1. Introduction
Proteins play an important role in practically every cellular process. Their functions, which range from catalyzing biochemical reactions to mediating cell-to-cell communication, are closely linked to their three-dimensional structures. Therefore, understanding protein structure is fundamental to expanding our knowledge of complex biological systems. An important aspect of protein structure is its flexibility. Proteins are not static entities but exhibit a certain degree of conformational plasticity that is crucial for their biological functions. Atomic displacement parameter, also known as the B-factor or temperature factor [
1,
2], provide valuable insights into the inherent flexibility of protein structure [
3,
4]. Derived from X-ray crystallography, this parameter quantifies the average displacement of individual atoms within a protein. A higher B-factor indicates greater movement of the atoms, suggesting regions of increased flexibility. Accurate prediction of B-factors is therefore of paramount importance as it allows researchers to study protein dynamics and gain an understanding of protein function.
A number of methods have been introduced to predict the B-factor of proteins based on packing density [
5], graph theory [
6,
7,
8], amino acid sequence [
9,
10,
11,
12], variations in local structural composition [
13], elastic networks of Cα atoms [
14], and deep learning algorithms [
15,
16]. Weiss (2007) [
17] pioneered the development of a linear model based on the parameters of close atomic contacts to predict B-factors. This original model was later improved by incorporating more sophisticated features, such as information about the complex network of interactions within the protein structure. This complex network can be described using graphlet orbits, a concept introduced by Pržulj (2007) [
18]. Graphlets are small, induced subgraphs that allow us to describe the local connectivity patterns around the nodes in the graph. Including graphlet orbits as a feature in a multiple linear regression model has been shown to improve the accuracy of predicting the B-factor [
19]. In addition to the linear models, the thermal fluctuations were evaluated using the Kirchhoff matrix, which is also known as the Laplacian matrix in spectral graph theory. The inverse of the Kirchhoff matrix, whose diagonal elements reflect the thermal motion of the atoms, proved to be suitable for estimating the B-factors of the Cα atoms [
20,
21,
22]. However, there are still some important challenges that need to be addressed to improve B-factor prediction. These challenges can be broadly divided into two categories: (i) data transformation (or pre-processing) and (ii) experimental conditions.
Data pre-processing or data transformation is the crucial first step in creating predictive models, as using raw data can affect the performance of the algorithms. For example, the distribution of B-factors in the protein model is not normal but rather skewed towards large B-factors. It has been shown that the distribution of B-factors follows an inverse gamma distribution [
23,
24].
Normalization or scaling is also required to compare B-factors between different proteins [
13,
25,
26,
27]. Note that B-factors vary not only due to actual atomic mobility, but also due to conditions related to computational methods (refinement) and X-ray diffraction. There are different but fairly standardized protocols for scaling protein B-factors before performing a qualitative and quantitative comparison. The two most common approaches are Z-score normalization and rescaling of B-factors in the range from 0 to 100 [
28,
29]. However, a unit cell can also contain multiple chains (e.g., multimeric proteins), and these chains can have significantly different B-factors. For example, the average B-factor of one monomer in a dimer may be 12 Å
2, while the other monomer has an average value of 33 Å
2 [
30]. Therefore, scaling of B-factors is required before a comparison can be made between monomers in multimeric proteins. This is particularly important when analyzing protein structures containing multiple chains (multimers) or mobile domains where bimodal or multimodal B-factor distributions can be observed [
23,
24]. Therefore, B-factor scaling is crucial when performing comparisons both within and between proteins.
In addition to the data transformation, the unique properties of X-ray crystallography must also be taken into account when preparing the data for the creation of the model. The proteins in the crystal are densely packed, resulting in numerous crystal contacts. Due to the crystal symmetry, the molecule in the asymmetric unit is surrounded by 7–10 molecules on average [
31]. Hinsen (2008) [
32] investigated the effects of close crystal contacts on atomic fluctuations using egg white lysozyme. The study demonstrated that crystal packing interactions can significantly influence the magnitude of atomic fluctuations. Although several studies have considered crystal contacts, they have not systematically evaluated the performance of models with and without the inclusion of crystal packing information.
