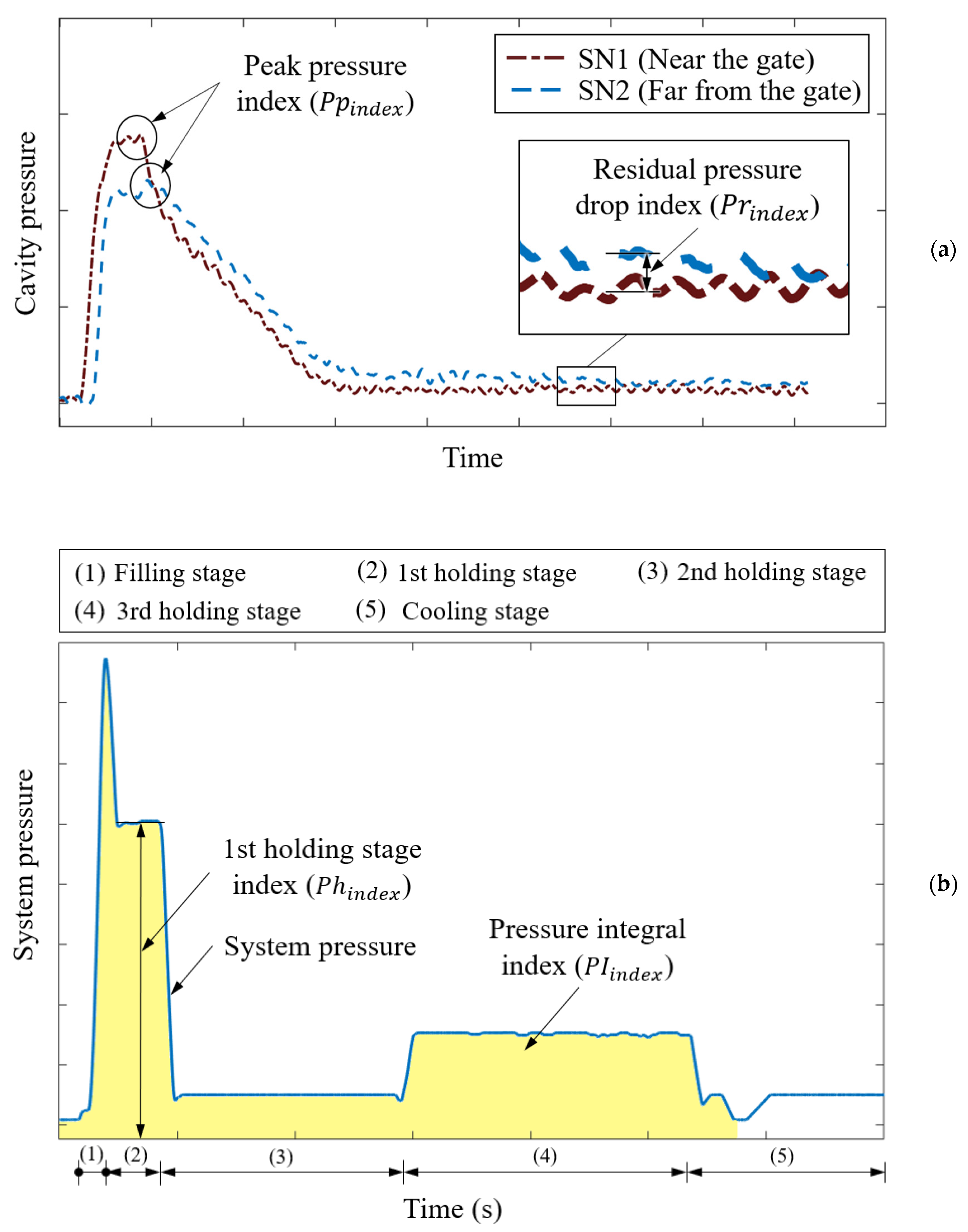
2.1. Quality Indices
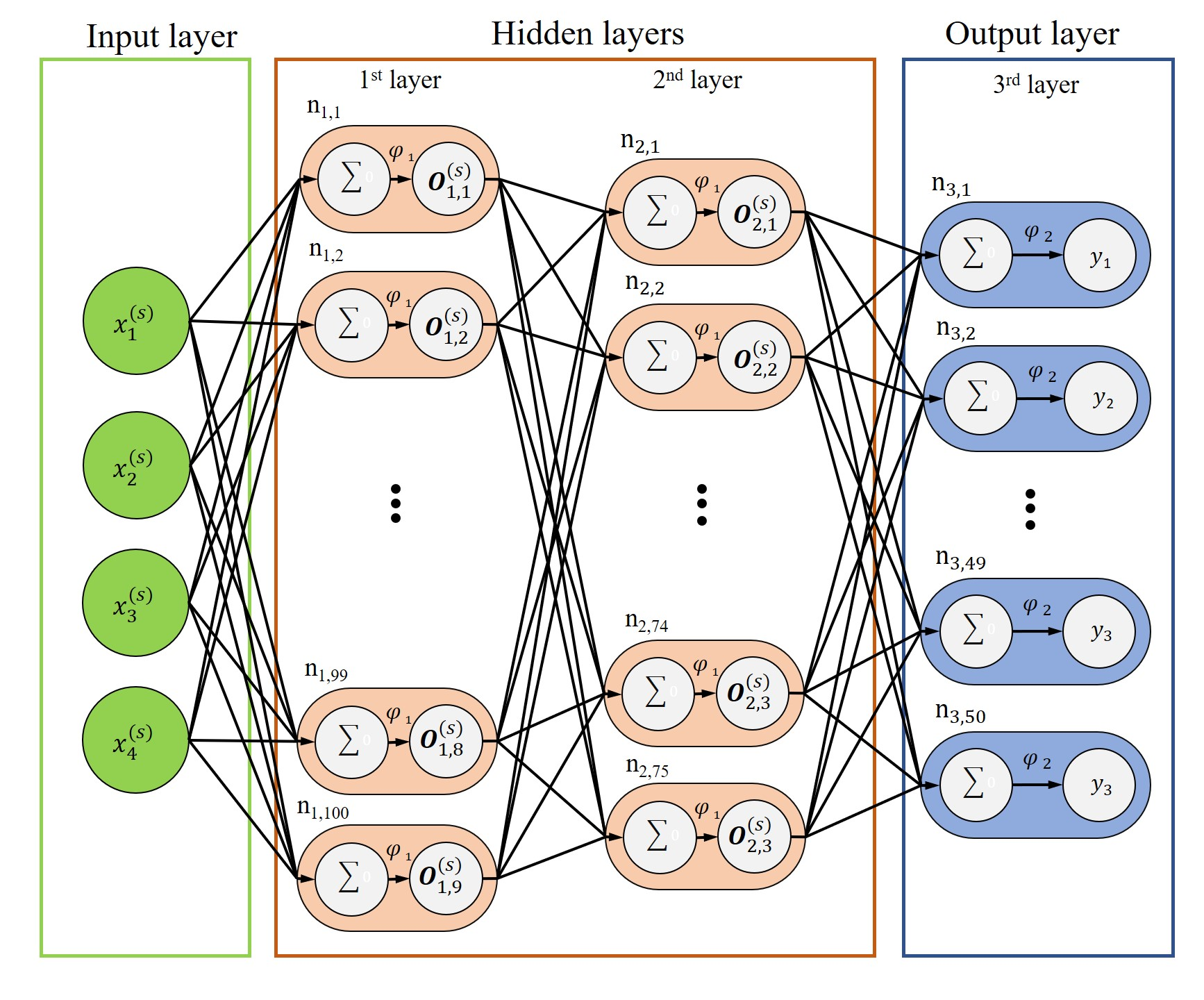
2.2. MLP Models
2.3. Outlier Filtering
2.4. Quality Classification
3. Experimental
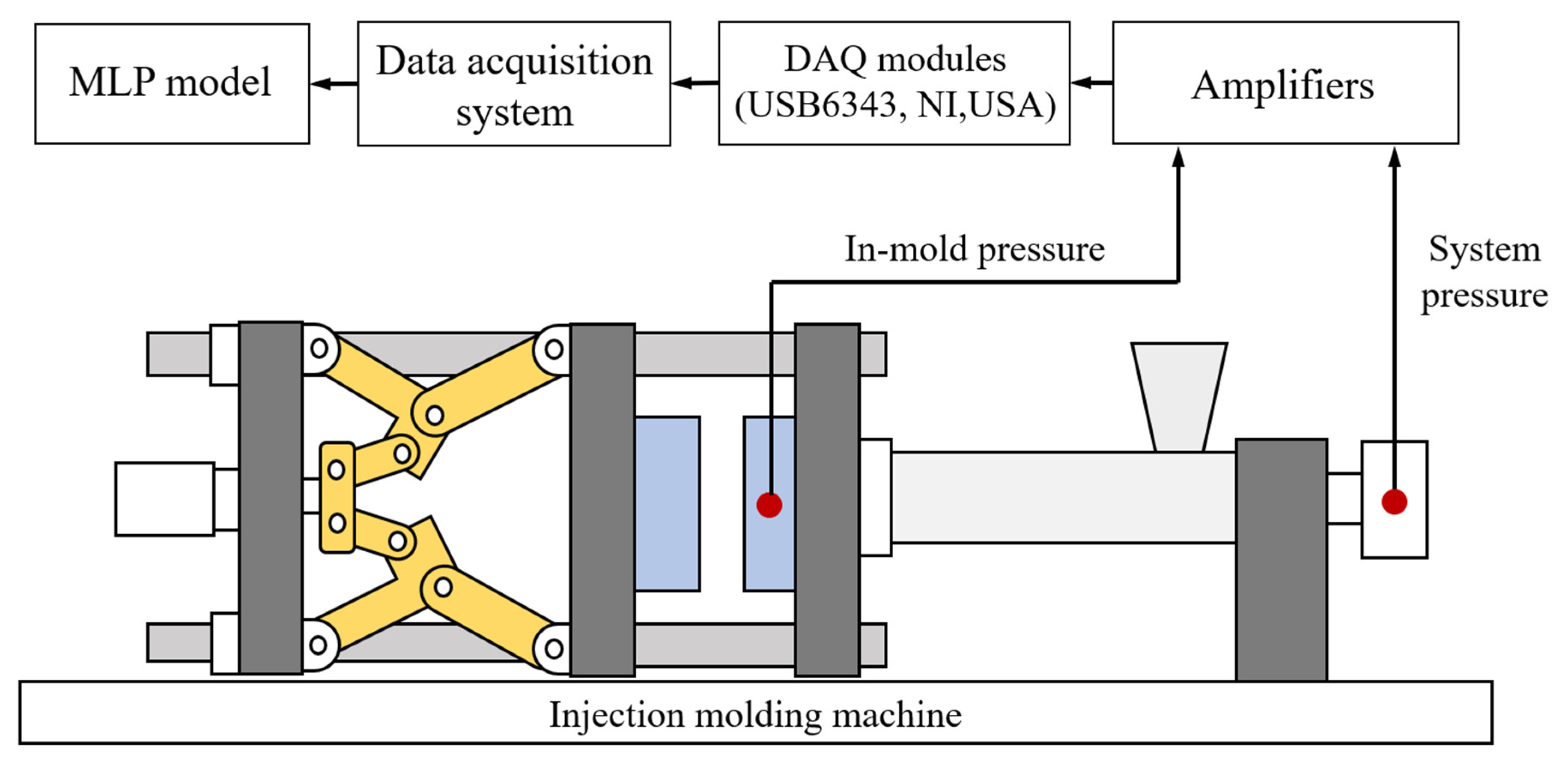
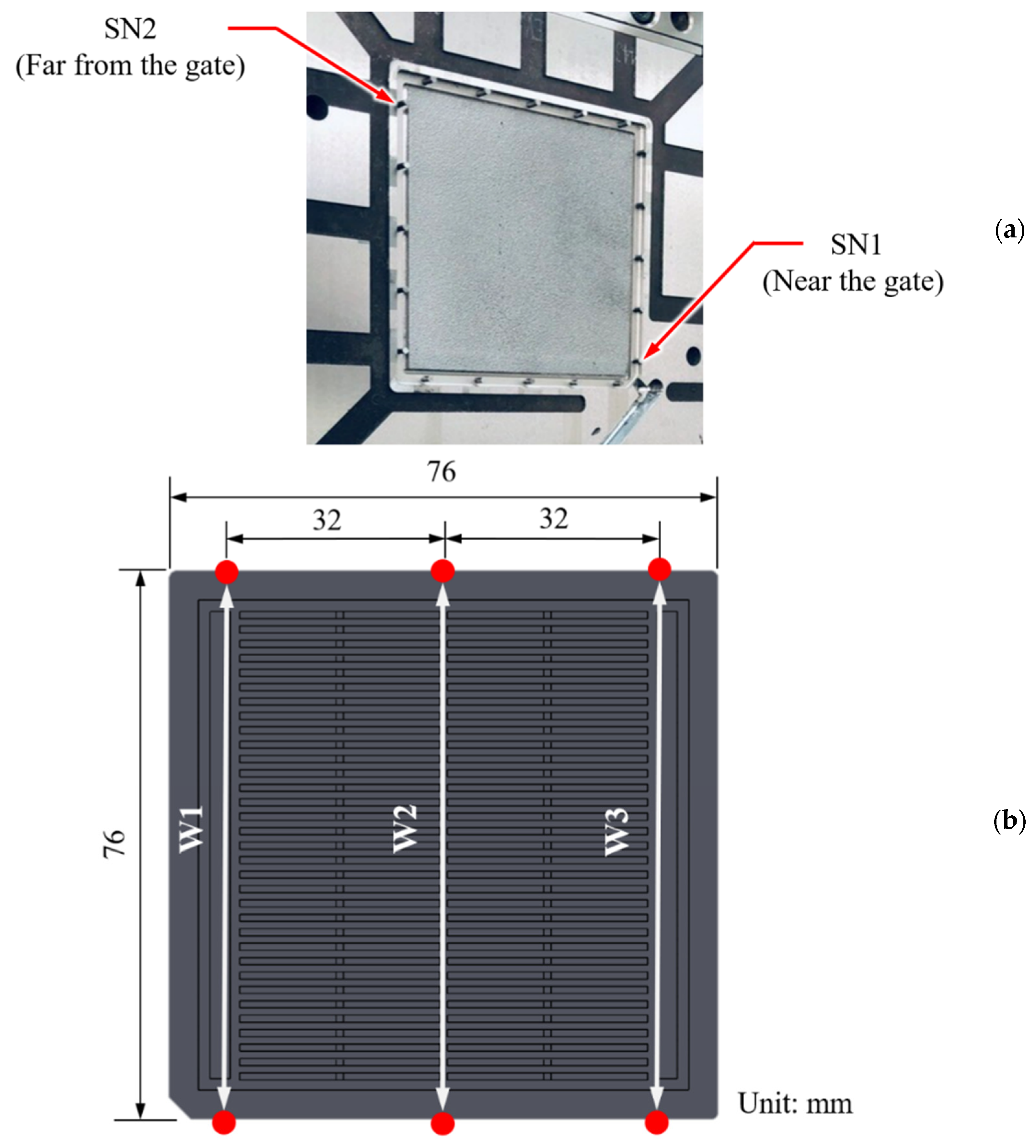
3.1. Injection Machine, Material, Mold, and Sensor
3.2. Outlier Filtering, and Quality Grading
3.3. MLP Model
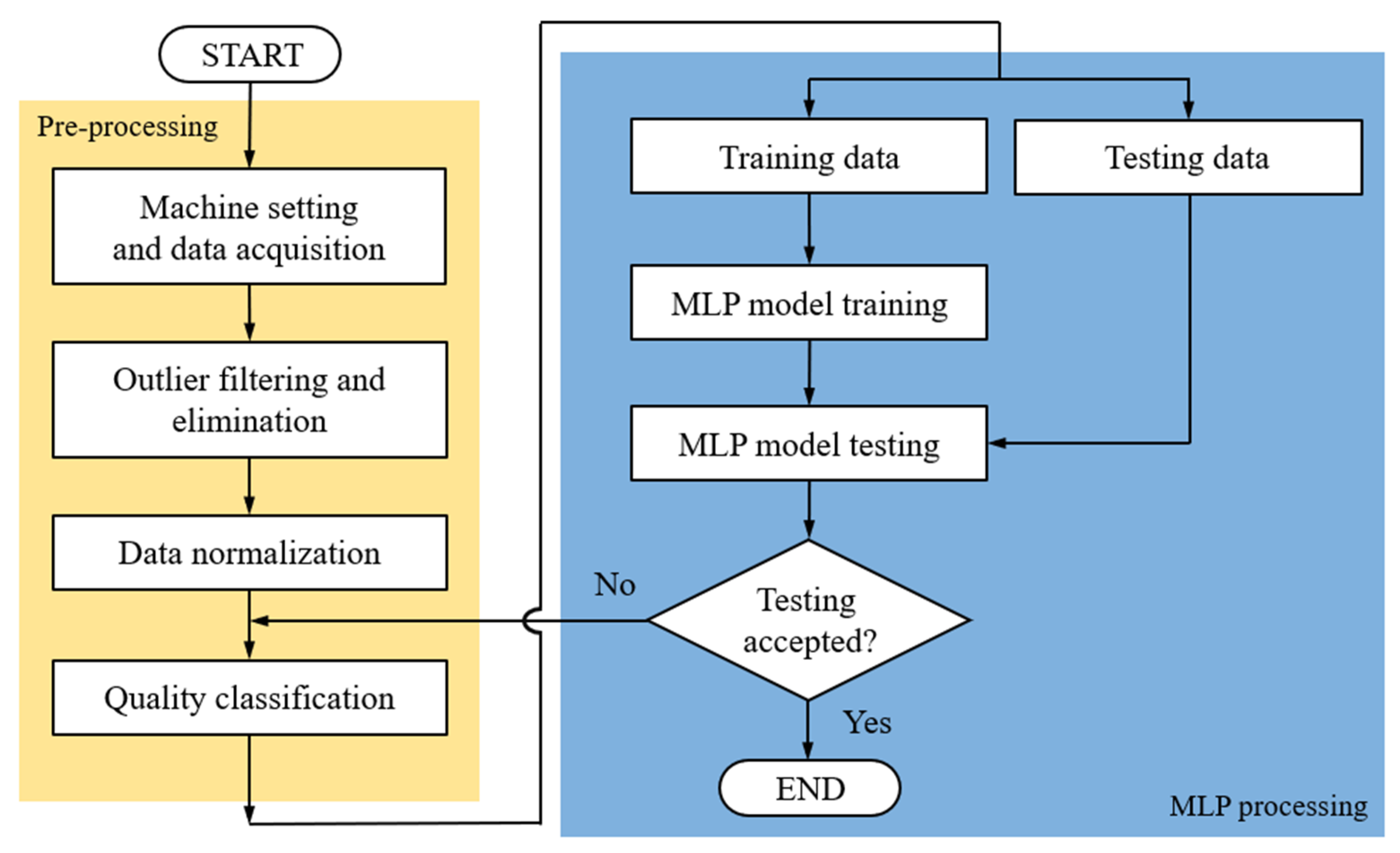
- Machine setting and data acquisition: Use the two-factor experiment method to adjust machine settings, and perform data acquisition to capture different pressure curves for each shot. Then, convert the pressure curves into quality indices. The width values of the part will be measured by a high-precision coordinate measuring machine as the qualities used in the next step;
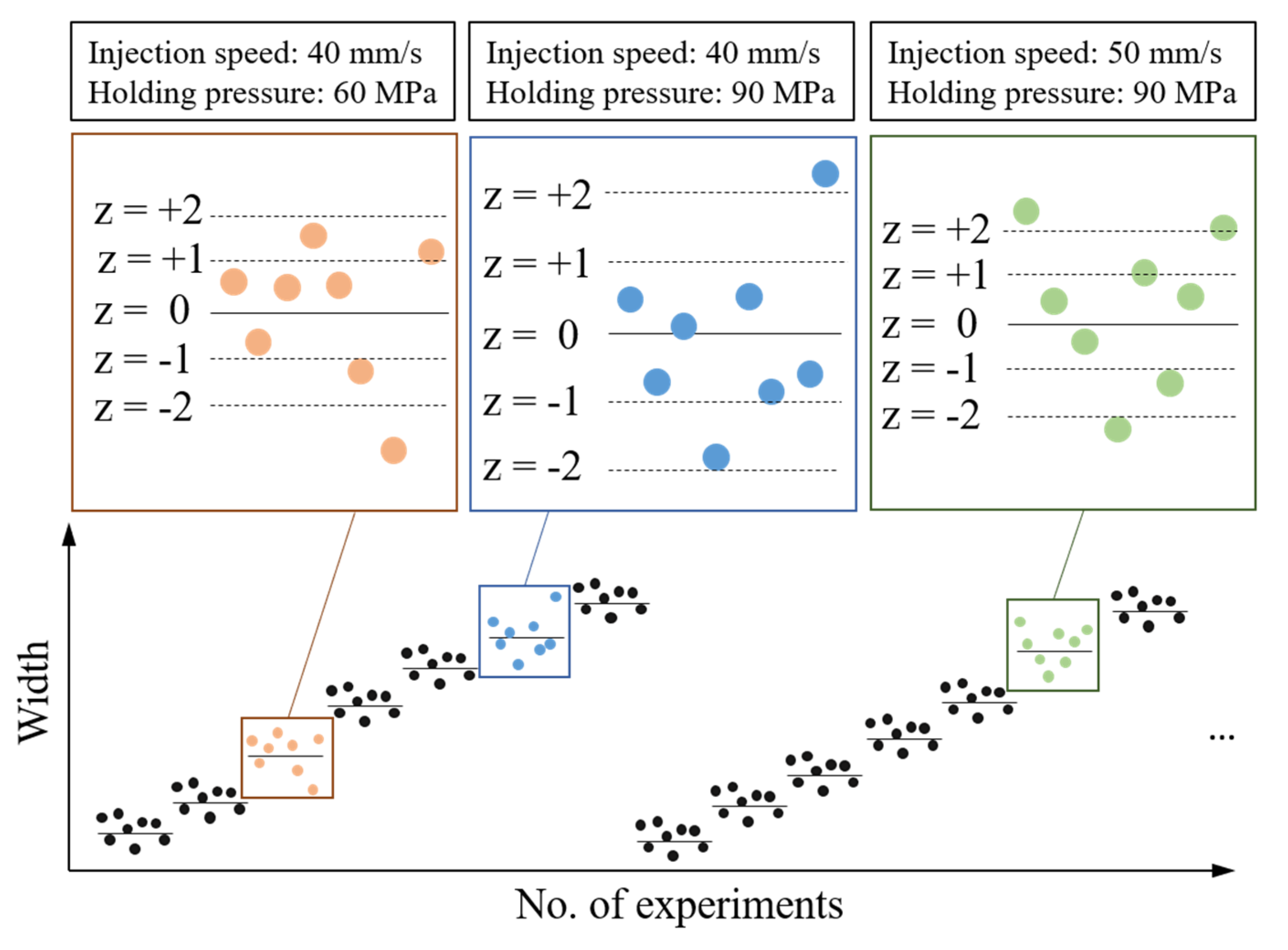