X-ray crystallography is a powerful technique that is used not only to determine protein structure but also, and very importantly, to study the detailed spatial arrangement and interactions between proteins and their ligands. However, a comprehensive analysis of the effects of ligands on the accuracy of B-factor prediction in protein–ligand complexes is still largely unexplored. Kondrashov et al. (2006) [
33] found a slight improvement in accuracy when ligands were included in their chemical network model to estimate Cα-atom flexibility. On the other hand, the linear model developed by Weiss (2007) [
17] and the multiple linear model based on the graphlet degree vector [
19] do not consider ligand atoms. Similarly, the influence of ligands and heteroatoms on B-factor prediction is not discussed in the work of Bramer and Wei (2018) and Pandey et al. (2023) [
15,
16], who used more advanced machine learning techniques to predict B-factors.
In order to improve data pre-processing and thereby increase the accuracy of the multiple linear model, this study aims to analyze how data transformation and the unique properties of X-ray crystallography affect the prediction and interpretation of B-factors in protein structures. This research therefore evaluates the impact of logarithmic transformation of B-factors on prediction accuracy and extends the knowledge of how appropriate scaling (or normalization) of B-factors improves their interpretation. In addition, the influence of large ligands and crystal contacts on the prediction of B-factors is evaluated. All these advances can significantly contribute to the accuracy of predicted B-factors and thus improve the interpretation of protein flexibility. Finally, the usefulness of a multiple linear model for the qualitative estimation of atomic positional fluctuations calculated by molecular dynamics is demonstrated.
3. Results and Discussion
3.1. The Improvement of Linear GDV Model
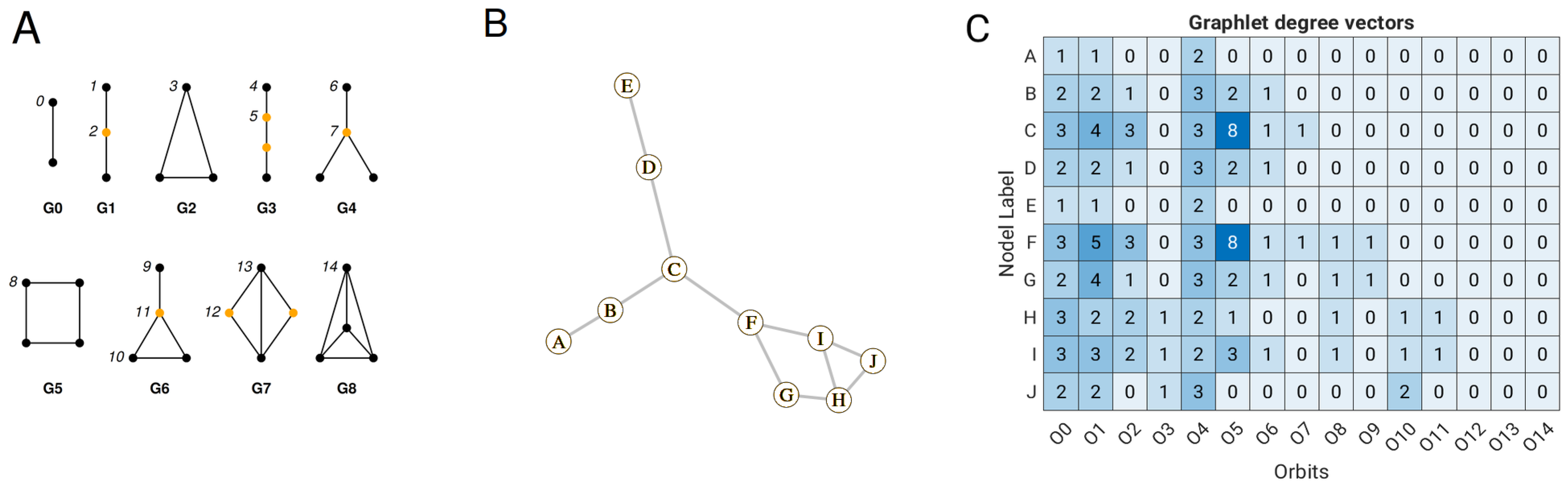
The linear GDV model was built on the data set of 1957 proteins but using different pre-processing approaches that include symmetry contact information, log transformation of B-factors, per-chain scaling of B-factors, and consideration of large ligands. The lowest correlation between deposited and predicted B-factors was achieved when no crystal contact (dataset 1) was used (
Figure 2). This suggests that the introduction of packing atom information improves the accuracy of B-factor prediction. It is interesting to see that the performance of the linear GDV model increased slightly when the cutoff distance for close crystal contact was extended from 7.5 Å to 15 Å. This seems contradictory since the cutoff distance for the construction of the graph was 7 Å, and the longer cutoff distance (extension from 7.5 Å to 15 Å) should not have any effect at first sight. The explanation for this is as follows: Increasing the cutoff distance has no effect on the orbit O
0, which is one edge deep and is the first feature of GDV. But it can affect, for example, orbits O
5 and O
10 (
Figure 1A), which contain information about deep contacts (up to 3 edges). Furthermore, the log transformation improved the average correlation from 0.75 (dataset 3) to 0.77 (dataset 4). This transformation helps to achieve a more normal distribution of the B-factors, which typically follow an inverse gamma distribution, and also attenuates the influence of outliers, thus improving the performance of the linear GDV model.