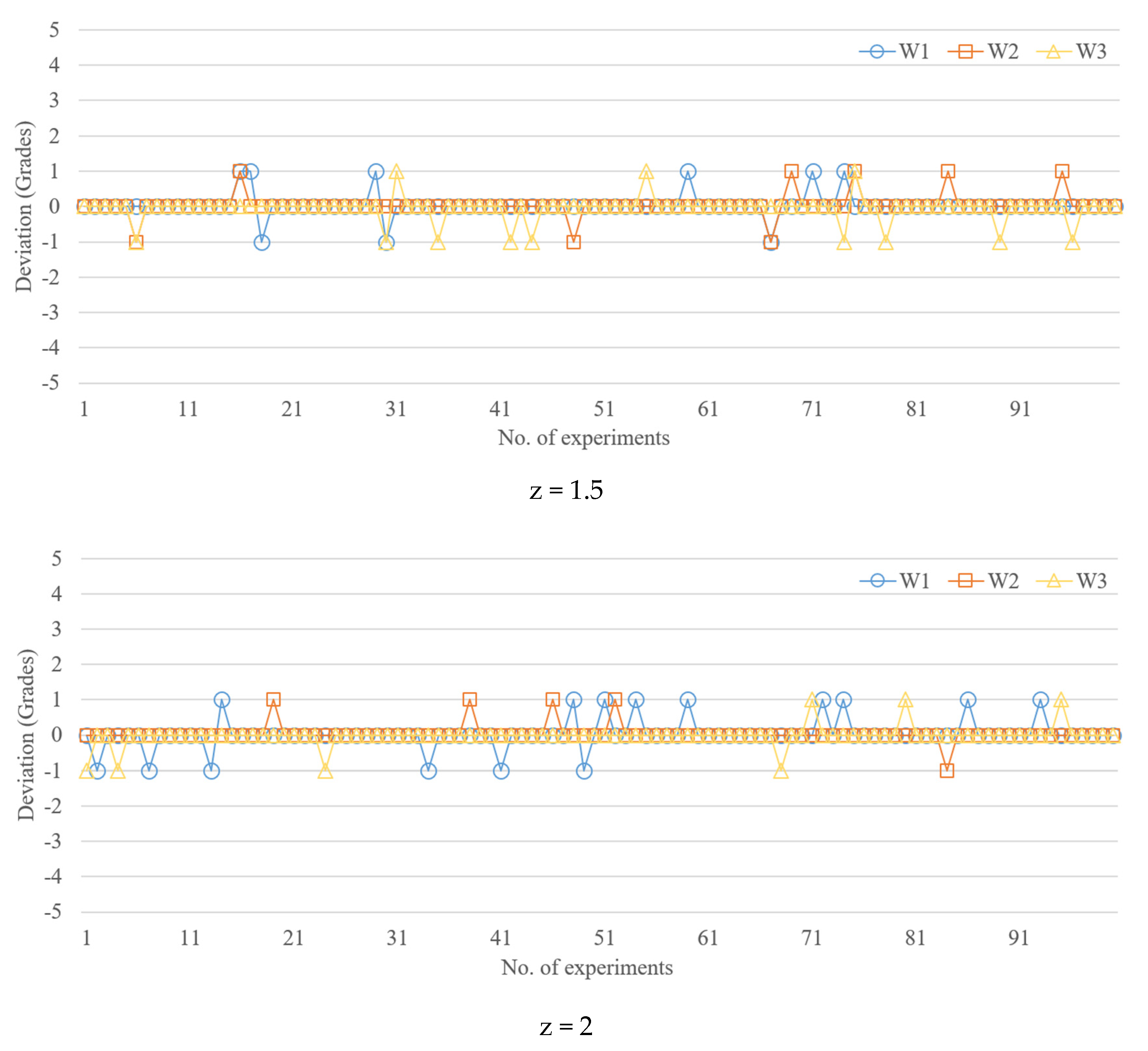
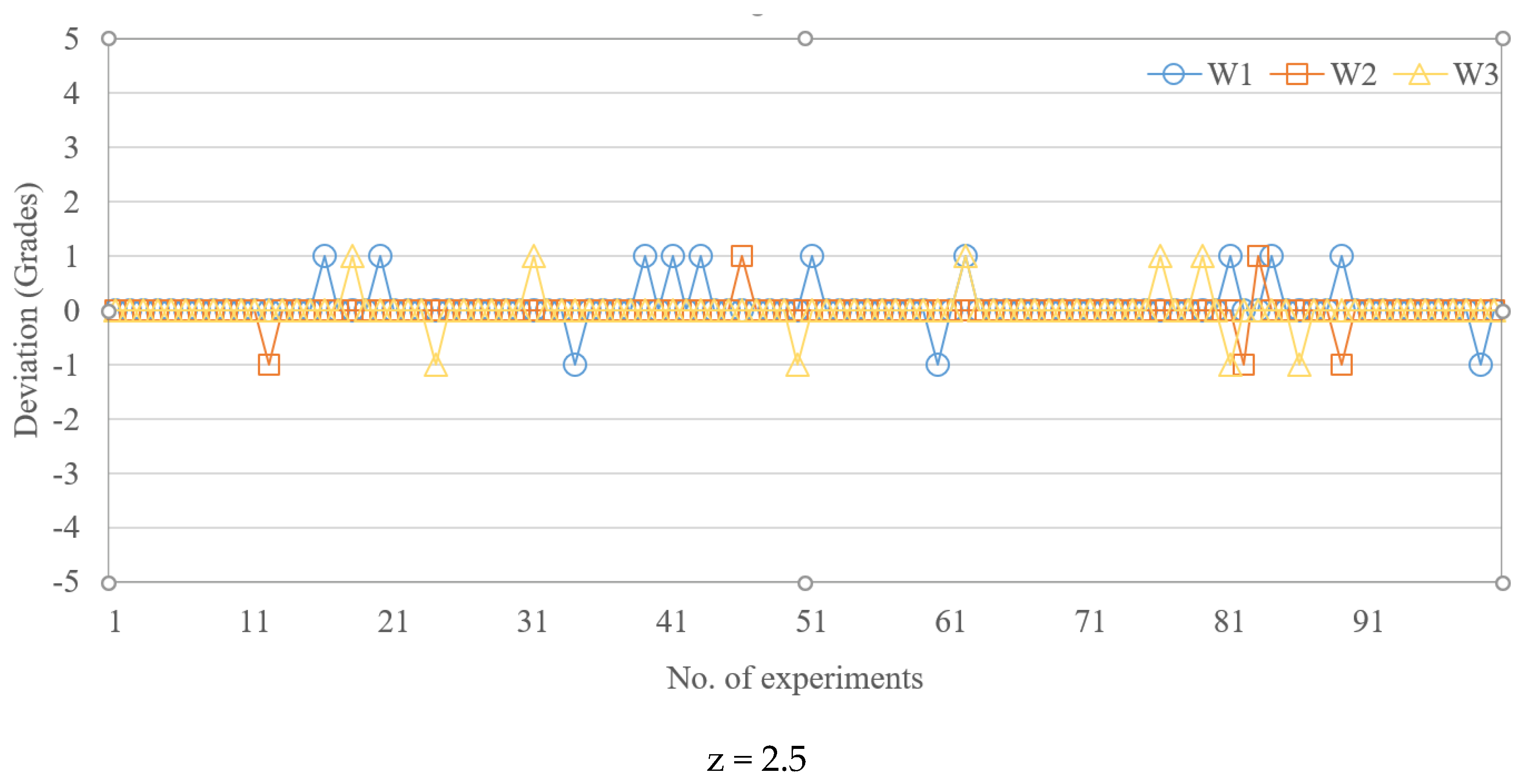
- Outlier filtering and elimination: The database obtained through the experimental design method will be judged its abnormal state by standard scores, which are set to 1.5, 2.0 and 2.5, respectively. Once the dataset obtained from the same machine setting is higher than this setting, it is defined as an outlier and filtered out;
- Data normalization: In order to reduce the influence of different data dimensions on convergence, this experiment normalizes the quality indices to an interval (0, 1);
- Quality classification: The width values are converted to various grades (5, 10, 20, and 50 in this study).
- The MLP processing stage includes:
- 5.