Figure S1 shows the coefficients of the linear GDV model, and it can be seen that the coefficients of the first three models where the cutoff distance of close contacts was increased from 0 Å to 7.5 Å and finally to 15 Å, are different, while for the linear GDV models where the log transformation, per-chain scaling, and ligand contacts were applied (dataset 4, 5, and 6), the coefficients of the linear model are more or less the same. In other words, the inclusion of crystal contacts changes the linear model directly, whereas the log transformation, per-chain scaling, and ligand contacts do not. The source of improvement in the latter cases is therefore a better quality of the data, either due to the appropriate per-chain scaling or due to the inclusion of the ligand atoms as close contacts. The final model (dataset 6) achieves a correlation of 0.78. It is worth noting that a recent study [
16] using a sequence-based deep learning model found a correlation of 0.8 for a dataset of 2442 proteins. Note that their analysis was limited to Cα atoms, whereas this study considers all protein atoms.
Anyway, we see that the per-chain scaling and the introduction of ligand atoms as close contacts do not lead to a significant improvement in the prediction of the whole dataset. The mean correlation value of log transformation (dataset 4), per-chain scaling, (dataset 5) and the introduction of ligand atoms as close contacts (dataset 6) is very similar (
Figure 2). The reason for this is that the log transformation is used in all protein models, while the per-chain scaling and the consideration of ligand atoms as close contacts are not used for all entries in the dataset. The per-chain scaling and the introduction of ligand atoms as close contacts were only used in a limited number of cases, 77 and 142, respectively. However, we can detect two outliers with a very low correlation (0.2 and 0.3) in the log transformation case (dataset 4), but these two outliers no longer exist in the per-chain scaling case (dataset 5), and when ligand atoms were used as close contacts (dataset 6). However, a closer look at the box-plot shows that the shortest whisker defining the lower outliers can be observed when using dataset 6. This dataset includes the log transformation, the per-chain scaling and the inclusion of ligand atoms (
Table 1).