- Training and testing data: A specific parameter group is selected as the input data, and the normalized data are divided into two groups, with 100 datapoints being used for model testing and the remaining datapoints being used for model training;
- 6.
- MLP model training: The MLP model in this experiment is built using modules in Python. The MLP model contains an input layer of four nodes; two hidden layers (one with 100 neural nodes and the other with 75 neural nodes); an output layer of 5, 10, 20, and 50 nodes which corresponds to various grades, respectively. Table 5 presents the hyperparameter settings for the experimental MLP model. The internal parameters of an MLP model are called hyperparameters: they indicate the feature settings of the training model [21,22] and include the number of iterations (epoch), batch size, number of hidden layers, number of neurons per layer, and learning rate. The optimization processing method is controlled by hyperparameter learning rate, and the lowest loss time function (when the value of loss function is lower than 1) is obtained under the experimental control as the basis. The training and testing (inferencing) time are less than 10 min and 0.003 s, respectively;
- 7.
- MLP model testing: When the model testing result meets the user-defined criteria (validation loss value is less than 1), the grade number was used to confirm the category of the predicted width. Otherwise, this step will return to quality classification and redo.
4. Results and Discussion
4.1. Effect of z-Score and Number of Grades on Training and Prediction Accuracy of MLP Model
4.2. Quality Assessment
5. Conclusions
- (1)