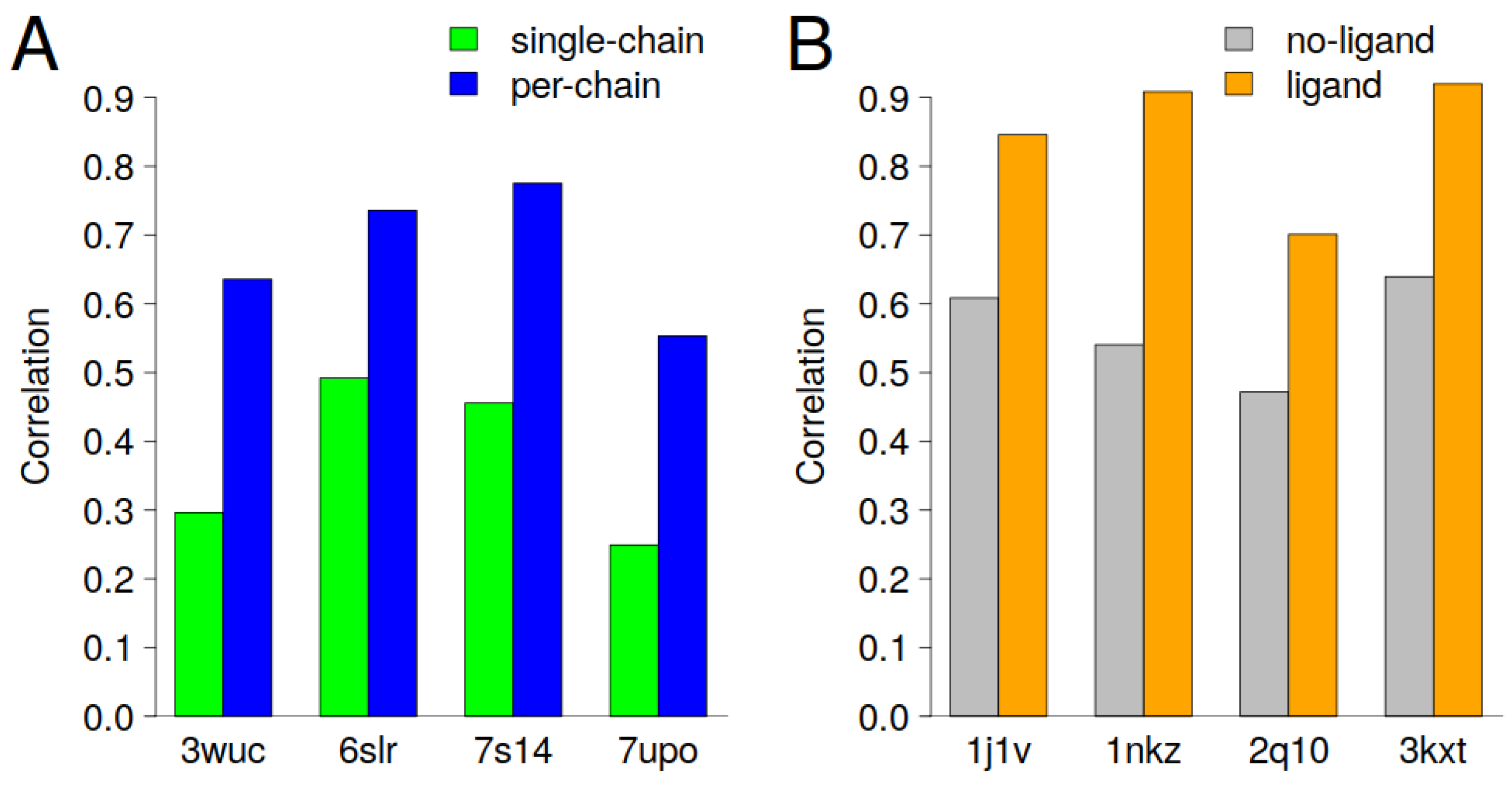
Figure 3 shows the cases with the largest improvements in correlation (>0.2) in the case of per-chain scaling and the introduction of ligand atoms as close contacts. It should be emphasized that the introduction of ligand atoms as close contacts and per-chain scaling is a case-dependent problem and that cryptographers should design and implement solutions that are specifically tailored to the unique characteristics of each case. For example, the protein could have a bimodal distribution of B-factors within a single chain, or a multimodal distribution that corresponds to translation–libration–screw groups rather than cryptographer-defined chain IDs. In addition, a statistical approach, e.g., Hartigan’s dip test for bimodality, can be used to decide whether the B-factors should be scaled according to defined groups. The next section discusses eight cases in which the prediction of the B-factor was significantly improved.
3.2. Case Studies—Per-Chain Scaling
The results presented in
Figure 3A demonstrate that per-chain scaling can enhance the interpretation of the predicted B-factors. For all four cases presented, we can see an increase in correlation of about 0.3 when per-chain scaling was applied. It is clear that the largest improvement was observed for entries that are homomeric or heteromeric proteins (
Figure S2A–D).
The biounit of PDBids: 3wuc, 6slr and 7s14 have two chains and the comparison of B-factors within each biounit shows that the mean B-factors are quite different (
Figure 4A,D,G). The PDBid: 3wuc case, for example, chain A has a mean B-factor of 22A
2, while chain B has a mean B-factor of 8A
2. The two clusters corresponding to two chains can also be seen in the scatter plots in
Figure 4B, while in
Figure 4C, where the B-factors are per-chain scaled, no separate groups can be seen. A similar conclusion can also be drawn for PDBid’s: 6slr and 7s14, where no separate clusters and a higher correlation were observed when per-chain scaling was applied (
Figure 4E,F,H,I).
More complex scenarios arise for proteins with three or more chains (
Figure S2D). We can see that in the case of PDBid: 7upo, two chains, namely A and B, have similar mean B-factors, while chain C has significantly higher B-factors (
Figure 4J). In this particular case, per-chain scaling improved from a rather low (0.25) to a medium (0.55) correlation (
Figure 4K,L).
Scaling is usually obligatory when B-factors are compared between proteins. In this study, the results suggest that, in some cases, per-chain scaling is required when dealing with homomeric or heteromeric proteins containing subunits with significantly different B-factors within the same unit cell. A direct comparison of the deposited B-factors between chains A, B, and C of PDBid:7upo without normalization could falsely give the impression that all atoms in chain C are more flexible than those in chains A and B. Higher deposited B-factors of chain C are probably related to crystallization effects, e.g., packing and symmetry-related interactions.
It is worth noting that the per-chain scaling does not change the independent variables. This is because the features or independent variables are only based on coordinates, parameters used in the construction of the graph, and the cutoff distance for the formation of node edges, while the per-chain scaling is related to the log transformation of the dependent variable.
3.3. Case Studies—Ligand Atoms as Close Contacts
Similar to the improvements observed in the implementation of per-chain scaling, the inclusion of ligand information in the construction of the graphs, which consequently affects the GDVs (features), can significantly improve the prediction of the B-factors in certain cases (see
Figure 3B). It is noteworthy that three of the four cases in which the correlation was significantly improved involved protein–DNA complexes (
Figure S3A–C). In these complexes, about 30% of the amino acids are in close contact with the ligand.
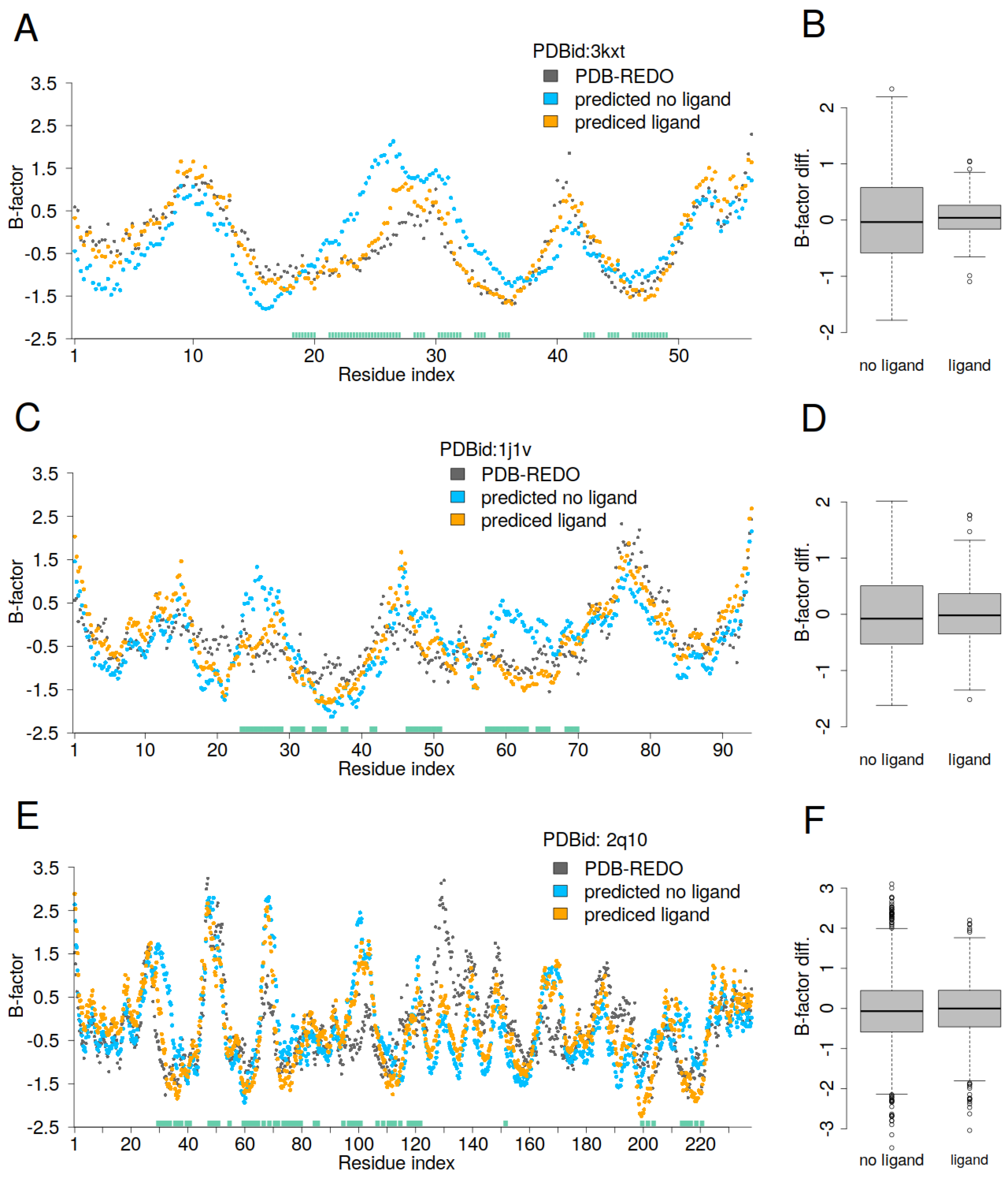
For the protein PDBid: 3kxt, residues from 20 to 35 show significantly higher predicted B-factors when the ligand is not present (
Figure 5A). For the protein PDBid: 1j1v, residues 25, 48, and 60, as well as the neighboring residues, also exhibit higher predicted B-factors when the ligand is excluded from the calculation (
Figure 5C). For the protein PDBid: 2q10, the clearest differences between the predicted and PDB-REDO B-factors occur around residue 30 and residues 200–220 (