- The use of quality indices in MLP model training could reduce the size of data, thus improving the training time. Phindex and PIindex were extracted from the system pressure curve, and Ppindex and Prindex were extracted from the near-gate and far-gate cavity pressure curves, respectively. According to the PCC, these four indices were highly related to the quality of the part widths; therefore, they helped to reduce the number of nodes and layers in the hidden layers. In the case study for predicting the width quality of the IC tray, the MLP model contained an input layer of four nodes, two hidden layers (one with 100 neural nodes and the other with 75 neural nodes), and an output layer whose number of nodes depended on the number of grades under consideration. Approximately 400 datasets (1600 datapoints) were used for model training, which yielded accurate learning results rapidly (the training time and the testing time are less than 10 min and 0.003 s, respectively);
- (2)
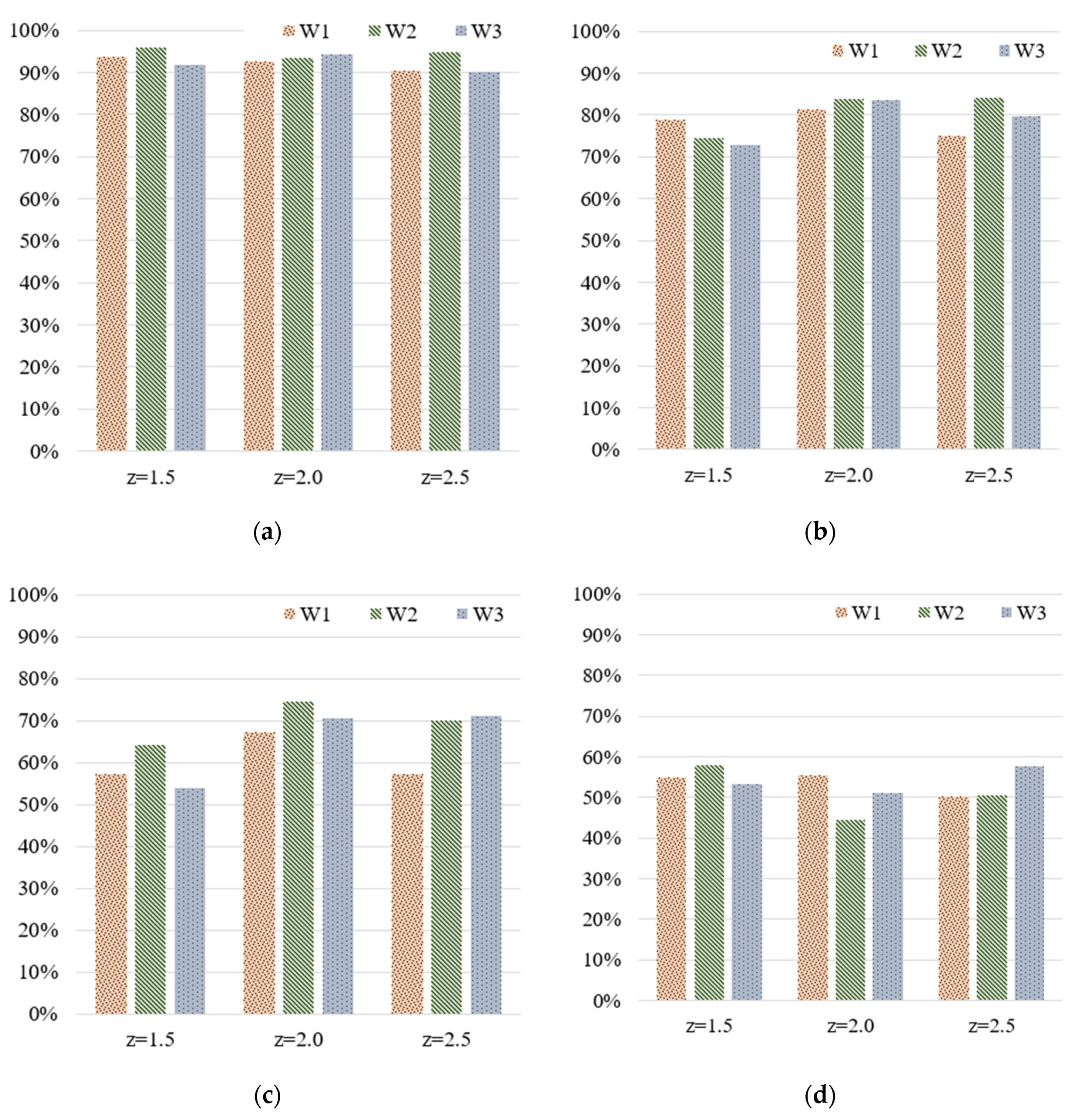
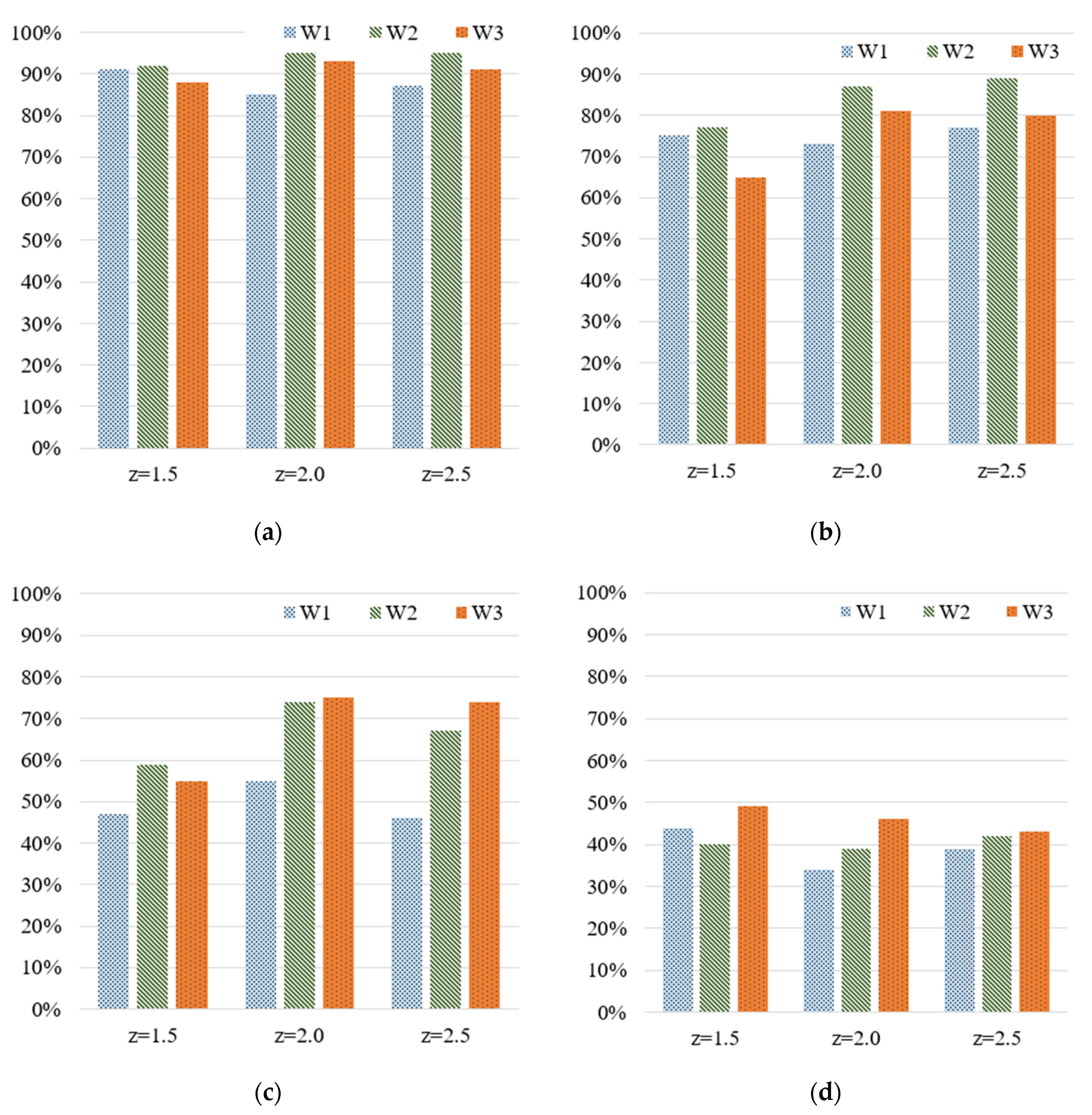
- Both the number of grades and the z-score had a considerable influence on the accuracy of quality prediction. In model training, the average prediction accuracy rates observed when 5, 10, 20, and 50 grades were used were approximately 92–94%, 75–83%, 58–71%, and 50–55%, respectively. Initially, the average training accuracy range for each z-score decreased as the number of grades increased. When the number of grades was low, the z-score did not have a considerable impact on training accuracy. However, because the use of more grades can provide more categories of part quality, we conclude that the z-score helped in improving the training accuracy.