Figure 5E). These regions correspond to the close contacts with the DNA. Remarkably, in addition to the overestimated B-factors, we also observe underestimations (lower B-factors) in regions where there are no close contacts between protein and DNA. The boxplots (
Figure 5B,D,F) show the difference between the PDB-REDO and predicted B-factors, and we can see that the linear GDV model both overestimates and underestimates the B-factors, with greater scatter when the ligand is not taken into account. While one might expect discrepancies primarily in regions of close contact between protein and ligand, a more comprehensive analysis of the entire protein, not just the contact region, is required. Ligand inclusion or exclusion alters the topology of the protein–ligand complex by redefining the boundaries between inner and outer residues. Residues that were previously classified as surface-exposed can become core residues as a result of ligand inclusion. Conversely, some core protein residues are less deeply buried within the protein–ligand complex than in the protein alone. This transition changes the interpretation of mobile and rigid residues. In general, residues that appear to move from core positions to more exposed positions within the protein–ligand complex exhibit increased relative flexibility. Conversely, residues at the protein–ligand interface tend to show lower relative flexibility.
The fourth example (PDBid: 1nkz) is the integral membrane light-harvesting complex II (LH2) of
Rhodobacter sphaeroides strain 10050. This model contains bacteriochlorophylls and rhodopin glucoside as non-protein atoms (
Figure S3D). Remarkably, almost all amino acids exhibit close contact to these heteroatoms, and the distribution of predicted B-factors differs significantly when comparing models with and without ligand atoms (
Figure 6A). The correlation between PDB-REDO and the predicted B-factors increases from 0.54 to 0.91 when heteroatoms are also taken into account (
Figure 3B). The exclusion of heteroatoms from the model falsely suggests that the central region of the protein, which corresponds to the membrane-embedded region, is very flexible. This misinterpretation arises because the model incorrectly predicts high B-factors in the protein region that interacts with the membrane.
Figure 6B illustrates a larger discrepancy, namely the underestimation and overestimation of B-factors when heteroatoms are excluded in the construction of the graph.
These cases demonstrated that not only the contacts of the crystal packing but also the presence of large ligands, especially when their molecular weight is comparable to that of the protein, can significantly affect the prediction of B-factors in the crystal structure.