- (3)
- In the prediction of the widths of the IC tray, a z-score of 2 provided the best performance in terms of prediction deviation, that is, 1 grade (17.7 µm). For 20 grades, a z-score of 2 provided the best performance in terms of prediction deviation, that is, four grades (35.6 µm). For 50 grades, a z-score of 2 provided the best performance in terms of prediction deviation, that is, 10 grades (35 µm). In summary, the z-score (z = 2 in this case) had a considerable impact on prediction accuracy;
- (4)
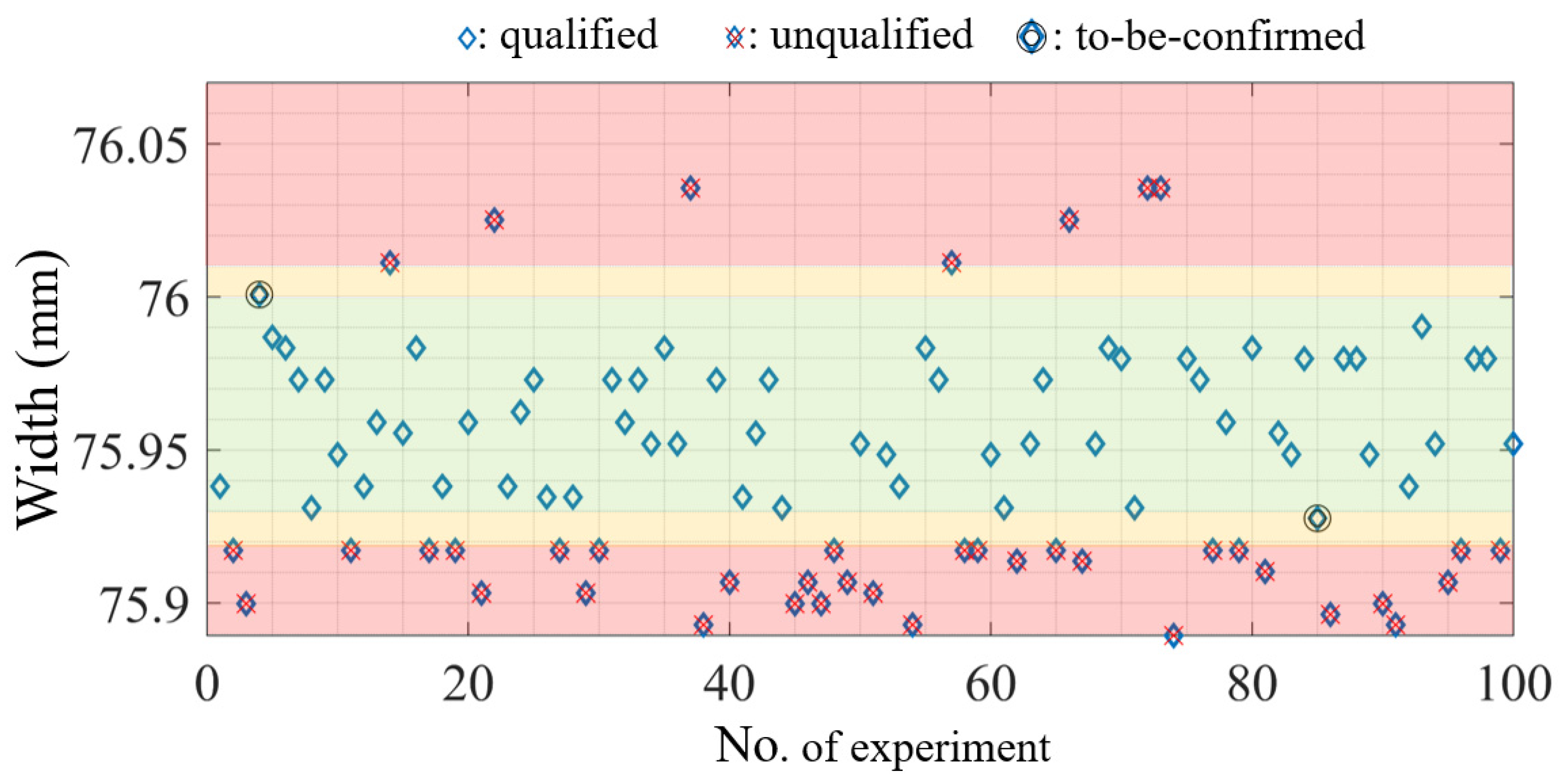
- This study also proposed the concepts of “qualified,” “unqualified,” and “to-be-confirmed” for evaluating part quality using the MLP model. The user-defined “to-be-confirmed” area was located between the “qualified” area and “unqualified” area; performing additional measurements to confirm the MLP model results is worthwhile. Therefore, the prediction of quality is more accurate when very few datasets (instead of all datasets) need to be verified. This method is suitable for use in industries.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Chen, J.-Y.; Yang, K.-J.; Huang, M.-S. Online quality monitoring of molten resin in injection molding. Int. J. Heat Mass Transf. 2018, 122, 681–693. [Google Scholar] [CrossRef]
- Nian, S.-C.; Li, M.-H.; Huang, M.-S. Warpage control of headlight lampshades fabricated using external gas-assisted injection molding. Int. J. Heat Mass Transf. 2015, 86, 358–368. [Google Scholar] [CrossRef]
- Huang, M.-S. Cavity pressure based grey prediction of the filling-to-packing switchover point for injection molding. J. Mater. Process. Technol. 2007, 183, 419–424. [Google Scholar] [CrossRef]
- Asadizanjani, N.; Gao, R.X.; Fan, Z.; Kazmer, D.O. Viscosity Measurement in Injection Molding Using A Multivariate Sensor. In Proceedings of the ASME/ISCIE 2012 International Symposium on Flexible Automation (ISFA2012), St. Louis, MO, USA, 18–20 June 2012; pp. 231–237. [Google Scholar]
- Gordon, G.; Kazmer, D.O.; Tang, X.; Fan, Z.; Gao, R.X. Quality control using a multivariate injection molding sensor. Int. J. Adv. Manuf. Technol. 2015, 78, 1381–1391. [Google Scholar] [CrossRef]
- Bula, K.; Różański, L.; Marciniak-Podsadna, L.; Wróbel, D. The use of IR thermography to show the mold and part temperature evolution in injection molding. Arch. Mech. Technol. Mater. 2016, 36, 40–43. [Google Scholar] [CrossRef][Green Version]
- Chen, J.-Y.; Zhuang, J.-X.; Huang, M.-S. Monitoring, prediction and control of injection molding quality based on tie-bar elongation. J. Manuf. Process. 2019, 46, 159–169. [Google Scholar] [CrossRef]
- Zhang, J.; Zhao, P.; Zhao, Y.; Huang, J.; Xia, N.; Fu, J. On-line measurement of cavity pressure during injection molding via ultrasonic investigation of tie bar. Sens. Actuators A Phys. 2019, 285, 118–126. [Google Scholar] [CrossRef]
- Ke, K.-C.; Huang, M.-S. Quality Prediction for Injection Molding by Using a Multilayer Perceptron Neural Network. Polymers 2020, 12, 1812. [Google Scholar] [CrossRef] [PubMed]
- Chen, J.Y.; Tseng, C.C.; Huang, M.S. Quality indexes design for online monitoring polymer injection molding. Adv. Polym. Technol. 2019, 2019, 1–20. [Google Scholar] [CrossRef]
- Chen, J.-Y.; Liu, C.-Y.; Huang, M.-S. Tie-Bar Elongation Based Filling-To-Packing Switchover Control and Prediction of Injection Molding Quality. Polymers 2019, 11, 1168. [Google Scholar] [CrossRef] [PubMed]
- Zhou, X.; Zhang, Y.; Mao, T.; Ruan, Y.; Gao, H.; Zhou, H. Feature extraction and physical interpretation of melt pressure during injection molding process. J. Mater. Process. Technol. 2018, 261, 50–60. [Google Scholar] [CrossRef]
- Oliaei, E.; Heidari, B.S.; Davachi, S.M.; Bahrami, M.; Davoodi, S.; Hejazi, I.; Seyfi, J. Warpage and Shrinkage Optimization of Injection-Molded Plastic Spoon Parts for Biodegradable Polymers Using Taguchi, ANOVA and Artificial Neural Network Methods. J. Mater. Sci. Technol. 2016, 32, 710–720. [Google Scholar] [CrossRef]
- Ozcelik, B.; Erzurumlu, T. Comparison of the warpage optimization in the plastic injection molding using ANOVA, neural network model and genetic algorithm. J. Mater. Process. Technol. 2006, 171, 437–445. [Google Scholar] [CrossRef]
- Reddy, B.S.; Reddy, K.T.; Reddy, K.V.K. Application of Artificial Neural Networks for the Prediction of Shrinkage and Warpage of Plastic Injection Molded Parts. Manag. J. Future Eng. Technol. 2008, 4, 21–27. [Google Scholar] [CrossRef]
- Yin, F.; Mao, H.; Hua, L.; Guo, W.; Shu, M. Back Propagation neural network modeling for warpage prediction and optimization of plastic products during injection molding. Mater. Des. 2011, 32, 1844–1850. [Google Scholar] [CrossRef]
- Bensingh, R.J.; Machavaram, R.; Boopathy, S.R.; Jebaraj, C. Injection molding process optimization of a bi-aspheric lens using hybrid artificial neural networks (ANNs) and particle swarm optimization (PSO). Measurement 2019, 134, 359–374. [Google Scholar] [CrossRef]