3.4. Qualitative Estimation of the Atom Fluctuations
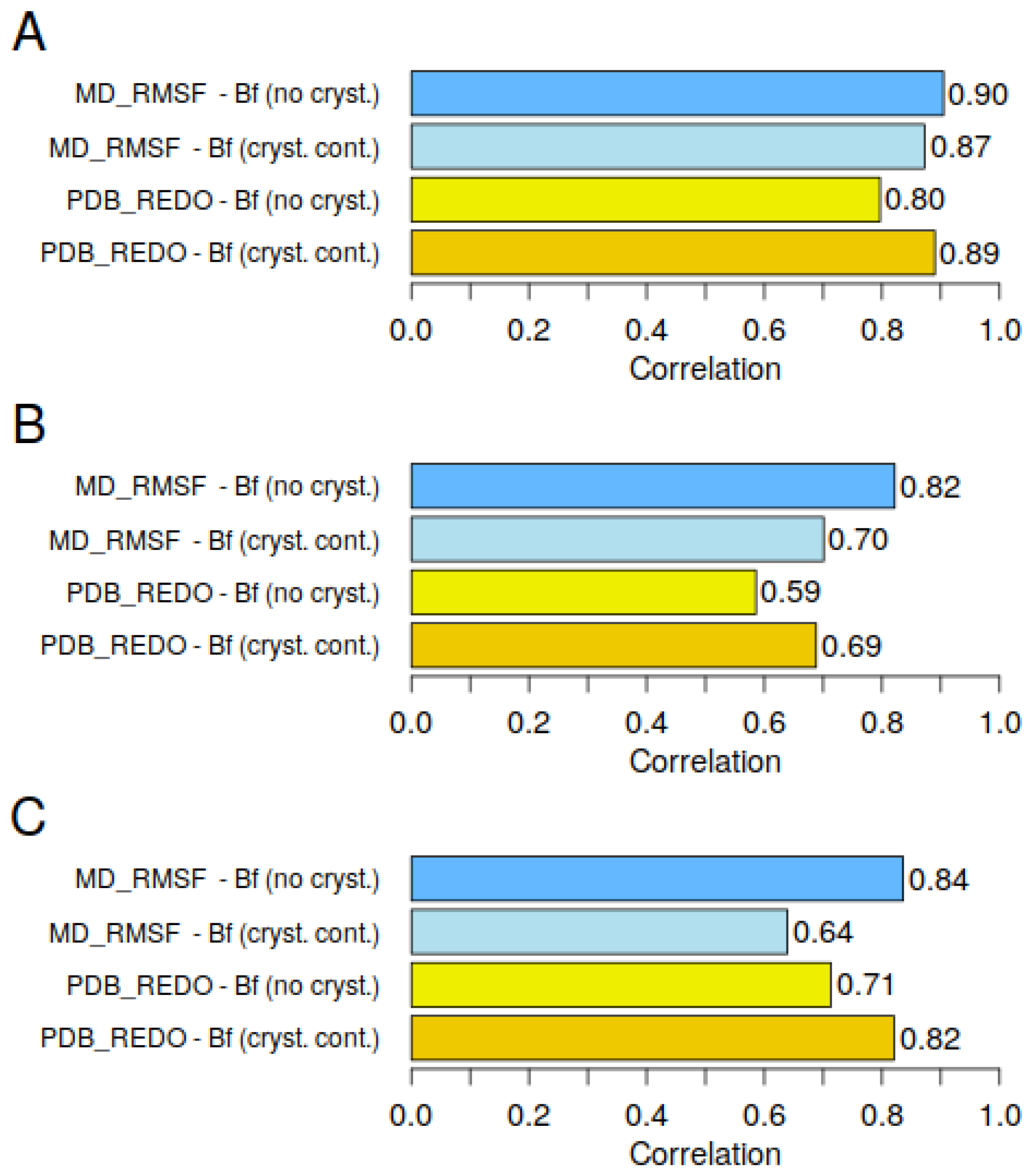
Although experimental B-factors provide valuable insights into protein flexibility and function, it is important to recognize their inherent limitations. B-factors are affected by experimental errors, data resolution, misplaced atoms in the protein model, radiation damage and crystal packing contacts. The latter can cause the determined B-factors to be artificially low, especially for outer residues, suggesting that certain regions of the protein structure can be more rigid than reasonably expected in the aqueous environment. In addition to the crystallographic B-factors, root–mean–square fluctuations calculated by molecular dynamics simulations can also be used as a powerful method to study protein flexibility. However, we should be aware that molecular dynamics also has its drawbacks. For example, it is strongly dependent on force fields, i.e., empirically parameterized equations to calculate the potential energy of a system of atoms. Despite some differences between the experimentally determined B-factors and the root–mean–square fluctuations of molecular dynamics (MD-RMSF), the conclusions on protein flexibility are generally consistent, although not identical.