- Guo, W.; Deng, F.; Meng, Z.; Hua, L.; Mao, H.; Su, J. A hybrid backpropagation neural network and intelligent algorithm combined algorithm for optimizing microcellular foaming injection molding process parameters. J. Manuf. Process. 2020, 50, 528–538. [Google Scholar] [CrossRef]
- Hwang, S.; Kim, J. Injection mold design of reverse engineering using injection molding analysis and machine learning. J. Mech. Sci. Technol. 2019, 33, 3803–3812. [Google Scholar] [CrossRef]
- Neter, J.; Wasserman, W. Applied Statistics, 4th ed.; Pearson: New York, NY, USA, 1993. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift. arXiv 2015, arXiv:1502.03167. [Google Scholar]
- Cooijmans, T.; Ballas, N.; Laurent, C.; Gülçehre, Ç.; Courville, A. Recurrent Batch Normalization. arXiv 2016, arXiv:1603.09025. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Item | Unit | Parameters | |
|---|---|---|---|
| Melt temperature | °C | 205 | |
| Mold temperature | °C | 60 | |
| Backpressure | MPa | 4.5 | |
| Clamping force | Tons | 70 | |
| Decompression on stroke | mm | 10 | |
| Holding speed limit | mm/s | 80 | |
| V/P switchover position | mm | 12.45 | |
| Cooling time | s | 16 | |
| Holding pressure | 1st stage | MPa | 40, 50, 60, 70, 80, 90, 100 |
| 2nd stage | MPa | 5 | |
| 3rd stage | MPa | 15 | |
| Holding time | 1st stage | s | 1 |
| 2nd stage | s | 4 | |
| 3rd stage | s | 5 | |
| Injection speed | mm/s | 40, 50, 60, 70, 80, 90, 100, 110, 120 | |
| Quality Indices | Sensor Position | Symbols | Pearson’s Correlation Coefficient | ||
|---|---|---|---|---|---|
| W1 | W2 | W3 | |||
| System pressure | 0.96 | 0.96 | 0.97 | ||
| System pressure | 0.79 | 0.81 | 0.78 | ||
| Near the gate | SN1 | 0.95 | 0.96 | 0.96 | |
| Far from the gate | SN2 | 0.93 | 0.93 | 0.92 | |
| z Score | Number of Outliers | ||
|---|---|---|---|
| W1 | W2 | W3 | |
| 2.5 | 0 | 0 | 0 |
| 2 | 10 | 15 | 11 |
| 1.5 | 52 | 50 | 52 |
| Grade Number | Standard Score, z | ||
|---|---|---|---|
| z = 1.5 | z = 2 | z = 2.5 | |
| 5 | 34.8 | 35.4 | 35.4 |
| 10 | 17.4 | 17.7 | 17.7 |
| 20 | 8.7 | 8.9 | 8.9 |
| 50 | 3.5 | 3.5 | 3.5 |
| Item | Parameter | |
|---|---|---|
| Software and version | Python 3.6.9 | |
| Loss function | Categorical Crossentropy | |
| Optimizer | Stochastic Gradient Descent | |
| Learning rate | 0.49 | |
| Activation function | Sigmoid function, Softmax function | |
| Metrics | Accuracy | |
| Batch size | 10 | |
| Epoch | 10000 | |
| No. total dataset | 352~404 (depends on the z score value) | |
| No. testing dataset | 100 | |
| No. neural node of: | Input layer | , , , |
| 1st hidden layer | 100 | |
| 2nd hidden layer | 75 | |
| Output layer | 5, 10, 20, 50 |
| Grade Number | Average Training Accuracy (%) | ||
|---|---|---|---|
| z = 1.5 | z = 2 | z = 2.5 | |
| 5 | 94 | 93 | 92 |
| 10 | 75 | 83 | 80 |
| 20 | 58 | 71 | 66 |
| 50 | 55 | 50 | 53 |
| Grade Number | Average Training Accuracy (%) | ||
|---|---|---|---|
| z = 1.5 | z = 2 | z = 2.5 | |
| 5 | 90 | 91 | 91 |
| 10 | 72 | 80 | 82 |
| 20 | 54 | 68 | 62 |
| 50 | 44 | 40 | 41 |
| Unit: Grade | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Average | Standard Deviation | Maximum Deviation | ||||||||
| W1 | W2 | W3 | W1 | W2 | W3 | W1 | W2 | W3 | ||
| Grade 5 | z = 1.5 | 0.09 | 0.08 | 0.12 | 0.29 | 0.27 | 0.33 | 1 | 1 | 1 |
| z = 2 | 0.15 | 0.05 | 0.07 | 0.36 | 0.22 | 0.26 | 1 | 1 | 1 | |
| z = 2.5 | 0.13 | 0.05 | 0.07 | 0.34 | 0.22 | 0.29 | 1 | 1 | 1 | |
| Grade 10 | z = 1.5 | 0.29 | 0.23 | 0.35 | 0.59 | 0.42 | 0.48 | 3 | 1 | 1 |
| z = 2 | 0.27 | 0.13 | 0.19 | 0.45 | 0.34 | 0.39 | 1 | 1 | 1 | |
| z = 2.5 | 0.23 | 0.13 | 0.24 | 0.42 | 0.42 | 0.57 | 1 | 3 | 4 | |
| Grade 20 | z = 1.5 | 0.88 | 0.56 | 0.6 | 1.16 | 0.83 | 0.74 | 5 | 4 | 2 |
| z = 2 | 0.68 | 0.32 | 0.32 | 0.89 | 0.58 | 0.6 | 4 | 2 | 2 | |
| z = 2.5 | 0.9 | 0.47 | 0.35 | 1.06 | 0.85 | 0.66 | 5 | 4 | 3 | |
| Grade 50 | z = 1.5 | 1.73 | 3.07 | 1.13 | 2.57 | 3.83 | 1.44 | 14 | 17 | 5 |
| z = 2 | 1.75 | 1.27 | 1.59 | 2.19 | 1.64 | 2 | 12 | 10 | 6 | |
| z = 2.5 | 1.74 | 1.71 | 1.59 | 2.41 | 2.35 | 2.15 | 15 | 12 | 11 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ke, K.-C.; Huang, M.-S. Quality Classification of Injection-Molded Components by Using Quality Indices, Grading, and Machine Learning. Polymers 2021, 13, 353. https://doi.org/10.3390/polym13030353
Ke K-C, Huang M-S. Quality Classification of Injection-Molded Components by Using Quality Indices, Grading, and Machine Learning. Polymers. 2021; 13(3):353. https://doi.org/10.3390/polym13030353
Chicago/Turabian StyleKe, Kun-Cheng, and Ming-Shyan Huang. 2021. "Quality Classification of Injection-Molded Components by Using Quality Indices, Grading, and Machine Learning" Polymers 13, no. 3: 353. https://doi.org/10.3390/polym13030353
APA StyleKe, K.-C., & Huang, M.-S. (2021). Quality Classification of Injection-Molded Components by Using Quality Indices, Grading, and Machine Learning. Polymers, 13(3), 353. https://doi.org/10.3390/polym13030353