Figure 7 shows the correlation between the experimental B-factors, the MD-RMSF. and the predicted B-factors. Two approaches were used to predict the B-factors: with and without crystal contacts. Again, it was confirmed that the crystal packing information improves the prediction of the crystallographic B-factors. Interestingly, however, the opposite effect is observed when the predicted B-factors are compared with the MD-RMSF. The exclusion of close crystal contact improves the correlation between the predicted B-factors and the MD-RMSF. The linear GDV model provides accurate predictions for both the B-factors and the MD-RMSF and consistently achieves high correlations—greater than 0.69 in the cases presented—when symmetry packing interactions are adequately accounted for.
Therefore, the GDV model can be used as a validation tool for crystallographic B-factors and as a first approximation to the MD-RMSF. Moreover, the difference between these two options (with and without close crystal contacts) gives us an insight into the influence of crystal packing on the possible conformational changes of the protein induced by crystal packing. It is important to note that the training dataset for the linear GDV model presented in this study is based solely on crystallographic B-factors. Consequently, its main function is still to predict crystallographic B-factors and evaluate the quality of the underlying PDB structures. However, this example shows that simply switching the consideration of crystal contacts on and off can provide valuable qualitative insights into the potential influence of crystal packing on the crystallized protein.
4. Conclusions
In this study, the influence of data transformation and various experimental factors on the prediction of protein B-factors was analyzed. The analysis reveals a relationship between the inclusion of ligand atoms and the prediction of B-factors. However, a limitation of the presented approach is the focus on relatively large ligands and the use of arbitrarily defined selection criteria. It should be emphasized that the simple inclusion of mobile solvent molecules would increase the number of close contacts, which could lead to an overestimation of the rigidity of the outer atoms—a problem that also applies to small ligands. Therefore, further research is needed to find out which and how many heteroatoms significantly influence the flexibility of certain protein regions.
Crystal packing, an inherent consequence of X-ray crystallography, leads to specific intermolecular contacts due to crystal symmetry. These symmetry-related contacts are not present in experimental techniques such as nuclear magnetic resonance and cryo-electron microscopy. The investigation demonstrates that close-symmetry contacts significantly affect the accuracy of B-factor prediction and should be considered in the validation of crystallographic B-factors.
Furthermore, the study highlights that the linear GDV model performs worse when crystal contacts are excluded, but at the same time, the linear GDV model predicts the MD-RMSF better. Thus, while crystal contacts need to be considered when validating B-factors, the linear GDV model without crystal contacts is better suited to qualitatively estimate the flexibility of proteins in an aqueous environment.
Recent advances in AI-assisted prediction of protein structures, such as AlphaFold2 and Rosetta [
47,
48], have dramatically increased the number of available 3D protein structures. However, these algorithms predict atomic coordinates without providing B-factors, which are essential for studying protein flexibility and function. Indeed, the pLDDT score, which estimates the confidence in the AlphaFold2 predictions and is entered into the file in the column normally reserved for crystallographic B-factors, does not correlate with the experimental temperature B-factor [
49].
A well-known limitation of X-ray-derived B-factors is that they contain experimental errors and primarily describe atomic displacement in a crystalline environment rather than in solution. A promising way to improve the linear GDV model to study protein flexibility could be the integration of molecular dynamics data. For example, ATLAS [
50], a database of standardized molecular dynamics simulations, provides RMSF values for all protein atoms that can replace the crystallographic B-factors to develop a model for rapid, qualitative predictions of protein flexibility.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}